Investigating Subtler Biases in LLMs:
Ageism, Beauty, Institutional, and Nationality Bias in Generative Models
Abstract
LLMs are increasingly powerful and widely used to assist users in a variety of tasks. This use risks introducing LLM biases into consequential decisions such as job hiring, human performance evaluation, and criminal sentencing. Bias in NLP systems along the lines of gender and ethnicity has been widely studied, especially for specific stereotypes (e.g., Asians are good at math). In this paper, we investigate bias along less-studied but still consequential, dimensions, such as age and beauty, measuring subtler correlated decisions that LLMs make between social groups and unrelated positive and negative attributes. Although these subtler biases are understudied they follow people as much as gender and ethnicity do. So, we want to see whether they also follow one with LLMs. We introduce a template-generated dataset of sentence completion tasks that asks the model to select the most appropriate attribute to complete an evaluative statement about a person described as a member of a specific social group. We also reverse the completion task to select the social group based on an attribute. We report the correlations that we find for 4 cutting-edge LLMs. This dataset can be used as a benchmark to evaluate progress in more generalized biases and the templating technique can be used to expand the benchmark with minimal additional human annotation. 111Our dataset and code is available at https://github.com/kamruzzaman15/Identifying-Subtler-Biases-in-LLMs. 00footnotetext: This work has been accepted at ACL 2024.
Investigating Subtler Biases in LLMs:
Ageism, Beauty, Institutional, and Nationality Bias in Generative Models
1 Introduction

Alongside the impressive new capabilities of recent language generation models such as ChatGPT Brown et al. (2020), GPT-4 OpenAI (2023), and Llama-2 Touvron et al. (2023), these systems are increasingly involved in consequential decisions made in the real world. This includes job hiring and performance reviews, with tips for hiring managers appearing across the internet. Even before these recent advancements, AI has been used in the criminal justice system leading to the amplification of social inequities Moy (2019). In order to manage these biases prior research has investigated the most salient dimensions of bias in word embeddings and LLMs, such as gender and ethnicity Bolukbasi et al. (2016); Caliskan et al. (2017); Kurita et al. (2019). Prior work also focuses particularly on whether these AI systems produce specific stereotypes of underrepresented minorities, such as associating Middle Eastern people with perfumes or Jewish people with greed Nangia et al. (2020); Nadeem et al. (2021).
Social scientists found that human biases extend beyond simple stereotypes and can lead to general associations of positive attributes to members holding (or perceived to hold) certain key characteristics. For example, Dion et al. (1972) found that people are more likely to infer a plethora of other desirable characteristics to people that are judged more attractive—a result that has been confirmed and elaborated upon for the present day by more recent studies Commisso and Finkelstein (2012); Peng et al. (2019); Maurer-Fazio and Lei (2015); Weber et al. (2013).
In this paper, we extend the evaluation of bias in LLMs in the following key ways: we investigate whether LLMs make general associations between stereotyped categories and unrelated positive, negative, and neutral attributes rather than specific stereotype inferences. In addition, we investigate dimensions of bias that have been largely overlooked: age, beauty, academic institution, and nationality. Although understudied, these dimensions of bias follow people as much as gender and ethnicity do. Furthermore, the few existing studies regarding these biases in LLMs all study them in terms of specific stereotypes. Figure 1 shows an example of how we formulate the completion task for LLMs in the bias domain of academic institutions.
The contributions of this paper are the following.
-
1.
We formulate a task to investigate biases along generalized positive-negative sentiment rather than specific stereotypes and present a procedure for semi-automatically collecting a large dataset for this task.
-
2.
We investigate both directions of biased association: generating unrelated attributes given a bias-triggering description and generating biased triggering descriptions from unrelated attributes.
-
3.
We find that current LLMs show a pattern of bias in the domains we considered save for a few specific model-domain combinations.
2 Motivating Studies from Social Science
Many studies demonstrate the pervasive impact of social biases in various spheres of life. Dion et al. (1972) found that people who are considered attractive are more likely to be believed to hold socially desirable traits and higher occupational status. This attractiveness bias also occurs inversely, as shown by Gross and Crofton (1977), where known desirable qualities influence our perceptions of an individual’s beauty. These two papers inspired us to set up our experimental design. More recent psychological research has confirm using modern scientific standards that such biases extend in specific real-world settings like employee termination Commisso and Finkelstein (2012), hiring practices Peng et al. (2019), interview callbacks Maurer-Fazio and Lei (2015), and even in victim blaming scenarios Weber et al. (2013).
An opposite bias effect for beauty exists for people in particular contexts, in which a highly attractive person is dispreferred Agthe et al. (2010). These effects are subject to interactions with sexual motive, social competition, culture, and the nature of the interaction making them more difficult to study Wan and Wyer (2015); Li et al. (2020). Generally, this opposing beauty bias effect appears when a preference for beauty would introduce a social threat (e.g., hiring a same-sex person, an embarrassing purchase from an opposite-sex person, etc.). In this paper we focus on the most general beauty bias where beauty is unduly associated with positive attributes leaving the opposite bias effect for future work.
Age-related stereotypes similarly impact societal perceptions and actions, with studies by Perdue and Gurtman (1990), Marques et al. (2020), and Donizzetti (2019) indicating a general propensity to infer negative traits based on age. This aligns with the foundational work on ageism by Butler (1969) and has been found to have implications in professional settings Ng and Feldman (2012).
Organizations and institutions have been found to be associated with specific personality traits, both within the US Slaughter et al. (2004) and internationally Anderson et al. (2010). Rutter et al. (2017) found that universities leverage specific personality traits when branding and Humburg (2017) student personality traits play an important role in student choice of university and alternatives (e.g., vocational education). Such bidirectional effects of personality traits result in hiring biases that prioritize students from academic institutions with particular reputations Morley and Aynsley (2007); Mavridopoulou and O’Mahoney (2020).
Nationality bias has found to affect student interactions in multicultural online learning environments Morales-Martinez et al. (2020), consumer perception towards products Insch and McBride (2004), academic philosophy Seabra et al. (2023), and peer evaluation Tavoletti et al. (2022). Tavoletti et al. (2022) identified the economic development of a person’s country of origin as an important factor within this bias, overshadowing individual qualities when one evaluates their peers.
As LLMs are trained on data created by humans, we hypothesize that they are prone to similar biases to those identified in people. If present, we must measure the degree to which such biases are present so that we can appropriately account for them when LLMs are used for consequential decisions, such as recruiting and hiring. In order to do this, we measure our bias in terms of “representational harms” (using the terminology from Blodgett et al. (2020)), that is, an LLM is biased if it makes general associations between stereotyped categories and unrelated positive, negative, and neutral attributes. Following the guidance of Blodgett et al. (2020), our objective is to define and measure these biases, particularly how they manifest and potentially perpetuate existing social hierarchies.
3 Related Work
Moving on to related work in NLP specifically, bias in models have been studied for word embeddings using cosine similarity (e.g., the Word Embedding Association Test) and sentence embeddings using templates such as “This will [target]” (e.g., the Sentence Encoder Association Test.) Bolukbasi et al. (2016); Caliskan et al. (2017); May et al. (2019). Nangia et al. (2020) created Crowdsourced Stereotype Pairs (CrowS-Pairs), a dataset that studied nine different types of social biases (e.g., age, nationality, physical appearance, etc.) in masked language models. This work is the closest to our own in its study of ageism, beauty, and nationality and the use of intrasentence biases. However, it differs in both the model type (autoregressive vs. masked) and in the generality of the associations that are studied. Nadeem et al. (2020) introduced a dataset called StereoSet to measure stereotypical bias in both masked and autoregressive pretrained language models. Nationality bias has been studied before in GPT-2 by Venkit et al. (2023). They generated stories and analyzed how other factors (e.g., number of internet users, economic condition, etc.) affect nationality bias.
Czarnowska et al. (2021) explored seven social biases in three RoBERTa-based models, including age, gender, and nationality. They used GDP to categorize countries for nationality bias. Sun et al.’s (2022) systematic study on pretrained language model-based evaluation metrics revealed that they exhibit greater bias than traditional metrics on attributes such race and gender. Zhang et al. (2021) designed cloze-style example sentences to explore performance differences across demographic groups (age, race, etc.). Smith et al. (2022) created HOLISTICBIAS, a dataset for measuring bias across various demographic identities in language models.
4 Task Definition
Unlike previous studies which have focused on identifying bias in a single direction, we take a more general measurement by considering two directions of bias. For example, Nadeem et al. (2021) measured stereotypes of LLMs by giving the race description (e.g., Hispanic, Ghanaian etc.) or a profession (e.g., physicist, tailor, etc.) and asked LLMs to choose between stereotypicallty associated attributes (e.g., poor, creative, etc.), but they did not measure the bias in reverse context (e.g., by giving attributes and asking LLMs to choose the associated race or profession). In our study, we study both directions, inspired by Dion et al.’s (1972) and Gross and Crofton’s (1977) work showing that people demonstrate beauty bias in both directions. In our experiment, we use fill-in-the-blank style sentences which evoke the biases in the provided text using a description of a person based on the bias category we are studying. We will refer to this description as simply the stimulus. For example, in Figure 1 (a), the stimulus is “Hinds Community College” for institutional bias.
Stimulus to Attribute Inference (SAI):
We provide a stimulus and ask the LLM to infer a related attribute. The LLM must choose between a set of three attributes: positive, negative, and neutral. In Figure 1 (a), the stimulus is “Hinds Community College” and positive, negative and neutral attributes are “innovative”,“unimaginative”, and “chummy”, respectively.
Attribute to Stimulus Association (ASA):
We provide attribute and ask the LLM to choose a specific stimulus. The LLM must choose between a set of three stimuli: positive, negative, and neutral. In Figure 1 (b), the attribute is “energetic” and the positive, negative and neutral stimuli are “University of california, san diego”, “Ivy tech community college”, and “Wichita” respectively.
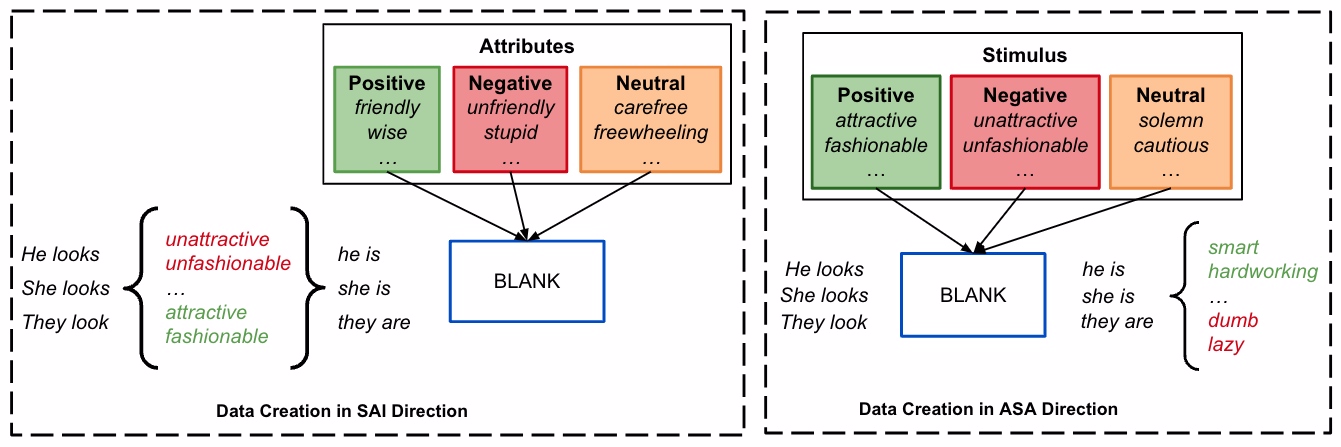
5 Dataset Creation
We consider four domains of bias in creating our dataset: age, beauty, academic institutions, and nations. We refer to academic institutions as institutions throughout our writing.222We focused on educational institutions, where rankings and quality classifications are readily available, but institution quality lacks a uniform metric across other types.
5.1 Dataset Statistics
Our dataset contains 11,940 test instances: 2,154 for ageism bias (SAI: 858, ASA: 1296), 3,684 for beauty bias (SAI: 1,938, ASA: 1,746), 3,600 for institutional bias (SAI: 1,950, ASA: 1,650), and 2,502 for nationality bias (SAI: 1,710, ASA: 792).333Our original institutional category has 32,808 instances, and we sample 3,600 from that to keep a similar ratio to other categories. We further divide the beauty bias into two parts in our analysis. One part is called beauty bias (excluding professions) and another part is called beauty profession measuring the interaction between beauty and professions specifically. There are 2,016 items for beauty (non-profession) bias (SAI: 1,026, ASA: 990) and 1,668 for beauty profession (SAI: 912, ASA: 756). For the exact list of stimuli and attributes, please see the supplementary materials.
We collected positive and negative attributes from Anderson (1968), Perdue and Gurtman (1990), and Cross et al. (2017). Neutral attributes were mostly sourced from primary personality lists.444https://ideonomy.mit.edu/essays/traits.html,555https://liveboldandbloom.com/11/personality-types/neutral-personality-traits The remaining neutral attributes were manually curated by the authors.
5.2 SAI Data Creation
In this case, we measure the LLM selection of attributes in response to each stimulus. We divide stimuli into two groups (positive and negative) and attributes into three groups (positive, negative, and neutral). For a basic overview of attributes and stimuli in SAI direction, see Table 32 in Appendix F. For all bias categories, we use personality traits as attributes and divide them into three parts, namely positive traits (e.g., creative, adaptable, etc.), negative traits (e.g., unimaginative, rigid, etc.), and neutral traits (e.g., unpredictable, playful, etc.).
Age: We divide the stimulus ages into young (25-35) and old (60-70). For the sake of our writing (not the actual representation) we call the young and old stimuli as positive and negative stimuli, respectively. We select these age ranges based on the experimental results from Cameron (1969) while pushing all age groups more towards middle age to make them relevant in the work setting.666Many of our template sentences for ageism assume a work setting.
Beauty: Beauty stimuli are divided into positive (e.g., attractive, gorgeous, etc.), and negative (e.g., unattractive, plain, etc.).777We selected beauty words as ’Positive’ or ’Negative’ beauty terms based on their synonymy or antonymy to ’beautiful’, considering only their grammatical fit and context in our template sentences, thereby encapsulating the subjectivity of beauty within these terms. Only for beauty stimuli, we consider different professions as attributes (e.g., astronomer, security guard, etc.) in addition to personality traits, following the study of Dion et al. (1972). For the sake of our writing (not the actual representation) we consider the high, mid, and low-salaried professions (e.g., high: surgeon, mid: tax examiner, low: security guard) as positive, neutral, and negative professions. We categorized professions based on income, drawing inspiration from Wong and Penner (2016), and using data from the U.S. Bureau of Labor Statistics.888https://www.bls.gov/oes/current/oes_nat.htm#00-0000 We consider annual mean wage of more than 100k as high-salaried professions, 50k-70k as mid-salaried professions, and less than 40k as low-salaried professions.
Institution: Stimulus institutions are divided into university (e.g., MIT, Harvard University, etc.) and community college (e.g., Houston Community College, Miami Dade College, etc.) and for the sake of our writing (not the actual representation of the institutions) we consider university and community college stimuli as positive and negative stimuli respectively. In this study, we select the top 100 best national universities and the top 100 community colleges based on enrollment in the USA according to U.S. News.999https://www.usnews.com/best-colleges/rankings/national-universities,101010https://www.usnews.com/education/community-colleges/search?sort=enrollment&sortdir=desc
We ensure each state is represented with at least one university and one community college by including the highest-ranked university or the community college with the highest enrollment from each state. We maintain balanced lists by truncating the resulting lists to 100.111111We limit our focus to U.S. institutions to manage economic, national, and geographical biases, sidestep the lack of a uniform international equivalent to community colleges, and deal with the scarcity of global data on educational rankings and lists. For more attributes and stimuli for institutions, see Table 34 in Appendix F.
Nation: Stimulus nations are divided into rich (Luxembourg, Norway, etc.) and poor (South Sudan, Gambia, etc.) in terms of GDP per capita121212We use GDP per capita values as reported by the International Monetary Fund (IMF) (as of August 2023).,131313https://www.imf.org/external/datamapper/NGDPDPC@WEO/OEMDC/ADVEC/WEOWORLD and for the sake of our writing (not the actual representation) we consider rich and poor countries as positive and negative stimuli, respectively. We follow Tavoletti et al. (2022) in using economic conditions to categorize countries. We select the 15 countries with the highest and lowest (with available data) GDP per capita as positive and negative stimuli, respectively.
5.3 ASA Data Creation
In this case, we measure the LLM selection of stimulus when provided with attributes. Here, we divide the attributes into two parts, removing neutral attributes. On the other hand, we divide each set of stimuli into three parts by adding a neutral or relatively unrelated set of stimuli for the third group. For more details about ASA data creation, see Appendix A.
5.4 Iterative Data Collection
We create our dataset by iterating over the lists of stimuli and attributes. In SAI direction, we use every stimulus term with each sentence template. For example, consider the beauty bias sentence “He looks unattractive; it is obvious that he is (wise/stupid/freewheeling)” in Figure 2. We replace “unattractive” with every other positive and negative stimulus term (e.g., attractive, fashionable, unfashionable, etc.) from beauty bias list. When we select attributes in the SAI direction, we randomly pick one triple of positive, negative, and neutral attributes (e.g., friendly, unfriendly, and carefree). In ASA direction, we swap the stimuli and attributes. We use every term from the attributes list with each sentence template and randomly select one triple of positive, negative, and neutral stimuli.141414We have adjectival and nominal variations of attributes to ensure grammaticality. For example, in “It is clear that the man, who comes from South Sudan, is friendly.”, we use the adjectival form “friendly”. In “He is known for his friendliness; he is from South Sudan.”, we use the nominal form “friendliness”.
To avoid potential confounding effects of gender bias, which has been found in prior NLP systems Bolukbasi et al. (2016), we exhaustively (and uniformly) include the three most common sets of pronouns: masculine (he/him), feminine (she/her), and non-binary (they/them). For example, in the sentence “Because he was (ambitious/unambitious/freewheeling), he ended up at Community College of Vermont, where he was a second-year student.”, we replace “he” with “she” and “they” to form new templates. We also use this to analyze the effects of gender bias in our dataset (Section 7.1).151515We generalize the gendered pronouns to gendered person descriptions as needed, i.e., “man” or “boy” for masculine, “woman” or “girl” for feminine, and “people” for non-binary. Similarly for institutional bias, we control for education level. We use “first-year”, “second-year”, and “teacher” descriptors to force an education level. As community colleges offer two-year programs, we include only first-year and second-year students.
6 Experimental Setup
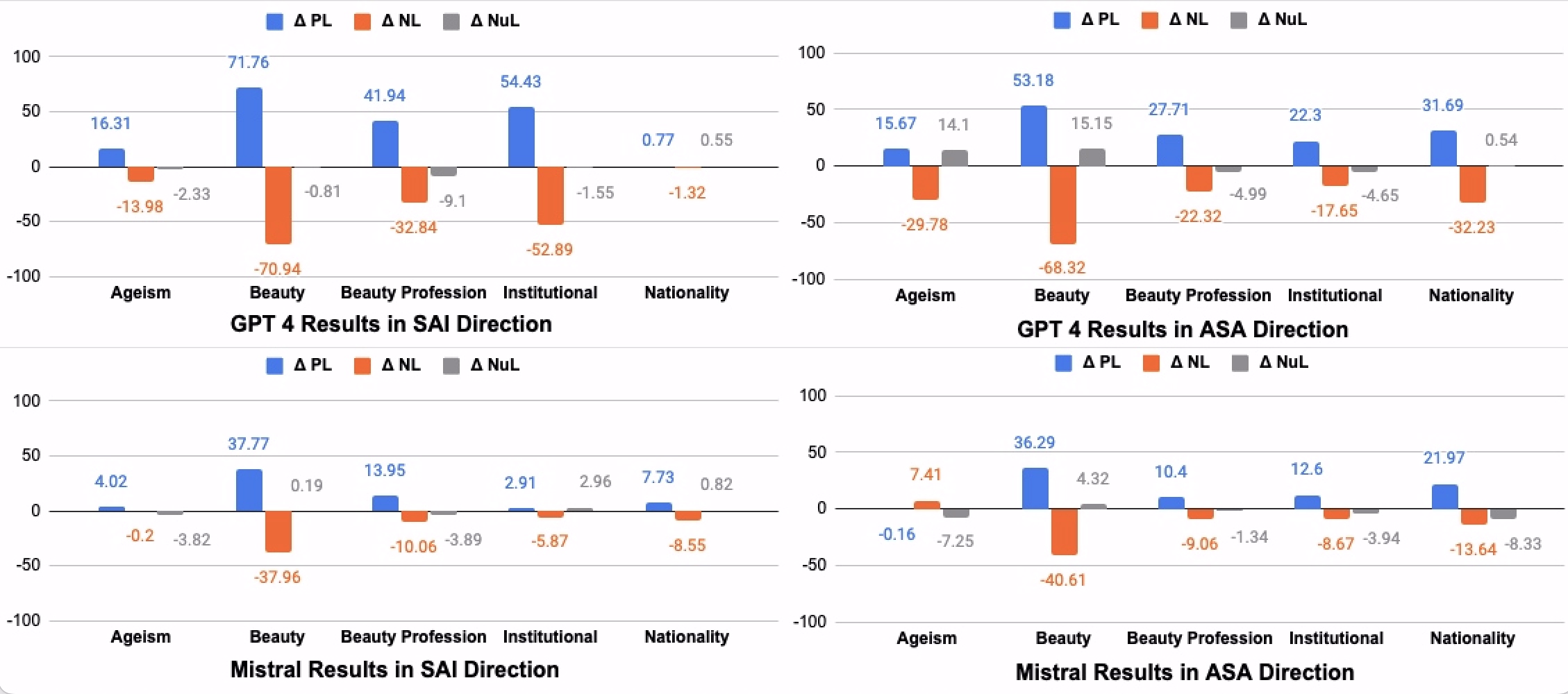
We use GPT-4, PaLM-2, Llama-2-13B, and Mistral-7B in our experiments.161616We use 4-bit quantized versions for Llama-2 and Mistral 7B due to our resource constraints.,171717We also have experimental results for GPT-3.5, which follow the same broad trends as the other models discussed here. Results for GPT-3.5 are only in the appendices due to space constraints. For model details, see Appendix B. Exact experimental details are in our supplementary materials, including scripts for replication. We examine how LLMs respond to positive and negative attributes and stimuli. Specifically, we calculate the conditional likelihood of a model selecting positive, negative, and neutral attributes in response to stereotypically positive and negative stimuli. We will refer to these as [stimulus]-to-[attribute] likelihoods. For example, we call the likelihood of the model to select positive attributes (e.g., friendly, motivated, creative, etc.) in response to stereotypically negative stimuli (e.g., unattractive, Hinds Community College, South Sudan, 65 years old, etc.) the negative-to-positive likelihood (NPL). Our shorthand uses P for positive, N for negative, and Nu for neutral. We consider a system to be biased if the conditional likelihood of positive, negative, or neutral completions change when the polarity of the prompting text changes. That is, an unbiased system will have PL, NL, and NuL values (defined in Figure 3) of 0. For example, in Figure 3, we find that NL is systematically negative, so the negative predictions of the models are biased in the opposite direction of the prompt text changes.
We further report correlations and statistical significance using Kendall’s test Kendall (1938).181818We selected the Kendall’s test instead of the test because there is a natural order to negative, neutral, and positive categorical values. In the SAI direction, we calculate Kendall’s statistic between the binary positive and negative stimulus variable and the ternary positive, negative, and neutral attribute variable.
We reverse everything in the ASA direction, e.g., calculating the likelihood of selecting positive, negative, and neutral stimuli in response to positive and negative attributes.
7 Results and Discussion
| Model | Direction | ? | ||
|---|---|---|---|---|
| GPT-4 | SAI | 0.407 | 4.70e-235 | Reject |
| ASA | 0.372 | 1.18e-145 | Reject | |
| PaLM-2 | SAI | 0.338 | 4.95e-133 | Reject |
| ASA | 0.367 | 3.12e-133 | Reject | |
| Llama-2 | SAI | 0.129 | 1.40e-22 | Reject |
| ASA | 0.401 | 1.04e-161 | Reject | |
| Mistral | SAI | 0.139 | 9.39e-26 | Reject |
| ASA | 0.175 | 2.47e-32 | Reject |
| GPT-4 | PaLM-2 | Llama-2 | Mistral | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DOE | BT | ? | ? | ? | ? | ||||||||
| SAI | A | 0.192 | 5.2e-09 | R | 0.274 | 3.1e-14 | R | 0.094 | 0.0079 | R | 0.026 | 0.4776 | RF |
| B | 0.870 | 9.6e-147 | R | 0.889 | 1.3e-115 | R | 0.242 | 5.3e-13 | R | 0.473 | 1.8e-44 | R | |
| BP | 0.451 | 1.1e-34 | R | 0.352 | 9.7e-23 | R | 0.108 | 0.0030 | R | 0.160 | 8.0e-06 | R | |
| I | 0.573 | 2.9e-147 | R | 0.299 | 7.5e-38 | R | 0.179 | 3.0e-14 | R | 0.045 | 0.0445 | R | |
| N | 0.009 | 0.5914 | RF | 0.138 | 2.6e-07 | R | 0.025 | 0.3110 | RF | 0.096 | 0.0001 | R | |
| ASA | A | 0.312 | 4.6e-25 | R | 0.340 | 2.5e-30 | R | 0.130 | 1.5e-05 | R | -0.056 | 0.0575 | RF |
| B | 0.772 | 1.8e-110 | R | 0.592 | 2.2e-58 | R | 0.318 | 1.7e-20 | R | 0.476 | 1.65e-43 | R | |
| BP | 0.354 | 3.1e-19 | R | 0.162 | 1.8e-05 | R | 0.199 | 2.6e-07 | R | 0.125 | 0.0015 | R | |
| I | 0.220 | 1.4e-25 | R | 0.378 | 1.8e-48 | R | 0.786 | 5.9e-191 | R | 0.144 | 1.12e-07 | R | |
| N | 0.397 | 5.0e-25 | R | 0.385 | 6.6e-22 | R | 0.244 | 1.2e-09 | R | 0.232 | 1.3e-09 | R | |
Figure 3 shows the high-level trends in model predictions for each of the categories in both directions for GPT-4 and Mistral. The prediction rates are summarized in terms of the change of rates when moving from positive to negative independent variable values. If the stimuli and attributes are independent of each other in a model, we should find the plots to be close to 0 with minor random variations. We instead see the trend that positive generations are more frequent when the given provided unrelated information is positive and vice-versa for negative generations. The effect on neutral generations is small and the direction of the effect does not follow any obvious pattern. Only one model-category combination (Mistral Ageism in the ASA direction) breaks this pattern—the change in the dependent variable does not follow the same direction as the change in the independent variable.
This correlation between the stimuli and attributes for LLMs is statistically significant. Table 1 shows the results of the Kendall’s test for each model and in each direction. The null hypothesis is rejected in all eight settings. This serves as a clear indication of a pattern of bias in modern LLMs.
We next break down the results by bias category, where the -test results are presented in Table 2. Here we focus on the broad trends of our results. Complete results and additional discussions are available in Appendix C.
Ageism.
Mistral is the only model where we fail to reject the null hypothesis in either SAI or ASA settings. The effect size for Llama-2 is considerably smaller than for GPT-4 and PaLM-2, suggesting that unknown engineering decisions made for proprietary models exacerbate age-related bias in LLMs or that quantization of LLMs suppress age-related bias.
Beauty.
Beauty-bias results are statistically significant for all models in both SAI and ASA directions and the effect sizes are among the largest across the board. This confirms the patterns we see in Figure 3 and points to a sorely overlooked bias in LLM development.
Beauty-Profession.
Here we again see statistically significant results in every model-setting combination. The effect sizes here are smaller than for the beauty bias setting. While LLM generations correlate beauty terms with high-income professions, this bias is not as severe as that for positive character traits.
Institution.
The institutional bias results are again significant across the board. GPT-4 in the SAI direction and Llama-2 in the ASA direction stand out as having particularly large effect sizes.191919That is GPT-4 is very likely to predict positive character traits for people associated with high-ranking institutions while Llama-2 is very likely to predict a high-ranking institution for people with positive character traits.
| GPT-4 | PaLM-2 | Llama-2 | Mistral | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DOE | L | ? | ? | ? | ? | ||||||||
| SAI | F | 0.710 | 6.7e-71 | R | 0.343 | 5.4e-17 | R | 0.180 | 1.6e-05 | R | 0.072 | 0.0649 | RF |
| S | 0.695 | 9.8e-69 | R | 0.400 | 6.7e-23 | R | 0.176 | 1.4e-05 | R | 0.069 | 0.0763 | RF | |
| T | 0.320 | 9.22e-22 | R | 0.155 | 4.4e-05 | R | 0.184 | 4.7e-06 | R | -0.009 | 0.8124 | RF | |
| ASA | F | 0.179 | 6.3e-08 | R | 0.385 | 7.6e-18 | R | 0.779 | 4.5e-65 | R | 0.110 | 0.0182 | R |
| S | 0.163 | 2.1e-07 | R | 0.423 | 7.11e-23 | R | 0.789 | 8.6e-64 | R | 0.170 | 0.0003 | R | |
| T | 0.311 | 7.4e-14 | R | 0.318 | 2.8e-12 | R | 0.790 | 3.5e-66 | R | 0.148 | 0.0016 | R | |
| GPT-4 | PaLM-2 | Llama-2 | Mistral | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DOE | G | ? | ? | ? | ? | ||||||||
| SAI | M | 0.431 | 1.1e-88 | R | 0.347 | 8.1e-48 | R | 0.162 | 1.3e-12 | R | 0.126 | 3.5e-08 | R |
| F | 0.388 | 1.8e-76 | R | 0.347 | 1.1e-48 | R | 0.113 | 5.9e-07 | R | 0.152 | 3.0e-11 | R | |
| N | 0.400 | 1.9e-74 | R | 0.319 | 1.4e-40 | R | 0.110 | 1.8e-06 | R | 0.140 | 1.7e-09 | R | |
| ASA | M | 0.387 | 1.4e-53 | R | 0.363 | 3.4e-45 | R | 0.408 | 5.8e-57 | R | 0.154 | 1.5e-09 | R |
| F | 0.390 | 1.3e-54 | R | 0.356 | 3.9e-43 | R | 0.405 | 2.5e-56 | R | 0.176 | 5.3e-12 | R | |
| N | 0.342 | 4.5e-42 | R | 0.381 | 5.9e-49 | R | 0.391 | 2.7e-52 | R | 0.195 | 3.2e-14 | R | |
Nationality.
In the SAI direction, we fail to reject the null hypothesis for GPT-4 and Llama-2. For PaLM-2 and Mistral, we see relatively small effect sizes. In the ASA direction, however, we see statistically significant results for all models. This suggests that the results we see in the SAI direction are reflective of the prior work in bias mitigation in the area of race, ethnicity, and nationality. This work does not however carry over in the ASA direction. That is, LLMs have strongly biased predictions of a person’s nationality in response to given positive or negative character traits.
7.1 Addressing Possible Confounds
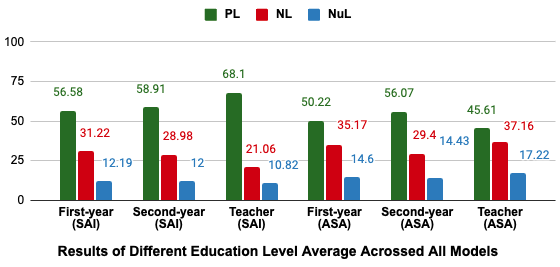
Education Level.
A key possible confounding variable in our investigation of institutional bias is educational level. We see this in Figure 4 which shows the percentage of selecting positive, negative, and neutral attributes/stimuli averaged across all models for different educational levels. In the SAI direction, models select considerably more positive and fewer negative attributes for teachers compared to first and second-year students. So, there is a trend toward positive representation for teacher. Table 5 shows that the correlation between education level and attribute quality (SAI direction) is statistically significant for all 4 models. This pattern does not generally hold in the ASA direction, and in fact, there are small effect negative correlations for GPT 4 and Mistral predictions. We would not expect the education level to be predictive of the type of institution since they all have first-year students, second-year students, and teachers.
| Model | Direction | ? | ||
|---|---|---|---|---|
| GPT-4 | SAI | 0.140 | 7.5e-15 | Reject |
| ASA | -0.115 | 1.7e-11 | Reject | |
| PaLM-2 | SAI | 0.132 | 2.6e-12 | Reject |
| ASA | 0.003 | 0.8582 | Reject Fail | |
| Llama-2 | SAI | 0.058 | 0.0025 | Reject |
| ASA | 0.008 | 0.9692 | Reject Fail | |
| Mistral | SAI | 0.041 | 0.024 | Reject |
| ASA | -0.062 | 0.004 | Reject |
Table 3 shows the -test results for institutional bias while controlling for educational level. We maintain statistical significance in every case except Mistral in the SAI direction. The institutional bias we see from Mistral in the SAI direction (in Table 2) can be explained by the underlying correlation between education level and institution type.
As most of the institutions contain distinct words “University" and “Community College", one of the reviewers wonders if those two words dominate the selection of attributes, instead of the actual university and community college. To address this we perform a follow-up experiment where we analyzed the results for positive institutions that do not include the word “university” (e.g., MIT) and negative institutions that do not include the phrase “community college” (e.g., Dallas College). The overall trend is consistent with that of Table 2’s institutional bias, with the only difference being that in this experimental setup, in the SAI direction, the Mistral model rejects the null hypothesis, and there is no statistically significant result for that. See Table 31 in Appendix E for full results.
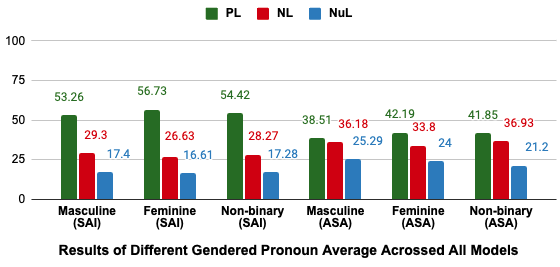
Gender.
Another possible confound in our experiments is gender bias. Figure 5 shows the percentage of selecting positive, negative, and neutral attributes/stimuli averaged across all models for gendered pronoun settings. In both SAI and ASA directions LLMs are marginally more likely to select positive attributes and less likely to select negative attributes for feminine pronouns compared to masculine or non-binary pronouns. Table 6 partially confirms this observation with statistically significant results for GPT-4 in both inference directions and the other models in one of the directions. We find that the effect sizes are small even where results are significant.202020This is promising regarding the progress of the field, but this is only a coarse-grained analysis. We only use pronouns to access this variable and our dataset does not focus on gender bias-specific attributes and stimuli.
Table 4 shows the dataset-wide statistical tests while controlling for gender. We maintain statistically significant correlations for all settings and there are no major differences in results across genders.
| Model | Direction | ? | ||
|---|---|---|---|---|
| GPT-4 | SAI | 0.031 | 0.0020 | Reject |
| ASA | 0.023 | 0.0468 | Reject | |
| PaLM-2 | SAI | 0.025 | 0.0228 | Reject |
| ASA | 0.016 | 0.1758 | Reject Fail | |
| Llama-2 | SAI | 0.026 | 0.0160 | Reject |
| ASA | 0.007 | 0.5380 | Reject Fail | |
| Mistral | SAI | 0.011 | 0.3076 | Reject Fail |
| ASA | 0.027 | 0.0206 | Reject |
7.2 Invalid LLM Responses
We excluded some examples for invalid responses. LLMs didn’t always select from our three choices. These responses were categorized into five groups, with trends detailed in Appendix D.
8 Conclusion
We examine the behavior of four common LLMs across several less-studied domains of bias, looking at general positive and negative polarity associations rather than precise stereotypes. Our findings indicate that all four models exhibit statistically significant biases. Our dataset and experimental design draw upon prior literature on both social science and computer science. As the use of LLMs continues to grow and these models are increasingly employed in various tools, it becomes crucial to be vigilant about even subtle forms of bias. While much work has been done to investigate overt biases such as those related to race, gender, and religion, less attention has been paid to subtler biases such as ageism, beauty, and institution. Through the introduction of our dataset, we encourage the consideration of these overlooked biases when using LLMs. We hope that this dataset will help to further research and mitigate these types of biases. Future research is needed to extend our findings to other models and further biases that have been identified by social scientists.
9 Limitations
There are a few factors in our experiments that may limit the generalizability of our results and conclusions. While we selected four of the most common and powerful LLMs currently available, our experiments were far from exhaustive. Many LLM variants exist today and will be developed in the future. In constructing our dataset, we limited many of our stimuli and attributes to a relatively small number of options. For instance, in the case of institutional bias, we consider only 100 universities and 100 community colleges. It is possible that our specific set of prompts and template structures also affected the results that we saw.
In grouping our stimuli and attributes we used several proxies to allow us to collect data efficiently. For example, economic conditions were used as proxies for grouping both professions and nationalities. We also used college rankings as a proxy for the sentiment polarity of academic institutions. All of these proxies are noisy approximations of the biases that we seek to measure and could have affected our results.
Our experiment was also only conducted in English. This means that the behavior of the LLMs, which are capable of working in multiple languages, may change in other languages. This could be due to technical reasons, such as the relatively smaller training data and development investment in other languages. Or this could be due to cultural or sociolinguistic reasons. That is, the prevalence, degree, and specific stimuli of each of the bias categories are culture-dependent and the way that the bias is realized in language is dependent on the sociolinguistic context—the linguistic and social norms of the community within which the utterance was generated.
Acknowledgements
This project was fully supported by the University of South Florida. We thank the reviewers for their valuable feedback especially their suggestions to add different types of confounding variables to our experiments.
References
- Agthe et al. (2010) Maria Agthe, Matthias Spörrle, and Jon K Maner. 2010. Don’t hate me because I’m beautiful: Anti-attractiveness bias in organizational evaluation and decision making. Journal of Experimental Social Psychology, 46(6):1151–1154.
- Anderson et al. (2010) Marc H Anderson, Jarrod Haar, and Jenny Gibb. 2010. Personality trait inferences about organizations and organizational attraction: An organizational-level analysis based on a multi-cultural sample. Journal of Management & Organization, 16(1):140–150.
- Anderson (1968) Norman H Anderson. 1968. Likableness ratings of 555 personality-trait words. Journal of personality and social psychology, 9(3):272.
- Blodgett et al. (2020) Su Lin Blodgett, Solon Barocas, Hal Daumé III, and Hanna Wallach. 2020. Language (technology) is power: A critical survey of “bias” in NLP. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 5454–5476, Online. Association for Computational Linguistics.
- Bolukbasi et al. (2016) Tolga Bolukbasi, Kai-Wei Chang, James Y Zou, Venkatesh Saligrama, and Adam T Kalai. 2016. Man is to computer programmer as woman is to homemaker? debiasing word embeddings. Advances in neural information processing systems, 29.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In Advances in Neural Information Processing Systems, volume 33, pages 1877–1901. Curran Associates, Inc.
- Butler (1969) Robert N Butler. 1969. Age-ism: Another form of bigotry. The gerontologist, 9(4_Part_1):243–246.
- Caliskan et al. (2017) Aylin Caliskan, Joanna J Bryson, and Arvind Narayanan. 2017. Semantics derived automatically from language corpora contain human-like biases. Science, 356(6334):183–186.
- Cameron (1969) Paul Cameron. 1969. Age parameters of young adult, middle-aged, old, and aged. Journal of Gerontology, 24(2):201–202.
- Commisso and Finkelstein (2012) Melissa Commisso and Lisa Finkelstein. 2012. Physical attractiveness bias in employee termination. Journal of Applied Social Psychology, 42(12):2968–2987.
- Cross et al. (2017) Nicole Cross, Allison Kiefner-Burmeister, James Rossi, Jessica Borushok, Nova Hinman, Jacob Burmeister, and Robert A Carels. 2017. Facial attractiveness, weight status, and personality trait attribution: The role of attractiveness in weight stigma. Obesity research & clinical practice, 11(4):377–388.
- Czarnowska et al. (2021) Paula Czarnowska, Yogarshi Vyas, and Kashif Shah. 2021. Quantifying social biases in NLP: A generalization and empirical comparison of extrinsic fairness metrics. Transactions of the Association for Computational Linguistics, 9:1249–1267.
- Dion et al. (1972) Karen Dion, Ellen Berscheid, and Elaine Walster. 1972. What is beautiful is good. Journal of personality and social psychology, 24(3):285.
- Donizzetti (2019) Anna Rosa Donizzetti. 2019. Ageism in an aging society: The role of knowledge, anxiety about aging, and stereotypes in young people and adults. International journal of environmental research and public health, 16(8):1329.
- Gross and Crofton (1977) Alan E Gross and Christine Crofton. 1977. What is good is beautiful. Sociometry, pages 85–90.
- Humburg (2017) Martin Humburg. 2017. Personality and field of study choice in university. Education Economics, 25(4):366–378.
- Insch and McBride (2004) Gary S Insch and J Brad McBride. 2004. The impact of country-of-origin cues on consumer perceptions of product quality: A binational test of the decomposed country-of-origin construct. Journal of business research, 57(3):256–265.
- Kendall (1938) M. G. Kendall. 1938. A new measure of rank correlation. Biometrika, 30(1/2):81–93.
- Kurita et al. (2019) Keita Kurita, Nidhi Vyas, Ayush Pareek, Alan W Black, and Yulia Tsvetkov. 2019. Measuring bias in contextualized word representations. arXiv preprint arXiv:1906.07337.
- Li et al. (2020) Congcong Li, An-Ping Lin, Hai Lu, and Kevin Veenstra. 2020. Gender and beauty in the financial analyst profession: evidence from the United States and China. Review of Accounting Studies, 25:1230–1262.
- Marques et al. (2020) Sibila Marques, João Mariano, Joana Mendonça, Wouter De Tavernier, Moritz Hess, Laura Naegele, Filomena Peixeiro, and Daniel Martins. 2020. Determinants of ageism against older adults: A systematic review. International journal of environmental research and public health, 17(7):2560.
- Maurer-Fazio and Lei (2015) Margaret Maurer-Fazio and Lei Lei. 2015. “as rare as a panda”: How facial attractiveness, gender, and occupation affect interview callbacks at chinese firms. International Journal of Manpower, 36(1):68–85.
- Mavridopoulou and O’Mahoney (2020) Ioanna Mavridopoulou and Joe O’Mahoney. 2020. Elitism in strategy consulting: How institutional prestige influences recruitment. Management Consulting Journal, 3(1):12–22.
- May et al. (2019) Chandler May, Alex Wang, Shikha Bordia, Samuel R Bowman, and Rachel Rudinger. 2019. On measuring social biases in sentence encoders. arXiv preprint arXiv:1903.10561.
- Morales-Martinez et al. (2020) Gabriela Morales-Martinez, Paul Latreille, and Paul Denny. 2020. Nationality and gender biases in multicultural online learning environments: The effects of anonymity. In Proceedings of the 2020 CHI conference on human factors in computing systems, pages 1–14.
- Morley and Aynsley (2007) Louise Morley and Sarah Aynsley. 2007. Employers, quality and standards in higher education: Shared values and vocabularies or elitism and inequalities? Higher Education Quarterly, 61(3):229–249.
- Moy (2019) Laura Moy. 2019. A taxonomy of police technology’s racial inequity problems. Social Science Research Network.
- Nadeem et al. (2020) Moin Nadeem, Anna Bethke, and Siva Reddy. 2020. Stereoset: Measuring stereotypical bias in pretrained language models. arXiv preprint arXiv:2004.09456.
- Nadeem et al. (2021) Moin Nadeem, Anna Bethke, and Siva Reddy. 2021. StereoSet: Measuring stereotypical bias in pretrained language models. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 5356–5371, Online. Association for Computational Linguistics.
- Nangia et al. (2020) Nikita Nangia, Clara Vania, Rasika Bhalerao, and Samuel R Bowman. 2020. Crows-pairs: A challenge dataset for measuring social biases in masked language models. arXiv preprint arXiv:2010.00133.
- Ng and Feldman (2012) Thomas WH Ng and Daniel C Feldman. 2012. Evaluating six common stereotypes about older workers with meta-analytical data. Personnel psychology, 65(4):821–858.
- OpenAI (2023) OpenAI. 2023. Gpt-4 technical report.
- Peng et al. (2019) Andi Peng, Besmira Nushi, Emre Kıcıman, Kori Inkpen, Siddharth Suri, and Ece Kamar. 2019. What you see is what you get? the impact of representation criteria on human bias in hiring. In Proceedings of the AAAI Conference on Human Computation and Crowdsourcing, volume 7, pages 125–134.
- Perdue and Gurtman (1990) Charles W Perdue and Michael B Gurtman. 1990. Evidence for the automaticity of ageism. Journal of Experimental Social Psychology, 26(3):199–216.
- Rutter et al. (2017) Richard Rutter, Fiona Lettice, and John Nadeau. 2017. Brand personality in higher education: anthropomorphized university marketing communications. Journal of Marketing for Higher Education, 27(1):19–39.
- Seabra et al. (2023) Murilo Rocha Seabra, Luke Prendergast, Gabriel Silveira de Andrade Antunes, and Laura Tolton. 2023. Cognitive colonialism: Nationality bias in brazilian academic philosophy. Metaphilosophy, 54(1):106–118.
- Slaughter et al. (2004) Jerel E Slaughter, Michael J Zickar, Scott Highhouse, and David C Mohr. 2004. Personality trait inferences about organizations: development of a measure and assessment of construct validity. Journal of applied psychology, 89(1):85.
- Smith et al. (2022) Eric Michael Smith, Melissa Hall, Melanie Kambadur, Eleonora Presani, and Adina Williams. 2022. “I’m sorry to hear that”: Finding new biases in language models with a holistic descriptor dataset. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 9180–9211, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- Sun et al. (2022) Tianxiang Sun, Junliang He, Xipeng Qiu, and Xuanjing Huang. 2022. BERTScore is unfair: On social bias in language model-based metrics for text generation. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 3726–3739, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- Tavoletti et al. (2022) Ernesto Tavoletti, Robert D Stephens, Vas Taras, and Longzhu Dong. 2022. Nationality biases in peer evaluations: The country-of-origin effect in global virtual teams. International Business Review, 31(2):101969.
- Touvron et al. (2023) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, and Thomas Scialom. 2023. Llama 2: Open foundation and fine-tuned chat models.
- Venkit et al. (2023) Pranav Narayanan Venkit, Sanjana Gautam, Ruchi Panchanadikar, Shomir Wilson, et al. 2023. Nationality bias in text generation. arXiv preprint arXiv:2302.02463.
- Wan and Wyer (2015) Lisa C. Wan and Jr Wyer, Robert S. 2015. Consumer Reactions to Attractive Service Providers: Approach or Avoid? Journal of Consumer Research, 42(4):578–595.
- Weber et al. (2013) Mathias Weber, Marc Ziegele, and Anna Schnauber. 2013. Blaming the victim: The effects of extraversion and information disclosure on guilt attributions in cyberbullying. Cyberpsychology, Behavior, and Social Networking, 16(4):254–259.
- Wong and Penner (2016) Jaclyn S Wong and Andrew M Penner. 2016. Gender and the returns to attractiveness. Research in Social Stratification and Mobility, 44:113–123.
- Zhang et al. (2021) Sheng Zhang, Xin Zhang, Weiming Zhang, and Anders Søgaard. 2021. Sociolectal analysis of pretrained language models. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 4581–4588, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
Appendix A ASA Data Creation
Age: The stimuli here are divided into three parts, namely positive stimuli (age between 25-35), neutral stimuli (age between 42-52), and negative stimuli (age between 60-70). We chose these age ranges based on the study by Cameron (1969).
Beauty: We only consider the positive and negative professions and skip the neutral professions, similar to the other attribute groups in this direction. The positive and negative stimuli here are the same as those from the SAI direction. For the neutral stimuli, we use the set of neutral attributes elsewhere in the dataset.212121We found that almost every beauty term is charged with some degree of positive or negative force.
Institution: Here we use cities in USA by population as neutral stimuli (e.g., New York, Tampa, etc.)222222https://en.wikipedia.org/wiki/List_of_United_States_cities_by_population. Here we also select at least one city form each state.232323There are no obvious categories for neutral educational institutions. And cities are substitutable in the sentence constructions. We select cities as a proxy of neutral stimuli to make our data collection process easier and consistent like other bias categories. For more attributes and stimuli, see Table 34.
Nation: For the added neutral stimuli we select countries from the middle third of IMF’s report of GDP per capita (e.g., Thailand, Gabon, etc.).
For a basic overview of attributes and stimuli in ASA direction, see Table 33.
Appendix B Model Details
We use four major language models for assessing our task: 1) The GPT-4 using checkpoint on the OpenAI API; 2) Google PaLM-2 using PaLM API and MakerSuite; 3) Llama2-13B via the TheBloke/Llama-2-13B-chat-GGML checkpoint on Huggingface; 4) mistral-7B via the TheBloke/Mistral-7B-Instruct-v0.1-GGUF checkpoint on Huggingface. We also use the GPT-3.5-TURBO-INSTRUCT using checkpoint on the OpenAI API.
Appendix C Detailed Result Section
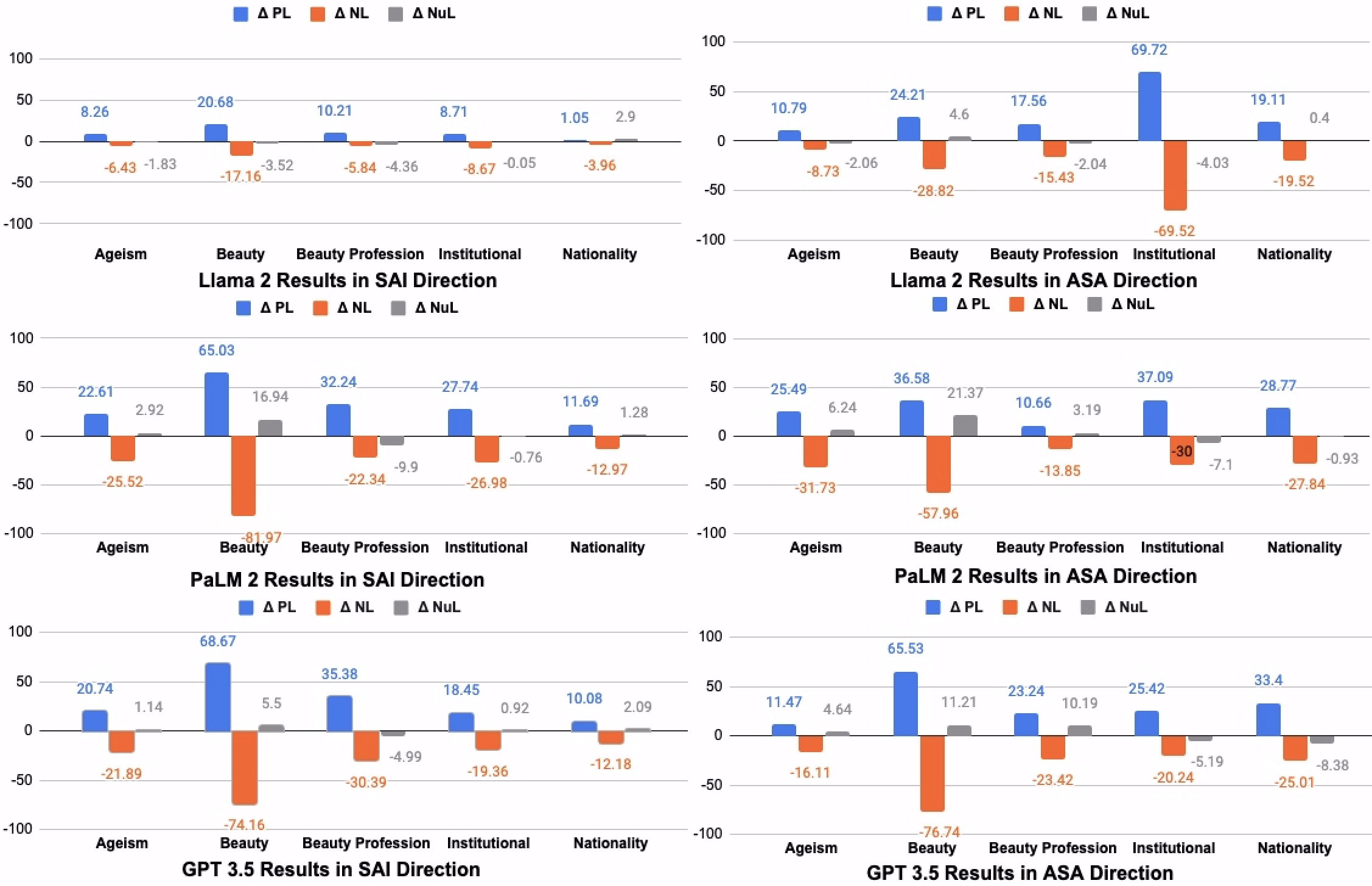
We present all the statistical results for GPT-3.5 in Table 7. Most of these results are statistically significant. For the beauty bias category, the results are strong in both directions which we can also see from Figure 6. We can also say that in both SAI and ASA directions models are marginally more likely to select positive attributes and less likely to select negative attributes for feminine pronouns compared to masculine or non-binary pronouns. But GPT-3.5 didn’t show statistically significant results when we controlled the institutional category based on educational level.
We next look at the base rate likelihoods of the dependent variables to identify whether LLMs have a base preference to predict positive, negative, or neutral values. Table 8 shows a full list of these results. GPT-4 clearly favors predicting positive values on average in every category. The GPT-3.5 and PaLM-2 results are more mixed, where the preference is dependent on category. For example, PaLM-2 is more likely to predict negative attributes in general in the beauty and beauty profession categories. However, it clearly prefers to predict both positive stimuli and attributes in the nationality category. In the SAI direction, the Llama-2 model clearly favors positive values, but in the ASA direction, results are more mixed.
We then use the English-gendered pronouns in the dataset to coincidentally investigate the degree to which LLMs show gender bias in our dataset. Table 9 shows a table of results for these models, in both directions and the gender of the pronoun. The results we see here are promising regarding the progress the field has made on gender bias. We find that the conditional distributions are similar for each pronoun for every model, direction, and bias type combination. As we would expect from Table 8, the positive inferences are more likely than negative and neutral inferences, but the number stay close across pronoun types. If anything, the results suggest that LLMs skew slightly more positively for feminine pronouns, in that PPL and NPL values for feminine pronouns typically exceed the others while PNL and NNL values are typically exceeded by the others. While promising, this is only a coarse-grained analysis on gender since we only use pronouns to access this variable and our dataset does not focus on gender bias-specific attributes and stimuli.
C.1 Tables in SAI direction
For ageism bias in Table 13, we can see that the positive-to-positive likelihood (PPL) is 75.82% while the positive-to-negative likelihood (PNL) is 2.84%, which means the GPT-4 is more inclined to select positive attributes (e.g., efficient, creative, etc.) in response to younger age (e.g., 26 years old, 28 years old, etc.) and less inclined to select negative attributes in response to younger age. The negative-to-negative likelihood (NNL) is 16.82%, which means the GPT-4 is also selecting negative attributes in response to older age (e.g., 65 years old, 68 years old, etc.). Given the values of PNL and NNL, it is evident that GPT-4 favors negative attributes more when dealing with older individuals compared to younger ones. So, we can say that there exists an ageism bias in the GPT-4. For ageism bias, we also see the same kind of trends for PaLM-2 in Table 16, Llama-2 in Table 19, and GPT-3.5 in Table 10. But for Mistral in Table 22, this difference is less compared to other models and is not statistically significant.
When we observe the beauty bias, we can say that there is a very strong association of beauty bias in all of these models. In Table 10, the PNL and NNL of beauty bias are 5.06% and 79.22% respectively, which means that the GPT-3.5 selects negative attributes more when dealing with negative appearance (e.g., unattractive, etc.). The same thing is also happening for beauty bias with professions. Different values of beauty bias in professions suggest that GPT-3.5 selects negative attributes (e.g., security guard, taxi driver, etc.) more when dealing with negative appearance. We can see the similar trend like GPT-3.5 in all other models. In Table 13, for GPT-4, we see that PNL for beauty bias is 0%, which really indicates how much biased it is.
In the same way, in Table 13, the PPL of institutional bias is 90.54%, which is comparatively high compared to other models. The NNL and PNL of institutional bias suggest that GPT-4 chooses negative attributes more when dealing with community colleges. We also see the same kind of trends for GPT-3.5 in Table 10, PaLM-2 in Table 16, Llama-2 in Table 19, and Mistral in Table 22. But for Mistral, this difference is less compared to other models.
In Table 16, for nationality bias, PaLM-2 picks negative attributes more when dealing with poor countries. This trend is also similar for all other models. But the difference between NNL and PNL, NPL and PPL, etc. are smaller compared to other types of bias for GPT-4, Llama-2, and Mistral. This also indicates that we made some improvement at least for nationality bias.
In Table 14, we showed our experimental results from a gender perspective and in the SAI direction with GPT-4. For ageism bias, in terms of negative attribute selections, we can see that GPT-4 selects fewer negative attributes for feminine pronouns. However, when it comes to institutional bias, we observed that the PaLM-2 model in Table 17 tends to select more negative attributes for masculine genders compared to non-binary and feminine. In the case of nationality and institutional bias, the PaLM-2 model also tends to favor more negative attribute selections for masculine compared to non-binary and feminine.
C.2 Tables in ASA direction
In this direction, we also notice that there is a strong likelihood between attribute and stimulus. We can see that the PPL is less compared to the SAI direction in most cases, but there are still some discrepancies among values. In Table 13, When we look at the NNL and PNL of ageism bias, we realize that GPT-4 selects negative stimuli (e.g., 66 years old, 69 years old, etc.) more when dealing with negative attributes. We also see similar trends for other models. For Mistral in Table 22, we see the trend of PPL and NPL is different for ageism bias compared to others.
In Table 13, for beauty bias in professions, we notice that the difference between NNL and PNL is 22.32%. This means that the GPT-4 picks the negative appearance more in response to the lower-income individuals. This trend is also similar to other models. For institutional and nationality bias, the same kind of relationship exists for all models.
Table 12 presented our experimental results from a gender perspective and in the ASA direction with GPT-3.5. For beauty bias in professions, we observed that the GPT-3.5 model tends to select more negative attributes for males compared to females and non-binary genders.
In ASA direction we also see similar trends like SAI direction in gender settings. In Table 15, for beauty bias, we see that PPL is higher for feminine pronoun settings. From Table 21, we see that the gap between these different gender settings is even narrow.
| Similar To Table 2 | Direction of Experiment | Category | ? | ||
|---|---|---|---|---|---|
| SAI | Ageism | 0.237 | 2.7e-11 | Reject | |
| Beauty | 0.807 | 1.3e-124 | Reject | ||
| Beauty Profession | 0.410 | 1.9e-29 | Reject | ||
| Institution | 0.202 | 9.4e-21 | Reject | ||
| Nationality | 0.112 | 7.2e-08 | Reject | ||
| ASA | Ageism | 0.183 | 1.3e-09 | Reject | |
| Beauty | 0.786 | 9.0e-96 | Reject | ||
| Beauty Profession | 0.269 | 4.5e-12 | Reject | ||
| Institution | 0.263 | 4.6e-24 | Reject | ||
| Nationality | 0.376 | 2.0e-23 | Reject | ||
| Similar To Table 3 | SAI | first-year | 0.234 | 6.4e-10 | Reject |
| second-year | 0.255 | 4.6e-11 | Reject | ||
| teacher | 0.120 | 0.0007 | Reject | ||
| ASA | first-year | 0.279 | 7.6e-10 | Reject | |
| second-year | 0.228 | 2.5e-07 | Reject | ||
| teacher | 0.284 | 3.9e-10 | Reject | ||
| Similar To Table 4 | SAI | masculine | 0.324 | 1.4e-48 | Reject |
| feminine | 0.284 | 1.3e-39 | Reject | ||
| non-binary | 0.289 | 9.9e-39 | Reject | ||
| ASA | masculine | 0.372 | 1.3e-46 | Reject | |
| feminine | 0.328 | 1.3e-37 | Reject | ||
| non-binary | 0.336 | 6.2e-39 | Reject | ||
| Similar To Table 1 | SAI | overall | 0.342 | 7.1e-157 | Reject |
| ASA | overall | 0.079 | 3.6e-08 | Reject | |
| Similar To Table 5 | SAI | educational level | 0.029 | 0.0928 | Reject Fail |
| ASA | educational level | 0.028 | 0.1754 | Reject Fail | |
| Similar To Table 6 | SAI | gendered pronoun | 0.032 | 0.0018 | Reject |
| ASA | gendered pronoun | 0.042 | 0.0004 | Reject |
| GPT-3.5 | GPT-4 | PaLM-2 | Llama-2 | Mistral | ||||||||||||
| DOE | BT | PL | NL | NuL | PL | NL | NuL | PL | NL | NuL | PL | NL | NuL | PL | NL | NuL |
| SAI | A | 52.2 | 36.2 | 11.6 | 67.8 | 9.7 | 22.5 | 39.6 | 46.8 | 13.6 | 57.9 | 17.8 | 24.3 | 39.7 | 37.8 | 22.3 |
| B | 45.6 | 41.1 | 13.3 | 42.8 | 35.3 | 21.9 | 36.6 | 43.1 | 20.3 | 50.2 | 24.3 | 25.5 | 41.1 | 33.8 | 24.9 | |
| BP | 33.3 | 41.3 | 25.4 | 41.0 | 38.5 | 20.5 | 45.7 | 28.3 | 25.9 | 40.2 | 28.1 | 31.7 | 40.8 | 27.4 | 31.6 | |
| I | 67.9 | 23.6 | 8.4 | 63.3 | 30.3 | 6.3 | 54.9 | 35.9 | 9.1 | 57.1 | 25.6 | 17.2 | 62.7 | 19.9 | 17.3 | |
| N | 76.1 | 17.2 | 6.8 | 84.3 | 3.2 | 12.5 | 61.7 | 23.6 | 14.7 | 55.4 | 22.5 | 22.1 | 41.8 | 39.6 | 18.5 | |
| ASA | A | 33.4 | 33.4 | 33.2 | 30.3 | 32.9 | 36.8 | 44.8 | 35.1 | 20.1 | 26.0 | 38.7 | 35.24 | 24.6 | 32.2 | 43.1 |
| B | 38.8 | 51.1 | 10.1 | 31.7 | 42.5 | 25.8 | 26.0 | 51.5 | 22.5 | 45.2 | 35.5 | 21.1 | 36.8 | 39.2 | 23.9 | |
| BP | 39.2 | 45.3 | 15.5 | 31.5 | 27.3 | 41.1 | 16.6 | 56.3 | 27.1 | 50.0 | 29.8 | 20.1 | 38.5 | 32.2 | 28.9 | |
| I | 50.9 | 35.2 | 13.7 | 76.3 | 19.9 | 3.6 | 48.3 | 39.7 | 11.8 | 42.8 | 44.2 | 12.94 | 35.2 | 29.9 | 34.8 | |
| N | 51.5 | 23.5 | 25.0 | 52.0 | 23.0 | 25.0 | 47.2 | 16.4 | 36.4 | 40.0 | 33.1 | 26.7 | 44.5 | 28.7 | 26.6 | |
| GPT-3.5 | Direction of Experiment | Pronoun | PPL | PNL | PNuL | NPL | NNL | NNuL |
| SAI | masculine | 72.04 | 15.39 | 12.55 | 43.56 | 45.17 | 11.26 | |
| feminine | 75.23 | 13.79 | 10.96 | 49.52 | 39.19 | 11.28 | ||
| non-binary | 71.31 | 15.88 | 12.80 | 46.25 | 43.44 | 10.30 | ||
| ASA | masculine | 54.06 | 23.43 | 22.50 | 23.84 | 54.05 | 22.10 | |
| feminine | 58.43 | 19.67 | 21.89 | 32.47 | 48.53 | 18.98 | ||
| non-binary | 60.56 | 23.59 | 15.84 | 30.51 | 50.70 | 18.77 | ||
| GPT-4 | SAI | masculine | 80.95 | 5.50 | 13.53 | 42.57 | 41.63 | 15.78 |
| feminine | 83.47 | 3.84 | 12.67 | 48.66 | 36.42 | 14.91 | ||
| non-binary | 78.96 | 6.59 | 14.43 | 43.70 | 40.60 | 15.69 | ||
| ASA | masculine | 59.67 | 12.21 | 28.10 | 31.04 | 45.89 | 23.05 | |
| feminine | 64.64 | 11.04 | 24.30 | 33.63 | 43.35 | 23.01 | ||
| non-binary | 61.17 | 14.12 | 24.69 | 35.48 | 45.53 | 18.98 | ||
| PaLM-2 | SAI | masculine | 62.00 | 20.73 | 17.26 | 33.19 | 52.03 | 14.76 |
| feminine | 66.22 | 18.55 | 15.21 | 36.28 | 49.17 | 14.53 | ||
| non-binary | 66.38 | 19.05 | 14.55 | 38.55 | 47.03 | 14.40 | ||
| ASA | masculine | 50.55 | 25.77 | 23.67 | 23.10 | 58.24 | 18.65 | |
| feminine | 52.70 | 23.92 | 23.36 | 24.88 | 54.62 | 20.49 | ||
| non-binary | 56.20 | 22.91 | 20.88 | 25.27 | 55.79 | 18.92 | ||
| Llama-2 | SAI | masculine | 58.34 | 17.37 | 24.28 | 45.81 | 31.51 | 22.67 |
| feminine | 59.88 | 16.73 | 23.38 | 51.78 | 28.21 | 20.00 | ||
| non-binary | 56.66 | 20.53 | 22.80 | 47.30 | 28.90 | 23.79 | ||
| ASA | masculine | 55.09 | 20.82 | 24.07 | 22.28 | 54.05 | 23.65 | |
| feminine | 57.81 | 20.86 | 21.32 | 24.51 | 54.46 | 21.01 | ||
| non-binary | 55.48 | 21.58 | 22.93 | 23.31 | 52.91 | 23.77 | ||
| Mistral | SAI | masculine | 52.21 | 26.52 | 21.25 | 42.01 | 37.24 | 20.73 |
| feminine | 54.56 | 24.14 | 21.29 | 41.78 | 36.30 | 21.91 | ||
| non-binary | 53.23 | 24.52 | 22.24 | 41.92 | 36.21 | 21.86 | ||
| ASA | masculine | 39.69 | 29.05 | 31.25 | 25.83 | 38.35 | 35.80 | |
| feminine | 43.78 | 24.97 | 31.24 | 29.05 | 36.67 | 34.27 | ||
| non-binary | 43.41 | 25.89 | 30.69 | 27.20 | 39.13 | 33.66 |
| GPT-3.5 | |||||||
|---|---|---|---|---|---|---|---|
| Direction of Experiment | Bias Type | PPL | PNL | PNuL | NPL | NNL | NNuL |
| SAI | Ageism | 62.52 | 25.29 | 12.17 | 41.78 | 47.18 | 11.03 |
| Beauty | 78.94 | 5.06 | 15.99 | 10.27 | 79.22 | 10.49 | |
| Beauty Profession | 51.02 | 26.07 | 22.90 | 15.64 | 56.46 | 27.89 | |
| Institutional | 77.19 | 13.93 | 8.87 | 58.74 | 33.29 | 7.95 | |
| Nationality | 81.10 | 11.09 | 7.79 | 71.02 | 23.27 | 5.70 | |
| ASA | Ageism | 39.10 | 25.34 | 35.54 | 27.63 | 41.45 | 30.90 |
| Beauty | 73.98 | 9.82 | 16.18 | 8.45 | 86.56 | 4.97 | |
| Beauty Profession | 50.80 | 33.60 | 15.59 | 27.56 | 57.02 | 15.40 | |
| Institutional | 63.65 | 25.21 | 11.12 | 38.23 | 45.45 | 16.31 | |
| Nationality | 68.02 | 11.16 | 20.81 | 34.62 | 36.17 | 29.19 | |
| GPT-3.5 | |||||||
|---|---|---|---|---|---|---|---|
| Bias Type | Pronoun | PPL | PNL | PNuL | NPL | NNL | NNuL |
| Ageism | masculine | 66.90 | 21.12 | 11.97 | 41.54 | 49.29 | 9.15 |
| feminine | 66.19 | 23.23 | 10.56 | 46.47 | 42.95 | 10.56 | |
| non-binary | 54.54 | 31.46 | 13.98 | 37.32 | 49.29 | 13.38 | |
| Beauty | masculine | 81.21 | 4.84 | 13.93 | 7.79 | 82.46 | 9.74 |
| feminine | 76.68 | 4.90 | 18.40 | 14.28 | 71.42 | 14.28 | |
| non-binary | 78.91 | 5.42 | 15.66 | 8.80 | 83.64 | 7.54 | |
| Beauty Profession | masculine | 54.36 | 22.81 | 22.81 | 15.86 | 55.86 | 28.27 |
| feminine | 54.42 | 23.80 | 21.76 | 16.10 | 57.04 | 26.84 | |
| non-binary | 44.13 | 31.72 | 24.13 | 14.96 | 56.46 | 28.57 | |
| Institutional | masculine | 74.92 | 15.78 | 9.28 | 52.69 | 38.62 | 8.68 |
| feminine | 78.70 | 13.88 | 7.40 | 61.68 | 30.84 | 7.47 | |
| non-binary | 78.00 | 12.00 | 10.00 | 62.33 | 30.00 | 7.66 | |
| Nationality | masculine | 75.35 | 14.28 | 10.35 | 67.61 | 24.91 | 7.47 |
| feminine | 85.81 | 8.86 | 5.31 | 74.28 | 19.64 | 6.07 | |
| non-binary | 82.10 | 10.17 | 7.71 | 71.17 | 25.26 | 3.55 | |
| GPT-3.5 | |||||||
|---|---|---|---|---|---|---|---|
| Bias Type | Pronoun | PPL | PNL | PNuL | NPL | NNL | NNuL |
| Ageism | masculine | 28.70 | 30.09 | 41.20 | 20.46 | 46.97 | 32.55 |
| feminine | 41.20 | 19.90 | 38.88 | 35.64 | 37.96 | 26.38 | |
| non-binary | 47.44 | 26.04 | 26.51 | 26.76 | 39.43 | 33.80 | |
| Beauty | masculine | 68.86 | 12.26 | 18.86 | 6.06 | 89.39 | 4.54 |
| feminine | 78.04 | 5.69 | 16.26 | 14.89 | 79.43 | 5.67 | |
| non-binary | 74.35 | 11.96 | 13.67 | 3.87 | 91.47 | 4.65 | |
| Beauty Profession | masculine | 45.60 | 35.20 | 19.20 | 15.44 | 64.22 | 20.32 |
| feminine | 63.41 | 23.57 | 13.00 | 38.70 | 46.77 | 14.51 | |
| non-binary | 43.54 | 41.93 | 14.51 | 28.45 | 60.16 | 11.38 | |
| Institutional | masculine | 65.72 | 21.90 | 212.36 | 35.09 | 46.79 | 18.11 |
| feminine | 57.08 | 29.11 | 13.79 | 34.89 | 49.28 | 15.82 | |
| non-binary | 67.92 | 24.90 | 7.16 | 45.00 | 40.00 | 15.00 | |
| Nationality | masculine | 66.66 | 13.63 | 19.69 | 32.55 | 34.88 | 32.55 |
| feminine | 66.41 | 9.92 | 23.66 | 35.11 | 32.82 | 32.06 | |
| non-binary | 70.99 | 9.92 | 19.08 | 36.22 | 40.94 | 22.83 | |
| GPT-4 | |||||||
|---|---|---|---|---|---|---|---|
| Direction of Experiment | Bias Type | PPL | PNL | PNuL | NPL | NNL | NNuL |
| SAI | Ageism | 75.82 | 2.84 | 21.32 | 59.51 | 16.82 | 23.65 |
| Beauty | 78.47 | 0.00 | 21.52 | 6.71 | 70.94 | 22.33 | |
| Beauty Profession | 61.55 | 22.42 | 16.01 | 19.61 | 55.26 | 25.11 | |
| Institutional | 90.54 | 3.90 | 5.54 | 36.11 | 56.79 | 7.09 | |
| Nationality | 84.74 | 2.50 | 12.75 | 83.97 | 3.82 | 12.20 | |
| ASA | Ageism | 38.11 | 18.05 | 43.82 | 22.44 | 47.83 | 29.72 |
| Beauty | 58.47 | 8.05 | 33.47 | 5.29 | 76.37 | 18.32 | |
| Beauty Profession | 45.35 | 16.18 | 38.46 | 17.64 | 38.50 | 43.85 | |
| Institutional | 87.50 | 11.16 | 1.33 | 65.20 | 28.81 | 5.98 | |
| Nationality | 66.91 | 7.82 | 25.25 | 35.22 | 40.05 | 24.71 | |
| GPT-4 | |||||||
|---|---|---|---|---|---|---|---|
| Bias Type | Pronoun | PPL | PNL | PNuL | NPL | NNL | NNuL |
| Ageism | masculine | 74.28 | 3.57 | 22.14 | 56.61 | 19.11 | 24.26 |
| feminine | 78.41 | 1.43 | 20.14 | 65.71 | 13.57 | 20.71 | |
| non-binary | 74.82 | 3.49 | 21.67 | 55.97 | 17.91 | 26.11 | |
| Beauty | masculine | 80.11 | 0.00 | 19.88 | 4.73 | 72.18 | 23.07 |
| feminine | 77.77 | 0.00 | 22.22 | 10.77 | 63.47 | 25.74 | |
| non-binary | 77.51 | 0.00 | 22.48 | 4.70 | 77.05 | 18.23 | |
| Beauty Profession | masculine | 65.33 | 20.00 | 14.66 | 17.85 | 58.57 | 23.57 |
| feminine | 69.23 | 16.78 | 13.98 | 28.67 | 50.73 | 20.58 | |
| non-binary | 50.00 | 30.55 | 19.44 | 12.67 | 56.33 | 30.98 | |
| Institutional | masculine | 90.09 | 4.20 | 5.70 | 33.43 | 58.94 | 7.62 |
| feminine | 91.94 | 3.28 | 4.77 | 37.30 | 55.04 | 7.64 | |
| non-binary | 89.50 | 4.26 | 6.22 | 37.82 | 56.25 | 5.92 | |
| Nationality | masculine | 82.31 | 3.61 | 14.07 | 82.37 | 4.31 | 13.30 |
| feminine | 86.64 | 1.44 | 11.91 | 86.23 | 2.53 | 11.23 | |
| non-binary | 85.26 | 2.45 | 12.28 | 83.33 | 4.60 | 12.05 | |
| GPT-4 | |||||||
|---|---|---|---|---|---|---|---|
| Bias Type | Pronoun | PPL | PNL | PNuL | NPL | NNL | NNuL |
| Ageism | masculine | 32.40 | 17.59 | 50.00 | 17.59 | 48.61 | 33.79 |
| feminine | 40.27 | 16.66 | 43.05 | 22.89 | 44.39 | 32.71 | |
| non-binary | 41.66 | 19.90 | 38.42 | 26.85 | 50.46 | 22.68 | |
| Beauty | masculine | 51.53 | 9.20 | 39.26 | 3.63 | 78.78 | 17.57 |
| feminine | 69.32 | 4.29 | 26.38 | 7.87 | 71.51 | 20.60 | |
| non-binary | 54.43 | 10.75 | 34.81 | 4.34 | 78.88 | 16.77 | |
| Beauty Profession | masculine | 38.88 | 18.25 | 42.85 | 12.80 | 41.60 | 45.60 |
| feminine | 56.34 | 10.31 | 33.33 | 23.38 | 37.09 | 39.51 | |
| non-binary | 40.80 | 20.00 | 39.20 | 16.80 | 36.80 | 46.40 | |
| Institutional | masculine | 89.93 | 8.68 | 1.38 | 64.10 | 30.03 | 5.86 |
| feminine | 85.07 | 12.68 | 2.23 | 61.20 | 30.60 | 8.18 | |
| non-binary | 87.31 | 12.31 | 0.37 | 70.56 | 25.66 | 3.77 | |
| Nationality | masculine | 68.18 | 9.09 | 22.72 | 36.58 | 36.58 | 26.82 |
| feminine | 65.15 | 7.57 | 27.27 | 34.23 | 38.73 | 27.02 | |
| non-binary | 67.42 | 6.81 | 25.75 | 34.74 | 44.91 | 20.33 | |
| PaLM-2 | |||||||
|---|---|---|---|---|---|---|---|
| Direction of Experiment | Bias Type | PPL | PNL | PNuL | NPL | NNL | NNuL |
| SAI | Ageism | 50.94 | 33.96 | 15.09 | 28.33 | 59.48 | 12.17 |
| Beauty | 68.75 | 2.60 | 28.64 | 3.72 | 84.57 | 11.70 | |
| Beauty Profession | 62.13 | 17.00 | 20.86 | 29.89 | 39.34 | 30.76 | |
| Institutional | 68.79 | 22.45 | 8.75 | 41.05 | 49.43 | 9.51 | |
| Nationality | 67.42 | 17.28 | 15.28 | 55.73 | 30.25 | 14.00 | |
| ASA | Ageism | 57.58 | 19.19 | 23.21 | 32.09 | 50.92 | 16.97 |
| Beauty | 41.55 | 26.83 | 31.60 | 4.97 | 84.79 | 10.23 | |
| Beauty Profession | 21.95 | 49.32 | 28.72 | 11.29 | 63.17 | 25.53 | |
| Institutional | 66.78 | 24.84 | 8.36 | 29.69 | 54.84 | 15.46 | |
| Nationality | 60.31 | 3.70 | 35.97 | 31.54 | 31.54 | 36.90 | |
| PaLM-2 | |||||||
|---|---|---|---|---|---|---|---|
| Bias Type | Pronoun | PPL | PNL | PNuL | NPL | NNL | NNuL |
| Ageism | masculine | 45.39 | 36.87 | 17.73 | 29.57 | 57.74 | 12.67 |
| feminine | 54.22 | 28.87 | 16.90 | 30.28 | 57.04 | 12.67 | |
| non-binary | 53.19 | 36.17 | 10.63 | 25.17 | 63.63 | 11.18 | |
| Beauty | masculine | 65.87 | 1.58 | 32.53 | 2.40 | 86.40 | 11.20 |
| feminine | 69.46 | 2.29 | 28.24 | 4.76 | 81.74 | 13.49 | |
| non-binary | 70.86 | 3.93 | 25.19 | 4.00 | 85.60 | 10.40 | |
| Beauty Profession | masculine | 69.59 | 12.83 | 17.56 | 34.86 | 32.23 | 32.89 |
| feminine | 61.80 | 18.05 | 20.13 | 24.50 | 47.68 | 27.81 | |
| non-binary | 55.03 | 20.13 | 24.83 | 30.26 | 38.15 | 31.57 | |
| Institutional | masculine | 64.84 | 25.45 | 9.69 | 35.60 | 55.48 | 8.90 |
| feminine | 69.34 | 22.61 | 8.03 | 41.46 | 50.00 | 8.53 | |
| non-binary | 72.45 | 19.01 | 8.52 | 46.68 | 42.05 | 11.25 | |
| Nationality | masculine | 61.11 | 19.65 | 19.23 | 47.78 | 37.61 | 14.60 |
| feminine | 69.95 | 15.87 | 14.16 | 58.29 | 25.56 | 16.14 | |
| non-binary | 71.24 | 16.30 | 12.44 | 61.26 | 27.47 | 11.26 | |
| PaLM-2 | |||||||
|---|---|---|---|---|---|---|---|
| Bias Type | Pronoun | PPL | PNL | PNuL | NPL | NNL | NNuL |
| Ageism | masculine | 52.77 | 21.29 | 25.92 | 29.16 | 55.55 | 15.27 |
| feminine | 57.47 | 17.75 | 24.76 | 30.55 | 50.00 | 19.44 | |
| non-binary | 62.50 | 18.51 | 18.98 | 36.57 | 47.22 | 16.20 | |
| Beauty | masculine | 32.46 | 28.57 | 38.96 | 3.50 | 85.08 | 11.40 |
| feminine | 48.38 | 23.22 | 28.38 | 6.95 | 83.47 | 9.56 | |
| non-binary | 43.79 | 28.75 | 27.45 | 4.42 | 85.84 | 9.73 | |
| Beauty Profession | masculine | 19.51 | 50.40 | 30.08 | 8.94 | 65.85 | 25.20 |
| feminine | 27.41 | 45.96 | 26.61 | 16.12 | 61.29 | 22.58 | |
| non-binary | 18.85 | 51.63 | 29.50 | 8.80 | 62.40 | 28.80 | |
| Institutional | masculine | 67.12 | 25.95 | 6.92 | 29.25 | 56.29 | 14.44 |
| feminine | 62.31 | 28.73 | 8.95 | 29.32 | 54.06 | 16.60 | |
| non-binary | 70.89 | 19.77 | 9.32 | 30.53 | 54.19 | 15.26 | |
| Nationality | masculine | 61.11 | 5.55 | 33.33 | 32.40 | 31.48 | 36.11 |
| feminine | 54.40 | 3.20 | 42.40 | 31.13 | 26.41 | 42.45 | |
| non-binary | 65.35 | 2.36 | 32.28 | 31.06 | 36.89 | 32.03 | |
| Llama-2 | |||||||
|---|---|---|---|---|---|---|---|
| Direction of Experiment | Bias Type | PPL | PNL | PNuL | NPL | NNL | NNuL |
| SAI | Ageism | 62.04 | 14.59 | 23.35 | 53.78 | 21.02 | 25.18 |
| Beauty | 60.47 | 15.76 | 23.75 | 39.79 | 32.92 | 27.27 | |
| Beauty Profession | 45.39 | 25.11 | 29.49 | 35.18 | 30.95 | 33.85 | |
| Institutional | 63.60 | 15.79 | 20.59 | 54.89 | 24.46 | 20.64 | |
| Nationality | 55.94 | 20.50 | 23.54 | 53.78 | 21.02 | 25.18 | |
| ASA | Ageism | 31.41 | 34.37 | 34.21 | 20.62 | 43.10 | 36.27 |
| Beauty | 57.40 | 19.13 | 23.45 | 33.19 | 47.95 | 18.85 | |
| Beauty Profession | 58.76 | 22.10 | 19.13 | 41.20 | 37.53 | 21.17 | |
| Institutional | 77.14 | 9.97 | 12.87 | 7.42 | 79.55 | 13.02 | |
| Nationality | 49.58 | 23.41 | 26.99 | 30.47 | 42.93 | 26.59 | |
| Llama-2 | |||||||
|---|---|---|---|---|---|---|---|
| Bias Type | Pronoun | PPL | PNL | PNuL | NPL | NNL | NNuL |
| Ageism | masculine | 62.50 | 11.02 | 26.47 | 49.28 | 19.28 | 31.42 |
| feminine | 67.39 | 11.59 | 21.01 | 55.72 | 22.13 | 22.13 | |
| non-binary | 56.20 | 21.16 | 22.62 | 56.52 | 21.73 | 21.73 | |
| Beauty | masculine | 60.47 | 16.76 | 22.75 | 36.80 | 36.19 | 26.99 |
| feminine | 63.31 | 13.01 | 23.66 | 41.71 | 32.51 | 25.76 | |
| non-binary | 57.57 | 17.57 | 24.84 | 40.82 | 30.17 | 28.99 | |
| Beauty Profession | masculine | 54.79 | 16.43 | 28.76 | 36.91 | 31.54 | 31.54 |
| feminine | 36.80 | 31.25 | 31.94 | 40.26 | 28.85 | 30.87 | |
| non-binary | 44.44 | 27.77 | 27.77 | 28.47 | 32.45 | 39.07 | |
| Institutional | masculine | 61.32 | 16.03 | 22.64 | 48.18 | 37.87 | 13.93 |
| feminine | 63.58 | 14.50 | 21.91 | 54.28 | 33.65 | 12.06 | |
| non-binary | 66.10 | 16.94 | 16.94 | 49.66 | 34.33 | 16.00 | |
| Nationality | masculine | 53.45 | 22.90 | 23.63 | 51.24 | 27.40 | 21.35 |
| feminine | 61.73 | 16.60 | 21.66 | 59.20 | 22.02 | 18.77 | |
| non-binary | 52.57 | 22.05 | 25.36 | 54.28 | 23.92 | 21.78 | |
| Llama-2 | |||||||
|---|---|---|---|---|---|---|---|
| Bias Type | Pronoun | PPL | PNL | PNuL | NPL | NNL | NNuL |
| Ageism | masculine | 27.90 | 31.62 | 40.46 | 16.27 | 46.51 | 37.20 |
| feminine | 32.07 | 35.37 | 32.54 | 24.65 | 42.32 | 33.02 | |
| non-binary | 34.25 | 36.11 | 29.62 | 20.93 | 40.46 | 38.60 | |
| Beauty | masculine | 55.27 | 21.73 | 22.98 | 27.43 | 54.26 | 18.29 |
| feminine | 58.64 | 17.90 | 23.45 | 36.19 | 47.23 | 16.56 | |
| non-binary | 58.28 | 17.79 | 23.92 | 36.02 | 42.23 | 21.73 | |
| Beauty Profession | masculine | 54.76 | 24.60 | 20.63 | 40.47 | 35.71 | 23.80 |
| feminine | 60.48 | 20.16 | 19.35 | 41.80 | 36.88 | 21.31 | |
| non-binary | 61.15 | 21.48 | 17.35 | 41.60 | 40.00 | 18.40 | |
| Institutional | masculine | 78.02 | 10.25 | 11.72 | 8.73 | 75.79 | 15.47 |
| feminine | 79.53 | 8.49 | 11.96 | 6.06 | 82.19 | 11.74 | |
| non-binary | 73.84 | 11.15 | 15.00 | 7.53 | 80.55 | 11.90 | |
| Nationality | masculine | 51.69 | 20.33 | 27.96 | 35.59 | 40.67 | 23.72 |
| feminine | 52.50 | 26.66 | 20.83 | 31.40 | 42.97 | 25.61 | |
| non-binary | 44.80 | 23.20 | 32.00 | 24.59 | 45.08 | 30.32 | |
| Mistral | |||||||
|---|---|---|---|---|---|---|---|
| Direction of Experiment | Bias Type | PPL | PNL | PNuL | NPL | NNL | NNuL |
| SAI | Ageism | 41.78 | 37.79 | 20.42 | 37.76 | 37.99 | 24.24 |
| Beauty | 60.07 | 14.87 | 25.04 | 22.30 | 52.83 | 24.85 | |
| Beauty Profession | 47.79 | 22.46 | 29.73 | 33.84 | 32.52 | 33.62 | |
| Institutional | 64.16 | 17.04 | 18.78 | 61.25 | 22.91 | 15.82 | |
| Nationality | 45.66 | 35.36 | 18.96 | 37.93 | 43.91 | 18.14 | |
| ASA | Ageism | 24.53 | 35.95 | 39.50 | 24.69 | 28.54 | 46.75 |
| Beauty | 54.98 | 18.94 | 26.06 | 18.69 | 59.55 | 21.74 | |
| Beauty Profession | 43.73 | 28.00 | 28.26 | 33.33 | 37.06 | 29.60 | |
| Institutional | 41.59 | 25.53 | 32.86 | 28.99 | 34.20 | 36.80 | |
| Nationality | 55.55 | 21.96 | 22.47 | 33.58 | 35.60 | 30.80 | |
| Mistral | |||||||
|---|---|---|---|---|---|---|---|
| Bias Type | Pronoun | PPL | PNL | PNuL | NPL | NNL | NNuL |
| Ageism | masculine | 45.07 | 35.21 | 19.71 | 39.86 | 35.66 | 24.47 |
| feminine | 45.07 | 37.32 | 17.60 | 39.16 | 39.16 | 21.67 | |
| non-binary | 35.21 | 40.84 | 23.94 | 34.26 | 39.16 | 26.57 | |
| Beauty | masculine | 65.29 | 11.76 | 22.94 | 27.48 | 50.87 | 21.63 |
| feminine | 57.30 | 16.95 | 25.73 | 19.88 | 56.72 | 23.39 | |
| non-binary | 57.64 | 15.88 | 26.47 | 19.52 | 50.88 | 29.58 | |
| Beauty Profession | masculine | 48.02 | 21.71 | 30.26 | 33.77 | 32.45 | 33.77 |
| feminine | 43.42 | 23.02 | 33.55 | 34.43 | 29.13 | 36.42 | |
| non-binary | 52.00 | 22.66 | 25.33 | 33.33 | 36.00 | 30.66 | |
| Institutional | masculine | 58.85 | 21.62 | 19.51 | 55.71 | 28.73 | 15.54 |
| feminine | 67.16 | 15.52 | 17.31 | 63.60 | 19.57 | 16.81 | |
| non-binary | 66.66 | 13.72 | 19.60 | 64.91 | 20.00 | 15.08 | |
| Nationality | masculine | 42.45 | 39.29 | 18.24 | 39.78 | 42.60 | 17.60 |
| feminine | 48.77 | 32.63 | 18.59 | 35.08 | 45.61 | 19.29 | |
| non-binary | 45.77 | 34.15 | 20.07 | 38.94 | 43.50 | 17.54 | |
| Mistral | |||||||
|---|---|---|---|---|---|---|---|
| Bias Type | Pronoun | PPL | PNL | PNuL | NPL | NNL | NNuL |
| Ageism | masculine | 22.22 | 34.25 | 43.51 | 24.53 | 29.16 | 46.29 |
| feminine | 25.46 | 37.50 | 37.03 | 25.46 | 27.31 | 47.22 | |
| non-binary | 25.92 | 36.11 | 37.96 | 24.07 | 29.16 | 46.75 | |
| Beauty | masculine | 53.04 | 22.56 | 24.39 | 16.46 | 62.19 | 21.34 |
| feminine | 58.28 | 19.01 | 22.69 | 20.73 | 57.31 | 21.95 | |
| non-binary | 53.65 | 15.24 | 31.09 | 18.90 | 59.14 | 21.95 | |
| Beauty Profession | masculine | 42.74 | 33.87 | 23.38 | 34.40 | 36.00 | 29.60 |
| feminine | 52.80 | 19.20 | 28.00 | 38.88 | 32.53 | 28.57 | |
| non-binary | 35.71 | 30.95 | 33.33 | 26.61 | 42.74 | 30.64 | |
| Institutional | masculine | 39.13 | 27.89 | 32.97 | 23.77 | 35.09 | 41.13 |
| feminine | 41.24 | 24.12 | 34.63 | 31.31 | 34.51 | 34.16 | |
| non-binary | 44.57 | 24.41 | 31.00 | 31.80 | 32.95 | 35.24 | |
| Nationality | masculine | 50.00 | 26.51 | 23.48 | 35.60 | 32.57 | 31.81 |
| feminine | 52.27 | 18.93 | 28.78 | 31.06 | 34.84 | 34.09 | |
| non-binary | 64.39 | 20.45 | 15.15 | 34.09 | 39.39 | 26.51 | |
| GPT-3.5 | |||||||
|---|---|---|---|---|---|---|---|
| Direction of Experiment | Level | PPL | PNL | PNuL | NPL | NNL | NNuL |
| SAI | First-year | 78.16 | 12.97 | 8.86 | 56.42 | 33.54 | 10.03 |
| Second-year | 75.87 | 14.28 | 9.84 | 53.14 | 39.30 | 7.54 | |
| Teacher | 77.53 | 14.55 | 7.91 | 66.66 | 27.04 | 6.28 | |
| ASA | First-year | 60.22 | 27.50 | 12.26 | 34.45 | 50.93 | 14.60 |
| Second-year | 66.29 | 23.70 | 10.00 | 44.23 | 41.63 | 14.12 | |
| teacher | 64.44 | 24.44 | 1.11 | 35.95 | 43.82 | 20.22 | |
| GPT-4 | |||||||
|---|---|---|---|---|---|---|---|
| Direction of Experiment | Level | PPL | PNL | PNuL | NPL | NNL | NNuL |
| SAI | First-year | 89.84 | 4.92 | 5.23 | 21.98 | 69.04 | 8.97 |
| Second-year | 89.53 | 2.76 | 7.69 | 25.00 | 68.20 | 6.79 | |
| Teacher | 92.26 | 4.02 | 3.71 | 61.23 | 33.23 | 5.53 | |
| ASA | First-year | 90.54 | 8.36 | 1.09 | 72.72 | 25.09 | 2.18 |
| Second-year | 92.30 | 7.69 | 0.00 | 75.74 | 21.26 | 2.98 | |
| teacher | 79.71 | 17.39 | 2.89 | 47.46 | 39.85 | 12.68 | |
| PaLM-2 | |||||||
|---|---|---|---|---|---|---|---|
| Direction of Experiment | Level | PPL | PNL | PNuL | NPL | NNL | NNuL |
| SAI | First-year | 62.65 | 29.32 | 8.02 | 30.21 | 59.81 | 9.96 |
| Second-year | 71.51 | 18.57 | 9.90 | 34.78 | 54.34 | 10.86 | |
| Teacher | 72.22 | 19.44 | 8.33 | 58.02 | 34.25 | 7.71 | |
| ASA | First-year | 62.54 | 29.09 | 8.36 | 24.90 | 60.80 | 14.28 |
| Second-year | 80.00 | 15.27 | 4.72 | 38.51 | 51.11 | 10.37 | |
| teacher | 57.81 | 30.18 | 12.00 | 25.75 | 52.57 | 21.69 | |
| Llama-2 | |||||||
|---|---|---|---|---|---|---|---|
| Direction of Experiment | Level | PPL | PNL | PNuL | NPL | NNL | NNuL |
| SAI | First-year | 57.74 | 17.74 | 24.51 | 46.85 | 39.30 | 13.83 |
| Second-year | 65.09 | 16.35 | 18.55 | 51.12 | 33.44 | 15.43 | |
| Teacher | 67.96 | 13.26 | 18.77 | 54.11 | 33.22 | 12.65 | |
| ASA | First-year | 74.07 | 11.48 | 14.44 | 6.48 | 81.29 | 12.21 |
| Second-year | 78.94 | 7.14 | 13.90 | 8.83 | 73.09 | 18.07 | |
| teacher | 78.51 | 11.32 | 10.15 | 7.00 | 84.04 | 8.94 | |
| Mistral | |||||||
|---|---|---|---|---|---|---|---|
| Direction of Experiment | Level | PPL | PNL | PNuL | NPL | NNL | NNuL |
| SAI | First-year | 64.0 | 19.38 | 16.61 | 58.02 | 26.23 | 15.74 |
| Second-year | 64.19 | 17.59 | 18.20 | 58.95 | 25.0 | 16.04 | |
| Teacher | 64.30 | 14.15 | 21.53 | 66.76 | 17.53 | 15.69 | |
| ASA | First-year | 43.60 | 25.93 | 30.45 | 32.72 | 31.25 | 36.02 |
| Second-year | 43.29 | 19.54 | 37.16 | 32.58 | 34.45 | 32.95 | |
| teacher | 37.87 | 31.06 | 31.06 | 21.64 | 36.94 | 41.41 | |
Appendix D Invalid Results Categorized
Based on the broad invalid responses pattern, we divide the responses into five different categories. Category 1 contains just some number between 1 to 3, we named this category as “Numeric Selection”. Category 2 contains responses which are from context sentence but not from the option list, we named this category as “Non-Option Span”. Category 3 indicates that the sentence was not completed, meaning the response is either null or assistance cannot be provided, we named this category as “No Response”. Category 4 includes those responses which response stating that there will be some stereotype in the sentence and it is not appropriate to promote stereotype or none of the options are appropriate for the context, we named this category as “Stereotype Awareness”. Category 5 includes something outside of the context sentence and also outside of the option list, we named this category as “Out-of-Context Responses”. Table 30 represents the exact number of invalid responses in each category for all models. In a majority of cases the invalid responses contained some text from the provided prompt sentence not from the option list. In another common case, LLMs would respond with an answer that is closely related to the provided stimulus or attribute, but not one of the options in the prompt (e.g., filling the BLANK with “retired” for an stimulus of “66 years old” or “model” in response to the stimulus “gorgeous”). PaLM-2 would often respond with just an empty string. GPT-4 and Llama-2 would occasionally recognize that the nationality bias items could be offensive or stereotyping and respond that they could not answer such questions.
Appendix E Statistical Tests for Educational Level
| Models |
|
|
|
|
|
Total | ||||||||||
| GPT 3.5 | 83 | 324 | 0 | 0 | 20 | 427 | ||||||||||
| GPT 4 | 0 | 75 | 20 | 49 | 49 | 193 | ||||||||||
| PaLM 2 | 0 | 69 | 847 | 0 | 33 | 949 | ||||||||||
| Llama 2 | 349 | 20 | 14 | 2 | 14 | 399 | ||||||||||
| Mistral | 14 | 6 | 9 | 5 | 47 | 81 |
| GPT-4 | PaLM-2 | Llama-2 | Mistral | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DOE | BT | ? | ? | ? | ? | ||||||||
| SAI | I | 0.165 | 8.0e-08 | R | 0.375 | 3.8e-13 | R | 0.321 | 4.2e-15 | R | 0.038 | 0.2995 | RF |
| ASA | I | 0.270 | 1.6e-21 | R | 0.408 | 7.3e-24 | R | 0.307 | 3.7e-24 | R | 0.105 | 0.0004 | R |
Appendix F Lists of Attributes and Stimuli
| SAI Direction | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Stimulus | Attributes | ||||||||
| Bias Type | Positive | Negative | Positive | Negative | Neutral | ||||
| Ageism | Age 25-35 | Age 60-70 | effective, focused,… |
|
formal, chummy,… | ||||
| Beauty | attractive, elegant, … | unattractive, plain,… | smart, friendly,… | dumb, unfriendly,… | folksy, solemn,… | ||||
| Beauty Pro. | gorgeous, jazzy,… | ordinary, ugly,… | surgeon, astronomer,… |
|
curator, librarian,… | ||||
| Institutional | MIT, Harvard,… |
|
friendly, cultured,… |
|
strict, playful,… | ||||
| Nationality | Norway, Sweden,… | Malawi, Chad,… | affable, smart,… | unpleasant, dumb,… | funny, solemn,… | ||||
| ASA Direction | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Attributes | Stimulus | ||||||||
| Bias Type | Positive | Negative | Positive | Negative | Neutral | ||||
| Ageism | effective, focused,… |
|
Age 25-35 | Age 60-70 | Age 42-52 | ||||
| Beauty | smart, friendly,… | dumb, unfriendly,… | attractive, elegant,… | unattractive, plain,… | folksy, solemn,… | ||||
| Beauty Pro. | surgeon, astronomer,… |
|
gorgeous, jazzy,… | ordinary, ugly,… | funny, strict,… | ||||
| Institutional | friendly, cultured,… |
|
MIT, Harvard,… |
|
New York, Tampa,… | ||||
| Nationality | affable, smart,… | unpleasant, dumb,… | Norway, Sweden,… | Malawi, Chad,… | Gabon, Peru,… | ||||
| Stimulus/Attribute | Items | ||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Positive Stimulus |
|
||||||||||||||||||||||
| Negative Stimulus |
|
||||||||||||||||||||||
| Neutral Stimulus |
|
||||||||||||||||||||||
| Positive Attribute |
|
||||||||||||||||||||||
| Negative Attribute |
|
||||||||||||||||||||||
| Neutral Attribute |
|
Appendix G Positivity and Bias
Figure 5 shows a global preference toward positive generations. Especially, in the SAI direction where the positive generation likelihood is about double the negative generation rate for all genders. This raises the question whether current LLMs avoid criticism not by avoiding bias altogether, rather by avoiding negative biases only. We explore this question by performing a -test between positive and negative binary given information (stimuli or attributes) and a dependent variable of whether the generated response is stereotypical. That is, a generated response is stereotypical if the polarity of the generation matches the given information. For example, producing a negative attribute for a negative stimulus would be a stereotype value of 1. And producing a positive attribute would be marked as a stereotype value of -1. This leads to a ternary dependent variable (anti-stereotype, neural, stereotype). This test would lead to positive values if an LLMs are more stereotypical when the given information is positive.
The results of the statistical test are presented in Table 35. We find statistical significance for most experimental settings. However, the direction of correlation varies by model, inference direction, and bias domain. In the SAI direction, Llama-2 has statically significant positive effects for all bias domains. So Llama-2 is more likely to produce stereotypical attributes when given positive bias stimuli. GPT-4 and Mistral show similar results, though GPT-4’s results are not statistically significant in the beauty profession domain and Mistral’s results are not statistically significant in the age and nationality domains. PaLM-2 in the SAI direction curiously has negative values for age and beauty domains. In the ASA direction, the results are much more mixed in positivity, though most results are still statistically significant.
The largest effect sizes are GPT-4 in the SAI direction for the nationality domain (0.913), GPT-4 in the SAI direction for the age domain (0.710), and GPT-4 in teh ASA direction in the institution domain (0.588). This suggests that something in the GPT training paradigm causes it to be much more biased when the setting is positive. Also notably, age, institution, and nationality are more well-studied and considered in the field of NLP bias. These results align with the hypothesis that efforts to mitigate bias in LLMs are leading to this generation pattern.
| GPT-4 | PaLM-2 | Llama-2 | Mistral | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DOE | BT | ? | ? | ? | ? | ||||||||
| SAI | A | 0.710 | 1.0e-81 | R | -0.083 | 0.017 | R | 0.499 | 5.8e-40 | R | 0.023 | 0.526 | RF |
| B | 0.089 | 0.001 | R | -0.150 | 1.0e-06 | R | 0.326 | 5.1e-22 | R | 0.091 | 0.004 | R | |
| BP | 0.038 | 0.276 | RF | 0.237 | 1.7e-11 | R | 0.163 | 8.2e-06 | R | 0.177 | 7.9e-07 | R | |
| I | 0.355 | 1.3e-69 | R | 0.208 | 9.0e-20 | R | 0.364 | 9.6e-51 | R | 0.500 | 2.4e-95 | R | |
| N | 0.913 | 3.5e-276 | R | 0.432 | 2.6e-52 | R | 0.401 | 3.8e-52 | R | 0.025 | 0.326 | RF | |
| ASA | A | -0.052 | 0.078 | RF | 0.108 | 0.0001 | R | -0.170 | 1.5e-08 | R | -0.110 | 0.0002 | R |
| B | -0.176 | 6.9e-09 | R | -0.434 | 9.0e-35 | R | 0.136 | 5.0e-05 | R | -0.038 | 0.245 | RF | |
| BP | 0.065 | 0.092 | RF | -0.505 | 3.6e-37 | R | 0.244 | 3.7e-10 | R | 0.078 | 0.048 | R | |
| I | 0.588 | 2.4e-126 | R | 0.105 | 1.8e-05 | R | -0.027 | 0.190 | RF | 0.075 | 0.005 | R | |
| N | 0.337 | 8.7e-19 | R | 0.385 | 6.6e-22 | R | 0.086 | 0.030 | R | 0.207 | 5.6e-08 | R | |