ifaamas \acmDOIdoi \acmISBN \acmConference[AAMAS’20]Proc. of the 19th International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2020), B. An, N. Yorke-Smith, A. El Fallah Seghrouchni, G. Sukthankar (eds.)May 2020Auckland, New Zealand \acmYear2020 \copyrightyear2020 \acmPrice
DeepMind \streetaddressLondon, UK
DeepMind \streetaddressLondon, UK
DeepMind \streetaddressLondon, UK
DeepMind \streetaddressLondon, UK
DeepMind \streetaddressLondon, UK
DeepMind \streetaddressLondon, UK
Learning to Resolve Alliance Dilemmas in Many-Player Zero-Sum Games
Abstract.
Zero-sum games have long guided artificial intelligence research, since they possess both a rich strategy space of best-responses and a clear evaluation metric. What’s more, competition is a vital mechanism in many real-world multi-agent systems capable of generating intelligent innovations: Darwinian evolution, the market economy and the AlphaZero algorithm, to name a few. In two-player zero-sum games, the challenge is usually viewed as finding Nash equilibrium strategies, safeguarding against exploitation regardless of the opponent. While this captures the intricacies of chess or Go, it avoids the notion of cooperation with co-players, a hallmark of the major transitions leading from unicellular organisms to human civilization. Beyond two players, alliance formation often confers an advantage; however this requires trust, namely the promise of mutual cooperation in the face of incentives to defect. Successful play therefore requires adaptation to co-players rather than the pursuit of non-exploitability. Here we argue that a systematic study of many-player zero-sum games is a crucial element of artificial intelligence research. Using symmetric zero-sum matrix games, we demonstrate formally that alliance formation may be seen as a social dilemma, and empirically that naïve multi-agent reinforcement learning therefore fails to form alliances. We introduce a toy model of economic competition, and show how reinforcement learning may be augmented with a peer-to-peer contract mechanism to discover and enforce alliances. Finally, we generalize our agent model to incorporate temporally-extended contracts, presenting opportunities for further work.
Key words and phrases:
deep reinforcement learning; multi-agent learning; bargaining and negotiation; coalition formation (strategic)1. Introduction
Minimax foundations. Zero-sum two-player games have long been a yardstick for progress in artificial intelligence (AI). Ever since the pioneering Minimax theorem v. Neumann (1928); VON NEUMANN and Morgenstern (1953); E. Shannon (1950), the research community has striven for human-level play in grand challenge games with combinatorial complexity. Recent years have seen great progress in games with increasingly many states: both perfect information (e.g. backgammon Tesauro (1995), checkers Schaeffer et al. (1992), chess, Campbell et al. (2002), Hex Anthony et al. (2017) and Go Silver et al. (2016)) and imperfect information (e.g. Poker Moravcík et al. (2017) and Starcraft Vinyals et al. (2017)).
The Minimax theorem v. Neumann (1928) states that every finite zero-sum two-player game has an optimal mixed strategy. Formally, if and are the sets of possible mixed strategies of the players and is the payoff matrix of the game, then , with referred to as the value of the game. This property makes two-player zero-sum games inherently easier to analyze, as there exist optimal strategies which guarantee each player a certain value, no matter what their opponent does.
In short, zero-sum two-player games have three appealing features:
-
(1)
There is an unambiguous measure of algorithm performance, namely performance against a human expert.
-
(2)
The size of the game tree gives an intuitive measure of complexity, generating a natural difficulty ordering for research.
-
(3)
The minimax and Nash strategies coincide, so in principle there is no need for a player to adapt to another’s strategy.
Limitations of zero-sum two-player games. The above properties of two-player zero-sum games makes them relatively easy to analyze mathematically, but most real-world interactions extend beyond direct conflict between two individuals. Zero-sum games are rare. Indeed, the chances of a random two-player two-action game being epsilon-constant-sum follow a triangular distribution, as shown empirically in Figure 1. Importantly, this distribution has low density near : zero-sum games are even rarer than one might naïvely expect. Thus, a research programme based around agent performance in two-player zero-sum games may fail to capture some important social abilities. More explicitly, property (3) is problematic: human intelligence is arguably predicated on our sociality Reader and Laland (2002), which exactly represents our ability to dynamically respond to a variety of co-players. Relatedly, natural environments are rarely purely adversarial; most environments are mixed-motive, where interactions between individuals comprise a combination of cooperation and competition. In other words, two-player constant-sum is a reasonable mathematical starting point for coarse-grained multi-agent interactions, but to understand the fine detail, we must move beyond this class of games.
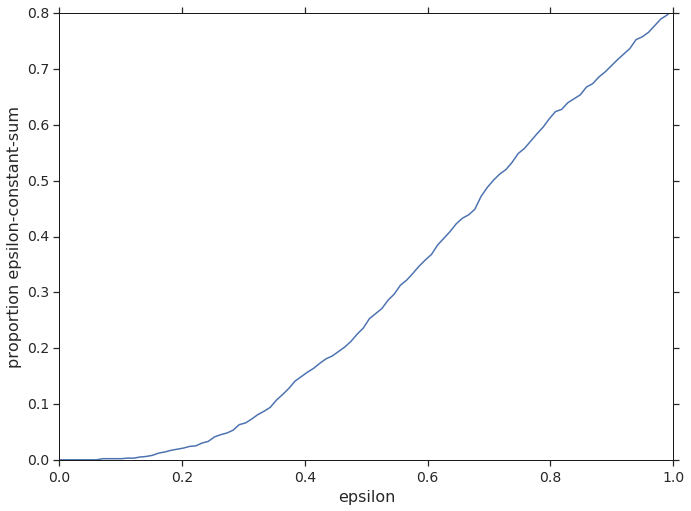
Approaches to multi-agent cooperation. There are various ways to move beyond zero-sum two-player interactions. One profitable avenue is provided by zero-sum games between two teams of agents, as done in environments such as soccer Liu et al. (2019) or Dota 2 OpenAI (2018). Here, each team of agents faces an internal coordination problem. However, in principle this does not address the limitation of (3) at the level of the team’s strategy. Moreover, since the teams are fixed, the individuals face no problem of team formation Gaston and DesJardins (2005); Sandholm et al. (1999); Bachrach et al. (2013), an important feature of socio-economic interactions, evinced by the substantial literature on cooperative game theory; see Drechsel (2010) for a review.
Alternatively, one might consider lifting the zero-sum restriction. Much recent work in multi-agent reinforcement learning (MARL) has focussed on social dilemmas with two or more players, e.g. Leibo et al. (2017); Pérolat et al. (2017); Hughes et al. (2018); Wang et al. (2018); Eccles et al. (2019); Lerer and Peysakhovich (2017); Foerster et al. (2017). These domains challenge learning agents to adapt and shape the learning of their co-players to achieve coordinated, cooperative outcomes without being exploited. In this sense, they directly address the limitations of (3). However, the general-sum case lacks the benefits conferred by properties (1) and (2). Indeed, there is no canonical metric of multi-agent performance, which makes comparisons between algorithms particularly difficult.
A third strand of work investigates scenarios in which cooperation is a given. Examples of such multi-agent learning problems include negotiation Cao et al. (2018), coalition formation Bachrach et al. (2019) and communication, both through a “cheap talk” channel Foerster et al. (2016); Mordatch and Abbeel (2017) and grounded in environment actions. These tasks certainly probe the abilities of agents to co-adapt, for they require intricate coordination. However, this is achieved at the expense of removing some of the adversarial dynamics. For example, in Hanabi any subset of agents are by definition incentivized to work together Bard et al. (2019).
Finally, back in the two-player zero-sum setting, it is possible to optimize not for win-rate against an arbitrary opponent, but rather for maximum winning margin against some fixed background of exploitable opponents. For instance, in rock-paper-scissors against an opponent who always plays rock, you should always play paper, eschewing the mixed Nash. By definition one must adapt to one’s co-players. Indeed, the identification of learning of robust best-responses has been extensively studied; see Vezhnevets et al. (2019); Lanctot et al. (2017); Vezhnevets et al. (2019); Balduzzi et al. (2019) for a range of applications. Nevertheless, the necessity of choosing background opponents removes some of the advantages conferred by properties (1) and (2).
Our contributions. The aims of this paper are threefold. Firstly to mathematically define the challenge of forming alliances. Secondly to demonstrate that state-of-the-art reinforcement learning, used to great effect in two-player zero-sum games, fails to form alliances. Thirdly, to provide a parsimonious and well-motivated mechanism for the formation of alliances by RL agents, namely contracts.
We focus on alliance formation in many-player (-player) zero-sum games as a fruitful and relatively understudied arena for AI research. More precisely, we examine symmetric zero-sum many-player games, and provide empirical results showing that alliance formation in such games often yields a social dilemma, thus requiring online adaptation between co-players. Viewing these games through the prism of reinforcement learning, we empirically show that standard independent reinforcement learning agents fail to learn to form alliances. We then propose a simple protocol that can be used to augment reinforcement learning agents, allowing them to learn peer-to-peer contracts, thus enabling them to make alliances. We study the impact of this protocol through a toy model of economic competition, demonstrating that contract-augment agents outperform the model-free baseline. Finally, we extend our model to incorporate enforcement by punishment, demonstrating the potential for our method to scale to spatially and temporally extended scenarios.
2. Preliminaries
2.1. Related work
We are far from the first to study many-player zero-sum games; see for instance Kraus et al. (1989); Nijssen (2013); Brown and Sandholm (2019); Paquette et al. (2019). Bonnet et al. (2018) have recently studied coalitions in Piglet, although they consider the coalition to be fixed from the beginning of the game. Our novel contributions come from studying alliance formation rigorously as a social dilemma, demonstrating the failure modes of MARL in alliance formation, and providing a mechanism for the learning of contracts. Despite much progress in this field, the problem of learning to form lasting, adaptable alliances without human data remains open.
As inspiration, the cooperative game theory literature provides several methods for coordinating agents in competitive settings Branzei et al. (2008); Chalkiadakis et al. (2011). That line of work typically focuses on the question of how to share the joint gains of a team between the team members, in a fair way Bilbao et al. (2000); Bachrach et al. (2010); Michalak et al. (2013) or in a way that fosters the stability of the coalition Chalkiadakis et al. (2011); Conitzer and Sandholm (2006); Dunne et al. (2008); Resnick et al. (2009). Such work has also been used as a foundation for building agents that cooperate and negotiate with humans Kraus (1997); Jennings et al. (2001); Mash et al. (2017); Rosenfeld and Kraus (2018). In particular, researchers have proposed algorithms for robust team formation Shehory and Kraus (1998); Gaston and DesJardins (2005); Klusch and Gerber (2002); Zlotkin and Rosenschein (1994) and sharing resources Choi et al. (2009); Rosenschein and Zlotkin (1994); Shamma (2007). Our work builds on these strong foundations, being the first to apply MARL in this setting, and demonstrating the efficacy of a concrete protocol that allows MARL agents to form alliances.
Our MARL approach augments agents with the ability to negotiate and form contracts regarding future actions. Many protocols have been suggested for multi-agent negotiation, as discussed in various surveys on the topic Shamma (2007); Kraus (1997); Rosenschein and Zlotkin (1994); Kraus and Arkin (2001). Some propose agent interaction mechanisms Smith (1980); Kuwabara et al. (1995); Sandholm et al. (1995); Sandholm and Lesser (1996); Fornara and Colombetti (2002), whereas others aim to characterize the stability of fair outcomes for agents Tsvetovat et al. (2000); Klusch and Gerber (2002); Conitzer and Sandholm (2004); Ieong and Shoham (2005). However, the focus here lies on solution concepts, rather than the online learning of policies for both acting in the world and developing social ties with others.
As MARL has become more ubiquitous and scalable, so has interest in dynamic team formation increased. In the two-player setting, the Coco- algorithm achieves social welfare maximizing outcomes on a range of gridworld games when reinforcement learning agents are augmented with the ability to sign binding contracts and make side payments Sodomka et al. (2013). For many-agent games, there has been much progress on achieving adhoc teamwork Stone et al. (2010) in fully cooperative tasks, including by modelling other agents Barrett et al. (2012), invoking a centralized manager Shu and Tian (2019) or learning from past teammates Barrett et al. (2017). To our knowledge, no previous literature has studied how alliances may be formed by learning agents equipped with a contract channel in many-agent zero-sum games.
As this paper was in review, two complementary works appeared. Jonge and Zhang (2020) equips agents with the ability to negotiate and form contracts as part of a search algorithm, aligned with yet distinct from our reinforcement learning approach. Shmakov et al. (2019) defines a framework for reinforcement learning in -player games, which could be used to scale up our results, but does not explicitly tackle the issue of alliance formation.
2.2. Multi-agent reinforcement learning
We consider multi-agent reinforcement learning (MARL) in Markov games Shapley (1953); Littman (1994a). In each game state, agents take actions based on a (possibly partial) observation of the state space and receive an individual reward. Agents must learn an appropriate behavior policy through experience while interacting with one another. We formalize this as follows.
Let be an -player partially observable Markov game defined on a finite set of states . The observation function specifies each player’s -dimensional view on the state space. From each state, each player may take actions from each of the sets respectively. As a result of the joint action the state changes, following the stochastic transition function , where denotes the set of discrete probability distributions over . We denote the observation space of player by . Each player receives an individual reward denoted by for player . We denote the joint actions, observations and policies for all players by , and respectively.
In MARL, each agent learns, independently through its own experience of the environment, a behavior policy , which we denote . Each agent’s goal is to maximize a long term -discounted payoff,111For all of our experiments, . namely
| (1) |
where is a sampled according to the distribution and is sampled according to the distribution . In our setup, each agent comprises a feedforward neural network and a recurrent module, with individual observations as input, and policy logits and value estimate as output. We train our agents with a policy gradient method known as advantage actor-critic (A2C) Sutton and Barto (2018), scaled up using the IMPALA framework Espeholt et al. (2018). Details of neural network configuration and learning hyperparameters are provided alongside each experiment to aid reproducibility.
3. Alliance Dilemmas
In this section we formally introduce the notion of an alliance dilemma, a definition which captures the additional complexity present in -player zero-sum games when .
Intuition. The simplest class of multi-player zero-sum games are the symmetric -action, -player repeated matrix games. Particularly interesting games in this class are those which reduce to two-player social dilemmas if one of the participants adheres to a fixed policy. Here, one agent can make the team formation problem hard for the other two, and may be able to unreasonably generate winnings, since independent reinforcement learning algorithms in social dilemmas converge to defecting strategies. In other words, a appropriately configured “stubborn” agent can force the two dynamic agents into a social dilemma, whence MARL finds the worst collective outcome for them: the Nash.222If each agent is running a no-regret algorithm then the average of their strategies converges to a coarse-correlated equilibrium Gordon et al. (2008). Empirically, there is much evidence in the literature to suggest that reinforcement learning does reliably find the Nash in social dilemma settings, but this is not theoretically guaranteed.
Social dilemmas. A two-player matrix game,
| R, R | S, T |
| T, S | P, P |
is called a social dilemma if and only if Chammah et al. (1965); Macy and Flache (2002):
-
(1)
: mutual cooperation is preferred to mutual defection.
-
(2)
: mutual cooperation is preferred to being exploited by a defector.
-
(3)
either : exploiting a cooperator is preferred over mutual cooperation (greed), or : mutual defection is preferred over being exploited by a defector (fear).
We say that the social dilemma is strict iff in addition
-
(4)
: mutual cooperation is preferred over an equal mix of defection and cooperation.
There is some debate as to the importance of this final condition: for example, several papers in the experimental literature violate it Beckenkamp et al. (2007). We shall demonstrate that pathological behavior arises in gradient-based learning even in non-strict social dilemmas. Thus from the perspective of alliances, the first three conditions should be considered to be the important ones.
Many-player zero-sum games. An -player -action matrix games is called zero-sum if and only if for each vector of simultaneous payoffs , the following holds: . In other words, a gain in utility for any one player must be exactly balanced by a loss in utility for the rest. A well-known corollary of this is that every outcome is Pareto efficient. However, from the perspective a -player alliance () within the zero-sum game, Pareto improvements are possible. Note that many-player zero-sum is strictly more general than the class of pairwise zero-sum games recently studied in the context of learning Balduzzi et al. (2019). Importantly, we make no restriction on the payoffs for interactions between strict subsets of players.
Alliance dilemmas. An alliance dilemma in an -player zero-sum -action matrix game is a social dilemma which arises for a -player subset, on the basis of the current policies of their co-players. Mathematically, denote the action space for player by with . An alliance dilemma is a social dilemma for players and which arises when the game is reduced according to some fixed policies for the rest of the players for .
It is not immediately clear whether such situations are ubiquitous or rare. In this section we shall show that at least in the atomic setting described above, alliance dilemmas arise often in randomly generated games. Moreover, we shall justify the informal statement that gradient-based learning fails to achieve reasonable outcomes in the presence of alliance dilemmas, by considering the learning dynamics in two easily interpretable examples.
3.1. Counting alliance dilemmas
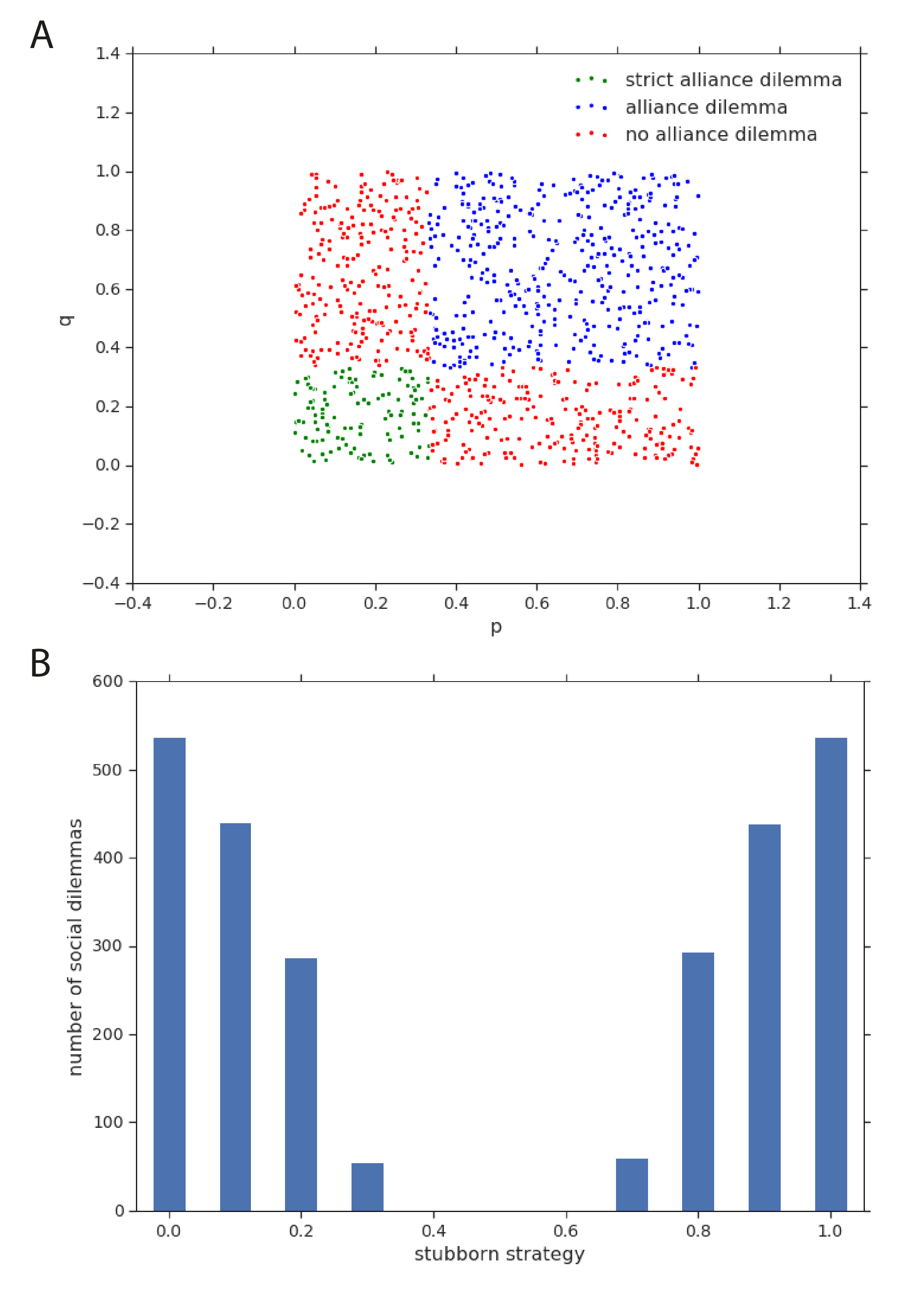
How often can a stubborn agent in symmetric three-player two-action matrix games generate a social dilemmas for their two opponents? To answer this question we randomly sample such games, parameterized by and as follows:
| Actions | Payoffs |
|---|---|
For each game we consider possibilities for the stubborn player’s policy, given by discretizing the probability of taking action with step size . For each of these we compute the resulting matrix game for the remaining players and check the social dilemma conditions. If any of these yield a social dilemma, then the original game is an alliance dilemma, by definition. Overall we find that 54% of games contain an alliance dilemma, with 12% of these being strict alliance dilemmas. Figure 2(A) depicts the distribution of these alliance dilemmas in - space. The striking structure is easily seen to be the effect of the linear inequalities in the definition of a social dilemma. Figure 2(B) demonstrates that alliance dilemmas arise for stubborn policies that are more deterministic. This stands to reason: the stubborn player must leach enough of the zero-sum nature of the game to leave a scenario that calls for cooperation rather than pure competition.
3.2. The failure of gradient-based learning
There are two values of and which result in easily playable games. When and we obtain the Odd One Out game. Here, you win outright if and only if your action is distinct from that of the other two players. Similarly, the combination and defines the Matching game. Here, you lose outright if and only if your action is distinct from that of the other two players. It is easy to verify that both of these games contain an alliance dilemma. Odd One Out has a non-strict greed-type dilemma, while Matching has a strict fear-type dilemma. This classification is intuitively sensible: the dilemma in Odd One Out is generated by the possibility of realizing gains, while the dilemma in Matching arises because of the desire to avoid losses.
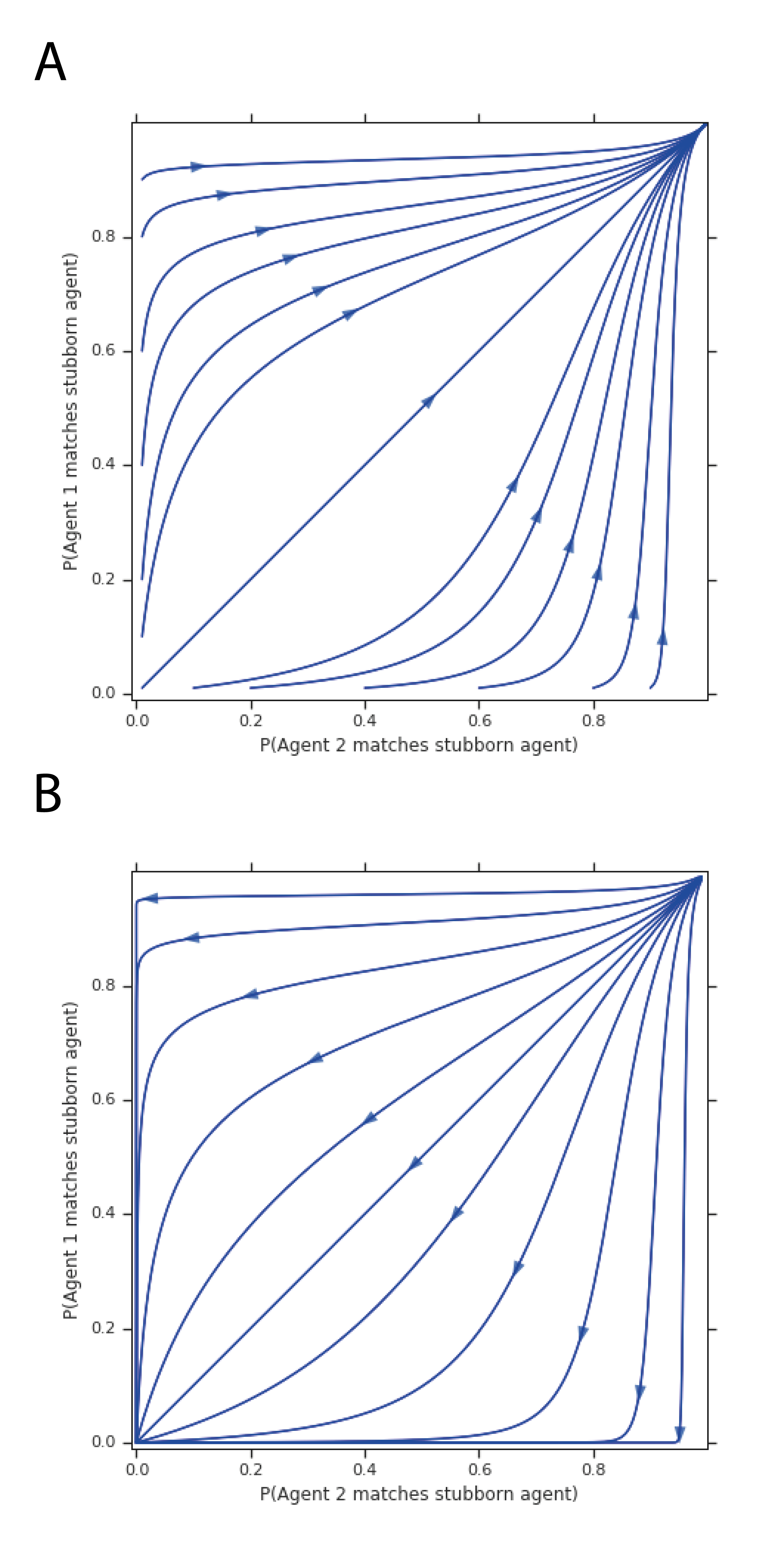
Despite the simplicity of these games, gradient-based learning fails to find alliances when pitched against a stubborn agent with a deterministic policy (see Figure 3). More precisely, in Matching the optimal solution for agents in an alliance is to match actions, taking the opposite action from the stubborn agent to gain reward each. However, policies initialised anywhere other than these optimal policies converge to both taking the same action as the stubborn agent, each getting reward . In Odd One Out, the optimal symmetric alliance solution is to each match the stubborn agent of the time, for an average reward of .333If non-stubborn agents both match the stubborn agent with probability , their expected joint return is . The learning dynamics of the system tend towards a fixed point in which both agents never match the stubborn agent, gaining no reward at all. In this game, we also see that the system is highly sensitive to the initial conditions or learning rates of the two agents; small differences in the starting point lead to very different trajectories. We provide a mathematical derivation in Appendix A which illuminates our empirical findings.
Despite the fact that Matching yields a strict social dilemma while Odd One Out gives a non-strict social dilemma, the learning dynamics in both cases fail to find the optimal alliances. As we anticipated above, this suggests that condition (4) in the definition of social dilemmas is of limited relevance for alliance dilemmas.
3.3. Gifting: an alliance dilemma
In the previous section we saw that alliance dilemmas are a ubiquitous feature of simultaneous-move games, at least in simple examples. We now demonstrate that the same problems arise in a more complex environment. Since our definition of alliance dilemma relies on considering the policy of a given agent as fixed at each point in time, we shift our focus to sequential-move games, where such analysis is more natural, by dint of only one player moving at a time.
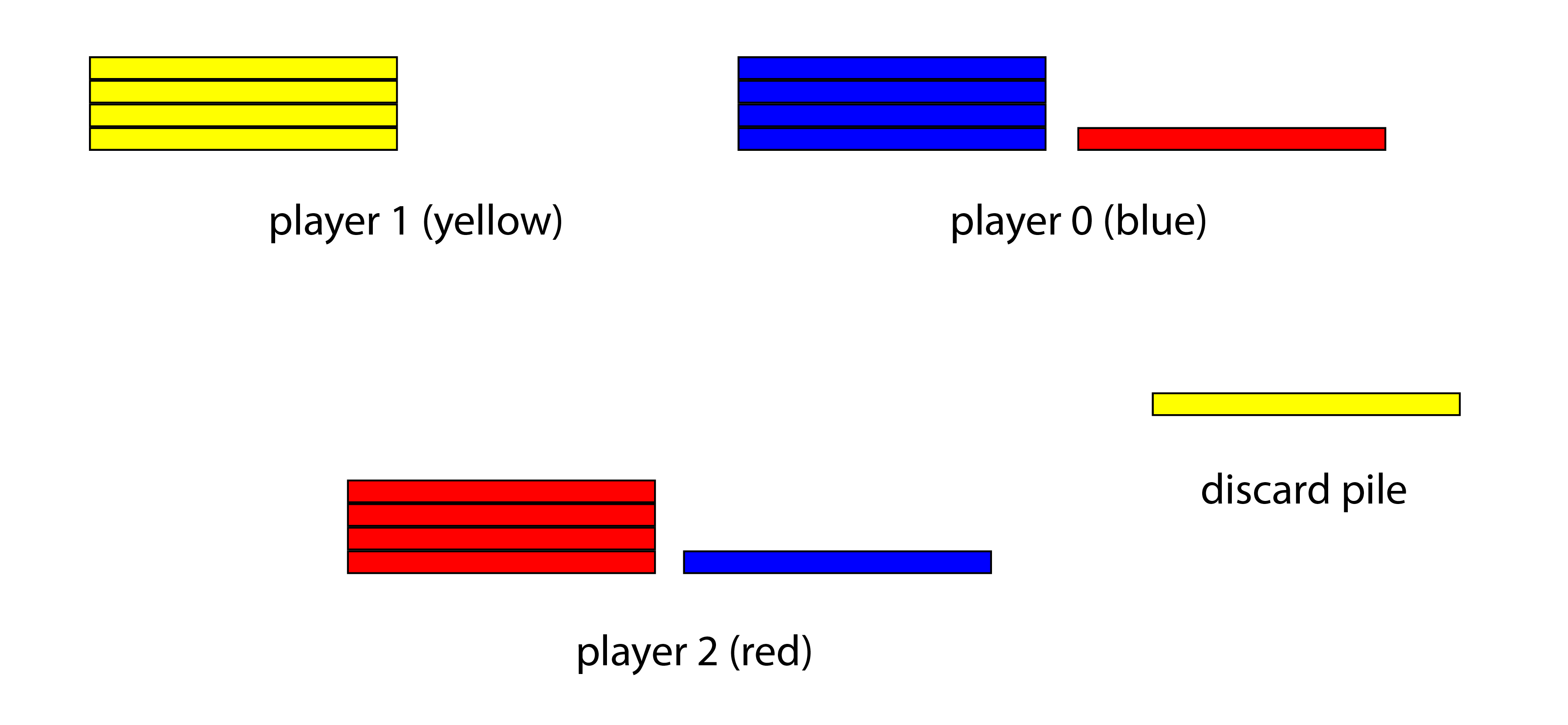
In the Gifting game (see Figure 4), each player starts with a pile of chips of their own colour (for our experiments, ). On a player’s turn they must take a chip of their own colour and either gift it to another player or discard it from the game. The game ends when no player has any chips of their own color left; that is to say, after turns. The winner is the player with the most chips (of any colour), with -way draws possible if players have the same number of chips. The winners share a payoff of equally, and all other players receive a payoff of . Hence Gifting is a constant-sum game, which is strategically equivalent to a zero-sum game, assuming no externalities. Moreover, it admits an interpretation as a toy model of economic competition based on the distribution of scarce goods, as we shall see shortly.
That “everyone always discards” is a subgame perfect Nash equilibrium is true by inspection; i.e. no player has any incentive to deviate from this policy in any subgame, for doing so would merely advantage another player, to their own cost. On the other hand, if two players can arrange to exchange chips with each other then they will achieve a two-way rather than a three-way draw. This is precisely an alliance dilemma: two players can achieve a better outcome for the alliance should they trust each other, yet each can gain by persuading the other to gift a chip, then reneging on the deal. Accordingly, one might expect that MARL fails to converge to policies that demonstrate such trading behavior.
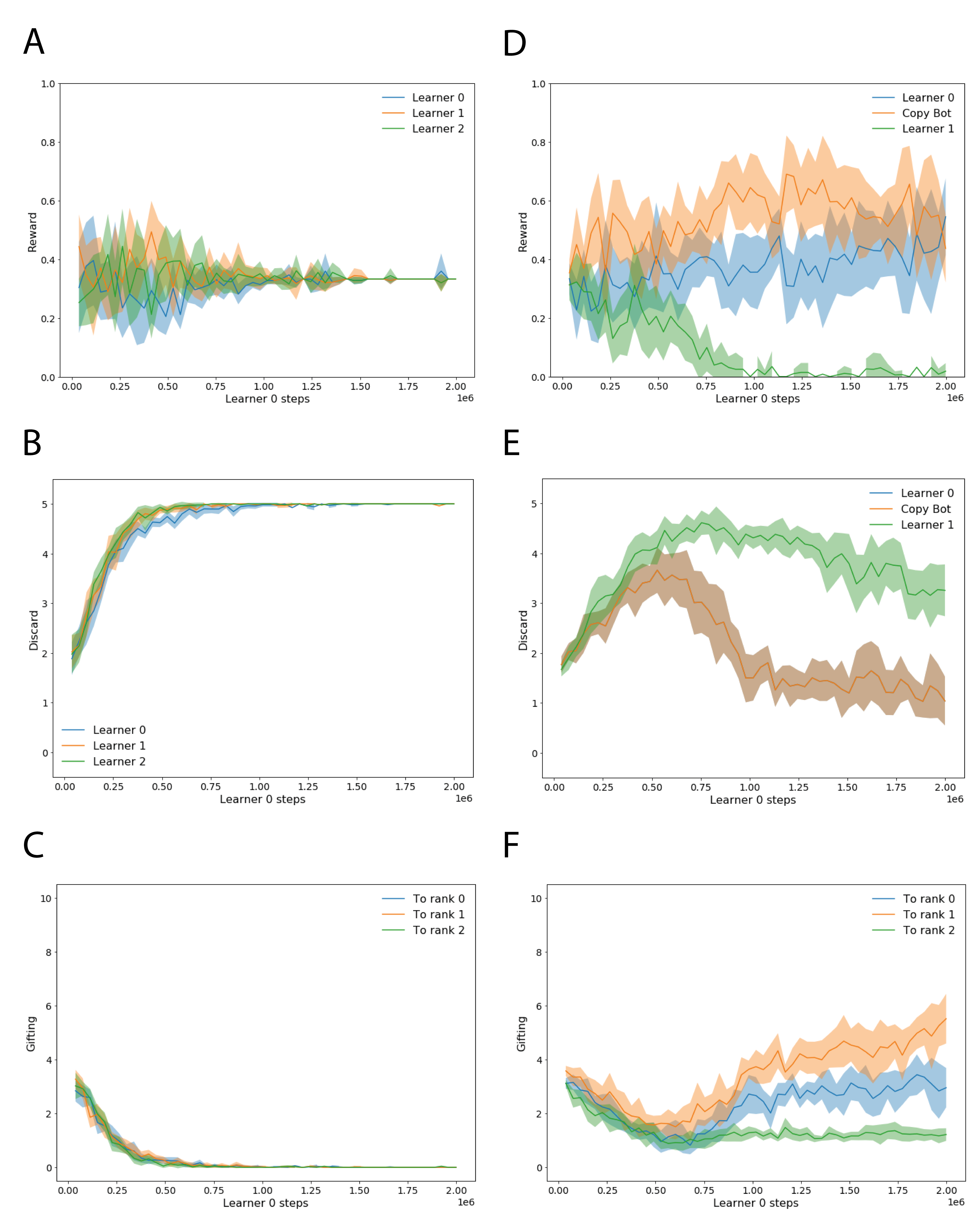
Results.444In each episode, agents are randomly assigned to a seat , or , so must generalize over the order of play. Each agent’s neural network comprises an MLP with two layers of hidden units, followed by an LSTM with hidden units. The policy and value heads are linear layers on top of the LSTM. We train with backpropagation-through-time, using an unroll length equal to the length of the episode. Optimization is carried out using the RMSProp optimizer, with decay , momentum , epsilon and learning rate . The entropy cost for the policy is . We perform training runs initialized with different random seeds and plot the average with 95% confidence intervals. This expectation is borne out by the results in Figure 5(A–C). Agents start out with different amounts of discarding behavior based on random initialization, but this rapidly increases. Accordingly, gifting behavior to agents decreases to zero during learning. The result is a three-way draw, despite that fact that two agents that agreed to exchange could do better than this. To demonstrate this final point, we replace the second player with a bot which reciprocates the gifting behavior of player ; see Figure 5(D–F). Under these circumstances, player learns to gift to player , leading to a two-way draw. Player initially learns to discard, but soon this behavior confers no additional reward, at which point the entropy regularizer leads to random fluctuation in the actions chosen.
We conclude that reinforcement learning is able to adapt, but only if an institution supporting cooperative behavior exists. MARL cannot create the kind of reciprocal behavior necessary for alliances ex nihilo. Inspired by the economics literature, we now propose a mechanism which solves this problem: learning to sign peer-to-peer contracts.
4. Contracts
4.1. Binding contracts
The origin of alliance dilemmas is the greed or fear motivation that drives MARL towards the Pareto-inefficient Nash equilibrium for any given -player subset.555See the definition of social dilemma in Section 3 for a reminder of these concepts. Humans are adept at overcoming this problem, largely on the basis of mutual trust van Lange et al. (2017). Much previous work has considered how inductive biases, learning rules and training schemes might generate trust in social dilemmas. Viewing the problem explicitly as an alliance dilemma yields a new perspective: namely, what economic mechanisms enable self-interested agents to form teams? A clear solution comes from contract theory Martimort (2017). Binding agreements that cover all eventualities trivialize trust, thus resolving the alliance dilemma.
Contract mechanism. We propose a mechanism for incorporating peer-to-peer pairwise complete contracts into MARL. The core environment is augmented with a contract channel. On each timestep, each player must submit a contract offer, which comprises a choice of partner , a suggested action for that partner , and an action which promises to take, or no contract. If two players offer contracts which are identical, then these become binding; that is to say, the environment enforces that the promised actions are taken, by providing a mask for the logits of the relevant agents. At each step, agents receive an observation of the contracts which were offered on the last timestep, encoded as a one-hot representation.
Contract-aware MARL. To learn in this contract-augmented environment, we employ a neural network with two policy heads, one for the core environment and another for the contract channel. This network receives the core environment state and the previous timestep contracts as input. Both heads are trained with the A2C algorithm based on rewards from the core environment, similarly to the RIAL algorithm Foerster et al. (2016). Therefore agents must learn simultaneously how to behave in the environment and how to leverage binding agreements to coordinate better with peers.
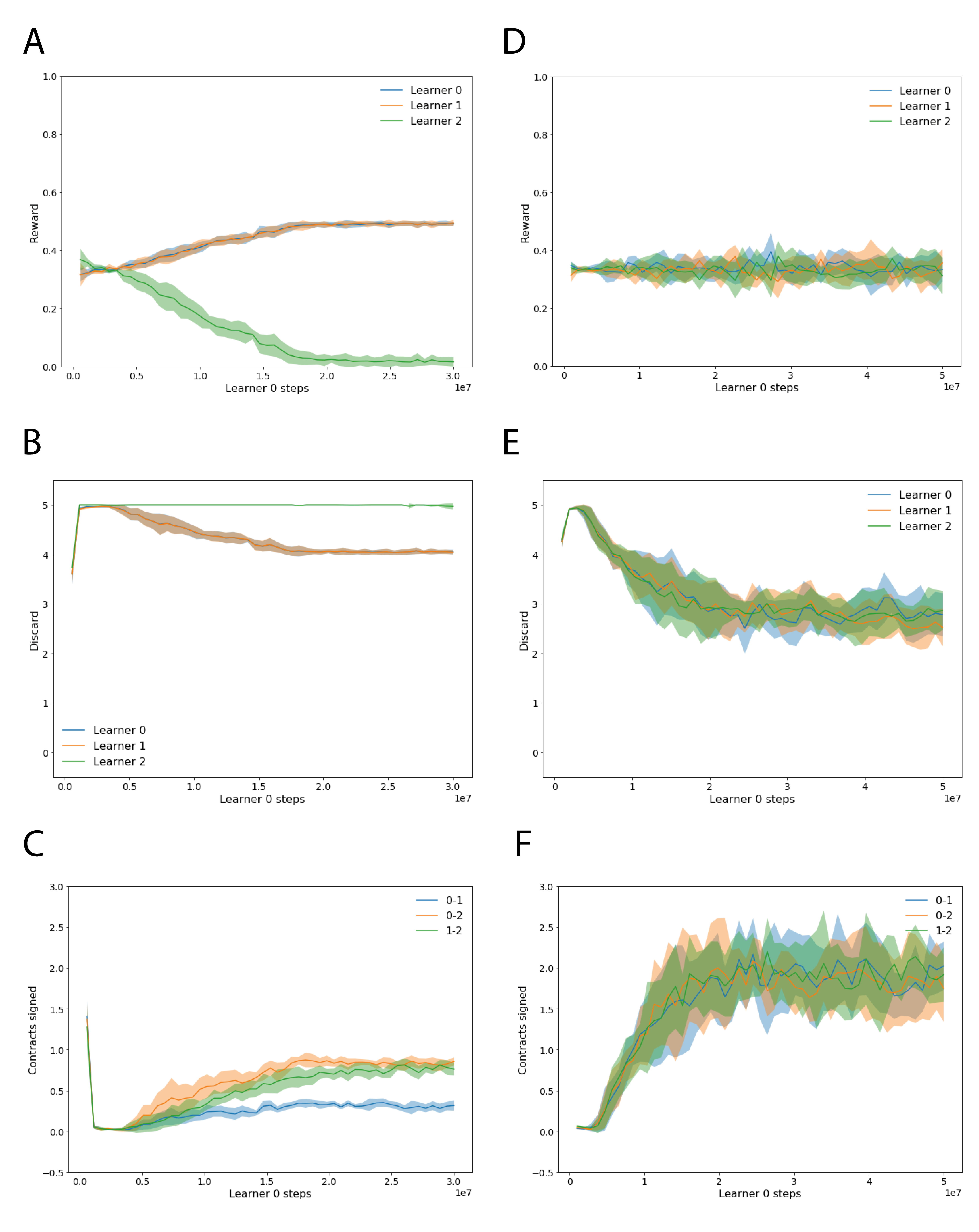
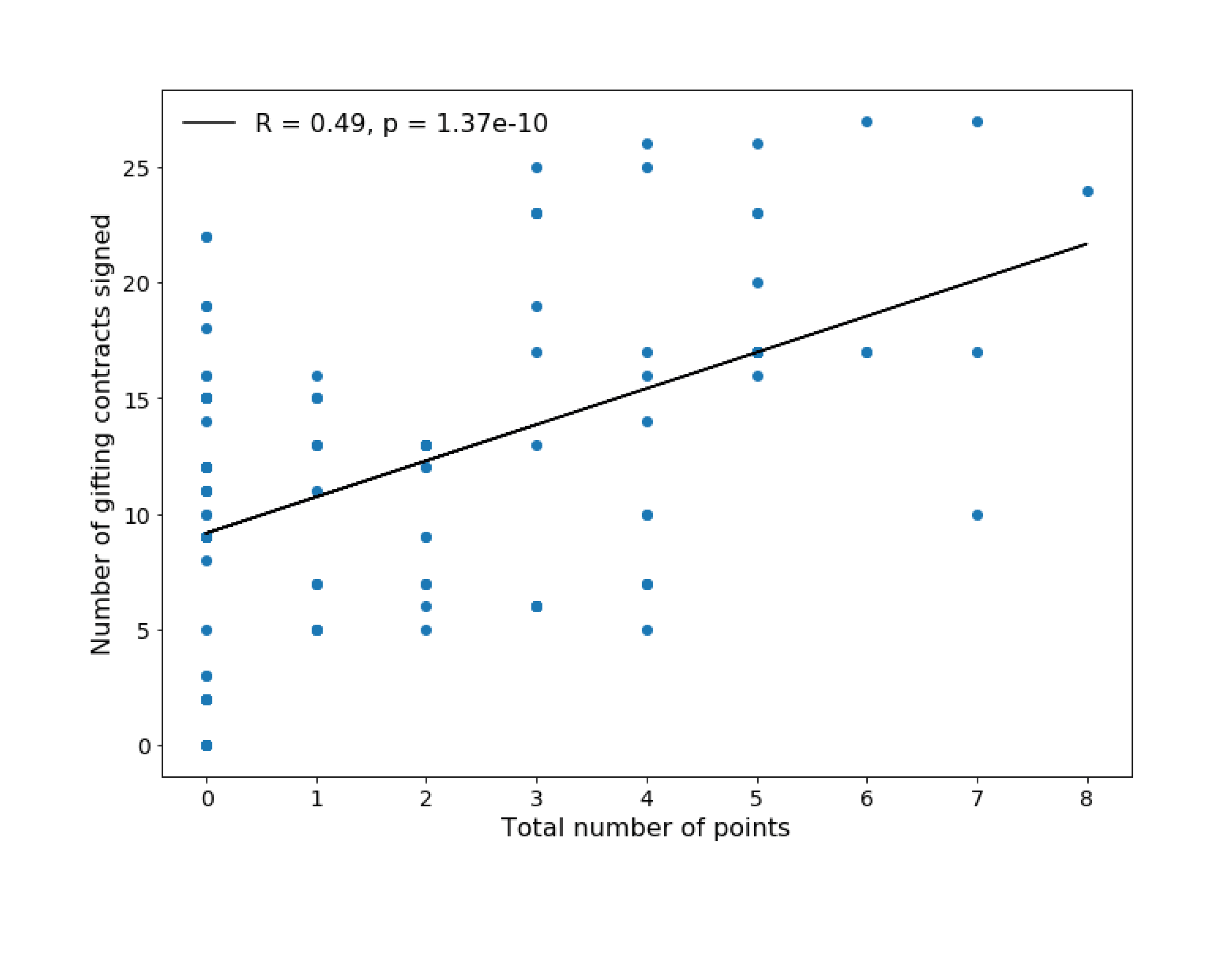
Results.666The neural network is identical to the baseline experiments, except for the addition of a linear contract head. The optimizer minimizes the combined loss where . We include an entropy regularizer for the contract policy, with entropy cost . Training and evaluation methodology are identical to the baseline experiments. We run two experiments to ascertain the performance benefits for contract-augmented agents. First, we train two contract-augmented agents and one A2C agent together. Figure 6(A–C) shows that the two contract-augmented agents (Learners and ) are able to achieve a -way draw and eliminate the agent without the ability to sign contracts. We then train three contract-augmented agents together. Figure 6(D) demonstrates the reward dynamics that result as agents vie to make deals that will enable them to do better than a -way draw. Figure 7 shows that signing contracts has a significant correlation with accruing more chips in a game, thus demonstrating that contracting is advantageous.
The benefits of contracting have an interesting economic interpretation. Without contracts, and the benefits of mutual trust they confer, there is no exchange of chips. In economic terms, the “gross domestic product” (GDP) is zero. Once agents are able to sign binding contracts, goods flow around the system; that is to say, economic productivity is stimulated. Of course, we should take these observations with a large grain of salt, for our model is no more than a toy. Nevertheless, this does hint that ideas from macro-economics may be a valuable source of inspiration for MARL algorithms that can coordinate and cooperate at scale. For instance, our model demonstrates the GDP benefits of forming corporations of a sufficiently large size but also a sufficiently small size .
4.2. Contracts with temporal extent
As it stands, our contract mechanism requires that contracts are fulfilled immediately, by invoking a legal actions mask on the agent’s policy logits. On the other hand, many real-world contracts involve a promise to undertake some action during a specified future period; that is to say, contracts have temporal extent. Furthermore, directly masking an agent’s action is a heavy-handed and invasive way to enforce that agents obey contractual commitments. By contrast, human contracts are typically enforced according to contract law Schwartz and Scott (2003). Indeed, in the language of Green (2012) “whatever else they do, all legal systems recognize, create, vary and enforce obligations”.
Legal systems stipulate that those who do not fulfil their contractual obligations within a given time period should be punished. Inspired by this, we generalize our contract mechanism. Contracts are offered and signed as before. However, once signed, agents have timesteps in which to take the promised action. Should an agent fail to do so, they are considered to have broken the contract, and receive a negative reward of . Once a contract is either fulfilled or broken, agents are free to sign new contracts.
Trembling hand. Learning to sign punishment-enforced contracts from scratch is tricky. This is because there are two ways to avoid punishment: either fulfil a contract, or simply refuse to sign any. Early on in training, when the acting policies are random, agents will learn that signing contracts is bad, for doing so leads to negative reward in the future, on average. By the time that the acting policies are sensibly distinguishing moves in different states of the game, the contract policies will have overfitted to never offering a contract.
To learn successfully, agents must occasionally be forced to sign contracts with others. Now, as the acting policies become more competent, agents learn that contracts can be fulfilled, so do not always lead to negative reward. As agents increasingly fulfil their contractual obligations, they can learn to sign contracts with others. While such contracts are not binding in the sense of legal actions within the game, they are effectively binding since agents have learned to avoid the negative reward associated with breaking a contract.
We operationalize this requirement by forcing agents to follow a trembling hand policy for contract offers. Every timestep, the contract mechanism determines whether there are two agents not already participating in a contract. The mechanism chooses a random contract between the two, and applies a mask to the logits of the contract policy of each agent. This mask forces each agent to suggest the chosen contract with a given minimum probability . We also roll out episodes without the trembling hand intervention, which are not used for learning, but plotted for evaluation purposes.
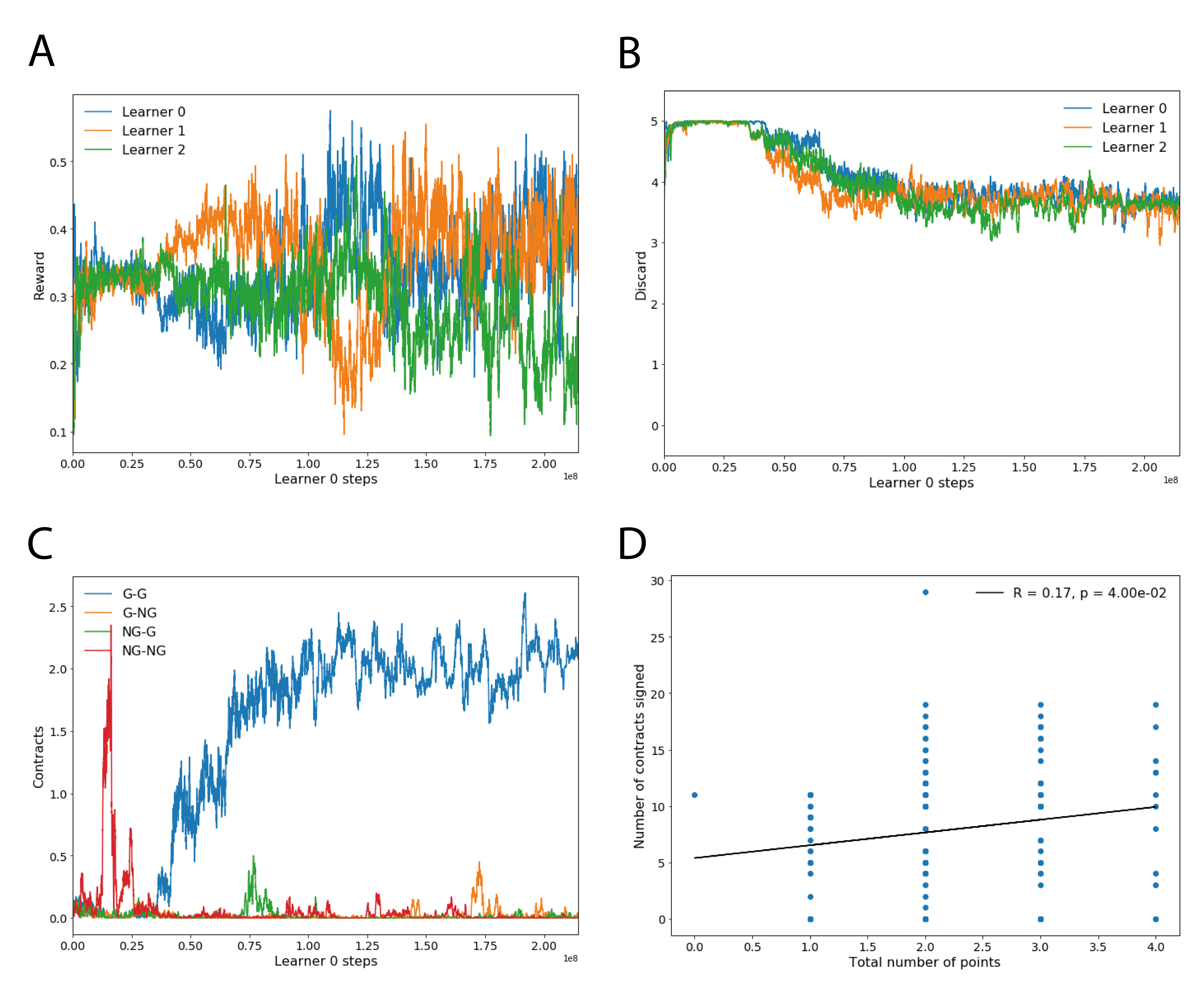
Results.777The neural network is identical to the binding contracts experiment. For the punishment mechanism, we choose , and . Training hyperparameters are as follows: learning rate , environment policy entropy cost , contract loss weight and contract entropy cost . All other hyperparameters are unchanged from the previous experiments. We ran one experiment to ascertain the ability of agents to learn to form gifting contracts. All agents are contract-aware and have trembling hand policies while learning. We display our results in Figure 8. Initially agents learn to discard, and indeed back this up by signing contract for mutual discarding behavior. However, after some time agents discover the benefits of signing gifting contracts. Thereafter, the agents vie with each other to achieve two-player alliances for greater reward. Interestingly, the agents do not learn to gift as much as in the binding contracts case: compare Figure 8(B) and Figure 6(E). This is likely because contracts are not always perfectly adhered to, so there is a remnant of the fear and greed that drives discarding behavior.
5. Conclusion
In this paper, we have made five key contributions. We (1) formalized one of the challenges of many-player zero-sum games by introducing the notion of an alliance dilemma. We (2) demonstrated that these are ubiquitous, and that (3) gradient-based and reinforcement learning fails to resolve them. We introduced (4) an approach for allowing MARL agents to form dynamic team, by augmenting the agents with a binding contract channel. These agents learn to use contracts as a mechanism for trusting a potential alliance partner. Finally, we (5) generalized our contract mechanism beyond the binding case, showing that agents learn to sign temporally-extended contracts enforced through punishment.
Future work. Our model suggests several avenues for further work. Most obviously, we might consider contracts in an environment with a larger state space, such a spatially extended gridworld. Here, agreeing on specific actions to take within an alliance is likely too granular. The alliance dilemma would emerge on the level of the meta-game defined by the policies of different players, defining a sequential alliance dilemma. There are at least two promising approaches in such a setting. Firstly, we could incorporate a centralized agent to whose policy agents could defer, should they wish to enter an alliance. Secondly, we could make contracts about an abstraction over the state of the environment, rather than about atomic actions. Further, one might want to include multiple rounds of contract negotiation per time step of the environment, along the lines of Williams et al. (2012).
More generally, it would be fascinating to discover how a system of contracts might emerge and persist within multi-agent learning dynamics without directly imposing mechanisms for enforcement. Such a pursuit may eventually lead to a valuable feedback loop from AI to sociology and economics. Relatedly, we might ask how to scale contracts beyond the bilateral case, given the exponential explosion of possible alliances with the number of players in the game. Indeed, real-world institutions sign large numbers of contracts simultaneously, each of which may involve several partners. Finally, we note that our contract mechanism provides a simple grounded “language” for agent interaction. We hope to draw a stronger connection between this work and the emergent communication literature in the future.
Outlook. Many-player zero-sum games are a common feature of the natural world, from the economic competition of Adam Smith Smith (1776) to Darwin’s theory of evolution Darwin (1859) which can be viewed as a zero-sum game for energy Van Valen (1980). In many-player zero-sum games a single agent cannot necessarily play a policy which is impervious to its opponent’s behavior. Rather, to be successful, an algorithm must influence the joint strategy across many players. In particular, zero-sum multi-player games introduce the problem of dynamic team formation and breakup. This problem is remarkably deep, touching three strands of multi-agent research beyond two-player zero-sum games:
-
(1)
Emergent teams must coordinate within themselves to effectively compete in the game, just as in team games like soccer.
-
(2)
The process of team formation may itself be a social dilemma. Intuitively, players should form alliances to defeat others; however, membership of a alliance requires individuals to contribute to a wider good which is not completely aligned with their self-interest.
-
(3)
Decisions must be made about which teams to join and leave, and how to shape the strategy of these teams. Here communication is vital, analogously to work on negotiation and contractual team formation.
In Section 1 we identified three appealing features of zero-sum two-player games. Many-player zero-sum games inherit the appealing properties (1) and (2) from their two-player counterparts. However, the restrictive property (3) does not hold, since there is no general analogue of the minimax theorem beyond -player games.888Although in restricted classes, a statement can be made Cai and Daskalakis (2011). For example, the minimax- algorithm Littman (1994b) is not applicable, because it fails to account for dynamic teams. We have demonstrated that many-player zero-sum games capture intricate, important and interesting multi-agent dynamics, amenable to formal study with appropriate definitions. We look forward to future developments of AI in this fascinating arena of study.
References
- (1)
- Anthony et al. (2017) Thomas Anthony, Zheng Tian, and David Barber. 2017. Thinking Fast and Slow with Deep Learning and Tree Search. CoRR abs/1705.08439 (2017). arXiv:1705.08439 http://arxiv.org/abs/1705.08439
- Bachrach et al. (2019) Yoram Bachrach, Richard Everett, Edward Hughes, Angeliki Lazaridou, Joel Leibo, Marc Lanctot, Mike Johanson, Wojtek Czarnecki, and Thore Graepel. 2019. Negotiating Team Formation Using Deep Reinforcement Learning. (2019). https://openreview.net/forum?id=HJG0ojCcFm
- Bachrach et al. (2013) Yoram Bachrach, Pushmeet Kohli, Vladimir Kolmogorov, and Morteza Zadimoghaddam. 2013. Optimal coalition structure generation in cooperative graph games. In Twenty-Seventh AAAI Conference on Artificial Intelligence.
- Bachrach et al. (2010) Yoram Bachrach, Evangelos Markakis, Ezra Resnick, Ariel D Procaccia, Jeffrey S Rosenschein, and Amin Saberi. 2010. Approximating power indices: theoretical and empirical analysis. Autonomous Agents and Multi-Agent Systems 20, 2 (2010), 105–122.
- Balduzzi et al. (2019) David Balduzzi, Marta Garnelo, Yoram Bachrach, Wojciech M. Czarnecki, Julien Pérolat, Max Jaderberg, and Thore Graepel. 2019. Open-ended Learning in Symmetric Zero-sum Games. CoRR abs/1901.08106 (2019). arXiv:1901.08106 http://arxiv.org/abs/1901.08106
- Bard et al. (2019) Nolan Bard, Jakob N. Foerster, Sarath Chandar, Neil Burch, Marc Lanctot, H. Francis Song, Emilio Parisotto, Vincent Dumoulin, Subhodeep Moitra, Edward Hughes, Iain Dunning, Shibl Mourad, Hugo Larochelle, Marc G. Bellemare, and Michael Bowling. 2019. The Hanabi Challenge: A New Frontier for AI Research. CoRR abs/1902.00506 (2019). arXiv:1902.00506 http://arxiv.org/abs/1902.00506
- Barrett et al. (2017) Samuel Barrett, Avi Rosenfeld, Sarit Kraus, and Peter Stone. 2017. Making friends on the fly: Cooperating with new teammates. Artificial Intelligence 242 (2017), 132 – 171. https://doi.org/10.1016/j.artint.2016.10.005
- Barrett et al. (2012) Samuel Barrett, Peter Stone, Sarit Kraus, and Avi Rosenfeld. 2012. Learning Teammate Models for Ad Hoc Teamwork. In AAMAS 2012.
- Beckenkamp et al. (2007) Martin Beckenkamp, Heike Hennig-Schmidt, and Frank Maier-Rigaud. 2007. Cooperation in Symmetric and Asymmetric Prisoner’s Dilemma Games. Max Planck Institute for Research on Collective Goods, Working Paper Series of the Max Planck Institute for Research on Collective Goods (03 2007). https://doi.org/10.2139/ssrn.968942
- Bilbao et al. (2000) JM Bilbao, JR Fernandez, A Jiménez Losada, and JJ Lopez. 2000. Generating functions for computing power indices efficiently. Top 8, 2 (2000), 191–213.
- Bonnet et al. (2018) François Bonnet, Todd W Neller, and Simon Viennot. 2018. Towards Optimal Play of Three-Player Piglet and Pig. (2018).
- Branzei et al. (2008) Rodica Branzei, Dinko Dimitrov, and Stef Tijs. 2008. Models in cooperative game theory. Vol. 556. Springer Science & Business Media.
- Brown and Sandholm (2019) Noam Brown and Tuomas Sandholm. 2019. Superhuman AI for multiplayer poker. Science 365, 6456 (2019), 885–890.
- Cai and Daskalakis (2011) Yang Cai and Constantinos Daskalakis. 2011. On Minmax Theorems for Multiplayer Games. In Proceedings of the Twenty-second Annual ACM-SIAM Symposium on Discrete Algorithms (SODA ’11). Society for Industrial and Applied Mathematics, Philadelphia, PA, USA, 217–234. http://dl.acm.org/citation.cfm?id=2133036.2133056
- Campbell et al. (2002) Murray Campbell, A.Joseph Hoane, and Feng hsiung Hsu. 2002. Deep Blue. Artificial Intelligence 134, 1 (2002), 57 – 83. https://doi.org/10.1016/S0004-3702(01)00129-1
- Cao et al. (2018) Kris Cao, Angeliki Lazaridou, Marc Lanctot, Joel Z. Leibo, Karl Tuyls, and Stephen Clark. 2018. Emergent Communication through Negotiation. CoRR abs/1804.03980 (2018). arXiv:1804.03980 http://arxiv.org/abs/1804.03980
- Chalkiadakis et al. (2011) Georgios Chalkiadakis, Edith Elkind, and Michael Wooldridge. 2011. Computational aspects of cooperative game theory. Synthesis Lectures on Artificial Intelligence and Machine Learning 5, 6 (2011), 1–168.
- Chammah et al. (1965) A.R.A.M. Chammah, A. Rapoport, A.M. Chammah, and C.J. Orwant. 1965. Prisoner’s Dilemma: A Study in Conflict and Cooperation. University of Michigan Press. https://books.google.co.uk/books?id=yPtNnKjXaj4C
- Choi et al. (2009) Han-Lim Choi, Luc Brunet, and Jonathan P How. 2009. Consensus-based decentralized auctions for robust task allocation. IEEE transactions on robotics 25, 4 (2009), 912–926.
- Conitzer and Sandholm (2004) Vincent Conitzer and Tuomas Sandholm. 2004. Computing Shapley values, manipulating value division schemes, and checking core membership in multi-issue domains. In AAAI, Vol. 4. 219–225.
- Conitzer and Sandholm (2006) Vincent Conitzer and Tuomas Sandholm. 2006. Complexity of constructing solutions in the core based on synergies among coalitions. Artificial Intelligence 170, 6-7 (2006), 607–619.
- Darwin (1859) Charles Darwin. 1859. On the Origin of Species by Means of Natural Selection. Murray, London. or the Preservation of Favored Races in the Struggle for Life.
- Drechsel (2010) Julia Drechsel. 2010. Selected Topics in Cooperative Game Theory. (07 2010). https://doi.org/10.1007/978-3-642-13725-9_2
- Dunne et al. (2008) Paul E Dunne, Wiebe van der Hoek, Sarit Kraus, and Michael Wooldridge. 2008. Cooperative boolean games. In Proceedings of the 7th international joint conference on Autonomous agents and multiagent systems-Volume 2. International Foundation for Autonomous Agents and Multiagent Systems, 1015–1022.
- E. Shannon (1950) Claude E. Shannon. 1950. XXII. Programming a computer for playing chess. Philos. Mag. 41 (03 1950), 256–275. https://doi.org/10.1080/14786445008521796
- Eccles et al. (2019) Tom Eccles, Edward Hughes, János Kramár, Steven Wheelwright, and Joel Z. Leibo. 2019. Learning Reciprocity in Complex Sequential Social Dilemmas. CoRR abs/1903.08082 (2019). arXiv:1903.08082 http://arxiv.org/abs/1903.08082
- Espeholt et al. (2018) Lasse Espeholt, Hubert Soyer, Rémi Munos, Karen Simonyan, Volodymyr Mnih, Tom Ward, Yotam Doron, Vlad Firoiu, Tim Harley, Iain Dunning, Shane Legg, and Koray Kavukcuoglu. 2018. IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures. CoRR abs/1802.01561 (2018). arXiv:1802.01561 http://arxiv.org/abs/1802.01561
- Foerster et al. (2016) Jakob N. Foerster, Yannis M. Assael, Nando de Freitas, and Shimon Whiteson. 2016. Learning to Communicate with Deep Multi-Agent Reinforcement Learning. CoRR abs/1605.06676 (2016). arXiv:1605.06676 http://arxiv.org/abs/1605.06676
- Foerster et al. (2017) Jakob N. Foerster, Richard Y. Chen, Maruan Al-Shedivat, Shimon Whiteson, Pieter Abbeel, and Igor Mordatch. 2017. Learning with Opponent-Learning Awareness. CoRR abs/1709.04326 (2017). arXiv:1709.04326 http://arxiv.org/abs/1709.04326
- Fornara and Colombetti (2002) Nicoletta Fornara and Marco Colombetti. 2002. Operational specification of a commitment-based agent communication language. In Proceedings of the first international joint conference on Autonomous agents and multiagent systems: part 2. ACM, 536–542.
- Gaston and DesJardins (2005) Matthew E Gaston and Marie DesJardins. 2005. Agent-organized networks for dynamic team formation. In Proceedings of the fourth international joint conference on Autonomous agents and multiagent systems. ACM, 230–237.
- Gordon et al. (2008) Geoffrey J. Gordon, Amy Greenwald, and Casey Marks. 2008. No-regret Learning in Convex Games. In Proceedings of the 25th International Conference on Machine Learning (ICML ’08). ACM, New York, NY, USA, 360–367. https://doi.org/10.1145/1390156.1390202
- Green (2012) Leslie Green. 2012. Legal Obligation and Authority. In The Stanford Encyclopedia of Philosophy (winter 2012 ed.), Edward N. Zalta (Ed.). Metaphysics Research Lab, Stanford University.
- Hughes et al. (2018) Edward Hughes, Joel Z. Leibo, Matthew G. Philips, Karl Tuyls, Edgar A. Duéñez-Guzmán, Antonio García Castañeda, Iain Dunning, Tina Zhu, Kevin R. McKee, Raphael Koster, Heather Roff, and Thore Graepel. 2018. Inequity aversion resolves intertemporal social dilemmas. CoRR abs/1803.08884 (2018). arXiv:1803.08884 http://arxiv.org/abs/1803.08884
- Ieong and Shoham (2005) Samuel Ieong and Yoav Shoham. 2005. Marginal contribution nets: a compact representation scheme for coalitional games. In Proceedings of the 6th ACM conference on Electronic commerce. ACM, 193–202.
- Jennings et al. (2001) Nicholas R Jennings, Peyman Faratin, Alessio R Lomuscio, Simon Parsons, Michael J Wooldridge, and Carles Sierra. 2001. Automated negotiation: prospects, methods and challenges. Group Decision and Negotiation 10, 2 (2001), 199–215.
- Jonge and Zhang (2020) Dave Jonge and Dongmo Zhang. 2020. Strategic negotiations for extensive-form games. Autonomous Agents and Multi-Agent Systems 34 (04 2020). https://doi.org/10.1007/s10458-019-09424-y
- Klusch and Gerber (2002) Matthias Klusch and Andreas Gerber. 2002. Dynamic coalition formation among rational agents. IEEE Intelligent Systems 17, 3 (2002), 42–47.
- Kraus (1997) Sarit Kraus. 1997. Negotiation and cooperation in multi-agent environments. Artificial intelligence 94, 1-2 (1997), 79–97.
- Kraus and Arkin (2001) Sarit Kraus and Ronald C Arkin. 2001. Strategic negotiation in multiagent environments. MIT press.
- Kraus et al. (1989) Sarit Kraus, Daniel Lehmann, and E. Ephrati. 1989. An automated Diplomacy player. Heuristic Programming in Artificial Intelligence: The 1st Computer Olympia (1989), 134–153.
- Kuwabara et al. (1995) Kazuhiro Kuwabara, Toru Ishida, and Nobuyasu Osato. 1995. AgenTalk: Coordination Protocol Description for Multiagent Systems.. In ICMAS, Vol. 95. 455–461.
- Lanctot et al. (2017) Marc Lanctot, Vinícius Flores Zambaldi, Audrunas Gruslys, Angeliki Lazaridou, Karl Tuyls, Julien Pérolat, David Silver, and Thore Graepel. 2017. A Unified Game-Theoretic Approach to Multiagent Reinforcement Learning. CoRR abs/1711.00832 (2017). arXiv:1711.00832 http://arxiv.org/abs/1711.00832
- Leibo et al. (2017) Joel Z. Leibo, Vinícius Flores Zambaldi, Marc Lanctot, Janusz Marecki, and Thore Graepel. 2017. Multi-agent Reinforcement Learning in Sequential Social Dilemmas. CoRR abs/1702.03037 (2017). arXiv:1702.03037 http://arxiv.org/abs/1702.03037
- Lerer and Peysakhovich (2017) Adam Lerer and Alexander Peysakhovich. 2017. Maintaining cooperation in complex social dilemmas using deep reinforcement learning. CoRR abs/1707.01068 (2017). arXiv:1707.01068 http://arxiv.org/abs/1707.01068
- Littman (1994a) M. L. Littman. 1994a. Markov Games as a Framework for Multi-Agent Reinforcement Learning. In Proceedings of the 11th International Conference on Machine Learning (ICML). 157–163.
- Littman (1994b) Michael L. Littman. 1994b. Markov Games As a Framework for Multi-agent Reinforcement Learning. In Proceedings of the Eleventh International Conference on International Conference on Machine Learning (ICML’94). Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 157–163. http://dl.acm.org/citation.cfm?id=3091574.3091594
- Liu et al. (2019) Siqi Liu, Guy Lever, Nicholas Heess, Josh Merel, Saran Tunyasuvunakool, and Thore Graepel. 2019. Emergent Coordination Through Competition. In International Conference on Learning Representations. https://openreview.net/forum?id=BkG8sjR5Km
- Macy and Flache (2002) Michael W. Macy and Andreas Flache. 2002. Learning dynamics in social dilemmas. Proceedings of the National Academy of Sciences 99 (2002), 7229–7236. https://doi.org/10.1073/pnas.092080099
- Martimort (2017) David Martimort. 2017. Contract Theory. Palgrave Macmillan UK, London, 1–11. https://doi.org/10.1057/978-1-349-95121-5_2542-1
- Mash et al. (2017) Moshe Mash, Yoram Bachrach, and Yair Zick. 2017. How to form winning coalitions in mixed human-computer settings. In Proceedings of the 26th international joint conference on artificial intelligence (IJCAI). 465–471.
- Michalak et al. (2013) Tomasz P Michalak, Karthik V Aadithya, Piotr L Szczepanski, Balaraman Ravindran, and Nicholas R Jennings. 2013. Efficient computation of the Shapley value for game-theoretic network centrality. Journal of Artificial Intelligence Research 46 (2013), 607–650.
- Moravcík et al. (2017) Matej Moravcík, Martin Schmid, Neil Burch, Viliam Lisý, Dustin Morrill, Nolan Bard, Trevor Davis, Kevin Waugh, Michael Johanson, and Michael H. Bowling. 2017. DeepStack: Expert-Level Artificial Intelligence in No-Limit Poker. CoRR abs/1701.01724 (2017). arXiv:1701.01724 http://arxiv.org/abs/1701.01724
- Mordatch and Abbeel (2017) Igor Mordatch and Pieter Abbeel. 2017. Emergence of Grounded Compositional Language in Multi-Agent Populations. CoRR abs/1703.04908 (2017). arXiv:1703.04908 http://arxiv.org/abs/1703.04908
- Nijssen (2013) Joseph Antonius Maria Nijssen. 2013. Monte-Carlo tree search for multi-player games. Maastricht University.
- OpenAI (2018) OpenAI. 2018. OpenAI Five. (2018). https://blog.openai.com/openai-five/
- Paquette et al. (2019) Philip Paquette, Yuchen Lu, Steven Bocco, Max O. Smith, Satya Ortiz-Gagne, Jonathan K. Kummerfeld, Satinder Singh, Joelle Pineau, and Aaron Courville. 2019. No Press Diplomacy: Modeling Multi-Agent Gameplay. (2019). arXiv:cs.AI/1909.02128
- Pérolat et al. (2017) Julien Pérolat, Joel Z. Leibo, Vinícius Flores Zambaldi, Charles Beattie, Karl Tuyls, and Thore Graepel. 2017. A multi-agent reinforcement learning model of common-pool resource appropriation. CoRR abs/1707.06600 (2017). arXiv:1707.06600 http://arxiv.org/abs/1707.06600
- Reader and Laland (2002) Simon M. Reader and Kevin N. Laland. 2002. Social intelligence, innovation, and enhanced brain size in primates. Proceedings of the National Academy of Sciences 99, 7 (2002), 4436–4441. https://doi.org/10.1073/pnas.062041299 arXiv:https://www.pnas.org/content/99/7/4436.full.pdf
- Resnick et al. (2009) Ezra Resnick, Yoram Bachrach, Reshef Meir, and Jeffrey S Rosenschein. 2009. The cost of stability in network flow games. In International Symposium on Mathematical Foundations of Computer Science. Springer, 636–650.
- Rosenfeld and Kraus (2018) Ariel Rosenfeld and Sarit Kraus. 2018. Predicting human decision-making: From prediction to action. Synthesis Lectures on Artificial Intelligence and Machine Learning 12, 1 (2018), 1–150.
- Rosenschein and Zlotkin (1994) Jeffrey S Rosenschein and Gilad Zlotkin. 1994. Rules of encounter: designing conventions for automated negotiation among computers. MIT press.
- Sandholm et al. (1999) Tuomas Sandholm, Kate Larson, Martin Andersson, Onn Shehory, and Fernando Tohmé. 1999. Coalition structure generation with worst case guarantees. Artificial Intelligence 111, 1-2 (1999), 209–238.
- Sandholm et al. (1995) Tuomas Sandholm, Victor R Lesser, et al. 1995. Issues in automated negotiation and electronic commerce: Extending the contract net framework. In ICMAS, Vol. 95. 12–14.
- Sandholm and Lesser (1996) Tuomas W Sandholm and Victor R Lesser. 1996. Advantages of a leveled commitment contracting protocol. In AAAI/IAAI, Vol. 1. 126–133.
- Schaeffer et al. (1992) Jonathan Schaeffer, Joseph Culberson, Norman Treloar, Brent Knight, Paul Lu, and Duane Szafron. 1992. A world championship caliber checkers program. Artificial Intelligence 53, 2 (1992), 273 – 289. https://doi.org/10.1016/0004-3702(92)90074-8
- Schwartz and Scott (2003) Alan Schwartz and Robert E. Scott. 2003. Contract Theory and the Limits of Contract Law. The Yale Law Journal 113, 3 (2003), 541–619. http://www.jstor.org/stable/3657531
- Shamma (2007) Jeff S Shamma. 2007. Cooperative control of distributed multi-agent systems. Wiley Online Library.
- Shapley (1953) L. S. Shapley. 1953. Stochastic Games. In Proc. of the National Academy of Sciences of the United States of America (1953).
- Shehory and Kraus (1998) Onn Shehory and Sarit Kraus. 1998. Methods for task allocation via agent coalition formation. Artificial intelligence 101, 1-2 (1998), 165–200.
- Shmakov et al. (2019) Alexander Shmakov, John Lanier, Stephen McAleer, Rohan Achar, Cristina Lopes, and Pierre Baldi. 2019. ColosseumRL: A Framework for Multiagent Reinforcement Learning in -Player Games. (2019). arXiv:cs.MA/1912.04451
- Shu and Tian (2019) Tianmin Shu and Yuandong Tian. 2019. M3RL: Mind-aware Multi-agent Management Reinforcement Learning. In International Conference on Learning Representations. https://openreview.net/forum?id=BkzeUiRcY7
- Silver et al. (2016) David Silver, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George van den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, Sander Dieleman, Dominik Grewe, John Nham, Nal Kalchbrenner, Ilya Sutskever, Timothy Lillicrap, Madeleine Leach, Koray Kavukcuoglu, Thore Graepel, and Demis Hassabis. 2016. Mastering the Game of Go with Deep Neural Networks and Tree Search. Nature 529, 7587 (Jan. 2016), 484–489. https://doi.org/10.1038/nature16961
- Smith (1776) Adam Smith. 1776. An Inquiry into the Nature and Causes of the Wealth of Nations. McMaster University Archive for the History of Economic Thought. https://EconPapers.repec.org/RePEc:hay:hetboo:smith1776
- Smith (1980) Reid G Smith. 1980. The contract net protocol: High-level communication and control in a distributed problem solver. IEEE Transactions on computers 12 (1980), 1104–1113.
- Sodomka et al. (2013) E. Sodomka, E.M. Hilliard, M.L. Littman, and Amy Greenwald. 2013. Coco-Q: Learning in stochastic games with side payments. 30th International Conference on Machine Learning, ICML 2013 (01 2013), 2521–2529.
- Stone et al. (2010) Peter Stone, Gal A. Kaminka, Sarit Kraus, and Jeffrey S. Rosenschein. 2010. Ad Hoc Autonomous Agent Teams: Collaboration without Pre-Coordination. In AAAI.
- Sutton and Barto (2018) Richard S. Sutton and Andrew G. Barto. 2018. Reinforcement Learning: An Introduction (second ed.). The MIT Press. http://incompleteideas.net/book/the-book-2nd.html
- Tesauro (1995) Gerald Tesauro. 1995. Temporal Difference Learning and TD-Gammon. Commun. ACM 38, 3 (March 1995), 58–68. https://doi.org/10.1145/203330.203343
- Tsvetovat et al. (2000) Maksim Tsvetovat, Katia Sycara, Yian Chen, and James Ying. 2000. Customer coalitions in the electronic marketplace. In AAAI/IAAI. 1133–1134.
- v. Neumann (1928) J. v. Neumann. 1928. Zur Theorie der Gesellschaftsspiele. Math. Ann. 100, 1 (01 Dec 1928), 295–320. https://doi.org/10.1007/BF01448847
- van Lange et al. (2017) P.A.M. van Lange, B. Rockenbach, and T. Yamagishi. 2017. Trust in Social Dilemmas. Oxford University Press. https://books.google.co.uk/books?id=e-fwswEACAAJ
- Van Valen (1980) L Van Valen. 1980. Evolution as a zero-sum game for energy. Evolutionary Theory 4 (1980), 289–300.
- Vezhnevets et al. (2019) Alexander Sasha Vezhnevets, Yuhuai Wu, Rémi Leblond, and Joel Z. Leibo. 2019. Options as responses: Grounding behavioural hierarchies in multi-agent RL. CoRR abs/1906.01470 (2019). arXiv:1906.01470 http://arxiv.org/abs/1906.01470
- Vinyals et al. (2017) Oriol Vinyals, Timo Ewalds, Sergey Bartunov, Petko Georgiev, Alexander Sasha Vezhnevets, Michelle Yeo, Alireza Makhzani, Heinrich Küttler, John Agapiou, Julian Schrittwieser, John Quan, Stephen Gaffney, Stig Petersen, Karen Simonyan, Tom Schaul, Hado van Hasselt, David Silver, Timothy P. Lillicrap, Kevin Calderone, Paul Keet, Anthony Brunasso, David Lawrence, Anders Ekermo, Jacob Repp, and Rodney Tsing. 2017. StarCraft II: A New Challenge for Reinforcement Learning. CoRR abs/1708.04782 (2017). arXiv:1708.04782 http://arxiv.org/abs/1708.04782
- VON NEUMANN and Morgenstern (1953) John VON NEUMANN and Oskar Morgenstern. 1953. Theory of Games and Economic Behavior / J. von Neumann, O. Morgenstern ; introd. de Harold W. Kuhn. SERBIULA (sistema Librum 2.0) 26 (01 1953).
- Wang et al. (2018) Jane X. Wang, Edward Hughes, Chrisantha Fernando, Wojciech M. Czarnecki, Edgar A. Duéñez-Guzmán, and Joel Z. Leibo. 2018. Evolving intrinsic motivations for altruistic behavior. CoRR abs/1811.05931 (2018). arXiv:1811.05931 http://arxiv.org/abs/1811.05931
- Williams et al. (2012) Colin Williams, Valentin Robu, Enrico Gerding, and Nicholas Jennings. 2012. Negotiating Concurrently with Unknown Opponents in Complex, Real-Time Domains.
- Zlotkin and Rosenschein (1994) Gilad Zlotkin and Jeffrey S Rosenschein. 1994. Coalition, cryptography, and stability: Mechanisms for coalition formation in task oriented domains. Alfred P. Sloan School of Management, Massachusetts Institute of Technology.
Appendix A Gradient-Based Learning
We provide a simple mathematical argument that illuminates the failure of gradient-based learning in the Odd One Out and Matching games. In these games the equilibria for policy gradients are easy to characterize. For example in the Odd One Out game () if players use strategy with probabilities , and respectively, then player ’s payoff is given by
The policy gradient with respect to is , with fixed points when or on the boundary, where or . Therefore the fixed points are (a) and (b) and permutations.
Note that (a) is unstable. With a softmax policy, (b) cannot be achieved exactly, but can be converged to. One player’s policy converges to , another’s to 0, and the third’s converges to either or . The two players who have the same policy have thus failed to resolve their alliance dilemma.