Learning Contraction Policies from Offline Data
Abstract
This paper proposes a data-driven method for learning convergent control policies from offline data using Contraction theory. Contraction theory enables constructing a policy that makes the closed-loop system trajectories inherently convergent towards a unique trajectory. At the technical level, identifying the contraction metric, which is the distance metric with respect to which a robot’s trajectories exhibit contraction is often non-trivial. We propose to jointly learn the control policy and its corresponding contraction metric while enforcing contraction. To achieve this, we learn an implicit dynamics model of the robotic system from an offline data set consisting of the robot’s state and input trajectories. Using this learned dynamics model, we propose a data augmentation algorithm for learning contraction policies. We randomly generate samples in the state-space and propagate them forward in time through the learned dynamics model to generate auxiliary sample trajectories. We then learn both the control policy and the contraction metric such that the distance between the trajectories from the offline data set and our generated auxiliary sample trajectories decreases over time. We evaluate the performance of our proposed framework on simulated robotic goal-reaching tasks and demonstrate that enforcing contraction results in faster convergence and greater robustness of the learned policy.
1 Introduction
While learning-based controllers have achieved significant success, they still lack safety guarantees. For instance, in general, the temporal evolution of a robot’s trajectories under a learned policy cannot be certified. On the other hand, when a system’s dynamics are known, control-theoretic properties, such as stability and contraction, directly examine the temporal progression of a system’s states to verify whether a system remains within a safe set, and whether the system’s trajectories converge. In this paper, we seek to enforce the desired temporal evolution of the closed-loop system’s states while learning the policy from an offline set of data, i.e. we seek to learn control policies such that under the learned policy, the convergence of a robot’s trajectories is achieved.
To achieve such trajectory convergence, our design approach leverages Contraction theory [1]. Contraction theory provides a framework for identifying the class of nonlinear dynamic systems that have asymptotic convergent trajectories. Intuitively, a region of the state space is a contraction space if the distance between any two close neighboring trajectories decays over time. This notion of convergence is relevant to many robotic tasks such as tracking controllers where we want a robot to either reach a goal or track a reference trajectory. In this paper, we want to learn policies from offline data such that they achieve convergence of a robot’s trajectories in closed loop. While contraction theory provides a simple and intuitive characterization of convergent trajectories, finding the distance metric with respect to which a robot’s trajectories exhibit contraction – which is called the contraction metric – is often non-trivial. To address this challenge, we propose to jointly learn the robot policy and its corresponding contraction metric.
We learn the robot dynamics model from an offline data set consisting of the robot’s state and input trajectories. This setting is similar to the setting of offline model-based reinforcement learning (RL) where a dynamics model and a policy are learned from a set of robot trajectories that are collected offline. Learning from offline data is appropriate for safety-critical applications where online data collection is dangerous [2]. We learn a dynamics model of the system from the data and propose a data augmentation algorithm for learning contraction policies. Randomly sampled states are propagated forward in time through the learned dynamics model to generate auxiliary sample trajectories. We then learn both our policy and our contraction metric such that the distance between the robot trajectories from the data set and the auxiliary sample trajectories decreases over time. Learning contraction policies is particularly relevant to offline RL as it allows us to regard the errors in the learned dynamics model as external disturbances and obtain a tracking error bound in regions where the learning errors of the dynamics model are bounded [3, 4].
We evaluate the performance of our proposed framework on a set of simulated robotic goal-reaching tasks. The performance of our proposed framework is compared with a number of control algorithms. We demonstrate that as a result of enforcing contraction, the robot’s trajectories converge faster to the goal position with a higher degree of accuracy. It is further shown that learning contraction policies increases the robustness of the learned policy with respect to learned dynamics model mismatch, i.e. enforcing contraction increases the robustness of the learned policies. In summary, our contributions are the following:
-
•
We propose a framework for learning convergent robot policies from an offline data set using Contraction theory.
-
•
We develop a data augmentation algorithm for learning contraction policies from the offline data set.
-
•
We provide a formal analysis for bounding contraction policy performance as a function of dynamics model mismatch.
-
•
We perform numerical evaluations of our proposed policy learning framework and demonstrate that enforcing contraction results in favorable convergence and robustness performance.
The organization of this paper is as follows. In Section 2, we provide an overview of the related and prior work. We provide an overview of Contraction theory in Section 3 and present our problem formulation in Section 4. We then discuss our proposed framework in Section 5. Section 6 provides a discussion and analysis of the robustness of learned contraction policies. In Section 7, we evaluate and compare the performance of our policy learning algorithm. Finally, we will conclude the paper in Section 8.
2 Related Work
For systems with unknown dynamics, several offline RL algorithms have been developed recently which either directly learn a policy using an offline data-set [5, 6, 7, 8] or learn a surrogate dynamics model from the offline data to learn an appropriate policy [9, 10]. However, the majority of such RL algorithms lack formal safety guarantees, and the convergent behavior of the learned policies is not certified [11, 12].
When the system dynamics are known, robust and certifiable control policy design can be achieved through various control-theoretic methods such as reachability analysis [13], Funnels [14, 15], and Hamilton-Jacobi analysis [16, 17]. Lyapunov stability criteria, Contraction Theory, and Control Barrier Functions have been extensively utilized for providing strong convergence guarantees for nonlinear dynamical systems [18, 19, 20, 21, 1]. However, even when the dynamics are known, finding a proper Lyapunov function or a control barrier function is itself a challenging task. To address these challenges, learning algorithms have been utilized for learning the Lyapunov and Control Barrier Functions [22, 23, 24]. [11] and [25] propose to learn contraction metrics to find contraction control policies for known systems.
Various recent works have considered combining control-theoretic tools with learning algorithms to enable learning safe policies even when dynamics are unknown. [26, 27] consider learning stable dynamics models. In [28], Contraction theory is used to learn stabilizable dynamics models of unknown systems. In [12, 29], Lyapunov functions are used for ensuring the stability of the learned policies. [30] proposed to learn the system dynamics and its corresponding Lyapunov function jointly to ensure the stability of the learned dynamics model.
In this work, we consider learning contraction policies from offline data for systems with unknown dynamics. Our work is closely related to [11] and [25], where Contraction theory has been used for certifying convergent trajectories. The current work is different in that, unlike these approaches where dynamics are explicitly known and assumed to be control-affine, we consider access to only an offline data set. We assume that we can learn an implicit model of system dynamics, in the form of a neural network function approximator, and provide robustness guarantees with respect to the errors of the learned dynamics model.
3 Contraction Theory
Contraction theory assesses the stability properties of dynamical systems by studying the convergence behavior of neighboring trajectories [1]. The convergence is established by directly examining the evolution of the weighted Euclidean distance of close neighboring trajectories. Formally, consider a differentiable autonomous discrete-time dynamical system defined as
| (1) |
with Jacobian
| (2) |
Now, consider a differential displacement . The differential displacement dynamics at are governed by
| (3) |
The system dynamics are contractive if there exists a full rank state dependant metric such that the system trajectories satisfy
| (4) |
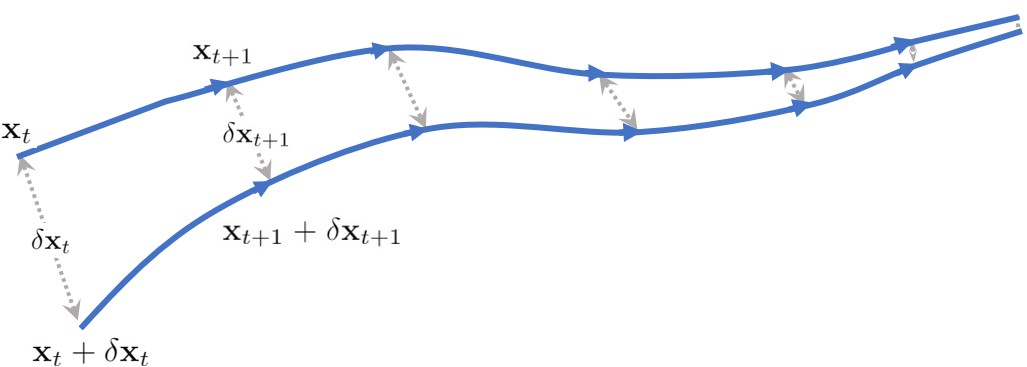
Equation (4) indicates that the weighted distance between any two infinitesimally close states decreases as the dynamics evolve [31]. When the distances between trajectories are measured in the Euclidean norm sense. Figure 1 illustrates the behavior of two trajectories of a contractive system when .
For a small finite displacement , as an approximation of infinitesimal small displacement , the first-order Taylor expansion of the system dynamics allows us to locally approximate the forward evolution of the displacement
| (5) |
Thus, we may approximate the contraction condition (4) as
| (6) |
Establishing a system as contractive allows for several useful stability properties to be deduced. We state motivating results from [1] in the following definition and proposition.
Definition 1
Given the discrete-time system , a region of the state space is called a contraction region with respect to a uniformly positive definite metric , if in that region
| (7) |
Proposition 1
A convex contraction region contains at most one equilibrium point.
It is shown in [1] that (7) is equivalent to condition (4) holding for all in the contraction region. Thus, by Proposition 1, we may conclude that a unique equilibrium exists within a convex region if (4) holds everywhere inside the region. Therefore, (6) represents a useful numerical analog that can be enforced in order to drive a region towards being contractive. By choosing a set of , we will use condition (6) to enforce contracting behavior of the closed-loop system. Going beyond autonomous systems, when a system is subject to control input , i.e., , contraction theory can be used to design state feedback policies such that the closed-loop system trajectories converge to a given reference state. This may be done by determining such that the convex region of interest is contractive and the unique equilibrium is the desired reference state. Such a control design process is outlined in the following sections.
4 Problem Formulation
We consider the problem of control policy design for a robot with unknown discrete-time dynamics model , where is convex, . We assume that we can use an offline data set consisting of tuples of state transitions and control inputs satisfying unknown system dynamics
| (8) |
Our objective is to obtain a data-driven state-feedback control policy to steer the system (8) towards a desired reference state , i.e. as . To compensate for the lack of knowledge of the true system dynamics, we propose using a model of the system dynamics that we learn from the offline data . Note that this indicates that our learned dynamics model may still not be available explicitly and may only be available as implicit dynamics such as neural networks approximators. More specifically, we aim to design a control policy that leverages the learned dynamics model
| (9) |
to drive the system asymptotically to .
5 Learning Deep Contraction Policies
To develop a policy that results in contractive behavior, we seek to enforce the approximate condition in (6), requiring the weighted distances of close neighboring trajectories to decrease over time. To enforce this condition, we need to ensure that we have sufficiently close neighboring points for each point within our training set. However, our training data set may not include such neighboring trajectories. We augment our data set with auxiliary trajectories that enable us to enforce this condition at each data point. That is, for each , we augment our data set with a sampled from
| (10) |
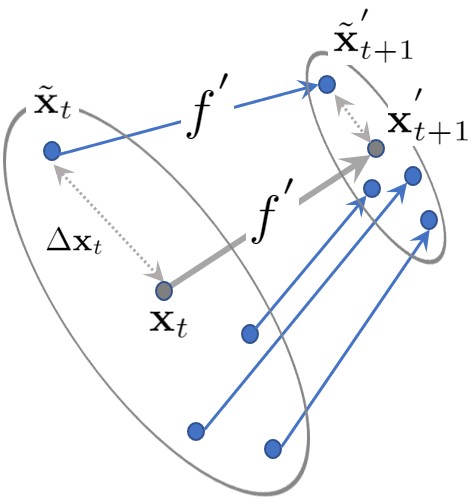
where the parameter is set in the training process. We sample points from to ensure that is a small displacement with respect to the training data set. Then, for each data point , we create the auxiliary state . Both of these points are propagated through our learned dynamics model to calculate the states at the next time step: and . The initial state, the auxiliary state, and the predicted evolution of these two states are then combined into a tuple . The collection of all such tuples over each form the augmented data set .
Now, we want to evaluate the contracting behavior of the controller through the learned model on the augmented data set . Thus, we seek to enforce condition (6) for the elements of
| (11) |
with respect to a contraction metric . Contractive behavior is illustrated in Figure 2, showing the weighted distance between and decays as the system evolves to and . We evaluate the approximate contraction condition only at the states that exist in the data set . This is due to the fact that the dynamics model is learned from and hence is expected to behave the most accurately at these points, which in turn will increase the quality of the learned policy. This will enforce contractive behavior with respect to the learned dynamics model . Later we will discuss how we can ensure contractive behavior of the closed-loop behavior of the true dynamics model .
Since in general, the contraction metric is not known, and it is directly coupled to the control policy, we propose a learning-based approach to jointly learn both the control policy and the metric with respect to which the policy exhibits contraction. We refer to such a policy as a deep contraction policy. To this end, let us start by assuming that we know a control policy that makes contractive. Consider now that we want to learn a corresponding contraction metric. Let this contraction metric be represented by a model which is parameterized by weights . We then obtain the best parameters of this contraction metric, denoted by , from
| (12) |
where
The term is an approximate measure of the contraction condition (11) which ideally should be negative for all elements of . Since enforcing (11) directly results in a non-differentiable optimization, we minimize (5) as a proxy for (11). Note that is computed over all data points in . When paired with differentiable contraction metric , the choice of loss function (5) is differentiable and is amenable to gradient decent optimization.
Now, let’s consider the more general case where both the policy and its contraction metric are unknown. We want to learn both the state-feedback policy and the contraction metric together. We want to learn a control policy represented by a function approximator , parameterized by weights , such that the closed-loop system is contractive with respect to the metric model . To achieve this, we propagate the initial data points in with the control policy model as and .
We obtain the parameters of the contraction metric , denoted by , and the parameters of the control policy , denoted by , by minimizing a loss function over the data set
| (13) |
where
Loss function (5) ensures that the region of interest is contractive with respect to and the learned dynamics model . However, so far there has been no mechanism to ensure that the unique equilibrium of the contractive system is indeed the desired reference value . To alleviate this, we need the learning process to be aware of the desired reference value, which we would like to be the equilibrium of the contraction region. The measure of awareness that we introduce is based on the ability of the controller to steer the system from an initial state to the desired state value in time steps, i.e. how close gets to . Therefore, to enforce the system’s states to contract to , we add another penalty term to our loss function to obtain the final loss function utilized for learning the policy and contraction metric:
| (14) |
where
| (15) |
is the tracking loss with as the penalty factor. Here, is the state value of the process , initialized at where is drawn from a countable set . The number of time steps is set by the designer and, as the reader may infer, affects the transient behavior of the closed-loop system.
6 Contraction of True Dynamics Under Learned Policy
A major concern regarding control policy design using a learned model from offline data is that of model mismatch. In order to bound the controller performance degradation, we assume a known upper bound on the Lipschitz constant of the model error , which we denote as . In practice, such an upper bound may be estimated by fitting a Reverse Weibull distribution over the data set [32, 33].
Lemma 1
Consider an unknown system and its learned model with an upper-bound estimation on the Lipschitz constant of as . The error between the learned model and the unknown system is bounded by , i.e. for all where
| (16) |
with
-
Proof
See Appendix.
The constant in Lemma 1 is the maximum distance that a point can have from its nearest data point .
Deep contraction policy learning proposed in Algorithm 1 ideally ensures contractive behavior of the controlled learned system at the states . More specifically, by defining an approximate measure of contraction condition (4) as
the controlled learned model being contractive is equivalent to for all and . Hence, it remains for us to verify whether the learned policy exhibits contraction with the true unknown system dynamics in the sense of contraction condition (4), i.e. for all and . We seek to derive a condition under which we are guaranteed that the controlled true dynamics are also contractive with the learned policy. To arrive to such quantification, we begin with contraction of the learned model at the training points, and end with an upper bound estimation of the contraction of the true dynamics at any points . The following Proposition establishes the condition under which the approximate contraction measure holds for the true robot dynamics under the trained .
Proposition 2
-
Proof
See Appendix.
7 Implementation & Evaluation
We evaluate the performance of the contraction policies in a set of goal-reaching robotic tasks by comparing our method against a number of offline control methods suitable for systems with learned dynamics models. In particular, we compare our framework with the following algorithms:
-
1.
MPC: An iterative Linear Quadratic Controller (iLQR) as described in [34] ran in a receding horizon fashion.
-
2.
Learning without contraction: To evaluate the effectiveness of the contraction penalty, we further evaluate the robot’s performance in the absence of any contraction terms in the loss function.
-
3.
Reinforcement Learning: We also use the state-of-the-art offline RL method Conservative Q-Learning (CQL) [35] for further comparisons.
We evaluate the performance of our approach on two different robotic settings involving nonlinear dynamical systems of varying complexity represented by neural networks. The dynamics of these systems have closed-form expressions, but it is assumed that we do not have access to such expressions. We assume that we only have access to a set of system trajectories and learn a dynamics model from the state-action trajectories. The learned dynamics are represented as neural networks to the model-based control methods: deep contraction policy, MPC controller, and contraction-free learning. The RL implementation develops the policy directly from the same offline data set that is used to train the dynamics model in a model-free fashion. This allows us to implement our algorithm on the learned systems while having an analytical baseline to compare against to quantify robustness. Additionally, we consider state and control sets defined by box constraints in order to constrain the size of the training data. Clearly for such constraints, is convex. The dynamical systems we have chosen for our performance evaluation are as follows:
-
1.
2D Planar Car: A planar vehicle that is capable of controlling its acceleration, , and angular velocity, . Here and where are the planar positions, is the velocity, and is the heading angle. The system dynamics are governed by: .
-
2.
3D Drone: An adaptation of a drone model that is given by [11] and [36]. This model describes an aerial vehicle capable of directly controlling the rate of change of it’s normalized thrust , and Euler Angles, . Here and where are the translational positions and velocities along the axis, respectively. Omitting the first order integrators in for brevity, the dynamics can then be expressed as , where is the acceleration due to gravity.
For both systems we assume a timestep of s and a final time of s.
7.1 Learning System Dynamics
All of the continuous dynamical systems described above are represented to our controllers as fully connected neural networks which capture the discretization of the model integration: . The training dataset is generated by aggregating reference trajectories through the state space generated from an iLQR controller applied directly to the true dynamics . The reference trajectories were chosen such that and for all . Trajectory data was used in order to implement a discounted multistep prediction error as in [37] until sufficient integration accuracy was achieved.
7.2 Controller Implementation
The contraction metric and control policy neural networks, and , are trained according to Algorithm 1.
For our ablation study, we remove the contraction penalty term and simply find a policy for minimizing the tracking error norm. Without a contraction penalty, the impact of contraction conditions during the learning process vanishes. In order to create a controller for this case, each is forward evolved a number of time steps under the learned control policy and trained with a discounted cumulative loss of the tracking error norms over each timestep.
For the MPC controller, the iLQR planner utilizes the learned dynamics model in order to calculate the linearization relative to the state and control inputs. This linearization is used along with weighting matrices in order to calculate an iLQR control law.
In order to train an offline reinforcement learning algorithm like CQL, the algorithm needs access to state, action, and reward pairs. We reutilize the offline iLQR trajectories created for dynamics learning as training episodes for the offline CQL RL algorithm. The reward at each time step is taken to be the negative norm of the tracking error at the next time step given the currently taken action.
Dynamics Model Test Loss Contraction learning No contraction term MPC iLQR 1 5.67e-05 2 8.19e-05 3 1.14e-04 4 1.58e-04 5 2.64e-04 ∗Values of N/A represent cases where sufficiently stabilizing controllers were not generated.
7.3 Performance Results
In order to compare the performance of our method with the alternative implementations outlined above, we propose a number of metrics to compare the controllers:
-
•
The time evolution of the tracking error, to quantify the controllers’ ability to converge to the desired reference .
-
•
The converged tracking error versus the initial tracking error, to quantify the controllers’ ability to operate over the working space .
-
•
Root Mean Square Error (RMSE) of the tracking error versus learned model loss, to quantify the controllers’ ability to deal with model mismatch.
For all analyses, the controllers were each presented with an identical set of 256 initial conditions within . The control methods were implemented as described above in an attempt to drive these initial states to the desired reference . The results were aggregated over the 256 initial conditions for the 2D car and 3D drone.
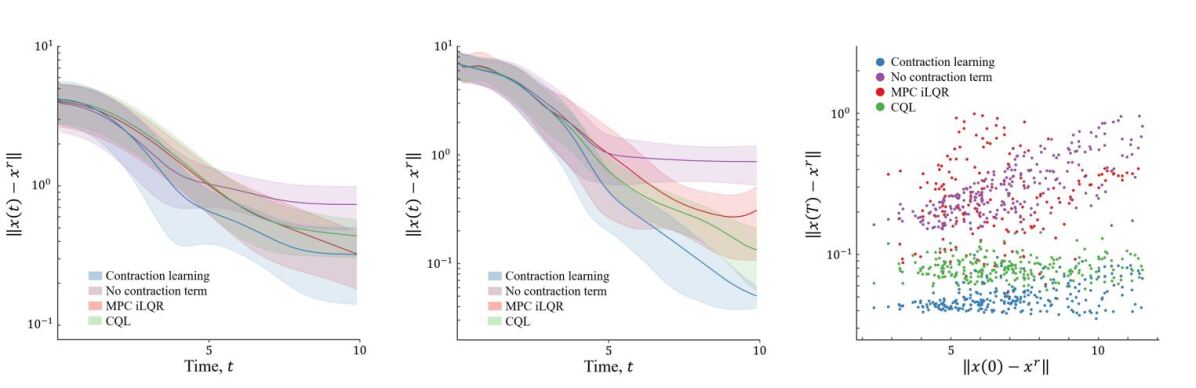
In the time evolution analysis, desirable controllers have trajectories that quickly converge, have minimal tracking error norm, and have high convergence precision. Results directly comparing all of the controllers relative to this performance measure for the two dynamical systems are given in Figure 3 (left and middle). The results show that over the two different systems and a multitude of initial conditions, the contraction learning policy performs well relative to the proposed comparison controllers. For the simpler dynamic system of the two, the 2D planar car, the results are comparable among all controllers but favor the contraction controller, while the more complex drone environment shows the clear benefits of our approach. The enforcement of contraction conditions forces nearby trajectories to converge to one another, and when near the reference point, this has the effect of reducing the norm of the tracking error further than the systems designed without contraction in mind. The contraction controller consistently has the lowest mean norm of the tracking error over all the sampled initial states.
Comparing the converged tacking error, in this case, the average of the final 10 timestamps of each trajectory, versus the initial tracking error gives insight into the performance of the controllers’ over the entire state and control space and . Cases with a higher initial tracking error represent trajectories that start closer towards the boundary of our working space . Favorable controllers are ones in which the converged tracking error remains constant or grows slowly as the initial tracking error increases. Figure 3 (right) directly shows this comparison. The results here clearly show that the MPC controller and the learned policy without the contraction terms have difficulty as the initial state norm gets further from the desired reference. For the MPC controller, the poor performance is likely caused by not having expressive enough dynamics due to the repeated linearization process. The contraction-free policy shows good performance for small initial tracking errors but quickly degrades as this value grows. Such a control method acts extremely locally. Training a collection of states to converge to the reference without the additional contraction structure does not yield favorable stability properties. The CQL policy and deep contraction learning generate trajectories with minimal degradation as the tracking error increases, with the contraction learning method consistently having the highest degree of performance.
Finally, for the 3D drone scenario, the impact of the learned dynamics model quality on the model-based controllers’ performance is studied. To this end, multiple models of different quality were learned from the same offline data set. Since the CQL policy is directly learned from the offline data and does not utilize the learned dynamics model, this method is omitted from this analysis. In this case, favorable controllers are ones in which the error grows slowly with increasing model inaccuracy. Comparison of the RMSE values of the tracking error norm over the length of the trajectories for the varying quality dynamics models are shown in Table 1. The contraction learning model shows favorable performance as dynamics model mismatch increases due to the robustness properties discussed in Section 6. For particularly low-quality learned dynamics models we even see that the deep contraction policy is able to generate stabilizing controllers where the contraction-free policy and MPC controller fail to do so.
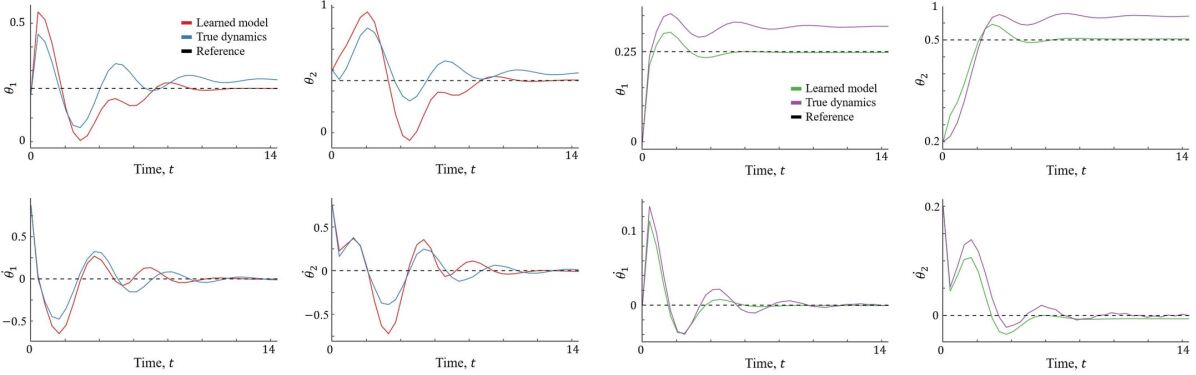
7.4 Non-control Affine Analysis
In order to quantify the ability of our deep contraction policy learning to generalize to more complex systems, we perform an illustrative analysis of our controller on the double pendulum model given in [38]. Such a system is chaotic with a non-affine control input. Figure 4 shows the comparison of two scenarios where the designed controller was implemented on both the learned model and the true dynamics. The trajectories show the controller is able to accomplish the task when applied to the learned model. However, when applied to the true dynamics, the controller positions the arms with a slight positional error while keeping the angular velocity at zero.
8 Conclusion and Future Work
In this paper, we established a framework for learning a converging control policy for an unknown system from offline data. We leveraged Contraction theory and proposed a data augmentation method for encoding the contraction conditions directly into the loss function. We jointly learned the control policy and its corresponding contraction metric. We compared our method with several state-of-the-art control algorithms and showed that our method provides faster convergence, a smaller tracking error, lower variance of trajectories. For our future work, we would like to extend the current work to develop the stochastic confidence bound of our control design approach design.
References
- [1] W. Lohmiller and J.-J. E. Slotine, “On contraction analysis for non-linear systems,” Automatica, vol. 34, no. 6, pp. 683–696, 1998.
- [2] S. Levine, A. Kumar, G. Tucker, and J. Fu, “Offline reinforcement learning: Tutorial, review, and perspectives on open problems,” arXiv preprint arXiv:2005.01643, 2020.
- [3] N. Boffi, S. Tu, N. Matni, J. Slotine, and V. Sindhwani, “Learning stability certificates from data,” arXiv preprint arXiv:2008.05952, 2020.
- [4] H. Tsukamoto, S. Chung, and J. Slotine, “Contraction theory for nonlinear stability analysis and learning-based control: A tutorial overview,” Annual Reviews in Control, 2021.
- [5] T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor,” in International conference on machine learning, pp. 1861–1870, PMLR, 2018.
- [6] A. Kumar, A. Zhou, G. Tucker, and S. Levine, “Conservative q-learning for offline reinforcement learning,” arXiv preprint arXiv:2006.04779, 2020.
- [7] T. Yu, G. Thomas, L. Yu, S. Ermon, J. Zou, S. Levine, C. Finn, and T. Ma, “Mopo: Model-based offline policy optimization,” Advances in Neural Information Processing Systems, vol. 33, pp. 14129–14142, 2020.
- [8] S. Levine, A. Kumar, G. Tucker, and J. Fu, “Offline reinforcement learning: Tutorial, review, and perspectives on open problems,” arXiv preprint arXiv:2005.01643, 2020.
- [9] L. Kaiser, M. Babaeizadeh, P. Milos, B. Osinski, R. Campbell, K. Czechowski, D. Erhan, C. Finn, P. Kozakowski, S. Levine, et al., “Model-based reinforcement learning for atari,” arXiv preprint arXiv:1903.00374, 2019.
- [10] T. Moerland, J. Broekens, and M. Jonker, “Model-based reinforcement learning: A survey,” arXiv preprint arXiv:2006.16712, 2020.
- [11] D. Sun, S. Jha, and C. Fan, “Learning certified control using contraction metric,” arXiv preprint arXiv:2011.12569, 2020.
- [12] F. Berkenkamp, M. Turchetta, A. P. Schoellig, and A. Krause, “Safe model-based reinforcement learning with stability guarantees,” arXiv preprint arXiv:1705.08551, 2017.
- [13] S. Vaskov, S. Kousik, H. Larson, F. Bu, J. Ward, S. Worrall, M. Johnson-Roberson, and R. Vasudevan, “Towards provably not-at-fault control of autonomous robots in arbitrary dynamic environments,” arXiv preprint arXiv:1902.02851, 2019.
- [14] R. Tedrake, “Lqr-trees: Feedback motion planning on sparse randomized trees,” 2009.
- [15] A. Majumdar and R. Tedrake, “Funnel libraries for real-time robust feedback motion planning,” The International Journal of Robotics Research, vol. 36, no. 8, pp. 947–982, 2017.
- [16] S. Herbert, M. Chen, S. Han, S. Bansal, J. Fisac, and C. Tomlin, “Fastrack: A modular framework for fast and guaranteed safe motion planning,” in 2017 IEEE 56th Annual Conference on Decision and Control (CDC), pp. 1517–1522, IEEE, 2017.
- [17] S. Bansal, M. Chen, F. J.F, and C. Tomlin, “Safe sequential path planning of multi-vehicle systems under presence of disturbances and imperfect information,” in American Control Conference, 2017.
- [18] H. K. Khalil and J. W. Grizzle, Nonlinear systems, vol. 3. Prentice hall Upper Saddle River, NJ, 2002.
- [19] J. Choi, F. Castañeda, C. Tomlin, and K. Sreenath, “Reinforcement learning for safety-critical control under model uncertainty, using control lyapunov functions and control barrier functions,” in Robotics: Science and Systems, 2020.
- [20] A. Taylor, A. Singletary, Y. Yue, and A. Ames, “Learning for safety-critical control with control barrier functions,” Proceedings of Machine Learning Research, vol. 1, p. 12, 2020.
- [21] A. Zaki, A. El-Nagar, M. El-Bardini, and F. Soliman, “Deep learning controller for nonlinear system based on lyapunov stability criterion,” Neural Computing and Applications, vol. 33, no. 5, pp. 1515–1531, 2021.
- [22] S. Richards, F. Berkenkamp, and A. Krause, “The lyapunov neural network: Adaptive stability certification for safe learning of dynamical systems,” in Conference on Robot Learning, pp. 466–476, PMLR, 2018.
- [23] A. Robey, H. Hu, L. Lindemann, H. Zhang, D. Dimarogonas, S. Tu, and N. Matni, “Learning control barrier functions from expert demonstrations,” in IEEE Conference on Decision and Control, pp. 3717–3724, 2020.
- [24] S. Chen, M. Fazlyab, M. Morari, G. Pappas, and V. Preciado, “Learning lyapunov functions for hybrid systems,” in Proceedings of the 24th International Conference on Hybrid Systems: Computation and Control, pp. 1–11, 2021.
- [25] H. Tsukamoto and S.-J. Chung, “Learning-based robust motion planning with guaranteed stability: A contraction theory approach,” IEEE Robotics and Automation Letters, 2021.
- [26] S. Khansari-Zadeh and A. Billard, “Learning stable nonlinear dynamical systems with gaussian mixture models,” Transactions on Robotics, vol. 27, no. 5, pp. 943–957, 2011.
- [27] J. Umlauft and S. Hirche, “Learning stable stochastic nonlinear dynamical systems,” in International Conference on Machine Learning, pp. 3502–3510, PMLR, 2017.
- [28] S. Singh, V. Sindhwani, J. Slotine, and M. Pavone, “Learning stabilizable dynamical systems via control contraction metrics,” arXiv preprint arXiv:1808.00113, 2018.
- [29] A. Taylor, V. Dorobantu, H. Le, Y. Yue, and A. Ames, “Episodic learning with control lyapunov functions for uncertain robotic systems,” in International Conference on Intelligent Robots and Systems, pp. 6878–6884, IEEE, 2019.
- [30] J. Kolter and G. Manek, “Learning stable deep dynamics models,” Advances in Neural Information Processing Systems, vol. 32, pp. 11128–11136, 2019.
- [31] W. Lohmiller and J.-J. E. J. J. E. Slotine, “On contraction analysis for non-linear systems,” Automatica, vol. 34, no. 6, pp. 683–696, 1998.
- [32] G. Wood and B. Zhang, “Estimation of the lipschitz constant of a function,” Journal of Global Optimization, vol. 8, no. 1, pp. 91–103, 1996.
- [33] C. Knuth, G. Chou, N. Ozay, and D. Berenson, “Planning with learned dynamics: Probabilistic guarantees on safety and reachability via lipschitz constants,” IEEE Robotics and Automation Letters, vol. 6, no. 3, pp. 5129–5136, 2021.
- [34] Y. Tassa, T. Erez, and E. Todorov, “Synthesis and stabilization of complex behaviors through online trajectory optimization,” in 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, pp. 4906–4913, 2012.
- [35] A. Kumar, A. Zhou, G. Tucker, and S. Levine, “Conservative q-learning for offline reinforcement learning,” CoRR, vol. abs/2006.04779, 2020.
- [36] S. Singh, A. Majumdar, J.-J. Slotine, and M. Pavone, “Robust online motion planning via contraction theory and convex optimization,” in 2017 IEEE International Conference on Robotics and Automation (ICRA), pp. 5883–5890, 2017.
- [37] A. Venkatraman, M. Hebert, and J. Bagnell, “Improving multi-step prediction of learned time series models,” in AAAI, 2015.
- [38] T. Stachowiak and T. Okada, “A numerical analysis of chaos in the double pendulum,” Chaos, Solitons & Fractals, vol. 29, no. 2, pp. 417–422, 2006.
9 Appendix
-
Lemma 1
We ground our error analysis on the training error of the tuples and propagate the error to the general state and control tuples .
The first and the second inequalities are obtained by adding and subtracting the terms and , and also using the norm and Lipschitz constant properties. If we define as the right hand side of the second inequality, then where
which concludes the proof.
-
Proposition 2
We want to derive a sufficient condition which ensures that contraction condition (11) holds for the true dynamics model. Using the learned dynamics model, the left-hand side of (11) for can be bounded for the true dynamics as
where , , , and . The inequality holds due to addition and subtraction of proper terms and norm properties. The inequality can be further simplified using the Frobenius norm of the contraction metric . Since, by assumption, the entries of the contraction metric are bounded by , we have . Having an upper bound estimate of the Lipschitz constant of entries of the contraction metric and recalling that from Lemma 1, leads to the result . In addition, using the estimated Lipschitz constant , we have that . Now, using the Lipschitz constant of as , we have that . Finally, we can write the following inequality:
(18) where . With Lipschitz constant , we can derive an upper bound for , and , such that where
. Finally by taking the expectation on Equation (Proposition 2), we get
which concludes the proof.