Inverse Cubic Iteration
Abstract
There are thousands of papers on rootfinding for nonlinear scalar equations. Here is one more, to talk about an apparently new method, which I call “Inverse Cubic Iteration” (ICI) in analogy to the Inverse Quadratic Iteration in Richard Brent’s zeroin method. The possibly new method is based on a cubic blend of tangent-line approximations for the inverse function. We rewrite this iteration for numerical stability as an average of two Newton steps and a secant step: only one new function evaluation and derivative evaluation is needed for each step. The total cost of the method is therefore only trivially more than Newton’s method, and we will see that it has order , thus ensuring that to achieve a given accuracy it usually takes fewer steps than Newton’s method while using essentially the same effort per step.
1 Introduction
Recently I wrote, with Erik Postma, a paper on blends of Taylor series [3]. A “blend” is just a two-point Hermite interpolant: if we have series for at and another series for the same function at then we can blend the series to get a (usually) better approximation to across the interval. The paper discusses how to compute high-order blends stably and efficiently in Maple, and looks at some applications of them.
In contrast, this paper looks at a low-order blend, and a particular application, namely rootfinding. In fact all we will need is a cubic. If we just use series up to and including terms of order at each point, namely and and and then these four pieces of information determine, as is well known, a cubic Hermite interpolant.
What is less well-known (but still perfectly well-known, to be honest) is that from these same pieces of information one can usually construct a cubic interpolant of the inverse function inv, also written . The data for that information is that the points of expansion are and , and the function values are and , and the derivative values are and : four pieces of information which together suffice to determine a cubic polynomial in that fits the data.
Of course we cannot have or , and indeed anywhere near the interval is bad news for a rootfinder: the root will be ill-conditioned, if it’s determined at all. If anywhere in the interval then the function is not guaranteed to be monotonic, and so the inverse function will not be defined in the whole neighbourhood. Throwing caution to the winds, we’re not going to worry about this at all.
2 Derivation of the Formula
Nearly any numerical analysis textbook will have an expression equivalent to the following for a cubic Hermite interpolant, fitting four pieces of information to get a cubic polynomial that fits those pieces of information:
| (1) |
where and . When , ; when , . Since the derivative we see that it all works out: when , and when and when .
Now we do the inverse. Put and . We see right away that we are in trouble if ; but then, by Rolle’s theorem there would be a place between and where if that were the case, and we have already said that we are going to ignore that difficulty. Indeed, both Inverse Quadratic Iteration (IQI) and the secant method also fail in that case, so at least we are in good company.
We want
| (2) |
By similar reasoning to before, we see that at then and , while at then and .
Why do this? The wonderfully simple trick of Inverse Quadratic Iteration, namely that to find an approximate value of that makes one simply substitutes into the Inverse formula, also works here. Putting means (a number between and ) and that gets us our definite value of . Doing this blindly, we get
| (3) |
This is correct, but I suspect numerically useless. To be honest, I didn’t even try it. Instead, I looked for a way to rewrite it to improve its numerical stability.
3 A numerically more stable expression
After a surprisingly small amount of algebraic manipulation (perhaps a generous share of luck was involved) I arrived at the following:
| (4) |
Call this iteration Inverse Cubic Iteration, or ICI. Instead of presenting a tedious transformation of the previous formula into the one above (it is equivalent, trust me, although I did make the sleight-of-hand transformation from and to and , implying iteration), I will verify that it has the appropriate behaviour in the next section; we will look there at how quickly it converges to a root (when it converges at all). The interesting part of this, to me, is that we can recognize all three terms in equation (4). There is a Newton iteration starting at , another at , and a secant iteration using both points. Then all three are averaged together111It might be numerically better still to average the previous points , and average the small updates , and then use this average update to improve the average of the previous points. Currently this is the way my implementation does it, but it may not make much difference.: the weights are , , and all divided by so that the weights all add up to , as they should. The most accurate estimate is given the most weight, by using the residuals on the other estimates. I think this is a rather pretty formula.
The numerical stability (or lack thereof) of the secant method and of Newton’s method is well-understood; by writing the secant method as above we make a “small change” to an existing value, and similarly Newton’s method is written in as stable a way as it can be. Thus we have what is likely to be a reasonably stable iteration formula.
Because this method uses two points and to generate a third point , it seems similar to the secant method. Because it uses derivatives at each point, it seems similar to Newton’s method. It is not very similar to IQI, which fits an inverse quadratic to three points and uses that to generate a fourth. Halley’s method and other Schröder iterations use higher derivatives and will be more expensive per step. [It might be interesting to try to average higher-order methods in a similar manner to speed up convergence even more; so far I have not been able to succeed in doing so. The simple trick of replacing by which transforms Newton’s method to Halley’s method (and speeds up secant) does not seem to work, with these weights.]
I am going to assume that we start with a single initial guess and then generate by a single step of Newton’s method. Then it is obvious that to carry out one step with equation (4) we need only one more function evaluation and one more derivative evaluation , because we can record the previous and instead of recomputing them. In the standard model of rootfinding iteration where the dominant cost is function evaluation and derivative evaluation, we see that this method is no more expensive than Newton’s method itself. But instead of computing and forgetting all about , once we have formed this Newton iteration we average it with the previous Newton iteration together with a secant iteration: the cost of forming this average is no more than a few floating-point operations, which we may consider to be trivial compared to the assumed treasury-breaking expense of evaluating and . When we try this on Newton’s classical example with an initial guess of we get Digits of accuracy after iterations ( Digits of accuracy after iterations).
I will sketch the cost of this method using the normal conventions in section 5.
4 The order of the method
If we assume that is the root we are searching for, , and that and then a straightforward and brutal series computation in Maple shows that
| (5) |
The error in the residual, which is what we will actually measure, is ever so slightly different: and so we can remove one factor from the denominator term above. Notice that each exactly solves ; this is a trivial observation, but often useful: by iterating, we get the exact solutions to slightly different equations. Here, though, it doesn’t matter. Both formulae show the trend of the errors. That is, the error in the next iterate is the square of the product of the two previous errors. This is satisfyingly analogous to that of the secant method (product of the two previous errors) and Newton’s method (square of the previous error). Solving the recurrence relation shows that the error is asymptotically the th power of the previous one; not quite cubic convergence, but substantially faster than quadratic convergence.
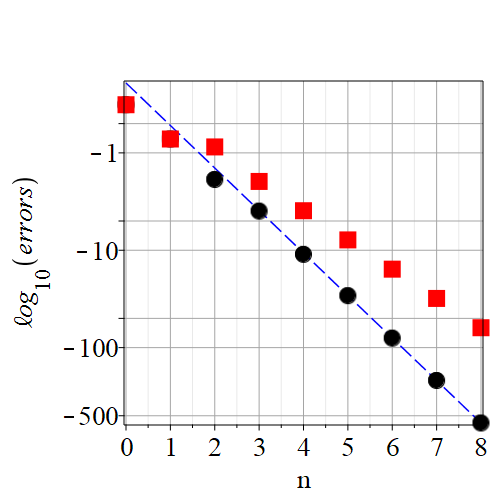
Let’s take the method out for a spin to see if practice matches theory. Consider the function . This has two places where , namely . Provided we stay away from there, we should be fine. Taking our initial guess to be , we then compute by Newton’s method as usual. Now we have two iterates to work with; we then compute , , , . Because convergence is so rapid, and I wanted to demonstrate it, I worked with Digits set to be . This was overkill, but it allows the plot in figure 1 to show clearly that the error in is about . Newton’s method (red squares) achieves only with the same effort. The ratios for , , , were, respectively, , , , , , , and . These fit the curve , demonstrating the near-cubic order of the method. The constant was found by fitting to the final data point. This trend predicts that the accuracy in would be . Re-doing the computation in Digits and extending to , we get , just as predicted.
5 The cost of the method
The best analysis—that I know—of the cost of Newton’s method for solving a scalar equation by iterating with constant precision is contained in [9]. There, the author weighs the cost of function evaluations and estimates that the cost of derivative evaluations are usually a modest factor larger than that of function evaluations; then, balancing the greater cost of Newton’s method per step against its general need for fewer iterations, he concludes that usually the secant method should win. Yes, the secant method usually takes more iterations; but each one usually costs only a fraction of a Newton step. It is only when the derivatives are unusually inexpensive that Newton’s method wins. For the example in figure 1 this is the case: the dominant cost of the function evaluation is the exponential, and that can be re-used in the derivative. So, for this particular problem, ICI should win over Newton’s method and even more decisively over the secant method. But to win over Newton’s method, ICI needs to take fewer iterations, because the cost per step is essentially identical to Newton’s method. ICI will never222“What, never?” “No, never!” “What, never?” “Hardly ever!” —the crew and Captain of HMS Pinafore take more iterations than Newton’s method. But will it take fewer?
That is actually the issue. Will we save any iterations at all? Newton’s method typically converges very rapidly, given a good initial guess. To give a very rough sketch, if the initial error is and all the constants are , we can expect a double precision answer in five iterations (actually the error then would be wasted: , and rounding errors would have made it at best ). ICI would have the sequence of errors , (same as Newton for the iterate, of course), squaring the product , then which is the same error that Newton achieved in four iterations. One more gets us which is a vast overkill; still, we have beaten Newton by one iteration with this initial error.
If instead the initial guess is only accurate to , not , then Newton takes six iterations while ICI also takes six: , , , , .
If instead the initial guess is accurate to then Newton takes five iterations, while ICI takes , , and at four iterations beats Newton.
The lesson seems clear: if one wants ultra-high precision, the ICI method will give the same results in fewer iterations of essentially the same cost. If one only wants a double precision result, then the number of iterations you save may not be much, if any (and if it doesn’t really beat Newton, then it won’t often beat the secant method). And both methods demand good initial guesses.
6 Initial guesses
I have been using the scheme “choose only one initial guess and let Newton’s method determine the next iterate” above. Obviously there are alternative strategies. I like this one because it’s usually hard enough to come up with one initial guess to a root, let alone two.
Using this strategy also allows one to plot basins of attraction: which initial guesses converge to which root? I took the function and sampled a by grid on , where and took at most iterations of ICI starting from each gridpoint; if the iteration converged (to ) earlier, that earlier result was recorded. Plotting the argument (phase) of the answer gives an apparent fractal diagram, very similar to that for Newton’s method, but different in detail. In particular, the basins of attraction are visibly disconnected. See figures 2 and 3.


7 Multiple roots and infinite derivatives
Of course this method won’t help with multiple roots. We’re dividing by derivatives, which go to zero if we approach a multiple root. It’s true that the method can work, but if it does it will work more slowly; even so, the sequence will just grow without bound. I tried this, on , with , and this expectation is correct. The method did converge in ten iterations to the double root , with an error of about , but note that Newton’s method also converges linearly for this problem.
Another place for failure of rootfinding is when any derivative is infinite—that is, at or near derivative singularities. The presence of up to the fourth derivative in the error formula (5) suggests that this method will be more sensitive to singularities than Newton’s method is.
8 Where to, next
The first question to ask is, can this work for nonlinear systems of equations? Even though this method, stripped of its origins, is just a weighted average of two Newton iterations and a secant iteration, all of which can be used for systems, I find that I am dubious. It’s not clear to me what to use for the scalar weights: replace e.g. by using some norm? Which norm? Perhaps it will work, with the right choice. But even if it did, for large systems the largest computational effort is usually spent in setting up and solving the linear systems: full Newton iteration is rarely used, when cheaper approximate iterations will get you there faster. Moreover, the real benefit of the higher speed of convergence of ICI isn’t fully felt at double precision or lower—I think it will only matter for quad precision (double-double!) or better.
I believe that the best that can be hoped for from this method is to be used in a computer algebra system for its high-precision scalar solvers, which currently might use other high-order iterations. It is here, if anywhere, where this method will be useful.
There may be similar two-step iterations of higher order, perhaps starting with “inverse quintic iteration” which uses terms up to the second derivative and would have order . I have not yet investigated any such schemes.
In ultra high-precision applications there is sometimes the option to change precision as you go. This is effective for Newton iteration; only the final function evaluation and derivative evaluation need to be done at the highest precision. I have not investigated the effects of variable precision on the efficiency of this method.
Then there are more practical matters: what to do in the inevitable case when ? [This happens when the iteration converges, for instance!] Or when is too small? It turns out that the details of the extremely practical zeroin method [1] which combines IQI with bisection and the secant method for increased reliability (this method is implemented in fzero command in Matlab) matter quite a bit. More improvements on the method can be found in [11], which make the worst-case behaviour better. Attention needs to be paid to these details.
Then there is another academic matter: in all those tens of thousands of papers on rootfinding, has nobody thought of this before? Really? Again, I find that I am dubious, although as a two-step method it is technically not one of Schröder’s iterations (which keep getting reinvented). And it’s not one of Kalantari’s methods either [5]. But it’s such a pretty method—surely someone would have noticed it before, and tried to write about it? Perhaps it’s an exercise in one of the grand old numerical analysis texts, like Rutishauser’s (which I don’t have a copy of).
There are (literally) an infinite number of iterative methods to choose from; see the references in [7] for a pointer to the literature, including to [10] and from there to G. W. Stewart’s translation of Schröder’s work from the th century, entitled “On infinitely many algorithms for solving equations”. The bibliography [8] has tens of thousands of entries.
However, searching the web for “Inverse Cubic Iteration” (surely a natural name) fails. We do find papers when searching for names like “Accelerated Newton’s method”, such as [4]; but the ones I have found are each different to ICI (for instance the last-cited paper finds a true third-order method; ICI is not quite third-order but only ). The method of [6], termed “Leap-Frog Newton”, is quite similar to ICI and consists of an intermediate Newton value followed by a secant step: this costs two function evaluations and a derivative evaluation per step (so is more expensive per step than is ICI which requires only one function evaluation and derivative evaluation per step after the first one) but is genuinely third order. I found this last paper by searching for “combining Newton and secant iterations,” so perhaps I could find papers describing closer matches to ICI, if only I could think of the correct search term. I am currently asking my friends and acquaintances if they know of any. Do you?
“Six months in the laboratory can save you three days in the library.”
—folklore as told to me by Henning Rasmussen
References
- [1] R. P. Brent. An algorithm with guaranteed convergence for finding a zero of a function. The Computer Journal, 14(4):422–425, 01 1971.
- [2] Robert M Corless and Nicolas Fillion. A graduate introduction to numerical methods, volume 10. Springer, 2013.
- [3] Robert M. Corless and Erik Postma. Blends in Maple. arXiv 2007.05041, 2020.
- [4] J. M. Gutiérrez and M. A. Hernández. An acceleration of Newton’s method: Super-Halley method. Appl. Math. Comput., 117(2–3):223–239, January 2001.
- [5] Bahman Kalantari. Polynomial root-finding and polynomiography. World Scientific, 2008.
- [6] A Bathi Kasturiarachi. Leap-frogging Newton’s method. International Journal of Mathematical Education in Science and Technology, 33(4):521–527, 2002.
- [7] Ao Li and Robert M Corless. Revisiting Gilbert Strang’s “a chaotic search for ”. ACM Communications in Computer Algebra, 53(1):1–22, 2019.
- [8] J.M. McNamee. Numerical methods for roots of polynomials. Elsevier Science Limited, 2007.
- [9] A. Neumaier. Introduction to numerical analysis. Cambridge University Press, 2001.
- [10] MS Petković, LD Petković, and D. Herceg. On Schröder’s families of root-finding methods. Journal of computational and applied mathematics, 233(8):1755–1762, 2010.
- [11] Gautam Wilkins and Ming Gu. A modified Brent’s method for finding zeros of functions. Numerische Mathematik, 123(1):177–188, 2013.
