Joint Beam Training and Positioning for Intelligent Reflecting Surfaces Assisted Millimeter Wave Communications
Abstract
Intelligent reflecting surface (IRS) offers a cost-effective solution to link blockage problem in mmWave communications, and the prerequisite of which is the accurate estimation of (1) the optimal beams for base station/access point (BS/AP) and mobile terminal (MT), (2) the optimal reflection patterns for IRSs, and (3) link blockage. In this paper, we carry out beam training designs for IRSs assisted mmWave communications to estimate the aforementioned parameters. To acquire the optimal beams and reflection patterns, we firstly perform random beamforming and maximum likelihood estimation to estimate angle of arrival (AoA) and angle of departure (AoD) of the line of sight (LoS) path between BS/AP (or IRSs) and MT. Then, with the estimated AoDs, we propose an iterative positioning algorithm that achieves centimeter-level positioning accuracy. The obtained location information is not only a fringe benefit but also enables us to cross verify and enhance the estimation of AoA and AoD, and it also facilitates the estimation of blockage indicator. Numerical results show the superiority of our proposed beam training scheme and verify the performance gain brought by location information.
I Introduction
Millimeter-wave (mmWave) band, ranging from 30GHz to 300GHz, has attracted great interests from both academia and industry for its abundant spectrum resources [1, 2]. The Wi-Fi standard IEEE 802.11ad runs on the 60GHz (V band) spectrum with data transfer rates of up to 7 Gbit/s [3, 4]. In 3GPP Release 15, 24.25-29.5GHz and 37-43.5GHz, as the most promising frequencies for the early deployment of 5G millimeter wave systems, are specified based on a time-division duplexing (TDD) access scheme [5]. The millimeter scale wavelength, on one hand, renders massive antennas integratable on an antenna array with portable size [6], and, on the other hand, results in severe free space path loss especially for non-line-of-sight (NLoS) paths. Directional transmission enabled by beamforming techniques is an energy efficient transmission solution to compensate for the path loss in mmWave communications [7]. By properly adjusting the phase shifts of each antenna elements, it concentrates the emitted energy in a narrow beam between transmitter and receiver. However, the directional link is easily blocked by obstacles like human bodies, walls, and furniture, attributed to the millimeter scale wavelength [8]. Once LoS path is blocked, it is highly possible that the blocked link cannot be restored no matter how the beam direction is adjusted, as the NLoS paths are not strong enough to serve as a qualified alternative link. Channel measurement campaigns reveal that power of the LoS component is about 13dB higher than the sum of power of NLoS components [9]. Therefore, blockage is the biggest hindrance to the large scale applications of mmWave band in mobile communication systems.
Recently, intelligent reflecting surface (IRS) [10, 11, 12, 13], a.k.a. reconfigurable intelligent surface (RIS) [14, 15], large intelligent surface (LIS) [16], passive (intelligent) reflectors/mirrors [17, 18, 19], or programmable metasurface [20, 21, 22], is proposed as an energy-effective and cost-effective hardware structure for future wireless communications. IRS is essentially a new type of electromagnetic surface structure which is typically designed by deliberately arranging a set of sophisticated passive scatterers or apertures in a regular array to achieve the desired ability for guiding and controlling the flow of electromagnetic waves [23]. Current applications of IRS to wireless communications can be categorized into two types, namely IRS modulator and IRS “relay”. In [20, 21, 22], amplitude/phase modulations over IRS are investigated. Through controlling the reflection coefficient of IRS, the incident carrier wave from a feed antenna can be digitally modulated without requiring high-performance radio frequency (RF) chains. A more extensive application of IRS is IRS “relay”, in which the radiated power from BS/AP towards IRS is reflected to MT via intelligently managing the phase shifters on IRS [14, 13, 15, 10, 11, 12, 16, 19, 17, 18]. It is noteworthy that the rationale behind IRS “relay” and conventional amplify-and-forward (AF) relay is significantly different. AF relay firstly receives signal and then re-generates and re-transmits signal. In contrast, IRS only reflects the ambient RF signals as a passive array and bypasses conventional RF modules such as power amplifier, filters, and ADC/DAC [11]. Hence, IRS “relay” incurs no additional power consumption and is free from thermal noise introduced by RF modules. In this sense, IRS can be regarded as a smart “mirror” that enables us to change the paradigm of wireless communications from adjusting to wireless channel to changing wireless channel [14, 24]. As an active way to make wireless channel better, IRS “relay” assisted wireless communications have attracted great interests from researchers. In [10], IRS is applied to mmWave communications to provide effective reflected paths and thus enhance signal coverage. In [12, 15, 17], joint optimization of the transmit beamforming by active antenna array at the BS/AP and reflect beamforming by passive phase shifters at the IRS is carried out. In [18], empirical studies are performed to analyze the capability of signal coverage enhancement for IRSs assisted mmWave MIMO at 28GHz. In [19], the reconfigurable 60GHz IRS is designed, implemented and deployed to strengthen mmWave connections for indoor networks threatened by blockage. The objective of the work is to validate IRS’s capability to address link blockage problem in mmWave communications, and beam training design is not investigated. Although extensive analytical and empirical studies have been done on IRSs assisted wireless communications in the aforementioned literature, these work either assume the availability of channel state information (CSI) or accurate measurement of BS/AP, MT and IRS’s position and direction.
In [11], a practical transmission protocol and channel estimation are firstly proposed for an IRS-assisted orthogonal frequency division multiplexing (OFDM) system under frequency-selective channels. In [13], by exploiting the channel correlation among different users, a channel estimation scheme with reduced training overhead is proposed. Specifically, with a typical user’s reflection channel vector, estimation of the other users’ reflection channel vector can be simplified as the estimation of a multiplicative coefficient. However, the aforementioned designs were performed in non-mmWave frequency band, and the direct application of them to mmWave communications will fail to utilize the sparse nature of mmWave channel. In [16], to facilitate channel estimation of IRSs assisted link over mmWave band or LoS dominated sub-6GHz band, an upgrade of IRS’s structure is proposed to add a small number of channel sensors to sense and process incident signal. Although [16] is intended to mmWave band, the proposed compressive sensing and deep learning algorithms are incompatible to current structure of IRS which is without channel sensors. In [25], cascade channel estimation of the BS/AP-IRS-MT link in mmWave band is firstly converted into a sparse signal recovery problem and then solved via conventional compressed sensing methods. However, [25] is based on a strong assumption that AoA and AoD parameters lie on the discretized grid. In [26], a two-step channel estimation protocol is proposed for the cascaded BS/AP-IRS-MT link in mmWave band, which includes hierarchical beamforming and high resolution sparse channel estimation. As the selection of fine beam set in hierarchical beamforming is fully dependent on the training results of the wide beams in the previous layer, hierarchical beamforming requires interactions between BS/AP and MT. Thus, the extension of the proposed scheme from single user scenario to multi-user scenario might be costly in training overhead. Besides, as IRS is primarily used in mmWave communications to combat blockage, estimation of blockage in both BS/AP-MT link and BS/AP-IRS-MT link is essential for IRSs assisted mmWave communications, while [16, 25, 26] all neglect blockage effects in their designs.
Due to the deployment of multiple IRSs, beam training of IRSs assisted mmWave communications requires much heavier training overhead than traditional mmWave communications. Also, as the purpose of IRSs is to combat blockage and expand coverage, an accurate estimation of blockage is essential to beam selection by BS/AP. In addition, the lack of RF chains results in the inability of IRSs to sense signal, which further complicates beam training for the paths assisted by IRSs. These three features jointly render traditional beam training methods [27, 28] incompetent in IRSs assisted mmWave communications. Despite the aforementioned new challenges of integrating IRSs to mmWave communications, a notable advantage is that the estimation of path parameters, e.g., AoA/AoD and blockage indicator, can be cross verified, thanks to the relatively large number of deployed IRSs. Specifically, three accurate estimates of AoA/AoD, associated with other essential information, e.g., direction of arrays, can yield the location of MT, and the location of MT will in turn reproduce the path parameters. In this way, the path parameters of IRSs assisted mmWave MIMO can be enhanced according to their geometric relationship. To estimate the channel parameters of IRSs assisted mmWave communications, we have made the following contributions in this paper:
-
•
We propose a flexible beam training method for IRSs assisted mmWave MIMO by breaking it down into several mathematically equivalent sub-problems, and we further perform random beamforming and maximum likelihood (ML) estimation to jointly estimate AoA and AoD of the dominant path in each sub-problem. The proposed scheme does not require feedback from MT at training stage, and thus can be performed in a broadcasting manner. Hence, the required training overhead will not increase over MT number.
-
•
We prove the uniqueness of the AoA and AoD estimated by beam training with random beamforming. We further study the impact of training length, and we prove that larger training length almost surely results in smaller pairwise error probability of AoA, AoD pair.
-
•
By sorting the reliability of the estimated AoA, AoD pairs, we propose an iterative positioning algorithm to estimate the location of MT, and, through numerical analysis, we show that the algorithm achieves centimeter-level positioning accuracy.
-
•
With the estimated position of MT, we propose to cross verify and enhance the estimation of path parameters, i.e., AoA and AoD, according to their geometric relationship. We further propose an accurate method of blockage estimation by comparing the ML estimate of pathloss and MT position based estimate of pathloss.
Numerical results show the superiority of our proposed beam training scheme and verify the performance gain brought by location information.
The rest of the paper is organized as follows. Section II introduces the system model. In Section III, we break down the beam training design of IRSs assisted mmWave communications. In Section IV, we propose beam training with random beamforming, and specifically we estimate path parameters and study the feasibility of the scheme. In Section V, we study the interplay between positioning and beam training. In Section VI, numerical results are presented. Finally, in Section VII, we draw the conclusion.
Notations: Column vectors (matrices) are denoted by bold-face lower (upper) case letters, denotes the -th element in the vector , , and represent conjugate, transpose and conjugate transpose operation, respectively, denotes the Frobenius norm of a vector or a matrix, is Hadamard product. Subtraction and addition of the cosine AoAs/AoDs are defined as and to guarantee the result is within the range .
II System Model
Consider a communication link between the BS/AP and an MT operating in mmWave band, where both ends adopt uniform linear array (ULA) antenna structure. To reduce wireless link blockage rate and thus guarantee the reliable linkage between BS and MT, a number of IRSs are deployed in the cell as shown in Figure 1, and BS/AP is able to control IRSs via cable or lower frequency radio link.
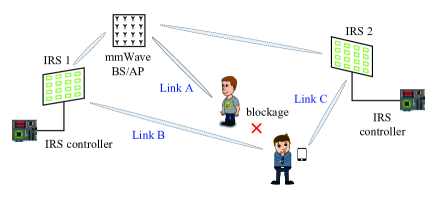
The channel response between BS/AP and MT without the assistance of IRSs is represented as [28]
| (1) |
where is the indicator of blockage of the LoS path, and , and are channel gain, cosine of AoA, and cosine of AoD of the -th path, respectively. The parameters characterize LoS path, which are of particular interest to us in mmWave communications. According to [14], the path gain of LoS is , where is the wavelength, and is the distance between BS and MT. Further, the steering vectors are given by
where is the number of antennas of BS/AP, is the number of antennas of MT.
We also assume that IRSs adopt ULA antenna structure. Thus, the channel response of the reflected path from BS to MT assisted (reflected) by the -th IRS is
| (2) |
where is the reflection vector that determines the reflection pattern of the -th IRS, is the indicator of blockage of the path reflected by the -th IRS and [14], in which is reflection loss, is the distance between BS and the -th IRS, is the distance between the -th IRS and MT. The equivalent path gain of the IRS reflected path can be written as
| (3) |
The steering vector is given by
| (4) |
where is the number of passive reflectors of the -th IRS. Based on (II), the optimal reflection coefficient vector that maximizes effective received power is .
Hence, the channel response between BS and MT with the assistance of IRSs is represented as
| (5) |
where
| (8) |
indicates the activation status of the -th IRS and can be configured by BS/AP.
When the reflection pattern of the vector is omnidirectional, IRS works as a scatterer that diffuses the energy radiated from BS. When , IRS works as a “mirror” that builds a virtual LoS (VLoS) path between BS and MT, and thus the energy from BS will be concentrated on MT, and is termed as the optimal reflection angle of the -th VLoS path. We can categorize channel components of into three types as in Eq. (5), namely LoS path component, VLoS path component, and NLoS path component. LoS path component is the direct path between BS and MT, VLoS path component consists of the paths between BS and MT reflected by IRSs, and NLoS path component consists of the paths between BS and MT reflected by scatters, e.g., walls, human bodies, and etc.
As NLoS path component usually varies fast and its weight to the channel is marginal especially in mmWave band, we are more interested in LoS path and VLoS paths. Hence, we intend to estimate (1) the optimal reflection angle of IRSs and (2) the path parameters of the LoS path and of the VLoS paths through beam training and location information aided parameter enhancement.
III Framework of Joint Beam Training and Positioning
For conventional mmWave communications, training overhead can be significantly reduced by exploiting the sparse nature of mmWave channel [28, 29]. However, with the assistance of IRSs, the sparse channel of mmWave band is artificially converted into rich scattering channel. The increased scattering effect, together with the unknown optimal reflection angle, jointly complicates the process of beam training. To make the over-complicated problem tractable, we propose to break down beam training of IRSs assisted mmWave MIMO into two sub-problems, and we further show that the two sub-problems are mathematically equivalent. Then, we propose a protocol for joint beam training and positioning which well accommodates multi-user scenario.
III-A Breakdown of Beam Training for IRSs Assisted MmWave MIMO
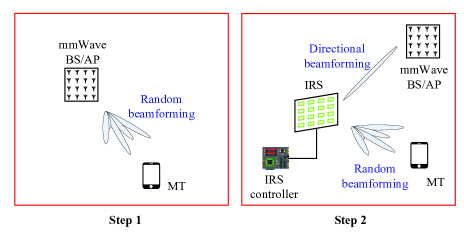
At first, it is noteworthy that AoA/AoD of the LoS path between IRSs and BS/AP can be accurately pre-measured, since both IRSs and BS/AP are pre-configured. Thus, and are used as prior knowledge hereafter. Then, beam training of IRSs assisted mmWave MIMO is carried out in the following two steps as illustrated in Figure 2.
Step 1. De-activate all the IRSs, and estimate the parameters of LoS path
To estimate the parameters, measures of channel are collected via Tx/Rx random beamforming in BS/AP side and MT side, i.e.,
| (9) |
where is transmit power, is the zero-mean complex Gaussian additive noise, is the pilot signal sent by the user, and are transmit random beamforming vector at BS/AP side and receive random beamforming vector at MT side111A good random beamforming codebook can be derived offline by high performance computers, and they will be pre-configured in BS/AP, IRS and MT side., respectively, and the entries of and are phase-only complex variables with invariable amplitude [30], i.e.,
is the phase shift value of the -th analog phase shifter in BS/AP side, is the phase shift value of the -th analog phase shifter in MT side.
As NLoS paths are much weaker than LoS path in mmWave band, i.e., are small compared to , we are very less likely to build an effective communication link via NLoS paths. Hence, the AoA, AoD pair that we are interested in is merely , and the term will be treated as interference. Considering the small scale and randomness of , we assume that follows complex Gaussian distribution for the simplicity of analysis222Although we assume that follows Gaussian distribution in theoretical analysis, the channel model to be applied in numerical simulations still considers NLoS components as in Eq. (1). . Then, the beam training problem for IRSs assisted mmWave MIMO communications is formulated as the estimation of from the following received signal
| (10) |
Adding the subscript to to denote the received signal in the -th time slot, we have
where .
To estimate AoA and AoD, channel measurements are to be collected and concatenated, and its vector form is derived as
| (11) |
where
Since
the covariance of the equivalent noise is thus . Let , as and are independent of each other, we have .
Based on the above analysis, beam training for the link between BS/AP and MT is summarized as follows.
Sub-problem 1: How to accurately estimate the parameter set from .
Step 2. Activate the -th IRS, de-activate the rest IRSs, and estimate the parameters of the -th VLoS path. Repeat the above process for the rest IRSs.
As is known, with the transmit beamforming vector , BS/AP is able to concentrate its power towards IRSs via transmit beamforming. Simultaneously, IRS performs passive random reflection and MT performs receive random beamforming, the received signal at MT side is written as
| (12) |
The interference term and are insignificant due to 1) the small NLoS path coefficients in mmWave band, 2) the spatial filtering impact, i.e., for .
Based on the above analysis, beam training for the reflected path between BS/AP and MT assisted by the -th IRS is summarized as follows.
Sub-problem 2:
How to accurately estimate the parameter set from .
Remark 1.
From (11) and (13), we can easily find that Sub-problem 1 and Sub-problem 2 are mathematically equivalent. Therefore, through flexible control over IRS, we are capable to decompose the complicated non-sparse channel estimation problem of IRSs assisted mmWave MIMO into a set of simplified sub-problems.
III-B Protocol of Joint Beam Training and Positioning
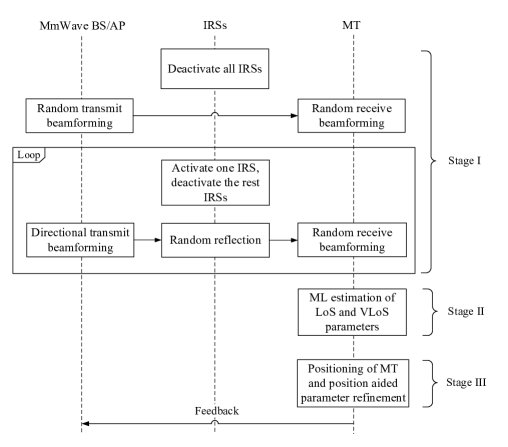
On the basis of beam training breakdown, we introduce the protocol for joint beam training and position in the IRSs assisted mmWave communication system.
The procedures of the proposed scheme are given in Figure 3. Specifically, the scheme is divided into three stages, i.e., Stage I. channel measurement, Stage II. parameter estimation and Stage III. positioning and location information aided parameter enhancement. In Stage I, the channel measurement vector in Eq. (11) and Eq. (13) are collected; In Stage II, ML estimation is performed to estimate the parameters of LoS path and VLoS paths in MT side, which will be introduced in Section IV; In Stage III, positioning and position aided path parameter refinement are performed in MT side, which will be introduced in Section V.
In practice, when an MT enters a cell, the prior information, e.g., random beamforming vector sequence of BS/AP, position of BS/AP and IRSs, will be sent to the MT via the lower frequency link, such as sub-6GHz link of 5G New Radio. Upon the request of high-speed mmWave data transmission, the random beamforming process in Stage I will be triggered periodically prior to data transmission to help setup initial beam alignment for new users and maintain beam alignment for the existing users. Then, in Stage II and Stage III, each MT performs parameters estimation, positioning and position aided parameter refinement based on its own channel measurement vector . Finally, the estimated path parameters are fed back to BS/AP by each MT individually to facilitate beamforming designs for the subsequent mmWave data transmission.
It is noteworthy that, as random beamforming is quasi-omnidirectional [31], the pilot sent by BS/AP can be received by MTs from all directions simultaneously. The broadcasting mechanism of random beamforming, which is similar to Global Positioning System (GPS), enables channel measurements to be collected and processed by each MT individually without causing interference. Therefore, training overhead of the proposed scheme will not increase with MT number, which renders the scheme particularly suitable for multi-user scenario.
IV Beam Training With Random Beamforming – Parameter Estimation and Feasibility Study
In this section, ML estimation method is applied to estimate the path parameters of LoS/VLoS paths from channel measurements sampled by random Rx/Tx beamforming. Furthermore, the feasibility of random beamforming based beam training is verified.
IV-A Maximum Log-likelihood Estimation of
For conciseness of expression, we write the unified model of sub-problem 1 and sub-problem 2 as
| (14) |
where is the indicator of blockage, is equivalent path gain ( or ), is cosine AoA, is equivalent cosine AoD ( or ), and .
It is noteworthy that estimation of should be performed merely when , as the measurement vector given that contains no information about . Therefore, we estimate the parameters through maximizing log-likelihood function under the assumption that , i.e.,
| (15) |
where
| (16) |
and the conditional probability is
| (17) |
IV-A1 Estimation of
IV-A2 Estimation of and
Next, we will jointly estimate and . Substituting Eq. (20) into Eq. (IV-A), we have
| (21) |
Since
| (22) |
the beam training problem is formulated as
P1 is a non-convex problem. However, as there are only two real-valued variables to be estimated, a simple yet efficient two-step algorithm can be readily applied to solve P1. For conciseness, let . The two-step algorithm is explained as follows.
Step 1. Joint AoA and AoD Coarse Search
Set quantization level and , and then exhaustively search for the largest maxima that satisfy
over the discrete grid
| (23) |
Step 2. Joint AoA and AoD Fine Search
For a given discrete maximum , run gradient descent search starting from as follows
| (30) |
where is the preset step size and the expressions of and are given in Appendix A. The iteration stops when , where is a preset parameter.
Repeat the above operations over the rest maxima derived in Step 1, and select the best one as . Then, the exact value of the estimated path gain can be subsequently obtained by substituting into Eq. (20).
Remark 2.
The complexity of Step 1 is . The complexity of Step 2 mainly arises from the computation of the gradients and , which, according to Eq. (A) and Eq. (A), is (or ). Hence, the complexity of Step 2 is or (), where the iteration number depends on step size and stopping criterion of the gradient method and is generally less than . Thus, the overall complexity is (or ).
IV-B Uniqueness of The Estimated AoA and AoD Pair
To delve into the effectiveness of beam training with random beamforming, conditions under which can be accurately estimated from the measurement signal are studied in the ideal scenario without noise or interference.
Firstly, two definitions of uniqueness are introduced as follows.
(1) Uniqueness of measurement signal representation, namely
| (31) |
(2) Uniqueness of estimated AoA and AoD pair, namely
| (32) |
Uniqueness of measurement signal representation means that any AoA, AoD pair that differs from cannot construct the measurement signal . It is an inherent property of the sampling method, which is primarily determined by . By contrast, uniqueness of the estimated AoA and AoD depends on both sampling method and estimation method. It indicates that AoA, AoD pair can be accurately estimated from the measurement signal using a specific estimation method.
In the following Theorem, we will study the relationship between the above two types of uniqueness.
Theorem 1.
As long as uniqueness of measurement signal representation is satisfied, ML method is capable to accurately estimate the AoA, AoD pair.
Proof.
See Appendix B. ∎
According to Theorem 1, the uniqueness of AoA and AoD estimation is equivalent to the uniqueness of measurement signal representation, which means we just need to investigate the conditions on which uniqueness of measurement signal representation can be achieved.
Before studying the sensing matrix , we will observe the signal space of channel response. The vectorized response of LoS path, namely , is a high dimensional (-dimensional) variable that is characterized by , and we define the signal space of as
| (33) |
is a nonlinear -dimensional () submanifold of with the parameters [32, 33]. As is the Kronecker product of two array steering vectors, is indeed the so-called array manifold [34]. Thus, one channel realization with the parameters can be seen as a point in the array manifold. The dimensionality can be interpreted as an “information level” of the signal, analogous to the sparsity level in compressive sensing problems [32, 35, 36]. In [32], it is proved that signals obeying manifold models can also be recovered from only a few measurements, simply by replacing the traditional compressive sensing model of sparsity with a manifold model for . The above statement is supported by Lemma 1.
Lemma 1.
For a random orthoprojector , the following statement
| (34) |
holds with high probability, when dimensionality of the projected low-dimensional space is sufficient 333The sufficient number of is related to and several manifold-related factors, e.g., condition number, volume, and geodesic covering regularity. Detailed analysis can be referred to [32, 33]. In practice, the exact relationship between the sufficient number and its dependent factors is of limited significance due to the following two reasons, (1) the received measurement signal is corrupted by noise, (2) can be online adjusted according to channel conditions., where , , is the isometry constant [32].
Remark 3.
is the Euclidean distance between two points , on the manifold, and is the Euclidean distance between the projected points on the image of (namely ). The isometry constant measures the degree that the pairwise Euclidean distance between points on is preserved under the mapping . Apparently, Lemma 1 indicates that is satisfied with high probability, as it is a weaker condition than Lemma 1.
Although the sensing matrix is not necessarily an orthoprojector, via singular value decomposition, it can be decomposed as , where , and . Then, we have , where is indeed the orthoprojector, and is a diagonal matrix with non-zero elements that scales the component in each dimension. implicates , which is equivalent to , namely, . Thus, it is easy to find that , where .
To conclude, the randomly generated sensing matrix has a large probability to guarantee the uniqueness of ML based joint AoA and AoD estimation.
IV-C On The Impact of Training Length
Theorem 1 indicates that, with random beamforming, Eq. (32) holds with high probability. In other words, in noiseless scenario, the distance gap between the highest peak (global optimum) and other peaks (other local optimums) exist with high probability. However, in practice, corrupted by noise and interference, the highest peak may (1) shift to its adjacent points, or (2) be transcended and replaced by other peaks. Error Type 1 incurs mild AoA, AoD estimation error followed by power loss of an acceptable level; Error Type 2 incurs significant AoA, AoD estimation error followed by beam misalignment. Apparently, we would like to avoid Error Type 2.
To study the estimation error, the pairwise error probability (PEP) of any two parameter sets and is derived in the following theorem.
Theorem 2.
The PEP that is mistaken as in relatively high SNR regime can be approximated as
| (35) |
where the Q-function is the tail distribution function of the standard normal distribution [37], and
Proof.
See Appendix C. ∎
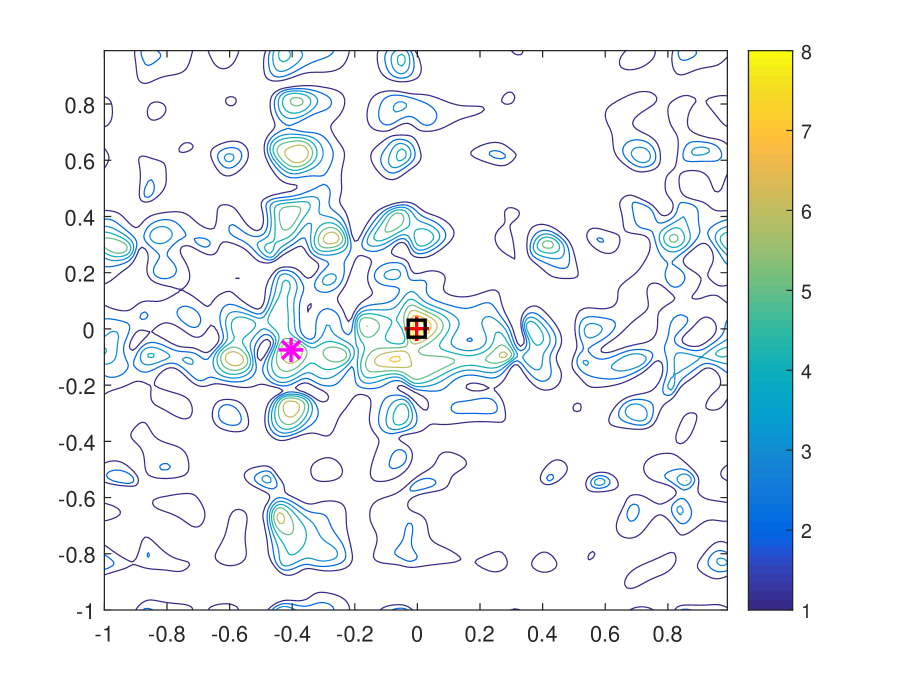
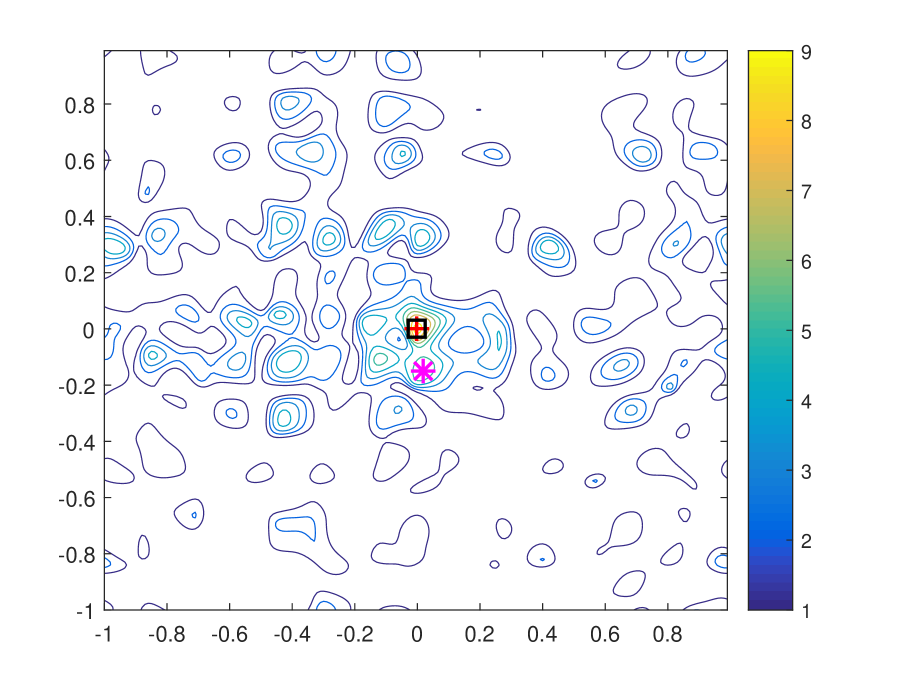
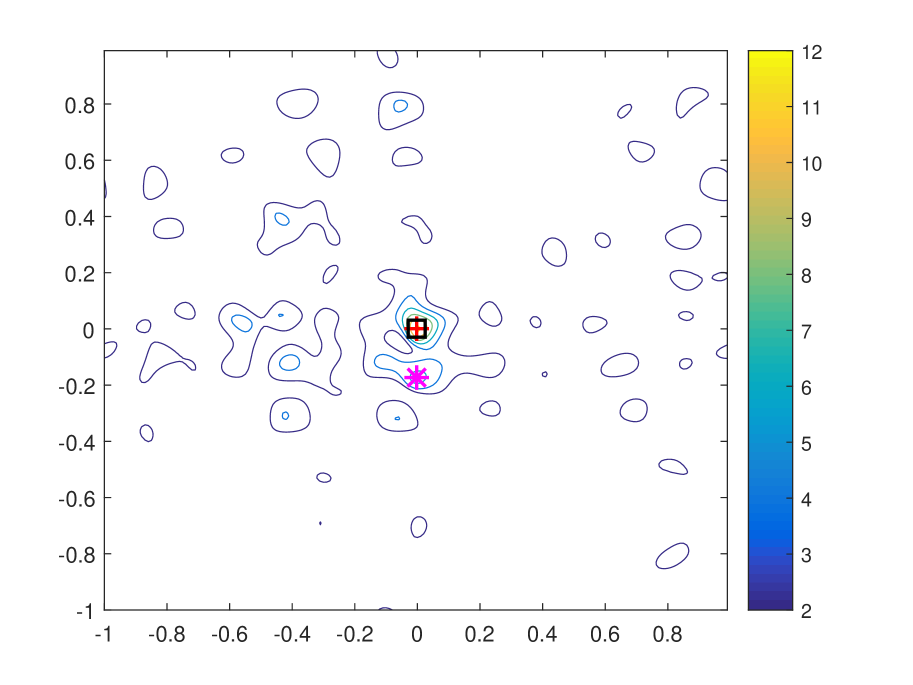
| Training Length | Peak 1 | Peak 2 | Peak 1 Peak 2 |
|---|---|---|---|
| 1.1156 | 1.1044 | 0.0112 | |
| 8.7223 | 7.2658 | 1.4573 | |
| 9.4986 | 5.8000 | 3.6986 | |
| 12.3338 | 6.6508 | 5.6830 |
Theorem 2 indicates that PEP is inversely proportional to . To build the connection between PEP and training length , Proposition 1 is derived.
Proposition 1.
is monotonically increasing over training length , where , i.e.,
| (36) |
and the equality holds only if
Proof.
See Appendix C. ∎
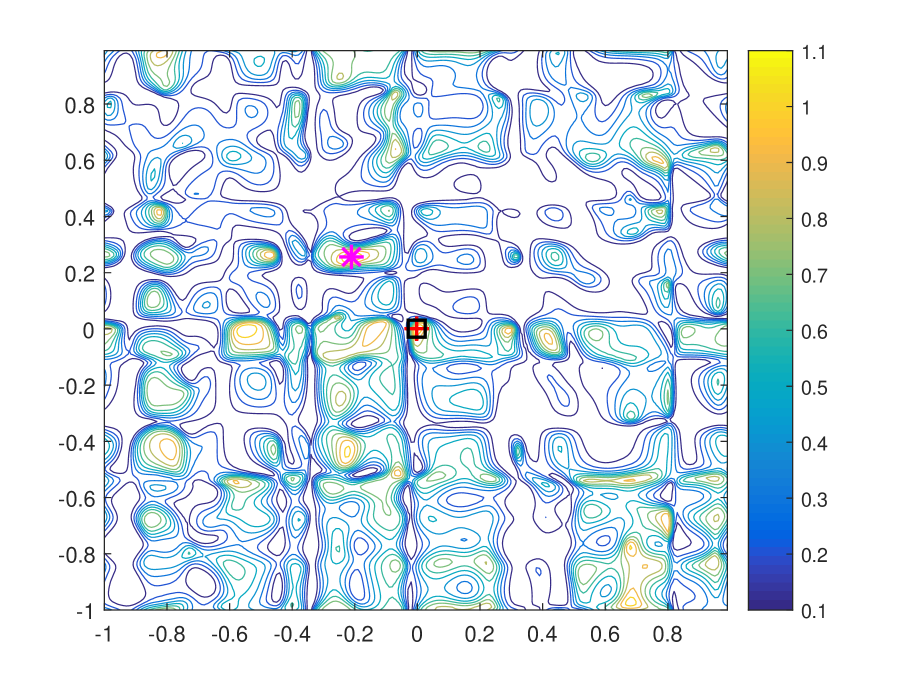
To verify Proposition 1, we plot the contour of with different training lengths in noiseless scenario in Figure 4. We set . As can be seen that the gap between the first and the second peaks increases over training length, and the value of which is given in Table I. In addition, we can find that position of the first peak is invariant to training length and remains the same as the actual AoA, AoD pair, while position of the second peak varies. This verifies the uniqueness of ML based joint AoA, AoD estimation.
Remark 4.
According to Proposition 1, with random beamforming, the PEP probability of an erroneous estimate being mistaken as the authentic parameters decreases almost surely over training length . Therefore, an appropriate can guarantee a satisfying accuracy of parameter estimation in scenarios with different SNR and interference levels.
V Interplay Between Positioning and Beam Training
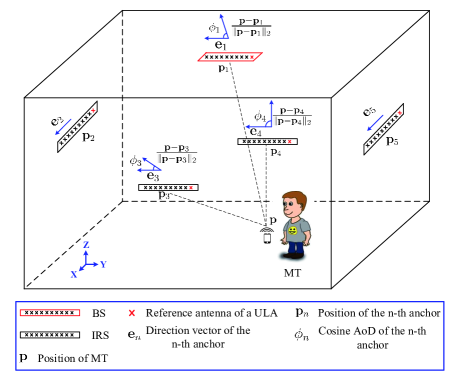
In IRSs assisted mmWave MIMO system, BS/AP and IRSs, with their positions and array directions being known by all the MTs, can be seen as anchor nodes or beacons. The AoDs derived at beam training stage enable MT to estimate its own position. Hence, IRSs assisted mmWave MIMO system is endowed with the capability of high-accuracy localization. The acquired position information is not only a fringe benefit, but also in turn facilitates beam training. The interplay between beam training and indoor positioning is explained as follows. AoD estimate of the unblocked reliable links can yield the position of MT, and the position of MT, associated with anchor positions and anchor directions, can improve the precision of AoD/AoA estimation and assist in the decision of blockage indicator .
V-A Reliability of The Estimated AoA, AoD Pair
To be concise, we treat BS/AP and IRSs as identical anchor nodes. The -st anchor is BS/AP and the rest anchors () are IRSs. Although we have already obtained sets of path parameters , we should be aware that the estimation is performed under the assumption that . In practice, LoS and VLoS paths may suffer from blockage (namely ) by moving obstacles, which will jeopardize the estimation of . Other than blockage, insufficient training length or low SNR may incur Error Type 2 of joint AoA and AoD estimation, which is defined in Section IV. C.
Therefore, it is essential to select the trustworthy parameters as the input of positioning algorithm. To this end, we introduce the metric – residual signal power ratio , to measure the reliability of , i.e.,
| (38) |
Recall that are obtained by minimizing , the yielded estimate will thus always result in . Therefore, the range of is .
Since the dominant component of mmWave channel is LoS path, the reconstructed signal should account for the majority of the received signal given that the parameters are accurate and residual signal power ratio should be smaller. Conversely, when blockage or Error Type 2 occurs, the parameters are heavily biased, and thus should be larger. Following the above heuristics, anchors’ reliability can be sorted.
V-B AoD Based Positioning
V-B1 Geometric Relationship Between AoDs and MT Position
We denote the index set of the reliable links as , position coordinates of the -th anchor as , ULA direction of the -th anchor as . Note that are known by MTs. The direction vector of the LoS path between MT and the -th anchor is , where is the position of MT. Thus, the geometric relationship between AoDs and MT position is expressed as
| (39) |
where is the estimate of cosine AoD of the -th link derived in beam training stage, is the actual cosine AoD that is dependent on position , and is estimation error. For illustrative purposes, a typical scenario of IRSs assisted mmWave communications is shown in Figure 5.
V-B2 Taylor Series Method for AoD Based Positioning
In the ideal case, when , we have . The equation corresponds to a right circular cone. There are unknown variables of MT’s position coordinates, thus the minimum sufficient number of unblocked links to estimate the 3-D position of MT is , which is the intersection of the three right circular cones. As IRSs are cost-effective compared with conventional mmWave devices, they can be massively installed with minimal effort. We can expect that IRSs assisted mmWave with a large number of delicately placed IRSs is capable to guarantee unblocked links with high probability.
In practice, estimation error cannot be zero. To estimate the 3-D position , least square criterion is adopted, i.e.,
| (40) | ||||
where is the position range of indoor MT, e.g., the 3-D space of lecture hall. As the objective function is non-convex, it is non-trivial to derive the analytical solution to the problem. Fortunately, Taylor-series estimation method is capable to effectively solve a large class of position-location problems[38]. Starting with a rough initial guess, the Taylor-series estimation method iteratively improves its guess at each step by determining the local linear least-sum-squared-error correction[38]. In AoD based positioning, with an initial position guess , the following approximation can be obtained through Taylor series expansion by neglecting -th order terms (), i.e.,
| (41) |
where the first order derivative is denoted as
| (42) |
Substituting (41) into (39), we have
| (43) |
Its matrix form is written as
| (44) |
where , , and
| (45a) | |||
| (45b) | |||
On the basis of (44), the Taylor series method for AoD based positioning is summarized in Algorithm 1.
V-B3 Reliable Link Set
An intuitive method to construct the set of reliable links is to select links with the smallest to avoid unreliable AoDs resulted from blockage and Error Type 2 of joint AoA, AoD estimation. However, it is non-trivial to determine the exact value of . Although anchors are theoretically sufficient to yield the position of MT in the ideal noiseless case, more anchors are desirable in practice for positioning algorithm to enhance the accuracy of position estimation.
To utilize as many reliable anchors as possible, the following strategy is proposed to iteratively construct the reliable link set . Firstly, we sort the anchors in ascending order according to residual signal power ratio . Then, starting from anchors, we iteratively increase the number of anchors used for positioning in Algorithm 1, and by the end of each iteration, we calculate the cost , where is the squared error of least square method in Eq. (40) and is the number of selected anchors. Finally, we select the output corresponding to the largest that satisfies as the estimated position of MT, where is a preset threshold444An appropriate can be obtained by carrying out a great number of Monte Carlo experiments offline. In our numerical experiment, we find that results in a good performance. .
V-C Parameter Estimation With The Aid of MT Position
With the estimated position , channel parameters can be refined according to the geometric relationship.
V-C1 AoD Refinement
With , AoD estimation is updated by
| (46) |
V-C2 AoA Refinement
To estimate AoA, the direction of ULA in MT’s side is essential. Therefore, we firstly find the least square estimate of by solving the following optimization problem.
| (47) | ||||
Note that can be derived in the iterative process according to Section V. A. 3.
The objective function of (47) can be rewritten in matrix form as
| (48) |
where , and . The optimization problem can be solved via projected gradient descent method [39], in which we iteratively update as follows.
| (49) | ||||
where is step size and .
Finally, with yielded by projected gradient descent method, AoA estimation is updated by
| (50) |
V-C3 Estimation of Blockage
As a prerequisite of our proposed blockage estimation method, we firstly introduce the estimation of , which is dependent on the values of . Note that the parameter estimate obtained in Section IV by ML estimation is under the assumption that , while it is probable that in fact. It would be misleading in the estimation of by directly substituting into (20). Therefore, we will use the estimates of AoA and AoD refined by position to assist the estimation of and , as they are cross verified by multiple anchors and are thus more reliable.
Theoretically, with the knowledge of , and , the decision of can be made by comparing the probabilities of conditioned on and . However, accurate estimation of and is challenging in practice. With respect to , its amplitude is estimable from the distance of MT, while its phase cannot be accurately estimated from the distance, as it is very sensitive to distance estimation error and may be affected by random initial phase of local oscillator in transmitter side.
Alternatively, a heuristic method is proposed to decide blockage indicator by comparing the pathloss estimated from and pathloss estimated from , i.e.,
| (58) |
where
| (60) |
BS/AP to MT distance and IRS to MT distance are attainable from , and is the preset threshold of pathloss distance (In numerical simulations, we set dB ).
VI Numerical Results
In this section, we numerically study the performance of the proposed joint beam training and positioning scheme for IRSs assisted mmWave MIMO.
VI-A Settings of Numerical Experiment
| Parameter | Value | ||||||
|---|---|---|---|---|---|---|---|
| Operating frequency | GHz | ||||||
| Noise power | dBm | ||||||
| Position of IRSs |
|
||||||
| Position of BS/AP | |||||||
| Direction of IRSs’ ULA |
|
||||||
| Direction of BS/AP’s ULA | |||||||
| Reflection loss | dB | ||||||
| Size of obstacles | meters | ||||||
| Altitude of MT | meters | ||||||
| Number of users | |||||||
| Number of NLoS paths | (only in Figure 7), | ||||||
| Number of antennas in BS/AP () | |||||||
| Number of antennas in MT () | |||||||
| Number of reflectors in IRS () |
We assume that IRSs-assisted mmWave MIMO system is deployed in an indoor scenario, e.g., lecture hall, and the length, width and height of which are meters, meters and meters, respectively. The rest system parameters are listed in Table II. For simplicity, we assume that AoA, AoD of NLoS paths follow uniform distribution, i.e., , and path coefficient follows complex Gaussian distribution, i.e., and dB. We model user (MT holder) as a cube with its length, width and height being m, m and m, respectively. We denote position of the MT held by user as , where follow uniform distribution, i.e., and . Users are uniformly distributed in the lecture hall under the non-overlapping constraint. For a typical MT, the other MT holders are its potential obstacles, and thus the blockage probability increases with user density.
VI-B Relationship Between User Density and Blockage Probability
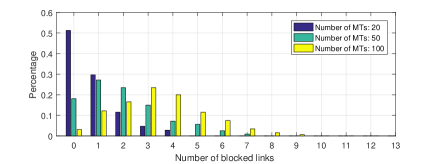
To gain insights into the relationship between user density and blockage probability, Figure 6 is presented where there are IRSs deployed, which means a total of LoS/VLoS links are available. From the Figure 6, we can see that when the number of MTs is , more than of channel realizations experience no link blockage, the largest number of blocked links is , and the percentage of which is less than ; when the number of MTs is , more than of channel realizations experience less than blocked links, the largest number of blocked links is , and the percentage of which is less than ; when the number of MTs is , more than of channel realizations experience less than blocked links, the largest number of blocked links is , and the percentage of which is almost negligible. Note that when there exists at least unblocked link, uninterrupted communication over mmWave band can be guaranteed, and when there exist at least unblocked links, positioning algorithm can be performed to locate MT and meanwhile enhance parameter estimation.
VI-C Performance of Beam Training with Random Beamforming
As the performance of joint beam training and positioning is fundamentally determined by the decomposed Sub-problem 1 for BS/AP-MT link and Sub-problem 2 for BS/AP-IRS-MT links, whose unified signal model is Eq. (14), we start numerical evaluation from the sub-problems, i.e., the beam training scheme with random beamforming proposed in Section IV. The blockage indicator of Eq. (14) is set as , and the random variable , where is the noise term and is the interference term. The noise term and is dBm according to Table II. The interference term is propagated via NLoS paths, and its entries are represented in Eq. (III-A) for BS/AP-MT link and in Eq. (13) for BS/AP-IRS-MT links. A notable difference between and is that the power of is proportional to transmit power. Since Sub-problem 1 and Sub-problem 2 are mathematically equivalent, we carry out the numerical study of beam training with random beamforming in BS/AP-MT link in this subsection.
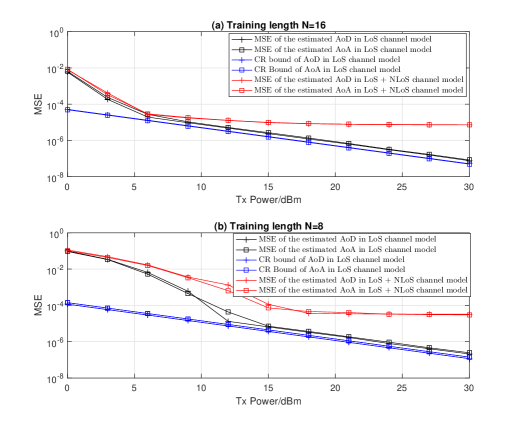
In Figure 7, we use mean squared error (MSE) of the estimated AoA/AoD as the performance metric, which is defined as , where are the estimated AoA and AoD of the LoS path, and are the exact values of AoA and AoD of the LoS path. The proposed beam training scheme is characterized by two steps, namely random beamforming and ML estimation. Random beamforming is performed to measure mmWave channel, and ML estimation is performed to estimate AoA and AoD of the LoS path based on channel measurements. To study the accuracy of ML estimator, we use Cramér-Rao bound555Since the estimation of is part of the joint estimation of , CRBs of and are obtained as the last two diagonal elements of the inverse of Fisher information matrix w.r.t. . The detailed derivation of CRB is omitted, as it follows the standard procedure.(CRB) in the ideal LoS channel (where ) as the benchmark. It can be seen from Figure 7(a) that, when the training length is , from dBm to dBm the empirical MSE of both AoA and AoD in LoS mmWave channel is significantly higher than CRB, but the performance gap gradually turns to be marginal from dBm to above. It indicates that, from dBm to dBm ML estimation of experiences Error Type 2 as mentioned in Section IV. C, in which the estimated AoA and AoD pair are far apart from their authentic values, and from dBm to above only Error Type 1 happens, in which the estimation error is mild and tightly lower bounded by CR bound. It validates the effectiveness of ML estimator in relative high SNR regimes. In practice, NLoS path’s impacts on beam training cannot be overlooked. In the numerical simulation of beam training in LoS + NLoS mmWave channel, we set the number of NLoS paths as . As can be seen from Figure 7(a) that, from dBm to dBm the empirical MSE of AoA and AoD in LoS + NLoS channel is slightly worse than that in LoS channel, which indicates that noise is the main detrimental factor. From dBm to above, the MSE curves turn to be flat, and this is because the impact of NLoS path, namely , does not diminish over SNR. A notable point is that MSE from dBm to above is around , which is satisfactorily accurate. To study the impact of training length, MSE performance comparison is also performed when in Figure 7(b). A remarkable difference from case is that the flat curves of empirical MSE start from dBm, and the values of which are around , which indicates that the impact of noise in case is more significant than case and thus verifies the benefits of increasing training length.
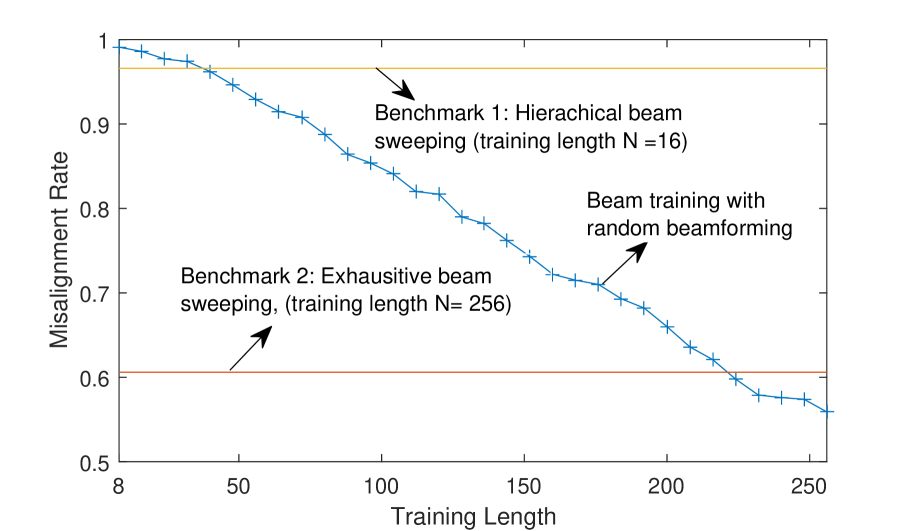
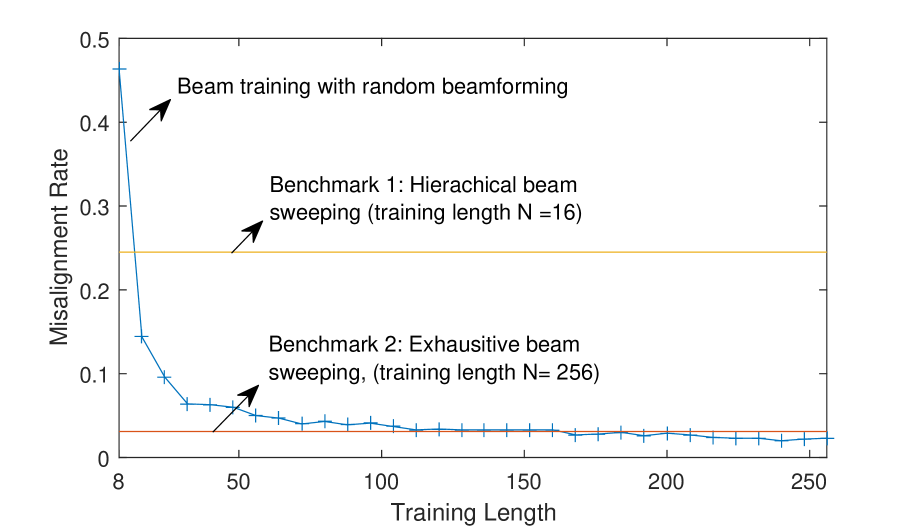
In Figure 8, we compare the performance of the proposed random beamforming based beam training scheme with the existing directional beamforming based beam training schemes [40, 28, 27]. Directional beamforming is used for beam training in a more straightforward way than random beamforming, in which the candidate beams pairs are explored through exhaustive/hierachical beam sweeping, and then the strongest beam pair is selected based on the received power of the candidates. Directional beams are selected from a pre-configured finite set corresponding to quantized angles, e.g., discrete Fourier Transform (DFT) codebook. To compare the performance of random beamforming and directional beamforming in beam training, we use beam misalignment rate as the performance metric, which measures the probability that beam training fails to find the strongest beam pair. For random beamforming based beam training, we select the best beam pair by quantizing the estimated AoA/AoD to its nearest codeword. Two types of directional beamforming techniques are used as the benchmarks, namely, exhaustive beam sweeping [40] and hierarchical beam sweeping [27, 28]. Exhaustive beam sweeping explores all the possible beam pairs and its training length is ; Hierarchical beam sweeping iteratively narrows down the direction search region and results in logarithmic training length, i.e., . By contrast, random beamforming is flexible with training length. In the simulation, we set the training length of random beamforming as to investigate the impact of training length. We compare the performance of random beamforming based beam training with directional beamforming based beam training at two SNR levels, i.e., dBm, dBm, in LoS + NLoS channel model. From Figure 8(a), it can be seen that, when dBm, the misalignment rate of exhaustive beam sweeping is , and the misalignment rate of hierarchical beam sweeping is . The beam misalignment rate of random beamforming is when training length is , and it decreases over training length and turns to be when training length is . It verifies the conclusion of Theorem 2 and indicates that random beamforming with an appropriate training length could achieve better performance than directional beamforming. From Figure 8(b), it can be seen that, when dBm, the misalignment rate of exhaustive beam sweeping is , and the misalignment rate of hierarchical beam sweeping is . As for random beamforming, the performance improvement over training length becomes more significant. Specifically, the misalignment rate is when training length is and sharply decreases to when , and finally it converges to when . It is noteworthy that the performance enhancement brought by increasing training length is marginal from . Therefore, the training length of random beamforming can be set adaptively according to SNR condition to achieve a satisfactory performance with moderate training cost.
VI-D Performance of Joint Beam Training and Positioning for IRSs Assisted MmWave Communications
In this subsection, we study the performance of joint beam training and positioning for IRSs assisted mmWave communications. The configurations of IRSs, BS and MT, which determine the path gain, AoA and AoD of the LoS path, are given in Table. II. In addition, we set the number of users as , which determines the blockage indicator, and we also set the number of NLoS as .
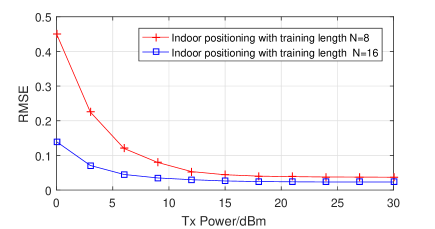
In Figure 9, the accuracy of indoor positioning of IRSs assisted mmWave MIMO is studied in terms of root mean squared error (RMSE). When the training length is for each LoS/VLoS path, RMSE is meter at dBm, and converges to meter from dBm to dBm, which indicates that, with the aid of IRSs, mmWave MIMO achieves centimeter accuracy in indoor scenario. When the training length is for each LoS/VLoS path, RMSE is meter at dBm, and converges to meter from dBm to dBm. Considering the reduced training length, the accuracy limit of meter for case in high SNR regimes is acceptable. However, the positioning accuracy of case is not satisfying in low SNR regimes. Through case analysis, we find that the correlation between residual ratio and the accuracy of is weakened by the increased level of noise and the reduced training length. In other words, a small may misleadingly correspond to an unreliable anchor node, and thus results in inaccurate estimate of position. To improve the accuracy, a more sophisticated positioning algorithm that iteratively sorts the reliability will be developed in the future.
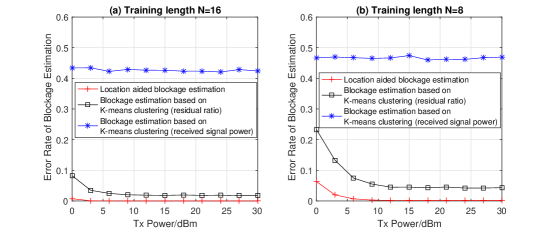
In Figure 10, the error rate of blockage estimation is studied. For the purpose of comparison, two methods are adopted as benchmarks, which are (1) received power based blockage estimation and (2) residual ratio based blockage estimation. For (1), it is straightforward that unblocked links have significantly higher received signal level than that of blocked links. However, as power level is an absolute quantity, without the prior knowledge such as the likely range of received power, it is possible to mistake the unblocked link between MT and faraway anchor as a blocked link. In contrast, residual ratio in (2) is a relative quantity, which is not dependant on the likely range of received power. However, the optimal threshold that is essential for blockage estimation is unavailable either. Therefore, we adopt the K-means clustering method to partition the observations into clusters, i.e., blocked links and unblocked links. When the training length is , we can see from the figure that position aided blockage estimation is slightly erroneous merely at dBm and becomes errorless when transmit power increases. With respect to the benchmark methods, although the estimation accuracy of residual ratio based K-means clustering method is worse than position aided blockage estimation, its error rate is below , which is acceptable. By contrast, the estimation error rate of received power based K-means clustering method is nearly , which indicates that the estimation is almost random. When the training length reduces to , the superiority of position aided blockage estimation is more remarkable, and this is owing to the cross-validation mechanism enabled by location information.
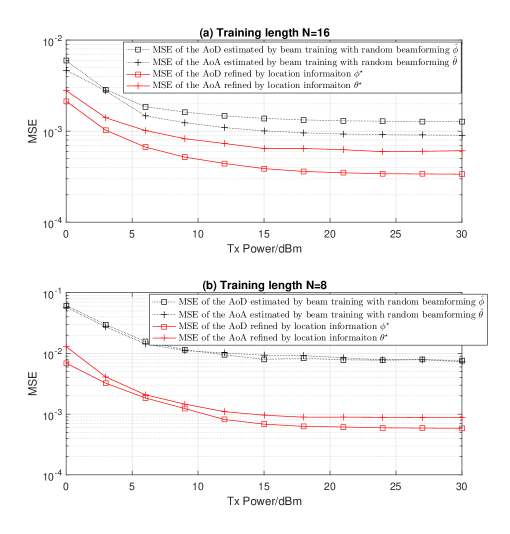
In Figure 11, MSE performance evaluation of AoA/AoD refined by location information is performed. To this end, we intentionally filter out the blocked links, and reserve AoA/AoD estimate of the unblocked links. As can be seen that AoA/AoD refined by location information is more accurate than AoA/AoD estimated by beam training with random beamforming. This is because location information is derived by multiple anchors, and AoA/AoD refinement according to geometric relationship means that the estimation is cross verified. It is noteworthy that the performance enhancement is more significant when the training length is for each LoS/VLoS path, from which we find the potential to reduce training length of beam training with the aid of location information. Another notable point is that AoA refined by location information is always worse than AoD refined by location information. This is because the direction vector is derived from estimation in (47), while the direction vectors of anchors are well known.
VII Conclusion
In this paper, beam training for IRSs assisted mmWave communications is studied. By breaking down beam training for IRSs assisted mmWave MIMO into several mathematically equivalent sub-problems, we perform random beamforming and maximum likelihood estimation to derive the optimal beam of BS/AP and MT and the optimal reflection pattern of IRSs. Then, by sorting the reliability of the estimated AoA, AoD paris, we propose an iterative positioning algorithm to acquire the position of MT, and with which we are able to cross verify and enhance the estimation of AoA and AoD, and accurately predict link blockage. Numerical results show the superiority of our proposed beam training scheme and verify the performance gain brought by location information.
Appendix A Partial derivatives of
The derivative of with respect to is
| (61) |
where and . Similarly, the derivative of with respect to is
| (62) |
where and .
Appendix B Proof of Theorem 1
Appendix C Proof of Theorem 2
Appendix D Proof of Proposition 1
Firstly, we write the expression of as
Thus
For the purpose of conciseness, let
As and are numbers, rather than vectors, we have
Then,
and equality holds when , namely,
| (66) |
References
- [1] Z. Pi and F. Khan, “An introduction to millimeter-wave mobile broadband systems,” IEEE Commun. Mag., vol. 49, no. 6, Jun. 2011.
- [2] S. Rangan, T. S. Rappaport, and E. Erkip, “Millimeter-wave cellular wireless networks: Potentials and challenges,” Proc. IEEE, vol. 102, no. 3, pp. 366–385, Mar. 2014.
- [3] T. Nitsche, C. Cordeiro, A. B. Flores, E. W. Knightly, E. Perahia, and J. C. Widmer, “IEEE 802.11 ad: directional 60 GHz communication for multi-Gigabit-per-second Wi-Fi,” IEEE Commun. Mag., vol. 52, no. 12, pp. 132–141, 2014.
- [4] A. I. Sulyman, A. T. Nassar, M. K. Samimi, G. R. MacCartney, T. S. Rappaport, and A. Alsanie, “Radio propagation path loss models for 5G cellular networks in the 28 GHz and 38 GHz millimeter-wave bands,” IEEE Commun. Mag., vol. 52, no. 9, pp. 78–86, 2014.
- [5] RP-172115, “Revised WID on New Radio Access Technology,” 2017.
- [6] A. Natarajan, S. K. Reynolds, M. Tsai, S. T. Nicolson, J. C. Zhan, D. G. Kam, D. Liu, Y. O. Huang, A. Valdes-Garcia, and B. A. Floyd, “A fully-integrated 16-element phased-array receiver in SiGe BiCMOS for 60-GHz communications,” IEEE J. Solid-State Circuits, vol. 46, no. 5, pp. 1059–1075, May 2011.
- [7] V. Raghavan, S. Subramanian, J. Cezanne, A. Sampath, O. Koymen, and J. Li, “Directional hybrid precoding in millimeter-wave MIMO systems,” in 2016 IEEE Global Communications Conference (GLOBECOM), 2016, pp. 1–7.
- [8] T. Bai and R. W. Heath, “Coverage and rate analysis for millimeter-wave cellular networks,” IEEE Trans. Wireless Commun., vol. 14, no. 2, pp. 1100–1114, 2014.
- [9] Z. Muhi-Eldeen, L. Ivrissimtzis, and M. Al-Nuaimi, “Modelling and measurements of millimetre wavelength propagation in urban environments,” IET Microw., Antennas Propag., vol. 4, no. 9, pp. 1300–1309, 2010.
- [10] P. Wang, J. Fang, X. Yuan, Z. Chen, H. Duan, and H. Li, “Intelligent reflecting surface-assisted millimeter wave communications: Joint active and passive precoding design,” arXiv preprint arXiv:1908.10734, 2019.
- [11] Y. Yang, B. Zheng, S. Zhang, and R. Zhang, “Intelligent reflecting surface meets OFDM: Protocol design and rate maximization,” arXiv preprint arXiv:1906.09956, 2019.
- [12] Q. Wu and R. Zhang, “Intelligent reflecting surface enhanced wireless network via joint active and passive beamforming,” IEEE Trans. Wireless Commun., vol. 18, no. 11, pp. 5394–5409, Nov 2019.
- [13] Z. Wang, L. Liu, and S. Cui, “Channel estimation for intelligent reflecting surface assisted multiuser communications,” arXiv preprint arXiv:1911.03084, 2019.
- [14] E. Basar, M. Di Renzo, J. de Rosny, M. Debbah, M.-S. Alouini, and R. Zhang, “Wireless communications through reconfigurable intelligent surfaces,” arXiv preprint arXiv:1906.09490, 2019.
- [15] C. Huang, A. Zappone, G. C. Alexandropoulos, M. Debbah, and C. Yuen, “Reconfigurable intelligent surfaces for energy efficiency in wireless communication,” IEEE Trans. Wireless Commun., vol. 18, no. 8, pp. 4157–4170, 2019.
- [16] A. Taha, M. Alrabeiah, and A. Alkhateeb, “Enabling large intelligent surfaces with compressive sensing and deep learning,” arXiv preprint arXiv:1904.10136, 2019.
- [17] C. Huang, A. Zappone, M. Debbah, and C. Yuen, “Achievable rate maximization by passive intelligent mirrors,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2018, pp. 3714–3718.
- [18] W. Khawaja, O. Ozdemir, Y. Yapici, F. Erden, M. Ezuma, and I. Guvenc, “Coverage enhancement for NLoS mmwave links using passive reflectors,” arXiv preprint arXiv:1905.04794, 2019.
- [19] X. Tan, Z. Sun, D. Koutsonikolas, and J. M. Jornet, “Enabling indoor mobile millimeter-wave networks based on smart reflect-arrays,” in IEEE INFOCOM, 2018, pp. 270–278.
- [20] W. Tang, X. Li, J. Y. Dai, S. Jin, Y. Zeng, Q. Cheng, and T. J. Cui, “Wireless communications with programmable metasurface: Transceiver design and experimental results,” China Commun., vol. 16, no. 5, pp. 46–61, 2019.
- [21] J. Zhao, X. Yang, J. Y. Dai, Q. Cheng, X. Li, N. H. Qi, J. C. Ke, G. D. Bai, S. Liu, S. Jin et al., “Programmable time-domain digital-coding metasurface for non-linear harmonic manipulation and new wireless communication systems,” Natl. Sci. Rev., vol. 6, no. 2, pp. 231–238, 2018.
- [22] W. Tang, J. Y. Dai, M. Chen, X. Li, Q. Cheng, S. Jin, K.-K. Wong, and T. J. Cui, “Programmable metasurface-based rf chain-free 8PSK wireless transmitter,” Electron. Lett., vol. 55, no. 7, pp. 417–420, 2019.
- [23] C. L. Holloway, E. F. Kuester, J. A. Gordon, J. O’Hara, J. Booth, and D. R. Smith, “An overview of the theory and applications of metasurfaces: The two-dimensional equivalents of metamaterials,” IEEE Antennas Propag. Mag., vol. 54, no. 2, pp. 10–35, 2012.
- [24] H. Yang, X. Cao, F. Yang, J. Gao, S. Xu, M. Li, X. Chen, Y. Zhao, Y. Zheng, and S. Li, “A programmable metasurface with dynamic polarization, scattering and focusing control,” Sci. Rep., vol. 6, p. 35692, 2016.
- [25] P. Wang, J. Fang, H. Duan, and H. Li, “Compressed channel estimation for intelligent reflecting surface-assisted millimeter wave systems,” IEEE Signal Processing Letters, 2020.
- [26] C. Jia, J. Cheng, H. Gao, and W. Xu, “High-resolution channel estimation for intelligent reflecting surface-assisted mmwave communications,” in 2020 IEEE 31st Annual International Symposium on Personal, Indoor and Mobile Radio Communications, 2020, pp. 1–6.
- [27] Z. Xiao, T. He, P. Xia, and X.-G. Xia, “Hierarchical codebook design for beamforming training in millimeter-wave communication,” IEEE Trans. Wireless Commun., vol. 15, no. 5, pp. 3380–3392, 2016.
- [28] A. Alkhateeb, O. El Ayach, G. Leus, and R. W. Heath, “Channel estimation and hybrid precoding for millimeter wave cellular systems,” IEEE J. Sel. Topics Signal Process., vol. 8, no. 5, pp. 831–846, 2014.
- [29] W. Wang and W. Zhang, “Orthogonal projection-based channel estimation for multi-panel millimeter wave MIMO,” IEEE Trans. Commun., vol. 68, no. 4, pp. 2173–2187, 2020.
- [30] A. Alkhateeb, G. Leus, and R. W. Heath, “Limited feedback hybrid precoding for multi-user millimeter wave systems,” IEEE Trans. Wireless Commun., vol. 14, no. 11, pp. 6481–6494, Nov. 2015.
- [31] N. J. Myers, Y. Wang, N. González-Prelcic, and R. W. Heath, “Deep learning-based beam alignment in mmwave vehicular networks,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2020, pp. 8569–8573.
- [32] R. G. Baraniuk and M. B. Wakin, “Random projections of smooth manifolds,” Found. Comput. Math., vol. 9, no. 1, pp. 51–77, 2009.
- [33] K. L. Clarkson, “Tighter bounds for random projections of manifolds,” in Proceedings of the twenty-fourth annual symposium on Computational geometry, 2008, pp. 39–48.
- [34] G. Efstathopoulos and A. Manikas, “Extended array manifolds: Functions of array manifolds,” IEEE Trans. Signal Process., vol. 59, no. 7, pp. 3272–3287, July 2011.
- [35] S. Foucart and H. Rauhut, A Mathematical Introduction to Compressive Sensing. Birkhäuser Basel, 2013, vol. 1, no. 3.
- [36] E. J. Candes, J. K. Romberg, and T. Tao, “Stable signal recovery from incomplete and inaccurate measurements,” Comm. Pure Appl. Math., vol. 59, no. 8, pp. 1207–1223, 2006.
- [37] M. Chiani, D. Dardari, and M. K. Simon, “New exponential bounds and approximations for the computation of error probability in fading channels,” IEEE Transactions on Wireless Communications, vol. 2, no. 4, pp. 840–845, 2003.
- [38] W. H. Foy, “Position-location solutions by Taylor-series estimation,” IEEE Trans. Aerosp. Electron. Syst., no. 2, pp. 187–194, 1976.
- [39] J. Liu and J. Ye, “Efficient Euclidean projections in linear time,” in Proceedings of the 26th Annual International Conference on Machine Learning, 2009, pp. 657–664.
- [40] M. Giordani, M. Polese, A. Roy, D. Castor, and M. Zorzi, “A tutorial on beam management for 3gpp nr at mmwave frequencies,” IEEE Communications Surveys & Tutorials, vol. 21, no. 1, pp. 173–196, 2018.