Learning -Level Structured Sparse Neural Networks Using Group Envelope Regularization
Abstract
The extensive need for computational resources poses a significant obstacle to deploying large-scale Deep Neural Networks (DNN) on devices with constrained resources. At the same time, studies have demonstrated that a significant number of these DNN parameters are redundant and extraneous. In this paper, we introduce a novel approach for learning structured sparse neural networks, aimed at bridging the DNN hardware deployment challenges. We develop a novel regularization technique, termed Weighted Group Sparse Envelope Function (WGSEF), generalizing the Sparse Envelop Function (SEF), to select (or nullify) neuron groups, thereby reducing redundancy and enhancing computational efficiency. The method speeds up inference time and aims to reduce memory demand and power consumption, thanks to its adaptability which lets any hardware specify group definitions, such as filters, channels, filter shapes, layer depths, a single parameter (unstructured), etc. The properties of the WGSEF enable the pre-definition of a desired sparsity level to be achieved at the training convergence. In the case of redundant parameters, this approach maintains negligible network accuracy degradation or can even lead to improvements in accuracy. Our method efficiently computes the WGSEF regularizer and its proximal operator, in a worst-case linear complexity relative to the number of group variables. Employing a proximal-gradient-based optimization technique, to train the model, it tackles the non-convex minimization problem incorporating the neural network loss and the WGSEF. Finally, we experiment and illustrate the efficiency of our proposed method in terms of the compression ratio, accuracy, and inference latency.
1 Introduction
In the past decade, significant progress has characterized the study of Deep Neural Networks (DNNs), which consistently demonstrate superior performance across the entire spectrum of machine learning tasks. As modern neural networks increase in size and complexity, with parameters often surpassing the number of available training samples, their deployment on resource-limited edge devices becomes increasingly challenging. This difficulty stems from the higher computational demands that lead to greater power consumption, longer inference times, and the need for substantial memory space for storage, which edge devices typically lack [1, 2]. Notwithstanding, many studies have revealed that modern neural networks tend to be excessively over-parametrized [3, 4]. This over-parametrization implies the existence of redundant parameters that could be pruned (or, nullified) without compromising network accuracy [5], which are also responsible for issues such as overfitting [6], memorization of random patterns in the data [7], and a potential degradation in generalization. The realization that numerous redundant parameters exist has prompted a quest for neural network architectures that are both sparse and efficient, which emerges as a prominent challenge in the field.
To mitigate the challenges associated with the deployment of modern large DNNs, numerous studies have suggested compressing their scale. Various approaches have been explored, including (unstructured) sparsity including regularization [8], pruning [9], low-rank approximation [3, 10], quantization [11, 12], and even sparse neural architecture search (NAS) [13, 12]. In the case of the unstructured sparsity-inducing, the most natural regularizer would be the so-called -pseudo-norm function that counts the number of nonzero elements in the input vector, i.e., . These sparse regularized minimization/training problems are of the form , or, alternatively, one can explicitly constrain the number of parameters used for regression and solve . Unfortunately, the -norm is a difficult function to handle being non-convex and even non-continuous. Indeed, these types of regression models are known to be NP-hard problems, in general, [14] (global optimal solution can not be computed in a reasonable time, even for a very small number of parameters). As a remedy for the inherent problem above, [15] proposed a highly efficient tractable convex relaxation technique, termed sparse envelope function (SEF), for the sum of both and norms. Specifically, [15] suggested using this relaxation as a regularizer term for a convex loss objective, particularly for a linear regression model, to achieve feature selection while explicitly limiting the number of features to be a fixed parameter . It was shown that the performance of this sparse inducing regularization method in both reconstruction of a sparse noisy signal and recovering its support, surpass the performance of state-of-the-art techniques, such as, the Elastic-net [16], -support norm [17], etc. Also, it was shown that the computational complexity of the SEF approach is linear in the number of parameters, while all others require at least quadratic in the number of features, thus SEF was found very attractive.
Not long ago, the idea of structured sparsification was used in [18, 19] to learn sparse neural networks that leverage tensor arithmetic in dedicated neural processing units (NPUs). In a nutshell, structured sparsity learning amounts to inducing sparsity onto structured components (e.g., channels, filters, or layers) in the neural network during the optimization procedure. This leads, in practice, to both low latency and lower power consumption, which can not be obtained by deploying unstructured sparse models on such modern hardware.
With the goal of enabling structured sparsification learning that can be customized for different NPU devices, in this paper we propose a novel generalized notion of the SEF regularizer to handle group structured sparsification in neural network training. Our new generalized regularization term selects the most essential predefined groups of neurons (which could be convolutional filters, channels, individual neurons, or any other user-defined/NPU definition, where is the total number of groups) and prunes all others, while maintaining minimal network accuracy degradation. We define the new regularization term mathematically, propose an efficient method to calculate its value and proximal operator, and suggest a new algorithm to solve the complete optimization problem involving the non-convex term, which is the composition of the loss function and the neural network output.
Related work.
The topic of regularization-based pruning received a lot of attention in recent years. Generally speaking, these studies can be divided into unstructured and structured pruning. Most prominent regularizers are the convex and norms [20, 21, 3], as well as the non-convex “norm” [22, 9, 23], where Bayesian methods and additional regularization terms for practicality, were used to deal with the non-convexity of the norm. Additional works of [24, 25] suggest methods for norm relaxation by employing minimization in general (nonorthogonal) dictionaries and leading to an error surface with fewer local minima than the norm. The motivation for these regularizers is their “sparsity-inducing” property which can be harnessed to learn sparse neural networks. While these fundamental papers significantly reduce the storage needed to store the networks on hardware, there were no benefits in reducing the inference latency time or either in cutting down power consumption. That is, the sparse neural networks, learned by the aforementioned methods, were not adapted to the tensor arithmetic of the hardware they aimed to run on.
The practical inefficiency of unstructured sparsity-inducing methods has led researchers to propose regularization-based structured pruning in favor of accelerating the running time. For example, [26, 18, 27] proposed the use of the Group Lasso regularization technique to learn sparse structures, and [28] uses Sparse Group Lasso, summing Group Lasso with the standard Lasso penalty. Other convex regularizers include the Combined Group and Exclusive Sparsity (CGES) [29], which extends Exclusive Lasso (in essence, squared over groups) [30] using Group Lasso. Recently, [19] suggested a family of nonconvex regularizers that blend Group Lasso with nonconvex terms (, [31], and SCAD [32]). Since [19] introduces non-convexity term into the penalty, it also requires an appropriate optimization scheme, for which the authors propose an Augmented Lagrangian type method. However, this optimization algorithm has an inner optimization loop with a high computational cost. Moreover, their extensive experiments do not show an accuracy or sparsity advantages over convex penalties, suggesting that it might be still desirable to use a convex regularizer. Other methods, such as [33, 34], focus on a group structure that captures the relations between parameters, neurons, and layers, in order to construct groups that can maximize network compression while minimizing accuracy loss. However, these methods still apply Group Lasso regularization. Specifically in [33], the authors introduce the concept of Zero-Invariant Groups (ZIGs), which includes all input and output connections between layers. In the context of CNNs, it extends the channel-wise grouping [18] to include corresponding batch normalization parameters. By using this group structure, entire blocks of parameters can be removed while keeping dimensions aligned between layers, and ultimately allowing network compression. Moreover, their optimization scheme utilizes a two-phase algorithm to include a half-space projection step, which they name HSPG. Lately, a novel methodology that applies adaptive optimization via weighted proximal operators to induce structured sparsity was suggested in [35] in seamlessly integrating numerical solvers to preserve convergence guarantees, albeit with computational efficiency concerns due to approximation requirements.
Finally, we mention that there exist other techniques for neural net compression, such as, quantization, low-rank decomposition, to name a few. In quantization, [36, 37, 38], the precision of the weights is reduced, by representing weights using a low number of bits (i.e., 8-bit) instead of higher one (i.e., 32-bit floating point values). The low-rank decomposition approach [39, 40, 41, 42] is based on the observation that many weight matrices in neural networks are highly correlated and can be well approximated by matrices with a lower rank. By decomposing a weight matrix into lower-rank matrices, one can reduce the total number of parameters in the network.
Notation.
We denote for the vector of all ones. For a positive integer , we denote . We denote by the component of with the the largest absolute value, meaning in particular that . refers to the number of elements in the set . Let , be an extended real-valued function, then, the conjugate function of , denoted by is defined as , for any . The bi-conjugate function is defined as the conjugate of the conjugate function, i.e., , for any . Finally, the proximal operator of a proper, lower semi-continuous convex function is defined as , for any . The sets and denote all non-negative and positive real numbers, respectively.
2 Structured sparsity via WGSEF
2.1 Problem formulation
In this subsection, we formulate the problem and introduce the weighted group sparse envelop function (WGSEF). Without loss of generality, our method is formulated on weights sparsity, but it can be directly extended to neuron sparsity (i.e., both weights and bias). Let be a dataset consisting of i.i.d. input output pairs . The general neural network training problem is formalized as the following regularized empirical risk minimization procedure on the parameters of a given neural network architecture ,
| (1) |
where, is the hypothesis, that is, a given neural network architecture, corresponds to a loss function, e.g., cross-entropy loss for classification, mean-squared error for regression, etc, is the parameters regularization term, is the regularization magnitude. Below, denotes the number of parameters.
The most predominant regularizer used for DNNs is the weight decay, also known as the norm regularization. It is known to prevent overfitting and to improve generalization since it enforces the weights to decrease proportionally to their magnitudes. The most natural way to force a predefined -level sparsity would be to constrain the number of non-zeros parameters (e.g., the model weights), which can be done by adding the constraint that , where is the required predefined level of sparsity. In this case, the training problem is formalized as follows,
| (2) | ||||
We refer to the above training problem as unstructured sparsification. In the case of structured sparsity, the parameters are divided into predefined disjoint sub-groups. These subgroups could define the building blocks architecture of DNNs, i.e., filters, channels, filter shapes, and layer depth. Consider the following definition.
Definition 1 (Group projection).
Let be a subset of indexes of size . Then, given some vector , the projection preserves only the entries of that belong to the set . Furthermore, let be an diagonal matrix, where if , and zero, otherwise. Note that .
Example 1.
Let , and accordingly , then with , and zero otherwise.
Following the above definition, let subsets be a given (non-overlapping) partition of , namely, , for all , and . Without loss of generality, we assume that ; otherwise, the groups would have different coordinates. Every group is associated with some weight , where , e.g., , namely, we normalize by the group size. For simplicity of notation, let , for . Then, our structured training problem is,
| (3) | |||
To wit, we constrain the number of groups which has at least one non-zero coordinate, to be at most . Let denote the set of all sparse groups, i.e.,
and define as the following extended real-valued function,
Then, the optimization problem in equation 3 can be reformulated as,
| (4) |
where . Equivalently, can be rewritten as , where for every .
The -norm that appears in 4, is a difficult function to handle being nonconvex and even non-continuous, making the problem an untraceable combinatorial NP hard problem [14]. Following the work in [15], one approach to deal with this inherent difficulty is to consider the best convex underestimator of . The later is its bi-conjugate function, namely, , which we refer to as the weighted group sparse envelope function (WGSEF).
Remark 1 (Generalization of SEF).
Consider the case , namely, every subset is a singleton and . Here, , where if and , otherwise. Accordingly, in this case, , and is exactly the classical SEF, namely, . Therefore, is indeed a new generalization of SEF to handle group sparsity.
2.2 Convex relaxation
Let us start by introducing some notation. For any and subgroups of indexes , we denote by the corresponding subgroup of coordinates in with the th largest -norm, i.e.
We next show that the conjugate of the group sparse envelopes is the weighted group hard thresholding function. In the sequel, we let be the diagonal positive-definite weights matrix, such that , and .
Lemma 1 (The weighted group sparse envelop conjugate).
Let subsets be a set of disjoint indexes that partition . Then, for any ,
| (6) |
Next, we obtain the bi-conjugate function of the weighted group sparse envelope. To express the following results explicitly, we will deliberately utilize the group projection definition 1 expressed as , for some set of indices .
Lemma 2 (The variational bi-conjugate weighted group sparse envelop).
Let be a set of disjoint subsets that partition . Then, for any , the bi-conjugate of the group sparse envelop is given by
| (7) |
where,
| (8) |
The following is a straightforward corollary of Lemma 7.
Corollary 2.1.
The following holds:
where is the standard SEF.
The above corollary implies that in order to calculate we only need to apply an algorithm that calculates the SEF at .
Remark 2.
Noting we observe that since is given, the number of operations required to calculate is linear w.r.t. . Thus, the computational complexity of calculating the vector is linear in .
2.3 Proximal mapping of the WGSEF
In this subsection, we will show how to efficiently compute the proximal operator of positive scalar multiples of . The ability to perform such an operation implies that it is possible to employ fast proximal gradient methods to solve equation 5. We begin with the following lemma that shows that the proximal operator can be determined in terms of the optimal solution of a convex problem that resembles the optimization problem defined in Lemma equation 7 for computing .
Lemma 3.
Let , , and be a set of disjoint subsets that partition . Then, is given by
where is the minimizer of
| (9) |
Next, we show that the proximal operator of reduces to an efficient one-dimensional search.
Corollary 3.1 (The proximal operator of ).
The solution of equation 9 with defined as111If , then equation 10 implies that for all .
| (10) |
for , and is a root of the function
| (11) |
which is nondecreasing and satisfies
and,
In addition, can be reformulated as the sum of pairs of the functions
such that,
The following important remarks are in order.
Remark 3 (Root search application for function 11).
Employing the randomized root search method in [15, Algorithm 1] with the one break point piece-wise linear functions , as an input to the algorithm, the root of can be found in time.
Remark 4 (Computational complexity of ).
The computation of boils down to a root search problem (see, Remark 3), which requires operations. In addition, before employing the root search, the assembly of , requires the calculations of the values of defined in Corollary 11. Note that for any calculating is equivalent to . Since ’s are given, the computational complexity of calculating all of is linear in , which is the dimension of . Thus, the total computational operations of calculating summarizes to with is the dimension of all groups parameters together.
3 Optimization procedure
The general training problem we are solving is of the form
| (12) |
where is continuously differentiable, but possibly nonconvex, and is a convex function, but nonsmooth. We adopt the ProxGen [44], which can accommodate momentum, and also has a proven convergence rate with a fixed and reasonable minibatch size of order (a comprehensive discussion on the selection of the optimization method is provided in the appendix A.4).
Next, we provide a convergence guarantee for Algorithm 1, as given in [45]. This result holds under several regularity assumptions which can be found in Appendix A.4.1.
Corollary 3.2.
Forthwith, we propose Algorithm 2, as an implementation of Algorithm 1 to solve equation 5, where and .
Calculating , commonly approached using a propagation algorithm, is at least linear in the number of parameters and is obviously getting more complex as the number of layers increases. Therefore, the calculation of the prox of the WGSEF is not a bottleneck of the update step complexity (since it is linear in the number of parameters). Notice that in our setting, one option is that the regularization may be separable by layer, as indicated by the regularization function’s definition . Therefore, in this case, is applied to each layer separately [43, Theorem 6.6] with different parameters per layer. Another option is that the regularization is applied to all groups’ layers collectively, namely, not in a per-layer fashion, to allow more flexibility in group selection. Formally, in this latter option, only a single pair of values needs to be selected, so . For example, regularization is applied simultaneously on filters across all convolutional layers at once, resulting in different filter sparsity levels in each layer, but overall adhering to the pre-defined filter sparsity level . The only condition for both options is that groups are not overlapping. We note that since Assumptions (C-)–(C-) are met, Algorithm 2 converges to an -stationary point. Another technique for solving equation 12 is using the HSPG family of algorithms in [46, 47]. These algorithms utilize a two-step procedure in which optimization is carried by standard first-order methods (i.e., subgradient or proximal) to find an approximation that is “sufficiently close” to a solution. This step is followed by a half-space step that freezes the sparse groups and applies a tentative gradient step on the dense groups. Over these dense groups, parameters are zeroed-out if a sufficient decrease condition is met, otherwise, a standard gradient step is executed. Notice that the half-space step, as a variant of a gradient method, requires the regularizer term to have a Lipschitz continuous gradient, which is not satisfied in our setting. However, this property is required only for the dense groups as there is no use of the gradient in groups that are already sparse. Since the continuity is violated only for sparse groups, the condition is satisfied in the required region. Finally, while the “sufficiently close” condition mentioned above cannot be verified in practice, simple heuristics to switch between steps still work well. We can either run the first-order step for a fixed number of iterations before switching to the half-space step, or, alternatively, run the first-order step until the sparsity level stabilizes, and then switch to the half-space step. The dense groups are defined as and sparse groups are defined as The HSPG pseudo-code (proximal-gradient variant) is given in Algorithm 3 (in the appendix A.6). We mention the enhanced variant of the standard HSPG algorithm named AdaHSPG+ [47] improves upon that implementing adaptive strategies that optimize performance, focusing on better handling of complex or dynamic problem scenarios where standard HSPG may be less efficient.
4 Experiments
In this section, we present a comprehensive benchmark of structured sparse-inducing regularization techniques. Our evaluation covers a wide range of model architectures, datasets, regularizers, optimizers, and pruning techniques. This extensive benchmarking demonstrates that WGSEF achieves state-of-the-art performance across all these dimensions.
4.1 Evaluation of sparsity-inducing optimization methods
To demonstrate the performance of Algorithm 2 in terms of compression and accuracy, as compared to state-of-the-art prox-SGD-based optimization methods, we use the following well-known DNNs benchmark architectures: VGG16 [48], ResNet18 [49], and MobileNetV1 [50]. These architectures were tested on the datasets CIFAR-10 [51] and Fashion-MNIST [52]. While WGSEF is a regularizer rather than an optimization algorithm, we benchmark it versus the Group Lasso regularizer using various optimization algorithms that are well-known for their superior performance with group sparsity inducing regularization. All experiments were conducted over 300 epochs. For the first 150 epochs, we employed Algorithm 2, and for the leftover epochs, we used the HSPG with the WGSEF acting as a regularizer (i.e., Algorithm 3). Experiments were conducted using a mini-batch size of on an A100 GPU. The coefficient for the WGSE regularizer was set to . In Table 1, we compare our results with those reported in [47]. The primary metrics of interest are the neural network group sparsity ratio, and the prediction accuracy (Top-1). Notably, the WGSE achieves a markedly higher group sparsity compared to all other methods except AdaHSPG+, for which we obtained slightly better results. It should be mentioned that all techniques achieved comparable generalization error rates on the validation datasets.
| Model | Dataset | Prox-SG | Prox-SVRG | HSPG | AdaHSPG+ | WGSEF |
| VGG16 | CIFAR-10 | 54.0 / 90.6 | 14.7 / 89.4 | 74.6 / 91.1 | 76.1 / 91.0 | 76.8 / 91.5 |
| F-MNIST | 19.1 / 93.0 | 0.5 / 92.7 | 39.7 / 93.0 | 51.2 / 92.9 | 51.9 / 92.8 | |
| ResNet18 | CIFAR-10 | 26.5 / 94.1 | 2.8 / 94.2 | 41.6 / 94.4 | 42.1 / 94.5 | 42.6 / 94.5 |
| F-MNIST | 0.0 / 94.8 | 0.0 / 94.6 | 10.4 / 94.9 | 43.9 / 94.9 | 44.2 / 94.9 | |
| MobileNetV1 | CIFAR-10 | 58.1 / 91.7 | 29.2 / 90.7 | 65.4 / 92.0 | 71.5 / 91.8 | 71.8 / 91.9 |
| F-MNIST | 62.6 / 94.2 | 42.0 / 94.2 | 74.3 / 94.5 | 78.9 / 94.6 | 79.1 / 94.5 |
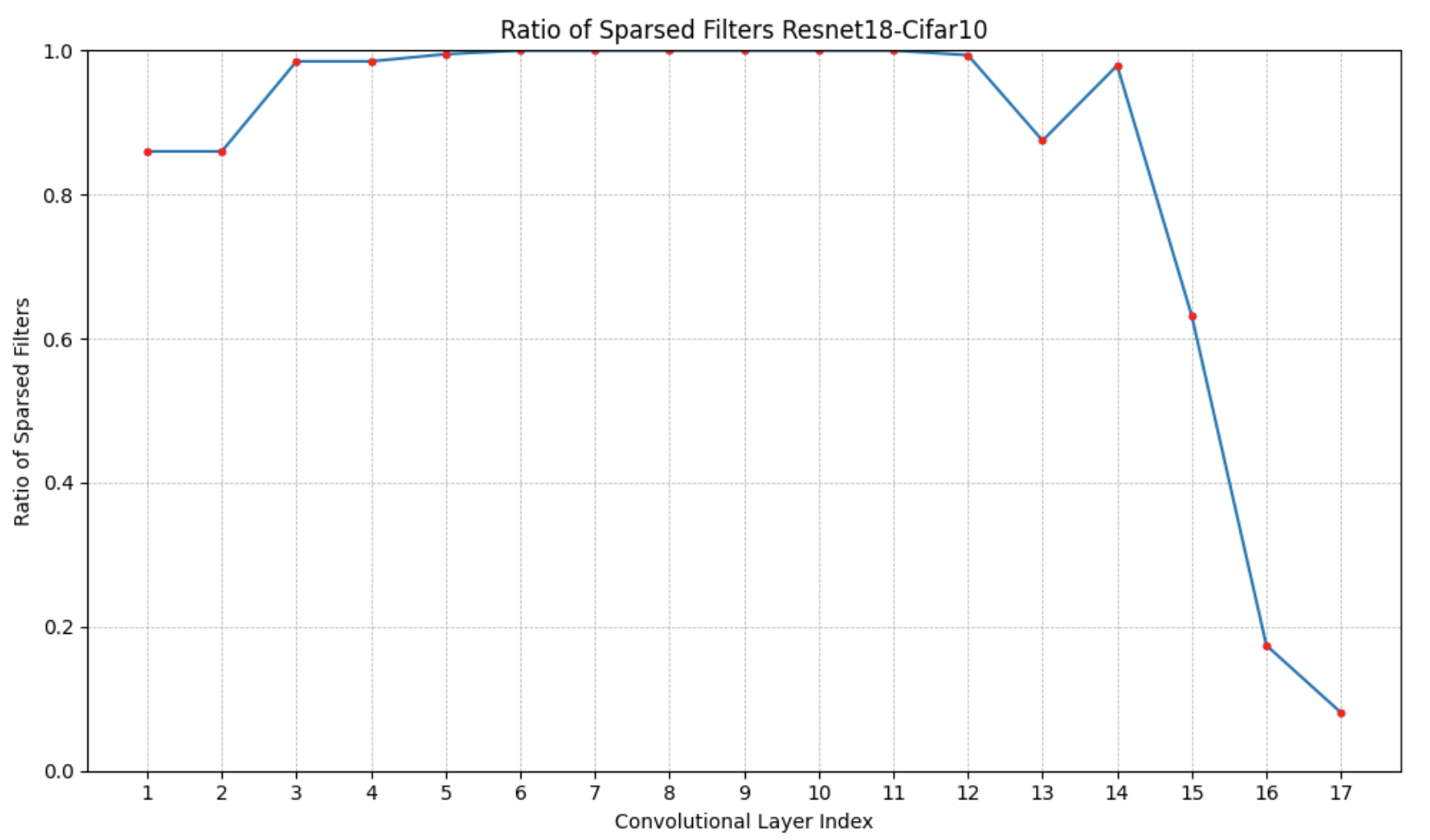
4.2 Evaluation of different sparsity-inducing regularizers
In this experiment, we trained deep residual networks ResNet40 [49] on CIFAR-10, while applying Algorithm 2, with a predefined sparsity level of for all filters in all convolutional layers of the network, over runs. Again, to have a fair comparison, the baseline model was trained using SGD, both with an initial learning rate of , regularization magnitude , a batch size of , and a cosine annealing learning rate scheduler. Our results in Table 2 demonstrate our method’s superiority over state-of-the-art structured sparsity-inducing regularizers. These results are similar to those in [19], and are obtained through a grid search process that varied the magnitude of regularization w.r.t. the sparsity level. Note that the model trained using our method achieved in speedup and reduction in FLOPs.
| Method | Error | Sparsed Filters |
|---|---|---|
| Baseline (SGD) | 6.854% | 0% |
| SGL1 [28] | 7.760% | 50.7% |
| SGL0 [19] | 8.146% | 53.4% |
| SGSCAD [53] | 8.026% | 52.2% |
| SGTL1 [19] | 8.096% | 53.7% |
| SGTL1L2 [54] | 7.968% | 53.7% |
| WGSEF | 7.264% | 54.3% |
4.3 Evaluation of different state-of-the-art pruning techniques on ImageNet
In this subsection, we compare our method to the state-of-the-art pruning techniques, which are often used as an alternative for model compression during (or, post) training. We train Resent50 with ImageNet dataset, using , with an initial learning rate of , sparsity level , and use a cosine annealing learning rate scheduler. In table 3, we compare our results to those obtained by the methods in [33]. We emphasize that, as mentioned later, some of the methods require several stages of training, fine-tuning, etc. Our method trains the model from scratch once, as well as OTO, and thus, this is the most fair comparison. Additionally, it should be noted that all techniques achieved comparable generalization error on the validation datasets, while our method achieved better compression performance as compared to all the other techniques.
| Method | FLOPs | Number of Params | Top-1 Acc. | Top-5 Acc. |
|---|---|---|---|---|
| Baseline | 100% | 100% | 76.1% | 92.9% |
| DDS-26 [55] | 57.0 % | 61.2 % | 71.8 % | 91.9 % |
| CP [56] | 66.7 % | - | 72.3 % | 90.8 % |
| RRBP [57] | 45.4 % | - | 73.0 % | 91.0 % |
| SFP [58] | 41.8 % | - | 74.6 % | 92.1 % |
| Hinge [59] | 46.6 % | - | 74.7 % | - |
| GBN-60[60] | 59.5 % | 68.2 % | 76.2 % | 92.8 % |
| ResRep [61] | 45.5 % | - | 76.2 % | 92.9 % |
| DDS-26 [62] | 57.0% | 61.2% | 71.8% | 91.9% |
| ThiNet-50 [63] | 44.2% | 48.3% | 71.0% | 90.0% |
| RBP [57] | 43.5% | 48.0% | 71.1% | 90.0% |
| GHS [64] | 52.9% | - | 76.4% | 93.1% |
| SCP [65] | 45.7% | - | 74.2% | 92.0% |
| OTO [33] | 34.5% | 35.5% | 74.7% | 92.1% |
| WGSEF | 34.2% | 35.1% | 74.2% | 92.0% |
4.4 Evaluation of different group structures
In this experiment, we demonstrate WGSEF’s performance across various architectures, datasets, and group structures. We specifically compare WGSEF to standard training using SGD without regularization. Our aim is to demonstrate WGSEF’s flexibility by showing its ability to accommodate different group structures, allowing for consideration of the input data, model architecture, hardware properties, etc. We examine the effectiveness of the WGSEF in the LeNet-5 convolutional neural network [66] (the architecture is Pytorch and not Caffe and is given in Appendix A.5), on the MNIST dataset [67]. The networks were trained without any data augmentation. We apply the WGSEF regularization on filters in convolutional layers using a predefined value for the sparsity level . Table 4 summarizes the number of remaining filters at convergence, FLOPs, and the speedups. We evaluate these metrics both for a LeNet-5 baseline (i.e., without sparsity learning), and our WGSEF sparsification technique. To ensure a fair and accurate comparison, the baseline model was trained using SGD. It can be seen that WGSEF reduces the number of filters in the convolution layers by a factor of half, as dictated by , while the accuracy level did not decrease. Furthermore, since the sparsification is structural, there is a significant improvement in FLOPs, as well as in the latency time of inference. Repeating the same experiment, but now constraining the number of non-pruned filters in the second convolutional layer to be at most 4 (i.e., at most quarter of the baseline), the accuracy slightly deteriorates; however, significant improvements can be observed in both the FLOPs number and the speed up, as expected. The networks were trained with a learning rate of , regularization magnitude , and a batch size of for epochs across runs.
|
Error | Filter (sparsity-level) | FLOPs | Speedup | |
|---|---|---|---|---|---|
| Baseline (SGD) | 0.84 | 6-16 | 100 -100 | 1.00 -1.00 | |
| WGSEF | 0.78 | 3-8 | 48.7 -21.6 | 2.06-4.53 | |
| WGSEF | 0.89 | 3-4 | 48.7 -14.7 | 2.06-7.31 | |
| LeNet-5 (MNIST) | Error | Parameters | FLOPs | Speedup | |
| Unstructured WGSEF | 0.76 | 75(/150)-1200(/2400) | 68.7 -59.2 | 1-1 |
In Table 5, we present the results when training both VGG16 and DenseNet40 [68] on CIFAR-100 [69], while applying WGSEF regularization with a predefined sparsity level with half the number of channels for VGG16, and of those for the DenseNet40. The baseline model was trained using SGD, both with an initial learning rate of and regularization magnitude .
|
Model | Error (%) |
|
|
||||||
|---|---|---|---|---|---|---|---|---|---|---|
| VGG16 | Baseline | 26.28 | ||||||||
| WGSEF | 26.46 | |||||||||
| DenseNet40 | Baseline | 25.36 | ||||||||
| WGSEF | 25.6 |
4.5 Impact of sparsification levels on model error and training dynamics
Here, we examine the effectiveness of WGSEF in training the LeNet-5, on the FasionMNIST dataset. The networks were trained without any data augmentation. We apply the WGSEF regularization on filters in convolutional layers using a predefined value for the sparsity level . Table 6 summarizes the number of remaining filters at convergence, FLOPs, and the speedups. We evaluate these metrics both for a LeNet baseline (i.e., without sparsity learning), and our WGSEF sparsification technique. To be accurate and fair in comparison, the baseline model was trained using SGD. We use a learning rate equal to , with a batch size of , a momentum , and epochs.
|
Error |
|
|
|
|||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Baseline | 11.1 | 6-16 | 9 | 1.0 -1.0 | |||||||
| WGSEF | 11 | 3-8 | 5 | 2-4.5 | |||||||
| WGSEF | 14 | 4-6 | 62 | 1.7-6.1 | |||||||
| WGSEF | 12.3 | 2-3 | 1 | 2-7.12 |
The second row of Table 6 shows that our method exhibits a significant decrease in the number of non-zero filters, specifically, half of the filters (groups of parameters) were nullified and at the same time the model performance is improved. The rest of the experiments show that there was a higher sparsification in the number of non-zero filters (groups of parameters), with only a negligible degradation in the model’s accuracy.
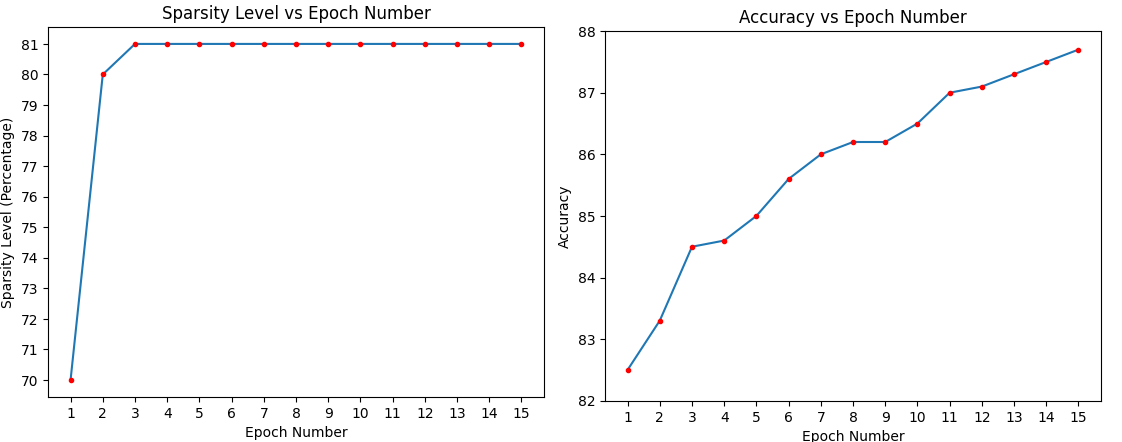
Finally, in Figure 2, we illustrate the sparsity level as a function of the epoch number, during the training of the model which corresponds to the last row of Table 6. The desired (predefined) sparsity level was rapidly attained within the first three epochs, while the model continued to improve its accuracy throughout the remaining epochs without compromising the achieved sparsity.
5 Discussion
In this study, we introduce a novel method for structured sparsification in neural network training, aiming to accelerate neural network inference and compress the neural network memory size, while minimizing the accuracy degradation (or improving accuracy). Our method utilizes a new novel regularizer, termed weighted group sparse envelope function (WGSEF), which is adaptable for pruning different specified neuron groups (e.g convolutional filter, channels), according to the unique requirements of NPU’s tensor arithmetic. Mathematically, the Weighted Group Sparse Envelope Function (WGSEF) represents the optimal convex underestimator of the combined sum of weighted norms and norms. In this context, the norm is applied to the squared norms of each group. During the neural network training, the WGSE regularizer selects the most essential predefined neuron groups, where that controls the compression of the network is configurable to the trainer. Consequently, the trained neural network benefits from reduced inference latency, a more compact size, and decreased power consumption. Additionally, we show that the computational complexity of the prox operator of WGSEF, a key component in the training phase, is linear relative to the number of group parameters. This ensures that it is highly efficient and which does not constitute a bottleneck in the calculation complexity of the training process.
The experimental results show the effectiveness of WGSEF in achieving high compression ratios (reduced memory demand), and speed up in inference, with negligible compromising in accuracy. Compared to the previous approaches, the proposed method stood out in its compression capabilities while maintaining similar network performance.
Along with the method’s ability to predetermine the extent of network compression to be obtained at the training convergence, it is essential to have a prior understanding of the maximum compression level that can be applied without compromising the network’s performance, and accordingly set the parameter. Naturally, it is also necessary to define the groups to which the pruning will be encouraged.
Future research could extend this work by delving into more intricate group definitions such as what could be defined in large language models. Moreover, we suggest studying a different mechanism for assessing the importance of each group being regulraized, as an alternative to the current approach which is based on the group’s squared norm magnitude.
References
- [1] Lei Deng, Guoqi Li, Song Han, Luping Shi, and Yuan Xie. Model compression and hardware acceleration for neural networks: A comprehensive survey. Proceedings of the IEEE, 108(4):485–532, 2020.
- [2] Yu Cheng, Duo Wang, Pan Zhou, and Tao Zhang. A survey of model compression and acceleration for deep neural networks. arXiv preprint arXiv:1710.09282, 2017.
- [3] Song Han, Huizi Mao, and William J. Dally. Deep compression: Compressing deep neural network with pruning, trained quantization and huffman coding. arXiv preprint arXiv:1510.00149, 2015b.
- [4] Karen Ullrich, Edward Meeds, and Max Welling. Soft weight-sharing for neural network compression. arXiv preprint arXiv:1702.04008, 2017.
- [5] Dmitry Molchanov, Arsenii Ashukha, and Dmitry Vetrov. Variational dropout sparsifies deep neural networks. In International Conference on Machine Learning, pages 2498–2507. PMLR, 2017.
- [6] Zeyuan Allen-Zhu, Yuanzhi Li, and Yingyu Liang. Learning and generalization in overparameterized neural networks, going beyond two layers. Advances in neural information processing systems, 32, 2019.
- [7] Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, and Oriol Vinyals. Understanding deep learning (still) requires rethinking generalization. Communications of the ACM, 64(3):107–115, 2021.
- [8] Baoyuan Liu, Min Wang, Hassan Foroosh, Marshall Tappen, and Marianna Pensky. Sparse convolutional neural networks. The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015.
- [9] Song Han, Jeff Pool, John Tran, and William Dally. Learning both weights and connections for efficient neural network. Advances in neural information processing systems, 28, 2015.
- [10] Emily L Denton, Wojciech Zaremba, Joan Bruna, Yann LeCun, and Rob Fergus. Exploiting linear structure within convolutional networks for efficient evaluation. arXiv preprint arXiv:1405.3866, pages 1269–1277, 2014.
- [11] Amir Gholami, Sehoon Kim, Zhen Dong, Zhewei Yao, Michael W Mahoney, and Kurt Keutzer. A survey of quantization methods for efficient neural network inference. In Low-Power Computer Vision, pages 291–326. Chapman and Hall/CRC, 2022.
- [12] Yan Wu, Aoming Liu, Zhiwu Huang, Siwei Zhang, and Luc Van Gool. Neural architecture search as sparse supernet. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 10379–10387, 2021.
- [13] Yibo Yang, Hongyang Li, Shan You, Fei Wang, Chen Qian, and Zhouchen Lin. Ista-nas: Efficient and consistent neural architecture search by sparse coding. Advances in Neural Information Processing Systems, 33:10503–10513, 2020.
- [14] Balas Kausik Natarajan. Sparse approximate solutions to linear systems. SIAM journal on computing, 24(2):227–234, 1995.
- [15] Amir Beck and Yehonathan Refael. Sparse regularization via bidualization. Journal of Global Optimization, 82(3):463–482, 2022.
- [16] Hui Zou and Trevor Hastie. Regularization and variable selection via the elastic net. Journal of the royal statistical society: series B (statistical methodology), 67(2):301–320, 2005.
- [17] Andreas Argyriou, Rina Foygel, and Nathan Srebro. Sparse prediction with the -support norm. Advances in Neural Information Processing Systems, 25, 2012.
- [18] Wei Wen, Chunpeng Wu, Yandan Wang, Yiran Chen, and Hai Li. Learning structured sparsity in deep neural networks. Advances in neural information processing systems, 29, 2016.
- [19] Kevin Bui, Fredrick Park, Shuai Zhang, Yingyong Qi, and Jack Xin. Structured sparsity of convolutional neural networks via nonconvex sparse group regularization. Frontiers in applied mathematics and statistics, page 62, 2021.
- [20] Zhuang Liu, Jianguo Li, Zhiqiang Shen, Gao Huang, Shoumeng Yan, and Changshui Zhang. Learning efficient convolutional networks through network slimming. In Proceedings of the IEEE international conference on computer vision, pages 2736–2744, 2017.
- [21] Jianbo Ye, Xin Lu, Zhe Lin, and James Z Wang. Rethinking the smaller-norm-less-informative assumption in channel pruning of convolution layers. arXiv preprint arXiv:1802.00124, 2018.
- [22] Christos Louizos, Max Welling, and Diederik P Kingma. Learning sparse neural networks through regularization. arXiv preprint arXiv:1712.01312, 2017.
- [23] Christos Louizos, Karen Ullrich, and Max Welling. Bayesian compression for deep learning. Advances in neural information processing systems, 30, 2017.
- [24] David L Donoho and Michael Elad. Optimally sparse representation in general (nonorthogonal) dictionaries via minimization. Proceedings of the National Academy of Sciences, 100(5):2197–2202, 2003.
- [25] Alice Delmer, Anne Ferréol, and Pascal Larzabal. On the complementarity of sparse l0 and cel0 regularized loss landscapes for doa estimation. Sensors, 21(18), 2021.
- [26] Vadim Lebedev and Victor Lempitsky. Fast convnets using group-wise brain damage, 2015.
- [27] Ming Yuan and Yi Lin. Model selection and estimation in regression with grouped variables. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 68(1):49–67, 2006.
- [28] Simone Scardapane, Danilo Comminiello, Amir Hussain, and Aurelio Uncini. Group sparse regularization for deep neural networks. Neurocomputing, 241:81–89, 2017.
- [29] Jaehong Yoon and Sung Ju Hwang. Combined group and exclusive sparsity for deep neural networks. In International Conference on Machine Learning, pages 3958–3966. PMLR, 2017.
- [30] Yang Zhou, Rong Jin, and Steven Chu-Hong Hoi. Exclusive lasso for multi-task feature selection. In Proceedings of the thirteenth international conference on artificial intelligence and statistics, pages 988–995. JMLR Workshop and Conference Proceedings, 2010.
- [31] Yifei Lou, Penghang Yin, Qi He, and Jack Xin. Computing sparse representation in a highly coherent dictionary based on difference of l_1 l 1 and l_2 l 2. Journal of Scientific Computing, 64:178–196, 2015.
- [32] Jianqing Fan and Runze Li. Variable selection via nonconcave penalized likelihood and its oracle properties. Journal of the American statistical Association, 96(456):1348–1360, 2001.
- [33] Tianyi Chen, Bo Ji, Tianyu Ding, Biyi Fang, Guanyi Wang, Zhihui Zhu, Luming Liang, Yixin Shi, Sheng Yi, and Xiao Tu. Only train once: A one-shot neural network training and pruning framework. Advances in Neural Information Processing Systems, 34:19637–19651, 2021.
- [34] Jiashi Li, Qi Qi, Jingyu Wang, Ce Ge, Yujian Li, Zhangzhang Yue, and Haifeng Sun. Oicsr: Out-in-channel sparsity regularization for compact deep neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7046–7055, 2019.
- [35] Tristan Deleu and Yoshua Bengio. Structured sparsity inducing adaptive optimizers for deep learning, 2023.
- [36] Matthieu Courbariaux, Itay Hubara, Daniel Soudry, Ran El-Yaniv, and Yoshua Bengio. Binarized neural networks: Training deep neural networks with weights and activations constrained to+ 1 or-1. arXiv preprint arXiv:1602.02830, 2016.
- [37] Mohammad Rastegari, Vicente Ordonez, Joseph Redmon, and Ali Farhadi. Xnor-net: Imagenet classification using binary convolutional neural networks. In Computer Vision–ECCV 2016, pages 525–542. Springer, 2016.
- [38] Yunchao Gong, Liu Liu, Ming Yang, and Lubomir Bourdev. Compressing deep convolutional networks using vector quantization. arXiv preprint arXiv:1412.6115, 2014.
- [39] Emily L Denton, Wojciech Zaremba, Joan Bruna, Yann LeCun, and Rob Fergus. Exploiting linear structure within convolutional networks for efficient evaluation. Advances in neural information processing systems, 27, 2014.
- [40] Max Jaderberg, Andrea Vedaldi, and Andrew Zisserman. Speeding up convolutional neural networks with low rank expansions. arXiv preprint arXiv:1405.3866, 2014.
- [41] Vadim Lebedev, Yaroslav Ganin, Maksim Rakhuba, Ivan Oseledets, and Victor Lempitsky. Speeding-up convolutional neural networks using fine-tuned cp-decomposition. arXiv preprint arXiv:1412.6553, 2014.
- [42] Yawei Li, Shuhang Gu, Christoph Mayer, Luc Van Gool, and Radu Timofte. Group sparsity: The hinge between filter pruning and decomposition for network compression, 2020.
- [43] Amir Beck. First-order methods in optimization. SIAM, 2017.
- [44] Jihun Yun, Aurélie C Lozano, and Eunho Yang. Adaptive proximal gradient methods for structured neural networks. Advances in Neural Information Processing Systems, 34:24365–24378, 2021.
- [45] Yang Yang, Yaxiong Yuan, Avraam Chatzimichailidis, Ruud JG van Sloun, Lei Lei, and Symeon Chatzinotas. Proxsgd: Training structured neural networks under regularization and constraints. In International Conference on Learning Representations (ICLR) 2020, 2020.
- [46] Tianyi Chen, Guanyi Wang, Tianyu Ding, Bo Ji, Sheng Yi, and Zhihui Zhu. Half-space proximal stochastic gradient method for group-sparsity regularized problem. arXiv preprint arXiv:2009.12078, 2020.
- [47] Yutong Dai, Tianyi Chen, Guanyi Wang, and Daniel Robinson. An adaptive half-space projection method for stochastic optimization problems with group sparse regularization. Transactions on Machine Learning Research, 2023.
- [48] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014.
- [49] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. CoRR, abs/1512.03385, 2015.
- [50] Andrew G Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, and Hartwig Adam. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861, 2017.
- [51] Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009.
- [52] Han Xiao, Kashif Rasul, and Roland Vollgraf. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms. arXiv preprint arXiv:1708.07747, 2017.
- [53] Jinchi Lv and Yingying Fan. A unified approach to model selection and sparse recovery using regularized least squares. 2009.
- [54] Hoang Tran and Clayton Webster. A class of null space conditions for sparse recovery via nonconvex, non-separable minimizations. Results in Applied Mathematics, 3:100011, 2019.
- [55] Zehao Huang, Naiyan Wang, and Naiyan Wang. Data-driven sparse structure selection for deep neural networks, 2018.
- [56] Yihui He, Xiangyu Zhang, and Jian Sun. Channel pruning for accelerating very deep neural networks, 2017.
- [57] Yuefu Zhou, Ya Zhang, Yanfeng Wang, and Qi Tian. Accelerate cnn via recursive bayesian pruning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3306–3315, 2019.
- [58] Yang He, Guoliang Kang, Xuanyi Dong, Yanwei Fu, and Yi Yang. Soft filter pruning for accelerating deep convolutional neural networks, 2018.
- [59] Yawei Li, Shuhang Gu, Christoph Mayer, Luc Van Gool, and Radu Timofte. Group sparsity: The hinge between filter pruning and decomposition for network compression. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8015–8024, 2020.
- [60] Zhonghui You, Kun Yan, Jinmian Ye, Meng Ma, and Ping Wang. Gate decorator: Global filter pruning method for accelerating deep convolutional neural networks, 2019.
- [61] Xiaohan Ding, Tianxiang Hao, Jianchao Tan, Ji Liu, Jungong Han, Yuchen Guo, and Guiguang Ding. Resrep: Lossless cnn pruning via decoupling remembering and forgetting, 2021.
- [62] Hengyuan Hu, Rui Peng, Yu-Wing Tai, and Chi-Keung Tang. Network trimming: A data-driven neuron pruning approach towards efficient deep architectures. arXiv preprint arXiv:1607.03250, 2016.
- [63] Jian-Hao Luo, Jianxin Wu, and Weiyao Lin. Thinet: A filter level pruning method for deep neural network compression. In Proceedings of the IEEE international conference on computer vision, pages 5058–5066, 2017.
- [64] Huanrui Yang, Wei Wen, and Hai Li. Deephoyer: Learning sparser neural network with differentiable scale-invariant sparsity measures. arXiv preprint arXiv:1908.09979, 2019.
- [65] Minsoo Kang and Bohyung Han. Operation-aware soft channel pruning using differentiable masks. In International Conference on Machine Learning, pages 5122–5131. PMLR, 2020.
- [66] Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998.
- [67] Yann LeCun and Corinna Cortes. Mnist handwritten digit database, 2010.
- [68] Gao Huang, Zhuang Liu, Laurens van der Maaten, and Kilian Q. Weinberger. Densely connected convolutional networks, 2018.
- [69] Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton. Cifar-100 (canadian institute for advanced research).
- [70] J v. Neumann. Zur theorie der gesellschaftsspiele. Mathematische annalen, 100(1):295–320, 1928.
- [71] Saeed Ghadimi, Guanghui Lan, and Hongchao Zhang. Mini-batch stochastic approximation methods for nonconvex stochastic composite optimization. Mathematical Programming, 155(1):267–305, 2016.
- [72] Sashank J Reddi, Suvrit Sra, Barnabas Poczos, and Alexander J Smola. Proximal stochastic methods for nonsmooth nonconvex finite-sum optimization. Advances in neural information processing systems, 29, 2016.
- [73] Aaron Defazio, Francis Bach, and Simon Lacoste-Julien. Saga: A fast incremental gradient method with support for non-strongly convex composite objectives. Advances in neural information processing systems, 27, 2014.
- [74] Rie Johnson and Tong Zhang. Accelerating stochastic gradient descent using predictive variance reduction. Advances in neural information processing systems, 26, 2013.
Appendix A Appendix
A.1 Proofs of results in Subsection 2.2
A.1.1 Proof of Lemma 1
Proof.
Let us define the axillary diagonal positive definite matrix , where the entry holds . Now, consider the following chain of equalities:
where, the set is given by
follows by the fact that the sum of the squares of the coordinates of the input vector in the support of the disjoint subset that completes the index space is equal to the sum of squares of the coordinates of the original vector, and follows by the fact that is the sum of square -norm of the disjoint subsets of with the smallest -norm, while is the sum of squared -norm of all disjoint subsets of .
A.1.2 Proof of Lemma 2
Proof.
We first note that
| (13) |
where
| (14) |
Now, Consider the following chain of inequalities:
| (15) | ||||
where follows by the fact that is a self-adjoint matrix, and follows from the fact that the objective function is concave w.r.t. and convex w.r.t , and the MinMax Theorem [70].
A.1.3 Proof of Corollary 2.1
Proof.
Directly by expression .
A.2 Proofs of results in Subsection 2.3
A.2.1 Proof of Lemma 3
Proof.
Recall that
Using Lemma 7, the above minimization problem can be written as
| (16) |
Solving for , we get that for any , if then,
meaning that,
| (17) |
or, equivalently,
| (18) |
Next, we show that is the minimizer of the problem . Equation equation 18 also holds when , since in that case, , for all . Plugging equation 18 in , yields,
| (19) | ||||
| (20) |
which concludes the proof.
A.2.2 Proof of Corollary 3.1
Proof.
Assigning a Lagrange multiplier for the inequality constraint in problem (16), we obtain the Lagrangian function
Therefore, the dual objective function is given by
| (21) |
for, and where for any and , the function is defined in [15] by
| (22) |
Thus, the dual of problem (9) is the maximization problem
| (23) |
A direct projection of Lemma [15, Lemma 2.4] is that if , the function has a unique minimizer over given by where it was shown that
for , otherwise , and the minimizer is given by
Problem (23), is concave differentiable and thus the minimizer holds , meaning
We observe that for any the functions are monotonically continuous nonincresing, and therefore utilizing Lemma [15, Lemma 3.1] is the a root of the nondecreasing function,
Note that for
while
Now, applying Lemma [15, Lemma 3.2], we deduce that , can be divided into the sum of the two following functions,
and thus can be reformulated as follows
A.3 Proof of Corollary 3.2
Proof.
The proof follows from [44, Corollary 1], by taking and .
A.4 Discussion on the selection of the optimization method
The general training problem we are solving is of the form
where is continuously differentiable, but possibly nonconvex, and is a convex function, but possibly nonsmooth. For practical reasons, we cannot store the full gradient . Hence, we would like to use a stochastic gradient type algorithm. However, such a structure posses several difficulties from an optimization perspective, as most research of stochastic first-order algorithms does not account for both nonconvex smooth term and a nonsmooth convex regularize. In [71] the authors provide an analysis of a simple stochastic proximal gradient algorithm, where at each iteration a minibatch of weights is updated using a gradient step followed by a proximal step. This algorithm is proved to converge, however, the rate of convergence depends heavily on the minibatch size, and, in fact, for reasonably sized minibatches it will not converge. [72] proposes variance-reduction type algorithms, but since these extend SAGA [73] and SVRG [74] to the nonconvex and nonsmooth setting, they require storing the gradient for each sample (SAGA) which requires storage, or recomputing the full gradient every iterations (SVRG), which is undesirable for training neural networks.
The ProxSGD algorithm appears appealing to our problem as it allows for momentum. While the algorithm has a convergence guarantee, the authors do not provide the rate, making it less appealing, given the known issue with the minibatch size. We have found the most suitable optimization algorithm to be ProxGen [44], as it can accommodate momentum, and also has a proven convergence rate with a fixed and reasonable minibatch size of order . Next, we provide a convergence guarantee for Algorithm 1, as given in [45]. The convergence is in terms of the subdifferential defined as follows.
Definition 2 (Fréchet Subdifferential).
Let be a real-valued function. The Fréchet subdifferential of at with is defined by
A.4.1 Assumptions
The following assumptions in terms of the objective function and the algorithm parameters are required:
-
(C-)
(-smoothness) The loss function is differentiable, -smooth, and lower-bounded:
-
(C-)
(Bounded variance) The stochastic gradient is unbiased with bounded variance:
-
(C-)
(i) Final step-vector is finite, (ii) the stochastic gradient is bounded, and (iii) the momentum parameter is exponentially decaying, namely,
with and .
Based on these assumptions we can state the following general convergence guarantee.