[datatype=bibtex, overwrite=true] \map \step[fieldsource=booktitle, match=\regexp.*Interspeech.*, replace=Proc. Interspeech] \step[fieldsource=journal, match=\regexp.*INTERSPEECH.*, replace=Proc. Interspeech] \step[fieldsource=booktitle, match=\regexp.*ICASSP.*, replace=Proc. ICASSP] \step[fieldsource=booktitle, match=\regexp.*icassp_inpress.*, replace=Proc. ICASSP (in press)] \step[fieldsource=booktitle, match=\regexp.*Acoustics,.*Speech.*and.*Signal.*Processing.*, replace=Proc. ICASSP] \step[fieldsource=booktitle, match=\regexp.*International.*Conference.*on.*Learning.*Representations.*, replace=Proc. ICLR] \step[fieldsource=booktitle, match=\regexp.*International.*Conference.*on.*Computational.*Linguistics.*, replace=Proc. COLING] \step[fieldsource=booktitle, match=\regexp.*SIGdial.*Meeting.*on.*Discourse.*and.*Dialogue.*, replace=Proc. SIGDIAL] \step[fieldsource=booktitle, match=\regexp.*International.*Conference.*on.*Machine.*Learning.*, replace=Proc. ICML] \step[fieldsource=booktitle, match=\regexp.*North.*American.*Chapter.*of.*the.*Association.*for.*Computational.*Linguistics:.*Human.*Language.*Technologies.*, replace=Proc. NAACL] \step[fieldsource=booktitle, match=\regexp.*Empirical.*Methods.*in.*Natural.*Language.*Processing.*, replace=Proc. EMNLP] \step[fieldsource=booktitle, match=\regexp.*Association.*for.*Computational.*Linguistics.*, replace=Proc. ACL] \step[fieldsource=booktitle, match=\regexp.*Automatic.*Speech.*Recognition.*and.*Understanding.*, replace=Proc. ASRU] \step[fieldsource=booktitle, match=\regexp.*Spoken.*Language.*Technology.*, replace=Proc. SLT] \step[fieldsource=booktitle, match=\regexp.*Speech.*Synthesis.*Workshop.*, replace=Proc. SSW] \step[fieldsource=booktitle, match=\regexp.*workshop.*on.*speech.*synthesis.*, replace=Proc. SSW] \step[fieldsource=booktitle, match=\regexp.*Advances.*in.*neural.*information.*processing.*, replace=Proc. NeurIPS] \step[fieldsource=booktitle, match=\regexp.*Advances.*in.*Neural.*Information.*Processing.*, replace=Proc. NeurIPS] \step[fieldsource=booktitle, match=\regexp.*Workshop.*on.* Applications.* of.* Signal.*Processing.*to.*Audio.*and.*Acoustics.*, replace=Proc. WASPAA] \step[fieldsource=publisher, match=\regexp.+, replace=] \step[fieldsource=month, match=\regexp.+, replace=] \step[fieldsource=location, match=\regexp.+, replace=] \step[fieldsource=address, match=\regexp.+, replace=] \step[fieldsource=organization, match=\regexp.+, replace=] 1Carnegie Mellon University, 2Sony Group Corporation, Japan
Joint Modelling of Spoken Language Understanding Tasks with Integrated Dialog History
Abstract
Most human interactions occur in the form of spoken conversations where the semantic meaning of a given utterance depends on the context. Each utterance in spoken conversation can be represented by many semantic and speaker attributes, and there has been an interest in building Spoken Language Understanding (SLU) systems for automatically predicting these attributes. Recent work has shown that incorporating dialogue history can help advance SLU performance. However, separate models are used for each SLU task, leading to an increase in inference time and computation cost. Motivated by this, we aim to ask: can we jointly model all the SLU tasks while incorporating context to facilitate low-latency and lightweight inference? To answer this, we propose a novel model architecture that learns dialog context to jointly predict the intent, dialog act, speaker role, and emotion for the spoken utterance. Note that our joint prediction is based on an autoregressive model and we need to decide the prediction order of dialog attributes, which is not trivial. To mitigate the issue, we also propose an order agnostic training method. Our experiments show that our joint model achieves similar results to task-specific classifiers and can effectively integrate dialog context to further improve the SLU performance.111Our code & models are publicly available as part of ESPnet-SLU toolkit.
Index Terms— spoken language understanding, spoken dialog system, end-to-end systems, joint modelling, speaker attributes
1 Introduction
Spoken dialogue systems aim to enable dialogue agents to engage in a more natural conversation with humans. They have commonly represented a possible dialogue by a series of frames [1, 2]. Each frame represents the type of task the user seeks and has attributes representing the information that can help the system to complete the task. These spoken dialog systems aim to automatically identify the topic of conversations as well as other dialog frame attributes (e.g., dialogue act, emotion) to engage in conversation with the user.
Conventional Spoken Language Understanding (SLU) [3, 4] systems independently process each utterance in a conversation. However, the meaning of an utterance in a spoken dialog depends on the context. Prior work has shown dialogue context to be particularly useful in resolving ambiguities and co-references [5, 6]. As a result, there has been extensive work on incorporating context to improve Natural Language Understanding (NLU) performance [7, 8, 9]. Prior work [10, 11, 12] on conversational speech has also shown strong improvements in ASR performance by incorporating dialog context. Thus, several approaches [13, 14, 15, 16] have looked into incorporating dialog history in pipeline based SLU systems. Recently, there has been some work [17, 18, 19] in incorporating context to improve end-to-end (E2E) SLU performance. One such approach [17] integrates dialog history into an E2E SLU system by using ASR transcripts of previous spoken utterances. There has also been an effort [18] to incorporate context directly from the audio of previous utterances.
However, these works mostly focus on building a single model for each SLU task like intent classification, dialog act classification, and emotion recognition. To jointly predict all the SLU tasks, we have to execute all models separately. Consequently, these models not only have a large memory footprint but also have high latency, which can affect the naturalness of spoken conversations [20] when these systems are deployed in commercial applications like voice assistants. Prior work has shown that jointly modeling different speech processing tasks together in a united framework can perform comparable to task-specific models [21, 22] while reducing latency [23]. Motivated by this work, we ask the following questions: (i) Can we jointly model all SLU tasks while incorporating context in a single unified implementation without much loss in performance? (ii) Does incorporating the SLU tags predicted at previous spoken utterances by the joint model help in better modeling spoken dialogue context? We seek to answer these questions by proposing a novel E2E SLU architecture that jointly models all the SLU tasks while effectively learning context from previous spoken utterances. This joint model uses an autoregressive decoder to predict dialog attributes one by one and the order in which the model predicts the SLU attributes may impact model performance. Hence, we investigate (iii) if we can use order agnostic training to make the model automatically predict in the optimal ordering during inference. Inspired by prior work on ASR [24], we also investigate (iv) if an intermediate CTC loss advances SLU performance further. We conduct extensive experiments on the recently released HarperValley [25] Bank dataset, which consists of dialogs between users and consumer bank agents. Our results show that our joint model performs at par with the individual classifiers for each SLU task, and incorporating dialog context and order agnostic training can further lead to significant improvements in performance. Our code and models are made publicly available as part of the ESPnet-SLU [26] toolkit.
The key contributions of our work are summarised below.
-
•
We propose a novel joint model that uses dialog context to jointly predict the intent, dialog act, speaker role and emotion.
-
•
We propose order agnostic training of the joint model and show an improvement in performance across all SLU tasks.
-
•
We investigate the efficacy of using SLU tags predicted from previous utterances to model dialog context.
-
•
We show that incorporating the usage of intermediate CTC loss can advance SLU performance.
2 Background: Dialog Context in SLU
The formulation for SLU with integrated dialog context extends the well-studied framework of NLU systems [7, 8, 9]. For NLU systems, dialog context sequence is represented as sequence of utterances, i.e., . Each utterance in the dialog context sequence is represented as , with length and vocabulary . Each utterance has a tag for each of the NLU tasks. In this work, each utterance has a tag from label sets , , and indicating dialogue act classification, intent classification, speaker role prediction, and emotion recognition, respectively. This produces a label sequence of the same length for each task, for instance, . Using the maximum a posteriori theory, NLU models seek to output ,,, and that maximise the posterior distribution ,, and given , respectively.
SLU introduces an additional complexity of modeling dialog context from the spoken utterance. Dialog context sequence is formed by spoken utterances, i.e., . Each spoken utterance is a sequence of dimensional speech feature of length frames. Similar to the NLU formulation, SLU systems seek to estimate the label sequence ,, and that maximise the posterior distribution ,, and given , respectively. We can model these posterior distributions as described in the subsections below.
2.1 Seperate E2E model with dialog context
Prior work [17] models each posterior, e.g., , using a sequence of transcripts by applying the Viterbi approximation:
| (1) | ||||
| (2) |
Their approach then assumes the conditional independence of from , to simplify the Eq 2:
| (3) |
Transcripts are computed using a separate ASR module that seeks to estimate that maximises . Using , we can modify Eq 3:
| (4) |
Prior work [17] models in Eq. 4 by passing ASR transcripts to a pretrained language model (LM) like BERT [27] and then concatenating these context embeddings to the acoustic embedding obtained from . They focus on building a separate model for each of the SLU tasks, which in the above description is dialogue act classification. Thus, to predict all the SLU tasks, all the separate models that estimate ,,, and independently need to be executed which can increase latency and computational cost and also does not consider the dependency between SLU tasks.
3 Proposed Joint E2E model w/ dialog context
In this work, we extend the prior work [17] on dialog integration discussed in section 2.1 and propose to jointly model all SLU tasks. We denote a single target containing all the SLU tags as and modify Eq. 4 with as shown below:
| (5) |
The SLU tags predicted for the previous spoken utterances i.e. may be incorporated (Eq. 5) to better model the dialog context unlike in prior work [17] which assumes conditional independence of from . In §5.1, we confirm experimentally whether this previous SLU tag condition is helpful. Further, by jointly modeling all the SLU tasks, we expect significantly lower latency and lightweight inference.
| Model | DA () | IC () | SR () | ER () | RTF () | Latency (msec.) () | Parameters () | Train time (sec.) () | ||
| Slowest | Total | Slowest | Total | |||||||
| Separate E2E model without context* ([18]) | 54.0 | |||||||||
| Separate E2E model with context* ([18]) | 58.3 | |||||||||
| Separate E2E models without context §2.1 | 55.5 | 47.1 | 91.9 | 91.4 | 1.58 | 3.28 | 1153 | 4515 | 457.6M | 4296 |
| Joint E2E model without context §3 | 55.8 | 47.7 | 91.5 | 90.6 | 1.15 | 1.58 | 293 | 1153 | 114.4M | 1381 |
| Joint E2E model with context §3 | 58.1 | 86.1 | 95.0 | 90.9 | 1.14 | 1.57 | 286 | 1133 | 152.7M | 1960 |
| + order agnostic training (Eq. 9) (proposed) | 58.8 | 86.5 | 95.1 | 91.1 | 1.15 | 1.58 | 289 | 1140 | 152.7M | 2040 |
| + previous SLU tag condition (Eq. 5) (ablation) | 58.3 | 86.5 | 94.6 | 90.8 | 1.23 | 1.54 | 310 | 1080 | 165.4M | 2613 |
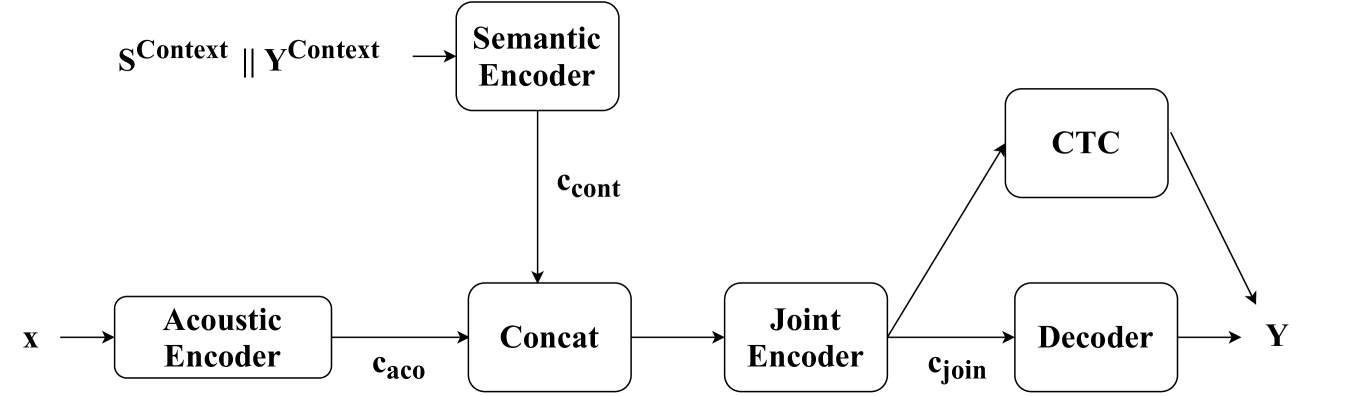
To realize this formulation, we propose a joint model architecture shown in Fig. 1. The input speech signal for each utterance i.e., in Eq. 5, is passed through an acoustic encoder () to generate acoustic embeddings .
| (6) |
We concatenate ASR transcripts and SLU tags for all previous spoken utterances and pass them through semantic encoder () like a pretrained LM to encode the dialog history:
| (7) |
The output of the semantic encoder is also passed to a linear layer to ensure that context embeddings have the same hidden dimension as acoustic embeddings . The acoustic and context embeddings are concatenated together () and attended by a joint encoder to produce the joint embedding :
| (8) |
The model is trained using joint CTC-attention training [28], where the CTC objective function is used to train the attention model encoder as an auxiliary task. Because we use an autoregressive decoder to predict tags one by one (Eq. 11), the likelihood is dependent on the order of SLU tags in the target sequence . This has been referred to as label ambiguity (or permutation) problem in prior work [29, 30]. Inspired by prior work on permutation invariant training [30, 31, 32], we use CTC objective function to perform permutation-free training as shown in Eq. 9, which is referred to as order agnostic training in this work. Let be the output sequence variable computed from the joint embedding , then the optimal permutation order is computed as:
| (9) |
where is the set of 4! possible permutations of SLU tags (da,ic,sr,er), is one such permutation and is the reference target with the order of SLU tags indicated by . Later, the optimal permutation is used for computing the attention decoder loss222We use the CTC loss to compute optimal order instead of decoder loss for lightweight modeling..
| Model | DA () | IC () | SR () | ER () |
|---|---|---|---|---|
| Joint E2E Model without context | 54.8 | 47.6 | 91.1 | 90.9 |
| w/ inter ctc | 55.8 | 47.7 | 91.5 | 90.6 |
For each pair of optimal decoding order and reference target (,), the attention likelihood is calculated as shown below.
| (10) | |||
| (11) |
where denotes a linear layer followed by the softmax function and is the term in target sequence. The joint likelihood can then be computed as a product of the individual likelihood for each of the SLU tags (i.e., from in [1,4]). It is important to note that this “order agnostic training” does not add any new model parameters. During inference, the model automatically picks the tag order, i.e., unlike training, we do not enforce the predicted tag order to have the minimum CTC loss. Further, our joint models can also be trained with an auxiliary ASR objective [26, 33] by making the model generate both the SLU tags and ASR transcript .
4 Experiment Setup
4.1 Datasets
To show the effectiveness of our joint model, we conducted experiments on publicly available HarperValleyBank [25] spoken dialog corpus, where dialogs are simulated conversations between bank employees and customers. The corpus consists of 1,446 conversations with 23 hours of audio and 25,730 utterances with human annotated transcripts. The utterances are spoken by 59 unique speakers and have annotations for the dialog act, intent of the conversation, speaker role, and emotional valence.
In this work, we trained a joint model that performs intent classification, dialog act recognition, emotion recognition and speaker attribute prediction. Dialogue act recognition is a multi-label multi-class classification whereas all other tasks are single-label multi-class classification. We followed the setup in prior work [18] and split the conversations into train, valid and test set333However, the prior work [17, 18] also uses an off the shelf ASR model to realign the audio with transcripts making their results not directly comparable to results obtained by our setup.. Similar to [17], we also removed non-lexical tokens such as [noise],[laughter] from the transcript. Our training set contains 1,174 conversations (9.2 hours of audio, 15,424 utterances), valid set contains 73 conversations (0.6 hours of audio, 964 utterances) and our test set contains 199 conversations (1.6 hours of audio, 2903 utterances). We report macro F1 for dialog act prediction and accuracy for intent classification, speaker role prediction and emotion recognition as recommended by prior work [17, 25]. The latency of our system is reported using two metrics: (1) Real time factor (RTF), which is the average time taken to process an input audio file as a ratio of the duration of input and (2) Endpoint latency which is the elapsed time from the utterance end to getting predictions for SLU tasks. We also show the training time per epoch for all our models.
| Model | DA () | IC () | SR () | ER () |
|---|---|---|---|---|
| Joint E2E Model with context | 58.1 | 86.1 | 95.0 | 90.9 |
| Joint E2E Model with oracle context | 58.5 | 87.0 | 95.2 | 91.1 |
4.2 Architecture details and training
Our approach is compared to state-of-the-art SLU task-specific baselines referred to as “Separate E2E models without context” (optimizes instead of in Eq. 4). We also compared with our proposed model without context, i.e., “Joint E2E model without context” which optimizes instead of in Eq. 5. This baseline joint E2E model does not incorporate order agnostic training defined in Eq. 9 and instead is trained using a fixed order of SLU tags. To understand the efficacy of our proposed modifications to [17], we first trained a joint model (referred to as “Joint E2E model with context”) that does not use SLU tags of previous spoken utterances (i.e. optimize instead of in Eq. 5) and also does not utilize order agnostic training. In our ablation study, we further trained proposed joint model that incorporates “order agnostic training” as defined in Eq. 9 and another joint model that incorporates “previous SLU tag condition” i.e. tags predicted for previous spoken utterances ( in Eq. 5).
Our models were implemented in pytorch [34] and experiments were conducted through the ESPNet-SLU [26, 35] toolkit. All the models were trained using an auxiliary ASR objective. Our task-specific baselines consist of 12 layer conformer [36, 37] encoder that inputs features extracted by a strong self-supervised speech model WavLM [38] and 6 layer transformer [39, 40] decoder. Our “Joint E2E model without context” has a similar architecture as task specific baselines. Prior work [24] used an intermediate CTC loss attached to an intermediate layer in the encoder network to regularize CTC training and improve performance. Inspired by this work, we experimented with adding intermediate CTC loss at layers 4, 6 and 8 of our conformer encoder. The “Joint E2E model without context” is used to generate dialog context444The Word Error Rate (WER) of ASR transcripts is 11.7. . We incorporated the usage of Transformers library [41] to get BERT-base-uncased [27] as semantic encoder ( in Eq. 7). The conformer architecture with intermediate CTC loss is leveraged as the joint encoder ( in Eq. 8) in our proposed models. Teacher forcing is used for all our models with integrated dialog context i.e., the context was created using ground truth transcripts during training. The training and inference of our models were performed using a single NVIDIA Tesla V100-32GB GPU. The inference was computed using 4 parallel jobs and we use the time when the utterance has been processed by all the jobs (i.e. time taken by slowest job) as well as the sum of time taken by all the jobs to compute latency metrics. All hyperparameters were selected based on validation performance.
5 Results
5.1 Main Results
Table 1 shows the results of our joint model both with and without using dialog context. The performance of our “Separate E2E models without context” (section 2.1) is similar to the baseline results reported in prior work [18], though these results are not directly comparable because of different data preparation setups. Our “Joint E2E model without context” performs at par with these task-specific models while significantly reducing latency555Task-specific baselines are executed one after other in sequential order. and the number of trainable model parameters, showcasing the utility of jointly modeling all SLU tasks. We investigated integrating dialog context in the joint model (“Joint E2E model with context” in Table 1) using formulation described in section 3 and observe a significant improvement in performance, particularly for intent, dialog acts, and speaker role identification, providing evidence that our proposed methodology can effectively encode the context. We further observe a performance gain using “order agnostic training”, as defined in Eq. 9, which confirms our hypothesis that the ordering of SLU tags while training can impact model performance. While our order agnostic training framework increases the training time as it requires the computation of CTC loss over all possible permutations of SLU tags (Eq. 9), this increase in training time is not very significant. We also experimented with “previous SLU tag condition” (i.e. attending to in Eq. 5) using only utterance-level annotated tags, i.e., dialog act, emotion, and speaker role, to encode context. This model achieves a performance gain in intent classification and dialog act prediction with comparable results on predicting other SLU tasks. We plan to further investigate the utility of SLU tags from previous spoken utterances in future work. Our joint E2E model with context also achieved similar performance to “Separate E2E model with context” [18] with no knowledge distillation from a text-based system, although the two models have different data preparation setups.
To better understand our joint model, we also perform an ablation study in Table 2 and infer that using intermediate CTC loss can stabilize training and improve the performance of our joint model.
| Order | Training (%) | Inference (%) | Sample Training Utterance |
|---|---|---|---|
| (sr, ic, da, er) | 35.0 | 40.1 | i’ve ordered your replacement debit card |
| (da, ic, sr, er) | 27.9 | 36.0 | uh well james my name is jennifer jones and i would like to reset my password please |
| (ic, sr, da, er) | 16.4 | 6.8 | thank you for calling have a great day |
| (ic, da, sr, er) | 14.5 | 7.5 | you too bye |
| (sr, da, ic, er) | 6.2 | 9.5 | hello this is harper valley national bank my name is patricia how can i help you today |
5.2 Using oracle context
To understand the impact of errors in ASR transcripts , we compute results of our joint E2E model with oracle context, i.e., using ground truth transcripts as in Eq. 5. Table 3 shows only a slight increase in performance compared with the model that uses ASR transcripts to encode context, indicating that it is robust to ASR errors.
5.3 Predicted ordering of SLU tags
We analyze the optimal order of SLU tags found during training using Eq. 9 in Table 4 and observe that optimal permutation sequence are among only 5 of 4! possible permutations of SLU tags. We compare it to the tag order predicted by our joint E2E model with context and order agnostic training. The predicted order of SLU tags during inference has a similar trend to the optimal order of SLU tags found during training, with (sr, ic, da, er) and (da, ic, sr, er) being the two most common orders. Further the training utterances with optimal order (sr, da, ic, er) are usually spoken at the start of the conversation and are mainly greetings, as shown in Table 4. We hypothesize that this tag order is optimal for these utterances as it is challenging to detect the intent of the conversation from these greeting utterances, and hence intent is predicted after the model decodes dialogue act and speaker role tags. This gives model the ability to incorporate the dependency on these tags to better extract the intent of current utterance. Our analysis is similar for other tag orders and we infer that we can validate the optimal tag order found for training utterances. After a more fine-grained analysis, we observe that test utterances that are similar to training utterances with optimal tag order are also predicted by the joint model in the same tag order during inference. This finding provides initial evidence to the hypothesis that the joint model learns to automatically predict in the optimal tag order during inference using order agnostic training. Based on this interesting insight and performance gains observed in Table 1, we recommend future studies on jointly modeling different SLU tasks to incorporate order agnostic training in their framework.
6 Conclusion
We propose a novel model architecture that can jointly model intent classification, dialogue act prediction, speaker role identification and emotion recognition with full integration of dialog history in spoken conversations. Our results show that the joint model achieves comparable performance to task-specific models with the additional benefits of low latency and lightweight inference. Our joint model can also successfully capture dialog context to improve the prediction performance of all SLU tasks significantly. We experimentally confirm that order agnostic training can further enhance performance. In future work, we plan to explore E2E integration of dialog context as well as knowledge distillation from a text-based system.
7 Acknowledgement
8 References
References
- [1] Renato De Mori et al. “Spoken language understanding” In IEEE Signal Processing Magazine 25.3, 2008, pp. 50–58
- [2] James F Allen et al. “Toward conversational human-computer interaction” In AI magazine 22.4, 2001, pp. 27–27
- [3] Bhuvan Agrawal et al. “Tie your embeddings down: Cross-modal latent spaces for end-to-end spoken language understanding” In arXiv preprint arXiv:2011.09044, 2020
- [4] Sujeong Cha et al. “Speak or Chat with Me: End-to-End Spoken Language Understanding with Flexible Inputs” In arXiv, 2021
- [5] Aditya Bhargava et al. “Easy contextual intent prediction and slot detection” In Proc. ICASSP, 2013, pp. 8337–8341
- [6] Puyang Xu and Ruhi Sarikaya “Contextual domain classification in spoken language understanding systems using recurrent neural network” In Proc. ICASSP, 2014, pp. 136–140
- [7] Pierre Colombo et al. “Guiding attention in sequence-to-sequence models for dialogue act prediction” In Proceedings of the AAAI Conference on Artificial Intelligence 34.05, 2020, pp. 7594–7601
- [8] Chandrakant Bothe et al. “A context-based approach for dialogue act recognition using simple recurrent neural networks” In arXiv preprint arXiv:1805.06280, 2018
- [9] Vipul Raheja and Joel Tetreault “Dialogue act classification with context-aware self-attention” In arXiv preprint arXiv:1904.02594, 2019
- [10] Suyoun Kim, Siddharth Dalmia and Florian Metze “Gated Embeddings in E2E Speech Recognition for Conversational-Context Fusion” In Proc. ACL, 2019, pp. 1131–1141 DOI: 10.18653/v1/P19-1107
- [11] Suyoun Kim, Siddharth Dalmia and Florian Metze “Cross-Attention End-to-End ASR for Two-Party Conversations” In Proc. Interspeech, 2019, pp. 4380–4384 DOI: 10.21437/Interspeech.2019-3173
- [12] Takaaki Hori et al. “Transformer-Based Long-Context End-to-End Speech Recognition.” In Proc. Interspeech, 2020, pp. 5011–5015
- [13] Yun-Nung Chen et al. “End-to-end memory networks with knowledge carryover for multi-turn spoken language understanding.” In Proc. Interspeech, 2016, pp. 3245–3249
- [14] Chinnadhurai Sankar et al. “Do neural dialog systems use the conversation history effectively? an empirical study” In arXiv preprint arXiv:1906.01603, 2019
- [15] Ankur Bapna et al. “Sequential dialogue context modeling for spoken language understanding” In arXiv preprint arXiv:1705.03455, 2017
- [16] Vedran Vukotić, Christian Raymond and Guillaume Gravier “A step beyond local observations with a dialog aware bidirectional GRU network for Spoken Language Understanding” In Proc. Interspeech, 2016, pp. 3241–3244
- [17] Jatin Ganhotra et al. “Integrating dialog history into end-to-end spoken language understanding systems” In arXiv preprint arXiv:2108.08405, 2021
- [18] Vishal Sunder et al. “Towards End-to-End Integration of Dialog History for Improved Spoken Language Understanding” In Proc. ICASSP, 2022, pp. 7497–7501
- [19] Natalia Tomashenko et al. “Dialogue history integration into end-to-end signal-to-concept spoken language understanding systems” In Proc. ICASSP, 2020, pp. 8509–8513
- [20] Siddhant Arora et al. “Two-Pass Low Latency End-to-End Spoken Language Understanding” In Proc. Interspeech, 2022, pp. 3478–3482 DOI: 10.21437/Interspeech.2022-10890
- [21] Tom O’Malley et al. “A conformer-based asr frontend for joint acoustic echo cancellation, speech enhancement and speech separation” In Proc. ASRU, 2021, pp. 304–311
- [22] Wangyou Zhang et al. “End-to-end dereverberation, beamforming, and speech recognition with improved numerical stability and advanced frontend” In Proc. ICASSP, 2021, pp. 6898–6902
- [23] Shuo-Yiin Chang et al. “Joint endpointing and decoding with end-to-end models” In Proc. ICASSP, 2019, pp. 5626–5630
- [24] Jaesong Lee and Shinji Watanabe “Intermediate loss regularization for CTC-based speech recognition” In Proc. ICASSP, 2021, pp. 6224–6228
- [25] Mike Wu et al. “Harpervalleybank: A domain-specific spoken dialog corpus” In arXiv preprint arXiv:2010.13929, 2020
- [26] Siddhant Arora et al. “Espnet-slu: Advancing spoken language understanding through espnet” In Proc. ICASSP, 2022, pp. 7167–7171
- [27] Jacob Devlin et al. “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding” In Proc. NAACL-HLT, 2019, pp. 4171–4186 DOI: 10.18653/v1/n19-1423
- [28] Suyoun Kim, Takaaki Hori and Shinji Watanabe “Joint CTC-attention based end-to-end speech recognition using multi-task learning” In Proc. ICASSP, 2017, pp. 4835–4839
- [29] Chao Weng et al. “Deep neural networks for single-channel multi-talker speech recognition” In IEEE/ACM Transactions on Audio, Speech, and Language Processing 23.10, 2015, pp. 1670–1679
- [30] John R Hershey et al. “Deep clustering: Discriminative embeddings for segmentation and separation” In Proc. ICASSP, 2016, pp. 31–35
- [31] Dong Yu et al. “Permutation invariant training of deep models for speaker-independent multi-talker speech separation” In Proc. ICASSP, 2017, pp. 241–245 DOI: 10.1109/ICASSP.2017.7952154
- [32] Xuankai Chang et al. “End-to-end monaural multi-speaker ASR system without pretraining” In Proc. ICASSP, 2019, pp. 6256–6260
- [33] Anoop Deoras et al. “Joint decoding for speech recognition and semantic tagging” In Proc. Interspeech, 2012, pp. 1067–1070 DOI: 10.21437/Interspeech.2012-324
- [34] Adam Paszke et al. “Pytorch: An imperative style, high-performance deep learning library” In Proc. NeurIPS 32, 2019, pp. 8024–8035
- [35] Shinji Watanabe et al. “ESPnet: End-to-End Speech Processing Toolkit” In Proc. Interspeech, 2018, pp. 2207–2211
- [36] Anmol Gulati et al. “Conformer: Convolution-augmented Transformer for Speech Recognition” In Proc. Interspeech, 2020, pp. 5036–5040 DOI: 10.21437/Interspeech.2020-3015
- [37] Pengcheng Guo et al. “Recent Developments on Espnet Toolkit Boosted By Conformer” In Proc. ICASSP, 2021, pp. 5874–5878 DOI: 10.1109/ICASSP39728.2021.9414858
- [38] Sanyuan Chen et al. “WavLM: Large-scale self-supervised pre-training for full stack speech processing” In arXiv preprint arXiv:2110.13900, 2021
- [39] Ashish Vaswani et al. “Attention is all you need” In Proc. NeurIPS 30, 2017, pp. 5998–6008
- [40] Shigeki Karita et al. “A Comparative Study on Transformer vs RNN in Speech Applications” In Proc. ASRU, 2019, pp. 449–456 DOI: 10.1109/ASRU46091.2019.9003750
- [41] Thomas Wolf et al. “Transformers: State-of-the-Art Natural Language Processing” In Proc. EMNLP, 2020, pp. 38–45 URL: https://www.aclweb.org/anthology/2020.emnlp-demos.6
- [42] J. Towns et al. “XSEDE: Accelerating Scientific Discovery” In Computing in Science & Engineering 16.5, 2014, pp. 62–74
- [43] Nicholas A Nystrom et al. “Bridges: a uniquely flexible HPC resource for new communities and data analytics” In Proc. XSEDE Conference: Scientific Advancements Enabled by Enhanced Cyberinfrastructure, 2015