Iterated Schrödinger bridge approximation
to Wasserstein Gradient Flows
Abstract.
We introduce a novel discretization scheme for Wasserstein gradient flows that involves successively computing Schrödinger bridges with the same marginals. This is different from both the forward/geodesic approximation and the backward/Jordan-Kinderlehrer-Otto (JKO) approximations. The proposed scheme has two advantages: one, it avoids the use of the score function, and, two, it is amenable to particle-based approximations using the Sinkhorn algorithm. Our proof hinges upon showing that relative entropy between the Schrödinger bridge with the same marginals at temperature and the joint distribution of a stationary Langevin diffusion at times zero and is of the order with an explicit dependence given by Fisher information. Owing to this inequality, we can show, using a triangular approximation argument, that the interpolated iterated application of the Schrödinger bridge approximation converge to the Wasserstein gradient flow, for a class of gradient flows, including the heat flow. The results also provide a probabilistic and rigorous framework for the convergence of the self-attention mechanisms in transformer networks to the solutions of heat flows, first observed in the inspiring work [SABP22] in machine learning research.
Key words and phrases:
Schrödinger bridges, Wasserstein gradient flows, JKO approximation, Fisher information, Sinkformers, Transformers, self-attention2000 Mathematics Subject Classification:
49N99, 49Q22, 60J601. Introduction
Let denote the space of square-integrable Borel probability measures on . Throughout this paper we will let refer to both the measure and the its Lebesgue density, whenever it exists. can be turned into a metric space equipped with the Wasserstein- metric [AGS08, Chapter 7]. We will refer to this metric space as simply the Wasserstein space. For any pair of probability measures in the Wasserstein space, let denote the set of couplings, i.e., joint distributions, with marginals . Further, define the relative entropy, also known as Kullback-Leibler (KL) divergence, between and as
| (1) |
To understand our results let us start with an example that was first described in [SABP22]. The static Schrödinger bridge ([Léo14]) at temperature with both marginals is the solution to the following optimization problem
| (2) |
where has density
| (3) |
If , define the barycentric projection [PNW22] as a function from to itself given by
| (4) |
Now define a map from to itself given by the following pushforward
| (5) |
We call this map to emphasize the central role of the Schrödinger bridge in its definition. That is, if , then is the law of the random variable . If , then should closely approximate the quadratic cost optimal transport plan from to itself [Léo12]. That is, one would expect to be approximately close to itself (see, for instance, [PNW22, Corollary 1]). Therefore, one expects , as well. Hence, the pushforward should not alter by much.
What happens if we iterate this map and rescale time with ? That is, fix some and a . Let . With , define iteratively
Define a continuous time piecewise constant interpolant . The question is whether, as , this curve on the Wasserstein space has an absolutely continuous limit? If so, can we write down its characterizing continuity equation?
Before we give the answer, consider the simulation in Figure 1. The figure considers a particle system approximation to the above iterative scheme. We push particles, initially distributed as a mixtures of two normal distributions, , via the dynamical system for and step size . At every step the Schrödinger bridge is approximated by the (matrix) Sinkhorn algorithm [Cut13] applied to the current empirical distribution of the particles and the corresponding barycenter is approximated from this estimate. The pushforward is then applied to the particles themselves. This gives a time evolving process of empirical distributions that can be thought of as a discrete approximation of our iterative scheme. One can see that the histogram gets smoothed out gradually and ends in a shape that appears to be a Gaussian distribution. In fact, this process of smoothing is reminiscent of the heat flow starting from . In the case of this simple starting distribution, the heat flow is known analytically. The curves of the heat flow are superimposed as continuous curves. The broken curves are the exact which, in this case, can also be computed. The histograms and the two curves all closely match with one another.
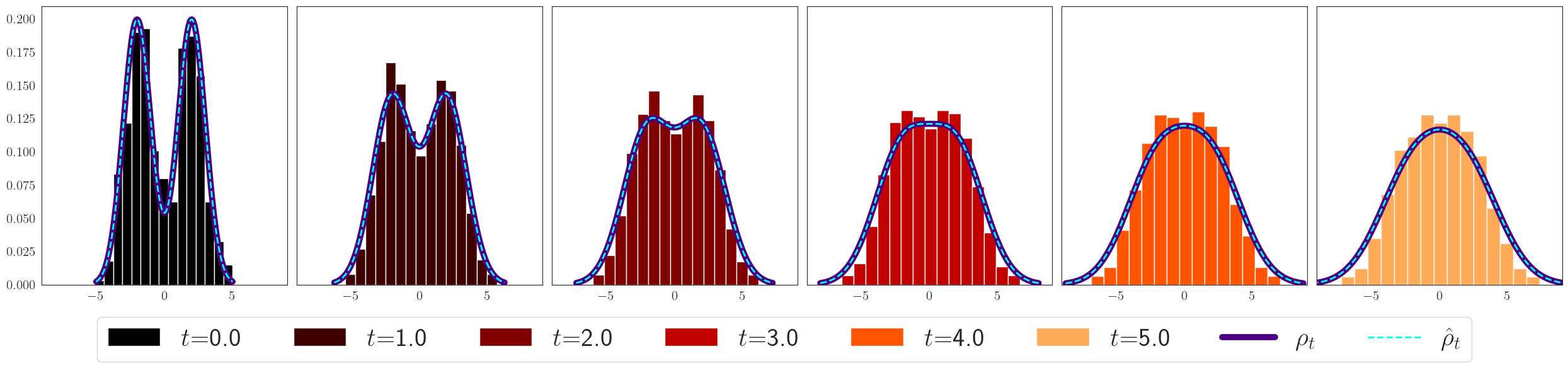
One of the results that we prove in this paper shows that, under appropriate assumptions, indeed converges to the solution of the heat equation , with initial condition . In a different context and language, this result was first observed in [SABP22, Theorem 1]. However, their proof is incomplete. See the discussion below. The statement of Theorem 4 in this paper lays down sufficient conditions under which this convergence happens.
It is well known from [JKO98, Theorem 5.1] that the heat flow is the Wasserstein gradient flow of (one half) entropy. We prove a generalization of the above result where a similar discrete dynamical system converges, under assumptions, to other Wasserstein gradient flows that satisfy an evolutionary PDE of the type [AGS08, eqn. (11.1.6)]. The general existence and uniqueness of gradient flows (curves of maximal slopes) in Wasserstein space are quite subtle [AGS08, Chapter 11]. However, evolutionary PDEs of the type [AGS08, eqn. (11.1.6)] include the classical case of the gradient flow of entropy as the heat equation and that of the Kullback-Leibler divergence (also called relative entropy) as the Fokker-Planck equation [JKO98, Theorem 5.1]. Our iterative approximating schemes always iterate a function of the barycentric projection of the Schrödinger bridge with the same marginals. The marginal itself changes with the iteration. Let us give the reader an intuitive idea how such schemes work.
The foundations of all these results can be found in Theorem 1 which shows that the two point joint distribution of a stationary Langevin diffusion is a close approximation of the Schrödinger bridge with equal marginals. More concretely, let be some element in for which the Langevin diffusion process with stationary distribution exists and is unique in law. This diffusion process is governed by the stochastic differential equation
| (6) |
where is the standard -dimensional Brownian motion. Therefore, for any , is an element in . Then, Theorem 1 shows that, under appropriate conditions on , the symmetrized relative entropy, i.e., the Jensen-Shannon divergence, between and the Schrödinger bridge is . Although this level of precision is sufficient for our purpose, it is shown via explicit computations in (28) that when is Gaussian this symmetrized relative entropy is actually , an order of magnitude tighter.
In any case, one would expect that, under suitable assumptions, the barycentric projection
| (7) |
The quantity is called the score function. This is a reformulation of [SABP22, Theorem 1] which states that the difference between the two sides converges to zero in . In other words, one would expect that, under suitable assumptions,
| (8) |
We claim this is approximately the solution of the heat equation at time , starting from .
To see this, recall that absolutely continuous curves (see [AGS08, Definition 1.1.1]) on the Wasserstein space are characterized as weak solutions [AGS08, eqn. (8.1.4)] of continuity equations
| (9) |
Here is the time-dependent Borel velocity field of the continuity equation whose properties are given by [AGS08, Theorem 8.3.1]. For any absolutely continuous curve, if belongs to the tangent space at ([AGS08, Definition 8.4.1]), [AGS08, Proposition 8.4.6] states the following approximation result for Lebesgue-a.e.
| (10) |
For example, if is the Wasserstein gradient flow of a function satisfying [AGS08, eqn. (11.1.6)], where is the first variation of (see [AGS08, Section 10.4.1]) at . For the heat flow, which is the gradient flow of (half) entropy, and . Comparing (8) with (10) explains the previous claim.
The claimed approximation in (8) is what we call one-step approximation. In a somewhat more general setting, this is proved in Theorem 2. Note that a crucial advantage we gain in the Schrödinger bridge scheme that is absent in Langevin diffusion or the continuity equation is that we no longer need to compute the score function . Instead it suffices to be able to draw samples from and compute the approximate Schrödinger bridge, say by the Sinkhorn algorithm [Cut13], as done in Figure 1.
To summarize, the flow of ideas in the paper goes as follows. First, we show that the Schrödinger bridge map , defined in its full generality in (SB), is an approximation the pushforward of by the tangent vector of the gradient flow (10). This is known to be close to the gradient flow curve itself [AGS08, Proposition 8.4.6]. So one may expect that an iteration of this idea, where an absolutely continuous curve approximated by iterated pushforwards such as (10) can be, under suitable assumptions, approximated by iterated Schrödinger bridge operators . One has to be mindful that the cumulative error remains controlled as we iterate, but in the best of situations this might work. And, in fact, it does for the heat flow, under suitable conditions, as proved in Theorem 4.
Now, a natural question is how general is this method? Can we approximate other gradient flows, say that of Kullback-Leibler with respect to a log-concave density? What about absolutely continuous curves that are not gradient flows? The case of KL is partially settled in this paper in Theorem 5. Let us state our proposed Schrödinger Bridge scheme in somewhat general notation. Consider a suitably nice functional and fix an initial measure . Suppose the gradient flow of can be approximated by a sequence of explicit Euler iterations , where, starting from , iteratively define
| (11) |
with being the Wasserstein gradient of at . Such an approximation scheme will be referred to as an explicit Euler iteration scheme and conditions must be imposed for it to converge to the underlying gradient flow. See Theorem 3 below for sufficient conditions.
Ignoring technical details, our goal is to approximate each such explicit Euler step via a corresponding Schrödinger bridge step. This is accomplished by the introduction of what we call a surrogate measure. For simplicity, consider the first step . Suppose that there is some such that , define the surrogate measure to be one with the density
| (12) |
As explained in (7), if we consider the Schrödinger bridge at temperature with both marginals to be , then . If we now define one step in the SB scheme as
| (SB) |
Observing that, as , we recover that . Notice that the choice of does not play a role except to guarantee that the surrogate in (12) is integrable. For the case of the heat flow, . Hence, if we pick , and then the scheme (5) becomes a special case of (SB).
Let us consider the sequence of iterates of (SB), interpolated in continuous time for some ,
Theorems 4 and 5 list sufficient conditions under which such a scheme converges uniformly to the gradient flow curve as for specific choices of functional .
We should point out that the primary reason why we need the assumptions in Theorems 4 and 5 is to guarantee that the errors go to zero uniformly over a growing number of iterations. Much of the technical work in this paper goes to produce a simple set of sufficient conditions to ensure this. Consequently, our theorems are specialized to the case of gradient flows of geodesically convex regular functions. But the scope of Schrödinger bridge scheme is potentially larger. As shown in Section 5.3 via explicit calculations, the Schrödinger bridge scheme may be used to approximate even time-reversed gradient flows. The corresponding PDEs, such as the backward heat equation/ Fokker-Planck, are ill-posed and care must be taken to implement any approximating scheme. Interestingly, if one replaces (5) by , then starting from a Gaussian initial distribution, and for all small enough , the iterates are shown to converge to the time-reversed gradient flow of one-half entropy.
In Section 3 we also generalize our Schrödinger bridge scheme (SB) by picking the surrogate measure depending on . This generalization is necessary to generalize the Schrödinger bridge scheme to cover tangent vectors that are not necessarily of the gradient type, but are approximated by a sequence of gradient fields. This generalization also covers the case of the renowned JKO scheme, [JKO98], which can be likened to the implicit Euler discretization scheme of the gradient flow curve. This, however, introduces an additional layer of complexity.
Some of the technical challenges we overcome in this paper involve proving results about Schrödinger bridges at low temperatures when the marginals are not compactly supported. The latter is a common assumption in the literature, see for example [Pal19, PNW22, CCGT22, SABP22]. However, the existence of Langevin diffusion requires an unbounded support. Much of this work is done in Section 2 which may be of independent interest. For example, we extend the expansion of entropic OT cost function from [CT21, Theorem 1.6] for the case of same marginals in (42). In all this analysis an unexpected mathematical object appears repeatedly, the harmonic characteristic ([CVR18]) defined below in (14). It appears in the computation of Fisher information of the Langevin and the Schrödinger bridges (see (37)) and in the geodesic approximation of the heat flow (Lemma 7). The role of this object merits a deeper study.
Discussion on [SABP22]. The inspiring work [SABP22] is one of the motivations of our investigations. The authors of [SABP22] propose and analyze a modification to the self-attention mechanism from the Transformer artificial neural network architecture in which the self-attention matrix is enforced to be doubly-stochastic. Since the Sinkhorn algorithm is applied to enforce double stochasticity, the architecture is called the Sinkformer. A major contribution of [SABP22] is the keen observation that self-attention mechanisms can be understood as determining a dynamical system whose particles are the input tokens (possibly after a suitable transformation). See also [GLPR24] for other work in this area. Specifically, [SABP22, Proposition 2,3] observes that, as a regularization parameter vanishes, the associated particle system under doubly-stochastic self-attention evolves according to the heat flow, and this property naturally follows from the doubly-stochastic constraints.
Theorems 1-5 can be understood as probabilistic approaches to [SABP22, Theorem 1], as well as a finer treatment to key steps of the mathematical analysis of the convergence to the heat flow equation. The first statement of [SABP22, Theorem 1] concerns the convergence of the rescaled gradients of entropic potentials for the Schrödinger bridge with the same marginals. Consider the so-called entropic (or, Schrödinger) potentials as defined later on in (19). In this language, [SABP22, Theorem 1] states that in , as . We are not able to prove this particular convergence; not least because we work in a slightly different setting, i.e., with measures fully supported on whereas [SABP22] assumes compact support (although, see the discussion after the proof of Theorem 1 for a similar result). Instead our argument relies on approximating the Schrödinger bridge by the Langevin diffusion which are undefined for measures with compact support. Moreover, in our paper we develop a general machinery that demonstrate the ability of the Schrödinger bridge scheme to approximate gradient flows of other functionals of interest beyond entropy.
2. Approximation of Schrödinger Bridge by Langevin Diffusion
2.1. Preliminaries
In this section we fix a measure with density given by for some function . Here, we follow the standard convention in optimal transport of using the same notation to refer to an absolutely continuous measure and its density. We will state assumptions on later. Let denote the collection of probability measures on with density and finite second moments. The aim of this section is to prove that when the two marginals are the same, then the Schrödinger bridge and the stationary Langevin diffusion with that marginal are very close in the sense made precise in Theorem 2.
We start by collating standard results about the Langevin diffusion and Schrödinger bridge and introducing the notions from stochastic calculus of which we will make use. The relevant notation is all summarized in Table Notations.
Let denote the set of continuous paths from to , equipped with the locally uniform metric. Denote the coordinate process by . Endow this space with a filtration satisfying the usual conditions [KS91, Chapter 1, Definition 2.25]. For , let denote the law on of the standard -dimensional Brownian motion started from . All stochastic integrals are Itô integrals.
Let and assume that , the stationary Langevin diffusion with stationary measure equal to , exists. That is, its law on is a weak solution to (6) with initial condition . Let denote the law of this process on , and let denote the law of the Langevin diffusion started from . As in the Introduction, for , set . Under suitable assumptions on (see Assumption 1 below), exists with a.s. infinite explosion time [Roy07, Theorem 2.2.19], and by [Roy07, Lemma 2.2.21] for each time the laws of and restricted to are mutually absolutely continuous with Radon-Nikodym derivative
| (13) |
The expression inside the integral of the is a distinguished quantity in the Langevin diffusion literature (see [LK93]). Denote it by
| (14) |
This function is called the harmonic characteristic in [CVR18, eqn. (2)], which provides a heuristic physical interpretation for and (the latter of which appears in Theorem 1) as the “mean acceleration” of the Langevin bridge. This quantity also appears in (69) as the second derivative in time of a quantity of interest, giving another way to see it as mean acceleration.
Let and denote the transition kernels for the standard -dimensional Brownian motion and the Langevin diffusion, respectively. By (13)
Notice that is expectation with respect to the law of the Brownian bridge from to over . Define the following function
| (15) |
Recall that is joint density of under Langevin; it is now equal to
| (16) | ||||
| (17) |
Let denote the corresponding Langevin semigroup and its extended infinitesmal generator (see [RY04, Chapter VII, Section 1] for definitions). That is, we have for and bounded and measurable that
Letting denote the collection of all twice continuously differentiable functions, by [RY04, Chapter VIII, Proposition 3.4] we have for that
| (18) |
We now define the static Schrödinger bridge with marginals equal to , denoted by . For an excellent and detailed account we refer readers to [Léo14] and references therein; we develop only the notions that we use within our proof. Under mild regularity assumptions on (for instance, finite entropy and a moment condition), it is known that for each , admits an -decomposition [Léo14, Theorem 2.8]. As we consider the equal marginal Schrödinger bridge, we can in fact insist that . Thus, there exists such that admits a Lebesgue density of the form
| (19) |
We refer to the as entropic potentials. Note that, in general, entropic potentials are unique up to a choice of constant; however, our convention of symmetry forces that each is indeed unique. Moreover, combining (3) and (19), the Schrödinger cost can be written in terms of the entropic potentials as
| (20) |
As outlined in [Léo14, Proposition 2.3], there is a corresponding dynamic Schrödinger bridge, obtained from (the “static” Schrödinger bridge) by interpolating with suitably rescaled Brownian bridges. More precisely, let denote the law of on , where is the reversible -dimensional Brownian motion. Then, the law of the -dynamic Schrödinger bridge on is given by where
| (21) |
where . Letting denote the (standard) heat semigroup, we define
| (22) |
where the second identity follows from the Markov property of .
Fix , set and call the -entropic interpolation from to itself, explicitly
| (23) |
By [Léo14, Proposition 2.3], we construct a random variable with law as follows. Let and be independent to the pair, then
| (24) |
Thanks to an analogue of the celebrated Benamou-Brenier formula for entropic cost ([GLR17, Theorem 5.1]), the entropic interpolation is in fact an absolutely continuous curve in the Wasserstein space. From [CT21, Equation (2.14)] the entropic interpolation satisfies the continuity equation (9) with given by
| (25) |
Moreover, under mild regularity assumptions on , we obtain the following entropic variant of Benamou-Brenier formulation [GLR17, Corollary 5.8] (with appropriate rescaling)
| (26) |
where is the Fisher information, defined for by . The infimimum in (26) is taken over all satisfying and (9). The optimal selection is given in (25). That is, the optimal selection is the entropic interpolation. For an AC curve , we will call the quantity the integrated Fisher information.
Lastly, for the same dynamic marginal Schrödinger bridge, we make the following observation about the continuity at of the integrated Fisher information along the entropic interpolation.
Lemma 1.
Let satisfy and , then .
2.2. Langevin Approximation to Schrödinger Bridge
Our main result of the section is the relative entropy bound between and given in Theorem 1.
Assumption 1.
Let for , and recall that . Assume that
-
(1)
is subexponential ([Ver18, Definition 2.7.5]), , is bounded below, as .
-
(2)
There exists and such that .
-
(3)
and .
These assumptions are, for instance, satisfied by the multivariate Gaussian with , positive definite. This provides an essential class of examples as explicit computations of the Schrödinger bridge between Gaussians are known [JMPC20]. In this instance, and thus
Importantly, for this establishes that and thus . More generally, when is polynomial such that these assumptions are also satisfied.
Additionally, we remark that the class of functions satisfying Assumption 1 is stable under the addition of functions such that and all of its derivatives up to and including order are bounded (e.g. ). It is also stable under the addition of linear and quadratic functions, so long as the resulting function has a finite integral when exponentiated.
We begin with a preparatory lemma establishing some important integrability poperties we make use of in the proof of Theorem 1.
Lemma 2.
Let satisfying Assumption 1.
-
(1)
For each , the densities along the entropic interpolation is uniformly subexponential, meaning that for each there is a constant such that for we have , where is the subexponential norm defined in [Ver18, Definition 2.7.5].
-
(2)
The following integrability conditions hold:
-
(a)
The function is in for all .
-
(b)
The function from to given by is in . Similarly, is in .
-
(c)
For any , .
-
(a)
Proof.
Fix and . Let be random variables with joint law . Let be independent of . Then as given in (24) has law . As is a norm, observe that for any
establishing the uniform upper bound on the subexponential norm.
It then follows that
This observation also establishes that is in . By assumption on , is also of uniform polynomial growth, and thus the same argument establishes the remaining claims. ∎
Theorem 1.
Before proving the theorem, we pause to comment on the sharpness of the inequality presented in (27). As the Schrödinger bridge is explicitly known for Gaussian marginals [JMPC20], consider the case . Define two matrices
It is well known that is the Ornstein-Uhlenbeck transition density. By [JMPC20], it is known that . One then computes
| (28) |
On the other hand, the entropic interpolation between Gaussians is computed in [GLR17], and is minimized at . From a computation in Section 5, see (71),
Altogether, the RHS of (27) is then . That is, the transition densities for the OU process provide a tighter approximation (an order of magnitude) for same marginal Schrödinger bridge than given by Theorem 1.
Proof of Theorem 1.
We argue in the following manner. First, using the densities for and given in (16) and (19), respectively, we compute their likelihood ratio and obtain exact expressions for the two relative entropy terms appearing in the statement of the Lemma. The resulting expression is the difference in expectation of the expression defined in (15) with respect to the Schrödinger bridge and Langevin diffusion. We then extract out the leading order terms from both expectations and show that they cancel. To obtain the stated rate of decay, we then analyze the remaining term with an analytic argument from the continuity equation.
Step 1. The following holds
| (29) |
To prove (29), from (16) and (19)
As both , we have that
Equation (29) follows by adding these expressions together.
Recall that is Wiener measure starting from , and
For the integral inside the , we rescale from to . By Brownian scaling the law of under is equal to the law of under with initial condition , which gives
As , thanks to an integration by parts,
Thus from (29) observe
Thus, to prove (31) it will suffice to show
| (32) |
Observe that
Thus, as and ,
| (33) |
On let denote the law of Brownian motion with initial distribution . By a well-known formula (see [DGW04, Equation (5.1)] for instance)
It then follows from the factorization of relative entropy that
As , (32) follows by (33) and the information processing inequality (see [AGS08, Lemma 9.4.5] for instance).
Step 3. Show is bounded above by the RHS in (27).
To start, apply Jensen’s inequality to interchange the and in the expression for in (30) to obtain
Since the dynamic Schrödinger bridge, defined in (21), disintegrates as the Brownian bridge once its endpoints are fixed [Léo14, Proposition 2.3], we have that
| (34) | ||||
| (35) |
where the last equality follows from Fubini’s Theorem.
Recall that is a weak solution for the continuity equation (9) if for all and
Integrating in time over for gives
We now use a density argument to extend the above identity to
| (36) |
For let be such that , , , and . As ,
By Lemma 2, . Moreover, it is shown in (38) that . Thus, by the Dominated Convegence Theorem
As and
and both upper bounds are integrable in their suitable spaces (again by Lemma 2 and (38)), (36) follows from dominated convergence by sending .
Integrating (36) once more in over , multiplying by , and plugging in (25) gives the RHS of (34) as
Apply Cauchy-Schwarz on to obtain for each
Thus, altogether we have that
| (37) |
Recall the entropic Benamou Brenier expression for entropic cost given in (26). By the optimality of (25) and suboptimality of the constant curve for all ,
Rearranging terms gives
| (38) |
With this inequality, (37) becomes the desired
Under Assumption 1 (2), Lemma 2 applies and gives that the rightmost constant has an upper bound once we consider for some . Thus, the nonnegativity of the LHS of (27) and Lemma 1 give the stated convergence as .
∎
2.3. Discussion
Integrated Fisher Information. Under additional assumptions the integrated Fisher information along the entropic interpolation in (27) can be replaced with a potentially more manageable quantity. In certain settings (for instance, when with finite entropy and Fisher information [GLRT20, Lemma 3.2]), there is a conserved quantity along the entropic interpolation called the energy, which we denote . With as defined in (25), for any
| (39) |
Now, evaluate (39) at . Then and . On the other hand, integrate (39) over , this also gives and thus
This in turn implies
Thus, assuming the conservation of energy holds under Assumption 1, replacing the bound in (38) with the RHS of the above inequality rewrites Theorem 1 as
| (40) |
Alternatively, (40) also holds when is a univariate Gaussian, as explicit computations of the entropic interpolation in this case from [GLR17] demonstrate that is minimized at .
Schrödinger Cost Expansion. In the course of proving Theorem 1, we recover a result in alignment with the expansion of Schrödinger cost about developed in [CT21, Theorem 1.6]. Under assumptions on bounded with compact support and finite entropy, [CT21, Theorem 1.6] states
| (41) |
Now, from the Pythagorean Theorem of relative entropy [Csi75, Theorem 2.2]
Recall from Step 2 of Lemma 1 that , so by Theorem 1 we obtain the following expansion of an upper bound of Schrödinger cost
| (42) |
Thus, in the same-marginal case (and under different regularity assumptions) the second order term in the Schrödinger expansion is zero.
Convergence of Potentials. Revisiting the inequality in (38) and recalling (25), observe that
By Lemma 1, for Lebesgue a.e. it holds that
| (43) |
This fact hints in the direction of a result on the convergence of rescaled gradients of entropic potentials. Suppose that the convergence in (43) holds at or (of course, a priori there is no way to guarantee such convergence at a specific ). In this case,
As , (43) would imply that in . This would be in accordance with [SABP22, Theorem 1], but now with fully supported densities.
3. One Step Analysis of Schrödinger Bridge Scheme
Fix and recall the tangent space at , denoted by , and defined in [AGS08, Definition 8.4.1] by
Now, consider a vector field , such that the surrogate measure (12) is defined. Our objective in this section is to lay down conditions under which the approximation stated below (SB) holds. More precisely, we show that
| (44) |
In fact, we will prove the above theorem in a somewhat more general form when the tangent vector field may not even be of a gradient form. The general setting is as follows. Consider a collection of vectors fields of gradient type , we wish to tightly approximate the pushforwards with . As a shorthand, we write
| (45) |
Suppose that for each there exists such that the surrogate measure defined in (12) exists. Set
| (46) |
Redefine one step in the SB scheme as
| (SB) |
where is the barycentric projection defined in (4).
In Theorem 2 we show that, under appropriate assumptions,
| (47) |
There are multiple reasons why one might be interested in this general setup. Firstly, we know that, for any , there exists a sequence of tangent elements of the type such that in . In particular, by an obvious coupling,
| (48) |
But, of course, if is not of the gradient form, one cannot construct a surrogate measure as in (12) to run the Schrödinger bridge scheme. A natural remedy is to show that (47) holds under appropriate assumptions. Then, combined with (48) we recover (44) even when is not a gradient.
There is one more reason why one might use the above generalized scheme. As explained in (11), we would like to iterate the Schrödinger bridge scheme to track the explicit Euler iterations of a Wasserstein gradient flow. However, the more natural discretization scheme of Wasserstein gradient flows is the implicit Euler or the JKO scheme. See (IE) in Section 4 for the details. In this case, however, the vector field , which is the Kantorovich potential between two successive steps of the JKO scheme, changes with . This necessitates our generalization. Hence, we continue with (46) and the generalized (SB) scheme.
The proof of (47) relies on the close approximation of the Langevin diffusion to the Schrödinger bridge provided in Theorem 1. To harness this approximation, we introduce an intermediatery scheme based on the Langevin diffusion, which we denote and define in the following manner. Let and consider the symmetric Langevin diffusion with stationary density as defined in (46). The drift function for this diffusion is . In analogy with the definition of in (4), define by
| (49) |
Next, in analogy with the definition of in (SB), define the Langevin diffusion update
| (LD) |
In analogy with Section 2, for set
We now make the following assumptions on the collection of densities defined in (46).
Assumption 2.
For each , as defined in (46) satisfies Assumption 1. Additionally
-
(1)
There exists such that converges weakly to and as . Moreover, Assumption 1 holds uniformly in in the following manner: there exists and , such that for all , and for , .
-
(2)
The are uniformly semi log-concave, that is, there exists such that for all , . Additionally, , where is the Hilbert-Schmidt norm.
-
(3)
and .
Remark 1.
In all our examples, is either always or always . Hence, this parameter simply needs to have a positive lower bound (in absolute value) and it does not scale with .
While these assumptions may appear stringent, they are indeed satisfied by a wide class of examples, see Section 5. In many of these examples, takes the form . Thus, condition (3) in Assumption 2 is satisfied if . For instance, when using (SB) to approximate (EE) for the gradient flow of entropy, for all and thus . Similarly, for approximating the gradient flow of from certain starting measures, , where is a normalizing constant, for all . See Section 5 for more detailed discussion.
We now provide a quantitative statement about the convergence stated in (47), where we take care to note the dependence on constants appearing in Assumption 2 as this upper bound must hold uniformly along iterations of this scheme in Section 4. Recall as defined in (45) and as defined in (SB).
Theorem 2.
Under Assumption 2, there exists a constant depending on , such that for all
In particular,
Hence, from the discussion following (48) we immediately obtain:
Corollary 1.
Let , and let be such that and the corresponding surrogate measures satisfy Assumption 2. Then
Proof of Theorem 2.
This result follows from Lemmas 3, 4, and 5 below. Lemmas 3 and 4 together prove an upper bound on that show, in particular,
and Lemma 5 proves an upper bound on which implies
That is, the three updates , , and are within of each other in the Wasserstein-2 metric. Theorem 2 now follows from the triangle inequality and simplifying the choice of the constant . ∎
We begin by converting the relative entropy decay established in Theorem 1 between the Schrödinger bridge and Langevin diffusion into a decay rate between their respective barycentric projections in the Wasserstein-2 metric. The essential tool for this conversion is a Talagrand inequality from [CG14, Theorem 1.8(3)].
Lemma 3.
Let . Under Assumption 2, there exists a constant depending on and such that
Moreover, with can be chosen to be increasing in .
Recall that is a constant chosen for integrability reasons outlined in (46)– it is simply an term as . See Remark 1.
Proof of Lemma 3.
Fix and . To avoid unnecessary subscripts, set . To start, we produce a coupling of and by applying a gluing argument (as in [Vil03, Lemma 7.6], for example) to the optimal couplings between corresponding transition densities for for the Langevin diffusion and -static Schrödinger bridge. From this coupling, we obtain a coupling of the desired barycentric projections of and . We then use the chain rule of relative entropy alongside the Talagrand inequality stated in [CG14, Theorem 1.8(3)] to obtain the inequality stated in the Lemma.
Let denote the transition densities of the stationary Langevin diffusion associated to . By [CG14, Theorem 1.8(3)], there a constant depending on and such that following Talagrand inequality holds for each
Let denote the conditional densities of the -static Schrödinger bridge with marginals . Construct a triplet of -valued random variables in the following way. Let , and let the conditional measures have the law of the quadratic cost optimal coupling between and . Denote the law of on by . Observe that is a coupling of and . Moreover, observe that is a coupling of and . Thus, to compute an upper bound of , it is sufficient to compute .
We first observe for each that by two applications of the (conditional) Jensen’s inequality, the optimality of , and the aforementioned Talagrand inequality
Hence, using the chain rule of relative entropy and the fact that the Langevin diffusion and Schrödinger bridge both start from
∎
Lemma 4.
Under Assumption 2, there exists a constant depending on , , and such that for all
| (50) |
In particular,
Proof.
Let and in analogy with the Section 2 let denote the -entropic interpolation from to itself and set
By the assumed uniform subexponential bound on the and uniform polynomial growth of , there exists a constant as specified in the Lemma statement such that
| (51) |
Theorem 1 and (51) then establish (50) when . It now remains to show that
| (52) |
First, we claim that converges weakly to as for all . As converges weakly to , the collection is tight. This implies that is tight. Let denote a weak subsequential limit– we will not denote the subsequence. It is clear that . In the terminology of [BGN22], the support of each is -cyclically invariant, where . As is a weak subsequential limit of the , the exact same argument presented in [BGN22, Lemma 3.1, Lemma 3.2], modified only superficially to allow for the different marginal in each , establishes that is -cyclically monotone. That is, is the quadratic cost optimal transport plan from to itself. Moreover, this argument shows that along any subsequence of decreasing to , there is a further subsequence converging to . Hence, the limit holds without passing to a subsequence. Construct a sequence of random variables with , and let be a standard normal random variable independent to the collection. Fix , and recall that . The Continuous Mapping Theorem gives that converges in distribution to as . As , this establishes the weak convergence of to as . By the lower semicontinuity of Fisher information with respect to weak convergence [Bob22, Proposition 14.2] and Fatou’s Lemma
As the last piece of the proof, we show in the following lemma below that is an approximation of the first step of the Euler iteration .
Lemma 5.
For satisfying Assumption 2,
Proof.
The proof follows by producing an intuitive coupling of and and then applying a semigroup property stated in [BGL14, Equation (4.2.3)]. Let be the semigroup associated to the Langevin diffusion corresponding to , then for all , , and in the domain of the Dirichlet form
| (53) |
Let , then by Dynkin’s formula
and thus
Also by definition
Thus, we have the upper bound
where the penultimate inequality follows from Jensen’s inequality. Then, perform a change of measure and apply (53) to obtain
∎
4. Iterated Schrödinger Bridge Scheme
In this section we present conditions under which suitably interpolated iterations of (SB) converge to the gradient flow of entropy and relative entropy (i.e. solutions to the parabolic heat equation and Fokker-Planck equation). Our results rely on the close approximation of to explicit Euler iterations that we define later on. We also present a collection of sufficient conditions for which iterations of (SB) converge to the gradient flow of geodesically convex functionals. Roughly put, our assumptions are that (1) the one step approximation given in Theorem 2 holds along iterations of (SB) (which we call consistency) and (2) the error of this approximation does not accumulate too rapidly over a finite time horizon (which is implied by the condition we call contractivity in the limit). Although these conditions seem reasonable (in Section 5 we show examples that satisfy them), it is not immediate how generally they hold.
4.1. Preliminaries
We set up some notation for subdifferential calculus in Wasserstein space. Let be a function that is proper, lower-semicontinuous, and -geodesically convex functional for some . Let . The subdifferential set of at is denoted by (see [AGS08, Definition 10.1.1] for definition of Fréchet subdifferentials). With , we make the assumptions that , the subset of absolutely continuous probability measures in . Using Brenier’s theorem [San15, Theorem 1.22], this implies that there exists a unique optimal transport map from any to any . We denote this map by . Since is -geodesically convex, is a regular functional [AGS08, Definition 10.1.4] which implies that for all , the subdifferential set contains a unique element with minimum norm. This unique minimum selection subdifferential is called the Wasserstein gradient hereon, denoted by , and belongs to the tangent space [AGS08, Definition 8.4.1]. We further assume that there exists an such that the functional
admits at least one minimum point for any and .
The two primary classes of examples that we consider later are (i) the (one half) entropy function for which the gradient flow is the probabilistic heat flow and (ii) (one half) relative entropy (AKA Kullback-Leibler divergence) with respect to a log-concave probability measure, i.e., , for some log-concave density . These are well-known examples for which the above assumptions are satisfied. In Section 5 we will cover examples that are not covered by our assumptions and yet, as we will show by direct computations, our iterated Schrödinger bridge scheme continues to perform well.
4.2. Gradient Flows and their Euler Approximations
Let denote the Wasserstein gradient flow of during time interval . We assume that it exists as an absolutely continuous curve that is the unique solution of the continuity equation
is assumed to be in .
Euler iterations of the Wasserstein gradient flow of , whether it is explicit or implicit, is a sequence of elements in the Wasserstein space , starting at some , given by an iterative map of the form (45), in the sense that , for . The continuous-time approximation curve is given by the piecewise constant interpolation
| (54) |
Definition 1 (First order approximation).
The sequence , or, equivalently, its continuous time interpolation is called a first-order approximation of a Wasserstein gradient flow if, for any ,
We now wish to develop sufficient conditions under which gives a first order approximation. We say that is consistent if for any ,
| (55) |
and is a contraction in the limit if
| (56) |
Remark 2.
Observe that if is a contraction, i.e. , then it is a contraction in the limit as well. Thus, this condition is a more general notion.
Theorem 3.
Suppose the map satisfies the two conditions - consistency and contraction in the limit. Then is a first-order approximation of the gradient flow .
Proof.
For any , by the triangle inequality and absolute continuity of
The second term above converges to with because . For the first term, consider the decomposition
| (57) |
Let , then by the assumptions of consistency and contraction in the limit, for all small enough
and
respectively. Thus, (57) gives the following recursion for and with
Hence, recursively,
As was arbitrary, this completes the proof. ∎
Explicit Euler Scheme
The explicit Euler scheme in the Wasserstein space can be obtained as an iterative geodesic approximation of the Wasserstein gradient flow minimizing for the choice of
| (EE) |
The explicit Euler scheme need not always give a first-order approximation sequence to a Wasserstein gradient flow. However, the assumptions in the statements of Theorems 4 and 5 provides sufficient conditions for which (EE) satisfies consistency and contraction in the limit. Consequently, Theorem 3 gives the uniform convergence of the scheme.
Implicit Euler Scheme
The implicit Euler scheme or, equivalently the JKO scheme [JKO98], in the Wasserstein space can be defined using the following map
| (IE) |
We quickly verify that when and , there exists such that . As , by Brenier’s Theorem there exists a unique gradient of a convex function that pushforwards to . Setting , it holds that as desired. The implicit Euler scheme starting from is given by . When is geodesically convex, it is known that Theorem 3 holds through [AGS08, Theorem 4.0.7, Theorem 4.0.9, Theorem 4.0.10]. We do not need to verify Definition 1.
In the next section we introduce our iterated Schrödinger bridge scheme that approximates the explicit scheme, under suitable assumptions.
4.3. Uniform Convergence
We now prove two theorems giving conditions under which iterations of (SB) provide a first order approximation to the gradient flow of and . The proof of both theorems rely on an appeal to a general result in Lemma 6 that gives sufficient conditions for (SB) iterates to approximate Euler iterates. In principle, Lemma 6 can be applied with given by implicit or explicit Euler iterations, but our Theorems 4 and 5 both only use explicit Euler iterations.
To simplify the bookkeeping of the constants introduced in Assumptions 2, we define two classes of probability densities. For , , and set
| (58) |
and
| (59) |
Lastly, recall the RHS of Theorems 1 and 2 and that is the entropic interpolation from to itself. We define
| (60) |
We now state the following theorem for the (probabilistic) heat flow:
| (61) |
starting at . Let denote the explicit Euler iteration map for the heat flow. That is, for
| (62) |
Theorem 4.
Assume that is such that
-
(1)
-
(2)
There exists and constants , and such that for all , .
-
(3)
There exists and such that for all and , .
Then is a first order approximation of the (probabilistic) heat flow.
Remark 3.
Theorem 4 lays down sufficient conditions under which [SABP22, Theorem 1] holds. Part of the assumptions are on the Schrödinger bridge iterates which are assumed to be nice enough such that our one step approximations hold uniformly. In Section 5, we show that these assumptions are indeed satisfied when is Gaussian. We are currently unable to verify that these natural conditions must be true once sufficiently stringent conditions (say, strong log concavity and enough smoothness) are assumed on the initial measure .
We now state an analogous theorem for the Wasserstein gradient flow of relative entropy. Fix a reference measure satisfying assumptions delineated in Theorem 5 below.
Let denote the explicit Euler iteration for the Fokker-Planck equation
| (63) |
That is, for
| (64) |
For and , let denote the surrogate measure obtained in the application of to , and let denote the corresponding integrability constant from (46). That is, is the probability density proportional to , for .
Theorem 5.
Let be convex, and assume that is such that
-
(1)
-
(2)
There exists , , and such that for all , , and for all .
-
(3)
(Regularity of Fokker-Planck) The collection is such that
Then is a first order approximation of the gradient flow of (one-half) KL divergence, i.e. the solution to (63).
Remark 4.
These assumed regularity of the Fokker-Planck is just requiring that the convergence given in [AGS08, Proposition 8.4.6] holds uniformly along the measures in . That is, if we start Fokker-Planck from any of the measures in , the explicit Euler iteration is a good enough approximation for small times, uniformly in . In Lemma 7 below we show that this statement is true for the heat flow since its corresponding transition kernel is a Gaussian convolution. It is also satisfied by the flow corresponding to the standard Ornstein-Uhlenbeck (OU) process for which the transition kernel is again a Gaussian convolution. In fact, Lemma 7 continues to hold in this case with minor modifications to the proof.
Observe the difference in the assumptions required for Theorems 4 and 5. The new assumptions in Theorem 5 are regarding the surrogate measures corresponding to the Schrödinger iterate . The reason for this difference is that for the heat flow and , for every and any . Hence the assumptions simplify.
Before proving Theorems 4 and 5, we present general conditions under which the iterates of (SB), called SB scheme, converge to the gradient flow of a functional . For a general case, it is difficult to show that a continuous time interpolation of the SB scheme is a first order approximation of the gradient flow (Definition 1). The following general conditions ensure uniform convergence to the gradient flow via Euler iterations. We then restrict ourselves to the specific cases when is entropy and relative entropy.
Assumption 3.
Fix be a geodesically convex functional and fix . With initial measure , let denote the gradient flow of . Let be a sequence of Euler iterations that gives rise to a first order approximation of the gradient flow of satisfying Definition 1. Moreover, assume that:
-
(1)
there is consistency of along the , meaning
(65) -
(2)
There is contraction in the limit, meaning
(66)
These assumptions are reminiscent of (55) and (56). Hence, the proof of the following lemma is very similar to that of Theorem 3.
Lemma 6.
Under Assumption 3,
Proof.
We now begin the proof of Theorem 4, which follows as an application of Lemma 6 once we verify Assumption 3 holds in this setting. The verification is a lengthy argument that relies on a tight approximation at small time of the explicit Euler step given in (62) and the heat flow, which we present in Lemma below.
Lemma 7.
Proof.
We consider two evolving particle systems. Let denote the (probabilistic) heat flow starting from , and set . Let be two particle systems with the same initial configuration solving the ODE (letting denote time derivative)
Observe that and . Now, define by . Observe that , giving that
| (68) |
By the chain rule and the fact that solves the heat equation, observe that
In analogy with Section 2, define
and compute that
Altogether, it now holds that
| (69) |
For a fixed , there uniform constant and (potentially slightly modified from and ) such that for all , . Let and be independent, then for the random variable has law . Moreover, as , the have bounded subexponential norm over . Hence, there exists a constant as described in the Lemma such that for , . Hence, applying Jensen’s inequality twice to (68) gives
establishing the Lemma. ∎
We now prove Theorem 4.
Proof of Theorem 4.
It suffices to verify that Assumption 3 holds in this setting.
Step 1: Explicit Euler Iterations are Consistent and Contractive in the Limit. Since is assumed to be in , by Lemma 7, along the heat flow starting at , there is a uniform constant such that, for any small enough and for all , .
Next, we establish contractivity in the limit. For a measure let denote the time marginal of the heat flow (61) at time started from . By contractivity of the heat flow with respect to initial data in the Wasserstein-2 metric [AGS08, Theorem 11.1.4],
It then follows from triangle inequality
Hence, by assumptions in the theorem statement, for small enough there is a universal constant such that for all
establishing contraction in the limit. This demonstrates that the explicit Euler iterations converge to the heat flow.
Step 2: SB Iterations are Consistent and Contractive in the Limit. To start, fix and . To compute from , we must obtain the surrogate measure for (SB). Pick , then the surrogate measure is the measure itself, that is, . This in turn gives . For consistency, by Theorem 2 and the assumptions in the statement of Theorem 4, for small enough there is a universal constant such that for all with
By the first assumption in the Theorem statement, consistency holds. Contractivity in the limit holds by the triagle inequality (as in the previous argument) and applying Lemma 7. ∎
5. Examples
In this section we compute explicit examples of iterated Schrödinger bridge approximations to various gradient flows and other absolutely continuous curves on the Wasserstein space. Since Schrödinger bridges are known in closed form for Gaussian marginals ([JMPC20]), our computations are limited to Gaussian models. First, we consider gradient flows of two convex functionals - 1) entropy and 2) KL divergence. Second, while not being gradient flows and aligning with our theoretical analysis in Section 4, we also consider time reversal of these gradient flows to showcase the curiously nice approximation properties of the (SB) scheme for these absolutely continuous curves in the Wasserstein space. These latter examples have recently become important in applications. For example, see [SSDK+20] for an application to diffusion based generative models in machine learning.
5.1. Explicit Euler discretization of the gradient flow of Entropy
We show via explicit calculations that (SB) iterations are close to the explicit Euler approximation of the heat flow starting from a Gaussian density. Here and the continuity equation for the gradient flow of is where . The explicit Euler iterations, , where , are given by where .
For , , we will calculate the (EE) and (SB) iterates and show that the SB step is an approximation of the explicit Euler step. Recall that the form of Schrödinger bridge with equal marginals is explicitly given by [JMPC20, Theorem 1] as
From this the barycentric projection can be computed as
| (70) |
For the choice of , , and the corresponding .
Now let’s check the sharpness of Theorem 2. By the explicit form of the distance between two Gaussians
Therefore, , which an order of magnitude sharper than Theorem 2.
Since both (SB) and (EE) schemes operate via linear pushforwards, then all steps of these schemes are mean-zero Gaussian distributed. For the SB scheme, the surrogate measure at each step is the same as the current measure, i.e. for all . Let and , then the iterates evolve through the following recursive relationship
To show that and are first-order approximations (Definition 1) of the Wasserstein gradient flow , we will show that the assumptions of Theorem 4 are satisfied.
First, let us consider assumption (1) of Theorem 4. The formula for the time marginals of the dynamic Schrödinger bridge between and itself at time is available from [GLR17] and given by
| (71) |
Also, it known that for , the Fisher information . Therefore, for , we have
| (72) |
Since for any , is monotonically increasing and bounded from below by . Hence,
Since the RHS above converges to zero as , we satisfy Assumption (1) of Theorem 4 with rate .
Now, we consider assumption (2) of Theorem 4. One can be convinced that for the Gaussian case, if both sequences and are bounded from below and above, then the assumption (2) is satisfied. Trivially, and are bounded from below by because they are monotonically increasing. Take . Using the identity for all , we have that and therefore . Consequently, is bounded from above by . Now, again using that , , and therefore is bounded from above by . Step 1 of the proof of Theorem 4 gives uniform convergence of and step 2 gives the uniform convergence of .
5.2. Explicit Euler discretization of the gradient flow of Kullback-Leibler
Now let us consider the Kullback-Leibler (KL) divergence functional where for . This is the Fokker-Planck equation corresponding to the Ornstein-Uhlenbeck process.
Now let us write the (SB) step at . For this functional, the selection of in (SB) becomes more delicate. The choice of for the surrogate measure is determined by the integrability of
If is log-concave, then since is convex the sign of depends on a comparison of the log-concavity of and . Suppose is more log-concave than , then may be taken to be . Consequently, the (SB) step is . On the other hand, if is more log-concave than the density , then may be taken to be . In this case, the (SB) step is .
For an initial , , we calculate the (SB) and the (EE) step and prove that the (SB) step is an approximation of the (EE) step. If , then is less log-concave than , and therefore . This surrogate measure satisfies Assumption 2. By (70), we have that . Now if , then is more log-concave than , and therefore . Note that this choice satisfies Assumption 2 (1-2, 4) but the ratio is unbounded. Nevertheless, we calculate the (SB) update using this surrogate measure and demonstrate one-step convergence, indicating that our assumptions in this paper are stronger than required. By (70) we have . The corresponding (EE) update is .
Again, we check the sharpness of Theorem 2 by explicitly calculating the distance between and . For any ,
Therefore, again which is an order of magnitude better than Theorem 2. As mentioned above, here is an example of a fast convergence rate even when the surrogate measure does not satisfy Assumption 2(3).
Iterates of the (SB) scheme can be defined beyond the one step in the similar manner if the sign convention remains same throughout the iterative process. The following calculation is done for which is not covered by our theorem. A similar calculation is valid for which is skipped. We claim that if is more log-concave than , then is also more log-concave than for small enough . This is because, using Taylor series expansion around , we have
Therefore, as long as , the SB steps approach monotonically toward the minimizer and the sign convention remains the same. Again, since both (SB) and (EE) schemes evolve via linear pushforwards, all steps are mean-zero Gaussian distributed. Denote and where and evolve via the following recursive relationship
The corresponding surrogate measures are given by .
We again show that the assumptions of Theorem 5 are satisfied to prove that and are first-order approximation schemes of the Wasserstein gradient flow . Using (71), we have that
where . The sequence is monotonically increasing because
and the prefactor of can be easily checked to be greater than . Moreover, each is bounded from below by its initial value . Therefore,
Since , the RHS converges to zero as at the order . Therefore, Assumption (1) of Theorem 5 is satisfied with rate .
Now, we show that assumption (2) of Theorem 5 is satisfied. Again, in the Gaussian case, it suffices to show that and is bounded from below and above. Since for any , the sequence , and equivalently , is monotonically increasing. Then trivially, is lower bounded by and are lower bounded by . Take . Using the identity for all , we have that . Therefore, and give recursive inequalities of similar form. Since , we have . Recursively, , which is bounded from above. Therefore, is bounded from above by and similarly, is bounded from above by , which is bounded as . Consequently, the assumptions of Theorem 5 are satisfied. Step 1 of the proof gives uniform convergence of (EE) scheme and step 2 gives the uniform convergence of the (SB) scheme.
5.3. Time reversal of gradient flows
Let us consider the time reversal of gradient flows of the functionals in the previous two examples. Specifically, if is the gradient flow of a functional with velocity field , then let denote the time reversed flow defined as . Naturally, the velocity field in the reverse process is negative of the velocity in the forward process, i.e. if denotes the velocity field of , then .
These absolutely continuous curves are not gradient flows and therefore do not benefit from the theoretical guarantees established in our theorems. Note that the corresponding PDEs, such as the backward heat equation, are well known to be ill-posed ([Olv13, page 129, eqn. 4.29]). However, interestingly, we observe that, for the time reversed gradient flows of entropy and KL divergence functionals with Gaussian marginals, the (SB) scheme approximates these curves with the same convergence rates. For both the examples below, these convergence rates are derived by directly showing that is consistent (55) and a contraction (a stronger version of contraction in limit (56)). Following that, we use Theorem 3 to prove that the (SB) iterates give a first-order approximation of the time reversed flow . Through the examples, we also highlight a key issue with approximating reversed time gradient flows: to have a valid first-order approximation (Definition 1) of , the step size should be small enough where the bound on depends on the properties of the iterates encountered in the future. We include these calculations below for readers’ curiosity and their practical importance in score-based generative modeling using diffusions [SSDK+20, LYB+24].
First, we consider the time reversed gradient flow of . Then, . Now we calculate the first (SB) step. For , the surrogate measure is where is chosen to ensure integrability of . Therefore, we may choose , which implies and the (SB) step is . Notice that the sign of is flipped compared to Section 5.1. This change ensures that the (SB) for the reverse flow is the opposite direction to the (SB) step of the forward flow. This is interesting as we can approximate both forward and reverse time gradient flow of entropy functional using appropriate direction of (SB) steps, calculated only using the current measure.
Now for an initial , we know that the gradient flow is given by . Then, we have and . Now we show that is an close approximation of . For any and ,
Denote , then the term containing above is . Using the identity with and , we can be convinced that constant . Further, using the identity for and for , we have that . Therefore, we have the consistency (55) result
| (73) |
Again, since (SB) scheme evolves via linear pushforwards, the sequence of (SB) steps are where follows the recursive relationship . Define the piecewise constant interpolation
Unlike the previous two examples, since is not a gradient flow, we do not invoke Theorem 6 to prove the uniform convergence of SB scheme. We instead directly show that is a first-order approximation (Definition 1) of . We have already shown consistency in (73). Now we show that , restricted to Gaussian measures, is Lipschitz with the Lipschitz constant of the order . Take and . Then, can be bounded above by the following string of inequalities
For , and hence we have the contraction
| (74) |
The sequence decreases monotonically because
and for all . Now we show that is bounded from below because for small enough . Using ,
If is uniformly less then for all , then . Consequently, the lowest value is . Therefore, choosing , we get that is bounded from below by . This highlights an inherent issue with approximating time-reversed gradient flows: a valid approximation depends on the choice of , which in turn depends on the variance of the flow at a future time. As a result, if we run an SB scheme with greater than the variance of , we might encounter the problem of an SB step with a negative variance.
By the triangle inequality
Using consistency (73),
and using Lipschitzness (74),
Since for all , , we have
Recursively,
Since , therefore, , proving the uniform convergence of to the curve as .
Finally, we consider the case of time reversed case of gradient flow of with . Since this case is very similar to the previous examples on the gradient flow of KL divergence and time reversed gradient flow of entropy, we limit explicit calculations. The velocity field . For an initial choice , the time reversed gradient flow, starting from time , is . For brevity of notation, let where . Now we will calculate the (SB) step. Again, we choose such that the surrogate measure is integrable. Using the same logic as Section 5.2, if (equivalently ), then may be taken to be giving and . Whereas if (equivalently ), then can be taken to be giving and . We will present calculations for case. Similar calculations follow for and have been skipped.
Now we prove that the (SB) step is an approximation of . Note that for and , and . Then
Denote , then the term containing above is . It is easy to see that . Further, using the identity for and for , we have that . Therefore, we have the consistency (55) result
| (75) |
Again since the (SB) scheme evolves via linear pushforwards, is a Gaussian measure for all and let . Then evolves via the recursive relationship . We prove uniform convergence of the SB scheme in the same way as the time reversed flow of entropy functional. The consistency is show above and now we show that the (SB) is a contraction for Gaussian measures. Take and . Then, exactly as in the case of time-reversed gradient flow of entropy,
For , and hence we have the contraction
| (76) |
Because for all , the sequence is monotonically decreasing and bounded from above by its initial value . Similar to the reversed time gradient flow of entropy, we get that the variance is bounded from below if is less than , which depends on the variance at time . Using the triangular argument from Theorem 3, for any ,
Therefore, , proving the uniform convergence of to the curve as .
References
- [AGS08] Luigi Ambrosio, Nicola Gigli, and Giuseppe Savaré. Gradient flows in metric spaces and in the space of probability measures. Lectures in Mathematics ETH Zürich. Birkhäuser Verlag, Basel, second edition, 2008.
- [BGL14] Dominique Bakry, Ivan Gentil, and Michel Ledoux. Analysis and geometry of Markov diffusion operators, volume 348 of Grundlehren der mathematischen Wissenschaften [Fundamental Principles of Mathematical Sciences]. Springer, Cham, 2014.
- [BGN22] Espen Bernton, Promit Ghosal, and Marcel Nutz. Entropic optimal transport: geometry and large deviations. Duke Math. J., 171(16):3363–3400, 2022.
- [Bob22] Sergey G. Bobkov. Upper bounds for Fisher information. Electron. J. Probab., 27:Paper No. 115, 44, 2022.
- [CCGT22] Alberto Chiarini, Giovanni Conforti, Giacomo Greco, and Luca Tamanini. Gradient estimates for the schrödinger potentials: convergence to the brenier map and quantitative stability, 2022.
- [CG14] P. Cattiaux and A. Guillin. Semi log-concave Markov diffusions. In Séminaire de Probabilités XLVI, volume 2123 of Lecture Notes in Math., pages 231–292. Springer, Cham, 2014.
- [Csi75] I. Csiszár. -divergence geometry of probability distributions and minimization problems. Ann. Probability, 3:146–158, 1975.
- [CT21] Giovanni Conforti and Luca Tamanini. A formula for the time derivative of the entropic cost and applications. J. Funct. Anal., 280(11):Paper No. 108964, 48, 2021.
- [Cut13] Marco Cuturi. Sinkhorn distances: Lightspeed computation of optimal transport. Advances in neural information processing systems, 26, 2013.
- [CVR18] Giovanni Conforti and Max Von Renesse. Couplings, gradient estimates and logarithmic Sobolev inequality for Langevin bridges. Probab. Theory Related Fields, 172(1-2):493–524, 2018.
- [DGW04] H. Djellout, A. Guillin, and H. Wu. Transportation cost-information inequalities and applications to random dynamical systems and diffusions. Ann. Probab., 32(3B):2702–2732, 2004.
- [GLPR24] Borjan Geshkovski, Cyril Letrouit, Yury Polyanskiy, and Philippe Rigollet. The emergence of clusters in self-attention dynamics. Arxiv preprint 2305.05465, 2024.
- [GLR17] Ivan Gentil, Christian Léonard, and Luigia Ripani. About the analogy between optimal transport and minimal entropy. Ann. Fac. Sci. Toulouse Math. (6), 26(3):569–601, 2017.
- [GLRT20] Ivan Gentil, Christian Léonard, Luigia Ripani, and Luca Tamanini. An entropic interpolation proof of the HWI inequality. Stochastic Process. Appl., 130(2):907–923, 2020.
- [JKO98] Richard Jordan, David Kinderlehrer, and Felix Otto. The variational formulation of the Fokker-Planck equation. SIAM J. Math. Anal., 29(1):1–17, 1998.
- [JMPC20] Hicham Janati, Boris Muzellec, Gabriel Peyré, and Marco Cuturi. Entropic optimal transport between unbalanced Gaussian measures has a closed form. NIPS’20, Red Hook, NY, USA, 2020. Curran Associates Inc.
- [KS91] Ioannis Karatzas and Steven E. Shreve. Brownian motion and stochastic calculus, volume 113 of Graduate Texts in Mathematics. Springer-Verlag, New York, second edition, 1991.
- [Léo12] Christian Léonard. From the Schrödinger problem to the Monge-Kantorovich problem. J. Funct. Anal., 262(4):1879–1920, 2012.
- [Léo14] Christian Léonard. A survey of the Schrödinger problem and some of its connections with optimal transport. Discrete Contin. Dyn. Syst., 34(4):1533–1574, 2014.
- [LK93] B. C. Levy and A. J. Krener. Dynamics and kinematics of reciprocal diffusions. Journal of mathematical physics, 34(5):1846–1875, 1993.
- [LYB+24] Sungbin Lim, Eun Bi Yoon, Taehyun Byun, Taewon Kang, Seungwoo Kim, Kyungjae Lee, and Sungjoon Choi. Score-based generative modeling through stochastic evolution equations in Hilbert spaces. Advances in Neural Information Processing Systems, 36, 2024.
- [Olv13] P.J. Olver. Introduction to Partial Differential Equations. Undergraduate Texts in Mathematics. Springer International Publishing, 2013.
- [Pal19] Soumik Pal. On the difference between entropic cost and the optimal transport cost, 2019. Arxiv 1905.12206. To appear in The Annals of Applied Probability.
- [PNW22] Aram-Alexandre Pooladian and Jonathan Niles-Weed. Entropic estimation of optimal transport maps, 2022.
- [Roy07] Gilles Royer. An initiation to logarithmic Sobolev inequalities, volume 14 of SMF/AMS Texts and Monographs. American Mathematical Society, Providence, RI; Société Mathématique de France, Paris, 2007. Translated from the 1999 French original by Donald Babbitt.
- [RY04] D. Revuz and M. Yor. Continuous Martingales and Brownian Motion. Grundlehren der mathematischen Wissenschaften. Springer Berlin Heidelberg, 2004.
- [SABP22] Michael E. Sander, Pierre Ablin, Mathieu Blondel, and Gabriel Peyré. Sinkformers: Transformers with doubly stochastic attention. In Gustau Camps-Valls, Francisco J. R. Ruiz, and Isabel Valera, editors, Proceedings of The 25th International Conference on Artificial Intelligence and Statistics, volume 151 of Proceedings of Machine Learning Research, pages 3515–3530. PMLR, 28–30 Mar 2022.
- [San15] Filippo Santambrogio. Optimal transport for applied mathematicians: Calculus of variations, PDEs, and modeling, volume 87. Springer, 2015.
- [SSDK+20] Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations, 2020. ArXiv version 2011.13456.
- [Ver18] Roman Vershynin. High-dimensional probability, volume 47 of Cambridge Series in Statistical and Probabilistic Mathematics. Cambridge University Press, Cambridge, 2018. An introduction with applications in data science, With a foreword by Sara van de Geer.
- [Vil03] Cédric Villani. Topics in optimal transportation, volume 58. American Mathematical Soc., 2003.
Notations
| Symbol | Explanation |
| Collection of continuous paths | |
| -times continuously differentiable functions | |
| Space of twice integrable probability measures on | |
| Space of twice integrable and absolutely continuous probability measures (with respect to Lebesgue measure) on | |
| Space of smooth and compactly supported functions in | |
| Wasserstein-2 distance between measures and in | |
| Optimal transport map from to (if it exists) | |
| Coordinatewise projections on , | |
| Wiener measure on with initial condition | |
| Reversible Wiener measure on | |
| Law of reversible Brownian motion with diffusion | |
| Brownian semigroup | |
| Brownian transition densities | |
| Law of stationary Langevin diffusion on | |
| Joint law of Langevin diffusion at time and , i.e. | |
| Transition densities for Langevin diffusion | |
| Extended generator for the Langevin diffusion | |
| Langevin semigroup | |
| -static Schrödinger bridge with marginals equal to | |
| Entropic potentials associated to | |
| Barycentric projection associated with , | |
| Law of -dynamic Schrödinger bridge on with initial and terminal distribution | |
| Entropic interpolation from to itself, | |
| Subexponential norm of a random variable, [Ver18, Definition 2.7.5] | |
| Tangent bundle of at | |
| Entropy of | |
| Kullback-Leibler divergence between and | |
| Fisher information of , for | |
| th iterate of Schrödinger bridge scheme starting from with stepsize | |
| th iterate of pushforward of form , where each is a vector field specified in context |