Learning Monocular Depth Estimation via Selective Distillation of Stereo Knowledge
Abstract
Monocular depth estimation has been extensively explored based on deep learning, yet its accuracy and generalization ability still lag far behind the stereo-based methods. To tackle this, a few recent studies have proposed to supervise the monocular depth estimation network by distilling disparity maps as proxy ground-truths. However, these studies naively distill the stereo knowledge without considering the comparative advantages of stereo-based and monocular depth estimation methods. In this paper, we propose to selectively distill the disparity maps for more reliable proxy supervision. Specifically, we first design a decoder (MaskDecoder) that learns two binary masks which are trained to choose optimally between the proxy disparity maps and the estimated depth maps for each pixel. The learned masks are then fed to another decoder (DepthDecoder) to enforce the estimated depths to learn from only the masked area in the proxy disparity maps. Additionally, a Teacher-Student module is designed to transfer the geometric knowledge of the StereoNet to the MonoNet. Extensive experiments validate our methods achieve state-of-the-art performance for self- and proxy-supervised monocular depth estimation on the KITTI dataset, even surpassing some of the semi-supervised methods.

1 Introduction
Depth estimation is one of the pivotal computer vision tasks widely used in many applications such as 3D reconstruction, autonomous driving, augmented reality, etc. Among several methods of obtaining depth information from images, monocular depth estimation aims to infer the depth from a single image. Thanks to the wide applications, low cost and small size of monocular cameras, monocular depth estimation has been extensively studied along with the recent development of deep learning and convolutional neural networks(CNNs). However, one of the biggest challenges of supervised monocular depth estimation [2, 30, 14, 12, 29, 13, 51] is that it requires a huge amount of expensive ground-truths. Utilizing synthetic data might be a possible solution for this issue, but training a monocular depth estimation network with synthetic datasets and evaluating it on real datasets is less applicable due to the large domain gap between the synthetic and real data. Alternatively, self-supervised monocular depth estimation methods [18, 37, 19, 38, 24, 51, 20, 6, 15] have been actively explored to reduce the photometric error between the reference image and the depth-projected image. However, as the depth projection is based on the view synthesis of the input images, it is sensitive to the input domain changes. Moreover, the accuracy is often less comparable to that of the supervised methods due to the inherent ambiguity of self-supervised loss functions [46].
To alleviate the aforementioned issues, a few recent works [22, 42, 46] have been proposed to use the disparity maps predicted by the stereo networks or traditional stereo matching methods such as Semi Global Matching (SGM) [23] as proxy ground-truths. They assume that the stereo-based methods generally provide better accuracy and have better generalization ability to other domains, to train monocular depth estimation networks. However, it is possible that monocular depth estimation could perform better than stereo-based methods in some areas. For instance, as shown in Fig. 1, stereo vision does not properly provide depth information in some areas, \eg, the occluded, textureless and reflective areas; while monocular depth estimation methods suffer less from such problems in these areas as it requires only a single view. Conversely, monocular depth estimation is ill-posed since the size of objects is ambiguous, which can be improved by geometric cues from disparity maps. The problem is that earlier studies do not take account of these crucial considerations.
Inspired by these studies, this paper proposes a novel approach by transferring stereo knowledge to the monocular depth estimation network, in consideration of the comparative advantage of stereo and monocular depth estimation methods. A stereo network that is pre-trained on a large amount of synthetic data is first adopted as a proxy supervisory network for learning monocular depth estimation. The pre-trained stereo network predicts the proxy disparity maps given a pair of stereo images. At this step, unlike other works [22, 42, 46] that directly leverage the disparity maps as proxy ground-truths, we design a novel decoder (MaskDecoder) which learns binary masks to selectively distill the proxy disparity maps. The learned masks indicate whether the proxy disparity maps provide superior pixel-wise estimation to the currently-estimated monocular depth maps or not. In other words, they imply the estimation can be improved if the masked pixels are guided by the proxy disparity map. To be more specific, every pixel in a learned binary mask selects either the proxy disparity(1) or the estimated depth(0) to define a dense virtual disparity map. The virtual disparity map is then optimized by the image reconstruction loss and edge-aware smoothness loss functions, which is equivalent to optimizing the selection of the binary masks. We elaborate the details in Sec. 3 and verify the selective distillation leads to superior accuracy to the direct distillation method. Moreover, as the MonoEncoder extracts features from only a single image, we further improve the accuracy of the monocular depth estimation by employing a novel Teacher-Student (T-S) module [45] between the both encoders of stereo and monocular networks. The T-S module aims to transfer the geometric knowledge from the StereoEncoder (Teacher) to the MonoEncoder (Student). We analyze the effectiveness of each proposed method and evaluate our framework on the KITTI dataset [16]. The experimental results show that the proposed methods achieve state-of-the-art performance compared to other self-, proxy- and semi-supervised monocular depth estimation networks.
2 Related work
In this section, we review the relevant stereo and monocular depth estimation literature and introduce several works that distill proxy supervision into the depth estimation.
Stereo depth estimation Stereo depth estimation aims to recover depth information by computing disparity from the correspondence across two images. According to [40], the traditional stereo depth estimation follows a typical pipeline consisting of four steps: matching cost computation, cost aggregation, optimization and disparity refinement. In this pipeline, CNNs [49, 8, 50, 31] have been usually utilized to compute matching costs between two sampled patches, replacing the conventional steps. However, since these methods rely on patch-similarity computation, they typically fail to incorporate context information for accurate depth estimation in ambiguous areas. To tackle this issue, some approaches [34, 25, 4] take advantage of contextual information from features of various scales in an end-to-end manner. Specifically, Mayer et al. [34] first propose an end-to-end network that deploys a 1D correlation layer called DispNetC. Nonetheless, most stereo networks still inherently struggle to handle textureless, reflective and strongly occluded areas in the stereo images.
Monocular depth estimation In contrast to the stereo-based methods, monocular depth estimation infers depth information from only a single image, yet an inherently ill-posed problem since pixels in the image can have multiple possible depths. Nevertheless, with the availability of ground-truth depth maps, CNN-based supervised learning methods [2, 30, 14, 12, 29, 13] have recently been sought. Although they have achieved remarkable results in accuracy, they often stuck in undesirable local optima. Moreover, obtaining labeled data or annotating ground-truths is costly in itself. Alternatively, numerous self-supervised methods have been proposed to overcome the dependence on the ground-truths. Garg et al. [15] first formulate the self-supervised monocular depth estimation through photometric coherence between stereo images. Godard et al. [18] further improve [15] by imposing a left-right consistency to the estimated disparity maps. Poggi et al. [38] more recently recast the training strategy of [18] to assume that three images aligned horizontally are available at training phase, overcoming the limitations caused by the binocular setup. Godard et al. [19] have extended their previous work [18] by their novel reprojection loss, auto-masking strategy and upsampling its depth estimations to the input resolution. Besides, a variety of monocular depth estimation methods have been explored with the aid of semantic segmentation [6], self-attention module [7, 24], camera intrinsic parameters [20] and generative adversarial networks [1, 10, 3], to name a few.
Proxy-supervised depth estimation No matter how the monocular depth estimation methods have been advanced, stereo-based methods are still generally known to provide better accuracy and have better generalization ability to other domains during evaluation than most monocular depth estimation networks. As a way of leveraging these advantages, a few recent works have suggested utilizing disparity maps from stereo vision as proxy ground-truths instead of expensive ground-truths to learn monocular depth estimation. Tosi et al. [42] suggest utilizing the SGM to generate disparity maps and distilling it as proxy labels for the proxy-supervised loss as well as the self-supervised loss for monocular depth estimation. Watson et al. [46] propose to generate a number of disparity maps by SGM to use them as depth hints for the network to escape from local minima. Since both works have utilized the traditional stereo methods, it is less time-consuming and provides more disparity maps than learning-based stereo methods. Rather than utilizing conventional methods(i.e, non-learning methods), Guo et al. [22] propose to distill stereo matching networks pre-trained on synthetic datasets, aiming to improve the generalization ability of monocular depth estimation network. They propose to use the disparity maps predicted by the pre-trained stereo network as proxy ground truths to supervise their monocular depth estimation network. However, they do not take account of the fact that stereo-based methods often fail to provide proper supervision to monocular depth estimation methods in some areas. We extend their idea in a way that is particularly designed for our purpose, namely, selective distillation of stereo knowledge.
3 Proposed methods
The goal of our methods is to estimate dense depth maps from a single image without any ground-truth depth maps such that are obtained by depth sensors (\egLiDARs), by distilling the stereo network only where the monocular depth estimation network needs to learn from it. This section first provides an overall pipeline of our framework and then describes the details of the proposed methods to further enhance the accuracy of depth estimation by selectively distilling the stereo knowledge.
3.1 Overall pipeline
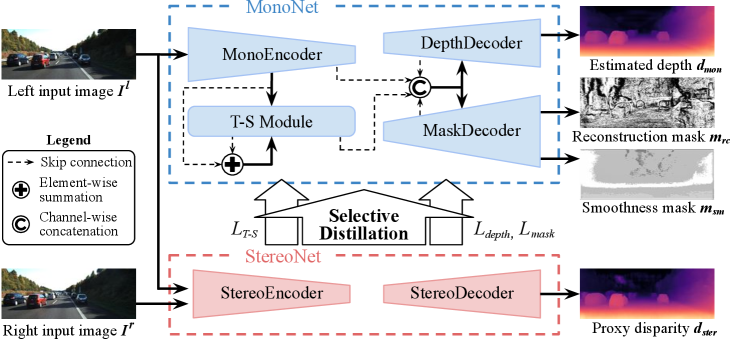
As illustrated in Fig. 2, our network consists of two sub-networks: MonoNet (top) and StereoNet (bottom). We make full use of large quantities of easy-to-acquire synthetic datasets by distilling disparity maps predicted by the StereoNet pre-trained on synthetic datasets since it is less desirable to train the MonoNet directly on synthetic datasets. We specifically adopt the pre-trained stereo networks from Guo et al. [22] as our StereoNet, since they have already verified the feasibility of using their stereo networks as a proxy supervisory network, though any other pre-trained stereo networks can be adopted. Since the size of features extracted from the StereoNet of each scale differs from that of the MonoNet’s features, they are resized to fit the size of the features from MonoNet at each scale for distillation. Please note that the StereoNet is never used during evaluation and none of its parameter is updated while training the MonoNet, since it is included in our framework only for the purpose of proxy distillation.
Meanwhile, our MonoNet is designed with a standard encoder-decoder architecture and extra T-S module as Fig. 2 depicts. Specifically, we adopt VGG-16 [41] pretrained on ImageNet [39] as our MonoEncoder and it extracts the initial feature volume of the same spatial resolution as the input image (), with the channel depth of , and then successively reduces the spatial resolution by half and doubles the channel depth. After then, as shown in Fig. 2, features extracted from the MonoEncoder pass through the extra convolutional layers (T-S module), turning into student features detailed in Sec. 3.3. Finally, the DepthDecoder learns to estimate multi-scale monocular depth maps while the MaskDecoder learns two different binary masks for selective distillation, discussed in detail in Sec. 3.2.
3.2 Selective distillation
To train our MonoNet, the StereoNet, pre-trained with a large amount of synthetic data, is utilized to provide proxy ground truths. A few related works have utilized the disparity maps predicted by stereo-based methods as proxy ground truths to directly supervise the monocular depth maps by using L1 loss or reverse Huber (berHu) loss. However, we note that the MonoNet should learn from the StereoNet only when it is required to, rather than carelessly learn from every pixel. For example, it is generally recognized that stereo-based methods show more weakness in occluded areas(i.e. textureless, repeated patterns) or close distance [33, 17] than monocular methods. Therefore, the MonoNet needs to discriminate and select only those areas where the proxy supervision is valid.
The MaskDecoder is designed to learn two binary masks that give selection criteria for the monocular depth estimation network to selectively distill the proxy disparity maps. Since there is no ground truth for these two binary masks, we use the commonly-used loss functions for self-supervised monocular depth estimation, image reconstruction loss and edge-aware smoothness loss. For the image reconstruction loss, the reference image is reconstructed in a way that the other image is warped to the reference viewpoint based on the predicted disparity , and then the photometric discrepancy between and is measured as:
| (1) |
Although the Structural Similarity(SSIM) has been generally used as a patch similarity measurement in an image reconstruction loss, we adopt the Zero mean Normalized Cross Correlation (ZNCC) with patch and set to 0.85, instead of the SSIM, following [5, 26]. Meanwhile, the predicted disparity is constrained to be locally smooth by the edge-aware smoothness loss as:
| (2) |
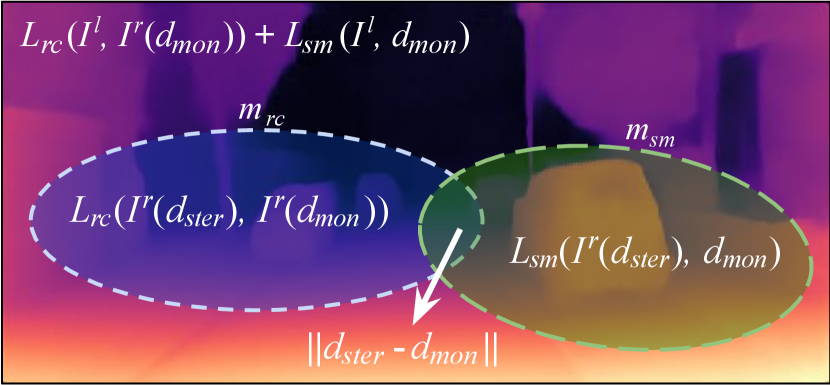
Each of the two binary masks and learns to form new virtual disparity maps and , respectively, by selecting between the proxy disparity map and currently-estimated monocular depth map for each pixel, as follows:
| (3) | |||
| (4) |
The virtual disparity maps and are then used to calculate and , respectively. For instance, aims to learn to optimally select between and to form that minimizes . Hence, the total loss for MaskDecoder is as follows:
| (5) |
The two binary masks are then utilized to train the DepthDecoder. As well as the two common loss functions of Eq. 1 and 2, the DepthDecoder is guided by the proxy disparity map , being conscious of the areas where it needs to improve upon (i.e. and ), as follows:
| (6) |
is interpreted as a region where the both criteria agree that is superior to . In those reliable areas, we further enforce the proxy supervision by using a L1 loss as illustrated in Fig. 3.
3.3 T-S module
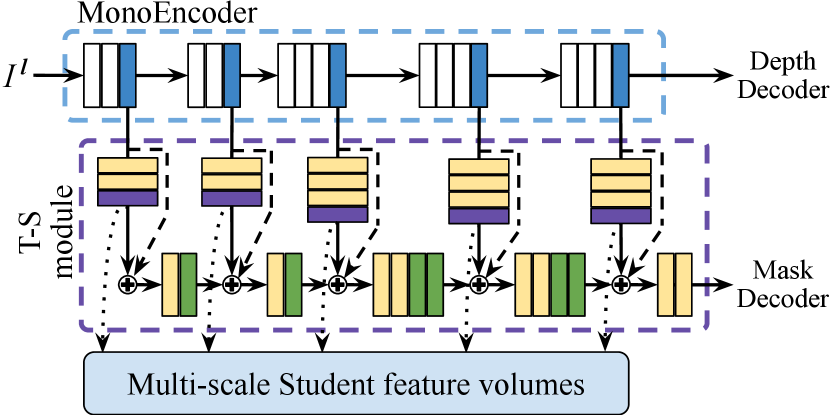
Structure It is reasonable to learn monocular depth estimation utilizing the geometric cues of the features encoded by the StereoNet. However, since our framework requires a single image during testing, it is unreliable to feed the features extracted from the stereo image pair directly to the MonoNet. Alternatively, we design a T-S module so that our MonoNet indirectly exploits geometric features from the learned student features. First, as Fig. 4 shows, each multi-scale feature volume extracted by the MonoEncoder undergoes additional convolutional layers and is made into a student feature volume of the same size as each feature volume from the Mono/StereoEncoder. This T-S module aggregates the features from the MonoEncoder and the newly generated student features through element-wise summation at each scale, followed by extra convolutions. The white and blue blocks indicate 33 convolution layer and 2D max pooling, respectively. The yellow, purple and green blocks in the T-S module indicate 33 convolution layer, 11 convolution with batch normalization, and 33 convolution of stride 2, respectively. ReLU is used as an activation function following each convolution in the MonoEncoder while Leaky ReLU is utilized in the T-S Module. The two different feature volumes extracted from the MonoEncoder and the T-S module at each scale are then concatenated with other feature volumes from the Depth/MaskDecoder in a channel-wise manner as Fig. 2 shows.
T-S loss functions To distill the teacher features into the student features, we propose to utilize three kinds of distillation loss functions. We first define the Feature Distillation loss based on the simple L2 distance norm:
| (7) |
where denotes the feature map extracted by an encoder, and (, ) the number of output channels and spatial dimensions of at -th scale, respectively. The subscripts and indicate whether each feature map is extracted by a Teacher (StereoEncoder) or a Student (MonoEncdoer).
Additionally, to take into account the fact that each channel has different weights of geometrical cues, the Channel Distillation loss, , is utilized for the student features to learn the each channel weight of the teacher features. The weight of -th channel and the Channel Distillation loss are defined as follows:
| (8) | |||
| (9) |
is designed based on the simple L2 distance between the channel-wise mean of various scale feature volumes extracted from the teacher encoder and the student encoder, while can be interpreted as the mean L2 distance between the feature volumes of teacher and student.
Inspired by [43, 35], we lastly suggest to use the Similarity Distillation loss, , which is based on the cosine similarity function. First we flatten into , and then derive the tensor = , which are normalized to unit length row-by-row, as = . The Similarity Distillation loss is then defined as
| (10) |
aims to penalize cosine dissimilarity between two feature maps, constraining the student feature maps to semantically resemble the teacher feature maps. Hence, the total loss function for the T-S feature distillation is defined as follows:
| (11) |

and balance the loss terms, empirically set to and , respectively. The effects of each T-S distillation loss function on depth estimation accuracy are discussed in Sec. 4.2.
To sum up, the entire network is trained to optimize the total loss function, , consisting of three losses , and as follows:
| (12) |
We empirically set the balancing-parameters and to be and respectively. Please note is set to be for our model without the T-S module.
4 Experiments
In this section, we first give the details of experimental setup. We then provide the ablation studies on the proposed methods that affect the monocular depth estimation accuracy. Lastly, we evaluate our framework on the Eigen test split of the KITTI dataset [16] and compare it to other state-of-the-art self-, proxy-, and semi-supervised methods.
| Datasets | Distillation Method | T-S Module | Lower the better | Higher the better | ||||||||
| Abs. Rel. | Sq. Rel. | RMSE | RMSE log | |||||||||
| S,K K | Direct [22] | 0.101 | 0.690 | 4.254 | 0.173 | 0.884 | 0.966 | 0.986 | ||||
| S,K K | Selective | 0.099 | 0.668 | 4.212 | 0.172 | 0.888 | 0.966 | 0.986 | ||||
| S,K K | Selective | ✓ | ✓ | 0.100 | 0.688 | 4.225 | 0.173 | 0.888 | 0.965 | 0.986 | ||
| S,K K | Selective | ✓ | ✓ | ✓ | 0.098 | 0.691 | 4.197 | 0.171 | 0.891 | 0.966 | 0.986 | |
| S,K K | Selective | ✓ | ✓ | ✓ | 0.097 | 0.666 | 4.169 | 0.169 | 0.893 | 0.967 | 0.986 | |
| S,K K | Selective | ✓ | ✓ | ✓ | ✓ | 0.093 | 0.650 | 4.147 | 0.169 | 0.897 | 0.967 | 0.986 |
| S K | Direct [22] | 0.109 | 0.822 | 4.656 | 0.192 | 0.868 | 0.958 | 0.981 | ||||
| S K | Selective | 0.100 | 0.719 | 4.387 | 0.182 | 0.883 | 0.962 | 0.984 | ||||
| S K | Selective | ✓ | ✓ | ✓ | ✓ | 0.098 | 0.729 | 4.411 | 0.182 | 0.889 | 0.963 | 0.983 |
4.1 Experimental setup
Datasets The two main stereo datasets of the KITTI [16] and the CityScapes [9] datasets are used to train and evaluate our framework. First, the KITTI dataset contains 61 outdoor scenes of rectified stereo pairs, captured from a moving car equipped with a LiDAR. For fair comparisons, we exploit the Eigen split [11] of the KITTI dataset containing 22,600 and 697 image pairs for training and testing respectively, with the standard cap of 80m [18]. On the other hand, the CityScapes dataset consisting of 22,973 urban stereo pairs is used only to pre-train our MonoNet which is finetuned on the KITTI dataset afterwards. We cut off the bottom part of the CityScapes image since most of the images include the car hood. Please note that we do not elaborate the details of the Scene Flow dataset [34] in this section, although it is used as the only synthetic dataset for training the proxy stereo networks. That is because we have particularly adopted the two pre-trained stereo networks from [22] as our StereoNet throughout the whole experiments; a StereoNet which is trained on the Scene Flow dataset alone (SK) and another which is subsequently finetuned on 100 scenes from the KITTI 2015 dataset with ground truth depth maps (S,KK). S and K denote the Scene Flow and the KITTI datasets, respectively.
Evaluation metrics Our framework is evaluated by the standard evaluation metrics for monocular depth estimation as following: absolute relative error (Abs. Rel.), squared relative error (Sq. Rel.), root mean squared error (RMSE), root mean squared logarithmic error (RMSE log) and accuracy with thresholds of [, , ]. represents the percentage of predicted depths which meet the condition that its maximum between ratio and inverse ratio with respect to the ground-truth depths is lower than a threshold, mathematically expressed as =(, ).
Implementation details During training, the Adam optimizer [27] is used with the parameters = , = and = . The input images and the proxy disparity maps are fed to our MonoNet after resized to the size of and are augmented following the same way as [22]. The MonoNet is trained for 50 epochs with the initial learning rate of halved at epoch 20, 35, 45. The batch size is set as 8 and 12 for the model with and without the T-S module respectively, in consideration of the number of parameters. In terms of network implementation, the MonoEncoder and T-S module extracts features at 5 scales while the Depth and MaskDecoder predicts depth and mask at 4 scales. Please see supplementary material for a detailed demonstration of the connections among the encoder, T-S module and decoders. Note the CityScapes training set is utilized to pre-train the MonoNet in the same manner as the KITTI training set is used.
4.2 Ablation study
Selective distillation As mentioned in Sec. 3.2, each of monocular and stereo-based methods shows superior estimation accuracy to each other in different regions. Along with this, Fig. 5 depicts the StereoNet shows poor depth estimation on some areas where it is hard to find matching correspondences, such as textureless or reflective areas (\egshadowed area or car windows), and areas where disparity discontinuity is repeated (\egthin fences). Since [22] is trained to directly distill the disparity maps without taking account of the aforementioned consideration, their monocular depth estimation network is supervised even in those areas where the proxy supervision is unreliable. As opposed to [22], the proposed selective distillation method has shown to successfully prevent training with the unreliable supervision from proxy disparity maps, while even improving the accuracy in areas where the monocular depth estimation network is superior to the stereo network.
The quantitative improvement on performance is demonstrated in Table 1. When we compare rows 1&2 and 7&8, our selective distillation method has achieved more accurate performance than the direct distillation method [22] in every evaluation metric on the Eigen test split of the KITTI dataset. In particular, comparison between rows 7 and 8 verifies that our MonoNet achieves more accurate performance on the real dataset (KITTI) even though the proxy stereo network is trained only on the synthetic datasets (SK). Note that it has improved more significantly than the case the proxy stereo network is finetuned on the real dataset. From this, it can be said that our selective distillation method becomes more crucial when the proxy stereo network is less reliable to distill.
| Method | Dataset | Supervision | Lower the better | Higher the better | |||||
| Abs. Rel. | Sq. Rel. | RMSE | RMSE log | ||||||
| Godard et al. [18] | K | Self | 0.148 | 1.344 | 5.927 | 0.247 | 0.803 | 0.922 | 0.964 |
| Wong et al. [47] | K | Self | 0.133 | 1.126 | 5.515 | 0.231 | 0.826 | 0.934 | 0.969 |
| Poggi et al. [38], pp | K | Self | 0.126 | 0.961 | 5.205 | 0.220 | 0.835 | 0.941 | 0.974 |
| Chen et al. [6] | K | Self | 0.118 | 0.905 | 5.096 | 0.211 | 0.839 | 0.945 | 0.977 |
| Guizilini et al. [21] | K | Self | 0.111 | 0.785 | 4.601 | 0.189 | 0.878 | 0.960 | 0.982 |
| Johnston et al. [24] | K | Self | 0.106 | 0.861 | 4.699 | 0.185 | 0.889 | 0.962 | 0.982 |
| Tosi et al. [42] | K | Proxy(SGM) | 0.111 | 0.867 | 4.714 | 0.199 | 0.864 | 0.954 | 0.979 |
| Watson et al. [46] | K | Proxy(SGM) | 0.102 | 0.762 | 4.602 | 0.189 | 0.880 | 0.960 | 0.981 |
| Guo et al. [22] | S K | Proxy(StereoNet) | 0.109 | 0.822 | 4.656 | 0.192 | 0.868 | 0.958 | 0.981 |
| Ours(w/o T-S module) | S K | Proxy(StereoNet) | 0.100 | 0.719 | 4.387 | 0.182 | 0.883 | 0.962 | 0.984 |
| Ours(Full model) | S K | Proxy(StereoNet) | 0.098 | 0.729 | 4.411 | 0.182 | 0.889 | 0.963 | 0.983 |
| Guo et al. [22] | S,K K | Proxy(StereoNet) | 0.101 | 0.690 | 4.254 | 0.173 | 0.884 | 0.966 | 0.986 |
| Ours(w/o T-S module) | S,K K | Proxy(StereoNet) | 0.099 | 0.668 | 4.212 | 0.172 | 0.888 | 0.966 | 0.986 |
| Ours(Full model) | S,K K | Proxy(StereoNet) | 0.093 | 0.650 | 4.147 | 0.169 | 0.897 | 0.967 | 0.986 |
| Kuznietsov et al. [28] | K | Semi(LiDAR GT) | 0.113 | 0.741 | 4.621 | 0.189 | 0.862 | 0.960 | 0.986 |
| Yang et al. [48] | K | Semi(LiDAR GT) | 0.097 | 0.734 | 4.442 | 0.187 | 0.888 | 0.958 | 0.980 |
| Method | Dataset | Supervision | Lower the better | Higher the better | |||||
|---|---|---|---|---|---|---|---|---|---|
| Abs. Rel. | Sq. Rel. | RMSE | RMSE log | ||||||
| Mahjourian et al. [32] | C,K | Self* | 0.159 | 1.231 | 5.912 | 0.243 | 0.784 | 0.923 | 0.970 |
| Wang et al. [44] | C,K | Self* | 0.148 | 1.187 | 5.496 | 0.226 | 0.812 | 0.938 | 0.975 |
| Zou et al. [52] | C,K | Self* | 0.146 | 1.182 | 5.215 | 0.213 | 0.818 | 0.943 | 0.978 |
| Wong et al. [47] | C,K | Self | 0.118 | 0.996 | 5.134 | 0.215 | 0.849 | 0.945 | 0.975 |
| Godard et al. [18], pp | C,K | Self | 0.114 | 0.898 | 4.935 | 0.206 | 0.861 | 0.949 | 0.976 |
| Poggi et al. [38], pp | C,K | Self | 0.111 | 0.849 | 4.822 | 0.202 | 0.865 | 0.952 | 0.978 |
| Pilzer et al. [36] | C,K | Self | 0.098 | 0.831 | 4.656 | 0.202 | 0.882 | 0.948 | 0.973 |
| Tosi et al. [42] | C,K | Proxy(SGM) | 0.096 | 0.673 | 4.351 | 0.184 | 0.890 | 0.961 | 0.981 |
| Guo et al. [22] | S,K C,K | Proxy(StereoNet) | 0.096 | 0.641 | 4.095 | 0.168 | 0.892 | 0.967 | 0.986 |
| Ours(w/o T-S module) | S,K C,K | Proxy(StereoNet) | 0.095 | 0.661 | 4.088 | 0.166 | 0.897 | 0.969 | 0.987 |
| Ours(Full model) | S,K C,K | Proxy(StereoNet) | 0.095 | 0.654 | 4.073 | 0.165 | 0.900 | 0.969 | 0.987 |
T-S loss functions To verify the validity of the proposed T-S module, we have conducted an ablation study by applying different combinations of the three different T-S loss functions, , and . Since the Feature Distillation loss has been set as the base loss function of the total T-S loss function, we first compare our model without the T-S module to that with the T-S module combined with alone. The results in Table 1 (rows 2 and 3) demonstrate that applying alone fails to properly transfer the stereo feature representations from the Teacher to the Student. We hypothesize this is because the volume of the feature is too large for the student to learn adequately. On the other hand, when is additionally applied (row 4), the performance on every metric except Sq. Rel. has been slightly improved. It can be said successfully enables to supervise the large number of channels in the student feature volume. Moreover, the addition of (row 5) brings larger improvement than when is additionally applied to . This is because successfully constrains the student features to learn semantic and geometrical knowledge from the teacher features. When combined with all the proposed T-S loss functions, our full model (rows 6 and 9) achieves significant improvement over the baseline model with the directive distillation method. Meanwhile, when we compare rows 2&6 and 8&9, the T-S module is much more effective when the Teacher network (StereoNet) is more reliable to distill, as apposed to the selective distillation.
4.3 Comparison with the state-of-the-arts
In this section, we compare our framework with the state-of-the-art self-, proxy-, and semi-supervised monocular depth estimation methods. In Table 2, ours and other different models are evaluated on the Eigen test split of the KITTI dataset. From the table, it can be noticed ours outperforms all the others significantly. In particular, even our model leveraging the StereoNet trained only on the synthetic dataset (SK) (rows 10 and 11) outperforms the semi-supervised methods supervised by the ground truth depth maps [28, 48] in most metrics. From these results, it can be said selectively distilling the proxy disparity maps allows to achieve even better performance than using the expensive ground truths. Besides, ours also significantly surpasses all the other state-of-the-art methods supervised in different settings.
In Table 3, we compare the performances of our model with other state-of-the-art monocular depth estimation models pre-trained on the CityScapes dataset before being finetuned on the KITTI dataset. We first train our MonoNet on the CityScapes dataset by selectively distilling a StereoNet that is trained only on the Scene Flow dataset(SC), and then finetune the pre-trained MonoNet on the Eigen train split of the KITTI dataset by distilling another StereoNet that is finetuned on the KITTI dataset (S,KK). We can see the results have improved over using the KITTI dataset alone. However, our full model has been slightly improved and even performances on some metrics declined. Nonetheless, our full model still outperforms all the other state-of-the-art models except on the Sq. Rel. metric.
5 Conclusion
In this paper, we pointed out that distillation of proxy disparity maps from stereo-based methods for monocular depth estimation should be selectively exploited. With this consideration, we proposed a novel framework for learning monocular depth estimation via selective distillation of the stereo knowledge to tackle the problems of the previous proxy-supervised monocular depth estimation methods. Qualitative results proved our selective distillation during training enables to avoid unreliable supervision of the proxy disparity map. In addition, extensive experiments demonstrated the T-S module combined with the various distillation loss functions further improves our network to achieve state-of-the-art performance of proxy-supervised monocular depth estimation methods, even outperforming some of the semi-supervised methods on the KITTI dataset.
References
- [1] Filippo Aleotti, Fabio Tosi, Matteo Poggi, and Stefano Mattoccia. Generative adversarial networks for unsupervised monocular depth prediction. In Proceedings of the European Conference on Computer Vision (ECCV), pages 0–0, 2018.
- [2] Ibraheem Alhashim and Peter Wonka. High quality monocular depth estimation via transfer learning. arXiv preprint arXiv:1812.11941, 2018.
- [3] Amir Atapour-Abarghouei and Toby P Breckon. Real-time monocular depth estimation using synthetic data with domain adaptation via image style transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2800–2810, 2018.
- [4] Jia-Ren Chang and Yong-Sheng Chen. Pyramid stereo matching network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5410–5418, 2018.
- [5] Long Chen, Wen Tang, and Nigel John. Self-supervised monocular image depth learning and confidence estimation. arXiv preprint arXiv:1803.05530, 2018.
- [6] Po-Yi Chen, Alexander H Liu, Yen-Cheng Liu, and Yu-Chiang Frank Wang. Towards scene understanding: Unsupervised monocular depth estimation with semantic-aware representation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2624–2632, 2019.
- [7] Yuru Chen, Haitao Zhao, and Zhengwei Hu. Attention-based context aggregation network for monocular depth estimation. arXiv preprint arXiv:1901.10137, 2019.
- [8] Zhuoyuan Chen, Xun Sun, Liang Wang, Yinan Yu, and Chang Huang. A deep visual correspondence embedding model for stereo matching costs. In Proceedings of the IEEE International Conference on Computer Vision, pages 972–980, 2015.
- [9] Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3213–3223, 2016.
- [10] Arun CS Kumar, Suchendra M Bhandarkar, and Mukta Prasad. Monocular depth prediction using generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pages 300–308, 2018.
- [11] David Eigen, Christian Puhrsch, and Rob Fergus. Depth map prediction from a single image using a multi-scale deep network. In Advances in neural information processing systems, pages 2366–2374, 2014.
- [12] Zhicheng Fang, Xiaoran Chen, Yuhua Chen, and Luc Van Gool. Towards good practice for cnn-based monocular depth estimation. In The IEEE Winter Conference on Applications of Computer Vision, pages 1091–1100, 2020.
- [13] Huan Fu, Mingming Gong, Chaohui Wang, Kayhan Batmanghelich, and Dacheng Tao. Deep ordinal regression network for monocular depth estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2002–2011, 2018.
- [14] Yukang Gan, Xiangyu Xu, Wenxiu Sun, and Liang Lin. Monocular depth estimation with affinity, vertical pooling, and label enhancement. In Proceedings of the European Conference on Computer Vision (ECCV), pages 224–239, 2018.
- [15] Ravi Garg, Vijay Kumar BG, Gustavo Carneiro, and Ian Reid. Unsupervised cnn for single view depth estimation: Geometry to the rescue. In European Conference on Computer Vision, pages 740–756. Springer, 2016.
- [16] Andreas Geiger, Philip Lenz, Christoph Stiller, and Raquel Urtasun. Vision meets robotics: The kitti dataset. The International Journal of Robotics Research, 32(11):1231–1237, 2013.
- [17] Yotam Gil, Shay Elmalem, Harel Haim, Emanuel Marom, and Raja Giryes. Monster: Awakening the mono in stereo. arXiv preprint arXiv:1910.13708, 2019.
- [18] Clément Godard, Oisin Mac Aodha, and Gabriel J Brostow. Unsupervised monocular depth estimation with left-right consistency. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 270–279, 2017.
- [19] Clément Godard, Oisin Mac Aodha, Michael Firman, and Gabriel J Brostow. Digging into self-supervised monocular depth estimation. In Proceedings of the IEEE international conference on computer vision, pages 3828–3838, 2019.
- [20] Ariel Gordon, Hanhan Li, Rico Jonschkowski, and Anelia Angelova. Depth from videos in the wild: Unsupervised monocular depth learning from unknown cameras. In Proceedings of the IEEE International Conference on Computer Vision, pages 8977–8986, 2019.
- [21] Vitor Guizilini, Rares Ambrus, Sudeep Pillai, Allan Raventos, and Adrien Gaidon. 3d packing for self-supervised monocular depth estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2485–2494, 2020.
- [22] Xiaoyang Guo, Hongsheng Li, Shuai Yi, Jimmy Ren, and Xiaogang Wang. Learning monocular depth by distilling cross-domain stereo networks. In Proceedings of the European Conference on Computer Vision (ECCV), pages 484–500, 2018.
- [23] Heiko Hirschmuller. Accurate and efficient stereo processing by semi-global matching and mutual information. In 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), volume 2, pages 807–814. IEEE, 2005.
- [24] Adrian Johnston and Gustavo Carneiro. Self-supervised monocular trained depth estimation using self-attention and discrete disparity volume. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4756–4765, 2020.
- [25] Alex Kendall, Hayk Martirosyan, Saumitro Dasgupta, Peter Henry, Ryan Kennedy, Abraham Bachrach, and Adam Bry. End-to-end learning of geometry and context for deep stereo regression. In Proceedings of the IEEE International Conference on Computer Vision, pages 66–75, 2017.
- [26] Taewoo Kim, Kwonyoung Ryu, Kyeongseob Song, and Kuk-Jin Yoon. Loop-net: Joint unsupervised disparity and optical flow estimation of stereo videos with spatiotemporal loop consistency. IEEE Robotics and Automation Letters, 5(4):5597–5604, 2020.
- [27] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- [28] Yevhen Kuznietsov, Jorg Stuckler, and Bastian Leibe. Semi-supervised deep learning for monocular depth map prediction. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 6647–6655, 2017.
- [29] Jin Han Lee, Myung-Kyu Han, Dong Wook Ko, and Il Hong Suh. From big to small: Multi-scale local planar guidance for monocular depth estimation. arXiv preprint arXiv:1907.10326, 2019.
- [30] Jae-Han Lee and Chang-Su Kim. Monocular depth estimation using relative depth maps. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 9729–9738, 2019.
- [31] Wenjie Luo, Alexander G Schwing, and Raquel Urtasun. Efficient deep learning for stereo matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5695–5703, 2016.
- [32] Reza Mahjourian, Martin Wicke, and Anelia Angelova. Unsupervised learning of depth and ego-motion from monocular video using 3d geometric constraints. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5667–5675, 2018.
- [33] Diogo Martins, Kevin Van Hecke, and Guido De Croon. Fusion of stereo and still monocular depth estimates in a self-supervised learning context. In 2018 IEEE International Conference on Robotics and Automation (ICRA), pages 849–856. IEEE, 2018.
- [34] Nikolaus Mayer, Eddy Ilg, Philip Hausser, Philipp Fischer, Daniel Cremers, Alexey Dosovitskiy, and Thomas Brox. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4040–4048, 2016.
- [35] Baoyun Peng, Xiao Jin, Jiaheng Liu, Dongsheng Li, Yichao Wu, Yu Liu, Shunfeng Zhou, and Zhaoning Zhang. Correlation congruence for knowledge distillation. In Proceedings of the IEEE International Conference on Computer Vision, pages 5007–5016, 2019.
- [36] Andrea Pilzer, Stephane Lathuiliere, Nicu Sebe, and Elisa Ricci. Refine and distill: Exploiting cycle-inconsistency and knowledge distillation for unsupervised monocular depth estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 9768–9777, 2019.
- [37] Matteo Poggi, Filippo Aleotti, Fabio Tosi, and Stefano Mattoccia. On the uncertainty of self-supervised monocular depth estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3227–3237, 2020.
- [38] Matteo Poggi, Fabio Tosi, and Stefano Mattoccia. Learning monocular depth estimation with unsupervised trinocular assumptions. In 2018 International Conference on 3D Vision (3DV), pages 324–333. IEEE, 2018.
- [39] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge. International journal of computer vision, 115(3):211–252, 2015.
- [40] Daniel Scharstein and Richard Szeliski. A taxonomy and evaluation of dense two-frame stereo correspondence algorithms. International journal of computer vision, 47(1-3):7–42, 2002.
- [41] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014.
- [42] Fabio Tosi, Filippo Aleotti, Matteo Poggi, and Stefano Mattoccia. Learning monocular depth estimation infusing traditional stereo knowledge. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 9799–9809, 2019.
- [43] Frederick Tung and Greg Mori. Similarity-preserving knowledge distillation. In Proceedings of the IEEE International Conference on Computer Vision, pages 1365–1374, 2019.
- [44] Chaoyang Wang, José Miguel Buenaposada, Rui Zhu, and Simon Lucey. Learning depth from monocular videos using direct methods. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2022–2030, 2018.
- [45] Lin Wang and Kuk-Jin Yoon. Knowledge distillation and student-teacher learning for visual intelligence: A review and new outlooks. arXiv preprint arXiv:2004.05937, 2020.
- [46] Jamie Watson, Michael Firman, Gabriel J Brostow, and Daniyar Turmukhambetov. Self-supervised monocular depth hints. In Proceedings of the IEEE International Conference on Computer Vision, pages 2162–2171, 2019.
- [47] Alex Wong and Stefano Soatto. Bilateral cyclic constraint and adaptive regularization for unsupervised monocular depth prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5644–5653, 2019.
- [48] Nan Yang, Rui Wang, Jorg Stuckler, and Daniel Cremers. Deep virtual stereo odometry: Leveraging deep depth prediction for monocular direct sparse odometry. In Proceedings of the European Conference on Computer Vision (ECCV), pages 817–833, 2018.
- [49] Sergey Zagoruyko and Nikos Komodakis. Learning to compare image patches via convolutional neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4353–4361, 2015.
- [50] Jure Zbontar, Yann LeCun, et al. Stereo matching by training a convolutional neural network to compare image patches. Journal of Machine Learning Research, 17(1-32):2, 2016.
- [51] Shanshan Zhao, Huan Fu, Mingming Gong, and Dacheng Tao. Geometry-aware symmetric domain adaptation for monocular depth estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 9788–9798, 2019.
- [52] Yuliang Zou, Zelun Luo, and Jia-Bin Huang. Df-net: Unsupervised joint learning of depth and flow using cross-task consistency. In Proceedings of the European conference on computer vision (ECCV), pages 36–53, 2018.