-SVD with Gradient Descent
Abstract
We show that a gradient-descent with a simple, universal rule for step-size selection provably finds -SVD, i.e., the largest singular values and corresponding vectors, of any matrix, despite nonconvexity. There has been substantial progress towards this in the past few years where existing results are able to establish such guarantees for the exact-parameterized and over-parameterized settings, with choice of oracle-provided step size. But guarantees for generic setting with a step size selection that does not require oracle-provided information has remained a challenge. We overcome this challenge and establish that gradient descent with an appealingly simple adaptive step size (akin to preconditioning) and random initialization enjoys global linear convergence for generic setting. Our convergence analysis reveals that the gradient method has an attracting region, and within this attracting region, the method behaves like Heron’s method (a.k.a. the Babylonian method). Empirically, we validate the theoretical results. The emergence of modern compute infrastructure for iterative optimization coupled with this work is likely to provide means to solve -SVD for very large matrices.
1 Introduction
The Task. Consider an a matrix of rank . Let SVD of be given as , where , with being the singular values of in decreasing order, (resp. ) be semi-orthogonal matrix containing the left (resp. right) singular vectors.111We adopt the convention that the -th element of the diagonal of is , and that -th column of (resp. of ) denoted (resp. denoted ) are its corresponding -th left (resp. left) singular vector. The condition number of is defined as . Our objective is to find the the -SVD of , i.e. the leading singular values, , corresponding left (resp. right) singular vectors (resp. ). For ease and clarity of exposition, we will consider that is symmetric, positive semi-definite in which case for all . Indeed, we can always reduce the problem of -SVD for any matrix to that of solving the -SVD of and , which are both symmetric, positive semi-definite.
A Bit of History. Singular Value Decomposition is fundamental linear algebraic operation, cf. see [33] for early history. It has become an essential tool for in modern machine learning with widespread applications in numerous fields including biology, statistics, engineering, natural language processing, econometric and finance, etc (e.g., see [5] for an exhaustive list and references therein).
Traditional algorithms for performing SVD or related problems like principal component analysis, or eigenvalue and eigenvector computation, have relied on iterative methods such as the Power method [28], Lancsos method [25], the QR algorithm [14], or variations thereof for efficient and better numerical stability [10]. Notably, these methods have also been combined with stochastic approximation schemes to handle streaming and random access to data [29]. The rich history of these traditional algorithms still impacts the solutions of modern machine learning questions [1, 21, 15, 30, 16].
Why Study Gradient Based Method? Given the rich history, it makes one wonder why look for another method? Especially, gradient based. To start with, the -SVD is a non-convex optimization and ability to understand success (or failure) of gradient based methods for non-convex setting can expand our understanding for optimization in general. For example, the landscape of loss function associated with PCA has served as a natural nonconvex surrogate to understand training for neural networks [2] [7][17, 19, 18, 32]. Perhaps the closest to this work are [13, 23, 32, 36, 24, 27]. It is also worth noting the recent interest in understanding non-convex matrix factorization [17, 19, 18, 32, 13, 23, 32, 36, 24, 27]. The gradient based methods are known to be robust with respect to noise or missing values, see [20]. Finally, the recent emergence of scalable compute infrastructure for iterative optimization methods like gradient based method can naturally enable computation of -SVD for very large scale matrices in a seamless manner, and potentially overcome existing challenges with scaling for SVD computation, see [31].
Main Result. Gradient descent for -SVD. Like the power method, the algorithm proceeds by sequentially finding one singular value and its corresponding singular vector at a time in a decreasing order until all the leading vectors are found. For finding top singular value and vector of , minimize objective
| (1) |
Towards that, gradient descent starts by randomly sampling an initial iterate, . Iteratively for , update
| (2) |
For the above algorithm, we establish the following:
Theorem 1.
Given a symmetric, positive semi-definite with , the iterate in (2) satisfies for all ,
| (3) | ||||
| (4) |
for any as long as
| (5) |
where are constant that only depend on the initial point ; with random initialization are almost surely strictly positive.
2 Related Work
Methods from linear algebra.
Computation of SVD is typically done via iterative methods that rely on one or combinations of few fundamental procedures, namely the power method [28], Lancsos method [25], or the QR algorithms [14]. However, these fundamental procedures are not always the most stable, which lead to a significant body of research in pursuit of better algorithms for SVD. The most advanced algorithms among these, typically perform a transformation of the matrix of interest to a bidiagonal matrix, then proceed by using variants of the QR algorithm to conclude [12] (see also [10] for an extensive literature). Similar to us, all these algorithms, must find at some stage or another sequentially the singular values and vectors. These methods are still of high relevance in modern machine learning questions [1, 15, 30, 16], especially the power method for its simplicity [21].
The proposed -SVD method with gradient descent is not, nor does it rely on, the power method, the Lancsoz method, or the QR method. It is conceptually a brand new method that we add to the arsenal of fundamental procedures for SVD computation. From a computational perspective, our gradient-based method (2) finds a leading singular value and vector to accuracy in iterations. This is exactly the same amount of iterations needed by the power method [28]. To the best of our knowledge, we present the first gradient based method for -SVD.
Gradient descent for nonconvex landscapes.
The convergence of gradient descent for nonconvex optimization landscapes has been studied to a large extent recently [2, 37, 17, 26, 19, 18, 22, 11]. Notably, in [17], it was shown that stochastic gradient descent converges asymptotically to local minima and escapes strict saddle points. In [26], it was also shown that even the vanilla gradient descent only converges to local minima provided all saddle points are strict and the step size is relatively small. Efficient procedure for saddle point escaping were also proposed in [22]. In the context of low-rank matrix problems, including robust PCA, matrix completion and matrix sensing, [19, 18] have highlighted that the optimization landscapes of these problems have no spurious local minima, namely the objectives have only strict saddle points and all local minima are also global minima. [4, 37] established convergence of Riemannian or geometric gradient descent methods.
While all these works are relevant to us, they often provide only asymptotic results, require strong conditions on the objective landscape, or require choosing sophisticated step sizes or knowledge of constants that are typically unknown to us. Therefore they do not directly compare with our findings. On the other hand, our results do not suffer from these limitations. Moreover, our convergence analysis is not asymptotic, shows global linear convergence, and follows a completely different proof strategy.
Nonconvex matrix factorization.
At the heart of the proposed -SVD method with gradient descent is establishing convergence of gradient descent for a nonconvex matrix factorization objective (1). More generally, the study of gradient descent for the nonconvex matrix factorization objective, often called the Burrer-Monteiro matrix factorization [3],
| (8) |
has recently stirred a lot of interest (see [8, 13, 23, 7, 6, 34, 32, 36, 35, 24, 27] and references therein). In the quest of understanding when gradient descent converges for (8), many questions were posed: what initialization leads to convergence? what step sizes should one choose? what convergence rate are possible?
Significant progress has been made in answering these questions often times in three parameterization regimes, namely, the over parameterized setting when , the exact parameterized setting when , and the under parameterized setting when . Typical linear convergence rates for gradient descent were initially established only locally (see [11, 7] and references therein), namely, when the initial starting point is sufficiently close to the optimal solution. This can be ensured by using spectral initialization which consists in running SVD and use the outcome as an initial starting point. [34] suggested the use of preconditioning to speed up computation time of gradient-based
| (9) |
with a choice of that is constant. They showed linear convergence for with spectral initialization. This result was later extended to in [36]. In these works the problem of spectral initialization remained. In a breakthrough paper, [32] showed that small random initialization is in fact enough to ensure global linear convergence. Notably, they established that gradient methods with fixed but small enough step size and with small random initialization, behave in a initial phase like a power method, thus bypassing the need for spectral initialization. This result was shown in the regime of . The work [24], showed that in fact preconditioning with random initialization is sufficient to ensure global linear convergence, when . In a concurrent work, LZMH [27] showed that even quadratic convergence rates can be attainable with preconditioning provided a so-called Nyström initialization is used, which is akin to having an initial random point that is in the span of the matrix .
Despite all this progress, none of the aforementioned works have presented results for the under parameterized regimes, except [7, 27]. Indeed, [7] have discussed the under parameterized case of , but they only showed local linear convergence (see their theorem 1.). [27] studied gradient descent with preconditioning and the so-called Nyström initialization in the case . They showed sub-linear convergence and required a complex choice of step sizes. More specifically to ensure an optimization accuracy of , they need iterations (see their Theorem 2), while instead, we achieve linear convergence, thus entailing gradient descent only needs iterations (see Theorem 1, and Theorem 2). Moreover their choice of the step size has to switch from a constant to one that is of order once the iterates are sufficiently close to the global solution while using preconditioning at the same time. It is not clear how this can be achieved. In contrast, the choice of the step size is an adaptive one for us (2) and is akin to simply using preconditioning.
Furthermore, existing convergence analysis tend to borrow from techniques and ideas in convex optimization. Instead, our analysis builds on the insight that there is a link between gradient descent presented in (2) and Heron’s method, which allows us to establish linear convergence in the under-parameterized regime.
Why study the under-parameterized setting?
While the under parameterized regime, especially the case is of fundamental importance as highlighted in [7]. For the purpose of computing -SVD it is important. Note that for , even if one finds an exact solution that minimizes the objective (8), then for any , orthogonal matrix , also minimizes (8). This rotation problem poses a challenge in using the objective (8) for -SVD while the objective (1) doesn’t.
3 Warm-up analysis; gradient descent as Heron’s method in disguise
A key insight from our analysis is the observation that gradient descent with adaptive step-size (2) behaves like Heron’s method. This is in stark contrast, with the observation of [32] suggesting that gradient descent for low-rank matrix factorization with a fixed step-size and small random initialization behaves like a power-method at an initial phase. To clarify our observation, we present here a convergence analysis in the simple yet instructive case of being exactly of rank .
First, let us note that gradient of the function at any given point is given by:
| (10) |
When is exactly of rank , i.e., , the gradient updates (2) become: for all ,
| (11) |
To further simplify things, let us consider that the initial point is randomly selected as follows:
| (12) |
Thus, we see that . This, together with the iterations (11), clearly shows that for all , . Hence, for all , we have:
| (13) |
We see then that is evolving precisely according to Heron’s method (a.k.a. the Babylonian method) for finding the square root of , which is a special case of Newton’s method. Below, we present the convergence rate of the method in this case:
Proposition 1.
We defer the proof of Proposition of 1 is immediate and corresponds exactly to the convergence analysis of Heron’s method. We provide a proof in Appendix A for completeness. The established convergence guarantee indicates that gradient descent converges at a quadratic rate, meaning, that in order to attain an error accuracy of order , the method only requires iterations.
It is worth mentioning that when the rank is exactly 1 then the objective corresponds to that of an exact-parameterization regime. The random initialization scheme (12) we consider is only meant for ease of exposition and has been studied in the concurrent work of [27]. Like us, they also obtain quadratic convergence in this exact-parameterization regime. Indeed, if one uses an alternative random initialization, say , then one only obtains a linear convergence rate.
In general, we do not expect the matrix to be exactly of rank . Extending the analysis to the generic setting is more challenging and is exactly the subject of §4.
4 Convergence analysis: gradient descent as Heron’s method in disguise
In this section, we present the key ingredients for proving Theorem 1. The proof is simple and can be broken into three intermediate steps: (i) establishing that gradient descent has a natural region of attraction; (ii) showing that once within this region of attraction aligns with at a linear rate; (iii) showing that the sequence is evolving according to an approximate Heron’s method, and is convergent to at a linear rate.
Most of our analysis holds for gradient descent with an adaptive step sizes and :
| (15) |
Without loss of generality, we consider that is randomly initialized as in (12). This choice of initialization allows us to simplify the analysis as it ensures that is in the image of . Most importantly, our analysis only requires that . It will be also convenient to define: for all , , the angle between and , which also satisfies:
| (16) |
whenever .
4.1 Region of attraction
It is crucial for gradient descent to stabilize in order to have to achieve. One hopes that the iterates do not escape to infinity or vanish at . It turns out that this is indeed the case and this is what we present in Lemma 1. We define:
| (17) | ||||
| (18) |
where it is not difficult to verify that and .
Lemma 1 (Attracting region of gradient descent).
The proof of Lemma 1 is differed to Appendix A.4. Remarkably, and do not arbitrarily degrade with the quality of the initial random point. Thus, the number of iterations required to enter the region , can be made constant if for instance one further constrains .
Furthermore, the fact that is non-decreasing is interesting because it means that can only get closer to . To see that, note that we have . Indeed, a consequence 1, is the following saddle-point avoidance result.
Lemma 2 (Saddle-point avoidance).
4.2 Alignment at linear rate
Another key ingredient in the analysis is Lemma 3 which we present below:
Lemma 3.
We defer the proof of Lemma 3 to Appendix A.6. The result shows that gradient descent is implicitly biased towards aligning its iterates with . This alignment happens at a linear rate with a factor that depends on , and this is why we require the condition . Actually, if , then our proof can be easily adjusted to show that will align with the singular subspace spanned by . Thus, our assumptions are without loss of generality.
4.3 Convergence with approximate Heron’s iterations
The final step of our analysis is to show that vanishes at a linear rate. We will only show this when (running gradient descent [eq:gradient]) because it has the cleanest proof. This is presented in the following lemma:
Lemma 4.
We provide simply a proof sketch to highlight how the the behavior of the iterates resemble those of an approximate Heron’s method. We refer the reader to Appendix A.7 for the complete proof.
Proof sketch of Lemma 4.
By taking the scalar product of the the two sides of the gradient update equation (2) with , we deduces that
| (24) |
Next, we can leverage Lemma 3 to show that the ratio converges to at a linear rate. We then recognize the familiar form of Heron’s iterations 13. Starting with this form, we can show converge of to . We spare the reader the tedious details of this part and refer them to the proof. ∎
Interestingly, the proof analysis thus far did not rely on any of the classical derivations for showing convergence of gradient methods which typically require special conditions on the objective.
4.4 Putting everything together
Theorem 3.
Given a symmetric, positive semi-definite with , the iterate in (2) satisfies for all ,
| (25) | ||||
| (26) |
as long as long
| (27) |
with positive constants that depend only on ; with random initialization are strictly positive almost surely.
5 Experiments
We present here some of our experimental findings that consolidate our theoretical findings. We mainly compare with the power method to test the sensitivity of the gradient method with respect to , , and runtime.
5.1 Experimental setup
Here we describe the generating mechanisms of the synthetic experiments we consider. We describe the generating mechanisms of the matrices we consider below:
The rank- setting.
For this setting, we consider matrices of rank . We generate and uniformly at random from the space of semi-orthogonal matrices of size , and set , with with , and varying in . These types of matrices, will be used to inspect the performance of the gradient descent method with respect to the gap .
The rank- settings.
Here, we focus on matrices of rank . First, we generate orthonormal matrices and uniformly at random from the space of semi-orthogonal matrices of size . Then we construct matrices of the form where and set the singular values to decay in three different ways:
-
•
(i) Exponentially decaying singular values. In this case, sample at random from , then set , for ;
-
•
(ii) Polynomially decaying singular values. Here we set , for .
-
•
(iii) Linearly decaying singular values. We sample uniformly at random from and uniformly at random from , then we set , for .
We use this setting to inspect the sensitivity of the gradient descent method with respect to scale of the matrix and compute time.
5.2 Implemented methods
When considering asymmetric matrices in the experiments, we apply -SVD with the considered methods on to identify the leading singular values of , and corresponding left singular vectors , we then simply recover the right singular vectors by setting , for .
-SVD with gradient descent.
The implementation -SVD with gradient is done by sequentially applying gradient descent to find one singular value and corresponding vectors at a time. At each time, we run gradient descent to minimize (1) with step sizes where . We use the initialization described in (12). For every run of gradient descent, we stop as soon as where is the tolerance threshold. We use . For a detailed pseudo-code refer to Appendix B.
-SVD with power method.
We implement a power method for finding the -SVD of . As with the gradient based method, we also proceed sequentially finding one singular value at a time and corresponding vector at a time. The method proceeds by iterating the equations until convergence. For the given tolerance , we stop as soon as . The method is initialized in the same fashion as the one with gradient descent. For a detailed pseudo-code refer to Appendix B.
5.3 Results
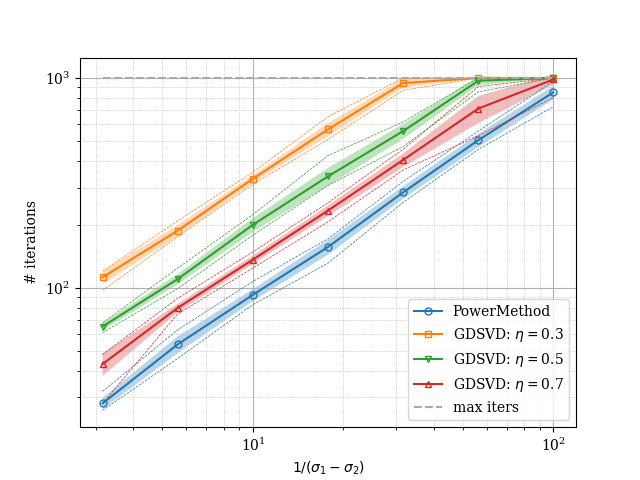
In Fig.1(a) we report the growth of the number of iterations as the gap changes running both the power method and gradient descent for finding the leading singular value and its corresponding vector. We generate matrices as described in the rank- setting for different values of . The curves are obtained by averaging over multiple curves. Indeed, we see that the the dependence on the gap does not depend on the size of the matrices which is consistent with our theoretical findings in Theorem 1.
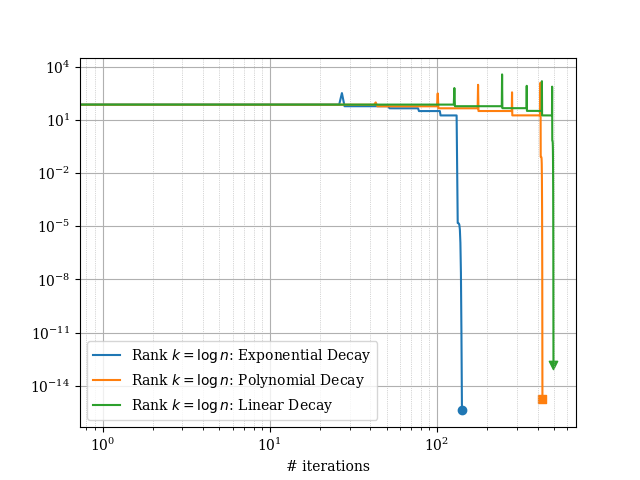
In Fig. 1(b), we illustrate the convergence of the -SVD method with gradient descent. The plots were obtained by running the method on matrices generated according to the rank- setting with . The results show that indeed the method converges as suggested by the theory (see Theorem 2).
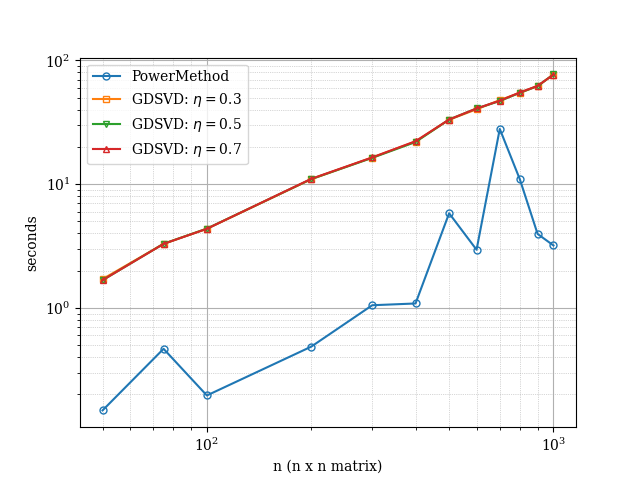
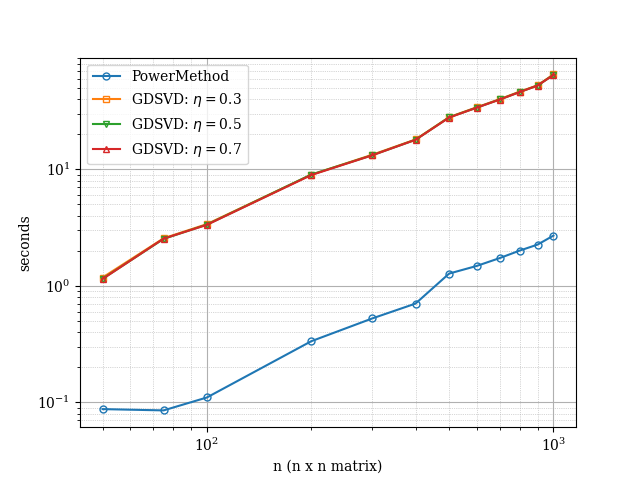
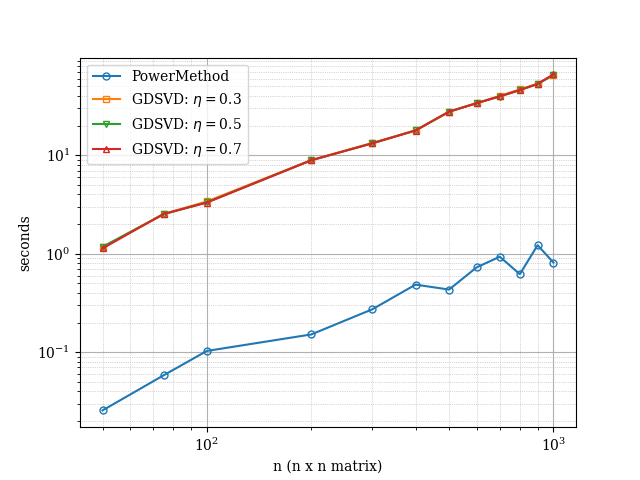
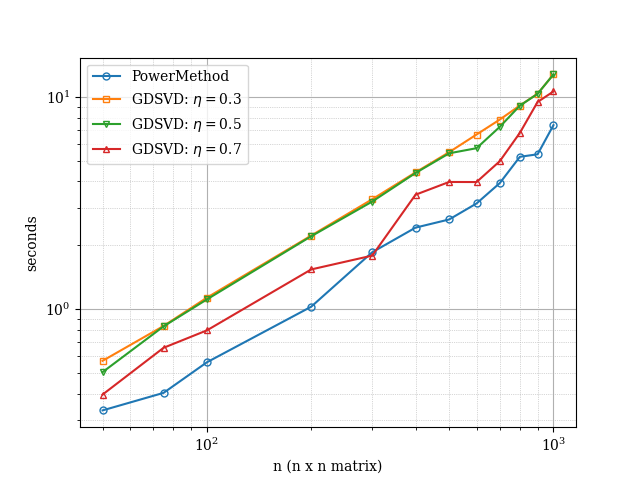
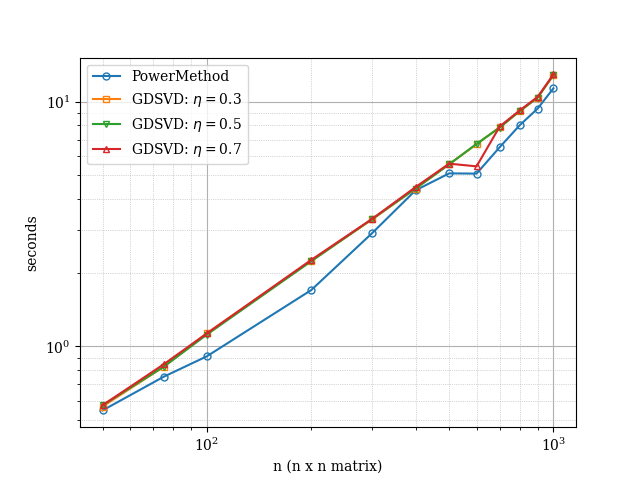
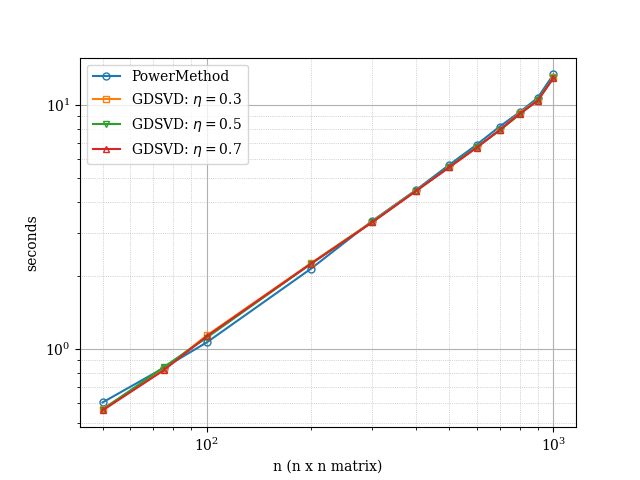
In Fig. 3 and Fig. 4 we report the evolution of the runtime of the various considered methods against the size of the matrices. Overall, we see that both, the -SVD method with gradient descent and with power method behave have similar performance. When the singular values are decaying linearly, we notice that the power method has some level of variance as the size increase suggesting some numerical instability of sorts but the methods do converge. In contrast, the -SVD method with gradient descent performs consistently across all experiments, thus suggesting robustness of the method.
6 Discussion & Conclusion
In this work, we presented a method for -SVD with gradient descent. The proposed gradient descent method uses an appealingly simple adaptive step-size towards optimizing a non-convex matrix factorization objective. We showed that the gradient method enjoys global linear convergence guarantee with random initialization in spite of the convexity of the optimization landscape. The method is shown to converge in the under parameterized setting, a result which to the best of our knowledge has eluded prior work. Critical to our convergence analysis is the observation that the gradient method behaves like Heron’s method. We believe this observation offers an interesting insight that might be of independent interest in the study of nonconvex optimization landscapes. Finally, we carried experimental results to corroborate our findings.
Because of modern computing infrastructure that allow for efficient and optimized deployment of gradient methods at scale, our method is likely to find use for computing -SVD for massively large matrices. Therefore a natural extension of our work is to develop a parallelized version of the gradient method and test it on massively large matrices.
Furthermore, gradient methods are known to possess robustness properties, thus we foresee that our proposed method will find widespread applications and further development, for settings where data is incomplete or noisy. In addition to this, a natural question is to investigate whether acceleration schemes may enhance the performance of the method, notably by reducing number of iterations required to achieve accuracy from to . Finally, another exciting direction is extending our method to solve tensor decompositions which are known to be notoriously expansive.
References
- ACLS [12] Raman Arora, Andrew Cotter, Karen Livescu, and Nathan Srebro. Stochastic optimization for pca and pls. In 2012 50th annual allerton conference on communication, control, and computing (allerton), pages 861–868. IEEE, 2012.
- BH [89] Pierre Baldi and Kurt Hornik. Neural networks and principal component analysis: Learning from examples without local minima. Neural networks, 2(1):53–58, 1989.
- BM [03] Samuel Burer and Renato DC Monteiro. A nonlinear programming algorithm for solving semidefinite programs via low-rank factorization. Mathematical programming, 95(2):329–357, 2003.
- BNR [10] Laura Balzano, Robert Nowak, and Benjamin Recht. Online identification and tracking of subspaces from highly incomplete information. In 2010 48th Annual allerton conference on communication, control, and computing (Allerton), pages 704–711. IEEE, 2010.
- CCF+ [21] Yuxin Chen, Yuejie Chi, Jianqing Fan, Cong Ma, et al. Spectral methods for data science: A statistical perspective. Foundations and Trends® in Machine Learning, 14(5):566–806, 2021.
- CCFM [19] Yuxin Chen, Yuejie Chi, Jianqing Fan, and Cong Ma. Gradient descent with random initialization: Fast global convergence for nonconvex phase retrieval. Mathematical Programming, 176:5–37, 2019.
- CLC [19] Yuejie Chi, Yue M Lu, and Yuxin Chen. Nonconvex optimization meets low-rank matrix factorization: An overview. IEEE Transactions on Signal Processing, 67(20):5239–5269, 2019.
- CLS [15] Emmanuel J Candes, Xiaodong Li, and Mahdi Soltanolkotabi. Phase retrieval via wirtinger flow: Theory and algorithms. IEEE Transactions on Information Theory, 61(4):1985–2007, 2015.
- CTP [19] Joshua Cape, Minh Tang, and Carey E Priebe. The two-to-infinity norm and singular subspace geometry with applications to high-dimensional statistics. 2019.
- CW [02] Jane K Cullum and Ralph A Willoughby. Lanczos algorithms for large symmetric eigenvalue computations: Vol. I: Theory. SIAM, 2002.
- DHL [18] Simon S Du, Wei Hu, and Jason D Lee. Algorithmic regularization in learning deep homogeneous models: Layers are automatically balanced. Advances in neural information processing systems, 31, 2018.
- DK [90] James Demmel and William Kahan. Accurate singular values of bidiagonal matrices. SIAM Journal on Scientific and Statistical Computing, 11(5):873–912, 1990.
- DSRO [15] Christopher De Sa, Christopher Re, and Kunle Olukotun. Global convergence of stochastic gradient descent for some non-convex matrix problems. In International conference on machine learning, pages 2332–2341. PMLR, 2015.
- Fra [61] John GF Francis. The qr transformation a unitary analogue to the lr transformation—part 1. The Computer Journal, 4(3):265–271, 1961.
- GH [15] Dan Garber and Elad Hazan. Fast and simple pca via convex optimization. arXiv preprint arXiv:1509.05647, 2015.
- GHJ+ [16] Dan Garber, Elad Hazan, Chi Jin, Cameron Musco, Praneeth Netrapalli, Aaron Sidford, et al. Faster eigenvector computation via shift-and-invert preconditioning. In International Conference on Machine Learning, pages 2626–2634. PMLR, 2016.
- GHJY [15] Rong Ge, Furong Huang, Chi Jin, and Yang Yuan. Escaping from saddle points—online stochastic gradient for tensor decomposition. In Conference on learning theory, pages 797–842. PMLR, 2015.
- GJZ [17] Rong Ge, Chi Jin, and Yi Zheng. No spurious local minima in nonconvex low rank problems: A unified geometric analysis. In International Conference on Machine Learning, pages 1233–1242. PMLR, 2017.
- GLM [16] Rong Ge, Jason D Lee, and Tengyu Ma. Matrix completion has no spurious local minimum. Advances in neural information processing systems, 29, 2016.
- H+ [16] Elad Hazan et al. Introduction to online convex optimization. Foundations and Trends® in Optimization, 2(3-4):157–325, 2016.
- HP [14] Moritz Hardt and Eric Price. The noisy power method: A meta algorithm with applications. Advances in neural information processing systems, 27, 2014.
- JGN+ [17] Chi Jin, Rong Ge, Praneeth Netrapalli, Sham M Kakade, and Michael I Jordan. How to escape saddle points efficiently. In International conference on machine learning, pages 1724–1732. PMLR, 2017.
- JJKN [17] Prateek Jain, Chi Jin, Sham Kakade, and Praneeth Netrapalli. Global convergence of non-convex gradient descent for computing matrix squareroot. In Artificial Intelligence and Statistics, pages 479–488. PMLR, 2017.
- JWP+ [24] Xixi Jia, Hailin Wang, Jiangjun Peng, Xiangchu Feng, and Deyu Meng. Preconditioning matters: Fast global convergence of non-convex matrix factorization via scaled gradient descent. Advances in Neural Information Processing Systems, 36, 2024.
- Lan [50] Cornelius Lanczos. An iteration method for the solution of the eigenvalue problem of linear differential and integral operators. 1950.
- LSJR [16] Jason D Lee, Max Simchowitz, Michael I Jordan, and Benjamin Recht. Gradient descent converges to minimizers. arXiv preprint arXiv:1602.04915, 2016.
- LZMH [24] Bingcong Li, Liang Zhang, Aryan Mokhtari, and Niao He. On the crucial role of initialization for matrix factorization. arXiv preprint arXiv:2410.18965, 2024.
- MPG [29] RV Mises and Hilda Pollaczek-Geiringer. Praktische verfahren der gleichungsauflösung. ZAMM-Journal of Applied Mathematics and Mechanics/Zeitschrift für Angewandte Mathematik und Mechanik, 9(1):58–77, 1929.
- OK [85] Erkki Oja and Juha Karhunen. On stochastic approximation of the eigenvectors and eigenvalues of the expectation of a random matrix. Journal of mathematical analysis and applications, 106(1):69–84, 1985.
- Sha [15] Ohad Shamir. A stochastic pca and svd algorithm with an exponential convergence rate. In International conference on machine learning, pages 144–152. PMLR, 2015.
- SMS+ [24] Łukasz Struski, Paweł Morkisz, Przemysław Spurek, Samuel Rodriguez Bernabeu, and Tomasz Trzciński. Efficient gpu implementation of randomized svd and its applications. Expert Systems with Applications, 248:123462, 2024.
- SS [21] Dominik Stöger and Mahdi Soltanolkotabi. Small random initialization is akin to spectral learning: Optimization and generalization guarantees for overparameterized low-rank matrix reconstruction. Advances in Neural Information Processing Systems, 34:23831–23843, 2021.
- Ste [93] Gilbert W Stewart. On the early history of the singular value decomposition. SIAM review, 35(4):551–566, 1993.
- TMC [21] Tian Tong, Cong Ma, and Yuejie Chi. Accelerating ill-conditioned low-rank matrix estimation via scaled gradient descent. Journal of Machine Learning Research, 22(150):1–63, 2021.
- XSCM [23] Xingyu Xu, Yandi Shen, Yuejie Chi, and Cong Ma. The power of preconditioning in overparameterized low-rank matrix sensing. In International Conference on Machine Learning, pages 38611–38654. PMLR, 2023.
- ZFZ [23] Gavin Zhang, Salar Fattahi, and Richard Y Zhang. Preconditioned gradient descent for overparameterized nonconvex burer–monteiro factorization with global optimality certification. Journal of Machine Learning Research, 24(163):1–55, 2023.
- ZJRS [16] Hongyi Zhang, Sashank J Reddi, and Suvrit Sra. Riemannian svrg: Fast stochastic optimization on riemannian manifolds. Advances in Neural Information Processing Systems, 29, 2016.
Appendix A Proofs
A.1 Proof of Proposition 1
Proof of Proposition 1.
First, we immediately see that the event holds almost surely.
We start with the observation that for all , . This is because by construction the initial point is already in the span of . Next, we have that for all ,
which leads to
In the above we recognize the iterations of a Babylonian method (a.k.a. as Heron’s method) for finding the square root of a real number. For completeness, we provide the proof of convergence. Let us denote
by replacing in the equation above we obtain that
With the choice , we obtain that
from which we first conclude that for all , (note that we already have ). Thus we obtain
This clearly implies that we have quadratic convergence. ∎
A.2 Proof of Theorem 1 and Theorem 3
Theorem 3 is an intermediate step in proving Theorem 1 and is therefore included in the proof below.
Proof of Theorem 1.
First, by applying Lemma 1 (with ), that after that for all , we have
and we also have
| (28) |
Thus, using the decompositions 6 and applying Lemma 3 and 4, we obtain that
We denote
and write
We can verify that
| (29) | |||
| (30) | |||
| (31) |
where we use the elementary fact that if then for any and for all . Thus, under condition (29) we obtain
In view of Lemma 6, the statement concerning follows similarly. At this stage we have shown the statement of Theorem 3.
We also see that
| (32) | ||||
| (33) |
where we used again the elementary fact . We conclude that if
then
∎
A.3 Error decompositions
Lemma 5.
Let symmetric matrices. Let (resp. ) be the eigenvalues of (resp. ) in decreasing order, and (resp. ) be their corresponding eigenvectors. Then, for all , we have
| (34) | ||||
| (35) |
where denotes the set of orthogonal matrices, and using the convention that .
Proof of 5.
The proof of the result is an immediate consequence of Davis-Kahan and the inequality (e.g., see [9]). The second inequality is simply Weyl’s inequality ∎
Lemma 6 (Error decompositions).
When , we have
Proof of Lemma 6.
For ease of notation, we use the shorthand . First, we have:
Next, we also have
Thus we obtain
| (36) |
Next, we have
∎
A.4 Proof of Lemma 1
Proof of Lemma 1.
Our proof supposes that which guaranteed almost surely by the random initialization (12).
Claim 1. First, we establish the following useful inequalities: for all ,
-
.
-
We start by noting that we can project the iterations of the gradient descent updates (15) onto , for all , gives
| (37) |
which follows because of the simple fact that . Thus, squaring and summing the equations (37) over , gives
| (38) |
Recalling that , we immediately deduce from (38) the inequality . Inequality because if , than thanks to it also follows .
Claim 2. Let us denote for all , , . We establish that the following properties hold:
-
is non-decreasing sequence
-
is a non-increasing sequence
-
for all , .
To prove the aforementioned claim we start by noting from (37) that for all , we have
| (39) |
Thus, from the Claim 1 (Eq. (ii)), we immediately see that for all , we have
| (40) | ||||
| (41) |
Now, we see that the l.h.s. inequality of Eq. (ii) in Claim 1, the combination of (40) and (39) leads to the following:
| (42) | ||||
| (43) | ||||
| (44) |
where we used in the elementary fact that for all . This concludes Claim 2.
Claim 3. We establish that if then, .
We can immediately see from Claim 1 that
| (45) | ||||
| (46) | ||||
| (47) | ||||
| (48) |
where we denote and note that .
Claim 4: If , then .
Indeed, start from the inequality in Claim 1, we can immediately verify that
| (49) |
Indeed we observe that if , then .
Claim 5: If , then there exists , such that , satisfying
| (50) |
Assuming that , let us define , the number of iterations required for . Using the r.h.s. of the inequality in Claim 1, and by definition of , we know that for ,
| (51) |
Iterating the above inequality, we obtain that
Now, let us note that can not be too large. More specifically, we remark that:
Therefore, it must hold that
Note that from Claim 3 and 4, as soon as , then it will never escape this region. Therefore, we only need to use Claim 5 if the first iterate is outside the region . ∎
A.5 Proof of Lemma 2
A.6 Proof of Lemma 3
Proof of Lemma 3.
We start from the observation that for all , we have
| (52) |
Now, note dividing the equations corresponding to and , we get
| (53) | ||||
| (54) | ||||
| (55) |
Thus, we have for all
which leads to
We recall that for all ,
which implies that
Hence,
Either or . Without loss of generality, we will present the case when , in which case and consequently . Let us further note that
∎
A.7 Proof of Lemma 4
Proof of Lemma 4.
Let us denote for all
| (56) | ||||
| (57) |
First, we verify that . Indeed, we have
where we used the fact that is a non-decreasing sequence, and used Lemma 3 to obtain the final bound. Thus, we see that .
Next, we also recall by assumption that , and by Lemma 1 that for all . Thus, we have:
| (58) |
Now, let us show that . We recall that
| (59) |
Thus, we have
| (60) | ||||
| (61) | ||||
| (62) | ||||
| (63) |
where in the last equality we used . We conclude from the above that for all
Thus, for all , we have
which further gives
To conclude, we will use the following elementary fact that for , we have
where in our case we have
Indeed, we obtain that
∎
A.8 Proof of Theorem 2
Proof.
We recall that and denote with . We will also denote the leading eigenvalue of by and its corresponding eigenvector by . Note that the leading singular value of is and its corresponding vector is . We also note that
| (64) | ||||
| (65) |
By application of gradient descent (2), we know that if method is run for large enough then for all for each , we have the guarantee:
| (67) | ||||
| (68) | ||||
| (69) |
Now, we show by induction that things remain well behaved. (for ), we have
(for ) We have
| (70) | |||||
| (71) | |||||
| (72) | |||||
(for ) we have
| (73) | |||||
| (74) | |||||
| (75) | |||||
and so forth, we see that at the end the error is at most
| (76) | ||||
| (77) | ||||
| (78) |
Let us denote
| (79) |
If is such that , for , and , then it will be ensured that the singular values of remain close to those of and stays positive definite. We may then apply gradient descent and use Theorem 1. Now, for a given , and a precision satisfying (79), by Theorem 1, running gradient descent long enough, namely , ensures that:
More precisely, is given by
In total, we need the total number of iterations to be
∎
A.9 Properties of the nonconvex objective
In the following lemma, we present a characterization of the properties of critical points of :
Lemma 7 (1 and 2 order optimality conditions).
Let , the following properties hold:
-
(i)
is a critical point, i.e. , if and only if or , .
-
(ii)
if for all , , then all local minima of the loss function are also global minima222We recall that is a local minima of iff and ., and all other critical points are strict saddle333We recall that is a strict saddle point iff , and .. More specifically, the only local and global minima of are the points and .
Appendix B Implementation and Experiments
In this section, we present and validate a GPU-friendly implementation of the -SVD methods discussed in §5. This implementation was developed on 6-core, 12-thread Intel chip, and tested on a 10-core, 20-thread Intel chip and NVIDIA CUDA 12.7.
B.1 Implementation details
Notation.
We use to denote the singular vector (column) of , to denote the singular vector (row) of , and to denote the entry.
Notes on implementation. A temporary file to store is memory-mapped during computation, rather than subtracting off previous rank-approximations each time is required. The latter takes only memory but significantly slows computation. The centralized implementations were written in Python 3.x and these are the versions tested for correctness guarantees. All of the tested SVD methods spend the most time on matrix-vector multiplication, which is easily parallelizable by spawning threads each responsible for computing one index of the resulting vector, so that each thread only requires space and time. Several implementations of parallelization were tested:
-
•
Cython: native Python fed through Cython
-
•
Numba: functions are jitted with Numba decorators
-
•
CuPy: and temporary variables are instantiated on the GPU device, rows/columns of are moved to the device when used for computation
-
•
C/OpenCilk: a C implementation was attempted with parallel library OpenCilk but it suffered from numerical stability issues and required a great deal of step-size engineering
None were satisfactory in reducing the scaling of runtime with input matrix size, possibly due to unideal memory management, but CUDA specific programming may be able to improve performance.
B.2 Correctness testing
Synthetic datasets with various singular value profiles were generated to test correctness. All datasets consist of stored in binary files, where are generated according to a scheme detailed below and computed as the square matrix result of ( ranges from 50 to 1,000).
Synthetic schemes.
-
1.
Rank dataset. is a orthonormal matrix generated using scipy.stats.ortho_group and a matrix generated the same way and transposed.
-
•
Exponential decay: where is generated by numpy.random.randint(1,10)
-
•
Polynomial decay:
-
•
Linear decay: , where is generated by numpy.random.randint(1,10) and is generated by numpy.random.rand(), regenerating until
-
•
-
2.
Rank 2 dataset. is a orthonormal matrix generated using scipy.stats.ortho_group and a matrix generated the same way and transposed. and chosen as for in increments.
Test procedure.
Test files were memory-mapped using np.memmap and checked for contiguous formatting using np.contiguousarray before passing into any SVD method. We record several metrics:
-
•
Approximation error:
-
•
Subspace error: (analogous for )
-
•
Orthogonal error: (analogous for )
including partial errors at the end of each iteration, as well as total runtime and final errors.