Large
deviations and stochastic volatility with jumps:
asymptotic implied volatility for affine models
Abstract.
Let denote the implied volatility at maturity for a strike , where and is the current value of the underlying. We show that has a uniform (in ) limit as maturity tends to infinity, given by the formula , for in some compact neighbourhood of zero in the class of affine stochastic volatility models. The function is the convex dual of the limiting cumulant generating function of the scaled log-spot process. We express in terms of the functional characteristics of the underlying model. The proof of the limiting formula rests on the large deviation behaviour of the scaled log-spot process as time tends to infinity. We apply our results to obtain the limiting smile for several classes of stochastic volatility models with jumps used in applications (e.g. Heston with state-independent jumps, Bates with state-dependent jumps and Barndorff-Nielsen-Shephard model).
Key words and phrases:
Large deviation principle; Stochastic volatility with jumps; Affine processes; Implied volatility in the large maturity limit2000 Mathematics Subject Classification:
60G44, 60F10, 91G201. Introduction
Let the process model a risky security under an equivalent martingale measure and let denote the implied volatility at maturity for a strike (see (53) for the precise definition of ). The main result of the present paper (Theorem 14) states that, if the log-spot follows an affine stochastic volatility process with jumps, then converges to as the maturity tends to infinity, where is given by the formula
| (1) |
The function is the limiting cumulant generating function of the scaled log-spot and is its convex dual (i.e. the Fenchel-Legendre transform of ). Locally uniform convergence of the implied volatility to is also established.
In [FJ11, FJM11] the limiting behaviour of the smile at large maturities in the Heston model is investigated. Theorem 14 can be viewed as a generalisation of the main result in [FJ11, FJM11]. Not only does it cover a large class of stochastic volatility models with jumps rather than a single affine model with continuous trajectories, but furthermore provides a better understanding of the limit: Theorem 14 states that the limit holds also at the critical points and , which are excluded from the analysis in [FJ11, FJM11], and the convergence on the set is shown to be uniform on compact subsets.
In the class of affine stochastic volatility models, the formula for the limiting implied volatility for a fixed strike proved in Tehranchi [Teh09] (see also [Lew00] in the case of the Heston model) also follows from (1), since in Theorem 14 the convergence is uniform on a compact neighbourhood of the origin. In [GL11], the authors give various representations for the implied volatility, including in the large-maturity regime, based on an assumed asymptotic behaviour of certain European derivatives in the underlying model, which is not specified. This representation is not fully explicit in terms of the model parameters and it is therefore unclear how to apply it directly to the class of affine stochastic volatility models.
Contribution of the paper is twofold. First we study the properties of the limiting cumulant generating function of the affine stochastic volatility models. Results in Lemma 9, Theorem 10 and Corollary 11 give new properties of the function , which are crucial for the understanding of the large deviation behaviour of the model. Second, the problem of understanding the limiting behaviour of option prices and the corresponding implied volatilities using the large deviation principle is tackled. The uniform limit in (on all compact subsets of ) of vanilla option prices is given in Theorem 13 for non-degenerate affine stochastic volatility models and exponential Lévy models (i.e. degenerate affine stochastic volatility models). As mentioned above Theorem 14 deals with the limiting implied volatility smiles in these classes of models.
Besides giving a formula, which relates model parameters
and the limiting implied volatility smile,
these theoretical results have the following practical consequences:
(1) in the large-maturity regime studied in this paper, the jumps in the model
influence the limiting implied volatility
smile as maturity tends to infinity (see examples in 6.1);
(2) for every affine stochastic volatility model there exists an exponential Lévy model
such that the smiles of the two models in the limit coincide. In other words the stochasticity of
volatility does not (in the affine class) enlarge the family of possible limiting implied volatility
smiles (see Section 6 for details).
The starting point of the analysis of the large deviation behaviour of an affine stochastic volatility process in the present paper is Theorem 8, taken from [KR11, Theorem 3.4]. This result describes certain properties of the limiting cumulant generating function , which are however insufficient to understand the essential smoothness of required in establishing the large deviation principle of . The main contribution of this paper in the area of affine processes is Theorem 10, which identifies sufficient conditions for the process that imply essential smoothness of the function . The conditions in Theorem 10 are easy to apply to the models of interest (see e.g. Section 2.2). Its proof goes beyond the analysis in [KR11] as one is forced to study the special Lévy-Khintchine form of the characteristics of the process, since their general convexity properties no longer suffice to establish the required behaviour of the limit.
The rest of the paper is organized as follows. In Section 2 we define the class of affine stochastic volatility processes and recall some of their properties. In Section 3 we review briefly basic concepts in the theory of large deviations and state the Gärtner-Ellis theorem. Section 4 establishes the large deviations principle for the scaled log-stock of an affine stochastic volatility model as maturity tends to infinity. Sections 5 and 6 respectively translate this result into option price and implied volatility asymptotics. Numerical examples are given at the end of Section 6.
2. Affine stochastic volatility models with jumps
Consider a stochastic model for a risky security given by
| (2) |
where the interest rate and the dividend yield are non-negative and constant and the log-price process starts at . Since the dynamics of is given under a risk-neutral measure, the forward price process is . We assume throughout the paper without loss of generality that is a forward price process (i.e. ). Denote by a process, starting at a constant level . The process can be interpreted as the instantaneous variance process of but may also control the arrival rate of jumps of . We make the following assumptions on the process throughout the paper.
- A1:
-
is a stochastically continuous, time-homogeneous Markov process with state-space , where .
- A2:
-
The cumulant generating function of is of a particular affine form: there exist functions and such that
for all , where the expectation exists.
Remarks.
(i) A1 and A2 make into an affine process in the sense of [DFS03].
(ii) A1 and A2 imply a homogeneity property of : if the starting value is shifted by , the law of the random variable is shifted by the vector for any .
(iii) Assumptions A1 and A2 imply that the variance process is a one-dimensional strong Markov process in its own right.
(iv) The law of iterated expectations applied to yields the flow-equations for and (see [DFS03, Eq. (3.8)–(3.9)]):
| (3) |
for all .
(v) It is shown in [KR11, Thm. 2.1] (see also [DFS03]) that if for , then for all and such that , the functions and satisfy the generalized Riccati equations
| (4a) | ||||
| (4b) | ||||
where
| (5) |
Furthermore for all we have .
(vi) If is a diffusion process, then ODEs (4) become classical Riccati. Note also that (4) follows from the flow equations (3) by differentiation with respect to .
(vii) and can for small be expressed implicitly in terms of and as
The functions and , defined in (5), must be of Lévy-Khintchine form (see [DFS03]). In other words
| (6a) | ||||
| (6b) | ||||
where , is the inner product on , denotes transposition, , are suitable truncation functions, which we fix by defining
and the parameters satisfy the following admissibility conditions:
-
•
are positive semi-definite -matrices with ;
-
•
, and ;
-
•
and are Lévy measures on and .
Assumptions A1 and A2, the generalized Riccati equations and the Lévy-Khintchine decomposition (6) lead to the following interpretation of and : characterizes the state-independent dynamics of the process while characterizes its state-dependent dynamics. The instantaneous characteristics of the Markov process are given as follows: the instantaneous covariance matrix, the instantaneous drift, the instantaneous arrival rate of jumps with jump heights in and the instantaneous killing rate.
The function defined below plays a key role in the characterisation of the martingale property of the process .
Definition 1.
For each such that , define as
Remarks.
(i) The condition implies that, for some the function is convex on and differentiable on , since the process does not have negative jumps. Therefore is a well-defined, possibly equal to , convex function given by the limit of as . It can be expressed explicitly as
Since serves as a forward price process under a risk-neutral measure in an arbitrage-free asset pricing model, it has to be conservative and a martingale and hence we assume:
- A3:
-
and .
In particular in assumption A3 means that the instantaneous killing rates and in (6) are zero and the condition is closely related to the functions and being identically equal to zero (see the generalized Riccati equations in (4)), which implies the martingale property of . The following non-degeneracy assumption will guarantee the stochasticity of volatility of the process .
- A4:
-
There exists some , such that .
Definition 2.
The process is a non-degenerate (resp. degenerate) affine stochastic volatility process if it satisfies assumptions A1 – A4 (resp. A1 – A3 and does not satisfy A4) and is the corresponding affine stochastic volatility model.
Remark.
Assumption A4 excludes the degenerate case where the distribution of does not depend on the volatility state . Indeed, if A4 is not satisfied, i.e. , then (4) implies that and for all where the expectation in assumption A2 exists. Hence if A4 does not hold, then A2, (6a) and the characterisation theorem for regular affine processes [DFS03, Theorem 2.7] imply that is an exponential Lévy model. In particular the class of affine stochastic volatility models includes the Black-Scholes model as a degenerate case.
The following proposition describes certain properties of and that will play a crucial role in Section 4.1.
Proposition 3.
Let be a non-degenerate affine stochastic volatility model and let the sets and be the effective domains of the functions and respectively. Then the following holds:
-
(A)
and are lower semicontinuous convex functions, which are continuously differentiable in the interiors and (in ), and their effective domains and are also convex;
-
(B)
and are either affine or strictly convex functions when restricted to one-dimensional affine subspaces of .
Proof.
The Lévy-Khintchine representation for and in (6) implies that they are cumulant generating functions of some (infinitely divisible) random vectors taking values in . Hölder’s inequality yields that and are convex. The dominated convergence theorem and the representation in (6) implies that and are analytic in and respectively. Fatou’s lemma implies that the functions and are lower semicontinuous. Since and are cumulant generating functions, the second derivative of their restriction to an affine subspace is either identically zero or strictly positive everywhere (each affine subspace in corresponds to a random variable which takes values in and may or may not be constant almost surely). This concludes the proof. ∎
2.1. SDE representation of affine stochastic volatility processes
In order to define an affine stochastic volatility model one needs to choose admissible parameters such that the corresponding process , which exists by [DFS03, Thm. 2.7], satisfies assumptions A1 – A3 (note that by A3 and will henceforth be ignored). This procedure yields a semigroup, and hence the law, of the Markov process which is in principle sufficient for option pricing. However path-wise descriptions of the pricing models in financial markets are widely used as they add to the intuitive understanding of the properties of the model. In the rest of this section we briefly describe a path-wise construction of the process , given in [DL06], and relate it to the most popular affine stochastic volatility models used in derivatives pricing.
Assume that the parameters are admissible and suppose in addition that the tails (i.e. the large jumps) of and satisfy:
| (7) |
where Let
| (8) |
Note that the integrals in (8) are finite by (7) and the parameters are admissible with appropriate truncation functions.
Let be a filtered probability space equipped with
-
a three-dimensional standard Brownian motion ,
-
a Poisson random measure on with compensator ,
-
a Poisson random measure on with compensator ,
where as usual denotes the state-space of the model. Let
be the compensated Poisson random measures and let be a -matrix such that . Theorem 6.2 in [DL06] implies that the system of SDEs
with initial condition , has a unique strong solution that is an affine Markov process with admissible parameters .
Remarks.
(i) The change of parameters and introduced in (8) is inessential. Its function is to establish the notational compatibility with [DL06].
(ii) The integrals in (2.1)–(2.1) against are taken over a random set whose -volume is proportional to . This, together with the structure of the Poisson random measure , reinforces the intuition that the jumps of the process that correspond to the integral term with respect to have random intensity which is proportional to .
2.2. Examples of affine stochastic volatility models
We now describe some of the affine stochastic volatility models that are of interest in the financial markets and can be obtained as solutions of the special cases of SDE (2.1)–(2.1).
2.2.1. Heston model
The log-price and the stochastic variance process are given under the risk-neutral measure by the SDE
where are Brownian motions with correlation parameter , and (see [Hes93]). The affine characteristics of the model are
| (11a) | ||||
| (11b) | ||||
It is easily seen that is given by
| (12) |
and it is trivial to check that A1 – A4 are satisfied.
2.2.2. Heston model with state-independent jumps
Let be a pure-jump Lévy process independent of the correlated Brownian motions and . The Heston-with-jumps model is defined by the SDEs
where and . Assume that is a spectrally negative Lévy process with characteristic exponent . Since only jumps down, this captures the generic situation in the modelling of equity markets. Assume further that the jumps of are integrable (i.e. ). In order to identify the coefficients in (2.1)–(2.1), we compensate so that it becomes a martingale and can hence be expressed as an integral against the compensated Poisson random measure . This implies
It is easily seen that , , , , and , where is the Dirac delta measure. Therefore , , and . The martingale condition () implies and the affine form of the model is given by
| (13a) | ||||
| (13b) | ||||
where is the compensated cumulant generating function of the jump part, i.e.
| (14) |
2.2.3. A model of Bates with state-dependent jumps
We consider the model given by
where as before , and the Brownian motions and are correlated with correlation . The jump component is given by , where is a Poisson random measure independent of and with intensity measure of the state-dependent form . Here denotes a Lévy measure on . A model of this kind has been proposed in [Bat00] to explain the time-variation of jump-risk implicit in observed option prices.
As in Section 2.2.2, we assume that the support of is contained in and that the inequality is satisfied. We can identify the parameters in (2.1)–(2.1) as , , , , , , , , and , where is the Dirac delta concentrated at . Hence we find
and , . The functions and for the Bates model are
| (15a) | ||||
| (15b) | ||||
where and the martingale property () was used to determine the value of the parameter . It is clear that and that A1 – A4 are satisfied.
2.2.4. The Barndorff-Nielsen-Shephard (BNS) model
The BNS model was introduced in [BNS01] as a model for asset pricing. Under a risk-neutral measure, it can be defined by the following SDE
where , and is a Lévy subordinator with the Lévy measure , i.e. a pure jump Lévy process that increases a.s. The cumulant generating function of takes the form
| (16) |
To conform with (7) we further assume that . The drift will be determined by the martingale condition for . The time-scaling is introduced in [BNS01] to make the invariant distribution of the variance process independent of . The distinctive features of the BNS model are that the variance process has no diffusion component, i.e. moves purely by jumps, and the negative correlation between variance and price movements is achieved by simultaneous jumps in and .
It follows from (2.1)–(2.1) and the SDE above that , , and
where denotes the indicator function of the half-line in . Therefore it follows that , , , and
The definition of in (6) and the martingale condition imply that we need to define , where is the cumulant generating function of given in (16). The BNS model is an affine stochastic volatility model with and given by
| (17a) | ||||
| (17b) | ||||
We have and the assumptions A1 – A4 are clearly satisfied.
3. Large deviation principle and the Gärtner-Ellis theorem
In this section we give a brief review of the key concepts of large deviations for a family of (possibly dependent) random variables and state a version of the Gärtner-Ellis theorem (see Theorem 6) that will be used to obtain the asymptotic behaviour of the option prices and implied volatilities. A general reference for all the concepts in this section is [DZ98, Section 2.3].
Let take values in and recall that is lower semicontinuous if is closed in for any (intuitively for any the values of near are either close to or greater than ). A nonnegative lower semicontinuous function is called a rate function. If in addition is compact for any , then is a good rate function.
Definition 4.
The family satisfies the large deviation principle (LDP) with the rate function if for every Borel set we have
with the convention (the interior and closure are relative to the topology of ).
An important consequence of Definition 4 is that if satisfies LDP and is continuous on , then .
The Gärtner-Ellis theorem (Theorem 6) gives sufficient conditions for to satisfy the LDP and in that case describes the rate function. Let be a cumulant generating function. Assume that for every
| (18) |
where is the effective domain of and is its interior in . Since is convex (by the Hölder inequality) for every , the limit is also convex by [Roc70, Theorem 10.8] and the set is an interval. Since , convexity of and imply for all . Furthermore the convexity implies that is continuous on . The statement in (18) is an important assumption of Gärtner-Ellis theorem (Theorem 6 below), which in particular implies . However the converse does not hold in general, i.e. if is a boundary point of a domain with non-empty interior, LDP may still hold true.
A further property of the function , which arises as an assumption in Theorem 6, is essential smoothness.
Definition 5.
A convex function is essentially smooth if
-
(a)
is non-empty;
-
(b)
is differentiable in ;
-
(c)
is steep, in other words it satisfies for every sequence in that converges to a boundary point of .
The Fenchel-Legendre transform (or convex dual) of is defined by the formula
| (19) |
with an effective domain . The following properties are immediate from the definition:
-
(i)
for all , since ;
-
(ii)
for all and hence is convex in the interval and continuous in the interior ;
-
(iii)
is lower semicontinuous on as it is a supremum of continuous (in fact linear) functions. Hence the level sets are closed.
In general can be strictly contained in and can be discontinuous at the boundary of (see [DZ98, Section 2.3] for elementary examples of such rate functions). Assumption (18) implies that for any , such that , and we have
| (20) |
Hence the set is compact for any and therefore is a good rate function.
Remarks.
(A) If is strictly convex, differentiable on and steep, which is the case in the applications in this paper, then and for each the equation has a unique solution in . Furthermore the formula
| (21) |
holds. This reduces the computation of
to finding the unique root of the
equation
,
where the strictly increasing function
is in most applications known in closed form.
(B) If
satisfies (18)
and
the function
satisfies the assumptions of Remark (A)
and is twice differentiable with
for all
,
then (21)
implies that the Fenchel-Legendre transform
is differentiable with the derivative
| (22) |
In particular (22) implies that is strictly convex on and that its global minimum is attained at the unique point given by
We state a simple version of the Gärtner-Ellis theorem (for the proof see [DZ98, Section 2.3]).
Theorem 6.
Let be a family of random variables that satisfies assumption (18) with the limiting cumulant generating function . If is essentially smooth and lower semicontinuous, then the LDP holds for with the good rate function .
4. Limiting cumulant generating function in affine stochastic volatility models
4.1. Non-degenerate affine stochastic volatility processes
Let be a non-degenerate affine stochastic volatility process (see Definition 2). The goal of the present section is to describe the limiting cumulant generating function of the family of variables , defined by
| (23) |
for every where the limit in (23) exists as an extended real number. The function will determine the limiting implied volatility smile of the model . To ensure that is finite on an interval that contains , which is key for establishing the LDP, a further assumption will be required:
- A5:
-
and , where is given in Definition 1.
This assumption will also imply that can be uniquely extended to a cumulant generating function of an infinitely divisible random variable.
In order to apply the Gärtner-Ellis theorem in our setting, we need to answer the following three questions: is well-defined as an extended real number by (23) for every , does the effective domain contain in its interior and is essentially smooth? Answers to these questions play a crucial role in establishing the large deviation principle, via Theorem 6, for affine stochastic volatility models. Theorem 10 and Corollary 11, proved in this section, provide easy to check sufficient conditions for the affirmative answers to hold.
It is shown in [KR11] that the function can be obtained from the functions and without the explicit knowledge of and (see Section 2 for definition of ). Lemma 7 and Theorem 8, taken from [KR11, Lemma 3.2 and Theorem 3.4], describe certain properties of the limiting cumulant generating function , which are needed in Section 5 but are insufficient to guarantee the essential smoothness of . The main contribution of the present section is Theorem 10, which identifies sufficient conditions for the process that imply essential smoothness of the function . The conditions in Theorem 10 are easy to apply to the models of Section 2.2, which will allow us to find their limiting implied volatility smiles.
Lemma 7.
Remarks.
(i) The proof of Lemma 7 in [KR11] is based on the analysis of the qualitative properties of the generalized Riccati equations in (4).
(ii) The function from Lemma 7 can be extended naturally to a lower semicontinuous function by . Then the extension, again denoted by , has the following properties:
-
•
is convex with effective domain and ;
-
•
the maximality of implies that for there exists no such that .
The next theorem, proved in [KR11, Theorem 3.4], describes further properties of the function and specifies its relationship to the limiting cumulant generating function defined in (23).
Theorem 8.
Let be a non-degenerate affine stochastic volatility process that satisfies assumption A5 and let be given by Lemma 7. Then the function defined in (23) satisfies
| (24) |
where is defined in (5) (see also (6)). Furthermore the inclusions hold: . The functions and can be extended uniquely to cumulant generating functions of infinitely divisible random variables and
| (25a) | ||||
| (25b) | ||||
Remark.
We say that explodes at the boundary if for any sequence in the interior that tends to a point in the boundary of (both the boundary and the interior of are relative to the topology of ) or equivalently is open. By Proposition 3 (A), the gradient is continuous on . Analogously to the one-dimensional case (see (c) in Definition 5), we say that is steep if for any sequence in the interior that tends to a point in the boundary of . It is clear that if explodes at the boundary, it is also steep but the converse may not be true.
Before we state and prove the main results of this section (Theorem 10 and Corollary 11), we establish Lemma 9, which states that in an affine stochastic volatility model, the limiting cumulant generating function cannot be identically equal to zero. This property will play an important role in understanding the limiting behaviour of the implied volatility smile (see e.g. Theorem 13).
Lemma 9.
Let be a non-degenerate affine stochastic volatility process that satisfies assumption A5 and let be given by (23). Assume further that the interior of the effective domain of contains the set and that for some . Then for all and for all . Furthermore we have for all .
Proof.
Note that since can be extended to a cumulant generating function of a random variable by Theorem 8, it is smooth in . Since is either identically equal to zero or strictly convex on by the remark following Theorem 8, the statement for all follows if we prove that for some .
The function is convex by (B) of Proposition 3. Furthermore it is either (I) strictly convex or (II) identically equal to zero (by A3). We analyse both cases.
(I) Strict convexity and A3 imply that for we have . The same argument implies that for , such that , the inequality holds. The Lévy-Khintchine representation of in (6) implies that
| (26) |
for any point in the interior of the effective domain . It is clear from (26) that on . Lemma 7 implies that for we have . Identity (24) in Theorem 8 yields
The last inequality follows from the strict convexity of . If , then and an analogous argument implies that . The inequality at the boundary points of the interval follows from the convexity of .
(II) Assume now that is identically equal to zero. For any in the interior of the effective domain of , the Lévy-Khintchine representation of in (6) yields
This implies and , where is a Lévy measure on with integrable small jumps and is the Dirac delta. The condition in A3 and the representation of in (6) yield . Hence we have
Since by assumption there exists such that , either or holds. Therefore identity (24) in Theorem 8, Lemma 7 and this representation of conclude the proof. ∎
Remark.
Theorem 10.
Let be a non-degenerate affine stochastic volatility process that satisfies assumption A5 and suppose that the function , where is defined in (5), is not identically equal to zero. If explodes at the boundary (i.e. is open), is steep and , then the function is well-defined by (23) as an extended real number for every and its effective domain is given by (see (24) for the definition of interval ). Furthermore is essentially smooth and the set is contained in the interior (relative to ) of .
Corollary 11.
Let be a non-degenerate affine stochastic volatility process that satisfies assumption A5 and assume that is not identically equal to zero. If either of the following conditions holds
-
(i)
has exponential moments of all orders, is steep, and contains and ,
-
(ii)
is a diffusion,
then the function is well-defined by (23) for every with effective domain . Moreover is essentially smooth and .
Proof of Corollary 11. Note that either of the conditions (i) or (ii) implies that and hence is open. Therefore (i) and the assumptions of Corollary 11 imply the assumptions of Theorem 10. If (ii) holds, then is a diffusion and
Clearly contains the set and is steep if is non-zero. In the case , the map is identically equal to zero, which contradicts the assumption in Corollary 11. Thus Corollary 11 follows from Theorem 10.
Proof of Theorem 10. The proof of this theorem is in two steps. In step (I) we show that and that, if we extend by to , we obtain an essentially smooth convex function. In step (II) of the proof we show that the limit in definition (23) exists for any as an extended real number and that definition of in (23) agrees for every with the extension of from the first part of the proof.
Step (I). Throughout this step we abuse notation by using to denote the extension of to described above. Theorem 8 and the remark following it imply that is essentially smooth (see Definition 5) if it is steep. We will prove the steepness of at the right endpoint of the interval and show that . The left endpoint and the fact can be treated by a completely symmetrical argument.
Let be a sequence in converging to . We use the shorthand notation and , where is the function given in Lemma 7 (note that the limit exists but may be infinite since is a cumulant generating function of a random variable and ). Since is convex on , the value is independent of the choice of sequence .
Claim 1. The inequalities and hold.
Indeed, since
by assumption A3, we get that .
Assume now that . Then
by Lemma 7 we have
and
.
Since
is continuously differentiable in
and
by assumption A5, the implicit function theorem
and Lemma 7
imply that
is in the set
.
Since
,
there exists
such that
and
.
Identity (24)
in Theorem 8
therefore
implies that
,
which contradicts the definition of
.
Therefore .
Lemma 7
implies that the sequence
is eventually (certainly when
) non-decreasing
and strictly positive.
This yields that
and the claim follows.
Discarding finitely many elements we may assume that and for all . If is infinite, it is not in the boundary of and the steepness of follows. If is finite but is infinite, identity (24) and the assumption that is non-zero imply . The steepness of follows from the convexity of . Therefore in the rest of the proof we can assume
| (27) |
without loss of generality.
Claim 2. The following statements hold true:
The statement in (a) follows from Lemma 7, assumption and the chain rule. To prove the first statement in (b), note that and hence . Lemma 7 therefore implies that the function is strictly convex with and therefore strictly increasing on . Pick such that and note that (by the definition of ) and (by representation (6) and ). Assumption in the theorem and the fact imply that the point lies in the interior of the triangle with vertices in the convex set . Therefore . Equality (29) follows by the chain rule. This proves the claim.
Claim 3. The following holds for any strictly increasing sequence with limit :
-
(a)
if , then
-
(b)
if , then
To prove the claim, assume that the conclusion of (a) does not hold. Since the sequence is non-decreasing by Lemma 7, there exists a finite positive number, denoted by , such that . Claim 2(a), applied to , implies for all and hence by (27) is in the closure of . However cannot be in the boundary of since explodes at the boundary by assumption and it holds (recall that for all ). Therefore . The derivatives are hence continuous at and, in the limit as , formula (28) and the fact imply
Therefore either or both partial derivatives at are non-zero. Suppose the former. For an arbitrary , the convexity of yields
Since (see assumptions A3 and A4), this leads to a contradiction. Hence and are non-zero and related by the equality above. By the implicit function theorem there exists an open interval containing and a function , such that for all . This contradicts the maximality of and proves Claim 3(a). Note that under assumption of Claim 3(b), must be a boundary point of . Since is steep this implies and the claim follows.
Theorem 10 follows easily if as . Indeed, assumption (27) and Lemma 7 imply that the sequence is strictly increasing and positive for all large . Since , Proposition 3 (B) implies that . The Lévy-Khintchine representation of in (6) implies for all . Since the gradient of the convex function is monotone on and for all , we find
Therefore by (29) we obtain
| (30) |
If as , the steepness of at follows from (27), (30) and the fact that is strictly positive and increasing. If as , then, since on , formula (29) implies Theorem 10.
If does not tend to infinity as
,
the following facts hold:
(since
is in the closure of
and
is steep),
as
(by Claim 3)
and
for all
(by Lévy-Khintchine representation (6)
of
).
The next claim plays a key role in the proof
of steepness of
.
Claim 4.
If does not tend to infinity as
,
then
.
In particular there exists
such that
for all large
.
Note first that is well-defined since . If , differentiation under the integral in (6) implies that and the support of is contained in the set . This would imply that for all , which contradicts the assumption in the theorem. Hence the claim follows.
To conclude the proof of Step (I), it remains to note that equality (29) applied at together with Claim 4 yield the steepness of in the case does not tend to infinity.
Step (II). We now prove that for any , the limit in (23) is equal to . This will conclude the proof of Theorem 10.
Let and define for all . We know that for all . Moreover by Step (I), is steep at the boundary of and . Since is infinitely divisible for all (see [DFS03, Theorem 2.15]), there exist random variables such that (i.e. is the cumulant generating function of ). Therefore there exists a random variable such that in distribution and, if we define for all , the equality holds on . Since is a cumulant generating function, it is lower semicontinuous and convex, and in particular continuously differentiable in the interior of its effective domain . But is steep and hence non-differentiable at the boundary of . Therefore it follows that and for all . However for all , the Skorokhod representation theorem and Fatou’s lemma imply
Hence the equality holds for . This concludes the proof of Theorem 10.
4.2. Degenerate affine stochastic volatility models
The remark following Definition 2 implies that in the case of a degenerate affine stochastic volatility process , the model is an exponential Lévy model (note also that A5 in this setting fails). Therefore Definition 2 and (6) imply that the characteristic exponent of possesses a Lévy-Khintchine characteristic triplet , where and a Lévy measure on , and satisfies
for all where the expectation exists. The independence and stationarity of the increments of imply that is a martingale if and only if , which is, in terms of the characteristic triplet , equivalent to and
| (32) |
The limiting cumulant generating function for the family of random variables , defined by the limit in (18), is in the case when is a Lévy process given trivially by in (4.2), which therefore also coincides with definition (23). The martingale condition for and the convexity of imply that is contained in the effective domain . In the case of affine stochastic volatility models we had to establish Theorem 10 to obtain sufficient condition for the set to be contained in the interior of the effective domain of . In the setting of Lévy processes it is well known (see e.g. [Sat99, Theorem 25.17]) that if and only if
| (33) |
Condition (33) implies that the interior of the effective domain of is of the form for some and . It is therefore clear that is steep if and only if
| (34) | and |
where the integrals are taken to be infinite if the integrands take infinite value for some finite (e.g. if or ). Note also that under assumption (32), the Lévy process is non-constant if and only if there is a Brownian component (i.e. ) or its paths are discontinuous (i.e. ). Hence the equality
implies for all . These arguments therefore imply Proposition 12, which is the analogue of Theorem 10 for Lévy processes.
Proposition 12.
Let be a non-constant Lévy process (i.e. the first component of a degenerate affine stochastic volatility process) with state-space , characteristic triplet and the characteristic exponent given by (4.2). Assume further that conditions (32), (33) and (34) are satisfied. Then the interior of the effective domain of is an interval , where are extended real numbers, is a convex essentially smooth limiting cumulant generating function for the family and the set is contained in the interior of . Furthermore, is smooth on and for all .
5. Rate functions and the option prices far from maturity
In this section we describe the limiting behaviour of a family of European options under an affine stochastic volatility model . These results will be used in Section 6 to prove the formulae for the limiting implied volatility smile.
In order to understand the limits of the vanilla option prices far from maturity in an affine stochastic volatility model , we will need to apply the large deviation principle for the family under a risk-neutral measure and under the measure , known as the share measure.111The name stems from the fact that under the numeraire asset is the risky security . Recall that for every the measure is equivalent to on the -field and the Radon-Nikodym derivative is given by
The limiting cumulant generating function for under is defined by
| (35) |
The function and its effective domain satisfy
| (36) |
where is the limiting cumulant generating function defined in (23) and is its effective domain. Note that if and only if . The identity in (36) implies the following relationship between the Fenchel-Legendre transforms (see (19) for the definition) of and :
| (37) |
Theorem 13 below describes the limiting behaviour of certain European derivatives under an affine stochastic volatility process . Before we state it, we collect the following facts.
Remarks.
(i) If is a non-degenerate affine stochastic volatility process that satisfies assumptions of Lemma 9, then the limiting cumulant generating functions and (defined in (23) and (35) respectively) are strictly convex with strictly positive second derivatives in the interior of their respective effective domains. Remark (B) after Definition 5 implies that their convex duals and are strictly convex and differentiable with respective unique global minima attained at
| (38) | and |
Lemma 9 also implies the following inequalities:
| (39) |
(ii) If is a degenerate affine stochastic volatility process that satisfies assumptions of Proposition 12, then is strictly increasing on and its image is equal to . The unique global minima of the Fenchel-Legendre transforms and are (by Remark (B) after Definition 5) explicitly given by
| (40a) | ||||
| (40b) | ||||
Formulae (40) show that the inequalities in (39)
hold also in the degenerate case.
(iii) In the case of the Black-Scholes model
(i.e.
),
the assumptions of Proposition 12
are satisfied.
The effective domains of
and
are equal to
and the following formulae hold
| (41) | and | ||||
| (42) | and |
Therefore we have and .
Theorem 13.
Let be a non-degenerate (resp. degenerate) affine stochastic volatility process that satisfies the assumptions of Theorem 10 or Corollaries 11 (i), 11 (ii) (resp. Proposition 12). Then the family of random variables satisfies the LDPs under the measures and with the respective good rate functions and , where is given in (23) (resp. (4.2)) and in (35). Fix , let be as in (38) (resp. (40)) and denote and for .
-
(i)
The asymptotic behaviour of a put option with strike is given by the following formula
-
(ii)
The asymptotic behaviour of a call option, struck at , is given by the formula
-
(iii)
The asymptotic behaviour of a covered call option with payoff is given by
Furthermore the convergence in (i)-(iii) is uniform in on compact subsets of .
Remarks.
(I) The formulae in (i), (ii) and (iii) of
Theorem 13
are continuous in
since
the value of
the Fenchel-Legendre transforms
(resp.
)
at
(resp.
)
is equal to zero.
Note further that the formulae in
Theorem 13
are independent of the starting value
of the model.
(II) The reason for studying the limiting behaviour of the put, call and
covered call in Theorem 13
lies in the fact that these payoffs yield non-trivial limits
on complementary subintervals of
,
thus
obtaining a non-trivial limit for every
.
This limit will be
compared
in Section 6
with the corresponding limit in the Black-Scholes
model, which will yield
the formula for the limiting implied volatility smile
under affine stochastic volatility models.
Proof.
Assume first that is a non-degenerate affine stochastic volatility process. The limiting cumulant generating function satisfies (18) and is essentially smooth either by Theorem 10 or by Corollaries 11 (i), 11 (ii). Hence its convex dual is non-negative (by (19) and the fact ), has compact level sets (by (20) and ) and is differentiable on with strictly increasing first derivative (by Lemma 9 and Remark (B) following Definition 5). Therefore by Theorem 6 the family satisfies the LDP under with the good rate function . Since , by (36) the function satisfies the condition in (18). Therefore all of the assumptions of Theorem 6 hold under and hence satisfies the LDP with the good rate function . Furthermore enjoys the same regularity on as the rate function . The LDPs in the degenerate case follow from the same argument with Theorem 10, Corollaries 11 (i), 11 (ii) and Lemma 9 replaced by Proposition 12.
We now prove the formulae in Theorem 13. Without loss of generality we may assume that , i.e. . The following inequality holds for all and :
Hence by taking expectations, logarithms, multiplying by and applying the LDP for under we obtain the following inequalities
Since is continuous on , strictly decreasing for and takes value at , the formula in Theorem 13 (i) holds.
We now consider the call option case. The following inequality holds for all and :
Again by taking expectations, changing measure to , applying logarithms, multiplying by and applying the LDP for under we obtain the following inequalities
Note that is a global minimum for at which value is attained. The continuity of implies the formula in Theorem 13 (ii).
In the case of the covered call, the following simple inequalities hold for all :
| (46) | |||||
| (47) | |||||
| (48) |
Inequality (46) and the LDP under measures and imply the inequalities
for any , and large enough. Assume now and note that in this case we have and . By (37) we obtain
for any and all large . Therefore we find the inequalities
for all . This proves the formula in Theorem 13 (iii) for .
Assume that and take expectations, change measure to , apply logarithms and multiply by the inequalities in (47) to obtain the following:
Since the LDP for under implies the formula in Theorem 13 (iii) that corresponds to .
Finally let . Inequalities in (48) imply the following
An application of the LDP for under completes the proof of part (iii).
We now show that the limits in the theorem are uniform in on compact sets in . Since the argument is similar in all the cases, we concentrate on Theorem 13 (i). Let be a finite interval in and define for any and
where denotes the continuous limit that appears in Theorem 13 (i). It follows that
We therefore find
| (49) |
Since we have already proved that for every and the limiting function is continuous, and hence uniformly continuous on every compact set, the inequality in (49) implies that the logarithms of the put option prices converge to uniformly in on compact sets in .
∎
6. Asymptotic behaviour of the implied volatility
The value of the European call option with strike and expiry in a Black-Scholes model (i.e. degenerate affine stochastic volatility model without jumps, see Section 4.2) is given by the Black-Scholes formula
| (50) |
and is the standard normal cumulative distribution function. Let be an affine stochastic volatility model from Definition 2 with the starting point . The implied volatility in the model for the strike and maturity is the unique positive number that satisfies the following equation in the variable :
| (51) |
Implied volatility is well-defined since the function is strictly increasing for positive (i.e. vega of a call option is strictly positive) and the right-hand side of (51) lies in the image of the Black-Scholes formula by a no-arbitrage argument. Put-call parity, which holds since is a true martingale, implies the identity , where denotes the price of the put option in the Black-Scholes model with volatility .
If the affine stochastic volatility process satisfies the assumptions of Theorem 13, then the implied volatility has the following limit
| (52) |
for any fixed strike , where is the rate function of the model (the second equality in (52) follows from (21) and (22)). Tehranchi [Teh09] proved that the first equality in (52) holds uniformly in on compact sets in for non-negative local martingales with cumulant generating functions that satisfy certain additional conditions. Note that the limit in (52) is independent of , which corresponds to the well-known flattening of the implied volatility smile at large maturities. The uniform limit (in ) on compact subsets of , given in (52), also follows from Theorem 14 for affine stochastic volatility processes (both in non-degenerate and degenerate, i.e. Lévy, cases).
In order to obtain a non-trivial limit at infinity we define the implied volatility for the strike , where , by
| (53) |
We will show that if satisfies the assumptions of Theorem 13, then the limiting implied volatility takes the form
| (54) |
where and are the Fenchel-Legendre transforms (see (19) for definition) of the limiting cumulant generating functions and of under and respectively and , . The function is by definition equal to if and otherwise.
Remarks.
(i)
Under the assumptions of
Theorem 13,
the points
,
are the locations of the unique global minima of the good rate functions
and
respectively and
by (39)
satisfy
.
Note that
for
and
for
and hence
the following strict inequality
holds
for all
.
(ii) The function
in (54)
is chosen so that it satisfies the following identities:
| (55) |
where the polynomials and are given in (42). Quantities of importance in the proof of Theorem 14 will be the following partial derivatives
| (56) |
(iii) In formula (54), the function is given as a linear combination of and . The coefficients in this linear combination are not uniquely determined by identities (55) (there are four possibilities). However definition (54) is the only choice that implies the following important properties
| (57) | |||||
| (58) |
which will be crucial in the proof of Theorem 14.
Note that (57) and (58)
trivially hold in the Black-Scholes model:
,
and the limiting smile is constant
and equal to
.
The inequality in (57)
on the interval
follows from the identity
and the fact that
for
we have
.
Likewise the identity
for
yields half of (58).
The other half of (57) and (58)
follow from analogous identities
involving
.
(iv) The arbitrary choice for
in (54)
is of no consequence since
.
Theorem 14.
Remark.
Proof.
We can assume without loss of generality that . Assume further that and pick . The goal is to find such that the following inequality holds for all large :
| (59) |
Inequality (57) implies that there exists such that and . By (56) we conclude that is strictly decreasing on the interval and hence obtain the following inequalities:
Since all the functions are continuous and identitiy (55) holds, there exists a such that and the strict inequalities hold
| (60) |
for all . Theorem 13 implies that the call option converges uniformly on the interval to . In particular in the Black-Scholes model we get and the convergence is uniform in on . Since satisfies by definition, the inequalities in (60) imply that
for all and all large . Since the Black-Scholes formula is strictly increasing in (i.e. vega is strictly positive), these inequalities imply (59). This proves uniform convergence on any compact subset of . The proof for a compact set is analogous.
We now consider convergence at the point . Pick any such that . Identity (42) implies that
The first inequality and the argument above imply that for all large . Since , the second inequality, Theorem 13 yields
for all large . This implies and hence proves the theorem for . The point can be dealt with analogously. ∎
The following corollary is a simple consequence of our results.
Corollary 15.
Let be a non-degenerate affine stochastic volatility process that satisfies the assumptions of Theorem 13. Then there exists a Lévy process , which satisfies assumptions of Theorem 14 as a degenerate affine stochastic volatility process, such that the limiting smiles of the models and are identical.
Proof.
Let be the limiting cumulant generating function for . Theorem 8 implies that is a cumulant generating function of an infinitely divisible random variable. By Theorem 10, the characteristic triplet of satisfies conditions (33) and (34). Therefore, if we define a Lévy process with this characteristic triplet, Theorem 14 and formula (54) imply that models and have identical limiting volatility smiles. ∎
Remarks.
(i) In other words Corollary 15
states that in the limit, non-degenerate affine stochastic volatility models
cannot generate the behaviour of implied volatility, which is different from
that generated by the processes with constant volatility and stationary,
independent increments.
(ii) Corollary 15 suggests the following natural
open question: can any limiting smile of an exponential Lévy model
be obtained as a limit of implied volatility smiles of a non-degenerate
affine stochastic volatility process? It is not immediately clear how to approach this
problem because the characterisation of the limiting cumulant generating function
of a model
,
given in Theorems 8
and 10,
does not give an explicit form
of Lévy-Khintchine
triplet of
.
6.1. Examples of limiting smiles
We now apply the analysis to the examples of affine stochastic volatility models described in Section 2.2. In each of the cases the limiting cumulant generating function is available in closed form. If the assumptions of Theorem 10 or Corollaries 11 (i), 11 (ii) are satisfied, then the convex dual is a good rate function and hence the formula in (54) defines the limiting smile as maturity tends to infinity.
6.1.1. Heston model
The characteristics are given in (11) and (see (12)). Assumption A5 is satisfied if and only if , which is equivalent to . Since it follows that is not identically . Since the assumptions of Corollary 11 (ii) are satisfied, Theorem 14 implies that the limiting smile is given by the formula in (54), where
| (61) |
This implies the main result in [FJ11], [FJM11]. A first order asymptotic expansion for the large maturity smile in the Heston model was obtained in [FJM10] using saddle point methods.
6.1.2. Heston model with state-independent jumps
The functions are given in (13) and . As in Section 6.1.1, implies that defined Section 2.2.2 is a non-degenerate affine stochastic volatility model that satisfies A5. As before assumption implies that is non-zero. , defined in (14), is a cumulant generating function of the compensated pure-jump Lévy process . Assume that there exists such that for , for and (34) holds for and (e.g. if the distribution of the absolute jump heights is exponential with parameter , then ). Under these assumptions on state-independent jumps, the function in (13a) is steep and . Hence Theorem 10 implies that the limiting cumulant generating function is of the form
where is as in (61), and Theorem 14 yields the limiting smile formula in (54). Note also that condition (34) on the jump measure is not necessary if for some , since in this case in (13a) is automatically steep.
6.1.3. A model of Bates with state-dependent jumps
The functions are given in (15). Again we assume and , which implies that defined in Section 2.2.3 is a non-degenerate affine stochastic volatility model that satisfies A5. It is clear from (15a) that the assumptions of Theorem 10 on are satisfied. Let be as in (15b) and assume that either for all or there exists such that for , for and for any sequence with . Then is open in (see (15b)) and Theorem 10 implies that the limiting cumulant generating function takes the form
6.1.4. The Barndorff-Nielsen-Shephard model
The functions are given in (17). Since and the jump measure is non-trivial (i.e. ), the process defined in Section 2.2.4 is a non-degenerate affine stochastic volatility process. Assume that defined in (16) is either finite for all or there exists with for , for and and (34) holds for and (e.g. if the distribution of the absolute jump heights is exponential with parameter , then ). Then (see (17a)) satisfies the assumptions of Theorem 10 and the limiting cumulant generating function is of the form
6.2. How close are the formula and the implied volatility for large maturity?
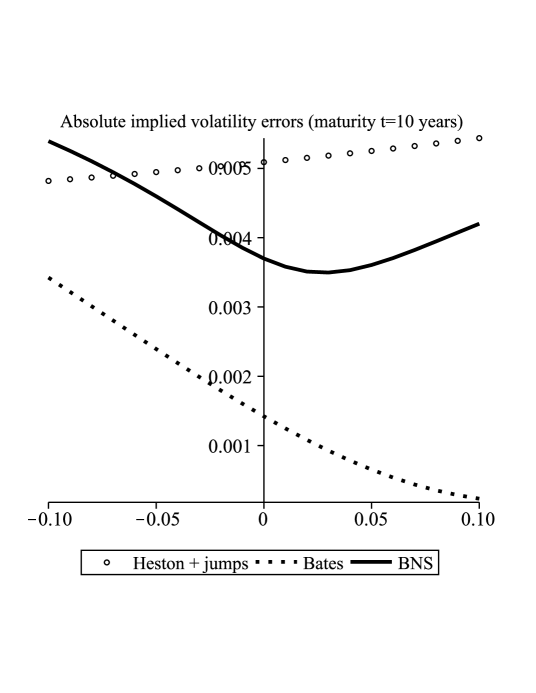
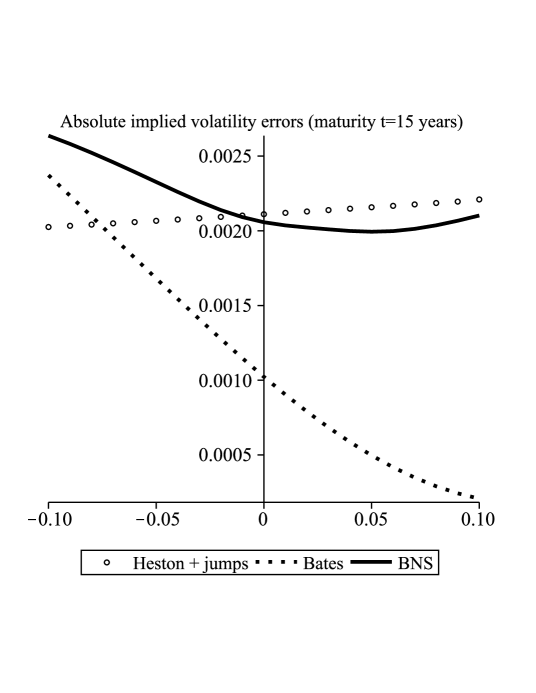
In this section we plot the difference for and for the models with jumps from Section 6.1 (see Figure 1). In the case equals 10 years the error is approximately basis points (bp) with the strike ranging from to of the spot. At the maturity of 15 years the error is approximately bp and ranges between and of the spot.
In the cases of Heston with state-independent jumps and Bates with state-dependent jumps we took the following diffusion parameters
and the Lévy measure with . The compensated cumulant generating function (see (14) for the definition of in Section 2.2.2 and note that it takes the same form in Section 2.2.3) is in this case given by
In the case of the BNS model we took a pure-jump subordinator with Lévy measure . The cumulant generating function (16) is given by for . We used the following values for the parameters
which were taken from [Sch03, Section 7.3] where the model was calibrated to the options on the S&P 500.
References
- [Bat00] D.S. Bates. Post-’87 crash fears in the S&P 500 futures option market. Journal of Econometrics, 94:181–238, 2000.
- [BNS01] O.E. Barndorff-Nielsen and N. Shephard. Non-Gaussian Ornstein–Uhlenbeck based models and some of their uses in financial economics. Journal of the Royal Statistical Society B, 63:167–241, 2001.
- [DFS03] D. Duffie, D. Filipovic, and W. Schachermayer. Affine processes and applications in finance. Annals of Applied Probability, 13(3):984–1053, 2003.
- [DL06] D.A. Dawson and Z. Li. Skew convolution semigroups and affine Markov processes. Annals of Probability, 34(3):1103–1142, 2006.
- [DZ98] A. Dembo and O. Zeitouni. Large deviations techniques and applications. Springer, Berlin, 2 edition, 1998.
- [FJ11] M. Forde and A. Jacquier. The large-maturity smile for the Heston model. Forthcoming in Finance & Stochastics, 2011.
- [FJM10] M. Forde, A. Jacquier, and A. Mijatović. Asymptotic formulae for implied volatility in the Heston model. Proceedings of the Royal Society A, 466(2124):3593–3620, 2010.
- [FJM11] M. Forde, A. Jacquier, and A. Mijatović. A note on essential smoothness in the Heston model. Forthcoming in Finance & Stochastics, 2011.
- [GL11] K. Gao and R. Lee. Asymptotics of implied volatility to arbitrary order. Preprint available at http://ssrn.com/abstract=1768383, 2011.
- [Hes93] S.L. Heston. A closed-form solution for options with stochastic volatility with applications to bond and currency options. Review of Financial Studies, 6(2):327–343, 1993.
- [KR11] M. Keller-Ressel. Moment explosions and long-term behavior of affine stochastic volatility models. Mathematical Finance, 1(21):73–98, 2011.
- [Lew00] A. Lewis. Option valuation under stochastic volatility. Finance Press, 2000.
- [Roc70] A. T. Rockafellar. Convex Analysis. Princeton University Press, New Jersey, 1970.
- [Sat99] K.I. Sato. Lévy Processes and Infinitely Divisible Distributions. Cambridge University Press, 1999.
- [Sch03] W. Schoutens. Lévy Processes in Finance: Pricing Financial Derivatives. Wiley, 2003.
- [Teh09] M.R. Tehranchi. Asymptotics of implied volatility far from maturity. Journal of Applied Probability, 46(3):629–650, 2009.