Learning Analytics from Spoken Discussion Dialogs in Flipped Classroom
Abstract
The flipped classroom is a new pedagogical strategy that has been gaining increasing importance recently. Spoken discussion dialog commonly occurs in flipped classroom, which embeds rich information indicating processes and progression of students’ learning. This study focuses on learning analytics from spoken discussion dialog in the flipped classroom, which aims to collect and analyze the discussion dialogs in flipped classroom in order to get to know group learning processes and outcomes. We have recently transformed a course using the flipped classroom strategy, where students watched video-recorded lectures at home prior to group-based problem-solving discussions in class. The in-class group discussions were recorded throughout the semester and then transcribed manually. After features are extracted from the dialogs by multiple tools and customized processing techniques, we performed statistical analyses to explore the indicators that are related to the group learning outcomes from face-to-face discussion dialogs in the flipped classroom. Then, machine learning algorithms are applied to the indicators in order to predict the group learning outcome as High, Mid or Low. The best prediction accuracy reaches 78.9%, which demonstrates the feasibility of achieving automatic learning outcome prediction from group discussion dialog in flipped classroom.
Index Terms:
Automatic Learning Outcome Prediction, Flipped Classroom, Learning Analytics, Spoken Discussion DialogI Introduction
Learning analytics is concerned with collection and analyses of data related to learning in order to inform and improve the learning process or their outcomes [1]. Applying properly learning analytics can not only track student progress but also improve student performance [2]. Recent advancements in the development of data science and machine learning techniques has led to a rise in popularity of learning analytics within the educational research field.
The flipped classroom is a new pedagogical method, which utilizes asynchronous video lectures and basic practice as homework, and conducts group-based problem solving discussions or activities in the classroom [3]. Since flipped classroom promotes cooperative learning [4, 5] and increases student engagement and motivation [6, 7], it is gaining increasing importance for teaching and learning in recent years. A common in-class activity for the flipped classroom is student group discussions, where participants are involved in solving problems together. Such discussion dialogs embed rich information that cannot be captured objectively by conventional data, such as students’ in-class sentiments, degree of concentration, amount of information exchange… etc. The information from in-class discussion dialogs may reflect the processes and progression of learning. Therefore, spoken discussion dialogs in flipped classroom deserve greater attention for learning analytics, which aims to collect and analyze the discussion dialogs in flipped classroom in order to explore indicators that reflect group learning outcomes. However, current studies in flipped classroom research field have not paid sufficient attention to this research problem, not only because of the difficulty in collecting such data in formal flipped classroom, but also because of the technological difficulties in analyzing such data. For one, speech recordings of group discussions present a source separation problem from multiple speakers, tackling overlapping speech, ambient noise and many other challenges. One may consider temporarily circumventing this problem of automatically transcribing the speech recordings by using manual transcripts, but this may be a laborious process. Moreover, many fields of technology including speech signal processing, natural language processing, data science and machine learning are required to be integrated together to conduct a holistic research, which is also a technical challenge. This work attempts to apply current technologies to analyze student group discussion dialogs in order to extract indicators of group learning outcomes. This may pave the way for deeper analysis into flipped classroom activities and their pedagogical values, and perhaps inform possible directions in developing future intelligent classroom.
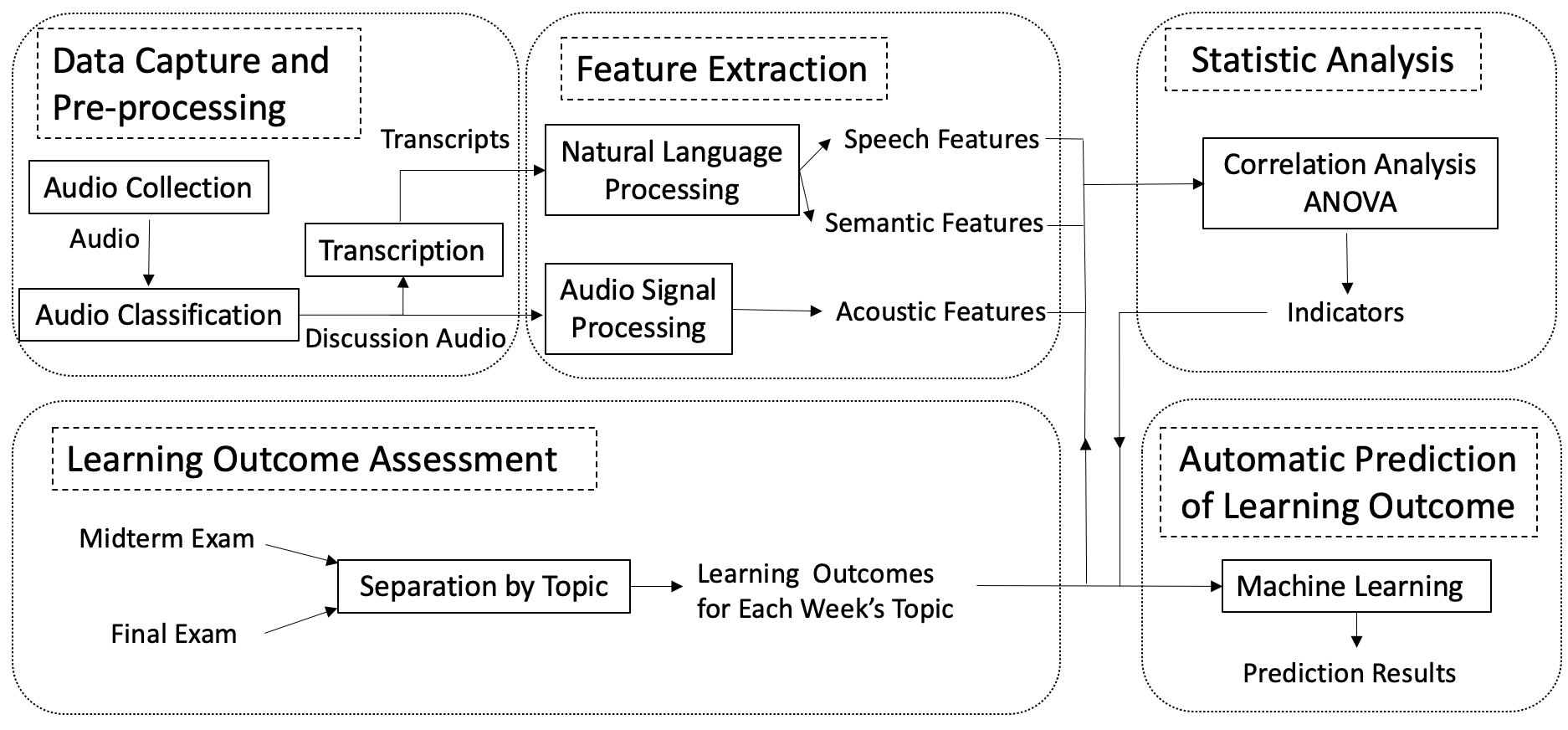
Fig. 1 shows the framework of this study. We have recently transformed a freshman engineering mathematics course from the conventional instructional strategy to the flipped classroom strategy. Students watched video-recorded lectures at home prior to group-based problem-solving discussion in class. Multiple audio data streams from multiple groups are collected non-intrusively throughout the semester, and a customized speech classification technology is applied to obtain student group discussion dialog audios. The dialog audios are then manually transcribed. Then, spoken dialog features are extracted by using some proper speech and language processing tools and techniques from bilingual transcription text data and audio data. Learning outcome is measured in terms of examinations. Several essential indicators from discussion dialogs that reflect the group learning outcome are found by statistical analysis. Then, indicators obtained from statistical analysis are used as input to a variety of machine learning algorithms in order to predict the group learning outcome as High, Mid or Low. Results indicate that it is feasible to use the indicators we found to automatically predict group learning outcome from face-to-face discussion dialog in flipped classroom.
To the best of our knowledge, this is a novel work in investigating learning analytics from spoken discussion dialogs in the flipped classroom. Contributions of the study include:
-
•
A new Chinese and English code-switched flipped classroom discussion audio corpus were non-intrusively recorded and transcribed.
-
•
Proper tools and customized techniques were introduced to obtain the spoken dialog features from multi-modal and code-switch discussion data, which not only could be generalized to other discussion dialogs, but also demonstrated the feasibility of dealing such data for learning analytics.
-
•
Indicators of group learning outcome were found out from flipped classroom in-class discussion dialog.
-
•
The feasibility of predicting group learning outcome from discussion dialog in flipped classroom was demonstrated.
The remaining sections of the paper are organized as follows: The related work of this research is introduced in Section 2. The capture and pre-processing of flipped classroom discussion dialog corpus is illustrated in Section 3. The spoken dialog features extraction from the audio and text data is described in Section 4. The group learning outcome assessment, as well as exploration of indicators that reflect the group learning outcome from in-class spoken dialogs of flipped classes are described in Section 5. The automatic prediction of group learning outcome based on flipped classroom in-class discussion dialog features is described in Section 6. The conclusion is stated in Section 7.
II Related Work
II-A Quantitative Research of Flipped Classroom
With the popularity of flipped classrooms in practical teaching and learning, much research in the field of education has been devoted to this topic in recent years.
Much previous work aimed to investigate whether the flipped classroom enhances student learning and motivation, often through comparisons with traditional teaching approaches. [Hew and Lo 2018] claimed that the flipped classroom approach in health professions education yields a significant improvement in student learning compared with traditional teaching methods [8]. By measuring students’ performance on the final examination and students’ self-reported satisfaction, [Joseph et al. 2021] found that flipped classroom improves nursing students’ performance and satisfaction in anatomy and physiology compared to a traditional classroom [9]. [Zhao et al. 2021] used questionnaires to demonstrate that students in the flipped class have a better learning performance than students in a traditional classroom [10]. By conducting a self-efficacy survey, [Namaziandost and Çakmak 2020] found that students in a flipped classroom have higher self-efficacy score compared to traditional classroom [11].
The strategy and design of the flipped classroom approach are important for its effectiveness [12, 13]. [Chen and Yen 2021] investigated how to make a better pre-class instruction when using animated demonstrations, in order to enhance student engagement and understanding in the flipped classroom [14]. By using self-efficacy questionnaire and interview questions, [Hsia and Sung 2020] found that the flipped classroom with peer review could significantly enhance students’ intrinsic motivation and strengthen their focus and reflection during activities [15]. [Song and Kapur 2017] compared the “productive failure-based flipped classroom”(PFFC) pedagogical design with traditional flipped classroom pedagogical design and they found that students in PFFC achieved higher scores in solving conceptual questions [16]. [Lin et al. 2021] proposed the “Scaffolding, Questioning, Interflow, Reflection and Comparison” mobile flipped learning approach (SQIRC-based mobile flipped learning approach) and found that the proposed approach improved the students’ learning performance, self-efficacy and learning motivation compared to traditional flipped classroom [17].
Previous work have also studied the impact of different indicators on learning performance in flipped classrooms. The indicators of students’ learning performance are investigated based on students’ learning strategies measured from students’ behaviors in pre-class activities such as online course and online assessment [18, 19]. [Wang 2021] explored indicators of learning outcome in the flipped classroom by analyzing learning management systems log data and questionnaires [20]. [Murillo-Zamorano et al. 2019] used questionnaires to investigate the causal relationships of knowledge, skills, and engagement with students’ satisfaction [21]. [Zheng and Zhang 2020] did analyses on students’ response of survey and found that students’ behaviors such as peer learning and help seeking were positively associated with students’ learning outcomes [22]. [Lin and Hwang 2018] studied how the students’ online feedback on video learning materials and video recordings of classmates’ work was relevant to their performance [23]. Quantitative measures such as learning hours and attendance have also been studied to identify their relevance to learning performance [24].
Although many quantitative researches on flipped classrooms have been conducted, few research paid attention to the in-class discussion dialogs. Spoken discussion dialogs commonly occur in flipped classrooms, which embed rich information related to learning that cannot be provided objectively by conventional data. Therefore, the spoken discussion dialogs in flipped classrooms should not be ignored in learning analytics.
II-B Research on Student’s Discussion Analyses
Due to increasing availability of sensors as well as computational resources and algorithms, some studies on analysis of face-to-face discussion were performed. [Kubasova et al. 2019] used verbal and nonverbal features of group discussions for predicting group performance in a cooperative game [25]. [Avci and Oya 2016] used aural and visual cues with their novel classifier to predict the group performance in decision-making tasks [26]. [Murray and Oertel 2018] predicted group performance in task-based interactions by utilizing speech and linguistic features [27]. However, these studies were conducted in the context of gaming or decision-making rather than in an educational context. [Ochoa et al. 2013] used a data set of video, audio and pen strokes to extract features that can discriminate between experts and non-experts in math problem discussions [28]. [Scherer et al. 2012] investigated predictors from audio and writing modalities for the separation and identification of socially dominant leaders and experts within a study group [29]. [Martinez-Maldonado et al. 2013] determined the level of cooperation at an enriched interactive tabletop from verbal and physical information [30]. [Reilly and Schneider 2019] conducted an educational experiment which showed that Coh-metrix could extract learning gain indicators, and they also predicted the quality of collaboration in discussions [31]. [Spikol et al. 2017] estimated the success of small collaborative learning groups in an experimental setting that extracted features from vision, user generated content and learning objects [32]. To the best of our knowledge, there is no prior work that investigates how the learning dynamics captured from student group discussion dialogs correlates with the learning outcomes in the flipped classroom.
III Discussion Dialog Data Capture and Pre-processing
III-A Flipping a Freshman Engineering Mathematics Course
This research is conducted in an engineering mathematics flipped classroom [33], which has recently been transformed from the conventional instructional setup. In this course, students watch lecture videos before class and solve in-class exercise problems in groups, aided by the professor and teaching assistants during the class time. The quality of group discussions in such flipped classroom is highly related to student group grade since problem solving discussions take up most of the class time. The remaining, minor portion of class time is for announcements and sharing of good solutions to given problems.
III-B Audio Capture of In-Class Discussion Dialogs
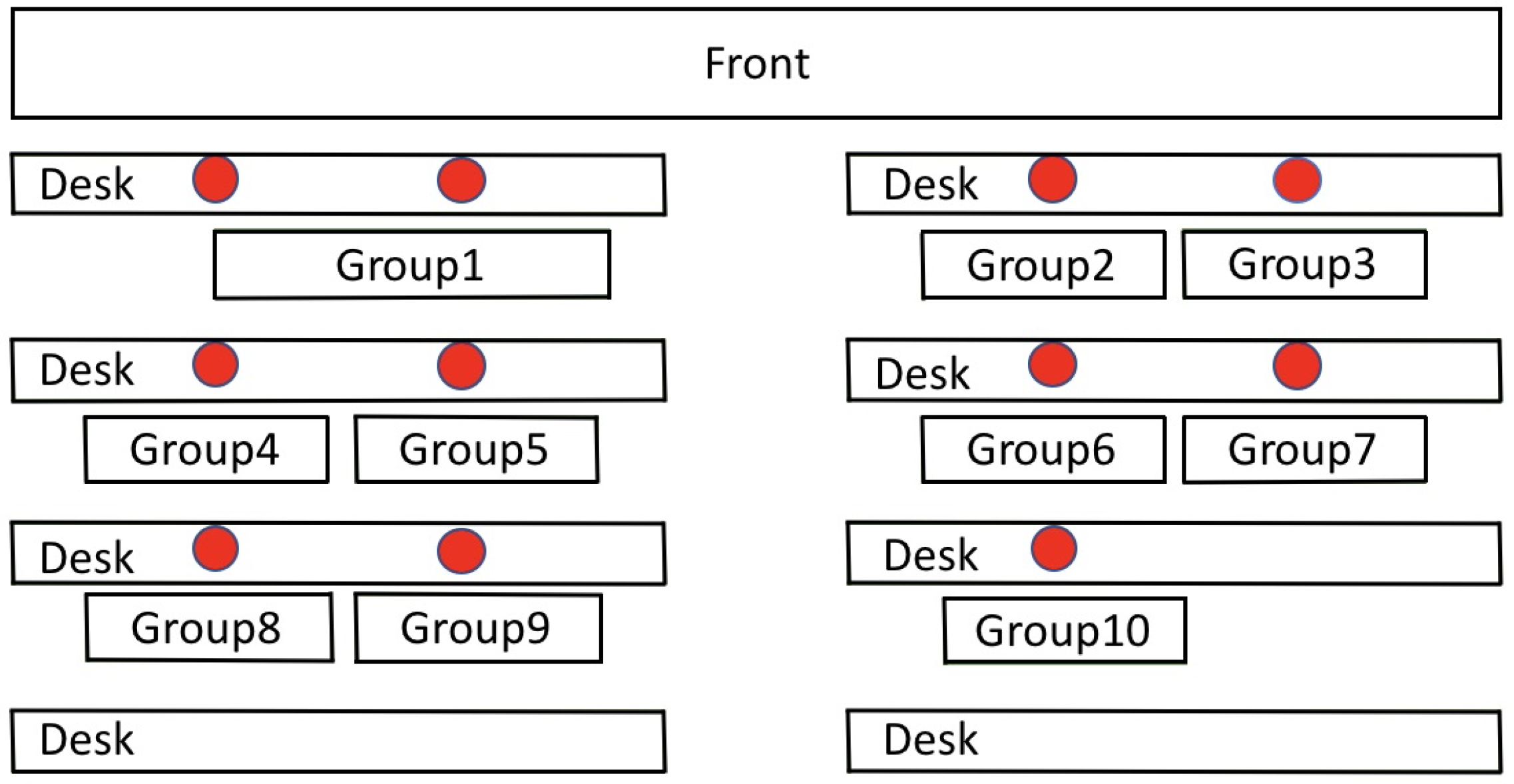
Students enrolled in the class form their own groups of 3-4 members for the semester. Students in the same group sat together in the classroom, which was a laboratory with computers. Fig. 2 shows the setup, where the red dots showed the placement of a speech recorder. We had selected the TASCAM DR-05 recorder because of its relative small size, and hence they could be placed in a non-intrusive position for each student group. Adjacent recorders were placed at least 1.5 meters apart and were positioned to point towards the members in the same student group for sound capture. The sampling rate was set at 44.1 kHZ. We obtained consent from the students through a consent form in order to record their speech during in-class discussions. We also offered the option that students were free to press the button to stop recording at any time during class, but no student did that throughout the whole semester. After the semester’s add-drop deadline for courses, we recorded discussions from the ten groups in class until the end of the semester.

III-C Pre-processing of Audio Recordings
Each recording contains discussion speech as well as broadcasted information such as general class announcements and solutions to problems. Since we are more interested in the portions of the audio that only contain group discussions, an unsupervised classification of lecture and discussion is achieved by using a customized audio processing technique [34]. In designing the classification algorithm, we aim to fully leverage the simultaneous recordings from the devices placed around the classroom. Specifically, lectures have high similarity across various simultaneous recordings. Therefore, after recordings are coarsely synchronized to a common start time by using Fast Fourier Transform (FFT) convolution, we compute the normalized similarity between a given window and temporally proximate window segments in other recordings. Histogram plot automatically categorizes higher similarity windows as lecture and lower ones as discussion. With the proposed method, broadcasted information is eliminated in each of our audio, and only discussion speech is further analyzed in this work.
III-D Discussion Dialog Transcription
Presently, we do not have a sufficiently accurate, Chinese-English code-switched automatic speech recognition system that can transcribe the discussion audio recordings. Instead, we use manual transcriptions, aiming for a diarization task of “who spoke what at when”. Fig. 3 shows an example of the transcription. Speech time information, speaker information and discussion content are recorded.
Discussion dialogs are segmented based on two criteria: 1) Speaker changes from one person to another. 2) The occurrence of a long pause of duration greater than a second. The start and end times of each segment are recorded. Transcribed speakers are classified as the professor, teaching assistants, in-group students and out-of-group students. The transcription focuses mainly on the speech of the in-group students as well as the professor, teaching assistants and out-of-group students who talk to in-group students. All other sounds are ignored. Each speaker is identified by a generic speaker label to protect privacy, such as Student Male 1(SM1), Student Female 1(SF1), Teaching assistant Male 1(TM1), Professor(P), Out-group Male 1(OM1), etc. Except for out-of-group speakers, the voice recordings of the in-group speakers are given to the transcriber so that they can label them with the most similar identifier. If a voice does not match any of the in-group speakers, it will be labeled as out-of-group. Overlapping speech from multiple speakers may occur, and the transcribers will try their best to offer separate transcriptions for the two speakers. Since this course is taught in English but students are mainly Chinese, the group discussions are often conducted in Chinese-English code-switch modes. The transcriptions will strictly follow the languages spoken. All of the transcriptions are double checked to ensure the quality of the transcription. All transcribers signed a confidentiality agreement to protect the confidentiality of the recordings.
IV Dialog Features Extraction
Multiple salient spoken dialog features should be extracted from the discussion dialog audio and text data for learning analytics. Speech features, semantic features and acoustic features are considered in this work. All of the features are initially extracted from each dialog segment, which is the basic unit of technical processing of dialog data. Then group-level features (e.g. sum/mean/variance of all segments) are created to represent the features of group discussion dialog (e.g. sum of math terms in discussion). Details of how to extract every feature from each dialog segment as well as the extraction of group-level features will be shown in this section.
IV-A Speech Features
In order to capture the activity and amount of information exchange in discussion, the following speech features are considered.
-
•
Speech Time (ST)
The original audio data is segmented and annotated with start and end timestamps. The duration between the start time and end time is calculated as the speech time of that segment.
-
•
Number of Words (NoW)
The number of words for each segment is a measure that differs in English and Chinese. English is counted in word-unit and Chinese is counted in character-unit. The punctuation is ignored.
-
•
Number of Turns (NoT)
As mentioned in Sect. III-D, the discussion dialog are segmented if speaker changes or a long pause of duration greater than one second occurs. The number of dialog turns is counted as number of dialog segments in transcription.
-
•
Speaking Rate Score (SRS)
Speaking rate for one segment is initially calculated as the number of words divided by the speech time. Then each segment is rated as Slow, Normal or Fast, which are subsequently scored as 0,1,2 respectively. The classification thresholds for Slow, Normal and Fast are based on statistical findings of Yuan et al. [35], which claimed that the normal speed of short spoken English is 100-120 words per minute and the normal speed of short spoken Chinese is 225-255 characters per minute. Thus the thresholds are calculated as an equation (1)(2)
(1) (2) where is the classification threshold between Slow and Normal, is the classification threshold between Normal and Fast, and are the proportion of English and Chinese used in one segment correspondingly.
IV-B Semantic Features
IV-B1 Topic Relevance of Discussion
In this work, some customized features are designed to measure the topic relevance of discussions by Natural Language Processing (NLP) techniques.
-
•
Math Terms (MT)
Since discussions are conducted in an engineering mathematics flipped classroom, detecting the mathematical terms in students’ discussion is conducive towards measuring topic relevance. In this work, a customized bilingual math glossary is derived from engineering mathematics textbooks in both Chinese and English. A count of matching math terms in each segment is calculated based on the glossaries.
-
•
Topic Relevance Score (TRS)
The use of word matching may not sufficiently reflect the topic relevance of students’ discussion, because there may be on-topic discussions that do not contain the exact terms in glossaries. Therefore, a scoring mechanism to measure the degree of topic relevance of each segment needs to be developed. We adopt word embeddings, a predominant word representation in NLP. A word can be represented as a vector, and words with similar meaning are closer in the vector space. In this study, we design a framework to score the topic relevance of each segment based on the word embedding technique. The score is between zero and one, higher score indicates higher topic relevance.
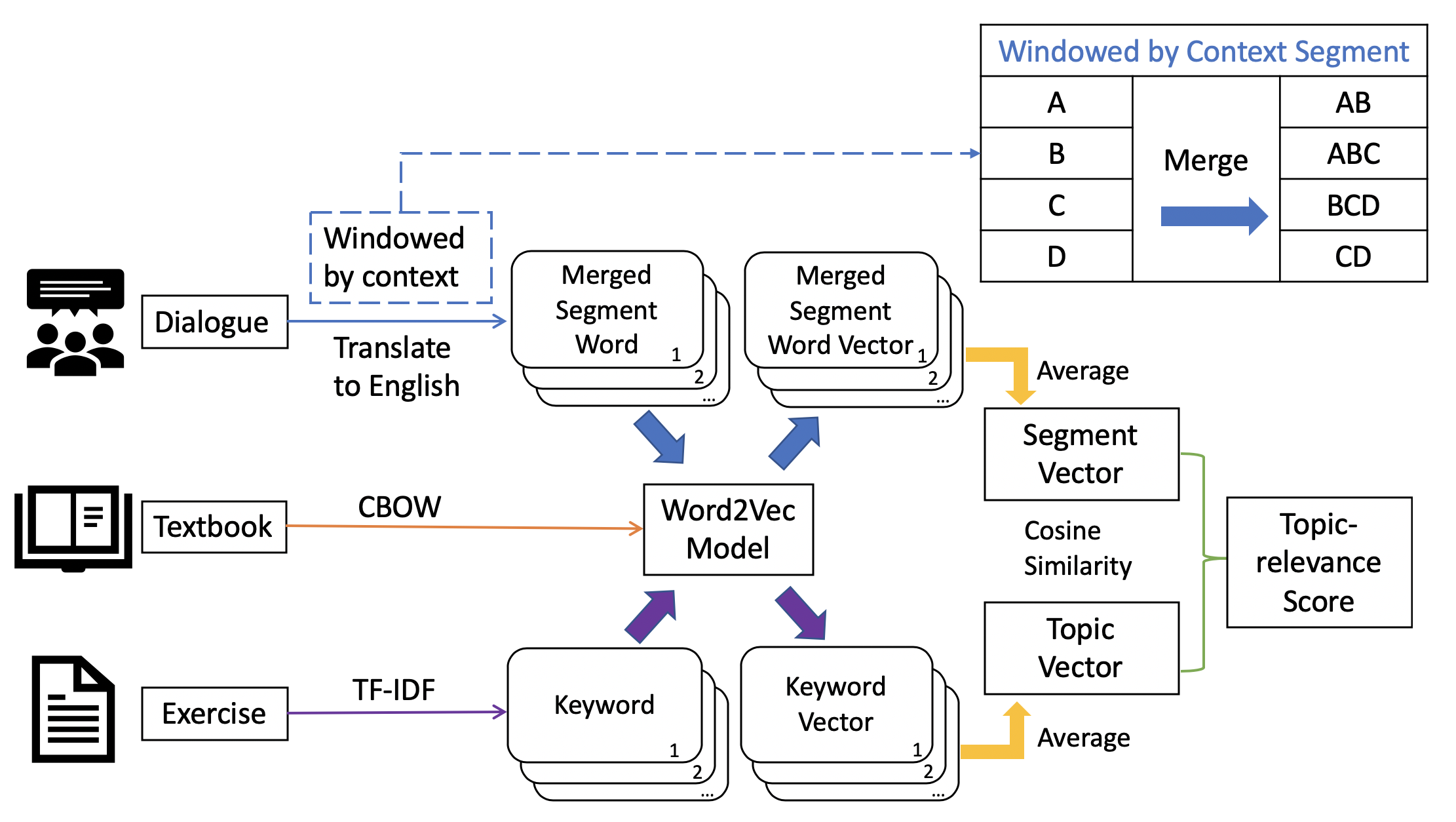
Figure 4: Framework of topic-relevance score measurement Fig. 4 provides an illustration of the framework. To represent the words in the field of mathematics, we trained a word embedding model based on the textbook [36] of this course. We used the Continuous Bag Of Words (CBOW) model architecture for word-embedding training, which is implemented by the Gensim Word2Vec tool [37]. Since students mainly discuss the in-class exercises which are assigned with different topics every week, keywords from the in-class exercises can represent the class topic for each week. Therefore, keywords from in-class exercises of each week are extracted using the TF-IDF algorithm [38]. Common NLP practice takes the average word embedding vectors to represent the general meaning of combined words [39, 40, 41]. Therefore, word vectors of keywords from each week’s in-class exercises are averaged to get a topic vector that represents the class topic of that week. In order to measure the topic relevance of each discussion segment, each segment should be represented by a vector which is the average word vector in that segment. Notably, instead of directly using each isolated segment, we consider the dialog context of neighbouring segments. The dialog context of a discussion segment further defines the meaning of that segment. Consider a simple scenario: student A said ’Yes it is’ in a math-related discussion and student B said ’Yes it is’ in a game-related discussion. Although the words are identical, the topic relevance scores should be different due to the different contexts. Therefore, a context window is used to pre-process the segments. As shown in Figure 4, each segment is merged with one segment before and one segment after, so that the words in a merged segment can better represent the meaning of the original segment. The course textbook and exercises are written in English, while discussions are usually conducted in Chinese. To standardize the use of language, segments are translated into English by the Google Translator API [42]. Then, the vectors of merged segment words are averaged to get the segment vector which represents the meaning of that segment. Finally a cosine similarity between the topic vector and segment vector is calculated, and each segment finally has a topic relevance score.
IV-B2 Context Cohesion of a Discussion
Context cohesion is an important feature for discussion dialogs, which was also used in previous work on discussion analysis [25]. This study computes the cohesion score to reflect context cohesion:
-
•
Cohesion Score (CS)
Cohesion score is calculated as a cosine similarity between current and subsequent segments in a discussion. The vector representation of each segment is the same as the vector representation used for topic relevance score.
IV-B3 Social Aspects of the Dialog
Social aspects of dialog, such as sentiment and cognitive processing, are also important features of discussion dialog. In this work, Linguistic Inquiry and Word Counting (LIWC) is applied to measure the social aspects of dialogs.
| Category | Explanation |
|---|---|
| Positive Emotion (PE) | An emotional reaction designed to express a positive affect |
| Negative Emotion (NE) | An unpleasant emotional reaction designed to express a negative affect |
| Anger | A strong feeling of annoyance, displeasure, or hostility |
| Anxiety | Feeling of worry, nervousness, or unease about something |
| Risk | The possibility that something unpleasant or unwelcoming will happen |
| Assent | The expression of approval or agreement |
| Negation | The contradiction or denial of something |
| Affect | Words depicting emotions |
| Tentative (Tent) | Words that indicate intention to try something |
| Certainty (Cert) | Having or showing complete conviction about something |
| Insight | An accurate and deep understanding of something |
| Causation (Caus) | The relationship between cause and effect |
| Conjunction (Conj) | A word used to connect clauses or sentences or to coordinate words in the same clause |
| Filler | A linguistic but meaningless unit that fills a particular slot in syntactic structure |
| Interrogative (Int) | Words used to purpose questions, e.g, who, what, where, how |
| Differentiation (Diff) | The action or process of distinguishing between two or more things |
| Comparison (Comp) | A consideration or estimate of the similarities or dissimilarities between two things |
| Quantity Unit (QU) | Measure word, usually occurs together with math-related words, more frequently used in Chinese |
| Leisure | Use of free time for enjoyment |
-
•
LIWC Features (LIWC)
LIWC is a dictionary-based text analysis application, which provides an efficient and effective method for studying various emotional, cognitive, and structural components present in individuals’ verbal and written speech samples [43, 44]. The original LIWC provides hundreds of categories of vocabulary, but not all of the categories fit the current investigation. Therefore, we manually select the suitable categories in LIWC, which is shown in Table I. Positive Emotion (PE), Negative Emotion (NE), Anger, Anxiety, Risk, Assent, Negation and Affect are used to measure the sentiments of the dialog. Tentative (Tent), Certainty (Cert), Insight, Causation (Caus), Conjunction (Conj), Filler, Interrogative (Int), Differentiation (Diff) and Comparison (Comp) are used to indicate cognitive processing. Moreover, Quantity Unit (QU) and Leisure can be used as supplements to measure the degree of topic relevance of dialog. Furthermore, LIWC provides both Chinese and English dictionaries for analysis. In order to deal with the bilingual dataset, we process the English words and Chinese characters separately by using both English and Chinese version of LIWC dictionary. The number of matched words for each LIWC category is counted in each segment based on the bilingual LIWC dictionaries.
IV-C Acoustic Features
The audio signal also contains a variety of information related to the dialog, such as emotions during discussions. Therefore, we extract certain features directly from the audio data. All of the audio features are first calculated for every frame (0.01 second in duration). Then the mean, maximal and minimal values within a segment are calculated as feature values of each segment. Gender broadly affects the values of audio features, especially related to F0. Presently we are not investigating the gender of the speakers, hence, all the audio features are gender-normalized. The following features are considered in this work:
-
•
Fundamental Frequency (F0)
The fundamental frequency (F0) of a speech signal refers to the approximate frequency of the (quasi-)periodic structure of voiced speech signals. F0 can be used to measure the level of arousal in discussions and it was used to disambiguate discussion roles between a leader and an expert in the work of Scherer et al [29]. In this work, F0 detection is performed by COVAREP [45].
-
•
Energy
-
•
Formants
In speech signal processing community, first formant (F1), second formant (F2) and third formant (F3) are the first, second and third acoustic harmonics of the fundamental frequency, respectively. Formants are important for emotion detection in Mandarin [46], and they were also used in the work of Worsley and Blikstein [47]. In our work, the value of F1, F2 and F3 are calculated based on the Praat software [48].
-
•
Glottal Features
Glottal features describe the movements of vocalizing muscles. Glottal features have been shown to have a relationship with emotions and demeanor [49, 50, 51, 52], and they have been used in the field of learning analytics [29]. In this work, creak [53], rd [54, 55], Peak Slope (PS) [56], the difference between the first and second harmonics (H1-H2), Quasi Open Quotient (QOQ) [57], Maxima Dispersion Quotient (MDQ) [58] and Normalized Amplitude Quotient (NAQ) [51] are extracted by using COVAREP [45].
Audio feature abbreviations are defined and used as follows: {Max, Min, Avg}_{F0, Energy, NAQ, etc.}. For instance, Max_F0 represents that the feature value of one segment is obtained by taking the maximum value of F0 within that segment.
IV-D Derivation of Group-level Features
The features mentioned in Sections IV-A, IV-B and IV-C are created for each dialog segment. In order to derive some characteristics in group discussion dialog, all features need to be transformed to group-level. In this work, 7 types of group-level features in 2 aspects are considered.
The segments spoken by an in-group student can be aggregated together to be the feature of this student. Characteristics of a group discussion can be measured by the mean/variance of all in-group students’ characteristics. Therefore, we first take the sum/mean of feature value across the segments for each in-group student, and then the mean/variance among all in-group students. For example, we first calculate the sum/mean number of math terms per segment for each in-group student, and then take the mean/variance across the students within the group. This provides us with 4 types of group-level features as shown below (take math term as example):
-
•
Mean of the total number of math terms spoken by each in-group student
-
•
Variance in the total number of math terms spoken by each in-group student
-
•
Mean of the average number of math terms spoken by each in-group student
-
•
Variance in the average number of math terms spoken by each in-group student
In addition, we also look at the entire discussion dialog of a group for the topic of a given week, which contains dialog segments including those from the professor and teaching assistants to give guidance, as well as from students in a neighboring group who join in temporarily. We can compute the sum/mean/variance for features across all segments in the entire discussion. This provides us with 3 types of group-level features as presented below (take math term as example):
-
•
Sum of the number of math terms in an entire discussion dialog
-
•
Mean of the number of math terms in an entire discussion dialog
-
•
Variance in the number of math terms in an entire discussion dialog
V Statistic Analyses between Dialog Features and Group Learning Outcome
V-A Group Learning Outcome Assessment
We chose to use the midterm and final examination scores as measurement of group learning outcomes. The curriculum was carefully designed in such that each week contains a set of unique topics, and exact questions from the midterm and final examinations can be identified for each topic. For example, topics in Week 9 are covered by questions 10 and 15 in the final examination. Such a mapping enables us to extract the grades of the members of a group on particular questions, in order to assess the group’s learning outcome for the topic of a given week. Considering that the grades of the midterm and final examinations respectively accounts for 20% and 30% of the final grade for each student, we decided to use proportional weighting to compute the learning outcome for a given student group on the topic of a specific week, as shown in Equation (4).
| (4) |
where represents the grades earned by the group members from the midterm exam questions for the topic of a specific week, represents the grades earned by the group members from the final exam questions for the topic of a specific week, the full marks of is represented by , and full marks of is represented by .
Since we are able to identify the group learning outcome for the topics covered in each week, we are also able to use the scores of the group to rank their relative learning outcome in each week. Since there are 10 groups in total, we can also give them a ranking score as 10(top) to 1(bottom). The ranking score comes in handy for comparison especially when the groups have very close scores for specific topics in a week.
V-B Statistical Analyses
In order to explore the indicators of group learning outcomes from group discussions, correlation analysis and ANalysis Of VAriance (ANOVA) are performed between group-level features and group learning outcomes.
V-B1 Correlation Analysis
-
•
Data
As mentioned above, we are able to derive the group learning outcome (through exam scores and ranking scores) for topics that are covered for each week. We have a total of 9 weeks of discussion data (after the add/drop period until the end of the semester) for 10 groups of students. Thus we have transcriptions for 90 group discussions, which form the basis of the correlation analysis.
-
•
Independent Variables
The group-level discussion features are treated as independent variables. We note that there is variability across the weekly topics. For example, a more fundamental topic may not have too many new math terms, as compared with a more advanced topic, and consequently there would be markedly more math terms spoken for advanced topics. In order to normalize for similar effects, we applied min-max normalization among all groups in each week to scale all group-level features from -1 to 1. After normalization, each group-level feature in one week maintains the same relative magnitudes across groups, and each of the group-level feature across different weeks has the same feature scale. This step facilitates comparison across different groups and across different weeks.
-
•
Dependent Variables
As mentioned in the previous section, we are able to extract the scores of relevant questions in the midterm and final exams and map them to the corresponding topics covered, as well as the week they were covered. We also used ranking scores as a presentation. These scores that measure group learning outcome are adopted as dependent variables.
V-B2 ANalysis Of VAriance (ANOVA)
-
•
Data
ANOVA is performed to explore indicators that could significantly distinguish between groups with high versus low performance on learning outcomes. The top three groups of each week are labeled as High Learning Outcome, whereas the bottom three groups of each week are labeled as Low Learning Outcome. As mentioned in Sect. V-B1, we have a total of 9 weeks of discussion data. Therefore, each category contains 27 group discussions, which makes up the 54 analyzed discussion data in total.
-
•
Independent Variables
The independent variables in ANOVA are two categories – High Learning Outcome and Low Learning Outcome, which is defined above.
-
•
Dependent Variables
All of the group-level features are adopted as dependent variables in ANOVA, which takes the same normalization as the correlation analysis. ANOVA is conducted on every group-level feature in order to examine whether it contributes significantly towards a High Learning Outcome versus Low Learning Outcome
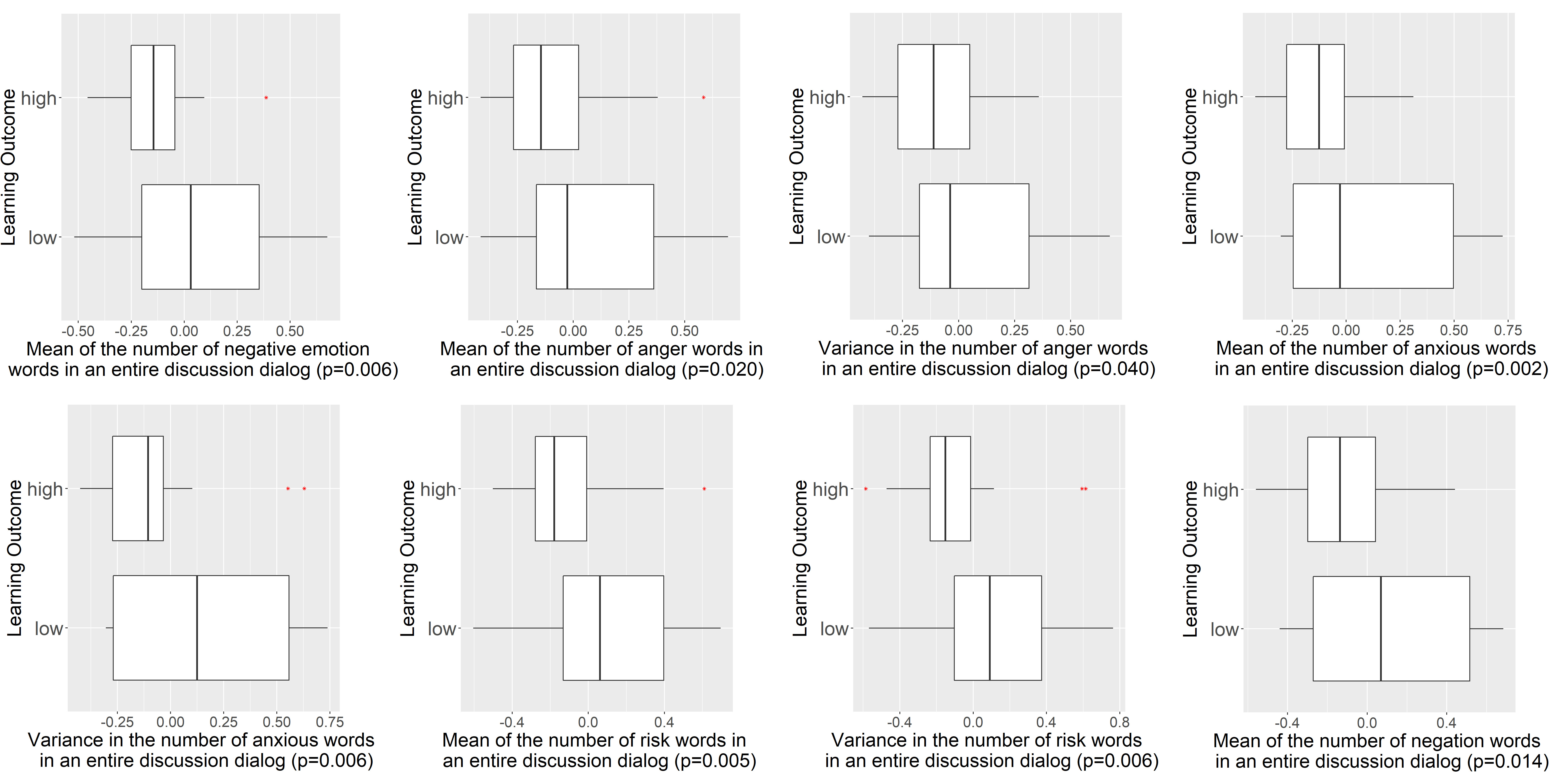
V-C Results and Discussion
In this section, we will highlight the key results from statistical analyses. Results from correlation analysis will be presented by scatter plot, where the y-axis is the measurement of learning outcome and the x-axis is the normalized group-level features. Pearson correlation coefficient (r-value) and p-value are also provided below each sub-figure. ANOVA results will be presented by box plots, where the y-axis is group learning outcome and the x-axis is the normalized group-level features. The p-value is also provided below each sub-figure. In this work, we conducted statistical analysis at the significance level .
V-C1 Topic Relevance
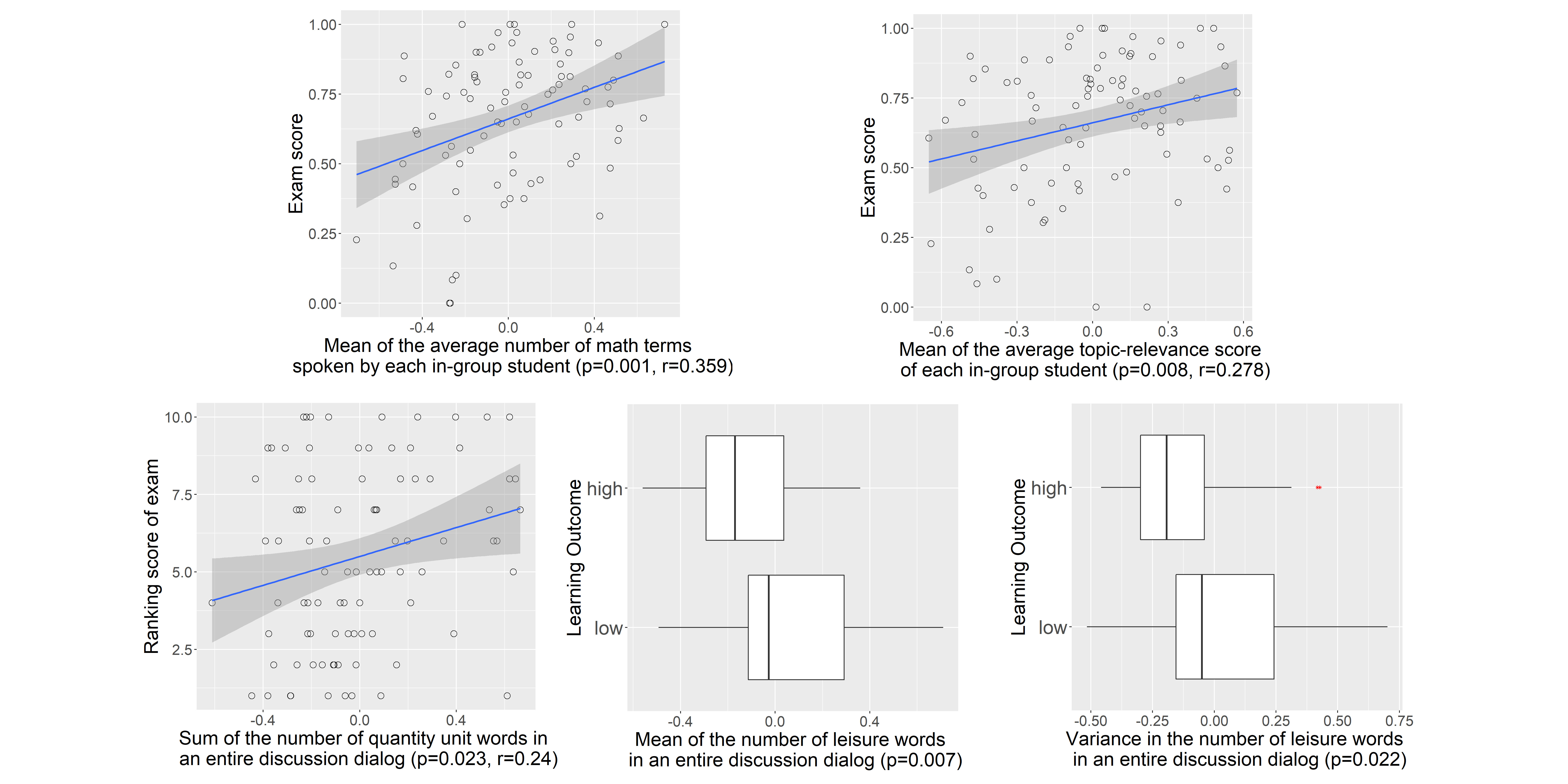
First, we find that topic relevance of group discussions are important indicators that reflect group learning outcome. Fig. 5 shows some results of statistical analysis between group learning outcome and features that represent topic relevance of discussions. For the features with more than one statistical significant group-level features that reflect similar analysis results, we select to show the analysis result with the lowest p-value. As mentioned in Sect. IV-B1, the number of math terms and topic relevance score can represent the relevance between the discussion dialogs and topic. Besides, as mentioned in Sect. IV-B3, “quantity unit” category in LIWC dictionaries can detect the measure words that usually occur together with math-related words. Therefore, the number of quantity unit words could indicate topic relevance of group discussions. As shown in Fig. 5, the mean of average number of math terms spoken by each in-group student, the mean of average topic relevance score of each in-group student, and the sum of the number of quantity unit words in an entire discussion dialog are positively correlated with the group learning outcome. Moreover, the “leisure” category in LIWC dictionaries could detect the leisure words that indicate students are relaxing for enjoyment rather than discussing the math-related topic. We observe from the ANOVA result that low learning outcome groups tend to have higher mean number of leisure words spoken in an entire discussion dialog, which suggests students in low learning outcome groups tend to have more relaxing off-topic discussion rather than on-topic discussion. We also find that high learning outcome groups tend to have lower variance in the number of leisure words in an entire discussion dialog, which suggests that high learning outcome groups tend to speak fewer leisure words. The topic relevance of in-class discussions should reflect the students’ concentration in class. Higher concentration generally have higher learning outcomes, which is reflected in the results.
V-C2 Sentiment
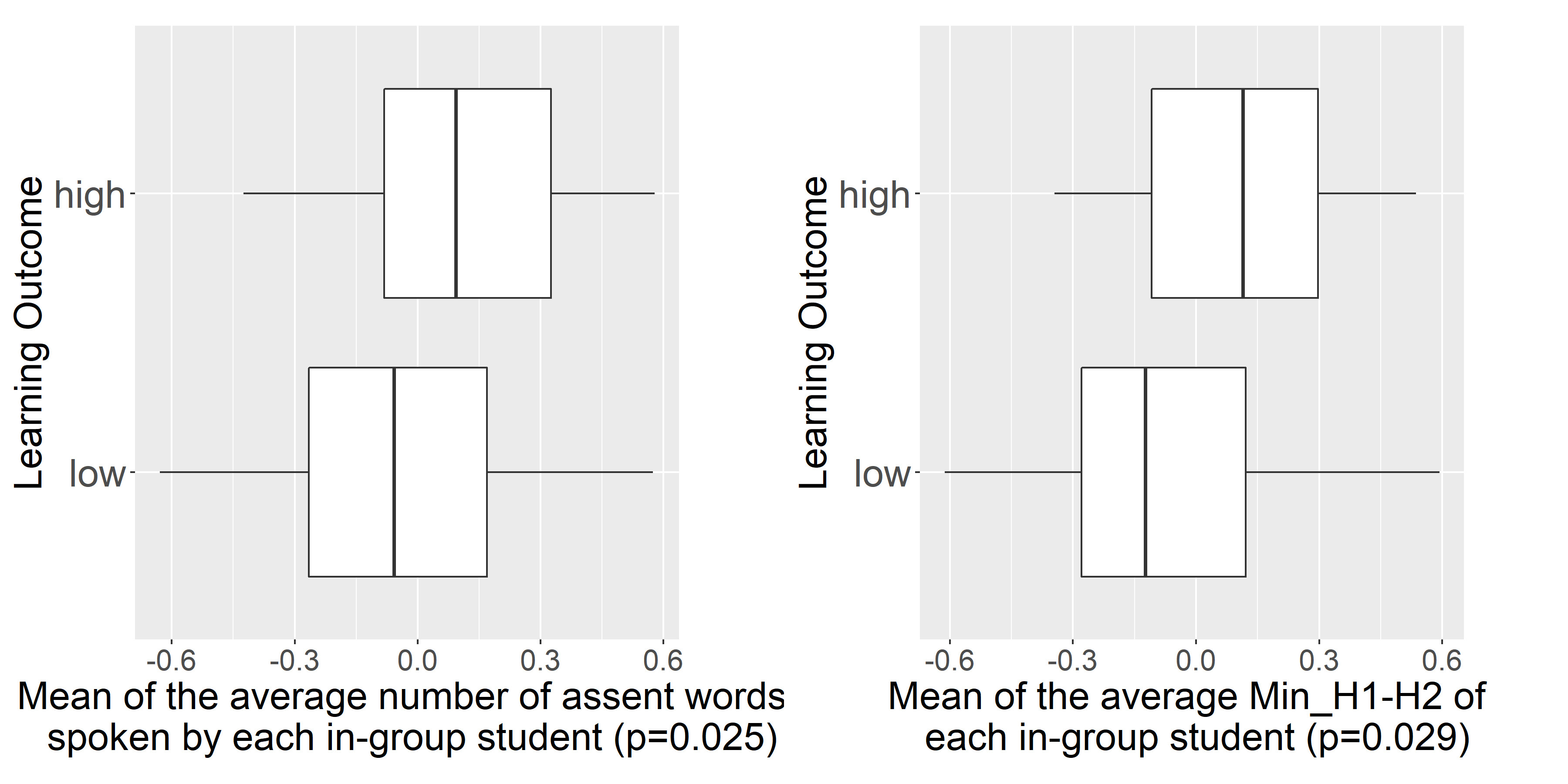
Sentiment is also an essential indicator that reflects group learning outcome. Fig. 6 and Fig. 7 show some results of statistical analysis between group learning outcome and features that indicate sentiment. For the features with more than one statistical significant group-level features that reflect similar analysis results, we select to show the analysis result with the lowest p-value. The “negative emotion”, “anger”, “anxiety”, “risk” and “negation” categories in LIWC dictionaries (mentioned in Sect. IV-B3) could indicate the negative sentiment. The “anger” and “anxiety” category in LIWC dictionaries detect words that reflect angry and anxious emotion, which are both negative sentiment. The “risk” category in LIWC dictionaries could detect the words that indicate something unpleasant or unwelcoming is likely to happen, which usually suggests a negative sentiment. The “negation” category in LIWC dictionaries could detect the contradiction or denial words, which usually contain negative sentiment. The ANOVA results show that the mean number of negative emotion/anger/anxiety/risk/negation words spoken in an entire discussion dialog are significantly greater in low learning outcome groups than in high learning outcome groups. Besides, we also find that the variance of number of anger/anxiety/risk words in an entire discussion dialog are all significantly lower in high learning outcome groups, which indicates that high learning outcome groups tend to insist on speaking a low number of negative sentiment words. In addition, the “assent” category in LIWC dictionaries detects the words that indicate the expression of approval or agreement, which implies positive sentiment. High Min_H1-H2 (mentioned in Sect. IV-C) indicates relief emotion, whereas low Min_H1-H2 indicates fear or panic emotions [52]. As shown in Fig. 7, the mean of average number of assent words spoken by each in-group student, and the mean of average Min_H1-H2 of each in-group student are significantly higher in high learning outcome groups than low learning outcome groups. Overall, groups with high learning outcome tend to have more positive sentiment, whereas low learning outcome groups tend to have more negative sentiment.
V-C3 Cognitive Processing
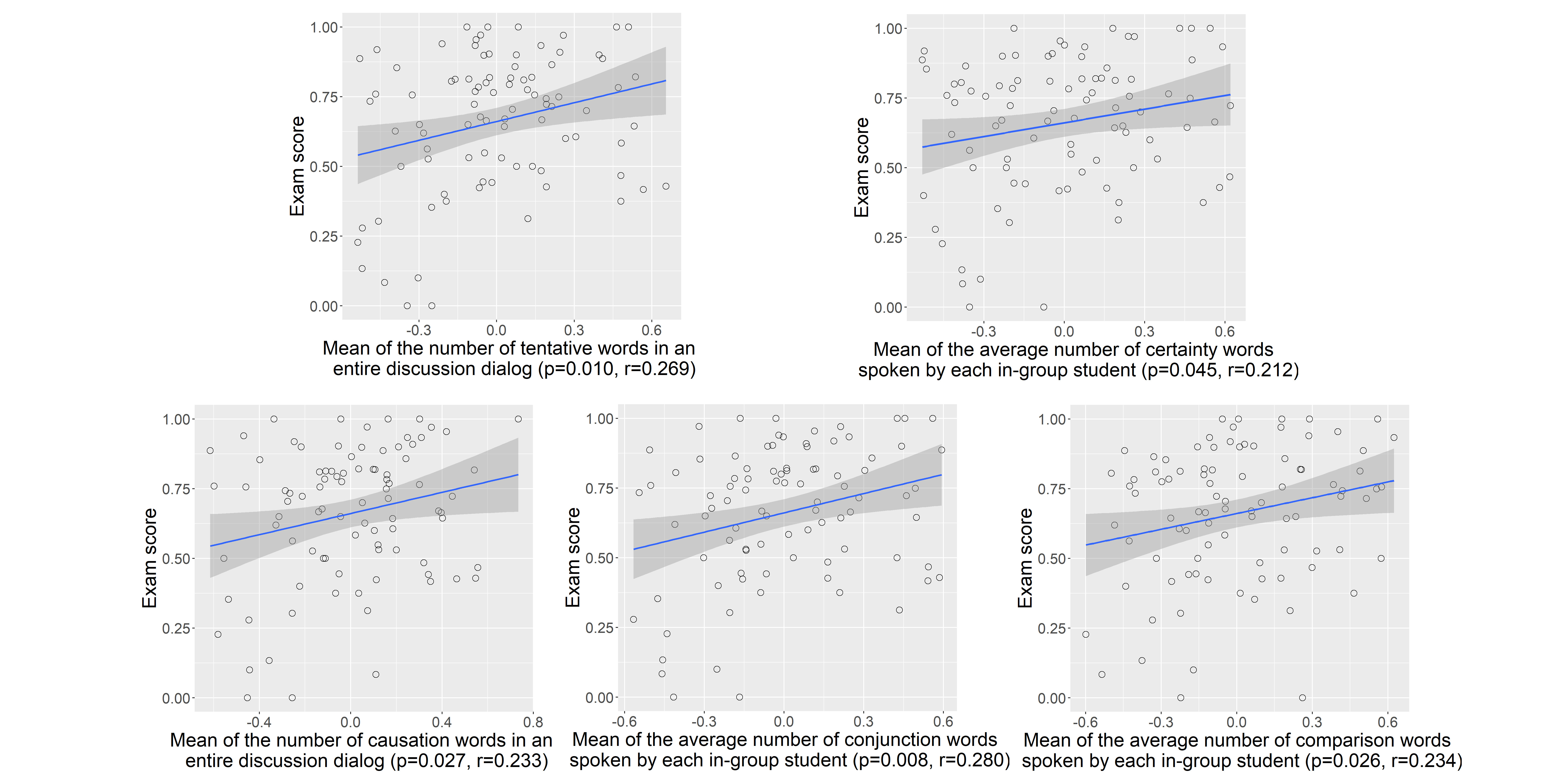
Fig. 8 shows some results of statistical analysis between group learning outcome and features that reflect cognitive processing. For the features with more than one statistical significant group-level features that reflect similar analysis results, we select to show the analysis result with the lowest p-value. As mentioned in Sect. IV-B3, “tentative”, “certainty”, “causation”, “conjunction” and “comparison” categories in LIWC dictionaries could measure the cognitive processing. The “tentative” category could detect the words that indicate intention to try something, which to some extent could reflect students’ curiosity in learning. We can observe from Fig. 8 that the mean of the number of tentative words in an entire discussion dialog shows significantly positive correlation with group learning outcome. The “certainty” category in LIWC dictionaries aims to detect the words that show conviction about something. Fig. 8 shows that the mean of the average number of certainty words spoken by each in-group student is positively correlated with group learning outcome, which indicates that higher learning outcome groups tend to have higher conviction in discussion. The “causation” category aims to detect the words that reflect the occurrence of relationship between cause and effect in discussions. The “conjunction” category aims to detect the words that reflect the occurrence of coordinative logic relation in discussions. The “comparison” category aims to detect the words that reflect the consideration of the similarities or dissimilarities between two things. These three categories in LIWC dictionaries can reflect the degree of logical thinking in discussions and more occurrences of these words indicate more logical thinking in discussions. Correlation analysis results show that the mean of the number of causation words in an entire discussion dialog, the mean of the average number of conjunction words spoken by each in-group student, the mean of the average number of comparison words spoken by each in-group student are all positively correlated with group learning outcome. The result supports that higher learning outcome groups tend to have more logical thinking in discussions.
V-C4 Information Exchange
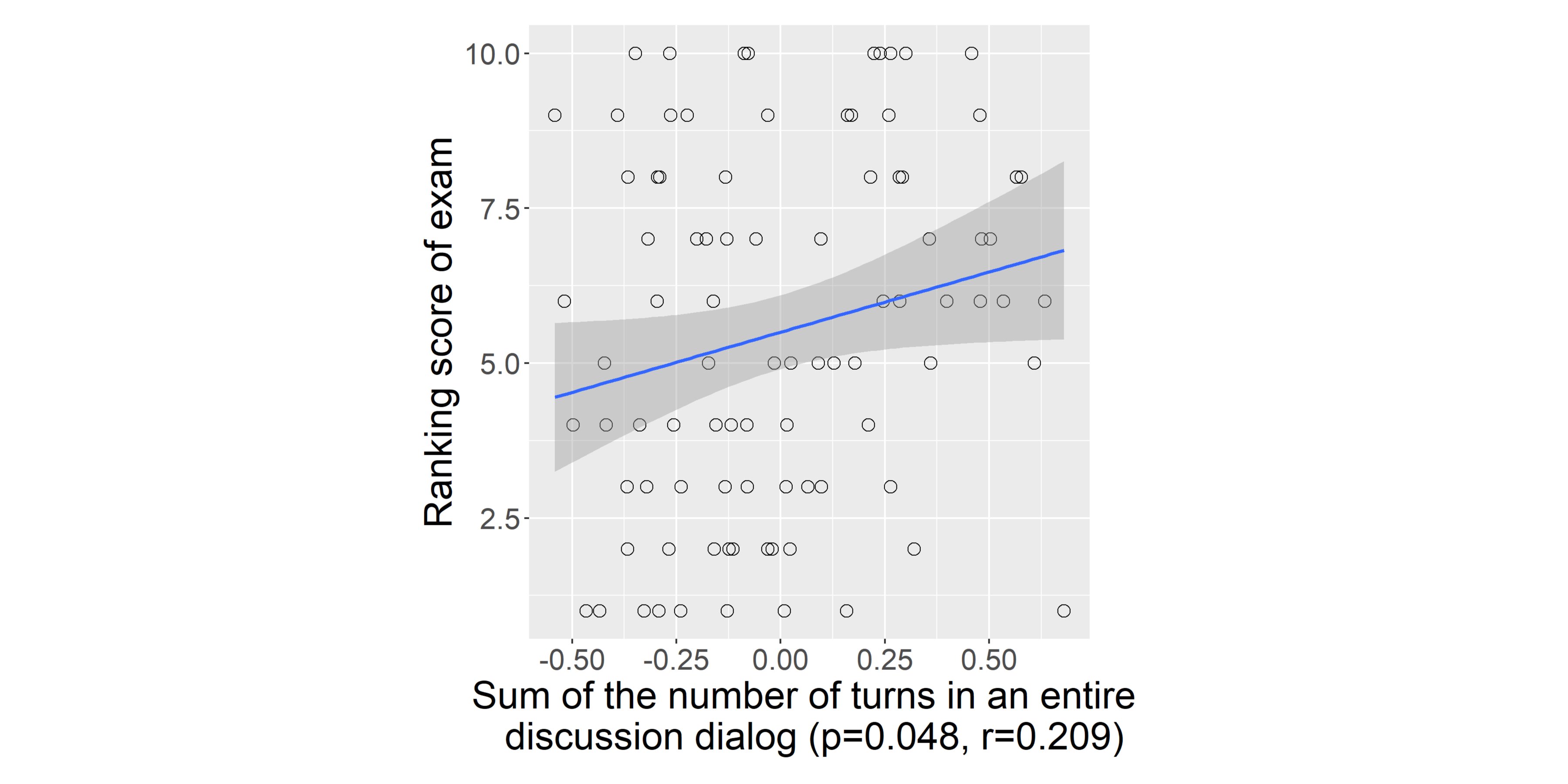
The number of dialog turns can reflect the degree of information exchange during discussions. Fig. 9 shows that the sum of the number of turns in a discussion dialog is positively correlated with the group learning outcome. This indicates that the degree of information exchange during discussions positively correlates with the group learning outcome.
V-C5 Context Relevance
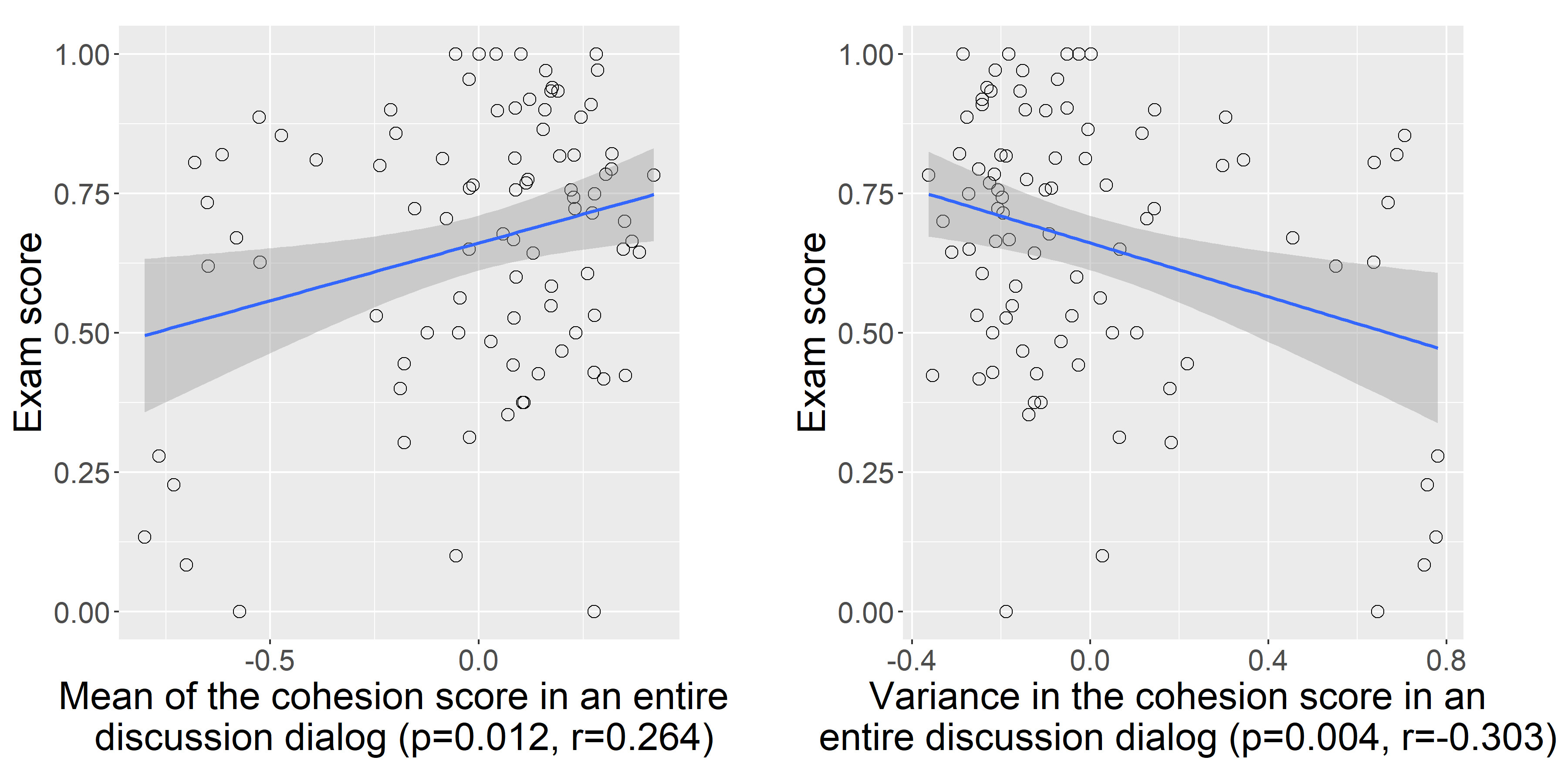
Fig. 10 shows some results of statistical analysis between group learning outcome and the feature that measures context relevance in discussions. For the statistical significant results with similar trends, we select to show the analysis result with the lowest p-value. As mentioned in Sect. IV-B2, the cohesion score is created to measure the context relevance of the discussion. Higher content similarity between two neighbouring segments leads to a higher cohesion score. Correlation analyses show that the mean of the cohesion score in an entire discussion dialog is positively correlated with the group learning outcome, which indicates that high context relevance discussions are associated with higher group learning outcome. Moreover, the variance of the cohesion score in an entire discussion dialog is negatively correlated with the group learning outcome, which indicates that stably high context relevance of discussions is positively correlated with group learning outcome.
VI Automatic Prediction of Group Learning Outcome from Discussion Dialog Features
Upon identifying the proper features from group discussions that reflect the group learning outcome, automatic prediction becomes possible. In this work, different machine learning algorithms are used to predict the group learning outcome based on statistically significant group-level features. First, we label the top three, middle four and bottom three groups based on learning outcomes of every week’s topics as High Learning Outcome, Mid Learning Outcome and Low Learning Outcome respectively. We have nine weeks of discussion data, thus our data consist of 27 High Learning Outcome discussions, 36 Mid Learning Outcome discussions and 27 Low Learning Outcome discussions (90 samples in all). It is understood that the experimental setup has limited data and the collection of group discussion data is challenging in both social and technical perspective. Although the experimental data is limited, we already have much more data than previous discussion analysis researches, where no more than 60 labelled group discussion data samples are collected [25, 26, 27, 28, 29, 30, 31, 32]. Then we select statistically significant group-level features based on statistical analyses. Sixty two features are selected. In order to further prevent overfitting, random projection [59] is applied to do the dimension reduction, which reduces the feature dimension from 62 to 45. Naive Bayes (NB), Neural Network (NN), K-Nearest Neighbours (KNN), Random Forest (RF), LightGBM (LGBM) [60], XGBoost (XGB) [61] and Support Vector Machine (SVM) are used to automatically classify the group learning outcome into High Learning Outcome, Mid Learning Outcome and Low Learning Outcome.
We perform five-fold cross-validation in prediction, which takes the prediction five times with five different subsets of test data and then take the average of prediction results. In each fold, data is divided into a training set and a test set with the ratio of 4:1. Then the training set is subdivided into a sub-training set and a validation set for five times, and collections of model hyper-parameters (e.g. value of regularization parameter and kernel coefficient in SVM) which are selected by Bayes optimization algorithm [62] are compared according to the average of five validation scores. We select the hyper-parameters with the best average validation score as the model hyper-parameters. Then the model is retrained on the whole training set using the selected hyper-parameters. Finally, the trained model is applied on the test set to get one out of five fold test score.
In each fold, the prediction accuracy is calculated according to the equation (5),
| (5) |
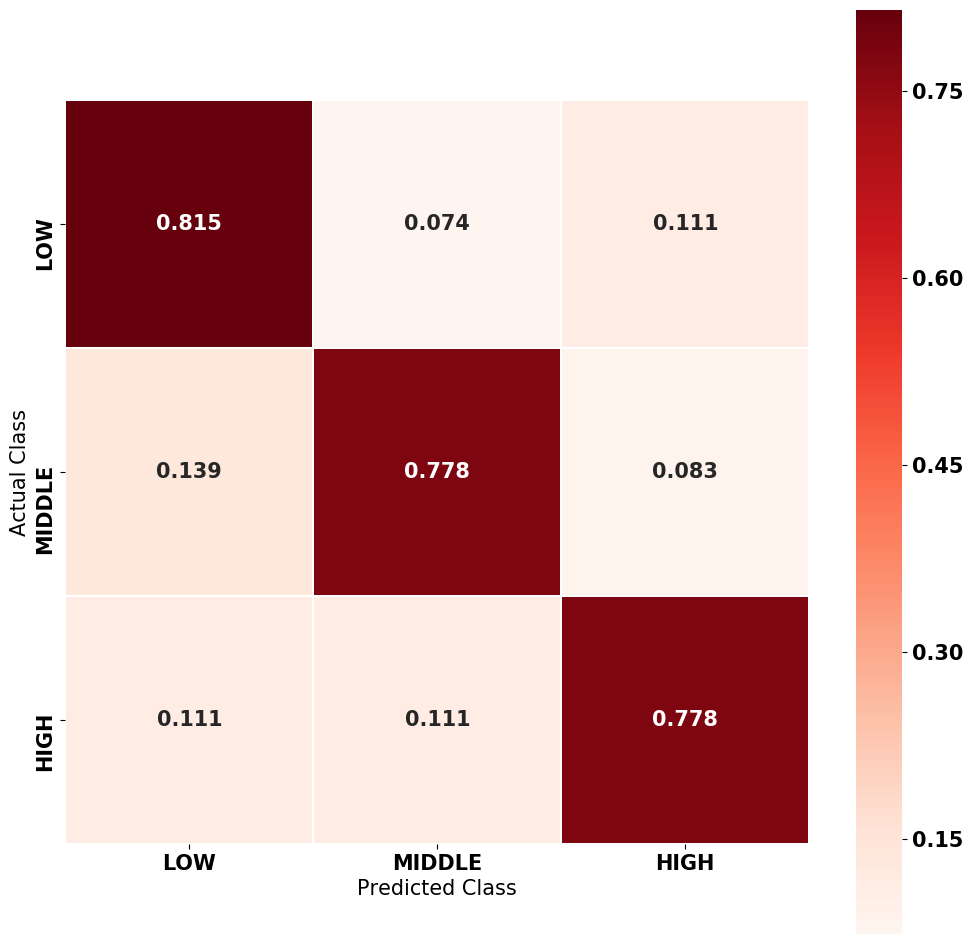
where represents the number of prediction results that match ground-truth labels, and represents the total number of test data in each fold. SVM model reaches the best prediction accuracy of 78.9%, which demonstrates the feasibility of achieving automatic group learning outcome prediction based on group discussion dialog in flipped classroom. The prediction results vastly outperform the random guess (33.3%), which indicates that our model derive meaningful classification from selected features. We also depict the confusion matrix from the prediction result of SVM model. As shown in Fig. 11, three classes are classified correctly in balance, only Low learning outcome has reached marginally higher recall than the other two classes.
VII Conclusion
This paper present a novel study on the correlation between student in-class discussion dialog and group learning outcomes in the flipped classroom. We collected a new Chinese and English code-switched flipped classroom audio corpus throughout a semester with stable student enrollment, and the group discussion audio was separated from the lecture audio by a customized speech classification technology. The group discussion audio recordings have been hand-transcribed with speaker diarization annotations in order to facilitate analysis. Some proper tools and customized technical processing frameworks are introduced to extract the spoken dialog features from bilingual dataset. Several important indicators from discussion dialog that reflect the group learning outcome were identified through statistical analysis. We found that topic relevance of discussions, positive sentiment in discussions, curiosity in learning, certainty in discussions, degree of logical thinking in discussions, information exchange during discussions and context cohesion of discussions are positively correlated with group learning outcome. Finally, machine learning algorithms were given statistically significant indicators to automatically classify the group learning outcome into high, middle or low. Best classification result reached the accuracy of 78.9%, which not only showed that the explored indicators did contribute to reflect the group learning outcome, but also demonstrated the feasibility of achieving automatic learning outcome prediction from group discussion dialog in flipped classroom.
References
- [1] G. Siemens, D. Gasevic, C. Haythornthwaite, S. Dawson, S. B. Shum, R. Ferguson, E. Duval, K. Verbert, R. Baker et al., “Open learning analytics: an integrated & modularized platform,” Ph.D. dissertation, Open University Press Doctoral dissertation, 2011.
- [2] M. M. Olmos and L. Corrin, “Learning analytics: A case study of the process of design of visualizations,” Journal of Asynchronous Learning Networks, vol. 16, no. 3, pp. 39–49, 2012.
- [3] J. L. Bishop, M. A. Verleger et al., “The flipped classroom: A survey of the research,” in ASEE national conference proceedings, Atlanta, GA, vol. 30, no. 9, 2013, pp. 1–18.
- [4] Z. de Araujo, S. Otten, and S. Birisci, “Mathematics teachers’ motivations for, conceptions of, and experiences with flipped instruction,” Teaching and Teacher Education, vol. 62, pp. 60–70, 2017.
- [5] J. Wang, M. Jou, Y. Lv, and C.-C. Huang, “An investigation on teaching performances of model-based flipping classroom for physics supported by modern teaching technologies,” Computers in Human Behavior, vol. 84, pp. 36–48, 2018.
- [6] M. A. N. Elmaadaway, “The effects of a flipped classroom approach on class engagement and skill performance in a blackboard course,” British Journal of Educational Technology, vol. 49, no. 3, pp. 479–491, 2018.
- [7] T. Long, J. Cummins, and M. Waugh, “Use of the flipped classroom instructional model in higher education: instructors’ perspectives,” Journal of computing in higher education, vol. 29, no. 2, pp. 179–200, 2017.
- [8] K. F. Hew and C. K. Lo, “Flipped classroom improves student learning in health professions education: a meta-analysis,” BMC medical education, vol. 18, no. 1, p. 38, 2018.
- [9] M. A. Joseph, E. J. Roach, J. Natarajan, S. Karkada, and A. R. R. Cayaban, “Flipped classroom improves omani nursing students performance and satisfaction in anatomy and physiology,” BMC nursing, vol. 20, no. 1, pp. 1–10, 2021.
- [10] L. Zhao, W. He, and Y.-S. Su, “Innovative pedagogy and design-based research on flipped learning in higher education,” Frontiers in Psychology, vol. 12, p. 230, 2021.
- [11] E. Namaziandost and F. Çakmak, “An account of efl learners’ self-efficacy and gender in the flipped classroom model,” Education and Information Technologies, pp. 1–15, 2020.
- [12] N. B. Milman, “The flipped classroom strategy: What is it and how can it best be used?” Distance learning, vol. 9, no. 3, p. 85, 2012.
- [13] I. T. Awidi and M. Paynter, “The impact of a flipped classroom approach on student learning experience,” Computers & Education, vol. 128, pp. 269–283, 2019.
- [14] C.-Y. Chen and P.-R. Yen, “Learner control, segmenting, and modality effects in animated demonstrations used as the before-class instructions in the flipped classroom,” Interactive Learning Environments, vol. 29, no. 1, pp. 44–58, 2021.
- [15] L.-H. Hsia and H.-Y. Sung, “Effects of a mobile technology-supported peer assessment approach on students’ learning motivation and perceptions in a college flipped dance class,” International Journal of Mobile Learning and Organisation, vol. 14, no. 1, pp. 99–113, 2020.
- [16] Y. Song and M. Kapur, “How to flip the classroom–“productive failure or traditional flipped classroom” pedagogical design?” Journal of Educational Technology & Society, vol. 20, no. 1, pp. 292–305, 2017.
- [17] Y.-N. Lin, L.-H. Hsia, and G.-J. Hwang, “Promoting pre-class guidance and in-class reflection: A sqirc-based mobile flipped learning approach to promoting students’ billiards skills, strategies, motivation and self-efficacy,” Computers & Education, vol. 160, p. 104035, 2021.
- [18] J. Jovanović, D. Gašević, S. Dawson, A. Pardo, N. Mirriahi et al., “Learning analytics to unveil learning strategies in a flipped classroom,” The Internet and Higher Education, vol. 33, no. 4, pp. 74–85, 2017.
- [19] J. Jovanovic, N. Mirriahi, D. Gašević, S. Dawson, and A. Pardo, “Predictive power of regularity of pre-class activities in a flipped classroom,” Computers & Education, vol. 134, pp. 156–168, 2019.
- [20] F. H. Wang, “Interpreting log data through the lens of learning design: Second-order predictors and their relations with learning outcomes in flipped classrooms,” Computers & Education, vol. 168, p. 104209, 2021.
- [21] L. R. Murillo-Zamorano, J. Á. L. Sánchez, and A. L. Godoy-Caballero, “How the flipped classroom affects knowledge, skills, and engagement in higher education: Effects on students’ satisfaction,” Computers & Education, vol. 141, p. 103608, 2019.
- [22] B. Zheng and Y. Zhang, “Self-regulated learning: the effect on medical student learning outcomes in a flipped classroom environment,” BMC medical education, vol. 20, pp. 1–7, 2020.
- [23] C.-J. Lin and G.-J. Hwang, “A learning analytics approach to investigating factors affecting efl students’ oral performance in a flipped classroom,” Journal of Educational Technology & Society, vol. 21, no. 2, pp. 205–219, 2018.
- [24] A. J. Boevé, R. R. Meijer, R. J. Bosker, J. Vugteveen, R. Hoekstra, and C. J. Albers, “Implementing the flipped classroom: an exploration of study behaviour and student performance,” Higher Education, vol. 74, no. 6, pp. 1015–1032, 2017.
- [25] U. Kubasova, G. Murray, and M. Braley, “Analyzing verbal and nonverbal features for predicting group performance,” arXiv preprint arXiv:1907.01369, 2019.
- [26] U. Avci and O. Aran, “Predicting the performance in decision-making tasks: From individual cues to group interaction,” IEEE Transactions on Multimedia, vol. 18, no. 4, pp. 643–658, 2016.
- [27] G. Murray and C. Oertel, “Predicting group performance in task-based interaction,” in Proceedings of the 20th ACM International Conference on Multimodal Interaction, 2018, pp. 14–20.
- [28] X. Ochoa, K. Chiluiza, G. Méndez, G. Luzardo, B. Guamán, and J. Castells, “Expertise estimation based on simple multimodal features,” in Proceedings of the 15th ACM on International conference on multimodal interaction, 2013, pp. 583–590.
- [29] S. Scherer, N. Weibel, L.-P. Morency, and S. Oviatt, “Multimodal prediction of expertise and leadership in learning groups,” in Proceedings of the 1st International Workshop on Multimodal Learning Analytics, 2012, pp. 1–8.
- [30] R. Martinez-Maldonado, Y. Dimitriadis, A. Martinez-Monés, J. Kay, and K. Yacef, “Capturing and analyzing verbal and physical collaborative learning interactions at an enriched interactive tabletop,” International Journal of Computer-Supported Collaborative Learning, vol. 8, no. 4, pp. 455–485, 2013.
- [31] J. M. Reilly and B. Schneider, “Predicting the quality of collaborative problem solving through linguistic analysis of discourse,” in Proceedings of The 12th International Conference on Educational Data Mining (EDM 2019). ERIC, 2019, pp. 149–157.
- [32] D. Spikol, E. Ruffaldi, L. Landolfi, and M. Cukurova, “Estimation of success in collaborative learning based on multimodal learning analytics features,” in 2017 IEEE 17th International Conference on Advanced Learning Technologies (ICALT). IEEE, 2017, pp. 269–273.
- [33] S. Jaggi, X. Wang, B. Dzodzo, Y. Jiang, and H. Meng, “Systematic and quantifiable approach to teaching elite students.”
- [34] H. Su, B. Dzodzo, X. Wu, X. Liu, and H. Meng, “Unsupervised methods for audio classification from lecture discussion recordings,” Proc. Interspeech 2019, pp. 3347–3351, 2019.
- [35] J. Yuan, M. Liberman, and C. Cieri, “Towards an integrated understanding of speaking rate in conversation,” in Ninth International Conference on Spoken Language Processing, 2006.
- [36] E. Kreyszig, H. Kreyszig, and E. J. Norminton, Advanced Engineering Mathematics, 10th ed. Hoboken, NJ: Wiley, 2011.
- [37] R. Řehůřek and P. Sojka, “Software Framework for Topic Modelling with Large Corpora,” in Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks. Valletta, Malta: ELRA, May 2010, pp. 45–50, http://is.muni.cz/publication/884893/en.
- [38] K. S. Jones, “A statistical interpretation of term specificity and its application in retrieval,” Journal of documentation, 1972.
- [39] T. Kenter, A. Borisov, and M. De Rijke, “Siamese cbow: Optimizing word embeddings for sentence representations,” arXiv preprint arXiv:1606.04640, 2016.
- [40] T. Kenter and M. De Rijke, “Short text similarity with word embeddings,” in Proceedings of the 24th ACM international on conference on information and knowledge management, 2015, pp. 1411–1420.
- [41] J. Zhao, M. Lan, and J. Tian, “Ecnu: Using traditional similarity measurements and word embedding for semantic textual similarity estimation,” in Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015), 2015, pp. 117–122.
- [42] G. Cloud, “Cloud translation documentation,” https://cloud.google.com/translate/docs, 2020, accessed: 2020-04-21.
- [43] C.-L. Huang, C. K. Chung, N. Hui, Y.-C. Lin, Y.-T. Seih, B. C. Lam, W.-C. Chen, M. H. Bond, and J. W. Pennebaker, “The development of the chinese linguistic inquiry and word count dictionary.” Chinese Journal of Psychology, 2012.
- [44] J. W. Pennebaker, R. L. Boyd, K. Jordan, and K. Blackburn, “The development and psychometric properties of liwc2015,” Tech. Rep., 2015.
- [45] G. Degottex, J. Kane, T. Drugman, T. Raitio, and S. Scherer, “Covarep—a collaborative voice analysis repository for speech technologies,” in 2014 ieee international conference on acoustics, speech and signal processing (icassp). IEEE, 2014, pp. 960–964.
- [46] X. Xu, Y. Li, X. Xu, Z. Wen, H. Che, S. Liu, and J. Tao, “Survey on discriminative feature selection for speech emotion recognition,” in The 9th International Symposium on Chinese Spoken Language Processing. IEEE, 2014, pp. 345–349.
- [47] M. Worsley and P. Blikstein, “Towards the development of learning analytics: Student speech as an automatic and natural form of assessment,” in Annual Meeting of the American Education Research Association (AERA), 2010.
- [48] P. Boersma et al., “Praat, a system for doing phonetics by computer,” Glot international, vol. 5, 2002.
- [49] J. Tao and Y. Kang, “Features importance analysis for emotional speech classification,” in International Conference on Affective Computing and Intelligent Interaction. Springer, 2005, pp. 449–457.
- [50] W. Lei, “Analyzing and modeling voice quality and jitter in emotional speech synthesis,” Master’s thesis, Tianjin University, 2006.
- [51] P. Alku, T. Bäckström, and E. Vilkman, “Normalized amplitude quotient for parametrization of the glottal flow,” the Journal of the Acoustical Society of America, vol. 112, no. 2, pp. 701–710, 2002.
- [52] S. Patel, K. R. Scherer, E. Björkner, and J. Sundberg, “Mapping emotions into acoustic space: The role of voice production,” Biological psychology, vol. 87, no. 1, pp. 93–98, 2011.
- [53] J. Laver, “The phonetic description of voice quality,” Cambridge Studies in Linguistics London, vol. 31, pp. 1–186, 1980.
- [54] G. Degottex, A. Roebel, and X. Rodet, “Phase minimization for glottal model estimation,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 19, no. 5, pp. 1080–1090, 2010.
- [55] S. Huber, A. Roebel, and G. Degottex, “Glottal source shape parameter estimation using phase minimization variants,” in International Conference on Spoken Language Processing, 2012, pp. 1990–9772.
- [56] J. Kane and C. Gobl, “Identifying regions of non-modal phonation using features of the wavelet transform,” in Twelfth Annual Conference of the International Speech Communication Association, 2011.
- [57] T. Hacki, “Classification of glottal dysfunctions on the basis of electroglottography,” Folia phoniatrica, vol. 41, no. 1, pp. 43–48, 1989.
- [58] J. Kane and C. Gobl, “Wavelet maxima dispersion for breathy to tense voice discrimination,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 21, no. 6, pp. 1170–1179, 2013.
- [59] E. Bingham and H. Mannila, “Random projection in dimensionality reduction: applications to image and text data,” in Proceedings of the seventh ACM SIGKDD international conference on Knowledge discovery and data mining, 2001, pp. 245–250.
- [60] G. Ke, Q. Meng, T. Finley, T. Wang, W. Chen, W. Ma, Q. Ye, and T.-Y. Liu, “Lightgbm: A highly efficient gradient boosting decision tree,” in Advances in Neural Information Processing Systems 30, I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, Eds. Curran Associates, Inc., 2017, pp. 3146–3154.
- [61] T. Chen and C. Guestrin, “Xgboost: A scalable tree boosting system,” in Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, 2016, pp. 785–794.
- [62] J. Snoek, H. Larochelle, and R. P. Adams, “Practical bayesian optimization of machine learning algorithms,” in Advances in neural information processing systems, 2012, pp. 2951–2959.