Learning Space-Time Continuous Neural PDEs from Partially Observed States
Abstract
We introduce a novel grid-independent model for learning partial differential equations (PDEs) from noisy and partial observations on irregular spatiotemporal grids. We propose a space-time continuous latent neural PDE model with an efficient probabilistic framework and a novel encoder design for improved data efficiency and grid independence. The latent state dynamics are governed by a PDE model that combines the collocation method and the method of lines. We employ amortized variational inference for approximate posterior estimation and utilize a multiple shooting technique for enhanced training speed and stability. Our model demonstrates state-of-the-art performance on complex synthetic and real-world datasets, overcoming limitations of previous approaches and effectively handling partially-observed data. The proposed model outperforms recent methods, showing its potential to advance data-driven PDE modeling and enabling robust, grid-independent modeling of complex partially-observed dynamic processes.
1 Introduction
††footnotetext: Source code and datasets can be found in our github repository.Modeling spatiotemporal processes allows to understand and predict the behavior of complex systems that evolve over time and space (Cressie and Wikle, 2011). Partial differential equations (PDEs) are a popular tool for this task as they have a solid mathematical foundation (Evans, 2010) and can describe the dynamics of a wide range of physical, biological, and social phenomena (Murray, 2002; Hirsch, 2007). However, deriving PDEs can be challenging, especially when the system’s underlying mechanisms are complex and not well understood. Data-driven methods can bypass these challenges (Brunton and Kutz, 2019). By learning the underlying system dynamics directly from data, we can develop accurate PDE models that capture the essential features of the system. This approach has changed our ability to model complex systems and make predictions about their behavior in a data-driven manner.
While current data-driven PDE models have been successful at modeling complex spatiotemporal phenomena, they often operate under various simplifying assumptions such as regularity of the spatial or temporal grids (Long et al., 2018; Kochkov et al., 2021; Pfaff et al., 2021; Li et al., 2021; Han et al., 2022; Poli et al., 2022), discreteness in space or time (Seo et al., 2020; Pfaff et al., 2021; Lienen and Günnemann, 2022; Brandstetter et al., 2022), and availability of complete and noiseless observations (Long et al., 2018; Pfaff et al., 2021; Wu et al., 2022). Such assumptions become increasingly limiting in more realistic scenarios with scarce data and irregularly spaced, noisy and partial observations.
We address the limitations of existing methods and propose a space-time continuous and grid-independent model that can learn PDE dynamics from noisy and partial observations made on irregular spatiotemporal grids. Our main contributions include:
-
•
Development of an efficient generative modeling framework for learning latent neural PDE models from noisy and partially-observed data;
-
•
Novel PDE model that merges two PDE solution techniques – the collocation method and the method of lines – to achieve space-time continuity, grid-independence, and data efficiency;
-
•
Novel encoder design that operates on local spatiotemporal neighborhoods for improved data-efficiency and grid-independence.
Our model demonstrates state-of-the-art performance on complex synthetic and real-world datasets, opening up the possibility for accurate and efficient modeling of complex dynamic processes and promoting further advancements in data-driven PDE modeling.
2 Problem Setup
In this work we are concerned with modeling of spatiotemporal processes. For brevity, we present our method for a single observed trajectory, but extension to multiple trajectories is straightforward. We observe a spatiotemporal dynamical system evolving over time on a spatial domain . The observations are made at arbitrary consecutive time points and arbitrary observation locations , where . This generates a sequence of observations , where contains -dimensional observations at the observation locations. We define as the observation at time and location . The number of time points and observation locations may vary between different observed trajectories.
We assume the data is generated by a dynamical system with a latent state , where is time and is spatial location. The latent state is governed by an unknown PDE and is mapped to the observed state by an unknown observation function and likelihood model :
| (1) | |||
| (2) |
where denotes partial derivatives wrt .
In this work we make two assumptions that are highly relevant in real-world scenarios. First, we assume partial observations, that is, the observed state does not contain all information about the latent state (e.g., contains pressure and velocity, but contains information only about the pressure). Second, we assume out-of-distribution time points and observation locations, that is, their number, positions, and density can change arbitrarily at test time.
3 Model
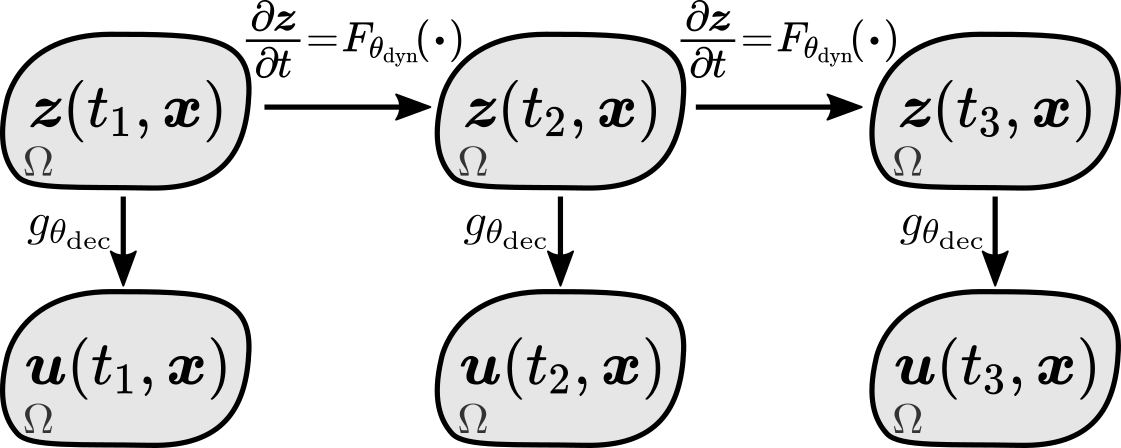
Here we describe the model components (Sec. 3.1) which are then used to construct the generative model (Sec. 3.2).
3.1 Model components
Our model consists of four parts: space-time continuous latent state and observed state , a dynamics function governing the temporal evolution of the latent state, and an observation function mapping the latent state to the observed state (see Figure 1). Next, we describe these components in detail.
Latent state.
To define a space-time continuous latent state , we introduce , where each corresponds to the observation location . Then, we define the latent state as a spatial interpolant of :
| (3) |
where maps to an interpolant which can be evaluated at any spatial location (see Figure 2). We do not rely on a particular interpolation method, but in this work we use linear interpolation as it shows good performance and facilitates efficient implementation.
Latent state dynamics.

Given a space-time continuous latent state, one can naturally define its dynamics in terms of a PDE:
| (4) |
where is a dynamics function with parameters . This is a viable approach known as the collocation method (Kansa, 1990; Cheng, 2009), but it has several limitations. It requires us to decide which partial derivatives to include in the dynamics function, and also requires an interpolant which has all the selected partial derivatives (e.g., linear interpolant has only first order derivatives). To avoid these limitations, we combine the collocation method with another PDE solution technique known as the method of lines (Schiesser, 1991; Hamdi et al., 2007), which approximates spatial derivatives using only evaluations of , and then let the dynamics function approximate all required derivatives in a data-driven manner. To do that, we define the spatial neighborhood of as , which is a set containing and its spatial neighbors, and also define , which is a set of evaluations of the interpolant at points in :
| (5) | |||
| (6) |
and assume that this information is sufficient to approximate all required spatial derivatives at . This is a reasonable assumption since, e.g., finite differences can approximate derivatives using only function values and locations of the evaluation points. Hence, we define the dynamics of as
| (7) |
which is defined only in terms of the values of the latent state, but not its spatial derivatives.
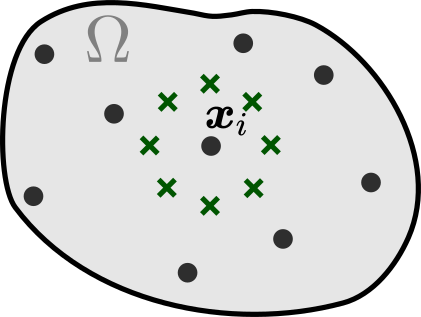
One way to define the spatial neighbors for is in terms of the observation locations (e.g., use the nearest ones) as was done, for example, in (Long et al., 2018; Pfaff et al., 2021; Lienen and Günnemann, 2022). Instead, we utilize continuity of the latent state , and define the spatial neighbors in a grid-independent manner as a fixed number of points arranged in a predefined patter around (see Figure 3). This allows to fix the shape and size of the spatial neighborhoods in advance, making them independent of the observation locations. In this work we use the spatial neighborhood consisting of two concentric circles of radius and , each circle contains 8 evaluation points as in Figure 3. In Appendix D we compare neighborhoods of various shapes and sizes.
Equation 7 allows to simulate the temporal evolution of at any spatial location. However, since is defined only in terms of a spatial interpolant of (see Eq. 3), with , it is sufficient to simulate the latent state dynamics only at the observation locations . Hence, we can completely characterize the latent state dynamics in terms of a system of ODEs:
| (8) |
For convenience, we define as the solution of the ODE system in Equation 8 at time with initial state and parameters . We also define as the spatial interpolant of as in Equation 3. We solve the ODEs using off the shelf differentiable ODE solvers from torchdiffeq package (Chen, 2018). Note that we solve for the state only at the observation locations , so to get the neighborhood values we perform interpolation at every step of the ODE solver.
Observation function.
We define the mapping from the latent space to the observation space as a parametric function with parameters :
| (9) |
where is the Gaussian distribution, is noise variance, and is -by- identity matrix.
3.2 Generative model

Training models of dynamic systems is often challenging due to long training times and training instabilities (Ribeiro et al., 2020; Metz et al., 2021). To alleviate these problems, various heuristics have been proposed, such as progressive lengthening and splitting of the training trajectories (Yildiz et al., 2019; Um et al., 2020). We use multiple shooting (Bock and Plitt, 1984; Voss et al., 2004), a simple and efficient technique which has demonstrated its effectiveness in ODE learning applications (Jordana et al., 2021; Hegde et al., 2022). We extent the multiple shooting framework for latent ODE models presented in (Iakovlev et al., 2023) to our PDE modeling setup by introducing spatial dimensions in the latent state and designing an encoder adapted specifically to the PDE setting (Section 4.2).
Multiple shooting splits a single trajectory with one initial state into consecutive non-overlapping sub-trajectories with initial states while imposing a continuity penalty between the sub-trajectories (see Figure 4). The index set contains time point indices for the ’th sub-trajectory. We also denote the temporal position of as and place at the first time point preceding the ’th sub-trajectory (except which is placed at ). Note that the shooting states have the same dimension as the original latent state i.e., . Multiple shooting allows to parallelize the simulation over the sub-trajectories and shortens the simulation intervals thus improving the training speed and stability. In Appendix D we demonstrate the effect of multiple shooting on the model training and prediction accuracy.
We begin by defining the prior over the unknown model parameters and initial states:
| (10) |
where and are zero-mean diagonal Gaussians, and the continuity inducing prior is defined as in (Iakovlev et al., 2023)
| (11) |
Intuitively, the continuity prior takes the initial latent state , simulates it forward from time to to get , and then forces to approximately match the initial state of the next sub-trajectory, thus promoting continuity of the full trajectory. We assume the continuity inducing prior factorizes across the grid points, i.e.,
| (12) | ||||
| (13) |
where is a diagonal Gaussian, and parameter controls the strength of the prior. Note that the term in Equation 13 equals the ODE forward solution at grid location .
Finally, we define our generative in terms of the following sampling procedure:
| (14) | |||||
| (15) | |||||
| (16) | |||||
with the following joint distribution (see Appendix A for details about the model specification.):
| (17) |
4 Parameter Inference, Encoder, and Forecasting
4.1 Amortized variational inference
We approximate the true posterior over the model parameters and initial states using variational inference (Blei et al., 2017) with the following approximate posterior:
| (18) |
where , and are diagonal Gaussians, and , and are variational parameters. To avoid direct optimization over the local variational parameters , we use amortized variational inference (Kingma and Welling, 2013) and train an encoder with parameters which maps observations to (see Section 4.2). For brevity, we sometimes omit the dependence of approximate posteriors on variational parameters and simply write e.g., .
In variational inference the best approximation of the posterior is obtained by minimizing the Kullback-Leibler divergence: , which is equivalent to maximizing the evidence lower bound (ELBO), defined for our model as:
The terms , , and are computed analytically, while terms and are approximated using Monte Carlo integration for expectations, and numerical ODE solvers for initial value problems. See Appendix A and B approximate posterior details and derivation and computation of the ELBO.
4.2 Encoder

Here we describe our encoder which maps observations to local variational parameters required to sample the initial latent state of the sub-trajectory at time point and observation location . Similarly to our model, the encoder should be data-efficient and grid-independent.
Similarly to our model (Section 3.1), we enable grid-independence by making the encoder operate on spatial interpolants of the observations (even if they are noisy):
| (19) |
where spatial interpolation is done separately for each time point . We then use the interpolants to define the spatial neighborhoods in a grid-independent manner.
To improve data-efficiency, we assume does not depend on the whole observed sequence , but only on some local information in a spatiotemporal neighborhood of and . We define the temporal neighborhood of as
| (20) |
where is a hyperparameter controlling the neighborhood size, and then define the spatiotemporal neighborhood of and as
| (21) |
Our encoder operates on such spatiotemporal neighborhoods and works in three steps (see Figure 5). First, for each time index it aggregates the spatial information into a vector . Then, it aggregates the spatial representations across time into another vector which is finally mapped to the variational parameters as follows:
| (22) |
Spatial aggregation.
Since the spatial neighborhoods are fixed and remain identical for all spatial locations (see Figure 5), we implement the spatial aggregation function as an MLP which takes elements of the set stacked in a fixed order as the input.
Temporal aggregation.
We implement as a stack of transformer layers (Vaswani et al., 2017) which allows it to operate on input sets of arbitrary size. We use time-aware attention and continuous relative positional encodings (Iakovlev et al., 2023) which were shown to be effective on data from dynamical systems observed at irregular time intervals. Each transformer layer takes a layer-specific input set , where is located at , and maps it to an output set , where each is computed using only the input elements within distance from , thus promoting temporal locality. Furthermore, instead of using absolute positional encodings the model assumes the behavior of the system does not depend on time and uses relative temporal distances to inject positional information. The first layer takes as the input, while the last layer returns a single element at time point , which represents the temporal aggregation .
Variational parameter readout.
Since is a fixed-length vector, we implement as an MLP.
4.3 Forecasting
Given initial observations at time points , we predict the future observation at a time point as the expected value of the approximate posterior predictive distribution:
| (23) |
The expected value is estimated via Monte Carlo integration (see Appendix C.4 for details).
5 Experiments

We use three challenging datasets: Shallow Water, Navier-Stokes, and Scalar Flow which contain observations of spatiotemporal system at grid points evolving over time (see Figure 6). The first two datasets are synthetic and generated using numeric PDE solvers (we use scikit-fdiff (Cellier, 2019) for Shallow Water, and PhiFlow (Holl et al., 2020) for Navier-Stokes), while the third dataset contains real-world observations (camera images) of smoke plumes raising in warm air (Eckert et al., 2019). In all cases the observations are made at irregular spatiotemporal grids and contain only partial information about the true system state. In particular, for Shallow Water we observe only the wave height, for Navier-Stokes we observe only the concentration of the species, and for Scalar Flow only pixel densities are known. All datasets contain // training/validation/testing trajectories. See Appendix C for details.
We train our model for 20k iterations with constant learning rate of and linear warmup. The latent spatiotemporal dynamics are simulated using differentiable ODE solvers from the torchdiffeq package (Chen, 2018) (we use dopri5 with rtol=, atol=, no adjoint). Training is done on a single NVIDIA Tesla V100 GPU, with a single run taking 3-4 hours. We use the mean absolute error (MAE) on the test set as the performance measure. Error bars are standard errors over 4 random seeds. For forecasting we use the expected value of the posterior predictive distribution. See Appendix C for all details about the training, validation, and testing setup.
Latent state dimension.
Here we show the advantage of using latent-space models on partially observed data. We change the latent state dimension from 1 to 5 and measure the test MAE. Note that for we effectively have a data-space model which models the observations without trying to reconstruct the missing states. Figure 7 shows that in all cases there is improvement in performance as the latent dimension grows. For Shallow Water and Navier-Stokes the true latent dimension is 3. Since Scalar Flow is a real-world process, there is no true latent dimension. As a benchmark, we provide the performance of our model trained on fully-observed versions of the synthetic datasets (we use the same architecture and hyperparameters, but fix to ). Figure 7 also shows examples of model predictions (at the final time point) for different values of . We see a huge difference between and . Note how apparently small difference in MAE at and for Scalar Flow corresponds to a dramatic improvement in the prediction quality.



Grid independence.
In this experiment we demonstrate the grid-independence property of our model by training it on grids with observation locations, and then testing on a coarser, original, and finer grids. We evaluate the effect of using different interpolation methods by repeating the experiment with linear, k-nearest neighbors, and inverse distance weighting (IDW) interpolants. For Shallow Water and Navier-Stokes the coarser/finer grids contain / nodes, while for Scalar Flow we have / nodes, respectively. Table 1 shows the model’s performance for different spatial grids and interpolation methods. We see that all interpolation methods perform rather similarly on the original grid, but linear interpolation and IDW tend to perform better on finer/coarser grids than k-NN. Performance drop on coarse grids is expected since we get less accurate information about the system’s initial state and simulate the dynamics on coarse grids. Figure 8 also shows examples of model predictions (at the final time point) for different grid sizes and linear interpolant.
| Dataset | Grid | k-NN | Linear | IDW |
|---|---|---|---|---|
| Coarser | ||||
| Shallow Water | Original | |||
| Finer | ||||
| Coarser | ||||
| Navier Stokes | Original | |||
| Finer | ||||
| Coarser | ||||
| Scalar Flow | Original | |||
| Finer |
Comparison to other models.
We test our model against recent spatiotemporal models from the literature: Finite Element Networks (FEN) (Lienen and Günnemann, 2022), Neural Stochastic PDEs (NSPDE) (Salvi et al., 2021), MAgNet (Boussif et al., 2022), and DINo (Yin et al., 2023). We also use Neural ODEs (NODE) (Chen et al., 2018) as the baseline. We use the official implementation for all models and tune their hyperparameters for the best performance (see App. C for details). For Shallow Water and Navier-Stokes we use the first 5 time points to infer the latent state and then predict the next 20 time points, while for Scalar Flow we use the first 10 points for inference and predict the next 10 points. For synthetic data, we consider two settings: one where the data is fully observed (i.e., the complete state is recorded) – a setting for which most models are designed – and one where the data is partially observed (i.e., only part of the full state is given, as discussed at the beginning of this section). The results are shown in Table 2. We see that some of the baseline models achieve reasonably good results on the fully-observed datasets, but they fail on partially-observed data, while our model maintains strong performance in all cases. Apart from the fully observed Shallow Water dataset where FEN performs slightly better, our method outperforms other methods on all other datasets by a clear margin. See Appendix C for hyperparameter details. In Appendix E we demonstrate our model’s capability to learn dynamics from noisy data. In Appendix F we show model predictions on different datasets.
| Model |
|
|
|
|
|
|||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NODE | ||||||||||||||
| FEN | ||||||||||||||
| SNPDE | ||||||||||||||
| DINo | ||||||||||||||
| MAgNet | NA | NA | ||||||||||||
| Ours |
6 Related Work
Closest to our work is Ayed et al. (2022), where they considered the problem of learning PDEs from partial observations and proposed a discrete and grid-dependent model that is restricted to regular spatiotemporal grids. Another related work is that of Nguyen et al. (2020), where they proposed a variational inference framework for learning ODEs from noisy and partially-observed data. However, they consider only low-dimensional ODEs and are restricted to regular grids.
Other works considered learning the latent space PDE dynamics using the “encode-process-decode” approach. Pfaff et al. (2021) use GNN-based encoder and dynamics function and map the observations to the same spatial grid in the latent space and learn the latent space dynamics. Sanchez et al. (2020) use a similar approach but with CNNs and map the observations to a coarser latent grid and learn the coarse-scale dynamics. Wu et al. (2022) use CNNs to map observations to a low-dimensional latent vector and learn the latent dynamics. However, all these approaches are grid-dependent, limited to regular spatial/temporal grids, and require fully-observed data.
Interpolation has been used in numerous studies for various applications. Works such as (Alet et al., 2019; Jiang et al., 2020; Han et al., 2022) use interpolation to map latent states on coarse grids to observations on finer grids. Hua et al. (2022) used interpolation as a post-processing step to obtain continuous predictions, while Boussif et al. (2022) used it to recover observations at missing nodes.
7 Conclusion
We proposed a novel space-time continuous, grid-independent model for learning PDE dynamics from noisy and partial observations on irregular spatiotemporal grids. Our contributions include an efficient generative modeling framework, a novel latent PDE model merging collocation and method of lines, and a data-efficient, grid-independent encoder design. The model demonstrates state-of-the-art performance on complex datasets, highlighting its potential for advancing data-driven PDE modeling and enabling accurate predictions of spatiotemporal phenomena in diverse fields. However, our model and encoder operate on every spatial and temporal location which might not be the most efficient approach and hinders scaling to extremely large grids, hence research into more efficient latent state extraction and dynamics modeling methods is needed.
References
- Alet et al. (2019) Ferran Alet, Adarsh Keshav Jeewajee, Maria Bauza Villalonga, Alberto Rodriguez, Tomas Lozano-Perez, and Leslie Kaelbling. Graph element networks: adaptive, structured computation and memory. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors, Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pages 212–222. PMLR, 09–15 Jun 2019. URL https://proceedings.mlr.press/v97/alet19a.html.
- Ayed et al. (2022) Ibrahim Ayed, Emmanuel de Bézenac, Arthur Pajot, and Patrick Gallinari. Modelling spatiotemporal dynamics from earth observation data with neural differential equations. Machine Learning, 111(6):2349–2380, 2022. doi: 10.1007/s10994-022-06139-2. URL https://doi.org/10.1007/s10994-022-06139-2.
- Blei et al. (2017) David M. Blei, Alp Kucukelbir, and Jon D. McAuliffe. Variational inference: A review for statisticians. Journal of the American Statistical Association, 112(518):859–877, Apr 2017. ISSN 1537-274X. doi: 10.1080/01621459.2017.1285773. URL http://dx.doi.org/10.1080/01621459.2017.1285773.
- Bock and Plitt (1984) H.G. Bock and K.J. Plitt. A multiple shooting algorithm for direct solution of optimal control problems*. IFAC Proceedings Volumes, 17(2):1603–1608, 1984. ISSN 1474-6670. doi: https://doi.org/10.1016/S1474-6670(17)61205-9. URL https://www.sciencedirect.com/science/article/pii/S1474667017612059. 9th IFAC World Congress: A Bridge Between Control Science and Technology, Budapest, Hungary, 2-6 July 1984.
- Boussif et al. (2022) Oussama Boussif, Yoshua Bengio, Loubna Benabbou, and Dan Assouline. MAgnet: Mesh agnostic neural PDE solver. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors, Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/forum?id=bx2roi8hca8.
- Brandstetter et al. (2022) Johannes Brandstetter, Daniel E. Worrall, and Max Welling. Message passing neural PDE solvers. In International Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=vSix3HPYKSU.
- Brunton and Kutz (2019) Steven L. Brunton and J. Nathan Kutz. Data-Driven Science and Engineering: Machine Learning, Dynamical Systems, and Control. Cambridge University Press, 2019. doi: 10.1017/9781108380690.
- Cellier (2019) Nicolas Cellier. scikit-fdiff, 2019. URL https://gitlab.com/celliern/scikit-fdiff.
- Chen (2018) Ricky T. Q. Chen. torchdiffeq, 2018. URL https://github.com/rtqichen/torchdiffeq.
- Chen et al. (2018) Ricky T. Q. Chen, Yulia Rubanova, Jesse Bettencourt, and David Duvenaud. Neural ordinary differential equations, 2018.
- Cheng (2009) Alexander H.-D. Cheng. Radial basis function collocation method. In Computational Mechanics, pages 219–219, Berlin, Heidelberg, 2009. Springer Berlin Heidelberg. ISBN 978-3-540-75999-7.
- Cressie and Wikle (2011) N. Cressie and C. K. Wikle. Statistics for Spatio-Temporal Data. Wiley, 2011. ISBN 9780471692744. URL https://books.google.fi/books?id=-kOC6D0DiNYC.
- Eckert et al. (2019) Marie-Lenat Eckert, Kiwon Um, and Nils Thuerey. Scalarflow: A large-scale volumetric data set of real-world scalar transport flows for computer animation and machine learning. ACM Transactions on Graphics, 38(6):239, 2019.
- Evans (2010) L. C. Evans. Partial Differential Equations. American Mathematical Society, 2010. ISBN 9780821849743.
- Glorot and Bengio (2010) Xavier Glorot and Yoshua Bengio. Understanding the difficulty of training deep feedforward neural networks. In Yee Whye Teh and Mike Titterington, editors, Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, volume 9 of Proceedings of Machine Learning Research, pages 249–256, Chia Laguna Resort, Sardinia, Italy, 13–15 May 2010. PMLR. URL https://proceedings.mlr.press/v9/glorot10a.html.
- Hamdi et al. (2007) S. Hamdi, W. E. Schiesser, and G. W Griffiths. Method of lines. Scholarpedia, 2(7):2859, 2007. doi: 10.4249/scholarpedia.2859. revision #26511.
- Han et al. (2022) Xu Han, Han Gao, Tobias Pfaff, Jian-Xun Wang, and Liping Liu. Predicting physics in mesh-reduced space with temporal attention. In International Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=XctLdNfCmP.
- Hegde et al. (2022) Pashupati Hegde, Cagatay Yildiz, Harri Lähdesmäki, Samuel Kaski, and Markus Heinonen. Variational multiple shooting for bayesian ODEs with gaussian processes. In The 38th Conference on Uncertainty in Artificial Intelligence, 2022. URL https://openreview.net/forum?id=r2NuhIUoceq.
- Hirsch (2007) Charles Hirsch. Numerical computation of internal and external flows: The fundamentals of computational fluid dynamics. Elsevier, 2007.
- Holl et al. (2020) Philipp Holl, Vladlen Koltun, Kiwon Um, and Nils Thuerey. phiflow: A differentiable pde solving framework for deep learning via physical simulations. In NeurIPS Workshop on Differentiable vision, graphics, and physics applied to machine learning, 2020. URL https://montrealrobotics.ca/diffcvgp/assets/papers/3.pdf.
- Hua et al. (2022) Chuanbo Hua, Federico Berto, Michael Poli, Stefano Massaroli, and Jinkyoo Park. Efficient continuous spatio-temporal simulation with graph spline networks. In ICML 2022 2nd AI for Science Workshop, 2022. URL https://openreview.net/forum?id=PBT0Vftuji.
- Iakovlev et al. (2023) Valerii Iakovlev, Cagatay Yildiz, Markus Heinonen, and Harri Lähdesmäki. Latent neural ODEs with sparse bayesian multiple shooting. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=moIlFZfj_1b.
- Jiang et al. (2020) Chiyu lMaxr Jiang, Soheil Esmaeilzadeh, Kamyar Azizzadenesheli, Karthik Kashinath, Mustafa Mustafa, Hamdi A. Tchelepi, Philip Marcus, Mr Prabhat, and Anima Anandkumar. Meshfreeflownet: A physics-constrained deep continuous space-time super-resolution framework. SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, Nov 2020. doi: 10.1109/sc41405.2020.00013. URL http://dx.doi.org/10.1109/SC41405.2020.00013.
- Jordana et al. (2021) Armand Jordana, Justin Carpentier, and Ludovic Righetti. Learning dynamical systems from noisy sensor measurements using multiple shooting, 2021.
- Kansa (1990) E.J. Kansa. Multiquadrics—a scattered data approximation scheme with applications to computational fluid-dynamics—ii solutions to parabolic, hyperbolic and elliptic partial differential equations. Computers and Mathematics with Applications, 19(8):147–161, 1990. ISSN 0898-1221. doi: https://doi.org/10.1016/0898-1221(90)90271-K. URL https://www.sciencedirect.com/science/article/pii/089812219090271K.
- Kingma and Ba (2017) Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization, 2017.
- Kingma and Welling (2013) Diederik P Kingma and Max Welling. Auto-encoding variational bayes, 2013.
- Kochkov et al. (2021) Dmitrii Kochkov, Jamie A. Smith, Ayya Alieva, Qing Wang, Michael P. Brenner, and Stephan Hoyer. Machine learning–accelerated computational fluid dynamics. Proceedings of the National Academy of Sciences, 118(21):e2101784118, 2021. doi: 10.1073/pnas.2101784118. URL https://www.pnas.org/doi/abs/10.1073/pnas.2101784118.
- Li et al. (2021) Zongyi Li, Nikola Borislavov Kovachki, Kamyar Azizzadenesheli, Burigede liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differential equations. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=c8P9NQVtmnO.
- Lienen and Günnemann (2022) Marten Lienen and Stephan Günnemann. Learning the dynamics of physical systems from sparse observations with finite element networks. In International Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=HFmAukZ-k-2.
- Long et al. (2018) Zichao Long, Yiping Lu, Xianzhong Ma, and Bin Dong. PDE-net: Learning PDEs from data. In Jennifer Dy and Andreas Krause, editors, Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pages 3208–3216. PMLR, 10–15 Jul 2018. URL https://proceedings.mlr.press/v80/long18a.html.
- Lu et al. (2021) Lu Lu, Pengzhan Jin, Guofei Pang, Zhongqiang Zhang, and George Em Karniadakis. Learning nonlinear operators via deeponet based on the universal approximation theorem of operators. Nature Machine Intelligence, 3(3):218–229, Mar 2021. ISSN 2522-5839. doi: 10.1038/s42256-021-00302-5. URL http://dx.doi.org/10.1038/s42256-021-00302-5.
- Metz et al. (2021) Luke Metz, C. Daniel Freeman, Samuel S. Schoenholz, and Tal Kachman. Gradients are not all you need, 2021.
- Murray (2002) James D. Murray. Mathematical Biology I. An Introduction, volume 17 of Interdisciplinary Applied Mathematics. Springer, New York, 3 edition, 2002. doi: 10.1007/b98868.
- Nguyen et al. (2020) Duong Nguyen, Said Ouala, Lucas Drumetz, and Ronan Fablet. Variational deep learning for the identification and reconstruction of chaotic and stochastic dynamical systems from noisy and partial observations. ArXiv, abs/2009.02296, 2020.
- Pfaff et al. (2021) Tobias Pfaff, Meire Fortunato, Alvaro Sanchez-Gonzalez, and Peter Battaglia. Learning mesh-based simulation with graph networks. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=roNqYL0_XP.
- Poli et al. (2022) Michael Poli, Stefano Massaroli, Federico Berto, Jinkyoo Park, Tri Dao, Christopher Re, and Stefano Ermon. Transform once: Efficient operator learning in frequency domain. In ICML 2022 2nd AI for Science Workshop, 2022. URL https://openreview.net/forum?id=x1fNT5yj41N.
- Ribeiro et al. (2020) Antônio H. Ribeiro, Koen Tiels, Jack Umenberger, Thomas B. Schön, and Luis A. Aguirre. On the smoothness of nonlinear system identification. Automatica, 121:109158, 2020. ISSN 0005-1098. doi: https://doi.org/10.1016/j.automatica.2020.109158. URL https://www.sciencedirect.com/science/article/pii/S0005109820303563.
- Salvi et al. (2021) Cristopher Salvi, Maud Lemercier, and Andris Gerasimovics. Neural stochastic pdes: Resolution-invariant learning of continuous spatiotemporal dynamics, 2021.
- Sanchez et al. (2020) Alvaro Sanchez, Dmitrii Kochkov, Jamie Alexander Smith, Michael Brenner, Peter Battaglia, and Tobias Joachim Pfaff. Learning latent field dynamics of pdes. 2020. We are submitting to Machine Learning and the Physical Sciences workshop with a submission deadline on October 2nd.
- Schiesser (1991) William E. Schiesser. The numerical method of lines: Integration of partial differential equations. 1991.
- Seo et al. (2020) Sungyong Seo, Chuizheng Meng, and Yan Liu. Physics-aware difference graph networks for sparsely-observed dynamics. In International Conference on Learning Representations, 2020. URL https://openreview.net/forum?id=r1gelyrtwH.
- Um et al. (2020) Kiwon Um, Robert Brand, Yun Fei, Philipp Holl, and Nils Thuerey. Solver-in-the-Loop: Learning from Differentiable Physics to Interact with Iterative PDE-Solvers. Advances in Neural Information Processing Systems, 2020.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. URL https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf.
- Voss et al. (2004) Henning Voss, J. Timmer, and Juergen Kurths. Nonlinear dynamical system identification from uncertain and indirect measurements. International Journal of Bifurcation and Chaos, 14, 01 2004.
- Wu et al. (2022) Tailin Wu, Takashi Maruyama, and Jure Leskovec. Learning to accelerate partial differential equations via latent global evolution. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors, Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/forum?id=xvZtgp5wyYT.
- Yildiz et al. (2019) Cagatay Yildiz, Markus Heinonen, and Harri Lähdesmäki. Ode2vae: Deep generative second order odes with bayesian neural networks. ArXiv, abs/1905.10994, 2019.
- Yin et al. (2023) Yuan Yin, Matthieu Kirchmeyer, Jean-Yves Franceschi, Alain Rakotomamonjy, and patrick gallinari. Continuous PDE dynamics forecasting with implicit neural representations. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=B73niNjbPs.
Appendix A Appendix A
A.1 Model specification.
Here we provide all details about our model specification. The joint distribution for our model is
| (24) |
Next, we specify each component in detail.
Parameter priors.
The parameter priors are isotropic zero-mean multivariate normal distributions:
| (25) | |||
| (26) |
where is the normal distribution, is a zero vector, and is the identity matrix, both have an appropriate dimensionality dependent on the number of encoder and dynamics parameters.
Continuity prior.
We define the continuity prior as
| (27) | ||||
| (28) | ||||
| (29) |
where is the normal distribution, is a zero vector, is the identity matrix, and is the parameter controlling the strength of the prior. Smaller values of tend to produce smaller gaps between the sub-trajectories.
Observation model
| (30) | ||||
| (31) | ||||
| (32) |
where is the normal distribution, is the observation noise variance, and is the identity matrix. Note again that above equals the ODE forward solution at grid location .
A.2 Approximate posterior specification.
Here we provide all details about the approximate posterior. We define the approximate posterior as
| (33) |
Next, we specify each component in detail.
Dynamics parameters posterior.
We define as
| (34) |
where and are vectors with an appropriate dimension (dependent on the number of dynamics parameters), and is a matrix with on the diagonal. We define the vector of variational parameters as . We optimize directly over and initialize using Xavier (Glorot and Bengio, 2010) initialization, while is initialized with each element equal to .
Decoder parameters posterior.
We define as
| (35) |
where and are vectors with an appropriate dimension (dependent on the number of decoder parameters), and is a matrix with on the diagonal. We define the vector of variational parameters as . We optimize directly over and initialize using Xavier (Glorot and Bengio, 2010) initialization, while is initialized with each element equal to .
Shooting variables posterior.
We define as
| (36) |
where the vectors are returned by the encoder , and is a matrix with on the diagonal. We define the vector of variational parameters as . Because the variational inference for the shooting variables is amortized, our model is trained w.r.t. the parameters of the encoder network, .
Appendix B Appendix B
B.1 Derivation of ELBO.
For our model and the choice of the approximate posterior the ELBO can be written as
| (37) | ||||
| (38) | ||||
| (39) | ||||
| (40) | ||||
| (41) | ||||
| (42) | ||||
| (43) |
Next, we will look at each term separately.
| (44) | ||||
| (45) | ||||
| (46) | ||||
| (47) | ||||
| (48) |
| (49) | ||||
| (50) | ||||
| (51) | ||||
| (52) | ||||
| (53) | ||||
| (54) | ||||
| (55) | ||||
| (56) | ||||
| (57) | ||||
| (58) | ||||
| (59) |
where is Kullback–Leibler (KL) divergence. Both of the KL divergences above have a closed form but the expectation w.r.t. does not.
| (60) |
B.2 Computation of ELBO.
We compute the ELBO using the following algorithm:
-
1.
Sample from .
-
2.
Sample by sampling each from with .
- 3.
-
4.
Compute ELBO (KL terms are computed in closed form, for expectations we use Monte Carlo integration with one sample).
Sampling is done using reparametrization to allow unbiased gradients w.r.t. the model parameters.
Appendix C Appendix C
C.1 Datasets.
Shallow Water.
The shallow water equations are a system of partial differential equations (PDEs) that simulate the behavior of water in a shallow basin. These equations are effectively a depth-integrated version of the Navier-Stokes equations, assuming the horizontal length scale is significantly larger than the vertical length scale. Given these assumptions, they provide a model for water dynamics in a basin or similar environment, and are commonly utilized in predicting the propagation of water waves, tides, tsunamis, and coastal currents. The state of the system modeled by these equations consists of the wave height , velocity in the -direction and velocity in the -direction . Given an initial state , we solve the PDEs on a spatial domain over time interval . The shallow water equations are defined as:
| (61) | |||
| (62) | |||
| (63) |
where is the gravitational constant.
The spatial domain is a unit square with periodic boundary conditions. We set sec. The solution is evaluated at randomly selected spatial locations and time points. We use spatial locations and time points. The spatial end temporal grids are the same for all trajectories. Since we are dealing with partially-observed cases, we assume that we observe only the wave height .
For each trajectory, we start with zero initial velocities and the initial height generated as:
| (64) | |||
| (65) |
where and .
The datasets used for training, validation, and testing contain , , and trajectories, respectively.
We use scikit-fdiff (Cellier, 2019) to solve the PDEs.
Navier-Stokes.
For this dataset we model the propagation of a scalar field (e.g., smoke concentration) in a fluid (e.g., air). The modeling is done by coupling the Navier-Stokes equations with the Boussinesq buoyancy term and the transport equation to model the propagation of the scalar field. The state of the system modeled by these equations consists of the scalar field , velocity in -direction , velocity in -direction , and pressure . Given an initial state , we solve the PDEs on a spatial domain over time interval . The Navier-Stokes equations with the transport equation are defined as:
| (66) | |||
| (67) | |||
| (68) | |||
| (69) |
where .
The spatial domain is a unit square with periodic boundary conditions. We set sec, but drop the first seconds due to slow dynamics during this time period. The solution is evaluated at randomly selected spatial locations and time points. We use spatial locations and time points. The spatial and temporal grids are the same for all trajectories. Since we are dealing with partially-observed cases, we assume that we observe only the scalar field .
For each trajectory, we start with zero initial velocities and pressure, and the initial scalar field is generated as:
| (70) | |||
| (71) |
where and .
The datasets used for training, validation, and testing contain , , and trajectories, respectively.
We use PhiFlow (Holl et al., 2020) to solve the PDEs.
Scalar Flow.

This dataset, proposed by Eckert et al. (2019), consists of observations of smoke plumes rising in hot air. The observations are post-processed camera images of the smoke plumes taken from multiple views. For simplicity, we use only the front view. The dataset contains 104 trajectories, where each trajectory has 150 time points and each image has the resolution 1080 1920. Each trajectory was recorded for seconds.
To reduce dimensionality of the observations we sub-sample the original spatial and temporal grids. For the temporal grid, we remove the first 50 time points, which leaves 100 time points, and then take every 4th time point, thus leaving 20 time points in total. The original 1080 1920 spatial grid is first down-sampled by a factor of 9 giving a new grid with resolution 120 213, and then the new grid is further sub-sampled based on the smoke density at each node. In particular, we compute the average smoke density at each node (averaged over time), and then sample the nodes without replacement with the probability proportional to the average smoke density (thus, nodes that have zero density most of the time are not selected). See example of a final grid in Figure 9. This gives a new grid with 1089 nodes.
We further smooth the observations by applying Gaussian smoothing with the standard deviation of 1.5 (assuming domain size 120 213).
We use the first 60 trajectories for training, next 20 for validation and next 20 for testing.
In this case the spatial domain is non-periodic, which means that for some observation location some of its spatial neighbors might be outside of the domain. We found that to account for such cases it is sufficient to mark such out-of-domain neighbors by setting their value to .
Time grids used for the three datasets are shown in Figure 10.



C.2 Model architecture and hyper-parameters.
Dynamics function.
For all datasets we define as an MLP. For Shallow Water/Navier-Stokes/Scalar Flow we use 1/3/3 hidden layers with the size of 1024/512/512, respectively. We use ReLU nonlinearities.
Observation function.
For all datasets we define as a selector function which takes the latent state and returns its first component.
Encoder.
Our encoder consists of three function: , , and . The spatial aggregation function is a linear mapping to . The temporal aggregation function is a stack of transformer layers with temporal attention and continuous relative positional encodings (Iakovlev et al., 2023). For all datasets, we set the number of transformer layers to 6. Finally, the variational parameter readout function is a mapping defined as
| (72) |
where is a linear layer (different for each line), and and are the variational parameters discussed in Appendix A.
Spatial and temporal neighborhoods.
We use the same spatial neighborhoods for both the encoder and the dynamics function. We define as the set of points consisting of the point and points on two concentric circles centered at , with radii and , respectively. Each circle contains 8 points spaced degrees apart (see Figure 11 (right)). The radius is set to . For Shallow Water/Navier-Stokes/Scalar Flow the size of temporal neighborhood () is set to //, respectively.
Multiple Shooting.
For Shallow Water/Navier-Stokes/Scalar Flow we split the full training trajectories into // sub-trajectories, or, equivalently, have the sub-trajectory length of //.
C.3 Training, validation, and testing setup.
Data preprocessing.
We scale the temporal grids, spatial grids, and observations to be within the interval .
Training.
We train our model for 20000 iterations using Adam (Kingma and Ba, 2017) optimizer with constant learning rate and linear warmup for 200 iterations. The latent spatiotemporal dynamics are simulated using differentiable ODE solvers from the torchdiffeq package (Chen, 2018) (we use dopri5 with rtol=, atol=, no adjoint). The batch size is 1.
Validation.
We use validation set to track the performance of our model during training and save the parameters that produce the best validation performance. As performance measure we use the mean absolute error at predicting the full validation trajectories given some number of initial observations. For Shallow Water/Navier-Stokes/Scalar Flow we use the first // observations. The predictions are made by taking one sample from the posterior predictive distribution (see Appendix C.4 for details).
Testing.
Testing is done similarly to validation, except that as the prediction we use an estimate of the expected value of the posterior predictive distribution (see Appendix C.4 for details).
C.4 Forecasting.
Given initial observations at time points , we predict the future observation at a time point as the expected value of the approximate posterior predictive distribution:
| (73) |
The expected value is estimated via Monte Carlo integration, so the algorithm for predicting is:
-
1.
Sample from .
-
2.
Sample from , where the variational parameters are given by the encoder operating on the initial observations as .
-
3.
Compute the latent state .
-
4.
Sample by sampling each from .
-
5.
Repeat steps 1-4 times and average the predictions (we use ).
C.5 Model comparison setup.
NODE.
For the NODE model the dynamics function was implemented as a fully connected feedforward neural network with 3 hidden layers, 512 neurons each, and ReLU nonlinearities.
FEN.
We use the official implementation of FEN. We use FEN variant without the transport term as we found it improves results on our datasets. The dynamics were assumed to be stationary and autonomous in all cases. The dynamics function was represented by a fully connected feedforward neural network with 3 hidden layers, 512 neurons each, and ReLU nonlinearities.
NSPDE.
We use the official implementation of NSPDE. We set the number of hidden channels to 16, and set modes1 and modes2 to 32.
DINo.
We use the official implementation of DINo. The encoder is an MLP with 3 hidden layers, 512 neurons each, and Swish non-linearities. The code dimension is . The dynamics function is an MLP with 3 hidden layers, 512 neurons each, and Swish non-linearities. The decoder has layers and channels.
MAgNet.
We use the official implementation of MAgNet. We use the graph neural network variant of the model. The number of message-passing steps is 5. All MLPs have 4 layers with 128 neurons each in each layer. The latent state dimension is 128.
Appendix D Appendix D
D.1 Spatiotemporal neighborhood shapes and sizes.
Here we investigate the effect of changing the shape and size of spatial and temporal neighborhoods used by the encoder and dynamics functions. We use the default hyperparameters discussed in Appendix C and change only the neighborhood shape or size. A neighborhood size of zero implies no spatial/temporal aggregation.
Initially, we use the original circular neighborhood displayed in Figure 11 for both encoder and dynamics function and change only its size (radius). The results are presented in Figures 12(a) and 12(b). In Figure 12(a), it is surprising to see very little effect from changing the encoder’s spatial neighborhood size. A potential explanation is that the dynamics function shares the spatial aggregation task with the encoder. However, the results in Figure 12(b) are more intuitive, displaying a U-shaped curve for the test MAE, indicating the importance of using spatial neighborhoods of appropriate size. Interestingly, the best results tend to be achieved with relatively large neighborhood sizes. Similarly, Figure 12(c) shows U-shaped curves for the encoder’s temporal neighborhood size, suggesting that latent state inference benefits from utilizing local temporal information.
We then examine the effect of changing the shape of the dynamics function’s spatial neighborhood. We use circle neighborhoods, which consist of equidistant concentric circular neighborhoods (see examples in Figure 11). Effectively, we maintain a fixed neighborhood size while altering its density. The results can be seen in Figure 13. We find that performance does not significantly improve when using denser (and presumably more informative) spatial neighborhoods, indicating that accurate predictions only require a relatively sparse neighborhood with appropriate size.





D.2 Multiple shooting.
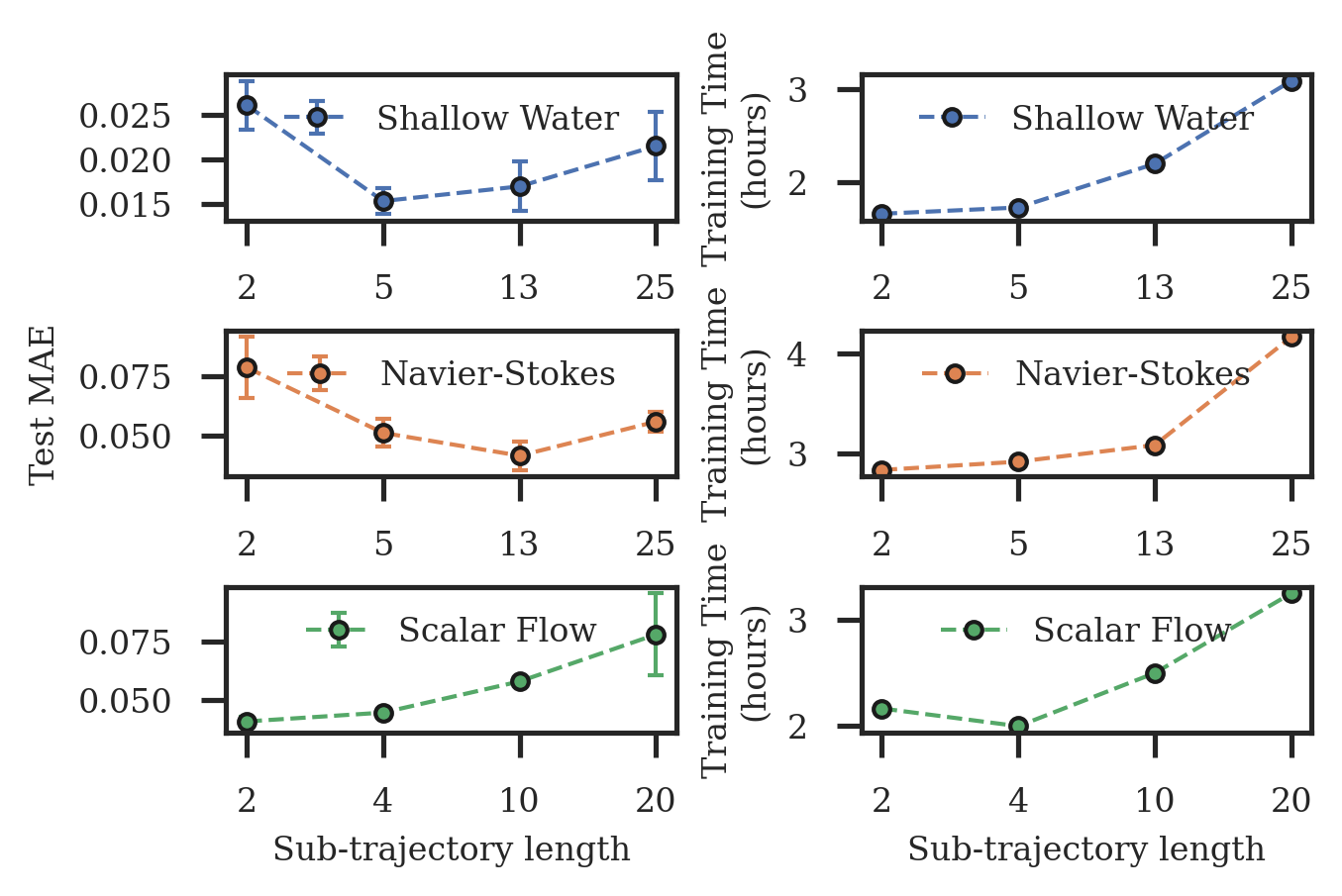
Here we demonstrate the effect of using multiple shooting for model training. In Figure 14 (left), we vary the sub-trajectory length (longer sub-trajectories imply more difficult training) and plot the test errors for each sub-trajectory length. We observe that in all cases, the best results are achieved when the sub-trajectory length is considerably smaller than the full trajectory length. In Figure 14 (right) we further show the training times, and as can be seen multiple shooting allows to noticeably reduce the training times.
Appendix E Appendix E
Noisy Data.
Here we show the effect of observation noise on our model and compare the results against other models. We train all models with data noise of various strengths, and then compute test MAE on noiseless data (we still use noisy data to infer the initial state at test time). Figure 15 shows that our model can manage noise strength up to 0.1 without significant drops in performance. Note that all observations are in the range .

Appendix F Appendix F
F.1 Model Predictions
We show (Fig. 16) predictions of different models trained on different datasets (synthetic data is partially observed).

F.2 Visualization of Prediction Uncertainty
Figures 17, 18, and 19 demonstrate the prediction uncertainty across different samples from the posterior distribution.


