Joint Calibration of Local Volatility Models with Stochastic Interest Rates using Semimartingale Optimal Transport
benjamin.joseph@maths.ox.ac.uk
2 BNP Paribas Global Markets
gregoire.loeper@bnpparibas.com
3 Mathematical Institute and St John’s College, University of Oxford
jan.obloj@maths.ox.ac.uk )
Abstract
We develop and implement a non-parametric method for joint exact calibration of a local volatility model and a correlated stochastic short rate model using semimartingale optimal transport. The method relies on the duality results established in [18] and jointly calibrates the whole equity-rate dynamics. It uses an iterative approach which starts with a parametric model and tries to stay close to it, until a perfect calibration is obtained. We demonstrate the performance of our approach on market data using European SPX options and European cap interest rate options. Finally, we compare the joint calibration approach with the sequential calibration, in which the short rate model is calibrated first and frozen.
1 Introduction
In financial engineering, calibration refers to the process of adjusting the model’s prices to the market prices. It is an essential task for pricing and hedging derivatives, often performed on an intraday basis.
For this purpose, two class of models emerge: the parametric, and the non-parametric ones. A typical example of parametric model is the Heston model. This type of model allows simplified (semi-analytic) pricing, as well as a clear financial interpretation for each of its parameters; however, its calibration capabilities are limited and it may even struggle to calibrate to a number of instruments comparable to the number of parameters. On the other hand, a non parametric model such as the local volatility model allows to match exactly a whole surface of European option prices, at the expense of requiring numerical simulations, and of lack of interpretability. Nevertheless, it is widely used across the industry.
Recently, a novel non-parametric approach to calibration exploiting semimartingale optimal transport (SOT) has been proposed, and applied for local volatility calibration in [11]. It builds on the methodology introduced in [26] and can also be seen as the stochastic extension of the celebrated time-continuous formulation of the classical OT problem by [2]. This approach is very versatile, and was then extended to local-stochastic volatility models in [12], to general path dependent products and constraints in [8], and to the joint calibration problem of SPX and VIX options in [9]. The last paper in particular showcased the ability of this method to obtain an exact calibration which was known to elude standard parametric models (see [10] for a general discussion on optimal transport based calibration). We mention here an earlier work [1], where the authors followed a similar path to calibration, based on a combination of non parametric exact calibration and regularization via entropic penalization.
All financial products exhibit a dependency to interest rates, as they involve future payments, and it is therefore natural to take into account the stochastic dynamics of interest rates in the calibration procedure. OT based calibration has recently been adapted by the authors of the present study to the context of equity products with stochastic interest rates [18]. Different approaches can be used in this task, either opting for a sequential calibration: the interest rates are calibrated (or given) first, and then a hybrid equity/rates model is calibrated to products exhibiting a dependency to both rates and equity dynamics, or, going for a joint calibration where the full covariance process is calibrated at once using rates and equity market prices.
In [18] a general duality result has been given, that covers both approaches. An application to the former case of sequential calibration was then proposed. This problem is naturally less involved numerically than the joint calibration problem.
In this paper, we use the previous duality result to address the joint calibration problem, given prices of European call options on equity and caps on the short rate. The resulting model is driven by a pair of correlated Brownian motions and has for state variables the equity underlying and the short rate. The algorithm is tested against real market data. We also compare the performance of joint calibration against sequential calibration considered in [18].
2 Formulation of Semimartingale Optimal Transport Calibration Problem
Our method offers exact joint calibration of the stock price’s process and the stochastic short rate processes to market prices of, respectively, European options, European calls and caps. We perform a non-parametric calibration of the drift and diffusion coefficients by recasting the calibration problem as a Semimartingale Optimal Transport (SOT) problem with discrete constraints (given by observed market data). Our SOT reformulation can be seen as a projection on to the space of exactly calibrated models: we start with a given reference model and the cost functional which we seek to penalize deviations from that reference. While enjoying the accuracy of exactly calibrating to chosen product prices, the penalization away from the reference model offers several advantages. First, it convexifies the problem giving a unique solution (for a fixed reference). Second, this convexity is known to give regularity to the solution (see [21], [22]). Third, it gives the user some control about choosing a meaningful reference model from which one tries not to depart too much.
We choose as a starting reference model a classic parametric model, calibrated as well as possible to market prices. As we explain below, to help convergence and smoothness, we propose to update iteratively the reference model: In each iteration, the reference model is taken as the output of the previous iteration. The reference model is also used as the starting point of the gradient descent. This ensures that the reference model is chosen if it matches the calibration constraints.
To illustrate the above methodology, we consider the CEV (constant elasticity of variance) model of [6, 7] under which the underlying, , follows
| (1) |
with , where are constants. In the sequel, we write and work with the log-price process. The short rate , is modelled using the Vasicek model of [27], and follows
| (2) |
with
| (3) |
The constants are chosen strictly positive, with the speed of mean reversion, the mean, and the volatility of the short rate.
All the modelling is done under the risk neutral (pricing) measure and the initial market values are given. We note that our methods extend easily to non-trivial initial distribution of which could be useful for forward-starting models, or a multi-period calibration. We fix the parameters of our reference model as and denote
| (4) |
The drift coefficient and the diffusion coefficient of the process under the reference model are thus given by:
| (5) |
Note that on the other hand there is no restriction on the parameters of the calibrating model, apart from risk neutrality and finiteness of the cost function. Our cost function being convex, see (8) below, combined with the classical Markovian mimicking arguments, see [13, 4] and [18, Lemma 3.2], imply that with no loss of generality we can restrict our attention to Markovian models where are functions of . Note that the initial value is known and hence a potential candidate model is specified simply via a choice of , where are positive definite symmetric matrices. Risk neutrality implies . Formally, these observations mean that our candidate model is of the following form, where we take probability measures from the set of measures such that , which we denote as , and we let be a Brownian motion under :
| (6) |
Further, we impose bounds on the diffusion coefficients:
This is desirable from the point of numerical stability, as well as being justifiable from the financial modelling point of view. The drift and diffusion then take values in the following admissible (convex) set, which depends on the interest state variable:
| (7) |
Define as the Frobenius norm, which is given by . We consider the following cost function
| (8) |
For two square matrices , denote the matrix inner product by . The Legendre-Fenchel transform of (see [25]) with respect to is defined by
| (9) |
We consider market data given as prices of European options on . Their maturities and payoffs are denoted respectively by and , and for technical reasons we approximate the call payoffs so that is continuous and bounded for all . The market price of these options are given by so given a candidate model , our market constraints are:
We denote models such that the above constraints are satisfied as . Note that in practice, we will only consider call options on and caps on interest rates. Given these constraints, we obtain the reference model (5) via a least squares parametric calibration. Specifically, let denote the prices of the options attained our model (1)–(3) with parameters . The reference model is obtained by numerically solving:
| (10) |
Where the minimisation is taken over and . To minimise this, we simply compute the price of the options given the parameters using the Feynman-Kac formula, then numerically compute the gradients with respect to the parameters using a central difference approximation, and then apply the L-BFGS algorithm of [20]. We ran the optimisation algorithm to a first order error of , which corresponded to an error of implied volatilities less than in the SPX call options, and of in the short rate cap options.
| Parameter | Initial Value | Parametrically Calibrated Value | Interpretation |
|---|---|---|---|
| 0.4 | 0.4115 | Volatility scaling of the CEV model | |
| 0.9 | 0.9362 | Power law in the CEV model | |
| -0.2 | -0.2037 | Instantaneous correlation between short rate and log-stock | |
| 0.03 | 0.0232 | Volatility of the Vasicek model | |
| 0.5 | 0.0156 | Speed of mean reversion in the Vasicek model | |
| 0.03 | 0.2852 | Mean to which Vasicek model reverts |
Now that the reference model is set, we can formulate the SOT-Calibration problem of [18]. We seek to find
This can rephrased in terms of and the discounted density , i.e., if for that is the density of then . We formalise this as follows:
Lemma 2.1 (Lemma 3.3 of [18]).
Let so that solves (6). Let be the law of conditional on . Define the ‘discounted density’
| (11) |
Then solves the ‘discounted’ version of the Fokker-Planck equation for :
| (12) |
Problem 2.2 (Primal Problem).
| (13) |
where the infimum is taken over subject to:
The above Fokker-Planck equation is understood in the sense of distributions. The duality for the above problem was established in [18, Theorem 3.5] and the dual problem is given by:
Theorem 2.3 (Dual Problem).
where the supremum is taken over and is the (unique, discontinuous in time) viscosity solution to the HJB equation:
| (14) |
with terminal condition . If is finite, then the infimum in Problem 2.2 is attained. If the sup is attained for some and corresponding solving (14), then the optimisers are given by
| (15) |
3 Solving the Semimartingale Optimal Transport Calibration Problem
3.1 Numerical Solutions for the Dual Problem
Our numerical approach focuses on solving the dual problem. Specifically, we solve the HJB equation (14) by following [18], which is an adaptation of the methods presented in [12] and [9]. We use a discretisation on a uniform spatial grid of for the log-stock and rescaled interest rates, and partition the time interval into days, so that . We discretise the HJB equation using an implicit finite difference method, with central difference approximations for the spatial derivatives. We choose a boundary far away enough such that the boundary conditions have less of an effect on the HJB equation solution, and our boundary conditions are such that the second derivative of does not change with time between each calibrating option. That is, for all on the boundary of our computational domain, and for a subsequence of the calibrating option maturity times such that for all are distinct, and with ,
(14) is a fully nonlinear parabolic PDE and we use a policy iteration method (see [24]) as in [18] to solve it. In our policy iteration procedure to approximate and , we compute the finite difference approximations of and using from the previous iteration. The used in the initial iteration is from the previous time step (that is ). With this approximated , we can apply an implicit finite differences method to one step of the HJB equation to obtain the new value of . This iteration is repeated until some specified tolerance is reached such that . In comparison to [18], we are now approximating all of the coefficients, so the iteration takes more steps and thus is less efficient at computing and . The jump discontinuities are handled by simply adding to the when we reach the timestep corresponding to . Once we have solved the HJB equation at all time steps, we then solve the linearised model pricing PDE (with coefficients and ) via the ADI method to generate the model prices.
Having solved the HJB equation for a fixed , we turn our attention to solving Problem 2.3 and finding the optimal . First, we observe that we can speed up the optimisation routine by providing a formula for the gradients. This formula is obtained in the same way as [9], but with the discounting appearing as a result of the term in the HJB equation and the Feynman-Kac formula.
Lemma 3.1.
Suppose Problem 2.2 is admissible, and define the dual objective function as
| (16) |
Then the gradients of the dual objective function are given by
| (17) |
Our initialisation is since if the reference model is already calibrated, then that will immediately return . Given a guess , we solve the HJB equation (14). From the solution of (14), we compute the diffusion coefficients from (15). For each instrument we compute the model price by solving
| (18) |
We can then compute the gradient corresponding to the difference between the model prices and and market prices, and finally use the L-BFGS algorithm to update .
3.2 Approximating the optimisers in (15)
In the step 9 of Algorithm 1 we have to Approximate from . This is a key step and it needs to be done efficiently. It is possible to derive an analytic formula for but this proves to have many subcases and to involve solving quartic equations. In consequence, this method is computationally costly. In our numerical experiments it proved far slower than the alternative which we now describe.
[5] provides a numerical scheme to evaluate the Legendre-Fenchel transform in time for discretisation points and dimensions. We remark as well that [23] provides a faster version in time, however it is difficult to separate the terms while maintaining positive semi-definiteness. Since (15) requires the evaluation of the spatial derivatives at all points of the grid, we cannot directly apply the methods to fully take advantage of the faster computational speed. However, we use the observation in equation (2.1) of [5], which allows us to decompose the maximisation component-wise, and apply the idea of evaluating the transform on bounded intervals for computational ease.
Lemma 3.2 (Approximating the Optimal Coefficients).
Define by:
and . The matrix is positive semidefinite and whenever
| (19) |
holds, then are the optimisers in (15).
The proof is given in Appendix B. It proceeds by solving (15) sequentially: we first solve for and subject to their bounds. This is easy to do as the expression is quadratic in each variable. We then solve for and use it to enforce the condition of positive semi-definiteness on the matrix . If (19) holds then the positive semi-definitiveness condition is not binding and the procedure returns the optimizer. Otherwise, we set to ensure is positive semi-definite but this means our approximation may differ from a global search over all positive semi-definite matrices . However, in all of our numerical experiments, (19) in fact holds everywhere so that, in practice, Lemma 3.2 provides the optimisers in (15) but at a fraction of the computational cost involved in solving (15) analytically as a constrained optimization (29).
3.3 Renormalisation and Reference Model Iteration
As in [18], in order to bring the short rate to the same order as the log-stock for finite difference approximation stability reasons, we perform the constant rescaling where we choose . In addition, we rescale the calibrating option prices and their payoffs by their vegas computed from their Black-Scholes implied volatility. This not only helps the stability of the numerical method, but also converts pricing errors into implied volatility errors since the vega represents how much the option price will change as the volatility changes by .
If Algorithm 1 is directly applied, then often it will output a model with spiky drift and diffusion surfaces which is undesirable. This is a result of our cost function penalising deviations from a reference model, which results in larger local changes to the surfaces, but with the rest of the overall surface being closer to the reference model. Moreover, instabilities from the and terms in and at maturity at the strikes of our options when adding in the jump discontinuities are unavoidable. In addition, sometimes the L-BFGS algorithm will get stuck and unable to progress. To avoid all of this and improve the convergence to our calibrated model, we apply a “reference model iteration” technique as in [9]. That is, once our optimisation routine finishes, we apply an interpolation and smoothing technique to the output model drift and diffusion terms, and then set those terms to our new reference model and re-run the calibration. The final output model is not smoothed since this would no longer be a calibrated model. This not only speeds up convergence, but also decreased sharp peaks that can arise in our calibrated local volatility surfaces otherwise.
4 Numerical Results: Market Data Example
We test our calibration procedure on market data111Data obtained from a Bloomberg terminal at the Saïd Business school in Oxford on 23/05/2022.. We used the one month LIBOR as a proxy for the short rate, and obtained the implied volatility and prices of the following options:
-
•
10 calls on the SPX with expiry 19/08/2022,
-
•
6 caps on the one month LIBOR with notional $10,000,000 and expiry 23/08/2022,
-
•
10 calls on the SPX with expiry 18/11/2022,
-
•
6 caps on the one month LIBOR with notional $10,000,000 and expiry 23/11/2022.
We have a total of options with payoff functions for the calls and for the caps, where is the notional value.
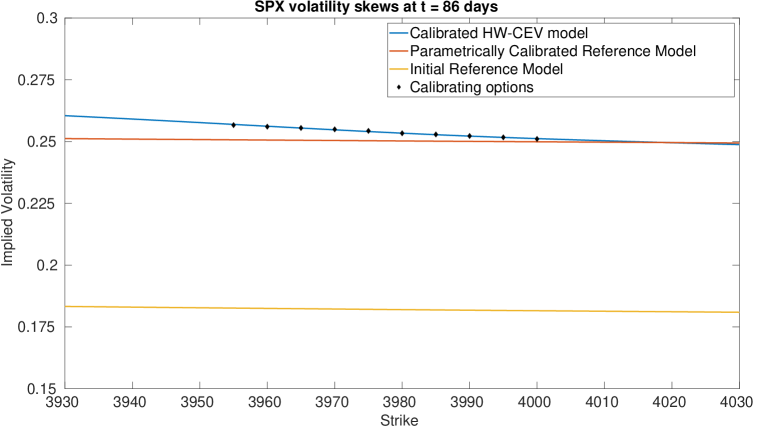
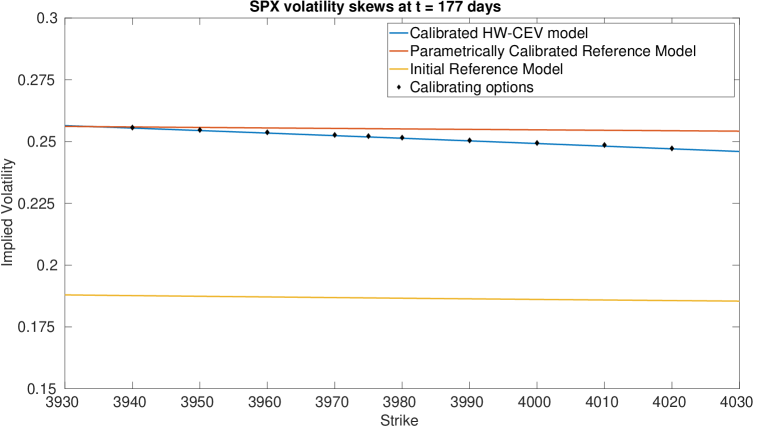
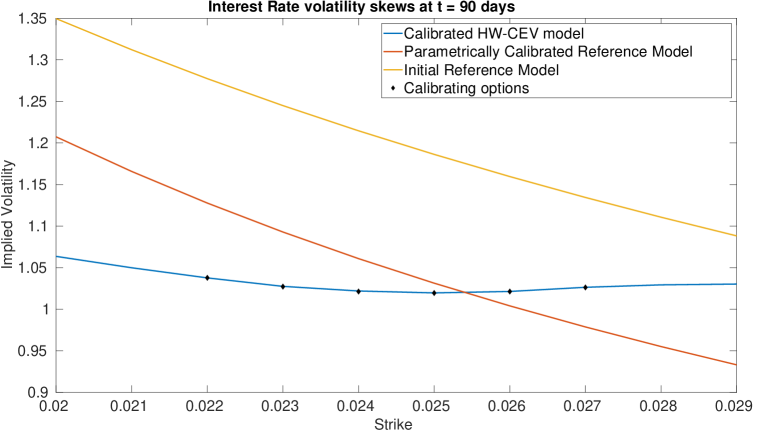
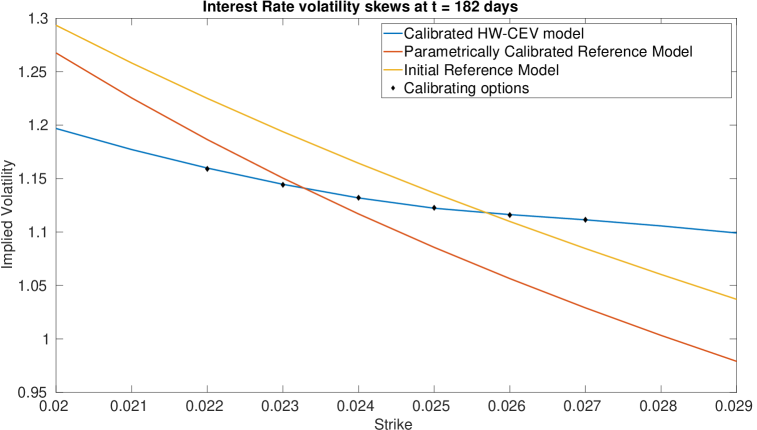
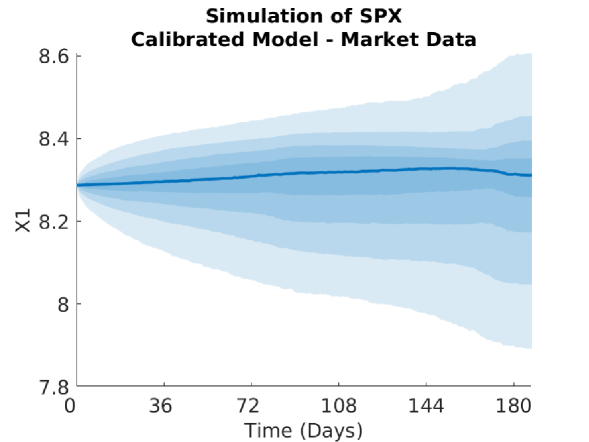
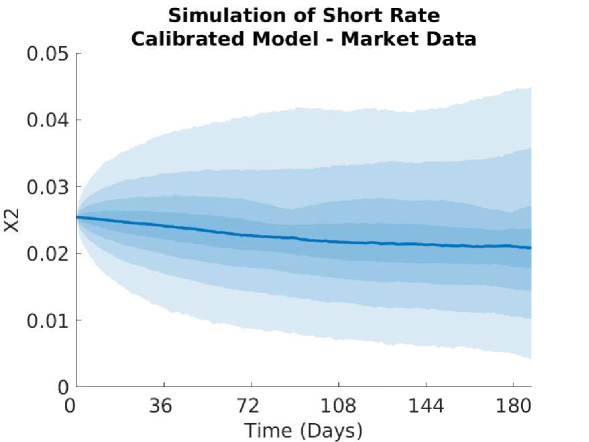
We display the optimisation parameters, and the bounds for and below. It is difficult to choose the bounds since too relaxed a bound will result in large values for and and also result in numerical instabilities for ; whereas too tight a bound will severely slow down the calibration. Even with these bounds chosen, we still saw some instabilities in on the maturity dates of the Calls, and in on the maturity dates of the Caps. Imposing the bounds reduced these instabilities significantly, but did not remove them entirely.
| Parameter | Value | Interpretation |
|---|---|---|
| Tolerance for the difference in model and observed IV | ||
| Tolerance in the policy iteration for | ||
| Lower bound for | ||
| Upper bound for | ||
| Lower bound for | ||
| Upper bound for |
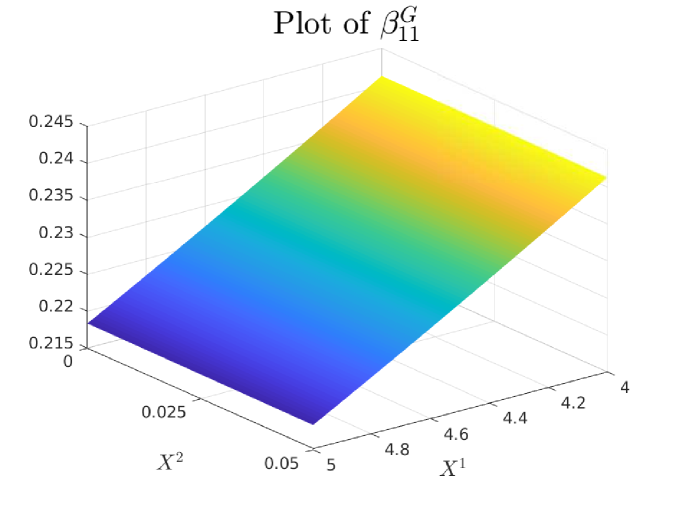
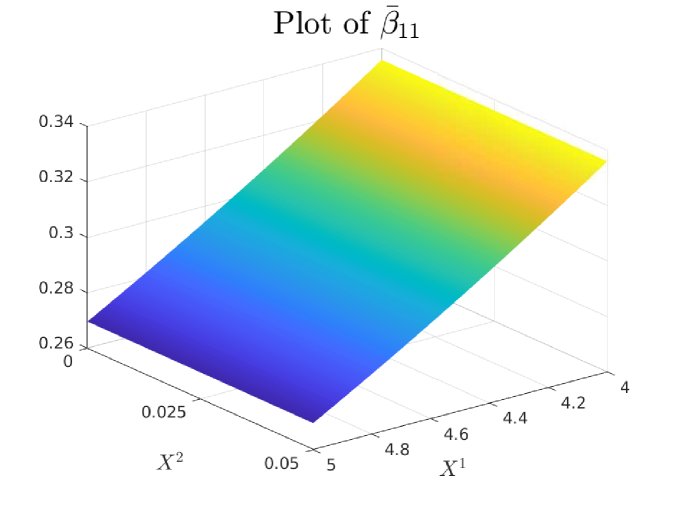
4.0.1 Plots of Drift and Diffusion Surfaces
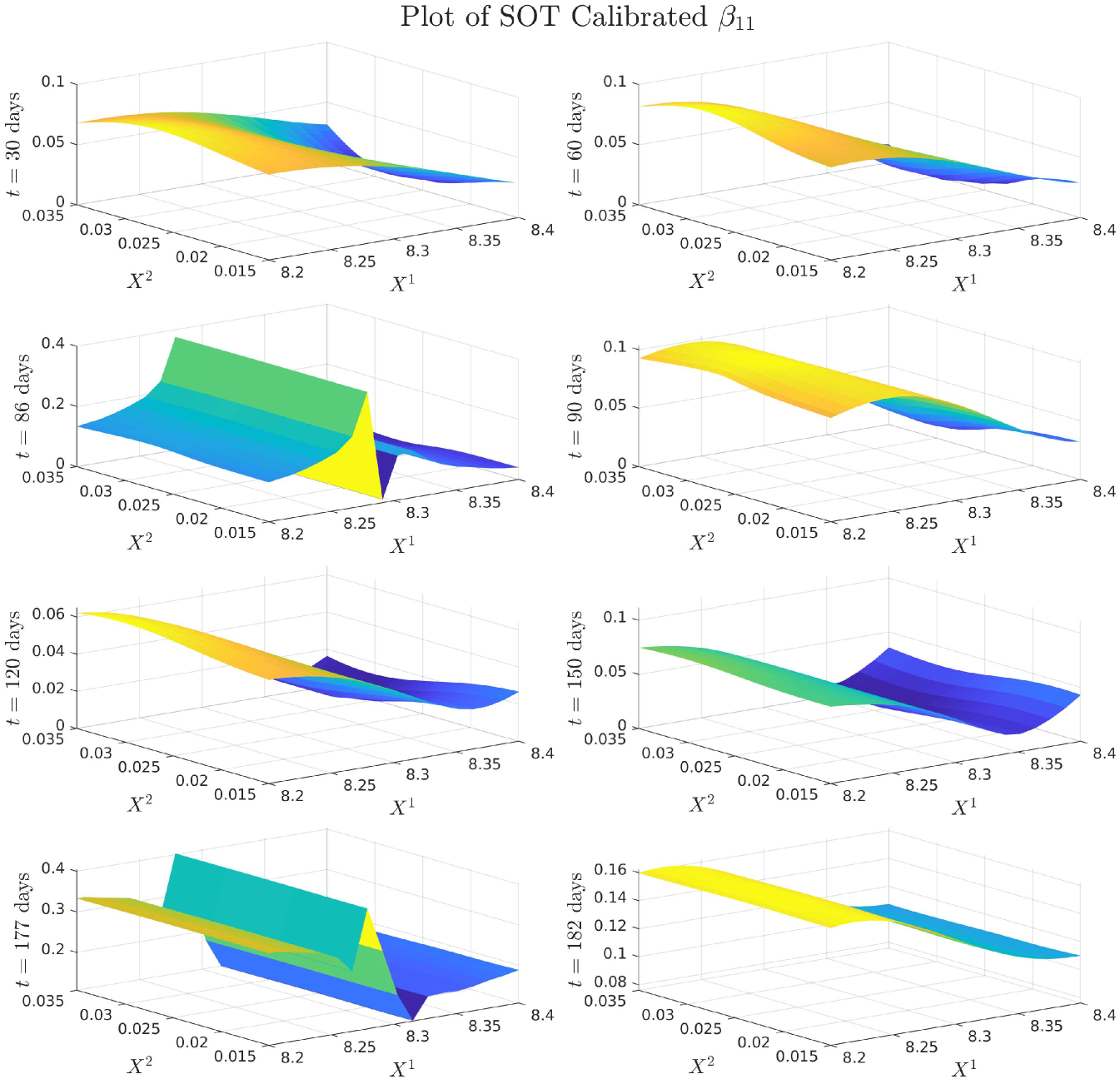
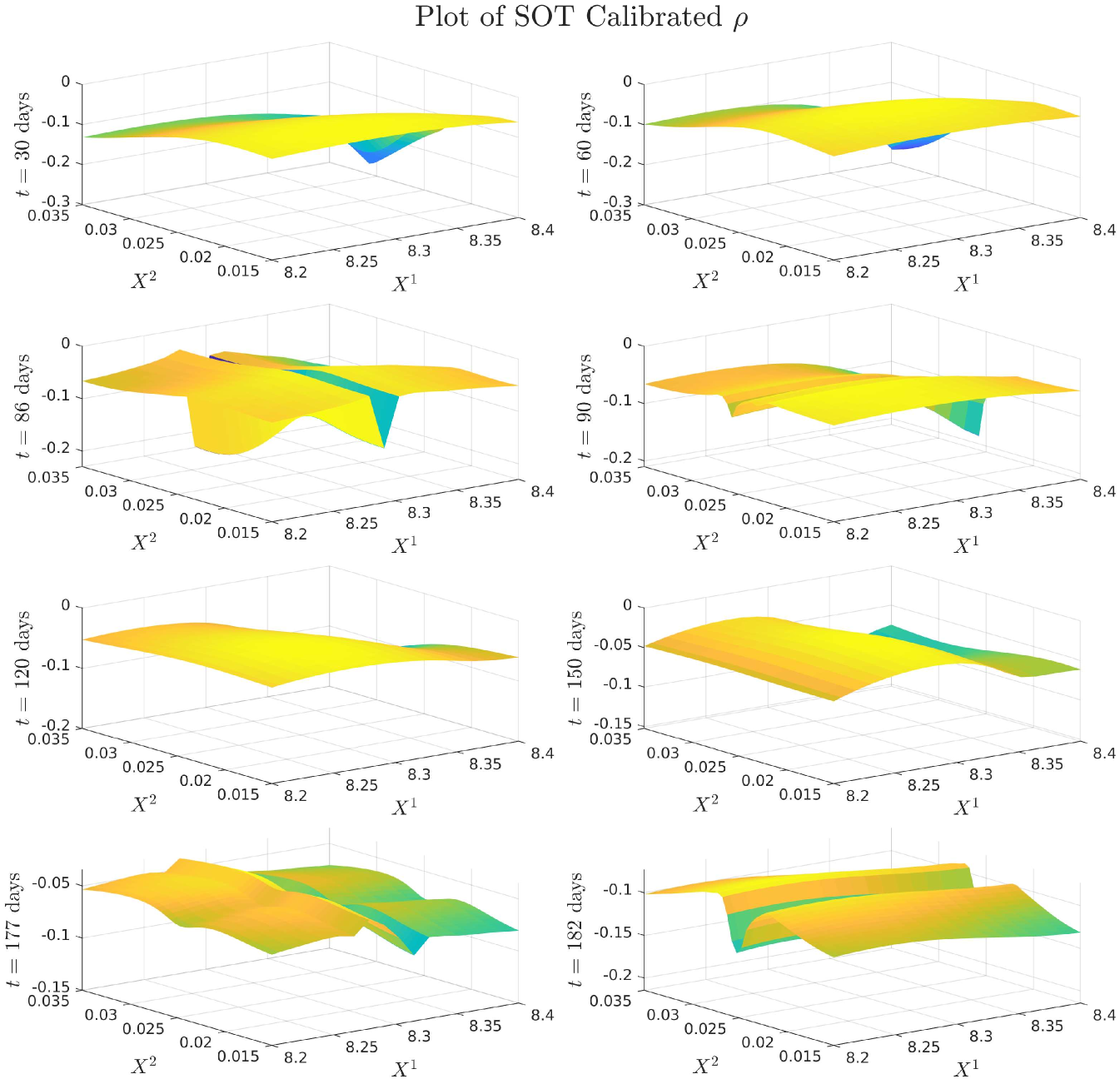
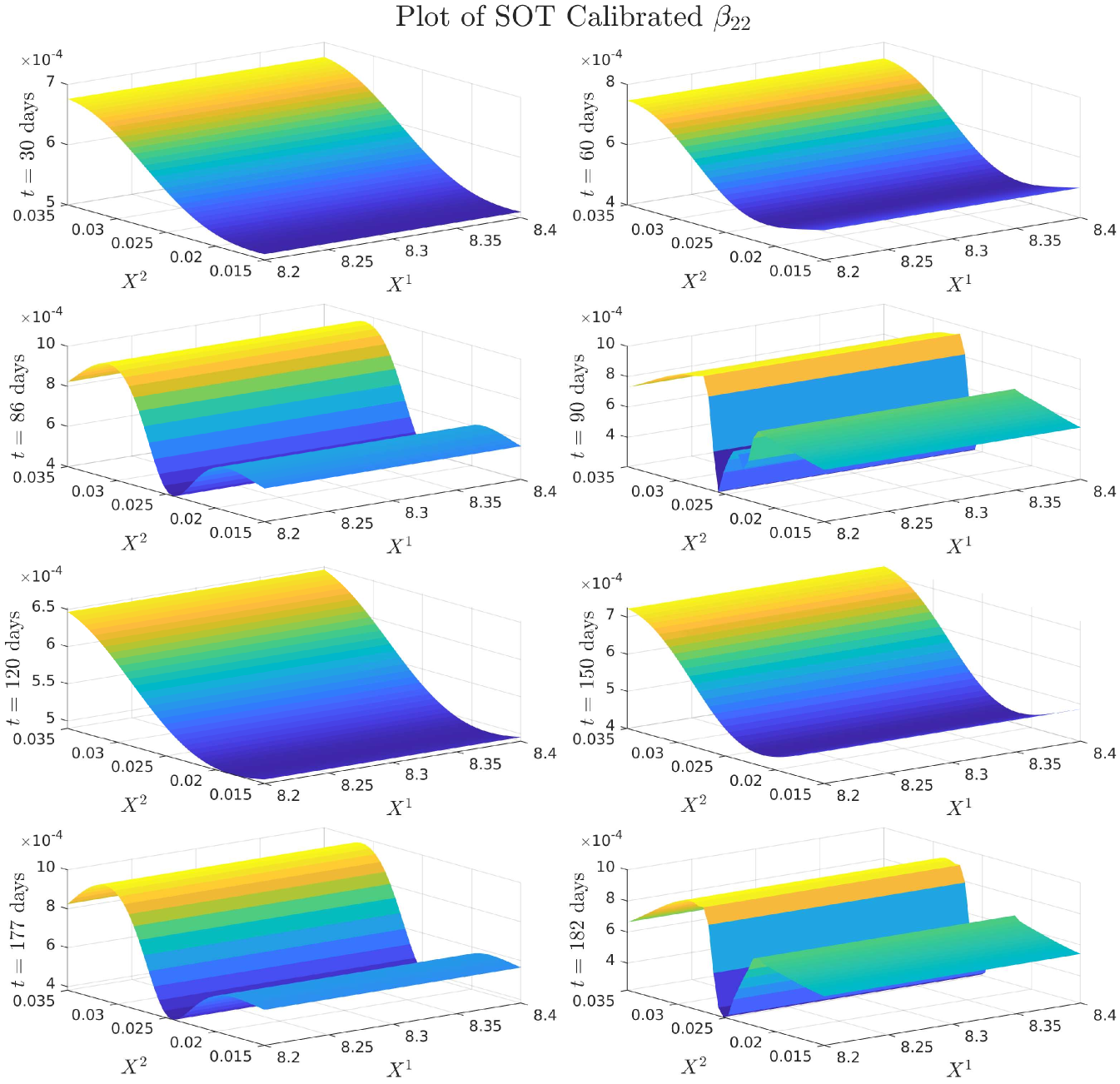
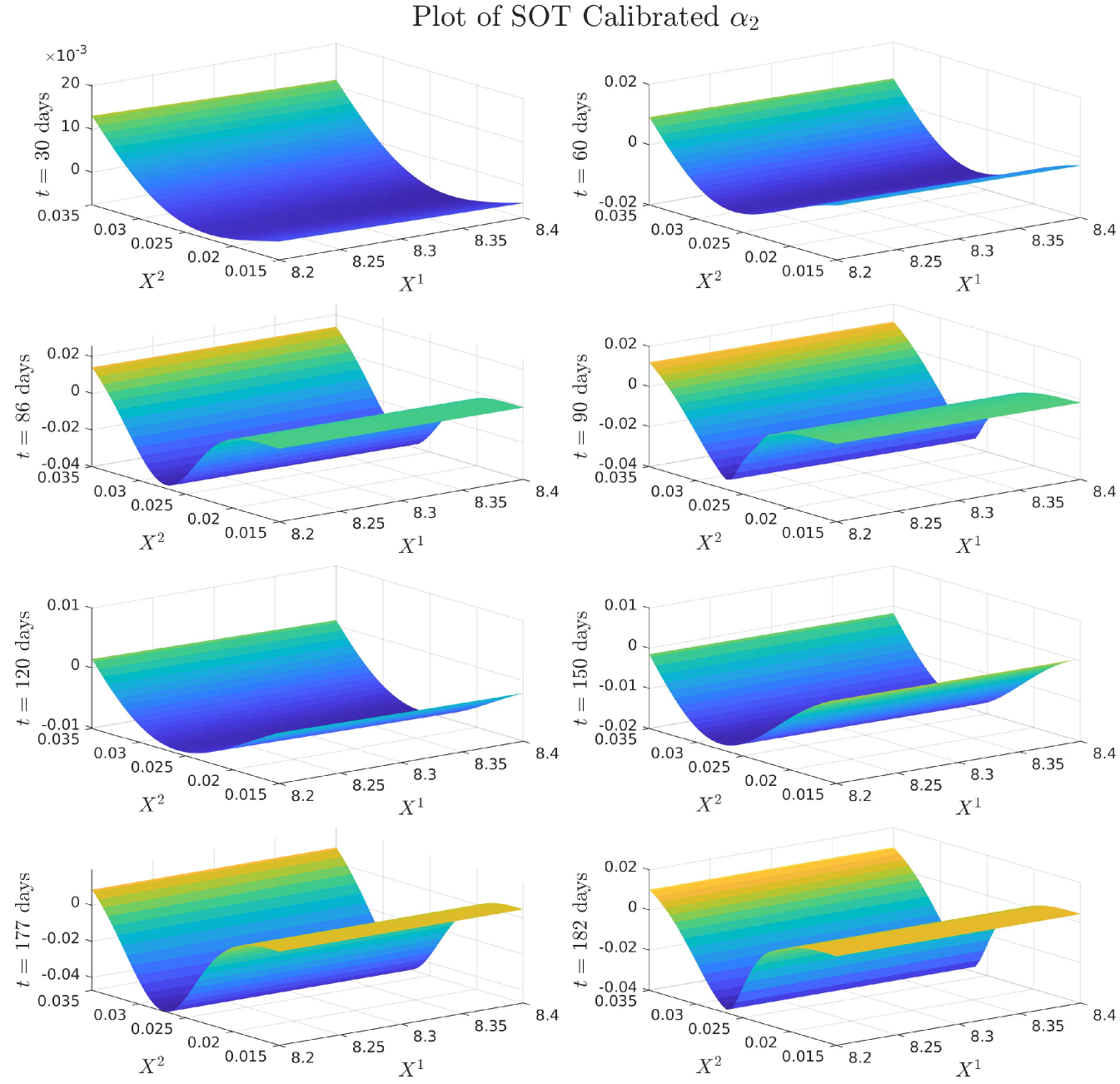
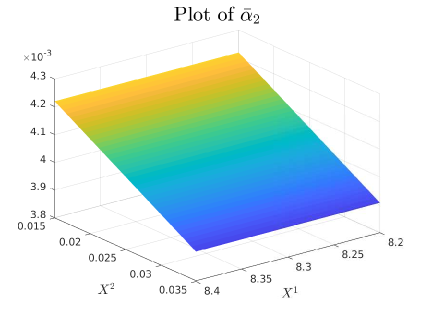
5 Numerical results: a comparison of three SOT Calibration approaches
Above we develop a joint calibration method for European options on a stock and on interest rates. In [18] a sequential approach was proposed in which the interest rates model was calibrated first and frozen for the subsequent calibration of a local volatility model for the stock prices. This was done under rigid restrictions on the structure of the correlation – it was conjectured this would speed up the numerics. We want to now compare the two approaches numerically, as well as introduce and compare a third approach which also proceeds sequentially but relaxes the assumptions on the correlation.
We test the methods on simulated data. We use the generating model as the reference model for the short rate. In the two cases where the interest rate is frozen, the surface plots of and will remain the same as the reference model, however and may be perturbed in the joint calibration case so we show all surface plots. Specifically, we take a Hull-White model for the interest rate, see [15, 16], and local volatility dynamics for the log-price:
| (20) | ||||
Where are constants and is a function of time, calibrated so that the dynamics of match the market data (e.g., suitable interest rates caps and floors). Both and being positive constants is not a particularly restrictive constraint as remarked in [3, 17]. Note that will therefore need to be calibrated to fit the term structure of interest rates seen in the market. Our reference model for the local volatility of the log-stock will be a CEV model, as above.
The difference in the calibration approach for all three methods is what process(es) are being calibrated, or equivalently the cost function employed, which then also leads to different formulae for the optimal coefficients. We review briefly the sequential method used in [18] and define its extension, the “full sequential” method. We then provide numerical results comparing the three approaches.
5.1 Sequential Calibration
We fix a reference function and restrict correlation to the following representation:
| (21) |
We then set:
| (22) |
We also require the inequality to keep as a correlation also. Since is on a much lower scale to , we have that , so this condition is not financially restrictive. To enforce this condition, we will define a convex function with a parameter :
The coefficients of each term ensure that is minimised over at with . We fix a reference local volatility function that represents the desired model. Since we wish to penalise deviations away from our reference volatility , we define our cost function as follows:
| (23) |
With this cost function and the reference model fixed by in (22), our dual formulation becomes
Problem 5.1 (Sequential Dual Formulation).
Where solves the HJB equation:
| (24) |
Lemma 5.2 (Analytic Formula for the Optimal Characteristic in Sequential Calibration).
The optimal characteristic in the HJB equation (24), is given by
| (25) |
We use in our numerical experiments, see Table 3.
5.2 “Full Sequential” Calibration
We introduce the notion of “full sequential” calibration, in which the correlation is treated as a free parameter rather than prescribed via (21). Our set now becomes:
| (26) |
We use the same cost function as in joint calibration, however since we have from the definition of that and , and moreover that , our cost function will simplify to:
| (27) |
Problem 5.3 (Full Sequential Dual Formulation).
Where solves the HJB equation:
| (28) |
In a similar way to Lemma 3.2, we obtain an approximation of the optimal and by first optimising over , and then over applying the positive semidefinite constraint in this variable given .
Lemma 5.4.
Let and define and by:
Then is a positive semi-definite matrix and whenever
then is the optimizer in (28).
5.3 Numerical Results
We solve Problem 5.1 and Problem 5.3 using the same methods as in Section 3.1. We provide a table of parameters used in the generating and reference models for our problem.
| Hull-White CEV Model | ||
| Parameter | Value | Interpretation |
| Initial log-stock price | ||
| Initial short rate scaled by | ||
| Tolerance for the difference in scaled model and market implied volatility | ||
| Tolerance for the policy iteration approximation of the optimal characteristics | ||
| 0.05 | Lower bound of in full sequential and joint calibration | |
| 1 | Upper bound of in full sequential and joint calibration | |
| 4 | Exponent in sequential calibration cost function | |
| 0.60 | Volatility scaling of generating CEV model | |
| 0.95 | Power law in generating CEV model | |
| Initial term structure of Hull-White generating model | ||
| 0.05 | Speed of mean reversion of Hull-White generating model | |
| 0.04 | Volatility of Hull-White generating model | |
| Instantaneous correlation between short rate and log-stock in generating model | ||
| 0.90 | Volatility scaling of reference CEV model | |
| 0.89 | Power law in reference CEV model | |
| Initial term structure of Hull-White reference model | ||
| 0.05 | Speed of mean reversion of Hull-White reference model | |
| 0.04 | Volatility of Hull-White reference model | |
| Instantaneous correlation between short rate and log-stock in reference model | ||
| Generating Model | Calibrated Model: | Calibrated Model: | Calibrated Model: | ||||||
| Sequential | Full Sequential | Joint | |||||||
| Option Type | Strike | Price | IV | Price | IV | Price | IV | Price | IV |
| SPX Call options days | 85 | 11.2142 | 0.4825 | 11.2139 | 0.4825 | 11.2139 | 0.4825 | 11.2152 | 0.4826 |
| 92 | 7.3755 | 0.4811 | 7.3757 | 0.4811 | 7.3749 | 0.4811 | 7.3750 | 0.4811 | |
| 99 | 4.6051 | 0.4803 | 4.6045 | 0.4803 | 4.6038 | 0.4802 | 4.6056 | 0.4804 | |
| 106 | 2.7426 | 0.4799 | 2.7420 | 0.4798 | 2.7419 | 0.4798 | 2.7426 | 0.4799 | |
| 113 | 1.5667 | 0.4797 | 1.5665 | 0.4797 | 1.5667 | 0.4797 | 1.5673 | 0.4797 | |
| 120 | 0.8624 | 0.4795 | 0.8623 | 0.4795 | 0.8629 | 0.4796 | 0.8626 | 0.4796 | |
| SPX Call options days | 85 | 14.0842 | 0.4821 | 14.0839 | 0.4821 | 14.0838 | 0.4821 | 14.0857 | 0.4822 |
| 92 | 10.502 | 0.4809 | 10.5021 | 0.4809 | 10.5007 | 0.4808 | 10.5027 | 0.4809 | |
| 99 | 7.6696 | 0.4797 | 7.6712 | 0.4798 | 7.6699 | 0.4798 | 7.6691 | 0.4797 | |
| 106 | 5.4943 | 0.4785 | 5.4952 | 0.4785 | 5.4936 | 0.4784 | 5.4952 | 0.4785 | |
| 113 | 3.8607 | 0.4767 | 3.8609 | 0.4768 | 3.8597 | 0.4767 | 3.8594 | 0.4767 | |
| 120 | 2.6499 | 0.4738 | 2.6498 | 0.4738 | 2.6495 | 0.4738 | 2.6499 | 0.4738 | |
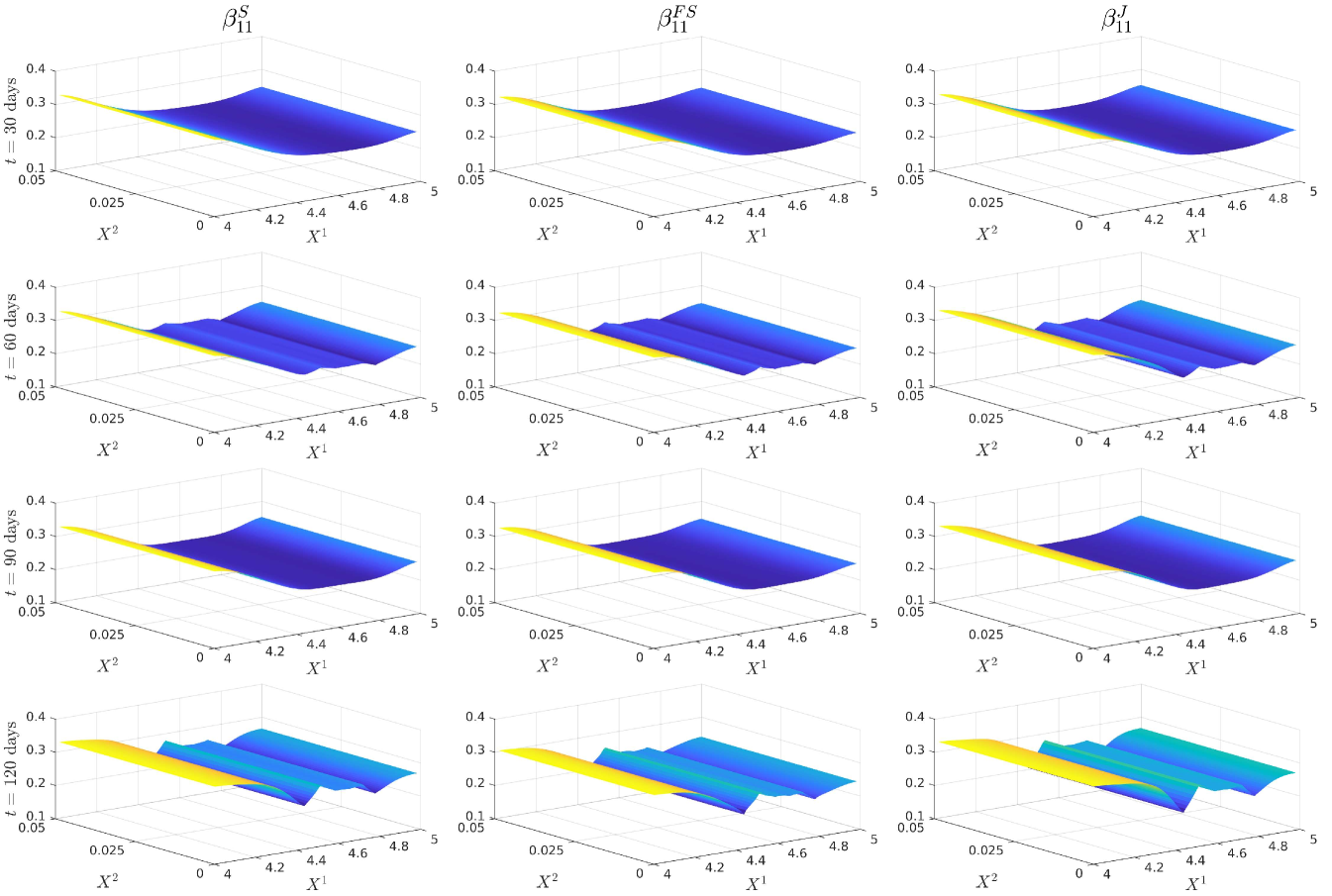
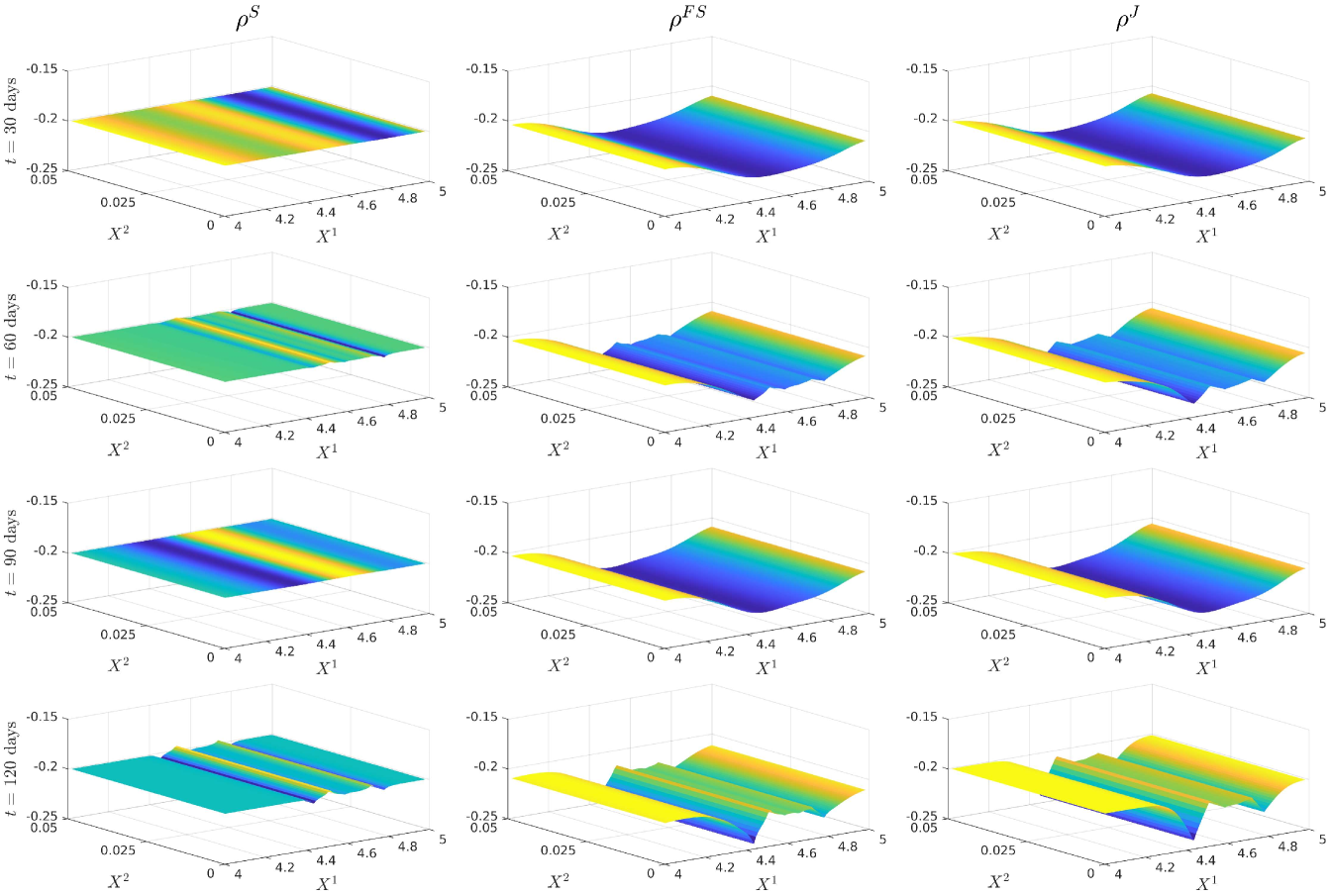
5.3.1 Implied Volatility and Monte Carlo Plots
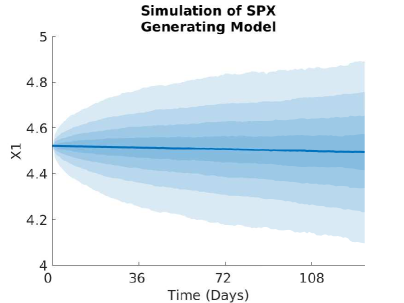
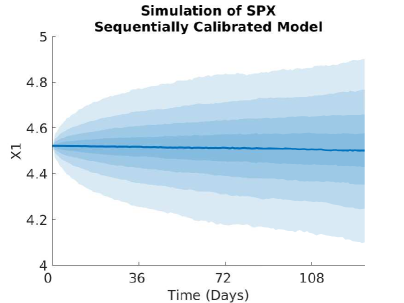
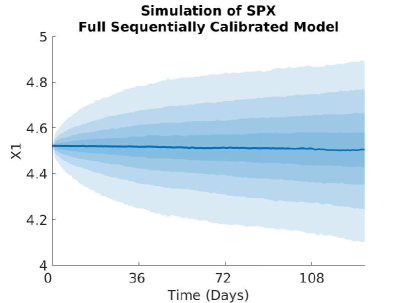
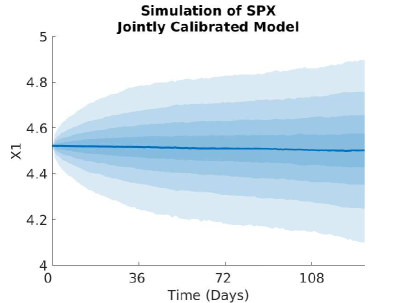
5.3.2 Plots of the Volatility and Correlation surfaces
For notational ease in the comparison, denote via a superscript the characteristic under the SOT sequential calibrated model, SOT full sequential calibrated model, SOT jointly calibrated model and generating model respectively. In order to provide a meaningful comparison of the three methods, we show plots of the difference in the surfaces for all five characteristics, and how all of them differ from the generating model. Plots of the actual surfaces are left in the appendix. We omit all plots for since in all three cases it is entirely specified by . We remark that the formulae for and given in Lemma 3.2 and Lemma 5.4 are upon a first glance the same, and both differ from the formula for given in (25). However, owing to the different cost functions and the fact that the joint problem allows for perturbations in the interest rate, whereas the full sequential problem does not, there is no expectation of the optimisers and being the same since the global optimisers of both problems may differ. We expect the correlation coefficient to be almost constant and close to the reference model, owing to the assumption on the correlation in (21), whereas we expect some deviation away from the reference model for and since we relax the assumptions on the correlation. The short rate volatility and short rate drift are assumed to be a priori correct due to the matching generating and reference models. Note that the coefficients are all fixed, and equal to these in the generating model, which we recall is also the reference model, i.e., we have222We confirmed this numerically in our results. and . However, in the joint calibration case we do not fix and and our optimisers given in Lemma 3.2 do not guarantee replication of the generating model. Nonetheless, since the cost function penalises deviations from the reference model, we expect that and will be close to the generating model with some small perturbations away fro and .
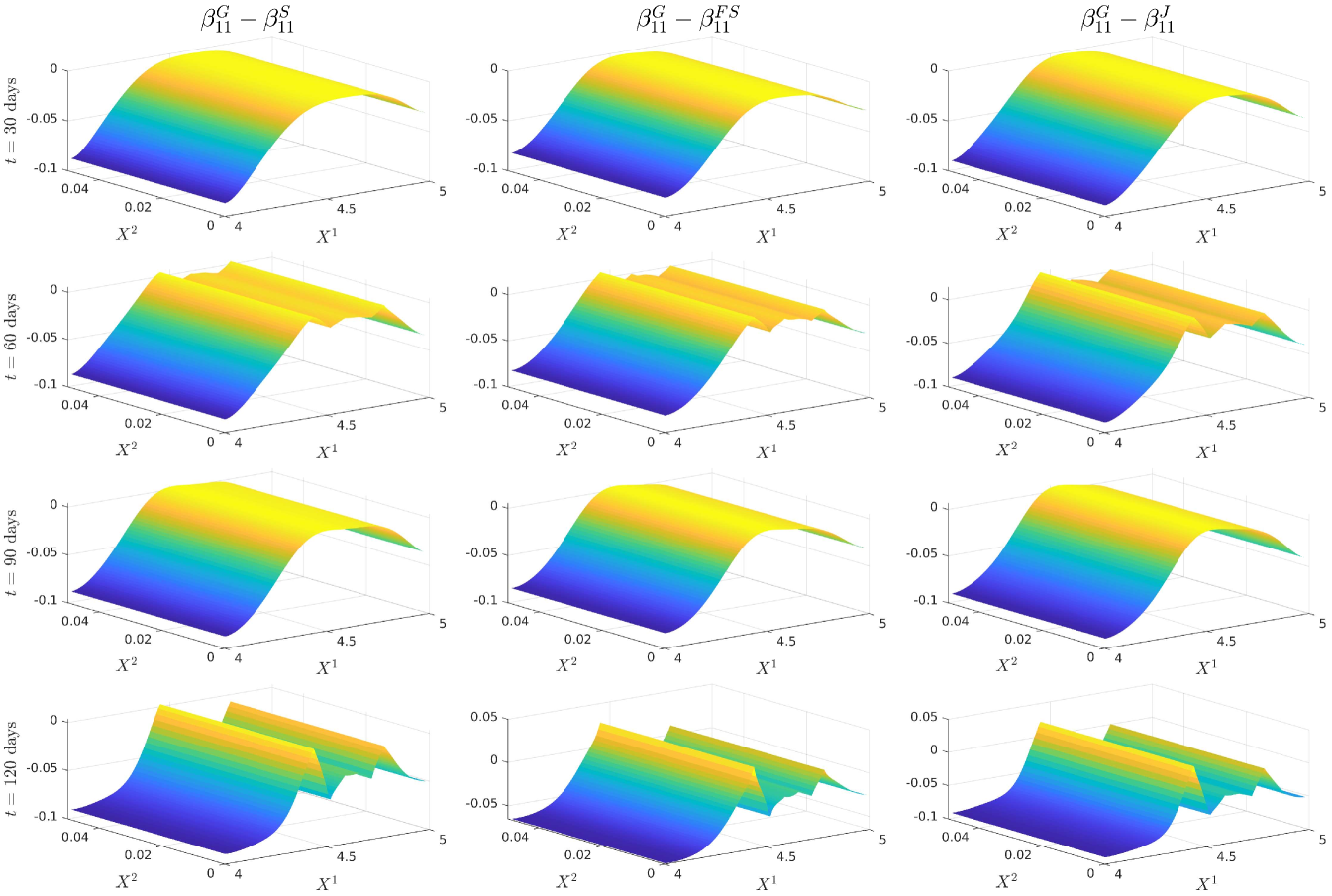
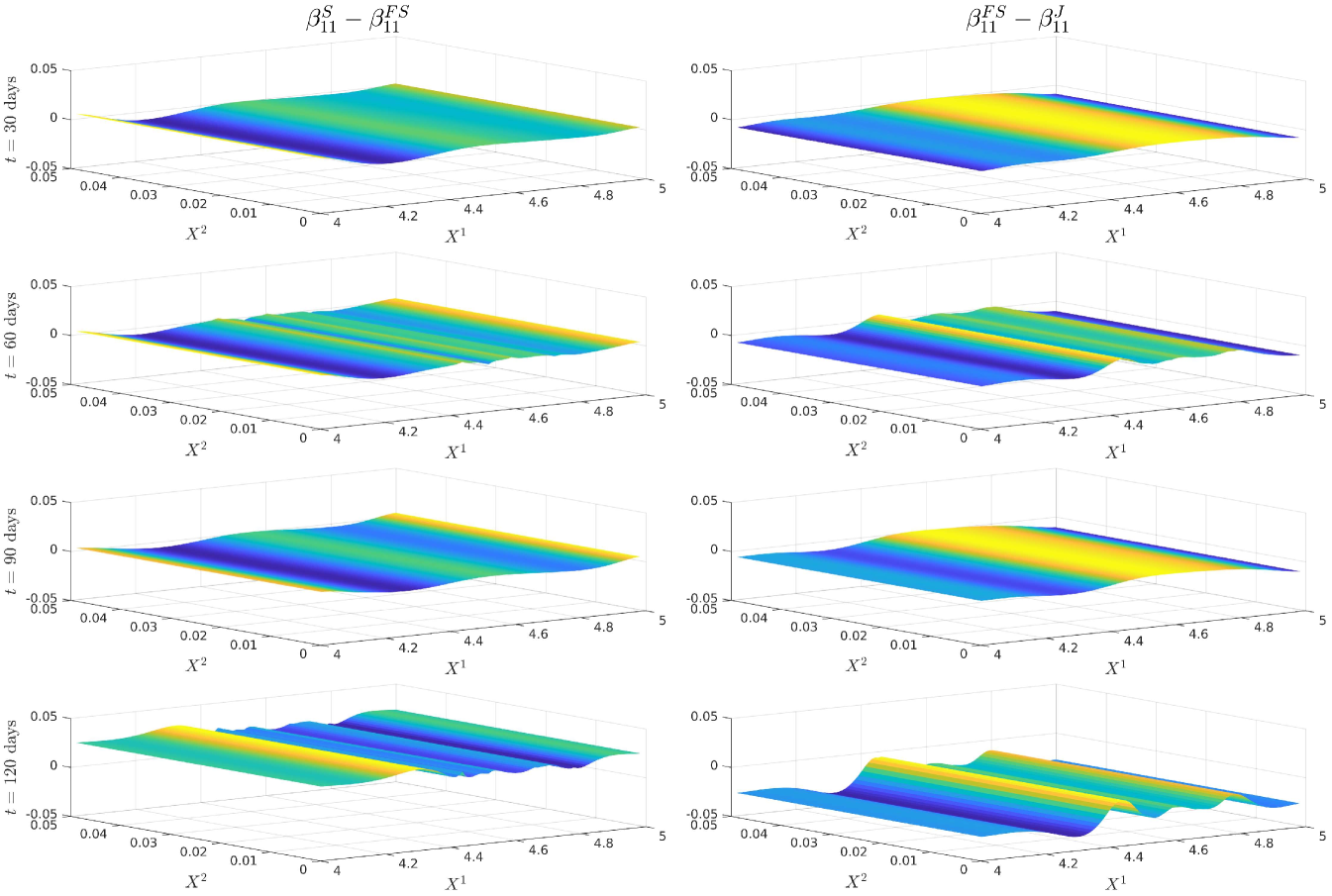
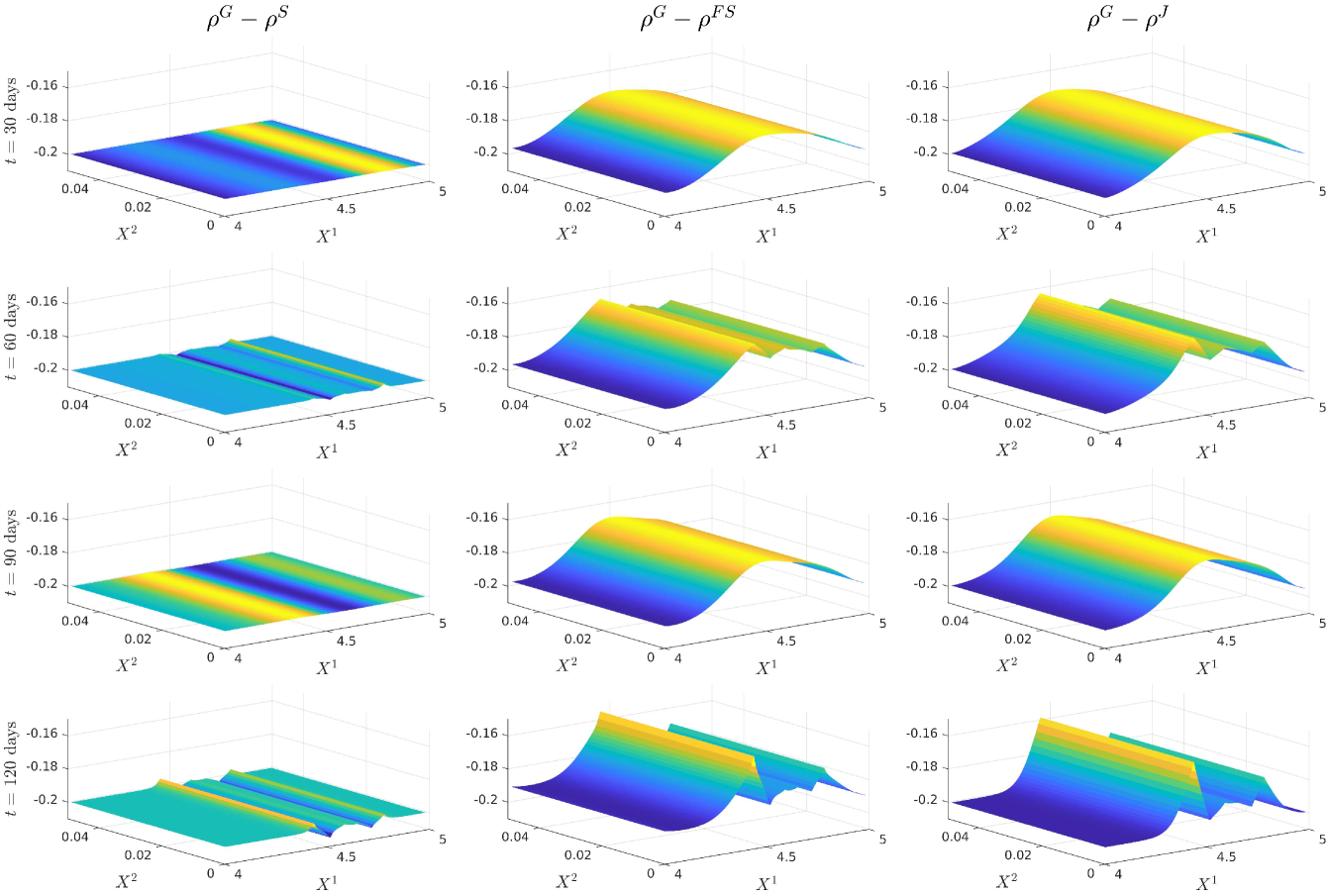
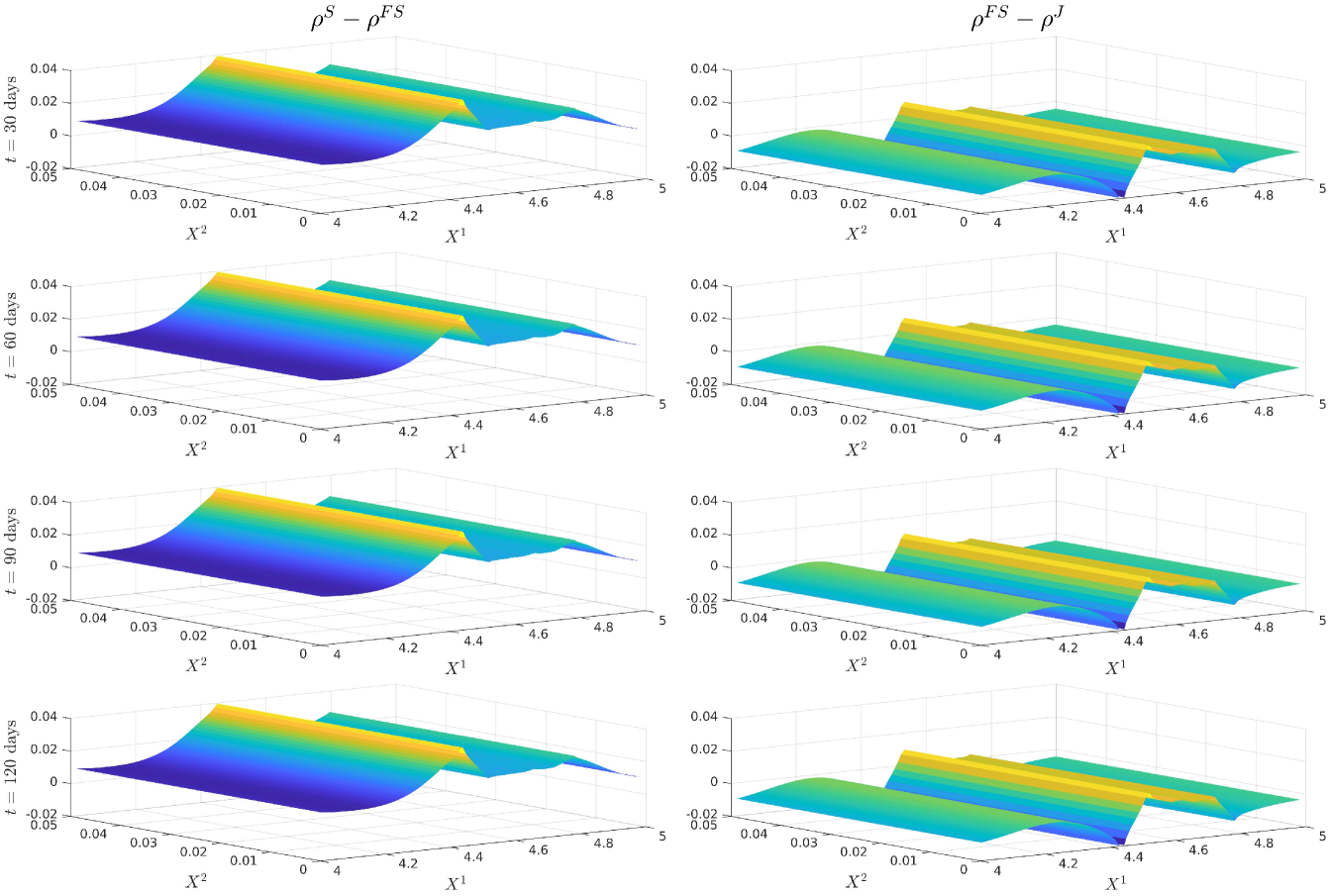
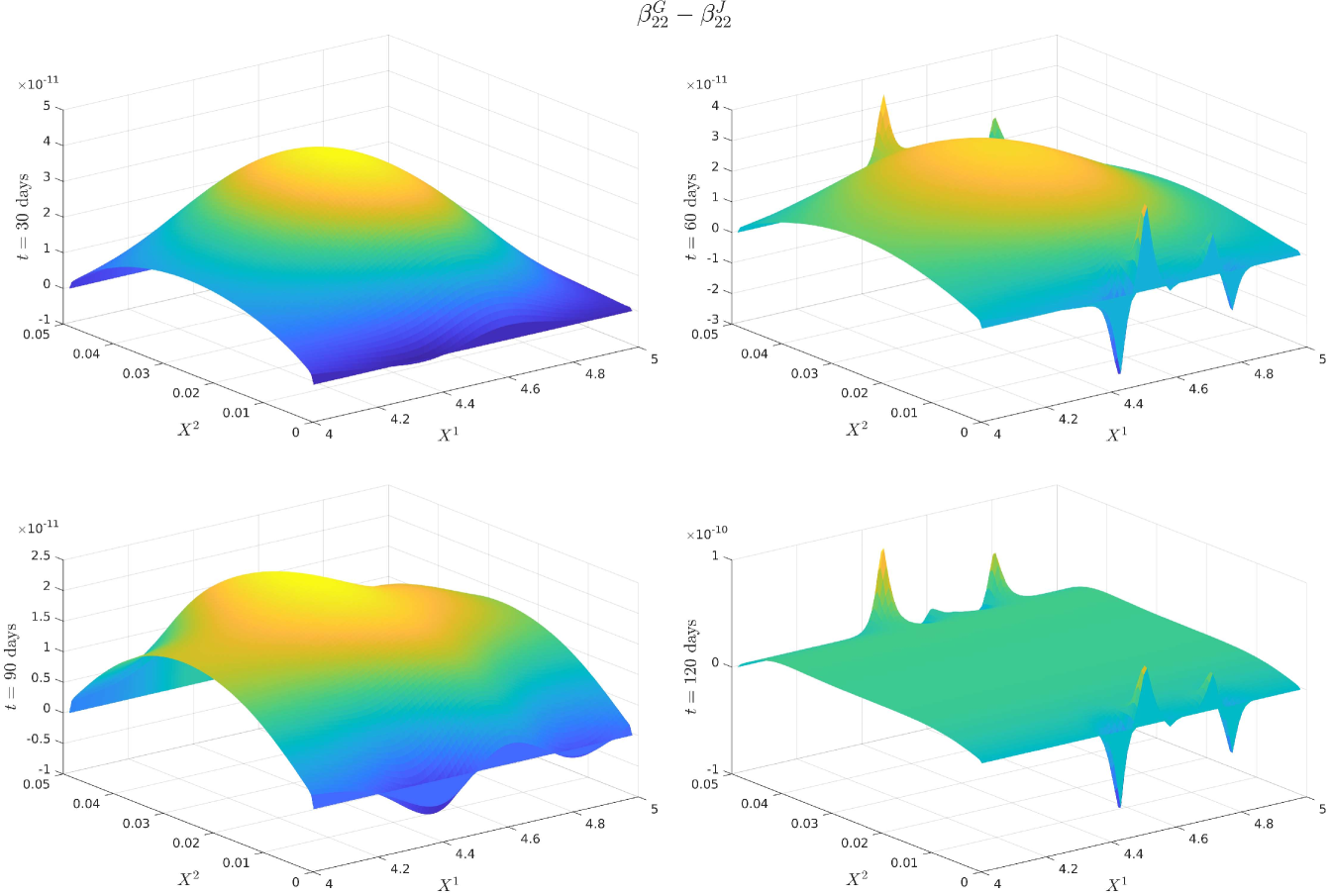
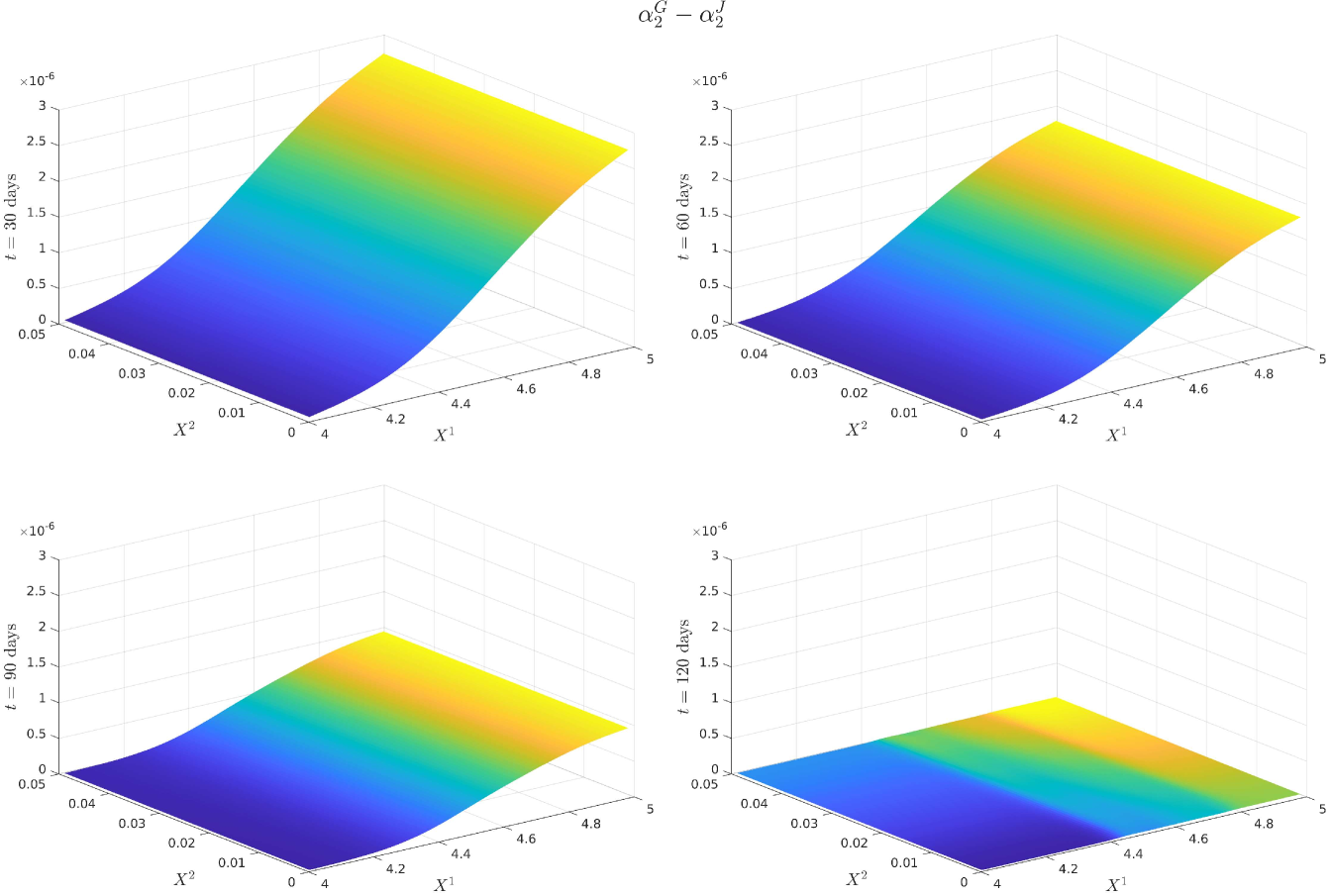
5.4 Discussion of the results
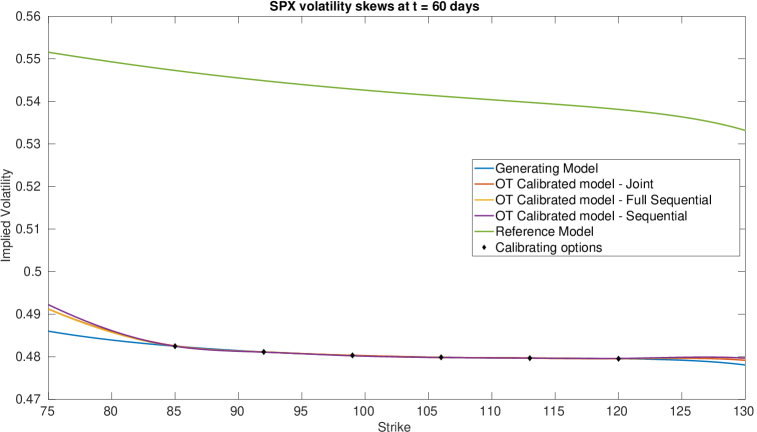
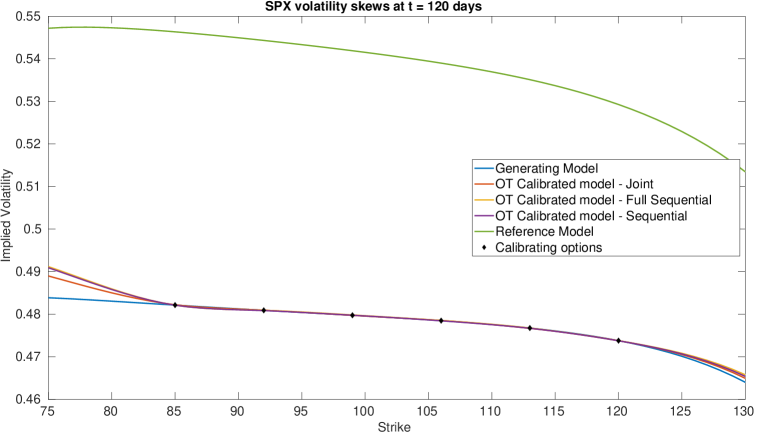
Figure 12 (a) demonstrates that all are near the generating model within the region of our strikes and then deviate in the same manner towards the reference model outside the region of calibrating call option strikes. This is expected behaviour since in all three cases, the cost functions penalise deviations away from a reference model volatility while enforcing that the observed call option prices are replicated. A remarkable result is that Figure 12 (b) shows that are all close at days despite being defined differently. We do however see some expected perturbations on those dates and a larger perturbation at days which is also observed in the larger fluctuations seen in Figure 12 (a). Figure 13 (a) demonstrates strong dependence on the reference model: all differ from by approximately , however and do perturb slightly towards to generating model in the region of strikes. Since our calibrating option has a payoff function only explicitly depending on the log-stock, this was expected behaviour since and are defined via . As remarked in [18], the extremely strong dependence on the reference model for arises mainly from the assumption on the form of the correlation given in (21). The differences observed in Figure 13 (b) arise from a fundamentally different handling of and that the volatility of the short rate is fixed so that will be different to . Nonetheless, since all three depend strongly on the reference model, these fluctuations are small.
All three methods converged to a good accuracy with a maximum error in implied volatility of , as shown in Table 4 and Figure 10, where in all three cases, we applied Algorithm 1 with the smoothed reference model iteration. A minimum of 10 smoothing iterations were applied in all three cases to generate smoother surfaces. Since each smoothing iteration terminates either when calibration error is achieved or when a threshold of function evaluations were attained, in practice around 20 were required for the sequential calibration case to converge, as opposed to full sequential and joint calibration which both converged on the smoothing iteration. The fastest in terms of computational time was the full sequential approach, taking just over an hour and the slowest was the joint calibration approach taking around three hours. Each epoch of a smoothed reference iteration was the fastest in sequential calibration. Joint calibration being the slowest was to be expected since it still computes the optimisers and at each point, which is more expensive that simply fixing them as in the other two methods.
Appendix A Plots of Calibrated Characteristics from the Comparison
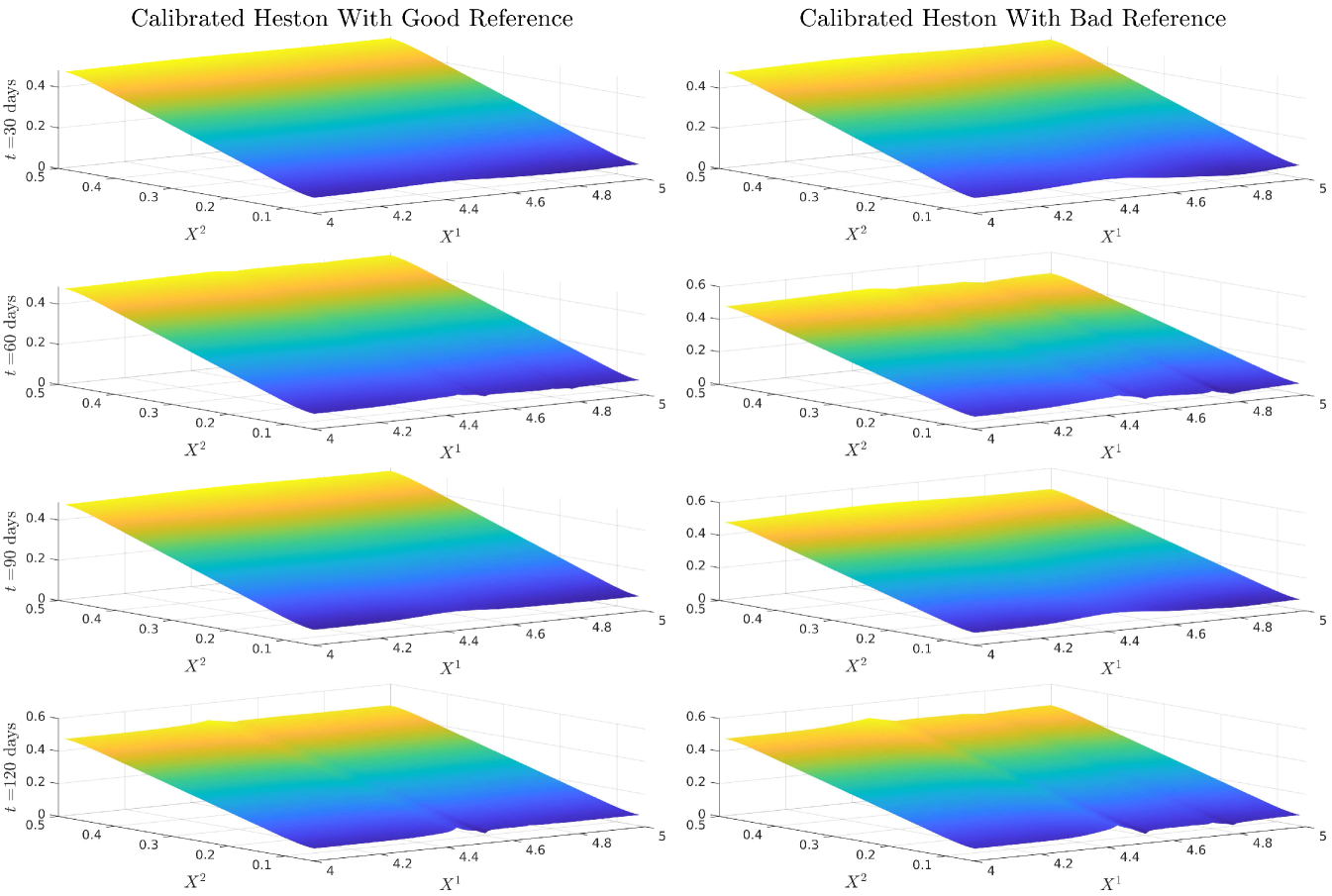
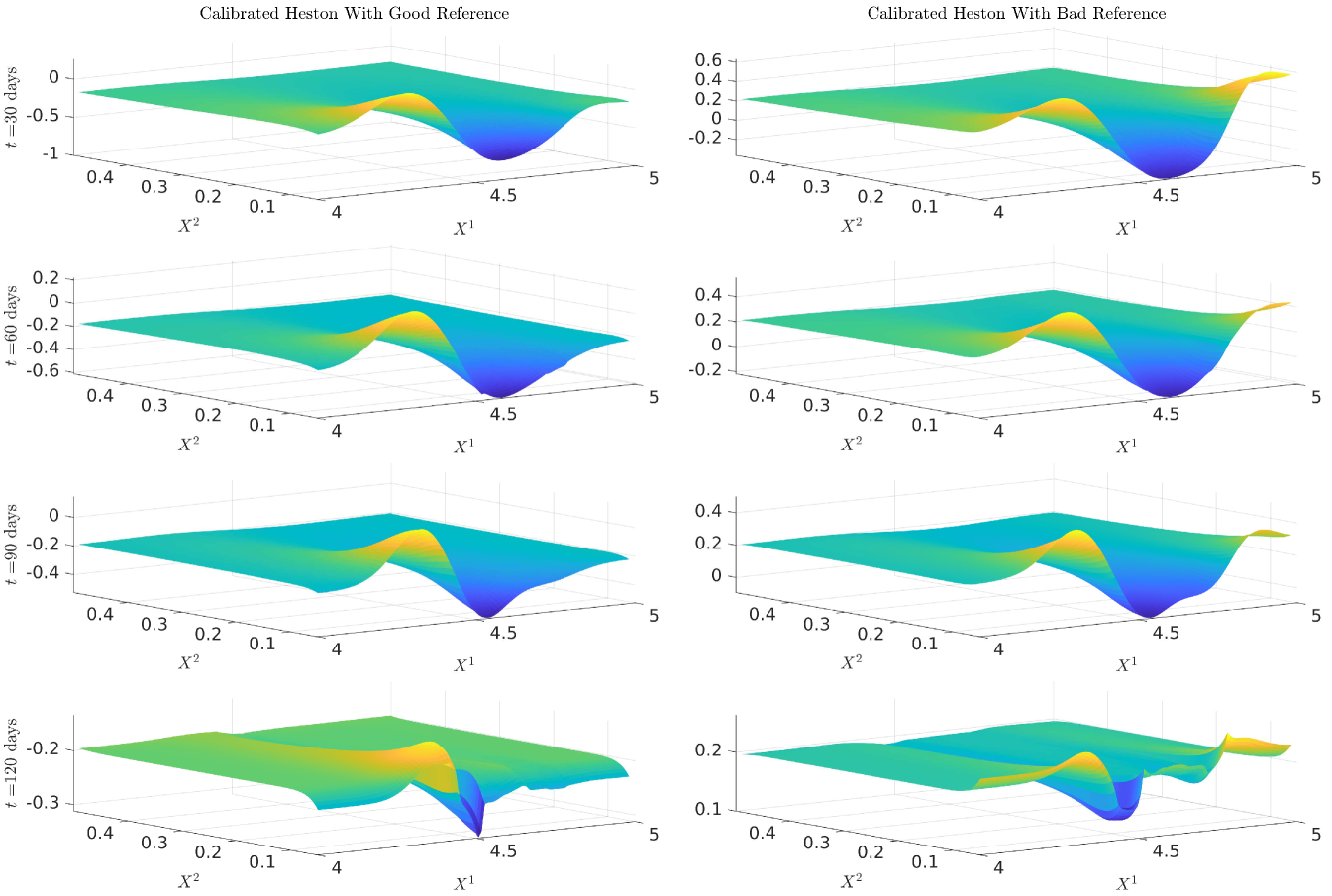
We only show the plots of and since is entirely determined by and Figure 12 and Figure 15 demonstrate that all three cases are extremely close or exactly equal to the generating model for and .
Appendix B Proof of Lemma 3.2
Since defined in (7) enforces that , we immediately have the first equality given an optimiser . We remark that any reference model will also follow the same constraint. Additionally, is enforced by the set . Therefore, since our cost function is given by (8), its Legendre-Fenchel transform is given by:
| (29) |
The gradient is given by the maximisers of (29), and by rearranging the term, we obtain the second equality:
Now, similarly rearranging (29)
We solve the minimisations of and inside the minimisation problem by taking:
Given and as above, we now may rewrite the outside constraint as and thus obtain:
In particular, in the first case, the condition is automatically satisfied and the procedure returns the optimizer. By taking and , we conclude the proof.
Appendix C Application of Full Sequential Calibration to Local-Stochastic Volatility Models
We observe there that the method of Section 5.2 can be applied to the local-stochatic volatility calibration setting of [12] to relax the constraint on the correlation imposed in that paper. In this setting, we assume our interest rate is zero and that our reference model is given by a Heston model, derived in [14]. The state variables are therefore our log-stock and a correlated stochastic term for the volatility, with dynamics given by:
where and . We assume that the state variable is known, so the model characteristics that we want to calibrate are the volatility of the log-stock and the correlation between the state variables. As before, the instruments that we calibrate this model to are European call options on the chosen stock. We now define our cost function in a similar manner to Section 5.2 by defining the convex set :
| (30) |
| (31) |
Since we have no stochastic discount factor, we no longer need the sub-probability measure approach of [18], and therefore can directly apply the duality result of [12, Proposition 3.7]. With our cost function defined in (31), we therefore obtain the following dual formulation:
Problem C.1 (Full Sequential Dual Formulation).
Where solves the HJB equation:
| (32) |
Similar to Lemma 5.4, we obtain the following approximation for and :
Lemma C.2.
Let and define and by
Then is a positive semi-definite matrix and whenever
then is the optimizer in (32).
We numerically solve this problem using the same methods as in Section 3.1, we show a table of parameters below. We simulate the call option prices from the generating model and test it against two reference models: a “good” reference model and a “bad” reference model. The parameters used in are those of the reference model.
| Heston Model | ||
| Parameter | Value | Interpretation |
| Initial log-stock price | ||
| Initial volatility | ||
| Tolerance for the difference in scaled model and market implied volatility | ||
| Tolerance for the policy iteration approximation of the optimal characteristics | ||
| 1 | Speed of volatility mean reversion in the generating model | |
| 0.05 | Long-term mean of the volatility in the generating model | |
| 0.2 | Volatility scaling of the volatility in the generating model | |
| -0.4 | Instantaneous correlation between the log-stock and volatility in the generating model | |
| 1.5 | Speed of volatility mean reversion in the reference model | |
| 0.07 | Long-term mean of the volatility in the reference model | |
| 0.15 | Volatility scaling of the volatility in the reference model | |
| -0.2 | Instantaneous correlation between the log-stock and volatility in the reference model | |
| 2 | Speed of volatility mean reversion in the reference model | |
| 0.09 | Long-term mean of the volatility in the reference model | |
| 0.3 | Volatility scaling of the volatility in the reference model | |
| 0.2 | Instantaneous correlation between the log-stock and volatility in the reference model | |
| Generating Model | Calibrated Model: | Calibrated Model: | |||||
| Good Reference | Bad Reference | ||||||
| Option Type | Strike | Price | IV | Price | IV | Price | IV |
| SPX Call options days | 85 | 11.0144 | 0.4840 | 11.0143 | 0.4840 | 11.0148 | 0.4841 |
| 92 | 7.1928 | 0.4808 | 7.1928 | 0.4808 | 7.1920 | 0.4808 | |
| 99 | 4.4416 | 0.4782 | 4.4419 | 0.4782 | 4.4414 | 0.4782 | |
| 106 | 2.6037 | 0.4761 | 2.6036 | 0.4761 | 2.6034 | 0.4760 | |
| 113 | 1.4564 | 0.4744 | 1.4562 | 0.4743 | 1.4562 | 0.4743 | |
| 120 | 0.7813 | 0.4729 | 0.7814 | 0.4730 | 0.7811 | 0.4729 | |
| SPX Call options days | 85 | 13.4256 | 0.4686 | 13.4260 | 0.4687 | 13.4256 | 0.4686 |
| 92 | 9.8367 | 0.4656 | 9.8372 | 0.4656 | 9.8370 | 0.4656 | |
| 99 | 7.0267 | 0.4628 | 7.0273 | 0.4628 | 7.0250 | 0.4627 | |
| 106 | 4.9025 | 0.4601 | 4.9043 | 0.4602 | 4.9034 | 0.4602 | |
| 113 | 3.3437 | 0.4574 | 3.3450 | 0.4575 | 3.3451 | 0.4575 | |
| 120 | 2.2243 | 0.4541 | 2.2249 | 0.4541 | 2.2252 | 0.4541 | |
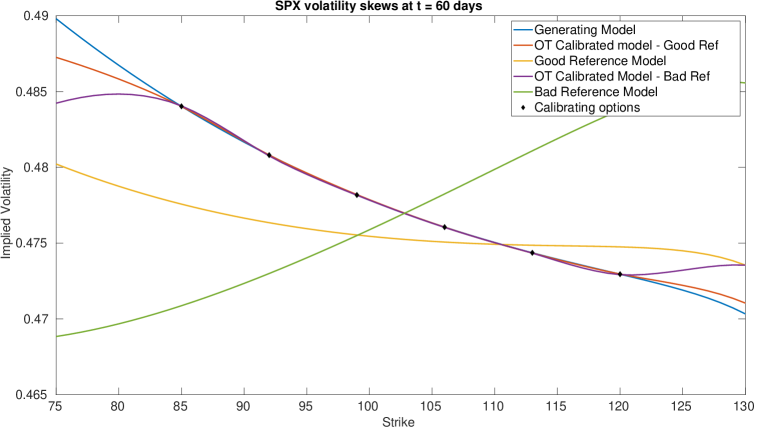
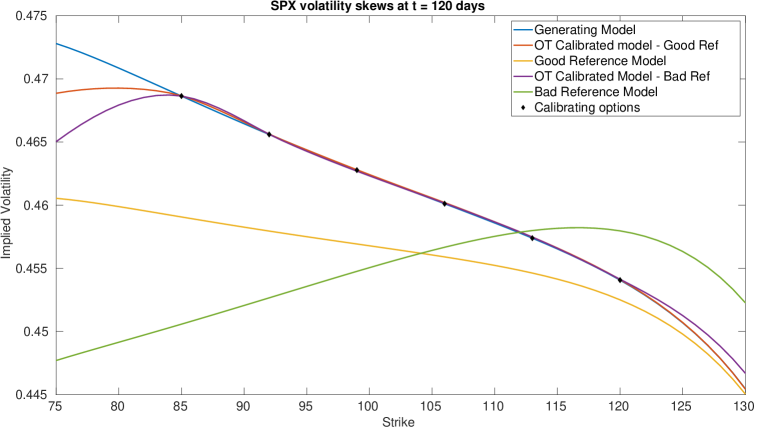
We remark that this approach can recover the implied volatility within the range of the strikes even when the reference model has completely the wrong shape of implied volatility. We now display the surfaces of SOT calibrated and . We notice that while the generating and reference models in are the same, our calibrated model is perturbed from the reference. We also notice that our calibrated correlation is close to the reference model correlation parameter in both cases, with deviations towards the generating model when we are in the range of our strikes and when is near zero. This strong dependence is also seen in our previous calibration approaches, and thus a good a priori estimate of would be needed in practice.
References
- [1] Marco Avellaneda, Craig Friedman, Richard Holmes and Dominick Samperi “Calibrating volatility surfaces via relative-entropy minimization” In Applied Mathematical Finance 4.1 Taylor & Francis, 1997, pp. 37–64
- [2] Jean-David Benamou and Yann Brenier “A computational fluid mechanics solution to the Monge-Kantorovich mass transfer problem” In Numerische Mathematik 84.3 Springer, 2000, pp. 375–393
- [3] Damiano Brigo and Fabio Mercurio “Interest rate models-theory and practice: with smile, inflation and credit” Springer Science & Business Media, 2007
- [4] Gerard Brunick and Steven Shreve “Mimicking an Itô process by a solution of a stochastic differential equation” In Annals of Applied Probability 23.4 Institute of Mathematical Statistics, 2013, pp. 1584–1628
- [5] Lucilla Corrias “Fast Legendre–Fenchel transform and applications to Hamilton–Jacobi equations and conservation laws” In SIAM journal on numerical analysis 33.4 SIAM, 1996, pp. 1534–1558
- [6] John Cox “Notes on option pricing I: Constant elasticity of variance diffusions” In Unpublished note, Stanford University, Graduate School of Business, 1975
- [7] John Cox “The constant elasticity of variance option pricing model” In Journal of Portfolio Management Pageant Media, 1996, pp. 15–17
- [8] Ivan Guo and Grégoire Loeper “Path dependent optimal transport and model calibration on exotic derivatives” In The Annals of Applied Probability 31.3 Institute of Mathematical Statistics, 2021, pp. 1232–1263
- [9] Ivan Guo, Grégoire Loeper, Jan Obłój and Shiyi Wang “Joint Modeling and Calibration of SPX and VIX by Optimal Transport” In SIAM Journal on Financial Mathematics 13.1 SIAM, 2022, pp. 1–31
- [10] Ivan Guo, Grégoire Loeper, Jan Obłój and Shiyi Wang “Optimal transport for model calibration” In Risk Magazine Risk. net, 2022
- [11] Ivan Guo, Grégoire Loeper and Shiyi Wang “Local volatility calibration by optimal transport” In 2017 MATRIX Annals Springer, 2019, pp. 51–64
- [12] Ivan Guo, Grégoire Loeper and Shiyi Wang “Calibration of local-stochastic volatility models by optimal transport” In Mathematical Finance 32.1 Wiley Online Library, 2022, pp. 46–77
- [13] István Gyöngy “Mimicking the one-dimensional marginal distributions of processes having an Itô differential” In Probability Theory and Related Fields 71.4 Springer, 1986, pp. 501–516
- [14] Steven Heston “A closed-form solution for options with stochastic volatility with applications to bond and currency options” In The Review of Financial Studies 6.2 Oxford University Press, 1993, pp. 327–343
- [15] John Hull and Alan White “Pricing interest-rate-derivative securities” In The Review of Financial Studies 3.4 Oxford University Press, 1990, pp. 573–592
- [16] John Hull and Alan White “Branching out” In Risk 7.7, 1994, pp. 34–37
- [17] John Hull and Alan White “A note on the models of Hull and White for pricing options on the term structure: Response” In The Journal of Fixed Income 5.2 Institutional Investor Journals Umbrella, 1995, pp. 97–102
- [18] Benjamin Joseph, Grégoire Loeper and Jan Obłój “Calibration of Local Volatility Models with Stochastic Interest Rates using Optimal Transport”, 2023 arXiv:2305.00200
- [19] Pierre-Louis Lions “Optimal control of diffusion processes and Hamilton–Jacobi–Bellman equations part 2: viscosity solutions and uniqueness” In Communications in Partial Differential Equations 8.11 Taylor & Francis, 1983, pp. 1229–1276
- [20] Dong Liu and Jorge Nocedal “On the limited memory BFGS method for large scale optimization” In Mathematical Programming 45.1 Springer, 1989, pp. 503–528
- [21] Grégoire Loeper “Option pricing with linear market impact and nonlinear Black-Scholes equations” In Ann. Appl. Probab. 28.5, 2018, pp. 2664–2726 DOI: 10.1214/17-AAP1367
- [22] Grégoire Loeper and Fernando Quiros “Interior second derivative estimates for nonlinear diffusions” In arXiv preprint arXiv:1812.11253, 2018
- [23] Yves Lucet “Faster than the fast Legendre transform, the linear-time Legendre transform” In Numerical Algorithms 16 Springer, 1997, pp. 171–185
- [24] K Ma and PA Forsyth “An unconditionally monotone numerical scheme for the two-factor uncertain volatility model” In IMA Journal of Numerical Analysis 37.2 Oxford University Press, 2017, pp. 905–944
- [25] R. Rockafellar “Convex analysis”, Princeton Mathematical Series, No. 28 Princeton University Press, Princeton, N.J., 1970
- [26] Xiaolu Tan and Nizar Touzi “Optimal transportation under controlled stochastic dynamics” In The Annals of Probability 41.5 Institute of Mathematical Statistics, 2013, pp. 3201–3240
- [27] Oldrich Vasicek “An equilibrium characterization of the term structure” In Journal of Financial Economics 5.2 Elsevier, 1977, pp. 177–188