Intrinsic dimension estimation for discrete metrics
Abstract
Real world-datasets characterized by discrete features are ubiquitous: from categorical surveys to clinical questionnaires, from unweighted networks to DNA sequences. Nevertheless, the most common unsupervised dimensional reduction methods are designed for continuous spaces, and their use for discrete spaces can lead to errors and biases. In this letter we introduce an algorithm to infer the intrinsic dimension (ID) of datasets embedded in discrete spaces. We demonstrate its accuracy on benchmark datasets, and we apply it to analyze a metagenomic dataset for species fingerprinting, finding a surprisingly small ID, of order 2. This suggests that evolutive pressure acts on a low-dimensional manifold despite the high-dimensionality of sequences’ space.
Data produced by experiments and observations are very often high-dimensional, with each data-point being defined by a sizeable number of features. To the please of modelers, real-world datasets seldom occupy this high-dimensional space uniformly, as strong regularities and constraints emerge. Such a property is what allows for low-dimensional descriptions of these high-dimensional data, ultimately making science possible.
In particular, data-points are often effectively contained in a manifold which can be described by a relatively small amount of coordinates. The number of such coordinates is called Intrinsic Dimension (ID). More formally, the ID is defined as the minimum number of variables needed to describe the data without significant information loss. Its knowledge is of paramount importance in unsupervised learning[1, 2, 3] and has found applications across disciplines. In solid state physics and statistical physics, the ID can be used as a proxy of an order parameter describing phase transitions[4, 5]; in molecular dynamics it can be used to quantify the complexity of a trajectory[6]; in deep learning theory the ID indicates how information is compressed throughout the various layers of a network [7, 8, 9]. During the last three decades much progress has been made in the development of sophisticated tools to estimate the ID[10, 11] and most estimators have been formulated (and are supposed to work) in spaces where distances can vary continuously. However, many datasets are characterised by discrete features and, consequently, discrete distances. For instance, categorical datasets like satisfaction questionnaires, clinical trials, unweighted networks, spin systems, protein, and DNA sequences fall into this category.
Two main methods are usually employed in these cases. The Box Counting (BC) estimator [12, 13, 14] — which is defined by measuring the scaling between the number of boxes needed to cover a dataset and the boxes size — provides good results for 2-3-dimensional datasets but is computationally demanding for higher-dimensional datasets. The second popular method is the Fractal Dimension (FD) estimator[12, 15, 16] and it is based on the assumption of a power law relationship for the number of neighbors within a sphere of radius from a given point, where is the fractal dimension of the data.This estimator has been successfully applied, on discrete datasets, to model the phenomena of dielectric breakdown [17] and Anderson Localization [18]. For non-fractal objects, both methods are reliable only in the limit of small boxes and small radii, since the manifold containing the data can be curved and the data points can be distributed non-uniformly[19]. However, in discrete spaces such a limit is not well defined due to the minimum distance induced by any discrete lattice, and this can lead to systematic errors [20, 21].
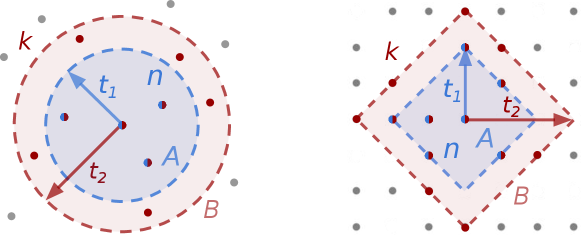
In this letter, we introduce an ID estimator explicitly formulated for spaces with discrete features. In discrete spaces, the ID can be thought of as the dimension of a (hyper)cubic lattice where the original data-points can be (locally) projected without a significant information loss. The key challenge in dealing with the discrete nature of the data lies in the proper definition of volumes on lattices. To this end, we introduce a novel method that makes use of Ehrhart’s theory of polytopes [22], which allows to enumerate the lattice points of a given region. By measuring a suitable statistics, depending on the number of data-points observed within a given (discrete) distance, one can infer the value of the dimension of the region, which we interpret as the ID of the dataset. The statistics we use is defined in such a way that density of points is required to be constant only locally and not in the whole dataset. Importantly, our estimator allows to explicitly select the scale at which the ID is computed.
Methods - We assume data points to be uniformly distributed on a generic domain, and that their density is . In such domain, we consider a region with volume . Since we are assuming points to be independently generated, the probability of observing points in is given by the Poisson distribution [23]
| (1) |
so that . Consider now a data-point and two regions and , one containing the other, and both containing the data-point: . Then the number of points and falling, respectively, in and are Poisson distributed with rates and . The conditional probability of having points in given that there are points in is
| (2) |
with
| (3) |
Thus . As far as the density is constant within and , is simply equal to the ratio of the volumes of the considered regions and, remarkably, density independent. This is a key property which, as we will show, allows using the estimator even when the density is approximately constant only locally, and varies, even substantially, across larger distance scales. One can then write a conditional probability of the observations (one for each data point), given the parameters and , which can possibly be point-dependent:
| (4) |
Such formulation assumes all the observations to be statistically independent. Strictly speaking this is typically not true, since the regions and of different points can be overlapping. We will address this issue in Supplementary Information (SI), demonstrating that neglecting correlations does not induce significant errors.
The next step consists in defining the volumes in Eq. (3) according to the nature of the embedding manifold. We now assume our space to be a lattice where the metric is a natural choice. In this space the volume is the number of lattice points contained in . According to Ehrhart theory of polytopes [24], the number of lattice points within distance in dimension from a given point amounts to [25]
| (5) |
where is the ordinary hypergeometric function. At a given , the above expression is a polynomial in of order . As a consequence, the ratio of volumes defining the value of in Eq. (3) becomes a ratio of two polynomials in . Given a dataset, the choice of and fixes the values of and in the likelihood (4). Its maximization with respect to allows to infer the data-manifold’s ID, which is simply given the root of equation (see SI for more details on the derivation)
| (6) |
where the mean value over and is intended over all the points of the dataset. The root can be easily found with standard optimization libraries. This procedure defines an ID estimator that, for brevity, we will call I3D (Intrinsic Dimension estimator for Discrete Datasets).
Very importantly, the ID estimate is density independent as such factor cancels out (see Eq. (3)). The error on the estimator has a theoretical lower bound, given by the Cramer-Rao inequality, which has an explicit analytic expression. As an alternative, the ID can be estimated by a Bayesian approach as the mean value of its posterior distribution, and the error estimated via the posterior variance (details in SI).
The estimation of the ID depends on the choice of the volumes of the smaller and larger regions, which are parametrised by the “radii” and . By varying , the radius of the largest probe region, one can explore the behaviour of the ID at different scales. The proper range of is dataset dependent and should be chosen by plotting the value of the ID as a function of it, as we will illustrate in the following. If the dataset has a well-defined ID, one will observe an (approximate) plateau in this plot. This leaves the procedure with one free parameter: the ratio and its choice influences the statistical error. In continuous space the ratio between volumes in Eq. (3) is simply and the Cramer-Rao variance has a simple dependence on the parameter . By minimising it with respect to , one obtains that the optimal value for the ratio is (see SI).
In order to check the goodness of the estimator, we test whether the number of points contained within the internal shells are actually distributed as a mixture of binomials, as our model assumes:
| (7) |
where is the the empirical probability distribution of the found by fixing . In the following we will compare the empirical cumulative distribution of to the cumulative distribution of .
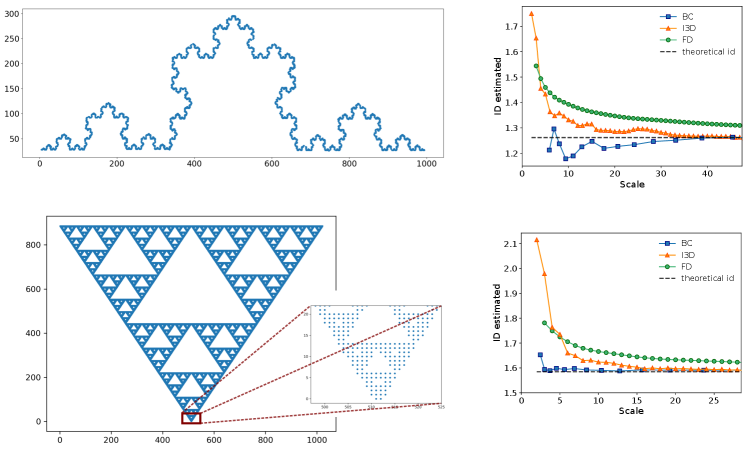
Results: Uniform distribution - We tested the I3D estimator on artificial datasets, and compared it against the two aforementioned methods: the Box Counting (BC) and the Fractal Dimension (FD). The BC estimate of the ID is obtained by a linear fit between the logarithm of the number of occupied covering boxes and the logarithm of the boxes side. Seemingly, for the FD, the linear fit is computed among the logarithm of the average number of neighbours within a given radius and the logarithm of the radius. In both cases, the scale reported in the figures is given by the largest box or radius included in the fit. We started by analysing uniformly-distributed points in 2d and 6d square lattices. We adopted periodic boundary conditions in order to reduce boundary effects as much as possible. For the I3D estimator, in this and all following cases, we set . Results are shown in Fig. 1.
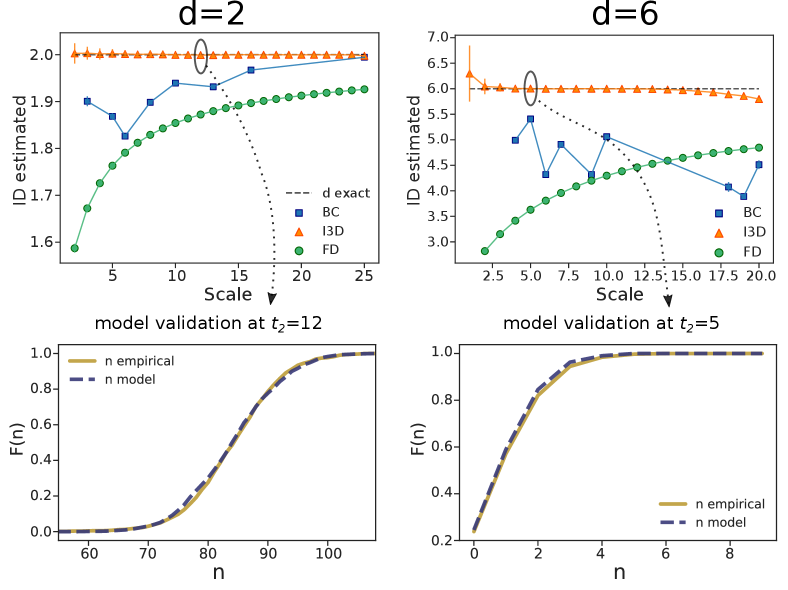
While the BC and FD proved to be reliable in finding the fractal dimension of repeating, self-similar lattices [12, 17], they do not manage to assess the proper dimension of randomly distributed points, especially at small scales. The I3D estimator, instead, returns accurate values for the ID at all scales and, importantly, provides the correct estimate also on self-similar lattices (see SI). Remarkably the I3D estimator allows to select the scale explicitly by varying the radius . In Fig. 1, lower panels, we also report a first example of model validation for I3D. The two cdfs (empirical and theoretical one, according to Eq. (7)) perfectly match, meaning that the ID estimation is reliable.
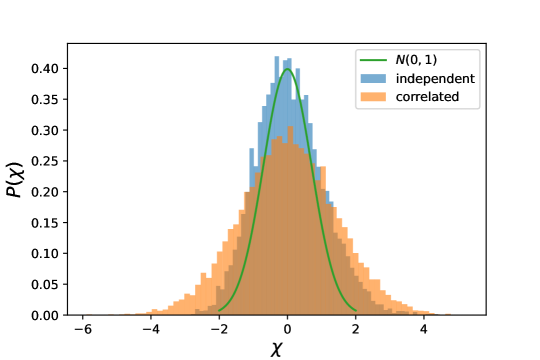
Gaussian distribution - Secondly, we tested the estimators on Gaussian distributed points in 5 dimensions, analysing a case in which the data are uncorrelated and a case in which a correlation is induced by a non-diagonal covariance matrix. In both cases, we set diagonal elements of the covariance matrix to (implying an effective standard deviation of the distribution of ), while off-diagonal terms –for correlated data– were uniformly extracted in the interval (0,2). The values were chosen in order to keep the dimension of the dataset under control, as correlations of the same order of the diagonal would reduce the dimensionality of the dataset. The points were projected on a lattice by taking the nearest integer in each coordinate.
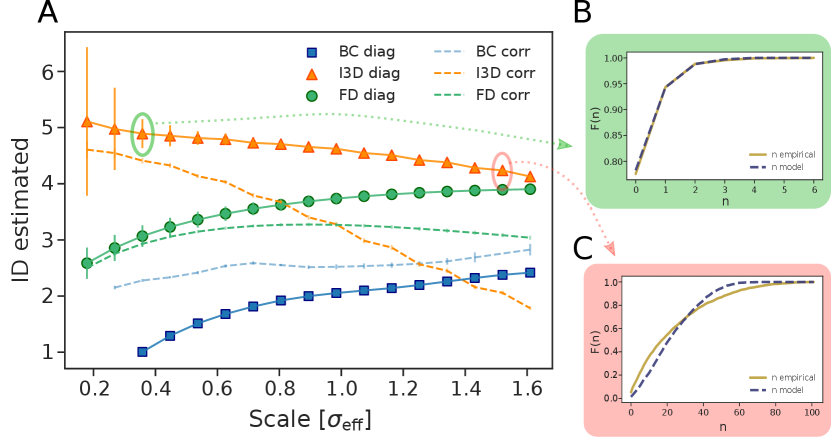
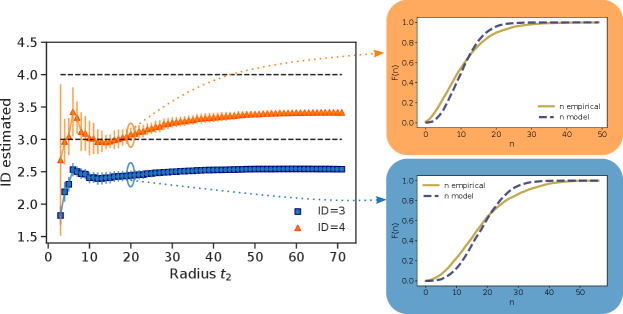
As one can observe in panel A of Fig.2, I3D is accurate as far as it explores a neighborhood where the density does not vary too much (namely, as far as ). Correspondingly, empirical and model cdfs in panel B are superimposed. Beyond such distance, neighborhoods are characterised by non-constant density; consequently, estimates gets less precise and, accordingly, the two cdfs show inconsistencies (panel C: ). On the other hand, the BC and FD estimations are far from desired values at any scales, for both correlated and uncorrelated cases.
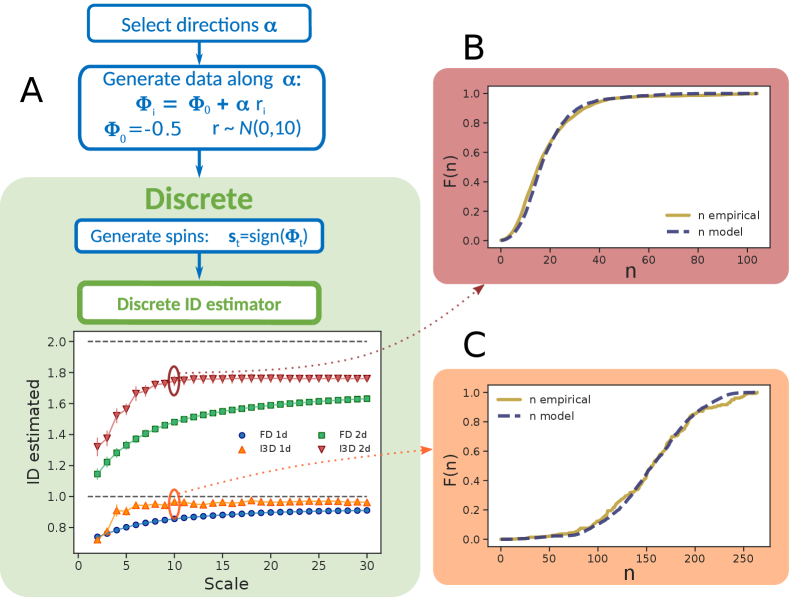
Spin dataset - As a third test, we created synthetic Ising-like spin systems with a tunable ID, which is given by the number of independent parameters used to generate the dataset. The 1d ensemble is obtained by generating a set of points belonging to a line embedded in with the process . Here, is a fixed random vector of unitary norm with uniformly distributed components and is the y-intercept that, for simplicity, is equal for all the components; are gaussian-distributed: and independently drawn for each sample . We then proceed to the discretization by extracting the , an ensemble of states of discrete spins. The pipeline is summarized in Fig.3. The role of is to introduce an offset in order to enhance the number of the reachable discrete states. In fact, for , we would obtain only two different states, given by , since the spins would change sign synchronously. An offset allows the angles and the spins to shift sign in an asynchronous way. The extension to higher dimensions is straightforward and consists in generating the initial points as , with . Due to the nature of data domain (a -dimensional hypercube with side 1), the BC cannot be applied, as boxes with side larger than 1 would include the whole data set. FD and I3D estimates for the 1d system are very close. This is not surprising as both continuous and discrete volumes (and, consequently, the neighbors) scale linearly with the radius. In the 2d case, I3D clearly outperforms the other methods, although even the best estimate remains slightly lower than the true value. This effect, due to non-uniform density, is relatively small and indeed the empirical and theoretical cdfs are rather consistent (panels B and C). Such an effect becomes more important as the dimension rises (see SI for examples in and ).
16S Genomics strands - Lastly, we present the application of our methodology to a real-world dataset in the field of genomics. The dataset consists of DNA sequences of nucleotides. We selected a dataset downloaded from the Qiita server (https://qiita.ucsd.edu/study/description/13596)[26]. In such study, they sequenced the v4 region of the 16S ribosomal RNA of the microbiome associated with sponges and algal water blooms. This small-subunit of rRNA genes is widely used to study the composition of microbial communities [27, 28, 29, 30]. Hamming distance and the binary mapping A:11, T:00, C:10 and G:01 were used to compute sequences’ distance. The canonical letter representation leads to almost identical results (see SI). To avoid dealing with isolated sequences, we kept only sequences having at least 10 neighbors within a distance of 10. Sequences come with their associated multiplicity, related to the number of times the same read has been found in the samples. We ignore such degeneracy and compute an ID which describes just the distribution of the points regardless of their abundance.
To begin with, we estimated the ID on a subset of sequences that are similar to each other. In order to find such sets, we perform a k-means clustering and calculate the ID separately for each of them. Panel A in Fig. 4 shows the ID at small to medium scale for one of such clusters. The empirical and reconstructed cdfs, performed at (see inset), are fairly compatible. Panel B shows the average and the standard deviation of the ID of all clusters (weighted according to the respective populations). One can appreciate that the ID is always between 1 and 3 in a wide range of distances, showing a plateau around 2 for .
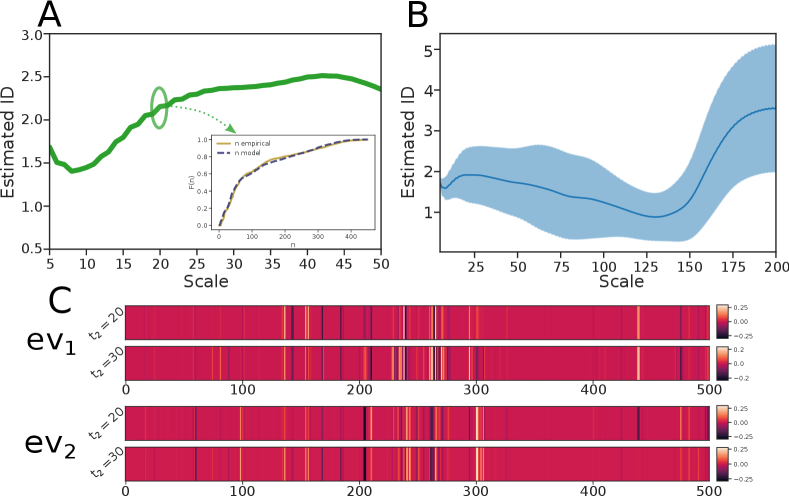
Such a low value for the ID is an interesting and unexpected feature, as it suggests that, despite the high-dimensionality of sequences’ space, evolution effectively operates in a low-dimensional space. Qualitatively, an ID 2 on a scale of 20 means that if one considers all the sequences differing by approximately 20 mutations from a given sequence, these mutations cannot be regarded as independent one from each other, but are correlated in such a way that approximately 18 degrees of freedom are effectively forbidden. The “direction” of these correlated mutations can be, at least approximately, measured by performing PCA in the space of sequences with the binary mapping. The first two dominant eigenvectors, shown in panel C, were estimated using all the sequences within a distance of 20 (top) and 30 (bottom) from the center of the cluster of Panel A. Remarkably, the eigenvectors do not change significantly on this distance range, indicating that, consistently with the low value of the ID, the data manifold on this scale can be approximately described by a two-dimensional plane. In order to provide an interpretation of the vectors defining this plane, we repeated this same analysis on the previously mentioned spin model. In this case, if the generative model is defined by two vectors and , the first two dominant eigenvectors of a PCA performed on 1000 points are contained in the span of the two generating vectors, with a residual of 0.04 (see SI for details). The components of a vector can then be qualitatively interpreted as proportional to the mutation probabilities of the associated nucleotide for a collective mutation process. In the genomics dataset this reasoning can applied only locally: the direction of correlated mutation is significantly different in different clusters, indicating that the data manifold is highly curved.
Conclusions - We presented an ID estimator formulated to analyze discrete datasets. Our method relies on few mathematical hypotheses and is asymptotically correct if the density is constant within the probe radius .
In order to prove the estimator’s effectiveness, we tested the algorithm against three different artificial datasets and compared it to the well known Box Counting and Fractal Dimension estimators. While the last two performed poorly, the new one achieved good results in all cases, providing reliable ID estimations corroborated by the comparison of empirical and model cumulative distribution functions for one of the observables.
We finally applied the estimator on a genomics dataset, finding an unexpectedly low ID which hints at strong constraints in the sequences’ space, and then exploited such information to give a qualitative interpretation of such ID.
The newly developed method paves the way to push the investigation even further, towards the extension to discrete metrics of distance-based algorithms and routines that are, nowadays, consolidated in the continuum, such as density estimation methods or clustering algorithms.
The code implementing the algorithm is available in open source within the DADApy [31] software.
I Acknowledgements
The authors thank Antonietta Mira, Alex Rodriguez and Marcello Dalmonte for the fruitful discussions. AG and AL acknowledge support from the European Union’s Horizon 2020 research and innovation program (Grant No. 824143, MaX ‘Materials design at the eXascale’ Centre of Excellence).
IM, AG, AL designed and performed the research. All authors wrote the paper. JG designed the application on genomics sequences.
References
- Solorio-Fernández et al. [2020] S. Solorio-Fernández, J. A. Carrasco-Ochoa, and J. F. Martínez-Trinidad, Artificial Intelligence Review 53, 907 (2020).
- Jović et al. [2015] A. Jović, K. Brkić, and N. Bogunović (Ieee, 2015) pp. 1200–1205.
- Bengio et al. [2013] Y. Bengio, A. Courville, and P. Vincent, IEEE transactions on pattern analysis and machine intelligence 35, 1798 (2013).
- Mendes-Santos et al. [2021a] T. Mendes-Santos, X. Turkeshi, M. Dalmonte, and A. Rodriguez, Physical Review X 11, 011040 (2021a).
- Mendes-Santos et al. [2021b] T. Mendes-Santos, A. Angelone, A. Rodriguez, R. Fazio, and M. Dalmonte, PRX Quantum 2, 030332 (2021b).
- Glielmo et al. [2021] A. Glielmo, B. E. Husic, A. Rodriguez, C. Clementi, F. Noé, and A. Laio, Chemical Reviews 121, 9722 (2021), pMID: 33945269, https://doi.org/10.1021/acs.chemrev.0c01195 .
- Ansuini et al. [2019] A. Ansuini, A. Laio, J. H. Macke, and D. Zoccolan, Advances in Neural Information Processing Systems 32 (2019).
- Doimo et al. [2020] D. Doimo, A. Glielmo, A. Ansuini, and A. Laio, Advances in Neural Information Processing Systems 33, 7526 (2020).
- Recanatesi et al. [2019] S. Recanatesi, M. Farrell, M. Advani, T. Moore, G. Lajoie, and E. Shea-Brown, arXiv preprint (2019).
- Campadelli et al. [2015] P. Campadelli, E. Casiraghi, C. Ceruti, and A. Rozza, Math. Probl. Eng. 2015 (2015), 10.1155/2015/759567.
- Camastra and Staiano [2016] F. Camastra and A. Staiano, Information Sciences 328, 26 (2016).
- Falconer [2004] K. Falconer, Fractal geometry: mathematical foundations and applications (John Wiley & Sons, 2004).
- Block et al. [1990] A. Block, W. von Bloh, and H. J. Schellnhuber, Phys. Rev. A 42, 1869 (1990).
- GRASSBERGER [1993] P. GRASSBERGER, International Journal of Modern Physics C 04, 515 (1993), https://doi.org/10.1142/S0129183193000525 .
- Grassberger and Procaccia [1983] P. Grassberger and I. Procaccia, Physical review letters 50, 346 (1983).
- Christensen and Moloney [2005] K. Christensen and N. R. Moloney, Complexity and criticality, Vol. 1 (World Scientific Publishing Company, 2005).
- Niemeyer et al. [1984] L. Niemeyer, L. Pietronero, and H. J. Wiesmann, Physical Review Letters 52, 1033 (1984).
- Kosior and Sacha [2017] A. Kosior and K. Sacha, Physical Review B 95, 104206 (2017).
- Facco et al. [2017] E. Facco, M. D’Errico, A. Rodriguez, and A. Laio, Scientific Reports 7, 1 (2017).
- Theiler [1990] J. Theiler, J. Opt. Soc. Am. A 7, 1055 (1990).
- Möller et al. [1989] M. Möller, W. Lange, F. Mitschke, N. Abraham, and U. Hübner, Physics Letters A 138, 176 (1989).
- Ehrhart [1977] E. Ehrhart, International Series of Numerical Mathematics, Vol.35 (1977).
- Moltchanov [2012] D. Moltchanov, Ad Hoc Networks 10, 1146 (2012).
- [24] “Eugène ehrhart - publications 1947-1996,” http://icps.u-strasbg.fr/~clauss/Ehrhart_pub.html, accessed: 2022-03-25.
- Beck and Robins [2007] M. Beck and S. Robins, Choice Reviews Online 45, 45 (2007).
- Bolyen et al. [2019] E. Bolyen et al., Nature Biotechnology 37, 852 (2019).
- Gray et al. [1984] M. W. Gray, D. Sankoff, and R. J. Cedergren, Nucleic Acids Research 12, 5837 (1984).
- Woese et al. [1990] C. R. Woese, O. Kandler, and M. L. Wheelis, Proceedings of the National Academy of Sciences 87, 4576 (1990).
- Weisburg et al. [1991] W. G. Weisburg, S. M. Barns, D. A. Pelletier, and D. J. Lane, Journal of bacteriology 173, 697 (1991).
- Jovel et al. [2016] J. Jovel, J. Patterson, W. Wang, N. Hotte, S. O’Keefe, T. Mitchel, T. Perry, D. Kao, A. L. Mason, K. L. Madsen, et al., Frontiers in microbiology 7, 459 (2016).
- Glielmo et al. [2022] A. Glielmo, I. Macocco, D. Doimo, M. Carli, C. Zeni, R. Wild, M. d’Errico, A. Rodriguez, and A. Laio, Patterns 3, 100589 (2022).
Intrinsic dimension estimation for discrete metrics
— Supplementary Information —
II Proof of Eq.(2)
We recall that
| (8) |
where we name and , so that since . Consequently, it holds that
| (9) |
where .
III Ehrhart polynomial theory and Cross-polytope enumerating function
According to Ehrhart theory, the volume of a lattice hypershpere of radius in dimension is given by the enumerating function[25]
| (10) |
where is assumed to be an integer value. In order to make this expression suitable for likelihood maximization, it can be conveniently rewritten using the analytical continuation
| (11) |
where the binomial coefficient are computed using the Gamma function: for non-integer . is the hypergeometric function. Here we report the first polynomials for :
-
:
1
-
:
-
:
-
:
-
:
By substituting integer values of , one recovers the volumes found with eq. 10. Using this expansion we can treat as a continuous parameter in our inference procedures.
IV Maximum Likelihood Estimation of the ID
Once the two radii and are fixed and the corresponding values of and are computed, the likelihood for data points is
| (12) |
where and depends explicitly only on . In order to make the expressions easier to read, we will write just from now on. The optimal value for can be found by means of a maximum likelihood estimation (MLE), which consists in setting equal to 0 the (log)derivative of the likelihood:
| (13) |
where the mean value are intended over all the points of the dataset and is the Jacobian of the transformation from to , which reads
| (14) |
IV.1 Cramer-Rao estimate of the variance of the ID
The Cramer-Rao inequality states that the variance of an unbiased estimator of an unknown parameter is bounded from below by the inverse of the Fisher information, namely
| (15) |
where
| (16) |
is the likelihood for a single sample and is the expected value over datapoints . Given the likelihood in eq. (12), by deriving (with respect to ) a second time the third line of eq.(13), one has
| (17) |
By inserting the MLE solution and performing the, sum one obtains
| (18) |
leading to the final result
| (19) |
Such an expression is finally evaluated at the found through the MLE procedure.
V Bayesian estimate of the ID
The ID can also be estimated through a Bayesian approach. The likelihood of the process is represented by a binomial distribution where the probability (hereafter named to avoid confusion) is given by the ratio of the shell volumes around any given point. The binomial pdf has a known conjugate prior: the beta distribution, whose expression is
| (20) |
where is the beta function. We make an agnostic assumption (since with do not have any information on the value of the ID) and set , so that will be uniformly distributed. The posterior distribution of the ratio of the volumes will still be a Beta distribution, with parameters updated as follows
| (21) | |||||
| (22) |
where and are the points falling within the inner and outer volumes around point ; the sum runs on all the points in the dataset.
In order to compute the expected value and the variance on , one has to extract its posterior distribution from the one of . The posterior of is obtained from the posterior of by a simple change of variables:
| (23) |
where the Jacobian is given by Eq. (14). By varying , one can estimate the posterior distribution of . Its first and second momenta will be the (Bayesian) estimates of the ID and of its confidence.
As far as we could observe, the ID found through MLE is always very close to the mean value of the posterior. The same occurs for the error estimate, which is typically very close to the Cramer-Rao bound. Small differences () have been observed in cases of few datapoints (). The reason is that the posterior distribution, for low values of and , can be slightly asymmetric, bringing to a discrepancy between the position of its maximum and its mean value. In most practical cases such an effect is negligible.
VI Statistical correlation in the numbers of data points in the probe regions.
The likelihood has the form in Eq. 12 under the assumption that the observations are statistically uncorrelated. However, if a point is close to another point , it is likely that their neighborhoods will be overlapping. This implies that the values for and will have a certain degree of correlation. In particular, in order to have a fully statistical independence, one should consider only points with a non-overlapping neighbours. Clearly this would reduce the number of available observations to compute the ID, making the estimate less reliable. Here we assess the entity of such correlations, or seemingly, how much the Bayesian and Cramer-Rao calculations underestimate the error.
To begin with, we generated 10000 realizations of 10000 uniformly distributed points on a 4-dimensional lattice. For each realization, we extracted ID and error using all available points; on the same dataset, we also computed the ID using only one random point, in order to gather statistically independent measurements. We then computed the distribution of the pool variable for the correlated ID measures as
| (24) |
where is the standard deviation of the posterior, and is the ground truth ID. We also computed the distribution of the pool variable for the ID estimates obtained using a single point
| (25) |
where is the standard deviation of the distribution of the single-point ID estimates. We expect and that’s what we obtained as shown from the blue histogram in Fig. 6. On the other hand, the distribution obtained for the pool of correlated measurements (orange histogram in Fig. 6) shows a higher spread, indicating that the systematically underestimate the error of the . This was expected, as both the Bayesian and likelihood formulation assume to sample statistically independent observations. We can then conclude that the statistical dependence of neighborhoods in the calculation of ID leads to an error estimate which is slightly below the correct value but it is still very indicative.
VII Analytical results in continuum space
The ID estimation scheme proposed in our work can be easily extended and applied to different metrics than the lattice one (used to build the I3D). In particular, within any metric in the continuum space, the volume of the hyper-spheres scales as a canonical power law of the radius multiplied by a prefactor depending on both the dimension and the value :
As a consequence, the ratio of volumes that occurs in the binomial distribution of eq. (3) becomes
| (26) |
Because of the well-behaved scaling of the volume with the radius in continuous metrics, all formulas presented so far for the discrete case consistently simplify, allowing for further analytical derivations concerning both the MLE and Bayes analyses, as shown in the two following sections.
VII.1 Maximum Likelihood Estimation and Cramer-Rao lower bound
In the continuum case, given the previous expression for the ratio of volumes, the MLE and Cramer-Rao relations can be utterly simplified from Eq. (6) so that we can obtain an explicit form for the intrinsic dimension. Concretely, by substituting into eq. (6) we find
| (27) |
for the MLE, while the Cramer Rao inequality (19) becomes
| (28) |
In order to have an estimate as precise as possible, we are interested in the value of that minimize the variance. Being (28) a convex function, we find a single minimum that corresponds to
| (29) |
where is the Lambert function. Of course in principle we don’t know the intrinsic dimension of the system, and thus we don’t have a direct way to practically select if not through successive iterations. This relationship tells us that higher needs higher to provide a better estimate. The above relation also suggests that the optimal ratio between the points in the two shell should approach . This implies that there is an optimal and precise fraction of points, and thus volumes, for which the estimated ID is more accurate. Supposing that we are able to find such , we might ask how the variance scales with the dimensionality of the system. We obtain that
| (30) |
This implies that the precision of our estimator scales with the square of the dimension.
VII.2 Bayes formulation
Also the Bayesian derivations bring to analytical results in the continuum case. In particular, from eq. (23), one obtains
| (31) |
From this expression one can easily derive the first and second momenta of the distribution. In particular, performing the change of variable , we have
| (32) |
where is the digamma function; in the last step we have inserted the definitions for and from Eq. (22). By exploiting the same change of variable, also the variance ends up into a simple expression:
| (33) |
where is the trigamma function.
VIII Fractal lattices
As a further test to check the goodness of I3D, we compared the performance of the estimators on discrete fractal lattices, where Box Counting (BC) and Fractal Dimension (FD) already proved to be reliable[12, 17]. In Fig. 7, we report the ID as a function of the scale for the Koch curve (above), whose ID is and the Sierpinski gasket (below), with an ID of . As one can appreciate, the FD converges to the proper values only for large scales, where the discrete nature of the dataset is negligible, while BC and I3D quickly find the correct ID. However, the I3D adds a piece of information: it clearly shows at which scale the "fractality" of data comes into play. Indeed, by looking at the inset of the Sierpinski gasket, one notices that at a scale smaller than five the 2-dimensional structure is still prevailing.
IX Spin systems
IX.1 PCA on discrete spins
Here we address the possibility of performing PCA on discrete datapoints, justifying the results of the last section of the main text. We start from recalling that the continuous spins were generated using a linear embedding , so that it is possible to retrieve the directions of the generating vectors using standard PCA and a number of points .
In the case of spin states, the retrieval of is not so straightforward. In particular, two spin states differ from each other by a finite (and possibly very small) amount of spin flips. This means that we have a piece of information only on a fraction of the features, namely the varying spins. For this reason, we need many more points in order to gather statistics about the behaviour of the spins and how often they flip across the dataset. The idea is that PCA eigenvectors can capture the frequency of spin flips and give a proxy of the embedding directions . The result for ID=1 is reported in Fig. 9 and compares the generating vector and the first PCA eigenvector . The overlap is almost perfect, as we have .

In higher dimensions, the eigenvectors will be rotated with respect to the original embedding vectors, so that a direct visual comparison cannot be made as in the previous case. Hence, we estimate the residual of the overlap, defined as
| (34) |
In the 2-dimensional case, we find that , meaning that, like for the 1-dimensional example, we are able to retrieve of the generative process information.
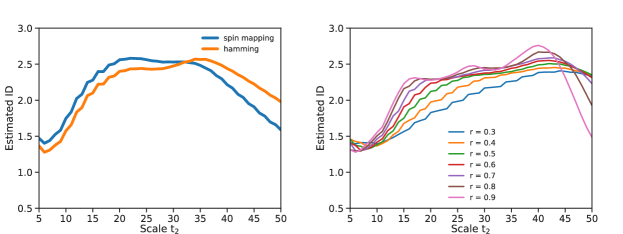
X Results for different nucleotide sequence distances and choices of radii ratio
One might wonder how the ID estimate depends on the metric used to compute the distance between sequences. As, anticipated in the main text, we considered two possible mappings. The first one maps each letter to a two spin state as follows: A:11, T:00, C:10 and G:01. The distance is then measured through Hamming or Manhattan indifferently. As a consequence complementary purine and pyrimidine are at distance 2, while other distances are just 1. The other possibility is to use the Hamming distance straightly on the sequences as they are, meaning that all nucleotides are equidistant one from the other. Fig. 10 (left) shows the ID as a function of the scale of the same cluster used in the main text. The behaviour of the ID depends very slightly on the chosen distance measure. For this reason we decided to stick to the spin mapping, as it allows retrieving the local "directions" of the generating process by a PCA analysis. Seemingly, different choices of the free parameter do not noticeably affect the ID estimate, especially in the plateau region (), where an ID can thus properly defined.