Koopman-Based Learning of Infinitesimal Generators
without Operator Logarithm
Abstract
To retrieve transient transition information of unknown systems from discrete-time observations, the Koopman operator structure has gained significant attention in recent years, particularly for its ability to avoid time derivatives through the Koopman operator logarithm. However, the effectiveness of these logarithm-based methods has only been demonstrated within a restrictive function space. In this paper, we propose a logarithm-free technique for learning the infinitesimal generator without disrupting the Koopman operator learning framework.
Index Terms:
Unknown nonlinear systems, Koopman operators, infinitesimal generator, system identification, verification.I Introduction
Verification of dynamical system properties and achieving autonomy are two important directions for the future of industrial intelligence, with applications in numerous fields, including mathematical finance, automated vehicles, power systems, and other physical sciences.
Witnessing the success of problem-solving within the data paradigm, there has been a surge of interest in revealing the governing equations of continuous-time dynamical systems from time-series data to better understand the underlying physical laws [1, 2]. Additional interests in safety-critical industries include data-driven stability and safety analysis, prediction, and control. Techniques such as Lyapunov and barrier certificates have proven effective [3, 4, 5, 6, 7]. It is worth noting, however, that these practical concerns require information on the vector fields, the value functions that abstract system performance, and the corresponding Lie derivatives, all underpinned by an understanding of the infinitesimal generator [8, 9, 10, 11, 12]. Considering nonlinear effects, challenges therefore arise in the converse identification of infinitesimal system transitions based on discrete-time observations that represent cumulative trajectory behaviors.
Direct methods, such as the sparse identification of nonlinear dynamics (SINDy) algorithm [13], have been developed to identify state dynamics by relying on nonlinear parameter estimation [14, 15] and static linear regression techniques. However, the accurate approximation of time derivatives of the state may not be achieved due to challenges such as low sampling rates, noisy measurements, and short observation periods. Furthermore, the data cannot be reused in the proposed structure for constructing other value functions (e.g., Lyapunov or barrier functions) for stability, reachability, and safety analysis. This limitation extends to verifying their Lie derivatives along the trajectories, which is crucial for demonstrating the evolving trends of the phase portraits.
Comparatively, the operator logarithm-based Koopman generator learning structure [16, 17, 18, 19] does not require the estimation of time derivatives, enabling a data-driven estimation of Lie derivatives. This approach can potentially circumvent the need for high sampling rates and extended observation periods. Heuristically, researchers tend to represent the Koopman operator by an exponential form of its infinitesimal generator as , leading to the converse representation for any . However, representing Koopman operators in exponential form requires the boundedness of the generator. Additionally, the operator logarithm is a single-valued mapping only within a specific sector of the spectrum. Recent studies [20, 21] have investigated the sufficient and necessary conditions under which the Koopman-logarithm-based generator learning method can be uniquely identified. However, these conditions are less likely to be verifiable for unknown systems.
In this paper, we introduce a logarithm-free generator learning scheme that does not require knowledge of the spectrum properties and present preliminary results. This scheme will be compatible with the current advances in [7] for Koopman-based construction of maximal Lyapunov functions. It is important to note that the method in [7] assumes full knowledge of the equilibrium point and acknowledges that verification of the constructed Lyapunov function depends on information about the actual system transitions, which may diminish its predictive value in stability analysis.
The rest of the paper is organized as follows. Preliminaries are covered in Section II. The formal finite-horizon approximation of the generator using Koopman operators is presented in Section III. The data-driven algorithm is discussed in Section IV. Finally, case studies are presented in Section V.
Due to page limitations and to enhance readability, this paper presents only the primary results of the proposed method. Detailed proofs are omitted and will be published elsewhere.
Notation: We denote by the Euclidean space of dimension , and by the set of real numbers. For and , we denote the ball of radius centered at by , where is the Euclidean norm. For a closed set and , we denote the distance from to by and -neighborhood of by . For a set , denotes its closure, denotes its interior and denotes its boundary. For finite-dimensional matrices, we use the Frobenius norm as the metric. Let be the set of continuous functions with domain . We denote the set of times continuously differentiable functions by .
II Preliminaries
II-A Dynamical Systems
Given a pre-compact state space , we consider a continuous-time nonlinear dynamical system of the form
| (1) |
where denotes the initial condition, and the vector field is assumed to be locally Lipschitz continuous. We denote by the forward flow, also known as the solution map.
The evolution of observable functions of system (1) restricted to is governed by the family of Koopman operators, defined by
| (2) |
for each , where is the composition operator. By the properties of the flow map, it can be easily verified that forms a semigroup, with its (infinitesimal) generator defined by
| (3) |
Within the space of continuous observable functions, the limit in Eq. (3) exists on the subspace of all continuously differentiable functions, indicating that . In this case, we can verify that the generator of Koopman operators is such that
Note that the finite-difference method [22, 23, 24] indirectly approximates the generator by setting a small terminal time without taking the limit on the r.h.s. of (3). Through this approximation scheme of the time derivative, it can be anticipated that the precision heavily depends on the size of that terminal time.
II-B Representation of Koopman Operators
If is a bounded linear operator that generates , then for each in the uniform (operator) topology. However, many of the differential operators that occur in mathematical physics are unbounded. We revisit some concepts to show how to interpret in terms of the possibly unbounded generator on an exponential scale.
Definition II.1 (Resolvents)
The resolvent set of is defined as . For any , the resolvent operator is defined as
| (4) |
which is a bounded linear operator [25, Chap. I, Theorem 4.3].
We further define the Yosida approximation of as
| (5) |
Note that is a family of bounded linear operators, and is well-defined for each .
Definition II.2 (Strong convergence)
Let be a Banach space. Let and , for each , be linear operators. Then, the is said to converge to strongly, denoted by , if for each . We also write .
Theorem II.3
[25, Chap. I, Theorem 5.5] for all on the uniform topology.
III The Formal Approximation of the Infinitesimal Generators
Section II presents preliminary results on representing Koopman operators using the asymptotic approximation of as approaches infinity. In this section, we aim to find the correct converse representation of based on . The ultimate goal is to leverage the Koopman learning structure to learn the generator.
Note that it is intuitive to take the operator logarithm such that when is bounded. The spectrum’s sector should be confined to make the logarithm a single-valued mapping [20, 21]. However, for an unbounded , there is no direct connection. In this section, we establish the connection for how the unbounded can be properly approximated based on .
III-A Asymptotic Approximations of Generators
Let be endowed with the uniform norm . Suppose that is a contraction semigroup where
for all . Then, , and by [25, Lemma 1.3.3], we have that converges strongly to . Specifically, when working on the subspace, the convergence rate is given by .
To address more general cases, we first present the following facts.
Proposition III.1
For system (1), there exist constants and such that for all . In addition, for any , the family is a semigroup with generator .
Intuitively, represents the uniform scaling of the magnitude of the Koopman operator, while indicates the dominant exponential growth or decay rate of the flow on . The above properties provide us with a tool to convert the dominant exponential growth or decay rate of the flow on by introducing an extra term to the original generator. Specifically, the transformation allows us to work in a topology (by shifting the direction of flows and uniformly compressing by ) that is equivalent to the uniform topology of continuous functions, where the semigroup is a contraction. The convergence of for and its reciprocal convergence rate can similarly be demonstrated in this new topology.
III-B Representation of Resolvent Operators
Motivated by representing by and the Yosida approximation for on , we establish a connection between and .
Proposition III.2
Let on be defined by
| (6) |
Then, for all ,
-
1.
for all ;
-
2.
for all .
Restricted to the subspace, to use the approximation in Section III-A, we can replace with .
Corollary III.3
For each ,
| (7) |
and on .
III-C Finite Time-Horizon Approximation
The current form of the improper integral in (7) cannot be directly used for a data-driven approximation. We need to further derive an approximation approach based on finite-horizon observable data. Below, we present a direct truncation modification based on (7).
Definition III.4
For any and , we define as
| (8) |
It can be shown that for any , the truncation in Definition III.4 results in an error term that is uniformly bounded for each observable function , with the dominant term being . This indicates that for any arbitrarily large , this truncation does not significantly affect the accuracy compared to the procedure from to .
For any fixed , we can therefore use
| (9) |
to approximate within a small time-horizon. We illustrate this approximation with the following simple example.
Example III.5
Consider the simple dynamical system and the observable function for any . Then, analytically, and . We test the validity of using Eq. (9). Note that, for sufficiently large , we have
and
With high-accuracy evaluation of the integral, we can achieve a reasonably good approximation.
IV Data-Driven Algorithm
We continue by considering a data-driven algorithm to learn , which indirectly approximate as demonstrated in Section III.
The idea is to modify the conventional Koopman operator learning scheme [26, 16, 7], which involves learning linear operators using a finite-dimensional dictionary of basis functions and representing the image function as a linear combination of the dictionary functions. To be more specific, obtaining a fully discretized version of the bounded linear operator based on the training data typically relies on the selection of a discrete dictionary of continuously differentiable observable test functions, denoted by
| (10) |
Then, the followings should hold:
1) Let be the eigenvalues and eigenvectors of . Let be the eigenvalues and eigenfunctions of . Then, for each ,
| (11) |
2) For any such that for some column vector , we have that
| (12) |
In this section, we modify the existing Koopman learning technique to obtain .
IV-A Generating Training Data
For any fixed , given a dictionary of the form (10), for each and each , we consider as the features and as the labels. To compute the integral, we employ numerical quadrature techniques for approximation. This approach inevitably requires discrete-time observations (snapshots), the number of which is denoted by , within the interval of the flow map .
To streamline the evaluation process for numerical examples, drawing inspiration from [27], for any and , we can assess both the trajectory and the integral, i.e. the pair , by numerically solving the following augmented ODE system
| (13) |
We summarize the algorithm for generating training data for one time period as in Algorithm 1.
IV-B Extended Dynamic Mode Decomposition Algorithm
After obtaining the training data using Algorithm 1, we can find by . The is given in closed-form as , where is the pseudo inverse. Similar to Extended Dynamic Mode Decomposition (EDMD) [26] for learning Koopman operators, the approximations (11) and (12) can be guaranteed. In addition, by the universal approximation theorem, all of the function approximations from above should have uniform convergence to the actual quantities.
It is worth noting that operator learning frameworks, such as autoencoders, which utilize neural networks (NN) as dictionary functions, can reduce human bias in the selection of these functions [5]. Incorporating the proposed learning scheme with NN falls outside the scope of this paper but will be pursued in future work.
Remark IV.1 (The Logarithm Method)
We compare the aforementioned learning approach of to those obtained using the benchmark approach as described in [16]. Briefly speaking, at a given , that method first obtains a matrix such that , where Let be the eigenvalues and eigenvectors of . Let be the eigenvalues and eigenfunctions of . Similar to and (12), for each , we have and for .
However, even when can be represented by , we cannot guarantee that , not to mention the case where the above logarithm representation does not hold. Denoting and , then it is clear that . The (possibly complex-valued) rotation matrix establishes the connection between finite-dimensional eigenfunctions and dictionary functions through data-fitting, ensuring that any linear combination within can be equivalently represented using with a cancellation of the imaginary parts.
This imaginary-part cancellation effect does not generally hold when applying the matrix logarithm. Suppose the imaginary parts account for a significantly large value, the mutual representation of and does not match in the logarithmic scale. An exception holds unless the chosen dictionary is inherently rotation-free with respect to the true eigenfunctions [20], or there is direct access to the data for allowing for direct training of the matrix. However, such conditions contravene our objective of leveraging Koopman data to conversely find the generator. In comparison, the approach in this paper presents an elegant method for approximating regardless of its boundedness. This enables the direct learning of without computing the logarithm, thereby avoiding the potential appearance of imaginary parts caused by basis rotation.
V Case Study
We provide a numerical example to demonstrate the effectiveness of the proposed approach. The research code can be found at https://github.com/Yiming-Meng/Log-Free-Learning-of-Koopman-Generators.
Consider the Van der Pol oscillator
with . We assume the system dynamics are unknown to us, and our information is limited to the system dimension, , and observations of sampled trajectories. To generate training data using Algorithm 1, for simplicity of illustration, we select and obtain a total of uniformly spaced samples in . We choose the dictionary as
| (14) |
where for each and . We also set and . The discrete form can be obtained according to Section IV-B. We apply the learned to identify the system vector fields, and construct a local Lyapunov function for the unknown system.
V-A System Identification
The actual vector field is
As we can analytically establish that and , we use the approximation to conversely obtain .
Note that and , where each for is a column unit vector with all components being except for the -th component, which is . To apply , we have that and .
In other words, we approximate and (and hence and ) using a linear combination of functions within . The weights for these approximations are given by and , respectively. We report the corresponding results in Table I and II.
We compare the aforementioned results with those obtained using the benchmark approach as described in [16] with the same and . As described in Remark IV.1, can be obtained such that and . Then, we have the approximation, as claimed by [16], and w.r.t. . According to [16, Section VI.A], we set to avoid the multi-valued matrix logarithm. We report the weights obtained by taking the real parts of and in Table III and IV, respectively. Multiple orders of magnitude in accuracy have been established using the proposed method.
It is worth noting that, unlike the experiment in [16] where , we deliberately choose different numbers for and , leading to non-negligible imaginary parts after taking the matrix logarithm of . The imaginary parts of the learned weights using the Koopman-logarithm approach are reported in Table V and VI. The presence of non-negligible imaginary parts indicates that the underlying system is sensitive to the selection of dictionary functions when employing the Koopman-logarithm approach, an effect that is significant and cannot be overlooked when aiming to minimize human intervention in identifying unknown systems in practice. Furthermore, the original experiment in [16] used samples for a data fitting, and when is reduced to , the quality of the operator learning deteriorates.
V-B Stability Prediction for the Reversed Dynamics
Observing the identified system dynamics, we anticipate that the time-reversed system is (locally) asymptotically stable w.r.t. the origin. We use the learned to construct polynomial Lyapunov functions based on the Lyapunov equation , where the sign on the r.h.s. is reversed due to the dynamics being reversed. To use and the library functions from , we define the weights as and seek a such that , with the objective of minimizing . Ignoring the small terms of the magnitude , the constructed Lyapunov function is given by
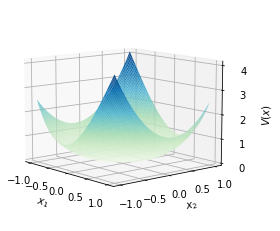
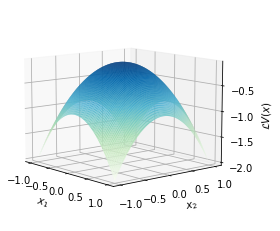
Additionally, is approximated by , with the maximal value observed at , which indicates that stability predition using the data-driven Lyapunov function is verified to be valid. This indicates that the stability prediction, as inferred using the data-driven Lyapunov function, is verified to be valid. The visualization can be found in Fig 1.
Remark V.1
The idea illustrated above can be expanded to cover a larger region of interest. Specifically, a Zubov equation, instead of a Lyapunov equation, can be solved within the Koopman learning framework using the same dataset [7] as proposed in Algorithm 1. The solution obtained can potentially serve as a Lyapunov function. Since it cannot guarantee the properties of the learned function’s derivatives, to confirm it as a true Lyapunov function, the data can be reused as in Algorithm 1 to verify its Lie derivative.
VI Conclusion
In this paper, we propose a logarithm-free Koopman operator-based learning framework for the infinitesimal generator, demonstrating both theoretical and numerical improvements over the method proposed in [16]. In particular, for more general cases where the generator is unbounded and, consequently, the logarithm of the Koopman operator cannot be used for representation, we draw upon the rich literature to propose an approximation (Eq. (9)) based on Yosida’s approximation. A convergence result, along with the convergence rate, is proved in this paper to guide users in tuning the parameters. A numerical example with application in system identification is provided in comparison with the experiment in [16] demonstrating the learning accuracy. Unlike the experiment in [16], where learning accuracy is sensitive to the choice of dictionary functions, the method presented in this paper shows significant improvement in this regard. In applications where automatic computational approaches surpass human computability, such as in constructing Lyapunov-like functions using the Lie derivative, the proposed logarithm-free method holds more promise. We will pursue future efforts to provide more analysis on the sampling rate, numerical simulations, and real-world applications using real data.
References
- [1] J. Sjöberg, Q. Zhang, L. Ljung, A. Benveniste, B. Delyon, P.-Y. Glorennec, H. Hjalmarsson, and A. Juditsky, “Nonlinear black-box modeling in system identification: a unified overview,” Automatica, vol. 31, no. 12, pp. 1691–1724, 1995.
- [2] R. Haber and H. Unbehauen, “Structure identification of nonlinear dynamic systems—a survey on input/output approaches,” Automatica, vol. 26, no. 4, pp. 651–677, 1990.
- [3] A. Mauroy and I. Mezić, “A spectral operator-theoretic framework for global stability,” in 52nd IEEE Conference on Decision and Control, pp. 5234–5239, IEEE, 2013.
- [4] A. Mauroy and I. Mezić, “Global stability analysis using the eigenfunctions of the Koopman operator,” IEEE Transactions on Automatic Control, vol. 61, no. 11, pp. 3356–3369, 2016.
- [5] S. A. Deka, A. M. Valle, and C. J. Tomlin, “Koopman-based neural lyapunov functions for general attractors,” in 61st Conference on Decision and Control (CDC), pp. 5123–5128, IEEE, 2022.
- [6] J. L. Proctor, S. L. Brunton, and J. N. Kutz, “Dynamic mode decomposition with control,” SIAM Journal on Applied Dynamical Systems, vol. 15, no. 1, pp. 142–161, 2016.
- [7] Y. Meng, R. Zhou, and J. Liu, “Learning regions of attraction in unknown dynamical systems via Zubov-Koopman lifting: Regularities and convergence,” arXiv preprint arXiv:2311.15119, 2023.
- [8] I. M. Mitchell, A. M. Bayen, and C. J. Tomlin, “A time-dependent Hamilton-Jacobi formulation of reachable sets for continuous dynamic games,” IEEE Transactions on Automatic Control, vol. 50, no. 7, pp. 947–957, 2005.
- [9] Y. Lin, E. D. Sontag, and Y. Wang, “A smooth converse lyapunov theorem for robust stability,” SIAM Journal on Control and Optimization, vol. 34, no. 1, pp. 124–160, 1996.
- [10] J. Liu, Y. Meng, M. Fitzsimmons, and R. Zhou, “Physics-informed neural network lyapunov functions: Pde characterization, learning, and verification,” arXiv preprint arXiv:2312.09131, 2023.
- [11] Y. Meng, Y. Li, M. Fitzsimmons, and J. Liu, “Smooth converse Lyapunov-barrier theorems for asymptotic stability with safety constraints and reach-avoid-stay specifications,” Automatica, vol. 144, p. 110478, 2022.
- [12] Y. Meng and J. Liu, “Lyapunov-barrier characterization of robust reach–avoid–stay specifications for hybrid systems,” Nonlinear Analysis: Hybrid Systems, vol. 49, p. 101340, 2023.
- [13] S. L. Brunton, J. L. Proctor, and J. N. Kutz, “Discovering governing equations from data by sparse identification of nonlinear dynamical systems,” Proceedings of the National Academy of Sciences, vol. 113, no. 15, pp. 3932–3937, 2016.
- [14] J. C. Nash and M. Walker-Smith, “Nonlinear parameter estimation,” An integrated system on BASIC. NY, Basel, vol. 493, 1987.
- [15] J. M. Varah, “A spline least squares method for numerical parameter estimation in differential equations,” SIAM Journal on Scientific and Statistical Computing, vol. 3, no. 1, pp. 28–46, 1982.
- [16] A. Mauroy and J. Goncalves, “Koopman-based lifting techniques for nonlinear systems identification,” IEEE Transactions on Automatic Control, vol. 65, no. 6, pp. 2550–2565, 2019.
- [17] S. Klus, F. Nüske, S. Peitz, J.-H. Niemann, C. Clementi, and C. Schütte, “Data-driven approximation of the Koopman generator: Model reduction, system identification, and control,” Physica D: Nonlinear Phenomena, vol. 406, p. 132416, 2020.
- [18] Z. Drmač, I. Mezić, and R. Mohr, “Identification of nonlinear systems using the infinitesimal generator of the Koopman semigroup—a numerical implementation of the Mauroy–Goncalves method,” Mathematics, vol. 9, no. 17, p. 2075, 2021.
- [19] M. Black and D. Panagou, “Safe control design for unknown nonlinear systems with koopman-based fixed-time identification,” IFAC-PapersOnLine, vol. 56, no. 2, pp. 11369–11376, 2023.
- [20] Z. Zeng, Z. Yue, A. Mauroy, J. Gonçalves, and Y. Yuan, “A sampling theorem for exact identification of continuous-time nonlinear dynamical systems,” in 2022 IEEE 61st Conference on Decision and Control (CDC), pp. 6686–6692, IEEE, 2022.
- [21] Z. Zeng and Y. Yuan, “A generalized nyquist-shannon sampling theorem using the koopman operator,” arXiv preprint, 2023.
- [22] J. J. Bramburger and G. Fantuzzi, “Auxiliary functions as Koopman observables: Data-driven analysis of dynamical systems via polynomial optimization,” Journal of Nonlinear Science, vol. 34, no. 1, p. 8, 2024.
- [23] A. Nejati, A. Lavaei, S. Soudjani, and M. Zamani, “Data-driven estimation of infinitesimal generators of stochastic systems,” IFAC-PapersOnLine, vol. 54, no. 5, pp. 277–282, 2021.
- [24] C. Wang, Y. Meng, S. L. Smith, and J. Liu, “Data-driven learning of safety-critical control with stochastic control barrier functions,” in 61st Conference on Decision and Control (CDC), pp. 5309–5315, IEEE, 2022.
- [25] A. Pazy, Semigroups of Linear Operators and Applications to Partial Differential Equations, vol. 44. Springer Science & Business Media, 2012.
- [26] M. O. Williams, I. G. Kevrekidis, and C. W. Rowley, “A data–driven approximation of the Koopman operator: Extending dynamic mode decomposition,” Journal of Nonlinear Science, vol. 25, pp. 1307–1346, 2015.
- [27] W. Kang, K. Sun, and L. Xu, “Data-driven computational methods for the domain of attraction and Zubov’s equation,” IEEE Transactions on Automatic Control, 2023.