Language Models as Few-Shot Learner for
Task-Oriented Dialogue Systems
Abstract
Task-oriented dialogue systems use four connected modules, namely, Natural Language Understanding (NLU), a Dialogue State Tracking (DST), Dialogue Policy (DP) and Natural Language Generation (NLG). A research challenge is to learn each module with the least amount of samples (i.e., few-shots) given the high cost related to the data collection. The most common and effective technique to solve this problem is transfer learning, where large language models, either pre-trained on text or task-specific data, are fine-tuned on the few samples. These methods require fine-tuning steps and a set of parameters for each task. Differently, language models, such as GPT-2 Radford et al. (2019) and GPT-3 Brown et al. (2020), allow few-shot learning by priming the model with few examples. In this paper, we evaluate the priming few-shot ability of language models in the NLU, DST, DP and NLG tasks. Importantly, we highlight the current limitations of this approach, and we discuss the possible implication to future work.
Acknowledgments
I would like to thanks Jason Wu for providing an easy to use code in ToD-BERT and for clarification about the code and tasks, Baolin Peng for the easy to use repository FewShotNLG and for providing help with the scorer, and Sumanth Dathathri for the discussion and insight about the limitation of the LM priming few-shots.
1 Introduction
Modularized task-oriented dialogues systems are the core of the current smart speaker generation (e.g., Alexa, Siri etc.). The main modules of such systems are Natural Language Understanding (NLU), Dialogue State Tracking (DST), Dialogue Policy (DP) and Natural Language Generation (NLG), each of which is trained separately using supervised and/or reinforcement learning. Thus a data collection process is required, which for some of the tasks can be laborious and expensive. For example, dialogue policy annotation has to be done by an expert, better by a professional linguist. Therefore, having a model that requires only few samples to actually perform well in the tasks is essential.
The most successful approach in few-shot learning for task-oriented dialogue systems is notably transfer learning, where a large model is firstly pre-trained on a large corpus to be then fine-tuned on specific tasks. For task-oriented dialogue systems, Wu et al. (2020) proposed TOD-BERT a large pre-trained model which can achieve better performance than BERT Devlin et al. (2019) in few-shots NLU, DST and DP. Liu et al. (2020) proposed a two-step classification for few-shot slot-filling, a key task for the NLU module. Similarly, Peng et al. (2020b) introduced a benchmark for few-shot NLG and a pre-trained language model (SC-GPT) specialized for the task. Further, a template rewriting schema based on T5 Raffel et al. (2019) was developed by Kale and Rastogi (2020) for few-shot NLG in two well-known datasets. Peng et al. (2020a) proposed a pre-trained language model (LM) for end-to-end pipe-lined task-oriented dialogue systems. In their experiments, they showed promising few-shot learning performance in MWoZ Budzianowski et al. (2018). Finally, several meta-learning approaches have been proposed for DP Xu et al. (2020), NLG/ACT Mi et al. (2019), pipelined end-to-end models Qian and Yu (2019) and personalized dialogue systems Madotto et al. (2019).
For performing few-shot learning, existing methods require a set of task-specific parameters since the model is fine-tuned with few samples. Differently, in this paper, we perform few-shot learning by priming LMs with few-examples Radford et al. (2019); Brown et al. (2020). In this setting, no parameters are updated, thus allowing a single model to perform multiple tasks at the same time. In this paper, we evaluate the few-shot ability of LM priming on the four task-oriented tasks previously mentioned (i.e., NLU, DST, DP, and NLG). Currently, GPT-3 Brown et al. (2020) is not available to the public; thus we experiment on different sizes GPT-2 Radford et al. (2019) models such as SMALL (117M), LARGE (762M), and XL (1.54B). All the experiments are run on a single NVIDIA 1080Ti GPU.
2 Basic Notation and Tasks
Let us define dialogue as the alternation of utterances between two speakers denoted by and respectively. An utterance is a sequence of words and the concatenation of utterances denotes a dialogue with turns. In this paper, we focus on the four task-oriented dialogue system tasks, and we briefly introduce the input-output of each task.
NLU
This task aims to extract slot-value pairs (SLOT-FILLING) and the intent (INTENT) from a user utterance . In the literature, the most common approach for NLU is to learn a BIO tagger for the slot-value pairs, and to learn a multi-class classifier for the intent. SLOT-FILLING gets as input a user utterance and produces a dictionary , where is a slot and is the possible value. Note that can also be None since some slots may not be mentioned in the utterance. The INTENT task gets a user utterance and classifies it into an intent class denoted by . Sometimes, the intent-classification is mixed with the domain classification.
DST
This task extracts slot-value pairs for a given dialogue, which can be considered as a dialogue-level of the NLU. Given a dialogue with turns as a sequence of utterance a DST model predicts a dictionary as in the NLU. Note that most of the existing DST models use the previously generated and just update the slots required using an NLU tagger.
ACT
This task predicts the next speech-act (e.g., INFORM, REQUEST etc.) given the current dialogue state, in the form of a dialogue or dictionary of slot-value pairs. This is usually stated as a reinforcement learning task in both online and offline settings. In this paper, we simplify the tasks, and instead of learning a dialogue policy, we perform dialogue act classification. This a multi-label classification task, since more than one speech-act can be used in an utterance. This task gets as input a user utterance and classifies it in to a set of possible speech-acts in .
NLG
This task maps a dialogue-act, which is made of a speech-act plus a dictionary of slot-value pairs, into natural language. The model gets as input a speech-act concatenated with a slot-value dictionary overall denoted as and it generates as output an utterance .
In the few-shot setting, a small number of input-output pairs is provided to the model, expecting a high degree of generalization.
3 Priming the LM for few-shot learning
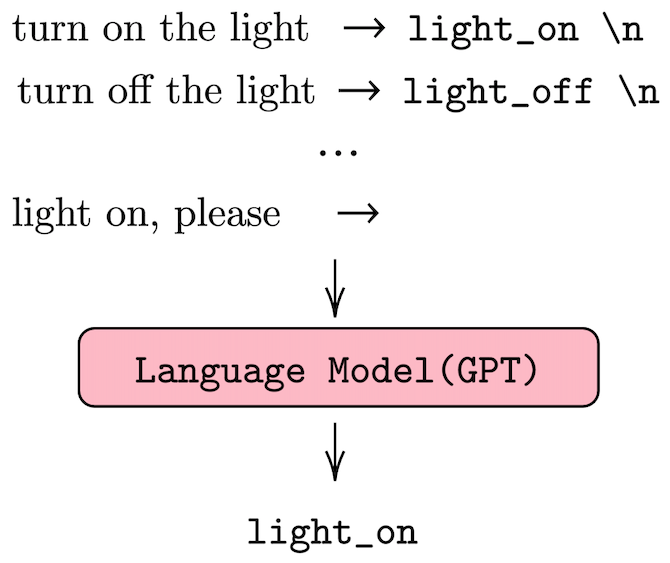
Differently from fine-tuning, few-shot learning with LMs requires designing prefixes to perform few-shot learning. In our four tasks, we use three categories of prefixes: binary, value-based and generative. In the following notation, we use to represent a generic input and for the -th shot samples, thus implying that the prefix remains fixed during the inference and can become any input. These prefixes are provided to the LM and the generate tokens become the actual prediction, Figure 1 show an example of intent recognition.
Binary
prefixes are used for classification (namely for intent-classification and speech-act detection). We treat every classification as binary, even multi-class. To perform the few-shot priming, we use the following prefix:
| (1) |
where one of the few-shot samples and is from other classes or from the false class if it exists. To predict classes, a set of prefixes is used and thus forwards is required.
Value-based
prefixes are used to assign the value of a certain slot given an utterance, or None if no value is provided. We define a prefix for each slot, similar to TRADE Wu et al. (2019), which requires forwarding the model times for decoding -slots. To perform the few-shot priming of one slot , we use the following prefix:
| (2) |
where is the assigned value from the few-shot training. This process is repeated for each slot to generate the dictionary .
Generative
prefixes are used to instruct the model to generate natural language given source information (e.g., NLG). The prefix is the following:
| (3) |
where and are generic sequences of words.
|
|
|
4 Experiments and Results
We use different prefix styles depending on the task and we compare the results of LM few-shot priming with those of the existing finetuning-base models. In all the experiments, we use different number of shots since different tasks may fit more or fewer samples in the 1024 max input size of GPT-2.
NLU
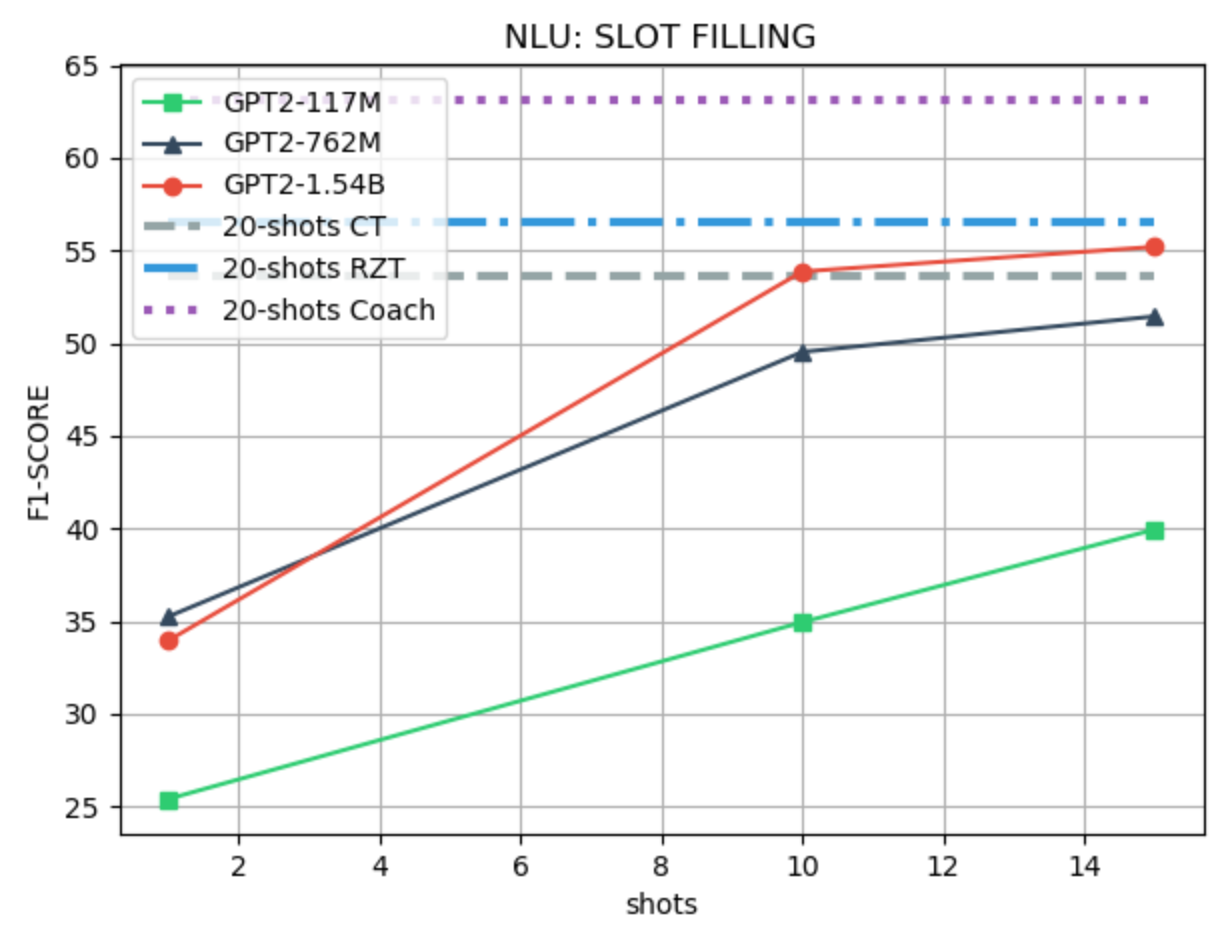
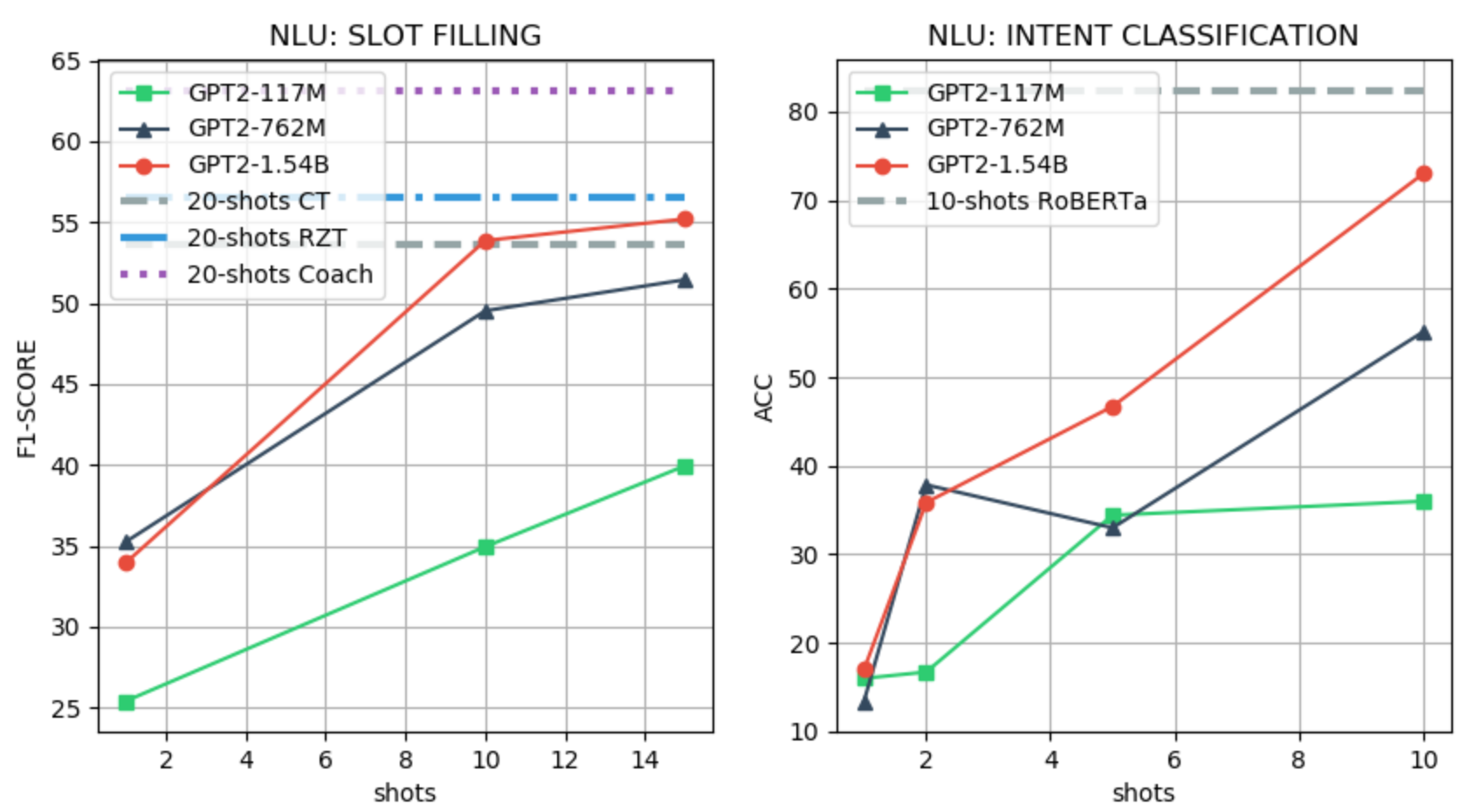
We use the SNIPS Coucke et al. (2018) dataset for evaluating the SLOT-FILLING and INTENT recognition tasks. For the SLOT-FILLING task, we follow the few-shot setting of Liu et al. (2020), and we use the official CoNLL F1 scorer as the evaluation metric. For the INTENT classification, we fine-tune RoBERTa Liu et al. (2019) with 10 samples and use accuracy as the evaluation metric. We use a value-based LM prefix for the SLOT-FILLING task with a maximum of 15 shots, and binary LM prefix for the INTENT classification task with a maximum of 10 shots. An example of a prefix for the SLOT-FILLING task and the few-shot performance evaluation are shown in Figure 2. Table 2 and 2 and Figure 5 show more detailed results.
DST
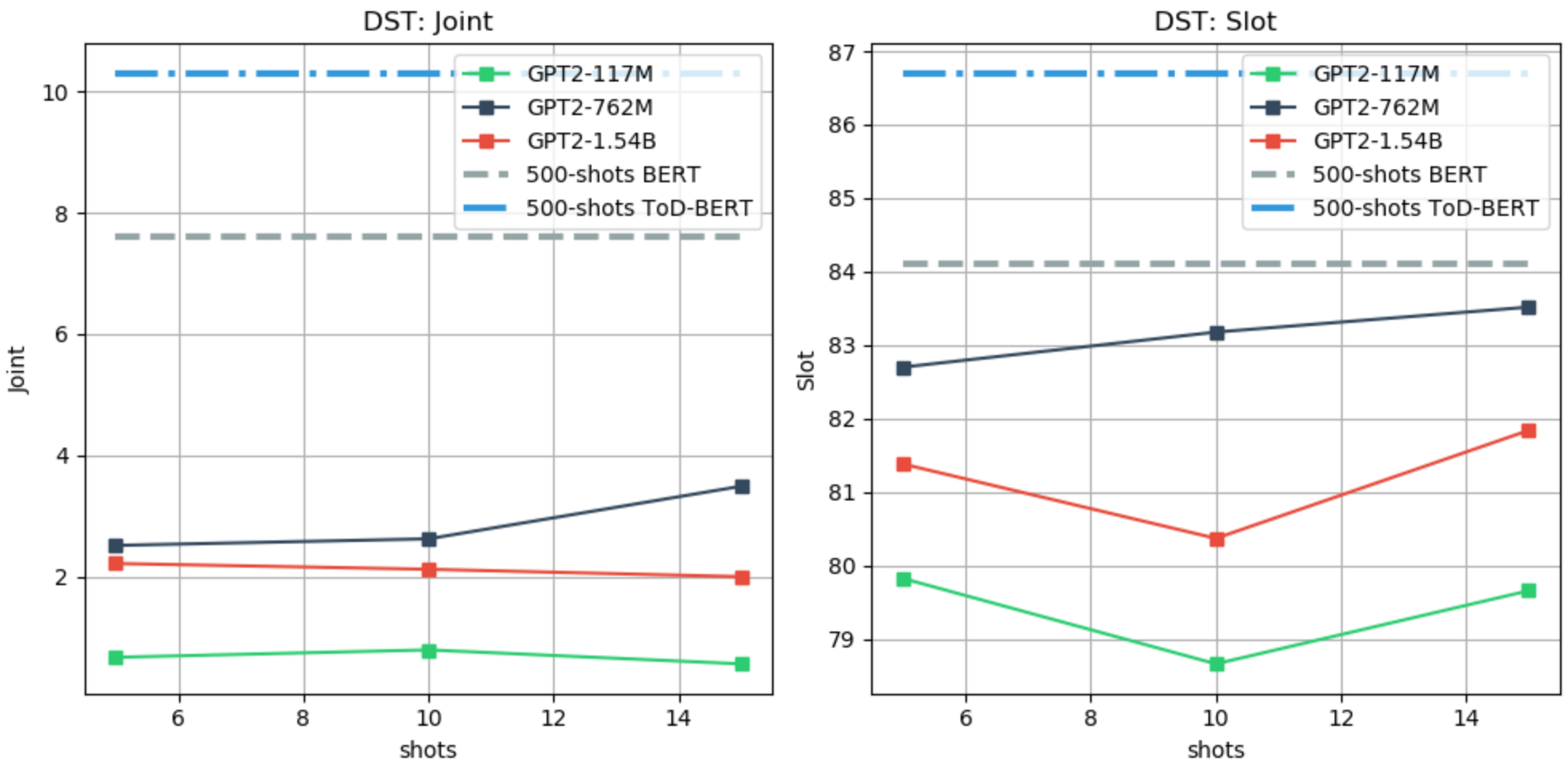
We use the MultiWoZ Budzianowski et al. (2018); Eric et al. (2019); Zang et al. (2020) dataset for evaluating the DST task. Differently from other works, we use the last user utterance only as input to the model, and we update the predicted-DST through turns. For the few-shot evaluation, we follow the setting of Wu et al. (2020), and we report the joint and slot accuracy. As baselines, we use TOD-BERT Wu et al. (2020) and BERT Devlin et al. (2019) fine-tuned with 10% of the training data, which is equivalent to 500 examples. We use a value-based LM prefix, as for the SLOT-FILLING task, with a maximum of 15 shots due to limited context. Table 4 and Figure 6 show more detailed results.
ACT
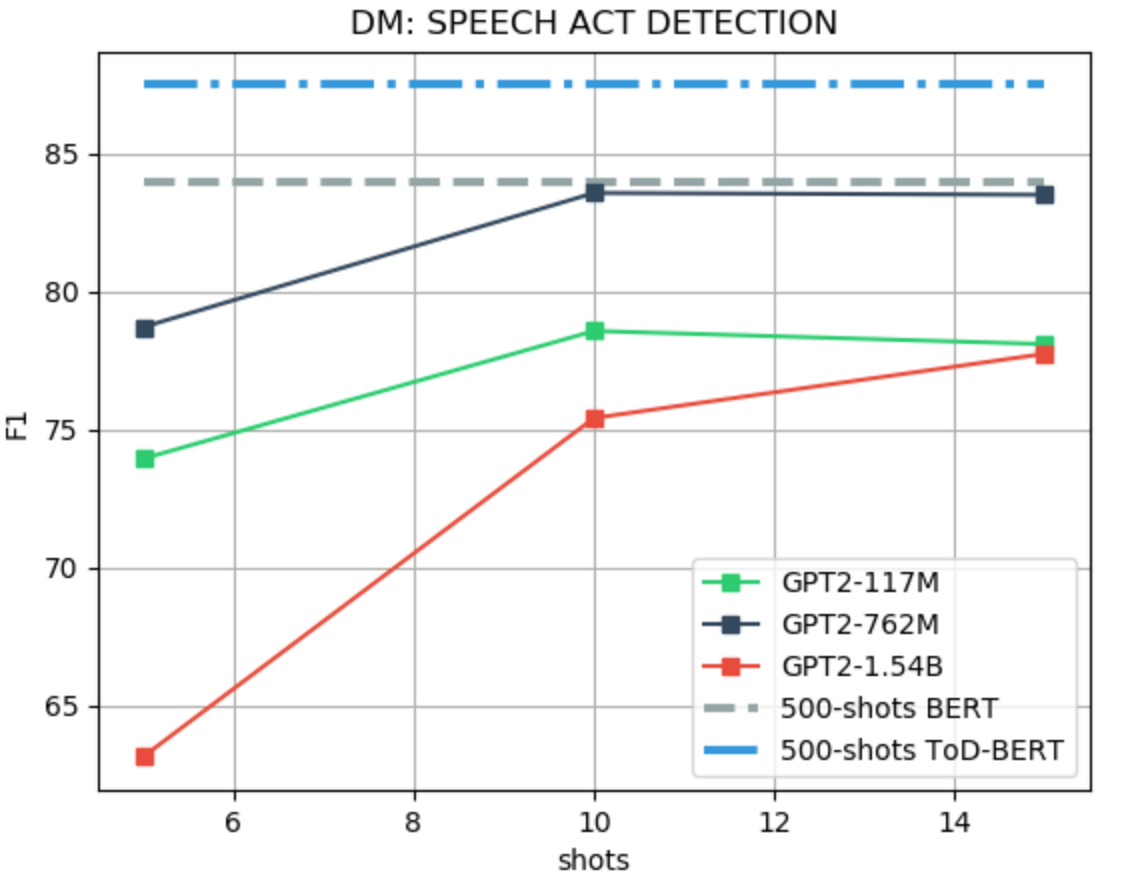
We use the MultiWoZ dataset for evaluating the speech ACT identification task. Differently from other works, only the system utterance is used as input to the model, instead of including the dialogue history and the user utterance as in Wu et al. (2020). For the few-shot evaluation, we follow the setting of Wu et al. (2020), i.e., F1-score. As baselines, we use TOD-BERT Wu et al. (2020) and BERT Devlin et al. (2019), fine-tuned with 10% of the training data, which is equivalent to 500 examples. We use a binary LM prefix, as for the intent classification task, with a maximum of 15 shots due to limited context. An example of a prefix for the ACT tasks and the few-shot performance evaluation is shown in Figure 3. Table 3 and Figure 7 show more detailed results.
NLG
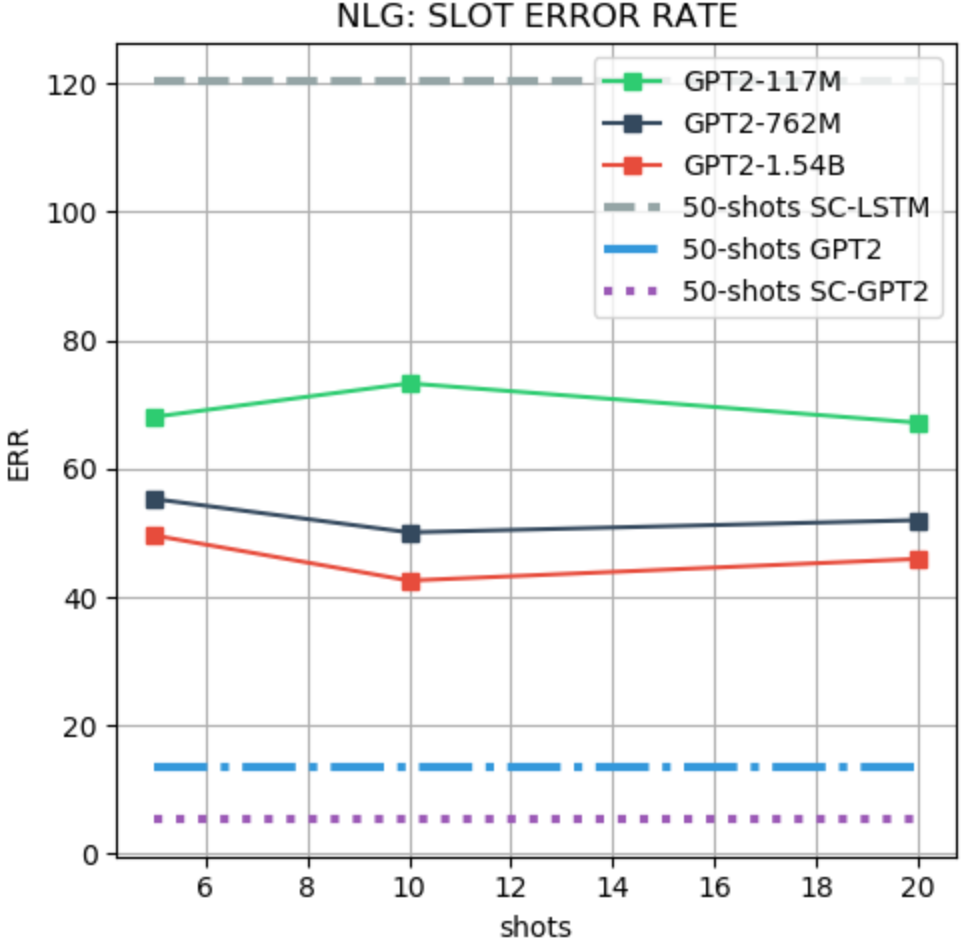
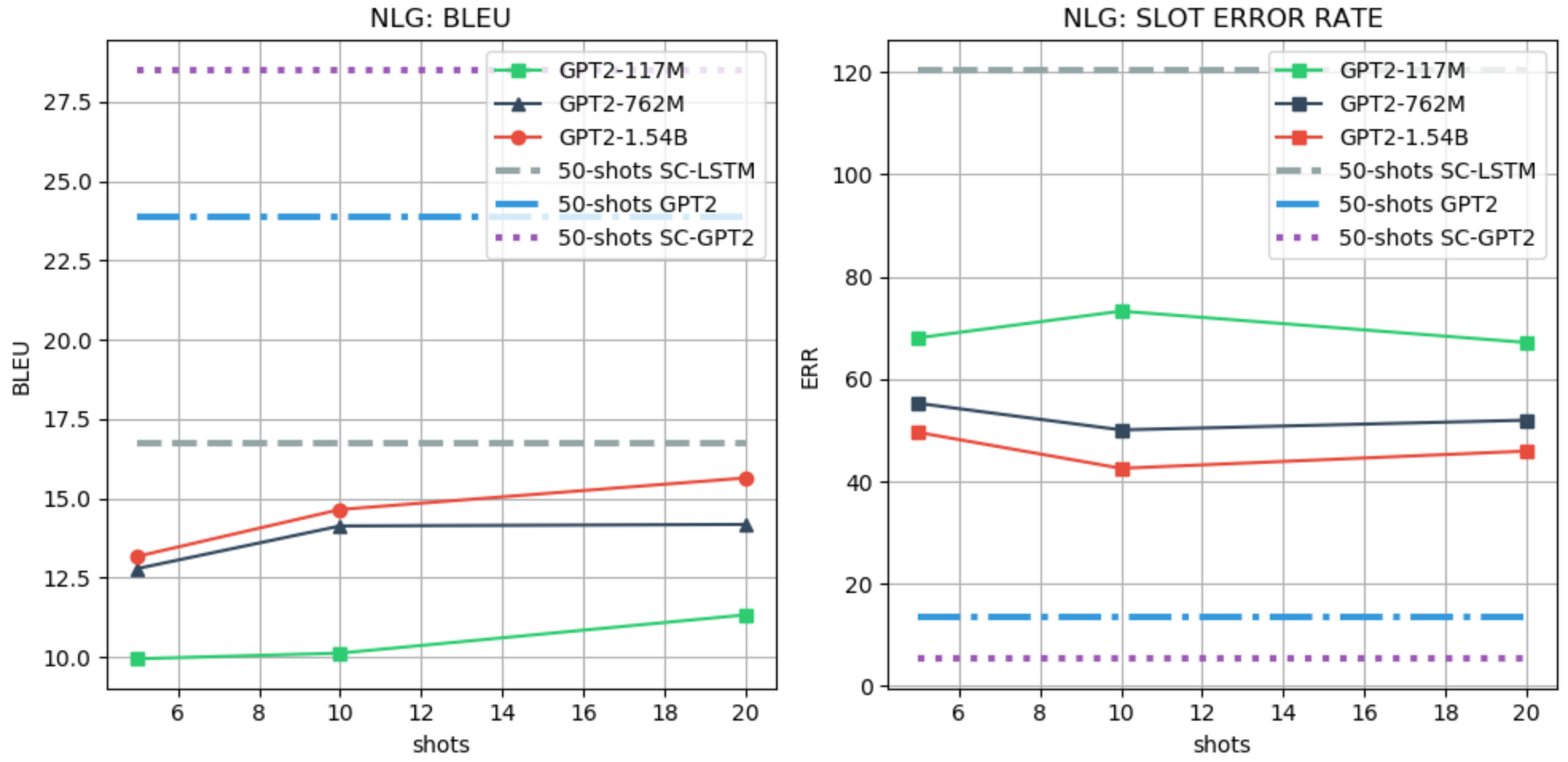
We use the FewShotWOZ Peng et al. (2020b) dataset for evaluating the NLG task. For the few-shot evaluation, we follow the setting of Peng et al. (2020b) and use the BLEU and slot error rate (SLR) as metrics. We use SC-LSTM, GPT-2, and SC-GPT-2 Peng et al. (2020b) as baselines, all fine-tuned with 50 examples from the training data. We use a generative LM prefix with a maximum of 20 shots due to limited context. An example of prefix for the NLG task and the few-shot performance evaluation is shown in Figure 4. Table 6 and 6, and Figure 8 show more detailed results.
5 Analysis and Limitation
From the experimental results, we observe that:
-
•
The larger the model the better the performance in both the NLU and NLG tasks, while, instead, in the DST and ACT tasks, GPT-2 LARGE (762M) performs better than the XL (1.54B) version. This is quite counterintuitive given the results reported for GPT-3. Further investigation is required to understand whether changing the prefix can help to improve the performance of larger models;
-
•
In the NLU, ACT and NLG, LM priming few-shot learning shows promising results, achieving similar or better performance than the weakest finetuning-based baseline, which also uses a larger number of shots. On the other hand, in DST the gap with the existing baseline is still large.
We also observe two limitations of the LM priming:
-
•
Using binary and value-based generation requires as many forwards as the number of classes or slots. Although these forward passes are independent, achieving few-shot learning this way is not as effective as directly generating the class or the tag (e.g., NLU). In early experiments, we tried to covert all the tasks into a generative format, thus making the model directly generate the sequence of tags or the class label. Unfortunately, the results in the generative format were poor, but we are unsure if larger LMs such as GPT-3 can perform better.
-
•
The current max-input length of GPT-2 (1024 tokens) greatly limits the number of shots that can be provided to the model. Indeed, in most of the tasks, no more than 15 shots can be provided, thus making it incomparable with existing models that use a larger number of shots.
6 Conclusion
In this paper, we demonstrate the potential of LM priming few-shot learning in the most common task-oriented dialogue system tasks (NLU, DST, ACT and NLG). Our experiments show that in most of the tasks larger LMs are better few-shot learners, confirming the hypothesis in Brown et al. (2020) and, in some cases, they can also achieve similar or better results than the weakest finetuning-based baseline. Finally, we unveil two limitations of the current LM priming few-shot learning the computational cost and the limited word context size. In future work, we plan to benchmark dialogue-specific models (e.g., DialGPT) and LM with longer context size (e.g., Transformer XL Dai et al. (2019), LongFormer Beltagy et al. (2020), and BigBird Zaheer et al. (2020) etc.). We also plan to investigate adversarial triggers Wallace et al. (2019) for improving the few-shot ability of LMs, and to benchmark end-to-end dialogue tasks.
References
- Beltagy et al. (2020) Iz Beltagy, Matthew E Peters, and Arman Cohan. 2020. Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150.
- Brown et al. (2020) Tom B Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. arXiv preprint arXiv:2005.14165.
- Budzianowski et al. (2018) Paweł Budzianowski, Tsung-Hsien Wen, Bo-Hsiang Tseng, Iñigo Casanueva, Stefan Ultes, Osman Ramadan, and Milica Gasic. 2018. Multiwoz-a large-scale multi-domain wizard-of-oz dataset for task-oriented dialogue modelling. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 5016–5026.
- Coucke et al. (2018) Alice Coucke, Alaa Saade, Adrien Ball, Théodore Bluche, Alexandre Caulier, David Leroy, Clément Doumouro, Thibault Gisselbrecht, Francesco Caltagirone, Thibaut Lavril, et al. 2018. Snips voice platform: an embedded spoken language understanding system for private-by-design voice interfaces. arXiv preprint arXiv:1805.10190.
- Dai et al. (2019) Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V Le, and Ruslan Salakhutdinov. 2019. Transformer-xl: Attentive language models beyond a fixed-length context. arXiv preprint arXiv:1901.02860.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186.
- Eric et al. (2019) Mihail Eric, Rahul Goel, Shachi Paul, Adarsh Kumar, Abhishek Sethi, Peter Ku, Anuj Kumar Goyal, Sanchit Agarwal, Shuyang Gao, and Dilek Hakkani-Tur. 2019. Multiwoz 2.1: A consolidated multi-domain dialogue dataset with state corrections and state tracking baselines. arXiv preprint arXiv:1907.01669.
- Kale and Rastogi (2020) Mihir Kale and Abhinav Rastogi. 2020. Few-shot natural language generation by rewriting templates. arXiv preprint arXiv:2004.15006.
- Liu et al. (2019) Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692.
- Liu et al. (2020) Zihan Liu, Genta Indra Winata, Peng Xu, and Pascale Fung. 2020. Coach: A coarse-to-fine approach for cross-domain slot filling. arXiv preprint arXiv:2004.11727.
- Madotto et al. (2019) Andrea Madotto, Zhaojiang Lin, Chien-Sheng Wu, and Pascale Fung. 2019. Personalizing dialogue agents via meta-learning. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 5454–5459.
- Mi et al. (2019) Fei Mi, Minlie Huang, Jiyong Zhang, and Boi Faltings. 2019. Meta-learning for low-resource natural language generation in task-oriented dialogue systems. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, pages 3151–3157. AAAI Press.
- Peng et al. (2020a) Baolin Peng, Chunyuan Li, Jinchao Li, Shahin Shayandeh, Lars Liden, and Jianfeng Gao. 2020a. Soloist: Few-shot task-oriented dialog with a single pre-trained auto-regressive model. arXiv preprint arXiv:2005.05298.
- Peng et al. (2020b) Baolin Peng, Chenguang Zhu, Chunyuan Li, Xiujun Li, Jinchao Li, Michael Zeng, and Jianfeng Gao. 2020b. Few-shot natural language generation for task-oriented dialog. arXiv preprint arXiv:2002.12328.
- Qian and Yu (2019) Kun Qian and Zhou Yu. 2019. Domain adaptive dialog generation via meta learning. arXiv preprint arXiv:1906.03520.
- Radford et al. (2019) Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners. OpenAI Blog, 1(8):9.
- Raffel et al. (2019) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2019. Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv preprint arXiv:1910.10683.
- Wallace et al. (2019) Eric Wallace, Shi Feng, Nikhil Kandpal, Matt Gardner, and Sameer Singh. 2019. Universal adversarial triggers for attacking and analyzing nlp. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2153–2162.
- Wu et al. (2020) Chien-Sheng Wu, Steven Hoi, Richard Socher, and Caiming Xiong. 2020. Tod-bert: Pre-trained natural language understanding for task-oriented dialogues. arXiv preprint arXiv:2004.06871.
- Wu et al. (2019) Chien-Sheng Wu, Andrea Madotto, Ehsan Hosseini-Asl, Caiming Xiong, Richard Socher, and Pascale Fung. 2019. Transferable multi-domain state generator for task-oriented dialogue systems. arXiv preprint arXiv:1905.08743.
- Xu et al. (2020) Yumo Xu, Chenguang Zhu, Baolin Peng, and Michael Zeng. 2020. Meta dialogue policy learning. arXiv preprint arXiv:2006.02588.
- Zaheer et al. (2020) Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, et al. 2020. Big bird: Transformers for longer sequences. arXiv preprint arXiv:2007.14062.
- Zang et al. (2020) Xiaoxue Zang, Abhinav Rastogi, Srinivas Sunkara, Raghav Gupta, Jianguo Zhang, and Jindong Chen. 2020. Multiwoz 2.2: A dialogue dataset with additional annotation corrections and state tracking baselines. arXiv preprint arXiv:2007.12720.
Appendix A Appendices
SLOT-FILLING add tune to my hype playlist entity_name = None add to playlist confidence boost here comes entity_name = here comes add the track bg knocc out to the rapcaviar playlist entity_name =
INTENT listen to westbam alumb allergic on google music playmusic = true rate this novel 4 points out of 6 playmusic = false add sabrina salerno to the grime instrumentals playlist playmusic =
|
|
|
| Model | Shots | PlayL | Rest. | Weather | PlayM. | RateBook | SearchC. | Find. | Avg |
| gpt2 | 1 | 31.9008 | 8.0350 | 16.4160 | 32.8150 | 43.6023 | 20.4974 | 24.4994 | 25.3951 |
| gpt2 | 10 | 46.2546 | 21.6707 | 19.1909 | 21.4724 | 56.2280 | 38.0345 | 41.7234 | 34.9392 |
| gpt2 | 15 | 54.7410 | 26.4663 | 17.7377 | 28.3369 | 63.8482 | 41.3968 | 47.0525 | 39.9399 |
| gpt2-large | 1 | 54.7548 | 39.4418 | 23.5223 | 20.8827 | 38.3591 | 26.6576 | 43.0562 | 35.2392 |
| gpt2-large | 10 | 71.6635 | 39.2936 | 27.7395 | 48.1905 | 61.4562 | 44.4720 | 53.8340 | 49.5213 |
| gpt2-large | 15 | 71.6569 | 45.5142 | 30.7992 | 46.3439 | 61.7858 | 42.8394 | 61.1420 | 51.4402 |
| gpt2-xl | 1 | 53.8250 | 26.2185 | 23.1651 | 28.7647 | 37.1651 | 37.4536 | 31.0224 | 33.9449 |
| gpt2-xl | 10 | 70.4698 | 40.5039 | 34.7138 | 40.4731 | 74.3899 | 52.0532 | 64.4166 | 53.8600 |
| gpt2-xl | 15 | 67.9448 | 46.9853 | 30.8481 | 44.4646 | 77.1531 | 51.8732 | 67.0917 | 55.1944 |
| Model | Shots | Micro | Macro | Acc |
| gpt2 | 1 | 0.1600 | 0.1553 | 16.0000 |
| gpt2 | 2 | 0.1671 | 0.1034 | 16.7143 |
| gpt2 | 5 | 0.3443 | 0.3223 | 34.4286 |
| gpt2 | 10 | 0.3600 | 0.3715 | 36.0000 |
| gpt2-large | 1 | 0.1343 | 0.1188 | 13.4286 |
| gpt2-large | 2 | 0.3786 | 0.3946 | 37.8571 |
| gpt2-large | 5 | 0.3300 | 0.3175 | 33.0000 |
| gpt2-large | 10 | 0.5514 | 0.5871 | 55.1429 |
| gpt2-xl | 1 | 0.1700 | 0.1346 | 17.0000 |
| gpt2-xl | 2 | 0.3586 | 0.3166 | 35.8571 |
| gpt2-xl | 5 | 0.4671 | 0.4371 | 46.7143 |
| gpt2-xl | 10 | 0.7300 | 0.7450 | 73.0000 |
| Model | Shots | Micro | Macro | Acc |
| gpt2 | 5 | 73.9364 | 54.7965 | 0.7394 |
| gpt2 | 10 | 78.5699 | 59.6442 | 0.7857 |
| gpt2 | 15 | 78.0943 | 59.8866 | 0.7809 |
| gpt2-large | 5 | 78.7105 | 62.2181 | 0.7871 |
| gpt2-large | 10 | 83.5762 | 68.6824 | 0.8358 |
| gpt2-large | 15 | 83.5102 | 68.2287 | 0.8351 |
| gpt2-xl | 5 | 63.1241 | 52.8427 | 0.6312 |
| gpt2-xl | 10 | 75.4120 | 62.2672 | 0.7541 |
| gpt2-xl | 15 | 77.7434 | 63.0193 | 0.7774 |
| Model | Shots | Joint | Slot |
| gpt2 | 5 | 0.7 | 79.8 |
| gpt2 | 10 | 0.8 | 78.7 |
| gpt2 | 15 | 0.6 | 79.7 |
| gpt2-large | 5 | 2.5 | 82.7 |
| gpt2-large | 10 | 2.6 | 83.2 |
| gpt2-large | 15 | 3.5 | 83.5 |
| gpt2-xl | 5 | 2.2 | 81.4 |
| gpt2-xl | 10 | 2.1 | 80.4 |
| gpt2-xl | 15 | 2.0 | 81.8 |
| Model | Shots | restaurant | laptop | hotel | tv | attraction | train | taxi | Avg |
| SC-LSTM | 50 | 15.90 | 21.98 | 31.30 | 22.39 | 7.76 | 6.08 | 11.61 | 16.71 |
| GPT-2 | 50 | 29.48 | 27.43 | 35.75 | 28.47 | 16.11 | 13.72 | 16.27 | 23.89 |
| SC-GPT | 50 | 38.08 | 32.73 | 38.25 | 32.95 | 20.69 | 17.21 | 19.70 | 28.51 |
| gpt2 | 5 | 9.93 | 17.75 | 14.85 | 16.29 | 5.50 | 0.26 | 5.01 | 9.94 |
| gpt2 | 10 | 8.10 | 17.75 | 16.85 | 16.29 | 5.84 | 1.30 | 4.71 | 10.12 |
| gpt2 | 20 | 10.68 | 17.75 | 19.15 | 16.29 | 4.89 | 3.24 | 7.28 | 11.32 |
| gpt2-large | 5 | 10.60 | 24.42 | 13.92 | 24.58 | 7.38 | 0.73 | 7.86 | 12.78 |
| gpt2-large | 10 | 13.10 | 24.42 | 20.68 | 24.58 | 6.68 | 3.18 | 6.25 | 14.13 |
| gpt2-large | 20 | 11.47 | 24.42 | 16.13 | 24.58 | 7.97 | 5.30 | 9.36 | 14.18 |
| gpt2-xl | 5 | 13.65 | 23.39 | 14.26 | 26.61 | 6.96 | 0.74 | 6.59 | 13.17 |
| gpt2-xl | 10 | 14.51 | 23.39 | 19.42 | 26.61 | 8.21 | 4.00 | 6.40 | 14.65 |
| gpt2-xl | 20 | 17.02 | 23.39 | 21.30 | 26.61 | 6.43 | 5.68 | 9.06 | 15.64 |
| Model | Shots | restaurant | laptop | hotel | tv | attraction | train | taxi | Avg |
| SC-LSTM | 50 | 48.02 | 80.48 | 31.54 | 64.62 | 367.12 | 189.88 | 61.45 | 120.44 |
| GPT-2 | 50 | 13.47 | 11.26 | 11.54 | 9.44 | 21.10 | 19.26 | 9.52 | 13.65 |
| SC-GPT | 50 | 3.89 | 3.39 | 2.75 | 3.38 | 12.72 | 7.74 | 3.57 | 5.35 |
| gpt2 | 5 | 60.48 | 60.84 | 73.63 | 72.66 | 81.79 | 60.54 | 66.67 | 68.09 |
| gpt2 | 10 | 72.75 | 60.84 | 78.02 | 72.66 | 80.49 | 88.75 | 59.52 | 73.29 |
| gpt2 | 20 | 70.36 | 60.84 | 74.18 | 72.66 | 67.20 | 68.96 | 55.95 | 67.16 |
| gpt2-large | 5 | 55.39 | 36.33 | 84.62 | 44.02 | 64.31 | 58.11 | 44.05 | 55.26 |
| gpt2-large | 10 | 57.49 | 36.33 | 62.09 | 44.02 | 52.31 | 73.27 | 25.00 | 50.07 |
| gpt2-large | 20 | 48.20 | 36.33 | 85.71 | 44.02 | 56.07 | 61.35 | 32.14 | 51.98 |
| gpt2-xl | 5 | 44.61 | 29.99 | 67.03 | 37.92 | 67.63 | 55.82 | 44.05 | 49.58 |
| gpt2-xl | 10 | 46.41 | 29.99 | 47.80 | 37.92 | 50.87 | 62.36 | 22.62 | 42.57 |
| gpt2-xl | 20 | 44.61 | 29.99 | 68.68 | 37.92 | 56.50 | 52.93 | 30.95 | 45.94 |