LazyPIM: Efficient Support for Cache Coherence
in Processing-in-Memory Architectures
Abstract
Processing-in-memory (PIM) architectures have seen an increase in popularity recently, as the high internal bandwidth available within 3D-stacked memory provides greater incentive to move some computation into the logic layer of the memory. To maintain program correctness, the portions of a program that are executed in memory must remain coherent with the portions of the program that continue to execute within the processor. Unfortunately, PIM architectures cannot use traditional approaches to cache coherence due to the high off-chip traffic consumed by coherence messages, which, as we illustrate in this work, can undo the benefits of PIM execution for many data-intensive applications.
We propose LazyPIM, a new hardware cache coherence mechanism designed specifically for PIM. Prior approaches for coherence in PIM are ill-suited to applications that share a large amount of data between the processor and the PIM logic. LazyPIM uses a combination of speculative cache coherence and compressed coherence signatures to greatly reduce the overhead of keeping PIM coherent with the processor, even when a large amount of sharing exists. We find that LazyPIM improves average performance across a range of data-intensive PIM applications by 19.6%, reduces off-chip traffic by 30.9%, and reduces energy consumption by 18.0%, over the best prior approaches to PIM coherence.
1 Introduction
For many modern data-intensive applications, main memory bandwidth continues to be a limiting factor, as data movement contributes to a large portion of a data-intensive application’s execution time and energy consumption. In fact, modern computing platforms are unable to scale performance linearly with the amount of data processed per each computing node [1]. The emergence of memory-intensive big-data applications, such as in-memory databases and graph processing frameworks, exacerbates this problem. These workloads often exhibit frequent data movement and random memory access patterns, placing high pressure on the memory system and making memory bandwidth a first-class problem for those workloads.
Recent advances in 3D-stacked technology enable promising solutions to alleviate the memory bandwidth problem. To exploit the high internal bandwidth available within 3D-stacked DRAM, several recent works explore processing-in-memory (PIM), also known as near-data processing (e.g., [1, 2, 12, 14, 54, 43, 42, 16, 38, 51, 11, 52]), where the processor dispatches parts of the application (PIM kernels) for execution at compute units (PIM cores) within DRAM. The specific functionality enabled by these PIM cores differs from proposal to proposal, with some work implementing specialized accelerators [1, 17] while others add simple general-purpose cores [12, 2] or GPU cores [54] in the logic layer.
To ensure correct execution, PIM architectures require coordination between the processor cores and the PIM cores. One of the primary challenges for coordination is cache coherence, which ensures that cores always use the correct version of the data (as opposed to stale data that does not include updates that were performed by other cores). If the PIM cores are coherent with the processor cores, the PIM programming model becomes relatively simple, as it then becomes similar to conventional multithreaded programming. Employing a common programming model for PIM that most programmers are familiar with can facilitate the widespread adoption of PIM.
However, it is impractical for PIM to utilize a traditional cache coherence protocol (e.g., MESI), as this forces a large number of coherence messages to traverse the narrow off-chip bus that exists between PIM cores and the processor cores, potentially undoing the benefits of high-bandwidth PIM execution. Most prior works on PIM assume that only a limited amount of data sharing occurs between the PIM kernels and the processor threads of an application. Thus, they sidestep coherence by employing solutions that restrict PIM to execute on non-cacheable data (e.g., [1, 11, 54]) or force the processor cores to flush or not access any data that could potentially be used by PIM (e.g., [11, 12, 42, 43, 14, 2]).
We comprehensively study two important classes of data-intensive applications, graph processing frameworks and in-memory databases, where we find there is strong potential for improvement using PIM. We make two key observations based on our analysis of these data-intensive applications: (1) some portions of the applications are better suited for execution in processor threads, and these portions often concurrently access the same region of data as the PIM kernels, leading to significant data sharing; and (2) poor handling of coherence eliminates a significant portion of the performance and energy benefits of PIM. As a result, we find that a good coherence mechanism is required to retain the full benefits of PIM across a wide range of applications (see Section 3) while maintaining the correct execution of the program. Our goal in this work is to propose a cache coherence mechanism for PIM architectures that logically behaves like traditional coherence, but retains all of the benefits of PIM.
To this end, we propose LazyPIM, a new cache coherence mechanism that efficiently batches coherence messages sent by the PIM cores. During PIM kernel execution, a PIM core speculatively assumes that it has acquired coherence permissions without sending a coherence message, and maintains all data updates speculatively in its cache. Only when the kernel finishes execution, the processor receives compressed information from the PIM core, and checks if any coherence conflicts occurred. LazyPIM uses compressed signatures [6] to track potential conflict information efficiently. Under the LazyPIM execution model, a conflict occurs only when the PIM core reads data that the processor updated (i.e., wrote to) before the conflict check takes place (see Section 4.1). If a conflict exists, the dirty cache lines in the processor are flushed, and the PIM core rolls back and re-executes the kernel. Our execution model for the PIM cores is similar to chunk-based execution [7] (i.e., each batch of consecutive instructions executes atomically), which prior work has harnessed for various purposes such as transactional memory [15] and deterministic execution [8]. Unlike past works, the processor in LazyPIM executes conventionally and never rolls back, which can make it easier to adopt PIM in general-purpose systems.
We find that LazyPIM is highly effective at providing cache coherence for PIM architectures, and avoids the high overheads of previous solutions even when a high degree of data sharing exists between the PIM kernels and the processor threads. Due to the high overhead of prior approaches to PIM coherence, PIM execution often fares worse than if we executed the workloads entirely on the CPU, with PIM execution providing worse performance, consuming more off-chip traffic, and consuming more energy in a number of cases. In contrast, for all of our workloads, LazyPIM retains most of the benefits of an ideal PIM mechanism that has no penalty for coherence, coming within 9.8% and 4.4% of the average performance and energy, respectively, for our 16-thread data-intensive workloads. LazyPIM reduces the execution time and energy by 66.0% and 43.7%, respectively, over CPU-only execution.
We make the following key contributions in this work:
-
•
We demonstrate that previously-proposed coherence mechanisms for PIM are not a good fit for workloads where a large amount of data sharing occurs between the PIM kernels and the processor threads. Prior mechanisms either take overly conservative approaches to sharing or generate high off-chip traffic, oftentimes undoing the benefits that PIM architectures provide.
-
•
We propose LazyPIM, a new hardware coherence mechanism for PIM. Our approach (1) reduces the off-chip traffic between the PIM cores and the processor, (2) avoids the costly overheads of prior approaches to provide coherence for PIM, and (3) retains the same logical coherence behavior as architectures without PIM to keep programming simple.
-
•
We show that on average for our 16-thread applications, LazyPIM improves performance by 19.6%, reduces off-chip traffic by 30.9%, and reduces energy consumption by 18.0% over the best prior coherence approaches, respectively, for each metric. LazyPIM enables PIM execution to always outperform CPU-only execution.
2 Background
In this section, we provide necessary background on PIM architectures. First, we study how 3D-stacked memory can deliver high internal bandwidth (Section 2.1). Then, we explore prior works on PIM (Section 2.2). Finally, we discuss the baseline PIM architecture that we study for this paper (Section 2.3).
2.1 3D-Stacked Memory
In recent years, a number of new DRAM architectures have been proposed to take advantage of 3D circuit integration technology [27, 25]. These architectures stack multiple layers of DRAM arrays together within a single chip. 3D-stacked memory employs through-silicon vias (TSVs), which are vertical wires that connect all stack layers together. Due to the available density of TSVs, 3D-stacked memories are able to provide much greater bandwidth between stack layers than they can provide off-chip. Several 3D-stacked memory architectures, such as High Bandwidth Memory (HBM) [20] and the Hybrid Memory Cube (HMC) [18], also provide the ability to perform low-cost logic integration directly within memory. Such architectures dedicate a logic layer within the stack for logic circuits. Within the logic layer, architects can implement functionality that interacts with both the DRAM cells in the other layers (using the TSVs) and the processor. For example, HMC uses part of the logic layer to buffer memory requests from the processor and perform memory scheduling [18].
2.2 Processing-in-Memory
The origins of PIM go back to proposals from the 1970s, where small processing elements were combined with small amounts of RAM to provide a distributed array of memories that perform computation [44, 48]. Early works such as EXECUBE [23] and IRAM [36] added logic within DRAM to perform vector operations. Later works [21, 10, 28, 34] proposed more versatile substrates that increased the flexibility and compute power available within DRAM. These proposals had limited to no adoption, as the proposed logic integration was too costly and did not solve many of the obstacles facing PIM.
With the advent of 3D-stacked memories, we have seen a resurgence of PIM proposals. Recent PIM proposals (e.g., [1, 11, 2, 12, 54, 14, 16, 17]) add compute units within the logic layer to exploit the high bandwidth available. These works have primarily focused on the design of the underlying logic that is placed within memory, and in many cases propose special-purpose PIM architectures that cater only to a limited set of applications.
2.3 Baseline PIM Architecture
Figure 1 shows the baseline organization of the PIM architecture in our paper. We refer to the compute units within the main processor as processor cores, which execute processor threads. We refer to the compute units within memory as PIM cores, which execute PIM kernels that are invoked by the processor threads. Note that LazyPIM can be used with any type of compute units that contain memory. In our evaluation, we assume that the compute units within memory consist of simple in-order cores. These PIM cores, which are ISA-compatible with the processor cores, are much weaker in terms of performance, as they lack large caches and sophisticated ILP techniques, and frequently do not implement all of the ISA. These weaker cores are more practical to implement within the DRAM logic layer.
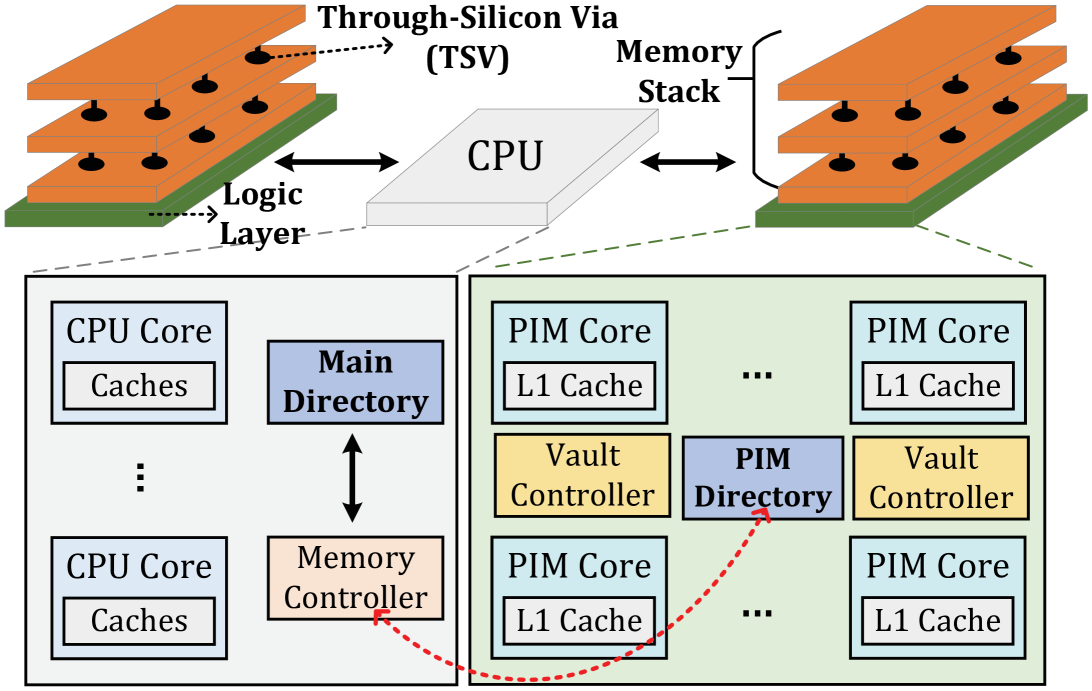
Each PIM core includes small private L1 I/D caches. The data cache is kept coherent using a local MESI directory called the PIM coherence directory, which resides within the DRAM logic layer. The processor caches maintain coherence using the traditional on-chip directory. The processor directory acts as the main coherence point for the system, interfacing with both the processor caches and the PIM coherence directory. As prior PIM works [1, 11] have done, we assume that direct segments [4] are used for PIM data, and that PIM kernels operate only on physical addresses.
3 Motivation
Systems with multiple independent processor cores rely on cache coherence to seamlessly allow multiple threads to exchange data with each other in the presence of a cache. If we treat the PIM cores as additional independent cores that remain coherent with the processor cores, we can greatly simplify the PIM programming model, by making it behave similarly to the behavior programmers expect for multithreaded programming. While recent PIM proposals acknowledge the need for some form of coherence between the PIM cores and processor cores [51, 11, 12], these works have largely sidestepped the issue by assuming that there is only a limited amount of data sharing that takes places between PIM kernels and processor threads during PIM kernel execution. In this section, we show that this assumption does not hold for many classes of applications that are well-suited for PIM execution.
3.1 Applications with High Data Sharing
An application benefits the most from PIM execution when its memory-intensive parts, which often exhibit poor locality and contribute to a large portion of the overall execution time, are dispatched to the PIM cores. Executing on the PIM cores allows the memory-intensive parts to benefit the most from the high bandwidth and low latency access available at the logic layer of the 3D-stacked DRAM. On the other hand, the compute-intensive parts of an application, typically the portions of code that exhibit high locality, must remain on the processor cores to maximize performance [2, 16, 12]. We discuss how we find the appropriate partitions between memory-intensive and compute-intensive parts of our applications in Section 6.2.
Prior work mostly assumes that there is only a limited amount of data sharing between the PIM kernels and the processor threads. However, this is not the case for many important applications, such as graph and database workloads. One class of examples is multithreaded graph processing frameworks, such as Ligra [45], where multiple threads operate on the same shared in-memory graph [53, 45]. Each thread executes a graph algorithm, such as PageRank. We studied a number of these algorithms [45] and found that when we convert each of them for PIM execution, only some portions of each algorithm were well-suited for PIM, while the remaining portions performed better if they stayed on the processor to exploit locality using large caches. This observation was also made by prior work [2]. With this partitioning, some threads execute on the processor cores while other threads (sometimes concurrently) execute on the PIM cores, with all of the threads sharing the graph and other intermediate data structures.
Another example is a modern in-memory database that supports hybrid transactional/analytical processing (HTAP) workloads. Today, analytic and transactional behaviors are being combined in a single hybrid database system, as observed in several academic and industrial databases [40, 49, 29], thanks to the need to perform real-time analytics on transactional data. The analytic portions of these hybrid databases are well-suited for PIM execution, as analytical queries have long lifetimes and touch a large number of database rows, leading to a large amount of random memory accesses and data movement [22, 30, 51]. On the other hand, even though transactional queries access the same data, they likely perform better if they stay on the processor, as they are short-lived and are often latency sensitive, accessing only a few rows each, which can easily fit in processor caches. In such workloads, concurrent accesses from both PIM kernels and processor threads are inevitable, as analytical queries benefit from executing near the data while transactions perform best on processor cores.
3.2 Prior Approaches to PIM Coherence
Shared data needs to remain coherent between the processor and PIM cores. In an ideal scenario, there would be no communication overhead for maintaining coherence. Traditional, or fine-grained, coherence protocols (e.g., MESI [35, 13]) have several qualities well suited for pointer-intensive data structures, such as those in graph workloads and databases. The path taken while traversing pointers during pointer chasing is not known ahead of time. As a result, even though a thread often accesses only a few dispersed pieces of the data structure, a coarse-grained mechanism has no choice but to acquire coherence permissions for the entire data structure. Fine-grained coherence allows the processor or PIM to acquire permissions for only the pieces of data within the shared structure that are actually accessed. In addition, fine-grained coherence can ease programmer effort when developing PIM applications, as multithreaded programs already use this programming model.
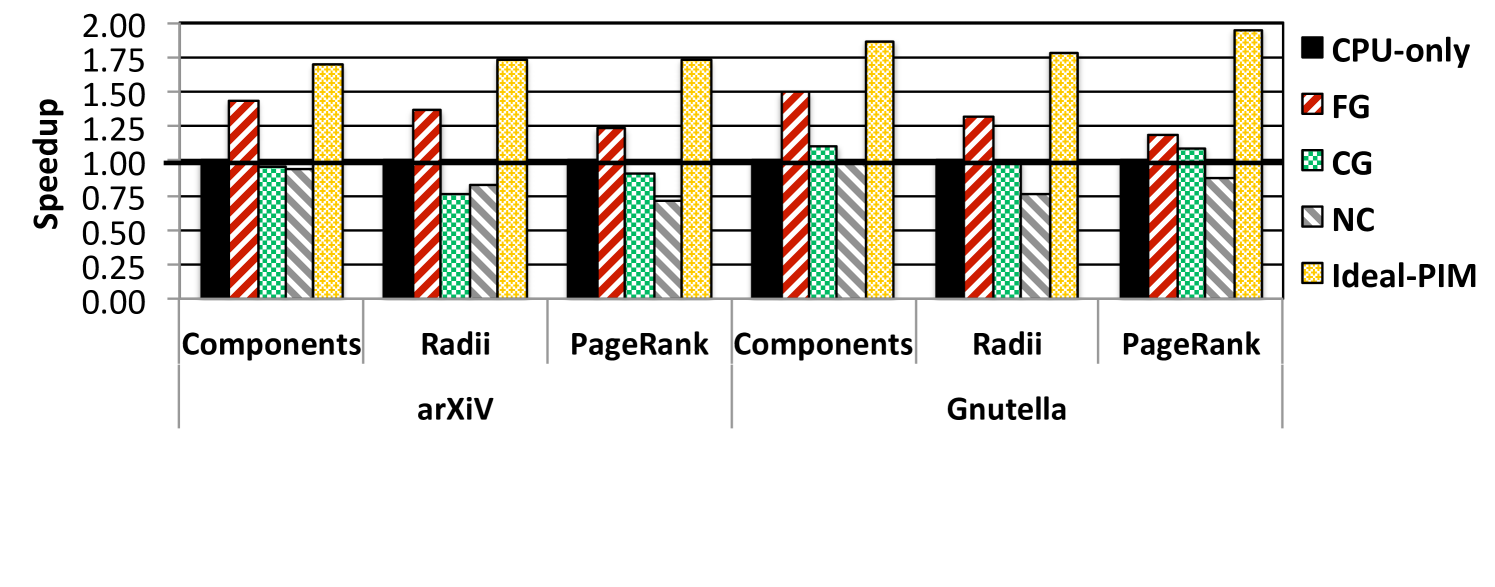
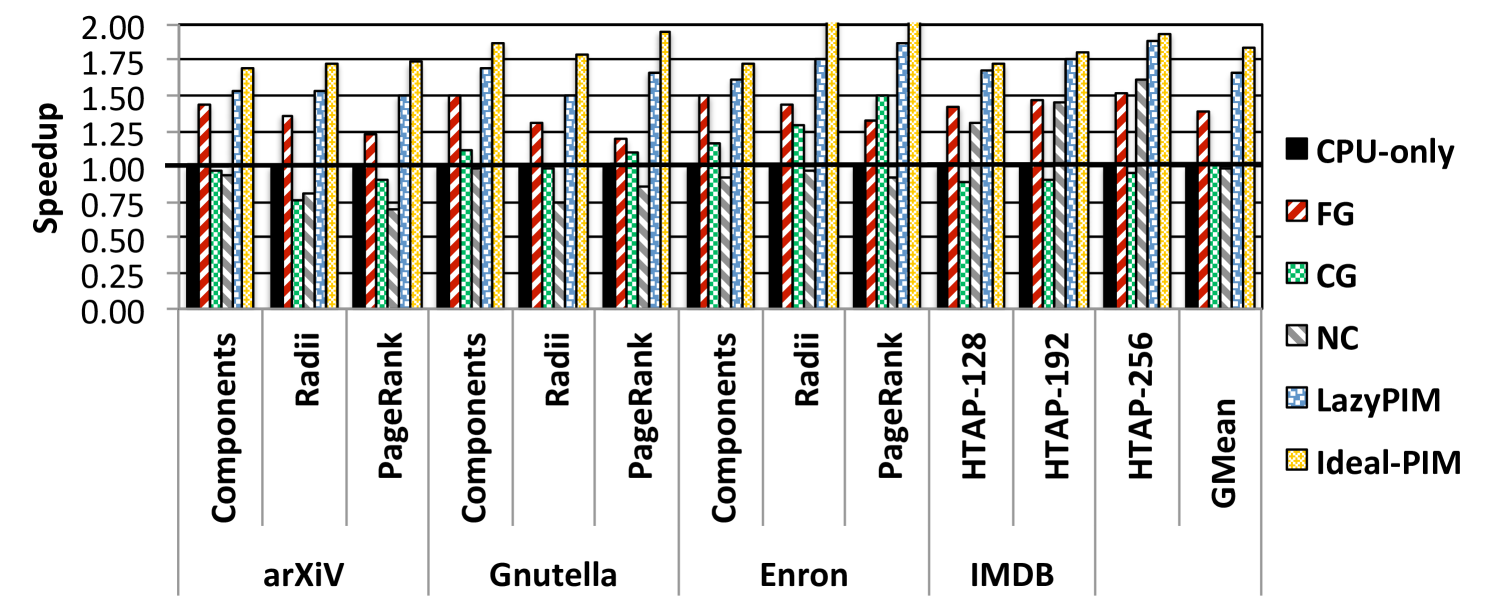
Unfortunately, if a PIM core participates in traditional coherence, it would have to send a message for every cache miss to the main directory in the processor, over a narrow pin-limited bus (we call this PIM coherence traffic). Figure 2 shows the speedup of PIM with different coherence mechanisms for a few example graph workloads, normalized to a CPU-only baseline (where the whole application runs on the processor).111See Section 6 for our methodology. To illustrate the impact of inefficient mechanisms, we also show the performance of an ideal mechanism where there is no performance penalty for coherence (Ideal-PIM). As shown in Figure 2, PIM with fine-grained coherence (FG) eliminates a significant portion of the Ideal-PIM improvement and often performs only slightly better than CPU-only execution due to its high PIM coherence traffic. As a result, while Ideal-PIM can improve performance by an average of 84.2%, FG only attains performance improvements of 38.7%.
To reduce the impact of PIM coherence traffic, there are three general alternatives to fine-grained coherence that have been proposed for PIM execution: (1) coarse-grained coherence, (2) coarse-grained locks, and (3) making PIM data non-cacheable in the processor.
Coarse-Grained Coherence. One approach to reduce PIM coherence traffic is to apply coarse-grained coherence. For example, we can maintain a single coherence entry for all of the PIM data. Unfortunately, this can still incur high overheads, as the processor must flush all of the dirty cache lines within the PIM data region every time the PIM core acquires permissions, even if the PIM kernel may not access most of the data. For example, with just four processor threads, the number of cache lines flushed for PageRank is 227x the number of lines actually required by the PIM kernel.1 Coherence at a smaller granularity, such as maintaining a coherence entry for each page [12], does not cause flushes for pages that are not accessed by the PIM kernel. However, this optimization is not beneficial for many data-intensive applications that perform pointer chasing, where a large number of pages are accessed non-sequentially, but only a few lines in each page are used, forcing the processor to flush every dirty page.
Coarse-Grained Locks. Another drawback of coarse-grained coherence is that data can ping-pong between the processor and the PIM cores whenever the PIM data region is concurrently accessed by both. Coarse-grained locks avoid ping-ponging by having the PIM cores acquire exclusive access to a region for the duration of the PIM kernel. However, coarse-grained locks greatly restrict performance. Our application study shows that PIM kernels and processor threads often work in parallel on the same data region, and coarse-grained locks frequently cause thread serialization. For our graph applications running on a representative input (Gnutella), coarse-grained locks block an average of 87.9% of the processor cores’ memory accesses during PIM kernel execution. The frequent blocking, along with the large number of unnecessary flushes, results in significant performance loss, as shown in Figure 2. PIM with coarse-grained locks (CG in Figure 2) can in some cases eliminate the entire benefit of Ideal-PIM execution, and performs 1.4% worse than CPU-only execution, on average. We conclude that using coarse-grained locks is not suitable for many important applications for PIM execution.
Non-Cacheable PIM Data. Another approach sidesteps coherence, by marking the PIM data region as non-cacheable in the processor [1], so that DRAM always contains up-to-date data. For applications where PIM data is almost exclusively accessed by the PIM cores, this incurs little penalty, but for many applications, the processor also accesses PIM data often. For our graph applications with a representative input (arXiV),1 the processor cores generate 38.6% of the total number of accesses to PIM data. With so many processor accesses, making PIM data non-cacheable results in high performance and bandwidth overhead. As shown in Figure 2, marking PIM data as non-cacheable (NC) fails to retain any of the benefits of Ideal-PIM, and always performs worse than CPU-only execution (3.2% worse on average). Therefore, while this approach avoids the overhead of coarse-grained mechanisms, it is a poor fit for applications that rely on processor involvement, and thus restricts when PIM is effective.
We conclude that prior approaches to PIM coherence eliminate a significant portion of the benefits of PIM when data sharing occurs, due to their high coherence overheads. In fact, they sometimes cause PIM execution to consistently degrade performance. Thus, an efficient alternative to fine-grained coherence is necessary to retain PIM benefits across a wide range of applications, including those applications where the overhead of coherence made them a poor fit for PIM in the past.
4 LazyPIM Coherence Behavior
Our goal is to design a coherence mechanism that maintains the logical behavior of traditional coherence while retaining the large performance and energy benefits of PIM. To this end, we propose LazyPIM, a new coherence mechanism that lets PIM kernels speculatively assume that they have the required permissions from the coherence protocol, without actually sending off-chip messages to the main (processor) coherence directory during execution. Figure 3 shows the high-level operation of LazyPIM. The processor launches a kernel on a PIM core (\small1⃝ in Figure 3), allowing the PIM kernel to execute with speculative coherence permissions while the processor thread executes concurrently (\small2⃝). Coherence states are updated only after the PIM kernel completes, at which point the PIM core transmits a single batched coherence message (i.e., compressed signatures containing all addresses that the PIM kernel read from or wrote to) back to the processor coherence directory (\small3⃝). The directory checks to see whether any conflicts occurred (\small4⃝). If a conflict exists, the PIM kernel rolls back its changes, conflicting cache lines are written back by the processor to DRAM, and the kernel re-executes. If no conflicts exist, speculative data within the PIM core is committed, and the processor coherence directory is updated to reflect the data held by the PIM core (\small5⃝). Note that in LazyPIM, the processor always executes non-speculatively, which ensures minimal changes to the processor design, thereby enabling easier adoption of PIM.

LazyPIM avoids the pitfalls of the mechanisms discussed in Section 3. With its compressed signatures, LazyPIM causes much less PIM coherence traffic than traditional coherence. Unlike coarse-grained coherence and coarse-grained locks, LazyPIM checks coherence only after it completes PIM execution, avoiding the need to unnecessarily flush a large amount of data. LazyPIM also allows for efficient concurrent execution of processor threads and PIM kernels: by executing speculatively, the PIM cores do not invoke coherence requests during concurrent execution, avoiding data ping-ponging and allowing processor threads to continue using their caches.
In the remainder of this section, we study three key aspects of coherence behavior under LazyPIM. Section 4.1 describes the conflicts that can occur when PIM kernels execute speculatively. Section 4.2 discusses how LazyPIM uses partial PIM kernel commits to reduce the overhead of rollback when a conflict occurs. Section 4.3 describes how multiple PIM kernels interact with each other without violating program correctness. Section 4.4 discusses how LazyPIM supports various synchronization primitives. We discuss the architectural support required to implement LazyPIM in Section 5.
4.1 Conflicts
In LazyPIM, a PIM kernel speculatively assumes during execution that it has coherence permissions on a cache line, without checking the processor coherence directory. In the meantime, the processor continues to execute non-speculatively. To resolve speculation without violating the memory consistency model, LazyPIM provides coarse-grained atomicity, where all PIM memory updates are treated as if they all occur at the moment that a PIM kernel commits. At this point, a conflict may be detected on a cache line read by the PIM kernel.
We explore three possible interleavings of read and write operations to a cache line where the use of coarse-grained atomicity by LazyPIM could result in unintended memory orderings. In this discussion, we assume a sequentially consistent memory model, though this reasoning can easily be applied to other memory consistency models, such as x86-TSO.
PIM Read and Processor Write to the Same Cache Line. This is a conflict. Any PIM read during the kernel execution should be ordered after the processor write (RAW, or read-after-write). However, because the PIM core does not check coherence while it is in the middle of kernel execution, the PIM read operation reads potentially stale data from DRAM instead of the output of the processor write (which sits in the processor cache). This is detected by the LazyPIM architecture, resulting in rollback and re-execution of the PIM kernel after the processor write is flushed to DRAM.
Processor Read and PIM Write to the Same Cache Line. This is not a conflict. With coarse-grained atomicity, any read by the processor during PIM execution is ordered before the PIM core’s write (WAR, or write-after-read). As a result, the processor should not read the value written by PIM. LazyPIM ensures this by marking the PIM write as speculative and maintaining the data in the PIM cache, preventing processor read requests from seeing any data flagged as speculative.
Note that if the programmer wants the processor’s read to see the PIM core write, they need to use a synchronization primitive (e.g., memory barrier) to enforce ordering between the processor and the PIM core. This scenario is identical to conventional multithreading, where an explicit ordering of memory operations must be enforced using synchronization primitives, which are supported by LazyPIM (see Section 4.4).
Processor Write and PIM Write to the Same Cache Line. This is not a conflict. With coarse-grained atomicity, any write by the processor during PIM kernel execution is ordered before the PIM core’s write (WAW, or write-after-write) since the PIM core write effectively takes place after the PIM kernel finishes. When the two writes modify different words in the same cache line, LazyPIM uses a per-word dirty bit mask in the PIM L1 cache to merge the writes, similar to [26]. Note that the dirty bit mask is only in the PIM L1 cache; processor caches remain unchanged. Whenever a WAW is detected, the processor’s copy of the cache line is sent to the PIM core undergoing commit, which uses its dirty bit mask to perform a merge. As with any conventional multithreaded application, if the programmer wishes to enforce a specific ordering of the two writes, they must insert a synchronization primitive, such as a write fence (see Section 4.4).
Example. Figure 4 shows an example timeline, where a PIM kernel is launched on PIM core PIM0 while execution continues on processor cores CPU0 and CPU1. As we mentioned previously, PIM kernel execution in LazyPIM behaves as if the entire kernel’s memory accesses take place at the moment coherence is checked, regardless of the actual time at which the kernel’s accesses are performed. Therefore, for every cache line read by PIM0, if CPU0 or CPU1 modify the line before the coherence check occurs, PIM0 unknowingly uses stale data, leading to incorrect execution. Figure 4 shows two examples of this: (1) CPU0’s write to line C during kernel execution; and (2) CPU0’s write to line A before kernel execution, which was not written back to DRAM.
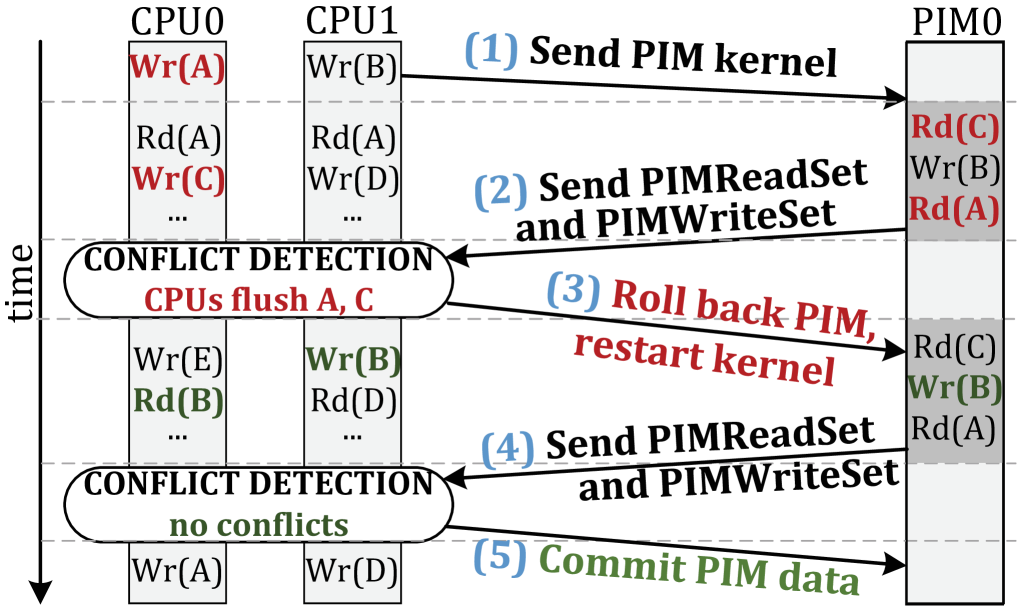
Due to the use of coarse-grained atomicity in LazyPIM, even if the PIM kernel writes to a cache line that is subsequently read by the processor before the PIM kernel finishes (such as the second PIM kernel write to line B in Figure 4), this is not a conflict. The PIM kernel write is speculatively held in the PIM core cache, and does not commit until after the PIM kernel finishes. Therefore, the processor read effectively takes place before the PIM kernel write, and thus does not read stale data. Likewise, there is no conflict when CPU1 and PIM0 both write to line B.
4.2 Partial Kernel Commits
One issue during LazyPIM conflict resolution is the overhead required to rollback and restart the PIM kernel. If we wait until the end of kernel execution to check coherence and attempt to commit PIM memory updates, the probability of a conflict increases, as both the processor and the PIM cores may have issued a large number of read and write operations. For applications with high amounts of data sharing, this can lead to frequent rollbacks. While we bound the maximum number of rollbacks that are possible for each kernel (see Section 5.5), we still incur the penalty of re-executing the entire kernel, even if the conflict did not take place in the early stages of kernel execution. Signature compression further exacerbates the problem by introducing false positives during the conflict detection process (Section 5.3), which increases the probability of a rollback taking place.
To reduce the probability of rollbacks occurring, we divide each PIM kernel into smaller chunks of execution, (which we call partial kernels), and perform a commit after each partial kernel completes, as shown in Figure 5. Employing partial kernel commits in LazyPIM offers three key benefits. First, we lower the probability of conflicts, as we now speculate for a shorter window of execution with fewer read and write operations. Second, we reduce the cost of performing a rollback, as the PIM kernel needs to roll back only to the last commit point instead of to the beginning of the kernel. Third, we can reduce both the size of the signature and the false positive rate (see Section 5.3), as the signature now needs to keep track of a much smaller set of addresses. The use of partial kernel commits continues to follow the coherence model we discussed earlier in the section, with all read and write operations for the partial kernel treated as if they all occur at the moment that the partial kernel commits.
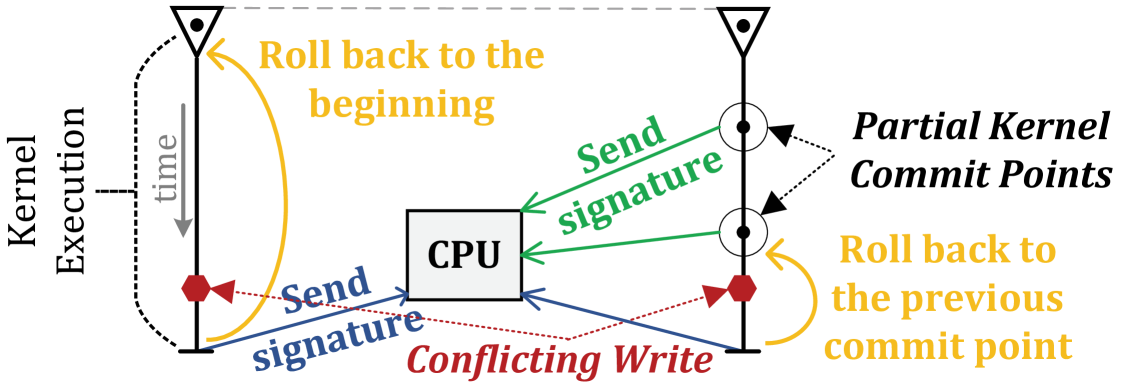
One tradeoff of employing partial kernel commits is the fact that we must now send coherence updates back to the processor more frequently. If we send coherence updates too often, we can undermine the bandwidth savings that LazyPIM provides. Ultimately, the effectiveness of partial kernel commit is dependent on the length of each partial kernel. We use two parameters to control the length of the partial kernel. First, a partial kernel is considered to be ready for commit if it performs a fixed number of memory accesses. This is motivated by our use of Bloom filters to implement our compressed signatures, which can saturate if too many entries are inserted into the filter (see Section 5.3). Second, for partial kernels with very low memory access rates, we also cap the number of instructions that can be executed by any one partial kernel. That way, if a rollback needs to occur, we provide an upper bound on the performance impact that rollback can have. We discuss these mechanisms for partial kernel sizing in Section 5.4.
4.3 Sharing Between PIM Kernels
LazyPIM allows data sharing between PIM cores to simplify the user programming model, to allow transparent communication between PIM cores, and to improve overall PIM performance. When multiple PIM kernels run together, the kernels execute on multiple PIM cores whose L1 caches are kept coherent with each other through the use of a local PIM directory, as we described in Section 2.3. While we observe no sharing of speculative data between PIM cores in any of our workloads, LazyPIM includes hardware mechanisms to allow the PIM cores to interact with each other safely. Our mechanism ensures that (1) the propagation of speculative data between PIM kernels is tracked; and (2) if one PIM kernel rolls back, any other uncommitted PIM kernel that read data produced by the rolled back kernel also rolls back. Note that LazyPIM ensures that livelock does not occur, guaranteeing forward progress (see Section 5.5).
LazyPIM ensures that the sharing of (potentially stale) data between multiple PIM kernels does not lead to incorrect execution. Each PIM core maintains a per-core bit vector (which we call speculative read bits). Whenever a PIM core reads speculative data written by another PIM core, it sets the corresponding speculative read bit for the ID of the PIM core that it read from. When the PIM core is ready to commit its kernel, the core checks to see whether any speculative read bits are set. If set, the core waits to perform its conflict detection until all of the PIM cores from which it read speculatively also complete their kernels. During conflict detection, if all of the signatures indicate no conflict, then the commit procedure continues for all of the PIM cores that shared data. If a conflict is detected in any of the cores’ signatures, then all of the cores roll back. In essence, whenever PIM cores share speculative data with each other, their memory operations are grouped together so that they all take place atomically, behaving as a single PIM kernel. We made this design choice to keep the design simple.
If no speculative data exchange takes place between PIM kernels, then each PIM kernel can commit independently without having to worry about any coordination. If two independent PIM kernels try to commit at the same time, the commit process serializes the commit requests.
4.4 Support for Synchronization Primitives
LazyPIM supports synchronization primitives and atomic operations. To guarantee atomicity and avoid ordering violations, LazyPIM forces a partial commit when a core reaches a synchronization primitive. The partial commit checks coherence permissions and ensures that all updates from the PIM core are immediately visible globally. By using partial commits, LazyPIM effectively provides coherence at a cache line granularity for synchronization primitives.
Let us look at the Acquire/Release primitives as an example. When a processor thread acquires a lock, it reads and updates a shared variable associated with the lock. If a PIM kernel attempts to acquire this lock, a partial commit forces the PIM kernel to read the updated value written by the processor thread, thus guaranteeing mutual exclusion. Once the processor thread has freed the lock, the PIM kernel can acquire the lock by writing to the shared variable, immediately performing a partial commit to make the lock acquisition globally visible. This ensures that the processor immediately sees the updated value of the shared variable. Note that during the partial commit, the processor cannot inadvertently update the shared value, as the partial commit mechanism locks all memory in the PIM data region.
5 LazyPIM Architecture
In this section, we discuss the hardware support LazyPIM provides for speculative execution and coherence conflict detection. Using simple programmer annotations (Section 5.1), LazyPIM tracks the data that might be accessed by the PIM kernels during speculative execution in hardware (Section 5.2). LazyPIM employs compressed signatures (Section 5.3) to record the accessed data until it detects that the partial kernel has finished executing (Section 5.4). Once the partial kernel finishes, LazyPIM performs signature-based conflict detection (Section 5.5). In order to reduce the probability of conflicts, LazyPIM tracks and proactively writes back dirty PIM data sitting in the processor cache by employing a variant of the Dirty-Block Index [41] (Section 5.6). We discuss the hardware overhead of LazyPIM in Section 5.7.
5.1 Program Interface
We provide a simple interface for programmers to port applications to LazyPIM. We show the implementation of a simple LazyPIM kernel within a program in Listing 1. The programmer identifies the portion(s) of the code to execute on PIM cores, using two macros (PIM_begin and PIM_end). The compiler converts the macros into instructions that we add to the ISA, which trigger and end PIM kernel execution. LazyPIM also needs to know which parts of the allocated data might be accessed by the PIM cores, which we call the PIM data region. We assume either the programmer or the compiler can annotate all of the PIM data using compiler directives or a PIM memory allocation API. This information is stored in the page table using per-page flag bits, indicating that a cache line might be accessed by a PIM kernel.
5.2 Speculative Execution
When an application reaches a PIM kernel trigger instruction, the processor dispatches the kernel’s starting PC and live-in registers to a free PIM core. The PIM core makes a checkpoint at the starting PC, in case a rollback is required later, and starts executing the kernel. The kernel speculatively assumes that it has coherence permissions for every cache line it accesses, without actually checking the processor directory. We add a one-bit flag to each cache line in the PIM core cache, as shown in Figure 6, to mark all data updates as speculative. If a speculative cache line is selected for eviction, the PIM core stops PIM kernel execution and attempts a partial kernel commit (see Section 5.4).
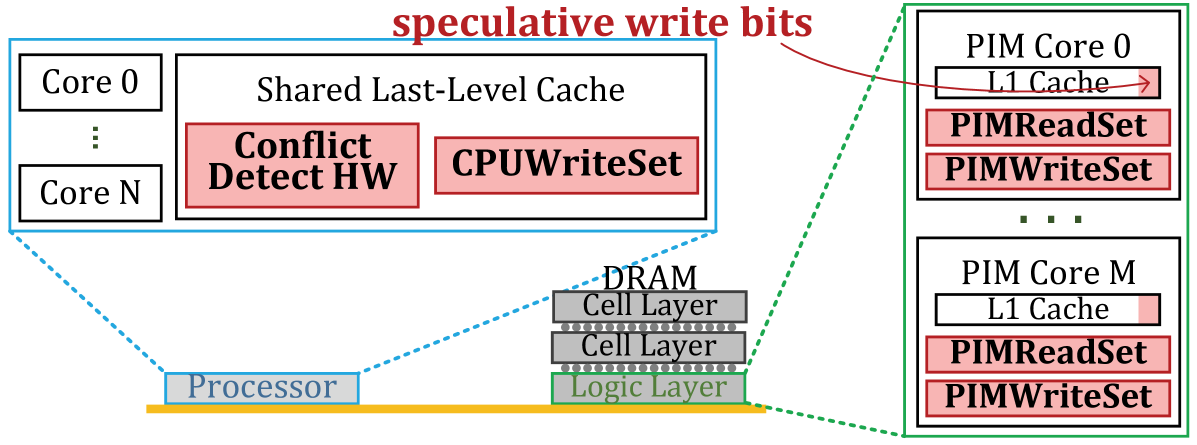
LazyPIM tracks three sets of cache line addresses during PIM kernel execution. These sets are recorded into three signatures (explained in detail in Section 5.3), as shown in Figure 6: (1) the CPUWriteSet (all CPU writes to the PIM data region), (2) the PIMReadSet (all PIM core reads), and (3) the PIMWriteSet (all PIM core writes). When a partial kernel starts, the processor scans the tag store and records all dirty cache lines in the PIM data region (identified using the page table flag bits from Section 5.1) in the CPUWriteSet. During PIM kernel execution, the processor updates the CPUWriteSet whenever it writes to a cache line in the PIM data region. In the PIM core, the PIMReadSet and PIMWriteSet are updated for every read and write performed by the partial PIM kernel. When the partial PIM kernel finishes execution, the three signatures are used to resolve speculation (see Section 5.5).
5.3 Signatures
LazyPIM uses fixed-length parallel Bloom filters [6] to implement the compressed signatures. The signatures store data by partitioning an -bit signature into segments (such that each segment is / bits wide). To add an address into the signature, each of the segments employs a unique hash function ( [39]) that maps the address to a single bit within the segment, which we call the hashed value. To check whether an address is present within the signature, we generate the hashed values of that address and then check to see if every corresponding bit is set in each segment. Bits that are set in the signature remain set until the signature is reset, preventing any false negatives from occurring. However, there may be some collision for the bits set by various hashed values, which can lead to a limited number of false positives.
Parallel Bloom filters allow us to easily determine if any conflicts occurred. We can quickly generate the intersection of two signatures (i.e., a list of hash values that exist in both signatures) by taking the bitwise AND of the two signatures. If we find that any of the segments in the intersection are empty, no conflicts exist between the two signatures. Otherwise, the intersection contains the hashed values of all addresses that might exist in both signatures (including potential false positives).
Signature Size. Bloom filter based signatures allow for a large number of addresses to be stored within a single fixed-length register. The size of the signature is directly correlated with both the number of addresses we want to store and the desired false positive rate. A larger signature leads to fewer false positives and therefore fewer rollbacks, which can improve performance. However, larger signatures require greater storage overhead and require more bandwidth when we send the PIMReadSet and PIMWriteSet to the processor for conflict detection (see Section 5.5). Therefore, our goal is to select a signature width that provides a balance between rollback minimization and bandwidth utilization.
For the PIMReadSet and PIMWriteSet, we use one 2 Kbit register for each signature with set to 4. We discuss how the signature size is used to control the length of partial kernels in Section 5.4. We can employ multiple 2 Kbit registers for the CPUWriteSet in order to increase the number of addresses that the signature can hold since the CPUWriteSet does not need to be transmitted off-chip (see Section 5.5). We find that expanding the CPUWriteSet capacity is helpful, as the CPUWriteSet records both the processor writes that occur during PIM kernel execution and the dirty cache lines that reside in the cache at the time partial kernel execution begins. Note that we must keep each register at the same 2 Kbit width (with ) as the PIMReadSet and PIMWriteSet so that we can perform an intersection test between the two. For every address stored in the CPUWriteSet, we use round robin selection to choose which of the registers the hashed value of the address is written to. During conflict detection, we intersect the PIMReadSet and PIMWriteSet with each of the registers in the CPUWriteSet.
5.4 Support for Partial Kernels
To maximize the effectiveness of partial kernel commits (see Section 4.2), we must ensure that the PIMReadSet and PIMWriteSet do not get saturated with too many addresses (which can lead to a high rate of false positives). LazyPIM avoids this by dynamically determining the size of each partial kernel. We determine the maximum number of addresses that we allow inside the PIMReadSet and PIMWriteSet, which we compute based on our desired false positive rate. One property of Bloom filters is that they can guarantee a maximum false positive rate for a given filter width and a set number of address insertions. To support this, we maintain one counter each for the PIMReadSet and PIMWriteSet of each PIM core, which is incremented every time we insert a new address. When we reach the maximum number of addresses for either signature, we stop the partial kernel and initiate the conflict detection process. In our implementation, we target a 30% false positive rate, which allows us to store up to 250 addresses within a 2 Kbit signature.
One potential drawback, as mentioned in Section 4.2, is that for PIM kernels with a low memory access rate, each partial kernel can consist of a large number of instructions, increasing the cost of rollback in the event of a conflict. To avoid the costly rollback overhead, we employ a third counter for each PIM core, which counts the number of instructions executed for the current partial kernel. If this counter exceeds a fixed threshold (set in our implementation empirically to 1 million instructions), we also stop the partial kernel, even if neither the PIMReadSet nor the PIMWriteSet are full.
5.5 Handling Conflicts
As discussed in Section 4.1, we need to detect conflicts that occur during PIM kernel execution, such as the PIM0 reads to lines A and C in Figure 4. In LazyPIM, when the partial kernel finishes execution, both the PIMReadSet and PIMWriteSet are sent back to the processor. We then compute the intersection of the PIMReadSet and CPUWriteSet to determine if any addresses exist in both signatures.
If no matches are detected between the PIMReadSet and the CPUWriteSet (i.e., no conflicts have occurred), the partial kernel commit starts. First, the intersection of the PIMWriteSet and CPUWriteSet is computed. If any matches are found, the conflicting cache lines are sent to the PIM core to be merged with the PIM core’s copy of the cache line (as discussed in Section 4.1). Second, any clean cache lines in the processor cache that match an address in the PIMWriteSet are invalidated. A message is then sent to the PIM core, allowing it to write its speculative cache lines back to DRAM. During the commit, all coherence directory entries for the PIM data region are locked to ensure atomicity. Finally, all signatures are erased, and the next partial kernel begins.
If an overlap is found between the PIMReadSet and the CPUWriteSet, a conflict may have occurred. The processor flushes only the dirty cache lines that match addresses in the PIMReadSet back to DRAM. During the flush, all PIM data directory entries are locked to ensure atomicity. Once the flush completes, a message is sent to the PIM core, telling it to invalidate all speculative cache lines, and to roll back to the beginning of the partial kernel using the checkpoint. All signatures are erased, and the PIM core restarts partial kernel execution. After re-execution finishes, conflict detection is performed again.
Note that during the commit process, processor cores do not stall unless they access the same data accessed by a PIM core. LazyPIM guarantees forward progress by acquiring a lock for each line in the PIMReadSet after a number of rollbacks (we empirically set this number to 3 rollbacks). This simple mechanism ensures there is no livelock even if the sharing of speculative data amongst PIM cores might create a cyclic dependency. Note that rollbacks are caused by CPU accesses to conflicting addresses, and not by the sharing of speculative data between PIM cores. As a result, once we lock conflicting addresses following 3 rollbacks, the PIM cores will not rollback again as there will be no conflicts, guaranteeing forward progress.
5.6 Dirty-Block Index for PIM Data
One issue that exacerbates the number of conflicts in LazyPIM is the need to record dirty PIM data within the processor cache as part of the CPUWriteSet, as any changes not written back to memory will not be observed by the PIM cores, even if the changes took place before the PIM kernel started (we refer to these as dirty conflicts). We analyze the impact of dirty conflicts, and make two key observations. First, across our workloads, majority of conflicts that occur are a result of dirty conflicts. Second, we observe that an average of 95.4% of the addresses inserted into the CPUWriteSet are due to dirty conflicts. If we were able to reduce the dirty conflict count, we could significantly reduce the overhead of conflict detection, and could reduce the probability of rollbacks.
In LazyPIM, we optimize the dirty conflict count by introducing a Dirty-Block Index [41]. The Dirty-Block Index (DBI) reorganizes the tag store of a cache to track the dirty cache lines of memory pages, which it then uses to opportunistically write back dirty data during periods of low cache and bandwidth utilization. LazyPIM employs what we call the PIM-DBI in the processor, which is in essence a DBI dedicated solely for the PIM data region. To simplify the implementation of DBI in LazyPIM, we maintain a cycle counter that triggers PIM-DBI at fixed intervals. Whenever PIM-DBI is triggered, it writes back dirty cache lines within the PIM data region to DRAM, which reduces the number of dirty conflicts that occur at the time a PIM kernel starts execution. Note that LazyPIM does not require the PIM-DBI.
5.7 Hardware Overhead
Each signature register in LazyPIM is 2 Kbits wide, with the PIMReadSet and PIMWriteSet consisting of a single register, while the CPUWriteSet includes 16 registers. Overall, each PIM core uses 512B for signature storage, while the processor uses 8KB in total. Aside from the signatures, LazyPIM’s overhead consists mainly of (1) 1 bit per page (0.003% of DRAM capacity) and 1 bit per TLB entry for the page table flag bits (Section 5.1); (2) a 0.2% increase in PIM core L1 size to mark speculative data (Section 5.2); (3) a 1.6% increase in PIM core L1 size for the dirty bit mask (Section 4.1); and (4) two 8-bit counters and one 20-bit counter in each PIM core to track the number of addresses and instruction count for partial kernels (Section 5.4).
To track speculative data sharing between PIM cores (Section 4.3), we also require bits in each PIM core for a system with PIM cores. For each PIM core, this comes to a total of 596 bytes of overhead in a system with 16 PIM cores. The PIM-DBI tag store (Section 5.6) is sized to track 1024 cache blocks, split into rows of 64 blocks each. A single row stores a 64-bit dirty bit array and a 48-bit tag, resulting in a total storage overhead of 224B.
6 Methodology
In this section, we discuss our methodology for evaluating LazyPIM. We study two types of data-intensive applications as case studies: graph workloads and in-memory databases (Section 6.1). We identified ideal candidates for PIM kernels within each application using a profile-driven procedure (Section 6.2). We used the full-system version of the gem5 simulator [5] to perform quantitative evaluations (Section 6.3).
6.1 Applications
Ligra [45] is a lightweight multithreaded graph processing system for shared memory multicore machines. We use three Ligra graph applications (PageRank, Radii, and Connected Components), with input graphs constructed from real-world network datasets [47]: Enron email communication network (73384 nodes, 367662 edges), arXiV General Relativity (10484 nodes, 28984 edges), and peer-to-peer Gnutella25 (45374 nodes, 109410 edges).
We also use an in-house prototype of an in-memory database (IMDB) that is capable of running both transactional queries (similar to TPC-C) and analytical queries (similar to TPC-H) on the same database tables, and represents modern IMDBs [40, 49, 29] that support HTAP workloads. Our transactional workload consists of 64K transactions, with each transaction performing reads or writes on a few randomly-chosen database tuples. Our three analytical workloads consist of 128, 192, or 256 analytical queries (for HTAP-128, HTAP-192, and HTAP-256, respectively) that use the select and join operations. The IMDB uses a state-of-the-art, highly-optimized hash join kernel code [50] tuned for IMDBs to service the join queries. We simulate an IMDB system that has 64 tables, where each table consists of 64K tuples, and each tuple has 32 fields. Tuples in tables are populated by a randomly generated uniformly-distributed integer.
6.2 Identifying PIM Kernels
We select PIM kernels from our applications with the help of OProfile [32]. Our goals during partitioning were to lower execution time and minimize data movement, which all PIM mechanisms aim to achieve [2, 11, 12]. As prior work [2] has shown, parts of the application that are either (1) compute-intensive or (2) cache-friendly should remain on the processor, as they can benefit from larger, more sophisticated cores with larger caches (as opposed to the small PIM cores). Thus, only memory-intensive portions of the code with poor cache locality are dispatched to the PIM cores for execution. To partition an application, we profiled its execution time, along with the miss rate for each function, using a training set input. Based on the profiling information, we selected candidate PIM portions conservatively, choosing portions where (1) the application spent a majority of its cycles (to amortize the overhead of launching PIM execution), and (2) a majority of the total last-level cache misses occurred (indicating high memory intensity and poor cache locality). From this set of candidate kernels, we selected only the kernels for each mechanism that had minimal coherence overhead under a given mechanism (i.e., they minimized the communication that occurred between the processor threads and the PIM kernels).
We modify each application to ship the selected kernels to the PIM cores. We manually annotated the PIM data set such that gem5 can distinguish between data that belongs to the PIM data region from data that does not. To ensure correct annotation, we tracked all of the data used by any PIM kernel, and replaced the malloc for all of this data with a specialized memory allocation function that we wrote, called pim_alloc. Our pim_alloc function automatically registers the allocated data as belonging to the PIM data region within gem5.
6.3 Simulation Environment
We use the gem5 [5] architectural simulator in full-system mode, using the x86 ISA, to implement our proposed coherence mechanism. DRAMSim2 [9] was used within gem5 to provide detailed DRAM timing behavior. We modified the DRAM model to emulate the high in-memory bandwidth available within HMC [18] for the PIM cores.
| Processor | 4–16 cores, 8-wide issue, 2 GHz frequency |
|---|---|
| L1 I/D Caches: 64kB private, 4-way associative, 64B blocks | |
| L2 Cache 2MB shared, 8-way associative, 64B blocks | |
| Coherence: MESI | |
| PIM | 4–16 cores, 1-wide issue, 2 GHz frequency |
| L1 I/D Caches: 64kB private, 4-way associative, 64B blocks | |
| Coherence: MESI | |
| HMC [18] | one 4GB cube, 16 vaults per cube, 16 banks per vault |
| Memory | DDR3-1600, 4GB, FR-FCFS scheduler |
We model the sum of the energy consumption that takes place within the DRAM, off-chip interconnects, and all caches. We also include DBI energy consumption and the energy used by other components of LazyPIM in our energy model. We model DRAM energy as the energy consumed per bit, leveraging estimates from prior work [19]. We estimate the energy consumption of all L1 and L2 caches using CACTI-P 6.5 [31], assuming a 22nm process. We model the off-chip interconnect using the method used by prior work [12], which estimates the HMC SerDes energy consumption as 3pJ/bit for data packets.
7 Evaluation
We examine how LazyPIM compares with prior coherence mechanisms for PIM. Unless otherwise stated, we assume that LazyPIM employs partial kernel commits as described in Section 5.4, and that it uses PIM-DBI, where all dirty PIM data in the processor caches is written back every 800K processor cycles. We show results normalized to a processor-only baseline (CPU-only), and compare to PIM execution using fine-grained coherence (FG), coarse-grained locks (CG), or non-cacheable PIM data (NC), as described in Section 3.2.
7.1 Performance
Figure 7 shows the performance improvement for a 16-core architecture (with 16 processor cores and 16 PIM cores) across all of our applications and input sets. Without any coherence overhead, the ideal PIM mechanism (Ideal-PIM, as defined in Section 3.2) significantly outperforms CPU-only across all applications, showing the potential of PIM execution on these workloads. The poor handling of coherence by CG and NC, and by FG in a number of cases, leads to drastic performance losses compared to Ideal-PIM, indicating that an efficient coherence mechanism is essential for PIM performance. For example, in many cases, NC and CG actually perform worse than CPU-only. In contrast, LazyPIM consistently retains most of Ideal-PIM’s benefits for all applications, coming within 9.8% of the Ideal-PIM performance, on average. LazyPIM outperforms all other approaches, improving average performance by 19.6% over FG, 65.9% over CG, 71.4% over NC, and 66.0% over CPU-only.
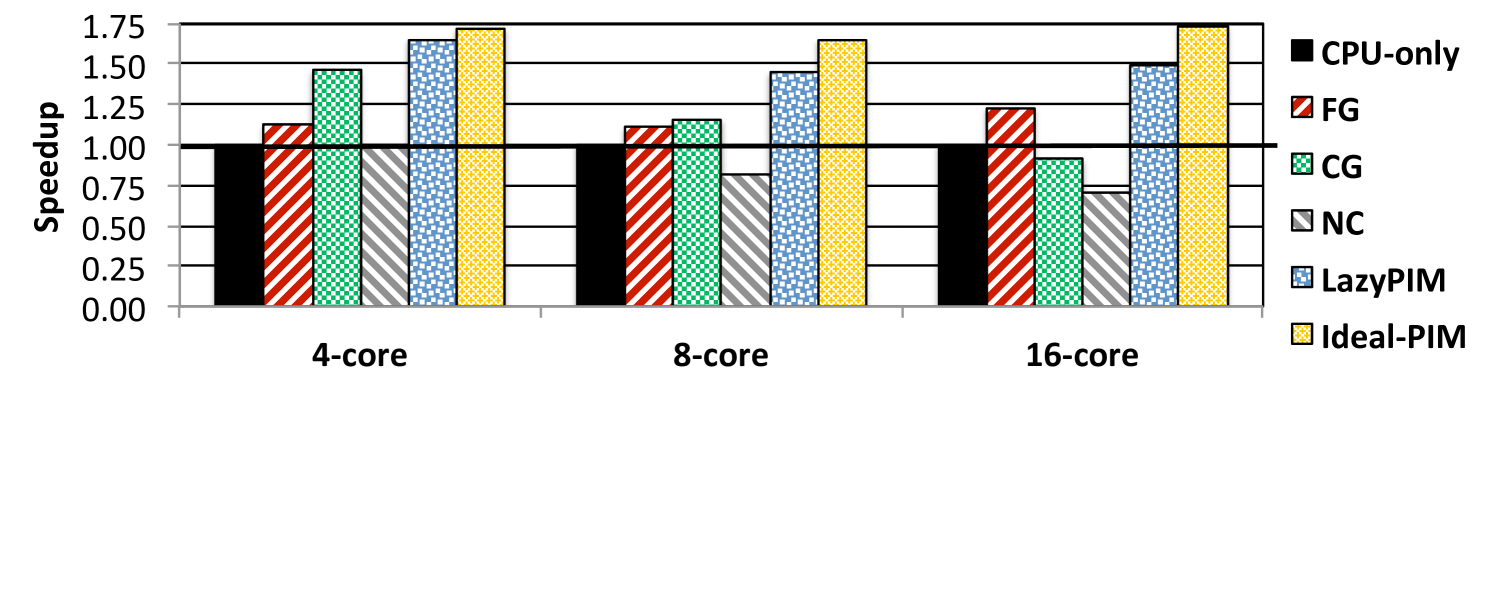
We select PageRank using the ArXiv input set for a case study on how performance scales as we increase the core count, shown in Figure 8. Ideal-PIM significantly outperforms CPU-only at all core counts. With NC, the processor threads incur a large penalty for going to DRAM frequently to access the PIM data region. CG suffers greatly due to (1) flushing dirty cache lines, and (2) blocking all processor threads that access PIM data during execution. In fact, processor threads are blocked for up to 73.1% of the total execution time with CG. With more core, the effects of blocking worsen CG’s performance. FG also loses a significant portion of Ideal-PIM’s improvements, as it sends a large amount of off-chip messages. Note that FG, despite its high off-chip traffic, scales better with core count than CG and NC, as it neither blocks processor cores nor slows down CPU execution. LazyPIM improves performance at all core counts.
We conclude that LazyPIM successfully harnesses the benefits of speculative coherence updates to provide performance improvements in a wide range of PIM execution scenarios, when prior coherence mechanisms cannot improve performance and often degrade it.
7.2 Off-Chip Traffic
Figure 9 shows the normalized off-chip traffic of the PIM coherence mechanisms for our 16-core system. LazyPIM significantly reduces overall off-chip traffic, with an average reduction of 30.9% over CG, the best prior approach in terms of traffic. CG has greater traffic than LazyPIM mainly because CG has to flush dirty cache lines before each PIM kernel invocation, while LazyPIM takes advantage of speculation to perform only the necessary flushes after the PIM kernel finishes execution. As a result, LazyPIM reduces the flush count (e.g., by 92.2% for Radii using arXiV), and thus lowers overall off-chip traffic (by 50.8% for our example). NC’s traffic suffers from the fact that all processor accesses to the PIM data region must go to DRAM. With respect to CPU-only, LazyPIM provides an average traffic reduction of 86.3%.
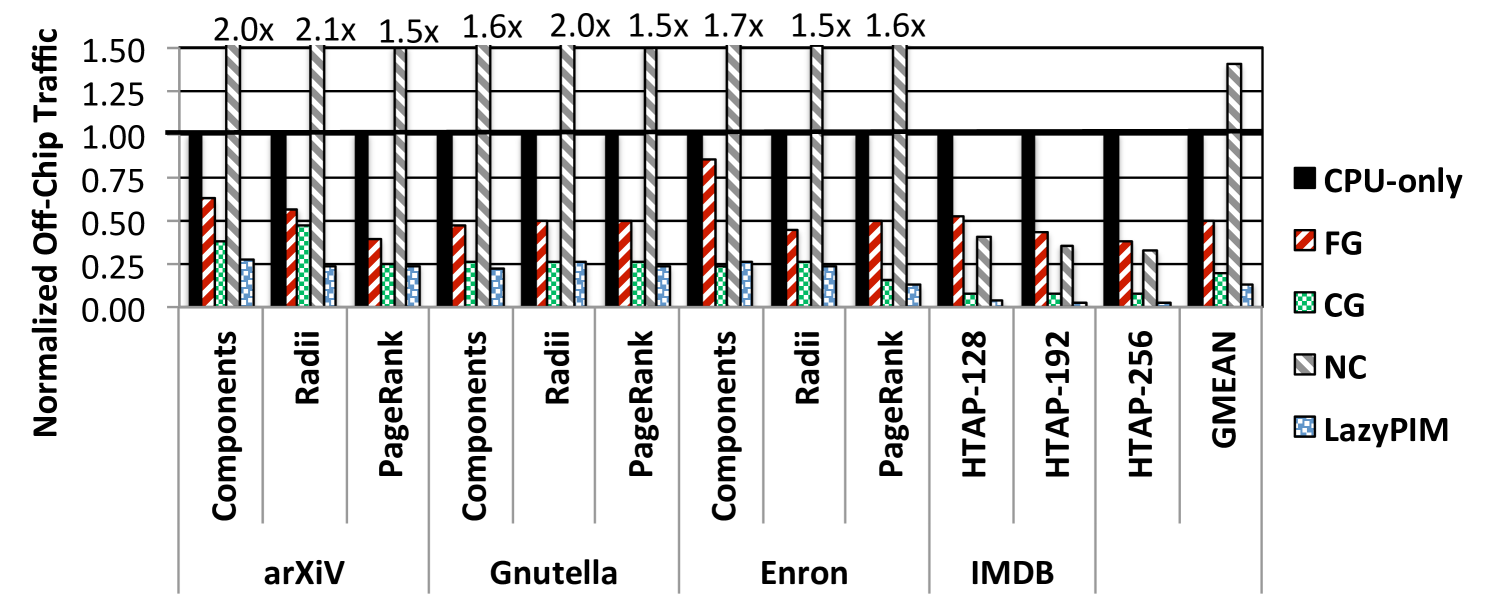
Figure 10 shows the normalized off-chip traffic as the number of cores increases, for PageRank using the arXiV graph. LazyPIM’s traffic scales better with core count than prior PIM coherence mechanisms. Due to false sharing, the number of flushes for CG scales superlinearly with thread count (not shown), increasing 6.2x from 4 to 16 threads. NC also scales poorly with core count, as more processor threads generate a greater number of accesses. In contrast, LazyPIM allows processor cores to cache PIM data, by enabling coherence efficiently, which lowers off-chip traffic on average by 88.3% with respect to NC.
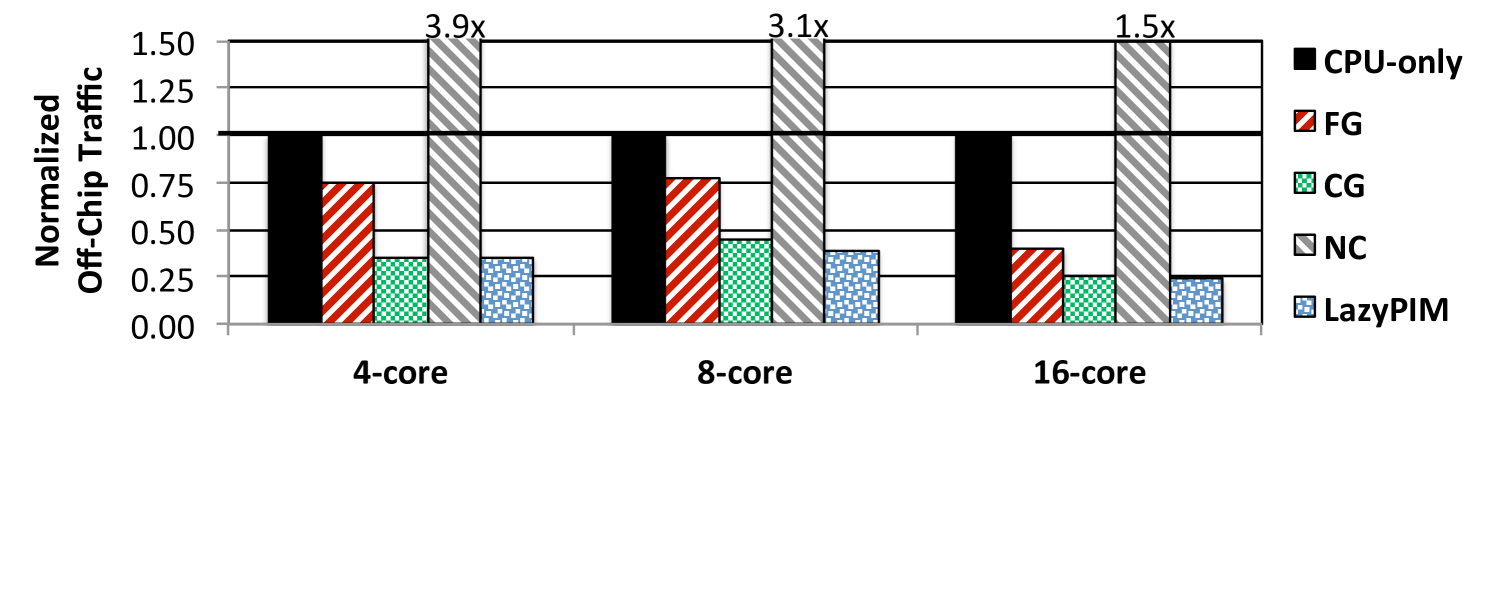
We conclude that the efficient approach to coherence employed by LazyPIM allows it to successfully provide fine-grained coherence behavior while still delivering reductions in off-chip traffic.
7.3 Energy
Figure 11 shows the energy consumption of the PIM coherence approaches for our 16-core system, normalized to CPU-only, across all of our applications and input sets. We find that LazyPIM comes within 4.4% of Ideal-PIM, and significantly reduces energy consumption, by an average of of 35.5% over FG, 18.0% over CG, 62.2% over NC, and 43.7% over CPU-only. The main energy improvement for LazyPIM over CPU-only comes from a reduction in interconnect and memory utilization, as LazyPIM successfully reduces data movement across the off-chip channel.
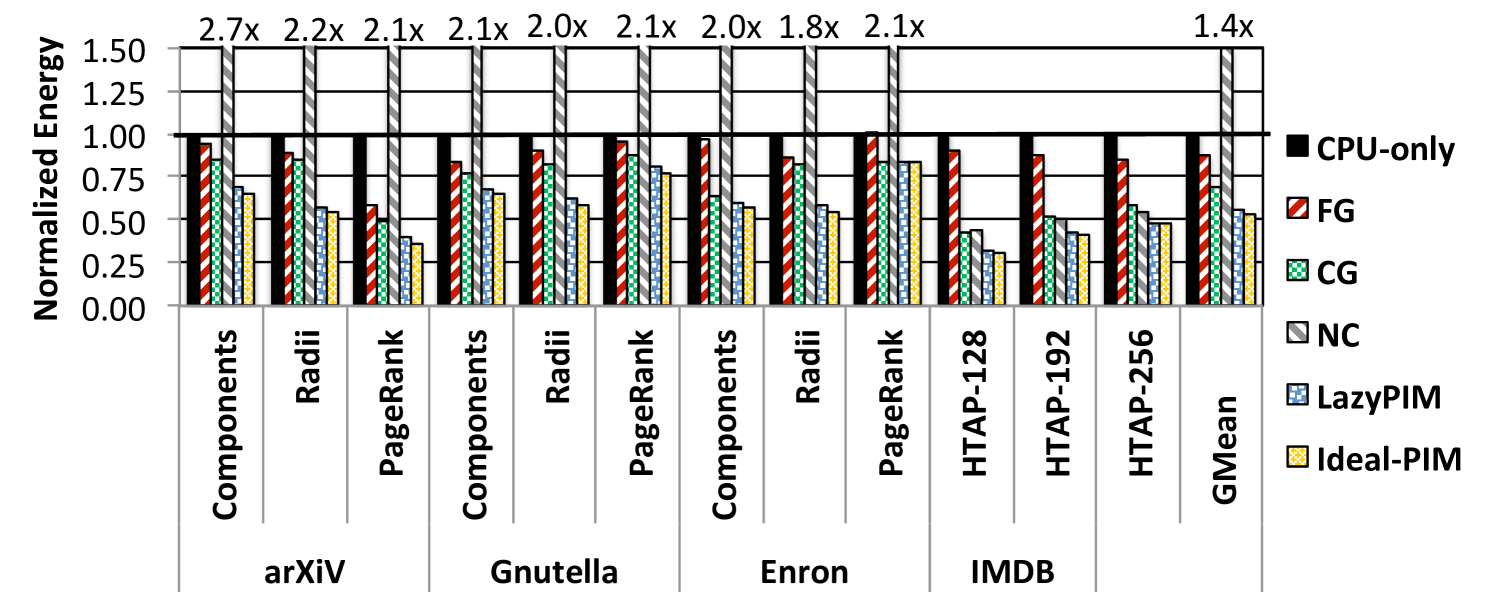
Other PIM coherence approaches are unable to retain these benefits, as FG, CG, and NC all consume more energy due to their poor handling of coherence. CG has a large number of writebacks, which leads to increased L1 and L2 cache lookups and a large amount of traffic sending dirty data back to DRAM preemptively. Thanks to these writebacks, the energy consumption of the HMC memory alone increases by 18.9% on average over CPU-only, canceling out CG’s net savings in interconnect energy (which was reduced by 49.1% over CPU-only). The energy consumption of NC suffers greatly from the large number of memory operations that are redirected from the processor caches to DRAM. While the cache energy consumption falls by only 7.1%, interconnect and HMC energy increase under NC by 3.1x and 4.5x, respectively. For FG, the large number of coherence messages transmitted between the processor and the PIM cores undoes a significant amount of the energy benefits of moving computation to DRAM.
We conclude that the speculative coherence update approach used by LazyPIM is effective at retaining the energy benefits of PIM execution.
7.4 Effect of Partial Kernel Commits
As we discussed in Section 4.2, dividing a PIM kernel into smaller partial kernels allows LazyPIM to lower both the probability of conflicts and false positives. Figure 12 shows the extent of the benefits that partial commits offer, for a signature size of 2 Kbits, for two representative 16-thread workloads: Components using the Enron graph, and HTAP-128. If we study an idealized version of full kernel commit, where no false positives exist, we find that a relatively high percentage of commits contain conflicts (47.1% for Components and 21.3% for HTAP). Using realistic signatures for full kernel commit, which includes the impact of false positives, the conflict rate increases to 67.8% for Components and 37.8% for HTAP.
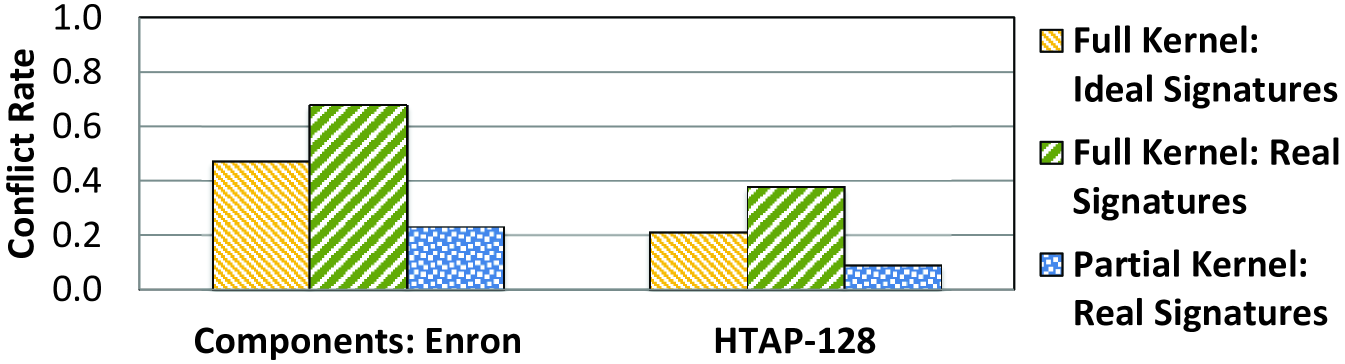
Whenever a conflict is detected, a rollback must be initiated. In the case of the full kernel signatures above, this means that approximately half of all commit attempts force LazyPIM to roll back to the beginning of the entire kernel. As Figure 12 shows, our partial kernel commit technique significantly reduces this burden. Even factoring in false positives, the conflict rate drops to 23.2% for Components and 9.0% for HTAP. Further helping partial kernel commit is the fact that in the cases when rollbacks do occur, the length of the rollback is smaller, as only a small portion of the kernel must be re-executed. We conclude that partial kernel commit is an effective technique at keeping the overheads of LazyPIM rollback low.
7.5 Effect of Signature Size
We study the impact of signature size on execution time, off-chip traffic, and the conflict rate, using two representative 16-thread workloads: Components using the Enron graph, and HTAP-128. Note that for all signature sizes, we continue to store 250 addresses per signature using partial kernel commit. Figure 13 shows these three factors, with execution time and off-chip traffic normalized to CPU-only, for our two representative 16-thread workloads. Increasing the signature size from 2 Kbits to 8 Kbits reduces the conflict rate by 30.0% for Components and by 29.3% for HTAP, which in turn results in a reduction in execution time of 10.1% and 10.9%, respectively, as the lower conflict rate results in a smaller number of rollbacks. The reduction in conflict rate is a direct result of the lower false positive rate with 8 Kbit signatures (a reduction of 31.4% for Components and 40.5% for HTAP). However, this comes at the cost of increased off-chip traffic, as the 8 Kbit signature requires 32.7% more traffic for Components and 31.4% more traffic for HTAP.
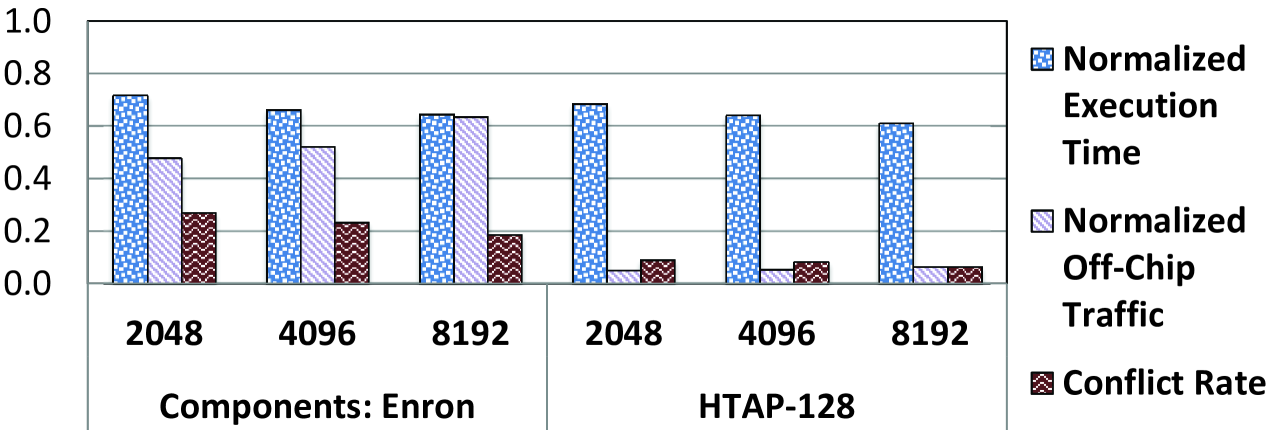
From our evaluations, we conclude that using a smaller 2 Kbit signature strikes a good balance between execution time and off-chip traffic across all of our workloads.
8 Related Work
Most recent PIM proposals assume that there is only a limited amount of data sharing between PIM kernels and the processor threads of an application. As a result, they employ a variety of naïve solutions to maintain coherence, such as (1) assuming that PIM kernels and processor threads never access data concurrently [17, 1], (2) making PIM data non-cacheable within the processor [1, 11, 38], (3) flushing all dirty cache lines in the processor before starting PIM execution [54, 12, 26], or (4) locking all of the PIM data during PIM execution [11, 51]. We already showed in Section 3 that the non-cacheable (2) and coarse-grained approaches (3,4) to coherence do not work well within the context of PIM.
Other proposals in related domains attempt to efficiently support coherence. HSC [37] reduces coherence traffic between the CPU and the GPU, but the trade-offs in the HSC CPU-GPU system are fundamentally different than in a CPU-PIM system. Unlike in a CPU-PIM system, which requires off-chip communication, both the CPU and the GPU in HSC are on-chip and are coherent through the last-level cache, making communication much cheaper. More importantly, HSC employs coarse-grained coherence to reduce the coherence traffic from the GPU to the directory, which we have demonstrated is unable to retain the benefits of PIM. FUSION [24] mitigates data movement between the CPU and on-chip accelerators and decreases the communication traffic between accelerators. FUSION employs traditional MESI (FG) coherence for communication between accelerators and the CPU. Because the accelerators are on-chip, the cost of data movement between the CPU and the accelerators is roughly the same as that between the accelerators themselves. However, in a CPU-PIM system, the cost of communication between the processor and the PIM cores over the off-chip channel far outweighs the cost of communication between PIM cores, and this off-chip communication cost can significantly degrade the benefits of using PIM. We showed in Section 3 that adopting FG coherence for a CPU-PIM system eliminates most benefits of PIM.
Other works [33, 46, 3] focus on reducing on-chip intra-GPU communication and coherence traffic. These works rely heavily on software assistance to reduce coherence complexity, which requires considerable programmer and compiler involvement (e.g., custom APIs, custom programming models), preventing their applicability to all types of applications. In contrast, LazyPIM can enable efficient off-chip coherence for any type of application by employing speculation coupled with simple programmer annotation. These works all attempt to reduce on-chip coherence, which is orthogonal to the goals of LazyPIM. While these works can be applied in conjunction with LazyPIM to reduce inter-PIM coherence traffic, they are not effective at reducing the off-chip coherence traffic that LazyPIM works to minimize.
9 Conclusion
We propose LazyPIM, a new cache coherence mechanism for PIM architectures. Prior approaches to PIM coherence generate very high off-chip traffic for important data-intensive applications. LazyPIM avoids this by avoiding coherence lookups during PIM kernel execution. The key idea is to use compressed coherence signatures to batch the lookups and verify correctness after the kernel completes. As a result of the more efficient approach to coherence employed by LazyPIM, applications that performed poorly under prior approaches to PIM coherence can now take advantage of the benefits of PIM execution. LazyPIM improves average performance by 19.6% reduces off-chip traffic by 30.9%, and reduces energy consumption by 18.0% over the best prior approachs to PIM coherence, while retaining the conventional multithreaded programming model.
References
- [1] J. Ahn, S. Hong, S. Yoo, O. Mutlu, and K. Choi, “A Scalable Processing-in-Memory Accelerator for Parallel Graph Processing,” in ISCA, 2015.
- [2] J. Ahn, S. Yoo, O. Mutlu, and K. Choi, “PIM-Enabled Instructions: A Low-Overhead, Locality-Aware Processing-in-Memory Architecture,” in ISCA, 2015.
- [3] J. Alsop, M. S. Orr, B. M. Beckmann, and D. A. Wood, “Lazy release consistency for gpus,” in MICRO, 2016.
- [4] A. Basu, J. Gandhi, J. Chang, M. D. Hill, and M. M. Swift, “Efficient Virtual Memory for Big Memory Servers,” in ISCA, 2013.
- [5] N. Binkert, B. Beckman, A. Saidi, G. Black, and A. Basu, “The gem5 Simulator,” Comp. Arch. News, 2011.
- [6] B. H. Bloom, “Space/Time Trade-offs in Hash Coding with Allowable Errors,” Commun. ACM, 1970.
- [7] L. Ceze, J. Tuck, P. Montesinos, and J. Torrellas, “BulkSC: Bulk Enforcement of Sequential Consistency,” in ISCA, 2007.
- [8] J. Devietti, B. Lucia, L. Ceze, and M. Oskin, “DMP: Deterministic Shared Memory Multiprocessing,” in ASPLOS, 2009.
- [9] DRAMSim2, http://www.eng.umd.edu/ blj/dramsim/.
- [10] J. Draper, J. Chame, M. Hall, C. Steele, T. Barrett, J. LaCoss, J. Granacki, J. Shin, C. Chen, C. W. Kang, I. Kim, and G. Daglikoca, “The Architecture of the DIVA Processing-in-memory Chip,” in SC, 2002.
- [11] A. Farmahini-Farahani, J. H. Ahn, K. Morrow, and N. S. Kim, “NDA: Near-DRAM Acceleration Architecture Leveraging Commodity DRAM Devices and Standard Memory Modules,” in HPCA, 2015.
- [12] M. Gao, G. Ayers, and C. Kozyrakis, “Practical Near-Data Processing for In-Memory Analytics Frameworks,” in PACT, 2015.
- [13] J. R. Goodman, “Using Cache Memory to Reduce Processor-memory Traffic,” in ISCA, 1983.
- [14] Q. Guo, N. Alachiotis, B. Akin, F. Sadi, G. Xu, T. M. Low, L. Pileggi, J. C. Hoe, and F. Franchetti, “3D-Stacked Memory-Side Acceleration: Accelerator and System Design,” in WoNDP, 2014.
- [15] L. Hammond, V. Wong, M. Chen, B. D. Carlstrom, J. D. Davis, B. Hertzberg, M. K. Prabhu, H. Wijaya, C. Kozyrakis, and K. Olukotun, “Transactional Memory Coherence and Consistency,” in ISCA, 2004.
- [16] K. Hsieh, E. Ebrahimi, G. Kim, N. Chatterjee, M. O’Conner, N. Vijaykumar, O. Mutlu, and S. Keckler, “Transparent Offloading and Mapping (TOM): Enabling Programmer-Transparent Near-Data Processing in GPU Systems,” in ISCA, 2016.
- [17] K. Hsieh, S. Khan, N. Vijaykumar, K. K. Chang, A. Boroumand, S. Ghose, and O. Mutlu, “Accelerating Pointer Chasing in 3D-Stacked Memory: Challenges, Mechanisms, Evaluation,” in ICCD, 2016.
- [18] Hybrid Memory Cube Specification 2.0, 2014.
- [19] J. Jeddeloh and B. Keeth, “Hybrid Memory Cube New DRAM Architecture Increases Density and Performance,” in VLSIT, 2012.
- [20] JEDEC, “JESD235: High Bandwidth Memory (HBM) DRAM,” 2013.
- [21] Y. Kang, W. Huang, S.-M. Yoo, D. Keen, Z. Ge, V. Lam, P. Pattnaik, and J. Torrellas, “FlexRAM: Toward an advanced intelligent memory system,” in ICCD. IEEE, 2012.
- [22] O. Kocberber, B. Grot, J. Picorel, B. Falsafi, K. Lim, and P. Ranganathan, “Meet the Walkers: Accelerating Index Traversals for In-Memory Databases,” in MICRO, 2013.
- [23] P. M. Kogge, “EXECUBE: A New Architecture for Scaleable MPPs,” in ICPP, 1994.
- [24] S. Kumar, A. Shriraman, and N. Vedula, “Fusion: Design Tradeoffs in Coherent Cache Hierarchies for Accelerators,” in ISCA, 2015.
- [25] D. Lee, S. Ghose, G. Pekhimenko, S. Khan, and O. Mutlu, “Simultaneous Multi-Layer Access: Improving 3D-Stacked Memory Bandwidth at Low Cost,” ACM TACO, 2016.
- [26] J. Lee, Y. Solihin, and J. Torrettas, “Automatically Mapping Code on an Intelligent Memory Architecture,” in HPCA, 2001.
- [27] G. H. Loh, “3D-Stacked Memory Architectures for Multi-Core Processors,” in ISCA, 2008.
- [28] K. Mai, T. Paaske, N. Jayasena, R. Ho, W. J. Dally, and M. Horowitz, “Smart Memories: A Modular Reconfigurable Architecture,” in ISCA, 2000.
- [29] MemSQL, Inc., “MemSQL,” http://www.memsql.com/.
- [30] N. Mirzadeh, O. Kocberber, B. Falsafi, and B. Grot, “Sort vs. Hash Join Revisited for Near-Memory Execution,” in ASBD, 2007.
- [31] N. Muralimanohar, R. Balasubramonian, and N. Jouppi, “Optimizing NUCA Organizations and Wiring Alternatives for Large Caches with CACTI 6.0,” in MICRO, 2007.
- [32] OProfile, http://oprofile.sourceforge.net/.
- [33] M. S. Orr, S. Che, A. Yilmazer, B. M. Beckmann, M. D. Hill, and D. A. Wood, “Synchronization using remote-scope promotion,” in ASPLOS, 2015.
- [34] M. Oskin, F. T. Chong, and T. Sherwood, Active Pages: A Computation Model for Intelligent Memory. IEEE Computer Society, 1998.
- [35] M. S. Papamarcos and J. H. Patel, “A Low-overhead Coherence Solution for Multiprocessors with Private Cache Memories,” in ISCA, 1984.
- [36] D. Patterson, T. Anderson, N. Cardwell, R. Fromm, K. Keeton, C. Kozyrakis, R. Thomas, and K. Yelick, “A Case for Intelligent RAM,” IEEE Micro, 1997.
- [37] J. Power, A. Basu, J. Gu, M. Hill, and D. Wood, “Heterogeneous system coherence for integrated CPU-GPU systems,” in Proceedings of the 46th Annual IEEE/ACM International Symposium on Microarchitecture. IEEE/ACM, 2013, pp. 457–467.
- [38] S. H. Pugsley, J. Jestes, H. Zhang, R. Balasubramonian, V. Srinivasan, A. Buyuktosunoglu, A. Davis, and F. Li, “NDC: Analyzing the Impact of 3D-stacked Memory+Logic Devices on MapReduce Workloads,” in ISPASS, 2014.
- [39] D. Sanchez, L. Yen, M. D. Hill, and K. Sankaralingam, “Implementing Signatures for Transactional Memory,” in MICRO, 2007.
- [40] SAP SE, “SAP HANA,” http://www.hana.sap.com/.
- [41] V. Seshadri, A. Bhowmick, O. Mutlu, P. B. Gibbons, M. A. Kozuch, and T. C. Mowry, “The Dirty-Block Index,” in ISCA, 2014.
- [42] V. Seshadri, K. Hsieh, A. Boroumand, D. Lee, M. A. Kozuch, O. Mutlu, P. B. Gibbons, and T. C. Mowry, “Fast Bulk Bitwise AND and OR in DRAM,” CAL, 2015.
- [43] V. Seshadri, Y. Kim, C. Fallin, D. Lee, R. Ausavarungnirun, G. Pekhimenko, Y. Luo, O. Mutlu, M. A. Kozuch, P. B. Gibbons, and T. C. Mowry, “RowClone: Fast and Energy-Efficient In-DRAM Bulk Data Copy and Initialization,” in MICRO, 2013.
- [44] D. E. Shaw, S. J. Stolfo, H. Ibrahim, B. Hillyer, G. Wiederhold, and J. Andrews, “The NON-VON Database Machine: A Brief Overview,” IEEE Database Eng. Bull., 1981.
- [45] J. Shun and G. E. Blelloch, “Ligra: A Lightweight Graph Processing Framework for Shared Memory,” in PPoPP, 2013.
- [46] M. D. Sinclair, J. Alsop, and S. V. Adve, “Efficient GPU Synchronization Without Scopes: Saying No to Complex Consistency Models,” in MICRO, 2015.
- [47] Stanford Network Analysis Project, http://snap.stanford.edu/.
- [48] H. S. Stone, “A Logic-in-Memory Computer,” IEEE Trans. Comput., 1970.
- [49] M. Stonebraker and A. Weisberg, “The VoltDB Main Memory DBMS.” IEEE Data Eng. Bull., 2013.
- [50] J. Teubner, G. Alonso, C. Balkesen, and M. T. Ozsu, “Main-Memory Hash Joins on Multi-Core CPUs: Tuning to the Underlying Hardware,” in ICDE, 2013.
- [51] S. L. Xi, O. Babarinsa, M. Athanassoulis, and S. Idreos, “Beyond the Wall: Near-Data Processing for Databases,” in DaMoN, 2015.
- [52] L. Xu, D. P. Zhang, and N. Jayasena, “Scaling Deep Learning on Multiple In-Memory Processors,” 2015.
- [53] J. Xue, Z. Yang, Z. Qu, S. Hou, and Y. Dai, “Seraph: An Efficient, Low-Cost System for Concurrent Graph Processing,” in HPDC, 2014.
- [54] D. P. Zhang, N. Jayasena, A. Lyashevsky, J. L. Greathouse, L. Xu, and M. Ignatowski, “TOP-PIM: Throughput-Oriented Programmable Processing in Memory,” in HPDC, 2014.