Kalman-based Stochastic Gradient Method with Stop Condition and Insensitivity to Conditioning
Abstract
Modern proximal and stochastic gradient descent (SGD) methods are believed to efficiently minimize large composite objective functions, but such methods have two algorithmic challenges: (1) a lack of fast or justified stop conditions, and (2) sensitivity to the objective function’s conditioning. In response to the first challenge, modern proximal and SGD methods guarantee convergence only after multiple epochs, but such a guarantee renders proximal and SGD methods infeasible when the number of component functions is very large or infinite. In response to the second challenge, second order SGD methods have been developed, but they are marred by the complexity of their analysis. In this work, we address these challenges on the limited, but important, linear regression problem by introducing and analyzing a second order proximal/SGD method based on Kalman Filtering (kSGD). Through our analysis, we show kSGD is asymptotically optimal, develop a fast algorithm for very large, infinite or streaming data sources with a justified stop condition, prove that kSGD is insensitive to the problem’s conditioning, and develop a unique approach for analyzing the complex second order dynamics. Our theoretical results are supported by numerical experiments on three regression problems (linear, nonparametric wavelet, and logistic) using three large publicly available datasets. Moreover, our analysis and experiments lay a foundation for embedding kSGD in multiple epoch algorithms, extending kSGD to other problem classes, and developing parallel and low memory kSGD implementations.
keywords:
Data Assimilation, Parameter Estimation, Kalman Filter, Proximal Methods, Stochastic Gradient Descent, Composite Objective FunctionsAMS:
62L12, 62J05, 68Q32, 90C53, 93E35sioptxxxxxxxx–x
1 Introduction
In the data sciences, proximal and stochastic gradient descent (SGD) methods are widely applied to minimize objective functions over a parameter of the form:
| (1) |
When the number of component functions, , is large, proximal and SGD methods are believed to require fewer memory and computing resources in comparison to classical methods (e.g. gradient descent, quasi-Newton) [5, 10]. However, proximal and SGD methods’ computational benefits are reduced by two algorithmic challenges: (1) the difficulty of developing computationally fast or justified stop conditions, and (2) the difficulty of overcoming sensitivity to the conditioning of the objective function [10, 35, 14, 23, 22, 42, 37, 8, 26].
In response to the challenge of developing computationally fast, justified stop conditions, many proximal and SGD methods guarantee convergence up to a user-specified probability by requiring multiple epochs — full passes over all component functions — to be completed, where the number of epochs increases as the user-specified probability increases [35, 14, 23, 22, 42, 37, 8, 26]. As a result, these proximal and SGD methods become inefficient when high communication costs are incurred for completing a single epoch, and such is the case when is very large, streaming or infinite [5].
In response to the challenge of overcoming sensitivity to the conditioning of the objective function, second order SGD methods have been developed. Unfortunately, second order SGD methods are marred by the complexity of their analysis owing to the nonlinear dynamics of their second order approximations, the stochastic nature of the gradients, and the difficulty of analyzing tuning parameters [1, 36, 6, 8]. For example, in the method of [1], the second order estimate averages weighted new information with a previous second order estimate. However, the second order estimate initialization and weight parameter tuning is difficult in practice [36, 6], and is not accounted for in the analysis [1]. In order to account for the tuning parameters, one successful second order SGD analysis strategy is an adapted classical Lyapunov approach [8, 26]. However, the Lyapunov approach falls short of demonstrating that these second order SGD methods are insensitive to the conditioning of the objective function. For example, the Lyapunov-based convergence theorem in [8] suggests that the convergence rate depends on the conditioning of the Hessian of the objective function times the conditioning of the BFGS estimates. Such a Lyapunov-based theoretical guarantee offers no improvement over what we achieve with the usual SGD [27, 7], and clash against what we intuitively expect from a second order method.
In this paper, we progress towards addressing these gaps by generalizing proximal and SGD methods using the principles of the Kalman Filter [20]; we refer to this generalization as Kalman-based stochastic gradient descent (kSGD). We analyze kSGD’s properties on the class of linear regression problems, which we concede is a limited class, but is an inherently important class as discussed further in §2. Moreover, we use a probabilistic approach to analyze kSGD’s stochastic second order dynamics and tuning parameter choices, thereby avoiding the difficulties associated with the Lyapunov approach. As a consequence of our analysis,
-
1.
We justify a computationally fast stop condition for the kSGD method, and demonstrate its effectiveness on several examples, thereby addressing the first algorithmic challenge faced by proximal and SGD methods.
-
2.
We prove that the kSGD method is insensitive to the conditioning of the objective function, thereby addressing the second algorithmic challenge faced by proximal and SGD methods.
-
3.
We show that the kSGD method aymptotically recovers the optimal stochastic gradient estimator for the linear regression problem.
-
4.
We create a provably convergent, fast and simple algorithm for solving the linear regression problem, which is robust to the choice of tuning parameters and which can be applied to very large, streaming or infinite data sources.
-
5.
We lay a foundation for embedding kSGD in multiple epoch algorithms, extending kSGD to other problem classes, and developing parallel and low memory kSGD implementations.
We organize the rest of the paper as follows. In §2, we formulate the linear regression problem, and discuss its importance. In §3, we construct an optimal proximal/SGD method from which we derive kSGD. In §4, we prove that kSGD approaches the optimal proximal/SGD method, we prove that kSGD is insensitive to the conditioning of the problem, we analyze the impact of tuning parameters on convergence, and we construct an adaptive tuning parameter strategy. In §5, we present a kSGD algorithm with a stop condition, and an adaptive tuning parameter selection algorithm. In §6, we compare the computational and memory complexities of kSGD with the usual SGD, and SQN [8]. In §7, we support the mathematical arguments herein using three numerical examples: a linear regression problem using a large data set provided by the Center for Medicare & Medicaid Services (CMS), a nonparametric wavelet regression problem using a large data set of gas sensor readings, and a logistic regression problem using a moderately sized data set of adult incomes. In §8, we summarize this work.
2 The Linear Regression Problem & Its Importance
First, the linear regression problem is formulated, and then its importance is discussed. In order to formulate the linear regression problem, the linear model must be specified:
Assumption 1.
Suppose that are independent, identically distributed, and such that:
where are independent, identically distributed mean zero random variables with variance , and are independent of all .
Remark 1.
The model does not assume a distribution for the errors, ; hence, the results presented will hold even if the model is misspecified with a reinterpretation of as the limiting mean residuals squared. In addition, if the model has heteroscedasticity, the convergence of the kSGD parameter estimate to will still hold in the results below as long as the supremum over all variances is bounded.
Informally, the linear regression problem is the task of determining from the data . To formalize this, the linear regression problem can be restated as minimizing a loss function over the data, which is ideally (see [3])
up to a positive multiplicative constant and conditioned on . Because the ideal linear regression loss, is a function of random variables , it is also a random variable. In order to simplify optimizing over the random variable , the linear regression objective function is taken to be the expected value of :
| (2) |
where .
Thus, the linear regression problem is the task of minimizing . However, on its own, the linear regression problem is ill-posed for several reasons. First, despite the simple form of the linear regression objective, it cannot be constructed because the distribution of is rarely known. To account for this, the linear regression objective function is replaced with the approximation
| (3) |
which is exactly of the form (1). Second, the linear regression objective’s Hessian, , may not be well-specified, that is, . One way to ensure that is to require
This requirement is collected in the next assumption:
Assumption 2.
. That is, .
For some results, Assumption 2 is strengthened by:
Assumption 3.
. That is, almost surely.
Third, from an optimization perspective, the minimizer of the linear regression objective must satisfy second order sufficiency conditions (Theorem 2.4 in [28]); that is, must be positive definite. This can be ensured by the weaker requirement
Assumption 4.
The linear span of the image of is . Specifically, for all unit vectors , .
To see how, suppose there is a unit vector such that . Then . Hence, almost surely, which contradicts Assumption 4.
Remark 2.
We suspect that Assumption 4 can be weakened by allowing to be orthogonal to a subspace. As a result, would no longer be unique, but would be specified by a hyperplane. To account for this in the analysis, the error measure would need to be replaced by the minimum distance between the estimate and this hyperplane, and the estimation sequence would need to be considered on the lower dimensional manifold specified by the image space of .
At first glance, the linear regression problem seems to be a limited problem class, and one that has already been sufficiently addressed; however, solving modern, very large linear regression problems is still a topic under active research (e.g. [13, 17]). One example of very large linear regression problems comes from recent physics studies in which background noise models are estimated from large simulated data sets using maximum likelihood estimation [9, 19], which can be recast as solving a sequence of very large linear regression problems [41]. Another example comes from genome-wide association studies in which multiple very large linear regression problems arise directly [38, 2]. For such linear regression problems, the high communication time of reading the entire data set renders multiple epoch algorithms impractical. One recourse is to apply the usual SGD; however, SGD will often stall before converging to a minimizer. Thus, kSGD becomes a viable alternative for solving such problems as it only requires a single pass through large data sets, and does not stall. These concepts are demonstrated on a linear regression problem on CMS medical claims payments in §7.1.
Moreover, the linear regression problem not only encompasses the usual linear model of Assumption 1, but also the normal means models which include many nonparametric regression models (see [29], Ch. 7 in [40]). For example, the linear regression problem in (3) includes B-spline regression, for which is replaced by a vector-valued function evaluated at [31]. The linear regression problem’s applicability to normal means models is demonstrated on a non-parametric wavelet regression problem on gas sensor reading data in §7.2.
Finally, the linear regression problem analysis is an essential step in generalizing the kSGD theory to other problem classes. To be explicit, a common pattern in nonlinear programming is to model the objective function locally as a quadratic, and determine the next iterate by minimizing this local model [4, 28]. Indeed, for objective functions with an underlying statistical model, the local quadratic model can be formalized using the theory of local asymptotic normality (see Ch. 5 in [39], Ch. 6 in [24]); thus, understanding the behavior of kSGD in a quadratic model is an essential step in extending the analysis of kSGD to other problem classes. This principle is demonstrated on a logistic regression problem for modeling adult income categories in §7.3.
Now that we have established the linear regression problem, we construct an optimal stochastic gradient estimator from which we will derive kSGD.
3 An Optimal Estimator & kSGD
Let , the -algebra of the random variables , and consider the following general update scheme
| (4) |
where is a random variable in and is measurable with respect to . Using Assumption 1, (4) can be rewritten as
We will choose an optimal in the sense that it minimizes the error between and given . Noting that is measurable with respect to , and using the independence, first moment and second moment properties of :
We now write , which gives:
Differentiating with respect to and solving for when this expression is set to nullity, we have that:
| (5) |
Moreover, the derivation gives us an update scheme for as well:
To summarize, we have the optimal stochastic gradient update scheme:
| (6) |
| (7) |
Because and are not known, we take the kSGD method to be:
| (8) |
| (9) |
where is arbitrary, and can be any positive definite matrix, but for simplicity, we will take it to be the identity. The sequence replace the unknown value and will be referred to as tuning parameters. We refer to as a parameter estimate, as the true covariance of the parameter estimate, and as the estimated covariance of the parameter estimate.
kSGD’s derivation raises several natural questions about the impact of the and substitutions on the behavior of kSGD:
-
1.
Does the estimated covariance, , approximate the true covariance, ? Indeed, if approximates then it is clear that kSGD approximates the optimal stochastic gradient estimator, and, because , can be used as a measure of the error between and . In §4.1, we prove that will bound arbitrarily well from above and below in the limit up to a multiplicative constant depending on (Theorem 3). Additionally, we show that , thereby proving that (Corollary 4). Consequently, can be used as a stop condition; thus, kSGD addresses the first algorithmic challenge faced by proximal and SGD methods.
-
2.
Given that the batch minimizer converges to at a rate , and this convergence rate has no dependence on the conditioning of the problem (see [27], Ch. 5 in [39]), how does kSGD’s convergence compare? In §4.2, we show that kSGD’s convergence rate is comparable to the batch minimizer’s convergence rate, and this rate has no dependence on the conditioning of the problem (Theorem 5, Corollary 6). Consequently, kSGD addresses the second algorithmic challenge faced by proximal and SGD methods.
-
3.
Finally, what role do the tuning parameters, , play in the convergence? In §4.3, are determined to play two roles: (1) moderate how tightly will bound , and (2) moderate how quickly . Specifically, when are within a few orders of magnitude of , the estimated covariance, , will tightly bound the true covariance, , and when are small, quickly. Unfortunately, if is very large, these two tuning parameter roles conflict. This conflict is reconciled with an adaptive tuning parameter strategy motivated in Theorem 8, and constructed, in a sense, in §4.4.
4 Analysis
In the analysis below, we use the following conventions and notation. Recalling that , we consider two types of error in our analysis:
| (10) |
and
| (11) |
which are related by .
4.1 Convergence of the Estimated Covariance and Estimated Parameter
Informally, the main result of this section, Theorem 3, states that bounds from above and below arbitrarily well in the limit. To establish Theorem 3, we will need two basic calculations collected in Lemmas 1 and 2. In the calculations below, we recall that is taken to be the identity for simplicity.
Lemma 1.
For , if then is symmetric, positive definite matrices and
Proof.
By the Sherman-Morrison-Woodbury matrix identity:
Hence, . So is symmetric and positive definite. Suppose this is true up to some . By induction and using the Sherman-Morrison-Woodbury matrix identity, we conclude our result:
∎
Lemma 2.
For , if then
and, recalling where ,
Proof.
Lemmas 1 and 2 suggest a natural condition on the tuning parameters in order to ensure that these calculations hold for all ; namely, we require for some and ,
| (13) |
Using this condition and Lemmas 1 and 2, we can also bound by for all
Using Lemma 1,
Using , we have
| (14) |
Because the true covariance, , is a measure of the error between the estimated, , and true parameter, , then we want , which inequality (14) suggests occurs if . The next theorem formalizes this claim.
Theorem 3.
Remark 3.
There is a conventional difference between “almost surely there exists a ” and “there exists a almost surely.” The first statement implies that for each outcome, , on a probability one set there is a . The latter statement implies for all . Thus, “almost surely there exists a ” is a weaker result than “there exists a almost surely”, but it is stronger than convergence in probability.
Proof.
To show that , it is equivalent to prove that , the maximum eigenvalue of , goes to . This is equivalent to showing that the minimum eigenvalue of , , diverges to infinity. Moreover, by Lemma 1 and the Courant-Fischer Principle (Ch. 4 in [11]), is a non-decreasing sequence. Hence, it is sufficient to show that a subsequence diverges to infinity, which we will define using the following stochastic process. Define the stochastic process by and
| (15) |
We will now show that the sequence diverges. By Lemma 1,
where
| (16) |
By the Courant-Fischer Principle,
| (17) |
Thus, we are left with showing that diverges almost surely. To this end, we will show that will be greater than some infinitely often. As a result, the sum must diverge to infinity. To show this, we will use a standard Borel-Cantelli argument (see Section 2.3 in [12]). Consider the events where the choice of comes from Lemma 14, in which . For such an , else we would have a contradiction. By Lemma 13, we have that are independent and that for all . Thus by the (Second) Borel-Cantelli Lemma (Theorem 2.3.5, [12]),
Hence, infinitely often, and thus as almost surely. Now, let , then almost surely there is a such that if ,
Applying this to inequality (14), we can conclude the result. ∎
As a simple corollary to Theorem 3, we prove that and converge to in some sense.
Corollary 4.
4.2 Insensitivity to Conditioning
The main result of this section, Theorem 5, states that approximates a scaling of the inverse Hessian. As a consequence, Corollary 6 states that kSGD’s convergence rate does not depend on the conditioning of the Hessian, thereby addressing the second algorithmic challenge faced by proximal and SGD methods. Moreover, Corollary 6 states that kSGD becomes arbitrarily close to the batch convergence rate in the limit (see [27], Ch.5 in [39]).
Theorem 5.
Proof.
Let be a non-negative sequence. Define and , and define the event
| (use Lemma 1) | ||||
for an arbitrary unit vector . Note that, by construction, are independent, mean zero random variables. By Lemma 15, almost surely, where . Therefore, by Markov’s Inequality and Lemma 16,
| (18) |
We now turn to relating to . Let . Then,
Now take where . Then, for every there is a such that for
Therefore,
Using (18), . ∎
Remark 4.
Given Assumption 3, it is likely that with a bit more work the probability of can be extended to some arbitrary where . Also, we can extend this result to a convergence in expectation by using the fact that .
Corollary 6.
Proof.
Now that kSGD has been shown to address the two algorithmic challenges faced by proximal and SGD methods, we turn our attention to carefully analyzing the effect that the tuning parameters have on convergence.
4.3 Conditions on Tuning Parameters
The tuning parameter condition, (13), raises two natural questions:
-
1.
Is the tuning parameter condition, (13), the necessary condition on tuning parameters in order to guarantee convergence?
-
2.
Given the wide range of possible tuning parameters, is there an optimal strategy for choosing the tuning parameters?
As will be shown in Theorem 7, the first question can be answered negatively. For example, Theorem 7 suggests that if the method converges the tuning parameters could have been for , which is an example not covered by condition (13).
Theorem 7.
Proof.
Using (12), premultiplying by , and taking conditional expectation with respect to :
Repeatedly applying the recursion, . Thus, for any is equivalent to . Note:
We will prove that if then the supremum of the trace of is finite, and therefore , which gives a contradiction. That is, we will show, by using Lemma 1, the supremum over all k of
is almost surely finite. The main tool used is Kolmogorov’s Three Series Theorem (Theorem 2.5.4 in [12]). Suppose that , and let . By Markov’s Inequality,
Thus, by Kolmogorov’s Three Series Theorem, . Hence, and we have a contradiction. ∎
Remark 5.
The second question can be understood by examining the two roles tuning parameters have in Theorem 3. First, the tuning parameters determine how quickly diverges: if the tuning parameters take on very small values, then, in light of (17), will diverge quickly. Therefore, the tuning parameters should be selected to be a fixed small value when the goal is to converge quickly. Second, the tuning parameter bounds, and , determine how tightly bounds : if and are close to then will have a tight lower and upper bound on . Therefore, from an algorithmic perspective, if the tuning parameter bounds are close to , then will be a better stop condition.
In the case when is of moderate size, the tuning parameters can be selected to be small thereby ensuring that fast convergence is achieved and that is a strong stop condition. On the other hand, if is large, the tuning parameters cannot satisfy both fast convergence and ensure that is a strong stop condition. These opposing tuning parameter goals can be reconciled with the following result.
Theorem 8.
Proof.
The construction of such a tuning parameter strategy is quite difficult because a sequence which almost surely converges to will never be known apriori. In practice, the construction of will then have to depend on the data ; therefore, a data dependent tuning parameter strategy will introduce measurability issues in Theorem 8. Thus, we only use Theorem 8 as motivation for constructing a tuning parameter strategy which estimates . The construction of such tuning parameters is the content of the next subsection.
4.4 Adaptive Choice of Tuning Parameters
We will define a sequence of tuning parameters which satisfy condition (13) and incrementally estimate when . This choice of tuning parameters will be determined by a two-step process:
-
1.
By defining a sequence of unbounded estimators which converge to in some sense.
- 2.
Remark 6.
The choice of imposes and in (13) The use of a single parameter, , for the bounds is strictly a matter of convenience. Using different lower and upper bounds is completely satisfactory from a theoretical perspective and can be a strategy to negotiate the trade-offs in choosing the tuning parameters. We state this case in §5.
We will use the following general form for estimators :
| (20) |
where, the residuals, , satisfy , and the hyperparameters, , are non-negative. One natural choice for the hyperparameters is for all . Indeed, such a choice has the following nice theoretical guarantee, which is a consequence of Proposition 10 below.
Corollary 9.
Although this result calls into question why are even considered in (20), it is misleading: if the initial residuals, , deviate from significantly, then a large number of cases must be assimilated in order for the estimator of to converge to . A common strategy to overcome this is to shrink the initial residuals — similarly, introduce forgetting factors — which converge to unity. That is, we consider a positive sequence such that . However, because can be designed, this procedure begs the question of how and when should approach . Indeed, the only guidance which can be given on this choice is to make depend on : once is sufficiently small, we have an assurance that should be faithful estimators of , and so should be near in this regime. Since are measurable with respect to , a more flexible condition is to allow to be measurable with respect to as well.
Remark 7.
Despite restricting to be measurable, there are still many strategies for choosing . For example, can be set using a hard or soft thresholding strategy depending on the . Regardless, the strategy for choosing should depend on the problem, and an uninformed choice is ill-advised unless a sufficient amount of data is being processed.
An additional strategy is to delay the index at which is calculated. To be specific, we can define a stopping time with respect to such that is finite almost surely, and let . Indeed, then the process will only be started once a specific condition has been met, such as if is below a threshold. This offers more flexibility than manipulating alone. These considerations on and are collected in the following assumption.
Assumption 5.
We are now ready to show that a tuning parameter strategy using Assumption 5 does indeed approximate in the limit.
Proof.
Applying (20) repeatedly,
| (Assumption 1) |
Taking the conditional expectations, using the Conditional Monotone Convergence Theorem (Theorem 5.1.2 in [12]), and using the facts that and are measurable with respect to by construction:
where we use the facts that (1) since and we are restricting to the event , and (2) are independent of , thus, are independent of . Using this equality, we will establish a lower and upper bound on .
Lower Bound. Since , we have . Let . Because is almost surely finite and almost surely, almost surely there is a such that if then . Therefore ,
almost surely.
Upper Bound. For an upper bound, using the same as for the lower bound, because is almost surely finite and by Theorem 3, almost surely there is a such that for
Since :
As , the third term will vanish and the second term will converge to almost surely by the Strong Law of Large Numbers. Therefore, almost surely
Since is arbitrary, it follows that the limit of the sequence exists and is equal to almost surely.
Bounds on . Define
From this definition, we have that for all , . In the next statement, for the maximum of a set of values, we use , and for the minimum we use . Applying this relationship to :
First, we consider the right hand side:
Applying the first part of Proposition 10, almost surely. For the reverse inequality:
By the first part of the result, the first term converges to , and we are left with showing that the second term converges to .
For the first term, we note that (1) the argument is bounded by , for which using an identical conditioning argument as in the first part of the proof, gives the quantity’s expectation as , and (2) because is finite almost surely and by the strong law of large numbers, almost surely . Therefore, by the conditional Dominated Convergence Theorem, the first term converges to almost surely.
For the cross term
| (Cauchy-Schwarz) | |||
where in the last line, the expectation and summation are alternated by the conditional Monotone Convergence Theorem. Using an identical conditioning argument as in the first part of the proof, and noting by Jensen’s inequality, the cross term is bounded by
Using the same argument as for the upper bound of , we have that for any
Therefore, the limit exists and is . To summarize:
∎
5 Algorithms
Using update equations (8) and (9), we state a provably convergent, fast and simple algorithm for solving the linear regression problem, Algorithm 1, which also has a computationally fast, justified stop condition (see Theorem 3), is insensitive to the problem’s conditioning (see Theorem 6), works for a robust choice of tuning parameters (see condition (13), and Theorem 7), and can be used on very large, infinite or streaming data sources.
When is very large, the stop condition can be improved by using a tuning parameter strategy which asymptotically estimates (see Theorem 8). Motivated by this result, a class of adaptive tuning parameter strategies was constructed (§4.4) and analytically shown to converge to in some sense (see Proposition 10). One example from this class of adaptive tuning parameter strategies is stated in Algorithm 2.
6 Complexity Comparison
| Method | Data Assim. | Gradient | Hessian | FP Ops | Memory |
|---|---|---|---|---|---|
| SGD | 1 | 1 | 0 | ||
| kSGD | 1 | 1 | 0 | ||
| SQN |
Table 1 reports several common metrics for assessing stochastic optimization algorithms. One notable property in Table 1 is that kSGD has the highest memory requirements. Therefore, when is large, kSGD would be infeasible; this can be addressed by making kSGD a low-memory method, but this will not be considered further in this paper. Another notable property is that the floating point costs per data point assimilated appear to be approximately the same for kSGD and SQN. However, the comparability of these two values depends on : for many statistical regression problems, would lead to rank deficient estimates of the Hessian, which would then lead to poorly scaled BFGS updates to the inverse Hessian. Therefore, should be taken to be larger than to ensure full rank estimates of the Hessian. In this case, SQN requires at least floating point operations per data point assimilated. Since is recommended to be or [8], SQN has a greater computational cost than kSGD when .
7 Numerical Experiments
Three problem were experimented on: a linear regression problem on medical claims payment by CMS [16, 30], an additive non-parametric Haar wavelet regression problem on gas sensor readings [32, 15], and a logistic regression problem on adult income classification [33, 21]. For each problem, the dimension of the unknown parameter (), number of observations (), condition number () of the Hessian at the minimizer, and the optimization methods implemented on the problem are collected in Table 2.
Remark 8.
For the linear and Haar wavelet regression problems, the Hessian does not depend on the parameter, and so it can be calculated directly. For the logistic regression problem, the minimizer was first calculated using generalized Gauss Newton (GN) [41] and confirmed by checking that the composite gradient at the minimizer had a euclidean norm no larger than ; then, the Hessian was calculated at this approximate minimizer.
| Problem | Methods | |||
|---|---|---|---|---|
| CMS-Linear | kSGD,SGD,SQN | |||
| Gas-Haar | kSGD, SGD, SQN | |||
| Income-Logistic | kSGD, SGD, SQN, GN |
For each method, intermediate parameter values, elapsed compute time, and data points assimilated (ADP) were periodically stored. Once the method terminated, the objective function was calculated at each stored parameter value using the entire data set. The methods are compared along two dimensions:
-
1.
Efficiency: the number of data points assimilated (ADP) to achieve the objective function value. The higher the efficiency of a method, the less information it needs to minimize the objective function. Thus, higher efficiency methods require fewer data points or fewer epochs in order to achieve the same objective function value in comparison to a lower efficiency method.
-
2.
Effort: the elapsed time (in seconds) to achieve the objective function value. This metric is a proxy for the cost of gradient evaluations, Hessian evaluations, floating point operations, and I/O latencies. Thus, higher effort methods require more resources or more time in order to achieve the same objective function value in comparison to a lower effort method.
The methods are implemented in the Julia Programming Language (v0.4.5). For the linear and logistic regression problem, the methods were run on an Intel i5 (3.33GHz) CPU with 3.7 Gb of memory; for the Haar Wavelet regression problem, the methods were run on an Intel X5650 (2.67GHz) CPU with 10 Gb of memory.
Remark 9.
The objective function for the linear and Haar wavelet regression is the mean of the residuals squared (MRS). Therefore, for these problems, the results are discussed in terms of MRS.
7.1 Linear Regression for CMS Payment Data
We modeled the medical claims payment as a linear combination of the patient’s sex, age and place of service. Because the explanatory variables were categorical, there were parameters. The optimal MRS was determined to be using an incremental QR algorithm [25].
The three methods, SGD, kSGD and SQN, were initialized at zero. For SGD, the learning rate was taken to be of the general form
| (21) |
where is the ADP, (see [34, 27]), , (see [5]), and . SGD was implemented for learning rates over a grid of values for , , and . The best learning rate, , achieved the smallest MRS. Note, this learning rate took only seconds longer per epoch than the fastest learning rate. For SQN, the parameters , and were allowed to vary between the recommended values , , [8], was allowed to take values , and the learning rate constant, , was allowed to vary over a grid of positive numbers. The best set of parameters, , came within of the optimal MRS with the smallest ADP and least amount of time. The tuning parameters for kSGD, summarized in Table 3, were selected to reflect the concepts discussed in §4.3 and were not determined based on any results from running the method.
| Label | |
|---|---|
| kSGD-1 | |
| kSGD-2 | |
| kSGD-3 |
Figure 1 visualizes the differences between SGD, kSGD and SQN in terms of efficiency and effort. In terms of efficiency, kSGD-1, kSGD-3 and SQN are comparable, whereas kSGD-2 and SGD perform quite poorly in comparison. For kSGD-2, this behavior is to be expected for large choices of as discussed below. For SGD, despite an optimal choice in the learning rate, it still does not come close to the optimal MRS after a single epoch. Even when SGD is allowed to complete multiple epochs so that its total elapsed time is greater than kSGD’s single epoch elapsed time (Figure 1, right), SGD does not make meaningful improvements towards the optimal MRS. Indeed, this is to be expected as the rate of convergence of SGD is where is the ADP [7], and, therefore, SGD requires approximately epochs to converge to the minimizer. We also see in Figure 1 (right) that kSGD-1 and kSGD-3 require much less effort to calculate the minimizer in comparison to SQN.
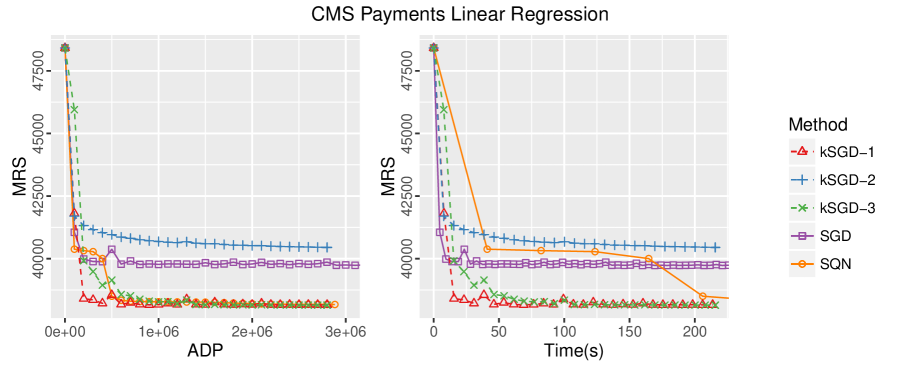
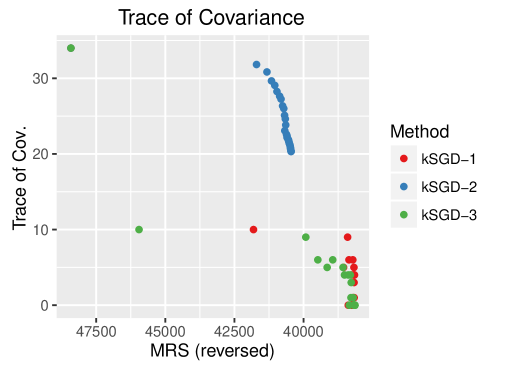
Figure 2 visualizes the behavior of the covariance estimates for each of the three kSGD tuning parameter choices. We highlight the sluggish behavior of for kSGD-2, which underscores one of the ideas discussed in §4.3: if is large, choosing to approximate for all will slow down the convergence of the algorithm. Another important property is that, despite some variability, is reflective of the decay in MRS; this property empirically reinforces the result in Theorem 3, and the claim that can be used as a stop condition in practice.
7.2 Nonparametric Wavelet Regression on Gas Sensor Readings
We modeled the ethylene concentration in a mixture of Methane, Ethylene and Air as an additive non-parametric function of time and sixteen gas sensor voltage readings. Because the response and explanatory variables were in bounded intervals, the function space was approximated using Haar wavelets without shifts [18]. The resolution for the time component was , and the resolution for each gas sensor was , which resulted in features and a parameter of dimension .
Remark 10.
Because of their high-cost of calculation, the features were calculated in advance of running the methods.
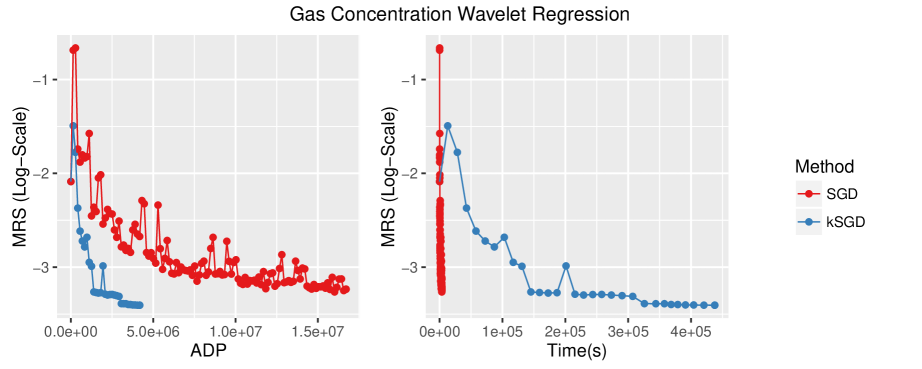
Again, SGD, kSGD and SQN were implemented and intialized at zero. For SGD, using the same criteria as described in §7.1, the best learning rate was found to be . For SQN, regardless of the choice of parameters (over a grid larger than the one used in §7.1), the BFGS estimates quickly became unstable and caused the parameter estimate to diverge. For kSGD, the method was implemented with .
Figure 3 compares SGD and kSGD. Although kSGD is much more efficient than SGD, it is remarkably slower than SGD. For this problem, this difference in effort can be reduced by using sparse matrix techniques since at most of the components in each feature vector are non-zero; however, for dense problems this issue can only be resolved by parallelizing the floating point operations at each iteration.
7.3 Logistic Regression on Adult Incomes
We modeled two income classes as a logistic model with eight demographic explanatory variables. Four of the demographic variables were continuous and the remaining four were categorical, which resulted in parameters.
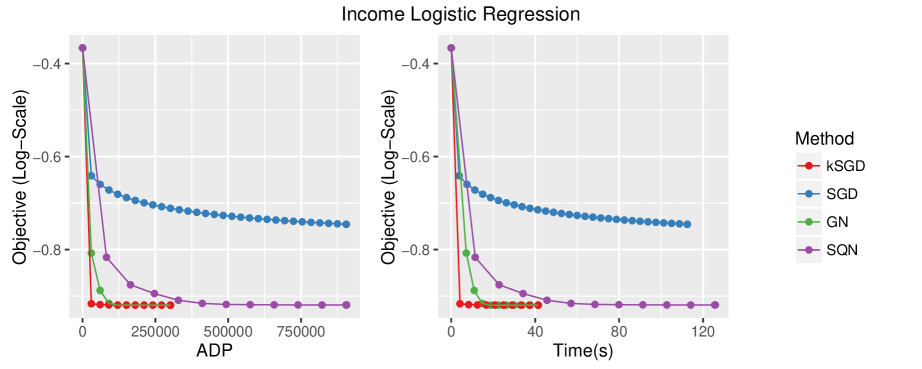
SGD, kSGD, SQN and GN were implemented and intialized at zero. For SGD, the best learning rate was found to be . For SQN, the best parameter set was found to be . For GN, there were no tuning parameters. kSGD was adapted to solve the GN subproblems up to a specified threshold on the trace of the covariance estimate. After one subproblem was solved, the threshold was decreased by a fixed factor, which was arbitrarily selected to be 5. The threshold was arbitrarily intialized at 15, and was started at and increased by a factor of until the method did not fail; the method succeeded when .
Figure 4 visualizes the efficiency and effort of the four methods. In general, the behavior of kSGD, SGD and SQN follow the trends in the two preceding examples. An interesting feature is that kSGD had greater efficiency and required less effort than GN. This is due to the fact that kSGD incompletely solves the GN subproblem away from the minimizer, while GN solves the subproblem exactly at each iteration. However, it is important to note that the choice of kSGD tuning parameters is not as straightforward for the logistic regression problem as it is for the linear regression problem, and appropriate choices will not be discussed further in this paper.
8 Conclusion
We developed and analyzed kSGD on the limited, but important class of linear regression problems. In doing our analysis, we achieve a method which (1) asymptotically recovers an optimal stochastic update method, (2) converges for a robust choice of tuning parameters, (3) is insensitive to the problem’s conditioning, and (4) has a computationally efficient stop condition. As a result of our analysis, we translated this method into a simple algorithm for estimating linear regression parameters; we then successfully implemented this algorithm for solving linear, non-parametric wavelet and logistic regression problems using real data. Moreover, our analysis provides a novel strategy for analyzing the convergence of second order SGD and proximal methods, which leads to theoretical results that correspond to intuitive expectations. Finally, our analysis provides a foundation for embedding kSGD in multiple epoch algorithms, extending kSGD to a larger class of problems, and developing parallel and low memory kSGD algorithms.
Appendix A Renewal Process
We show that the stochastic process defined in (15) is a renewal process (see Section 4.4 in [12]). We define the inter-arrival times, for all .
Lemma 11.
If are independent and identically distributed, then are independent and identically distributed.
Proof.
Let
Note that is independent of , and so:
Finally, has the same distribution as . Therefore:
We have established that are identically distributed. Now let be positive integers with . Let .
Just as above, is independent of and so:
Applying the argument recursively, we have established independence. ∎
Lemma 12.
If are independent, identically distributed, and satisfy Assumption 4, then and for all .
Proof.
We prove that is bounded by a geometric random variable and so its expectation must exist. Let . In this notation, we have that . We will now decompose into , where with . By construction:
Let denote the inter-arrival times defined by . On the event that , we have that with such that is orthogonal to , and by Assumption 4, there is a . Then, . Thus, . Therefore, . Now, by Lemma 11, are independent and identically distributed. Therefore, . ∎
Lemma 13.
If are independent and identically distributed, then defined in (16) are independent and identically distributed. In particular, the eigenvalues of are independent and identically distributed.
Proof.
Let and be a measurable set.
Thus, are identically distributed. By the independence of and the independence of , which is established in Lemma 11, are independent because they are functions of independent random variables. Finally, since the eigenvalues of can be calculated using the Courant-Fisher Principle, we have that they too are independent and identically distributed. ∎
Lemma 14.
Proof.
By Lemma 13, we need only consider . Suppose there exists a with such that . Note, by Assumption 2 and Cauchy-Schwarz, the expectation is well defined. Since by construction, almost surely
Thus, for all . However, by construction, Assumption 4 and Lemma 12, span and almost surely, hence there is an such that almost surely. Therefore, we have a contradiction. ∎
Appendix B Some Properties of Random Variables
In this section, we establish some useful properties of random variables.
Lemma 15.
Suppose random variable taking values in . Then, for ,
almost surely.
Proof.
The lower bound is straightforward. For the upper bound, let be any unit vector. By Cauchy-Schwartz:
where . Thus the first set of inequalities holds almost surely. Moreover, the first set of inequalities imply . Hence,
∎
Lemma 16.
Let be mean zero, independent random variables with . Then
Proof.
Note that and are independent. Hence, in the polynomial expansion, any monomial with a term that has unity exponent is going to have a zero expectation. So, we need to count all monomials whose terms have exponents at least two in the expansion:
-
1.
There are terms of the form .
-
2.
There are terms of the form with ways of choosing the exponents.
-
3.
There are terms of the form with ways of choosing the exponents.
-
4.
There are terms of the form with ways of choosing the exponents.
Since almost surely by assumption, we have that: . ∎
Acknowledgements
This work is supported by the Department of Statistics at the University of Chicago. I would also like to express my deep gratitude to Mihai Anitescu for his insightful feedback on the many drafts of this work and his generous patience and guidance throughout the research and publication process. I would also like to thank Madhukanta Patel, who, despite her illnesses and advanced age, scolded me if I momentarily stopped working on this manuscript while sitting at her bedside. I am also deeply grateful to the reviewers for their detailed readings and useful criticisms.
References
- [1] Shun-Ichi Amari, Hyeyoung Park, and Kenji Fukumizu, Adaptive method of realizing natural gradient learning for multilayer perceptrons, Neural Computation, 12 (2000), pp. 1399–1409.
- [2] Yurii S Aulchenko, Maksim V Struchalin, and Cornelia M van Duijn, Probabel package for genome-wide association analysis of imputed data, BMC bioinformatics, 11 (2010), p. 1.
- [3] Derek Bean, Peter J Bickel, Noureddine El Karoui, and Bin Yu, Optimal m-estimation in high-dimensional regression, Proceedings of the National Academy of Sciences, 110 (2013), pp. 14563–14568.
- [4] Dimitri P Bertsekas, Nonlinear Programming, Athena scientific, 1999.
- [5] Dimitri P. Bertsekas, Incremental Gradient, Subgradient, and Proximal Methods for Convex Optimization: A Survey, 2010, ch. 4.
- [6] Antoine Bordes, Léon Bottou, and Patrick Gallinari, Sgd-qn: Careful quasi-newton stochastic gradient descent, The Journal of Machine Learning Research, 10 (2009), pp. 1737–1754.
- [7] Olivier Bousquet and Léon Bottou, The tradeoffs of large scale learning, in Advances in Neural Information Processing Systems, 2008, pp. 161–168.
- [8] RH Byrd, SL Hansen, Jorge Nocedal, and Y Singer, A stochastic quasi-newton method for large-scale optimization, SIAM Journal on Optimization, 26 (2016), pp. 1008–1031.
- [9] ATLAS collaboration, TA Collaboration, et al., Observation of an excess of events in the search for the standard model higgs boson in the gamma-gamma channel with the atlas detector, ATLAS-CONF-2012-091, 2012.
- [10] Patrick L Combettes and Jean-Christophe Pesquet, Proximal splitting methods in signal processing, in Fixed-point algorithms for inverse problems in science and engineering, Springer, 2011, pp. 185–212.
- [11] Richard Courant and David Hilbert, Method of Mathematical Physics, vol I, New York: Interscience, 1953.
- [12] Rick Durrett, Probability: Theory and Examples, Cambridge University Press, 2010.
- [13] Diego Fabregat-Traver, Yurii S Aulchenko, and Paolo Bientinesi, Solving sequences of generalized least-squares problems on multi-threaded architectures, Applied Mathematics and Computation, 234 (2014), pp. 606–617.
- [14] Olivier Fercoq and Peter Richtárik, Accelerated, parallel, and proximal coordinate descent, SIAM Journal on Optimization, 25 (2015), pp. 1997–2023.
- [15] Jordi Fonollosa, Sadique Sheik, Ramón Huerta, and Santiago Marco, Reservoir computing compensates slow response of chemosensor arrays exposed to fast varying gas concentrations in continuous monitoring, Sensors and Actuators B: Chemical, 215 (2015), pp. 618–629.
- [16] Centers for Medicare & Medicaid, Basic stand alone carrier line items public use files, 2010.
- [17] Alvaro Frank, Diego Fabregat-Traver, and Paolo Bientinesi, Large-scale linear regression: Development of high-performance routines, arXiv preprint arXiv:1504.07890, (2015).
- [18] Alfred Haar, On the theory of orthogonal function systems, Math. Ann, 69 (1910), pp. 331–371.
- [19] Piotr Jaranowski and Andrzej Królak, Gravitational-wave data analysis. formalism and sample applications: The gaussian case, Living Rev. Relativity, 15 (2012).
- [20] Rudolph Emil Kalman, A new approach to linear filtering and prediction problems, Journal of Fluids Engineering, 82 (1960), pp. 35–45.
- [21] Ron Kohavi, Scaling up the accuracy of naive-bayes classifiers: A decision-tree hybrid., in KDD, vol. 96, Citeseer, 1996, pp. 202–207.
- [22] Jakub Konečnỳ, Jie Liu, Peter Richtárik, and Martin Takáč, ms2gd: Mini-batch semi-stochastic gradient descent in the proximal setting, Selected Topics in Signal Processing, IEEE Journal on, 10 (2016), pp. 242–255.
- [23] Jakub Konečnỳ and Peter Richtárik, Semi-stochastic gradient descent methods, arXiv preprint arXiv:1312.1666, (2013).
- [24] Lucien Le Cam and Grace Lo Yang, Asymptotics in statistics: some basic concepts, Springer Science & Business Media, 2012.
- [25] Alan J Miller, Algorithm as 274: Least squares routines to supplement those of gentleman, Applied Statistics, (1992), pp. 458–478.
- [26] Philipp Moritz, Robert Nishihara, and Michael I Jordan, A linearly-convergent stochastic l-bfgs algorithm, arXiv preprint arXiv:1508.02087, (2015).
- [27] Noboru Murata, A statistical study of on-line learning, Online Learning and Neural Networks. Cambridge University Press, Cambridge, UK, (1998), pp. 63–92.
- [28] Jorge Nocedal and Stephen Wright, Numerical optimization, Springer Science & Business Media, 2006.
- [29] Michael Nussbaum, Asymptotic equivalence of density estimation and gaussian white noise, The Annals of Statistics, (1996), pp. 2399–2430.
- [30] Belgium Network of Open Source Analytical Consultants, Biglm on your big data in open source r, it just works – similar as in sas, 2012.
- [31] Jeffrey S Racine, A primer on regression splines, URL: http://cran. r-project. org/web/packages/crs/vignettes/splineprimer. pdf, (2014).
- [32] UCI Machine Learning Repository, Gas sensor array under dynamic gas mixtures data set, 2015.
- [33] UCI Machine Learning Respository, Adult data set, 1996.
- [34] Herbert Robbins and Sutton Monro, A stochastic approximation method, The Annals of Mathematical Statistics, (1951), pp. 400–407.
- [35] Nicolas L Roux, Mark Schmidt, and Francis R Bach, A stochastic gradient method with an exponential convergence rate for finite training sets, in Advances in Neural Information Processing Systems, 2012, pp. 2663–2671.
- [36] Nicol N Schraudolph, Jin Yu, and Simon Günter, A stochastic quasi-newton method for online convex optimization, in International Conference on Artificial Intelligence and Statistics, 2007, pp. 436–443.
- [37] Shai Shalev-Shwartz and Tong Zhang, Accelerated proximal stochastic dual coordinate ascent for regularized loss minimization, Mathematical Programming, (2014), pp. 1–41.
- [38] Tanya M Teslovich, Kiran Musunuru, Albert V Smith, Andrew C Edmondson, Ioannis M Stylianou, Masahiro Koseki, James P Pirruccello, Samuli Ripatti, Daniel I Chasman, Cristen J Willer, et al., Biological, clinical and population relevance of 95 loci for blood lipids, Nature, 466 (2010), pp. 707–713.
- [39] Aad W Van der Vaart, Asymptotic statistics, vol. 3, Cambridge University Press, 2000.
- [40] Larry Wasserman, All of nonparametric statistics, Springer Science & Business Media, 2006.
- [41] Robert WM Wedderburn, Quasi-likelihood functions, generalized linear models, and the gauss—newton method, Biometrika, 61 (1974), pp. 439–447.
- [42] Lin Xiao and Tong Zhang, A proximal stochastic gradient method with progressive variance reduction, SIAM Journal on Optimization, 24 (2014), pp. 2057–2075.