Knowledge Enhanced Multi-intent Transformer Network for Recommendation
Abstract.
Incorporating Knowledge Graphs (KGs) into Recommendation has attracted growing attention in industry, due to the great potential of KG in providing abundant supplementary information and interpretability for the underlying models. However, simply integrating KG into recommendation usually brings in negative feedback in industry, mainly due to the ignorance of the following two factors: i) users’ multiple intents, which involve diverse nodes in KG. For example, in e-commerce scenarios, users may exhibit preferences for specific styles, brands, or colors. ii) knowledge noise, which is a prevalent issue in Knowledge Enhanced Recommendation (KGR) and even more severe in industry scenarios. The irrelevant knowledge properties of items may result in inferior model performance compared to approaches that do not incorporate knowledge. To tackle these challenges, we propose a novel approach named Knowledge Enhanced Multi-intent Transformer Network for Recommendation (KGTN), which comprises two primary modules: Global Intents Modeling with Graph Transformer, and Knowledge Contrastive Denoising under Intents. Specifically, Global Intents with Graph Transformer focuses on capturing learnable user intents, by incorporating global signals from user-item-relation-entity interactions with a well-designed graph transformer, and meanwhile learning intent-aware user/item representations. On the other hand, Knowledge Contrastive Denoising under Intents is dedicated to learning precise and robust representations. It leverages the intent-aware user/item representations to sample relevant knowledge, and subsequently proposes a local-global contrastive mechanism to enhance noise-irrelevant representation learning. Extensive experiments conducted on three benchmark datasets show the superior performance of our proposed method over the state-of-the-arts. And online A/B testing results on Alibaba large-scale industrial recommendation platform also indicate the real-scenario effectiveness of KGTN. The implementations are available at: https://github.com/CCIIPLab/KGTN.
1. Introduction
Knowledge graphs (KGs) have emerged as a promising approach to enhance the accuracy and interpretability of recommender systems in both academic and industry scenarios. By incorporating entities and relations, KGs provide a rich source of information for user/item representation learning, which not only captures the diverse relationships among items (such as the same item brand), but also allows for the interpretation of user preferences (such as attributing a user’s selection of a clothing to its fashionable style).
In an effort to effectively integrate the item-side KG information into recommendation, considerable research efforts have been devoted to Knowledge Enhanced Recommendation (aka. KGR). Early studies (zhang2016collaborative; huang2018improving; wang2018dkn) directly integrate knowledge graph embeddings with items to enhance their representations. Some subsequent studies (hu2018leveraging; shi2018heterogeneous; wang2019explainable) enrich the interactions via meta-paths that capture relevant connectivities between users and items with KG. They either select prominent paths over KG (sun2018recurrent), or represent the interactions with multi-hop paths from users to items (hu2018leveraging; wang2019explainable). Nevertheless, most of them heavily rely on manually designed meta-paths, which makes it hard to optimize in reality. As a result, later methods have embraced Graph Neural Networks (GNNs) (wang2021learning; wang2019kgat) to automatically aggregate high-order information over KG, which iteratively integrate multi-hop neighbors into representations and have demonstrated promising performance for recommendation. Most recently, there have been efforts to incorporate Contrastive Learning (CL) into KGR for addressing noisy knowledge and long-tail problems (yang2022knowledge; zou2022multi; wang2024exploring) via contrasting the user-item (collaborative part) and item-entity (knowledge part) graphs.
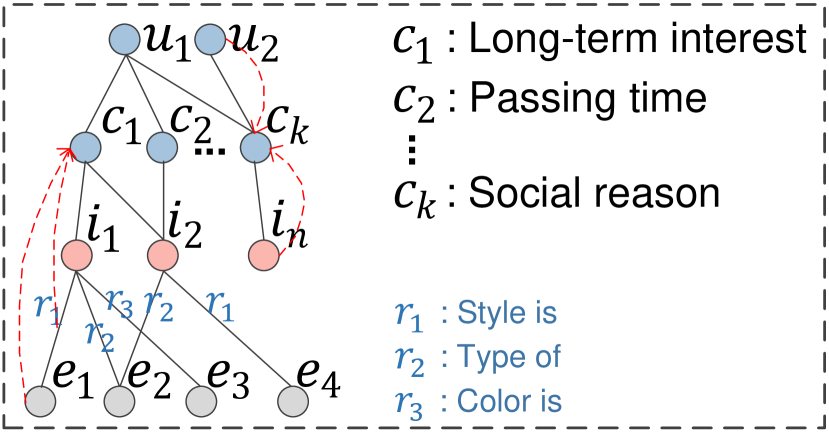
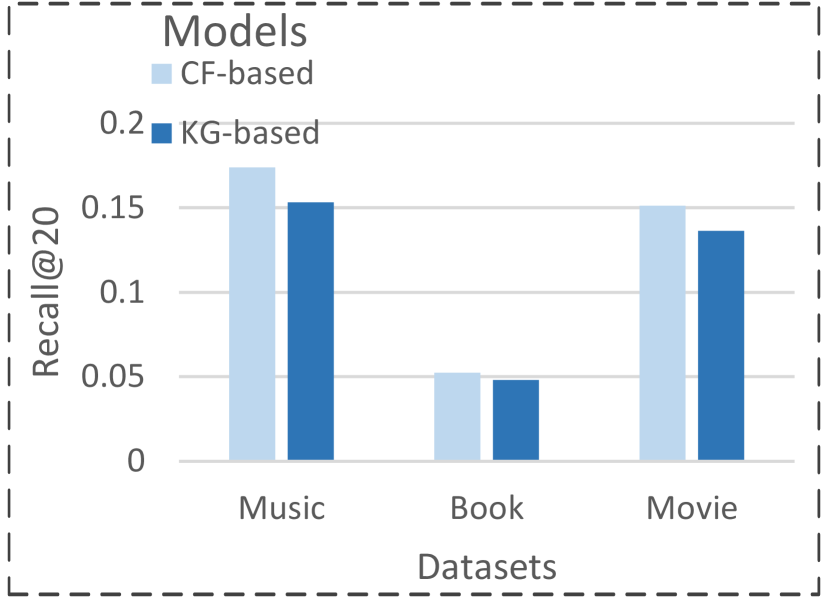
However, current KGR methods usually bring poor performance in large-scale industry scenarios, due to their commonly overlooking two crucial factors: 1) Users’ multiple intents underlying interaction behavior. For instance, as depicted in Figure 1(a), users may have diverse intentions when shopping in Alibaba E-commerce platform, such as long-term interest, passing time, or social reason, etc. 2) Redundant Knowledge information. In the context of user intents, some knowledge facts in the KG may be irrelevant noise (chen2022attentive), which can potentially disrupt the learning process of user/item representations. As shown in Figure 1(b), incorporating KGs may result in a worse model performance than the models without KG utilization (the details of comparison could refer to Section 4.2 ).
But still, it’s not trivial to model user intents in KGR, since user intents may be composed of multiple heterogeneous information, including items, relations, and entities. Previous multi-intent modeling methods usually define the intents as a linear combination of either interacted items (wang2020disentangled) or entire relation sets (wang2021learning), then update the intent representations through local aggregation in the user-intent-item heterogeneous graph. Nevertheless, such a multi-intent learning paradigm may not fully meet the requirements for KGR, as it neglects the global information in intent defining and learning. To illustrate this, we present an example in Figure 1(a). In this example, user may purchase the item for the intent of long-term interest, resulting in a focus on clothing style (e.g., whether it is fashionable), which means intent is associated with KG relation and entity ; while may buy the item for the intent of social reason (such as friend recommend), which means intent is associated with user and item .
In this paper, we focus on modeling user intents behind interaction behaviors with global collaborative (user-item) and knowledge (item-relation-entity) information, and exploiting these modeled intents to guide knowledge sampling, facilitating fine-grained and accurate user/item representation learning. We propose a novel model, KGTN, which comprises two essential components for solving the foregoing limitations: i) Global Intents Modeling with Graph Transformer. We predefine intent representations for user/item, then learn these intents with global information from collaborative and knowledge graphs. Specifically, it first merges knowledge information into items, then propose a novel graph transformer in the user-item graph to learn global intents and generate intent-aware user/item representations. ii) Knowledge Contrastive Denoising under Intents. KGTN first exploits the intent-aware user/item representations to guide the knowledge sampling, effectively pruning the irrelevant knowledge. Then a novel local-global contrastive mechanism is proposed here to denoise the user/item representations. Empirically, KGTN outperforms the state-of-the-art models on three benchmark datasets in offline testing, and achieves significant improvements in online A/B testing.
Our contributions of this work can be summarized as follows:
-
•
General Aspects: We emphasize the importance of intent modeling with global information, which plays a crucial role in fine-grained representation learning and knowledge denoising.
-
•
Novel Methodologies: We propose a novel model KGTN, which models user intents from global signals with a novel graph transformer; and denoises item representations with i) knowledge denoising under intents, and ii) local-global graph contrastive learning.
-
•
Multifaceted Experiments: We conduct extensive offline experiments on three benchmark datasets and online A/B testing on Alibaba recommendation platform. The results demonstrate the advantages of our KGTN in better representation learning.
2. Problem Formulation
In this section, we begin by formulating the structural data of CF (user-item interactions) and KG (item-relation-entity knowledge) in KGR, then present the problem statement.
Interaction Data. In a typical recommendation scenario, let be a set of users and a set of items. Let be the user-item interaction matrix, where indicates that user engaged with item , such as behaviors like clicking or purchasing; otherwise .
Knowledge Graph. A KG stores luxuriant real-world facts associated with items, encompassing item attributes or external commonsense knowledge, in the form of a heterogeneous graph (shi2018heterogeneous). Let be the KG, where , , represent the head, relation, tail of a knowledge triple, respectively; and denote the sets of entities and relations in . In many recommendation scenarios, an item corresponds to one entity . We hence establish a set of item-entity alignments , where indicates that item can be aligned with an entity in KG. With the alignments between items and KG entities, KG is able to profile items and offer complementary information to the interaction data.
Problem Statement. Given the user-item interaction matrix and the KG , KGR aims to learn a function that can predict how likely a user would adopt an item.
3. Methodology
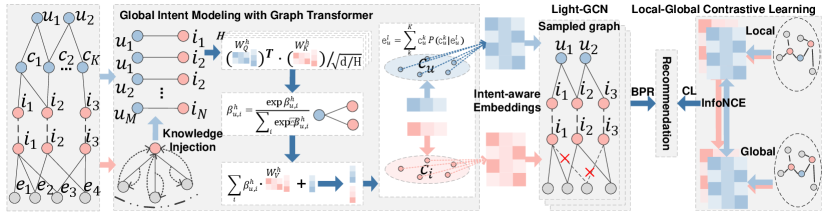
We now present the proposed Knowledge Enhanced Multi-intent Transformer Network for Recommendation (KGTN). KGTN aims at modeling user intents with global information and exploiting user intents to denoise KG for accurate and robust user/item representation learning. Figure 2 displays the framework of KGTN, which mainly consists of two key components: 1) Global Intent Modeling with graph transformer. Initially, KGTN defines a set of learnable global intents for users and items. It then models these intents and learns intent-aware user/item representations, via integrating global signals with a graph transformer in the user-item graph, where knowledge information has been encoded into items. 2) Knowledge Contrastive Denoising under intents. It first exploits the learned intent-aware user/item representations to sample intent-relevant knowledge, then designs a contrastive self-supervised task between the local aggregation and global aggregation features within the sampled graph to facilitate robust representation learning.
3.1. Global Intents Modeling with Graph Transformer
3.1.1. Intent Initialization with Global signals
When interacting with items, users often have diverse intents, such as preferences for specific clothing brands and styles, friends recommending, or passing time with randomly clicking (wang2021learning; ren2023disentangled). To capture these diverse intents, we assume different intents and from the user and item sides, respectively, where the intents on the item side can also be understood as the theme or context of the item, for example, a user who intends to purchase a fashionable dress may like clothes of “young” topic. Our predictive objective of user-item preference can be presented as follows:
| (1) |
Specifically, we define global intent prototypes and for user and item, respectively. With these predefined intent prototypes, we then are supposed to integrate them into user/item representations, and update them with related global signals.
3.1.2. Intent Modeling with graph transformer
Towards accurately modeling user intents with global information and learning intent-aware user/item representations, we perform an intent-aware information propagation with these learnable intents. Specifically, intent-aware user/item embeddings are acquired by an attentive sum of the intent prototypes, and user/item embeddings of each layer are updated by aggregating the global user/item/relation/entity signals.
Formally, we could get intent-aware user/item representations at the -th user/item embedding layer, by aggregating information across different learnable intent prototypes (including and ), using the following design:
| (2) | ||||
| (3) |
where the and denotes the importance score of for th user embeddings that has encodes the global signals. Similarly, the denotes the importance score of for th item embeddings.
As for the way of calculating the th user/item embeddings, we propose to adopt a two-step process to encode the global user/item/ relation/entity information in the whole heterogeneous graph. The first step is to merge the knowledge information (including both relation and entity) into item embeddings with a proposed relation-aware graph aggregation, making the item representation more comprehensive and informative. It injects the relational context into the embeddings of the neighboring entities, and weighting them with the knowledge rationale scores (It’s worth noting that items are a subset of knowledge entities), as follows:
| (4) | ||||
where denotes concat operation, denotes the set of neighboring entities.
Then the second step is to apply a novel graph transformer among user-item graph, which encodes global user/item/entity information into user/item representations. By doing so, the user/item representations of each layer are integrated with global signals, which would be exploited into intent modeling and representation updating, as follows:
| (5) |
where denotes the number of attention heads (indexed by ). is the binary indicator to decide whether to calculate the attentive relations between user and item . denotes the attention weight for user-item interaction pair w.r.t. the -th head representation space. denotes the query, key, the value embedding projection for the -th head, respectively.
By integrating global information into users/items, we could learn intent-aware user/item representations and update the learnable intents according to Equation 2.
3.2. Knowledge Contrastive Denoising under Intents
It is intuitive that noisy or irrelevant connections between entities in knowledge graphs can lead to suboptimal representation learning, which is opposite to original purpose of introducing the KG. To eliminate the noise effect in the KG and distill informative signals that benefit the recommendation task, we propose to highlight important connections consistent to user intents, while removing the irrelevant ones.
3.2.1. Knowledge Sampling under intents.
With the intent-aware user/item representations, we then try to denoise the item-entity graph by removing the irrelevant edges and nodes and sampling the important ones. We first exploit the intent-aware representations to calculate the importance score of knowledge triplets (i.e., the item-relation-entity pairs) same as Equation 4, then add the Gumbel noise (jang2017categorical) to the learned importance scores to improve the sampling robustness, as follows:
| (6) | ||||
where is a random variable sampled from a uniform distribution. Then it follows a top-k sampling strategy for generating the new item-entity graph that removes the irrelevant edges and nodes:
| (7) |
where is the sampled triples in item-entity graph, which would be used to replace the original graph structure in the following user/item representation learning.
3.2.2. Local-Global Knowledge Contrastive Learning
With the sampled item-entity graph, we then propose to iteratively update the intent-aware representations in it. And inspired by previous contrastive learning based methods that align the item representations from KG and CF to denoise, we further propose a local-global contrastive mechanism to improve the robustness of representation learning.
Specifically, we exploit the user-item graph and sampled item-entity graph to perform light information aggregation with intent-aware user/item representations as input , for acquiring a robust and effective intent-aware user/item representations, as follows:
| (8) |
where memorize the global signals, and we hence get final representations of user/item .
Besides the supervised user/item representation learning, we propose to perform a contrastive learning between the nodes embeddings that encode global signals and local signals, which is different from traditional cl-based methods that contrast the CF and KG parts. We perform information aggregation in the sampled graph with the initial user/item representations to acquire the local results , while utilizing the intent-aware user/item representations that contains global signals to acquire the global results . Then perform layer-wise contrastive learning between local and global results.
The local aggregation layer embeddings and global aggregation layer embeddings are made to be contrasted in a layer-wise way. We generate each positive pair using the embeddings of the same user (item) from the local view and each of the global view, and other nodes form the negative pairs. We could get the contrastive loss of users as follows:
| (9) |
where denotes the cosine similarity calculating, and denotes a temperature parameter. And similarly we could get the contrastive loss of item . By summing the two contrastive losses we hence have the total local-global contrastive loss .
3.3. Model Prediction
After learning intent-aware user/item representations with global signals and performing contrastive learning between local and global information, we have multi-layer intent-aware representations for user/item. By summing all the layers’ representations, we have the final user/item representations and predict their matching score through inner product, as follows:
| (10) |
By adopting a BPR loss (rendle2012bpr) to reconstruct the historical data, which encourages the prediction scores of a user’s historical items to be higher than the unobserved items, we acquire the supervised loss:
| (11) |
where is the training dataset consisting of the observed interactions and unobserved counterparts ; is the sigmoid function.
3.4. Multi-task Training
To combine the recommendation task with the self-supervised task, we optimize the whole model with a multi-task training strategy. We combine the local-global contrastive loss with BPR loss, and learn the model parameter via minimizing the following objective function:
| (12) |
where is the model parameter set, is a hyperparameter to determine the local-global contrastive loss ratio, and are two hyperparameters to control the contrastive loss and regularization term, respectively.
4. Experiment
| Book-Crossing | MovieLens-1M | Last.FM | ||
|---|---|---|---|---|
| User-item Interaction | # users | 17,860 | 6,036 | 1,872 |
| # items | 14,967 | 2,445 | 3,846 | |
| # interactions | 139,746 | 753,772 | 42,346 | |
| Knowledge Graph | # entities | 77,903 | 182,011 | 9,366 |
| # relations | 25 | 12 | 60 | |
| # triplets | 151,500 | 1,241,996 | 15,518 |
| Model | Book-Crossing | MovieLens-1M | Last.FM | |||
|---|---|---|---|---|---|---|
| AUC | F1 | AUC | F1 | AUC | F1 | |
| BPRMF | 0.6583 | 0.6117 | 0.8920 | 0.7921 | 0.7563 | 0.7010 |
| CKE | 0.6759 | 0.6235 | 0.9065 | 0.8024 | 0.7471 | 0.6740 |
| RippleNet | 0.7211 | 0.6472 | 0.9190 | 0.8422 | 0.7762 | 0.7025 |
| PER | 0.6048 | 0.5726 | 0.7124 | 0.6670 | 0.6414 | 0.6033 |
| KGCN | 0.6841 | 0.6313 | 0.9090 | 0.8366 | 0.8027 | 0.7086 |
| KGNN-LS | 0.6762 | 0.6314 | 0.9140 | 0.8410 | 0.8052 | 0.7224 |
| KGAT | 0.7314 | 0.6544 | 0.9140 | 0.8440 | 0.8293 | 0.7424 |
| CKAN | 0.7420 | 0.6671 | 0.9082 | 0.8410 | 0.8418 | 0.7592 |
| KGIN | 0.7273 | 0.6614 | 0.9190 | 0.8441 | 0.8486 | 0.7602 |
| CG-KGR | 0.7498 | 0.6689 | 0.9110 | 0.8359 | 0.8336 | 0.7433 |
| KGCL | 0.7453 | 0.6679 | 0.9184 | 0.8437 | 0.8455 | 0.7596 |
| MCCLK | 0.7625 | 0.6777 | 0.9252 | 0.8559 | 0.8663 | 0.7753 |
| KGTN | 0.7901* | 0.6876* | 0.9372* | 0.8642* | 0.8904* | 0.7996* |
| Model | Book-Crossing | MovieLens-1M | Last.FM | |||
|---|---|---|---|---|---|---|
| R@10 | R@20 | R@10 | R@20 | R@10 | R@20 | |
| BPRMF | 0.0334 | 0.0525 | 0.0939 | 0.1512 | 0.0923 | 0.1740 |
| CKE | 0.0421 | 0.0562 | 0.0867 | 0.1364 | 0.0780 | 0.1532 |
| RippleNet | 0.0507 | 0.0622 | 0.1082 | 0.1766 | 0.0942 | 0.1520 |
| PER | 0.0322 | 0.0481 | 0.0523 | 0.1204 | 0.0540 | 0.1167 |
| KGCN | 0.0496 | 0.0540 | 0.0965 | 0.1720 | 0.1416 | 0.1776 |
| KGNN-LS | 0.0422 | 0.0526 | 0.1286 | 0.1757 | 0.1312 | 0.1933 |
| KGAT | 0.0522 | 0.0670 | 0.1468 | 0.2296 | 0.1640 | 0.2313 |
| CKAN | 0.0462 | 0.0566 | 0.1511 | 0.2400 | 0.1412 | 0.2465 |
| KGIN | 0.0555 | 0.0699 | 0.1511 | 0.2404 | 0.1758 | 0.2487 |
| CG-KGR | 0.0612 | 0.0781 | 0.1621 | 0.2495 | 0.1578 | 0.2106 |
| KGCL | 0.0679 | 0.0845 | 0.1633 | 0.2499 | 0.1759 | 0.2471 |
| MCCLK | 0.0769 | 0.0936 | 0.1642 | 0.2503 | 0.1835 | 0.2598 |
| KGTN | 0.1060* | 0.1275* | 0.1841* | 0.2826* | 0.2104* | 0.3106* |
Aiming to answer the following research questions, we conduct both offline experiments and online A/B tests on three public datasets and Alibaba online platform:
-
•
RQ1: How does KGTN perform, compared to present models?
-
•
RQ2: How do the main components in KGTN affect its effectiveness?
-
•
RQ3: How do different hyper-parameter settings affect KGTN?
-
•
RQ4: How does KGTN perform with noisy injection?
-
•
RQ5: How does KGTN perform in a live system serving billions of users?
4.1. Experiment Settings
4.1.1. Dataset and Metrics
Three benchmark datasets are utilized to evaluate the effectiveness of KGTN: Last.FM 111https://grouplens.org/datasets/hetrec-2011/, Book-Crossing 222http://www2.informatik.uni-freiburg.de/~cziegler/BX/, and MovieLens-1M 333https://grouplens.org/datasets/movielens/1m/. The detailed statistics of them are summarized in Table 1, which vary in size and sparsity and make our experiments more convincing. As for the data pre-process, we first follow RippleNet (wang2018ripplenet) to transform their explicit feedback into implicit one, and randomly sample negative samples from his unwatched items with the size equal to his positive ones to construct the negative parts. As for the sub-KG construction, we follow RippleNet (wang2018ripplenet) and use Microsoft Satori444https://searchengineland.com/library/bing/bing-satori to construct it for MovieLens-1M, Book-Crossing, and Last.FM datasets. Each sub knowledge graph that follows the triple format is a subset of the whole KG with a confidence level greater than 0.9.
We evaluate our method in two experimental scenarios: (1) In click-through rate (CTR) prediction, we apply the trained model to predict each interaction in the test set. We adopt two widely used metrics (wang2018ripplenet; wang2019knowledge) and to evaluate CTR prediction. (2) In top- recommendation, we use the trained model to select items with the highest predicted click probability for each user in the test set, and we choose Recall@ to evaluate the recommended sets.
4.1.2. Baselines
To demonstrate the effectiveness of our proposed KGTN, we compare it with four types of KGR methods: CF-based methods (BPRMF (rendle2012bpr)), embedding-based method (CKE (zhang2016collaborative), RippleNet (wang2018ripplenet)), path-based method (PER (yu2014personalized)), GNN-based methods(KGCN (wang2019knowledge), KGNN-LS (wang2019knowledge-aware), KGAT (wang2019kgat), CKAN (wang2020ckan), KGIN (wang2021learning), CG-KGR (chen2022attentive)), CL-based methods (KGCL(yang2022knowledge), MCCLK (zou2022multi)).
4.1.3. Parameter Settings
We implement our KGTN and all baselines in Pytorch and carefully tune the key parameters. For a fair comparison, we fix the embedding size to 64 for all models, and the embedding parameters are initialized with the Xavier method (glorot2010understanding). We optimize our method with Adam (kingma2014adam) and set the batch size to 2048. A grid search is conducted to confirm the optimal settings, we tune the learning rate among and of regularization term among . Other hyper-parameter settings are provided in Table 1. The best settings for hyper-parameters in all comparison methods are researched by either empirical study or following the original papers.
4.2. Performance Comparison (RQ1)
We report the empirical results of all methods in Table 2 and Table 3. The improvements and statistical significance test are performed between KGTN and the strongest baselines (highlighted with underline). Analyzing such performance comparison, we have the following observations:
-
•
Our proposed KGTN achieves the best results. KGTN consistently outperforms all baselines across three datasets in terms of all measures, which achieves significant improvements over the strongest baselines w.r.t. AUC by 2.76%, 1.20%, and 2.41% in Book, Movie, and Music respectively, and demonstrates its effectiveness. We attribute such improvements to the following aspects: (1) By modeling user intents with global signals, KGTN is able to learn user/item representations in a more fine-grained and comprehensive manner; (2) The knowledge sampling strategy under intents could remove less relevant knowledge information for a robust representation learning; (3) The local-global contrastive learning improves the representation learning in a self-supervised manner, via contrasting the local and global information.
-
•
Incorporating KG not always benefits recommender system. Comparing CKE with BPRMF, leaving KG untapped limits the performance of BPRMF, which shows the effectiveness of KG information. While PER gets a worse performance than BPRMF, which means that only incorporating suitable knowledge could benefit the model. This fact stresses the importance of knowledge sampling and knowledge denoising.
-
•
GNN has a strong power of graph learning. Most of the GNN-based methods perform better, suggesting the importance of modeling long-range connectivity for graph representation learning. This fact inspires us to go beyond the local aggregation paradigm, and to consider the global signals.
-
•
Contrastive Learning is effective. The most recently proposed CL-based methods have the best performance, which shows the effectiveness of incorporating a self-supervised task for improving representation learning. It inspires us to design proper contrastive mechanisms to denoise the knowledge and improve the model performance.
4.3. Ablation Studies (RQ2)

As shown in Figure 3, here we examine the contributions of main components in our model to the final performance by comparing KGTN with the following three variants: 1) : In this variant, the knowledge sampling under intents module is removed. 2) : This variant removes local-global contrastive mechanism. 3) : This variant removes the multi-intent modeling, which means both global intent modeling and knowledge contrastive denoising do not exist in this variant. The results of two variants and KGTN are reported in Figure 3, from which we have the following observations:
-
•
Removing both knowledge sampling and local-global contrasting would degrade model performance, which shows their effectiveness in representation learning.
-
•
Ablating the multi-intent modeling brings the worst performance, which shows the importance of incorporating global signals and considering multiple intents.
4.4. Sensitivity Analysis (RQ3)
4.4.1. Impact of graph transformer depth.
| Book | Movie | Music | ||||
|---|---|---|---|---|---|---|
| Auc | F1 | Auc | F1 | Auc | F1 | |
| =1 | 0.7901 | 0.6876 | 0.9372 | 0.8642 | 0.8904 | 0.7996 |
| =2 | 0.7743 | 0.6783 | 0.9349 | 0.8623 | 0.8834 | 0.8068 |
| =3 | 0.7603 | 0.6709 | 0.9278 | 0.8481 | 0.8785 | 0.7951 |
To study the influence of graph transformer depth, we vary in range of {1, 2, 3} on book, movie, and music datasets. As shown in Table 4, KGTN performs best when . It convinces that one iteration is enough for integrating the global signals into user/item representations, which shows its low reliance on model depth.
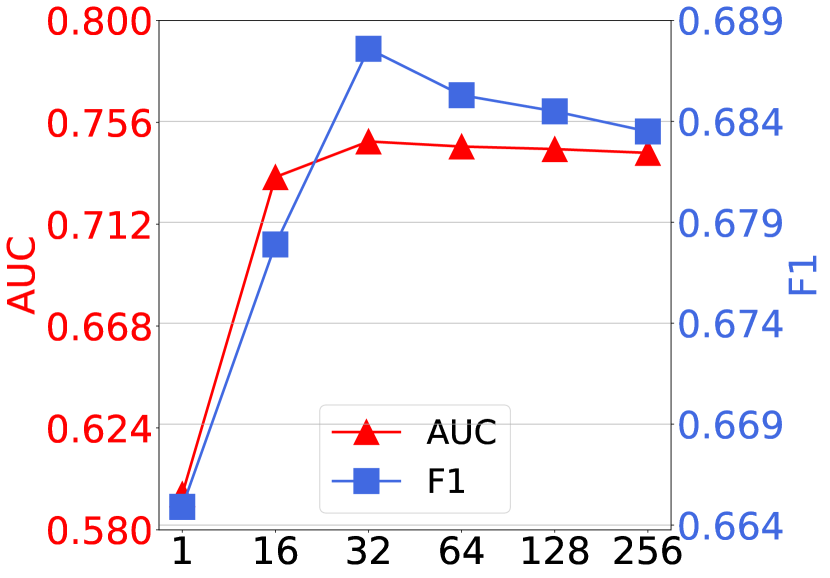
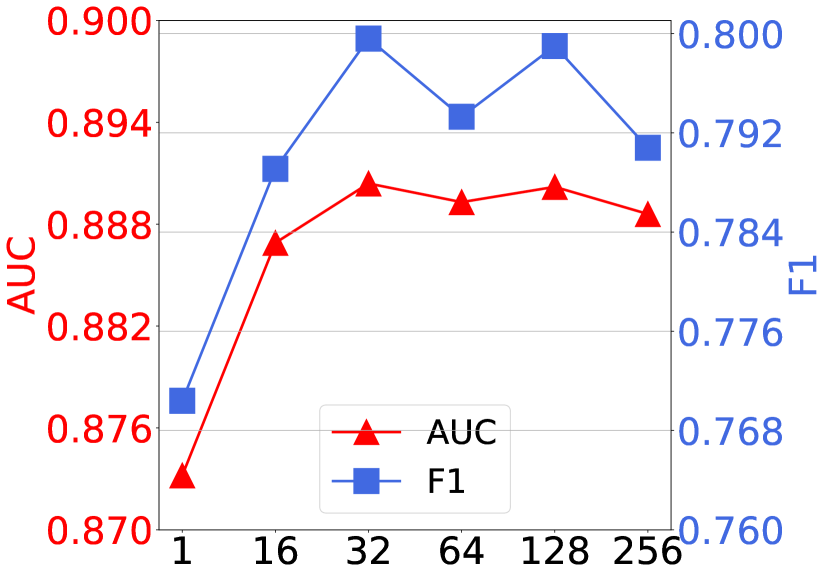
4.4.2. Impact of intent number .