Intrinsic Knowledge Evaluation on Chinese Language Models
Abstract
Recent NLP tasks have benefited a lot from pre-trained language models (LM) since they are able to encode knowledge of various aspects. However, current LM evaluations focus on downstream performance, hence lack to comprehensively inspect on which aspect and to what extent have they encoded knowledge. This paper addresses both queries by proposing four tasks on syntactic, semantic, commonsense, and factual knowledge, aggregating to a total of questions covering both linguistic and world knowledge in Chinese. Throughout experiments, our probes and knowledge data prove to be a reliable benchmark for evaluating pre-trained Chinese LMs. Our work is publicly available at https://github.com/ZhiruoWang/ChnEval
1 Introduction
Recent years witnessed much success achieved by pre-trained LMs in the field of Natural Language Processing (Peters et al., 2018; Devlin et al., 2019). The performance of these models is often evaluated on downstream tasks like reading comprehension (RC), natural language inference (NLI), and sentiment analysis (SA). However, improvements on downstream hardly explain the reasons behind models’ excellence, as well as what they learn during pre-training. Therefore, an emerging body of work starts to investigate the knowledge encoded in their contextual representations.
Linguistic probing methods are designed to uncover the intriguing properties stored in the contextual representations. Among the linguistic knowledge, syntax is broadly explored across sensitive structures (Goldberg, 2019), grammatical correctness (Marvin and Linzen, 2018), and parsing dependencies (Hewitt and Manning, 2019). However, existing language probes face three challenges: (1) A skewing on syntax, for few semantic tasks ever study the contextual representations; (2) Most probes are built as classifiers that require extra training. It raises the question ‘Do the representations encode linguistic structure, or just that the probe has learned the linguistic task’ (Hewitt and Liang, 2019)? and (3) Existing probing tasks scope to only an English language setting.
In addition to the linguistics, tasks on common sense and facts are also introduced to test models on memorizing real-world knowledge during pre-training (Bisk et al., 2019; Zhou et al., 2019; Petroni et al., 2019). Nonetheless, the knowledge encoding ability of BERT is controversial (Poerner et al., 2019), and the template-based cloze questions are often too short to be leveraged by models for informative contextualizations.
Inspired by the above works, this paper proposes the first intrinsic knowledge evaluation benchmark of Chinese pre-trained LMs. Linguistically, it covers both the syntactic and semantic knowledge. One task aims at the language-specific syntactic features of Chinese, and another on language-independent semantic features. Meanwhile, we inspect world knowledge from two tasks on common sense and facts, further enable questions with natural contexts. All of the four tasks are designed to fit the LM structures and capabilities, i.e. making predictions directly from deep contextualized embeddings without additional tuning.
In the experiments, we test not only off-the-shelf models from CLUE project (Xu et al., 2020), but also four BERT variants granted with different training objectives that mimic BERT, RoBERTa, SpanBERT, and ALBERT. Our tasks and data sets prove to constitute a reliable evaluation benchmark. It effectively illustrates the advantages and disadvantages of different LMs over various aspects of knowledge.
2 Knowledge and Evaluation
2.1 Linguistic Knowledge
Linguistic knowledge is fundamental to language understanding. To examine the linguistic knowledge encoded in pre-trained LMs, we propose two language probing tasks to address both the syntactic and semantic regularities.
2.1.1 Syntactic Regularities
Chinese is a typical analytic language without explicit inflections, but uses function words and word order to convey grammatical information (Li et al., 2018). In the following case, the auxiliary word ‘le’ indicates the perfective tense, and the preposition ‘bǎ’ is used to emphasize the object by changing the word order from S-V-O to S-bǎ–O-V:
wǒ(I) bǎ shū(book) kàn(read) wán(finish) le.
(I have finished reading the book.)
A good word-level test on syntax, hence, is whether they can utilize function words aptly. This paper considers five categories of function words: conjunctions (C), adverbs (D), prepositions (P), auxiliary words (U), and direction nouns (ND). In this task, we mask function words in sentences to form cloze questions, in which the models leverage contextual information to make predictions.
2.1.2 Semantic Regularities
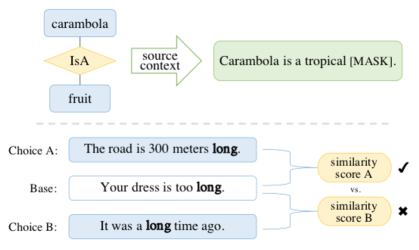
As noted by Firth (1957), ‘you shall know a word by the company it keeps’. To comprehend a polysemous word, one must dynamically infer its meaning from surrounding contexts. For example, meanings of the word ‘long’ vary in
A: The road is long.
B: I have been exercising for a long time.
While in A it measures a substantive object, B tells a lapse of time.
Since pre-trained LMs can inherently capture complexities of word use (Peters et al., 2018), we propose a word sense similarity task to test their discrimination between nuances. Intuitively, given
C: The table is 1-meter long.
A qualified model shall put this ‘long’ akin to that of A, and set it apart with B. As such, this task is built as multiple-choice questions. Each has three sentences—base, answer, and distractor—with identical words. Meaning of target words accords in base-answer and differs in base-distractor. Their final-layer contextual representations , and are taken, to compute the cosine similarities of base-answer and base-distractor pairs. We expect base-answer to score higher.
2.2 World Knowledge
Besides learning linguistic knowledge, tasks like Question Answering (QA) and Reading Comprehension (RC) often require real-world knowledge beyond contexts. We investigate world knowledge in common sense and encyclopedia facts.
2.2.1 Common Sense
Common sense is practical judgments about routine affairs. For example, ‘the hot weather’ makes you‘thirsty’ shows a causality. If a model can sense the common ‘thirsty’ from the premise of a hot day, it can benefit from this logical inference. Following Petroni et al. (2019) that uses ConceptNet (Speer et al., 2017) word pairs, we take the Chinese pairs, put them into the provided text templates (Kuo et al., 2009), and mask items to create clozes.
2.2.2 Encyclopedia Fact
Facts, often as (entity, relation, attribute) triples in Knowledge Bases, are helpful in NLP scenarios. To answer ‘How do carambolas taste like?’, a prior knowledge (carambola, IsA, fruit) can inform the possibly sweet or sour taste of fruits.
Different from the template-based commonsense clozes, we present fact triples in their natural contexts (i.e. the source texts that they were extracted from), to allow more contextual information and minimize manual intervention. That is, we link the above triple to its wiki introduction111Only triples fully covered by its wikitext are kept. Paired contents are sheared to lengths within characters.. After masking the item ‘fruit’, the input reads: Carambola is a tropical [MASK] in Southeast Asia. The greater chances that a model predicts words right, the better we assume its encoding of concerned knowledge is.
| Knowledge | Task | Form | Sub-class | Size |
|---|---|---|---|---|
| syntactic | function word prediction | cloze questions | 5 | 29345 |
| semantic | word sense similarity | multiple-choice questions | N/A | 5790 |
| commonsense | target (pair item) prediction | cloze questions | N/A | 3111 |
| encyclopedia | target (triple item) prediction | cloze questions | N/A | 1062 |
2.3 Dataset Construction
In general, our tasks have two forms: (1) multiple-choice questions for semantic knowledge; and (2) cloze questions for function word, commonsense and fact inferences. Unlike existing probing tasks that use additional classifiers, our tasks allow pre-trained LMs to make predictions directly from their contextual representations. This design mitigates influences of the tuning process (Hewitt and Liang, 2019), hence can enable a fairer overall evaluation.
The word sense similarity task uses sentences in CTC corpus222http://www.aihanyu.org/basic_v2/index.html, a Chinese textbook corpus with manual sense labeling on polysemous words. To balance the data set, we allow at most questions per meaning and questions per word, resulting in questions from words.
For syntactic knowledge, we extract sentences that have function words from CTC corpus as well, in the end created clozes for type (C, D, P, U, ND) respectively.
Regarding world knowledge, we present common sense using templates and factual triples in natural contexts just as described above. Target items—prefer objectrelation (if has)subjects—are masked to create cloze questions. Common sense adapts from the Chinese part of ConceptNet (Speer et al., 2017), in which pairs from relation types are usable after professional manual inspection. For facts, we built clozes using a Chinese Knowledge Base built upon encyclopedia called CN-DBpedia (Xu et al., 2017).
In these data sets, target words only appear once in their contexts, and sentences within a data set never repeat. We end up obtained four data sets counting to questions in total. Table 1 is a summary of these knowledge data sets. See more details of manual checks and illustrated examples in Appendix B and C. For evaluation results, unless otherwise stated, we report the average score if multiple classes occur333Calculate prediction accuracy firstly within each category, then averaged across classes..
| Data Set | Metrics | BERT | BERT | BERT | RoBERTa |
|---|---|---|---|---|---|
| -wwm | -wwm-ext | -wwm-ext | |||
| syntactic | P@1/10 | 38.8 / 76.8 | 42.7 / 77.8 | 42.4 / 77.5 | 56.9 / 88.0 |
| semantic | acc. | 69.7 | 69.8 | 71.2 | 73.1 |
| commonsense | P@1/10 | 3.38 / 21.63 | 1.32 / 18.55 | 2.12 / 15.30 | 19.83 / 43.56 |
| encyclopedia | P@1/10 | 29.1 / 65.1 | 34.8 / 67.7 | 32.6 / 68.9 | 60.3 / 85.7 |
| CMRC (Cui et al., 2019b) | avg. EM/F1 | 68.7 / 86.3 | 69.1 / 86.7 | 70.0 / 87.0 | 71.4 / 88.8 |
| XNLI (Conneau et al., 2018) | avg. acc. | 77.5 | 78.0 | 78.3 | 78.3 |
| ChnSentiCorp (Cui et al., 2019a) | avg. acc. | 94.7 | 95.0 | 94.7 | 94.8 |
| THUCNews (Sum et al., 2016) | avg. acc. | 97.6 | 97.6 | 97.5 | 97.5 |
| Data Set | Metrics | MLM | MLM + SBO | MLM + SOP | MLM + NSP |
|---|---|---|---|---|---|
| syntactic | P@1/10 | 53.4 / 86.4 | 41.4 / 78.1 | 36.3 / 72.7 | 50.0 / 83.8 |
| semantic | acc. | 73.4 | 69.0 | 70.1 | 71.6 |
| commonsense | P@1/10 | 13.95 / 37.93 | 7.88 / 22.50 | 3.44 / 16.33 | 9.39 / 37.39 |
| encyclopedia | P@1/10 | 69.5 / 90.7 | 48.3 / 80.2 | 33.7 / 69.1 | 63.6 / 85.0 |
3 Experiment
3.1 Models
Many Chinese language models are publicly available at CLUE (Xu et al., 2020). To reduce computing cost and keep candidates comparable in size, we test the models in BASE-size: BERT (Devlin et al., 2019), BERT-wwm, BERT-wwm-ext, and RoBERTa-wwm-ext (Cui et al., 2019a)444More specified model configurations list in Appendix C.
Also, to compare the performance between training objectives, we implement four variants:
BERT (MLM+NSP): Masked Language Model and Next Sentence Prediction as in BERT.
RoBERTa (MLM): Remove NSP, often benefit from longer sequences and fewer topic conflicts.
SpanBERT (MLM+SBO): Add a span-shrunk version of the Subject Boundary Objective (Joshi et al., 2020). We mask single tokens instead of spans to control variables.
ALBERT (MLM+SOP): Replace NSP with the Sentence Order Prediction (Lan et al., 2019), guide bi-spans on inter-logic rather than topic conformity.
Training from scratch costs, so we initialize them with BERT-base-chinese and train for additional steps at a batch size using Baidu Baike corpus. Other settings align with BERT.
3.2 Results and discussion
Table 2 shows the results of off-the-shelf models, on our intrinsic knowledge tasks and four extrinsic NLP tasks. Our three observations read as follows.
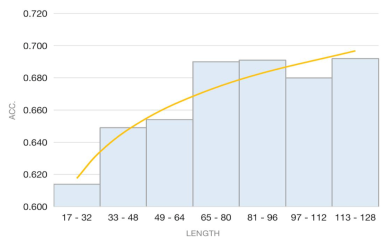
First, pre-trained Chinese LMs using natural contexts capture the linguistic and factual knowledge well. However, they do poorly on commonsense questions, probably because they are not fully capable of storing relationally-structured knowledge (Poerner et al., 2019). For another, template-based clozes might be too short triggers for models to yield informative contextual representations. To further verify our hypothesis, we bucket fact clozes based on text length, study the trend depending on lengths, then illustrate in Figure 2.
Second, pre-process with whole-word-masking and pre-train with additional data, consistently enhance the performance in most intrinsic tasks. Removing the NSP objective further helps. RoBERTa-wwm-ext, who integrates all of the three advantages, scores the highest on intrinsic tasks.
Third, by comparing the intrinsic tasks against extrinsic ones, we observe that the intrinsic tasks ring more sensitive to changes in model structures and training data. Among extrinsic tasks, only in Reading Comprehension that models consistently improve with upgraded masking strategy and training corpora. XNLI doesn’t lead to any difference between BERT-wwm-ext and RoBERTa-wwm-ext. The other two classification tasks vary trivially across four models. These results suggest that our intrinsic tasks can reflect model discrepancies in more elaborate ways than extrinsic ones, further, unveil knowledge encoding from various aspects.
Note that these intrinsic knowledge evaluations can also shed light on the structural design of LMs. Since most off-the-shelf models vary diversely (in the corpus, parameters, and more), we focus on a single factor, the training objectives. We implemented four BERT variants and make a preliminary study of their effects on knowledge encoding abilities. As shown in Table 3. MLM (RoBERTa) strikes the best in all knowledge aspects. Boundary information (SBO) barely helps, for it may suit spans better than single tokens. NSP surpasses SOP in most cases, showing a priority of topic conformity at bi-span training.
4 Conclusion and Future Work
In this paper, we present the first intrinsic knowledge evaluation data set of Chinese pre-trained LMs, ranging from syntactic, semantic, commonsense, to factual knowledge. The experiments show that our tasks and data sets constitute a reliable evaluation benchmark. It effectively uncovers not only the pros and cons of different LMs over a varied aspects of knowledge. Further, it offers insight on structural designs. With these tasks, we can make an in-depth analysis of LM knowledge encoding in the future and better understand the “black box” of Neural Network methods. Last but not least, our task building methods can apply well to other language environments.
References
- Bisk et al. (2019) Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. 2019. Piqa: Reasoning about physical commonsense in natural language. arXiv preprint arXiv:1911.11641.
- Conneau et al. (2018) Alexis Conneau, Ruty Rinott, Guillaume Lample, Adina Williams, Samuel R. Bowman, Holger Schwenk, and Veselin Stoyanov. 2018. Xnli: Evaluating cross-lingual sentence representations. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics.
- Cui et al. (2019a) Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, Ziqing Yang, Shijin Wang, and Guoping Hu. 2019a. Pre-training with whole word masking for chinese bert. arXiv preprint arXiv:1906.08101.
- Cui et al. (2019b) Yiming Cui, Ting Liu, Wanxiang Che, Li Xiao, Zhipeng Chen, Wentao Ma, Shijin Wang, and Guoping Hu. 2019b. A span-extraction dataset for Chinese machine reading comprehension. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 5886–5891, Hong Kong, China. Association for Computational Linguistics.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186.
- Firth (1957) John R Firth. 1957. A synopsis of linguistic theory, 1930-1955. Studies in linguistic analysis.
- Goldberg (2019) Yoav Goldberg. 2019. Assessing bert’s syntactic abilities. arXiv preprint arXiv:1901.05287.
- Hewitt and Liang (2019) John Hewitt and Percy Liang. 2019. Designing and interpreting probes with control tasks. arXiv preprint arXiv:1909.03368.
- Hewitt and Manning (2019) John Hewitt and Christopher D Manning. 2019. A structural probe for finding syntax in word representations. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4129–4138.
- Joshi et al. (2020) Mandar Joshi, Danqi Chen, Yinhan Liu, Daniel S Weld, Luke Zettlemoyer, and Omer Levy. 2020. Spanbert: Improving pre-training by representing and predicting spans. Transactions of the Association for Computational Linguistics, 8:64–77.
- Kuo et al. (2009) Yen-ling Kuo, Jong-Chuan Lee, Kai-yang Chiang, Rex Wang, Edward Shen, Cheng-wei Chan, and Jane Yung-jen Hsu. 2009. Community-based game design: experiments on social games for commonsense data collection. In Proceedings of the acm sigkdd workshop on human computation, pages 15–22.
- Lan et al. (2019) Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. 2019. Albert: A lite bert for self-supervised learning of language representations. arXiv preprint arXiv:1909.11942.
- Li et al. (2018) Shen Li, Zhe Zhao, Renfen Hu, Wensi Li, Tao Liu, and Xiaoyong Du. 2018. Analogical reasoning on chinese morphological and semantic relations. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 138–143.
- Marvin and Linzen (2018) Rebecca Marvin and Tal Linzen. 2018. Targeted syntactic evaluation of language models. arXiv preprint arXiv:1808.09031.
- Peters et al. (2018) Matthew E Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. 2018. Deep contextualized word representations. arXiv preprint arXiv:1802.05365.
- Petroni et al. (2019) Fabio Petroni, Tim Rocktäschel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, Alexander H Miller, and Sebastian Riedel. 2019. Language models as knowledge bases? arXiv preprint arXiv:1909.01066.
- Poerner et al. (2019) Nina Poerner, Ulli Waltinger, and Hinrich Schütze. 2019. Bert is not a knowledge base (yet): Factual knowledge vs. name-based reasoning in unsupervised qa. arXiv preprint arXiv:1911.03681.
- Speer et al. (2017) Robyn Speer, Joshua Chin, and Catherine Havasi. 2017. Conceptnet 5.5: An open multilingual graph of general knowledge. In Thirty-First AAAI Conference on Artificial Intelligence.
- Sum et al. (2016) M Sum, J Li, Z Guo, Y Zhao, Y Zheng, X Si, and Z Liu. 2016. Thuctc: an efficient chinese text classifier. GitHub Repository.
- Xu et al. (2017) Bo Xu, Yong Xu, Jiaqing Liang, Chenhao Xie, Bin Liang, Wanyun Cui, and Yanghua Xiao. 2017. Cn-dbpedia: A never-ending chinese knowledge extraction system. In International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems, pages 428–438. Springer.
- Xu et al. (2020) Liang Xu, Xuanwei Zhang, Lu Li, Hai Hu, Chenjie Cao, Weitang Liu, Junyi Li, Yudong Li, Kai Sun, Yechen Xu, et al. 2020. Clue: A chinese language understanding evaluation benchmark. arXiv preprint arXiv:2004.05986.
- Zhou et al. (2019) Xuhui Zhou, Yue Zhang, Leyang Cui, and Dandan Huang. 2019. Evaluating commonsense in pre-trained language models. arXiv preprint arXiv:1911.11931.
Appendix A Model Specifications
Here we specify several configuration details about off-the-shelf candidates in Table 4.
| - | Masking | Data Source | Training Steps | Optimizer |
|---|---|---|---|---|
| BERT | WordPiece | wiki | AdamW | |
| BERT-wwm | WWM | wiki | LAMB | |
| BERT-wwm-ext | WWM | wiki+ext | LAMB | |
| RoBERTa-wwm-ext | WWM | wiki+ext | AdamW |
Appendix B Data Sets
Chinese Knowledge Evaluation (CKE) benchmark includes four tasks on linguistic and world knowledge. For a better illustration, a summary of the data sets is shown in Table 5.
| Knowledge | Data Set | Task | Form | Sub-class | Size |
|---|---|---|---|---|---|
| linguistic | syntactic | word function prediction | cloze questions | conjunction (C) | 3776 |
| adverb (D) | 10132 | ||||
| preposition (P) | 5887 | ||||
| auxiliary (U) | 5711 | ||||
| direction nouns (ND) | 3839 | ||||
| semantic | word-sense similarity | multiple-choice questions | N/A | 5790 | |
| world | commonsense | target (pair item) prediction | cloze questions | N/A | 3111 |
| encyclopedia | target (triple item) prediction | cloze questions | N/A | 1062 |
Appendix C Manual Check
The source of linguistic knowledge has been repetitively checked by professionals. Encyclopedia facts are supported with references and open to user reviews. Hence, their resulting knowledge data sets have ensured qualities. Similarly, to ensure the quality of commonsense data, a series of manual revisions are performed on ConceptNet (the Chinese part) by six graduate students of linguistics majors. Also, to ensure a unified common sense and language sense, training and annotation trials are performed before the revision. Revisions on the Chinese ConceptNet pairs include:
Step 1: Cases having non-unique answers are removed.
Step 2: Cases not in line with human commonsense are manually filtered out. They can be categorized into three types:
illogical or perverse: (relation: MotivatedByGoal)
你会[?]因为你没钱。[哭]
(You will [?] because you have no money. [cry])
indefinite answer: (relation: HasSubevent)
可能代表一种元素。[钠]
([?] may represent an element. [sodium])
violate universal value: (relation: Desires)
[?]惧怕庙宇。[鬼]
([?] fear temple. [ghost])
Step 3: For cases that conform to common sense but are ungrammatical, sentences are further manually modified or re-written. For an example of the relation type ’Causes’(though the English translation may hardly make sense):
镜子会让你[照]。
(The mirror will let you take a look.)
changes to: 镜子是用来[照]的。
(The mirror is used for taking a look.)
Note that after modifying the ungrammatical parts, the original relation type of that sentence may not be retained, such as the ‘Causes’ changes to ‘UsedFor’ in the above example. Therefore, the final dataset no longer divides into different relation types but combines into a single file.
Step 4: Finally, manually proofread the results of Step 2 and Step 3.
Appendix D Examples
In this section, we illustrate several examples for each of the four introduced tasks.
Syntactic Regularities
For the syntax of words, we showcase one function word for each function class in Table 6.
| Function | Word | Sentence |
|---|---|---|
| conjunction (C) | 但 | 我会跳舞,但跳得不怎么样。 |
| I can dance, but not very well. | ||
| adverb (D) | 很 | 我在青岛住过三年,很喜爱它。 |
| I have lived in Qingdao for three years and love it very much. | ||
| preposition (P) | 被 | 你看,花瓶也被他们打破了。 |
| Look, the vase was also broken by them. | ||
| auxiliary (U) | 吗 | 知道是什么意思吗? |
| Do you know what it means? | ||
| direction nouns (ND) | 里 | 小狗怎么在厨房里叫呢? |
| Why do puppies bark in the kitchen? |
Semantic Regularities
For the meaning of words, we take the Chinese word ‘兜’ () as an example, Table 7 the candidate sentences that are extracted from the textbook corpus, and Table 8 lists two example questions that are generated from the candidates.
| Word | Sense ID | Candidate Sentences |
|---|---|---|
| 兜 | 0 | 连小学生也有手机,只要装在衣服兜儿里就可以。 |
|
||
| 推让了半天,最后我还是把钱塞进了他的兜里。 | ||
| After a long time, I still put the money in his pocket. | ||
| 母亲实在太想孙子了,进屋就从兜儿里掏出一把糖来给孙子。 | ||
|
||
| 1 | 车夫回来的时候兜不到生意。 | |
| The driver couldn’t take business when he came back. | ||
| 2 | 我喜欢从一条熟的道路出去溜达,然后从一条生的道路兜个圈子回家。 | |
|
||
| 假如我显露出困惑,老师就会停顿他讲解的步伐,在原地连兜几个圈子。 | ||
|
| No. | Type | Sentences |
|---|---|---|
| 0 | Base | 我喜欢从一条熟的道路出去溜达,然后从一条生的道路兜个圈子回家。 |
|
||
| Answer | 假如我显露出困惑,老师就会停顿他讲解的步伐,在原地连兜几个圈子。 | |
|
||
| Distractor | 连小学生也有手机,只要装在衣服兜儿里就可以。 | |
|
||
| 1 | Base | 推让了半天,最后我还是把钱塞进了他的兜里。 |
| After a long time, I still put the money in his pocket. | ||
| Answer | 母亲实在太想孙子了,进屋就从兜儿里掏出一把糖来给孙子。 | |
|
||
| Distractor | 车夫回来的时候兜不到生意。 | |
| The driver couldn’t take business when he came back. |
Common Sense
We examplify word pairs and text templates for each relation in Table 9.
| Subject | Object | Text Template |
|---|---|---|
| 床 | 卧室 | 床在卧室里。 |
| bed | bedroom | Bed is in the bedroom. |
| 悲伤 | 哭 | 悲伤的时候,你会哭。 |
| sad | cry | When you are sad, you cry. |
| 热 | 流汗 | 热的时候会流汗。 |
| hot | sweat | Sweat when it is hot. |
| 优酪乳 | 甜 | 优酪乳是甜的。 |
| yogurt | sweet | Yogurt is sweet. |
Encyclopedia Fact
For factual information, we present knowledge triples in their sourced natural contexts as in Table 10.
| Entity | Relation | Attribute |
| 长尾棕蝠 | 目 | 翼手目 |
| Long-tailed brown bats | order | pterodactyles |
| 长尾棕蝠是哺乳动物,翼手目、蝙蝠科动物。 | ||
| Long-tailed brown bats are mammals, pterodactyles, bats. | ||
| 清香砂锅鸡 | 主要原料 | 酒 |
| Fragrant Casserole Chicken | main ingredients | wine |
| 清香砂锅鸡是一道美食,主要原料有鸡、香菇、酒。 | ||
| The main ingredients of Fragrant Casserole Chicken are chicken, mushrooms, and wine. | ||
| 塔吉克国旗 | 颜色 | 红 |
| the national flag of Tajikistan | color | red |
| 塔吉克国旗,主要颜色是红、白、绿三色。 | ||
| The national flag of Tajikistan is mainly red, white and green. | ||