Learning Deep Input-Output Stable Dynamics
Abstract
Learning stable dynamics from observed time-series data is an essential problem in robotics, physical modeling, and systems biology. Many of these dynamics are represented as an inputs-output system to communicate with the external environment. In this study, we focus on input-output stable systems, exhibiting robustness against unexpected stimuli and noise. We propose a method to learn nonlinear systems guaranteeing the input-output stability. Our proposed method utilizes the differentiable projection onto the space satisfying the Hamilton-Jacobi inequality to realize the input-output stability. The problem of finding this projection can be formulated as a quadratic constraint quadratic programming problem, and we derive the particular solution analytically. Also, we apply our method to a toy bistable model and the task of training a benchmark generated from a glucose-insulin simulator. The results show that the nonlinear system with neural networks by our method achieves the input-output stability, unlike naive neural networks. Our code is available at https://github.com/clinfo/DeepIOStability.
1 Introduction
Learning dynamics from time-series data has many applications such as industrial robot systems [1], physical systems[2], and biological systems [3, 4]. Many of these real-world systems equipped with inputs and outputs to connect for each other, which are called input-output systems [5]. For example, biological systems sustain life by obtaining energy from the external environment through their inputs. Such real-world systems have various properties such as stability, controllability, and observability, which provide clues to analyze the complex systems.
Our purpose is to learn a complex system with “desired properties” from a dataset consisting of pairs of input and output signals. To represent the target system, this paper considers the following nonlinear dynamics:
| (1) |
where the inner state , the input , and the output belong to a signal space that maps time interval to the Euclidean space. We denote the dimension of , , and as , , and , respectively.
Recently, with the development of deep learning, many methods to learn systems from time-series data using neural networks have been proposed [6, 7, 8]. By representing the maps in Eq. (1) as neural networks, complex systems can be modeled and trained from a given dataset. However, guaranteeing that a trained system has the desired properties is challenging.
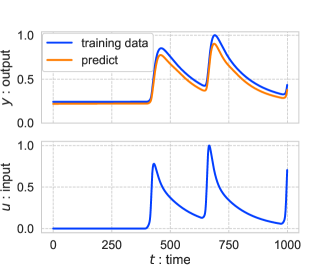 |
 |
| (A) | (B) |
A naively trained system fits the input signals contained in the training dataset, but does not always fit for new input signals. For example, Figure 1 shows our preliminary experiments where we naively learned neural networks in Eq. (1) from input and output signals. The trained neural networks provided small predictive errors for an input signal in the training dataset (Figure 1 (A) ). Contrastingly, the unbounded output signals were computed by the trained system with new step input signals (Figure 1 (B) ). The reason can be expected that the magnitude (integral value) of this input signal was larger than that of the input signals in the training dataset.
The internal stability is known as one of the attractive properties that should be often satisfied in real-world dynamical systems. The conventional methods to train internal stable systems consisting of neural networks adopt the Lyapunov-based approaches [9, 10, 11]. These methods focus on the internal system, in the input-output system (1). Thus, how to learn the entire system (1) with the desired property related to the influence of the input signal is still challenging.
We propose a novel method to learn a dynamical system consisting of neural networks considering the input-output stability. The notion of the input-output stability is often used together with the Hamilton-Jacobi inequality for controller design of the target system in the field of control theory. The Hamilton-Jacobi inequality is one of the sufficient conditions for the input-output stability. The feature of this condition is that the variable for an input signal does not appear in the expression, i.e., we do not need to evaluate the condition for unknown inputs [12]. To the best of our knowledge, this is the first work that establishes a learning method for the dynamical systems consisting of neural networks using the Hamilton-Jacobi inequality.
The contributions of this paper are as follows:
-
•
This paper derives differentiable projections to the space satisfying the Hamilton-Jacobi inequality.
-
•
This paper presents the learning method for the input-output system proven to always satisfy the Hamilton-Jacobi inequality.
-
•
This paper also provides a loss function derived from the Hamilton-Jacobi inequality. By combining this loss function with the projection described above, efficient learning can be expected.
-
•
This paper presents experiments using two types of benchmarks to evaluate our method.
2 Background
This section describes the stability, a standard definition of the input-output stability, and the Hamilton-Jacobi inequality.
First, we define the stability of the nonlinear dynamical system (1). If the norm ratio of the output signal to the input signal is bounded, the system is stable and this norm ratio is called the gain. The norm on the input and output signal space is used for the definition of the stability. To deal with the stability on the nonlinear system (1), we assume that the origin of the internal system is an asymptotically stable equilibrium point and . Since the translation of any asymptotically stable equilibrium points is possible, this assumption can be satisfied without loss of generality.
Definition 1.
Next, we describe a sufficient condition of the stability using the Lyapunov function , where the function is positive semi-definite, i.e., and . The Hamilton-Jacobi inequality is an input-independent sufficient condition.
Proposition 1 ([5, Theorem 5.5]).
Let be locally Lipschitz and let and be continuous. If there exist a constant and a continuously differentiable positive semi-definite function such that
| (3) |
then the system (1) is stable and the gain is less than or equal to . This condition is called the Hamilton-Jacobi inequality.
The above proposition can be generalized to allow the more complicated situations such as limit-cycle and bistable cases, where the domain contains multiple asymptotically stable equilibrium points. The equilibrium point assumed in this proposition can be replaced with positive invariant sets by extending the norm [13]. Furthermore, by mixing multiple Lyapunov functions, this proposition can be generalized around multiple isolated equilibrium points.
3 Method
The goal of this paper is to learn the stable system represented by using neural networks . The Hamiltonian-Jacobi inequality, which implies the stability, is expressed by . We present a method to project onto the space where the Hamilton-Jacobi inequality holds.
3.1 Modification of nonlinear systems
Supposing , , and , a triplet map denote as nominal dynamics. Introducing a distance on the triplet maps, the nearest triplet satisfying the Hamilton-Jacobi inequality from the nominal dynamics is called modified dynamics . The purpose of this section is to describe the modified dynamics associated with the nominal dynamics by analytically deriving a projection onto the space satisfying the Hamilton-Jacobi inequality.
The problem of finding the modified dynamics is written as a quadratic constraint quadratic programming (QCQP) problem for the nominal dynamics . Since there is generally no analytical solution for QCQP problems, we aim to find the particular solution by adjusting the distance on the triplets.
To prepare for the following theorem, we define the ramp and the clamp functions as
and define the Hamilton-Jacobi function as
| (4) |
where is a given positive definite function. A way to design is to determine the desired positive invariant set and design the increasing function around this set. For example, if the target system has a unique stable point, can be regarded as the positive invariant set and the increasing function can be designed as .
Theorem 1.
Consider that the following optimal problem:
| (5a) | |||
| (5b) | |||
where . The solution of (5) is given by
where
Proof:.
See Appendix A. ∎
The objective function of (5a) is a new distance between the nominal dynamics and the modified dynamics . This new distance allows the derivation of analytical solutions by combining three distances of , , and .
Focusing on the objective function (5a), the constant represents the ratio of the distance scale of to and . When , the result of this problem (5) are consistent with the projection of the conventional method that guarantee internal stability [9]. As the constant converges , the modification method of Theorem 1 approaches and to and , respectively. In this case, the objective function (5a) becomes the distance between to . Therefore, the following corollary is satisfied.
Corollary 1.
The solution of
| (6a) | |||
| (6b) | |||
is given by
Proof:.
This solution is easily derived from Theorem 1. ∎
Corollary 1 derives a solution of a linear programming problem rather than QCQP problems. Replacing the Hamilton-Jacobi function with the time derivative of a positive definite function , this corollary matches the result of the conventional study [9].
When the map is fixed as , a similar solution as Theorem 1 is derived. Although Corollary 1 is proved by changing , the modified dynamics with the fixed are not derived. We reprove this modified dynamics in a similar way to Theorem 1.
Corollary 2.
Proof:.
See Appendix A. ∎
3.2 Loss function
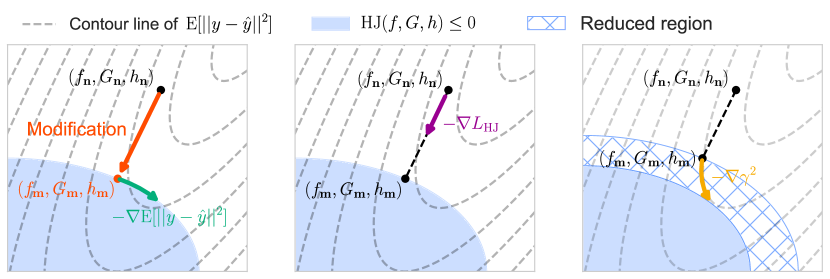
(A) (B) (C)
We represent as neural networks and denote as the stable dynamics modified by Theorem 1, Corollary 1, or 2. Note that the modification depends on the candidate of gain . Figure 2 (A) shows the sketch of this modification, where the blue region satisfies the Hamilton-Jacobi inequality.
Since the nonlinear system of the modified dynamics is represented as ordinary differential equations (ODEs) consisting of the differentiable functions ,, and , the techniques of training neural ODEs can be applied [14]. Once a loss function is designed, the parameters of neural networks in the modified system can be learned from given data.
| (9) |
where and are non-negative coefficients.
The first term shows the prediction error of the output signal ( Figure 2 (A)). A dataset consists of tuples where the initial value , the input signal , and the output signal . The predicted output is calculated from , , and the modified dynamics .
The second term aims to improve the nominal dynamics closer to the modified dynamics and is defined as
where is a positive constant ( Figure 2 (B)). Since this term is a form of the hinge loss, represents the magnitude of the penalties for the Hamilton-Jacobi inequality. To evaluate this inequality for any , we introduce a distribution of over the domain . In our experiments, this distribution is decided as a Gaussian distribution where the mean is placed at the asymptotically stable point and the variance is an experimental parameter. Without this second term of the loss function, there are degrees of freedom in the nominal dynamics, i.e., multiple nominal dynamics give the same loss by the projection, which negatively affects the parameter learning.
The modifying parameter can be manually designed for the application or automatically trained from data by introducing the last term. This training explores smaller while keeping the same level of the prediction error (Figure 2 (C)).
4 Related work
Estimating parameters of a given system is traditionally studied as system identification. In the field of system identification, much research on the identification of linear systems have been done, where the maps in Eq. (1) assumes to be linear [15]. Linear state-space models include identification methods by impulse response like the Eigensystem Realization Algorithm (ERA)[16], by the state-space representation like Multivariable Output Error State sPace (MOESP)[17] and ORThogonal decomposition method (ORT)[18]. System identification methods for non-state-space models, unlike our target system, contain Dynamic Mode Decomposition with control (DMDc)[19] and its nonlinear version, Sparse Identification of Nonlinear DYnamics with control (SINDYc)[20]. Also, the nonlinear models such as the nonlinear ARX model [21] and the Hammerstein-Wiener model [22] have been developed and often trained by error minimization. For example, the system identification method using a piece-wise ARX model allows more complicated functions by relaxing the assumption of linearity [21].
These traditional methods often concern gray-box systems, where the maps in Eq. (1) are partially known [23]. This paper deals with a case of black-box systems, where , , and in the system (1) are represented by neural networks. Our method can be used regardless of whether all , , and functions are parameterized using neural networks. So, our method can be easily applied to application-dependent gray-box systems when the functions , , and are differentiable with respect to the parameters.
Because the input-output system (1) can be regarded as a differential equation, our study is closely related to the method of combining neural networks and ODEs [7, 14]. These techniques have been improved in recent years, including discretization errors and computational complexity. Although we used an Euler method for simplicity, we can expect that learning efficiency would be further improved by using these techniques.
The internal stability is a fundamental property in ODEs, and learning a system with this property using neural networks plays an important role in the identification of real-world systems [24]. In particular, the first method to guarantee the internal stability of the trained system has been proposed in [9]. Furthermore, another method [25] extends this method to apply positive invariant sets, e.g. limit cycles and line attractors. Encouraged by these methods based on the Lyapunov function, our method further generalizes these methods using the Hamilton-Jacobi inequality to guarantee the input-output stability.
In this paper, the Lyapunov function is considered to be given, but this function can be learned from data. Since a pair of dynamics (1) and has redundant degrees of freedom, additional assumptions are required to determine uniquely. In [9], it is realized by limiting the dynamics to the internal system and restricting to a convex function [26].
Lyapunov functions are also used to design controllers, where the whole system should satisfy the stability condition. A method for learning such a controller using neural nets has been proposed [27]. This method deals with optimization problems over the space that satisfies the stability condition, which is similar to our method. Whereas we solve the QCQP problem to derive the projection onto the space, this method uses a Satisfiability Modulo Theories (SMT) solver to satisfy this condition. The method has also been extended to apply unknown systems [28].
5 Experiments
We conduct two experiments to evaluate our proposed method. The first experiment uses a benchmark dataset generated from a nonlinear model with multiple asymptotically equilibrium points. In the next experiment, we applied our method to a biological system using a simulator of the glucose-insulin system.
5.1 Experimental setting
Before describing the results of the experiments, this section explains the evaluation metrics and our experimental setting.
For evaluation metrics, we define the root mean square error (RMSE) and the average gain (GainIO) for the given input and output signals as follows:
where is the number of signals in the dataset. and are the input and output signal at the -th index, respectively. The prediction signal is computed from , the trained dynamics, and the initial state. Note that the integral contained in the norm is approximated by a finite summation. The RMSE is a metric of the prediction errors related to the output signal, and the GainIO is a metric of the property of the stability. Whether the target system satisfies or does not satisfy the stability, the GainIO with a given finite-size dataset can be calculated. The GainIO error is defined by the absolute error between the GainIO of the test dataset and that of the prediction.
In our experiments, 90 of the dataset is used for training and the remaining 10 is used for testing. We retry five times for all experiments and show the mean and standard deviations of the metrics.
For simplicity in our experiments, the sampling step for the output is set as constant and the Euler method is used to solve ODEs. is put at an asymptotically stable point for each benchmark and is known. In this experiment, to prevent the state from diverging during learning of dynamics, the clipping operation is used so that the absolute values of the states are less than ten.
For comparative methods, we use vanilla neural networks, ARX, ORT [18], MOESP [17], and piece-wise ARX[21]. In the method of vanilla neural networks, the maps in the nonlinear system (1) is represented by using three neural networks, i.e., this method is consistent with a method used in Figure 1. To determine the hyperparameters of comparative methods except for neural networks, the grid search is used. Note that these comparative methods only consider the prediction errors.
For training each method with neural networks, an NVIDIA Tesla T4 GPU was used. Our experiments are totally run on 20 GPUs over about three days.
5.2 Bistable model benchmark
The first experiment is carried out using a bistable model, which is known as a bounded system with multiple asymptotically equilibrium points. This bistable model is defined as
The internal system of this model has two asymptotically stable equilibrium points .
We generate 1000 input and output signals for this experiment. To construct this dataset, we prepare input signals using positive and negative pulse wave signals whose pulse width is changed at random. The input and output signals on the period are sampled with an interval . In this benchmark, we set the number of dimensions of the internal system as one and use a fixed function , a mixture of the two positive definite functions.
In the result of our experiments, we name the proposed methods modified by Theorem 1, Corollary 1, and 2 as DIOS-fgh, DIOS-f, and DIOS-fg, respectively. In these methods, the parameters of our loss function are set as and . Also, DIOS-fgh+ uses and under the same conditions as DIOS-fgh. For this example (1000 input signal), it took about 1 hour using 1 GPU to learn one model training.
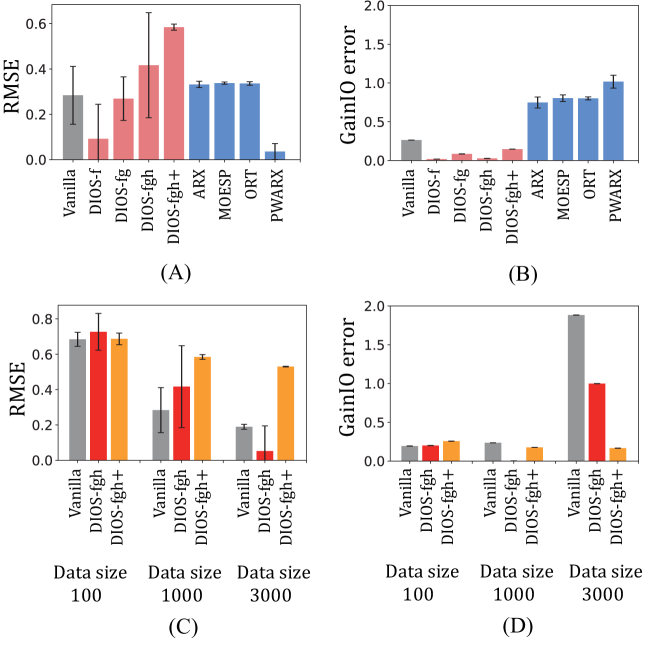
The results of the RMSE and the GainIO error in this experiment are shown in Figure 3. Figures 3 (A) and (B) demonstrate that a piece-wise ARX model (PWARX) gives very low RMSE but its GainIO error is high. Our proposed methods achieve a small GainIO error while keeping the RMSE. Note that linear models such as MOESP and ORT only approach one point although the bistable model has two asymptotically stable equilibrium points. Figures 3 (C) and (D) display the effect of dataset sizes. When the dataset size was varied to 100, 1000, and 3000, the result of the larger dataset provided the smaller RMSE for all methods. The vanilla neural networks do not consider the gain, so the GainIO error was large in the case of the low RMSE.
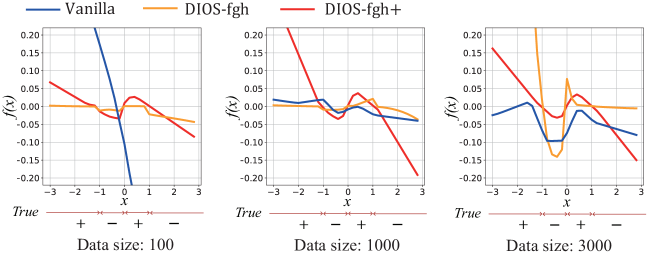
Figure 4 shows the relationship between and in the trained system in (1) to compare the vanilla neural networks, DIOS-fgh and DIOS-fgh+. DIOS-fgh and DIOS-fgh+ successfully find two stable points, i.e., the trained function had roots of two stable points and an unstable point . Especially, these stable points were robustly estimated in the trained system using our presented loss function (DIOS-fgh+) even when the dataset size was small. The vanilla neural networks failed to obtain the two stable points in all cases.
5.3 Glucose-insulin benchmark
This section addresses an example of the identification of biological systems. We consider the task of learning the glucose-insulin system using a simulator [32] to construct responses for various inputs and evaluate the robustness of the proposed method for unexpected inputs. This simulator outputs the concentrations of plasma glucose and insulin for the appearance of plasma glucose per minute . To determine the realistic input , we adopt another model, an oral glucose absorption model [33].
Using this simulator, 1000 input and output signals are synthesized for this experiment. The input and output signals are sampled with a sampling interval and 1000 steps for each sequence. In this benchmark, we set the number of dimensions of the internal system as six, fix a positive definite function , and use our loss function with and . Training one model for this examples (1000 input signal) tooks about 7.5hours using 1GPU. The hyperparameters including the number of layers in the neural networks, the learning rate, optimizer, and the weighted decay are determined using the tree-structured Parzen estimator (TPE) implemented in Optuna [34].
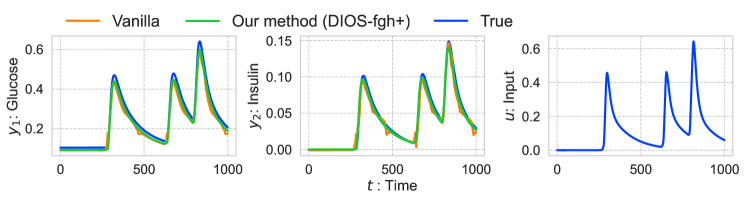
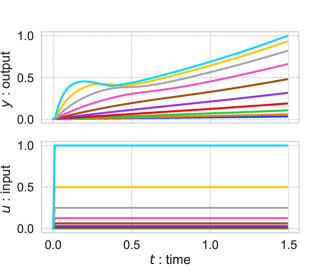
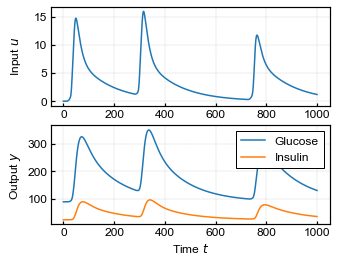
The RMSE of vanilla and our proposed method are 0.0103 and 0.0050, respectively. So, from the perspective of RMSE, these methods achieved almost the same performance. Figure 5 shows input and output signals in the test dataset and the predicted output by vanilla neural networks and our method (DIOS-fgh+). The stability of the system using the vanilla neural networks is not guaranteed. Since the proposed method guarantees the stability, the output signals of DIOS-fgh+ are bounded even if the input signals are unexpectedly large.
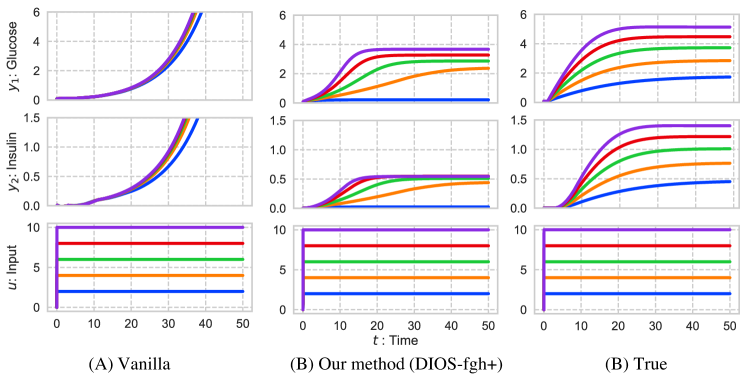
To demonstrate this, we conducted an additional experiment using the trained system. Figure 6 shows the transition of output behavior caused by the magnitude of the input signal changing from 2 to 10. Note that the maximum magnitude in the training dataset is one. In this experiment, was changed to and the clipping operation was removed to deal with the large values of the state.
This result shows the output of the vanilla neural networks quickly diverged with an unexpectedly large input. Contrastingly, the output behavior of our proposed method is always bounded. Therefore, we actually confirmed that our proposed method satisfies the stability.
6 Conclusion
This paper proposed a learning method for nonlinear dynamical system guaranteeing the stability. By theoretically deriving the projection of a triplet to the space satisfying the Hamilton-Jacobi inequality, our proposed method realized the stability of trained systems. Also, we introduced a loss function to empirically achieve a smaller gain while reducing prediction errors. We conducted two experiments to learn dynamical systems consisting of neural networks. The first experiment used a nonlinear model with multiple asymptotically equilibrium points. The result of this experiment showed that our proposed method can robustly estimate a system with multiple stable points. In the next experiment, we applied our method to a biological system using a simulator of the glucose-insulin system. It was confirmed that the proposed method can successfully learn a proper system that works well under unexpectedly large inputs due to the stability. There is a limitation that our method cannot apply the system without the stability. Future work will expand the stability-based method to a more generalized learning method by dissipativity and apply our approach of this study to stochastic systems.
Acknowledgements
This research was supported by JST Moonshot R&D Grant Number JPMJMS2021 and JPMJMS2024. This work was also supported by JSPS KAKENHI Grant No.21H04905 and CREST Grant Number JPMJCR22D3, Japan. This paper was also based on a part of results obtained from a project commissioned by the New Energy and Industrial Technology Development Organization (NEDO).
References
- [1] Jan Swevers, Walter Verdonck, and Joris De Schutter. Dynamic model identification for industrial robots. IEEE control systems magazine, 27(5):58–71, 2007.
- [2] Steven L. Brunton, Joshua L. Proctor, and J. Nathan Kutz. Discovering governing equations from data by sparse identification of nonlinear dynamical systems. Proceedings of the national academy of sciences, 2016.
- [3] Timothy S. Gardner, Diego Di Bernardo, David Lorenz, and James J. Collins. Inferring genetic networks and identifying compound mode of action via expression profiling. Science, 301(5629):102–105, 2003.
- [4] Geoffrey Roeder, Paul K Grant, Andrew Phillips, Neil Dalchau, and Edwards Meeds. Efficient amortised bayesian inference for hierarchical and nonlinear dynamical systems. Proceeding of International Conference on Machine Learning (ICML), 2019.
- [5] Hassan K. Khalil. Nonlinear systems. Prentice-Hall, 3rd edition, 2002.
- [6] Rahul G. Krishnan, Uri Shalit, and David Sontag. Structured inference networks for nonlinear state space models. In Proceedings of the AAAI Conference on Artificial Intelligence, page 2101–2109, 2017.
- [7] Ricky T.Q. Chen, Yulia Rubanova, Jesse Bettencourt, and David Duvenaud. Neural ordinary differential equations. In Advances in Neural Information Processing Systems (NeurIPS), volume 31, 2018.
- [8] Yaofeng Desmond Zhong, Biswadip Dey, and Amit Chakraborty. Symplectic ode-net: Learning hamiltonian dynamics with control. In Proceeding of International Conference on Learning Representations, 2019.
- [9] Gaurav Manek and J. Zico Kolter. Learning stable deep dynamics models. In Advances in Neural Information Processing Systems (NeurIPS), volume 32, 2019.
- [10] Nathan Lawrence, Philip Loewen, Michael Forbes, Johan Backstrom, and Bhushan Gopaluni. Almost surely stable deep dynamics. In Advances in Neural Information Processing Systems (NeurIPS), volume 33, 2020.
- [11] Andreas Schlaginhaufen, Philippe Wenk, Andreas Krause, and Florian Dörfler. Learning stable deep dynamics models for partially observed or delayed dynamical systems. In Advances in Neural Information Processing Systems (NeurIPS), volume 34, 2021.
- [12] Arjan van der Schaft. -Gain and Passivity Techniques in Nonlinear Control. Springer Publishing Company, Incorporated, 3rd edition, 2016.
- [13] W.M. Haddad and V.S. Chellaboina. Nonlinear Dynamical Systems and Control: A Lyapunov-Based Approach. Princeton University Press, 2008.
- [14] Xinshi Chen. Review: Ordinary differential equations for deep learning. CoRR, abs/1911.00502, 2019.
- [15] Tohru Katayama. Subspace Method for System Identification. Springer, 2005.
- [16] Jer-Nan Juang and Richard S Pappa. An eigensystem realization algorithm for modal parameter identification and model reduction. Journal of guidance, control, and dynamics, 8(5):620–627, 1985.
- [17] Michel Verhaegen and Patrick Dewilde. Subspace model identification part 1. the output-error state-space model identification class of algorithms. International journal of control, 56(5):1187–1210, 1992.
- [18] Tohru Katayama, Hideyuki Tanaka, and Takeya Enomoto. A simple subspace identification method of closed-loop systems using orthogonal decomposition. IFAC Proceedings Volumes, 38(1):512–517, 2005.
- [19] Joshua L Proctor, Steven L Brunton, and J Nathan Kutz. Dynamic mode decomposition with control. SIAM Journal on Applied Dynamical Systems, 15(1):142–161, 2016.
- [20] Steven L Brunton, Joshua L Proctor, and J Nathan Kutz. Sparse identification of nonlinear dynamics with control (SINDYc). IFAC-PapersOnLine, 49(18):710–715, 2016.
- [21] Andrea Garulli, Simone Paoletti, and Antonio Vicino. A survey on switched and piecewise affine system identification. In IFAC Proceedings Volumes, volume 45, pages 344–355. IFAC, 2012.
- [22] Adrian Wills, Thomas B. Schon, Lennart Ljung, and Brett Ninness. Identification of hammerstein-wiener models. Automatica, 49(1):70–81, 2013.
- [23] Lennart Ljung. System identification. In Signal analysis and prediction, pages 163–173. Springer, 1998.
- [24] Martin Braun and Martin Golubitsky. Differential equations and their applications. Springer, 1983.
- [25] Naoya Takeishi and Yoshinobu Kawahara. Learning dynamics models with stable invariant sets. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 9782–9790, 2021.
- [26] Brandon Amos, Lei Xu, and J Zico Kolter. Input convex neural networks. In International Conference on Machine Learning, pages 146–155, 2017.
- [27] Ya-Chien Chang, Nima Roohi, and Sicun Gao. Neural lyapunov control. In Advances in Neural Information Processing Systems (NeurIPS), volume 32, 2019.
- [28] Vrushabh Zinage and Efstathios Bakolas. Neural koopman lyapunov control. arXiv:2201.05098, 2022.
- [29] Daniel Gedon, Niklas Wahlström, Thomas B. Schön, and Lennart Ljung. Deep state space models for nonlinear system identification. In Proceedings of the 19th IFAC Symposium on System Identification (SYSID), 2021.
- [30] Junyoung Chung, Kyle Kastner, Laurent Dinh, Kratarth Goel, Aaron C. Courville, and Yoshua Bengio. A recurrent latent variable model for sequential data. In Advances in Neural Information Processing Systems (NeurIPS), volume 28, 2015.
- [31] Justin Bayer and Christian Osendorfer. Learning stochastic recurrent networks. ArXiv, abs/1411.7610, 2014.
- [32] A. De Gaetano and O. Arino. A statistical approach to the determination of stability for dynamical systems modelling physiological processes. Mathematical and Computer Modelling, 31(4):41–51, 2000.
- [33] Chiara Dalla Man, Robert A. Rizza, and Claudio Cobelli. Meal simulation model of the glucose-insulin system. IEEE Transactions on Biomedical Engineering, 54(10):1740–1749, 2007.
- [34] Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. Optuna: A next-generation hyperparameter optimization framework. In Proceedings of the 25rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2019.
Appendix A Proof of Theorem 1 and Corollary 2
Lemma 1.
Suppose that is a positive definite matrix, a vector , a scalar , and positive constants , . The solution of this problem
| minimize | |||
| subject to |
is given by
where
Proof:.
See Appendix B. ∎
To keep the notation short in the following proofs, we define
Proof of Theorem 2: For the Hamilton-Jacobi function of the modified dynamics , the map and each row of the map don’t depend on the orthogonal vector of . Hence, and are written as
where is scalar and . depends only on the norm in , i. e.,
where is scalar.
The optimal function (5a) is rewritten as the , , and , i.e.,
Also, the condition of constraint (5b) is rewritten as
If , , and
then this optimal problem (5) of this theorem becomes a problem used in Lemma 1. The optimal point of , and is given by
Therefore, Theorem 1 is derived.
Proof of Theorem 2:
Appendix B Proof of the particular solution of QCQP
This section presents the proof of the following QCQP problem.
| minimize | (10a) | |||
| subject to | (10b) | |||
where is a positive definite matrix. We classify this problem according to the parameter and .
First, the solution of this optimal problem is switched depending on the positive or negative value of .
Lemma 2.
Proof:.
Also, the solution of the new optimal problem (11) is switched by the ratio between and .
Lemma 3.
If , the solution equals the solution of the following QCQP problem, such that
| minimize | (14a) | |||
| subject to | (14b) | |||
Proof:.
The optimal problem (11) is split on the sign of .
Case :
The optimal problem of this case is written as
| minimize |
If , there is no optimal point. Otherwise , the optimal point is written as
The optimal point does not satisfies the condition , because
where is a positive definite matrix and .
Case :
The solution of the simple QCQP problem (14) is easily derived using the method of Lagrange multiplier.
Lemma 4.
The solution of the simple QCQP problem (14) is given by
Proof:.
Lemma 1.
The solution of the problem (10) is given by
| (17a) | ||||
| (17b) | ||||
Appendix C Overall schematic of the learning process
Algorithm 1 shows the overall schematic of the learning process. The first line defines the modified dynamics from the nominal dynamics , defined by the neural network, where is a set of parameters of the nominal dynamics. The 2-7 line represents a training loop, where the gradient-based optimization methods can be used by using the forward and backward calculation. Note that an ODE solver is used for forward calculation, and Algorithm 2 shows the forward calculation when the Euler method is used. For simplicity, mini-batch computation omitted in this schematic.
Appendix D Neural network architecture and hyper parameters
| parameter name | range | type |
|---|---|---|
| learning rate | – | log scale |
| weight decay | – | log scale |
| batch size | – | integer |
| optimizer | AdamW, Adam, RMSProp | categorical |
| layer for | – | integer |
| layer for | – | integer |
| layer for | – | integer |
| dim. for a hidden layer of | integer | |
| dim. for a hidden layer of | integer | |
| dim. for a hidden layer of | integer | |
| – | log scale | |
| Initial scale parameter for | – | log scale |
| Stop gradient for projection | true, false | boolean |
This section details how to determine the neural network architecture. The architecture and hyper parameters of the neural networks were basically determined by Bayesian optimizing using the validation dataset.
Table 1 shows the search space of Bayesian optimization. The first three parameters: learning rate, weight decay, and batch size are parameters for training the neural networks. Also, an optimizer is selected from AdamW, Adam, and RMSProp. The structure of neural network is determined from the number of intermediate layers and dimensions for each layer. One layer in our setting consists of a fully connected layer with a ReLU activation. The last three rows represent parameters related to our proposed methods. is a parameter of the loss function . Initial scale parameter is multiplied with the output of to prevent the value of from becoming large in the initial stages of learning. When , which determine the behavior of the internal system, outputs a large value, it diverges due to time evolution, and the learning of the entire system may not progress. Therefore, it is empirically preferable to start with a small value for at the initial stage of learning. When the flag of ‘stop gradient for projection’ is false, backward computation related to the second term of modification of and is disabled. Note that modification related to and consists of two terms (see Theorem 1). Setting this parameter to false resulted in better performance in our all experiments.
We ran 300 trials using the Bayesian optimization for the bistable model benchmark and the glucose insulin benchmark with the above settings, and the hyper parameters obtained are shown in Table 2, where the number of dimensions for each hidden layer is shown in tuple from the order closest to the input layer.
Hyperparameters of comparative methods were determined by grid search using the validation dataset. ARX and PWARX have an order parameter of the autoregressive model, and this parameter is searched in the range of . The number of iterations was set to 10000 so that the optimization of PWARX converges sufficiently. MOESP and ORT have an internal dimension () and the number of subsequences used for estimation ().
| parameter name | bistable | glucose insulin |
|---|---|---|
| learning rate | ||
| weight decay | ||
| batch size | ||
| optimizer | RMSProp | RMSProp |
| layer for | ||
| layer for | ||
| layer for | ||
| dim. for a hidden layer of | (17,10,22) | (8) |
| dim. for a hidden layer of | (34) | (27,29) |
| dim. for a hidden layer of | (10,62,58) | (35,18) |
| Initial scale parameter for | ||
| Stop gradient for projection | false | false |
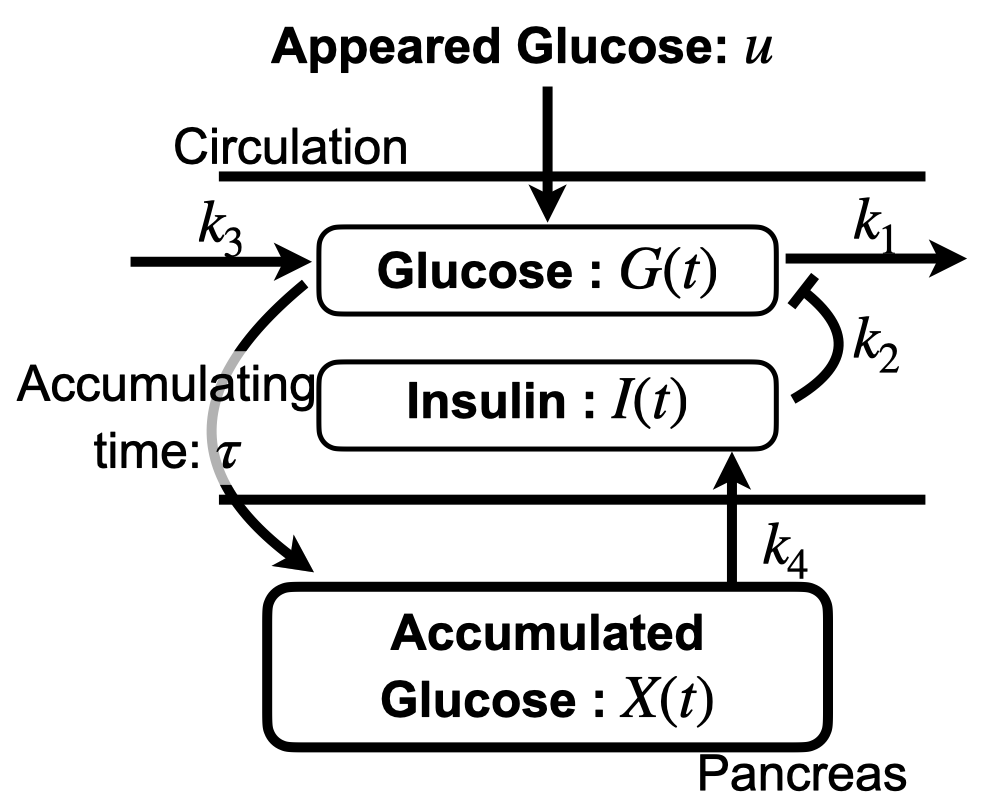
Appendix E Glucose-Insulin system
Glucose concentration in the blood is modeled as a time-delay system regulated by insulin concentration (See Fig. 7 (A)) [32]. Suppose that , and are the glucose, insulin, and accumulated glucose plasma concentration ([mg/100ml],[UI/ml],and [min mg/100ml], respectively) and is the amount of ingested glucose per minute [min-1 mg/100ml]. The dynamics of each concentration is given by
where is a spontaneous glucose disappearance rate, is an insulin-dependent glucose disappearance rate, is a constant increase in plasma glucose concentration, is an insulin disappearance rate, is an insulin release rate per the average glucose concentration within the last minute.
This system has a unique asymptotically stable equilibrium point on the nonlinear plain such that
Here we set the initial state of this model as and set the model parameters as shown in the following Table 3. Furthermore, we adopt the output of the previous oral glucose absorption system [33] as (See Fig. 7 (B)), and the glucose absorption amount is normalized based on human blood volume per body weight (0.80[100 ml/kg]).
| Parameter | Value | Unit |
|---|---|---|
| 3.13 | ||
| min |
 |
 |
| (A) | (B) |