Joint Learning of Linear Time-Invariant Dynamical Systems
Abstract
Linear time-invariant systems are very popular models in system theory and applications. A fundamental problem in system identification that remains rather unaddressed in extant literature is to leverage commonalities amongst related systems to estimate their transition matrices more accurately. To address this problem, we investigate methods for jointly estimating the transition matrices of multiple systems. It is assumed that the transition matrices are unknown linear functions of some unknown shared basis matrices. We establish finite-time estimation error rates that fully reflect the roles of trajectory lengths, dimension, and number of systems under consideration. The presented results are fairly general and show the significant gains that can be achieved by pooling data across systems, in comparison to learning each system individually. Further, they are shown to be robust against moderate model misspecifications. To obtain the results, we develop novel techniques that are of independent interest and are applicable to similar problems. They include tightly bounding estimation errors in terms of the eigen-structures of transition matrices, establishing sharp high probability bounds for singular values of dependent random matrices, and capturing effects of misspecified transition matrices as the systems evolve over time.
keywords:
Multiple Linear Systems; Data Sharing; Finite Time Identification; Autoregressive Processes; Joint Estimation., , ,
1 Introduction
The problem of identifying the transition matrices in linear time-invariant (LTI) systems has been extensively studied in the literature [8, 26, 29]. Recent papers establish finite-time rates for accurately learning the dynamics in various online and offline settings [16, 36, 39]. Notably, existing results are established when the goal is to identify the transition matrix of a single system.
However, in many application areas of LTI systems, one observes state trajectories of multiple dynamical systems. So, in order to be able to efficiently use the full data of all state trajectories and utilize the possible commonalities the systems share, we need to estimate the transition matrices of all systems jointly. The range of applications is remarkably extensive, including dynamics of economic indicators in US states [35, 40, 42], flight dynamics of airplanes at different altitudes [6], drivers of gene expressions across related species [5, 19], time series data of multiple subjects that suffer from the same disease [38, 41], and commonalities among multiple subsystems in control engineering [43].
In all these settings, there are strong similarities in the dynamics of the systems, which are unknown and need to be learned from the data. Hence, it becomes of interest to develop a joint learning strategy for the system parameters, by pooling the data of the underlying systems together and learn the unknown similarities in their dynamics. In particular, this strategy is of extra importance in settings wherein the available data is limited, for example when the state trajectories are short or the dimensions are not small.
In general, joint learning (also referred to as multitask learning) approaches aim to study estimation methods subject to unknown similarities across the data generation mechanisms. Joint learning methods are studied in supervised learning and online settings [10, 4, 32, 33, 3]. Their theoretical analyses are obtained rely on a number of technical assumptions regarding the data, including independence, identical distributions, boundedness, richness, and isotropy.
However, for the problem of joint learning of dynamical systems, additional technical challenges are present. First, the observations are temporally dependent. Second, the number of unknown parameters is the square of the dimension of the system, which impacts the learning accuracy. Third, since in many applications the dynamics matrices of the underlying LTI systems might possess eigenvalues of (almost) unit magnitude, conventional approaches for dependent data (e.g., mixing) inapplicable [16, 36, 39]. Fourth, the spectral properties of the transition matrices play a critical role on the magnitude of the estimation errors. Technically, the state vectors of the systems can scale exponentially with the multiplicities of the eigenvalues of the transition matrices (which can be as large as the dimension). Accordingly, novel techniques are required for considering all important factors and new analytical tools are needed for establishing useful rates for estimation error. Further details and technical discussions are provided in Section 3.
We focus on a commonly used setting for joint learning that involves two layers of uncertainties. It lets all systems share a common basis, while coefficients of the linear combinations are idiosyncratic for each system. Such settings are adopted in multitask regression, linear bandits, and Markov decision processes [14, 22, 31, 44]. From another point of view, this assumption that the system transition matrices are unknown linear combinations of unknown basis matrices can be considered as a first-order approximation for unknown non-linear dynamical systems [27, 30]. Further, these compound layers of uncertainties subsume a recently studied case for mixtures of LTI systems where under additional assumptions such as exponential stability and distinguishable transition matrices, joint learning from unlabeled state trajectories outperforms individual system identification [11].
The main contributions of this work can be summarized as follows. We provide novel finite-time estimation error bounds for jointly learning multiple systems, and establish that pooling the data of state trajectories can drastically decrease the estimation error. Our analysis also presents effects of different parameters on estimation accuracy, including dimension, spectral radius, eigenvalues multiplicity, tail properties of the noise processes, and heterogeneity among the systems. Further, we study learning accuracy in the presence of model misspecifications and show that the developed joint estimator can robustly handle moderate violations of the shared structure in the dynamics matrices.
In order to obtain the results, we employ advanced techniques from random matrix theory and prove sharp concentration results for sums of multiple dependent random matrices. Then, we establish tight and simultaneous high-probability confidence bounds for the sample covariance matrices of the systems under study. The analyses precisely characterize the dependence of the presented bounds on the spectral properties of the transition matrices, condition numbers, and block-sizes in the Jordan decomposition. Further, to address the issue of temporal dependence, we extend self-normalized martingale bounds to multiple matrix-valued martingales, subject to shared structures across the systems. We also present a robustness result by showing that the error due to misspecifications can be effectively controlled.
The remainder of the paper is organized as follows. The problem is formulated in Section 2. In Section 3, we describe the joint-learning procedure, study the per-system estimation error, and provide the roles of various key quantities. Then, investigation of robustness to model misspecification and the impact of violating the shared structure are discussed in Section 4. We provide numerical illustrations for joint learning in Section 5 and present the proofs of our results in the subsequent sections. Finally, the paper is concluded in Section 10.
Notation. For a matrix , denotes the transpose of . For square matrices, we use the following order of eigenvalues in terms of their magnitudes: . For singular values, we employ and . For any vector , let denote its norm. We use to denote the matrix operator-norm for and : . When , we simply write . For functions , we write , if for a universal constant . Similarly, we use and , if for all , and for all , respectively, where are large enough constants. For any two matrices of the same dimensions, we define the inner product . Then, the Frobenius norm becomes . The sigma-field generated by is denoted by . We denote the -th component of the vector by . Finally, for , the shorthand is the set .
2 Problem Formulation
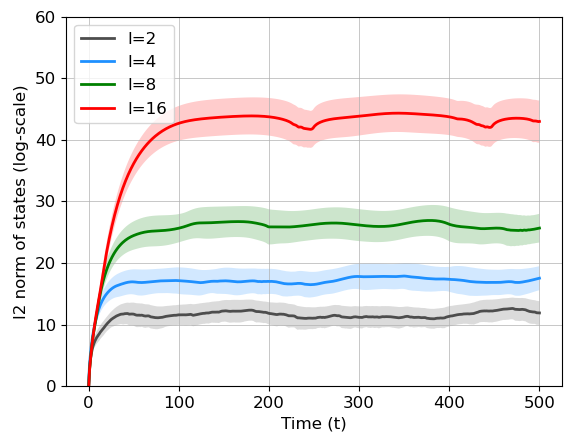
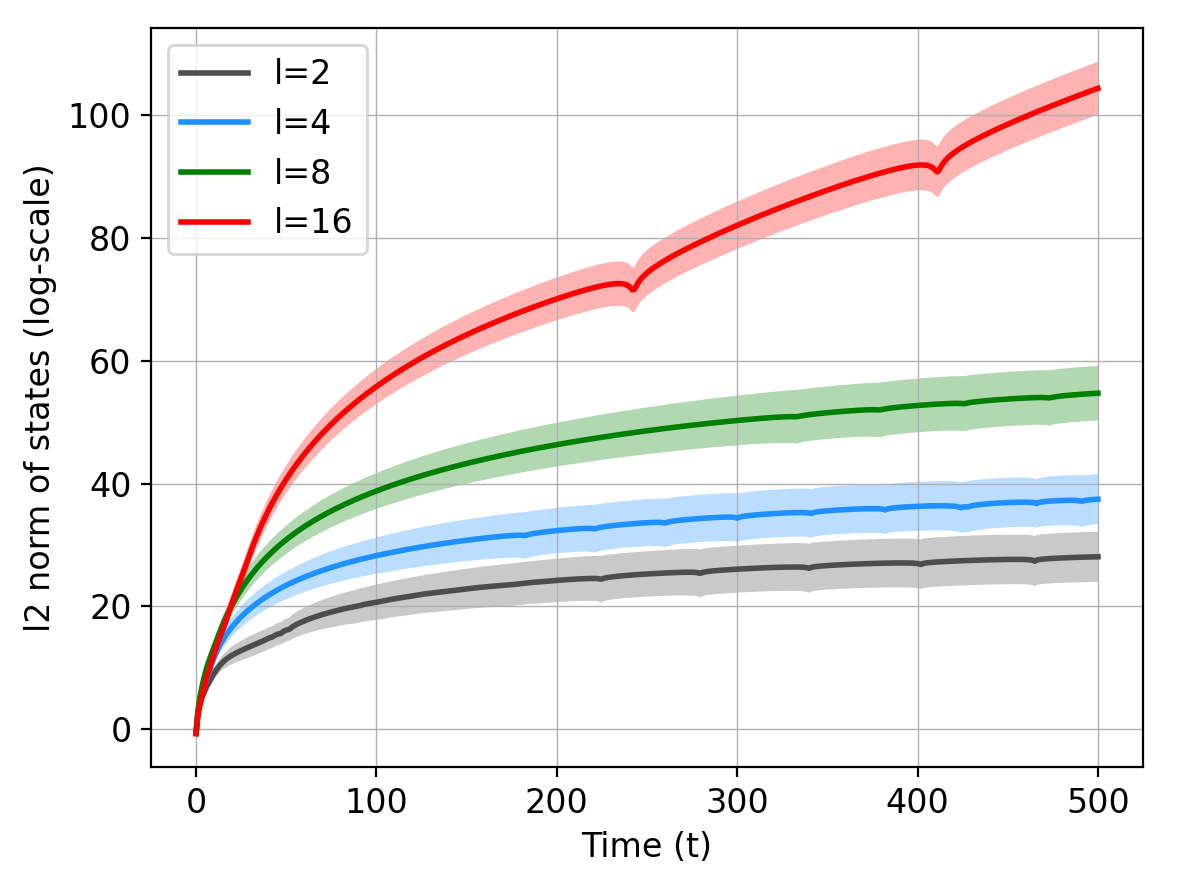
Our main goal is to study the rates of jointly learning dynamics of multiple LTI systems. Data consists of state trajectories of length from different systems. Specifically, for and , let denote the state of the -th system, that evolves according to the Vector Auto-Regressive (VAR) process
| (1) |
Above, denotes the true unknown transition matrix of the -th system and is a mean zero noise. For succinctness, we use to denote the set of all transition matrices . The transition matrices are related as will be specified in Assumption 3.
Note that the above setting includes systems with longer memories. Indeed, if the states obey
then, by concatenating in one larger vector , the new state dynamics is (1), for and
We assume that the system states do not explode in the sense that the spectral radius of the transition matrix can be slightly larger than one. This is required for the systems to be able to operate for a reasonable time length [25, 15]. Note that this assumption still lets the state vectors grow with time, as shown in Figure 1.
Assumption 1.
For all , we have , where is a fixed constant.
In addition to the magnitudes of the eigenvalues, further properties of the transition matrices heavily determine the temporal evolution of the systems. A very important one is the size of the largest block in the Jordan decomposition of , which will be rigorously defined shortly. This quantity is denoted by in (4). The impact of on the state trajectories is illustrated in Figure 1, wherein we plot the logarithm of the magnitude of state vectors for linear systems of dimension . The upper plot depicts state magnitude for stable systems and for blocks of the size in the Jordan decomposition of the transition matrices. It illustrates that the state vector scales exponentially with . Note that can be as large as the system dimension .
Moreover, the case of transition matrices with eigenvalues close to (or exactly on) the unit circle is provided in the lower panel in Figure 1. It illustrates that the state vectors grow polynomially with time, whereas the scaling with the block-size is exponential. Therefore, in design and analysis of joint learning methods, one needs to carefully consider the effects of and .
Next, we express the probabilistic properties of the stochastic processes driving the dynamical systems. Let denote the filtration generated by the the initial state and the sequence of noise vectors. Based on this, we adopt the following ubiquitous setting that lets the noise process be a sub-Gaussian martingale difference sequence. Note that by definition, is -measurable.
Assumption 2.
For all systems , we have and . Further, is sub-Gaussian; for all :
Henceforth, we denote .
The above assumption is widely-used in the finite-sample analysis of statistical learning methods [1, 17]. It includes normally distributed martingale difference sequences, for which Assumption 2 is satisfied with . Moreover, if the coordinates of are (conditionally) independent and have sub-Gaussian distributions with constant , it suffices to let . We let a common noise covariance matrix for the ease of expression. However, the results simply generalize to covariance matrices that vary with time and across the systems, by appropriately replacing upper- and lower-bounds of the matrices [16, 36, 39].
For a single system , its underlying transition matrices can be individually learned from its own state trajectory data by using the least squares estimator [16, 36]. We are interested in jointly learning the transition matrices of all systems under the assumption that they share the following common structure.
Assumption 3 (Shared Basis).
Each transition matrix can be expressed as
| (2) |
where are common matrices and contains the idiosyncratic coefficients for system .
This assumption is commonly-used in the literature of jointly learning multiple parameters [14, 44]. Intuitively, it states that each system evolves by combining the effects of systems. These unknown systems behind the scene are shared by all systems , the weight of each of which is reflected by the idiosyncratic coefficients that are collected in for system . Thereby, the model allows for a rich heterogeneity across systems.
The main goal is to estimate by observing for and . To that end, we need a reliable joint estimator that can leverage the unknown shared structure to learn from the state trajectories more accurately than individual estimations of the dynamics. Importantly, to theoretically analyze effects of all quantities on the estimation error, we encounter some challenges for joint learning of multiple systems that do not appear in single-system identification.
Technically, the least-squares estimate of the transition matrix of a single system admits a closed form that lets the main challenge of the analysis be concentration of the sample covariance matrix of the state vectors. However, since closed forms are not achievable for joint-estimators, learning accuracy cannot be directly analyzed. To address this, we first bound the prediction error and then use that for bounding the estimation error. To establish the former, after appropriately decomposing the joint prediction error, we study its scaling with the trajectory-length and dimension, as well as the trade-offs between the number of systems, number of basis matrices, and magnitudes of the state vectors. Then, we deconvolve the prediction error to the estimation error and the sample covariance matrices, and show useful bounds that can tightly relate the largest and smallest eigenvalues of the sample covariance matrices across all systems. Notably, this step that is not required in single-system identification is based on novel probabilistic analysis for dependent random matrices.
In the sequel, we introduce a joint estimator for utilizing the structure in Assumption 3 and analyze its accuracy. Then, in Section 4 we consider violations of the structure in (2) and establish robustness guarantees.
3 Joint Learning of LTI Systems
In this section, we propose an estimator for jointly learning the transition matrices. Then, we establish that the estimation error decays at a significantly faster rate than competing procedures that learn each transition matrix separately by using only the data trajectory of system .
Based on the parameterization in (2), we solve for and , as follows:
| (3) |
where is the averaged squared loss across all systems:
In the analysis, we assume that one can approximately find the minimizer in (3). Although the loss function in (3) is non-convex, thanks to its structure, computationally fast methods for accurately finding the minimizer are applicable. Specifically, the loss function in (3) is quadratic and the non-convexity is the bilinear dependence on . The optimization in (3) is of the form of explicit rank-constrained representations [9]. For such problems, it has been shown under mild conditions that gradient descent converges to a low-rank minimizer at a linear rate [48]. Moreover, it is known that methods such as stochastic gradient descent have global convergence, and these bilinear non-convexities do not lead to any spurious local minima [20]. In addition, since the loss function is biconvex in and , alternating minimization techniques converge to global optima, under standard assumptions [23]. Nonetheless, note that a near-optimal minimum for the objective function is sufficient, and we only need to estimate the product accurately instead of recovering both and . More specifically, the error of the joint estimator in (3) degrades gracefully in the presence of moderate optimization errors. For instance, suppose that the optimization problem is solved up to an error of from a global optimum. It can be shown that an additional term of magnitude arises in the estimation error, due to this optimization error. Numerical experiments in Section 5 illustrate the implementation of (3).
In the sequel, we provide key results for the joint estimator in (3) and establish the high probability decay rates of .
The analysis leverages high probability bounds on the sample covariance matrices of all systems, denoted by
For that purpose, we utilize the Jordan forms of matrices, as follows. For matrix , its Jordan decomposition is , where is a block diagonal matrix; , and for , each block is a Jordan matrix of the eigenvalue . A Jordan matrix of size for is
| (4) |
Henceforth, we denote the size of each Jordan block by , for , and the size of the largest Jordan block for system by . Note that for diagonalizable matrices , since is diagonal, we have . Now, using this notation, we define
| (5) |
where and
The quantities in the definition of can be interpreted as follows. The term is similar to the condition number of the similarity matrix in the Jordan decomposition that is used to block-diagonalize the matrix. Moreover, for stable matrices, and for transition matrices with (almost) unit eigenvalues, capture the long term influences of the eigenvalues. In other words, indicates the amount that contributes to the growth of , for and . When , scales polynomially with the trajectory length , since influences of the noise vectors do not decay as grows, because of the accumulations caused by the unit eigenvalues. The exact expressions are in Theorem 1 below. Note that while is used to obtain an analytical upper bound for the whole range , it is not tight for small values of and tighter expressions can be obtained using the analysis in the proof of Theorem 1.
To introduce the following result, we define next. First, for some that will be determined later, for system , define , where . Then, we establish high probability bounds on the sample covariance matrices with the detailed proof provided in Section 6.
Theorem 1 (Covariance matrices).
The above two expressions for show that for , the largest eigenvalue of the covariance matrix grows linearly in , whereas for , the bounds scale exponentially with the multiplicities of the eigenvalues. Note that the bounds in Theorem 1 and the estimation error results stated hereafter require the trajectories for each system to be longer than . The precise definition for can be found in the statement of Lemma 2 in Section 6.
For establishing the above, we extend existing tools for learning linear systems [1, 16, 36, 45]. Specifically, we leverage truncation-based arguments and introduce the quantity that captures the effect of the spectral properties of the transition matrices on the magnitudes of the state trajectories. Further, we develop strategies for finding high probability bounds for largest and smallest singular values of random matrices and for studying self-normalized matrix-valued martingales.
Importantly, Theorem 1 provides a tight characterization of the sample covariance matrix for each system, in terms of the magnitudes of eigenvalues of , as well as the largest block-size in the Jordan decomposition of . The upper bounds show that grows exponentially with the dimension , whenever . Further, if has eigenvalues with magnitudes close to , then scaling with time can be as large as . The bounds in Theorem 1 are more general than that appears in some analyses [36, 39], and can be used to calculate the latter term. Finally, Theorem 1 indicates that the classical framework of persistent excitation [7, 21, 24] is not applicable, since the lower and upper bounds of eigenvalues grow at drastically different rates.
Next, we express the joint estimation error rates.
Definition 1.
Denote , and let , , , , and . Note that .
Theorem 2.
The proof is provided in Section 7. By putting Theorems 1 and 2 together, the estimation error per-system111In order to obtain a guarantee for the maximum error over all systems, additional assumptions on the matrix are required. This problem falls beyond the scope of this paper and we leave it to a future work. is
| (7) |
The above expression demonstrates the effects of learning the systems in a joint manner. The first term in (7) can be interpreted as the error in estimating the idiosyncratic components for each system. The convergence rate is , as each is a -dimensional parameter and for each system, we have a trajectory of length . More importantly, the second term in (7) indicates that the joint estimator in (3) effectively increases the sample size for the shared components , by pooling the data of all systems. So, the error decays as , showing that the effective sample size for is .
In contrast, for individual learning of LTI systems, the rate is known [16, 18, 36, 39] to be
Thus, the estimation error rate in (7) recovers the rate for a single system (), and it significantly improves for joint learning, especially when
| (8) |
Note that the above conditions are as expected. First, when , the structure in Assumption 3 does not provide any commonality among the systems. That is, for , the LTI systems can be totally arbitrary and Assumption 3 is automatically satisfied. This prevents reductions in the effective dimension of the unknown transition matrices, and also prevents joint learning from being any different than individual learning. Similarly, precludes all commonalities and indicates that are too heterogeneous to allow for any improved learning via joint estimation.
Importantly, when the largest block-size varies significantly across the systems, a higher degree of shared structure is needed to improve the joint estimation error for all systems. Since and depend exponentially on (as shown in Figure 1 and Theorem 1) and can be as large as , we can have . Hence, in this situation we incur an additional dimension dependence in the error of the joint estimator. Note that such effects of are unavoidable (regardless of the employed estimator). Moreover, in this case, joint learning rates improve if . Therefore, our analysis highlights the important effects of the large blocks in the Jordan form of the transition matrices.
The above is an inherent difference between estimating dynamics of LTI systems and learning from independent observations. In fact, the analysis established in this work includes stochastic matrix regressions that the data of system consists of
| (9) |
wherein the regressors are drawn from some distribution , and is the response. Assume that are independent as vary. Now, the sample covariance matrix for each system does not depend on . Hence, the error for the joint estimator is not affected by the block-sizes in the Jordan decomposition of . Therefore, in this setting, joint learning always leads to improved per-system error rates, as long as the necessary conditions and hold.
4 Robustness to Misspecifications
In Theorem 2, we showed that Assumption 3 can be utilized for obtaining an improved estimation error, by jointly learning the systems. Next, we consider the impacts of misspecified models on the estimation error and study robustness of the proposed joint estimator against violations of the structure in Assumption 3.
Let us first consider the deviation of the dynamics of each system from the shared structure. Specifically, by employing the matrix to denote the deviation of system from Assumption 3, suppose that
| (10) |
Then, denote the total misspecification by . We study the consequences of the above deviations, assuming that the same joint learning method as before is used for estimating the transition matrices.
Theorem 3.
The proof of Theorem 3 is provided in Section 8. In (11), we observe that the total misspecification imposes an additional error of for jointly learning all system. Hence, to obtain accurate estimates, we need the total misspecification to be smaller than the number of systems , as one can expect. The discussion following Theorem 2 is still applicable in the misspecified setting and indicates that in order to have accurate estimates, the number of the shared bases must be smaller than as well. In addition, compared to individual learning, the joint estimation error improves despite the unknown model misspecifications, as long as
This shows that when the total misspecification is proportional to the number of systems; , we pay a constant factor proportional to on the per-system estimation error. Note that in case all systems are stable, according to Theorem 1, the maximum condition number does not grow with , but it scales exponentially with . The latter again indicates an important consequence of the largest block-sizes in Jordan decomposition that this work introduces.
Moreover, when a transition matrix has eigenvalues close to or on the unit circle in the complex plane, by Theorem 1, the factor grows polynomially with . Thus, for systems with infinite memories or accumulative behaviors, misspecifications can significantly deteriorate the benefits of joint learning. Intuitively, the reason is that effects of notably small misspecifications can accumulate over time and contaminate the whole data of state trajectories, because of the unit eigenvalues of the transition matrices . Therefore, the above strong sensitivity to deviations from the shared model for systems with unit eigenvalues seems to be unavoidable.
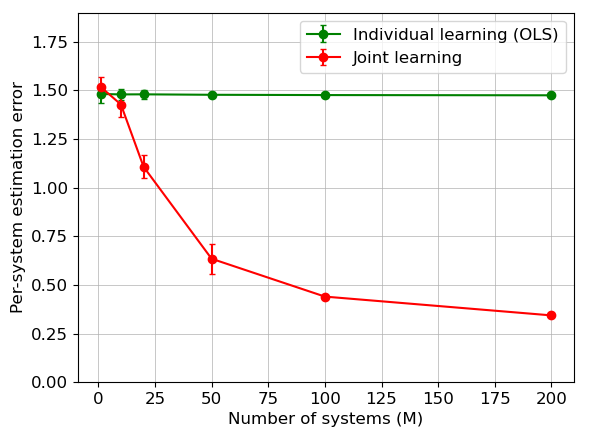
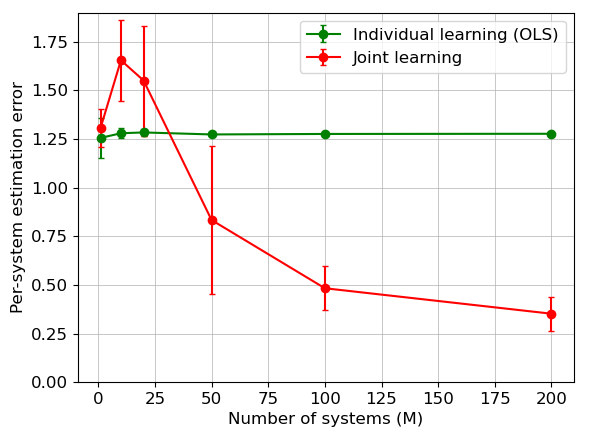
For example, if for the total misspecification we have , for some , joint estimation improves over the individual estimators, as long as . Hence, when all systems are stable, the joint estimation error rate improves when the number of systems satisfies . Otherwise, idiosyncrasies in system dynamics dominate the commonalities. Note that larger values of correspond to smaller misspecifications. On the other hand, Theorem 3 implies that in systems with (almost) unit eigenvalues, the impact of is amplified. Indeed, by Theorem 1, for unit-root systems, joint learning improves over individual estimators when . That is, for benefiting from the shared structure and utilizing pooled data, the number of systems needs to be as large as .
In contrast, if for some , the joint estimation error for the regression problem in (9) incurs only an additive factor of , regardless of the largest block-sizes in the Jordan decompositions and unit-root eigenvalues. Thus, Theorem 3 further highlights the stark difference between joint learning from independent, bounded, and stationary observations, and from state trajectories of LTI systems.
5 Numerical Illustrations
We complement our theoretical analyses with a set of numerical experiments which demonstrate the benefit of jointly learning the systems. We investigate two main aspects of our theoretical results: (i) benefits of joint learning when the systems share a common linear basis, for different values of , and (ii) interplay of the spectral radii of the system matrices with the joint-estimation error. To that end, we compare the estimation error for the joint estimator in (3) against the ordinary least-squares (OLS) estimates of the transition matrices for each system individually. For solving (3), we use a minibatch gradient-descent-based implementation with Adam as the optimization algorithm [28]. Due to the bilinear form of the optimization objective, gradient descent methods can lead to convergence and computational issues for and . Although prior studies utilize norm regularizations to address this issue in some cases [44], we do not use any such regularization in our objective function in (3). Notably, our unregularized minimization exposes no convergence issue in the simulations we performed.
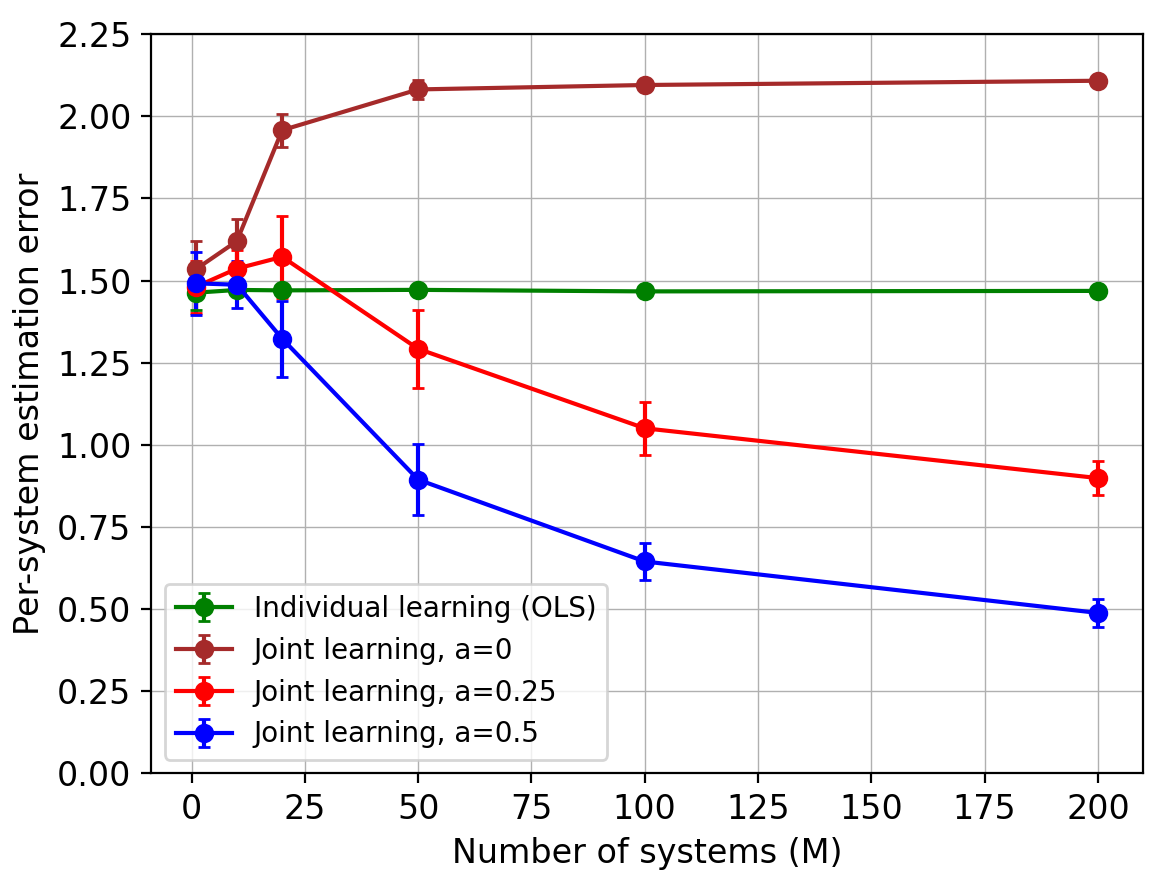
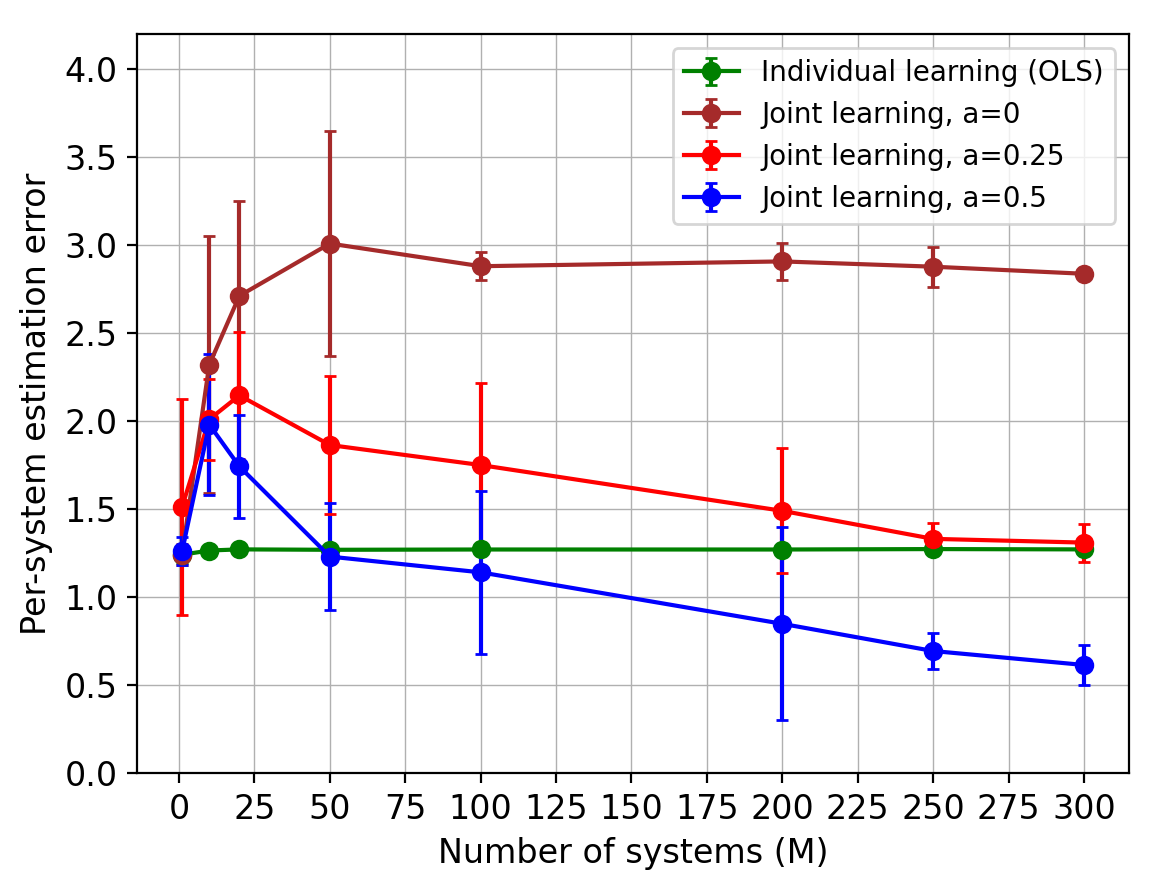
For generating the systems, we consider settings with the number of bases , dimension , trajectory length , and the number of systems . We simulate two cases:
(i) the spectral radii are in the range , and
(ii) all systems have an eigenvalue of magnitude .
The matrices are generated randomly, such that each entry of is sampled independently from the standard normal distribution . Using these matrices, we generate systems by randomly generating the idiosyncratic components from a standard normal distribution. For generating the state trajectories, noise vectors are isotropic Gaussian with variance . Additional numerical simulations using Bernoulli random matrices are provided in Appendix A.
We simulate the joint learning problem both with and without model misspecifications. For the latter, deviations from the shared structure are simulated by the components , which are added randomly with probability for . The matrices are generated with independent Gaussian entries of variance , leading to and , according to the dimension .
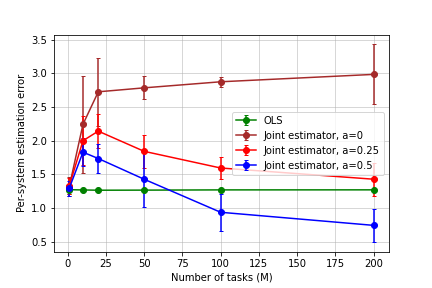
To report the results, for each value of in Figure 2 (resp. Figure 3), we average the errors from (resp. ) random replicates and plot the standard deviation as the error bar. Figure 2 depicts the estimation errors for both stable and unit-root transition matrices, versus . It can be seen that the joint estimator exhibits the expected improvement against the individual one.
More interestingly, in Figure 3(a), we observe that for stable systems, the joint estimator performs worse than the individual one, when significant violations from the shared structure occurs in all systems (i.e., ). Note that it corroborates Theorem 3, since in this case the total misspecification scales linearly with . However, if the proportion of systems which violate the shared structure in Assumption 3 decreases, the joint estimation error improves as expected ().
Figure 3(b) depicts the estimation error for the joint estimator under misspecification for systems that have an eigenvalue on the unit circle in the complex plane. Our theoretical results suggest that the number of systems needs to be significantly larger in this case to circumvent the cost of misspecification in joint learning. The figure corroborates this result, wherein we observe that the joint estimation error is larger than the individual one, if all systems are misspecified (i.e., ). Decreases in the total misspecification (i.e., ) improves the error rate for joint learning, but requires larger number of systems than the stable case.
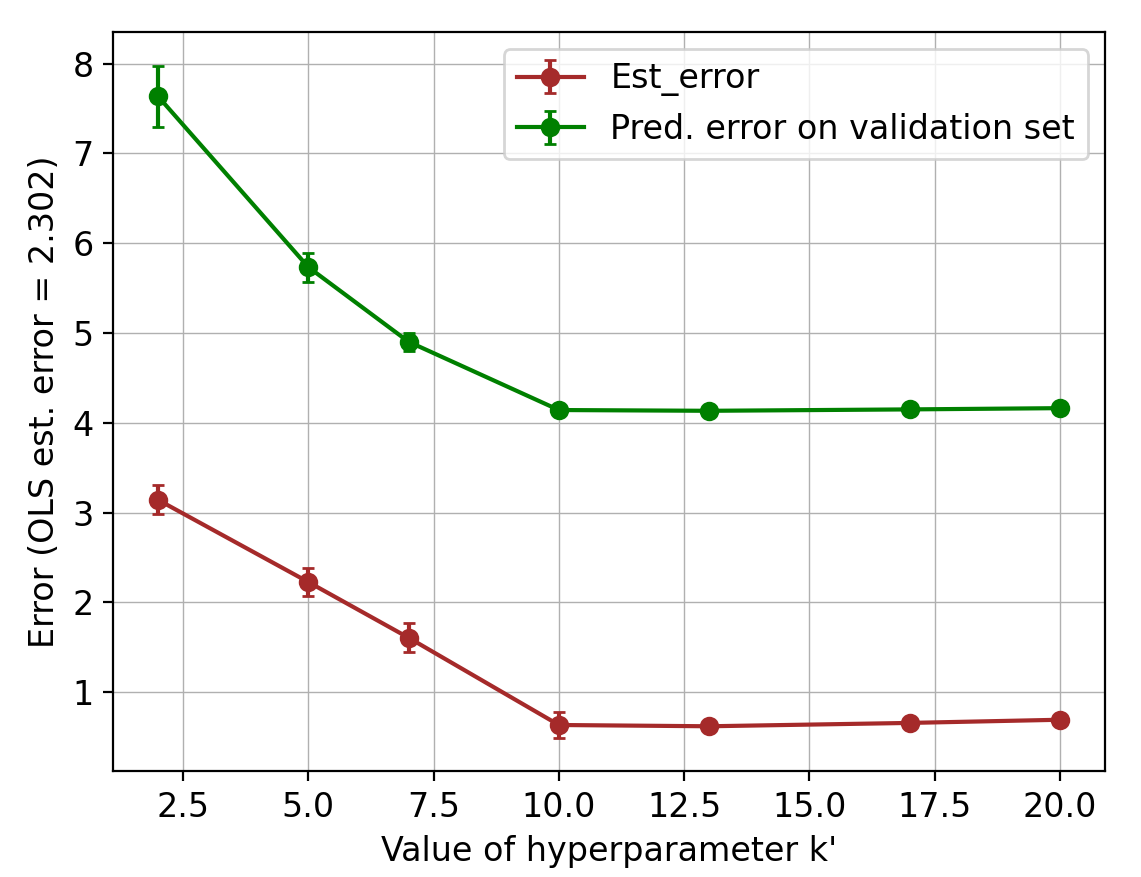
Finally, we discuss the choice of the number of bases for applying the joint estimator to real data. It can be handled by model selection methods such as elbow criterion and information criteria [2, 37], as well as robust estimation methods in panel data and factor models [12, 13]. In fact, for all , the structural assumption is satisfied and leads to similar learning rates, while can lead to larger estimation errors. In Figure 4, we provide a simulation (with ) and report the per-system estimation error, as well as the prediction error on a validation data (which is a subset of size ). Across all runs in the experiment, we observed that if the hyperparameter is chosen according to the elbow criteria, the resulting number of basis models is either equal to the true value , or slightly larger. For misspecified models, the optimal choice of can vary, in the sense that large misspecifications can be added to the shared basis (i.e., ).
6 Proof of Theorem 1
In this and the following sections, we provide the detailed proofs for our results. We start by analysing the sample covariance matrix for each system which is then used to derive the estimation error rates in Theorem 2 and Theorem 3. For clarity, some details of the proofs are delegated to Appendix C. In Section 9, we provide the general probabilistic inequalities that are used throughout the proofs. Now, we prove high probability bounds for covariance matrices in Theorem 1.
6.1 Upper Bounds on Covariance Matrices
To prove an upper bound on each system covariance matrix, we use an approach for LTI systems that relies on bounding norms of exponents of matrices [16]. Using and in (5) and , the first step is to bound the sizes of all state vectors under the event in Proposition 7.
Proposition 1 (Bounding ).
For all , under the event , we have:
where .
Proof.
As before, each transition matrix admits a Jordan normal form as follows: , where is a block-diagonal matrix . Each Jordan block is of size . Note that for each system, the state vector satisfies:
Now, letting be the same as in Proposition 7, we can bound the -norm of the state vector as follows:
For any matrix, the norm is equal to the maximum row sum. Since the powers of a Jordan matrix will follow the same block structure as the original one, we can bound the operator norm by the norm of each block. The maximum row sum for the -th power of a Jordan block is: . Using this, we will bound the size of each state vector for the case when
-
(I)
the spectral radius of satisfies ,
-
(II)
or, when , for a constant .
Case I
When the Jordan block for a system matrix has eigenvalues strictly less than 1, we have:
Thus, for this case, each state vector can be upper bounded as . When the matrix is diagonalizable, each Jordan block is of size , which leads to the upper-bound , for all . Therefore for diagonalizable , we can let .
Case II
When , we get , for all . Therefore, since is the largest Jordan block, we have:
Therefore, the magnitude of each state vector grows polynomially with , the exponent being at most . For example, when is diagonalizable, the Jordan block for the unit root is of size , givin .
So, for systems with unit roots, the bound on each state vector is as expressed in the proposition. ∎
Using the high probability upper bound on the size of each state vector, we can upper bound the covariance matrix for each system as follows:
Lemma 1 (Upper bound on ).
For all , the sample covariance matrix of system can be upper bounded under the event , as follows:
-
(I)
When all eigenvalues of the matrix are strictly less than in magnitude (), we have
-
(II)
When some eigenvalues of the matrix are close to , i.e. , we have:
Proof.
First note that we have:
Therefore, by Proposition 7, when all eigenvalues of are strictly less than , we have:
For the case when , we get:
∎
6.2 Lower Bound for Covariance Matrices
A lower bound result for the idiosyncratic covariance matrices can be derived using the probabilistic inequalities in the last section. We provide a detailed proof below.
Lemma 2 (Covariance lower bound.).
Define . For all , if the per-system sample size is greater than defined as
if , and
if , then with probability at least , the sample covariance matrix for system can be bounded from below: .
Proof.
We bound the covariance matrix under the events , in Propositions 7, 8, as well as the one in Proposition 10. As we consider a bound for all systems, we drop the system subscript here. Using (1), we have:
Since , under the event it holds that
Thus, for any unit vector (i.e., on the unit sphere ), we have
Now, by Proposition 10 with , we get the following result for the martingale and , with probability at least :
Thus, we get:
Hence, we have:
whenever is larger than
Using the upper bound analysis in Lemma 1, we show that it suffices for to be lower bounded as
when is strictly stable, and as
when . Since, both quantities on the RHS grow at most logarithmically with , there exists such that it holds for all . Combining the failure probability for all events, we get the desired result. ∎
7 Proof of Theorem 2
In this section, we use the result in Theorem 1 to analyze the estimation error for the estimator in (3), under Assumption 3. For ease of presentation, we rewrite the problem by transforming the vector output space to scalar values. For that purpose, we introduce some notation to express transition matrices in vector form and rewrite (3). First, for each state vector , we create different covariates of size . So, for , the vector contains in the -th block of size and elsewhere.
Then, we express the system matrix as a vector . Similarly, the concatenation of all vectors can be coalesced into the matrix . Analogously, will denote the concatenated dimensional vector of noise vectors for system . Thus, the structural assumption in (2) can be written as:
| (12) |
where and . Similarly, the overall parameter set can be factorized as , where the matrix contains the true weight vectors . Thus, expressing the system matrices in this manner leads to a low rank structure in (12), so that the matrix is of rank . Using the vectorized parameters, the evolution for the components of all state vectors can be written as:
| (13) |
For each system , we therefore have a total of samples, where the statistical dependence now follows a block structure: covariates of are all constructed using , next using and so forth. To estimate the parameters, we solve the following optimization problem:
| (14) |
where contains all state vectors stacked vertically and contains the corresponding matrix input. We denote the covariance matrices for the vectorized form by . Recall, that the sample covariance matrices for all systems are denoted by
We further use the following notation: for any parameter set , we define as , where each column is the prediction of states with . That is,
Thus, denotes the ground truth mapping for the training data of the systems and is the prediction error across all coordinates of the state vectors that each of which is of dimension .
By Assumption 3, we have , where is an orthonormal matrix and . We start by the fact that the estimates and minimize (3), and therefore, have a smaller squared prediction error than . Hence, we get the following inequality:
| (15) |
We can rewrite , for all , where is an idiosyncratic projection vector for system . Since our joint estimator is a least squares objective with bilinear terms, we first decompose the prediction error for the estimator, similar to the linear regression setting [14, 44]. In subsequent analyses, we use different matrix concentration results and LTI estimation theory in order to account for the temporal dependence and spectral properties of the systems. Our first step is to bound the prediction error for all systems.
Lemma 3.
For any fixed orthonormal matrix , the total squared prediction error in (3) for can be decomposed as follows:
| (16) |
The proof of Lemma 3 can be found in the extended version of this paper [34]. Our next step is to bound each term on the RHS of (16). To that end, let be an -cover of the set of orthonormal matrices in . In (16), we select the matrix to be an element of such that . Note that since is an -cover, such matrix exists. We can bound the size of such a cover using Lemma 5, and obtain .
We now bound each term in the following propositions using the auxiliary results in Section 9 and covariance matrix bounds in the previous section. The detailed proofs for all of the following results are available in the extended version [34]. Using Proposition 9, we bound the following expression in the second term of (16), as follows.
Proposition 2.
Under Assumption 3, for the noise process defined for each system, with probability at least , we have:
Based on the bound in Proposition 2, we can bound the third term in (16) as follows:
Proposition 3.
Under Assumption 2 and Assumption 3, with probability at least , we have:
| (17) |
Next, we show a multitask concentration of martingales projected on a low-rank subspace.
Proposition 4.
For an arbitrary orthonormal matrix in the -cover defined in Lemma 5, let be a positive definite matrix, and define , , and . Then, letting be the event
we have
| (18) |
7.1 Proof of Estimation Error in Theorem 2
Proof.
We now use the bounds we have shown for each term before and give the final steps by using the error decomposition in Lemma 3. Let be the cardinality of the -cover of the set of orthonormal matrices in that we defined in Lemma 3. Let denote the expression . So, substituting the termwise bounds from Proposition 2, Proposition 3, and Proposition 4 in Lemma 3, with probability at least , it holds that:
| (19) |
For the matrix , we now substitute , which implies that . Similarly, for the matrix , we get . Thus, substituting and in Theorem 1, with probability at least , the upper-bound in Proposition 4 becomes:
Substituting this in (19) with , , with probability at least , we have:
Noting that for , with probability at least , we get:
As , we can rewrite the above inequality as:
The above quadratic inequality for the prediction error implies the following bound, which holds with probability at least :
Since the smallest eigenvalue of the matrix is at least (Theorem 1), we can convert the above prediction error bound to an estimation error bound and get
which implies the desired bound for the solution of (3).
∎
8 Proof of Theorem 3
Here, we provide the key steps for bounding the average estimation error across the systems for the estimator in (3) in presence of misspecifications :
where we use to denote the bound on misspecification in task and set . In the presence of misspecifications, we have , where is an orthonormal matrix, , and is the misspecification error. As the analysis here shares its template with the proof of Theorem 2, we provide a sketch with the complete details delegated to the extended version [34]. Same as in Section 7, we start with the fact that minimize the squared loss in (3). However, in this case, we get an additional term caused by on the misspecifications :
| (20) |
We follow a similar proof strategy as in Section 7 and account for the additional terms arising due to the misspecifications . The error in the shared part, , can still be rewritten as where is a matrix containing an orthonormal basis of size in and is the system specific vector. We now show a decomposition similar to Lemma 3:
Lemma 4.
Under the misspecified shared linear basis structure in (10), for any fixed orthonormal matrix , the low rank part of the total squared error can be decomposed as follows:
| (21) |
We bound each term on the RHS of (21) individually. Similar to Section 7, we choose the orthonormal matrix . Then, we use the following results, for which the proofs are provided in the longer version [34].
Proposition 5 (Bounding ).
For the model in (10), with probability at least , it holds that
| (22) |
Proposition 6 (Bounding ).
Under Assumption 2 and (10), with probability at least we have:
| (23) |
Finally, we are ready to put the above intermediate results together. Using the decomposition in Lemma 4 and the term-wise upper bounds above, one can derive the desired estimation error rate. Below, we show the final steps with appropriate substitution for constants. A detailed proof can be found in Appendix D.
As before, we substitute the termwise bounds from Propositions 5, 6 and 4 in Lemma 4 with values , (in Theorem 1), . Noting that and , by setting we finally get the following quadratic inequality in the error term :
The quadratic inequality for the prediction error implies the following bound with probability at least :
Since , an estimation error bound for the solution of (3):
9 Auxiliary Probabilistic Inequalities
In this section, we state the general probabilistic inequalities which we used in proving the main results in the previous sections. The proofs for these results can be found in Appendix B.
Proposition 7 (Bounding the noise sequence).
For , and , let be the event
| (24) |
Then, we have . For simplicity, we denote the above upper-bound by .
Proposition 8 (Noise covariance concentration).
For and , let be the event
Then, if , we have .
Define as the pooled noise matrix as follows:
| (25) |
with each column vector as the concatenated noise vector for the -th system.
Proposition 9 (Bounding total magnitude of noise).
For the joint noise matrix defined in (25), with probability at least , we have:
We denote the above event by .
The following result shows a self-normalized martingale bound for vector valued noise processes.
Proposition 10.
For the system in (1), for any and system , with prob. at least , we have:
where and is a deterministic positive definite matrix.
Lemma 5 (Covering low-rank matrices [14]).
For the set of orthonormal matrices (with ), there exists that forms an -net of in Frobenius norm such that , i.e., for every , there exists and .
10 Concluding Remarks
We studied the problem of jointly learning multiple linear time-invariant dynamical systems, under the assumption that their transition matrices can be expressed based on an unknown shared basis. Our finite-time analysis for the proposed joint estimator shows that pooling data across systems can provably improve over individual estimators, even in presence of moderate misspecifications. The results highlight the critical roles of the spectral properties of the system matrices and the number of the basis matrices, in the efficiency of joint estimation. Further, we characterize fundamental differences between joint estimation of system dynamics using dependent state trajectories and learning from independent stationary observations. Considering different shared structures, extensions of the presented results to explosive systems, or those with high-dimensional transition matrices, as well as joint learning of multiple non-linear dynamical systems, all are interesting avenues for future work that this paper paves the road towards.
Acknowledgements
The authors appreciate the helpful comments of the reviewers on the initial version of this paper. AM is supported in part by a grant from the Open Philanthropy Project to the CHAI and NSF CAREER IIS-1452099.
References
- [1] Yasin Abbasi-Yadkori, Dávid Pál, and Csaba Szepesvári. Improved algorithms for linear stochastic bandits. In Proceedings of the 24th International Conference on Neural Information Processing Systems, pages 2312–2320, 2011.
- [2] Hirotugu Akaike. A new look at the statistical model identification. IEEE transactions on automatic control, 19(6):716–723, 1974.
- [3] Pierre Alquier, Mai The Tien, Massimiliano Pontil, et al. Regret bounds for lifelong learning. In Artificial Intelligence and Statistics, pages 261–269. PMLR, 2017.
- [4] Rie Kubota Ando and Tong Zhang. A framework for learning predictive structures from multiple tasks and unlabeled data. Journal of Machine Learning Research, 6(Nov):1817–1853, 2005.
- [5] Sumanta Basu, Ali Shojaie, and George Michailidis. Network granger causality with inherent grouping structure. The Journal of Machine Learning Research, 16(1):417–453, 2015.
- [6] John T Bosworth. Linearized aerodynamic and control law models of the X-29A airplane and comparison with flight data, volume 4356. National Aeronautics and Space Administration, Office of Management …, 1992.
- [7] Stephen Boyd and Sosale Shankara Sastry. Necessary and sufficient conditions for parameter convergence in adaptive control. Automatica, 22(6):629–639, 1986.
- [8] Boris Buchmann and Ngai Hang Chan. Asymptotic theory of least squares estimators for nearly unstable processes under strong dependence. The Annals of statistics, 35(5):2001–2017, 2007.
- [9] Samuel Burer and Renato DC Monteiro. A nonlinear programming algorithm for solving semidefinite programs via low-rank factorization. Mathematical Programming, 95(2):329–357, 2003.
- [10] Rich Caruana. Multitask learning. Machine learning, 28(1):41–75, 1997.
- [11] Yanxi Chen and H Vincent Poor. Learning mixtures of linear dynamical systems. In International Conference on Machine Learning, pages 3507–3557. PMLR, 2022.
- [12] Alexander Chudik, Kamiar Mohaddes, M Hashem Pesaran, and Mehdi Raissi. Debt, inflation and growth-robust estimation of long-run effects in dynamic panel data models. 2013.
- [13] Valentina Ciccone, Augusto Ferrante, and Mattia Zorzi. Factor models with real data: A robust estimation of the number of factors. IEEE Transactions on Automatic Control, 64(6):2412–2425, 2018.
- [14] Simon Shaolei Du, Wei Hu, Sham M Kakade, Jason D Lee, and Qi Lei. Few-shot learning via learning the representation, provably. In International Conference on Learning Representations, 2020.
- [15] Mohamad Kazem Shirani Faradonbeh, Ambuj Tewari, and George Michailidis. Finite-time adaptive stabilization of linear systems. IEEE Transactions on Automatic Control, 64(8):3498–3505, 2018.
- [16] Mohamad Kazem Shirani Faradonbeh, Ambuj Tewari, and George Michailidis. Finite time identification in unstable linear systems. Automatica, 96:342–353, 2018.
- [17] Mohamad Kazem Shirani Faradonbeh, Ambuj Tewari, and George Michailidis. Input perturbations for adaptive control and learning. Automatica, 117:108950, 2020.
- [18] Mohamad Kazem Shirani Faradonbeh, Ambuj Tewari, and George Michailidis. On adaptive linear–quadratic regulators. Automatica, 117:108982, 2020.
- [19] André Fujita, Joao R Sato, Humberto M Garay-Malpartida, Rui Yamaguchi, Satoru Miyano, Mari C Sogayar, and Carlos E Ferreira. Modeling gene expression regulatory networks with the sparse vector autoregressive model. BMC systems biology, 1(1):1–11, 2007.
- [20] Rong Ge, Chi Jin, and Yi Zheng. No spurious local minima in nonconvex low rank problems: A unified geometric analysis. In International Conference on Machine Learning, pages 1233–1242. PMLR, 2017.
- [21] Michael Green and John B Moore. Persistence of excitation in linear systems. Systems & control letters, 7(5):351–360, 1986.
- [22] Jiachen Hu, Xiaoyu Chen, Chi Jin, Lihong Li, and Liwei Wang. Near-optimal representation learning for linear bandits and linear rl. In International Conference on Machine Learning, pages 4349–4358. PMLR, 2021.
- [23] Prateek Jain and Purushottam Kar. Non-convex optimization for machine learning. Foundations and Trends® in Machine Learning, 10(3-4):142–336, 2017.
- [24] Benjamin M Jenkins, Anuradha M Annaswamy, Eugene Lavretsky, and Travis E Gibson. Convergence properties of adaptive systems and the definition of exponential stability. SIAM journal on control and optimization, 56(4):2463–2484, 2018.
- [25] Katarina Juselius and Zorica Mladenovic. High inflation, hyperinflation and explosive roots: the case of Yugoslavia. Citeseer, 2002.
- [26] Thomas Kailath, Ali H Sayed, and Babak Hassibi. Linear estimation. Prentice Hall, 2000.
- [27] Wei Kang. Approximate linearization of nonlinear control systems. In Proceedings of 32nd IEEE Conference on Decision and Control, pages 2766–2771. IEEE, 1993.
- [28] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In ICLR (Poster), 2015.
- [29] TL Lai and CZ Wei. Asymptotic properties of general autoregressive models and strong consistency of least-squares estimates of their parameters. Journal of multivariate analysis, 13(1):1–23, 1983.
- [30] Weiwei Li and Emanuel Todorov. Iterative linear quadratic regulator design for nonlinear biological movement systems. In ICINCO (1), pages 222–229. Citeseer, 2004.
- [31] Rui Lu, Gao Huang, and Simon S Du. On the power of multitask representation learning in linear mdp. arXiv preprint arXiv:2106.08053, 2021.
- [32] Andreas Maurer. Bounds for linear multi-task learning. Journal of Machine Learning Research, 7(Jan):117–139, 2006.
- [33] Andreas Maurer, Massimiliano Pontil, and Bernardino Romera-Paredes. The benefit of multitask representation learning. The Journal of Machine Learning Research, 17(1):2853–2884, 2016.
- [34] Aditya Modi, Mohamad Kazem Shirani Faradonbeh, Ambuj Tewari, and George Michailidis. Joint learning of linear time-invariant dynamical systems. arXiv preprint arXiv:2112.10955, 2021.
- [35] M Hashem Pesaran. Time series and panel data econometrics. Oxford University Press, 2015.
- [36] Tuhin Sarkar and Alexander Rakhlin. Near optimal finite time identification of arbitrary linear dynamical systems. In International Conference on Machine Learning, pages 5610–5618, 2019.
- [37] Gideon Schwarz. Estimating the dimension of a model. The annals of statistics, pages 461–464, 1978.
- [38] Anil K Seth, Adam B Barrett, and Lionel Barnett. Granger causality analysis in neuroscience and neuroimaging. Journal of Neuroscience, 35(8):3293–3297, 2015.
- [39] Max Simchowitz, Horia Mania, Stephen Tu, Michael I Jordan, and Benjamin Recht. Learning without mixing: Towards a sharp analysis of linear system identification. In Conference On Learning Theory, pages 439–473. PMLR, 2018.
- [40] A Skripnikov and G Michailidis. Joint estimation of multiple network granger causal models. Econometrics and Statistics, 10:120–133, 2019.
- [41] Andrey Skripnikov and George Michailidis. Regularized joint estimation of related vector autoregressive models. Computational statistics & data analysis, 139:164–177, 2019.
- [42] James H Stock and Mark W Watson. Dynamic factor models, factor-augmented vector autoregressions, and structural vector autoregressions in macroeconomics. In Handbook of macroeconomics, volume 2, pages 415–525. Elsevier, 2016.
- [43] Sagar Sudhakara, Aditya Mahajan, Ashutosh Nayyar, and Yi Ouyang. Scalable regret for learning to control network-coupled subsystems with unknown dynamics. IEEE Transactions on Control of Network Systems, 2022.
- [44] Nilesh Tripuraneni, Chi Jin, and Michael Jordan. Provable meta-learning of linear representations. In International Conference on Machine Learning, pages 10434–10443. PMLR, 2021.
- [45] Roman Vershynin. High-dimensional probability: An introduction with applications in data science, volume 47. Cambridge university press, 2018.
- [46] H Victor, De la Peña, Tze Leung Lai, and Qi-Man Shao. Self-normalized processes: Limit theory and Statistical Applications. Springer, 2009.
- [47] Martin J Wainwright. High-dimensional statistics: A non-asymptotic viewpoint, volume 48. Cambridge University Press, 2019.
- [48] Lingxiao Wang, Xiao Zhang, and Quanquan Gu. A unified computational and statistical framework for nonconvex low-rank matrix estimation. In Artificial Intelligence and Statistics, pages 981–990. PMLR, 2017.
Appendix A Additional Numerical Simulations
In order to completely visualize the dependence on all the parameters ( and ) other than the number of systems , one needs to vary all parameters ( and ) at different rates and plot the estimation errors. Such extensive empirical analyses do not constitute the focus of this paper, and are indeed studied in the existing literature of learning one system individually. For example, the dependence on for the estimation error is well understood and cannot be better than [16, 36, 39].
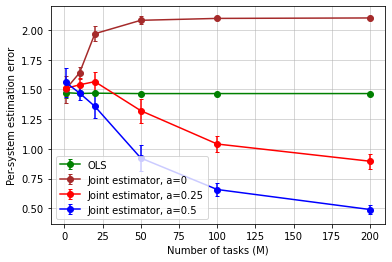
Moreover, we further verify that different random matrices for the shared linear basis lead to similar joint learning curves. We simulate the experiments by using random matrices whose entries are sampled from a uniform distribution over the range (followed by normalization steps to obtain the desired stable or unit-root dynamics). The results, reported in Figure 5 below, show the same benefits of joint learning compared to individual estimation, as shown in the paper.
Appendix B Proofs of Auxiliary Results
Here, we give proofs of the probabilistic inequalities and intermediate results in Section 9.
Proposition
[Restatement of Proposition 7] For , and , let be the event
| (26) |
Then, we have . For simplicity, we denote the above upper-bound by .
Proof.
Let be the -th member of the standard basis of . Using the sub-Gaussianity of the random vector given the sigma-field , we have
Therefore, taking a union bound over all basis vectors , all systems , and all time steps that , we get the desired result by letting . ∎
Proposition
[Restatement of Proposition 8] For and , let be the event
Then, if , we have .
Proof.
Here, we will bound the largest eigenvalue of the deviation matrix . For the spectral norm of this matrix, using Lemma 5.4 from Vershynin [45], we have:
where is a -cover of the unit sphere . Now, it holds that . Thus, we get:
Using some martingale concentration arguments, we first bound the probability on the RHS for a fixed vector . Then, taking a union bound over all will lead to the final result.
For a given , since is conditionally sub-Gaussian with parameter , the quantity is a conditionally sub-exponential martingale difference. Using Theorem 2.19 of Wainwright [47], for small values of , we have
where is some universal constant. Taking a union bound, setting total failure probability to , and letting , we obtain that with probability at least , it holds that
According to Weyl’s inequality, for , we have:
∎
Proposition
[Restatement of Proposition 9] For the joint noise matrix defined in (25), with probability at least , we have:
We denote the above event by .
Proof.
For each system , we know that . Similar to the previous proof, we know that follows a conditionally sub-exponential distribution given . Using the sub-exponential bound for martingale difference sequences, for large enough we get:
with probability at least . ∎
Next, we show the proof of Proposition 10 based on the following well-known probabilistic inequalities below. The first inequality is a concentration bound for self-normalized martingales, which can be found in Lemma 8 and Lemma 9 in the work of Abbasi-Yadkori et al. [1]. More details about self-normalized process can be found in the work of Victor et al. [46].
Lemma 1.
Let be a filtration. Let be a real valued stochastic process such that is measurable and is conditionally -sub-Gaussian for some , i.e.,
Let be an -valued stochastic process such that is measurable. Assume that is a positive definite matrix. For any , define
Then with probability at least , for all we have
The second inequality is the following discretization-based bound shown in Vershynin [45] for random matrices:
Proposition B.4.
Let be a random matrix. For any , let be an -net of such that for any , there exists with . Then for any , we have:
With the aforementioned results, we now show the proof of Proposition 10.
Proposition
[Restatement of Proposition 10] For the system in (1), for any and system , with probability at least , we have:
where and is a deterministic positive definite matrix.
Proof B.5.
For the partial sum , using Proposition B.4 with , we get:
where is a fixed unit norm vector in . We can now apply Lemma 1 with the sub-Gaussian noise sequence to get the final high probability bound.
Appendix C Remaining Proofs from Section 7
In this section, we provide a detailed analysis of the average estimation error across the systems for the estimator in (3). We start with the proof of Lemma 3 which bounds the prediction error for all systems :
Lemma
[Restatement of Lemma 3] For any fixed orthonormal matrix , the total squared prediction error in (3) for can be decomposed as follows:
| (27) |
Proof C.6.
We first define and as the block diagonal matrices in , with each block of and containing and , respectively. Let be the regularized covariance matrix of projected covariates . For any orthonormal matrix , we define , and proceed as follows:
| (28) | ||||
| (29) | ||||
| (30) | ||||
| (31) |
The first equality in (28) uses the fact that the error matrix is of rank at most and then introduces a matrix leading to the two terms on the RHS. In inequality (29), we use Cauchy-Schwartz inequality to bound the first term with respect to the norm induced by matrix . The next step (30) again follows by simple algebra where rewrite the term as and collect the terms accordingly. Finally, in the last step (31), we again use the Cauchy-Schwarz inequality to rewrite the first and last terms from the previous step.
Now, note that . Thus, for the last term in the RHS of (31), we can use the reverse triangle inequality for any two vectors , with and . Hence, we have:
| (32) |
Further, since (Theorem 1), we have for all . Thus, we can rewrite the previous inequality as:
In the second inequality, we simply expand the term using the relation .
We will now give a detailed proof of the bound of each term on the rhs of (16). As stated in the main text, we select the matrix to be an element of (cover of set of orthonormal matrices in ) such that .
Proposition
[Restatement of Proposition 2] Under Assumption 3, for the noise process defined for each system, with probability at least , we have:
| (33) |
Proof C.7.
In order to bound the term above, we use the squared loss inequality in (7) as follows:
which leads to the inequality . Using the concentration result in Proposition 9, with probability at least , we get
Thus, we have , with probability at least which gives:
Proposition
[Restatement of Proposition 3] Under Assumption 2 and Assumption 3, with probability at least , we have:
| (34) |
Proof C.8.
Using Cauchy-Schwarz inequality and Proposition 2, we bound the term as follows:
Proposition
[Restatement of Proposition 4] For an arbitrary orthonormal matrix in the -cover defined in Lemma 5, let be a positive definite matrix, and define , , and . Then, consider the following event:
For , we have:
| (35) |
Proof of Proposition 4
First, using the vectors defined in Section 3, for the matrix , define . It is straightforward to see that .
Now, we show that the result can essentially be stated as a corollary of the following result for a univariate regression setting:
Lemma 2 (Lemma 2 of [22]).
Consider a fixed matrix and let . Consider a noise process adapted to the filtration . If the noise is conditionally sub-Gaussian for all : , then with probability at least , for all , we have:
In order to use the above result in our case, we consider the martingale sum . Under Assumption 2, we can use the same argument as in the proof of Lemma 2 in Hu et al. [22] as:
Thus, for a fixed matrix and , with probability at least ,
Finally, we take a union bound over the -cover set of orthonormal matrices to bound the total failure probability by .
C.1 Putting Things Together
We now use the bounds we have shown for each term before and give the final steps in the proof of Theorem 2 by using the error decomposition in Lemma 3 as follows: From Lemma 3, with we have:
Now, let be the cardinality of the -cover of the set of orthonormal matrices in that we defined in Lemma 3. So, substituting the termwise bounds from Proposition 2, Proposition 3, and Proposition 4, with probability at least , it holds that:
| (36) |
For the matrix , we now substitute , which implies that . Similarly, for the matrix , we get . Thus, substituting and in Theorem 1, with probability at least , the upper-bound in Proposition 4 becomes:
Substituting this in (36) with , with probability at least , we have:
Noting that and for , we obtain:
The above quadratic inequality for the prediction error implies the following bound, which holds with probability at least .
Since the smallest eigenvalue of the matrix is at least (Theorem 1), we can convert the above prediction error bound to an estimation error bound and get
which implies the following estimation error bound for the solution of (3):
Appendix D Detailed Proof of the Estimation Error in Theorem 3
In this section, we provide a detailed proof of the average estimation error across the systems for the estimator in (3) in presence of misspecifications :
Recall that, in this case, we get an additional term in the squared loss decomposition for which depends on the misspecifications as follows:
| (37) |
The error in the shared part, , can still be rewritten as where is a matrix containing an orthonormal basis of size in and is the system specific vector. We now prove the squared loss decomposition result stated in Lemma 4:
Lemma
[Restatement of Lemma 4] Under the misspecified shared linear basis structure in (10), for any fixed orthonormal matrix , the low rank part of the total squared error can be decomposed as follows:
Proof D.9.
Letting and as defined in Appendix C, recall that we define be the regularized covairance matrix of projected covariates . For any orthonormal matrix , we define and proceed as follows:
The first equality uses the fact that the error matrix is low rank upto a misspecification term. The first inequality follows by using Cauchy-Schwarz inequality. In the last step, we have used the sub-additivity of square root to rewrite the first term in two parts. Now, we can rewrite the error as:
We will now bound each term individually. For the matrix , we choose it to be an element of which is an -cover of the set of orthonormal matrices in . Therefore, for any , there exists such that . We can bound the size of such a cover using Lemma 5 as .
Proposition
[Restatement of Proposition 5] For the multi-task model specified in (10), for the noise process defined for each system, with probability at least , we have:
Proof D.10.
In order to bound the term above, we use the squared loss inequality in (37) and (10) as follows:
which leads to the inequality . Using the concentration result in Proposition 9, with probability at least , we get
Thus, we have with probability at least . We now use this to bound the initial term:
Proposition
[Restatement of Proposition 6] Under Assumption 2 and the shared structure in (10), with probability at least we have:
Proof D.11.
Using Cauchy-Schwarz inequality, we bound the term as follows:
D.1 Putting Things Together
We now use the bounds we have shown for each term before and give the final steps in the proof of Theorem 3 by using the error decomposition in Lemma 4 as follows:
Proof D.12.
From Lemma 4, we have:
Now, substituting the termwise bounds from Proposition 5, Proposition 6 and Proposition 4, with probability at least we get:
| (38) |
In the definition of , we now substitute thereby implying . Similarly, for matrix , we get . Thus, substituting and (in Theorem 1), with probability at least , we get:
Substituting this in (38) with , with probability at least we have:
Noting that and , by setting we have:
The quadratic inequality for the prediction error implies the following bound that holds with probability at least :
Since , we can convert the prediction error bound to an estimation error bound as follows:
which finally implies the estimation error bound for the solution of (3):