Learning Manifold Implicitly via Explicit Heat-Kernel Learning
Abstract
Manifold learning is a fundamental problem in machine learning with numerous applications. Most of the existing methods directly learn the low-dimensional embedding of the data in some high-dimensional space, and usually lack the flexibility of being directly applicable to down-stream applications. In this paper, we propose the concept of implicit manifold learning, where manifold information is implicitly obtained by learning the associated heat kernel. A heat kernel is the solution of the corresponding heat equation, which describes how “heat” transfers on the manifold, thus containing ample geometric information of the manifold. We provide both practical algorithm and theoretical analysis of our framework. The learned heat kernel can be applied to various kernel-based machine learning models, including deep generative models (DGM) for data generation and Stein Variational Gradient Descent for Bayesian inference. Extensive experiments show that our framework can achieve state-of-the-art results compared to existing methods for the two tasks.
1 Introduction
Manifold is an important concept in machine learning, where a typical assumption is that data are sampled from a low-dimensional manifold embedded in some high-dimensional space. There have been extensive research trying to utilize the hidden geometric information of data samples [1, 2, 3]. For example, Laplacian eigenmap [1], a popular dimensionality reduction algorithm, represents the low-dimensional manifold by a graph built based on the neighborhood information of the data. Each data point serves as a node in the graph, edges are determined by methods like k-nearest neighbors, and weights are computed using Gaussian kernel. With this graph, one can then compute its essential information such as graph Laplacian and eigenvalues, which can help embed the data points to a k-dimensional space (by using the smallest non-zero eigenvalues and eigenvectors), following the principle of preserving the proximity of data points in both the original and the embedded spaces. Such an approach ensures that as the number of data samples goes to infinity, graph Laplacian converges to the Laplacian-Beltrami operator, a key operator defining the heat equation used in our approach.
In deep learning, there are also some methods try to directly learn the Riemannian metric of manifold other than its embedding. For example, [4] and [5] approximate the Riemannian metric by using the Jacobian matrix of a function, which maps latent variables to data samples.
Different from the aforementioned existing results that try to learn the embedding or Riemannian metric directly, we propose to learn the manifold implicitly by explicitly learning its associated heat kernel. The heat kernel describes the heat diffusion on a manifold and thus encodes a great deal of geometric information of the manifold. Note that unlike Laplacian eigenmap that relies on graph construction, our proposed method targets at a lower-level problem of directly learning the geometry-encoded heat kernel, which can be subsequently used in Laplacian eigenmap or diffusion map [1, 6], where a kernel function is required. Once the heat kernel is learned, it can be directly applied to a large family of kernel-based machine learning models, thus making the geometric information of the manifold more applicable to down-stream applications. There is a recent work [7] utilizing heat kernel in variational inference, which uses a very different approach from ours. Specifically, our proposed framework approximates the unknown heat kernel by optimizing a deep neural network, based on the theory of Wasserstein Gradient Flows (WGFs) [8]. In summary, our paper has the following main contributions.
-
•
We introduce the concept of implicit manifold learning to learn the geometric information of the manifold through heat kernel, propose a theoretically grounded and practically simple algorithm based on the WGF framework.
-
•
We demonstrate how to apply our framework to different applications. Specifically, we show that DGMs like MMD-GAN [9] are special cases of our proposed framework, thus bringing new insights into Generative Adversarial Networks (GANs). We further show that Stein Variational Gradient Descent (SVGD) [10] can also be improved using our framework.
-
•
Experiments suggest that our proposed framework achieves the state-of-the-art results for applications including image generation and Bayesian neural network regression with SVGD.
Relation with traditional kernel-based learning
Our proposed method is also related to kernel selection and kernel learning, and thus can be used to improve many kernel based methods. Compared to pre-defined kernels, our learned kernels can seamlessly integrate the geometric information of the underlying manifold. Compared to some existing kernel-learning methods such as [11, 12], our framework is more theoretically motivated and practically superior. Furthermore, [11, 12] learn kernels by maximizing the Maximum Mean Discrepancy (MMD), which is not suitable when there is only one distribution involved, e.g., learning the parameter manifold in Bayesian Inference.
2 Preliminaries
2.1 Riemannian Manifold
We use to denote manifold, and to denote the dimensionality of manifold . We will only briefly introduce the needed concepts, with formal definitions and details provided in the Appendix. A Riemannian manifold, , is a real smooth manifold associated with an inner product, defined by a positive definite metric tensor , varying smoothly on the tangent space of . Given an oriented Riemannian manifold, there exists a Riemannian volume element [13], which can be expressed in local coordinates as: , where is the absolute value of the determinant of the metric tensor’s matrix representation; and denotes the exterior product of differential forms. The Riemannian volume element allows us to integrate functions on manifolds. Let be a smooth, compactly supported function on manifold . The integral of over is defined as . Now we can define the probability density function (PDF) on manifold [14, 15]. Let be a probability measure on such that . A PDF of on is a real, positive and intergrable function satisfying: .
Ricci curvature tensor plays an important role in Riemannian geometry. It describes how a Riemannian manifold differs from an Euclidean space, represented as the volume difference between a narrow conical piece of a small geodesic ball in manifold and that of a standard ball with a same radius in Euclidean space. In this paper, we will focus on Riemannian manifolds with positive Ricci curvatures.
2.2 Heat Equation and Heat Kernel
The key ingredient in implicit manifold learning is heat kernel, which encodes extensive geodesic information of the manifold. Intuitively, the heat kernel describes the process of heat diffusion on the manifold , given a heat source and time . Throughout the paper, when is assumed to be fixed, we will use to denote for notation simplicity. Heat equation and heat kernel are defined as below.
Definition 1 ([16])
Let be a connected Riemannian manifold, and be the Laplace-Beltrami operator on . The heat kernel is the minimal positive solution of the heat equation: .
Remarkably, heat kernel encodes a massive amount of geometric information of the manifold, and is closely related to the geodesic distance on the manifold.
Lemma 1 ([16])
For an arbitrary Riemannian manifold , as , where is the geodesic distance on manifold and .
This relation indicates that learning a heat kernel also learns the corresponding manifold implicitly. For this reason, we call our method “implicit” manifold learning. It is known that heat kernel is positive definite [17], contains all the information of intrinsic geometry, fully characterizes shapes up to isometry [18]. As a result, heat kernel has been widely used in computer graphics [18, 19].
2.3 Wasserstein Gradient Flows
Let denote the space of probability measures on . Assume that is endowed with a Riemannian geometry induced by 2-Wasserstein distance, i.e., the distance between two probability measures is defined as: , where is the set of joint distribution on satisfying the condition that its two marginals equal to and , respectively. Let be a functional on , mapping a probability measure to a real value. Wasserstein gradient flows describe the time-evolution of a probability measure , defined by a partial differential equation (PDE): , where . Importantly, there is a close relation between WGF and the heat equation on manifold.
Theorem 2 ([20])
Let be a connected and complete Riemannian manifold with Riemannian volume element , and be the Wasserstein space of probability measures on equipped with the 2-Wasserstein distance . Let be a continuous curve in . Then, the followings are equivalent:
1. is a trajectory of the gradient flow for the negative entropy ;
2. is given by for , where is a solution to the heat equation , satisfying: , and for , .
3 The Proposed Framework
Our intuition of learning the heat kernel (thus learning a manifold implicitly) is inspired by Theorem 2, which indicates that one can learn the probability density function (PDF) on the manifold from the corresponding WGF. To this end, we first define the evolving PDF induced by a WGF.
Definition 2 (Evolving PDF)
Let be a connected and complete Riemannian manifold with Riemannian volume element ; be the trajectory of a WGF of negative entropy with initial point . We call the evolving function satisfying the evolving PDF of induced by the WGF.
In the following, we start with some theoretical foundation of heat-kernel learning, which shows that two evolving PDFs induced by the WGF of negative entropy on a given manifold approaches each other at an exponential convergence rate, indicating the learnability of the heat kernel. We then propose an efficient and practical algorithm, where neural network and gradient descent are applied to learn a heat kernel. Finally, we apply our algorithm for Bayesian inference and DGMs as two down-stream applications. All proofs are provided in the Appendix.
3.1 Theoretical Foundation of Heat-Kernel Learning
Our goal in this section is to illustrate the feasibility and convergence speed of heat-kernel learning. We start from the following theorem.
Theorem 3
With the same setting as in Definition 2, suppose the manifold has positive Ricci curvature, let , be two evolving PDFs induced by the WGF of negative entropy with the corresponding probability measures being and , respectively. If , then almost everywhere as . Furthermore, converges to 0 exponentially fast.
Theorem 3 is a natural extension of Proposition 4.4 in [20], which says that two trajectories of WGF for negative entropy would approach each other. We extend their results from probability measures to evolving PDFs. Thus, if one can learn the trajectory of an evolving PDF , it can be used to approximate the true heat kernel (which corresponds to in Theorem 3 by Theorem 2).
One potential issue is that if the heat kernel itself converges fast enough to 0 in the time limit of , the convergence result in Theorem 3 might be uninformative, because one ends up with an almost zero-output function. Fortunately, we can prove that the convergence rate of is faster than that of .
Theorem 4
Let be a complete Riemannian manifold without boundary or compact Riemannian manifold with convex boundary . Suppose the manifold has positive Ricci curvature. Then converges to 0 at most polynomially as .
In addition, we can also prove a lower bound of the heat kernel for the non-asymptotic case of . This plays an important role when developing our practical algorithm. We will incorporate the lower bound into optimization by Lagrangian multiplier in our algorithm.
Theorem 5
Let be a complete Riemannian manifold without boundary or compact Riemannian manifold with convex boundary . If has positive Ricci curvature bounded by and its dimension , we have for and small , where is a constant depending on and such that as , and is the gamma function.
Theorem 5 implies that for any finite time , there is a lower bound of the heat kernel, which depends on the time and manifold shape, and is independent of the distance between and . In fact, there also exists an upper bound [21], which depends on the geodesic distance between and . However, we will show later that the upper bound has little impact in our algorithm, and is thus omitted here.
3.2 A Practical Heat-Kernel Learning Algorithm
We now propose a practical framework to solve the heat-kernel learning problem. We decompose the procedure into three steps: 1) constructing a parametric function to approximate the in Theorem 3; 2) bridging and the corresponding ; and 3) updating by solving the WGF of negative entropy, leading to an evolving PDF . We want to emphasize that by learning to evolve as a WGF, the time is not an explicit parameter to learn.
Parameterization of
We use a deep neural network to parameterize the PDF. Because also depends on , we propose to parameterize as a function with two inputs: , which is the evolving PDF to approximate the heat kernel (with certain initial conditions). To guarantee the positive semi-definite property of a heat kernel, we utilize some existing parameterizations using deep neural networks [9, 11, 12], where [11] is a special case of [12]. We adopt two ways to construct the kernel. The first way is based on [9], where the parametric kernel is constructed as:
| (1) |
The second way is based on [12], and we construct a parametric kernel as:
| (2) |
where in (2), are neural networks, are samples from some implicit distribution which are constructed using neural networks. Details of implementing (2) can be found in [12].
A potential issue with these two methods is that they can only approximate functions whose maximum value is 1, i.e., . In practice, this can be satisfied by scaling it with an unknown time-aware term, , as . Because depends only on and , it can be seen as a constant for fixed time and manifold . As we will show later, the unknown term will be cancelled, and thus would not affect our algorithm.
Bridging and
We rely on the WGF framework to learn the parametrized PDF. To achieve this, note that from Definition 2, and are connected by the Riemannian volume element . Thus, given , if one is able to solve in the WGF, is also readily solved. However, is typically intractable in practice. Furthermore, notice that is a function with two inputs. This means for data samples , there are evolving PDFs and corresponding trajectories , to be solved, which is impractical.
To overcome this challenge, we propose to solving the WGF of , the averaged probability measure of . We approximate the averaged measure by Kernel Density Estimation (KDE) [22]: given samples on a manifold and the parametric function , we calculate the unnormalized average . Consequently, the normalized average satisfying is formulated as:
| (3) |
We can see that the scalar is cancelled, and it will not affect our final algorithm.
Updating
Finally, we are left with solving in the WGF. We follow the celebrated Jordan-Kinderlehrer-Otto (JKO) scheme [23] to solve with the discrete approximation (3). The JKO scheme is rephrased in the following lemma under our setting.
Lemma 6 ([20])
Consider probability measures in . Fix a time step and an initial value with finite 2nd moment. Recursively define a sequence of local minimizer by where denotes the 2-Wasserstein distance. If we further define a discrete trajectory: . Then weakly as for , where is a trajectory of the gradient flow of negative entropy H.
Based on Theorem 5 and Lemma 6 , we know that to learn the kernel function at time , we can use the Lagrange multiplier to define the following optimization problem for time :
| (4) |
where , are hyper-parameters, time step is , is a given probability measure corresponding to a previous time. The last term is introduced to reflect the constraint of reflected in Theorem 5. Also, the Wasserstein term can be approximated using the Sinkhorn algorithm [24]. Our final algorithm is described in Algorithm 1, some discussions are provided in the Appendix. Note that in practice, mini-batch training is often used to ease computational complexity.
3.3 Applications
3.3.1 Learning Kernels in SVGD
SVGD [10] is a particle-based algorithm for approximate Bayesian inference, whose update involves a kernel function . Given a set of particles , at iteration , the particle is updated by
| (5) |
Here is the target distribution to be sampled from. Usually, a pre-defined kernel such as RBF kernel with median trick is used in SVGD. Instead of using pre-defined kernels, we propose to improve SVGD by using our heat-kernel learning method: we learn the evolving PDF and use it as the kernel function in SVGD. By alternating between learning the kernel with Algorithm 1 and updating particles with (5), manifold information can be conveniently encoded into SVGD.
3.3.2 Learning Deep Generative Models
Our second application is to apply our framework to DGMs. Compared to that in SVGD, application in DGMs is more involved because there are actually two manifolds: the manifold of training data and the manifold of the generated data . Furthermore, depends on model parameters , and hence varies during the training process.
Let denote a generator, which is a neural network parameterized by . Let the generated sample be , with random noise following some distribution such as the standard normal distribution. In our method, we assume that the learning process constitutes an manifold flow with representing generator’s training step. After each generator update, samples from the generator are assumed to form an manifold. Our goal is to learn a generator such that approaches . Our method contains two steps: learning the generator and learning the kernel (evolving PDF).
Learning the generator
We adopt two popular kernel-based quantities as objective functions for our generator, the Maximum Mean Discrepancy (MMD) [25] and the Scaled MMD (SMMD) [26], in which our learned heat kernels are used to compute these quantities. MMD and SMMD can be used to measure the difference between distributions. Thus, we update the generator by minimizing them. Details of the MMD and SMMD are given in the Appendix.
Learning the kernel
Different from the simple single manifold setting in Algorithm 1, we consider both the training data manifold and the generated data manifold in learning DGMs. As a result, instead of learning the heat kernel of or , we propose to learn the heat kernel of a new connected manifold, , that integrates both and . We will derive a regularized objective based on (4) to achieve our goal.
The idea is to initialize with one of the two manifolds, and , and then extend it to the other manifold. Without loss of generality, we assume that at the beginning. Note that it is unwise to assume , since and could be very different at the beginning. As a result, might be the only case satisfying , which does not contain any useful geometric information. First of all, we start with by consider in (4). Next, to incorporate the information of , we consider in (4) and regularize it with , where , and is the closest point to on . The regularization constrains to be closed to (extending to ). Since the norm regularization is infeasible to calculate, we will derive an upper bound below and use that instead. Specifically, for kernels of form (1), by Taylor expansion, we have:
| (6) |
where , and denotes the Frobenius norm. Consider in (4) will lead to the same bound because of symmetry.
Finally, we consider in (4) and regularize , where , and are the closest points to and on . A similar bound can be obtained.
Furthermore, instead of directly bounding the multiplicative terms in (6), we find it more stable to bound every component separately. Note that can be bounded from above using spectral normalization [27] or being incorporated into the objective function as in [26]. We do not explicitly include it in our objective function. As a result, incorporating the base learning kernel from (1), our optimization problem becomes:
| (7) | ||||
| (8) |
Our algorithm for DGM with heat kernel learning is shown in Appendix. When SMMD is used as the objective function for the generator, we also scale (3.3.2) by the same factor as scaling SMMD.
Theoretical property and relation with existing methods:
Following the work in [26], we first study the continuity in weak-topology of our kernel when applied in MMD. The continuity in weak topology is an important property because it means that the objective function can provide good signal to update the generator [26], without suffering from sudden jump as in the Jensen-Shannon (JS) divergence or Kullback-Leibler (KL) divergence [28].
Theorem 7
With (6) bounded, MMD of our proposed kernel is continuous in weak topology, i.e., if then , where means convergence in distribution.
Proof of Theorem 7 directly follows Theorem 2 in [26]. Plugging (8) into (3.3.2), it is interesting to see some connections of existing methods with ours: 1) If one sets , our method reduces to MMD-GAN [9]. Furthermore, if the scaled objectives are used, our method reduces to SMMD-GAN [26]; 2) If one sets , our method reduces to the MMD-GAN with repulsive loss [29].
In summary, our method can interpret the min-max game in MMD-based GANs from a kernel-learning point of view, where the discriminators try to learn the heat kernel of some underlying manifolds. As we will show in the experiments, our model achieves the best performance compared to the related methods. Although there are several hyper-parameters in (3.3.2), we have made our model easy to tune due to the connection with GANs. Specifically, one can start by selecting a kernel based GAN, e.g., setting as MMD-GAN, and only tune .
4 Experiments
4.1 A Toy Experiment
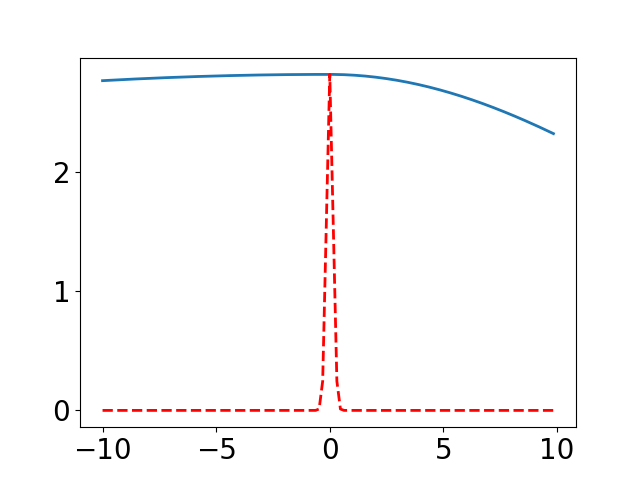
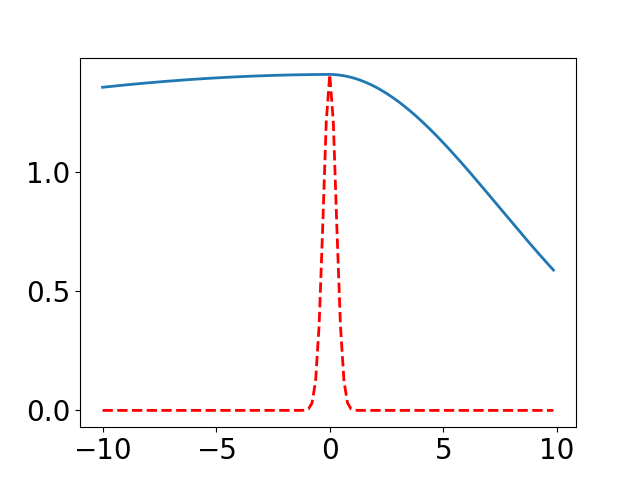
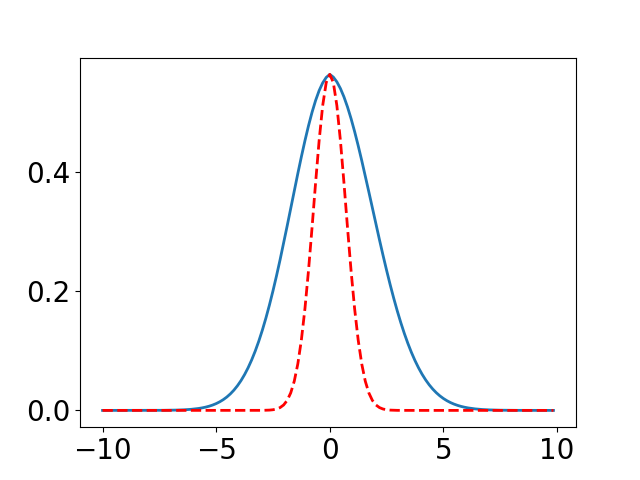
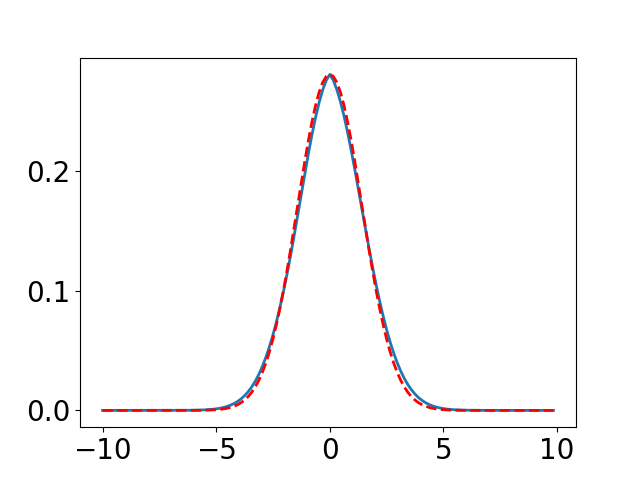
We illustrate the effectiveness of our method by comparing the difference between a learned PDF and the true heat kernel on the real line , i.e., the 1-dimensional Euclidean space. In this setting, the heat kernel has a closed form of , where the maximum value is . We uniformly sample 512 points in as training data, the kernel is constructed by (1), where a 3-layer neural network is used. We assume that every gradient descent update corresponds to time step. The evolution of and are shown in Figure 1.
4.2 Improved SVGD
We next apply SVGD with the kernel learned by our framework for BNN regression on UCI datasets. For all experiments, a 2-layer BNN with 50 hidden units, 10 weight particles, ReLU activation is used. We assign the isotropic Gaussian prior to the network weights. Recently, [30] proposes the matrix-valued kernel for SVGD (denoted as MSVGD-a and MSVGD-m). Our method can also be used to improve their methods. Detailed experimental settings are provided in the Appendix due to the limitation of space. We denote our improved SVGD as HK-SVGD, and our improved matrix-valued SVGD as HK-MSVGD-a and HK-MSVGD-m. The results are reported in Table 1. We can see that our method can improve both the SVGD and matrix-valued SVGD. Additional test log-likelihoods are reported in the Appendix. One potential criticism is that 10 particles are not sufficient to well describe the parameter manifold. We thus conduct extra experiments, where instead of using particles, we use a 2-layer neural network to generate parameter samples for BNN. The results are also reported in the Appendix. Consistently, better performance is achieved.
Combined Concrete Kin8nm Protein Wine Year SVGD HK-SVGD (ours) MSVGD-a MSVGD-m HK-MSVGD-a (ours) HK-MSVGD-m (ours)
4.3 Deep Generative Models
CelebA ImageNet FID IS FID IS WGAN-GP SN-GAN SMMD-GAN SN-SMMD-GAN Repulsive HK (ours) HK-DK (ours) – – CIFAR-10 STL-10 FID IS FID IS DC-GAN architecture WGAN-GP SN-GAN SMMD-GAN SN-SMMD-GAN CR-GAN – – Repulsive HK (ours) HK-DK (ours) ResNet architecture SN-GAN CR-GAN – – Repulsive Auto-GAN HK (ours) HK-DK (ours) BigGAN Setting BigGAN – – – CR-BigGAN – – –
Finally, we apply our framework to high-quality image generation. Four datasets are used in this experiment: CIFAR-10, STL-10, ImageNet, CelebA. Following [26, 29], images are scaled to the resolution of , and respectively. Following [26, 27], we test 2 architectures on CIFAR-10 and STL-10, 1 architecture on CelebA and ImageNet. We report the standard Fréchet Inception Distance (FID) [31] and Inception Score (IS) [32] for evaluation. Architecture details and some experiments settings can be found in Appendix.
We compared our method with some popular and state-of-the-art GAN models under the same experimental setting, including WGAN-GP [33], SN-GAN[27], SMMD-GAN, SN-SMMD-GAN [26], CR-GAN [34], MMD-GAN with repulsive loss [29], Auto-GAN [35]. The results are reported in Table 2 where HK and HK-DK represent our model with kernel (1) and (2). More results are provided in the Appendix. HK-DK exhibits some convergence issues on CelebA, hence no result is reported. We can see that our models achieve the state-of-the-art results (under the same experimental setting such as the same/similar architectures). Furthermore, compared to Auto-GAN, which needs 43 hours to train on the CIFAR-10 dataset due to the expensive architecture search, our method (HK with ResNet architecture) needs only 12 hours to obtain better results. Some randomly generated images are also provided in the Appendix.
5 Conclusion
We introduce the concept of implicit manifold learning, which implicitly learns the geometric information of an unknown manifold by learning the corresponding heat kernel. Both theoretical analysis and practical algorithm are derived. Our framework is flexible and can be applied to general kernel-based models, including DGMs and Bayesian inference. Extensive experiments suggest that our methods achieve consistently better results on different tasks, compared to related methods.
Broader Impact
We propose a fundamentally novel method to implicitly learn the geometric information of a manifold by explicitly learning its associated heat kernel, which is the solution of heat equation with initial conditions given. Our proposed method is general and can be applied in many down-stream applications. Specifically, it could be used to improve many kernel-related algorithms and applications. It may also inspire researchers in deep learning to borrow ideas from other fields (mathematics, physics, etc.) and apply them to their own research. This can benefit both fields and thus promote interdisciplinary research.
Acknowledgements
The research of the first and third authors was supported in part by NSF through grants CCF-1716400 and IIS-1910492.
References
- [1] Mikhail Belkin and Partha Niyogi. Laplacian eigenmaps for dimensionality reduction and data representation. Neural computation, 15(6):1373–1396, 2003.
- [2] Joshua B Tenenbaum, Vin De Silva, and John C Langford. A global geometric framework for nonlinear dimensionality reduction. science, 290(5500):2319–2323, 2000.
- [3] Sam T Roweis and Lawrence K Saul. Nonlinear dimensionality reduction by locally linear embedding. science, 290(5500):2323–2326, 2000.
- [4] Georgios Arvanitidis, Lars Kai Hansen, and Søren Hauberg. Latent space oddity: on the curvature of deep generative models, 2017.
- [5] Hang Shao, Abhishek Kumar, and P. Thomas Fletcher. The riemannian geometry of deep generative models, 2017.
- [6] Ronald R Coifman and Stéphane Lafon. Diffusion maps. Applied and computational harmonic analysis, 21(1):5–30, 2006.
- [7] Dimitris Kalatzis, David Eklund, Georgios Arvanitidis, and Søren Hauberg. Variational autoencoders with riemannian brownian motion priors. arXiv preprint arXiv:2002.05227, 2020.
- [8] Luigi Ambrosio, Nicola Gigli, and Giuseppe Savaré. Gradient flows: in metric spaces and in the space of probability measures. Springer Science & Business Media, 2008.
- [9] Chun-Liang Li, Wei-Cheng Chang, Yu Cheng, Yiming Yang, and Barnabás Póczos. Mmd gan: Towards deeper understanding of moment matching network. In Advances in Neural Information Processing Systems, pages 2203–2213, 2017.
- [10] Qiang Liu and Dilin Wang. Stein variational gradient descent: A general purpose bayesian inference algorithm. In Advances in neural information processing systems, pages 2378–2386, 2016.
- [11] Chun-Liang Li, Wei-Cheng Chang, Youssef Mroueh, Yiming Yang, and Barnabas Poczos. Implicit kernel learning. In The 22nd International Conference on Artificial Intelligence and Statistics, pages 2007–2016, 2019.
- [12] Yufan Zhou, Changyou Chen, and Jinhui Xu. Kernelnet: A data-dependent kernel parameterization for deep generative modeling, 2019.
- [13] John M Lee. Riemannian manifolds: an introduction to curvature, volume 176. Springer Science & Business Media, 2006.
- [14] Xavier Pennec. Probabilities and statistics on riemannian manifolds: Basic tools for geometric measurements. Citeseer, 1999.
- [15] Omer Bobrowski and Sayan Mukherjee. The topology of probability distributions on manifolds. Probability theory and related fields, 161(3-4):651–686, 2015.
- [16] Alexander Grigor’yan, Jiaxin Hu, and Ka-Sing Lau. Heat kernels on metric measure spaces. In Geometry and analysis of fractals, pages 147–207. Springer, 2014.
- [17] John Lafferty and Guy Lebanon. Diffusion kernels on statistical manifolds. J. Mach. Learn. Res., 6:129–163, December 2005.
- [18] Jian Sun, Maks Ovsjanikov, and Leonidas Guibas. A concise and provably informative multi-scale signature based on heat diffusion. In Computer graphics forum, volume 28, pages 1383–1392. Wiley Online Library, 2009.
- [19] Keenan Crane, Clarisse Weischedel, and Max Wardetzky. Geodesics in heat: A new approach to computing distance based on heat flow. ACM Transactions on Graphics (TOG), 32(5):152, 2013.
- [20] Matthias Erbar. The heat equation on manifolds as a gradient flow in the wasserstein space. In Annales de l’IHP Probabilités et statistiques, volume 46, pages 1–23, 2010.
- [21] Peter Li and Shing Tung Yau. On the parabolic kernel of the schrödinger operator. Acta Mathematica, 156(1):153–201, 1986.
- [22] Zdravko I Botev, Joseph F Grotowski, Dirk P Kroese, et al. Kernel density estimation via diffusion. The annals of Statistics, 38(5):2916–2957, 2010.
- [23] Richard Jordan, David Kinderlehrer, and Felix Otto. The variational formulation of the fokker–planck equation. SIAM journal on mathematical analysis, 29(1):1–17, 1998.
- [24] Marco Cuturi. Sinkhorn distances: Lightspeed computation of optimal transport. In C. J. C. Burges, L. Bottou, M. Welling, Z. Ghahramani, and K. Q. Weinberger, editors, Advances in Neural Information Processing Systems 26, pages 2292–2300. Curran Associates, Inc., 2013.
- [25] Arthur Gretton, Karsten Borgwardt, Malte Rasch, Bernhard Schölkopf, and Alex J Smola. A kernel method for the two-sample-problem. In Advances in neural information processing systems, pages 513–520, 2007.
- [26] Michael Arbel, Dougal Sutherland, MikoNaj Bińkowski, and Arthur Gretton. On gradient regularizers for mmd gans. In Advances in Neural Information Processing Systems, pages 6700–6710, 2018.
- [27] Takeru Miyato, Toshiki Kataoka, Masanori Koyama, and Yuichi Yoshida. Spectral normalization for generative adversarial networks. In International Conference on Learning Representations, 2018.
- [28] Martin Arjovsky, Soumith Chintala, and Léon Bottou. Wasserstein generative adversarial networks. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pages 214–223, 2017.
- [29] Wei Wang, Yuan Sun, and Saman Halgamuge. Improving mmd-gan training with repulsive loss function. In International Conference on Learning Representations, 2018.
- [30] Dilin Wang, Ziyang Tang, Chandrajit Bajaj, and Qiang Liu. Stein variational gradient descent with matrix-valued kernels. In Advances in neural information processing systems, pages 7836–7846, 2019.
- [31] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In Advances in neural information processing systems, pages 6626–6637, 2017.
- [32] T. Salimans, I. Goodfellow, W. Zaremba, V. Cheung, A. Radford, and X. Chen. Improved techniques for training GANs. In NIPS, 2016.
- [33] Ishaan Gulrajani, Faruk Ahmed, Martin Arjovsky, Vincent Dumoulin, and Aaron C Courville. Improved training of wasserstein gans. In Advances in neural information processing systems, pages 5767–5777, 2017.
- [34] Han Zhang, Zizhao Zhang, Augustus Odena, and Honglak Lee. Consistency regularization for generative adversarial networks. In International Conference on Learning Representations, 2020.
- [35] Xinyu Gong, Shiyu Chang, Yifan Jiang, and Zhangyang Wang. Autogan: Neural architecture search for generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, pages 3224–3234, 2019.
- [36] Shun-ichi Amari and Hiroshi Nagaoka. Methods of information geometry, volume 191. American Mathematical Soc., 2007.
- [37] Sigmundur Gudmundsson. An Introduction to Riemannian Geometry - Lecture Notes in Mathematics. Lund University, 2018.
- [38] Karl-Theodor Sturm et al. On the geometry of metric measure spaces. Acta mathematica, 196(1):65–131, 2006.
- [39] Alec Radford, Luke Metz, and Soumith Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint arXiv:1511.06434, 2015.
- [40] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016.
- [41] MikoNaj Bińkowski, Dougal J Sutherland, Michael Arbel, and Arthur Gretton. Demystifying mmd gans. In International Conference on Learning Representations, 2018.
Appendix A Riemannian Manifold
Definition 3 (Manifold)
[36] Let be a set. If there exists a set of coordinate systems for satisfying the conditions below, is called an -dimensional differentiable manifold, or simply manifold.
-
1.
Each element of is a one-to-one mapping from to some open subset of ;
-
2.
For all , given any one-to-one mapping from to , the following holds:
By diffeomorphism, we mean that and its inverse are both (infinitely many times differentiable). Infinitely differentiable is not necessary actually, we may consider this notation as ’sufficiently smooth’.
We will use to denote the tangent space of at point , and to denote the vector fields.
Definition 4 (Riemannian Metric and Riemannian Manifold)
[37] Let be a manifold, be the comminicative ring of smooth functions on , and be the set of smooth vector fields on forming a module over . A Riemannian metric on is a tensor field such that for each , the restriction of to the tensor product with:
is a real scalar product on the tangent space . The pair is called a Riemannian manifold. The geometric properties of which depend only on the metric are said to be intrinsic or metric properties.
One classical example is that the Riemannian manifold is nothing but the m-dimensional Euclidean space.
The Riemannian curvature tensor of a manifold is defined by
on vector fields . For any two tangent vector , we use to denote the Ricci tensor evaluated at , which is defined to be the trace of the mapping given by .
We use to denote that a manifold’s Ricci curvature is bounded from below by , in the sense that for all .
Appendix B Proof of Theorem 3
Theorem 3 Let be a connected, complete Riemannian manifold with Riemannian volume element and positive Ricci curvature. Assume that the heat kernel is Lipschitz continous. Let , be two evolving PDFs induced by WGF for negative entropy as defined in Definition 2, their corresponding probability measure are and . If , then almost everywhere as ; furthermore, converges to 0 exponentially fast.
Proof We start by introducing the following lemma, which is Proposition 4.4 in [20].
Lemma 8 ([20])
Assume . Let and be two trajectories of the gradient flow of negative entropy functional with initial distribution and , respectively, then
In particular, for a given initial value , there is at most one trajectory of the gradient flow.
What we need to do is to extend the results of Lemma 8 from probability measures to probability density functions. Following some previous work, we first define the projection operator.
Definition 5 (Projection Operator)
[8] Let denote the projection operators defined on the product space respectively such that:
if , the marginals of are the probability measures
We then introduce the following lemma which utilize the projection operator.
Lemma 9
[8] Let , , be a sequence of Radon separable metric spaces, and , , where denotes the 2-plan (i.e. transportation plan between two distributions) with given marginals . Let , with the canonical product topology. Then there exist such that
| (9) |
Now we are ready to prove the theorem.
Appendix C Proof of Theorem 4 and Theorem 5
Theorem 5 Let be a complete Riemannian manifold without boundary or compact Riemannian manifold with convex boundary . If has positive Ricci curvature bounded by and its dimension . Let be the heat kernel of
where denotes the outward-pointing unit normal to boundary . Then
for and small , where is a constant depending on and such that as , and is the gamma function.
Proof We start by introducing the following lemma:
Lemma 10
[21] Let be a complete Riemannian manifold without boundary or compact Riemannian manifold with convex boundary . Suppose that the Ricci curvature of is non-negative. Let be the heat kernel of
Then, the heat kernel satisfies
for some constant depending on and such that as , where denotes the geodesic ball with radius around . Moreover, by symmetrizing,
Lemma 10 comes from the Theorem 4.1 and Theorem 4.2 in [21]. Then we need to introduce the definition of CD condition and Lemma 11.
Definition 6 (CD condition)
[38] For Rimennian manifold , the curvature-dimension (CD) condition is satisfied if and only if the dimension of manifold is less or equal to d and Ricci curvature is bounded from below by .
Lemma 11
[38] For every metric measure space which satisfies the curvature-dimension condition for some real numbers and , the support of is compact and has diameter
where the diameter is defined as
Now we are ready to prove the Theorem.
Let be a complete Riemannian manifold with positive Ricci curvature and dimension , then
Because Euclidean Space can be seen as a manifold with constant sectional curvature 0. By Bishop-Gromov inequality we have the following for manifold with non-negative Ricci curvature:
i.e. the volume of a geodesic ball with radius around is less than the ball with same radius in a -dimensional Euclidean space. According to the volume of n-ball, we have
Thus we have
Using Lemma 10, we have:
Using Lemma 11 and , we have:
We now can conclude Theorem 5.
The term is increasing, and is decreasing polynomially. We can see that the lower bound of heat kernel decrease to 0 polynomially with respect to t. Thus heat kernel value decrease to 0 at most polynomially with respect to t.
Theorem 4 Let be a complete Riemannian manifold without boundary or compact Riemannian manifold with convex boundary . Assume it has positive Ricci curvature. denotes its Riemannian volume element. Let be the heat kernel of
where denotes the outward-pointing unit normal to boundary . Then converges to 0 at most polynomially as , which is slower than .
Appendix D MMD and SMMD
In our proposed method for deep generative models, MMD is used as the objective function for the generator, which is defined as:
| (10) |
where are probability distributions of the training data and the generated data, respectively. MMD measures the difference between two distributions. Thus, we want it to be minimized.
Generator can also use SMMD [26] as the objective function, which is defined as:
| (11) |
where is the dimensionality of the data, denotes the element of , and is a hyper-parameter.
Appendix E Algorithms
E.1 Algorithms for DGM with heat kernel learning
First of all, let’s introduce a similar objective function for kernel with form (2), which can be used to replace (3.3.2).
Similarly to (6), for kernels with form (2), we have the following bound:
| (12) | ||||
Incorporating this bound into objective as (3.3.2), the optimization problem for learning kernel with form (2) becomes:
| (13) | ||||
Now we present the algorithm of DGM with heat kernel learning here.
E.2 Some discussions
Instead of initializing the by Equation (3), we can also simply initialize it to be , which represents the discrete uniform distribution. In this case, we set the for time to be
where unknown constant is also cancelled.
To approximate , we may use either
or
In practice, these different implementations may need different hyper-parameter settings, and have different performances. Furthermore, we observed that using unnormalized density estimation instead of also leads to competitive results.
Appendix F Experimental Results and Settings on Improved SVGD
We provide some experimental settings here. Our implementation is based on TensorFlow with a Nvidia 2080 Ti GPU. To simplify the setting, the RBF-kernel is used in all layers except the last one, which is learned by our method (1) with a 2-layer neural network.In other words, we only learn the parameter manifold for the last layer. Following [30], we run 20 trials on all the datasets except for Protein and Year, where 5 trials are used. At each trial, we randomly choose of the dataset as the training set, and the rest as the testing set. For large datasets like Year and Combined, we use the Adam optimizer with a batch size of 1000, and use batch size of 100 for all other datasets. Before every update of the BNN parameters, we run Algorithm 1 with ; and 5 Adam update steps are implemented to solve (4). For matrix-valued SVGD, We use the same experimental setting, except that the number of update steps for solving (4) is chosen from , based on hyper-parameter tuning.
We report the average test log-likelihood in Table 3, from which we can also see that our proposed method improves model performance.
Combined Concrete Kin8nm Protein Wine Year SVGD HK-SVGD (ours) MSVGD-a MSVGD-m HK-MSVGD-a (ours) HK-MSVGD-m (ours)
Instead of using particles, we further improve our proposed HK-SVGD by introducing a parameter generator, which takes Gaussian noises as inputs and outputs samples of parameter distribution for BNNs. We use a 2-layer neural network to model this generator, 10 samples are generated at each iteration. We denote the resulting model as HK-ISVGD, and compare it with vanilla SVGD and our proposed HK-SVGD. Results on UCI regression are shown in Table 4 and Table 5. We can see that introducing the parameter sample generator will lead to performance improvement on most of the datasets.
Combined Concrete Kin8nm Protein Wine Year SVGD HK-SVGD (ours) HK-ISVGD (ours)
Combined Concrete Kin8nm Protein Wine Year SVGD HK-SVGD (ours) HK-ISVGD (ours)
Appendix G Model Architectures and Some Experiments Settings on DGM
We provide some experimental details of image generation here. Our implementation is based on TensorFlow with a Nvidia 2080 Ti GPU.
For CIFAR-10 and STL-10, we test them on 2 architectures: DC-GAN based [39] and ResNet based architectures [40, 41]. The DC-GAN based architecture contains a 4-layer convolutional neural network (CNN) as the generator, with a 7-layer CNN representing in (1) and (2). In the ResNet based architecture, the generator and are both 10-layer ResNet. For ImageNet, we use the same ResNet based architecture as CIFAR-10 and STL-10. For CelebA, the generator is a 10-layer ResNet, while is a 4-layer CNN.
For CIFAR-10, STL-10 and ImageNet, spectral normalization is used, while we scale the weights after spectral normalization by 2 on CIFAR-10 and STL-10. We set , for the Adam optimizer and , in Algorithm 2. Only one step Adam update is implemented for solving (3.3.2). Output dimension of is set to be 16. For all the experiments with kernel (2), both and are parameterized by 2-layer fully connected neural networks.
For CelebA, we scale the kernel learning objective, i.e. (3.3.2), by in as SMMD. Spectral regularization [26] is used. We set , for the Adam optimizer and , , in Algorithm 2. Only one step Adam update is implemented for solving (3.3.2). Output dimension of is set to be 1, because scaled objective with dimension larger than 1 is time consuming.
As for evaluation, CIFAR-10, STL-10 and ImageNet are evaluated on 100k generated images, while CelebA is evaluated on 50k generated images due to the memory limitation.
Appendix H More Results on Image Generation










