Is Offline Decision Making Possible with Only Few Samples?
Reliable Decisions in Data-Starved Bandits via Trust Region Enhancement
Abstract
What can an agent learn in a stochastic Multi-Armed Bandit (MAB) problem from a dataset that contains just a single sample for each arm? Surprisingly, in this work, we demonstrate that even in such a data-starved setting it may still be possible to find a policy competitive with the optimal one. This paves the way to reliable decision-making in settings where critical decisions must be made by relying only on a handful of samples.
Our analysis reveals that stochastic policies can be substantially better than deterministic ones for offline decision-making. Focusing on offline multi-armed bandits, we design an algorithm called Trust Region of Uncertainty for Stochastic policy enhancemenT (TRUST) which is quite different from the predominant value-based lower confidence bound approach. Its design is enabled by localization laws, critical radii, and relative pessimism. We prove that its sample complexity is comparable to that of LCB on minimax problems while being substantially lower on problems with very few samples.
Finally, we consider an application to offline reinforcement learning in the special case where the logging policies are known.
1 Introduction
In several important problems, critical decisions must be made with just very few samples of pre-collected experience. For example, collecting samples in robotic manipulation may be slow and costly, and the ability to learn from very few interactions is highly desirable (Hester & Stone, 2013; Liu et al., 2021). Likewise, in clinical trials and in personalized medical decisions, reliable decisions must be made by relying on very small datasets (Liu et al., 2017). Sample efficiency is also key in personalized education (Bassen et al., 2020; Ruan et al., 2023).
However, to achieve good performance, the state-of-the-art algorithms may require millions of samples (Fu et al., 2020). These empirical findings seem to be supported by the existing theories: the sample complexity bounds, even minimax optimal ones, can be large in practice due to the large constants and the warmup factors (Ménard et al., 2021; Li et al., 2022; Azar et al., 2017; Zanette et al., 2019).
In this work, we study whether it is possible to make reliable decisions with only a few samples. We focus on an offline Multi-Armed Bandit (MAB) problem, which is a foundation model for decision-making (Lattimore & Szepesvári, 2020). In online MAB, an agent repeatedly chooses an arm from a set of arms, each providing a stochastic reward. Offline MAB is a variant where the agent cannot interact with the environment to gather new information and instead, it must make decisions based on a pre-collected dataset without playing additional exploratory actions, aiming at identifying the arm with the highest expected reward (Audibert et al., 2010; Garivier & Kaufmann, 2016; Russo, 2016; Ameko et al., 2020).
The standard approach to the problem is the Lower Confidence Bound (LCB) algorithm (Rashidinejad et al., 2021), a pessimistic variant of UCB (Auer et al., 2002) that involves selecting the arm with the highest lower bound on its performance. LCB encodes a principle called pessimism under uncertainty, which is the foundation principle for most algorithms for offline bandits and reinforcement learning (RL) (Jin et al., 2020; Zanette et al., 2020; Xie et al., 2021; Yin & Wang, 2021; Kumar et al., 2020; Kostrikov et al., 2021).
Unfortunately, the available methods that implement the principle of pessimism under uncertainty can fail in a data-starved regime because they rely on confidence intervals that are too loose when just a few samples are available. For example, even on a simple MAB instance with ten thousand arms, the best-known (Rashidinejad et al., 2021) performance bound for the LCB algorithm requires 24 samples per arm in order to provide meaningful guarantees, see Section 3.3. In more complex situations, such as in the sequential setting with function approximation, such a problem can become more severe due to the higher metric entropy of the function approximation class and the compounding of errors through time steps.
These considerations suggest that there is a “barrier of entry” to decision-making, both theoretically and practically: one needs to have a substantial number of samples in order to make reliable decisions even for settings as simple as offline MAB where the guarantees are tighter. Given the above technical reasons, and the lack of good algorithms and guarantees for data-starved decision problems, it is unclear whether it is even possible to find good decision rules with just a handful of samples.
In this paper, we make a substantial contribution towards lowering such barriers of entry. We discover that a carefully-designed algorithm tied to an advanced statistical analysis can substantially improve the sample complexity, both theoretically and practically, and enable reliable decision-making with just a handful of samples. More precisely, we focus on the offline MAB setting where we show that even if the dataset contains just a single sample in every arm, it may still be possible to compete with the optimal policy. This is remarkable, because with just one sample per arm—for example from a Bernoulli distribution—it is impossible to estimate the expected payoff of any of the arms! Our discovery is enabled by several key insights:
-
•
We search over stochastic policies, which we show can yield better performance for offline-decision making;
-
•
We use a localized notion of metric entropy to carefully control the size of the stochastic policy class that we search over;
-
•
We implement a concept called relative pessimism to obtain sharper guarantees.
These considerations lead us to design a trust region policy optimization algorithm called Trust Region of Uncertainty for Stochastic policy enhancemenT (TRUST), one that offers superior theoretical as well as empirical performance compared to LCB in a data-scarce situation.
Moreover, we apply the algorithm to selected reinforcement learning problems from (Fu et al., 2020) in the special case where information about the logging policies is available. We do so by a simple reduction from reinforcement learning to bandits, by mapping policies and returns in the former to actions and rewards in the latter, thereby disregarding the sequential aspect of the problem. Although we rely on the information of the logging policies being available, the empirical study shows that our algorithm compares well with a strong deep reinforcement learning baseline (i.e, CQL from Kumar et al. (2020)), without being sensitive to partial observability, sparse rewards, and hyper-parameters.
2 Additional related work
Multi-armed bandit (MAB) is a classical decision-making framework (Lattimore & Szepesvári, 2020; Lai & Robbins, 1985; Lai, 1987; Langford & Zhang, 2007; Auer, 2002; Bubeck et al., 2012; Audibert et al., 2009; Degenne & Perchet, 2016). The natural approach in offline MABs is the LCB algorithm (Ameko et al., 2020; Si et al., 2020), an offline variant of the classical UCB method (Auer et al., 2002) which is minimax optimal (Rashidinejad et al., 2021).
The optimization over stochastic policies is also considered in combinatorial multi-armed bandits (CMAB) (Combes et al., 2015). Most works on CMAB focus on variants of the UCB algorithm (Kveton et al., 2015; Combes et al., 2015; Chen et al., 2016) or of Thompson sampling (Wang & Chen, 2018; Liu & Ročková, 2023), and they are generally online.
Our framework can also be applied to offline reinforcement learning (RL) (Sutton & Barto, 2018) whenever the logging policies are accessible. There exist a lot of practical algorithms for offline RL (Fujimoto et al., 2019; Peng et al., 2019; Wu et al., 2019; Kumar et al., 2020; Kostrikov et al., 2021). Theory has also been investigated extensively in tabular domain and function approximation setting (Nachum et al., 2019; Xie & Jiang, 2020; Zanette et al., 2021; Xie et al., 2021; Yin et al., 2022; Xiong et al., 2022). Some works also tried to establish general guarantees for deep RL algorithms via sophisticated statistical tools, such as bootstrapping (Thomas et al., 2015; Nakkiran et al., 2020; Hao et al., 2021; Wang et al., 2022; Zhang et al., 2022).
We rely on the notion of pessimism, which is a key concept in offline bandits and RL. While most prior works focused on the so-called absolute pessimism (Jin et al., 2020; Xie et al., 2021; Yin et al., 2022; Rashidinejad et al., 2021; Li et al., 2023), the work of Cheng et al. (2022) applied pessimism not on the policy value but on the difference (or improvement) between policies. However, their framework is very different from ours.
We make extensive use of two key concepts, namely localization laws and critical radii (Wainwright, 2019), which control the relative scale of the signal and uncertainty. The idea of localization plays a critical role in the theory of empirical process (Geer, 2000) and statistical learning theory (Koltchinskii, 2001, 2006; Bartlett & Mendelson, 2002; Bartlett et al., 2005). The concept of critical radius or critical inequality is used in non-parametric regression (Wainwright, 2019) and in off-policy evaluation (Duan et al., 2021; Duan & Wainwright, 2022, 2023; Mou et al., 2022).
3 Data-Starved Multi-Armed Bandits
In this section, we describe the MAB setting and give an example of a “data-starved” MAB instance where prior methods (such as LCB) can fail. We informally say that an offline MAB is “data-starved” if its dataset contains only very few samples in each arm.
Notation We let for a positive integer We let denote the Euclidean norm for vectors and the operator norm for matrices. We hide constants and logarithmic factors in the notation. We let for any and () means () for some numerical constant means that both and hold.
3.1 Multi-armed bandits
We consider the case where there are arms in a set with expected reward We assume access to an offline dataset of action-reward tuples, where the experienced actions are i.i.d. from a distribution . Each experienced reward is a random variable with expectation and independent Gaussian noises For we denote the number of pulls to arm in by or while the variance of the noise for arm is denoted by We denote the optimal arm as and the single policy concentrability as where is the distribution that generated the dataset. Without loss of generality, we assume the optimal arm is unique. We also write Without loss of generality, we assume there is at least one sample for each arm (such arm can otherwise be removed).
3.2 Lower confidence bound algorithm
One simple but effective method for the offline MAB problem is the Lower Confidence Bound (LCB) algorithm, which is inspired by its online counterpart (UCB) (Auer et al., 2002). Like UCB, LCB computes the empirical mean associated to the reward of each arm along with its half confidence width . They are defined as
| (1) |
This definition ensures that each confidence interval brackets the corresponding expected reward with probability :
| (2) |
The width of the confidence level depends on the noise level , which can be exploited by variance-aware methods (Zhang et al., 2021; Min et al., 2021; Yin et al., 2022; Dai et al., 2022). When the true noise level is not accessible, we can replace it with the empirical standard deviation or with a high-probability upper bound. For example, when the reward for each arm is restricted to be within a simpler upper bound is
Unlike UCB, the half-width of the confidence intervals for LCB is not added, but subtracted, from the empirical mean, resulting in the lower bound . The action identified by LCB is then the one that maximizes the resulting lower bound, thereby incorporating the principle of pessimism under uncertainty (Jin et al., 2020; Kumar et al., 2020). Specifically, given the dataset LCB selects the arm using the following rule:
| (3) |
Rashidinejad et al. (2021) analyzed the LCB strategy. Below we provide a modified version of their theorem.
Theorem 3.1 (LCB Performance).
Suppose the noise of arm is sub-Gaussian with proxy variance Let Then, we have
-
1.
(Comparison with any arm) With probability at least for any comparator policy , it holds that
(4) -
2.
(Comparison with the optimal arm) Assume for any and Then, with probability at least one has
(5)
The statement of this theorem is slightly different from that in Rashidinejad et al. (2021), in the sense that their suboptimality is over instead of a high-probability one. Rashidinejad et al. (2021) proved the minimax optimality of the algorithm when the single policy concentrability and the sample size
3.3 A data-starved MAB problem and failure of LCB
In order to highlight the limitation of a strategy such as LCB, let us describe a specific data-starved MAB instance, specifically one with arms, equally partitioned into a set of good arms (i.e., ) and a set of bad arms (i.e., ). Each good arm returns a reward following the uniform distribution over while each bad arm returns a reward which follows .
Assume that we are given a dataset that contains only one sample per each arm. Instantiating the LCB confidence interval in (2) with and one obtains
Such bound is uninformative, because the lower bound for the true reward mean is less than the reward value of the worst arm. The performance bound for LCB confirms this intuition, because Theorem 3.1 requires at least samples in each arm to provide any guarantee with probability at least (here ).
3.4 Can stochastic policies help?
At a first glance, extracting a good decision-making strategy for the problem discussed in Section 3.3 seems like a hopeless endeavor, because it is information-theoretically impossible to reliably estimate the expected payoff of any of the arms with just a single sample on each.
In order to proceed, the key idea is to enlarge the search space to contain stochastic policies.
Definition 3.2 (Stochastic Policies).
A stochastic policy over a MAB is a probability distribution
To exemplify how stochastic policies can help, consider the behavioral cloning policy, which mimics the policy that generated the dataset for the offline MAB in Section 3.3. Such policy is stochastic, and it plays all arms uniformly at random, thereby achieving a score around with high probability. The value of the behavioral cloning policy can be readily estimated using the Hoeffding bound (e.g., Proposition 2.5 in Wainwright (2019)): with probability at least (here is the number of arms and is the true standard deviation), the value of behavioral cloning policy is greater or equal than
Such value is higher than the one guaranteed for LCB by Theorem 3.1. Intuitively, a stochastic policy that selects multiple arms can be evaluated more accurately because it averages the rewards experienced over different arms. This consideration suggests optimizing over stochastic policies.
By optimizing a lower bound on the performance of the stochastic policies, it should be possible to find one with a provably high return. Such an idea leads to solving an offline linear bandit problem, as follows
| (6) |
where is a suitable confidence interval for the policy and is the empirical reward for the -th arm defined in (1). While this approach is appealing, enlarging the search space to include all stochastic policies brings an increase in the metric entropy of the function class, and concretely, a factor (Abbasi-Yadkori et al., 2011; Rusmevichientong & Tsitsiklis, 2010; Hazan & Karnin, 2016; Jun et al., 2017; Kim et al., 2022) in the confidence intervals (in (6)), which negates all gains that arise from considering stochastic policies. In the next section, we propose an algorithm that bypasses the need for such factor by relying on a more careful analysis and optimization procedure.
4 Trust Region of Uncertainty for Stochastic policy enhancemenT (TRUST)
In this section, we introduce our algorithm, called Trust Region of Uncertainty for Stochastic policy enhancemenT (TRUST). At a high level, the algorithm is a policy optimization algorithm based on a trust region centered around a reference policy. The size of the trust region determines the degree of pessimism, and its optimal problem-dependent size can be determined by analyzing the supremum of a problem-dependent empirical process. In the sequel, we describe 1) the decision variables, 2) the trust region optimization program, and 3) some techniques for its practical implementation.
4.1 Decision variables
The algorithm searches over the class of stochastic policies given by the weight vector of Definition 3.2. Instead of directly optimizing over the weights of the stochastic policy, it is convenient to center around a reference stochastic policy which is either known to perform well or is easy to estimate. In our theory and experiments, we consider a simple setup and use the behavioral cloning policy weighted by the noise levels if they are known. Namely, we consider
| (7) |
When the size of the noise is constant across all arms, the policy is the behavioral cloning policy; when differs across arms, minimizes the variance of the empirical reward
where is defined in (1). Using such definition, we define as decision variable the policy improvement vector
| (8) |
This preparatory step is key: it allows us to implement relative pessimism, namely pessimism on the improvement—represented by —rather than on the absolute value of the policy . Moreover, by restricting the search space to a ball around , one can efficiently reduce the metric entropy of the policy class and obtain tighter confidence intervals.
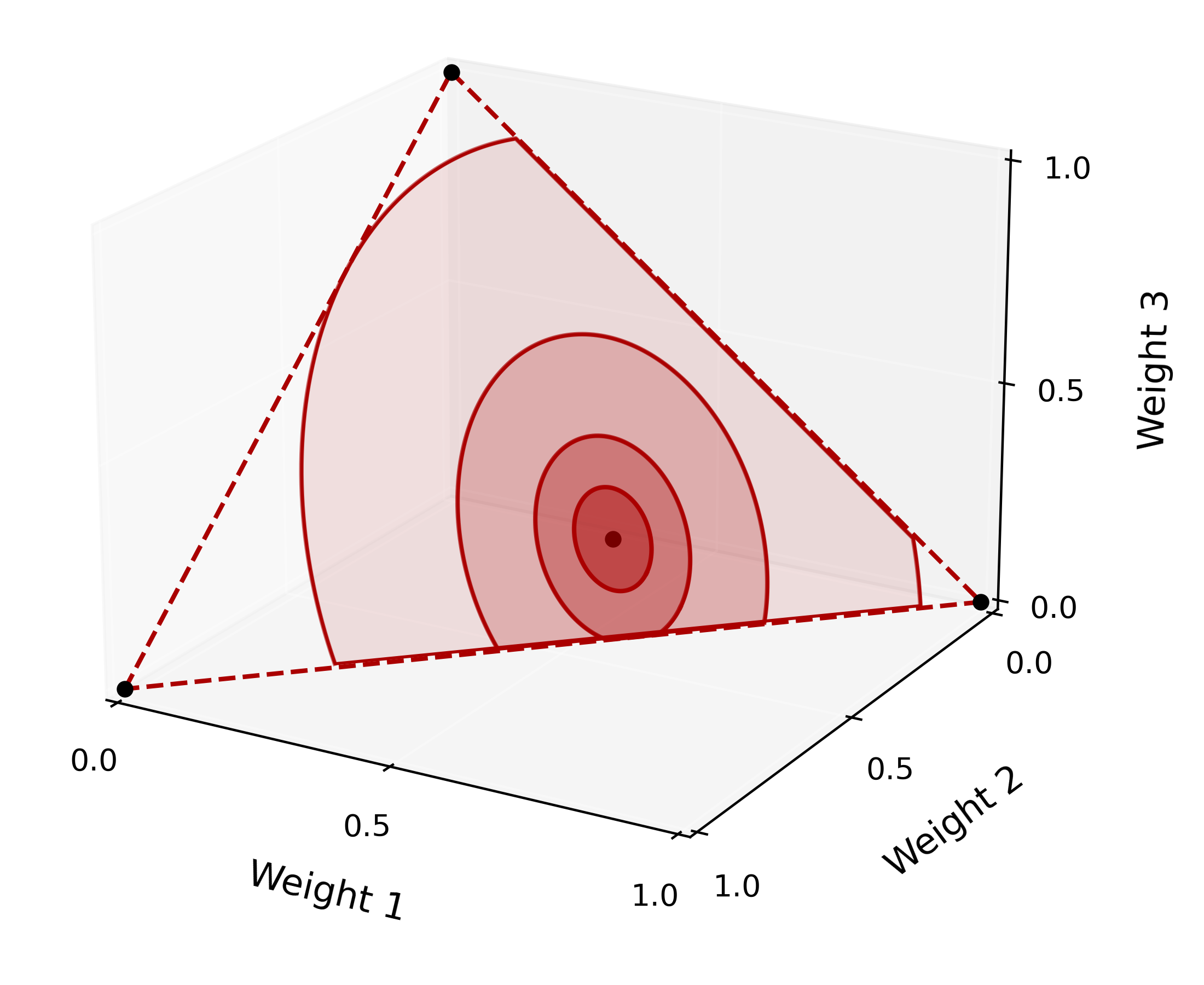
4.2 Trust region optimization
Trust region.
TRUST (Algorithm 1) returns the stochastic policy where is the reference policy defined in (7) and is the policy improvement vector. In order to accurately quantify the effect of the improvement vector we constrain it to a trust region centered around where is the radius of the trust region. More concretely, for a given radius the trust region is defined as
| (9) |
The trust region above serves two purposes: it ensures that the policy still represents a valid stochastic policy, and it regularizes the policy around the reference policy . We then search for the best policy within by solving the optimization program
| (10) |
Computationally, the program (10) is a second-order cone program (Alizadeh & Goldfarb, 2003; Boyd & Vandenberghe, 2004), which can be solved efficiently with standard off-the shelf libraries (Diamond & Boyd, 2016).
When , the trust region only includes the vector , and the reference policy is the only feasible solution. When , the search space includes all stochastic policies. In this latter case, the solution identified by the algorithm coincides with the greedy algorithm which chooses the arm with the highest empirical return. Rather than leaving as a hyper-parameter, in the next section we highlight a selection strategy for based on localized Gaussian complexities.
Critical radius.
The choice of is crucial to the performance of our algorithm because it balances optimization with regularization. Such consideration suggests that there is an optimal choice for the radius which balances searching over a larger space with keeping the metric entropy of such space under control. The optimal problem-dependent choice can be found as a solution of a certain equation involving a problem-dependent supremum of an empirical process. More concretely, let be the feasible set of (e.g., ). We define the critical radius as
Definition 4.1 (Critical Radius).
The critical radius of the trust region is the solution to the program
| (11) |
Such equation involves a quantile of the localized gaussian complexity of the stochastic policies identified by the trust region. Mathematically, this is defined as
Definition 4.2 (Quantile of the supremum of Gaussian process).
We denote the noise vector as which by our assumption is coordinate-wise independent and satisfies We define as the smallest quantity such that with probability at least , for any it holds that
| (12) |
In essence, is an upper quantile of the supremum of the Gaussian process which holds uniformly for every We also remark that this quantity depends on the feasible set and the trust region , and hence, is highly problem-dependent.
The critical radius plays a crucial role: it is the radius of the trust region that optimally balances optimization with uncertainty. Enlarging enlarges the search space for , enabling the discovery of policies with potentially higher return. However, this also brings an increase in the metric entropy of the policy class encoded by , which means that each policy can be estimated less accurately. The critical radius represents the optimal tradeoff between these two forces. The final improvement vector that TRUST returns, which we denote as , is determined by solving (10) with the critical radius . In mathematical terms, we express this as
| (13) |
where is defined in (11).
Implementation details
Since it can be difficult to solve (11) for a continuous value of , we use a discretization argument by considering the following candidate subset:
| (14) |
where is the decaying rate and is the largest possible radius, which is the maximal weighted distance from the reference policy to any vertex. Mathematically, this is defined as
Our analysis that leads to Theorem 5.1 takes into account such discretization argument.
In line 2 of Algorithm 1, the algorithm works by estimating the quantile of the supremum of the localized Gaussian complexity that appears in Definition 4.2, and then choose the that maximizes the objective function in (11). Although can be upper bounded analytically, in our experiments we aim to obtain tighter guarantees and so we estimate it via Monte-Carlo. This can be achieved by 1) sampling independent noise vectors , 2) solving and 3) estimating the quantile via order statistics. More details can be found in Appendix B.
In summary, our practical algorithm can be seen as solving the optimization problem
where is the empirical reward vector with defined in (1). Here, is computed according to the Monte-Carlo method defined in Algorithm 2 in Appendix B and is the candidate subset for radius defined in (14). This indicates a balance between the empirical reward of a stochastic policy and the local entropy metric it induces, representing
5 Theoretical guarantees
In this section, we provide some theoretical guarantees for the policy returned by TRUST.
5.1 Problem-dependent analysis
We present 1) an improvement over the reference policy , 2) a sub-optimality gap with respect to any comparator policy and 3) an actionable lower bound on the performance of the output policy.
Given a stochastic policy , we let denote its value function. Furthermore, we denote a comparator policy by a triple such that
Theorem 5.1 (Main theorem).
TRUST has the following properties.
-
1.
With probability at least the improvement over the behavioral policy is at least
(15) where
-
2.
With probability at least for any stochastic comparator policy , the sub-optimality of the output policy can be upper bounded as
(16) -
3.
With probability at least the data-dependent lower bound on satisfies
(17) where is the policy output by Algorithm 1.
Our guarantees are problem-dependent as a function of the Gaussian process ; in Section 6 we show how these can be instantiated on an actual problem, highlighting the tightness of the analysis.
Equation 15 highlights the improvement with respect to the behavioral policy. It is expressed as a trade-off between maximizing the improvement and minimizing its uncertainty . The presence of the indicates that TRUST achieves an optimal balance between these two factors. The state of the art guarantees that we are aware of highlight a trade-off between value and variance (Jin et al., 2021; Min et al., 2021). The novelty of our result lies in the fact that TRUST optimally balances the uncertainty implicitly as a function of the ‘coverage’ as well as the metric entropy of the search space. That is, TRUST selects the most appropriate search space by trading off its metric entropy with the quality of the policies that it contains.
The right-hand side in Equation 17 gives actionable statistical guarantees on the quality of the final policy and it can be fully computed from the available dataset; we give an example of the tightness of the analysis in Section 6.
Localized Gaussian complexity .
In Theorem 5.1, we upper bound the suboptimality via a notion of localized metric entropy It is the quantile of the supremum of a Gaussian process, which can be efficiently estimated via Monte Carlo method (e.g., see Appendix B) or concentrated around its expectation. The expected value of is also localized Gaussian width, a concept well-established in statistical learning theory (Bellec, 2019; Wei et al., 2020; Wainwright, 2019). More concretely, this is the localized Gaussian width for an affine simplex:
where denotes the simplex in and is the weighted matrix. Moreover, this localized Gaussian width can be upper bound via
| (18) |
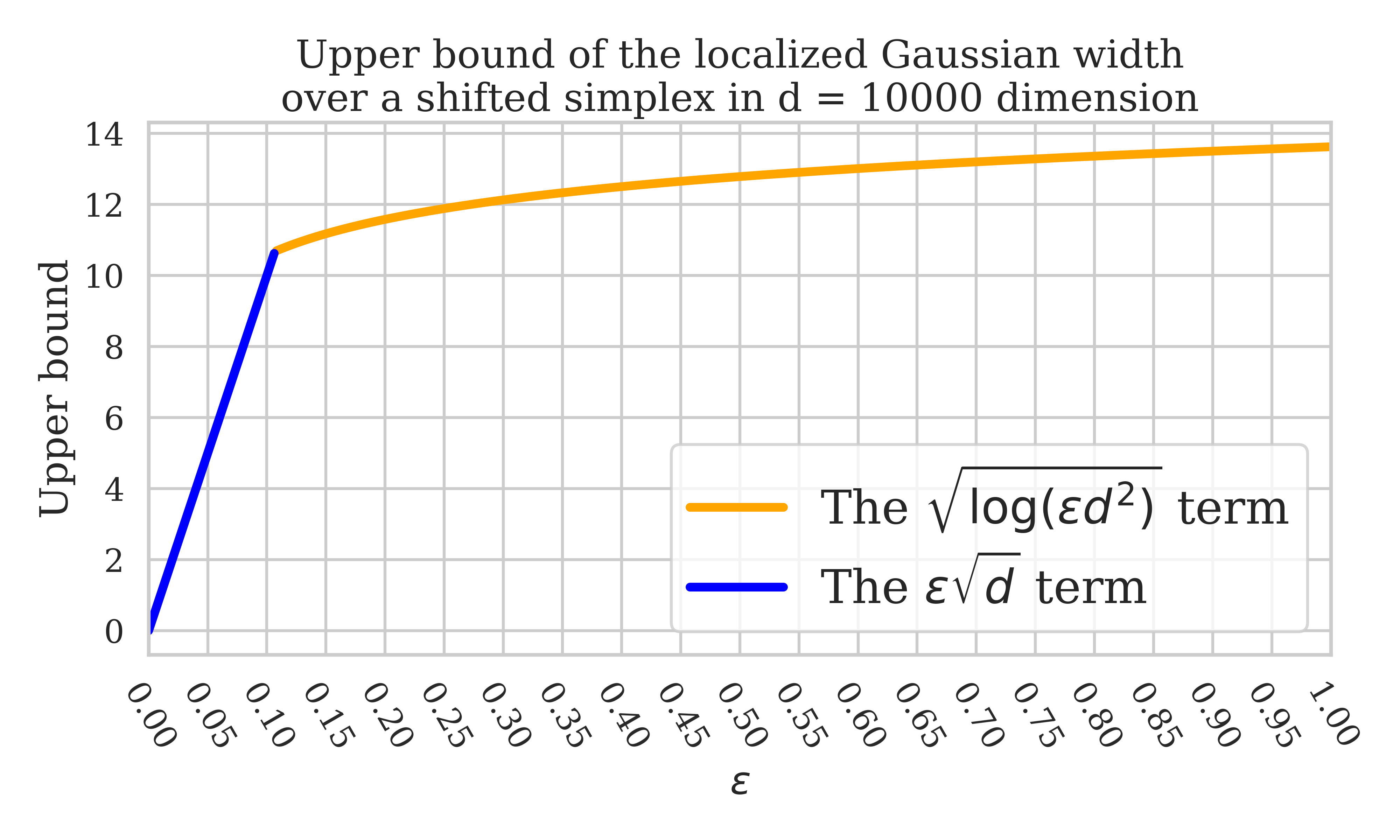
To make it clearer, we plot this upper bound for localized Gaussian width in Figure 2. In (18), the rate matches the minimax lower bound up to universal constant (Gordon et al., 2007; Lecué & Mendelson, 2013; Bellec, 2019). To see the implication of the upper bound (18), let’s consider a simple example where the logging policy is uniform over all arms. We denote the optimal arm as and define
as the concentrability coefficient. By applying (18) and some concentration techniques (see Wainwright, 2019), we can perform a fine-grained analysis for the suboptimality induced by Specifically, with probability at least one has
| (19) |
Note that, the high-probability upper bound here is minimax optimal up to constant and logarithmic factor (Rashidinejad et al., 2021) when Moreover, this example of uniform logging policy is an instance where LCB achieves minimax sub-optimality (up to constant and log factors) (see the proof of Theorem 2 in Rashidinejad et al., 2021). In this case, TRUST will achieve the same level of guarantees for the suboptimality of the output policy. We also empirically show the effectiveness of TRUST in Section 6. The full theorem for a fine-grained analysis for the suboptimality and its proof are deferred to Appendix C.
5.2 Proof of Theorem 5.1
To prove Lemma C.3, we first define the following event
| (20) |
When happens, the quantity can upper bound the supremum of the Gaussian process we care about, and hence, we can effectively upper bound the uncertainty for any stochastic policy using It follows from the Definition 4.2 that the event happens with probability a leas
We can now prove all the claims in the theorem, starting from the first and the second. A comparator policy identifies a weight vector , an improvement vector and a radius such that and In fact, we can always take to be the minimal value such that The first claim in Equation 15 can be proved by establishing that with probability at least
| (21) |
where is the policy weight returned by Algorithm 1. In order to show Equation 21, we can decompose using the fact that and to obtain
| (22) |
To further lower bound the RHS above, we have the following lemma, which shows that Algorithm 1 can be written in an equivalent way.
Lemma 5.2.
The output of Algorithm 1 satisfies
| (23) |
This shows that Algorithm 1 optimizes over an objective function which consists of a signal term (i.e., ) minus a noise term (i.e., ). Applying this lemma to (22), we know
| (24) |
After recalling that under
| (25) |
plugging the (25) back into (24) concludes the bound in Equation 21, which also proves our first claim. Rearranging the terms in Equation 21 and taking supremum over all comparator policies, we obtain
| (26) |
which proves the first claim since
In order to prove the last claim, it suffices to lower bound the policy value of the reference policy From (7), we have which implies with probability at least
| (27) |
from the standard Hoeffding inequality (e.g., Prop 2.5 in Wainwright (2019)). Combining (22) and (27), we obtain
| (From (22)) | ||||
| (From (27)) |
with probability at least Therefore, we conclude.
Augmentation with LCB
Compared to classical LCB, Algorithm 1 considers a much larger searching space, which encompasses not only the vertices of the simplex but the inner points as well. This enlargement of searching space shows great advantage, but this also comes with the price of larger uncertainty, especially when the width is large. In LCB, one considers the uncertainty by upper bound the noise at each vertex uniformly, while in our case, the uniform upper bound for a sub-region of the shifted simplex must be considered. When is large, the trust region method will induce larger uncertainty and tend to select a more stochastic policy than LCB and hence, can achieve worse performance. To determine the most effective final policy, one can always combine TRUST (Algorithm 1) with LCB and select the better one between them based on the lower bound induced by two algorithms. By comparing the lower bounds of LCB and TRUST, the value of the finally output policy is guaranteed to outperform the lower bound for either LCB or TRUST with high probability. We defer the detailed algorithm and its theoretical guarantees to Appendix E.
6 Experiments
We present simulated experiments where we show the failure of LCB and the strong performance of TRUST. Moreover, we also present an application of TRUST to offline reinforcement learning.
6.1 Simulated experiments
A data-starved MAB
We consider a data-starved MAB problem with arms denoted by . The reward distributions are
| (28) |
Namely, the set of good arms have reward random variables from a uniform distribution over with unit mean, while the bad arms return a Gaussian reward with zero mean. We consider a dataset that contains a single sample for each of these arms.
We test Algorithm 1 on this MAB instance with fixed variance level . We set the reference policy to be the behavioral cloning policy, which coincides with the uniform policy. We also test LCB and the greedy method which simply chooses the policy with the highest empirical reward.
In this example, the greedy algorithm fails because it erroneously selects an arm with a reward , but such reward can only originate from a normal distribution with mean zero. Despite LCB incorporates the principle of pessimism under uncertainty, it selects an arm with average return equal to zero; its performance lower bound given by the confidence intervals is which is almost vacuous and very uninformative. The behavioral cloning policy performs better, because it selects an arm uniformly at random, achieving the score .
| Behavior Policy | Greedy Method | LCB | LCB Lower Bound |
| 0.5 | 0 | 0 | -1.5 |
| max reward | Policy Improvement by TRUST | TRUST | TRUST Lower Bound |
| 1.0 | 0.42 | 0.92 | 0.6 |
Algorithm 1 achieves the best performance: the value of the policy that it identifies is which almost matches the optimal policy. The lower bound on its performance computed by instantiating the RHS in (17) is around , a guarantee much tighter than that for LCB.
In order to gain intuition on the learning mechanics of TRUST, in Figure 3 we progressively enlarge the radius of the trust region from zero to the largest possible radius (on the axis) and plot the value of the policy that maximizes the linear objective for each value of the radius . Note that we rescale the range of to make the largest possible be one. In the same figure we also plot the lower bound computed with the help of equation (17).
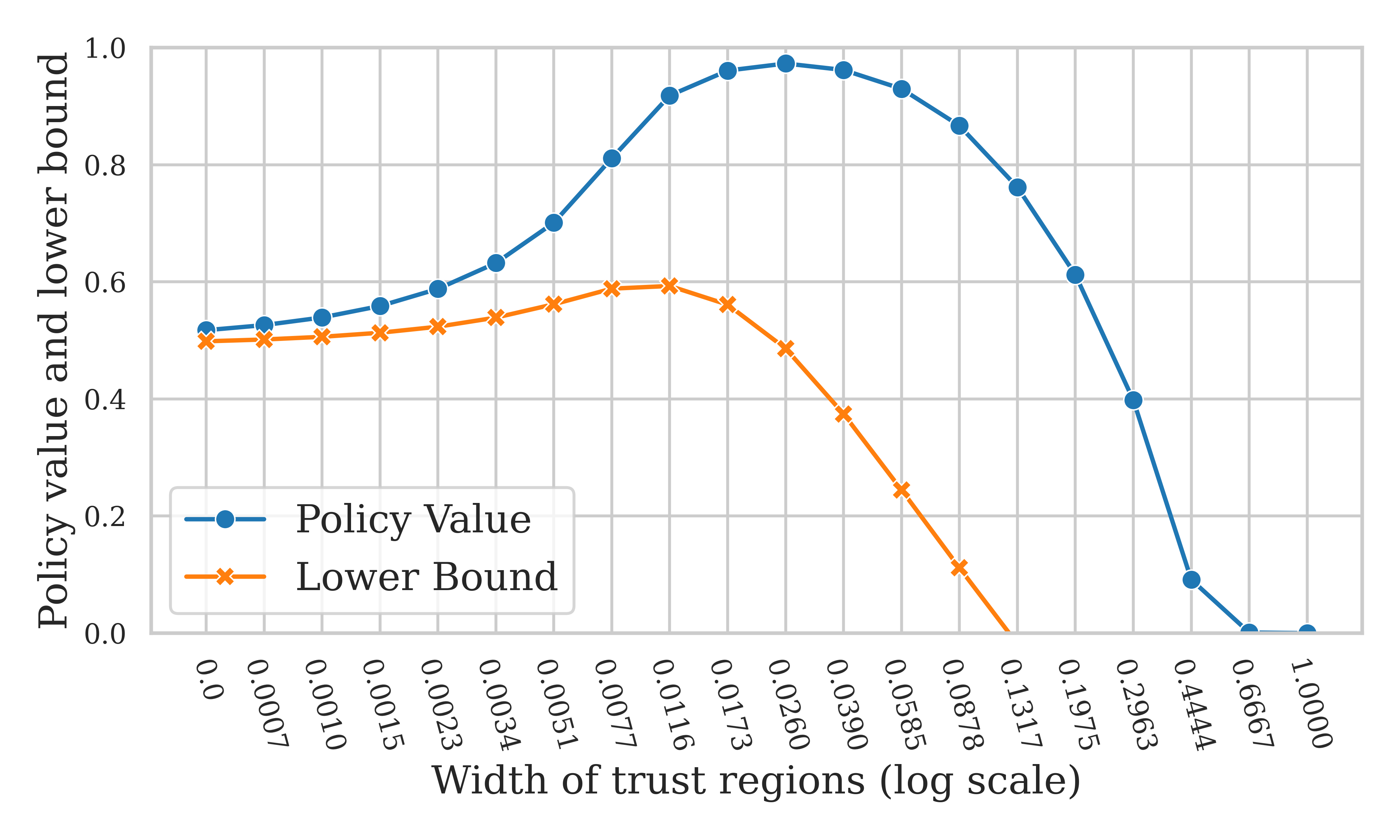
Initially, the value of the policy increases because the optimization in (10) is performed over a larger set of stochastic policies. However, when approaches one, all stochastic policies are included in the optimization program. In this case, TRUST greedily selects the arm with the highest empirical reward which is from a normal distribution with mean zero. The optimal balance between the size of the policy search space and its metric entropy is given by the critical radius , which is the point where the lower bound is the highest.
A more general data-starved MAB
Besides the data-starved MAB we constructed, we also show that in general MABs, the performance of TRUST is on par with LCB, but TRUST will have a much tighter statistical guarantee, i.e., a larger lower bound for the value of the returned policy. We did experiments on a -arm MAB where the reward distribution is
| (29) |
We ran TRUST Algorithm 1 and LCB over 8 different random seeds. When we have a single sample for each arm, TRUST will get a similar score as LCB. However, TRUST give a much tighter statistical guarantee than LCB, in the sense that the lower bound output by TRUST is much higher than that output by LCB so that TRUST can output a policy that is guaranteed to achieved a higher value. Moreover, we found the policies output from TRUST are much more stable than those from LCB. In all runs, while the lowest value of the arm chosen by LCB is around 0.24, all policies returned by TRUST have values above 0.65 with a much smaller variance, as shown in Table 2.
| LCB | TRUST | |
|---|---|---|
| mean reward | 0.718 | 0.725 |
| mean lower bound | 0.156 | 0.544 |
| variance | 0.265 | 0.038 |
| minimal reward | 0.239 | 0.658 |
6.2 Offline reinforcement learning
In this section, we apply Algorithm 1 to the offline reinforcement learning (RL) setting under the assumption that the logging policies which generated the dataset are accessible. To be clear, our goal is not to exceed the performance of the state of the art deep RL algorithms—our algorithm is designed for bandit problems—but rather to illustrate the usefulness of our algorithm and theory.
Since our algorithm is designed for bandit problems, in order to apply it to the sequential setting, we map MDPs to MABs. Each policy in the MDP maps to an action in the MAB, and each trajectory return in the MDP maps to an experienced return in the MAB setting. Notice that this reduction disregards the sequential aspect of the problem and thus our algorithm cannot perform ‘trajectory stitching’ (Levine et al., 2020; Kumar et al., 2020; Kostrikov et al., 2021). Furthermore, it can only be applied under the assumption that the logging policies are known.
Specifically we consider a setting where there are multiple known logging policies, each generating few trajectories. We test Algorithm 1 on some selected environments from the D4RL dataset (Fu et al., 2020) and compare its performance to the (CQL) algorithm (Kumar et al., 2020), a popular and strong baseline for offline RL algorithms.
Since the D4RL dataset does not directly include the logging policies, we generate new datasets by running Soft Actor Critic (SAC) (Haarnoja et al., 2018) for 1000 episodes. We store 100 intermediate policies generated by SAC, and roll out 1 trajectory from each policy.
We use some default hyper-parameters for CQL.111We use the codebase and default hyper-parameters in https://github.com/young-geng/CQL. We report the unnormalized scores in Table 3, each averaged over 4 random seeds. Algorithm 1 achieves a score on par with or higher than that of CQL, especially when the offline dataset is of poor quality and when there are very few—or just one—trajectory generated from each logging policy. Notice that while CQL is not guaranteed to outperform the behavioral policy, TRUST is backed by Theorem 5.1. Moreover, while the performance of CQL is highly reliant on the choice of hyper-parameters, TRUST is essentially hyper-parameters free.
| CQL | TRUST | ||
|---|---|---|---|
| Hopper | 1-traj-low | 499 | 999 |
| 1-traj-high | 2606 | 3437 | |
| Ant | 1-traj-low | 748 | 763 |
| 1-traj-high | 4115 | 4488 | |
| Walker2d | 1-traj-low | 311 | 346 |
| 1-traj-high | 4093 | 4097 | |
| HalfCheetah | 1-traj-low | 5775 | 5473 |
| 1-traj-high | 9067 | 10380 | |
Additionally, while CQL took around 16-24 hours on one NVIDIA GeForce RTX 2080 Ti, TRUST only took 0.5-1 hours on 10 CPUs. The experimental details are included in Appendix F.
7 Conclusion
In this paper we make a substantial contribution towards sample efficient decision making, by designing a data-efficient policy optimization algorithm that leverages offline data for the MAB setting. The key intuition of this work is to search over stochastic policies, which can be estimated more easily than deterministic ones.
The design of our algorithm is enabled by a number of key insights, such as the use of the localized gaussian complexity which leads to the definition of the critical radius for the trust region.
We believe that these concepts can be used more broadly to help design truly sample efficient algorithms, which can in turn enable the application of decision making to new settings where a high sample efficiency is critical.
8 Impact Statement
This paper presents a work whose goal is to advance the field of decision making under uncertainty. Since our work is primarily theoretical, we do not anticipate negative societal consequences.
References
- Abbasi-Yadkori et al. (2011) Abbasi-Yadkori, Y., Pal, D., and Szepesvari, C. Improved algorithms for linear stochastic bandits. In Advances in Neural Information Processing Systems (NIPS), 2011.
- Alizadeh & Goldfarb (2003) Alizadeh, F. and Goldfarb, D. Second-order cone programming. Mathematical programming, 95(1):3–51, 2003.
- Ameko et al. (2020) Ameko, M. K., Beltzer, M. L., Cai, L., Boukhechba, M., Teachman, B. A., and Barnes, L. E. Offline contextual multi-armed bandits for mobile health interventions: A case study on emotion regulation. In Proceedings of the 14th ACM Conference on Recommender Systems, pp. 249–258, 2020.
- Audibert et al. (2009) Audibert, J.-Y., Bubeck, S., et al. Minimax policies for adversarial and stochastic bandits. In COLT, volume 7, pp. 1–122, 2009.
- Audibert et al. (2010) Audibert, J.-Y., Bubeck, S., and Munos, R. Best arm identification in multi-armed bandits. In COLT, pp. 41–53, 2010.
- Auer (2002) Auer, P. Using confidence bounds for exploitation-exploration trade-offs. Journal of Machine Learning Research, 3(Nov):397–422, 2002.
- Auer et al. (2002) Auer, P., Cesa-Bianchi, N., and Fischer, P. Finite-time analysis of the multiarmed bandit problem. Machine learning, 47:235–256, 2002.
- Azar et al. (2017) Azar, M. G., Osband, I., and Munos, R. Minimax regret bounds for reinforcement learning. In International Conference on Machine Learning, pp. 263–272. PMLR, 2017.
- Bartlett & Mendelson (2002) Bartlett, P. L. and Mendelson, S. Rademacher and gaussian complexities: Risk bounds and structural results. Journal of Machine Learning Research, 3(Nov):463–482, 2002.
- Bartlett et al. (2005) Bartlett, P. L., Bousquet, O., and Mendelson, S. Local rademacher complexities. The Annals of Statistics, 33(4):1497–1537, 2005.
- Bassen et al. (2020) Bassen, J., Balaji, B., Schaarschmidt, M., Thille, C., Painter, J., Zimmaro, D., Games, A., Fast, E., and Mitchell, J. C. Reinforcement learning for the adaptive scheduling of educational activities. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, pp. 1–12, 2020.
- Bellec (2019) Bellec, P. C. Localized gaussian width of m-convex hulls with applications to lasso and convex aggregation. 2019.
- Boyd & Vandenberghe (2004) Boyd, S. and Vandenberghe, L. Convex Optimization. Cambridge University Press, 2004.
- Bubeck et al. (2012) Bubeck, S., Cesa-Bianchi, N., et al. Regret analysis of stochastic and nonstochastic multi-armed bandit problems. Foundations and Trends® in Machine Learning, 5(1):1–122, 2012.
- Chen et al. (2016) Chen, W., Wang, Y., Yuan, Y., and Wang, Q. Combinatorial multi-armed bandit and its extension to probabilistically triggered arms. The Journal of Machine Learning Research, 17(1):1746–1778, 2016.
- Cheng et al. (2022) Cheng, C.-A., Xie, T., Jiang, N., and Agarwal, A. Adversarially trained actor critic for offline reinforcement learning. arXiv preprint arXiv:2202.02446, 2022.
- Combes et al. (2015) Combes, R., Talebi Mazraeh Shahi, M. S., Proutiere, A., et al. Combinatorial bandits revisited. Advances in neural information processing systems, 28, 2015.
- Dai et al. (2022) Dai, Y., Wang, R., and Du, S. S. Variance-aware sparse linear bandits. arXiv preprint arXiv:2205.13450, 2022.
- Degenne & Perchet (2016) Degenne, R. and Perchet, V. Anytime optimal algorithms in stochastic multi-armed bandits. In International Conference on Machine Learning, pp. 1587–1595. PMLR, 2016.
- Diamond & Boyd (2016) Diamond, S. and Boyd, S. Cvxpy: A python-embedded modeling language for convex optimization. The Journal of Machine Learning Research, 17(1):2909–2913, 2016.
- Duan & Wainwright (2022) Duan, Y. and Wainwright, M. J. Policy evaluation from a single path: Multi-step methods, mixing and mis-specification. arXiv preprint arXiv:2211.03899, 2022.
- Duan & Wainwright (2023) Duan, Y. and Wainwright, M. J. A finite-sample analysis of multi-step temporal difference estimates. In Learning for Dynamics and Control Conference, pp. 612–624. PMLR, 2023.
- Duan et al. (2021) Duan, Y., Wang, M., and Wainwright, M. J. Optimal policy evaluation using kernel-based temporal difference methods. arXiv preprint arXiv:2109.12002, 2021.
- Fu et al. (2020) Fu, J., Kumar, A., Nachum, O., Tucker, G., and Levine, S. D4rl: Datasets for deep data-driven reinforcement learning. arXiv preprint arXiv:2004.07219, 2020.
- Fujimoto et al. (2019) Fujimoto, S., Meger, D., and Precup, D. Off-policy deep reinforcement learning without exploration. In International conference on machine learning, pp. 2052–2062. PMLR, 2019.
- Garivier & Kaufmann (2016) Garivier, A. and Kaufmann, E. Optimal best arm identification with fixed confidence. In Conference on Learning Theory, pp. 998–1027. PMLR, 2016.
- Geer (2000) Geer, S. A. Empirical Processes in M-estimation, volume 6. Cambridge university press, 2000.
- Gordon et al. (2007) Gordon, Y., Litvak, A. E., Mendelson, S., and Pajor, A. Gaussian averages of interpolated bodies and applications to approximate reconstruction. Journal of Approximation Theory, 149(1):59–73, 2007.
- Haarnoja et al. (2018) Haarnoja, T., Zhou, A., Abbeel, P., and Levine, S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In International conference on machine learning, pp. 1861–1870. PMLR, 2018.
- Hao et al. (2021) Hao, B., Ji, X., Duan, Y., Lu, H., Szepesvári, C., and Wang, M. Bootstrapping statistical inference for off-policy evaluation. arXiv preprint arXiv:2102.03607, 2021.
- Hazan & Karnin (2016) Hazan, E. and Karnin, Z. Volumetric spanners: an efficient exploration basis for learning. Journal of Machine Learning Research, 2016.
- Hester & Stone (2013) Hester, T. and Stone, P. Texplore: real-time sample-efficient reinforcement learning for robots. Machine learning, 90:385–429, 2013.
- Jin et al. (2020) Jin, Y., Yang, Z., and Wang, Z. Is pessimism provably efficient for offline rl? arXiv preprint arXiv:2012.15085, 2020.
- Jin et al. (2021) Jin, Y., Yang, Z., and Wang, Z. Is pessimism provably efficient for offline rl? In International Conference on Machine Learning, pp. 5084–5096. PMLR, 2021.
- Jun et al. (2017) Jun, K.-S., Bhargava, A., Nowak, R., and Willett, R. Scalable generalized linear bandits: Online computation and hashing. Advances in Neural Information Processing Systems, 30, 2017.
- Kim et al. (2022) Kim, Y., Yang, I., and Jun, K.-S. Improved regret analysis for variance-adaptive linear bandits and horizon-free linear mixture mdps. Advances in Neural Information Processing Systems, 35:1060–1072, 2022.
- Koltchinskii (2001) Koltchinskii, V. Rademacher penalties and structural risk minimization. IEEE Transactions on Information Theory, 47(5):1902–1914, 2001.
- Koltchinskii (2006) Koltchinskii, V. Local rademacher complexities and oracle inequalities in risk minimization. 2006.
- Kostrikov et al. (2021) Kostrikov, I., Nair, A., and Levine, S. Offline reinforcement learning with implicit q-learning. arXiv preprint arXiv:2110.06169, 2021.
- Kumar et al. (2020) Kumar, A., Zhou, A., Tucker, G., and Levine, S. Conservative q-learning for offline reinforcement learning. arXiv preprint arXiv:2006.04779, 2020.
- Kveton et al. (2015) Kveton, B., Wen, Z., Ashkan, A., and Szepesvari, C. Tight regret bounds for stochastic combinatorial semi-bandits. In Artificial Intelligence and Statistics, pp. 535–543. PMLR, 2015.
- Lai (1987) Lai, T. L. Adaptive treatment allocation and the multi-armed bandit problem. The annals of statistics, pp. 1091–1114, 1987.
- Lai & Robbins (1985) Lai, T. L. and Robbins, H. Asymptotically efficient adaptive allocation rules. Advances in applied mathematics, 6(1):4–22, 1985.
- Langford & Zhang (2007) Langford, J. and Zhang, T. The epoch-greedy algorithm for multi-armed bandits with side information. Advances in neural information processing systems, 20, 2007.
- Lattimore & Szepesvári (2020) Lattimore, T. and Szepesvári, C. Bandit Algorithms. Cambridge University Press, 2020.
- Lecué & Mendelson (2013) Lecué, G. and Mendelson, S. Learning subgaussian classes: Upper and minimax bounds. arXiv preprint arXiv:1305.4825, 2013.
- Levine et al. (2020) Levine, S., Kumar, A., Tucker, G., and Fu, J. Offline reinforcement learning: Tutorial, review, and perspectives on open problems. arXiv preprint arXiv:2005.01643, 2020.
- Li et al. (2022) Li, G., Shi, L., Chen, Y., Chi, Y., and Wei, Y. Settling the sample complexity of model-based offline reinforcement learning. arXiv preprint arXiv:2204.05275, 2022.
- Li et al. (2023) Li, Z., Yang, Z., and Wang, M. Reinforcement learning with human feedback: Learning dynamic choices via pessimism. arXiv preprint arXiv:2305.18438, 2023.
- Liu et al. (2021) Liu, R., Nageotte, F., Zanne, P., de Mathelin, M., and Dresp-Langley, B. Deep reinforcement learning for the control of robotic manipulation: a focussed mini-review. Robotics, 10(1):22, 2021.
- Liu & Ročková (2023) Liu, Y. and Ročková, V. Variable selection via thompson sampling. Journal of the American Statistical Association, 118(541):287–304, 2023.
- Liu et al. (2017) Liu, Y., Logan, B., Liu, N., Xu, Z., Tang, J., and Wang, Y. Deep reinforcement learning for dynamic treatment regimes on medical registry data. In 2017 IEEE international conference on healthcare informatics (ICHI), pp. 380–385. IEEE, 2017.
- Ménard et al. (2021) Ménard, P., Domingues, O. D., Jonsson, A., Kaufmann, E., Leurent, E., and Valko, M. Fast active learning for pure exploration in reinforcement learning. In International Conference on Machine Learning, pp. 7599–7608. PMLR, 2021.
- Min et al. (2021) Min, Y., Wang, T., Zhou, D., and Gu, Q. Variance-aware off-policy evaluation with linear function approximation. Advances in neural information processing systems, 34:7598–7610, 2021.
- Mou et al. (2022) Mou, W., Wainwright, M. J., and Bartlett, P. L. Off-policy estimation of linear functionals: Non-asymptotic theory for semi-parametric efficiency. arXiv preprint arXiv:2209.13075, 2022.
- Nachum et al. (2019) Nachum, O., Dai, B., Kostrikov, I., Chow, Y., Li, L., and Schuurmans, D. Algaedice: Policy gradient from arbitrary experience. arXiv preprint arXiv:1912.02074, 2019.
- Nakkiran et al. (2020) Nakkiran, P., Neyshabur, B., and Sedghi, H. The deep bootstrap framework: Good online learners are good offline generalizers. arXiv preprint arXiv:2010.08127, 2020.
- Peng et al. (2019) Peng, X. B., Kumar, A., Zhang, G., and Levine, S. Advantage-weighted regression: Simple and scalable off-policy reinforcement learning. arXiv preprint arXiv:1910.00177, 2019.
- Rashidinejad et al. (2021) Rashidinejad, P., Zhu, B., Ma, C., Jiao, J., and Russell, S. Bridging offline reinforcement learning and imitation learning: A tale of pessimism. arXiv preprint arXiv:2103.12021, 2021.
- Ruan et al. (2023) Ruan, S., Nie, A., Steenbergen, W., He, J., Zhang, J., Guo, M., Liu, Y., Nguyen, K. D., Wang, C. Y., Ying, R., et al. Reinforcement learning tutor better supported lower performers in a math task. arXiv preprint arXiv:2304.04933, 2023.
- Rusmevichientong & Tsitsiklis (2010) Rusmevichientong, P. and Tsitsiklis, J. N. Linearly parameterized bandits. Mathematics of Operations Research, 35(2):395–411, 2010.
- Russo (2016) Russo, D. Simple bayesian algorithms for best arm identification. In Conference on Learning Theory, pp. 1417–1418. PMLR, 2016.
- Si et al. (2020) Si, N., Zhang, F., Zhou, Z., and Blanchet, J. Distributionally robust policy evaluation and learning in offline contextual bandits. In International Conference on Machine Learning, pp. 8884–8894. PMLR, 2020.
- Sutton & Barto (2018) Sutton, R. S. and Barto, A. G. Reinforcement learning: An introduction. MIT Press, 2018.
- Thomas et al. (2015) Thomas, P., Theocharous, G., and Ghavamzadeh, M. High confidence policy improvement. In International Conference on Machine Learning, pp. 2380–2388. PMLR, 2015.
- Vershynin (2020) Vershynin, R. High-dimensional probability. University of California, Irvine, 2020.
- Wainwright (2019) Wainwright, M. J. High-dimensional statistics: A non-asymptotic viewpoint, volume 48. Cambridge university press, 2019.
- Wang et al. (2022) Wang, K., Zhao, H., Luo, X., Ren, K., Zhang, W., and Li, D. Bootstrapped transformer for offline reinforcement learning. Advances in Neural Information Processing Systems, 35:34748–34761, 2022.
- Wang & Chen (2018) Wang, S. and Chen, W. Thompson sampling for combinatorial semi-bandits. In International Conference on Machine Learning, pp. 5114–5122. PMLR, 2018.
- Wei et al. (2020) Wei, Y., Fang, B., and J. Wainwright, M. From gauss to kolmogorov: Localized measures of complexity for ellipses. 2020.
- Wu et al. (2019) Wu, Y., Tucker, G., and Nachum, O. Behavior regularized offline reinforcement learning. arXiv preprint arXiv:1911.11361, 2019.
- Xie & Jiang (2020) Xie, T. and Jiang, N. Batch value-function approximation with only realizability. arXiv preprint arXiv:2008.04990, 2020.
- Xie et al. (2021) Xie, T., Cheng, C.-A., Jiang, N., Mineiro, P., and Agarwal, A. Bellman-consistent pessimism for offline reinforcement learning. arXiv preprint arXiv:2106.06926, 2021.
- Xiong et al. (2022) Xiong, W., Zhong, H., Shi, C., Shen, C., Wang, L., and Zhang, T. Nearly minimax optimal offline reinforcement learning with linear function approximation: Single-agent mdp and markov game. arXiv preprint arXiv:2205.15512, 2022.
- Yin & Wang (2021) Yin, M. and Wang, Y.-X. Towards instance-optimal offline reinforcement learning with pessimism. arXiv preprint arXiv:2110.08695, 2021.
- Yin et al. (2022) Yin, M., Duan, Y., Wang, M., and Wang, Y.-X. Near-optimal offline reinforcement learning with linear representation: Leveraging variance information with pessimism. arXiv preprint arXiv:2203.05804, 2022.
- Zanette et al. (2019) Zanette, A., Brunskill, E., and J. Kochenderfer, M. Almost horizon-free structure-aware best policy identification with a generative model. In Advances in Neural Information Processing Systems, 2019.
- Zanette et al. (2020) Zanette, A., Lazaric, A., Kochenderfer, M. J., and Brunskill, E. Provably efficient reward-agnostic navigation with linear value iteration. In Advances in Neural Information Processing Systems, 2020.
- Zanette et al. (2021) Zanette, A., Wainwright, M. J., and Brunskill, E. Provable benefits of actor-critic methods for offline reinforcement learning. arXiv preprint arXiv:2108.08812, 2021.
- Zhang et al. (2022) Zhang, R., Zhang, X., Ni, C., and Wang, M. Off-policy fitted q-evaluation with differentiable function approximators: Z-estimation and inference theory. In International Conference on Machine Learning, pp. 26713–26749. PMLR, 2022.
- Zhang et al. (2021) Zhang, Z., Yang, J., Ji, X., and Du, S. S. Improved variance-aware confidence sets for linear bandits and linear mixture mdp. Advances in Neural Information Processing Systems, 34:4342–4355, 2021.
Appendix A One-sample case with strong signals
In this section, we give a simple example of one-sample-per-arm case. This can be view as a special case of data-starved MAB and Theorem 5.1 can be applied to get a non-trivial guarantees. Specifically, consider an MAB with arms. Assume the true mean reward vector is and the noise vector is That is, the first arms have rewards independently sampled from and the rewards for other arms are independently sampled from The stochastic reference policy is set to the uniform one, i.e.,
We apply Algorithm 1 to this MAB instance. In the next theorem, we will show that for a specific the optimal improvement in (denoted as in (10)) can achieve an improved reward value of constant level.
Proposition A.1.
Assume and noise For any with probability at least the improvement of policy value can be lower bounded by
where the improvement vector in is defined in (10). Therefore, for and with probability at least we can get a constant policy improvement
Proof.
We define the optimal improvement vector as
Then, from the definition of , we have
| (30) |
In order to lower bound the policy value improvement, it suffices to lower bound the signal part and upper bound the noise. We denote as a hyperplane in To deal with the signal part, it suffices to notice that
We denote as the orthogonal projection of on the and In the strong signal case, we have
Then, the signal part satisfies
| (31) |
On the other hand, we notice that when
So actually the inequality in the (31) should be an equation, which implies
| (32) |
For the noise part, we decompose the noise as where is the orthogonal projection of on Then, from one has
This implies From our assumption, is a chi-square random variable with degree so from the Example 2.11 in Wainwright (2019), we know with probability at least one has
This implies
The last inequality comes from for positive . Moreover, since is a fixed vector, we know So with probability at least one has
Combining the two terms above, one has with probability at least it holds
| (33) |
Appendix B Monte Carlo computation
As discussed in Section 4, we can estimate using classical Monte Carlo method. In this section, we illustrate the detailed implementation. We first sample i.i.d. noise and then solve for each to get suprema. We eventually select the -th largest values of all suprema as our estimate for the bonus function, where is a pre-computed integer dependent on and the pre-determined failure probability Here, the program is a second-order cone program and can be efficiently solved via standard off-the shelf libraries (Alizadeh & Goldfarb, 2003; Boyd & Vandenberghe, 2004; Diamond & Boyd, 2016). The pseudocode for the Monte-Carlo sampling is in Algorithm 2.
To determine we denote as the i.i.d. noise vector for and We denote the order statistics of -s as Suppose the cumulative distribution function of is then from the property of the order statistics, we know the cumulative distribution function of is
We denote as the -lower quantile of the random variable , then we have For integer and , we define as the maximal integer such that With this definition, we take a fixed and a total failure tolerance for all , then we take
as the threshold number. Under this choice, for any , with probability at least , it holds On the other hand, with probability , it holds that This implies
with probability at least . From a union bound, we know with probability at least , the bound above holds for any
Appendix C A fine-grained analysis to the suboptimality
We have shown a problem-dependent upper bound for the suboptimality in (16). In this section, we will give a further upper bound for and hence, for the suboptimality. We have the following theorem. The proof is deferred to Section C.1.
Theorem C.1.
For a policy (deterministic or stochastic), we denote its reward value as . TRUST has the following properties.
-
1.
We denote a comparator policy as a triple such that We take the discrete candidate set defined in (14). With probability at least for any stochastic comparator policy the sub-optimality of the output policy of Algorithm 1 can be upper bounded as
(34) where is defined as any quantity satisfying
(35) is the decaying rate defined in (14),
-
2.
(Comparison with the optimal policy) We further assume for and assume the offline dataset is generated from the policy with Without loss of generality we assume is the optimal arm and denote the optimal policy as . We write
(36) When with probability at least , one has
(37) Specially, when we have with probability at least
(38)
We remark that (34) is problem-dependent, and it gives an explicit upper bound for in (16). This is derived by first concentrating around , which is well-defined as localized Gaussian width or local Gaussian complexity (Koltchinskii, 2006), and then upper bounding the localized Gaussian width of a convex hull via tools in convex analysis (Bellec, 2019). Different from (4), when represents a single arm, (34) relies not only on , but on for as well, since the size of trust regions depend on for all
Notably, (38) gives an analogous upper bound depending on and , which is comparable to the bound for LCB in (5) up to constant and logarithmic factors. This indicates that, when behavioral cloning policy is not too imbalanced, TRUST is guaranteed to achieve the same level of performance as LCB. In fact, this improvement is remarkable since TRUST is exploring a much larger policy searching space than LCB, which encompasses all stochastic policies (the whole simplex) rather than the set of all single arms only. We also remark that both (5) and (51) are worst-case upper bound, and in practice, we will show in Section 6 that in some settings, TRUST can achieve good performance while LCB fails completely.
Is TRUST minimax-optimal?
We consider the hard cases in MAB (Rashidinejad et al., 2021) where LCB achieves the minimax-optimal upper bound and we show for these hard cases, TRUST will achieve the same sample complexity as LCB up to log and constant factors. More specifically, we consider a two-arm MAB and the uniform behavioral cloning policy For we define and are two MDPs whose reward distributions are as follows.
where is the Bernoulli distribution with probability The next result is a corollary from Theorem C.1.
Corollary C.2.
We define as above for Assume Then, we have
-
1.
The minimax optimal lower bound for the suboptimality of LCB is
(39) where is the expectation over the offline dataset
-
2.
The upper bound for suboptimality of TRUST mathces the lower bound above up to log factor. Namely, for any one has
(40)
The first claim comes from Theorem 2 of (Rashidinejad et al., 2021), while the second claim is a direct corollary to Theorem C.1.
C.1 Proof of Theorem C.1
Proof.
Recall from Theorem 5.1 that for any comparator policy defined above, one has
where The following lemma upper bounds the quantile of Gaussian suprema for each The proof is deferred to Section C.2.
Lemma C.3.
For one can upper bound as follows.
| (41) |
where and is a quantity satisfying
| (42) |
Applying Lemma C.3 to we obtain
| (43) |
Since , we know from our discretization scheme in (14)
| (44) |
Bridging (44) into (43), we obtain our first claim. In order to get the second claim, we take for and which is the vector pointing at the vertex corresponding to the optimal arm from the uniform reference policy defined in (7). Then, we have
where is the sample size for the optimal arm Therefore, we can further bound (43) as
| (45) |
Finally, we take a specific value of and lower bound via Chernoff bound in Lemma C.7. From Lemma C.7, we know that when with probability at least we have
| (46) |
for any Recall the definition of in (42), we know that can be arbitrary value greater than Then, when , one has
We denote (when there are multiple minimizers, we arbitrarily pick one). Then, we have
Therefore, we take in (45) and apply to obtain
| (47) |
which proves (37). Finally, when one has
Therefore, we conclude. ∎
C.2 Proof of Lemma C.3
Proof.
Recall that is the improvement vector, is the noise vector, where entries are independent and and is the sample size of arm in the offline dataset. To proceed with the proof, let’s further define
| (48) |
With this notation, one has
We also write the equivalent trust region (for ) as
| (49) |
where is the policy weight for the reference policy. From the definition above, one has for any
Then, we apply Lemma C.4 to for a One has with probability at least
From a union bound, one immediately has with probability at least for any it holds that
| (50) |
From the definition of in (4.2), we know that is the minimal quantity that satisfy (50) with probability at least Therefore, one has
| (51) |
Note that, the first term in the RHS of (51) is well-defined as localized Gaussian width over the convex hull defined by the trust region (or equivalently, ). We denote
| (52) |
We immediately have that is a convex hull of points in and the vertices of this convex hull are the vertices of the simplex in shifted by the reference policy In what follows, we plan to apply Lemma C.5 to the localized Gaussian width of However, is not subsumed by the unit ball in so we need to do some additional scaling. Note that, the zero vector is included in Let’s compute the farthest distance for the vertices of We denote the -th vertex of as
| (53) |
The -norm of this improvement vector is
where is the total sample size of the offline dataset. Therefore, the maximal radius of can be upper bounded by , where is any quantity that satisfies
| (54) |
We denote Then, from Lemma C.5, one has
| ( can be got by scaling bt ) | ||||
| (Take and in Lemma C.5) | ||||
| ( for any ) |
This finishes the proof. ∎
C.3 Auxiliary lemmas
Lemma C.4 (Concentration of Gaussian suprema, Exercise 5.10 in Wainwright (2019)).
Let be a zero-mean Gaussian process, and define . Then, we have
where is the maximal variance of the process.
Lemma C.5 (Localized Gaussian Width of a Convex Hull, Proposition 1 in Bellec (2019)).
Let and be the convex hull of points in We write and Assume Let be a standard Gaussian vector. Then, for all one has
| (55) |
where
Lemma C.6 (Chernoff bound for binomial random variables, Theorem 2.3.1 in Vershynin (2020)).
Let be independent Bernoulli random variables with parameters . Consider their sum and denote its mean by . Then, for any , we have
Lemma C.7 (Chernoff bound for offline MAB).
Under the setting in Theorem C.1, we have
Proof.
Appendix D Proof of Lemma 5.2
Proof.
Recall the definition of
| (56) |
We additionally define
| (57) |
Specially, if there is no such that then we define . Then we know for any ( is the largest possible radius) and a finite set it holds that
| (58) |
For any , recall is the optimal improvement vector within defined in (10). It holds that
| (since does not depend on ) | ||||
| ( so ) | ||||
On the other hand, when and one has so
where the last inequality comes from the fact that when by definition of the trust region in (4.2). Combining two inequalities above, we have for any
| (59) |
where the variables in RHS above are and , and Therefore, from the definition of we have
This finishes the proof. ∎
Appendix E Augmentation with LCB
To determine the most effective final policy, we can compare the outputs of the LCB and Algorithm 1 and combine both policies, based on the relative magnitude of their corresponding lower bounds. Specifically, the combined policy is
| (60) |
where is defined in (1) and is defined in Definition 4.2. This combined policy will perform at least as well as LCB with high probability. More specifically, we have
Corollary E.1.
We denote the arm chosen by LCB as . We also denote as the true reward of a policy (deterministic or stochastic). With probability at least one has
| (61) |
Proof.
We denote and as the empirical reward of the policy returned by LCB and Algorithm 1, respectively. Recall the uncertainty term of LCB in (1) and of Algorithm 1 in (E), we write and . Then, from Theorem 5.1, (2) and a union bound, we know with probability at least it holds that
which implies
| (By (E)) | ||||
| (By the definition of in (3)) |
Therefore, we conclude. ∎
Appendix F Experiment details
We did experiments on Mujoco environment in the D4RL dataset (Fu et al., 2020). All environments we test on are v3. Since the original D4RL dataset does not include the exact form of logging policies, we retrain SAC (Haarnoja et al., 2018) on these environment for 1000 episodes and keep record of the policy in each episode. We test 4 environments in two settings, denoted as ’1-traj-low’ and ’1-traj-high’. In either setting, the offline dataset is generated from 100 policies with one trajectory from each. In the ’1-traj-low’ setting, the data is generated from the first 100 policies in the training process of SAC, while in the ’1-traj-high’ setting, it is generated from the policy in -th episodes in the training process.
For all experiments on Mujoco, we average the results over 4 random seeds (from 2023 to 2026), and to run CQL, we use default hyper-parameters in https://github.com/young-geng/CQL to run 2000 episodes. For TRUST, we run it using a fixed standard deviation level for all experiments.