mOhaoyang[#1]
Is Large Language Model Good at Database Knob Tuning? A Comprehensive Experimental Evaluation
Abstract.
Knob tuning plays a crucial role in optimizing databases by adjusting knobs to enhance database performance. However, traditional tuning methods often follow a Try-Collect-Adjust approach, proving inefficient and database-specific. Moreover, these methods are often opaque, making it challenging for DBAs to grasp the underlying decision-making process.
The emergence of large language models (LLMs) like GPT-4 and Claude-3 has excelled in complex natural language tasks, yet their potential in database knob tuning remains largely unexplored. This study harnesses LLMs as experienced DBAs for knob-tuning tasks with carefully designed prompts. We identify three key subtasks in the tuning system: knob pruning, model initialization, and knob recommendation, proposing LLM-driven solutions to replace conventional methods for each subtask.
We conduct extensive experiments to compare LLM-driven approaches against traditional methods across the subtasks to evaluate LLMs’ efficacy in the knob tuning domain. Furthermore, we explore the adaptability of LLM-based solutions in diverse evaluation settings, encompassing new benchmarks, database engines, and hardware environments. Our findings reveal that LLMs not only match or surpass traditional methods but also exhibit notable interpretability by generating responses in a coherent “chain-of-thought” manner. We further observe that LLMs exhibit remarkable generalizability through simple adjustments in prompts, eliminating the necessity for additional training or extensive code modifications.
Drawing insights from our experimental findings, we identify several opportunities for future research aimed at advancing the utilization of LLMs in the realm of database management.
PVLDB Reference Format:
PVLDB, 14(1): XXX-XXX, 2020.
doi:XX.XX/XXX.XX
This work is licensed under the Creative Commons BY-NC-ND 4.0 International License. Visit https://creativecommons.org/licenses/by-nc-nd/4.0/ to view a copy of this license. For any use beyond those covered by this license, obtain permission by emailing info@vldb.org. Copyright is held by the owner/author(s). Publication rights licensed to the VLDB Endowment.
Proceedings of the VLDB Endowment, Vol. 14, No. 1 ISSN 2150-8097.
doi:XX.XX/XXX.XX
PVLDB Artifact Availability:
The source code, data, and/or other artifacts have been made available at https://github.com/intlyy/Knob-Tuning-with-LLM.
1. Introduction
Configuration knobs control many aspects of database systems (e.g., memory allocation, thread scheduling, caching mechanisms), and different combinations of knob values significantly affect performance, resource usage, and robustness of the database (Chaudhuri and Narasayya, 2007). In general, given a workload, knob tuning aims to judiciously adjust the values of knobs to improve the database performance (Zhao et al., 2023a). For example, the MySQL database has about 260 knobs, of which adjusting the InnoDB_buffer_ pool_size and tmp_table_size can significantly improve database query processing efficiency (Li et al., 2019). Therefore, it is vital to set proper values for the knobs.
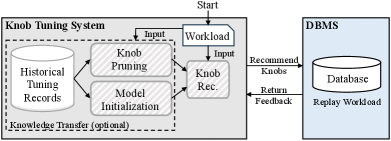
Traditional knob tuning relies on database administrators (DBAs) to manually try out typical knob combinations based on their experience. This process is labor-intensive and impractical for a large number of database instances (e.g., tens of thousands on cloud platforms) (Pavlo et al., 2021). Leveraging machine learning techniques, researchers have developed various automated knob tuning systems capable of identifying suitable knob values without human intervention (Aken et al., 2017; Li et al., 2019; Kanellis et al., 2022; Lin et al., 2022a; Tan et al., 2019). The workflow of these systems is depicted in Figure 1, with the left side illustrating the tuning system and the right side representing the target database management system (DBMS). Upon receiving a workload, the tuning method suggests a configuration for the DBMS, which is then tested with the workload to measure performance metrics (e.g., latency or transactions per second). Subsequently, based on this feedback, the tuning method refines its policy and proposes a new configuration. Through multiple iterations of “Try-Collect-Adjust”, an optimized configuration can be achieved to enhance database performance significantly under the given workload.
The knob tuning system can be segmented into three key components: knob recommendation, knob pruning, and model initialization. Knob recommendation serves as the cornerstone of the tuning system, offering suggestions for suitable configurations tailored to the workload. The approaches for knob recommendation fall into four primary categories: reinforcement learning (RL) based approaches (Cai et al., 2022; Li et al., 2019; Zhang et al., 2021b; Trummer, 2022), Bayesian optimization (BO) based techniques (Duan et al., 2009; Zhang et al., 2021a; Aken et al., 2017; Zhang et al., 2022b), deep learning (DL) based methods (Tan et al., 2019; Aken et al., 2021; Lin et al., 2022b), and heuristic methods (Zhu et al., 2017; Chen et al., 2011). Given the expansive search space of configurations, these tuning methods typically necessitate numerous interactions with the DBMS, with each iteration involving workload execution. This iterative process is both time and resource-intensive. To address this challenge, various knowledge transfer methods (Cereda et al., 2021; Aken et al., 2017; Li et al., 2019; Zhang et al., 2021a; Saltelli, 2002) have been introduced, leveraging past tuning records to expedite the tuning process. These methods can be classified into two categories: knob pruning and model initialization. Knob pruning targets the selection of crucial knobs and the determination of their reasonable ranges for the specific workload, thereby reducing the configuration space (Duan et al., 2009; Saltelli, 2002; Sullivan et al., 2004; Tan et al., 2019; Tibshirani, 1996; Kanellis et al., 2020; Debnath et al., 2008). On the other hand, model initialization focuses on initializing the learnable model within the knob recommendation methods, which can accelerate their convergence speed (Zhang et al., 2021a; Aken et al., 2017; Li et al., 2019; Feurer, 2018; Zhang et al., 2021b; Cereda et al., 2021; Ge et al., 2021). It should be noted that the knob pruning and model initialization techniques usually occur at the beginning of the tuning phase, which are optional components of the tuning system. Then, the knob recommendation methods iteratively interact with DBMS until the database performance coverage or stop conditions are triggered.
Limitations of Existing Methods. Despite the notable performance achieved by current methods, they still exhibit the following limitations. (1) Knob pruning and model initialization techniques often heavily rely on historical tuning data or domain knowledge (e.g., database manual, and forum discussions) to expedite current tuning tasks. For instance, knob pruning methods like Lasso (Tibshirani, 1996) and Sensitivity Analysis (Nembrini et al., 2018) necessitate extensive historical tuning data for calculating knob importance rankings and GPTuner (Lao et al., 2024) and DB-BERT (Trummer, 2022) requires manually collected knob-tuning-related texts to optimize the configuration space. Similarly, model initialization methods like QTune (Li et al., 2019) also rely on historical data for pre-training actor and critic models. However, acquiring such data can be costly, particularly when addressing new database kernels or hardware environments, requiring data collection from scratch. (2) Regarding knob recommendation methods, many of them need to replay the workload in each iteration to capture performance metrics. Due to the limited exploration and exploitation capabilities of these methods, they often require numerous iterations, leading to significant time and resource expenses. (3) Almost all database knob tuning approaches operate as black boxes. This opacity makes it challenging for DBAs to understand the rationale behind recommended outcomes and complicates their ability to intervene effectively in case of issues.
Our Proposal. This paper aims to explore the feasibility of utilizing LLMs to emulate the behaviors of DBAs in performing knob-tuning-related subtasks, including knob pruning, model initialization, and knob recommendation. Recent advancements in LLMs have yielded remarkable breakthroughs in diverse domains, such as mathematical reasoning (Ahn et al., 2024), text-to-SQL (Li et al., 2024), and tool using (Qin et al., 2023). LLMs are famous for vast knowledge, strong reasoning capabilities, and remarkable interpretability, offering potential solutions to the aforementioned limitations within the tuning system. Therefore, integrating LLMs into the database knob tuning system represents a promising direction for research. While LLM-based tuning methods like GPTuner (Lao et al., 2024) have been proposed, existing work primarily focuses on knob pruning, only one subtask within the broader knob tuning process.
In this study, we carefully craft prompts for each tuning subtask and evaluate LLMs’ performance through comparative experiments against previous state-of-the-art (SOTA) methods. Given the diverse array of LLMs available, our evaluation extends beyond a single model. We explore a spectrum of powerful LLMs, including GPT-3.5 (Ouyang et al., 2022), GPT-4-Turbo (OpenAI, 2023b), GPT-4o (Openai, 2024), and Claude-3-Opus (Anthropic, 2024). However, as these powerful LLMs are closed-sourced, concerns related to data privacy and high usage costs may arise. To address this, we additionally consider several open-source LLMs, such as LLaMA3 (Meta, 2024) and Qwen2 (Cloud, 2024), which offer the advantage of local deployment.
Our primary experiments are conducted using an Online Transaction Processing (OLTP) benchmark (SYSBENCH (Kopytov, 2024)) in conjunction with the MySQL database engine. In addition, given the inherent adaptability of LLMs, which allows them to generalize to new scenarios through prompt adjustments, we also conduct comprehensive assessments to evaluate the generalizability of our LLM-based solutions across diverse workloads, database engines, and hardware environments. We believe that this study can serve as a source of inspiration for more AI4DB tasks, such as query optimization and index recommendation.
We make the following contributions in this paper:
-
•
We investigate the capabilities of LLMs in executing three knob tuning subtasks: knob pruning, model initialization, and knob recommendation. For each subtask, we carefully craft prompts to guide the LLMs in effectively addressing the specific objectives.
-
•
In our experiments, we comprehensively evaluate both closed-source and open-source LLMs, offering researchers and practitioners a thorough understanding of the strengths and limitations of various LLMs.
-
•
We additionally assess the generalizability of LLMs by conducting experiments across various benchmarks, database engines, and hardware environments.
-
•
Based on our findings, we explore future research directions and potential challenges in the domain of utilizing LLMs for knob tuning.
The remainder of the paper is organized as follows. We formally define the problems in Section 2, followed by a description of the integration of LLMs with three database knob tuning subtasks in Section 3. Then, Section 4-8 presents our experimental evaluation and main findings. Finally, we discuss research opportunities in Section 9 and conclude in Section 10.
2. PROBLEM DEFINITION
Consider a modern database system equipped with tunable knobs, represented as . Each knob might be either continuous or categorical, covering a range of configurable database aspects like work memory size and maximum connection limits. Every knob is assigned a value within a predetermined range , signifying the allowable value spectrum for that knob. The combination of possible knob values forms a huge multi-dimensional configuration space, represented by . A specific point within this space signifies a unique database configuration, characterized by a set of knob values .
In the context of optimizing database performance, we define the performance metric as , representing factors like throughput or latency that we seek to enhance. For a given database instance , workload , and a specific configuration , the resulting performance metric is observed after applying in the database engine and executing on .
As illustrated in Figure 1, a complete knob tuning system encompasses three important subtasks: knob pruning, model initialization, and knob recommendation. The objective of this study is to explore the ability of LLMs to execute these subtasks, prompting us to define the problem for each subtask via LLMs as follows.
LLMs for Knob Pruning. In modern database systems, although there are hundreds of adjustable knobs, not all knobs are equally important under specific workloads. For example, working memory size is vital to memory-intensive workloads, maximum IO concurrency is vital to IO-intensive workloads. Hence, considering the characteristics of and , the goal of knob pruning is to identify the most impactful knobs and define their crucial ranges. By reducing the search space, knob tuners can concentrate on adjusting these selected knobs in the constrained ranges and thus streamline the tuning process. Formally, we have:
| (1) |
where denotes the large language model, represents the pre-defined prompt used for the knob pruning task, and the outputs and represent the LLM-selected significant knobs and their respective important ranges. Notably, unlike traditional knob pruning methods such as Lasso (Tibshirani, 1996) and Sensitivity Analysis (Nembrini et al., 2018), which only select knobs, the LLM-based approach can also recommend important value ranges for the selected knobs. Furthermore, unlike Lasso (Tibshirani, 1996) and Sensitivity Analysis (Nembrini et al., 2018), which rely on historical tuning data, and the existing LLM-based method GPTuner (Lao et al., 2024) and DB-BERT (Trummer, 2022), which requires manually collected knob-tuning-related texts for input augmentation, our LLM-based approach harnesses the inherent capacity of LLMs to emulate the actions of DBAs for knob pruning. Given that powerful LLMs have likely encountered tuning-related manuals and web pages during pre-training, the primary objective is to instruct them to follow knob pruning guidelines and leverage their internal knowledge.
LLMs for Model Initialization. In practical scenarios, workloads often exhibit dynamic changes, with workload pressures varying significantly over time (from morning to evening, weekdays to weekends, or workdays to holidays). It is widely acknowledged that tuning a specific configuration is necessary for different workloads. However, starting the tuning process from scratch for each workload requires multiple iterations of database interactions, which can be time-consuming and resource-intensive. To accelerate the tuning speed, several transfer learning-based studies have been proposed to leverage knowledge from historical tuning records as the initialization of the tuning method, facilitating quicker convergence.
Instead of accumulating extensive historical tuning data for model initialization, we propose leveraging LLMs to recommend a set of effective initial knob configurations for the new workload. These LLM-generated configurations can then be used to initialize traditional Bayesian Optimization (BO)-based tuning methods, such as HEBO (Cowen-Rivers et al., 2022) and VBO (Duan et al., 2009). By eliminating the initial phase of random exploration, this methodology enables the BO-based methods to rapidly converge to a suitable configuration, accelerating the overall tuning process. Specifically, we use LLMs to sample a set of effective configurations for a given workload on database :
| (2) |
where indicates the prompt used to recommend configurations, represents the default configuration, signifies the space of possible configurations, represents the database’s feedback under the default configuration, and the output consists of a set of effective configurations derived from the LLM. The default configuration, denoted as , serves as an anchor point, guiding LLMs to adjust only the knobs requiring modification while maintaining the settings of those that do not necessitate changes. The database’s feedback consists of performance metrics (such as latency or transactions per second) and internal metrics (such as lock_deadlocks and os_data_writes). The feedback can provide insights into system states, enabling LLMs to identify performance bottlenecks and make necessary adjustments to the default configuration. The set of configurations generated by the LLM can be used to initialize the BO-based tuning methods, serving as their starting data points.
LLMs for Knob Recommendation. The knob recommendation component is pivotal within the tuning system, responsible for suggesting the optimal configuration for specific workloads to enhance performance metrics. Existing techniques, including the prominent BO-based methods (Duan et al., 2009; Zhang et al., 2021a; Aken et al., 2017; Zhang et al., 2022b) as well as RL-based approaches (Cai et al., 2022; Li et al., 2019; Zhang et al., 2021b; Trummer, 2022), often require hundreds of iterations to converge, hindered by their limited abilities in balancing exploration and exploitation. In this study, we posit that LLMs, with their advanced understanding of database feedback and superior exploration and exploitation capabilities, can pinpoint appropriate configurations in significantly fewer iterations.
The LLM-based knob tuning approach is iterative: starting from the default configuration, we employ LLMs to progressively refine the configuration based on the database feedback. Formally, the refinement process is defined as:
| (3) |
here, also denotes the knob recommendation prompt, and signifies the current configuration, represents the database feedback under current configuration, the output represent the refined configuration. Subsequently, is applied in the database, and the workload is executed to gather the feedback . Then, we can start a new iteration to refine . Initially, and are and , respectively. This refinement process iterates several times until reaching the stop criterion.
Summary. In this section, we propose dividing the knob tuning tasks into three key subtasks and formulating solutions for each using LLMs. The goal is to replace traditional methods with LLM-based solutions for each subtask and evaluate their effectiveness, rather than presenting a comprehensive framework where all three subtasks are solved by LLMs.
3. KNOB TUNING WITH LLM
In this section, we will delve into the details of constructing prompts for three fundamental tuning subtasks.
3.1. Knob Pruning
For a given workload, knob pruning is a critical process aimed at identifying the most important knobs and narrowing their permissive ranges, which can reduce the search space of the knob recommendation methods. Leveraging the LLM as an alternative to traditional knob pruning methods involves incorporating several important elements within the prompt. As illustrated in Figure 2, the prompt for knob pruning contains the following elements:
-
•
“Task Description” describes the objective of the LLM.
-
•
“Candidate Knobs” provides detailed information about candidate knobs within the database engine, encompassing knob names, allowable ranges, types of knobs, and their respective descriptions.
-
•
“Workload and Database Information” contains crucial details about the workload, data characteristics, database kernel, and the hardware.
-
•
“Output Format” specifies the response format of the LLM. Specifically, it requires the LLM to enumerate the names of the chosen knobs, as well as their corresponding ranges and types, in an organized JSON format.

3.2. Model Initialization
The model initialization technique is designed to speed up the tuning process by leveraging historical tuning records to initialize the model used in the knob recommendation methods. In this paper, we concentrate on utilizing LLMs to produce a set of effective configurations for the given workload. Subsequently, these configurations can be used to initialize the BO-based methods, effectively accelerating their convergence speed. As illustrated in Figure 3, we construct the prompt for model initialization in the following format:
-
•
“Task Description” outlines the objective of the LLM.
-
•
“Demonstration for Knob Refinement” includes a knob refinement instance, which aims to serve as the one-shot example in the prompt for demonstration purposes. This instance includes a current configuration, inner metrics, and a refined configuration.
-
•
“Environment” contains the information about database kernel and hardware information. The database kernel details encompass the database engine’s name and version. The hardware information specifies the number of CPUs and the available memory resources. In addition, we also include the text descriptions of each inner metric and tunable knob.
-
•
“Information about Current Workload” includes features about the current workload, such as workload type (OLAP or OLTP) and read-write ratio, and data statistics in the database.
-
•
“Output Format” specifies the format for LLM responses.
-
•
“Current Configuration” displays the default values of the knobs, which serve as the anchor point as discussed in Section 2.
-
•
“Database Feedback” showcases the performance and inner metrics of the database when executing the given workload under the default configuration. Incorporating this feedback is essential, as DBAs often depend on these metrics to assess the database’s status and implement necessary adjustments. For example, confronted with a low cache hit rate, DBAs typically choose to increase the cache size to improve database performance.
In practice, we utilize the LLM for multiple samplings to acquire a collection of effective configurations. These configurations then act as the initial points for BO-based knob recommendation methods.

3.3. Knob Recommendation
The knob recommendation emerges as the crucial subtask within the tuning system, aimed at identifying a promising configuration for a specific workload. As elaborated in Section 2, the LLM undertakes the task of knob recommendation through an iterative process. Initially starting from the default configuration, the LLM employs iterative refinements based on feedback from the database. The prompt for knob recommendation closely mirrors the prompt of model initialization, as depicted in Figure 3. The key distinction lies in the fact that, for knob recommendation, both the “Current Configuration” and “Database Feedback” are subject to change with each iteration.
4. GENERAL SETUPS OF EVALUATION
This study conducts a series of comprehensive evaluations to assess the efficacy of various LLMs across three database knob tuning subtasks. We detail the configurations of the primary experiments, encompassing hardware, software, benchmark, tuning settings, and large language models, as outlined below:
Hardware and Software. Our knob tuning framework is deployed across three distinct servers. The first server, dedicated to the tuning system, is equipped with 48 CPUs and 256 GB of RAM. The second server, designated for the DBMS deployment, features 8 CPUs and 16 GB of RAM, running RDS MySQL version 5.7. The third server is allocated for deploying local LLMs and is equipped with two NVIDIA A100 80GB GPUs, 80 CPUs, and 256 GB of memory. We utilize vLLM (Kwon et al., 2023) as the backend to manage local LLMs. These three machines are interconnected via an intranet, communicating through a high-speed network.
The first server, functioning as the tuning system, controls coordination among three distinct servers. In our LLM-integrated knob tuning framework, the tuning system acts as a bridge between the second server (DBMS) and the third server (local LLMs), handling the interactions between them. For example, for the knob recommendation task, the tuning system first sends the default configuration to the second server to obtain feedback from the database. Then, the tuning system integrates the workload features, current configuration, database feedback, and other required information into a prompt and then sends it to the third server to obtain the LLM’s response (i.e., refined configuration). We should note that, for closed-source LLMs, we access them through APIs, eliminating the need for using the third server.
Benchmark. Following previous work (Zhang et al., 2022a, b; Li et al., 2019), we employ SYSBENCH (Kopytov, 2024), a prevalent OLTP benchmark, for our evaluation. In particular, we focus on the OLTP-Read-Write workload within SYSBENCH, representing a workload that encompasses both read and write operations typical in OLTP scenarios. Subsequently, we load 50 tables within SYSBENCH, with each table housing 1,000,000 rows of records, culminating in approximately 13 GB of data. For a specific configuration, to conduct a stress test, we run the workload for two minutes to obtain the transactions per second (TPS) metric as the database performance. We restart the database after applying a new configuration to guarantee that all knobs have been correctly configured.
Tuning Settings. In the knob pruning task, both LLMs and baseline methods are tasked with identifying 10 significant knobs from the provided set of 100 candidate knobs. Following this selection, we utilize the traditional knob recommendation method, SMAC (Hutter et al., 2011), to identify a suitable configuration using these 10 chosen knobs. In the context of model initialization and knob recommendation, we manually select 20 crucial knobs for further tuning. For model initialization, we leverage the LLM-generated configurations to initialize a BO-based knob recommendation method, VBO (Duan et al., 2009), aiming to expedite its tuning process. For knob recommendation, we directly compare LLMs against those of traditional knob recommendation methods, including DDPG (Lillicrap et al., 2016), SMAC (Hutter et al., 2011), and VBO (Duan et al., 2009).
Evaluation Metric. We evaluate our methods and baselines across two key dimensions: the tuning efficiency score (TES) and the optimal database performance (ODP). As illustrated in Figure 1, we have noticed that a significant portion of the tuning process is dedicated to the DBMS side, as each iteration requires the workload to be replayed using the newly suggested configuration. To minimize the influence of external variables such as network latency, we introduce the TES metric, which quantifies the iterations needed to achieve peak database performance in the tuning process. In addition, the ODP metric measures the maximum achievable TPS during the tuning procedure.
Large Language Models. With the rapid advancement of LLMs, a plethora of models have surfaced, demonstrating a wide range of capabilities and applications across various domains (Zhao et al., 2023b). Typically, closed-source LLMs like GPT-4o and Claude-3-Opus are more powerful than available open-source models. However, closed-source LLMs come with certain limitations, including (1) concerns regarding data privacy and (2) high utilization costs. Opting for less powerful but open-source LLMs can help mitigate these issues. Therefore, to provide a comprehensive evaluation of current LLMs, we have included 4 closed-source LLMs and 3 open-source SOTA LLMs in our evaluation. Specifically, our evaluation features the following closed-source LLMs: GPT-3.5 (Ouyang et al., 2022), GPT-4o (OpenAI, 2024), GPT-4-Turbo (OpenAI, 2023a), and Claude-3-Opus (Anthropic, 2024). For publicly available LLMs, we have selected: Llama3-8B-Instruct111https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct (Meta, 2024), Llama3-70B-Instruct222https://huggingface.co/meta-llama/Meta-Llama-3-70B-Instruct (Meta, 2024), and Qwen2-7B333https://huggingface.co/Qwen/Qwen2-7B-Instruct (Cloud, 2024).
5. Knob Pruning
5.1. Baselines
To evaluate the knob pruning capability of LLMs, we utilize a learning-based method, SHAP (Lundberg and Lee, 2017), as a competitive baseline. SHAP provides a unified framework for interpreting the significance of each knob. By analyzing a given set of tuning observations, where each observation consists of a ¡configuration, performance metric¿ pair, the importance of each knob is determined through the calculation of its SHAP value. As highlighted in (Zhang et al., 2022a), SHAP currently stands out as the most effective learning method for assessing the importance of knobs. To gather training data for SHAP, we collect approximately 6000 observations for the SYSBENCH workload using the Latin Hypercube Sampling (LHS) method (McKay, 1992), which can sample configurations across the entire configuration space. Subsequently, we execute the workload under these configurations to acquire their corresponding performance metrics.
In addition, we invite an industry database expert to conduct the knob pruning task as a human annotation baseline. Specifically, we allow the expert to identify crucial database knobs and their important value ranges based on his own expertise and experience. The expert is also permitted to consult with other experienced database administrators, the broader database community, and official MySQL documentation to complete the task.
After narrowing the search space, we then utilize a traditional knob recommendation method, SMAC (Hutter et al., 2011), to optimize these selected knobs for a maximum of 120 iterations. We record the configuration and corresponding database performance in each iteration to calculate the TES and ODP metrics.
5.2. LLMs for Knob Pruning
For LLMs, we utilize the prompt illustrated in Figure 2 to perform the knob pruning from the candidate knobs. It is worth noting that, during the inference of the LLM, we set the temperature parameter to 0 to guarantee deterministic outcomes.
5.3. Experimental Results
The experimental results are illustrated in Figure 4. Our observations are as follows: (1) In the knob pruning task, certain LLMs (Claude-3-Opus, GPT-4o, and GPT-4-Turbo) demonstrate comparable or even superior performance to that of the database expert. Upon analysis, we discover a significant similarity between the knobs selected by the LLMs and those chosen by the expert. For instance, Table 1 showcases the top 10 most critical knobs identified by the database expert, GPT-4o, and SHAP. Notably, the knobs selected by GPT-4o closely align with those chosen by the database expert. This resemblance may be attributed to the extensive training data utilized for GPT-4o (and other LLMs), which incorporates MySQL community discussions, relevant articles, blogs, and official documentation (Zhou et al., 2024). Consequently, the LLM can emulate the behavior of the database expert, leading to similar knob pruning outcomes. (2) Furthermore, we note that nearly all evaluated LLMs outperform the previous learning-based method, SHAP, in terms of both convergence speed and optimal database performance, with GPT-4o exhibiting the most favorable results. After examining the selection outcomes produced by SHAP, we observe a distinct knob set compared to GPT-4o and the database expert.
| Database Expert | LLM (GPT-4o) | SHAP |
| innodb_buffer_pool_size | innodb_buffer_pool_size | innodb_buffer_pool_size |
| tmp_table_size | tmp_table_size | tmp_table_size |
| max_heap_table_size | max_heap_table_size | max_heap_table_size |
| innodb_log_file_size | innodb_log_file_size | innodb_compression_failure_threshold_pct |
| innodb_flush_log_at_trx_commit | innodb_flush_log_at_trx_commit | query_prealloc_size |
| query_cache_size | query_cache_size | innodb_thread_concurrency |
| table_open_cache | table_open_cache | table_open_cache_instances |
| sort_buffer_size | innodb_io_capacity | sort_buffer_size |
| max_connections | join_buffer_size | innodb_max_dirty_pages_pct_lwm |
| key_buffer_size | thread_cache_size | innodb_purge_threads |
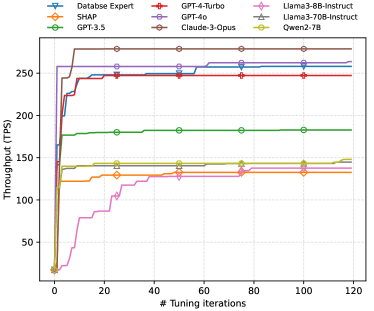
In delving into why GPT-4o surpasses the performance of the database expert in this task, a closer examination of their differences reveals a key distinction: as shown in Table 1, GPT-4o opts for knob “join_buffer_size” while the database expert selects knob “max_connections”. Increasing “join_buffer_size” can enhance the efficiency of the join operator, consequently boosting overall database performance. On the other hand, the impact of increasing “max_connections” on database performance is not always beneficial. If “max_connections” exceeds the actual number of connections required by the workload, increasing the value of this knob will have no discernible effect on the database performance.
5.4. Main Findings
Our main findings of this section are summarized as follows:
-
•
In the knob pruning task, certain LLMs (such as Claude-3-Opus and GPT-4o) demonstrate superior performance, surpassing even that of the DBAs. Furthermore, nearly all LLMs exhibit superior performance compared to the learning-based baseline, SHAP.
-
•
The knobs chosen by some LLMs closely resemble those selected by the database expert, indicating the potential for LLMs to replace DBAs in automating the process of pruning knobs.
-
•
We observe closed-source LLMs are much better than open-source LLMs in this task, indicating that the source of the LLM can have a substantial impact on this task.
-
•
Simply prompting LLMs without fine-tuning any parameters can achieve performance levels comparable to that of humans, showcasing the remarkable flexibility and adaptability of LLMs in effectively addressing this task.
-
•
Therefore, one promising future direction is to fine-tune an LLM tailored for knob pruning, potentially enabling it to surpass experts by a considerable margin.
6. Model Initialization
6.1. Baselines
To further enhance tuning efficiency, a series of model initialization methods (Aken et al., 2017; Li et al., 2019; Zhang et al., 2021a) have been introduced to use the past tuning records to initialize learnable models in the knob recommendation methods.
Current model initialization methods can be broadly categorized into three main groups: workload mapping, model ensemble, and pre-training. Workload mapping, as proposed by OtterTune (Aken et al., 2017), involves matching the target workload with the most similar historical workloads and leveraging their tuning observations to initialize the surrogate model. This approach can be integrated into a wide range of BO-based knob recommendation methods. The model ensemble technique, as described in ResTune (Zhang et al., 2021a), entails collecting a set of well-established tuning models on historical workloads and then combining these models to guide the optimization of current tuning model for new workloads. Lastly, the pre-training technique is commonly utilized in RL-based knob recommendation methods, as seen in works such as QTune (Li et al., 2019) and CDBTune (Zhang et al., 2021b). This process involves initially pre-training parameters of the actor and the critic within the RL algorithm using a set of historical tuning records. Subsequently, when facing a new workload, the pre-trained models will be further fine-tuned. By avoiding the necessity to train models from randomly initialization, this technique could expedite the tuning process.
We have chosen representative methods from each category as baselines. For workload mapping, we have selected the OtterTune method (Aken et al., 2017) integrated with the BO-based knob recommendation method VBO (Duan et al., 2009). In the model ensemble category, we are using the ResTune method (Zhang et al., 2021a) combined with the meta-learning knob recommendation method RGPE (Feurer, 2018). Lastly, for pre-training, we adopt QTune (Li et al., 2019) as the baseline, which aims to accelerate the RL-based knob recommendation method DS-DDPG. In this section, all knob recommendation methods undergo 400 iterations with or without model initialization techniques.
6.2. LLMs for Model Initialization
We first use the prompt illustrated in Figure 3 to sample 10 potentially effective configurations from LLMs. Subsequently, in the initial stages of VBO, we replace randomly sampled configurations with these 10 LLM-generated configurations to expedite its tuning process. To quantify the acceleration potential facilitated by LLMs, we consider the original VBO method for comparison. To generate a set of configurations from LLMs, we utilize nucleus sampling (Holtzman et al., 2020) with a temperature of 1.0 and a top-p value of 0.98. During our experimentation, we observe that certain sampled configurations are duplicated. As a result, we iteratively perform samplings until we acquire 10 distinct configurations.
6.3. Experimental Results
Type Model ODP PE TES Speedup Traditional Method VBO 154.73 0% 316 0% VBO + Mapping 154.37 -0.23% 279 11.71% RGPE + Model Ensemble 158.02 0.42% 215 42.67% DS-DDPG + Pre-training 162.15 33.10% 313 -216.16% Closed Source LLM VBO + GPT-3.5 127.68 -17.48% 176 44.30% VBO + GPT-4-Turbo 152.01 -1.93% 84 73.41% VBO + GPT-4o 126.65 -18.29% 90 71.51% VBO + Claude-3-Opus 126.09 -18.65% 2 99.37% Open Source LLM VBO + Llama3-8B-Instruct 153.16 -1.19% 90 71.51% VBO + Llama3-70B-Instruct 154.68 -0.03% 90 71.51% VBO + Qwen2-7B 153.58 -0.74% 100 68.35%
We present the experimental results in Table 2. To provide a more intuitive understanding of the effectiveness of different initialization methods, we adopt the approach outlined in (Zhang et al., 2022a) to introduce two additional metrics: performance enhancement (PE) and speedup. Specifically, we represent the TES and ODP values for the base knob recommendation method without initialization as and , and for the method with initialization as and . In the OLTP benchmark, a higher TPS value represents better performance. Therefore, the performance enhancement is calculated as follows:
| (4) |
and the speedup is defined as follows:
| (5) |
The PE metric assesses whether the initialization technique can aid the base knob recommendation method in identifying superior configurations. Subsequently, the speedup metric measures the degree to which the initialization technique expedites the tuning process. Higher values for both PE and speedup indicate improved performance of an initialization method.
The experimental findings are detailed in Table 2. Initially, we observe that the workload mapping technique yields a modest speedup of 11.71%. This outcome could be attributed to the limited utilization of historical tuning records. Moving on to the model ensemble technique, despite delivering a substantial 42.67% speedup, it still necessitates 215 iterations to reach peak performance. The outcomes of the pre-training technique are surprising. While it does lead to a significant performance improvement of 33.10%, it also causes a drastic decrease in speedup by -216.16%, a result that is unacceptable. In summary, these conventional initialization techniques do not clearly expedite the tuning process, which still necessitates 200-300 iterations to achieve the optimal performance.
For using LLMs in the model initialization task, we first observe that some LLMs (GPT-3.5, GPT-4o, and Claude-3-Opus) exhibit relatively poor performance enhancement and largely under-perform the base model (i.e., VBO). After analyzing the sampling configurations of these LLMs, we find that despite providing 20 knobs in the prompt, these models predominantly adjust only a handful of knobs, leaving the rest at default settings. Consequently, the 10 LLM-generated configurations exhibit significant similarities. Utilizing these configurations to initialize VBO might limit its capacity to explore uncharted areas and thus result in poor performance enhancement. To address this issue, one approach is to increase the temperature value to inject more randomness during the sampling phase. Among the other LLMs, including GPT-4-Turbo, Llama3-8B-Instruct, Llama3-70B-Instruct, and Qwen2-7B, a slight performance decrease (less than 2%) is observed, falling within an acceptable range. Moreover, initializing VBO with LLM-generated configurations leads to a noticeable acceleration in convergence speed. Notably, LLMs have shown an average speedup of 71.42%, with some achieving an impressive 99.37% boost. In essence, utilizing LLMs for initializing VBO requires a careful balance between ODP and TES. Given the minor performance impact and significant tuning acceleration, this trade-off is deemed acceptable.
6.4. Main Findings
Our main findings of this section are summarized as follows:
-
•
Existing model initialization methods do not demonstrate an obvious speedup in the tuning process, often necessitating hundreds of iterations to identify a suitable configuration. On the other hand, LLMs have shown their capability to greatly expedite the convergence of BO-driven knob recommendation approaches through the generation of initial configurations.
-
•
In contrast to the findings in knob pruning, we note that open-source LLMs outperform closed-source LLMs in this particular task. This disparity arises from the tendency of closed-source LLMs to frequently generate similar configurations, thereby constraining the exploration and exploitation capacities of the subsequent BO-based knob recommendation method.
-
•
Hence, a promising direction for future exploration lies in leveraging LLMs to generate a variety of valuable and distinct configurations to initialize the base knob recommendation methods.
7. Knob Recommendation
7.1. Baselines
The knob recommendation phase stands out as the core component of the entire tuning system, exerting a direct influence on the final tuning performance. Within this section, we evaluate LLMs’ knob recommendation capability against three widely-used traditional knob tuners: Vanilla Bayesian Optimization (VBO) (Duan et al., 2009), Sequential Model-based Algorithm Configuration (SMAC) (Hutter et al., 2011), and Deep Deterministic Policy Gradient (DDPG) (Lillicrap et al., 2016). VBO is a BO-based konb recommendation method utilizing a vanilla Gaussian Process (GP) as its surrogate model. The vanilla GP aims to model the relationship between the configuration and the database performance (Duan et al., 2009; Aken et al., 2017). On the other hand, SMAC is another BO-based approach that utilizes a random forest algorithm as its surrogate model to guide the tuning process (Breiman, 2001). DDPG is an RL-based method that has been widely integrated into existing knob tuning frameworks. It distinguishes itself from traditional RL algorithms like deep Q-learning (Maglogiannis et al., 2018) by its ability to operate in both discrete and continuous action spaces. DDPG involves the training of two neural networks: the actor network, responsible for selecting actions (i.e., configurations) based on database states, and the critic network, which evaluates the chosen action’s reward (e.g., latency or transactions per second). This reward signal updates the actor network, enabling it to make better decisions in subsequent iterations. Following the settings used in Section 6.2, all these base knob tuners undergo 400 iterations.
7.2. LLMs for Knob Recommendation
As outlined in Section 2, we frame the knob recommendation task for LLMs as an “iteratively refining” process. Specifically, starting from the default configuration, we iteratively refine the current configuration using feedback from the database. In our evaluation, we also introduce a new metric called “IR TPS” to measure the database performance after the Initial Refinement step. Considering the high cost associated with using closed-source models, we restrict the LLMs to undergo a maximum of 30 rounds of refinement. Furthermore, we set the temperature to 0 to generate deterministic LLM outputs.
7.3. Experimental Results
| Type | Method | IR TPS | ODP | TES |
| Traditional Method | Default | - | 17.45 | - |
| DDPG | - | 120.71 | 99 | |
| SMAC | - | 157.25 | 375 | |
| VBO | - | 155.10 | 316 | |
| Closed Source LLM | GPT-3.5 | 16.38 | 116.62 | 24 |
| GPT-4-Turbo | 145.06 | 155.30 | 9 | |
| GPT-4o | 117.96 | 126.05 | 13 | |
| Claude-3-Opus | 26.70 | 148.51 | 23 | |
| Open Source LLM | Llama3-8B-Instruct | 20.90 | 125.88 | 25 |
| LlaMa3-70B-Instruct | 28.84 | 145.12 | 3 | |
| Qwen2-7B | 143.58 | 154.94 | 14 |
We present experimental results in Table 3. In the realm of traditional methods, two BO-based strategies, SMAC and VBO, surpass the singular RL-based method, DDPG, in terms of ODP, leading to enhanced database performance. Nevertheless, in terms of TES, both BO-based methods require over 300 iterations, a considerable increase compared to DDPG, which achieves convergence in just 99 iterations.
For LLMs in the knob recommendation task, we observe remarkable results. Specifically, it’s impressive that some LLMs, including GPT-4-Trubo, GPT-4o, and Qwen2-7B, show a great performance enhancement over the default configuration within only one-step refinement (see “IR TPS”). This finding reveals that the LLM has the potential to be an end-to-end knob recommendation method without extensive iterations required in existing methods. Furthermore, leveraging feedback from the database, LLMs can iteratively suggest enhanced configurations, attaining comparable database performance to traditional methods but with significantly fewer iterations. Notably, in the instances of GPT-4-Turbo and Qwen2-7B, their refined configurations closely rival the top-performing traditional method, SMAC (155 versus 157), yet GPT-4-Turbo and Qwen2-7B achieve optimal performance in just 9 and 14 iterations, respectively, compared to SMAC’s 375 iterations. These findings indicate that LLMs possess the capability to comprehensively understand and utilize database feedback to refine configurations for enhanced overall database performance, showcasing remarkable exploration and exploitation capabilities.
Furthermore, LLMs demonstrate better interpretability in contrast to traditional black-box approaches. Illustrated in Figure 5, when assigned the role of configuration recommendation, the LLM consistently provides detailed rationales and considerations in the “chain-of-thought” (Wei et al., 2022) manner for each adjustment made to the knobs. This attribute not only bolsters practical applicability but also enhances the reliability of the results. On the other hand, by presenting the reasoning behind its recommendations, LLMs can help DBAs in making informed decisions, fostering a collaborative and streamlined process of knob recommendation.

Finally, by comparing “IR TPS” and ODP metric in Table 3, we can observe that the “iterative refinement” strategy can significantly improve the quality of the recommended configurations for some LLMs. Take Claude-3-Opus as an example: initially, the first refinement yields only 26 TPS. However, through the iterative refinement process, a significantly superior configuration yielding 148 TPS is identified. To examine the correlation between the number of iterations and database performance, we present the findings in Figure 6. Our analysis reveals that nearly all LLMs effectively leverage the database feedback to suggest improved configurations in the iteration process.
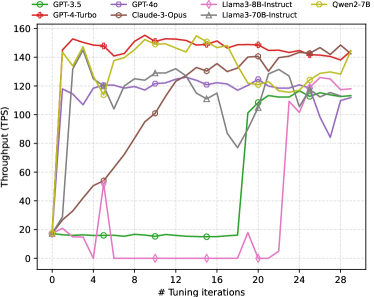
7.4. Main Findings
Our main findings of this section are summarized as follows:
-
•
In terms of tuning effectiveness, LLMs demonstrate a remarkable ability to achieve database performance on par with traditional methods. Moreover, LLMs can pinpoint promising configurations in significantly fewer iterations, showcasing impressive tuning efficiency.
-
•
Contrasted with traditional black-box methods, the knobs suggested by LLMs offer enhanced interpretability. For DBAs, these LLM-recommended knobs are more “traceable”, facilitating further adjustments based on their expert knowledge.
-
•
We do not observe a notable performance difference between open-source and closed-source LLMs in the knob recommendation task. Both variants demonstrate similar effectiveness.
-
•
The development of an end-to-end LLM-based knob recommendation approach could represent a promising research avenue. Such a method has the potential to eliminate the need for extensive iterations present in previous methods.
8. Generalizability of LLMs
In this section, we delve into the generalizability of LLMs by expanding our evaluation framework to encompass new benchmarks, database engines, and hardware environments. As detailed in Section 4, our primary evaluations are conducted using the SYSBENCH benchmark, the MySQL engine, and a server with 8 CPUs and 16 GB of RAM. Therefore, we can modify a single variable—keeping the others constant—to assess the LLMs’ adaptability and performance across diverse scenarios. For example, transitioning from the SYSBENCH to the JOB benchmark (Leis et al., 2015), switching from MySQL to PostgreSQL, or changing from one server configuration to another allows us to create new evaluation contexts.
Traditional methods, when confronted with new evaluation environments, typically require substantial code modifications, exhaustive data collections, and comprehensive re-training. These processes are not only time-consuming but also demand significant labor and resources. In contrast, LLMs offer a distinct advantage due to their prompt-driven nature; modifying prompts can enable smooth transitions across diverse evaluation setups.
As previously outlined, knob recommendation is central to the tuning system and directly impacts database performance. This section, therefore, focuses on the proficiency of LLMs in the task of knob recommendation. Given the flexibility of LLMs, tasks such as knob pruning and model initialization can also be efficiently completed by adjusting the prompts provided to the LLMs for new evaluation scenarios.
8.1. Setup
To establish new evaluation setups, we consider modifications across three key dimensions: benchmark, database engine, and machine instance.
Benchmark. To broaden our evaluation of LLMs’ knob recommendation abilities to analytical workloads, we introduce an OLAP benchmark named JOB (Leis et al., 2015). JOB comprises 113 benchmarked queries featuring intricate joins and a database instance storing 9GB of data. We consolidate all 113 queries into a single OLAP workload.
Database Engine. To assess the versatility of LLMs across different database engines, we have chosen two famous open-source database systems: PostgreSQL and TiDB (Huang et al., 2020). Initially released in 1996, PostgreSQL stands out as a widely adopted relational database recognized for its advanced functionalities, reliability, and adeptness in handling complex queries. We are confident that a wealth of manuals and online forums dedicated to PostgreSQL exist on the internet, and LLMs have extensively pre-trained on this content to assimilate domain knowledge related to PostgreSQL. For our experiments, we employ PostgreSQL version 10.0, carefully choosing 20 crucial knobs for optimization, while maintaining the default values for others as specified in the configuration file.
On the other hand, TiDB is a new database engine (released in 2017) that focuses on the distributed database system, supporting Hybrid Transactional and Analytical Processing (HTAP) workloads (Huang et al., 2020). Given that TiDB is a relatively new player in the database engine landscape, with limited discussion available online, it offers an opportunity to assess the adaptability of LLMs to newer database engines. In practice, we use TiDB version 8.2 and instantiate the TiDB cluster with a complete topology, simulating the production deployment. This setup includes 3 TiKV instances (row-based storage engine), 1 TiFlash instance (column-based storage engine), 1 TiDB instance (distributed database server), 1 PD instance (placement driver), and 1 Monitor. Following the official documentation, we pinpoint 7 important knobs for tuning, leaving the remainder at their automatic, hardware-configured default settings. This contrasts with PostgreSQL, where TiDB’s default knob values adjust dynamically to match the hardware specifications.
Hardware Environment. To explore the generalizability at the hardware level, we have deployed the MySQL database on a distinct machine featuring 40 CPUs and 256 GB of RAM. For clarity, we will refer to the prior machine with 8 CPUs and 16GB of RAM as machine A, and designate this new machine with 40 CPUs and 256GB of RAM as machine B.
8.2. Experimental Results
8.2.1. Evaluation on Varying Benchmark.
We have substituted SYSBENCH with an OLAP benchmark JOB and tasked LLMs with recommending a configuration to minimize the latency of the specified workload. The results of our experiments are detailed in Table 4. In this table, “IR Latency” denotes the latency of the workload (in seconds) under the configuration produced through the initial refinement step. “ODPAP” represents the minimum latency achieved during the whole refinement process.
After analyzing the results, the following key findings emerge: (1) Almost all LLMs are able to identify appropriate configurations after the initial refinement, highlighting the potential of LLMs as an end-to-end knob recommendation solution. (2) Moreover, through iterative refinement, GPT-4-Turbo and Llama3-70B-Instruct outperform the leading traditional method, SMAC, by identifying comparable or superior configurations on the JOB benchmark. (3) Lastly, LLMs demonstrate impressive tuning efficiency, typically requiring only a few iterations to achieve promising configurations. We should emphasize that, in the context of an OLAP workload, enhanced tuning efficiency is more critical compared to an OLTP workload. For OLTP, we evaluate a configuration’s performance through a stress test over a fixed period. In contrast, OLAP tuning involves evaluating a configuration’s performance by executing all SQL statements in a workload. This can lead to significantly high time costs, especially when encountering slow SQL queries, resulting in an extremely long evaluation time for a tuned configuration. Therefore, OLAP workloads necessitate more efficient tuning strategies.
These findings indicate that even after transitioning the benchmark from OLTP to OLAP, LLMs can consistently recommend top-tier configurations by effectively understanding and incorporating the characteristics of the OLAP benchmark.
8.2.2. Evaluation on Varying Database Engine.
After substituting MySQL with PostgreSQL and TiDB, we present the experimental results in Table 5. Specifically, for PostgreSQL, we observe similar results on MySQL: Compared to the default configuration, both traditional methods and LLMs can find much better configurations. In addition, LLMs only require 1%-10% steps of traditional methods while finding comparable configurations.
For the newer database engine TiDB, its capability to automatically set default knob values based on hardware specifications significantly contributes to its superior performance over PostgreSQL in the “Default” setting, with TiDB achieving 164.00 TPS compared to PostgreSQL’s 52.00 TPS. This automatic optimization presents a notable challenge for knob recommendation methodologies, as the baseline performance is already optimized. As illustrated in Table 5, configurations recommended by the DDPG algorithm even fall short of TiDB’s default settings. In addition, the initial refinement of GPT-3.5, GPT-4o, and Qwen2-7B also lead to a decline in database performance. Nonetheless, through iterative refinement and leveraging database feedback, all LLMs eventually surpass the default configurations. Remarkably, Claude-3-Opus outperforms the traditional method SMAC in terms of ODP with a score of 265.71 versus 263.53 and demonstrates greater efficiency in TES, requiring only 21 iterations compared to SMAC’s 342 iterations.
These findings underscore the robustness of LLMs across diverse database engines. By presenting knob descriptions and inner metric details in the prompt, LLMs leverage their internal knowledge and linguistic comprehension ability acquired during pre-training to extrapolate to unfamiliar database engines.
8.2.3. Evaluation on Varying Hardware Environment.
After migrating our MySQL database to a more powerful server (referred to as machine B), we detail the experimental outcomes in Table 6. The enhanced CPU capabilities and increased RAM on machine B necessitate a broader range for certain knobs, thereby complicating the task of pinpointing the optimal configuration. The experimental data reveal that LLMs significantly outperform traditional knob recommendation methods on this upgraded hardware. Notably, the most effective traditional method, SMAC, achieves a database performance of 1343.68 TPS, whereas GPT-4-Turbo, GPT-4o, Claude-3-Opus, and Qwen2-7B, exceed this benchmark with considerably fewer iterations, achieving 1546.26, 1462.42, 2424.77, 1450.23 TPS, respectively.
These findings underscore the adaptability of LLMs to hardware modifications, attributed primarily to their comprehensive understanding of the relationship between knob settings and hardware specifications, which effectively circumvents these challenges.
| Type | Method | IR Latency | ODPAP | TES |
| Traditional Method | Default | - | 2594.27 | - |
| DDPG | - | 853.11 | 179 | |
| SMAC | - | 675.28 | 146 | |
| VBO | - | 716.90 | 116 | |
| Closed Source LLM | GPT-3.5 | 812.92 | 757.98 | 19 |
| GPT-4-Turbo | 712.38 | 643.77 | 7 | |
| GPT-4o | 852.29 | 833.36 | 3 | |
| Claude-3-Opus | 829.15 | 794.95 | 12 | |
| Open Source LLM | Llama3-8B-Instruct | 932.64 | 799.72 | 9 |
| LlaMa3-70B-Instruct | 829.12 | 673.23 | 7 | |
| Qwen2-7B | 799.63 | 713.19 | 12 |
Type Method PostgreSQL TiDB IR TPS ODP TES IR TPS ODP TES Traditional Method Default - 52.00 - - 164.00 - DDPG - 133.75 193 - 109.59 311 SMAC - 147.03 189 - 263.53 342 VBO - 140.52 116 - 253.01 355 Closed Source LLM GPT-3.5 136.32 136.32 1 156.21 180.89 10 GPT-4-Turbo 126.88 143.77 12 218.43 255.73 5 GPT-4o 68.95 142.36 19 110.69 218.20 4 Claude-3-Opus 101.73 127.95 5 263.43 265.71 21 Open Source LLM Llama3-8B-Instruct 124.82 144.41 11 165.05 221.13 8 LlaMa3-70B-Instruct 120.10 152.68 3 179.88 213.03 3 Qwen2-7B 100.94 120.35 13 153.75 198.62 17
| Type | Method | IR TPS | ODP | TES |
| Traditional Method | Default | - | 500.42 | - |
| DDPG | - | 1129.01 | 210 | |
| SMAC | - | 1343.68 | 287 | |
| VBO | - | 1271.61 | 371 | |
| Closed Source LLM | GPT-3.5 | 1280.16 | 1287.91 | 7 |
| GPT-4-Turbo | 1473.48 | 1546.26 | 2 | |
| GPT-4o | 1360.93 | 1462.42 | 13 | |
| Claude-3-Opus | 2050.79 | 2424.77 | 3 | |
| Open Source LLM | Llama3-8B-Instruct | 732.26 | 1099.31 | 19 |
| LlaMa3-70B-Instruct | 1007.37 | 1021.16 | 5 | |
| Qwen2-7B | 1317.86 | 1450.23 | 9 |
8.3. Main Findings
-
•
Compared to conventional approaches, LLMs consistently deliver stable and commendable results across various benchmarks, database engines, and hardware configurations. Furthermore, employing LLMs in these new evaluation contexts requires minimal code adjustments due to their flexibility through prompting techniques. This insight highlights the potential of LLMs in navigating more complex and dynamic tuning environments and tasks.
-
•
Our observations indicate that, in most new evaluation settings, closed-source LLMs outperform their open-source counterparts, suggesting superior generalization capabilities in closed-source models.
-
•
LLMs demonstrate proficiency with well-established database engines like MySQL and PostgreSQL. In the case of newer database engines such as TiDB, LLMs can effectively adapt by incorporating specific knob and metric information within the prompts, facilitating a smooth transition to unfamiliar environments.
-
•
Among the LLMs evaluated, GPT-4-Turbo and Claude-3-Opus consistently exhibit the most reliable performance. Given their proprietary nature, a promising direction for future work involves creating an open-source LLM that matches or exceeds the capabilities of these closed-source models.
9. discussion
In this section, we summarize our main findings in this work and explore potential avenues for future research.
9.1. Main Findings
Finding 1: LLMs have demonstrated impressive abilities in enhancing database management across three pivotal subtasks in knob tuning: knob pruning, model initialization, and knob recommendation. Particularly in the knob recommendation task, LLMs can identify comparable or superior configurations with only a few iterations, showcasing their tuning efficiency.
Finding 2: We have noted that LLMs consistently employ a “chain-of-thought” approach in generating responses across various subtasks. Consequently, leveraging LLM-based solutions can greatly improve interpretability in addressing knob-tuning-related challenges
Finding 3: Diverse LLMs exhibit varying levels of performance across three knob tuning subtasks, with no single LLM consistently surpassing the others. This phenomenon can likely be attributed to the differences in the training corpora among various LLMs. Nevertheless, when considering closed-source LLMs, it is evident that GPT-4-Turbo delivers superior performance across various scenarios. On the other hand, for open-source LLMs, Llama3-70B-Instruct emerges as a commendable option.
Finding 4: LLMs demonstrate impressive generalizability across diverse evaluation scenarios, encompassing new benchmarks, database kernels, and hardware environments. This capability necessitates no further training, merely the adjustment of prompts.
9.2. Research Opportunities
Opportunity 1: For the task of knob pruning, we can fine-tune an LLM to better capture the relationship between the workload and its important knobs. In addition, we can also use the retrieval-augmented generation (RAG) technique to efficiently utilize more tuning experiences from the website.
Opportunity 2: For the task of model initialization, finding a way to sample diverse and useful configurations from LLMs would be a promising direction.
Opportunity 3: For knob recommendation, we can use LLMs to perform end-to-end knob recommendation by designing a more comprehensive prompting pipeline or fine-tuning an LLM using a high-quality training set containing numerous ¡workload, optimal configuration¿ data pairs.
Opportunity 4: As we mentioned above, no single LLM consistently outperforms the others in our evaluations. Therefore, a promising research direction is to design a method that dynamically selects appropriate LLM for the given evaluation setup.
Opportunity 5: Finally, creating a pre-trained LLM specifically designed for database management could significantly benefit the database community. To achieve this, we could gather a substantial corpus related to databases from the web and further pre-train an LLM, thereby infusing it with domain-specific knowledge.
10. Conclusion
Large Language Models (LLMs) have proven their efficacy and resilience across an extensive array of natural language processing tasks. In this paper, we conduct thorough experiments to explore LLMs’ capabilities in the context of database knob tuning. We decompose the tuning system into three distinct subtasks: knob pruning, model initialization, and knob recommendation, and then use LLMs to complete each of them. To accomplish this, we transform each subtask into a sequence-to-sequence generation task and meticulously design their respective prompt templates. Compared to conventional state-of-the-art techniques, LLMs not only exhibit superior performance in these areas but also show remarkable interpretability by generating suggestions in a chain-of-thought manner. Furthermore, we conduct a variety of experiments to assess the adaptability of LLMs under different evaluation setups, such as changing workloads, database engines, and hardware configurations. We hope that this study will not only advance the field of knob tuning but also encourage further AI-driven tasks in databases, including query optimization, index recommendation, and more.
References
- (1)
- Ahn et al. (2024) Janice Ahn, Rishu Verma, Renze Lou, Di Liu, Rui Zhang, and Wenpeng Yin. 2024. Large Language Models for Mathematical Reasoning: Progresses and Challenges. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics, EACL 2024: Student Research Workshop, St. Julian’s, Malta, March 21-22, 2024. Association for Computational Linguistics, 225–237.
- Aken et al. (2017) Dana Van Aken, Andrew Pavlo, Geoffrey J. Gordon, and Bohan Zhang. 2017. Automatic Database Management System Tuning Through Large-scale Machine Learning. In Proceedings of the 2017 ACM International Conference on Management of Data, SIGMOD Conference 2017, Chicago, IL, USA, May 14-19, 2017, Semih Salihoglu, Wenchao Zhou, Rada Chirkova, Jun Yang, and Dan Suciu (Eds.). ACM, 1009–1024. https://doi.org/10.1145/3035918.3064029
- Aken et al. (2021) Dana Van Aken, Dongsheng Yang, Sebastien Brillard, Ari Fiorino, Bohan Zhang, Christian Billian, and Andrew Pavlo. 2021. An Inquiry into Machine Learning-based Automatic Configuration Tuning Services on Real-World Database Management Systems. Proc. VLDB Endow. 14, 7 (2021), 1241–1253. https://doi.org/10.14778/3450980.3450992
- Anthropic (2024) Anthropic. 2024. Introducing the next generation of Claude. (2024). Available at: https://www.anthropic.com/news/claude-3-family.
- Breiman (2001) Leo Breiman. 2001. Random Forests. Mach. Learn. 45, 1 (2001), 5–32. https://doi.org/10.1023/A:1010933404324
- Cai et al. (2022) Baoqing Cai, Yu Liu, Ce Zhang, Guangyu Zhang, Ke Zhou, Li Liu, Chunhua Li, Bin Cheng, Jie Yang, and Jiashu Xing. 2022. HUNTER: An Online Cloud Database Hybrid Tuning System for Personalized Requirements. In SIGMOD ’22: International Conference on Management of Data, Philadelphia, PA, USA, June 12 - 17, 2022, Zachary G. Ives, Angela Bonifati, and Amr El Abbadi (Eds.). ACM, 646–659. https://doi.org/10.1145/3514221.3517882
- Cereda et al. (2021) Stefano Cereda, Stefano Valladares, Paolo Cremonesi, and Stefano Doni. 2021. CGPTuner: a Contextual Gaussian Process Bandit Approach for the Automatic Tuning of IT Configurations Under Varying Workload Conditions. Proc. VLDB Endow. 14, 8 (2021), 1401–1413. https://doi.org/10.14778/3457390.3457404
- Chaudhuri and Narasayya (2007) Surajit Chaudhuri and Vivek R. Narasayya. 2007. Self-Tuning Database Systems: A Decade of Progress. In Proceedings of the 33rd International Conference on Very Large Data Bases, University of Vienna, Austria, September 23-27, 2007, Christoph Koch, Johannes Gehrke, Minos N. Garofalakis, Divesh Srivastava, Karl Aberer, Anand Deshpande, Daniela Florescu, Chee Yong Chan, Venkatesh Ganti, Carl-Christian Kanne, Wolfgang Klas, and Erich J. Neuhold (Eds.). ACM, 3–14. http://www.vldb.org/conf/2007/papers/special/p3-chaudhuri.pdf
- Chen et al. (2011) Haifeng Chen, Wenxuan Zhang, and Guofei Jiang. 2011. Experience Transfer for the Configuration Tuning in Large-Scale Computing Systems. IEEE Trans. Knowl. Data Eng. 23, 3 (2011), 388–401. https://doi.org/10.1109/TKDE.2010.121
- Cloud (2024) Alibaba Cloud. 2024. Qwen2 Github. (2024). https://github.com/QwenLM/Qwen2.
- Cowen-Rivers et al. (2022) Alexander I. Cowen-Rivers, Wenlong Lyu, Rasul Tutunov, Zhi Wang, Antoine Grosnit, Ryan-Rhys Griffiths, Alexandre Max Maraval, Jianye Hao, Jun Wang, Jan Peters, and Haitham Bou-Ammar. 2022. HEBO: An Empirical Study of Assumptions in Bayesian Optimisation. J. Artif. Intell. Res. 74 (2022), 1269–1349. https://doi.org/10.1613/JAIR.1.13643
- Debnath et al. (2008) Biplob K. Debnath, David J. Lilja, and Mohamed F. Mokbel. 2008. SARD: A statistical approach for ranking database tuning parameters. 2008 IEEE 24th International Conference on Data Engineering Workshop (2008), 11–18. https://api.semanticscholar.org/CorpusID:7670739
- Duan et al. (2009) Songyun Duan, Vamsidhar Thummala, and Shivnath Babu. 2009. Tuning Database Configuration Parameters with iTuned. Proc. VLDB Endow. 2, 1 (2009), 1246–1257. https://doi.org/10.14778/1687627.1687767
- Feurer (2018) Matthias Feurer. 2018. Scalable Meta-Learning for Bayesian Optimization using Ranking-Weighted Gaussian Process Ensembles. https://api.semanticscholar.org/CorpusID:51795721
- Ge et al. (2021) Jia-Ke Ge, Yanfeng Chai, and Yunpeng Chai. 2021. WATuning: A Workload-Aware Tuning System with Attention-Based Deep Reinforcement Learning. J. Comput. Sci. Technol. 36, 4 (2021), 741–761. https://doi.org/10.1007/S11390-021-1350-8
- Holtzman et al. (2020) Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. 2020. The Curious Case of Neural Text Degeneration. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net. https://openreview.net/forum?id=rygGQyrFvH
- Huang et al. (2020) Dongxu Huang, Qi Liu, Qiu Cui, Zhuhe Fang, Xiaoyu Ma, Fei Xu, Li Shen, Liu Tang, Yuxing Zhou, Menglong Huang, Wan Wei, Cong Liu, Jian Zhang, Jianjun Li, Xuelian Wu, Lingyu Song, Ruoxi Sun, Shuaipeng Yu, Lei Zhao, Nicholas Cameron, Liquan Pei, and Xin Tang. 2020. TiDB: A Raft-based HTAP Database. Proc. VLDB Endow. 13, 12 (2020), 3072–3084. https://doi.org/10.14778/3415478.3415535
- Hutter et al. (2011) Frank Hutter, Holger H. Hoos, and Kevin Leyton-Brown. 2011. Sequential Model-Based Optimization for General Algorithm Configuration. In Learning and Intelligent Optimization - 5th International Conference, LION 5, Rome, Italy, January 17-21, 2011. Selected Papers (Lecture Notes in Computer Science), Carlos A. Coello Coello (Ed.), Vol. 6683. Springer, 507–523. https://doi.org/10.1007/978-3-642-25566-3_40
- Kanellis et al. (2020) Konstantinos Kanellis, Ramnatthan Alagappan, and Shivaram Venkataraman. 2020. Too Many Knobs to Tune? Towards Faster Database Tuning by Pre-selecting Important Knobs. In USENIX Workshop on Hot Topics in Storage and File Systems. https://api.semanticscholar.org/CorpusID:220836791
- Kanellis et al. (2022) Konstantinos Kanellis, Cong Ding, Brian Kroth, Andreas Müller, Carlo Curino, and Shivaram Venkataraman. 2022. LlamaTune: Sample-Efficient DBMS Configuration Tuning. Proc. VLDB Endow. 15, 11 (2022), 2953–2965. https://doi.org/10.14778/3551793.3551844
- Kopytov (2024) Alexey Kopytov. 2024. Scriptable database and system performance benchmark. (2024). Available at: https://github.com/akopytov/sysbench/.
- Kwon et al. (2023) Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient Memory Management for Large Language Model Serving with PagedAttention. In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles.
- Lao et al. (2024) Jiale Lao, Yibo Wang, Yufei Li, Jianping Wang, Yunjia Zhang, Zhiyuan Cheng, Wanghu Chen, Mingjie Tang, and Jianguo Wang. 2024. GPTuner: A Manual-Reading Database Tuning System via GPT-Guided Bayesian Optimization. Proc. VLDB Endow. 17, 8 (2024), 1939–1952.
- Leis et al. (2015) Viktor Leis, Andrey Gubichev, Atanas Mirchev, Peter A. Boncz, Alfons Kemper, and Thomas Neumann. 2015. How Good Are Query Optimizers, Really? Proc. VLDB Endow. 9, 3 (2015), 204–215. https://doi.org/10.14778/2850583.2850594
- Li et al. (2019) Guoliang Li, Xuanhe Zhou, Shifu Li, and Bo Gao. 2019. QTune: A Query-Aware Database Tuning System with Deep Reinforcement Learning. Proc. VLDB Endow. 12, 12 (2019), 2118–2130. https://doi.org/10.14778/3352063.3352129
- Li et al. (2024) Haoyang Li, Jing Zhang, Hanbing Liu, Ju Fan, Xiaokang Zhang, Jun Zhu, Renjie Wei, Hongyan Pan, Cuiping Li, and Hong Chen. 2024. CodeS: Towards Building Open-source Language Models for Text-to-SQL. Proc. ACM Manag. Data 2, 3 (2024), 127.
- Lillicrap et al. (2016) Timothy P. Lillicrap, Jonathan J. Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. 2016. Continuous control with deep reinforcement learning. In 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, May 2-4, 2016, Conference Track Proceedings, Yoshua Bengio and Yann LeCun (Eds.). http://arxiv.org/abs/1509.02971
- Lin et al. (2022a) Chen Lin, Junqing Zhuang, Jiadong Feng, Hui Li, Xuanhe Zhou, and Guoliang Li. 2022a. Adaptive Code Learning for Spark Configuration Tuning. In 38th IEEE International Conference on Data Engineering, ICDE 2022, Kuala Lumpur, Malaysia, May 9-12, 2022. IEEE, 1995–2007. https://doi.org/10.1109/ICDE53745.2022.00195
- Lin et al. (2022b) Chen Lin, Junqing Zhuang, Jiadong Feng, Hui Li, Xuanhe Zhou, and Guoliang Li. 2022b. Adaptive Code Learning for Spark Configuration Tuning. In 38th IEEE International Conference on Data Engineering, ICDE 2022, Kuala Lumpur, Malaysia, May 9-12, 2022. IEEE, 1995–2007. https://doi.org/10.1109/ICDE53745.2022.00195
- Lundberg and Lee (2017) Scott M. Lundberg and Su-In Lee. 2017. A Unified Approach to Interpreting Model Predictions. In Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, Isabelle Guyon, Ulrike von Luxburg, Samy Bengio, Hanna M. Wallach, Rob Fergus, S. V. N. Vishwanathan, and Roman Garnett (Eds.). 4765–4774. https://proceedings.neurips.cc/paper/2017/hash/8a20a8621978632d76c43dfd28b67767-Abstract.html
- Maglogiannis et al. (2018) Vasilis Maglogiannis, Dries Naudts, Adnan Shahid, and Ingrid Moerman. 2018. A Q-Learning Scheme for Fair Coexistence Between LTE and Wi-Fi in Unlicensed Spectrum. IEEE Access 6 (2018), 27278–27293. https://doi.org/10.1109/ACCESS.2018.2829492
- McKay (1992) Michael D. McKay. 1992. Latin Hypercube Sampling as a Tool in Uncertainty Analysis of Computer Models. In Proceedings of the 24th Winter Simulation Conference, Arlington, VA, USA, December 13-16, 1992, Robert C. Crain (Ed.). ACM Press, 557–564. https://doi.org/10.1145/167293.167637
- Meta (2024) Meta. 2024. Introducing Meta Llama 3: The most capable openly available LLM to date. (2024). https://ai.meta.com/blog/meta-llama-3/.
- Nembrini et al. (2018) Stefano Nembrini, Inke R. König, and Marvin N. Wright. 2018. The revival of the Gini importance? Bioinform. 34, 21 (2018), 3711–3718. https://doi.org/10.1093/BIOINFORMATICS/BTY373
- OpenAI (2023a) OpenAI. 2023a. GPT-4 is OpenAI’s most advanced system, producing safer and more useful responses. (2023). https://openai.com/index/gpt-4/.
- OpenAI (2023b) OpenAI. 2023b. GPT-4 Technical Report. CoRR abs/2303.08774 (2023). https://doi.org/10.48550/ARXIV.2303.08774 arXiv:2303.08774
- Openai (2024) Openai. 2024. Hello gpt-4o. (2024). Available at: https://openai.com/index/hello-gpt-4o/.
- OpenAI (2024) OpenAI. 2024. Hello GPT-4o. (2024). https://openai.com/index/hello-gpt-4o/.
- Ouyang et al. (2022) Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, and Ryan Lowe. 2022. Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022.
- Pavlo et al. (2021) Andy Pavlo, Matthew Butrovich, Lin Ma, Prashanth Menon, Wan Shen Lim, Dana Van Aken, and William Zhang. 2021. Make Your Database System Dream of Electric Sheep: Towards Self-Driving Operation. Proc. VLDB Endow. 14, 12 (2021), 3211–3221. https://doi.org/10.14778/3476311.3476411
- Qin et al. (2023) Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun. 2023. ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs. CoRR abs/2307.16789 (2023).
- Saltelli (2002) Andrea Saltelli. 2002. Sensitivity Analysis for Importance Assessment. Risk analysis : an official publication of the Society for Risk Analysis 22 (07 2002), 579–90. https://doi.org/10.1111/0272-4332.00040
- Sullivan et al. (2004) David G. Sullivan, Margo I. Seltzer, and Avi Pfeffer. 2004. Using probabilistic reasoning to automate software tuning. In Proceedings of the International Conference on Measurements and Modeling of Computer Systems, SIGMETRICS 2004, June 10-14, 2004, New York, NY, USA, Edward G. Coffman Jr., Zhen Liu, and Arif Merchant (Eds.). ACM, 404–405. https://doi.org/10.1145/1005686.1005739
- Tan et al. (2019) Jian Tan, Tieying Zhang, Feifei Li, Jie Chen, Qixing Zheng, Ping Zhang, Honglin Qiao, Yue Shi, Wei Cao, and Rui Zhang. 2019. iBTune: Individualized Buffer Tuning for Large-scale Cloud Databases. Proc. VLDB Endow. 12, 10 (2019), 1221–1234. https://doi.org/10.14778/3339490.3339503
- Tibshirani (1996) Robert Tibshirani. 1996. Regression Shrinkage and Selection via the Lasso. Journal of the royal statistical society series b-methodological 58 (1996), 267–288. https://api.semanticscholar.org/CorpusID:16162039
- Trummer (2022) Immanuel Trummer. 2022. DB-BERT: A Database Tuning Tool that ”Reads the Manual”. In SIGMOD ’22: International Conference on Management of Data, Philadelphia, PA, USA, June 12 - 17, 2022, Zachary G. Ives, Angela Bonifati, and Amr El Abbadi (Eds.). ACM, 190–203. https://doi.org/10.1145/3514221.3517843
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. In Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022.
- Zhang et al. (2021b) Ji Zhang, Ke Zhou, Guoliang Li, Yu Liu, Ming Xie, Bin Cheng, and Jiashu Xing. 2021b. $\hbox {CDBTune}^{+}$: An efficient deep reinforcement learning-based automatic cloud database tuning system. VLDB J. 30, 6 (2021), 959–987. https://doi.org/10.1007/S00778-021-00670-9
- Zhang et al. (2022a) Xinyi Zhang, Zhuo Chang, Yang Li, Hong Wu, Jian Tan, Feifei Li, and Bin Cui. 2022a. Facilitating Database Tuning with Hyper-Parameter Optimization: A Comprehensive Experimental Evaluation. Proc. VLDB Endow. 15, 9 (2022), 1808–1821. https://doi.org/10.14778/3538598.3538604
- Zhang et al. (2021a) Xinyi Zhang, Hong Wu, Zhuo Chang, Shuowei Jin, Jian Tan, Feifei Li, Tieying Zhang, and Bin Cui. 2021a. ResTune: Resource Oriented Tuning Boosted by Meta-Learning for Cloud Databases. In SIGMOD ’21: International Conference on Management of Data, Virtual Event, China, June 20-25, 2021, Guoliang Li, Zhanhuai Li, Stratos Idreos, and Divesh Srivastava (Eds.). ACM, 2102–2114. https://doi.org/10.1145/3448016.3457291
- Zhang et al. (2022b) Xinyi Zhang, Hong Wu, Yang Li, Jian Tan, Feifei Li, and Bin Cui. 2022b. Towards Dynamic and Safe Configuration Tuning for Cloud Databases. In SIGMOD ’22: International Conference on Management of Data, Philadelphia, PA, USA, June 12 - 17, 2022, Zachary G. Ives, Angela Bonifati, and Amr El Abbadi (Eds.). ACM, 631–645. https://doi.org/10.1145/3514221.3526176
- Zhao et al. (2023b) Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie, and Ji-Rong Wen. 2023b. A Survey of Large Language Models. CoRR abs/2303.18223 (2023). https://doi.org/10.48550/ARXIV.2303.18223 arXiv:2303.18223
- Zhao et al. (2023a) Xinyang Zhao, Xuanhe Zhou, and Guoliang Li. 2023a. Automatic Database Knob Tuning: A Survey. IEEE Trans. Knowl. Data Eng. 35, 12 (2023), 12470–12490. https://doi.org/10.1109/TKDE.2023.3266893
- Zhou et al. (2024) Xuanhe Zhou, Zhaoyan Sun, and Guoliang Li. 2024. DB-GPT: Large Language Model Meets Database. Data Sci. Eng. 9, 1 (2024), 102–111. https://doi.org/10.1007/S41019-023-00235-6
- Zhu et al. (2017) Yuqing Zhu, Jianxun Liu, Mengying Guo, Yungang Bao, Wenlong Ma, Zhuoyue Liu, Kunpeng Song, and Yingchun Yang. 2017. BestConfig: tapping the performance potential of systems via automatic configuration tuning. In Proceedings of the 2017 Symposium on Cloud Computing, SoCC 2017, Santa Clara, CA, USA, September 24-27, 2017. ACM, 338–350. https://doi.org/10.1145/3127479.3128605