Joint Data Deepening-and-Prefetching for Energy-Efficient Edge Learning
Abstract
The vision of pervasive machine learning (ML) services can be realized by training an ML model on time using real-time data collected by internet of things (IoT) devices. To this end, IoT devices require offloading their data to an edge server in proximity. On the other hand, high dimensional data with a heavy volume causes a significant burden to an IoT device with a limited energy budget. To cope with the limitation, we propose a novel offloading architecture, called joint data deepening and prefetching (JD2P), which is feature-by-feature offloading comprising two key techniques. The first one is data deepening, where each data sample’s features are sequentially offloaded in the order of importance determined by the data embedding technique such as principle component analysis (PCA). No more features are offloaded when the features offloaded so far are enough to classify the data, resulting in reducing the amount of offloaded data. The second one is data prefetching, where some features potentially required in the future are offloaded in advance, thus achieving high efficiency via precise prediction and parameter optimization. To verify the effectiveness of JD2P, we conduct experiments using the MNIST and fashion-MNIST dataset. Experimental results demonstrate that the JD2P can significantly reduce the expected energy consumption compared with several benchmarks without degrading learning accuracy.
I Introduction
With the wide spread of internet of things (IoT) devices, a huge amount of real-time data have been continuously generated. It can be fuel for operating various on-device machine learning (ML) services, e.g., object detection and natural language processing, if provided on time. One viable technology to this end is edge learning, where an ML model is trained at the edge server in proximity using the data offloaded from IoT devices [1]. Compared to the learning at the cloud server, IoT devices can offer the latest data to the edge server before out-of-date, and the resultant ML model can reflect the current environment precisely without a dataset shift [2] or catastrophic forgetting [3].
On the other hand, as the concerned environment becomes complex, the data collected by each device tends to be high-dimensional with heavy volume, thus causing a significant burden to offload data for an IoT device with a limited energy budget. Several attempts have been proposed in the literature to address this issue, whose main thrust is to selectively offload data depending on the importance of data to the concerned ML model. In [4], motivated by the classic support vector machine (SVM) technique, data importance was defined inversely proportional to its uncertainty, which corresponds to the margin to the decision boundary. A selective retransmission decision was optimized by allowing more transmissions for data with high uncertainty, leading to the corresponding ML model’s fast convergence. In the same vein, the scheduling issue of multi-device edge learning has been tackled in [5], where a device having more important data samples is granted access to the medium more frequently. In [6], a data sample’s gradient norm obtained during training a deep neural network (DNN) was regarded as the corresponding importance metric. It enables each mobile device to select data sample that is likely to contribute to its local ML model training in a federated edge learning system. In [7], data importance was defined at the dispersed level of dataset distribution. A device with an important dataset is allowed to assign more bandwidth to accelerate the training process.
Aligned with the trend, we aim to develop a novel edge learning architecture, called joint data deepening and prefetching (JD2P). The above prior works quantify the importance of each data sample or the entire dataset, bringing about a significant communication overhead when raw data become complex with a higher dimension. On the other hand, the proposed JD2P leverages the technique of data embedding to extract a few features from raw data and sort them in the order of importance. This allows us to design a feature importance-based offloading technique, called data deepening; Features are sequentially offloaded in the important order and stop offloading the next one if reaching the desired performance. Besides, several data samples’ subsequent features can be offloaded proactively before requested, called data prefetching, which extends the offloading duration and thus achieves higher energy efficiency. Through relevant parameter optimizations and extensive simulation studies using the MNIST and fashion-MNIST dataset, it is verified that the JD2P reduces the expected energy consumption significantly than several benchmarks without degrading learning accuracy.
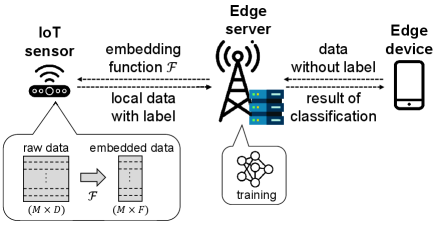
II System Model
This section describes our system model, including the concerned scenario, data structure, and offloading model.
II-A Edge Learning Scenario
Consider an edge learning network comprising a pair of the edge server and the IoT sensor as a data collector (see Fig. 1). We aim at training a binary classifier using local data with two classes collected by the IoT sensor. Due to the IoT sensor’s limited computation capability, the edge server is requested to train a classifier with the local data offloaded from IoT sensor instead of training the classifier on the IoT sensor.
II-B Data Embedding
Consider samples measured at the sensor, denoted by , where is the index of data sample, i.e., . We assume that the class of each sample is known, denoted by . Each raw data sample’s dimension, say , is assumed to be equivalent. The dimension is in general sufficiently high to reflect complex environments, which is known as an obstacle to achieve high-accuracy classification [8]. Besides, a large amount of energy is required to offload these raw data to the edge server. To overcome these limitations, these high dimensional raw data can be embedded into a low-dimensional space using data embedding techniques [9], such as principle component analysis (PCA) [10] and auto-encoder [11]. Specifically, given less than , there exists a mapping function such that
| (1) |
where represents the embedded data with features. We assume that the edge device knows the embedding function , which has been trained by the edge server using the historical data set. We use PCA as a primary feature embedding technique due to its low computational overhead, while other techniques are straightforwardly applicable. Partial or all features of each embedded data are offloaded depending on the offloading and learning designs introduced in the sequel.
II-C Offloading Model
The entire offloading duration is slotted into rounds with seconds. The channel gain in round is denoted as with . We assume that channel gains are constant over one time slot and independently and identically distributed (i.i.d.) over different rounds. Following the models in [12] and [13], the transmission power required to transmit bits in round , denoted as , is modeled by a monomial function and is given as where is the energy coefficient, represents the monomial order, and is an allowable transmission duration for bits. The typical range for a monomial order is because this order depends on the specific modulation and coding scheme. Then, the energy consumption in round , which is the product of and , is given as
| (2) |
It is shown that energy consumption is proportional to the transmitted data size , and inversely proportional to the transmission time . For energy-efficient edge learning, it is necessary to decrease the amount of transmitted data and increase the transmission time.
III Joint Data Deepening-and-Prefetching
This section aims at describing JD2P as a novel architecture to realize energy-efficient edge learning. The overall architecture is briefly introduced first and the detailed techniques of JD2P are elaborated next.
III-A Overview
The proposed JD2P is a feature-by-feature offloading control for energy-efficient classifier training, built on the following definition.
Definition 1 (Data Depth).
A embedded data sample is said to have depth when features from to , say , are enough to correctly predict its class.
By Definition 1, we can offload less amount of data required to train the classifier and the resultant energy consumption can be reduced if depths of all data are known in advance. On the other hand, each data sample’s depth can be determined after the concerned classifier is trained. Eventually, it is required to process each data’s depth identification and classifier training simultaneously to cope with the above recursive relation, which is technically challenging. To this end, we propose two key techniques summarized below.
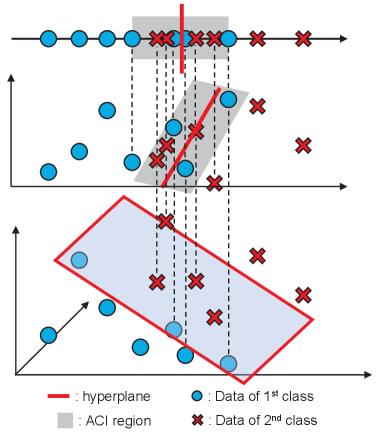
III-A1 Data Deepening
It is a closed-loop offloading decision whether to offload a new feature or not based on the current version of a classifier. Specifically, consider the -depth classifier defined as one trained through features from to , say for all where denotes an index set of data samples that may have a depth of . We use a classic SVM for each depth classifier111The extension to other classifiers such as DNN and convolutional neural network (CNN) are straightforward, which remains for our future work., whose decision hyperplane is given as
| (3) |
where is the vector perpendicular to the hyperplane and is the offset parameter. Given a data sample for , the distance to the hyperplane in (3) can be computed as
| (4) |
where represents the Euclidean norm. The data sample is said to be a clearly classified instance (CCI) by the -depth classifier if is no less than a threshold to be specified in Sec. III-B. Otherwise, it is said to be a ambiguous classified instance (ACI). In other words, CCIs are depth- data not requiring an additional feature. Only ACIs are thus included in a new set , given as
| (5) |
As a result, the edge server requests the edge device to offload the next feature for . Fig. 2 illustrates the graphical example of data deepening from -dimensional to -dimensional spaces. The detailed process is summarized in Algorithm 1 except the design of the threshold .
III-A2 Data Prefetching
As shown in Fig. 3, the round comprises an offloading duration for the -th features (i.e., ) and a training duration for the -depth classifier, and a feedback duration for a new ACI set in (5). Without loss of generality, the feedback duration is assumed to be negligible due to its small data size and the edge server’s high transmit power. Note that can be available when starting round , and a sufficient amount of time should be reserved for training the -depth classifier. Denote as the corresponding training duration. In other words, the offloading duration should be no more than , making energy consumption significant as becomes longer.
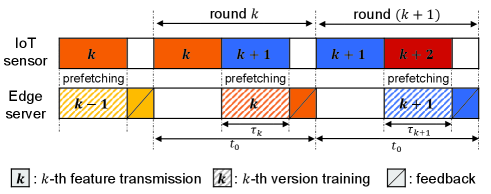
It can be overcome by offloading the partial data samples’ features in advance during the training process, called prefetching. The resultant offloading duration can be extended from to , enabling the IoT device to reduce energy consumption, according to (2). On the other hand, the prefetching decision is based on predicting on whether the concerned data sample becomes ACIs. Unless correct, the excessive energy is consumed to prefetch useless features. Balancing the tradeoff is a key, which will be addressed by formulating a stochastic optimization in Sec. IV-A.
III-B Threshold Design for Data Deepening
This subsection deals with the threshold design to categorize whether the concerned data sample is ACI or CCI based on the -depth classifier. The stochastic distribution of each class can be approximated in a form of -variate Gaussian processes using the Gaussian mixture model (GMM) [14]. As shown in Fig. 4, the overlapped area between two distributions is observed. The data samples in the area are likely to be misclassified. We aim at setting the threshold in such a way that most data samples in the overlapped area are included except a few outliners located in each tail.
To this end, we introduce the Mahalanobis distance (MD) [15] as a metric representing the distance from each instant to the concerned distribution. Given class , the MD is defined as
| (6) |
where with and being the distribution’s mean vector and covariance matrix respectively, which are obtainable through the GMM process. It is obvious that is a scale-free random variable and we attempt to set the threshold as the value whose cumulative distribution function (CDF) of becomes , namely,
| (7) |
Noting that the square of follows a chi-square distribution with degree-of-freedom, the CDF of this distribution for is defined as :
| (8) |
where is gamma function defined as and is the lower incomplete gamma function defined as . In a closed-form, the threshold can be given as
| (9) |
where represents the inverse CDF of chi-square distribution with degree-of-freedom. Due to the scale-free property, the threshold is identically set regardless of the concerned class; thus, the index of class can be omitted, namely, . Given , the each distribution can be truncated as
| (10) |
Last, the threshold is set by the maximum distance from the hyperplane in (3) to an arbitrary -dimensional point in the overlapped area of and , given as
| (11) |
The process to obtain the threshold is summarized in Algorithm 2.
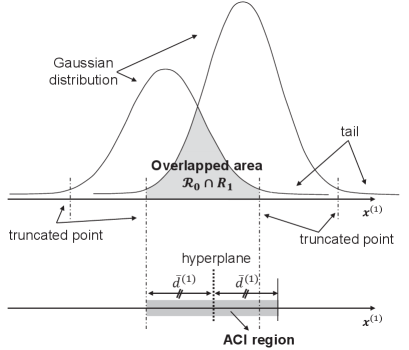
Remark 1 (Symmetric ACI Region).
Noting that each class’s covariance matrix is different, the resultant truncated areas of and become asymmetric. To avoid the classifier overfitted to one class, we choose the common distance threshold for both classes, say in (11), corresponding to the maximum distance between the two.
III-C Hierarchical Edge Inference
After rounds, the entire classifier has a hierarchical structure comprising from -depth to -depth classifiers. Consider that a mobile device sends an unlabeled data sample to the edge server, which is initially set as an ACI. Starting from the -depth classifier, the data sample passes through different depth classifiers in sequence until it is changed to an CCI. The last classifier’s depth is referred to as the data sample’s depth. In other words, its classification result becomes the final one.
IV Optimal Data Prefetching
This section deals with selecting the size of prefetched data in the sense of minimizing the expected energy consumption of the sensor.
IV-A Problem Formulation
Consider the prefetching duration in round , say , which is equivalent to the training duration of the -depth classifier, as shown in Fig. 3. The number of data samples in is denoted by . Among them, data samples are randomly selected and their -th features are prefetched. The prefetched data size is , where represents the number of bits required to quantize feature data222The quantization bit rate depends on the value of intensity. For example, one pixel of MNIST data has intensities and can be quantized 8 bits, i.e., .. Given the channel gain , the resultant energy consumption for prefetching is
| (12) |
Here, the number of prefetched data is a discrete control parameter ranging from to . For tractable optimization in the sequel, we regard as a continuous variable within the range, which is rounded to the nearest integer in practice.
Next, consider the offloading duration in round , say . Among the data samples in , a few number of data, denoted by , remain after the prefetching. Given the channel gain , the resultant energy consumption is
| (13) |
Note that is determined after the -depth classifier is trained. In other words, is random at the instant of the prefetching decision. Denote as the ratio of a data sample in being included in . Then, follows a binomial distribution with parameters and , whose probability mass function is for . Given , the expected energy consumption is
| (14) |
where is the expectation of the inverse channel gain, which can be known a priori due to its i.i.d. property.
IV-B Optimal Prefetching Control
This subsection aims at deriving the closed-form expression of the optimal prefetching number by solving IV-A. The main difficulty lies in addressing the -th moment , of which the simple form is unknown for general . To address it, we refer to the upper bound of the -th moment in [16],
| (15) |
where is the mean of the binomial distribution with parameters and . It is proved in [16] that the above upper bound is tight when the order is less than the mean . Therefore, instead of solving IV-A directly, the problem of minimizing the upper bound of the objective function can be formulated as
| s.t. | (P2) |
Note that P2 is a convex optimization, enabling us to derive the closed-form solution. The main result is shown in the following proposition.
Proposition 1 (Optimal Prefetching Policy).
Given the ratio of prefetching in round , the optimal prefetching data size , which is the solution to P2, is
| (16) |
where .
Proof:
Define the Lagrangian function for P2 as
where is a Lagrangian multipliers. Since P2 is a convex optimization, the following KKT conditions are necessary and sufficient for optimality:
| (17a) | |||
| (17b) | |||
| (17c) | |||
First, if is positive, then should be equal to due to the slackness condition of (17c), making the LHS of (17b) strictly positive. In other words, the optimal multiplier is zero to satisfy (17b). Second, with , the LHS of condition (17a) is always strictly negative unless . As a result, given , should be strictly positive and satisfy the following equality condition:
| (18) |
Solving (18) leads to the optimal solution of P2, which completes the proof of this proposition.
Remark 2 (Effect of Parameters).
Assume that the number of ACIs in slot , say , is significantly larger than . We can approximate (16) as . Noting that the term represents the expected number of ACIs in slot , the parameter controls the portion of prefetching as follows:
-
•
As the current channel gain becomes larger or the training duration increases, the parameter increases and the optimal solution reaches near to the ;
-
•
As becomes smaller and decreases, both and converge to zero.
V Simulation Results
In this section, simulation results are presented to validate the superiority of JD2P over several benchmarks. The parameters are set as follows unless stated otherwise. The entire offloading duration consists of rounds (), each of which is set to (sec). For offloading, the channel follows the Gamma distribution with the shape parameter and the probability density function , where the gamma function and the mean . The energy coefficient is set to , according to [12]. The monomial order of the energy consumption model in (2) is set as . For computing and prefetching, the reserved training duration is assumed constant for all and fixed to (sec) for .
We use the MNIST and fashion MNIST datasets for training and testing. Both datasets include training samples and test samples with gray-scaled pixels. The number of each dataset’s classes is . We conduct experiments with every possible pair of classes, namely, pairs. PCA is applied for data embedding. For comparison, we consider two benchmark schemes. The first one is to use data deepening only without data prefetching. The second one is full offloading, where all data samples’ features are offloaded first, and the classifier is trained using them. To be specific, the offloading duration of each round is except the last one reduced as .
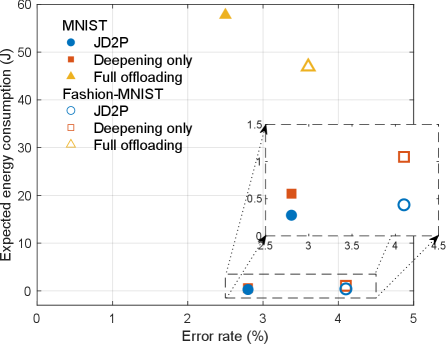
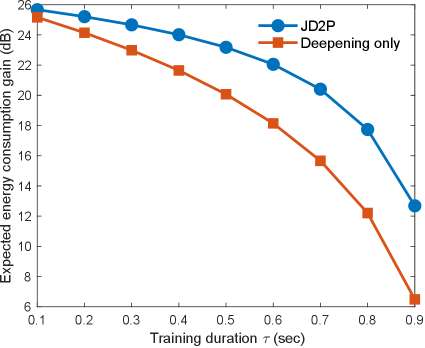
First, the expected energy consumption (in Joule) versus the error rate (in %) is plotted in Fig. 5. It is shown that the proposed JD2P consumes less energy than the full offloading scheme, namely, dB and dB energy gain for MNIST and fashion-MNIST, respectively, at cost of the marginal degradation in the error rate. The effectiveness of data prefetching is demonstrated in Fig. 6, plotting the curves of the expected energy consumption gain against the prefetching duration in the case of the MNIST dataset333The case of the fashion MNIST dataset follows the tendency similar to that of MNIST although the result is omitted in this paper. The JD2P’s expected energy consumption is always smaller than the scheme of data deepening only by sophisticated control of prefetching data in Sec. IV. On the other hand, when compared with the full offloading scheme, the energy gain of JD2P decreases as increases. In other words, a shorter offloading duration compels more data samples to be prefetched, wasting more energy since many prefetched data samples are likely to become CCIs while not being used for the following training.
VI Concluding remarks
This study explored the problem of multi-round technique for energy-efficient edge learning. Two criteria for achieving energy efficiency are 1) reducing the amount of offloaded data and 2) extending the offloading duration. JD2P was proposed by addressing both, while integrating data deepening and data prefetching with measuring feature-by-feature data importance and optimizing the amount of prefetched data to avoid wasting energy. Our comprehensive simulation study demonstrated that JD2P can significantly reduce the expected energy consumption compared to several benchmarks.
Though the current work targets to design a simple SVM-based binary classifier with PCA as a key data embedding technique, the proposed JD2P is straightforwardly applicable to more challenging scenarios, such as a multi-class DNN classifier with an advanced data embedding technique. Besides, it is interesting to analyze the performance of JD2P concerning various parameters, which is essential to derive rigorous guidelines for JD2P’s practical use.
References
- [1] G. Zhu, D. Liu, Y. Du, C. You, J. Zhang, and K. Huang, “Toward an intelligent edge: Wireless communication meets machine learning,” IEEE communications magazine, vol. 58, no. 1, pp. 19–25, 2020.
- [2] J. Quinonero-Candela, M. Sugiyama, A. Schwaighofer, and N. D. Lawrence, Dataset shift in machine learning. Mit Press, 2008.
- [3] I. J. Goodfellow, M. Mirza, D. Xiao, A. Courville, and Y. Bengio, “An empirical investigation of catastrophic forgetting in gradient-based neural networks,” arXiv preprint arXiv:1312.6211, 2013.
- [4] D. Liu, G. Zhu, Q. Zeng, J. Zhang, and K. Huang, “Wireless data acquisition for edge learning: Data-importance aware retransmission,” IEEE Transactions on Wireless Communications, vol. 20, no. 1, pp. 406–420, 2020.
- [5] D. Liu, G. Zhu, J. Zhang, and K. Huang, “Data-importance aware user scheduling for communication-efficient edge machine learning,” IEEE Transactions on Cognitive Communications and Networking, vol. 7, no. 1, pp. 265–278, 2020.
- [6] Y. He, J. Ren, G. Yu, and J. Yuan, “Importance-aware data selection and resource allocation in federated edge learning system,” IEEE Transactions on Vehicular Technology, vol. 69, no. 11, pp. 13 593–13 605, 2020.
- [7] A. Taïk, Z. Mlika, and S. Cherkaoui, “Data-aware device scheduling for federated edge learning,” IEEE Transactions on Cognitive Communications and Networking, vol. 8, no. 1, pp. 408–421, 2021.
- [8] P. Domingos, “A few useful things to know about machine learning,” Communications of the ACM, vol. 55, no. 10, pp. 78–87, 2012.
- [9] L. Zheng, S. Wang, and Q. Tian, “Coupled binary embedding for large-scale image retrieval,” IEEE transactions on image processing, vol. 23, no. 8, pp. 3368–3380, 2014.
- [10] H. Abdi and L. J. Williams, “Principal component analysis,” Wiley interdisciplinary reviews: computational statistics, vol. 2, no. 4, pp. 433–459, 2010.
- [11] G. E. Hinton and R. R. Salakhutdinov, “Reducing the dimensionality of data with neural networks,” science, vol. 313, no. 5786, pp. 504–507, 2006.
- [12] Y. Tao, C. You, P. Zhang, and K. Huang, “Stochastic control of computation offloading to a helper with a dynamically loaded cpu,” IEEE Transactions on Wireless Communications, vol. 18, no. 2, pp. 1247–1262, 2019.
- [13] W. Zhang, Y. Wen, K. Guan, D. Kilper, H. Luo, and D. O. Wu, “Energy-optimal mobile cloud computing under stochastic wireless channel,” IEEE Transactions on Wireless Communications, vol. 12, no. 9, pp. 4569–4581, 2013.
- [14] C. M. Bishop and N. M. Nasrabadi, Pattern recognition and machine learning. Springer, 2006, vol. 4, no. 4.
- [15] M. Bensimhoun, “N-dimensional cumulative function, and other useful facts about gaussians and normal densities,” Jerusalem, Israel, Tech. Rep, pp. 1–8, 2009.
- [16] T. D. Ahle, “Sharp and simple bounds for the raw moments of the binomial and poisson distributions,” Statistics & Probability Letters, vol. 182, p. 109306, 2022.