Kernel-based Optimally Weighted Conformal Prediction Intervals
Abstract
Conformal prediction has been a popular distribution-free framework for uncertainty quantification. In this work, we present a novel conformal prediction method for time-series, which we call Kernel-based Optimally Weighted Conformal Prediction Intervals (KOWCPI). Specifically, KOWCPI adapts the classic Reweighted Nadaraya-Watson (RNW) estimator for quantile regression on dependent data and learns optimal data-adaptive weights. Theoretically, we tackle the challenge of establishing a conditional coverage guarantee for non-exchangeable data under strong mixing conditions on the non-conformity scores. We demonstrate the superior performance of KOWCPI on real time-series against state-of-the-art methods, where KOWCPI achieves narrower confidence intervals without losing coverage.
1 Introduction
Conformal prediction, originated in Vovk et al. (1999, 2005), offers a robust framework explicitly designed for reliable and distribution-free uncertainty quantification. Conformal prediction has become increasingly recognized and adopted within the domains of machine learning and statistics (Lei et al., 2013; Lei and Wasserman, 2014; Kim et al., 2020; Angelopoulos and Bates, 2023). Assuming nothing beyond the exchangeability of data, conformal prediction excels in generating valid prediction sets under any given significance level, irrespective of the underlying data distribution and model assumptions. This capability makes it particularly valuable for uncertainty quantification in settings characterized by diverse and complex models.
Going beyond the exchangeability assumption has been a research challenge, particularly as many real-world datasets (such as time-series data) are inherently non-exchangeable. Tibshirani et al. (2019) addresses situations where a feature distribution shifts between training and test data and restores valid coverage through weighted quantiles based on the likelihood ratio of the distributions. More recently, Barber et al. (2023) bounds the coverage gap using the total variation distance between training and test data eights and minimizes this gap using pre-specified data-independent weights. However, it remains open to how to appropriately optimize the weights.
To advance conformal prediction for time series, we extend the prior sequential predictive approach (Xu and Xie, 2023a, b) by incorporating nonparametric kernel regression into the quantile regression method on non-conformity scores. A key challenge of adapting this method to time-series data lies in selecting optimal weights to accommodate the dependent structure of the data. To ensure valid coverage of prediction sets, it is crucial to select weights inside the quantile estimator so that it closely approximates the true quantile of non-conformity scores.
In this paper, we introduce KOWCPI, which utilizes the Reweighted Nadaraya-Watson estimator (Hall et al., 1999) to facilitate the selection of data-dependant optimal weights. This approach anticipates that adaptive weights will enhance the robustness of uncertainty quantification, particularly when the assumption of exchangeability is compromised. Our method also addresses the weight selection issue in the weighted quantile method presented by Barber et al. (2023), as KOWCPI allows for the calculation of weights in a data-driven manner without prior knowledge about the data.
In summary, our main contributions are:
-
•
We propose KOWCPI, a sequential time-series conformal prediction method that performs nonparametric kernel quantile regression on non-conformity scores. In particular, KOWCPI learns optimal data-driven weights used in the conditional quantiles.
-
•
We prove the asymptotic conditional coverage guarantee of KOWCPI based on the classical theory of nonparametric regression. We further obtain the marginal coverage gap of KOWCPI using the general result for the weights on quantile for non-exchangeable data.
-
•
We demonstrate the effectiveness of KOWCPI on real time-series data against state-of-the-art baselines. Specifically, KOWCPI can achieve the narrowest width of prediction intervals without losing marginal and approximate conditional (i.e., rolling) coverage empirically.
1.1 Literature
RNW quantile regression
In Hall et al. (1999), the Reweighted Nadaraya-Watson (RNW, often referred to as Weighted or Adjusted Nadaraya-Watson) estimator was suggested as a method to estimate the conditional distribution function from time-series data. This estimator extends the renowned Nadaraya-Watson estimator (Nadaraya, 1964; Watson, 1964) by introducing an additional adjustment to the weights, thus combining the favorable bias properties of the local linear estimator with the benefit of being a distribution function by itself like the original Nadaraya-Watson estimator (Hall et al., 1999; Yu and Jones, 1998). The theory of the regression quantile with the RNW estimator has been further developed by Cai (2002). Furthermore, Cai (2002) and Salha (2006) demonstrated that the RNW estimator is consistent under strongly mixing conditions, which are commonly observed in time-series data. In this work, we adaptively utilize the RNW estimator within the conformal prediction framework to construct sequential prediction intervals for time-series data, leveraging its data-driven weights for quantile estimation and the weighted conformal approach.
Conformal prediction with weighted quantiles
Approaches using quantile regression instead of empirical quantiles in conformal prediction have been widespread (Romano et al., 2019; Kivaranovic et al., 2020; Gibbs et al., 2023). These methods utilize various quantile regression techniques to construct conformal prediction intervals, and the convergence to the oracle prediction width can be shown under the consistency of the quantile regression function (Sesia and Candès, 2020). Another recent work by Guan (2023) uses kernel weighting based on the distance between the test point and data to perform localized conformal prediction, which further discusses the selection of kernels and bandwidths. Recent work in this direction of utilizing the weighted quantiles, including Lee et al. (2023); Angelopoulos et al. (2023), continues to be vibrant. As we will discuss later, our approach leverages techniques in classical non-parametric statistics when constructing the weights.
Time-series conformal prediction
There is a growing body of research on time-series conformal prediction (Xu and Xie, 2021b; Gibbs and Candès, 2021). Various applications include financial markets (Gibbs and Candès, 2021), anomaly detection (Xu and Xie, 2021a), and geological classification (Xu and Xie, 2022). In particular, Gibbs and Candès (2021, 2022) sequentially construct prediction intervals by updating the significance level based on the mis-coverage rate. This approach has become a major methodology for handling non-exchangeable data, leading to several subsequent developments (Feldman et al., 2022; Auer et al., 2023; Bhatnagar et al., 2023; Zaffran et al., 2022). On the other hand, Xu and Xie (2023b); Xu et al. (2024) take a slightly different approach by conducting sequential quantile regression using non-conformity scores. Our study aims to integrate non-parametric kernel estimation for sequential quantile regression, addressing the weight selection issues identified by Barber et al. (2023). Additionally, our research aligns with Guan (2023), particularly in utilizing a dissimilarity measure between the test point and the past data.
2 Problem Setup
We begin by assuming that the observations of the random sequence , are obtained sequentially. Notably, may represent exogenous variables that aid in predicting , the historical values of itself, or a combination of both. (In Appendix A, we expand our discussion to include cases where the response is multivariate.) A key aspect of our setup is that the data are non-exchangeable and exhibit dependencies, which are typical in time-series data where temporal or sequential dependencies influence predictive dynamics.
Suppose we are given a pre-specified point predictor trained on a separate dataset or on past data. This predictor maps a feature variable in to a scalar point prediction for . Given a user-specified significance level , we use the initial observations to construct prediction intervals for in a sequential manner from onwards.
Two key types of coverage targeted by prediction intervals are marginal coverage and conditional coverage. Marginal coverage is defined as
| (1) |
which ensures that the true value falls within the interval at least of the time, averaged over all instances. On the other hand, conditional coverage is defined as
| (2) |
which is a stronger guarantee ensuring that given each value of predictor , the true value falls within the interval at least of the time.
3 Method
In this section, we introduce our proposed method, KOWCPI (Kernel-based Optimally Weighted Conformal Prediction Intervals), which embodies our approach to enhancing prediction accuracy and robustness in the face of time-series data. We delve into the methodology and algorithm of KOWCPI in-depth, highlighting how the Reweighted Nadaraya-Watson (RNW) estimator integrates with our predictive framework.
Consider prediction for a univariate time series, . We have predictors given to us at time , , which can depend on the past observations , and possibly other exogeneous time series . Given a pre-trained algorithm , we also have a sequence of non-conformity scores indicating the accuracy of the prediction:
We denote the collection of the past non-conformity scores at time as
We construct the prediction interval with significance level at time as follows:
| (3) | ||||
Here, is a quantile regression algorithm that returns an estimate of the -quantile of the residuals, which we will explain through this section. We consider asymmetrical confidence intervals to ensure the tightest possible coverage.
3.1 Reweighted Nadaraya-Watson estimator
The Reweighted Nadaraya-Watson (RNW) estimator is a general and popular method for quantile regression. Observe , , where , and the predictors can be -dimensional. The goal is to predict the quantile , , given a test point using training samples. The RNW estimator introduces adjustment weights on the predictors to ensure consistent estimation. We define the probability-like adjustment weights , , by maximizing the empirical log-likelihood , subject to , and
| (4) | ||||
| (5) |
The RNW estimate of the conditional CDF is defined as follows:
| (6) |
where the weights are given by
| (7) |
Here, the kernel is a kernel function, and for . Any reasonable choice of kernel function is possible; however, to ensure the validity of our theoretical results discussed in Section 4, the kernel should be nonnegative, bounded, continuous, and possess compact support. An example is , where is the Epanechnikov kernel.
The computation of reduces to a simple one-dimensional convex minimization problem:
Lemma 3.1 ((Hall et al., 1999; Cai, 2001)).
The adjustment weights , , for the RNW estimator are given as
| (8) |
where denotes the first element of a vector , and is the minimizer of:
| (9) |
Lemma 3.1 is a starting point for the proof of the asymptotic conditional coverage property of our algorithm later on.
3.2 RNW for conformal prediction
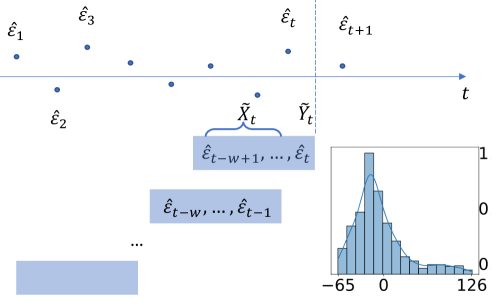
To perform the quantile regression for prediction interval construction at time , we use a sliding window approach, breaking the past residuals into overlapping segments of length . We construct the predictors and responses to fit the RNW estimator as follows:
With RNW estimator fitted on , the conditional -quantile estimator is defined as
| (10) |
After time , we update by removing the oldest residual and adding the newest one, then repeat the process (see Algorithm 1). In Section 4, we prove that due to the consistency of , KOWCPI achieves asymptotic conditional coverage despite the significant temporal dependence introduced by using overlapping segments of residuals.
Bandwidth selection
While it is theoretically possible to calculate the optimal bandwidth that minimizes the asymptotic mean-squared error, this requires additional derivative estimation, which significantly complicates the problem. Consequently, similar to general non-parametric models, one can use cross-validation to select the bandwidth. However, cross-validation can be computationally burdensome and may deteriorate under dependent data (Fan et al., 1995). Therefore, we adapt the non-parametric AIC (Cai and Tiwari, 2000), used for bandwidth selection in local linear estimators. This method is applicable because the RNW estimator belongs to the class of linear smoother (Cai, 2002). We choose the bandwidth that minimizes
| (11) |
where is the residual sum of squares, and is a linear smoothing operator (Hastie, 1990), with the -th element given by
Window length selection
To select the window length , cross-validation can be employed. One approach is to use a weighted sum of the average under-coverage rate and the average width obtained for a given as the criterion. Another approach could involve choosing with the smallest average width that achieves a target coverage in the validation set. In experiments, we observed that the performance is less sensitive to the choice of across a broader range compared to the bandwidth , although the selection of and interactively affects the performance.
4 Theory
In this section, we introduce the theoretical properties of the RNW estimator, a quantile regression method we use, and demonstrate in Theorem 4.9 that our KOWCPI asymptotically displays conditional coverage under the strong mixing of residuals. It turns out that the asymptotic conditional coverage gap can be derived from known results in the context of kernel quantile regression.
4.1 Marginal coverage
We begin by bounding the marginal coverage gap of the KOWCPI method. The following result shows the coverage gap using our weights, compared with the oracle weights; the results are established using a similar strategy as in (Tibshirani et al., 2019, Lemma 3):
Proposition 4.1 (Non-asymptotic marginal coverage gap).
Denote by the joint density of . Then, we have
| (12) | ||||
where is the discrete gap defined in (17), and is the vector of oracle weights with each entry is defined as
| (13) |
and is a permutation on .
The implication of Proposition 4.1 is that
-
•
The “under-coverage” depends on the -distance between the learned optimal weights and oracle-optimal weights (that depends on the true joint distribution of data).
-
•
Note that the oracle weights cannot be evaluated, because in principle, it requires considering the possible shuffled observed residuals and their joint distributions.
-
•
The form of the oracle weights from (13) offers an intuitive basis for algorithm development: we can practically estimate the weights through quantile regression, utilizing previously observed non-conformity scores.
4.2 Conditional coverage
In this section, we derive the asymptotic conditional coverage property of KOWCPI. For this, we introduce the assumptions necessary for the consistency of the RNW estimator. To account for the dependency in the data, we assume the strong mixing of the residual process.
A stationary stochastic process on a probability space with a probability measure is said to be strongly mixing (-mixing) if a mixing coefficient defined as
satisfies as , where , , denotes a -algebra generated by . The mixing coefficient quantifies the asymptotic independence between the past and future of the sequence .
Assumption 4.2 (Mixing of the process).
The stationary process is strongly mixing with the mixing coefficient for some .
Due to stationarity, the conditional CDF of the realized residual does not depend on the index ; thus, denote
as the conditional CDF of the random variable given . In addition, we introduce the following notations:
-
•
Let be the marginal density of at . (Note that due to stationarity, we can have a common marginal density.)
-
•
Let denote the joint density of and .
The following assumptions (4.3-4.5) are common in nonparametric statistics, essential for attaining desirable properties such as the consistency of an estimator (Tsybakov, 2009).
Assumption 4.3 (Smoothness of the conditional CDF and densities).
For fixed and ,
-
(i)
.
-
(ii)
is twice continuously partially differentiable with respect to .
-
(iii)
and is continuous at .
-
(iv)
There exists such that for all and .
Regarding Assumption 4.3, we would like to remark that there is a negative result: without additional assumptions about the distribution, it is impossible to construct finite-length prediction intervals that satisfy conditional coverage (Lei and Wasserman, 2014; Vovk, 2012).
Assumption 4.4 (Regularity of the kernel function).
The kernel is a nonnegative, bounded, continuous, and compactly supported density function satisfying
-
(i)
,
-
(ii)
for some ,
-
(iii)
and for some .
Assumptions 4.4-(i), (ii), and (iii) are standard conditions (Wand and Jones, 1994) that require to be “symmetric” in a sense that that the weighting scheme relies solely on the distance between the observation and the test point. For example, if is isometric, i.e., for some univariate kernel function , it can satisfy these conditions using widely adopted kernels such as the Epanechnikov kernel.
Assumption 4.5 (Bandwidth selection).
As , the bandwidth satisfies
We note that Assumption 4.5 is met when selecting the (theoretically) optimal bandwidth , which minimizes the asymptotic mean squared error (AMSE) of the RNW estimator, provided that .
We prove the following proposition following a similar strategy as (Salha, 2006) by fixing several technical details:
Proposition 4.6 (Consistency of the RNW estimator).
This proposition implies pointwise convergence in probability of the RNW estimator, and since it is the weighted empirical CDF, this pointwise convergence implies uniform convergence in probability (Tucker, 1967, p.127-128). Consequently, we obtain the consistency of the conditional quantile estimator in (10) to the true conditional quantile given as
As a direct consequence of Corollary 4.7, the asymptotic conditional coverage of KOWCPI is guaranteed by the consistency of the quantile estimator used in our sequential algorithm.
Corollary 4.8 (Asymptotic conditional coverage guarantee).
Thus, employing quantile regression using the RNW estimator for prediction residuals derived from the time-series data of continuous random variables, assuming strong mixing of these residuals, KOWCPI can achieve approximate conditional coverage with a sufficient number of residuals utilized.
To further specify the rate of convergence, define the discrete gap
| (17) |
Theorem 4.9 (Conditional coverage gap).
Given that the adjustment weights uniformly concentrate to (Steikert, 2014), one can see that the conditional coverage gap tends to zero, although its precise rate remains an open question.
5 Experiments
| Electric | Wind | Solar | ||||
| Coverage | Width | Coverage | Width | Coverage | Width | |
| KOWCPI | 0.90 | 0.22 | 0.91 | 2.41 | 0.90 | 48.8 |
| Plain NW | 0.89 | 0.31 | 0.95 | 3.58 | 0.41 | 20.1 |
| SPCI | 0.90 | 0.29 | 0.94 | 2.61 | 0.92 | 84.2 |
| EnbPI | 0.93 | 0.36 | 0.92 | 5.25 | 0.87 | 106.0 |
| ACI | 0.89 | 0.32 | 0.88 | 8.26 | 0.89 | 143.9 |
| FACI | 0.89 | 0.28 | 0.91 | 7.77 | 0.89 | 141.9 |
| AgACI | 0.91 | 0.30 | 0.88 | 7.54 | 0.90 | 144.6 |
| SF-OGD | 0.79 | 0.25 | 0.11 | 0.29 | 0 | 0.50 |
| SAOCF | 0.93 | 0.33 | 0.76 | 4.00 | 0.64 | 33.5 |
| SCP | 0.87 | 0.30 | 0.86 | 8.20 | 0.89 | 142.0 |
In this section, we compare the performance of KOWCPI against state-of-the-art conformal prediction baselines using real time-series data. We aim to show that KOWCPI can consistently reach valid coverage with the narrowest prediction intervals.
Dataset. We consider three real time series from different domains. The first ELEC2 data set (eletric) (Harries, 1999) tracks electricity usage and pricing in the states of New South Wales and Victoria in Australia for every 30 minutes over a 2.5-year period in 1996–1999. The second renewable energy data (solar) (Zhang et al., 2021) are from the National Solar Radiation Database and contain hourly solar radiation data (measured in GHI) from Atlanta in 2018. The third wind speed data (wind) (Zhu et al., 2021) are collected at wind farms operated by MISO in the US. The wind speed record was updated every 15 minutes over a one-week period in September 2020.
Baselines. We consider Sequential Predictive Conformal Inference (SPCI) (Xu and Xie, 2023b), Ensemble Prediction Interval (EnbPI) (Xu and Xie, 2023a), Adaptive Conformal Inference (ACI) (Gibbs and Candès, 2021), Aggregated ACI (AgACI) (Zaffran et al., 2022), Fully Adaptive Conformal Inference (FACI) (Gibbs and Candès, 2022), Scale-Free Online Gradient Descent (SF-OGD) (Orabona and Pál, 2018; Bhatnagar et al., 2023), Strongly Adaptive Online Conformal Prediction (SAOCP) (Bhatnagar et al., 2023), and vanilla Split Conformal Prediction (SCP) (Vovk et al., 2005). Additionally, we included a comparison where weights were derived from the original Nadaraya-Watson estimator (Plain NW). For the implementation of ACI-related methods, we utilized the R package AdaptiveConformal (https://github.com/herbps10/AdaptiveConformal). For SPCI and EnbPI, we used the Python code from https://github.com/hamrel-cxu/SPCI-code.
Setup and evaluation metrics. In all comparisons, we use the random forest as the base point predictor with the number of trees . Every dataset is split in a 7:1:2 ratio for training the point predictor, tuning the window length and bandwidth , and constructing prediction intervals, respectively. The window length for each dataset is fixed and determined through cross-validation, while the bandwidth is selected by minimizing the nonparametric AIC, as detailed in (11).
Besides examining marginal coverage and widths of prediction intervals on test data, we also focus on rolling coverage, which is helpful in showing approximate conditional coverage at specific time indices. Given a rolling window size , rolling coverage at time is defined as
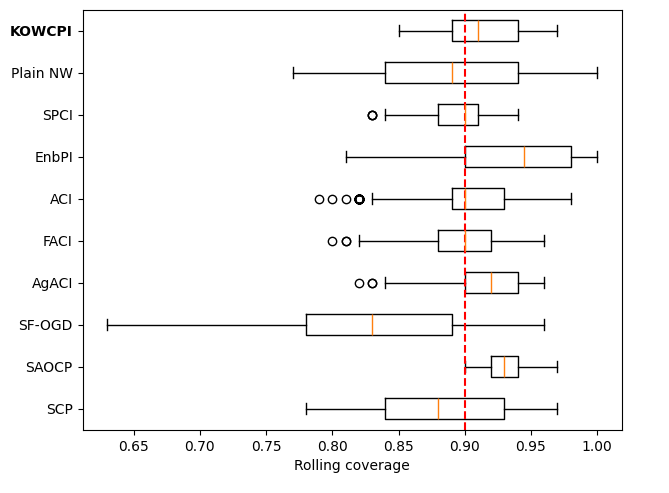
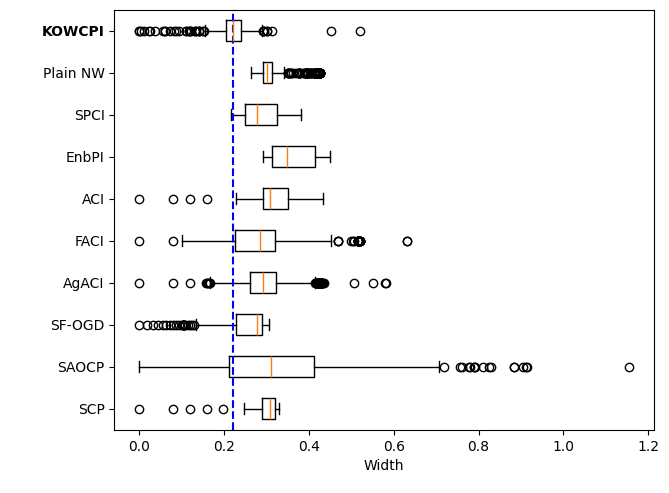
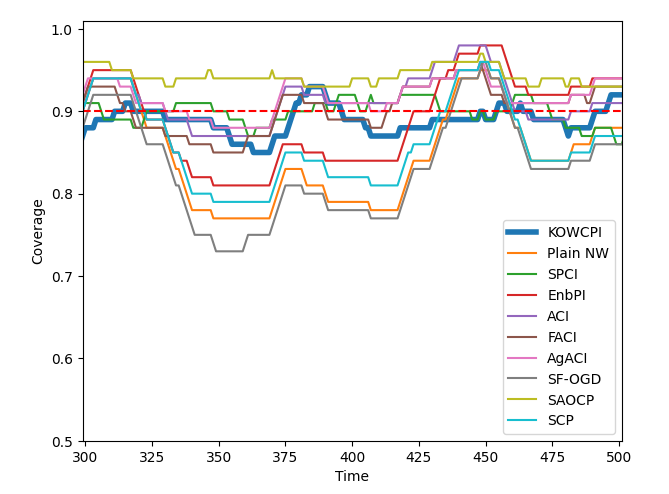
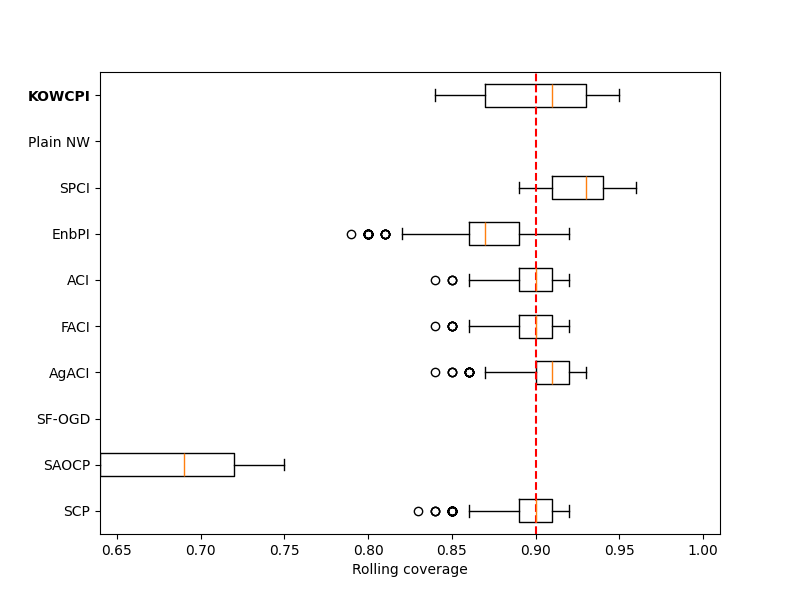
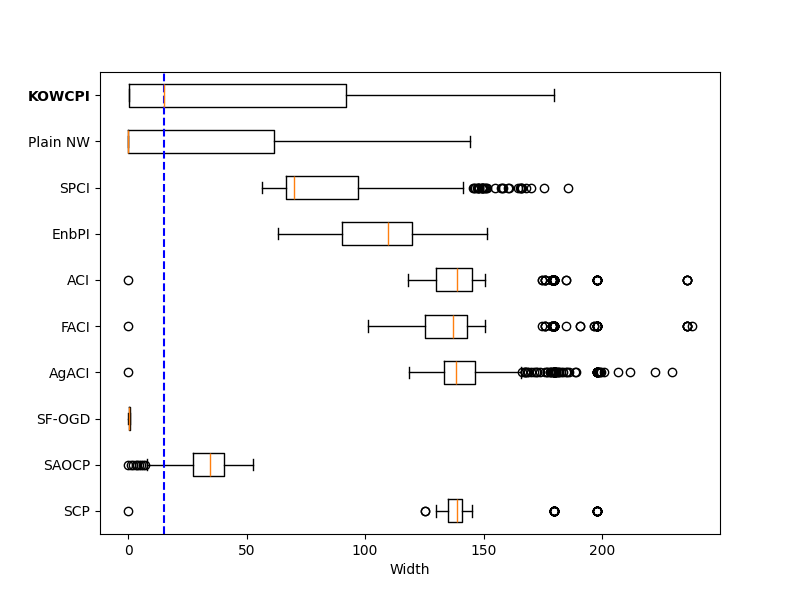
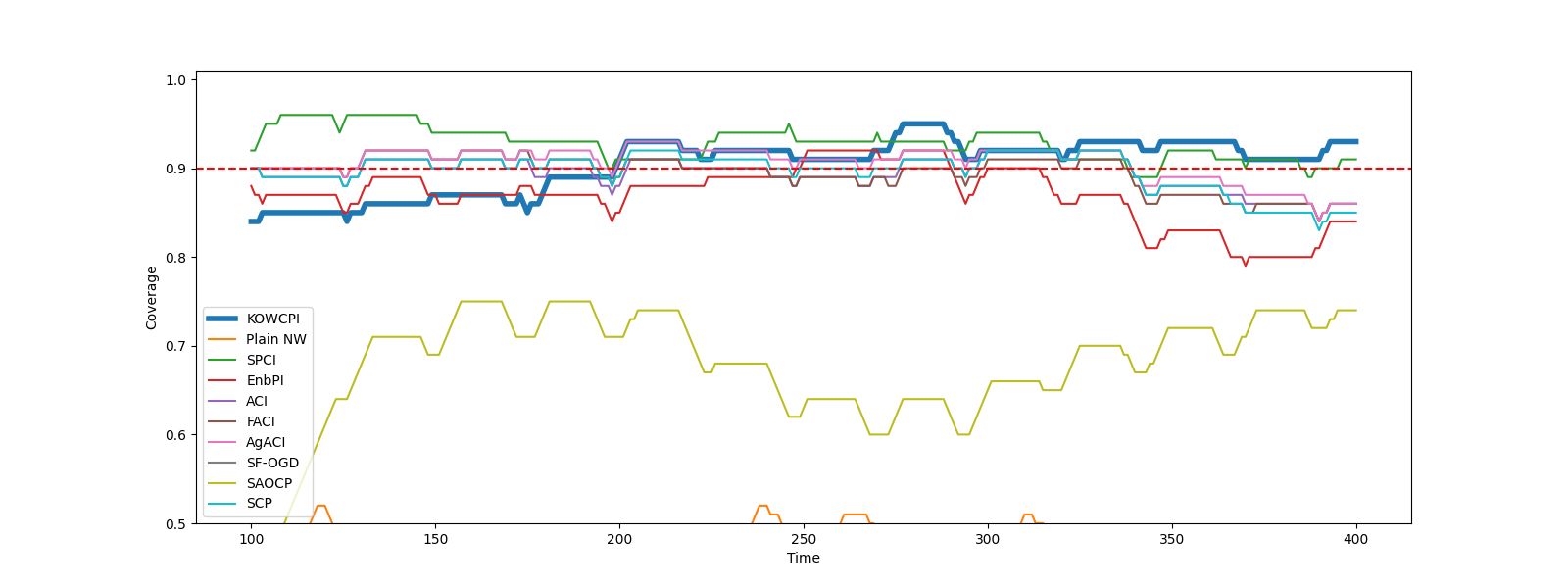
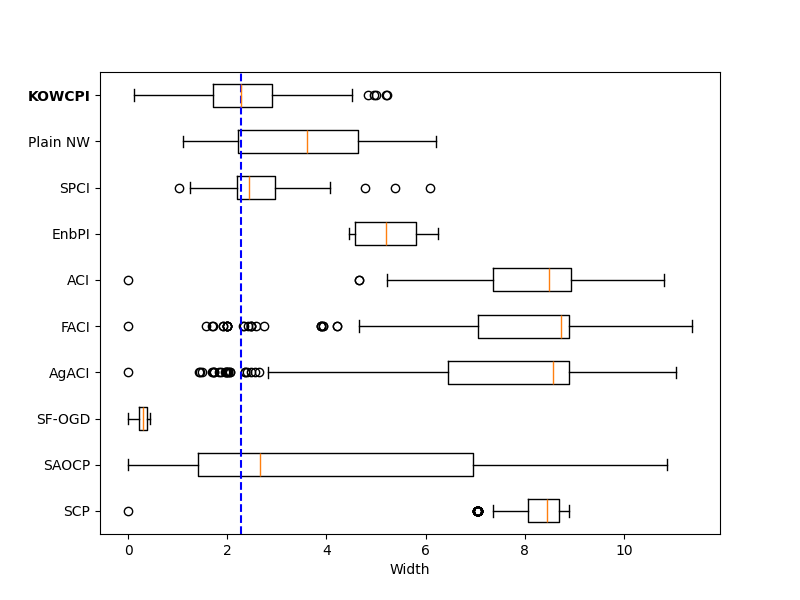
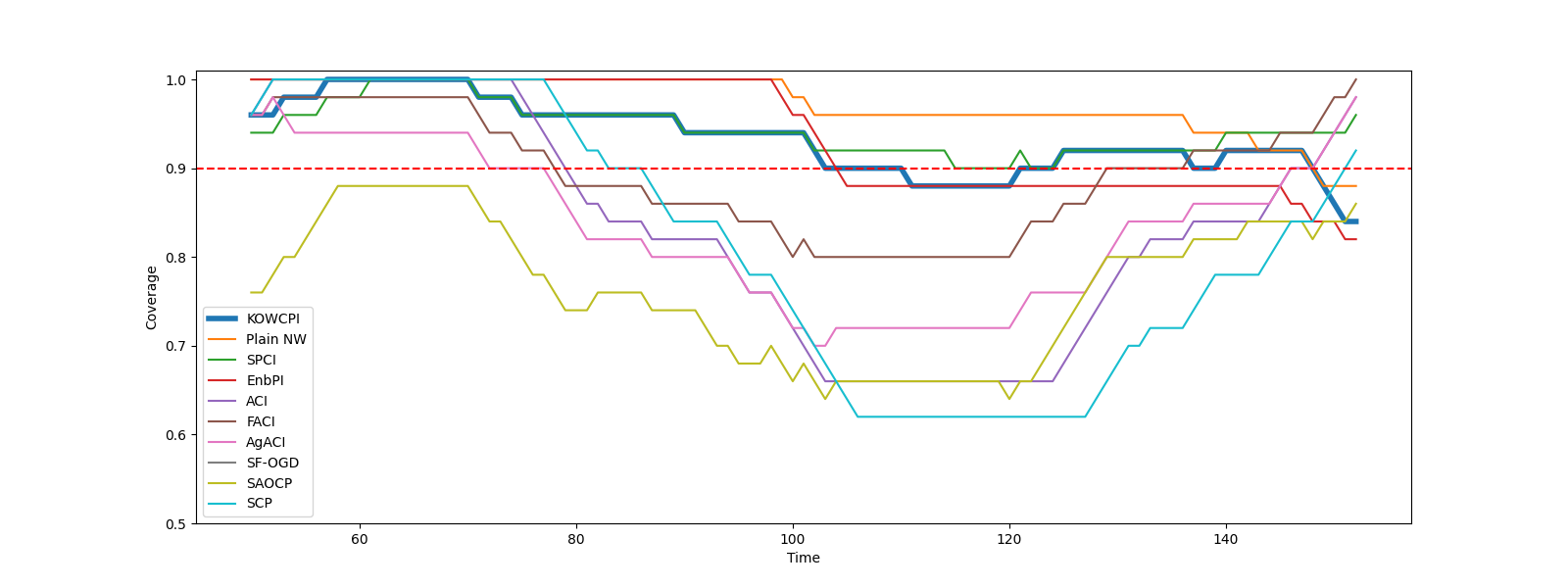
Results. The empirical marginal coverage and width results for all methods are summarized in Table 1. The results indicate that KOWCPI consistently achieves the 90% target coverage and maintains the smallest average width compared to the alternative state-of-the-art methods. While all methods, except SF-OGD, SAOCF, and Plain NW nearly achieve marginal coverage under target , KOWCPI produces the narrowest average width on all datasets. In terms of rolling results, we show in Figures 2 and 2 that the coverage of KOWCPI intervals consistently centers around 90% throughout the entire test phase. Additionally, Figure 2 shows that KOWCPI intervals are also significantly narrower with a smaller variance than the baselines. Lastly, Figure 2 shows weights (in log scale) by the RNW estimator at the first time index of test data. We note that the most recent set of non-conformity scores (in terms of time indices) receives the heaviest weighting, which is natural due to the greatest similarity between the first test datum and training data closest to it in time. In Appendix C, we show additional comparisons of KOWCPI against the baselines on the other two datasets in terms of rolling results, where KOWCPI remains consistently better.
6 Conclusion
In this paper, we introduced KOWCPI, a method to sequentially construct prediction intervals for time-series data. By incorporating the classical Reweighted Nadaraya-Watson estimator into the weighted conformal prediction framework, KOWCPI effectively adapts to the dependent structure of time-series data by utilizing data-driven adaptive weights. Our theoretical contributions include providing theoretical guarantees for the asymptotic conditional coverage of KOWCPI under strong mixing conditions and bounding the marginal and conditional coverage gaps. Empirical validation on real-world time-series datasets demonstrated the effectiveness of KOWCPI compared to state-of-the-art methods, achieving narrower prediction intervals without compromising empirical coverage.
Future work could explore adaptive window selection, where the size of the non-conformity score batch is adjusted dynamically to capture shifts in the underlying distribution. Additionally, the natural compatibility of kernel regression with multivariate data can be leveraged to expand the utility of KOWCPI for multivariate time-series data, as detailed in Appendix A. There is also potential for improving theoretical guarantees and improving practical performance by designing alternative non-conformity scores.
Acknowledgments
This work is partially supported by an NSF CAREER CCF-1650913, NSF DMS-2134037, CMMI-2015787, CMMI-2112533, DMS-1938106, DMS-1830210, and the Coca-Cola Foundation.
References
- Abdous and Theodorescu [1992] B. Abdous and R. Theodorescu. Note on the spatial quantile of a random vector. Statist. Probab. Lett., 13(4):333–336, 1992.
- Angelopoulos et al. [2023] A. Angelopoulos, E. Candès, and R. J. Tibshirani. Conformal PID Control for Time Series Prediction. In Advances in Neural Information Processing Systems, 2023.
- Angelopoulos and Bates [2023] A. N. Angelopoulos and S. Bates. Conformal Prediction: A Gentle Introduction. Foundations and Trends® in Machine Learning, 16(4):494–591, 2023.
- Auer et al. [2023] A. Auer, M. Gauch, D. Klotz, and S. Hochreiter. Conformal Prediction for Time Series with Modern Hopfield Networks. In Advances in Neural Information Processing Systems, 2023.
- Barber et al. [2023] R. F. Barber, E. J. Candès, A. Ramdas, and R. J. Tibshirani. Conformal prediction beyond exchangeability. The Annals of Statistics, 51(2):816 – 845, 2023.
- Bhatnagar et al. [2023] A. Bhatnagar, H. Wang, C. Xiong, and Y. Bai. Improved Online Conformal Prediction via Strongly Adaptive Online Learning. In Proceedings of the 40th International Conference on Machine Learning, 2023.
- Cai [2001] Z. Cai. Weighted Nadaraya-Watson regression estimation. Statistics & Probability Letters, 51(3):307–318, 2001.
- Cai [2002] Z. Cai. Regression quantiles for time series. Econometric Theory, 18(1):169–192, 2002.
- Cai and Tiwari [2000] Z. Cai and R. C. Tiwari. Application of a local linear autoregressive model to BOD time series. Environmetrics, 11(3):341–350, 2000.
- Fan et al. [1995] J. Fan, N. E. Heckman, and M. P. Wand. Local Polynomial Kernel Regression for Generalized Linear Models and Quasi-Likelihood Functions. Journal of the American Statistical Association, 90(429):141–150, 1995.
- Feldman et al. [2022] S. Feldman, L. Ringel, S. Bates, and Y. Romano. Achieving Risk Control in Online Learning Settings. arXiv preprint arXiv:2205.09095, 2022.
- Gibbs and Candès [2021] I. Gibbs and E. Candès. Adaptive Conformal Inference Under Distribution Shift. Advances in Neural Information Processing Systems, 34:1660–1672, 2021.
- Gibbs and Candès [2022] I. Gibbs and E. Candès. Conformal Inference for Online Prediction with Arbitrary Distribution Shifts. arXiv preprint arXiv:2208.08401, 2022.
- Gibbs et al. [2023] I. Gibbs, J. J. Cherian, and E. J. Candès. Conformal Prediction With Conditional Guarantees. arXiv preprint arXiv:2305.12616, 2023.
- Guan [2023] L. Guan. Localized conformal prediction: a generalized inference framework for conformal prediction. Biometrika, 110(1):33–50, 2023.
- Hall et al. [1999] P. Hall, R. C. Wolff, and Q. Yao. Methods for Estimating a Conditional Distribution Function. Journal of the American Statistical Association, 94(445):154–163, 1999.
- Harries [1999] M. Harries. SPLICE-2 Comparative Evaluation: Electricity Pricing. Technical report, University of New South Wales, School of Computer Science and Engineering, 1999.
- Hastie [1990] T. J. Hastie. Generalized additive models. CRC Press, 1990.
- Ibragimov et al. [1971] I. A. Ibragimov, Y. V. Linnik, and J. F. C. Kingman. Independent and Stationary Sequences of Random Variables. Wolters-Noordhoff., 1971.
- Kim et al. [2020] B. Kim, C. Xu, and R. Barber. Predictive inference is free with the jackknife+-after-bootstrap. Advances in Neural Information Processing Systems, 33:4138–4149, 2020.
- Kivaranovic et al. [2020] D. Kivaranovic, K. D. Johnson, and H. Leeb. Adaptive, Distribution-Free Prediction Intervals for Deep Networks. In Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics, 2020.
- Lee et al. [2023] Y. Lee, R. F. Barber, and R. Willett. Distribution-free inference with hierarchical data. arXiv preprint arXiv:2306.06342, 2023.
- Lei and Wasserman [2014] J. Lei and L. Wasserman. Distribution-free prediction bands for non-parametric regression. Journal of the Royal Statistical Society Series B: Statistical Methodology, 76(1):71–96, 2014.
- Lei et al. [2013] J. Lei, J. Robins, and L. Wasserman. Distribution-Free Prediction Sets. Journal of the American Statistical Association, 108(501):278–287, 2013.
- Masry [1986] E. Masry. Recursive probability density estimation for weakly dependent stationary processes. IEEE Transactions on Information Theory, 32(2):254–267, 1986.
- Nadaraya [1964] E. A. Nadaraya. On Estimating Regression. Theory of Probability & Its Applications, 9(1):141–142, 1964.
- Orabona and Pál [2018] F. Orabona and D. Pál. Scale-free online learning. Theoretical Computer Science, 716:50–69, 2018.
- Romano et al. [2019] Y. Romano, E. Patterson, and E. Candès. Conformalized Quantile Regression. In Advances in Neural Information Processing Systems, 2019.
- Salha [2006] R. Salha. Kernel Estimation for the Conditional Mode and Quantiles of Time Series. PhD thesis, University of Macedonia, 2006.
- Sesia and Candès [2020] M. Sesia and E. J. Candès. A comparison of some conformal quantile regression methods. Stat, 9(1):e261, 2020.
- Stankevičiūtė et al. [2021] K. Stankevičiūtė, A. Alaa, and M. van der Schaar. Conformal time-series forecasting. In Advances in Neural Information Processing Systems, 2021.
- Steikert [2014] K. U. Steikert. The weighted Nadaraya-Watson Estimator: Strong consistency results, rates of convergence, and a local bootstrap procedure to select the bandwidth. PhD thesis, University of Zurich, 2014.
- Sun and Yu [2024] S. H. Sun and R. Yu. Copula conformal prediction for multi-step time series prediction. In The Twelfth International Conference on Learning Representations, 2024.
- Tibshirani et al. [2019] R. J. Tibshirani, R. Foygel Barber, E. Candès, and A. Ramdas. Conformal Prediction Under Covariate Shift. Advances in Neural Information Processing Systems, 32, 2019.
- Tsybakov [2009] A. B. Tsybakov. Introduction to Nonparametric Estimation. Springer, 2009.
- Tucker [1967] H. G. Tucker. A Graduate Course in Probability. Academic Press, 1967.
- Vovk [2012] V. Vovk. Conditional validity of inductive conformal predictors. In Proceedings of the Asian Conference on Machine Learning, 2012.
- Vovk et al. [1999] V. Vovk, A. Gammerman, and C. Saunders. Machine-Learning Applications of Algorithmic Randomness. In Proceedings of the Sixteenth International Conference on Machine Learning, 1999.
- Vovk et al. [2005] V. Vovk, A. Gammerman, and G. Shafer. Algorithmic Learning in a Random World. Springer, 2005.
- Wand and Jones [1994] M. P. Wand and M. C. Jones. Kernel Smoothing. CRC press, 1994.
- Watson [1964] G. S. Watson. Smooth regression analysis. Sankhyā: The Indian Journal of Statistics, Series A, 26:359–372, 1964.
- Xu and Xie [2021a] C. Xu and Y. Xie. Conformal Anomaly Detection on Spatio-Temporal Observations with Missing Data. arXiv preprint arXiv:2105.11886, 2021a.
- Xu and Xie [2021b] C. Xu and Y. Xie. Conformal prediction interval for dynamic time-series. In Proceedings of the 38th International Conference on Machine Learning, 2021b.
- Xu and Xie [2022] C. Xu and Y. Xie. Conformal prediction set for time-series. arXiv preprint arXiv:2206.07851, 2022.
- Xu and Xie [2023a] C. Xu and Y. Xie. Conformal prediction for time series. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(10):11575–11587, 2023a.
- Xu and Xie [2023b] C. Xu and Y. Xie. Sequential Predictive Conformal Inference for Time Series. In Proceedings of the 40th International Conference on Machine Learning, 2023b.
- Xu et al. [2024] C. Xu, H. Jiang, and Y. Xie. Conformal prediction for multi-dimensional time series by ellipsoidal sets. arXiv preprint arXiv:2403.03850, 2024.
- Yu and Jones [1998] K. Yu and M. C. Jones. Local Linear Quantile Regression. Journal of the American Statistical Association, 93(441):228–237, 1998.
- Zaffran et al. [2022] M. Zaffran, O. Féron, Y. Goude, J. Josse, and A. Dieuleveut. Adaptive Conformal Predictions for Time Series. In Proceedings of the 39th International Conference on Machine Learning, 2022.
- Zhang et al. [2021] M. Zhang, C. Xu, A. Sun, F. Qiu, and Y. Xie. Solar Radiation Ramping Events Modeling Using Spatio-temporal Point Processes. arXiv preprint arXiv:2101.11179, 2021.
- Zhu et al. [2021] S. Zhu, H. Zhang, Y. Xie, and P. Van Hentenryck. Multi-resolution spatio-temporal prediction with application to wind power generation. arXiv preprint arXiv:2108.13285, 2021.
Appendix A Multivariate time series
In the main text, our discussion has centered on cases where the response variables are scalars. Here, we explore the natural extension of our methodology to handle scenarios with multivariate responses. This extension requires defining multivariate quantiles, introducing a multivariate version of the RNW estimator for estimating these quantiles [Salha, 2006], and adapting our KOWCPI method for multivariate responses.
Multivariate conditional quantiles
Consider a strongly mixing stationary process , which is a realization of random variable . Following Abdous and Theodorescu [1992], we first define a pseudo-norm function for as
for , where is the Euclidean norm on . Let
Definition A.1 (Multivariate conditional quantile [Abdous and Theodorescu, 1992]).
Define a multivariate conditional -quantile for as
| (A.1) |
Remark A.2 (Compatibility with univariate quantile function).
For a scalar , its conditional quantile given is
for any . Thus, Definition A.1 is consistent with the univariate case.
Multivariate RNW estimator
Multivariate KOWCPI
Suppose we are sequentially observing , . Based on the construction of the multivariate version of the RNW estimator, we can extend our KOWCPI approach to multivariate responses in the same manner as described in Algorithm 1, with multivariate residuals
as non-conformity scores. This adaptation allows for the application of our methodology to a broader range of data scenarios involving dependent data with multivariate response variables, which were similarly studied in [Xu et al., 2024, Sun and Yu, 2024, Stankevičiūtė et al., 2021].
Appendix B Proofs
The following lemma is adapted from the proof of Lemma 1 of Tibshirani et al. [2019]; however, we do not assume exchangeability.
Lemma B.1 (Weights on quantile for non-exchangeable data).
Given a sequence of random variables with joint density and a sequence of observations . Define the event
Then we have for ,
Note that when the residuals are exchangeable, , as also observed in Tibshirani et al. [2019]. Now we prove Proposition 4.1.
Proof of Proposition 4.1.
The proof assumes that , for , are almost surely distinct. However, the proof remains valid, albeit with more complex notations involving multisets, if this is not the case. Denote by the -quantile of the distribution on , and by the point mass distribution at . Define the event . Then, by the tower property, we have
where , and in the last line, we have used the result from Lemma B.1,
Denote the weighted empirical distributions based on as
This gives the marginal coverage gap as
where we denote by the total variation distance between probability measures, and the second inequality is due to the definition of the total variation distance. ∎
B.1 Proof of asymptotic conditional coverage of KOWCPI (Corollary 4.8 and Theorem 4.9)
In deriving the asymptotic conditional coverage property of KOWCPI, the consistency of the RNW estimator plays a crucial role. Therefore, we first introduce the proof of Proposition 4.6, which discusses the consistency of the CDF estimator. Corollary 4.7, which states the consistency of the quantile estimator, is a natural consequence of Proposition 4.6 and leads us to the proof for our main results, Corollary 4.8 and Theorem 4.9. Proof of Proposition 4.6 adopts the similar strategy as Salha [2006] and Cai [2002].
To prove Proposition 4.6, it is essential to first understand the nature of the adjustment weight . Thus, Lemma 3.1 is not only crucial for the practical implementation of the RNW estimator but also indispensable in the proof process of Proposition 4.6.
Proof of Lemma 3.1.
For display purposes, denote as . By (5), we have that
| (A.4) |
Let
where are the Lagrange multipliers. From for , we get
Since ’s sum up to 1 as in (4), letting , we have
Using (4) again with (A.4), this gives
and therefore (8) holds. With (5), this gives
Note that , implying that is indeed a convex function. ∎
Lemma B.2.
Proof.
Decomposing in bias and variance terms, we get
where . Note that due to the tower property. Now, let
Then, by Lemma B.2, we have that
| (A.6) |
Define
so that
| (A.7) |
Therefore, we will derive Proposition 4.6 by controlling the terms , and .
Lemma B.3.
Under the assumptions of Proposition 4.6,
| (A.8) |
Proof.
Let
so that . Since , we have that , and thus
| (A.9) |
Also, due to the stationarity of , we have that
| (A.10) |
By Assumption 4.4, we have that , which gives . Therefore, through expansion, we have
where in the third line is the convolution operator. To control the second term in the right-hand side of (A.10), we borrow the idea of Masry [1986]. Choose and decompose
We have that for some constant . By Assumption 4.3-(iv), we obtain
so that
By Assumption 4.4, we have , so that . Then, by Theorem 17.2.1 of Ibragimov et al. [1971], we have that
Thus, we get
Therefore, we obtain
| (A.11) |
∎
Lemma B.4.
Under the assumptions of Proposition 4.6,
| (A.12) | ||||
| (A.13) |
Proof.
Finally, by applying the expansion argument routinely, we get
| (A.15) |
∎
Proof of Corollary 4.8.
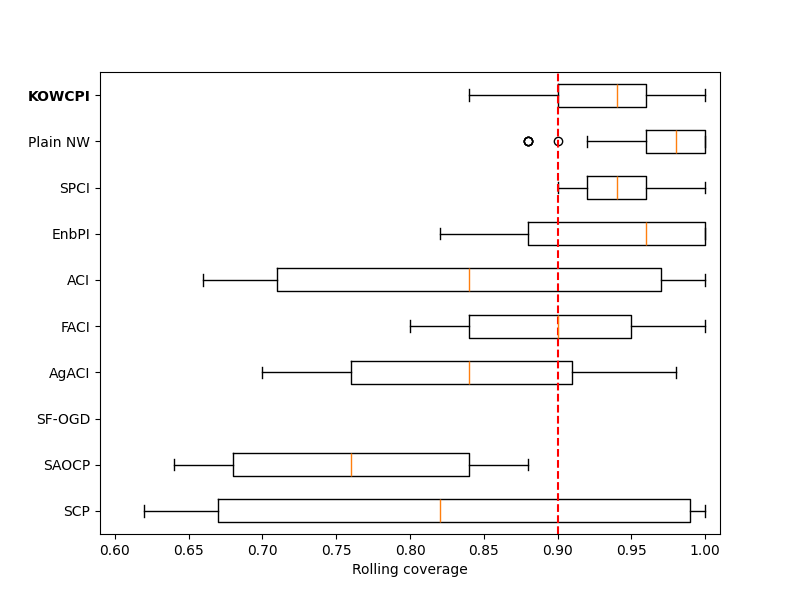
Appendix C Additional experiment results
We show additional rolling comparison on the solar (Figure A.1) and wind dataset (Figure A.2), where the setup and conclusions remain consistent with those on the electric dataset (Figure 2).