Learning a Better Initialization for Soft Prompts via Meta-Learning
Abstract
Prompt tuning (PT) is an effective approach to adapting pre-trained language models to downstream tasks. Without a good initialization, prompt tuning doesn’t perform well under few-shot settings. So pre-trained prompt tuning (PPT) (Gu et al., 2022a) is proposed to initialize prompts by leveraging pre-training data. We propose MetaPT (Meta-learned Prompt Tuning) to further improve PPT’s initialization by considering latent structure within the pre-training data. Specifically, we introduce the structure by first clustering pre-training data into different auxiliary tasks with unsupervised methods. Then we use these tasks to pre-train prompts with a meta-learning algorithm. Such a process can make prompts learn a better initialization by discovering commonalities among these auxiliary tasks. We evaluate our method on seven downstream tasks. Our MetaPT achieves better and more stable performance than the state-of-the-art method.
1 Introduction
Pre-trained language models (PLMs) (e.g. BERT Devlin et al., 2019; T5 Raffel et al., 2020; GPT3 Brown et al., 2020b) have demonstrated outstanding performances in various downstream NLP tasks. Full-model tuning (FT) and prompting are two methods that leverage PLMs for downstream tasks. FT adapts PLMs to downstream tasks by introducing task-specific training objects and fine tuning all parameters of PLMs. Instead of tuning the entire PLMs, prompting methods probe the knowledge in PLMs by templates (i.e. prompts) to solve downstream tasks. FT shows state-of-art performance in most scenarios. But as size of pre-trained language model increases, fine tuning and then storing the whole model parameters would be quite expensive. In contrast, prompting doesn’t need to tune the entire PLMs, which makes it parameter-efficient. Therefore, prompting gradually becomes an alternative solution for FT to utilize large-scale PLMs.
There are two types of Prompts: hard prompts and soft prompts. Hard prompts are human-designed discrete tokens while soft prompts are continuous embeddings of language models. Brown et al. (2020a) first introduce the concept of hard prompts. They find that behaviors of GPT3 could be modulated by text prompts. For example, we want to know the sentiment of the sentence “I love this movie”. We could add a template “Overall, it was a <mask> movie” at the end of the sentence. So the input sentence would be “I love this movie. Overall, it was a <mask> movie”. The hard prompt forces the PLMs to predict the mask token as well as the sentiment of the sentence. Soft prompts are templates with their own tunable parameters and perform prompting directly into the continuous embedding space of the model. Soft prompts could be directly trained by data from downstream tasks, while hard-prompts have to rely on costly human specialists to design templates for each task. Moreover, hard prompts have to be human-interpretable natural language, whereas soft prompts can be the continuous embeddings of the model with more representation ability (Liu et al., 2021a).
Prompt tuning (PT) (Lester et al., 2021) is a simple but effective prompting method that combines hard prompts and soft prompts together. PT adds a series of tunable tokens at the beginning of the sequence as soft prompts and also adds human designed template to the sequence as hard prompts. When adapting PLMs to downstream tasks, PT freezes all parameters of PLMs and only trains the soft prompts. In that way, features of downstream tasks will be learned without breaking the inner structure of PLMs. PT achieves comparable performance to full-model tuning with sufficient data. But it performs poorly under few-shot settings due to its sensitivity to the initialization of soft prompts. This disadvantage significantly affects the practical application of PT.
Pre-trained prompt tuning (PPT) (Gu et al., 2022b) is proposed to adapt prompt tuning to few-shot settings. PPT pre-trains soft prompts with self-supervised pre-training tasks and then apply pre-trained prompts to few-shot downstream tasks. PPT generally groups all text classification tasks into different formats and designs a self-supervised pre-training task for each format to pre-train prompts. PPT demonstrate its effectiveness when using large-scale PLMs.
However, PPT still has limitations, as it mixes all pre-training data together and treats each data point equally. Since PPT updates prompt parameters at every data point, it learns more about the specific feature of each data point rather than general features of the entire task. However, knowledge learned from pre-training data is not necessarily applicable to downstream tasks because pre-training task and downstream task are different. As a result, PPT retains too much redundant information only relevant to the pre-training task in the initialization of soft prompts, which consequently impedes model performance on downstream tasks.
To obtain a better initialization for soft prompts, we incorporate meta-learning into prompt tuning. We propose an innovative unsupervised method to create meta-learning tasks for prompts and then introduce a model-agnostic meta-learning method to pre-train prompts. By our unsupervised clustering method, latent structure of pre-training data is represented by the distribution of meta tasks. Through meta-learning, general features are incorporated to the initialization of the soft prompts. Our meta-learned prompts achieve faster and more stable adaptation to downstream tasks. We named our method Meta-learned Prompt Tuning “MetaPT”. Our experiments show that MetaPT outperforms full-model tuning and pre-trained prompt tuning on the base-size model.
2 Related work
Hard Prompts The basic idea of hard prompts is to use a discrete human-designed natural language prompt to query a language model. Hard Prompt first show its effectiveness in Brown et al. (2020b). They discover that a frozen GPT-3 model’s behavior could be modulated by text prompts. After that, much effort is made to automatically search for prompt templates in a discrete space. Jiang et al. (2021) apply a mining-based method to automatically search for suitable templates in a given task. Yuan et al. (2021) and Haviv et al. (2021) perform paraphrasing to prompts with different methods. Basically, they both paraphrase an already constructed prompt as a seed prompt and then paraphrase it into a set of candidate prompts and select the prompt with the best performance from this set. Shin et al. (2020) implement gradient-based search over actual tokens to find templates with downstream application training samples. Gao et al. (2021) and Ben-David et al. (2022) turn prompt templates searching into task-generation task and use text-generation model T5 to generate prompts.
Soft Prompts There are also methods exploring soft prompts which incorporate prompting directly into the continuous embedding space of the model. Prefix tuning (Li and Liang, 2021) is a method that freezes the model parameters and tunes the prefix activations prepended to each layer in the encoder stack. Lester et al. (2021) propose a further simplified approach called prompt tuning, which only tunes the additional tunable tokens prepended to the input text. P-tuning v2 (Liu et al., 2021b) adapted the idea of prompt tuning by adding prompts in different layers as pre-fix tokens rather than only the input embedding. Its performance can be comparable to full-model tuning across both scales and tasks.
Though the above soft prompt related methods perform well with sufficient training data, they all become much worse under few-shot learning settings. Pre-trained prompt tuning (Gu et al., 2022a) is introduced to enhance the performance of prompt tuning when training data is limited. They group typical classification tasks into three formats and create one self-supervised pre-training task for each format. Pre-trained by these self-supervised tasks, prompt tuning could reach or even outperform full-model tuning methods under few-shot settings.
Meta Learning
Meta-Learning, or learning about learning, aims to improve the learning algorithm itself. One popular meta-learning framework would be Model-Agnostic Meta-Learning(MAML) proposed by Finn et al. (2017). MAML could be directly applied to any learning problem and leads to great performance with a small amount of training data. MAML-related approaches are adopted in various NLP tasks. Dou et al. (2019) treat some high resources datasets in GLUE (Wang et al., 2018) as auxiliary tasks and use the rest of them as target tasks to test the performance. Qian and Yu (2019) applies MAML to an end-to-end dialog system for domain adaption and then Qian et al. (2021) incorporates a meta-teacher model to optimize the domain adaption process.
3 Background
In this section, we introduce basic knowledge about prompt tuning. Following Lester et al. (2021), we turn all the text classification tasks into text generation tasks. We first pre-process input samples to adjust to prompt tuning setting and then formulate the idea of prompt tuning.
3.1 Pre-processing
Pre-processing is necessary to adjust the input sample to text-to-text form. Specifically, there are two steps to pre-process the input samples.
Label Mapping We first map labels to our pre-defined concrete tokens.
Taking a 5-class sentiment classification task as an example, the original labels are numbers from 0-4 which denotes the sentiment intensity. We map , , , , and then directly use these mapping results as label tokens. Since pre-trained language model is trained on natural languages, mapping labels to real words usually leads to decent performance Gu et al. (2022b).
Prompt Adding In the second step, we add prompts to the input sentence. we implement a hybrid prompt (Gu et al., 2022a) which combines soft prompts and hard prompts together to achieve the best performance.
The prompt we applied is designed with the following template: a set of soft prompts embedding is prepended to the input sequence features, and then the manually desigend hard prompt “It was . ” would be added at the end of the input sentence, where denotes the mask token in the pre-trained language model.
3.2 Formulation
Different from full-model tuning which tunes parameters of the entire pre-trained language model, prompt tuning only modifies the parameters of prompts prepended to the input sentence. Fine-tuning process of adapting pre-trained language model to a downstream classification task could be represented by optimizing the following log-likelihood objective:
where is an input sample in , is an input sentence and is its label.
Prompt tuning freezes parameters of language model and only tunes soft prompts . Mathematically, hybrid prompt tuning could be represented by optimizing the following log-likelihood objective:
where is the concrete token mapped from label y, denotes fitting input sentence to a hard prompt template and denotes prepending soft prompts to the beginning of input sequence.
Pre-trained prompt tuning Gu et al. (2022a) proposes to pre-train soft prompts on rich-resource pretraining dataset , in order to improve the performance on downstream tasks under few-shot settings. Instead of directly training prompts on pre-training data , we propose meta-learned prompt tuning to further enhance the performance of prompt tuning under few-shot settings. Pre-training data is first divided into different auxiliary meta tasks by unsupervised methods and then prompts are trained during and a model-agnostic meta-learning phase on these meta tasks.
4 Meta-learned Prompt Tuning
In this section, we describe our model training pipeline. We first describe the process of gathering pre-training data for meta-learning. Then, we introduce different unsupervised methods to cluster pre-training data into different groups as auxiliary tasks for meta-learning. Finally, we describe our prompt-MAML algorithm to train and find a good initialization for soft prompts.
We aim to encode more general features shared by pre-training data and downstream tasks to the initialization of prompts so that the model could adapt faster to downstream tasks.
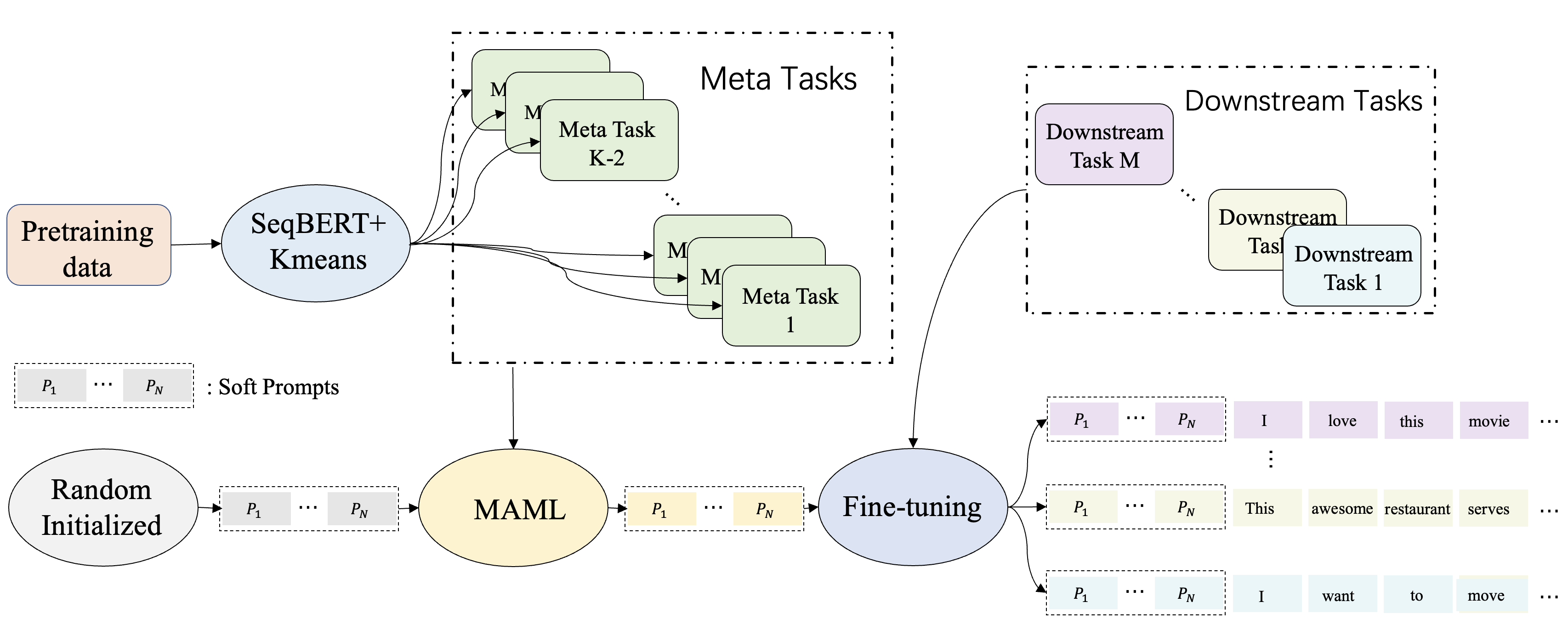
4.1 Constructing Pre-training Data
There are mainly two methods to construct pre-training data for our algorithm. The first one is to directly choose a high resource dataset similar to the target task as pre-training data. The second one is to create pre-training data unsupervisedly. In our experiment setting, we focus on sentiment classification tasks. It’s worth mentioning that for sentiment classification task, we still couldn’t avoid relying on an existing dataset to create pseudo labels in our second method. The main difference between the first method and the second method is that the pre-training data in the method only covers one domain while the pre-training data created by the second method is an open domain. Besides, from the second method we could create unlimited data as long as we are able to collect enough large corpus from open web.
For the first method, we directly treat a 5-class sentiment classification large-scale dataset Yelp5 (Zhang et al., 2015) as pre-training data. For the second method, we adopt the method proposed by Gu et al. (2022a) to create pseudo labels for sentences from a large open-domain corpus. We train another model to annotate pseudo labels for the sentences in a large corpus.
4.2 Designing Meta-learning Tasks
After constructing pre-training data in section 4.1, we group the data into different clusters as auxiliary meta tasks used for meta-learning. We propose two unsupervised methods to separate the pre-training data into several meta tasks. By these unsupervised clustering methods, latent structure within pre-training data is revealed. Based on that structure, prompts could learn to incorporate some common internal features to the initialization through meta-learning. With such general information encoded in the initialization of prompts, the model can achieve great performance with limited training data from downstream tasks.
4.2.1 Kmeans Tasks
In this method, we group pre-training data into different classes by K-means clustering. Assume pre-training data we get from section 4.1 is
| (1) |
We first implement sentence-BERT(Reimers and Gurevych, 2019) to derive semantically meaningful sentence embeddings from pre-train data samples.
| (2) |
Then we apply unsupervised K-means to cluster pre-training data into different classes according to their sentence embeddings. We first set K to the number of clusters, then we generate K different meta tasks from pre-training data:
| (3) | ||||
| (4) |
We want to avoid prompts from learning too much redundant semantic information that only relevant to pre-training data, but learning how to extract information from language models for sentiment classification. Through K-means clustering, samples containing similar sentence embeddings are grouped into the same task. During the meta-learning process, prompts keep the general features of task type (sentiment classification in our case) and throw away some redundant semantic information only relevant to domain of pre-training data. The task type information retained in the initialization is going to play a key role in the subsequent main task few-shot learning.
4.2.2 LDA Tasks
Latent Dirichlet Allocation (LDA) is an alternative way to group pre-training data into different clusters. It is a generative statistical model to automatically group documents into different topics. LDA aims to discover the hidden themes in the collection of data. We apply LDA to group pre-training data into different tasks according to their topics. Pre-training samples in the same task would have similar themes while samples across different tasks would differ in their themes. By grouping pretraining data into different clusters according to their hidden themes, we hope to eliminate unimportant variations in the topics among pre-training data, while maintaining information related to task type in the prompts.
4.3 Prompt-MAML Algorithm
After we get a set of meta tasks obtained via an unsupervised method, we utilize MAML to learn general features among these meta tasks. We first randomly initialize the parameter of soft prompts . For each meta task , m training samples are sampled from that task. Taking in m samples, the model output . Then we calculate the average loss of these m samples and temporarily updates soft prompts with gradient descent.
| (5) |
After optimizing the prompts, we sampled another m samples and calculate the loss with the updated prompts. We add loss for to total loss and repeat the same process for other meta tasks until we go over all the meta tasks. Finally, we update the prompts by minimizing the final total loss.
| (6) |
This is a complete process of one-step updates for prompts. We keep optimizing the prompts until the validation accuracy of meta tasks stop growing. The whole algorithm of Meta-learned prompt tuning is shown below.
| Methods | SST5 | SST2 | Amazon5 | Amazon2 | Sentihood | SemEvalr | SemEvall |
| FT | |||||||
| PPT | |||||||
| MetaPT | |||||||
| MetaPT(Y) |
5 Experiments
Our experiments are built on the T5 base model from HuggingFace Wolf et al. (2020).
Downstream Datasets We focus on the sentiment classification tasks. Specifically, the downstream datasets include SST-5 (Socher et al., 2013), SST-2 (Socher et al., 2013), Amazon-5 (Zhang et al., 2015), Amazon-2 (Zhang et al., 2015), Sentihood (Saeidi et al., 2016), and SemEval-2016 (Pontiki et al., 2016). SemEval-2016 has two tasks in different domains: restaurant and laptop. These two tasks are denoted by SemEvalr and SemEvall respectively. Detailed information of these datasets could be found in Appendix B. We randomly select 40 samples from original dataset for both few-shot training and validation.
Pre-training Data We mainly gathering two different sources of pre-training data here. For the first source, we directly choose Yelp5 as pretraining data. Yelp5 has 650,000 training samples only covering the domain of restaurant. For the second source, we first train a RoBERTa-base model on Yelp5. Then we randomly sample 10GB of data from OpenWebText (Gokaslan and Cohen, 2019) and apply the trained RoBERTa model to annotate labels for the sampled data. We only keep data samples with high confidence and throw away the samples which model is unsure about. After balancing pseudo data, we get 1,000,000 balanced training samples with open domains. These two sources of data correspond to MetaPT(Y) and MetaPT respectively in Table 1. For both two sources of data We set cluster number to 10. We implement Sentence-BERT-base model to extract sentence features from pre-training data. Then we apply K-means to group pre-training data into 10 clusters as auxiliary tasks for meta-learning.
Hyperparameters Following Lester et al. (2021), we set the soft-prompt as 100 tunable tokens. During the meta-learning phase, we implement Adam with weight decay as the optimizer. We set the learning rate to 0.08, learning rate to 0.025, the batch size to 4, early stop patience to 6, and the max updating step of MAML to 20000. During the downstream prompt tuning phase, we implement AdamW as the optimizer. We use the linear scheduler with 20 warm up steps to achieve a learning rate of 0.003. We set batch size to 4, the max epoch to 200, and the patience for early stopping to 5. To achieve a reliable result, we run all the experiments for five times with different random seeds and report the mean numbers, along with their deviations.
More experimental arguments of pre-trained prompt tuning and full-model tuning could be found in Appendix A.
6 Results
6.1 Main Results
As shown in the Table 1, we mainly compare the performance of full-model tuning (FT), pre-trained prompt tuning (PPT), meta-learned prompt tuning (MetaPT) on different sentiment classification tasks. We also include results of MetaPT(Y) in the table, which is a variation of MetaPT. Instead of being trained on the pseudo data, MetaPT(Y) is directly trained on Yelp5. According to Gu et al. (2022a), the performance of plain prompt tuning lags far behind FT and PPT, we don’t include it in our main table. We have three observations from results in Table 1.
First, MetaPT consistently achieves better results than PPT over all seven tasks. MetaPT outperforms PPT by prevent overfitting on pre-training datasete. Benefitting from MAML algorithm, MetaPT only transfer general features to the initialization of prompts and throw out redudant information. MetaPT also outperforms FT for most of the tasks. Because we utilize the extra pre-training data to train the soft prompt without destroying the inner structure of language model. However, full-model tuning achieves the best score on the Sentihood dataset because the examples in this dataset are simple and easy to learn for full-model tuning. From the example shown in Appendix B, the input of Sentihood is shorter than other datasets, and the words appeared in this sentihood is more commonly used in daily life. Also, its labels only has 2 classes good and bad. Due to above three reasons, we believe that training samples of Sentihood are close to what language model learned through pre-training and would cause less destruction to inner structure of language model through full-model tuning. Therefore, full-model tuning can quickly learn the Sentihood task with a few data points.
Second, MetaPT(Y) also outperforms PPT and FT on most tasks. And MetaPT(Y) achieves even better results than MetaPT on some tasks. We look into the results on SST-5 and we find that the recall score of MetaPT is much lower than MetaPTy on the label terrible (0.22 vs. 0.61). We believe this is caused by some pseudo data samples with poor quality. When creating pseudo labels, the classifier trained by Yelp5 tends to annotate text with the label terrible with high probability, even though the text is irrelevant to terrible from the human perspective. For example, “Both parties agreed to have 1,410 troops located in juba, lueth said, and there are already 1,370 opposition soldiers in the capital.” is considered as terrible with high confidence by classifier while we don’t discover any sentiment here. This tendency results in the low quality of pseudo data with the label terrible which confuses the MetaPT during MAML. Even though Yelp5 covers only restaurant domain, MetaPT(Y) still shows great performance when adapting to sentiment tasks in other domains. This suggests that our MetaPT is able to learn the general features, which enable the prompt be easily generalized to other domains.
Finally, MetaPT is much more stable than both PPT and FT. Most methods would suffer from high variance under few-shot setting due to their sensitivity to different training samples. The performance of FT varies tremendously when we select different few-shot samples for FT. However, MetaPT shows remarkable stability facing different training samples. The standard deviation of MetaPT is much lower than both FT and PPT across all downstream tasks. This phenomenon indicates that MetaPT is more robust under few shot settings.
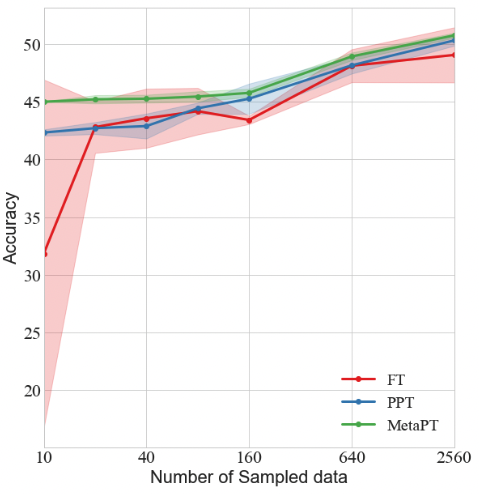
We show the tendency of how performance of FT, PPT, MetaPT varies when the number of training samples increases on SST-5. As shown in Figure 2, when the number of training samples grows from 10 to 2,560, MetaPT is consistently better than PPT and FT, while PPT also has a small advantage over FT. It should be noted that, the full-model tuning method will eventually catch up with other two prompt tuning methods as the number of training samples keep increasing. All three methods will converge to similar performance when training data is sufficient.
6.2 Ablation Study
In this section, we discuss how much pre-training data we need to obtain a good result, how the method of clustering affects the performance and how the number of clusters influences results. All the experiments are evaluated on SST-5.
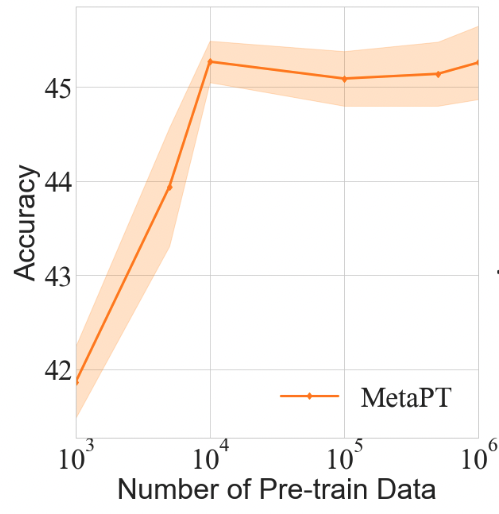
Scale of pre-training data
We want to minimize the pre-training data we used without undermining the performance of our model. We set the number of pre-train samples from 1,000 to 1,000,000. And then we implement Kmeans to cluster them into 10 classes for meta-learning. As the Figure 3(a) shows, the accuracy grows rapidly when the number pre-training data increases from 1,000 to 10,000. After 10,000 training samples, the performance does not change much as the number of training samples increases. This result suggests that more pre-training data samples are not necessarily along with better performance in our method. When the size of pre-train data reaches the level of 10,000, it is enough for our model to get acceptable performance.
Methods of clustering We design four different methods of clustering to get meta tasks. They are K-means clustering, LDA clustering, random clustering, and label clustering. For K-means clustering, we apply a Sentence-BERT-base model to extract sentence features from pre-training samples and then implement K-means to cluster these samples into different groups according to their sentence features. For LDA clustering, we group training samples according to the hidden themes extracted by the LDA topic model. For the random method, we randomly split the total pre-train dataset into different groups. For the label method, we cluster the data samples with the same label into the same group. When the clustering number is large than the number of labels, we just randomly split samples with the same label into more groups.We fixed the cluster number as 10 in this experiment.
From the result shown in Table 2 we notice that K-means clustering is most effective and LDA is next to it. When we cluster randomly or according to their labels, the performance of MetaPT degrades to the same level as PPT.
| Methods | Accuracy |
| K-means | 46.240.42 |
| LDA | 44.100.83 |
| random | 42.951.05 |
| label | 42.840.76 |
| PPT | 42.891.08 |
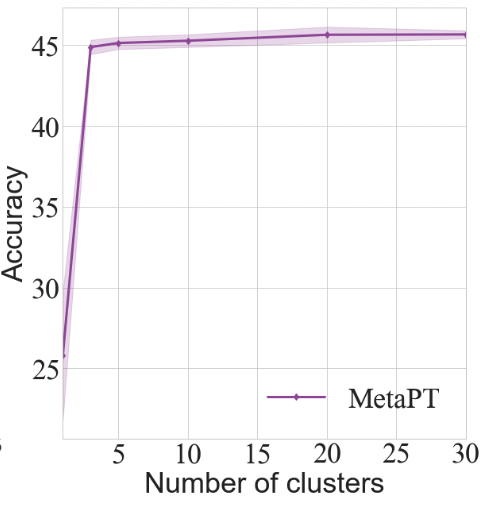
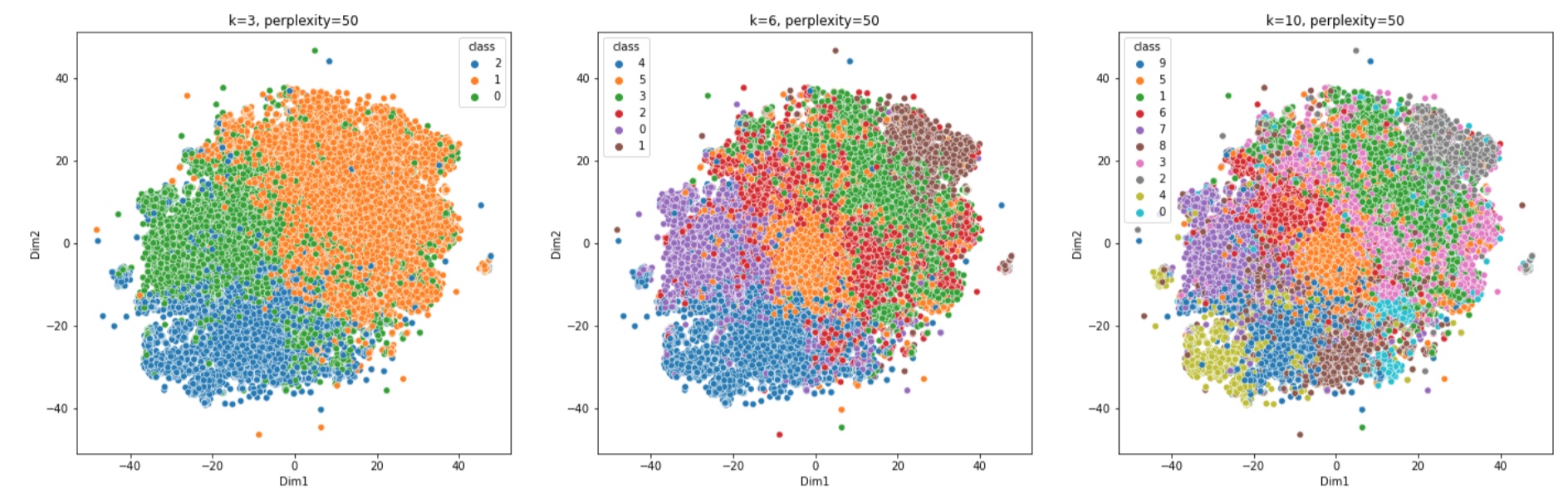
Number of clusters We examine the cluster number from 3-30 and compare performance. We fix the clustering method as K-means. As shown in the Figure 3(b), the accuracy grows rapidly at first as cluster number increases but later it converges. Considering both effectiveness and efficiency, MetaPT is able to achieve promising results when k=10. We also visualize the result of K-means clustering when cluster number equals to 3, 6, 10 in Figure 4. From the TSNE of our K-means clusters, we could see that data is well grouped into different clusters according to their sentence embeddings. After we reduce the sentence features of Different samples to two-dimensionality, different samples in the same clusters are close to each other and are distinguishable from samples in other clusters, which demonstrates that meta tasks derived from K-means indeed contain useful common latent features.
7 Conclusions
In this paper, we present the meta-learned prompt tuning framework. Specifically, we propose to cluster pre-training data into different groups to create auxiliary tasks for meta-learning, and then pre-train prompts with the Model-Agnostic Meta-Learning method. We explore our method based on the sentiment classification task and evaluate our meta-learned prompts on seven downstream datasets under a few-shot setting. The results demonstrate that meta-learned prompt tuning achieves better performance and stability than the state-of-the-art methods. We also conduct ablation study on different sources of pre-training data and different ways to obtain meta tasks.
In the future, we plan to apply our method to larger pre-trained language model, e.g. T5-xxlarge. We also plan to extend our evaluation tasks from sentiment classification to other general natural language processing tasks, e.g. sentence pairing, to explore the generalizability of our method. We hope that our work stimulates further research in how to leverage prompts to solve NLP tasks with pre-trained language models.
References
- Ben-David et al. (2022) Eyal Ben-David, Nadav Oved, and Roi Reichart. 2022. Pada: Example-based prompt learning for on-the-fly adaptation to unseen domains. Transactions of the Association for Computational Linguistics, 10:414–433.
- Brown et al. (2020a) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020a. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
- Brown et al. (2020b) Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, T. J. Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeff Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020b. Language models are few-shot learners. ArXiv, abs/2005.14165.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics.
- Dou et al. (2019) Zi-Yi Dou, Keyi Yu, and Antonios Anastasopoulos. 2019. Investigating meta-learning algorithms for low-resource natural language understanding tasks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 1192–1197, Hong Kong, China. Association for Computational Linguistics.
- Finn et al. (2017) Chelsea Finn, P. Abbeel, and Sergey Levine. 2017. Model-agnostic meta-learning for fast adaptation of deep networks. In ICML.
- Gao et al. (2021) Tianyu Gao, Adam Fisch, and Danqi Chen. 2021. Making pre-trained language models better few-shot learners. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 3816–3830, Online. Association for Computational Linguistics.
- Gokaslan and Cohen (2019) Aaron Gokaslan and Vanya Cohen. 2019. Openwebtext corpus. http://Skylion007.github.io/OpenWebTextCorpus.
- Gu et al. (2022a) Yuxian Gu, Xu Han, Zhiyuan Liu, and Minlie Huang. 2022a. Ppt: Pre-trained prompt tuning for few-shot learning. ArXiv, abs/2109.04332.
- Gu et al. (2022b) Yuxian Gu, Xu Han, Zhiyuan Liu, and Minlie Huang. 2022b. PPT: Pre-trained prompt tuning for few-shot learning. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8410–8423, Dublin, Ireland. Association for Computational Linguistics.
- Haviv et al. (2021) Adi Haviv, Jonathan Berant, and Amir Globerson. 2021. BERTese: Learning to speak to BERT. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 3618–3623, Online. Association for Computational Linguistics.
- Jiang et al. (2021) Zhengbao Jiang, Jun Araki, Haibo Ding, and Graham Neubig. 2021. How can we know when language models know? on the calibration of language models for question answering. Transactions of the Association for Computational Linguistics, 9:962–977.
- Lester et al. (2021) Brian Lester, Rami Al-Rfou, and Noah Constant. 2021. The power of scale for parameter-efficient prompt tuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 3045–3059, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Li and Liang (2021) Xiang Lisa Li and Percy Liang. 2021. Prefix-tuning: Optimizing continuous prompts for generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 4582–4597, Online. Association for Computational Linguistics.
- Liu et al. (2021a) Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. 2021a. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ArXiv, abs/2107.13586.
- Liu et al. (2021b) Xiao Liu, Kaixuan Ji, Yicheng Fu, Zhengxiao Du, Zhilin Yang, and Jie Tang. 2021b. P-tuning v2: Prompt tuning can be comparable to fine-tuning universally across scales and tasks. ArXiv, abs/2110.07602.
- Pontiki et al. (2016) Maria Pontiki, Dimitris Galanis, Haris Papageorgiou, Ion Androutsopoulos, Suresh Manandhar, Mohammad AL-Smadi, Mahmoud Al-Ayyoub, Yanyan Zhao, Bing Qin, Orphée De Clercq, Véronique Hoste, Marianna Apidianaki, Xavier Tannier, Natalia Loukachevitch, Evgeniy Kotelnikov, Nuria Bel, Salud María Jiménez-Zafra, and Gülşen Eryiğit. 2016. SemEval-2016 task 5: Aspect based sentiment analysis. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), pages 19–30, San Diego, California. Association for Computational Linguistics.
- Qian et al. (2021) Kun Qian, Wei Wei, and Zhou Yu. 2021. A student-teacher architecture for dialog domain adaptation under the meta-learning setting. In AAAI.
- Qian and Yu (2019) Kun Qian and Zhou Yu. 2019. Domain adaptive dialog generation via meta learning. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 2639–2649, Florence, Italy. Association for Computational Linguistics.
- Raffel et al. (2020) Colin Raffel, Noam M. Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. ArXiv, abs/1910.10683.
- Reimers and Gurevych (2019) Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence embeddings using Siamese BERT-networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3982–3992, Hong Kong, China. Association for Computational Linguistics.
- Saeidi et al. (2016) Marzieh Saeidi, Guillaume Bouchard, Maria Liakata, and Sebastian Riedel. 2016. SentiHood: Targeted aspect based sentiment analysis dataset for urban neighbourhoods. In Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, pages 1546–1556, Osaka, Japan. The COLING 2016 Organizing Committee.
- Shin et al. (2020) Taylor Shin, Yasaman Razeghi, Robert L. Logan IV, Eric Wallace, and Sameer Singh. 2020. AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 4222–4235, Online. Association for Computational Linguistics.
- Socher et al. (2013) Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D. Manning, Andrew Ng, and Christopher Potts. 2013. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, pages 1631–1642, Seattle, Washington, USA. Association for Computational Linguistics.
- Wang et al. (2018) Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. 2018. GLUE: A multi-task benchmark and analysis platform for natural language understanding. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pages 353–355, Brussels, Belgium. Association for Computational Linguistics.
- Wolf et al. (2020) Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander Rush. 2020. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45, Online. Association for Computational Linguistics.
- Yuan et al. (2021) Weizhe Yuan, Graham Neubig, and Pengfei Liu. 2021. Bartscore: Evaluating generated text as text generation. In NeurIPS.
- Zhang et al. (2015) Xiang Zhang, Junbo Jake Zhao, and Yann LeCun. 2015. Character-level convolutional networks for text classification. ArXiv, abs/1509.01626.
Appendix A Training Settings
We provide detailed training settings used for full-model tuning (FT), pre-trained prompt tuning (PPT). Instead of following Gu et al. (2022b), we find another set of hyperparameters. Both FT and PPT achieve better performances on T5-base model than results reported in Gu et al. (2022b).
A.1 Full-model Tuning
We implement AdamW as the optimizer. We apply a linear scheduler with 20 warm up steps and set the learning rate to 0.00003. We set batch size to 4, max epochs to 200. We evaluate results on validation set every epoch and and set the patience for early stopping to 5.
A.2 Pre-trained Prompt Tuning
We apply pseudo data created in section 5 as pre-training data for PPT. During pre-training phase, we implement AdamW as the optimizer. We apply the linear scheduler with 20 warm up steps and set the learning rate to 0.003. We set the batch size to 4 and max epoch to 5 (1,250,000 max steps). We evaluate prompts on validation set every 20,000 steps and set the patience of early stop to 5.
During downstream prompt tuning phase, we adopt the same training setting as downstream prompt tuning in meta-learned prompt tuning. We implement AdamW as the optimizer. We use the linear scheduler with 20 warm up steps and set the learning rate to 0.003. We set batch size to 4, the max epoch to 200, and the patience for early stopping to 5.
Appendix B Dataset Examples
Here we provide detailed information and examples for all the datasets we used. Pre-training dataset includes Yelp5 (Zhang et al., 2015). The downstream datasets include SST-5 (Socher et al., 2013), SST-2 (Socher et al., 2013), Amazon-5 (Zhang et al., 2015), Amazon-2 (Zhang et al., 2015), Sentihood (Saeidi et al., 2016), and SemEval-2016 (Pontiki et al., 2016). SemEval-2016 has two tasks in different domains: restaurant and laptop. These two tasks are denoted by SemEvalr and SemEvall respectively. Domains, number of classes and examples of all datasets are shown in Table 3.
| Dataset | Domain | classes | Example |
| Yelp-5 | restaurant | 5 | “dr. goldberg offers everything i look for in a general practitioner. he’s nice and easy to talk to without being patronizing; he’s always on time in seeing his patients; he’s affiliated with a top-notch hospital (nyu) which my parents have explained to me is very important in case something happens and you need surgery; and you can get referrals to see specialists without having to see him first. really, what more do you need? i’m sitting here trying to think of any complaints i have about him, but i’m really drawing a blank.” positive++ |
| SST-5 | movie | 5 | “unlike the speedy wham-bam effect of most hollywood offerings , character development – and more importantly , character empathy – is at the heart of italian for beginners” positive++ |
| SST-2 | movie | 2 | “jason x is positively anti-darwinian : nine sequels and 400 years later , the teens are none the wiser and jason still kills on auto-pilot ” negative |
| Amazon-5 | product | 5 | “nice screen for a nice price but….. i compared a few different flat panels with review before i narrowed down my pick, which ended up with the sylvania as over well liked. the picture got great reviews which yes it does have a good picture to look at but there are other important qualities you enjoy that makes viewing tv all the better. for example: sound… how was that forgotten?in this flat panel, it was. what a disappointment. if this is consider stereo than why does it sound like its coming from a tin can with no base at all. then too boot, if you play the dvd, the sound drops and you have to really turn up the volume to hear.i want the whole package deal: space saving, great picture, and good sound. i want to enjoy the whole experience of watching and listening. how about you?” positive |
| Amazon-2 | product | 2 | “not an ultimate guide. firstly,i enjoyed the format and tone of the book (how the author addressed the reader). however, i did not feel that she imparted any insider secrets that the book promised to reveal. if you are just starting to research law school, and do not know all the requirements of admission, then this book may be a tremendous help. if you have done your homework and are looking for an edge when it comes to admissions, i recommend some more topic-specific books. for example, books on how to write your personal statment, books geared specifically towards lsat preparation (powerscore books were the most helpful for me), and there are some websites with great advice geared towards aiding the individuals whom you are asking to write letters of recommendation. yet, for those new to the entire affair, this book can definitely clarify the requirements for you.” negative |
| Sentihood | neighborhood | 2 | “a friend of mine lived in location1 and she liked it, though other people have told me it’s a bit rough” negative |
| SemEvalr | restaurant | 3 | “if you’ve ever been along the river in weehawken you have an idea of the top of view the chart house has to offer” positive |
| SemEvall | labtop | 3 | “so if anyones looking to buy a computer or laptop you should stay far far away from any that have the name toshiba on it” negative |