11email: voutharoja.bhanu06@gmail.com, {lizhen.qu, fatemeh.shiri}@monash.edu
Language Independent Neuro-Symbolic Semantic Parsing for Form Understanding
Abstract
Recent works on form understanding mostly employ multimodal transformers or large-scale pre-trained language models. These models need ample data for pre-training. In contrast, humans can usually identify key-value pairings from a form only by looking at layouts, even if they don’t comprehend the language used. No prior research has been conducted to investigate how helpful layout information alone is for form understanding. Hence, we propose a unique entity-relation graph parsing method for scanned forms called LaGNN, a language-independent Graph Neural Network model. Our model parses a form into a word-relation graph in order to identify entities and relations jointly and reduce the time complexity of inference. This graph is then transformed by deterministic rules into a fully connected entity-relation graph. Our model simply takes into account relative spacing between bounding boxes from layout information to facilitate easy transfer across languages. To further improve the performance of LaGNN, and achieve isomorphism between entity-relation graphs and word-relation graphs, we use integer linear programming (ILP) based inference. Code is publicly available at https://github.com/Bhanu068/LAGNN.
Keywords:
Document Layout Analysis Graph Neural Network Language Independent Deep Learning1 Introduction
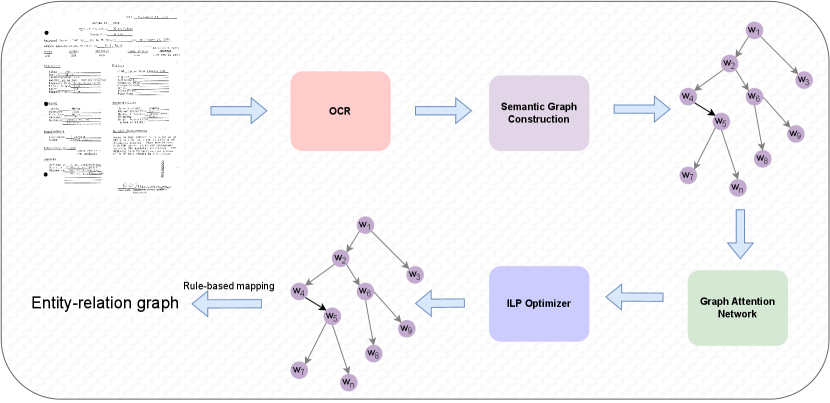
Despite the growing popularity of e-forms, paper forms are still widely used to collect data by various types of organizations, from government agencies to private companies. A large body of collected data, especially historical data, is still available only in paper forms or scanned document images. To digitize such data, we introduce the task of entity-relation graph parsing for form understanding, which maps the document image of a form to a structured entity-relation graph. As a result, users can explore and analyze semantic information in such entity-relation graphs without any need to read the original document images.
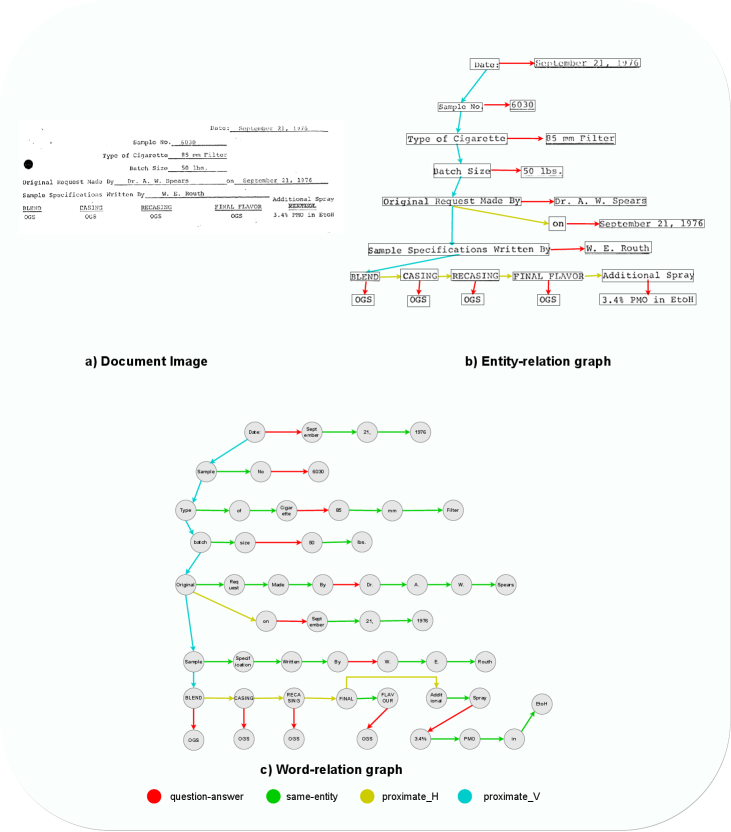
Entity relation graphs are introduced for forms in FUNSD [12], which are annotated on a small sample of scanned forms. Herein, an entity is a group of words representing a semantic and spatial standpoint, such as question and answer, and a relation is a directed edge between two entities, as illustrated in Fig. 1. Such graphs are layout-agnostic. However, such graphs are not always fully connected via those relations due to neglecting the layout information between entities. In contrast, form designers often put semantically relevant entities close to each other in a form, hence spatial proximateness is informative for semantic relevance between entities or relations.
Prior models on form understanding tackle at least two subtasks in the sequel, which are entity recognition and relation extraction [6]. The former identifies a group of words belonging to the same semantic entity and the label of the entity, while the latter predicts the relation between any two entities. Such a pipeline may easily lead to error propagation because the models for relation extraction are not able to fix errors of entity recognition, not to mention the exploitation of proximateness between relations to build a fully connected entity-relation graph. However, entity-relation graph parsing by tacking both subtasks jointly is challenging because the time complexity of inference is quadratic to the number of tokens in a form, as shown in Sec. 3.
The use of large-scale pre-trained language models or multimodal transformers dominates in the recent studies on form understanding [26, 11, 6]. However, such models require large-scale data for pre-training, especially for multilingual document understanding. For example, LanguageXLM needs 30 million documents in 53 languages for pre-training [6]. Adding any new languages or new document collections often requires re-training of the models. In contrast, humans are often capable of recognizing key-value pairs from a form by only using layout information, even though they may not understand the language in the form. However, no prior studies explore to what degree layout information is useful for language-agnostic form understanding.
In this work, we propose a novel language-agnostic Graph Neural Networks (GNN) model for entity-relation graph parsing of scanned forms, coined LaGNN. To facilitate navigation in an entity-relation graph and retain proximateness of entities and relations after parsing, we add two types of relations for proximateness to entity-relation graphs: i) vertically proximate, coined proximate_(V), and ii) horizontally proximate, coined proximate_(H). To mitigate error propagation in pipeline approaches, we introduce a word-relation graph representation so that our model parses a document image into such a graph, which is subsequently converted to a fully connected entity-relation graph by deterministic rules. This simplification enables linear inference time. To support language-agnostic form understanding without using pre-trained language models, our model only considers features extracted from layout information. Furthermore, we apply integer linear programming (ILP) based inference to ensure that the generated graphs satisfy the properties of entity-relation graphs.
The main contributions of this paper are summarised as follows:
-
•
We propose a language-agnostic GNN model, coined LaGNN, for parsing scanned forms into a word-relation graph, which is isomorphic to a fully connected entity-relation graph with two new relations based on proximateness.
-
•
We propose a designated ILP-based inference method to ensure that i) the generated graphs are fully connected, and ii) relations in a graph are logically coherent.
-
•
The extensive experimental results show that our model significantly outperforms the competitive baselines in terms of all metrics in the monolingual settings and the averaged metrics in the zero-shot multilingual settings.
2 Related Work
Deep learning techniques have dominated document interpretation tasks [28, 1, 21] in the past decade. Grid-based techniques [13, 7, 17] were suggested for representing 2D documents. In these techniques, first character-level or word-level embeddings are used to represent text, and later CNNs are used to categorize them into different field types.
Self-supervised pre-training has had a lot of success lately. Recent work on structured document pre-training [26, 25, 6, 23, 15] has pushed the boundaries, drawing inspiration from the success of pre-trained language models on multiple downstream NLP tasks. The BERT architecture was altered by LayoutLM [26] by including 2D spatial coordinate embeddings. By considering the visual aspects as independent tokens, LayoutLMv2 [25] outperformed LayoutLM. To optimize the use of unlabeled document data, extra pre-training activities were investigated. In contrast to StructuralLM [15], who suggested cell-level 2D position embeddings and the accompanying pre-training target, SelfDoc [16] developed the contextualization across a block of text. To unify many issues surrounding natural language, TILT [19] suggests a pre-trained layout-aware multimodal encoder-decoder Transformer. The useful coarse-grained information like natural units and salient visual regions are ignored by the current layout-aware multimodal Transformers. In an effort to include coarse-grained information into pre-trained layout-aware multimodal Transformers, [24] argues that both fine-grained and coarse-grained multimodal information is useful for document understanding and proposes a multi-grained and multimodal transformer, ERNIE-mmLayout.
However, the preceding Structured Document Understanding (SDU) methods mostly rely on a single language, which is usually English, making them rather constrained in terms of multilingual application scenarios. LayoutXLM [6] was the first to incorporate a multilingual text model InfoXLM [3] initialization to LayoutLMv2 framework for multilingual pre-training with structured documents. However, a laborious procedure of multilingual data collecting, cleansing, and pre-training was necessary. To address this issue, LiLT [23], a straightforward yet powerful language-independent layout Transformer for monolingual/multilingual structured document interpretation was proposed. LiLT employs BiACM to achieve language-independent cross-modality interaction and an efficient asynchronous optimization technique for both textual and non-textual flows in pre-training using two pre-training objectives.
Current state-of-the-art approaches to these document understanding challenges have made use of the power of large pre-trained language models, focusing on language more than the visual and geometrical information in a text, and end up using hundreds of millions of parameters in the process [9]. Additionally, the majority of these models are trained using a massive transformer pipeline, which necessitates the pre-training of enormous amounts of data. In this sense, models that are independent of language were proposed [5, 20]. [5] concentrated on identifying entity relationships in forms using a straightforward CNN as a text line detector, and then they find key-value relationship pairs using heuristics based on the model’s scores for each connection candidate. Later, [20] reformulated the issue as a semantic segmentation (pixel labelling) task with a focus on extracting the form structure. They employed a U-Net based architecture pipeline, which was quite effective at concurrently predicting all levels of the document hierarchy. For form understanding, [2] employed GCNs to solve the entity grouping, labelling, and entity linking tasks. They did not utilize any visual features and instead used word embeddings and bounding box information as the main node features, and k-nearest neighbours to obtain edge features. The FUDGE [4] framework was then created as an extension of [5] to help with form understanding. It proposes relationship pairings using the same detection CNN as in [5], considerably improving the state-of-the-art on both the semantic entity labeling and entity linking tasks. Then, because predicting key-value connection pairs and the semantic labels for text entities are two tasks that are closely associated, a GCN was implemented using plugged visual features from the CNN. Inspire by FUDGE [4], a task-agnostic GNN-based framework called Doc2Graph [9] that adopts a similar joint prediction of both the tasks, semantic entity labeling and entity linking utilizing a node classification and edge classification module, respectively, without relying on heuristics to establish associations between words or entities was developed. To take advantage of the relative location of document objects via polar coordinates, a novel GNN architecture pipeline with node and edge aggregation functions is implemented.
3 Methodology
Entity-relation graph parsing for form understanding is concerned with mapping a document image to an entity-relation graph. To reduce inference time complexity, we propose to map a scanned form image to a novel word-relation graph, which is isomorphic to the corresponding entity-relation graph. Then entity-relation graphs can be directly constructed from word-relation graphs using deterministic rules.
Formally, an entity-relation graph is denoted by , composed of a set of entities and a set of relations between entities . Each entity is a word sequence labeled by a type , and each word is associated with a bounding box [12]. The set includes question, answer, and section. A relation is denoted by a directed edge from an entity to another entity labeled by , where includes the following relations.
-
•
Question-answer, denoted by a directed edge from a question to the corresponding answer.
-
•
Header-question, denoted by a directed edge from a section and a question belonging to that section.
-
•
Proximate_(V), denoted by an undirected edge between an entity A and the first entity B in the first line below it, which is not an answer and there is no relation between A and B or the parent of B.
-
•
Proximate_(H), denoted by an undirected edge between an entity A and the closest entity labeled as question or header to its right in the same line.
In contrast, a word-relation graph depicted in Fig. 2 comprises a set of nodes consisting of only the words in a document, and a set of relations between those words. A relation in is a tuple from a word to another word labeled by , where the edge label set augments by adding word-level relations. More details are provided in Sec.3.1
As illustrated in Fig.1, to parse document images into word-relation graphs, we first apply an off-the-shelf Optical Character Recogniser docTR [18] to map a document image into a set of cells, whereby each cell is a sequence of bounding boxes and each bounding box corresponds to a word. Then we apply our model LaGNN to estimate the probabilities of relations between each possible pair of words largely based on relative distances between bounding boxes. To construct a word-relation graph, we apply a designated ILP inference algorithm to assign relation labels to word pairs jointly.
3.1 Word-Relation Graph
A naive solution that directly parses a document image to an entity-relation graph results in a time complexity quadratic to the number of words in a document in the worst case. First, a model needs to identify if a word belongs to the same group of its adjacent words, followed by predicting relations between any pairs of word groups. In the worst case, if each entity comprises only one word, the time complexity is because the number of edge predictions is , where is the number of words in a document. In fact, the average word lengths of entities in FUNSD [12] is 3.4, the actual inference time complexity is not far from the worst case. The cost is estimated without considering the one for estimating word groups for each entity.
We map entity-relation graphs to word-relation graphs so that entity-relation graph parsing becomes the task of predicting relations between words in a word-relation graph. To eliminate the task of entity recognition, we introduce an undirected relation same-entity to link two adjacent words in the same word sequence of an entity. For a relation between two entities in an entity-relation graph, we adapt the relation labels in entity-relation graphs to word-level relations:
-
•
Question-answer, the last word in a question is linked to the first word in the corresponding answer.
-
•
Header-question, the first word in a section is linked to the first word of the corresponding question.
-
•
Proximate_(V), the first word in is linked to the first word in .
-
•
Proximate_(H), the last word in is linked to the first word in .
-
•
Same-entity, the adjacent words within an entity are connected with this relation.
The conversion process is deterministic because i) for a relation between two entities, either the first or the last word of an entity is linked, and ii) same-entity links only adjacent words in an entity. Thus it is straightforward to revert the process to map a word-relation graph and an entity-relation graph by using rules. As a result, an word-relation graph is isomorphic to an entity-relation graph.
3.2 LaGNN Model
In this section, we present LaGNN that parses a document image to a word-relation graph, which is reformulated as predicting relations between words in a document. In contrast to prior studies [6, 26], our model relies on relative distances between the bounding boxes of words, which are robust across languages, rather than linguistic features. Moreover, we adopt Graph Attention Network (GAT) [22] to capture the similarities of relations between the neighbours of a word. However, we slightly modify GAT model to include edge features in addition to node features in message passing. We do this by concatenating our edge features with node features before performing the message passing. The coherence of predicted relations and graph properties of a word-relation graph are ensured by ILP at the inference stage.
Similar to prior works [26, 6], we apply the off-the-shelf OCR model [18] to map document images to bags of words. The OCR outputs are reorganized by sorting lines from top to bottom and arranging words from left to right in their original order by using their bounding-box coordinates. For each word , we define its neighbourhood as the set of words, to which it can potentially have relations. The set consists of at most nearest words, including the word to the right of and the words below it. This definition of neighbourhood is motivated by the fact that the edge score between two words is independent of the orientation of the edge. Hence, during inference, we only compute edge scores between a word and each word in its neighbourhood to avoid repeated computations.
We observe that a significant proportion of the neighbours of a word have the same relations. For example, all words in an answer composed of multiple words are associated with the relation same-entity. By viewing a form as a word-relation graph, we take the GAT model as our backbone because it supports both node features and edge features. Herein, each node is represented by a normalized bounding box coefficient vector , where and denotes the width and the height of a document image respectively. To support cross-lingual parsing, we represent an edge only by a relative spacing feature vector . Such a feature vector is computed based on both horizontal and vertical relative distances between their normalized bounding boxes. Specifically, given two words and with the bounding boxes (), and () respectively, the spacing between and is calculated along x and y-axis by
As a result, the spacing feature vector .
In comparison with the prior works [26, 25, 11, 6], which use text, image, and layout features altogether, our model is more parameter efficient by adopting only language-independent and layout-agnostic features. Due to those simple features, our model contains only 7.3K parameters, significantly less than those transformer-based models, which have approximately 200-400M parameters.
3.3 Inference
We formulate the inference problem as an integer linear program that aims to identify the most likely word-relation graph satisfying the graph properties outlined in Sec. 3.1.
Given an edge embedding , we compute a score for each possible label by using a linear layer. As a word-relation graph is sparse, we extend to the set by adding a relation no-relation, which indicates there is no relation between two words. Let be a binary variable indicating if there is an edge with a label between and , the solution to the following integer linear program is the most likely word-relation graph.
| (1) |
where denotes the constraint matrix and is the corresponding constant vector.
We formulate five constraints specific to documents for efficient joint inference using integer linear programming:
-
•
Connectivity constraint (C1): The generated word-relation graphs are fully connected such that there is a path between any pair of nodes in a graph.
-
•
QA constraint (C2): If a relation between two words is question-answer, where denotes question-answer, then the next immediate relation must be either proximate_(H) () or same-entity (). Let the next relation is denoted by , this constraint is defined as:
-
•
Single label constraint (C3): There is only one relation in between any pair of nodes in a word-relation graph.
-
•
At least one semantic relations (C4): A word is part of an entity. Therefore, it is linked to another word via same-entity if the entity contains multiple words. If the word is at the beginning or the end of an entity, it points to another entity via either question-answer or header-question. In other words, a word is involved in at least one relation in . If an entity contains a single word, it should be associated with either question-answer or header-question. Otherwise, if a word is associated only with or , we cannot determine which entity it belongs to and the type of the corresponding entity.
-
•
At least one semantic relation in the neighbourhood (C5): The previous constraint can still fail to exclude the cases that a word is only involved in same-entity in . In such a case, the word is expected to be at either end of an entity. If we need to infer the type of entity, this word should be linked to another word via either question-answer or header-question. Therefore, if a word is linked with a same-entity relation, it should be linked to a different word with a relation in .
After parsing a document image into a word-relation graph, we apply the deterministic rules introduced in Sec. 3.1 to convert the graph into an entity-relation graph.
3.4 Model Training
Inspired by [8], we apply the cross-entropy loss to each pair of nodes during training. The construction of word-relation graphs is realized by the ILP-based inference method detailed above.
| (2) |
where and denote the ground-truth labels and predicted labels respectively.
4 Experiments
We compare our model with the state-of-the-art methods on both monolingual and multilingual form datasets. The results show that our models significantly outperform the baselines in terms of relation prediction on word-relation graphs in both settings, which leads further to superior performance on entity-relation graphs. The extensive ablation studies demonstrate the effectiveness of incorporating structural information using GAT and the constraints during ILP-based inference.
4.1 Datasets
FUNSD [12] It is a form understanding dataset consisting of 199 noisy documents which are fully annotated. It has a total of 9,707 semantic entities over 31,485 words. In the official data split, the 199 samples are divided into 149 training samples and 50 testing samples. However, we further split the 149 samples into 139 training and 10 validation samples. Our test split is the same as the official split. Each entity is labelled with one of the four semantic entity labels - ”question”, ”answer”, ”header”, and ”other”. This dataset is widely employed for semantic entity labelling and relation extraction tasks.
XFUND [27] This is a multilingual benchmark dataset comprising 199 forms that are labeled by humans in 7 languages, which are Chinese (ZH), Japanese (JA), Spanish (ES), French (FR), Italian (IT), German (DE), Portuguese (PT). The dataset is divided into 149 forms for training and 50 for testing. In the ground-truth annotations, each entity is labeled with either ”question”, ”answer”, ”header”, or ”other”. Following previous works [6, 23], we use this dataset to compare our model with existing state-of-the-art models in the zero-shot settings.
To obtain the relation annotations in entity-relation graphs on both datasets, we apply rules to generate the relation annotations based on entity annotations, followed by manually checking all document images for correctness. Due to the isomorphism between word-relation graphs and entity-relation graphs, we map the resulting entity-relation graphs to word-relation graphs by using the deterministic rules.
| Model | Parameters | Modality | Precision () | Recall () | F1 () |
|---|---|---|---|---|---|
| XLM-RoBERTaBASE | - | T | 0.563 | 0.561 | 0.561 |
| InfoXLMBASE | - | T | 0.593 | 0.603 | 0.598 |
| LayoutLM | 11M | T+L+I | 0.664 | 0.666 | 0.665 |
| LayoutXLMBASE | 30M | T+L+I | 0.709 | 0.715 | 0.712 |
| LayoutLMv2 | 11M | T+L+I | 0.722 | 0.712 | 0.717 |
| StructuralLM | 11M | T+L | 0.741 | 0.749 | 0.745 |
| LiLT[InfoXLM]BASE | 11M | T+L | 0.792 | 0.786 | 0.789 |
| LayoutLMv3 | 11M | T+L+I | 0.801 | 0.809 | 0.805 |
| Ours | 8.1K | L | 0.837 | 0.854 | 0.845 |
| Ours + Constraints | 8.1K | L | 0.848 | 0.861 | 0.854 |
| Model | Precision () | Recall () | F1 () |
|---|---|---|---|
| LayoutLM | 0.753 | 0.757 | 0.755 |
| LayoutXLMBASE | 0.791 | 0.796 | 0.793 |
| LayoutLMv2 | 0.847 | 0.852 | 0.849 |
| LiLT[InfoXLM]BASE | 0.864 | 0.881 | 0.872 |
| LayoutLMv3 | 0.898 | 0.903 | 0.900 |
| LaGNN | 0.921 | 0.936 | 0.928 |
4.2 Implementation Details
The entity-relation graphs are constructed using Deep Graph Library (DGL). We use a single-layer GAT with 3 heads and a hidden dimension size of 64 for both node and edge features. We train our model using Adam optimizer for 500 iterations with a learning rate of . If the performance on the validation data does not improve after 100 iterations, training stops early. During training, we save the model checkpoint based on its performance on validation data. For inference on the test set, the checkpoint with the best performance across all training epochs is loaded. We train our model on 1 GTX 1080Ti 12 GB GPU.
4.3 Monolingual Results on FUNSD
We first evaluate our model on the word-relation graphs on FUNSD by considering the task as relation extraction between words. More specifically, we run the state-of-the-art models LayoutLM [26], LayoutLMv2 [25], LayoutLMv3 [11], StructuralLM [15], LayoutXLM [6], InfoXLMBASE [3], and LiLT[InfoXLM]BASE [23] to predict entities, followed by relation extraction.
For baselines, we perform relation extraction by following the approach in [6]. First, we create all possible entity pairs as relation candidates. Each candidate is represented by the concatenation of the corresponding entity representations. Furthermore, the representation of an entity is first constructed by concatenating the embedding of the first token of each entity and the entity type embedding, followed by feeding them through two position-wise feed-forward networks (FFN) modules. The resulting relation candidate representations are fed into a bi-affine classifier for relation classification. The conversion from entity-relation graphs to word-relation graphs is performed by the same set of deterministic rules introduced in Sec. 3.1.
Table 1 reports the relation extraction results on word-relation graphs in terms of Precision, Recall, and F1. For each metric, we take the micro-average among the relations in . The two variations of our model achieve superior performance over the baselines by only using the relative spacing features. In contrast, all baselines use textual features extracted from large language models that require pre-training on large-scale datasets. Some of the baselines, such as variations of LayoutLM, require even vision features. The number of parameters of our models is also significantly smaller than their competitors. Although pre-trained language models are widely used in a number of AI applications, our work raises the basic question for future research “Are language models necessary for form recognition?”.
Apart from relation extraction, we also evaluate the models in terms of entity recognition on converted entity-relation graphs. Table 2 summarizes the results based on an exact match in terms of Precision, Recall, and F1.
| Model | Pretraining | FUNSD | XFUND | Avg | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Language | Size | EN | JA | ZH | DE | FR | PT | ES | IT | ||
| XLM-RoBERTaBASE | - | - | 0.587 | 0.116 | 0.132 | 0.335 | 0.400 | 0.354 | 0.281 | 0.286 | 0.311 |
| InfoXLMBASE | - | - | 0.601 | 0.132 | 0.159 | 0.357 | 0.398 | 0.352 | 0.295 | 0.300 | 0.324 |
| LayoutXLMBASE | Multilingual | 30M | 0.701 | 0.258 | 0.240 | 0.443 | 0.568 | 0.549 | 0.461 | 0.499 | 0.464 |
| LiLT[InfoXLM]BASE | English | 11M | 0.771 | 0.303 | 0.349 | 0.562 | 0.691 | 0.613 | 0.554 | 0.586 | 0.553 |
| Ours | - | 0.845 | 0.611 | 0.625 | 0.636 | 0.679 | 0.641 | 0.651 | 0.625 | 0.664 | |
| Ours + Constraints | - | 0.853 | 0.625 | 0.626 | 0.647 | 0.673 | 0.641 | 0.644 | 0.638 | 0.669 | |
4.4 Zero-Shot Multilingual Results
We further evaluate model performance by applying the models trained on FUNSD directly to the scanned forms in other languages on XFUND. Herein, we compare our models with the state-of-the-art methods: XLM-RoBERTaBASE, InfoXLMBASE, LayoutXLMBASE [6], and LiLT[InfoXLM]BASE [23]. The latter two models are pre-trained on large-scale document datasets of size 30M and 11M respectively.
Table 3 reports the corresponding zero-shot multilingual relation extraction results on the word-relation graphs of XFUND dataset. Overall, our best model outperforms the baselines in 7 out of 8 languages in terms of F1. The geometric mean of the F1 is more than 10% better than the strongest baseline. It is noteworthy that performance improvement is achieved without any time-consuming pre-training. We only use the 139 forms from the FUNSD dataset to train our models. Our models based on relative spacing features are more transferrable than those multilingual language models on this task. A further inspection shows that our models benefit from the fact that the space between two words within an entity, as well as the distance between a question word and an answer word, are similar across languages. In this zero-shot multilingual setting, incorporating the constraints into inference does not always help, though it leads to improvements in 6 out of 8 languages.
| Model | Precision | Recall | F1 |
|---|---|---|---|
| GraphSAGE | 0.756 | 0.768 | 0.761 |
| GCNs | 0.814 | 0.823 | 0.818 |
| LaGNN- Edgefeats | 0.705 | 0.717 | 0.710 |
| LaGNN + Edgefeats | 0.837 | 0.854 | 0.845 |
| LaGNN + Edgefeats + all constrs | 0.848 | 0.861 | 0.854 |
| LaGNN + Edgefeats + all constrs - C4+C5 | 0.846 | 0.860 | 0.852 |
| LaGNN + Edgefeats + all constrs - C1 | 0.845 | 0.858 | 0.851 |
| LaGNN + Edgefeats + all constrs - C2 | 0.840 | 0.851 | 0.845 |
| Constraints | Number of violations |
|---|---|
| C1 | 71 |
| C2 | 169 |
| C3 | 0 |
| C4 | 51 |
| C5 | 10 |
| Model | Precision | Recall | F1 |
|---|---|---|---|
| LaGNN + Edgefeats in lower-level and at classifier | 0.837 | 0.854 | 0.845 |
| LaGNN + Edgefeats in lower-level and not at classifier | 0.713 | 0.725 | 0.718 |
| LaGNN + Edgefeats not in lower-level but at classifier | 0.831 | 0.849 | 0.840 |
| LaGNN- Edgefeats | 0.705 | 0.717 | 0.710 |
4.5 Ablation Study
We evaluate the effectiveness of using GAT, edge features, constraints in ILP, and the size of neighbourhood in our model. To show the usefulness of GAT, we compare it with GraphSAGE [10] and graph convolutional networks (GCNs) [14] by using the same features. For edge features, we run ablation studies by removing them with or without applying ILP. To understand the usefulness of the constraints during inference, we remove the connectivity constraint (C1), QA constraint (C2), and the last two semantic constraints (C4+C5) respectively from the full model.
As shown in Table 4, it is expected that our full model performs the best among all variations. Removing relative spacing features leads to the largest drop in terms of all metrics. GAT demonstrates its strengths over the two alternative neural structures. Removing any of the constraints, the model performance drops slightly. Among them, C2 is clearly the most useful one among them in terms of improving performance. As such, C2 is the qa constraint that is designed to correct the wrongly predicted question-answer relation labels, which are one of the most frequent model prediction errors based on our evaluation. Before applying ILP, we observe that there were 169 out of 51775 word pairs in the test set that violate this constraint. Table 5 illustrates the number of violations in the predictions of LaGNN before applying the constraint-based inference.
The constraints C4 and C5 are designed to ensure isomorphism between entity-relation graphs and word-relation graphs. This constraint assists in preventing any isolated word pairs that are not connected to an entity (question, or header). For instance, if a question has more than one word in the answer, the words within the answer are linked together using the same-entity relation. The last word of the question and the first word of the answer are linked by the question-answer relation. When transforming a word-relation graph to an entity-relation graph, we take into account the rule that any word pairs with a same-entity connection following a question-answer relation are mapped to the entity relation ”answer” in the entity-relation graph. However, if LaGNN predicts a different relation for a word pair within the answer than same-entity, this will result in an inaccurate mapping of word-relation graph to entity-relation graph. Additionally, a word pair can only have a same-entity relation if it is part of a chain of words whose head is linked to either a ”question” or a ”header.” It is impossible to have an isolated word pair with a same-entity relation that isn’t related to either the ”question” or ”header” in our proposed way of word-relation graph construction. However, a few of the LaGNN model’s relation predictions could result in isolated word pairs. In order to prevent this, our uniquely designed semantic constraints correct these mistakes and aid in the accurate mapping of the word-relation graph to the entity-relation graph. There are 134 total isolated word pairings before semantic constraints are applied. However, with the application of the constraints, there were no violations, and the performance benefit from using semantic constraints—which are made particularly to achieve isomorphism between word-relation graph and entity-relation graph —is very little.
Where to put edge features To demonstrate the significance of using spacing between pairs of nodes as its edge feature, we conduct four experiments with and without edge features. The results for these experiments are available in Table 6. Our key objective is to determine whether it is more effective to concatenate edge features with node features when computing the node attention rather than doing so only at the model’s final classifier layer. It is evident that employing edge features solely while computing node attention (row 2) results in much lower performance than using the model’s final (classifier) layer (row 3). Nevertheless, it is still marginally preferable to not use edge features at all (row 4). The optimal performance can be obtained by employing edge features while computing node attention as well as at the last layer of the model (row 1).
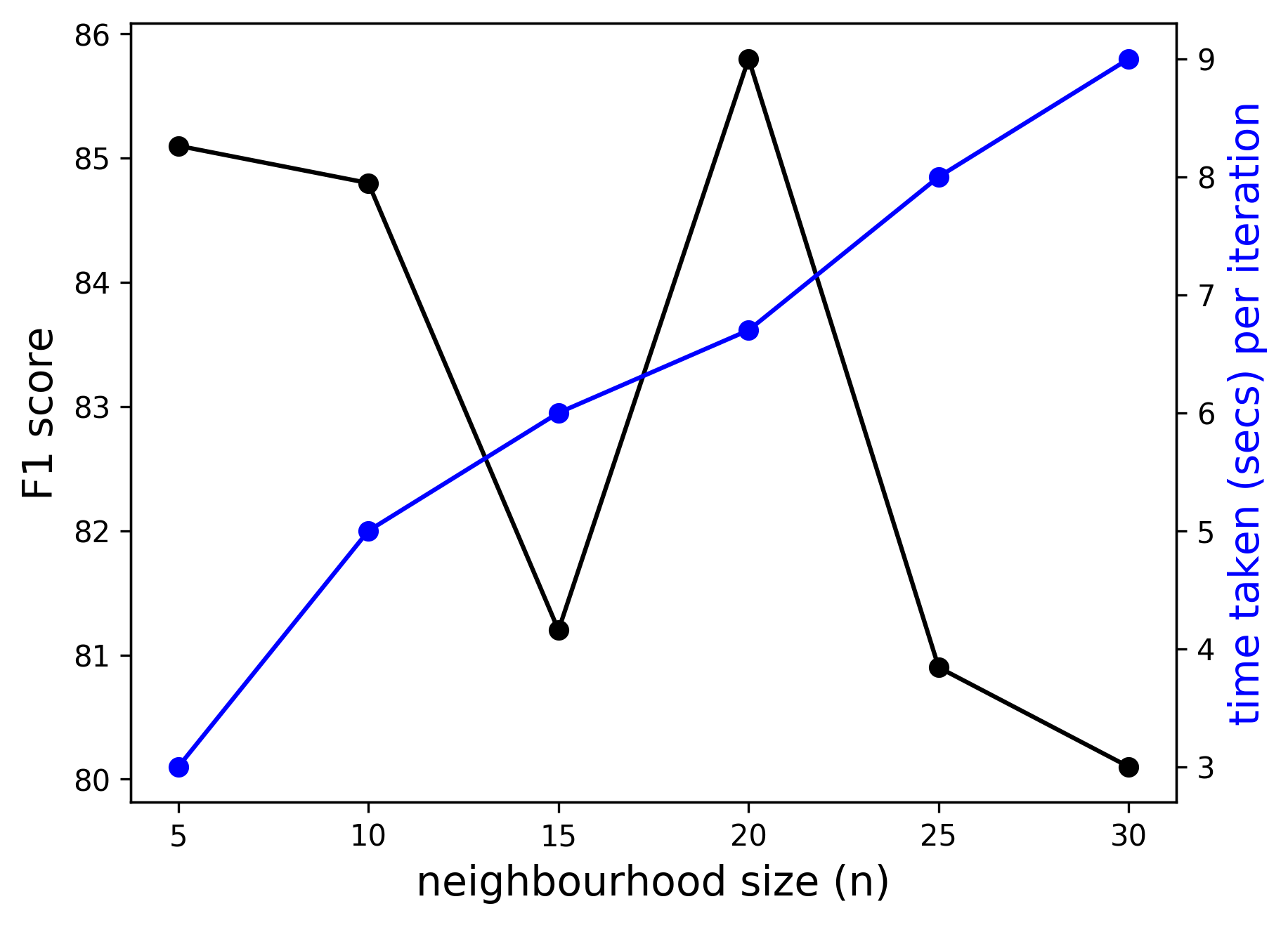
Effect of neighbourhood size On both datasets, the ”linking” key found in the JSON annotation files of the ground-truth documents is used to construct the ground-truth graphs. There are no ground-truth annotation files accessible during the inference. Therefore, the model must decide which nodes should be connected to which nodes. The ”no-link” relation label enables the model to discover which nodes ought to be connected by an edge. Each word or node in the graph is linked to the following words or nodes in the document using an edge labelled no-relation. The edges predicted with a ”no-link” relation label are removed prior to applying the ILP inference. We experiment with various to examine the impact of neighbourhood size on the model’s performance. As increases, the computational time increases. We determine an ideal value for by finding an optimal trade-off between computation time and performance.
5 Conclusion
In this work, we propose a novel entity-relation graph parsing model called LaGNN that is language independent. Our model parses a document image into a word-relation graph in order to minimize error propagation of pipeline approaches and reduce the time complexity of inference. This graph is then transformed by deterministic rules into a fully linked entity-relation graph. Due to this simplification, inference time is sharply reduced. Our model simply takes into account relative spacing features extracted from layout information in order to allow language-independent form understanding without the use of pre-trained language models. To ensure that the generated graphs match the specifications of entity-relation graphs, we use ILP-based inference by incorporating designated constraints for this task. Our experimental results on the multilingual XFUND and FUSND datasets demonstrate that our proposed approach produces superior results over competitive baselines. In particular, on the zero-short multilingual form understanding task, our model surpasses recent strong baselines by a large margin. Additionally, we conduct extensive ablation studies that demonstrate the effectiveness of each new design choice we proposed.
References
- [1] Borges Oliveira, D.A., Viana, M.P.: Fast cnn-based document layout analysis. In: 2017 IEEE International Conference on Computer Vision Workshops (ICCVW). pp. 1173–1180 (2017). https://doi.org/10.1109/ICCVW.2017.142
- [2] Carbonell, M., Riba, P., Villegas, M., Fornés, A., Lladós, J.: Named entity recognition and relation extraction with graph neural networks in semi structured documents. In: 2020 25th International Conference on Pattern Recognition (ICPR). pp. 9622–9627 (2021). https://doi.org/10.1109/ICPR48806.2021.9412669
- [3] Chi, Z., Dong, L., Wei, F., Yang, N., Singhal, S., Wang, W., Song, X., Mao, X.L., Huang, H., Zhou, M.: InfoXLM: An information-theoretic framework for cross-lingual language model pre-training. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. pp. 3576–3588. Association for Computational Linguistics, Online (Jun 2021). https://doi.org/10.18653/v1/2021.naacl-main.280, https://aclanthology.org/2021.naacl-main.280
- [4] Davis, B., Morse, B., Price, B., Tensmeyer, C., Wiginton, C.: Visual fudge: Form understanding via dynamic graph editing. In: Lladós, J., Lopresti, D., Uchida, S. (eds.) Document Analysis and Recognition – ICDAR 2021. pp. 416–431. Springer International Publishing, Cham (2021)
- [5] Davis, B.L., Morse, B., Cohen, S.D., Price, B.L., Tensmeyer, C.: Deep visual template-free form parsing. 2019 International Conference on Document Analysis and Recognition (ICDAR) pp. 134–141 (2019)
- [6] Déjean, H., Clinchant, S., Meunier, J.: Layoutxlm vs. GNN: an empirical evaluation of relation extraction for documents. CoRR abs/2206.10304 (2022)
- [7] Denk, T.I., Reisswig, C.: {BERT}grid: Contextualized embedding for 2d document representation and understanding. In: Workshop on Document Intelligence at NeurIPS 2019 (2019), https://openreview.net/forum?id=H1gsGaq9US
- [8] Domke, J.: Structured learning via logistic regression. Advances in Neural Information Processing Systems 26 (2013)
- [9] Gemelli, A., Biswas, S., Civitelli, E., Lladós, J., Marinai, S.: Doc2graph: a task agnostic document understanding framework based on graph neural networks (2022). https://doi.org/10.48550/ARXIV.2208.11168, https://arxiv.org/abs/2208.11168
- [10] Hamilton, W., Ying, Z., Leskovec, J.: Inductive representation learning on large graphs. Advances in neural information processing systems 30 (2017)
- [11] Huang, Y., Lv, T., Cui, L., Lu, Y., Wei, F.: Layoutlmv3: Pre-training for document AI with unified text and image masking. In: Magalhães, J., Bimbo, A.D., Satoh, S., Sebe, N., Alameda-Pineda, X., Jin, Q., Oria, V., Toni, L. (eds.) MM ’22: The 30th ACM International Conference on Multimedia, Lisboa, Portugal, October 10 - 14, 2022. pp. 4083–4091. ACM (2022)
- [12] Jaume, G., Ekenel, H.K., Thiran, J.: FUNSD: A dataset for form understanding in noisy scanned documents. In: 2nd International Workshop on Open Services and Tools for Document Analysis, OST@ICDAR 2019, Sydney, Australia, September 22-25, 2019. pp. 1–6. IEEE (2019)
- [13] Katti, A.R., Reisswig, C., Guder, C., Brarda, S., Bickel, S., Höhne, J., Faddoul, J.B.: Chargrid: Towards understanding 2D documents. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. pp. 4459–4469. Association for Computational Linguistics, Brussels, Belgium (Oct-Nov 2018). https://doi.org/10.18653/v1/D18-1476, https://aclanthology.org/D18-1476
- [14] Kipf, T.N., Welling, M.: Semi-supervised classification with graph convolutional networks. In: International Conference on Learning Representations (2017), https://openreview.net/forum?id=SJU4ayYgl
- [15] Li, C., Bi, B., Yan, M., Wang, W., Huang, S., Huang, F., Si, L.: StructuralLM: Structural pre-training for form understanding. In: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). pp. 6309–6318. Association for Computational Linguistics, Online (Aug 2021). https://doi.org/10.18653/v1/2021.acl-long.493, https://aclanthology.org/2021.acl-long.493
- [16] Li, P., Gu, J., Kuen, J., Morariu, V.I., Zhao, H., Jain, R., Manjunatha, V., Liu, H.: Selfdoc: Self-supervised document representation learning. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 5648–5656 (2021)
- [17] Lin, W., Gao, Q., Sun, L., Zhong, Z., Hu, K., Ren, Q., Huo, Q.: Vibertgrid: A jointly trained multi-modal 2d document representation for key information extraction from documents. In: Document Analysis and Recognition – ICDAR 2021: 16th International Conference, Lausanne, Switzerland, September 5–10, 2021, Proceedings, Part I. p. 548–563. Springer-Verlag, Berlin, Heidelberg (2021), https://doi.org/10.1007/978-3-030-86549-8_35
- [18] Mindee: doctr: Document text recognition. https://github.com/mindee/doctr (2021)
- [19] Powalski, R., Łukasz Borchmann, Jurkiewicz, D., Dwojak, T., Pietruszka, M., Pałka, G.: Going full-tilt boogie on document understanding with text-image-layout transformer. In: IEEE International Conference on Document Analysis and Recognition (2021)
- [20] Sarkar, M., Aggarwal, M., Jain, A., Gupta, H., Krishnamurthy, B.: Document structure extraction using prior based high resolution hierarchical semantic segmentation. In: European Conference on Computer Vision (2020)
- [21] Siegel, N., Lourie, N., Power, R., Ammar, W.: Extracting scientific figures with distantly supervised neural networks. Proceedings of the 18th ACM/IEEE on Joint Conference on Digital Libraries (2018)
- [22] Veličković, P., Cucurull, G., Casanova, A., Romero, A., Liò, P., Bengio, Y.: Graph attention networks. In: International Conference on Learning Representations (2018), https://openreview.net/forum?id=rJXMpikCZ
- [23] Wang, J., Jin, L., Ding, K.: LiLT: A simple yet effective language-independent layout transformer for structured document understanding. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 7747–7757. Association for Computational Linguistics, Dublin, Ireland (May 2022). https://doi.org/10.18653/v1/2022.acl-long.534, https://aclanthology.org/2022.acl-long.534
- [24] Wang, W., Huang, Z., Luo, B., Chen, Q., Peng, Q., Pan, Y., Yin, W., Feng, S., Sun, Y., Yu, D., Zhang, Y.: Mmlayout: Multi-grained multimodal transformer for document understanding. In: Proceedings of the 30th ACM International Conference on Multimedia. p. 4877–4886. MM ’22, Association for Computing Machinery, New York, NY, USA (2022). https://doi.org/10.1145/3503161.3548406, https://doi.org/10.1145/3503161.3548406
- [25] Xu, Y., Xu, Y., Lv, T., Cui, L., Wei, F., Wang, G., Lu, Y., Florêncio, D.A.F., Zhang, C., Che, W., Zhang, M., Zhou, L.: Layoutlmv2: Multi-modal pre-training for visually-rich document understanding. In: Zong, C., Xia, F., Li, W., Navigli, R. (eds.) Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP 2021, (Volume 1: Long Papers), Virtual Event, August 1-6, 2021. pp. 2579–2591. Association for Computational Linguistics (2021)
- [26] Xu, Y., Li, M., Cui, L., Huang, S., Wei, F., Zhou, M.: Layoutlm: Pre-training of text and layout for document image understanding. CoRR abs/1912.13318 (2019)
- [27] Xu, Y., Lv, T., Cui, L., Wang, G., Lu, Y., Florencio, D., Zhang, C., Wei, F.: XFUND: A benchmark dataset for multilingual visually rich form understanding. In: Findings of the Association for Computational Linguistics: ACL 2022. pp. 3214–3224. Association for Computational Linguistics, Dublin, Ireland (May 2022). https://doi.org/10.18653/v1/2022.findings-acl.253, https://aclanthology.org/2022.findings-acl.253
- [28] Yang, X., Yumer, E., Asente, P., Kraley, M., Kifer, D., Giles, C.L.: Learning to extract semantic structure from documents using multimodal fully convolutional neural networks. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) pp. 4342–4351 (2017)