Large subgraphs in pseudo-random graphs
Abstract.
We consider classes of pseudo-random graphs on vertices for which the degree of every vertex and the co-degree between every pair of vertices are in the intervals and respectively, for some absolute constant , and . We show that for such pseudo-random graphs the number of induced isomorphic copies of subgraphs of size are approximately same as that of an Erdős-Réyni random graph with edge connectivity probability as long as , when . When we obtain a similar result. Our result is applicable for a large class of random and deterministic graphs including exponential random graph models (ERGMs), thresholded graphs from high-dimensional correlation networks, Erdős-Réyni random graphs conditioned on large cliques, random -regular graphs and graphs obtained from vector spaces over binary fields. In the context of the last example, the results obtained are optimal. Straight-forward extensions using the proof techniques in this paper imply strengthening of the above results in the context of larger motifs if a model allows control over higher co-degree type functionals.
1. Introduction
In the context of probabilistic combinatorics, the origin of random graphs dates back to [29] where Erdős used probabilistic methods to show the existence of a graph with certain Ramsey property. Soon after some of the foundational work on random graphs was established in [25, 26, 27]. The simplest model of random graph is as follows: Fix and start with vertex set . For ease of notation hereafter, we denote . Fix . The graph is formed by randomly drawing an edge between every pair of vertices , with probability . This random graph is known as Erdős-Réyni random graph with edge connectivity probability . In the sequel we use to denote this graph (also known as binomial random graph in the literature). This model has stimulated an enormous amount of work over the last fifty years aimed at understanding properties of (see [6, 31] and the references therein) in particular in the large network limit.
In the last decade there has been an explosion in the amount of empirical data on real world networks in a wide array of fields including statistics, machine learning, computer science, sociology, epidemiology. This has stimulated the development of a multitude of models to explain many of the properties of real world networks including high clustering coefficient, heavy tailed degree distribution and small world properties; see e.g. [34, 1] for wide-ranging surveys; see [23, 41, 17] for a survey of rigorous results on the formulated models. Although such network models are not as simple as an Erdős-Rényi graph, one would still like to investigate whether these posses properties similar to an Erdős-Rényi graph. Therefore, it is natural to ask about how similar/dissimilar such network models are compared to an Erdős-Rényi graph. Many researchers have delved deep into these questions and have found various conditions under which a given graph , with vertex set and edge set looks similar to an Erdős-Rényi random graph. In literature these graphs are known by various names. Following Krivelevich and Sudakov [32], we call them pseudo-random graphs.
One key property of an Erdős-Rényi random graph is the following: For any two subsets of vertices the number of edges in a , whose one end point is in and the other is in , is roughly equal to , where denotes the cardinality of a set. Hence, if a pseudo-random graph is similar to , then it must also satisfy similar properties. This motivated researchers to consider graphs which possess the above property.
Foundational work for these sorts of questions began with Thomason [37, 38] in the mid-eighties where he used the term Jumbled graph (see Definition 3.1) to describe such graphs. Roughly it provided quantitative bounds on similarity between pseudo-random graphs and a . This study provided some examples of jumbled graphs and explored various properties of them. It exposed a whole new interesting research area and numerous results were obtained afterwards. Further fundamental work in this area was established by Chung, Graham, and Wilson in [16]. They coined the term quasi-random graphs to describe their models of pseudo-random graphs. They provided several equivalent conditions of pseudo-randomness; one of their major results is described in Section 3, Theorem 3.2 . Paraphrasing these results, loosely they state the following:
For a graph to be pseudo-random one must have that the number of induced isomorphic copies of any subgraph of fixed size (e.g. is a triangle) must be roughly equal to that of a .
Another class of pseudo-random graphs is Alon’s -graph (see [2]). These graphs are -regular graphs on vertices such that the second largest absolute eigenvalue of its adjacency matrix is less than or equal to . Various graph properties are known for -graphs (see [32] and the references therein).
As described above, the availability of data on real-world networks has stimulated a host of questions in an array of field, in particular in finding large motifs in observed networks such as large cliques or communities (representing interesting patterns in biological or social networks) or understanding the limits of search algorithms in cryptology. Many of these questions are computationally hard and one is left with brute search algorithms over all possible subgraphs of a fixed size to check existence of such motifs. Thus a natural question (again loosely stated) is as follows:
Can we find simple conditions on a sequence of graphs such that the number of induced isomorphic copies of any subgraph of growing size (e.g. is a clique of size ) must be roughly equal to that in ? What are the fundamental limits of such conditions?
Here we consider a class of pesudo-random graphs and study the number of induced copies of large subgraphs in those. More precisely, we will assume that our graph satisfies the following two assumptions for some absolute constant , and :
Assumption A1.
Assumption A2.
Here for any , , where means that is connected to by an edge in . These two conditions are very natural to assume. For example, using Hoeffding’s ineqaulity it is easy to check that for assumptions (A1) and (A2) are satisfied for any with super-polynomially high probability. As we will see below, besides there are many examples of graph ensembles which satisfy assumptions (A1)-(A2). Further, these two specifications are quite basic and often very easy to check for a given graph (random or deterministic).
In our main theorem below we show that for any such graph sequence the number of induced isomorphic copies of any slowly growing sub-graph is approximately same as that of an Erdős-Rényi random graph with edge connectivity . Before stating our main theorem let us introduce some notation: For any , let us denote be the collection of all graph with vertex set . Further given any graph , denote to be the number of induced isomorphic copies of in and to be edge-set of . Next, for , define . We also write to denote the natural logarithm, i.e. logarithm with respect to the base . When needed, we will specify the base and write as . For any two positive integers , let us denote . Now we are ready to state our main theorem.
Theorem 1.1.
Let be a sequence of graphs satisfying assumptions (A1) and (A2). Then, there exists a positive constant , depending on , such that
| (1.1) |
as .
Remark 1.2.
Note that
Thus Theorem 1.1 establishes that the number of induced isomorphic copies of large graphs are approximately same as that of an Erdős-Rényi graph. In the proof of Theorem 1.1 we actually obtain bounds on the rate of convergence to zero of the lhs of (1.1). Using these rates, one can allow and to go to zero and obtain modified versions of (1.1) in those cases. See Remark 7.8 for more details. For clarity of presentation we work with fixed values of and in Theorem 1.1. In Section 2.5 we give an example of a graph model where the result Theorem 1.1 is optimal.
Remark 1.3 (Existence of large motifs).
The above result shows that under assumptions (A1) and (A2), the associated sequences of graphs are strongly pseudo-regular in the sense that the count of large motifs in the graph is approximately the same as in Erdős-Rényi random graph. A weaker question is asking existence of large motifs; to fix ideas let for a constant and denote a clique on vertices. Then one could ask the import of Assumptions (A1) and (A2) on the existence of ; this corresponds to
We study these questions in work in progress.
We will see in Section 2.5 that the conclusion of Theorem 1.1 cannot be improved unless one has more assumptions on the graph sequence. Below we consider one such direction to understand the implications of our proof technique if one were to assume bounds on the number of common neighbors of three and four vertices.
Assumption A3.
Assumption A4.
Under these above two assumptions we obtain the following improvement of Theorem 1.1.
Theorem 1.4.
Let be a sequence of graphs satisfying assumptions (A1)-(A4). Then, there exists a positive constant , depending on , such that
| (1.2) |
as .
From the proof of Theorem 1.4 it will be clear that adding more assumptions on the common neighbors of a larger collection of vertices may further improve Theorem 1.1. To keep the presentation of current work to manageable length we restrict ourselves only to the above extension. Proof of Theorem 1.4 can be found in Section 7.
We defer a full discussion of related work to Section 3. The rest of this paper is organized as follows:
Outline of the paper.
-
(i)
In Section 2 we apply Theorem 1.1 to exponential random graph models (ergms) in the high temperature regime (Section 2.1), random geometric graphs (Section 2.2), conditioned Erdős-Rényi random graphs (Section 2.3), and random regular graphs (Section 2.4). Section 2.5 describes a network model where Theorem 1.1 is optimal. Proofs of all these results can be found in Section 8.
-
(ii)
Section 3 discusses the relevance of our results, connections to existing literature as well as possible extensions and future directions to pursue.
-
(iii)
In Section 4 we provide an outline of our proof technique. We start this section by stating Proposition 4.1, which is the sub-case of Theorem 1.1 for . For clarity of presentation, we only explain the idea behind the proof of Proposition 4.1. Along with the proof idea we introduce necessary notation and definitions.
- (iv)
- (v)
2. Applications of Theorem 1.1
In this section we consider four different random graph ensembles: exponential random graph models, random geometric graphs, Erdős-Rényi random graphs conditioned on a large clique, and random -regular graphs. We show that for these four random graph ensembles Theorem 1.1 can be applied (and adapted) to show that the number of induced isomorphic slowly growing subgraphs are close to that of an Erdős-Rényi random graph. In Section 2.5 considering an example of a sequence of deterministic graphs we show that one may not extend the conclusion of Theorem 1.1 without any additional assumptions on the graph sequence.
2.1. Exponential random graph models (ergm)
The exponential random graph model (ergm) is one of the most widely used models in areas such as sociology and political science since it gives a flexible method for capturing reciprocity (or clustering behavior) observed in most real world social networks. The last few years have seen major breakthroughs in rigorously understanding the behavior of ergm in the large network limt (see [5, 15] and the references therein). It has been shown that in the high temperature regime (which we precisely define in Assumption 2.1), these models converge in the so-called cut-distance, a notion of distance between graphs established in [7], [8], to the same limit as an Erdős-Rényi random graph as the number of vertices increase, where the edge connectivity probability of the Erdős-Rényi random graph is determined explicitly by a function of the parameters (see [15]). In particular this implies that the number of induced isomorphic copies of any subgraph on fixed number of vertices are asymptotically same as in an Erdős-Rényi random graph in that high temperature regime (see [7, Theorem 2.6]). In this section we strengthen the above result to show that in the high temperature regime the number of induced isomorphic copies of subgraphs of growing size in an ergm are approximately same with that of an Erdős-Rényi graph, with appropriate edge connectivity probability.
We start with a precise formulation of the model. We will stick to the simplest specification of this model which incorporates edges and triangles although we believe that the results below carry over for any model in the ferromagnetic case as long as one is in the high temperature regime. Let and note that any simple graph on vertices can be represented by a tuple . Here if vertices are connected by an edge and otherwise. On this space, we define the Hamiltonian as follows.
| (2.1) |
Note that is just the number of edges in whilst is the number of triangles. Thus the above Hamiltonian has a simpler interpretation as
For simplicity we write for the parameters of the model, and consider the probability measure,
| (2.2) |
In the sequel, to ease notation, we will suppress and write the above, often as . Now for later use we define the function via,
| (2.3) |
Below we state the assumption on the ergm with which we work in this paper.
Assumption 2.1.
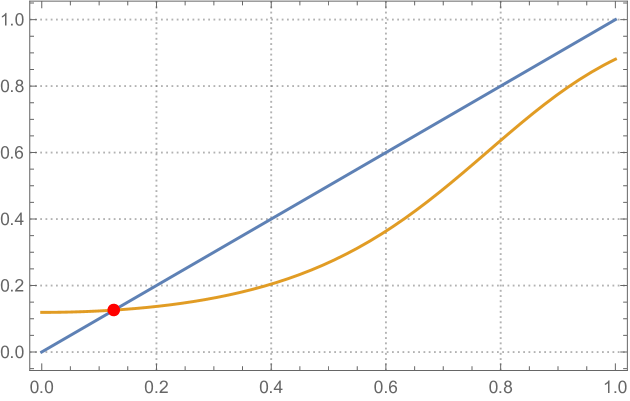
We assume that we are in the ferromagnetic regime, namely . Further we assume that the parameters are in the high temperature regime (see also [5]). That is, there exists a unique solution to the equation
| (2.4) |
and further
| (2.5) |
See Figure 1 below for a graphical description of our setting. In passing we note that the above two conditions can be succinctly expressed using the function as defined in (2.3) as,
| (2.6) |
Now we are ready to state the main result regarding ergm.
Theorem 2.2.
Let denote an Erdős-Rényi random graph with edge connectivity probability . Let satisfying assumption 2.1. Then as , we have,
where is some positive constant depending only on .
2.2. Thresholded graphs from high-dimensional correlation networks
In this section we consider thresholded graphs obtained from high-dimensional random geometric graphs. Roughly in a geometric graph the vertices are points in some metric space and two vertices are connected if they are within a specified threshold distance. These models have drawn wide interests from different branches of science such as machine learning, statistics etc. It is of interest to study these graphs when the dimension of the underlying metric space is growing with the number of vertices. In the context of applications, one major are of applications of this model is neuroscience, while it is impossible to give even a representative sample of related papers, a starting point would be [11, 35, 24] and the references therein. Paraphrasing from [11, Page 187] (with parts (c) and (d) most relevant for this paper):
“Structural and functional brain networks can be explored using graph theory through the following four steps: ”
- (a)
Define the network nodes. These could be defined as electroencephalography or multielectrode-array electrodes, or as anatomically defined regions of histological, MRI or diffusion tensor imaging data.
- (b)
Estimate a continuous measure of association between nodes. This could be the spectral coherence or Granger causality measures between two magnetoencephalography sensors, or the inter-regional correlations in cortical thickness or volume MRI measurements estimated in groups of subjects.
- (c)
Generate an association matrix by compiling all pairwise associations between nodes and (usually) apply a threshold to each element of this matrix to produce a binary adjacency matrix or undirected graph.
- (d)
Calculate the network parameters of interest in this graphical model of a brain network and compare them to the equivalent parameters of a population of random networks.”
As a test-bed, we study the simplest possible setting for such questions, first studied rigorously in [21] and [10], and study the behavior of the graph as dimension is growing with the number of vertices. To describe the model, we closely follow [21]. Write for the unit sphere in , where denotes the usual Euclidean metric. Suppose be points chosen independently and uniformly distributed on . Fix . We will use these points to construct a graph with vertex set as follows: For say that vertex is connected to if and only if
Here is the usual inner product operation on and is a constant chosen such that
| (2.7) |
Call the resulting graph . See Figure 2 for a pictorial representation.
Maximal clique behavior in this model was studied in [21]. Further it was shown in [21] that the total variation distance between and goes to zero as while is fixed. It was further shown in [10] that the total variation distance between and goes to zero if grows faster than while the distance goes to if . In this section we will consider weaker notions of convergence of graphs and establish that random geometric graphs look similar to Erdős-Rényi when is growing as slow as for some . Below we work with following assumption on random geometric graphs.
Assumption 2.3.
We consider random geometric graphs with and as .
We split our result on into two parts. In first part we consider induced isomorphic copies of any fixed graph.
Theorem 2.4.
If for some , then as and we have,
for all finite subgraph .
Theorem 2.4 shows that the number of induced isomorphic copies of any fixed graph is asymptotically same as that of an Erdős-Rényi random graph. Therefore, from [7, Theorem 2.6] it follows that and are arbitrarily close in cut-metric as soon as is poly-logarithmic in . Theorem 2.4 is actually a consequence of the following stronger result. This result shows that the number of copies of “large subgraphs” are asymptotically same as that of Erdős-Rényi random graph. However, the size of the subgraphs one can consider depends on how fast “grows” compared to . More precisely, we have the following result.
Theorem 2.5.
Let be a random geometric graph on vertices satisfying Assumption 2.3. Then, we have,
where
for some large positive constants and .
Remark 2.6.
Note that if is poly-logarithmic in then from Theorem 2.5 it follows that the number of induced isomorphic copies of subgraphs of size upto are roughly same as that an Erdős-Rényi random graph. Proof of Theorem 2.5 can be found in Section 8. As described in Remark 1.3 the question considered in this paper is refined in the sense that we want the number of large motifs in the model under consideration to closely match the corresponding number in an Erdős-Rényi random graph; this second object grows exponentially in the size of the motif being considered. Thus small errors build up as will be seen in the proofs. In future work we will consider the problem described in Remark 1.3 where one is only interested in the existence of large motifs.
2.3. Erdős-Rényi random graphs conditioned on large cliques
Finding maximal cliques in graphs is a fundamental problem in computational complexity. One natural direction of research is average case analysis; more precisely studying this problem in the context of the Erdős-Rényi random graph. Here it is known that the maximal clique in is . Simple greedy algorithms have been formulated to find cliques of size in polynomial time but no algorithms are known for finding cliques closer to the maximal size of with small, in polynomial time. The situation is different when one places (hides) a clique of large size in the random graph, the so-called hidden clique problem especially when the size of the hidden clique is of size for some absolute constant . Here a number of polynomial algorithms have been formulated to discover the maximal clique. For example [3] proposed a spectral algorithm that finds a hidden clique of size in polynomial time. In [20] the authors devised an almost linear time non-spectral algorithm to find a clique of size . Dekel, Gurel-Gurevich, and Peres in [19] describe the “most important” open problem in this area as devising an algorithm (or proving the lack of existence thereof) that finds a hidden clique of size in polynomial time. Motivated by these questions we investigate the following question,
How does an Erdős-Rényi random graph look like when the largest clique is of size ?
We check that the graph is strongly pseudo random graph even when the largest clique is of size for some .
Theorem 2.7.
Let be the Edős-Rényi random graph with connectivity probability . Fix , and define
and
Let denote the event that the maximal clique size in is greater than or equal to . If , for some positive constants , and such that , then
| (2.8) |
as . In particular by Theorem 1.1, the assertion in (1.1) holds with high probability as with .
Remark 2.8.
It would be interesting to further explore the implications of the above result and in particular see if this result negates the existence of polynomial time algorithms for finding hidden cliques in if the size of the hidden clique is . We defer this to future work.
Remark 2.9.
For clarity of the presentation of the proof of Theorem 2.7 we consider only . We believe it can be extended for any .
2.4. Random -regular graphs
For positive integers and , the random -regular graph is a random graph which is chosen uniformly among all regular graphs on vertices of degree . One key difference between and is that the edges in are not independent of each other. However, using different techniques researchers have been able to study different properties of . For more details, we refer the reader to [6, 31]. Here we study the number of induced isomorphic copies of large subgraph in . We obtain the following result. Before stating the result let us recall implies that theres exists constant and such that , for all large values of .
Theorem 2.10.
Let be a random regular graph with . Then, there exists a positive constant such that
| (2.9) |
as , in probability.
The proof of Theorem 2.10 is a direct application of Theorem 1.1 once we establish that satisfies conditions (A1)-(A2). However, this is already known in the literature.
Theorem 2.11 ([33, Theorem 2.1(i)]).
Let be a random regular graph with . Then,
Remark 2.12.
Remark 2.13.
Very recently, during the final stages of writing of this paper, Konstantin and Youssef [39] improved a previously existing bound on the second largest absolute value of the adjacency matrix of a random -regular graph and showed that it is with probability tending to one. Hence, using [39] one can re-derive Theorem 2.10 from [32, Theorem 4.10].
2.5. Optimality of Theorem 1.1: Binary graph
Now as mentioned above we provide the example which shows that the result Theorem 1.1 is optimal. This corresponds to a graph on a vector space over the binary field. For any odd integer this graph is a graph on vertices where and “” is to emphasize “binary” which we now elucidate. The vertices of are binary tuples of length with odd number of ones except the vector of all ones. Note that every vertex has also a vector representation. We draw an edge between two vertices and if and only if , where the multiplication and the addition are the corresponding operations in the binary field. Now we are ready to state the main result on .
Theorem 2.14.
Let be the graph described above. It has the following properties:
-
(i)
There exists an absolute constant such that
as .
-
(ii)
Let denote the empty graph with vertex set . Then for any ,
as . Moreover the size of the largest independent set in is .
-
(iii)
Recall that is the complete graph with vertex set . Then for any , setting we have
for all large .
Proof of Theorem 2.14(i) is a direct application of Theorem 1.1. We only need to verify that assumptions (A1)-(A2) are satisfied by the graph sequence with and . Theorem 2.14(ii)-(iii) have deeper implications in the context of pseudo-random graphs. Theorem 2.14(ii) shows that if in (1.1) we restrict ourselves to some subsets of then one may be able to improve the conclusion of Theorem 1.1. Whereas, Theorem 2.14(iii) shows that one cannot expect any such improvement to hold uniformly for all subgraphs in beyond the barrier, as predicted by Theorem 1.1. Therefore, Theorem 1.1 gives us an optimal result under the assumptions (A1)-(A2). Theorem 2.14(ii) further shows that even if we restrict our attention to some subset of any improvement must not go beyond .
3. Discussion and related results
In this Section we provide a wide-ranging discussion both of related work as well as future directions. We begin our discussion with Thomason’s Jumbled graphs.
3.1. Jumbled graphs
In the context of pseudo-random graphs results similar to (1.1) first appeared in the work of Thomason [37]. To explain his result, let us define his notion of Jumbled graph.
Definition 3.1.
A graph is called -jumbled if for every subset of vertices , one has
| (3.1) |
where denotes the number of edges whose both end points are in .
In [37, Theorem 2.10] it was shown that for -jumbled graphs, with , (1.1) holds whenever is such that . In [28] it was established that must be (recall implies that ). When , then we must have for (1.1) to hold for -jumbled graphs. Note that, when , under the same assumption on we establish Theorem 1.1.
Pseudo-random graphs satisfying assumptions (A1)-(A2) and jumbled graphs are not very far from each other. For example, if satisfies (A1)-(A2), then one can check that is a -jumbled graph (see [37, Theorem 1.1]). On the other hand, if is a -jumbled graph then all but few vertices satisfy assumption (A1) for any (see [37, Lemma 2.1]). So our assumptions (A1)-(A2) and the condition (3.1) are somewhat comparable.
The advantage with (A1)-(A2) is that given any graph one can easily check those two conditions. On other hand, given any large graph, it is almost impossible to check the condition (3.1) for all . For example, condition (3.1) would be very hard to establish for ergms, random geometric graphs, Erdős-Rényi random graphs conditioned on the existence of a large clique, and even random -regular graphs. We have already seen in Section 2 that for these graphs one can use Theorem 1.1 and deduce that the number of slowly growing subgraphs in those graphs are approximately same as that of an Erdős-Rényi random graph with an appropriate edge connectivity probability.
As mentioned above, if (A1)-(A2) are satisfied by graph , then it is also jumbled graph with certain parameters. Therefore. one can try to apply [37, Theorem 2.10] to obtain a result similar to ours. However, the application of [37, Theorem 2.10] yields a sub-optimal result in the following sense. Note that both random -regular graphs and exponential random graph models satisfy assumptions (A1)-(A2) with (see Theorem 2.11 and Theorem 8.1). Therefore, applying Theorem 1.1 one would obtain that the number of induced isomorphic copies of subgraphs of size (for ease of explanation, let us consider only the case in Theorem 2.10 and Theorem 2.2) are asymptotically same as that of an . However, application of [37, Theorem 1.1] and [37, Theorem 2.10] implies that the same holds for . Therefore Theorem 1.1 improves the result of [37].
We now turn our attention to the class of pseudo-random graphs defined by Chung, Graham, and Wilson [16].
3.2. Quasi-random graphs
One of our main motivations for this work was the notion introduced by Chung, Graham, and Wilson [16]. We state the main theorem in their paper that relates various graph parameters and any of them can be taken as a definition of pseudo-randomness. Before stating that result recall that for a sequence of reals one writes to imply that as . We only state parts of the main theorem of [16] that are relevant in the context of our result.
Theorem 3.2 ([16]).
Let be fixed. Then for any graph sequence , the following are equivalent:
-
:
For any , where is any arbitrary fixed positive integer
(3.2) where denotes the number of labelled occurrences of the subgraph in .
-
:
For each subset of vertices
(3.3) -
:
(3.4)
Although [16, Theorem 1] was proved only for one can easily adapt their technieues to easily extend the result for any . In this paper one of our main aims is to understand the role of concentration inequalities and rates of convergence in the above conditions. That is, if we specify the rates of convergence in (3.3) and/or in (3.4), then a natural question is whether one can accommodate a slowly growing in (3.2). Motivated by this observation we began this work. Note that our assumptions (A1)-(A2) are similar to above.
Investigating the proof of Theorem 1.1 one can easily convince oneself that we do not need the maximum over all vertices (and pair of vertices) in (A1)-(A2). The proof goes through as long as the assertions (A1)-(A2) hold on the average. Indeed, using Markov’s inequality, and increasing by some multiple of , one can establish that (A1)-(A2) holds for all but few vertices. This does not change the conclusion Theorem 1.1 and it only increases the constant . For clarity of presentation we do not pursue this generalization and work with the assumption that (A1)-(A2) holds for all vertices (and pair of vertices).
In the context of quasi-random graphs attempts have been made to prove that (3.2) holds even one allows to go to infinity. In [18] Chung and Graham showed that if a subgraph is not an induced subgraph of then one must have a set of size such that deviates from by at least . This implies that in a quasi-random graph at least one induced copy of every subgraph of size must be present.
One may also want to check upon plugging in the rates of convergence from (A1)-(A2) and following the steps in the proof of [16, Theorem 1] whether it is possible to show (3.2) for subgraphs of growing size. It can indeed be done. However, the arguments break down at . Note that this is much weaker than Theorem 1.1. To understand why the argument stops at we need discuss the key idea behind the proof of [16, Theorem 1] which is deferred to Section 4.
Next we direct our attention to Alon’s graph.
3.3. Alon’s graphs
A graph is called an -graph if it is a -regular graph on vertices whose second largest absolute eigenvalue is . A number of properties of such graphs have been studied (see [32] and the references therein). For such graphs the number of induced isomorphic copies of large subgraphs is also well understood (see [32, Section 4.4]). From [32, Theorem 4.1] it follows that -graphs contain the correct number of cliques (and independent sets) of size if satisfies the condition . Thus, to apply [32, Theorem 4.1] one needs a good bound on the second largest absolute eigenvalue . For nice graph ensembles it is believed that one should have . However, this has been established only in few examples. For example, when for a random -regular this has been established very recently in [39]. Any bound on of the form , for some , yield a sub-optimal result when applied to [32, Theorem 4.10]. On the other hand, our method being a non-spectral technique, does not require any bound on and the conditions (A1)-(A2) are much easier to check.
3.4. Optimality, limitations and future directions
We have already seen that Theorem 1.1 is optimal in the sense that one cannot improve the conclusion of Theorem 1.1 without adding further assumptions. One can consider two possible directions for improvements. The first of those is to have more conditions on the graph sequence. For example, one may assume controls on the number of common neighbors of three and four vertices. This indeed improves the conclusion of Theorem 1.1 when . This is seen in Theorem 1.4.
Another direction we are currently pursuing is extending Theorem 1.1 to the setting of models which incorporate community structure. Here the comparative model is not the Erdős-Rényi random graph but the stochastic block model. Community detection and clustering on networks have spawned an enormous literature over the last decade, see the survey [30] and the references therein. One can easily extend the ideas of Theorem 1.1 to count the number of induced isomorphic copies of large subgraphs in a stochastic block model. To keep the clarity of the presentation of the current work we defer this generalization to a separate paper.
4. Notation and Proof Outline
In this section our goal is to discuss the idea behind the proof of our main result. For clarity of presentation we consider the sub-case separately. That is we establish the following result first.
Proposition 4.1.
Let be a sequence of graphs satisfying the following two conditions:
| (4.1) |
| (4.2) |
There exists a positive constant , such that
| (4.3) |
as .
Once we prove Proposition 4.1 the proof of Theorem 1.1 is an easy adaptation. Proof of Proposition can be found in Section 5 and the proof of Theorem 1.1 is deferred to Section 7. This section is devoted to outline the ideas of the proof of Theorem 1.1. For clarity once again we focus on the sub-case .
For any graph on vertices, let us define
| (4.4) |
and let .
Note that, in order to prove Proposition 4.1, it is enough to show that as , uniformly for all graphs and all , where is some finite positive constant. If satisfies assumptions (4.1)-(4.2), then one can easily check that the required result holds for . So, one natural approach to extend the same for larger values of is to use an induction-type argument. The key to such an argument is a recursive estimate of the errors (see Lemma 5.1).
Therefore the main idea behind the proof of Proposition 4.1 lies in obtaining a bound on in terms of . To explain the idea more elaborately let us first introduce few notation. Our first definition will be a notion about generalized neighborhood.
Definition 4.2 (Generalized neighborhood).
Let denote the adjacency matrix of the graph .
-
(a)
For any , and define
That is, for and the denote the collection of neighbors and non-neighbors of respectively. By a slight abuse of notation will also denote cardinality of the set in context. For later use, we also denote .
-
(b)
For any set of vertices we denote . That is, denotes the collection of neighbors (non-neighbors, if ) of in . Further, for ease of writing we will continue to use the notation for the cardinality of the set in context.
The parameter in Definition 4.2 is required to consider all subgraphs of any given size. For example, if we are interested in finding the number of cliques in then it is enough to consider , whereas for independent sets we will need .
With the help of this definition let us now again continue explaining the idea of the proof. For ease of explanation let us assume that we are interested in proving the main result only for cliques. Suppose we already have the desired conclusion for . Note that a collection of vertices forms a clique of size if and only if any of them form a clique of size , and the -th vertex is the common neighbor of the first vertices. We use this simple idea to propagate our estimate in the error .
If we have an Erdős-Réyni random graph with edge connectivity probability , then we see that given any vertices the expected number of common neighbors of those vertices is . This implies that the number of cliques of size is approximately same with the number of the cliques of size of multiplied by .
To formalize this idea for graphs satisfying (4.1)-(4.2) we need to show that for any collection of vertices and we must have that . For ease of writing we have the next definition.
Definition 4.3.
For and , let us denote
Further denote
| (4.5) |
Equipped with the above definition, as noted earlier, our goal is to show that for graphs satisfying (4.1)-(4.2). However, such an estimate is not feasible for all choices of vertices . Instead we show that such an estimate can be obtained for most of the vertices which we call “good” vertices, whereas the vertices for which the above does not hold are termed as “bad” vertices. More precisely we have the following definition.
Definition 4.4.
Fix . For any given set , and , define
Throughout this paper, we fix an
| (4.6) |
for some appropriately chosen large constant , which we determine later during the proof. Since we work with this fixed choice of through out the paper (except in the proof of Theorem 2.5), for brevity of notation we drop the subscript from in the definition of and write instead. Next for a given collection of vertices and , we set
Moreover, letting , define
Equipped with above definition it is easy to show by induction that for any and such that , for all , we have (see Lemma 5.2). However, our notion of “good” vertices is useful only when the cardinality of collection of “bad” vertices is small compared to that of “good” vertices. To show this we work with the following definition.
Definition 4.5.
Fix two positive integers . Let be a graph on vertices, and be any one of the sub-graphs of induced by vertices. Define to be the (unordered) collection of vertices such that the sub-graph induced by them is isomorphic to . Similarly define . Further given any , denote , and for any , denote , for . Then define
If there are more than one relabeling of such that the conditions of are satisfied choose one of them arbitrarily. When and are clear from the context, for brevity we simply write .
We noted above that to show that one needs , for all . Thus if we have a collection of vertices such that and , for all , then we cannot carry out our argument. To prevent such cases we consider all possible relabeling of in Definition 4.5. Since we only count the number of isomorphic copies of subgraphs the relabeling of Definition 4.5 does not cause any harm.
Coming back to the proof of main result we note that we need to establish that the cardinality of is small. To prove this we start by bounding for every , , and . The key to the latter is a bound on the variance of , which can be obtained using (4.1)-(4.2). Stitching these arguments together show that we then have the desired bound for for most of the vertices.
Recall from Proposition 4.1 that this argument stops at . This is due to the fact that for such values of the cardinality of “good” vertices become comparable with that of “bad” vertices. On the set of “bad” vertices one does not have a good estimate on . Therefore, one cannot proceed with this scheme beyond . The rest of the argument involves finding good bounds on and an application of Cauchy-Schwarz inequality which relate with . The required bound on is easy to obtain using (4.1)-(4.2). To complete the proof one also requires a good bound on , where is the collection of vertices such that the graph induced by those vertices is . This bound can be easily derived upon combining the previously mentioned estimates on and .
The above scheme of the proof of Theorem 1.1 has been motivated by the proof of [16, Theorem 1]. As mentioned earlier in Section 3, plugging in (4.1)-(4.2), and repeating their proof would have only yielded the conclusion of Proposition 4.1 only upto . There is a key modification in our approach which we describe below. Likewise in the proof of Proposition 4.1, in [16] they also need to bound . However, they bound the former by a much larger quantity, namely . Since for large the cardinality of is much smaller compared to direct application of the techniques from [16, Theorem 1] provides a much weaker conclusion. Here we obtain the required bound in a more efficient way by defining “good” and “bad” vertices, and controlling them separately. Here we should also mention that a similar idea was used in the work of Thomason [37] in the context of jumbled graphs.
5. Proof of Proposition 4.1
In this section we prove Proposition 4.1. As mentioned in Section 4 the proof is based on an induction-type argument and relies heavily in obtaining a recursive relation between and , where we recall that
and . In this section we prove the following desired recursive relation.
Lemma 5.1.
Proof of Proposition 4.1.
The key to the proof is the recursive estimate obtained in Lemma 5.1. Note that for Lemma 5.1 to hold, one needs to verify that (5.1) is satisfied. To this end, observe that if , for , then (5.1) is indeed satisfied for . Therefore, by Lemma 5.1, we have . Thus, using Lemma 5.1 repeatedly we see that we would be able to control if we have a good bound on , where the bound on the latter follows from our assumptions (4.1)-(4.2). Below we make this idea precise.
We begin by noting that, if (5.2) holds for , then by induction it is easy to show that
| (5.3) |
where, for ,
Since , from (5.3) it can also be deduced that
| (5.4) |
Now, note that there only two graphs in , namely the complete graph and the empty graph on two vertices. Therefore,
where the last step follows from (4.1). This combining with (5.4) yields
| (5.5) |
whenever (5.2) holds for . Now the rest of the proof is completed by induction.
Now we turn our attention to the proof of Lemma 5.1. As already seen in Section 4 we need to establish that given any and if , for all , then . We establish this claim formally in the lemma below.
Lemma 5.2.
We also need to show that the cardinality of “bad” vertices is relatively small. This is derived in the following lemma.
Lemma 5.3.
Recall that we also need bounds on . This is obtained from the following lemma.
Lemma 5.4.
For any , let , and be the number of zeros in . Then for any ,
| (5.7) |
We further have
| (5.8) |
Finally we need to bound . Building on Lemma 5.2, Lemma 5.3, and Lemma 5.4 we obtain the required bound in the lemma below.
Lemma 5.5.
Let be a sequence of graphs satisfying (4.1)-(4.2). Fix any positive integer , and let be a graph on vertices. Assume that
for all and all graphs on vertices. Fix any . Then, there exists a positive constant , depending only on , and another positive constant , depending only on , such that for any , we have
| (5.9) |
for all large .
Before going to the proof let us mention one more lemma that is required to prove the main result inductively. Its proof is elementary. We include the proof for completion.
Lemma 5.6.
Fix , a graph on vertices with vertex set . Let be the sub-graph of with vertex set . Then, there exists a such that
| (5.10) |
Proof.
For any collection of vertices , let be the sub-graph induced by those vertices. Let and be two graphs with vertex sets and , respectively. We write , if under the permutation , for which for all , the graphs are same. Then, for any given collection of vertices , if for some permutation of the vertices , then there are actually many such permutations. Thus recalling the definition of we immediately deduce that
We also note that , if and only if and , for some appropriately chosen . Thus, recalling the definition of we see that
Now noting that is invariant under any permutation of coordinates of and recalling the definitions of and again, we observe that the rhs of the above equation is same as the the rhs of (5.10), which completes the proof.
Now we are ready to prove Lemma 5.1.
Proof of Lemma 5.1.
Fix any graph with vertex set . Applying the triangle inequality we have
| (5.11) | ||||
Recalling the definition of and using Lemma 5.4, we note that
| (5.12) |
where the last inequality follows from that fact that . Now to control Term III, using Lemma 5.4 we have
Therefore, using the triangle inequality,
| (5.13) |
Now it remains to bound Term I. To this end, using Lemma 5.6 and the triangle inequality, from Lemma 5.5 we obtain
| Term I | ||||
| (5.14) |
where in the last step we use the fact that . Finally combining (5.12)-(5.14) we complete the proof.
6. Preparatory Technical Lemmas
We begin with the proof of Lemma 5.2. Before going to the proof let us recall the definition of “good” vertices from Definition 4.4. Using Definition 4.4 the proof follows by induction.
Proof of Lemma 5.2.
Note that, by our assumption (4.1)-(4.2), we have good bounds on (see (6.3)). We propagate this bound for a general by induction. Using induction we will prove a slightly stronger bound. Namely we will prove the following:
| (6.1) |
From (6.1) the conclusion follows by noting that .
To this end, using the triangle inequality we note that
Since , we therefore have
for all . Recalling that and using induction hypothesis we obtain
Since , as , the induction hypothesis further implies
| (6.2) |
for all large , and hence we have (6.1). This completes the proof.
We now proceed to the proof of Lemma 5.3. That is, we want to show that the number of “bad” vertices is negligible. To prove Lemma 5.3 we first show that the number of vertices such that is small. To this end, we first prove the following variance bound. Here for ease of exposition write , etc where the expectations will be taken with respect to the empirical measure over .
Lemma 6.1.
Proof.
Recall that , where is the adjacency matrix of the graph . Therefore, we have
Remark 6.2.
Note that for an Erdős-Réyni graph with edge connectivity probability , one can show that , for any subset vertices , where the variance is with respect to the randomness of the edges and the uniform choice of the vertex . For pesudo-random graphs satisfying (4.1)-(4.2), repeating the same steps as in the proof of Lemma 6.1, we can also obtain that
Therefore, we see that pseudo-random graphs satisfying (4.1)-(4.2) are not much different from in this aspect.
From Lemma 6.1, using Markov’s inequality we obtain the following result.
Lemma 6.3.
Proof.
The proof is a straightforward application of Lemma 6.1. From Lemma 6.1, by Chebychev’s inequality we deduce,
for every . Setting , from above we therefore obtain
| (6.4) |
Next we note that
and thus using (6.3), we further have
| (6.5) |
Thus combining (6.4)-(6.5) the required result follows upon using triangle inequality.
We now use Lemma 6.3 to prove Lemma 5.3. Before going to the proof of Lemma 5.3 we need one more elementary result.
Lemma 6.4.
Let be any graph with vertex set , and be one of its vertex-deleted induced sub-graph. That is, is the sub-graph induced by the vertices for some . Then
Proof.
Let us denote to be the vertex-stablilizer sub-group. That is,
Clearly can be embedded into , and hence . Thus we only need to show that
Using Lagrange’s theorem (see [22, Section 3.2] for more details), we note that this boils down to showing that the number of distinct left cosets of in is less than or equal to . To this end, it is easy to check that for any , if , then . Since is a permutation on , we immediately have the desired conclusion.
Now we are ready to prove Lemma 5.3.
Proof of Lemma 5.3.
Recalling the definition of (see Definition 4.5), we see that given any , there exists a relabeling , such that (see Definition 4.5 for a definition of ). We also note that for . Therefore using Lemma 5.2 we note that
Thus applying Lemma 6.3, using the union bound, from our assumption on we immediately deduce that
Recall that by our assumption
Further applying Lemma 6.4 repetitively we deduce that
Hence using Stirling’s approximation we obtain
Using the fact that , for , we further note that
| (6.6) |
Next note that the function is decreasing in for all . Thus
| (6.7) |
Thus
| (6.8) |
Recalling the definition of we note that
Thus, if , we have . Therefore noting that
| (6.9) |
from (7) we deduce
for all large . Hence, to complete the proof it only remains to show that .
To this end, fixing , denote Using the Mean-Value Theorem, and recalling the fact that , we note that
This completes the proof.
Building on Lemma 5.3 we now derive a bound on and which will later be used in the proof of Lemma 5.5.
Lemma 6.5.
Let be a sequence of graphs satisfying (4.1)-(4.2). Fix any positive integer , and let be a graph on vertices. Assume that
for all graphs on vertices and all . Fix any . Then, there exists a large absolute constant , such that for any , we have
| (6.10) |
and
| (6.11) |
We prove this lemma using Lemma 5.3 but since we cannot apply it directly we resort to the following argument. Roughly the idea is to find a re-ordering, for any tuples such that for some we can safely plug in the correct estimate for the first elements from Lemma 5.2 and for the last terms can be controlloed by error estimates obtained from Lemma 5.3. Below we provide the formal argument.
Proof.
We begin by claiming that given any , there exists a reordering , , and such that for all , and for all .
Indeed, choose and arbitrarily, and choose and accordingly. That is, if , and , for some indices and , then set , and . Next, partition the set , where , and . For , if there is a vertex such that , where , then set , and . If there is more than choice, choose one of them arbitrarily. Now continue by induction. That is, having chosen partition the set , where , and . Again for some , if there is a vertex such that , where , then set , and .
Note that if the above construction stops at , then it is obvious that for all , and for all , and hence we have our claim.
For brevity, let us denote to be the collection of all , such that for some re-ordering of we have for all , and for all . Given a , it may happen that belong to for two different indices . To avoid confusion we choose the smallest index . When we denote the corresponding set by instead of . Equipped with these notations, we now note that
| (6.12) |
We show the first term in the rhs of (6.12) is the dominant term, and other term is negligible. First we find a good estimate on the dominant term.
To this end, from Lemma 5.2, using the union bound, and choosing , we obtain that
| (6.13) |
On the other hand, if , then for some , and some sub-graph of the graph , induced by vertices. Given any graph on vertices, there are at most many induced sub-graphs on vertices, and given any there are at most many choices of . Since , from Lemma 5.3 we deduce
| (6.14) |
Now taking a union over , we further obtain
This together with (6.13), upon recalling the definition of , now implies that
| (6.15) |
This provides the necessary error bound for the first term in the rhs of (6.12). We now bound the second term appearing in the rhs of (6.12).
Proceeding to control the second term, we first observe that is invariant under the permutation of the coordinates of (with same permutation applied on ). Thus
Now note that if then for the corresponding we have , for all . Therefore using Lemma 5.2, we obtain that
This together with (6.14), now implies
| (6.16) |
Thus combining (6.15)-(6.16), from (6.12) we deduce that
This completes the proof of (6.10). To prove (6.11) we proceed similarly as above. As before, we split the sum in two parts
Proceeding as in (6.16) we see that
| (6.17) |
On the other hand, using (5.6) we deduce
| (6.18) |
We next prove Lemma 5.4 where we obtain bounds on .
Proof of Lemma 5.4.
Recall that
where
(see Definition 4.3). Therefore
Now interchanging the summations we arrive at (5.7). To prove (7.5) we begin by observing the following inequality:
| (6.19) |
For ease of writing, let us assume that . Then, using (6.19), from (6.3), upon applying the triangle inequality, we deduce
Since for , and for , we further obtain that
| (6.20) |
which proves the upper bound in (7.5).
To obtain the lower bound of we proceed similarly to deduce that
Using the facts that for , we have , we further have,
| (6.21) |
This completes the proof.
Now combining the previous results we complete the proof of Lemma 5.5.
Proof of Lemma 5.5.
To prove the lemma we use Cauchy-Schwarz inequality as follows
| (6.22) |
Note that we have already obtained bounds on the first two terms inside the square bracket from Lemma 6.5. The bound on the third term was derived in Lemma 5.4. We obtain bounds on the last term follows upon combining Lemma 6.5 and Lemma 5.4. We then plug in these estimates one by one, and combine them together to finish the proof.
7. Proofs of Theorem 1.1 and Theorem 1.4
The proof of Theorem 1.1 uses the same ideas as in the proof of Proposition 4.1. Since in Theorem 1.1 we allow any , unlike Proposition 4.1 the argument cannot be symmetric with respect to the presence and absence of an edge. This calls for changes in some definitions and some of the steps in the proof of Proposition 4.1. Below we explain the changes and modifications necessary to extend the proof of Proposition 4.1 to establish Theorem 1.1.
Fix a positive integer and let be a graph with vertex set . Further, for , let be the sub-graph of induced by the vertices . Recall that in Proposition 4.1 we showed that the number of induced isomorphic copies of is approximately same as that of an Erdős-Réyni graph by showing that the same is true for for every , and given any such isomorphic copy, , of in , the number of common generalized neighbors (recall Definition 4.2) of the vertices of is about . Putting these two observations together we propagated the error estimates.
Since in the set-up of Theorem 1.1 the presence and absence of an edge do not have the same probability, the number of common generalized neighbors of the vertices of should depend on the number of edges present in that common generalized neighborhood. Therefore we cannot use Definition 4.4 and Definition 4.5 to define Good and Bad vertices. To reflect the fact that we adapt those definitions as follows. For ease of writing let us denote .
Definition 7.1.
For any given set , and , define
where for some large constant .
Next we need to extend Lemma 5.2, Lemma 5.3, Lemma 5.4, and Lemma 5.5 to allow any . To this end, we note that Lemma 5.2 extends to the following result.
Lemma 7.2.
Let be a sequence of graphs satisfying assumptions (A1) and (A2). Fix , and let and . Let . If , for all , and , then
| (7.1) |
for all large .
Proof.
Similar to the proof of Lemma 5.2 we use induction. For any , let us denote . We consider two cases and separately. Below we only provide the argument for . Proof of the other case is same and hence omitted.
Focusing on the case , using the triangle inequality we have
Since , we also have
Now using the induction hypothesis and proceeding as in Lemma 5.2 we complete the proof.
The next step to prove Theorem 1.1 is to extend Lemma 5.3 for any . Recall that a key ingredient in the proof of Lemma 5.3 is the variance bound obtained in Lemma 6.1. Here using assumptions (A1) and (A2), proceeding same as in the proof of Lemma 6.1, one can easily obtain the following variance bound. We omit its proof. For clarity of presentation, hereafter, without loss of generality, we assume that . For , interchanging the roles of and , one can obtain the same conclusions.
Lemma 7.3.
Let be a sequence of graphs satisfying assumptions (A1) and (A2). Then for any set and ,
for some constant , depending only on .
Lemma 7.4.
Let be a sequence of graphs satisfying (A1) and (A2). Fix any two positive integers , and let be a graph on vertices. Fix any one of the sub-graphs of induced by vertices. Assume that
There exists a large positive constant , depending only on such that, for any given , and , we have
for all large .
Proof.
First using the variance bound from Lemma 7.3 proceeding as in Lemma 6.3 we obtain
where . Further, using Lemma 7.2 we note that
where in the second inequality above we use the fact that . Therefore, applying Stirling’s approximation and proceeding as in (6.6)-(6.7) we obtain
| (7.2) |
Since
we note that if , then . Further noting that and we proceed as in the proof of Lemma 5.3 to arrive at the desired conclusion.
Next note that a key ingredient in the proof of Lemma 5.5 is Lemma 6.5. Therefore, we also need to find the analogue of Lemma 6.5 for general .
Lemma 7.5.
Let be a sequence of graphs satisfying (A1) and (A2). Fix any positive integer , and let be a graph on vertices. Assume that
for all graphs on vertices and all . Fix any . Then, there exists a large positive constant , depending only on , such that for any , we have
| (7.3) |
and
| (7.4) |
Proof.
The proof is again mostly similar to that of Lemma 6.5. Changes are required in only couple of places. Proceeding same as in the proof of Lemma 6.5 we see that (6.15) extends to
To extend (6.16) we first note that for there exists a relabeling such that , for all . Therefore using Lemma 7.2, we obtain that
where in the last step we again used the fact that . Proceeding similar to (6.16) we then deduce
The rest of the proof requires similar adaptation. We omit the details.
Imitating the proof of Lemma 5.4 we then obtain the following lemma.
Lemma 7.6.
For any , let . Then for any ,
| (7.5) |
Since we have all the required ingredients we can prove Theorem 1.1 imitating the proof of Proposition 4.1. The details are omitted.
Remark 7.7.
If one is only interested in counting the number of cliques of independent sets in satisfying (A1)-(A2) the from the proof of Theorem 1.1 it follows that one slightly improve the conclusion of Theorem 1.1. For example, when considering the number of cliques one can replace in (1.1) by , whereas for independent sets one can replace the same by .
Remark 7.8.
Note that in the proof of Theorem 1.1 we obtained a rate of convergence for the lhs of (1.1). Therefore we can easily consider such that as . Indeed, in the random geometric graph setting when the dimension of the space is poly-logarithmic of the number of points, the assumptions (A1)-(A2) are satisfied with as . To apply Theorem 1.1 there, we adapt our current proof to accommodate . For more details on this, see proof of Theorem 2.5. Similarly we can also consider . This would establish a version of Theorem 1.1 for sparse graphs. Further details are omitted.
We now proceed to the proof of Theorem 1.4. For clarity of presentation we once again only provide the proof for . Recall that a key to the proof of Theorem 1.1 is the variance bound obtained in Lemma 7.3. Using Chebychev’s inequality, Lemma 7.3 was then applied to . With the help of two additional assumptions (A3)-(A4) we improve that bound by using Markov’s inequality with fourth power. To do that, first we obtain the following bound on the fourth central moment of .
Lemma 7.9.
Let be a sequence of graphs satisfying assumptions (A1)-(A4) with . Then for any set , and ,
| (7.6) |
for some constant , depending only on .
The main advantage of Lemma 7.9 compared to Lemma 6.1 is the absence of on the rhs of (7). This helps in obtaining a better bound on “bad” vertices. Its proof is a simple consequence of assumptions (A1)-(A4).
Proof.
One can easily check that
| (7.7) |
Now using (A1)-(A4) we find bounds on each of the terms in the rhs of (7.7). Considering the first term in the rhs of (7.7) we see that
We further note that
Using (A1)-(A4) we therefore deduce that
| (7.8) |
for some absolute constant . By similar arguments we also obtain that
| (7.9) |
Next from Lemma 7.9 using Markov’s inequality we immediately obtain the following result.
Lemma 7.10.
Let be a sequence of graphs satisfying assumptions (A1)-(A4) with . Fix . Then, there exists a positive constant , depending only on , such that for any set , and
where .
Note the difference between of Lemma 7.10 and of Lemma 6.3. Presence of in is the key to the improvement of Theorem 1.1. Using Lemma 7.10 we now complete the proof of Theorem 1.4.
Proof of Theorem 1.4.
We begin by noting that Lemma 5.2 and Lemma 5.4 continue to hold as long as . Thus to improve Theorem 1.1 the key step is to establish that the number of “bad” vertices is negligible for all , when . That is, we need to improve Lemma 5.3 under the current set-up. To this end, we note that
Therefore, if , we have . Repeating the remaining steps of the proof of Lemma 5.3 one can extend its conclusion for all . Since The proofs of other lemmas are based on Lemma 5.3 one can improve those as well and hence repeating the other steps of the proof of Theorem 1.1 one can obtain Theorem 1.4. We omit rest of the details.
Remark 7.11.
Adding more assumptions on the graph sequence, e.g. bounds on the number of common neighbors of five and six vertices, one may potentially improve Theorem 1.4 further. We do not pursue that direction.
8. Proofs of the applications of Theorem 1.1
8.1. Proof of Theorem 2.2
We start this section with the following concentration result for the ergm model.
Theorem 8.1 (Concentration results).
We note that Theorem 2.2 follows immediately from the above concentration result and Theorem 1.1, upon applying Borel Cantelli lemma. Hence, the rest of the section will be devoted in proving Theorem 8.1.
Proof of (8.2) actually follows from the proofs of [14, Lemma 10, Lemma 11]. To describe the results of [14] we need to introduce the following notation.
For each , in the sequel we write
| (8.3) |
for the normalized co-degree. Now recalling the definition of (see (2.3)), we paraphrase two of the main results of [14] relevance to us.
Lemma 8.2 ([14, Lemma 10, Lemma 11]).
Under Assumption 2.1, for any , for all ,
| (8.4) |
Further there exists a constant such that for each ,
| (8.5) |
To prove (8.2) we do not need (8.5) directly. However, its proof will suffice in this case. More precisely, we will prove the following lemma which is sufficient to deduce (8.2).
Lemma 8.3.
Under Assumption 2.1, for any , for all ,
| (8.6) |
Further, given any , there exists a positive constant such that ,
| (8.7) |
Most of the proof of Lemma 8.3 has been carried out in [14]. Here we will only provide outlines, and we refer the interested readers to [14]. To prove (8.1), along with Lemma 8.3, we will need the following result.
Lemma 8.4.
Let . Fix any vertex and let denote the degree of this vertex. Then for any ,
8.1.1. Proofs of Lemma 8.3 and Lemma 8.4
In this section we prove Lemma 8.3 and Lemma 8.4. The key technique here is Chatterjee’s method for concentration inequalities via Stein’s method [12, 13]. We start by quoting the following result which we apply to prove the lemmas.
Theorem 8.5 ([13, Theorem 1.5]).
Let denote a separable metric space and suppose be an exchangeable pair of valued random variables. Suppose be a square integrable anti-symmetric function (i.e. ) and let . Write,
Assume that for all . Further assume there exist constants such that almost surely one has . Then for any ,
Remark 8.6.
Since is an anti-symmetric function, it is easy to check that the function as defined above satisfies . Thus the above gives concentration of about it’s expectation.
Next we state a simple lemma that describes an equivalence between the high-temperature regime as stated in Assumption 2.1 and a technical condition that arose in [14]. Proof follows from elementary calculus and hence omitted.
Lemma 8.7.
Now we are ready to prove the lemmas. First we start with the proof of Lemma 8.4.
Proof of Lemma 8.4.
Our plan is to apply Theorem 8.5. To do so, we need to construct an exchangeable pair, which is done in the following way: We start from configuration , and choose a vertex uniformly at random. Conditional on , sample the edge from the conditional distribution given the rest of the edges. We denote to be this new configuration. It is easy to see that form an exchangeable pair, and from the definition of we also note that, conditional on ,
| (8.8) |
In particular this implies that (see (2.3) for the definition of ). Now let denote the degree of in the new configuration . For later use, let denote the normalized co-degree between and in , and note that conditional on , . Now define the anti-symmetric function,
| (8.9) |
Using (8.8) it is easy to check that,
| (8.10) |
To apply Theorem 8.5, we next need to find an upper bound on . To this end, it is easy to note that . Next, note that . Upon observing that , we further deduce
Therefore recalling the definition of defined in Theorem 8.5, we have that
which upon applying Theorem 8.5 with and completes the proof.
We now prove Lemma 8.3. Since, most of the work is already done in [14] we provide an outline here for completeness.
Proof of Lemma 8.3.
Once again the key idea is to use Theorem 8.5. In this case, fixing , we construct the exchangeable pair as follows: Given a graph we choose a vertex uniformly at random and replace the edges with using the conditional distribution of these edges conditional on the rest of the edges. This gives us the new graph . Let us write for the normalized co-degree of in . Similar to (8.8), it is easy to verify using the form of the Hamiltonian that for ,
Now defining the anti-symmetric function , a careful analysis similar to the proof of Lemma 8.4 completes the proof of (8.6). Note that (8.6) holds only when . This condition on is needed because the quantity for which concentration is desired, is not exactly in this case. So one needs to apply triangle inequality, and hence we require the aforementioned lower bound on for (8.6) to hold.
Next building on (8.6), we now proceed to prove (8.7). To this end, let
Then using union bound, from (8.4), we deduce that given any , there exists such that,
| (8.11) |
Let and abusing notation let . Similarly let . Since we are in the ferromagnetic regime, i.e. , note that is an increasing non-negative function. Thus,
Rearranging and carrying out a similar analysis for we get,
| (8.12) |
This motivates defining the function
| (8.13) |
Using Lemma 8.7 it is very easy to see that is the unique solution of and further for , whereas for . One also has that the derivative . These observations, upon applying Inverse Function Theorem, imply that there exist such that if then and further
Now by (8.12), and . Thus on the event , considering all the cases, we have
However the latter implies that
which upon applying yields. This completes the proof.
Equipped with Lemma 8.3 and Lemma 8.4 we are now ready to prove the concentration result Theorem 8.1.
We start with the proof for the degree of vertices namely (8.1). We will see that this result follows directly if we are able to prove (8.2). We start with the following concentration inequality.
Proof of Theorem 8.1.
We begin by noting that (8.2) is immediate from Lemma 8.3. Thus it only remains to establish (8.1). Noting that is -Lipschitz on and using that by definition, , from Lemma 8.3, we get that,
| (8.14) |
Further using union bound, by Lemma 8.4, and enlarging if needed, we also have that,
| (8.15) |
Combining the above with (8.14) completes the proof.
8.2. Proof of Theorem 2.5
In this section our goal is to provide the proof of Theorem 2.5. Hence, we first need to show that assumptions (A1)-(A2) hold for random geometric graphs. This is derived in the following concentration result.
Theorem 8.8 (Concentration result).
Consider random geometric graphs satisfying Assumption 2.3. Then for any , the following holds almost surely, for all large :
-
(a)
(8.16) -
(b)
For every pair , there exists , possibly random, such that
(8.17) -
(c)
Moreover
(8.18) and is some constant depending only on .
Note that (8.16)-(8.17) does not establish that the random geometric graphs satisfy (A1)-(A2). In fact, when the dimension of the space is poly-logarithmic of the number of points one cannot expect to establish (A1)-(A2) for any for an arbitrarily small . However, using (8.18) we see that one can establish (A1)-(A2) for random geometric graphs with
We use this key observation to carefully adapt the proof of Theorem 1.1 to establish Theorem 2.5.
Proof of Theorem 2.5.
We start by redefining the notion of “good” vertices. Since in this current set-up we work with instead of a fixed it is natural to have the following definition: For any given set , and , we here define
where and is some large constant. Equipped with this definition we can easily make necessary changes in the proof of Theorem 1.1 to complete the proof in the current set-up.
In summary, the roles of and from the proof of Theorem 1.1 will be replaced by and in this proof. Keeping this in mind, we proceed below.
Proceeding exactly same as in Lemma 7.2 we deduce that if , , , and , for all , then
| (8.19) |
for all large , where . Next we need to extend Lemma 7.4 in the current set-up. Recall a key to the proof of Lemma 7.4 is the variance bound of Lemma 7.3. Lemma 7.3 can be extended in the context of random geometric graph to yield
| (8.20) |
From (8.20) it also follows that
where we recall . We note that if , then . Now repeating the remaining steps of the proof of Lemma 7.4 we obtain the following result: For any two positive integers let be a graph on vertices. Fix any one of the sub-graphs of induced by vertices. Assume that
There exists a large positive constant , depending only on such that, for any given , and , we have
| (8.21) |
for all large .
To complete the proof we now need to extend Lemma 7.5 and Lemma 7.6. Since Lemma 7.5 is built upon Lemma 7.4 we obtain necessary modifications of Lemma 7.5 using (8.21). The main difference here is the rate of convergence. More precisely, appearing in the rate of convergence in Lemma 7.5 should be replaced by in the current set-up. Next recalling the proof of Lemma 7.6 we see that the conclusion of Lemma 7.6 continues to hold for all . Combining these ingredients one can now easily finish the proof. We omit the tedious details.
Thus it only remains to establish Theorem 8.8. We break the proof of Theorem 8.8 into two parts. In Section 8.2.1 we prove (8.16)-(8.17) and in Section 8.2.2 we establish (8.18).
Before going to the proof, let us observe that uniform points on can be generated as follows: Let be i.i.d. standard Normal random vectors namely where is the origin in and is the identity matrix. Then, setting
| (8.22) |
where denotes the Euclidean norm in , we see that are i.i.d. uniform points on . Here, we will this representation of , because it allows us to use properties of Gaussian random vectors. For future reference let us denote .
8.2.1. Proof of (8.16)-(8.17).
Proof of (8.16).
For ease of writing, without loss of generality, let us consider the vertex . Note that conditional on , one can construct an orthogonal transformation such that in the new coordinates, whilst for are i.i.d. . To ease notation we will continue to refer to these as . Thus note that . In particular the constant is such that,
| (8.23) |
Further for each we write for the event that vertex and are connected by an edge in . Then we have,
This implies that the distribution of the degree of vertex is . Now, applying Chernoff’s inequality we obtain concentration inequality for . For any other vertex one can derive the same bound proceeding same as above. Thus the union bound and Borel Cantelli lemma completes the proof of (8.16).
Proof of (8.17).
We only establish (8.17) for . Proof for any other pair of vertices is exactly same. One can then complete the proof of (8.17) by taking a union bound over every pair .
As in the proof of (8.16), without loss of generality, let whist all other points are constructed as in (8.22). We start by conditioning on . For the rest of this section, write and for the corresponding conditional probability and conditional expectation. Then note that,
In particular, under we have that is a where,
| (8.24) |
Now using Chernoff’s inequality and taking expectation over , we obtain
where , which upon taking a union over completes the proof.
8.2.2. Proof of (8.18).
Here again we establish (8.18) for . The proof for arbitrary is same, and therefore one can complete the proof by taking a union bound. Thus it is enough to prove (8.18) only for . To simplify notation, we let
| (8.25) |
Note that has a standard Bivariate Normal distribution with correlation . If were zero, then we would have immediately deduced that (8.18) holds. Here, we show that with large probability, and therefore should not differ much from . Below, we make this idea precise. We begin with two concentration results on Gaussian random vectors.
Lemma 8.9.
Let be i.i.d. standard Normal random variables and let be the vector representation of this in . Then there exists such that for all and all ,
Proof.
First note that since is a one-Lipschitz function, standard Gaussian concentration (for example, see [9]) implies that
| (8.26) |
Since has a chi-distribution, this implies that
| (8.27) |
where is the Gamma function. Standard results on asymptotics for the Gamma function (see, for example [40]) imply
Using this in (8.27), upon combining with (8.26) completes the proof.
Note that the first co-ordinate of is given by . Lemma 8.9 implies that with large probability. The next simple Lemma establishes concentration rates about the order of magnitude.
Lemma 8.10.
Under Assumption 2.3, such that for ,
Proof.
To ease notation, let . Then note that,
The upper bound on the first term in the rhs above follows from Lemma 8.9, whereas standard tail bounds for the Normal distribution gives upper bound on the second term. Combining them together completes the proof.
As already noted has a bivariate Normal distribution. Therefore we will need some estimates on the distribution function of a bivariate Normal distribution. To this end, throughout the sequel, let denote the standard Normal distribution function and let , where has a standard bivariate Normal distribution with correlation . Then we have the following result.
Lemma 8.11 ([42]).
Fix and . Let has a standard bivariate Normal distribution with correlation . Then denoting , one has
Finally to evaluate (8.24), we need the following asymptotic behavior of .
Lemma 8.12 ([21, Lemma 1]).
Fix and assume . Then there exists a constant , depending only on , such that one has
Proof of (8.18).
First let us define the event
| (8.28) |
We will show that on , we have . By the same argument one can extend the result for all pairs . Therefore, the proof completes by setting , applying Lemma 8.10, taking a union bound, and applying Borel Cantelli lemma.
We break the proofs into two parts. First we show that on , we have . Denoting , we note
| (8.29) |
By Lemma 8.9, we have . To bound Term A we use the fact that under , has a standard bivariate Normal distribution with correlation as defined in (8.25). First let us consider the case . Using Lemma 8.11 with , we obtain
Next, applying Lemma 8.12 we note
| (8.30) |
for another constant , depending only on . Therefore using the Mean-Value Theorem we further obtain that
| (8.31) |
Moreover, note that on the event we have and by Assumption 2.3 we have . Hence, using the Mean-Value Theorem again
| (8.32) |
for some other constant . Combining (8.31)-(8.32) we obtain the desired bound for Term A when .
When , we cannot directly use Lemma 8.11. Instead we use the following result:
for any and (see [36, Eqn. (C)], [42, pp. 2294]). Now using the lower bound from Lemma 8.11, we obtain . We have already seen above that . Therefore proceeding as above we can argue that . Then proceeding similarly as above we obtain the desired upper bound for Term A when . The details are omitted.
Now it remains to find a lower bound on . To this end, it is easy to note that
where
Proceeding as in the case of , one can complete the proof. We omit the details.
8.3. Proof of Theorem 2.7.
To prove Theorem 2.7 we need a good estimate on . It is well known that the number of copies of any subgraph in an Erdős-Rényi random graph is well approximated in total variation distance, by a Poisson distribution with appropriate mean (see [4, Section 5.1]). Combining [4, Theorem 5.A] and [4, Lemma 5.1.1(a)] results in the following proposition. Here for any two probability measures and defined on , write for the total variation distance between these measures. Abusing notation write , when , and .
Proposition 8.13.
Let be the Edős-Rényi random graph with connectivity probability . For any graph let denote the cardinality of the vertex set of , and be the same for the edge set. Further write
where denote the number elements in the automorphism groups of . Then
| (8.33) |
For any isomorphic copy of , let be the collections of all subgraphs of the complete graph on vertices that are isomorphic to with exactly edges not in . Then
| (8.34) |
Proof of Theorem 2.7.
First note that . Thus it is enough to prove that
| (8.35) |
Using Hoeffding’s inequality we obtain
Thus taking a union bound
| (8.36) |
Now to control the denominator of (8.35) we use Proposition 8.13. Note that, if we are able to show that the rhs of (8.33), excluding the term , is , then from (8.33) we deduce that
This therefore implies that
| (8.37) |
Next note
Since , using Stirling’s approximation, we have
As it is easy to check that
and hence , as . Therefore , for large , and so from (8.37) we further have,
| (8.38) |
Next we observe
Since with , we have
proving
Thus to complete the proof we only need to show that for , where and are some positive constants,
| (8.39) |
Using (8.34) we note that
for any isomorphic copy of the complete graph on vertices. If and are two different isomorphic copies of the complete graph on vertices, with common vertices between them, then there are edges of that are not part of the edge set of . Thus the above expression simplifies to the following:
| (8.40) |
Now we need to control the summation appearing in the rhs of (8.40). Denoting
we note
| (8.41) |
Thus
| (8.42) |
Using the above equivalent condition of we show below that the sequence monotonically decreases initially, achieves a minimum for , and then monotonically increases afterwards for all except possibly for . This observation helps us to compute , and therefore we can easily obtain an upper bound on summation appearing in the rhs of (8.40). To this end, note that for any fixed if , then
for any , proving that is strictly decreasing for . We next try to find a necessary condition on . If , then using (8.42) we note that we must have
where in the last step we use the fact that . The above expression therefore implies that . Hence, if a minimum of occurs at , then we should have that . Next we show that for any , for all , except possibly for . To see this, consider
| (8.43) |
Since , and , the product of the ratio
can be made as close to as needed for all large . Also note that if , then
Hence, from (8.43) we conclude that is monotonically increasing for all integer between , and . Hence, from (8.40) we have
It is easy to note that
and thus we obtain (8.39) completing the proof.
Remark 8.14.
In [4, Example 5.1.4] the number of copies of large complete subgraphs of an Erdős-Réyni graph on vertices is also shown to converge to a Poisson distribution in total variation distance. However, their set-up significantly differs from ours. In particular, they assume that the connectivity probability of the Erdős-Réyni graph satisfies the inequality , and , neither of which holds here. Both in [4, Example 5.1.4], and Lemma 2.7 the starting point is (8.33)-(8.34). However, the analysis of the terms appearing in (8.34) are done differently.
8.4. Proof of Theorem 2.14
Recall that is a graph on vertices where its vertices are binary tuples of length containing an odd number of ones, excluding the vector of all ones, where . A pair of vertices and are connected if , where additions and multiplications are the corresponding operations in the binary field. It is easy to see that is a -regular graph with . Also it can be shown that the number of common neighbors for any pair of adjacent vertices is and the same for a pair of non-adjacent vertices is (See [32, Section 3, Example 4]). Therefore, it is immediate that satisfies (A1)-(A2) with , and . Thus the proof of Theorem 2.14(i) is a direct application of Theorem 1.1. In the rest of this section we prove Theorem 2.14(ii)-(iii). To complete the proof we need the following elementary result.
Lemma 8.15.
Let be a binary matrix with such that . Then given any binary vector of length such that it belongs to the column space of , the number of solutions of the linear system of equation is .
The proof of Lemma 8.15 is easy and follows from standard linear algebra argument and an induction argument. We omit the details. Now we are ready to prove Theorem 2.14(ii)-(iii). First we begin with the proof of Theorem 2.14(ii).
Proof of Theorem 2.14(ii).
First let us find the size of the largest independent set in . To this end, let us assume that forms an independent set of size . Then, we have that for all . We further claim that is a set of mutually independent vectors when viewed as vectors of length over the binary field. To see this, if possible let us assume that there exists coefficients , , not all of them zero, such that
| (8.44) |
Note that for all , where is the vector of all ones. Therefore, taking an inner product with on both sides of (8.44) we have that for all which is a contradiction. Therefore forms an independent set of size . Since the number of independent vectors of length over any field is at most , recalling that , the assertion about that size of the maximal independent set in is established.
Now let us show that the number of independent sets of size is roughly same as that of a . We begin by noting that if is an independent set then so is and must be a common non-neighbor of . To find the number of common non-neighbors we define to be the matrix whose rows are . Then we note that must be a solution of
| (8.45) |
The first rows of (8.45) ensures that is a common non-neighbor of and the last row ensures that the number of ones in is odd, which is necessary for to be a vertex of . From Lemma 8.15 it follows that, if , then the number of such solutions is . We also observe that any of cannot be a solution of (8.45). Because
Thus we deduce that given any collection of vertices , if then the number of common non-neighbors is . Now let us try to understand when one can have . If then we must have coefficients , all of them not zero, such that
| (8.46) |
Since for , taking an inner product with from (8.46) we deduce that . Since forms an independent set of size , we have that for . Thus taking an inner product with for , from (8.46) we further deduce that for all . Combining the last two observations we deduce that must be even and for all . Therefore we can only have when is an independent set. This further implies that
| (8.47) |
whenever . It is also easy to check that in this case there are no solution to the linear system of equations (8.45). In summary we have the following situation. Given any independent set , one of the following two conditions hold:
-
•
and there are common non-neighbors of .
-
•
(only when is even). Then (8.47) holds, and there are no common non-neighbors of .
Using these observations we are now ready to prove our claim for the independent sets.
We start by choosing , which we can obviously do in many ways. For any such choice of there are many non-neighbors of . This is the number of choices of . For any such choice of , by our above argument there are choices of such that is a common non-neighbor of and . Out of these many choices if then we cannot extend to a larger independent set as we have already seen that in this case there no common non-neighbor of these three vertices. Thus the number of choices of such that it can be extended to form a larger independent set is . For each of these choices we again have already established that . Therefore, we obtain that the number of choices of is . Continuing the above we see that the number of independent sets of size is
as . In the last two steps we use the fact that . An easy calculation yields that
Since the proof completes.
To prove Theorem 2.14(iii) it will be easier to consider the following alternate representation of the vertices of . Note that for any vertex in we can define such that . Instead of considering as its vertices, equivalently we can view as a graph with vertices . Note that in this representation and are connected if and only if . We work with this representation to prove Theorem 2.14(iii). Theorem 2.14(iii) actually follows from [37]. We include the proof for completeness. It can be noted that the same proof shows the existence of a clique of size in .
Proof of Theorem 2.14(iii).
Denote and fix any positive integer . We create a clique of size as follows: First we consider mutually independent vectors which form a clique of size and then we pick more vectors from . Since , it is easy to check that any vector belonging to is a common neighbor of . Therefore we obtain a clique of size . Thus we only need to count in how many ways one can construct mutually independent vectors which themselves form a clique and in how many ways one can choose more vectors from the span of those mutually independent vectors.
Fix and let be a collection mutually independent vectors. Then is a common neighbor of if , where is a matrix with rows , and is the zero vector. Since for and is a collection of mutually independent vectors, we have . Therefore, number of solutions of is . Removing many vectors that belong to we obtain that the number of choices of common neighbors of that are independent from the latter collection of vectors is . Continuing by induction we then deduce that the number of mutually independent vectors such that they themselves form a clique of size is
Recalling that , we now have that the number of cliques of size in is at least
Since for , one has , we obtain that . Finally noting that in the number of cliques of size is approximately the proof completes.
Acknowledgements
Much of the work was done while AB was a visiting assistant professor at Department of Mathematics, Duke University. SB has been partially supported by NSF-DMS grants 1310002, 160683, 161307 and SES grant 1357622. SC has been partially supported by SES grant 1357622 and by a research assistantship from SAMSI. AN has been partially supported by NSF-DMS grants 1310002 and 1613072.
References
- [1] Réka Albert and Albert-László Barabási. Statistical mechanics of complex networks. Reviews of modern physics, 74(1):47, 2002.
- [2] Noga Alon. Tough ramsey graphs without short cycles. Journal of Algebraic Combinatorics, 4(3):189–195, 1995.
- [3] Noga Alon, Michael Krivelevich, and Benny Sudakov. Finding a large hidden clique in a random graph. Random Structures and Algorithms, 13(3-4):457–466, 1998.
- [4] Andrew D Barbour, Lars Holst, and Svante Janson. Poisson approximation. Clarendon Press Oxford, 1992.
- [5] Shankar Bhamidi, Guy Bresler, and Allan Sly. Mixing time of exponential random graphs. Ann. Appl. Probab., 21(6):2146–2170, 2011.
- [6] Béla Bollobás. Random graphs. In Modern Graph Theory, pages 215–252. Springer, 1998.
- [7] Christian Borgs, Jennifer T Chayes, László Lovász, Vera T Sós, and Katalin Vesztergombi. Convergent sequences of dense graphs i: Subgraph frequencies, metric properties and testing. Advances in Mathematics, 219(6):1801–1851, 2008.
- [8] Christian Borgs, Jennifer T Chayes, László Lovász, Vera T Sós, and Katalin Vesztergombi. Convergent sequences of dense graphs ii. multiway cuts and statistical physics. Annals of Mathematics, 176(1):151–219, 2012.
- [9] Stéphane Boucheron, Gábor Lugosi, and Pascal Massart. Concentration inequalities: A nonasymptotic theory of independence. OUP Oxford, 2013.
- [10] Sébastien Bubeck, Jian Ding, Ronen Eldan, and Miklós Z Rácz. Testing for high-dimensional geometry in random graphs. Random Structures & Algorithms, 2016.
- [11] Ed Bullmore and Olaf Sporns. Complex brain networks: graph theoretical analysis of structural and functional systems. Nature Reviews Neuroscience, 10(3):186–198, 2009.
- [12] Sourav Chatterjee. Concentration inequalities with exchangeable pairs. ProQuest LLC, Ann Arbor, MI, 2005. Thesis (Ph.D.)–Stanford University.
- [13] Sourav Chatterjee. Stein’s method for concentration inequalities. Probab. Theory Related Fields, 138(1-2):305–321, 2007.
- [14] Sourav Chatterjee, Partha S Dey, et al. Applications of stein?s method for concentration inequalities. The Annals of Probability, 38(6):2443–2485, 2010.
- [15] Sourav Chatterjee, Persi Diaconis, et al. Estimating and understanding exponential random graph models. The Annals of Statistics, 41(5):2428–2461, 2013.
- [16] Fan R. K. Chung, Ronald L. Graham, and Richard M. Wilson. Quasi-random graphs. Combinatorica, 9(4):345–362, 1989.
- [17] Fan RK Chung and Linyuan Lu. Complex graphs and networks, volume 107. American mathematical society Providence, 2006.
- [18] FRK Chung and RL Graham. On graphs not containing prescribed induced subgraphs. A Tribute to Paul Erdos, Cambridge University Press, Cambridge, pages 111–120, 1990.
- [19] Yael Dekel, Ori Gurel-Gurevich, and Yuval Peres. Finding hidden cliques in linear time with high probability. Combinatorics, Probability and Computing, 23(01):29–49, 2014.
- [20] Yash Deshpande and Andrea Montanari. Finding hidden cliques of size sqrt N/e in nearly linear time. Foundations of Computational Mathematics, 15(4):1069–1128, 2015.
- [21] Luc Devroye, András György, Gábor Lugosi, and Frederic Udina. High-dimensional random geometric graphs and their clique number. Electronic Journal of Probability, 16:2481–2508, 2011.
- [22] David Steven Dummit and Richard M Foote. Abstract algebra, volume 3. Wiley Hoboken, 2004.
- [23] Richard Durrett. Random graph dynamics, volume 200. Citeseer, 2007.
- [24] Victor M Eguiluz, Dante R Chialvo, Guillermo A Cecchi, Marwan Baliki, and A Vania Apkarian. Scale-free brain functional networks. Physical review letters, 94(1):018102, 2005.
- [25] P. Erdős and A. Rényi. On random graphs. I. Publ. Math. Debrecen, 6:290–297, 1959.
- [26] P. Erdős and A. Rényi. On the evolution of random graphs. Bull. Inst. Internat. Statist., 38:343–347, 1961.
- [27] P. Erdős and A. Rényi. On the strength of connectedness of a random graph. Acta Math. Acad. Sci. Hungar., 12:261–267, 1961.
- [28] P. Erdős and J. Spencer. Imbalances in -colorations. Networks, 1:379–385, 1971/72.
- [29] Paul Erdös. Some remarks on the theory of graphs. Bulletin of the American Mathematical Society, 53(4):292–294, 1947.
- [30] Santo Fortunato. Community detection in graphs. Physics reports, 486(3):75–174, 2010.
- [31] Svante Janson, Tomasz Luczak, and Andrzej Rucinski. Random graphs, volume 45. John Wiley & Sons, 2011.
- [32] Michael Krivelevich and Benny Sudakov. Pseudo-random graphs. In More sets, graphs and numbers, pages 199–262. Springer, 2006.
- [33] Michael Krivelevich, Benny Sudakov, Van H Vu, and Nicholas C Wormald. Random regular graphs of high degree. Random Structures & Algorithms, 18(4):346–363, 2001.
- [34] Mark EJ Newman. The structure and function of complex networks. SIAM review, 45(2):167–256, 2003.
- [35] Cornelis J Stam and Jaap C Reijneveld. Graph theoretical analysis of complex networks in the brain. Nonlinear biomedical physics, 1(1):1, 2007.
- [36] GP Steck and DB Owen. A note on the equicorrelated multivariate normal distribution. Biometrika, 49(1/2):269–271, 1962.
- [37] Andrew Thomason. Pseudo-random graphs. North-Holland Mathematics Studies, 144:307–331, 1987.
- [38] Andrew Thomason. Random graphs, strongly regular graphs and pseudorandom graphs. Surveys in combinatorics, 123:173–195, 1987.
- [39] Konstantin Tikhomirov and Pierre Youssef. The uniform model for -regular graphs: concentration inequalities for linear forms and the spectral gap. arXiv preprint arXiv:1610.01765, 2016.
- [40] Francesco Giacomo Tricomi, Arthur Erdélyi, et al. The asymptotic expansion of a ratio of gamma functions. Pacific J. Math, 1(1):133–142, 1951.
- [41] Remco Van Der Hofstad. Random graphs and complex networks. Available on http://www. win. tue. nl/rhofstad/NotesRGCN. pdf, page 11, 2009.
- [42] R Willink. Bounds on the bivariate normal distribution function. Communications in Statistics-Theory and Methods, 33(10):2281–2297, 2005.