Joint Power Allocation and Rate Control for Rate Splitting Multiple Access Networks with Covert Communications
Abstract
Rate Splitting Multiple Access (RSMA) has recently emerged as a promising technique to enhance the transmission rate for multiple access networks. Unlike conventional multiple access schemes, RSMA requires splitting and transmitting messages at different rates. The joint optimization of the power allocation and rate control at the transmitter is challenging given the uncertainty and dynamics of the environment. Furthermore, securing transmissions in RSMA networks is a crucial problem because the messages transmitted can be easily exposed to adversaries. This work first proposes a stochastic optimization framework that allows the transmitter to adaptively adjust its power and transmission rates allocated to users, and thereby maximizing the sum-rate and fairness of the system under the presence of an adversary. We then develop a highly effective learning algorithm that can help the transmitter to find the optimal policy without requiring complete information about the environment in advance. Extensive simulations show that our proposed scheme can achieve positive covert transmission rates in the finite blocklength regime and non-saturating rates at high SNR values. More significantly, our achievable covert rate can be increased at high SNR values (i.e., 20 dB to 40 dB), compared with saturating rates of a conventional multiple access scheme.
Index Terms:
Rate splitting multiple access, covert communications, deep reinforcement learning, power allocation, rate control.I Introduction
Recent years have witnessed the growing interest in six-generation (6G) networks from both academia and industry. It is envisioned that 6G will enable the Internet-of-Things (IoT) in which a massive number of devices can communicate via wireless environments. To accommodate such a growing demand of connections in future wireless networks, a modern multiple access scheme with high efficiency and flexibility is an urgent need. Rate Splitting Multiple Access (RSMA) has recently emerged as a novel communication technique that can flexibly and efficiently manage interference and thus increase the overall performance for the downlink of the wireless systems [2, 1]. In RSMA, each message at the transmitter is first split into two parts, i.e., a common part and private part. The common parts of all the messages are combined into a single common message. The common message is then encoded using a shared codebook. The private messages are independently encoded for the respective users. After receiving these messages, each user decodes the common and private messages with the Successive Interference Cancellation (SIC) to obtain its original message. By partially decoding and partially treating interference as noise, RSMA can enhance spectral efficiency, energy efficiency, and security of multiple access systems [4, 3, 6, 7, 5, 8]. Thanks to its outstanding features, RSMA can tackle many emerging problems in 6G and gain enormous attention from both industry and academia [1].
I-A Challenges of RSMA
Although possessing the advantages, the RSMA scheme is facing two main challenges. Unlike conventional multiple access schemes, e.g., Spatial Division Multiple Access (SDMA) which treats interference as noise or Non-Orthogonal Multiple Access (NOMA) which successively removes multi-user interference during the decoding process, RSMA partially decodes the messages and partially treat multi-user interference as noise. The RSMA transmitter hence needs to jointly optimize the power allocation and rate control for different messages to maximize the energy and spectral efficiency for the whole system. Aiming to address such problems, several research works have been proposed in the literature. In [9], the authors consider a rate splitting approach with heterogeneous Channel State Information at the Transmitter (CSIT). Two groups of CSIT qualities are considered and the transmitter is assumed to have either partial CSIT or no-CSIT. For the no-CSIT scenario, the users decode their messages by treating interference as noise without using a rate splitting strategy. In contrast, for the partial CSIT scenarion, a rate splitting strategy is applied and a fraction of total power is allocated equally among private symbols and common symbols. Simulation results show that with the proposed power allocation scheme, the sum-rate of users in the group with the rate splitting strategy can gain significant improvement compared to those in the group without using any rate splitting strategy. Similarly, in [7], the authors study a rate splitting strategy for a multi-group of users in a large-scale RSMA system. A more complex precoding design for power and rate allocated to users is proposed to find the maximum sum-rate of the system. The simulation results reveal that a precoding design with rate splitting can benefit sum-rate of the system. However, the authors in [7] only consider a perfect CSIT scenario in which the BS is assumed to know exact information of the channel and the channel is assumed to be fixed. In order to relax these assumptions, the authors in [6] and [10] consider a similar system, but under imperfect CSIT. In this case, a stochastic optimization formulation is proposed to deal with the uncertainty of the channel with imperfect CSIT. In [10], the authors show that with rate splitting under imperfect CSIT, the sum-rate of the system can achieve non-saturating rates at high SNR values compared to saturating rates of a conventional scheme, i.e., SDMA. In [6], the authors further investigate the impacts of different error models on the system performance. Numerical results reveal that in addition to the expected sum-rate gains, the benefits of rate splitting also include relaxed CSIT quality requirements and enhanced achievable rate regions compared with a conventional transmission scheme. A comprehensive analysis of RSMA performance is studied in [4]. In this work, through many simulations and performance analysis, they show that the rate splitting techniques are able to softly bridge the two extremes of fully treating interference as noise and fully decoding interference. Thus, in comparison with conventional multiple access approaches, e.g., SDMA and NOMA, RSMA can gain significant rate enhancement. Although the aforementioned works propose solutions to improve system performance for RSMA networks, the channel state distribution (or channel state matrix) is always assumed to be known by the transmitter. In addition, optimization methods in these works also introduce additional variables, e.g., equalizers and weights, that are highly correlated with the channel state. Thus, unavailability or drastic changes of the channel state information, e.g., due to mobility of users of link’s failures [12], can result in significant degradation of these algorithms. Therefore, a more flexible framework that not only deals with the dynamics of the environment but also efficiently manages power allocation and rate control for RSMA without requiring complete or partial information, e.g., posterior distributions, of the channel state, is in an urgent need.
The second challenge that RSMA is facing is security. Although a new data rate region can be achieved with RSMA, investigation on RSMA’s security is still in its early stage. Several works, such as [3, 14] and [13], are proposed to address the eavesdropping issues in RSMA networks. In particular, the authors in [3] propose a cooperative RSMA scheme to enhance the secrecy sum-rate of the system in which the common messages can be used not only as desired messages but also artificial noise. In this case, it is shown that the proposed cooperative secure rate splitting scheme outperforms conventional SDMA and NOMA schemes in terms of secrecy sum-rate. However, [3] only considers the perfect CSIT scenario in which the transmitter has complete information of the channel state. In order to address the challenges caused by imperfect CSIT, the authors in [14] investigate the impacts of imperfect CSIT on the secrecy rate of the system. Specifically, to deal with imperfect CSIT, a worst-case uncertainty channel model is taken into consideration with the goal to mitigate simultaneously inter-user interference and maximize the secrecy sum-rate. The simulation results show the robustness of the proposed solution against the imperfect CSIT of RSMA, and the secure transmission is also guaranteed. Furthermore, in comparison with NOMA, RSMA shows significant secrecy rate enhancement. In [13], a secure beamforming design is also proposed to maximize the weighted sum-rate under user’s secrecy rate requirement. Unlike [3] and [14], the authors in [13] consider the presence of an internal eavesdropper, i.e., an illegitimate user, that not only receives its messages but also wiretaps messages intended for other legitimate users. To deal with this internal eavesdropper, all user’s secrecy rate constraints are taken into consideration. The simulation results suggest that RSMA can outperform the baseline scheme in terms of weighted sum-rate.
All of the above works and others in literature only focus on dealing with the passive eavesdroppers, i.e., the eavesdroppers try to listen passively to the communication channel to derive the original message. To deal with such passive eavesdroppers, the transmitter can adaptively select different transmission rates [13] or utilize artificial noise [3] to confuse the eavesdropper, and thereby minimizing the information disclosure. However, in these cases, the eavesdropper can still detect and receive the signals from the transmitter, and thus it can still decode the information if it has a more powerful hardware computation, e.g., through employing cooperative processing with other eavesdroppers, or better antennas gains compared with those of the transmitter [16, 17]. The passive eavesdropper scenario cannot address the problem in which the eavesdropper is able to manipulate or control the environment [16]. For example, by manipulating the environment, the adversary can bias the resulting bits in the key establishment process [18]. In applications requiring a high security protection, e.g., military and IoT healthcare applications, leaking a small amount of data can result in a break of the whole system and/or cause effects to the users. Therefore, in this work, to further prevent potential information leakage, we focus on a more challenging adversary model in which we need to control the power and transmission rates allocated to users, so that the adversary is unable to detect transmissions on the channels. In this way, the possibility of leaking information can be minimized.
I-B Contributions and Organization
In this work, we aim to develop a novel framework that addresses the aforementioned problems. In particular, we consider a scenario in which an adversary, i.e., a warden, is present in the communication range of a Base Station (BS), i.e., the transmitter, and multiple mobile users, i.e., the receivers. The warden is assumed to be able to observe constantly the channel with a radiometer and interrupt the channel if it detects transmissions on the channel [15, 21]. Thus, it is challenging for the BS to allocate jointly power and control transmission rates for all the messages while hiding these messages from the warden. To minimize the probability of being detected by the warden, a possible policy for the BS is to decrease the power allocated to the messages, so that the warden can be confused the transmitted signals with noise. However, an inappropriate implementation can result in zero data rates at the receivers [15]. To maximize the transmission rate of the system and at the same time guarantee non-zero rate at each user, we formulate the problem of the BS as a max-min fairness problem. In particular, the BS aims to maximize the expected minimum rate (min-rate) of the system under the uncertainty of the environment. Furthermore, we consider a covert constraint that is derived from the theory of covert communications (i.e., low probability of detection communications) [20, 22, 23]. In this way, our proposed framework can help the BS secretly communicate with the legitimate mobile users with a small probability of being detected by the warden.
To find the optimal solution for the optimization formulation above, we develop a learning algorithm based on Proximal Policy Optimization (PPO) [28]. By leveraging recent advances of deep reinforcement learning techniques [25, 26, 27], our proposed algorithm can effectively find the optimal policy for the BS without requiring complete information of the channel in advance. Specifically, our proposed algorithm takes the feedback from users via the uplink as inputs of the deep neural networks and then outputs the corresponding joint power allocation and rate control policy for the BS. This procedure is similar to the conventional optimization-based schemes in the view of implementation and resource. The differences in our proposed algorithm are twofold. First, our proposed algorithm is a model-free deep reinforcement learning algorithm which does not require a complete model of the environment, i.e., the channel state matrix or channel distribution, in advance. Second, the policy obtained by our proposed algorithm can be adaptively adjusted in cases the channel dynamics change over time, e.g., time-varying channel. Thus, our proposed algorithm is expected to show more flexibility and robustness against the uncertainty and dynamics of the wireless environment. With the obtained optimal policy, we then show that our proposed method can also achieve covert communications between the BS and mobile users by dynamically adjusting power and transmission rates allocated to the messages.
Here, we note that our previous work presented in [24] only focuses on power allocation problem without considering the security impact on the RSMA system. Furthermore, in this current work, we further investigate the rate and security performance of RSMA in the finite blocklength (FBL) regime where the achievable covert rate is limited and no longer follows the Shannon capacity (i.e., infinite blocklength regime). Thus, our framework can be applicable for a wide range of applications which include transmission between IoT devices where the transmitted data is expected to be sporadic and the number of channel uses is limited. In short, our main contributions are as follows:
-
•
We develop a novel stochastic optimization framework to achieve the max-min fairness of the considered RSMA network with the covert constraint. This framework enables the BS to make optimal decisions to maximize the expected min-rate under the covert requirement as well as the dynamics and uncertainty of surrounding environment. To the best of our knowledge, this is the first work that considers covert communications for RSMA. Therefore, our proposed framework is a promising solution for secure and reliable, high data transmission rate applications.
-
•
We propose a highly effective learning algorithm to make the best decisions for the BS. This learning algorithm enables the BS to quickly find the optimal policy through feedback from the users by leveraging advantages of both deep learning and reinforcement learning techniques. Furthermore, our proposed learning algorithm can effectively handle the continuous action and state spaces for the BS through using the PPO technique.
-
•
We conduct intensive simulations to evaluate the efficiency of the proposed framework and reveal insightful information. Specifically, the simulation results show that the positive covert rate is achievable with RSMA in the finite blocklength regime where the achievable covert rate is limited and no longer follows the Shannon capacity (i.e., infinite blocklength regime). More interestingly, with high values of transmission power (i.e., 20 dB to 40 dB), our achievable covert rate can be increased while the achievable covert rate of a baseline multiple access scheme, i.e., SDMA, is saturated. Thus, beyond conventional wireless networks, our framework can be applicable for IoT networks in which the data transmitted between devices is expected to be sporadic and with a relatively small quantity of information .
The rest of our paper is organized as follows. Our system model is described in Section II. Then, we formulate the stochastic optimization problem for the covert-aided RSMA networks in Section III. We provide details of our proposed learning algorithm to maximize the covert rate of the system in Section IV. After that, our simulation results are discussed in Section V, and Section VI concludes the paper.
II System Model
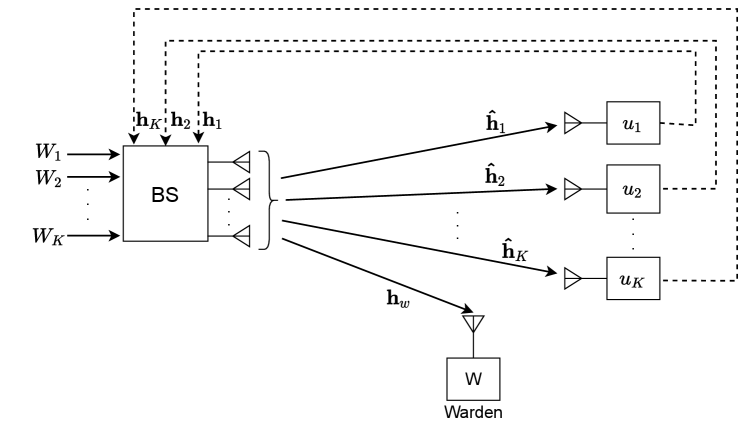
We consider a system that consists of one -antenna BS, a set of single-antenna legitimate users (), and a warden as illustrated in Fig. 1. The warden has ability to interrupt the channel if it detects any transmissions from the BS. The BS wants to transmit information to the users with a minimum probability of being detected by the warden [19]. The BS has a set of messages to be transmitted to the users. The message intended for user , denoted as , is split into a common part and a private part (), with the lengths of and , respectively. The common parts of all messages are combined into a single common message . The single common message and private messages are independently encoded into streams (i.e., common stream), (i.e., private streams), respectively. The transmitted signal of the BS is thus defined as follows:
| (1) |
where and are the beamforming vectors for the common and private stream and , respectively. Let denote the estimated channel between the BS and user , denote the channel between the BS and the warden. The received signal at user is calculated as follows:
| (2) |
where is the Additive White Gaussian Noise (AWGN) at the receiver. Note that the estimated channel at the BS is obtained from feedback of the users which contains estimation errors, i.e., , where is the actual channel state and is the estimation error. The SINRs of the common and private messages, denoted as and , respectively, can be calculated as follows:
| (3) | ||||
where is the beamformer of the BS. The transmission power at the BS is constrained by .
In the FBL regime, the achievable covert rate of the private message at user is calculated as follows [29, 30, 31]:
| (4) |
where is the length of message . is the decoding error probability at user , and is the inverse Q-function of [29]. To guarantee that the common message can be correctly decoded by all the users, the achievable covert rate of the common message is calculated by [29, 30]:
| (5) |
Since is shared between users such that is the user ’s portion of the common rate with . The total achievable rate of the user is then defined by [4]:
| (6) |
As a result, the covert sum-rate of the BS is defined by a sum of over users, i.e., .
With the presence of noise, the warden needs to make a binary decision, i.e., (i) the BS is transmitting or (ii) the BS is not transmitting, based on its observations [19]. For this, the warden distinguishes two hypotheses and , where denotes the null hypothesis, i.e., the BS is not transmitting, and denotes the alternative hypothesis, i.e., the BS is transmitting. In particular, the two hypotheses are defined as follows:
| (7) |
where and are the received signal and noise signal at the warden, respectively. is the transmitted signal from the BS. It is noted that the warden does not know the codebook of transmitted signals and the hypothesis test of the warden can be performed as follows. First, the warden collects a row vector of independent readings from his channel to the BS. Then the warden generates the test statistic on the collected vector. The goal of the warden is to minimize the error detection rate, which is given by:
| (8) |
where is the false alarm probability and is the miss detection probability. and are the binary decisions of the warden that infer whether the BS is transmitting or not, respectively. We can derive the lower bound of as follows [30]:
| (9) |
where and are the probability distributions of the observations when the BS transmits (i.e., is true) or when the BS does not transmit (i.e., is true), respectively. is the relative entropy between two probability distributions and .
Proposition 1
The relative entropy (Kullback–Leibler divergence) between two probability distributions and , denoted by , can be calculated as follows:
| (10) |
In covert communications, we normally have as the covertness requirement, where is an arbitrarily small value [30]. Following (9), in this paper, we adopt as the covertness requirement.
In the covert-aided systems, the achievable data rate is usually small or asymptotically approached zero [19, 30]. To achieve the maximum rate of the system and non-zero data rate for each user, we consider a max-min fairness problem in which the optimization problem is formulated as maximizing the expected minimum data rate (min-rate) among users [7]. Let denote the message-splitting vector and denote the common rates for the common messages. The stochastic optimization problem of the BS is then formulated as follows:
| (11a) | ||||
| s.t. | (11b) | |||
| (11c) | ||||
| (11d) | ||||
| (11e) | ||||
| (11f) | ||||
where is the average rate of the system with is the channel matrix of the system. is the minimum rate requirement (QoS) of user and is length of the message . The problem in (11) can be described as follows. (11b) and (11c) illustrate the power constraint and packet length constraint of the BS, respectively. (11d) is the common rate constraint. (11e) and (11f) are covert constraint and QoS constraint, respectively. Optimizing (11) is very challenging under the dynamics and uncertainty of the communication channel, i.e., the channel gain between the BS and user changes over time, and the channel state is unknown to the BS. In this paper, we thus propose a deep reinforcement learning approach to obtain the optimal policy for the BS under the dynamics and uncertainty of the environment. It is noted that we only use the channel matrix in the optimization problem above to illustrate the stochastic nature of the system. In the next section, we show that the optimization problem (11) can be transformed into maximizing the expected discounted reward in the deep reinforcement learning setting without requiring any information from channel matrix . Details of notations used in this paper are summarized in Table I.
| Variable | Definition |
|---|---|
| Number of users | |
| Number of antennas at the BS | |
| Message intended to transmit to user | |
| Common and private parts split from | |
| Length of (bits) | |
| Lengths of and | |
| Transmission power of the BS | |
| Transmission beamformer of the BS | |
| Vector of messages’ lengths at the BS | |
| Common rate vector allocated to users | |
| SINRs of the common and private messages at user | |
| Channel between the BS and user | |
| Channel between the BS and warden | |
| Achievable covert rates of and | |
| Achievable rate of user | |
| Achievable (covert) sum-rate | |
| Covert requirement | |
| Relative entropy between two probability distributions and | |
| Minimum rate requirement of user | |
| State space and action space of the BS | |
| State, action, and reward of the BS at time step | |
| Penalty of the BS for taking action | |
| Policy and policy parameter vector of the BS |
III Problem Formulation
III-A Deep Reinforcement Learning
Before introducing our mathematical formulation, we first describe the fundamentals of DRL. In conventional reinforcement learning (RL) settings, an agent aims to learn an optimal policy through interacting with an environment in discrete decision time steps. At each time step , the agent first observes its current state in a state space of the system. Based on the observed state and current policy , the agent takes an action in the action space . The policy can be a mapping function from a state to an action (deterministic) or a probability distribution over actions (stochastic). After taking the action , the agent transits to a new state and observes an immediate reward . The goal of the agent is to find an optimal policy that can be obtained by maximizing a discounted cumulative reward.
In conventional RL settings, the agent usually deals with a policy search problem in which the convergence time of the RL algorithm depends on the search space and . In environments with large discrete state-action space or continuous state-action space, the optimal policy is either nearly impossible or time-consuming to find. To address this problem, RL algorithms combined with deep neural networks, namely DRL, show significant performance improvements over conventional RL algorithms [33]. In DRL algorithms, the policy is defined by a probability distribution over actions, i.e., , where is a parameter vector of the deep neural network. The parameter vector can be trained by action-value methods, e.g., DQN [33], or policy gradient methods, e.g., PPO [28]. Action-value methods and policy gradient methods have their advantages and drawbacks which we will discuss later in Section III-C. In the following, we formulate our considered problem in the DRL setting by defining state space, action space, and immediate reward function in which the BS is empowered by an intelligent DRL agent.
III-B DRL-based Optimization Framework
We introduce the proposed DRL-based optimization framework for the joint power allocation and transmission rate control problem of the BS as follows. The state space of the BS is defined by:
| (12) |
where is the channel state feedback of the user to the BS. is the length of the message intended for user . Note that the channel state feedback from the users contains estimation errors, i.e., , where is the actual channel state and is the estimation error. The channel of user is realized as
| (13) |
where and are control variables [4]. The channel estimation error follows a complex Gaussian distribution, i.e., , where is inversely proportional to the transmission power at the BS, i.e., where is the degree of freedom (DoF) variable [4]. Note that the channel of the warden is unknown to the BS and thus is not included in the state space of the BS. We define the channel between the warden and the BS as follows:
| (14) |
At each time step , the BS allocates the transmission power to the users, splits the messages to common and private messages, and controls transmission rate for the messages. Thus, the action space of the BS is defined as follows:
| (15) |
The reward function is designed to maximize the min-rate of the BS as in (11). To encourage the BS to optimize the min-rate while the covert and QoS constraints of users are taken into consideration, we penalize the BS for each violated constraint. For this, the immediate reward can be defined as follows:
| (16) |
where is the penalty received by the BS for action that does not satisfy the covert constraint and QoS constraint in (11). The penalty is defined as follows:
| (17) | ||||
where and are control variables. is the indicator function in which if , and otherwise . The meaning of can be expressed as follows. The penalty is increased with each of covert or QoS constraints, i.e., (11e) and (11f), multiplying with corresponding weights and (). The penalty is then normalized so that (i.e., the first line of (17)). The penalty can be rewritten as the sum of two components, i.e., covert penalty and QoS penalty as shown in the second line of (17). Note that the penalty of the BS can be calculated by using the feedback mechanism. Once the users receive the messages from the BS, they calculate the data rates of the messages and send the calculated data rates back to the BS along with their minimum rate requirements (QoS requirements) [34]. Based on the feedback from users, the BS can calculate the corresponding QoS penalty. Similarly, the BS can be notified by the users if the channel is interrupted by the warden and the covert penalty can be calculated accordingly. Our designed immediate reward aims to encourage the BS to minimize the penalty to 0. Thus, the max-min fairness is guaranteed while covert and QoS constraints are satisfied.
III-C Optimization Formulation
We consider a stochastic policy of the BS (i.e., ), as a probability that action is taken given the current state , i.e., , where is the policy parameter vector of the deep neural network. Let denote the expected discounted reward of the BS by following policy :
| (18) |
where is the state transition probability distribution which models the dynamics of the environment, i.e., the dynamics of channel state information. Here, is unknown to the BS. Our goal is to find the optimal policy for the BS that maximizes ), i.e.,
| (19) | ||||
| s.t. | ||||
Maximizing is very challenging as we consider that the state and action spaces are continuous. It is noted that in (19), we do not require the complete information of the channel, i.e., channel matrix in (11), as other works in literature [7, 6, 9, 10]. Instead, the patterns of the channel can be learned through feedback from the users with deep neural networks. For this, we develop a learning algorithm based on a policy gradient method, namely Proximal Policy Optimization (PPO) [28], to approximate the optimal policy of the BS. PPO is a sample-efficient algorithm which can work under the large continuous state and action spaces and can deal with the uncertainty of the channel state.
IV Proximal Policy Optimization Algorithm
IV-A PPO Algorithm
As we discussed in Section III-A, action-value methods and policy gradient methods have their own advantages and drawbacks. In action-value methods, each action of the agent can be categorized by a real positive value, e.g., Q-value [33], and once the optimal policy is obtained, the optimal actions can be obtained by selecting the maximum action-value at each state. This family of algorithms is well studied for environments with discrete action space, e.g., a game requires a player to turn left, right, or jump. Thus, the action-value methods are suitable for discrete action space and the optimal policy can be effectively estimated if the number of actions are relatively small. However, in many cases, the action of an agent cannot be categorized by discrete action-values, e.g., a task requires controlling a robot arm by using continuous force. For this, policy gradient methods can be applied by directly estimating the policy of the agent instead of using a greedy selection over action-values. The policy of the agent can be a distribution, e.g., Gaussian, over actions. Therefore, instead of finding the action-values of the agent, policy gradient algorithms aim to find the “shape” of the action distribution, i.e., mean and variance of the distribution.
In our problem, all considered actions in (11) are continuous, and thus only gradient policy methods can be used. In the following, we describe an effective algorithm based on PPO [28] to maximize the min-rate of the BS. The operation of PPO in our proposed framework is illustrated in Fig. 2. In particular, input of the policy update procedure is the joint state of channel and packets’ lengths to be sent at the BS. Output is the BS’s policy, i.e., action distributions. We use one Gaussian distribution to illustrate the output of the policy update in Fig. 2 for the sake of presentation simplicity. In our actual implementation, the action of the BS has multiple dimensions and each dimension can be represented by a Gaussian distribution which differs in mean and variance values. The details of PPO algorithm are as follows.
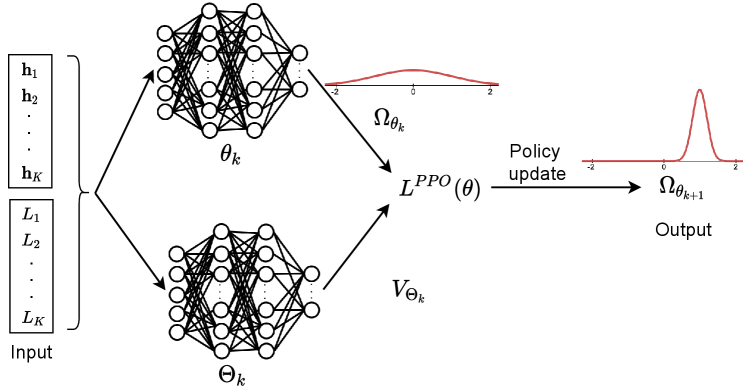
The PPO uses two deep neural networks as a policy parameter vector and a value function vector, denoted by and , respectively, to efficiently update the policy. The policy parameter vector can be updated by using a gradient ascent method as follows:
| (20) |
where is the step size, and is a gradient estimator. The gradient estimator can be calculated by differentiating a loss function as follows:
| (21) |
It can be observed from (20) and (21) that the choice of the loss function has a significant impact on the policy update. should have a small variance so that it does not cause bad gradient updates which result in significant decreases of . Since continuous action space is sensitive to the policy update, a minor negative change in updating can lead to destructively large policy updates [28]. To overcome this problem, PPO algorithm uses a loss function to replace :
| (22) |
where is the advantage function and is the clip function. estimates whether the action taken is better than the policy’s default behavior and limits significant updates which may degrade . The advantage function at time step can be defined by:
| (23) |
where is the action value function and is the state value function. The clip function is thus defined as follows [28]:
| (24) |
The idea of PPO is to prevent the new policy from being attracted to go far away from the old policy . The first term inside the operator in (22), i.e., , is the surrogate objective which takes into consideration the probability ratio between the new policy and old policy, i.e., . The second term, i.e., , removes the incentive for moving this probability ratio outside of the interval . The pseudo-code of the PPO algorithm is described in Algorithm 1.
The main steps of the PPO algorithm can be described as follows. First, a policy parameter vector and a value function parameter vector are randomly initialized (i.e., lines 2 and 3 in Algorithm 1). Second, at each policy update episode, numbered by , the BS collects a set of trajectories , i.e., a batch of state, action, and reward values, by running current policy over time steps (i.e., line 5). After that, the cumulative reward is calculated as in line 6. Next, the BS computes the advantage function as in (23) (i.e., line 6). With the obtained advantage function, the loss function can be calculated as (22) and the policy parameter vector can be updated as line 8 in Algorithm 1. Finally, the value function parameter vector can be updated as in line 9. The procedure is repeated until the cumulative reward values converge to saturating values.
IV-B Complexity Analysis
We further analyze the computational complexity of the PPO algorithm used in our considered system. Since the PPO uses deep neural networks as an approximator function, the complexity mostly depends on updating these networks. As the two deep neural networks in PPO share the same architecture, the complexity of updating these networks can be analyzed as follows. Each network consists of an input layer , two fully-connected layers and , and an output layer . Let be the size of the layer , i.e., the number of neurons in layer . The complexity of the two networks can be calculated by . At each episode update, a trajectory, i.e., a batch of state, action, and reward values, are sampled by running the current policy to calculate the advantage function and value function to update the network. Thus, the total complexity of the training process is , where is the size of the trajectory sampled from environment. There are two main reasons that PPO is a sample-efficient algorithm. First, the size of a trajectory is relatively small, i.e., from hundreds to thousands [28], compared with the size of a replay memory in conventional action-value methods, e.g., from 50,000 to 1,000,000 in DQN [33] . Here, in our simulations, is set at 200. Second, the size of the output layer of PPO is equal to the number of action dimensions. As a result, the size of the output layer can be significantly smaller than those of action-value methods that discrete continuous action space into different chunks to compute the action values, e.g., Q-values. Clearly, the architecture of the deep neural networks are simple enough to be implemented in the base stations which are usually equipped with sufficient computing resources.
V Performance Evaluation
V-A Parameter Setting
We consider our simulation parameters as follows. We use the same parameters for the RSMA and covert communications as those in [4, 30]. The total transmission power of the BS is set to be (dB). The control variables of channel in (13) are set at , and . Furthermore, the channel estimation errors are set at , , and [4]. Those equivalent values for the warden in (14) are set as and . The covert requirement parameter [30]. Unlike conventional transmission schemes, covert communications require a relatively low data rate to hide information from the warden/adversary. Therefore, we set the QoS requirements of the users to be (bps/Hz). We assume that the length of message to be sent at the BS follows uniform distribution with the minimum and maximum values are 0 and 1 kilobits, respectively, i.e., (kilobits). The number of antennas at the BS and the number of users are set as .
For the deep neural networks, our parameters are set as follows. The two deep neural networks representing the policy parameter vector and the value function vector, i.e., and , respectively, share the same architecture. Each deep neural network has two fully connected layer and each layer contains 64 neurons. The number of neurons in the output layer is equal to the number of dimensions of action, i.e., . The number of neurons in the input layer is equal to the number of dimensions of the joint state at the BS (as shown in Fig. 2), i.e., . The learning rate and clip values of PPO are adopted from [28].
In the following, we investigate the performance of our proposed PPO algorithm on RSMA and SDMA systems, denoted as P-RSMA and P-SDMA, respectively. To further understand the impacts of covert communications on both RSMA and SDMA systems, we run various simulations for scenarios in the FBL regime and infinite blocklength (IBL) regime. It is noted that in the IBL regime, the BS can achieve full data rate with Shannon capacity and the covert constraint, i.e., constraint (11e), is temporarily removed. In the case of covert communications under consideration with FBL, the optimization problem is fully considered as in (11). Furthermore, we introduce other baselines in which a Greedy algorithm is applied. This is to evaluate efficiency of the proposed learning algorithm. These baselines, denoted as G-RSMA and G-SDMA, aim to obtain the maximum immediate reward at each time step, compared with all the historical reward values stored in a buffer, without considering the long-term cumulative reward. In the following, we investigate the performance of all the aforementioned schemes. The considered metrics are (i) average (covert) min-rate (or average reward) and (ii) average (covert) sum-rate.
V-B Simulation Results
V-B1 Convergence property
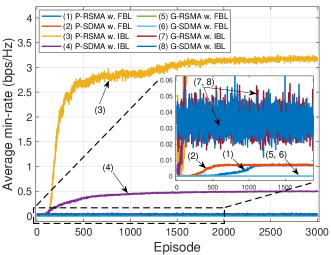
We first investigate the convergence performance of the proposed P-RSMA and P-SDMA in the IBL regime (lines (3), (4), (7), and (8) in Fig. 3). It can be observed from Fig. 3 that the proposed P-RSMA achieves the highest min-rate and sum-rate values, followed by P-SDMA (lines (3) and (4)). The reason is that in the IBL regime, the BS can obtain the data rate with full Shannon capacity. The results also suggest that RSMA outperforms SDMA in both min-rate and sum-rate, which strongly confirms that RSMA performs better than SDMA [4]. In the same IBL regime, the min-rate and sum-rate obtained of G-RSMA and G-SDMA are much lower than those of P-RSMA and P-SDMA (lines (7) and (8)). The reason is that the Greedy algorithm only considers historical rewards and immediate rewards without aiming to maximize the long-term reward. Unlike the Greedy scheme, the PPO with deep neural networks can iteratively update the policy toward the maximum cumulative reward. Furthermore, bad updates negating the reward values are eliminated with clip function (24). Thus, the learning curves obtained by P-RSMA and P-SDMA are much more stable.
In the FBL regime, it can be observed that the min-rate and sum-rate obtained by all the schemes are much lower than those in the IBL regime (lines (1), (2), (5), and (6)). The reason is that (i) the data rate is no longer following the Shannon capacity and (ii) the data rate is reduced close to 0 to achieve covertness [19]. With G-RSMA and G-SDMA (lines (5) and (6)), the min-rate and sum-rate are 0. In other words, the Greedy algorithm can only achieve covert communications by reducing the data rate to 0 and no information can be exchanged between the BS and users. With P-RSMA and P-SDMA (lines (1) and (2)), both min-rate and sum-rate values are relatively small but remained positive when the algorithm converges. These results confirm that with the proposed PPO algorithm, the BS and users can exchange covert information without being detected by the warden.
V-B2 Impacts of transmission power
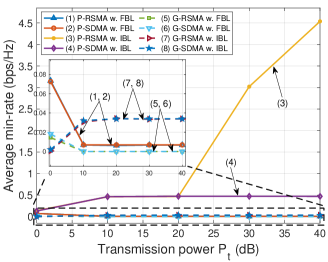
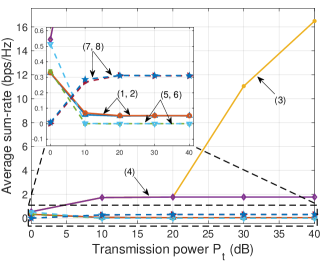
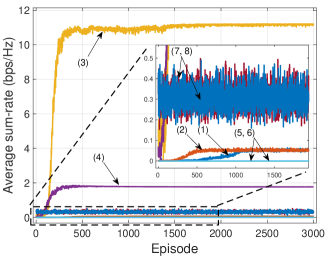
Next, in Fig. 4 we vary the transmission power at the BS and evaluate the performance of the proposed schemes. Similarly, we first discuss the performance of all the schemes in the IBL regime. It can be observed that the min-rate and sum-rate obtained by P-RSMA and P-SDMA increase with the transmission power at the BS (lines (3) and (4)). Unlike RSMA, SDMA’s data rate is saturated with high transmission power [7]. In low power transmission region (e.g., 0 dB to 20 dB), the difference between RSMA and SDMA is insignificant [2]. Similar to the results in Fig. 3, the min-rate and sum-rate of G-RSMA and G-SDMA are much lower than those of P-RSMA and P-SDMA.
In the FBL regime, it can be observed that the min-rate and sum-rate obtained by P-RSMA and P-SDMA are much lower than those in the IBL regime (lines (1) and (2)). When increases, the data rates of P-RSMA and P-SDMA remain unchanged at 0.007 bps/Hz for the average min-rate and 0.05 bps/Hz for the average sum-rate. These results imply that with the proposed PPO algorithm, the covert communications between the BS and users can be maintained at a positive rate. In other words, the covertness can always be achieved regardless of the transmission power at the BS. Unlike the PPO, the Greedy algorithm can only hide information from the warden by reducing the data rate to 0 or no information can be exchanged (lines (5) and (6)).
V-B3 Impacts of covert constraint
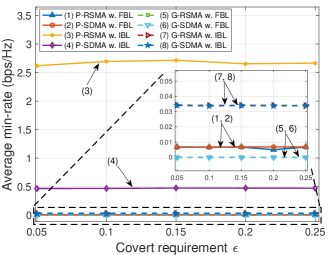
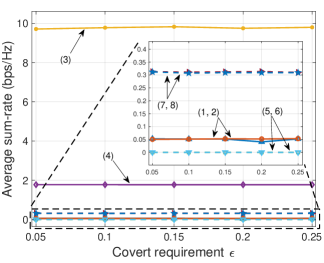
In Fig. 5, we evaluate the impacts of the covert constraint to the system performance by varying in (11e). Similarly, we first discuss the results in the IBL regime. Since the impacts of the covert constraint are not considered in this regime, it is clearly observed that the average min-rate and sum-rate values of P-RSMA and P-SDMA (lines (3) and (4)) remain stable and significantly higher than those of the baselines G-RSMA and G-SDMA (lines (7) and (8)) with the increase of the covert constraint parameter .
In the FBL regime, the average min-rate and sum-rate values obtained by P-RSMA and P-SDMA remain stable as increases (lines (1) and (2)). In particular, these saturated values are 0.007 bps/Hz for min-rate and 0.05 bps/Hz for sum-rate. For the baselines G-RSMA and G-SDMA (lines (5) and (6)), the obtained min-rate and sum-rate values are equal to 0, which illustrates that these baselines cannot achieve covert transmissions in the considered setting.
V-B4 Impacts of blocklength
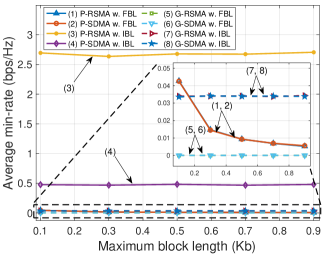
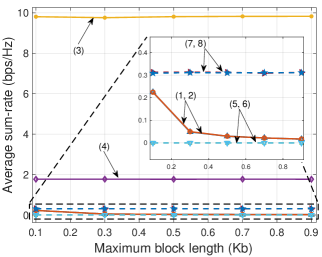
Finally, in Fig. 6, we investigate the impacts of blocklength, i.e., the length of the message being sent at the BS, to the system performance. We vary the distributions of the packet length at the BS with different intervals. In particular, we consider nine distribution intervals that are , (Kilobits). Note that in Fig. 6, we denote these distributions by their maximum values for the sake of simplicity. It can be observed that, in the IBL regime where , the values of min-rate and sum-rate of all the schemes are independent with the blocklength (lines (3), (4), (7), and (8)). However, in the FBL regime, the min-rate and sum-rate values obtained by P-RSMA and P-SDMA decrease as the blocklength increases (lines (1) and (2)). In other words, the higher the blocklength of message is sent from the BS, the lower the data rate can be achieved. This finding is similar to mathematical analysis derived in [19]. According to [19], the number of bits that can be covertly transmitted, denoted as , asymptotically approaches zero and follows a square root law, i.e., as . Unlike the positive data rate values achieved by the proposed schemes, the min-rate and sum-rate values of the baselines G-RSMA and G-SDMA remain at 0 (lines (5) and (6)).
VI Conclusion
In this paper, we have developed a novel dynamic framework to jointly optimize power allocation and rate control for the RSMA networks under the uncertainty of surrounding environment and with requirements about covert communications. In particular, our proposed stochastic optimization framework can adjust its transmission power together with message splitting based on its observations from surrounding environment to maximize the rate performance for the whole system. Furthermore, we have developed a learning algorithm that can not only help to BS to deal with continuous action and state spaces effectively, but also quickly find the optimal policy for the BS without requiring the completed information about surrounding environment in advance. Extensive simulations have demonstrated that with the obtained policy, the BS can dynamically adjust power and transmission rates to users, so that the achievable covert rate can be maximized. At the same, the BS can minimize the probability of being detected by the warden.
-A Relative entropy between two distributions and
As defined in the hypothesis test of the warden in (7), we have the distribution of the i.i.d. Gaussian random variables with variance is , which corresponds to the case when the BS is not transmitting. Note that the warden does not know the codebook. Therefore, the warden’s probability distribution of the transmitted symbols is of zero-mean i.i.d. Gaussian random variables with variance . Since we have the signal is transmitted with power at the transmitter and channel between the warden and the BS is defined in (14), we have . Therefore, the distribution of is as follows:
| (25) |
Let and , we have the respective probability distribution functions of and are as follows:
| (26) |
| (27) |
The relative entropy between and is then calculated by:
| (28) |
Now we need to solve . We expand and apply linearity:
| (29) |
We first solve . For this, we integrate by parts, i.e., . Let and , we can calculate and . We now have:
| (30) |
can be solved as follows. We substitute . becomes:
| (31) |
Note that we have a special integral in , i.e., is a Gauss error function. Let’s plug in :
| (32) |
Plug in :
| (33) |
Once is solved, can be calculated as follows. Let’s substitute . becomes:
| (34) |
Use the previous result of Gauss error function, we have:
| (35) |
| (36) |
Finally, we have:
| (37) |
Undo substitution for and , we have:
| (38) |
The proof of Proposition 1 is now completed.
References
- [1] O. Dizdar, Y. Mao, W. Han, and B. Clerckx, “Rate-splitting multiple access: A new frontier for the PHY layer of 6G,” in 2020 IEEE 92nd Vehicular Technology Conference (VTC2020-Fall), Jul. 2020, pp. 1-7.
- [2] O. Dizdar, Y. Mao, W. Han, and B. Clerckx, “Rate-splitting multiple access for downlink multi-antenna communications: Physical layer design and link-level simulations,” in 2020 IEEE 31st Annual International Symposium on Personal, Indoor and Mobile Radio Communications, Aug. 2020, pp. 1-6.
- [3] P. Li, M. Chen, Y. Mao, Z. Yang, B. Clerckx, and M. Shikh-Bahaei, “Cooperative rate-splitting for secrecy sum-rate enhancement in multiantenna broadcast channels,” in 2020 IEEE 31st Annual International Symposium on Personal, Indoor and Mobile Radio Communications (PIMRC), Oct. 2020, pp. 1-6.
- [4] Y. Mao, B. Clerckx, and V. O. Li, “Rate-splitting multiple access for downlink communication systems: bridging, generalizing, and outperforming SDMA and NOMA,” EURASIP Journal on Wireless Communications and Networking, no. 1, pp. 1-54, Dec. 2018.
- [5] Y. Mao, B. Clerckx, and V. O. K. Li, “Energy efficiency of rate-splitting multiple access, and performance benefits over SDMA and NOMA,” in 15th Internaltional Symposium of Wireless Communication Systems (ISWCS), Aug. 2018, pp. 1–5.
- [6] H. Joudeh and B. Clerckx, “Sum-rate maximization for linearly precoded downlink multiuser MISO systems with partial CSIT: A rate-splitting approach,” IEEE Transactions on Communications, vol. 64, no. 11 , pp. 4847–4861, Nov. 2016.
- [7] H. Joudeh, and B. Clerckx, “A rate-splitting strategy for max-min fair multigroup multicasting,” in 2016 IEEE 17th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Jul. 2016, pp. 1-5.
- [8] G. Zhou, Y. Mao, and B. Clerckx, “Rate-splitting multiple access for multi-antenna downlink communication systems: Spectral and energy efficiency tradeoff,” IEEE Transactions on Wireless Communications, Dec. 2021.
- [9] E. Piovano, H. Joudeh, and B. Clerckx, “Overloaded multiuser MISO transmission with imperfect CSIT,” in 50th Asilomar Conference on Signals, Systems, and Computers, Nov. 2016.
- [10] H. Joudeh and B. Clerckx, “Robust transmission in downlink multiuser MISO systems: A rate-splitting approach,” IEEE Transactions on Signal Processing, vol. 64, no. 23, pp. 6227–6242, Dec. 2016.
- [11] Z. Yang, M. Chen, W. Saad, and M. Shikh-Bahaei, “Optimization of rate allocation and power control for rate splitting multiple access (RSMA),” IEEE Transactions on Communications, vol. 69, no. 9, pp. 5988-6002, Jun. 2021.
- [12] S. Guo, and X. Zhou, “Robust power allocation for NOMA in heterogeneous vehicular communications with imperfect channel estimation,” in 2017 IEEE 28th Annual International Symposium on Personal, Indoor, and Mobile Radio Communications, Oct. 2017, pp. 1-5.
- [13] H. Xia, Y. Mao, B. Clerckx, X. Zhou, S. Han, and C. Li, “Weighted sum-rate maximization for rate-splitting multiple access based secure communication,” arXiv preprint, arXiv:2201.08472, Jan. 2022.
- [14] H. Fu, S. Feng, W. Tang, and D. W. K. Ng, “Robust secure beamforming design for two-user downlink MISO rate-splitting systems,” IEEE Transactions on Wireless Communications, vol. 19, no. 12, pp. 8351-8365, Sep. 2020.
- [15] S. Yan, X. Zhou, J. Hu, and S. V. Hanly, “Low probability of detection communication: Opportunities and challenges,” IEEE Wireless Communications, vol. 26, no. 5, pp. 19-25, Oct. 2019.
- [16] W. Trappe, “The challenges facing physical layer security,” IEEE Communications Magazine, vol. 53, no. 6, pp. 16-20, Jun. 2015.
- [17] X. He and A. Yener, “Providing Secrecy When the Eaves- dropper Channel is Arbitrarily Varying: A Case for Multiple Antennas,” in 48th Annual Allerton Conference on Communication, Control and Computing, Sep. 2010, pp. 1228–35.
- [18] S. Jana, S. N. Premnath, M. Clark, S. K. Kasera, N. Patwari, and S. V. Krishnamurthy, “On the effectiveness of secret key extraction from wireless signal strength in real environments,” in 15th International Conference on Mobile computing and Networking, Sep. 2009, pp. 321-332.
- [19] B. A. Bash, D. Goeckel, and D. Towsley, “Limits of reliable communication with low probability of detection on AWGN channels,” IEEE Journal on Selected Areas in Communications, vol. 31, no. 9, pp. 1921-1930, Aug. 2013.
- [20] L. Tao, W. Yang, S. Yan, D. Wu, X. Guan, and D. Chen, “Covert communication in downlink NOMA systems with random transmit power,” IEEE Wireless Communications Letters, no., 9, vol. 11, pp. 2000-2004, Jul. 2020.
- [21] S. Yan, B. He, X. Zhou, Y. Cong, and A. L. Swindlehurst, “Delay-intolerant covert communications with either fixed or random transmit power,” IEEE Transactions on Information Forensics Security, vol. 14, no. 1, pp. 129–140, Jan. 2018.
- [22] Y. E. Jiang, L. Wang, H. Zhao, and H. H. Chen, “Covert communications in D2D underlaying cellular networks with power domain NOMA,” IEEE Systems Journal, vol. 14, no. 3, pp. 3717-3728, Feb. 2020.
- [23] M. Forouzesh, P. Azmi, N. Mokari, and D. Goeckel, “Robust power allocation in covert communication: Imperfect CDI,” IEEE Transactions on Vehicular Technology, vol. 70, no. 6, pp. 5789-5802, Apr. 2021.
- [24] N. Q. Hieu, D. T. Hoang, D. Niyato, and D. I. Kim, “Optimal power allocation for rate splitting communications with deep reinforcement learning,” IEEE Wireless Communications Letters, vol. 10, no. 12, pp. 2820-2823, Oct. 2021.
- [25] N. C. Luong, D. T. Hoang, S. Gong, D. Niyato, P. Wang, Y. C. Liang, and D. I. Kim, “Applications of deep reinforcement learning in communications and networking: A survey,” IEEE Communications Surveys & Tutorials, vol. 21. no. 4, pp. 3133-3174, May 2019.
- [26] B. R. Kiran, I. Sobh, V. Talpaert, P. Mannion, A. A. Al Sallab, S. Yogamani, and P. Pérez, “Deep reinforcement learning for autonomous driving: A survey,” to appear in IEEE Transactions on Intelligent Transportation Systems, Feb. 2021.
- [27] R. S. Sutton, and A. G. Barto, Reinforcement learning: An introduction, MIT press, 2018.
- [28] J. Schulman, et al., “Proximal policy optimization algorithms,” arXiv preprint, arXiv:1707.06347, 2017.
- [29] X. Sun, S. Yan, N. Yang, Z. Ding, C. Shen, and Z. Zhong, “Short-packet downlink transmission with non-orthogonal multiple access,” IEEE Transactions on Wireless Communications, vol. 17, no. 7, pp. 4550-4564, Apr. 2018.
- [30] S. Yan, B. He, Y. Cong, and X. Zhou, “Covert communication with finite blocklength in AWGN channels,” in 2017 IEEE International Conference on Communications, May 2017, pp. 1-6.
- [31] F. Shu, T. Xu, J. Hu, and S. Yan, “Delay-constrained covert communications with a full-duplex receiver,” IEEE Wireless Communications Letters, vol. 8, no. 3, pp. 813-816, Jan. 2019.
- [32] M. Dai and B. Clerckx, “Multiuser millimeter wave beamforming strategies with quantized and statistical CSIT,” IEEE Transactions on Wireless Communications, vol. 16, no. 11, pp. 7025–7038, Nov. 2017.
- [33] V. Mnih, et al, “Human-level control through deep reinforcement learning,” Nature, vol. 518, no. 7540, pp. 529-533, Feb. 2015.
- [34] H. Yang, Z. Xiong, J. Zhao, D. Niyato, L. Xiao, and Q. Wu, “Deep reinforcement learning-based intelligent reflecting surface for secure wireless communications,” IEEE Transactions on Wireless Communications, vol. 20, no. 1, pp. 375-388, Sep. 2020.