Learning Trajectories are Generalization Indicators
Abstract
This paper explores the connection between learning trajectories of Deep Neural Networks (DNNs) and their generalization capabilities when optimized using (stochastic) gradient descent algorithms. Instead of concentrating solely on the generalization error of the DNN post-training, we present a novel perspective for analyzing generalization error by investigating the contribution of each update step to the change in generalization error. This perspective enable a more direct comprehension of how the learning trajectory influences generalization error. Building upon this analysis, we propose a new generalization bound that incorporates more extensive trajectory information. Our proposed generalization bound depends on the complexity of learning trajectory and the ratio between the bias and diversity of training set. Experimental observations reveal that our method effectively captures the generalization error throughout the training process. Furthermore, our approach can also track changes in generalization error when adjustments are made to learning rates and label noise levels. These results demonstrate that learning trajectory information is a valuable indicator of a model’s generalization capabilities.
1 Introduction
The generalizability of a Deep Neural Network (DNN) is a crucial research topic in the field of machine learning. Deep neural networks are commonly trained with a limited number of training samples while being tested on unseen samples. Depite the commonly used independent and identically distributed (i.i.d.) assumption between the training and testing sets, there often exists a varying degree of discrepancy between them in real-world applications. Generalization theories study the generalization of DNNs by modeling the gap between the empirical risk [36] and the popular risk [36]. Classical uniform convergence based methods [20] adopt the complexity of the function space to analyze this generalization error. These theories discover that more complex function space results in a larger generalization error [37]. However, they are not well applicable for DNNs [32, 22]. In deep learning, the double descent phenomenon [6] exists, which tells that larger complexity of function space may lead to smaller generalization error. This violates the aforementioned property in uniform convergence methods and imposes demands in studying the generalization of DNNs.
Although the function space of DNNs is vast, not all functions within that space can be discovered by learning algorithms. Therefore, some representative works bound the generalization of DNNs based on the properties of the learning algorithm, e.g. , stability of algorithm [11], information-theoretic analysis [39]. These works rely on the relation between the input (i.e. , training data) and output (weights of the model after training) of the learning algorithm to infer the generalization ability of the learned model. Here, the relation refers to how the change of one sample in the training data impacts the final weights of model in the stability of algorithms while referring to the mutual information between the weights and the training data in the information-theoretic analysis. Although some works [24, 11] leverage some information from training process to understand the properties of learning algorithm, there is limited trajectory information conveyed.
The purpose of this article is to enhance our theoretical comprehension of the relation between learning trajectory and generalization. While some recent experiments [9, 13] have shown a strong correlation between the information contained in learning trajectory and generalization, the theoretical understanding behind this is still underexplored. By investigating the contribution of each update step to the change in generalization error, we give a new generalization bound with rich trajectory related information. Our work can serve as a starting point to understand those experimental discoveries.
1.1 Our Contribution
Our contributions can be summarized below:
-
•
We demonstrate that learning trajectory information serves as a valuable indicator of generalization abilities. With this motivation, we present a novel perspective for analyzing generalization error by investigating the contribution of each update step to the change in generalization error.
-
•
Utilizing the aforementioned modeling technique, we introduce a novel generalization bound for deep neural networks (DNNs). Our proposed bound provides a greater depth of trajectory-related insights than existing methods.
-
•
Our method effectively captures the generalization error throughout the training process. And the assumption corresponding to this method is also confirmed by experiments. Furthermore, our approach can also track changes in generalization error when adjustments are made to learning rates and label noise levels.
2 Related Work
Generalization Theories
Existing works on studying the generalization of DNNs can be divided into three categories: the methods based on the complexity of function space, the methods based on learning algorithms, and the methods based on PAC Bayes. The first category considers the generalization of DNNs from the perspective of the complexity of the function space. Many methods for measuring the complexity of the function space have been proposed, e.g. , VC dimension [38], Rademacher Complexity [4] and covering number [32]. These works fail in being applied to DNN models since the complexity of the function space of a DNN model is too large to deliver a trivial result [40]. This thus motivates recent works to rethink the generalization of DNNs based on the accessible information in different learning algorithms such as stability of algorithm [11], information-theoretic analysis [39]. Among them, the stability of algorithm [7] measures how one sample change of training data impacts the model weights finally learned, and the information theory [29, 30, 39] based generalization bounds rely on the mutual information of the input (training data) and output (weights after training) of the learning algorithm. Another line is PAC Bayes [19] based method, which bounds the expectation of the error rates of a classifier chosen from a posterior distribution in terms of the KL divergence from a given prior distribution. Our research modifies the conventional Rademacher Complexity to calculate the complexity of the space explored by a learning algorithm, which in turn helps derive the generalization bound. Our approach resembles the first category, as we also rely on the complexity of the function space. However, our method differs as we focus on the function space explored by the learning trajectory, rather than the entire function space. The novelty of our technique lies in addressing the issue of dependence on training data within the function space explored by the learning trajectory, a dependency that is not permitted by the original Rademacher Complexity Theory.
Generalization Analysis for SGD
The optimization plays an nonnegligible role in the success of DNN. Therefore, there are many prior works studying the generalization of DNNs by exploring property of SGD, which could be summarized into two categories: stability of SGD and information-theoretic analysis. The most popular way of the former category is to analyze the stability of the weights updating. Hardt et al. [11] is the first work to analyze the stability of SGD with the requirements of smooth and Lipschitz assumptions. Its follow-up works try to discard the smooth [5], or Lipschitz [25] assumptions towards getting a more general bound. Information-theoretic methods leverage the chain rule of KL-divergence to calculate the mutual information between the learned model weights and the data. This kind of works is mainly applied for Stochastic Gradient Langevin Dynamics(SGLD), i.e. , SGD with noise injected in each step of parameters updating [28]. Negrea et al. [23], Haghifam et al. [10] improve the results using data-dependent priors. Neu et al. [24] construct an auxiliary iterative noisy process to adapt this method to the SGD scenario. In contrast to these studies, our approach utilizes more information related to learning trajectories. A more detailed comparison can be found in Table 2 and Appendix B.
3 Generalization Bound
Let us consider a supervised learning problem with a instance space and a parameter space . The loss function can be defined as . We denote the distribution of the instance space as . The i.i.d samples draw from are denoted as . Given parameters , the empirical risk and popular risk are denoted as , and respectively. Our work studies the generalization error of the learned model, i.e. . For an optimizaiton process, the learning trajectory is represented as a function . We use to denote the weights of model after times updating, where . The learning algorithm is defined as , where the second input denotes all randomness in the algorithm , including the randomness in initialization, batch sampling et al. . We simply use to represent a random choice for the second input term. Given two functions , and we use to denote 2 norm. If is a set, then denotes the number of elements in . denotes taking the expectiation conditioned on .
Let mini-batch be a random subset sampled from dataset , and we have . The averaged function value of mini-batch is denoted as . The parameters updated with gradient descent can be formulated as:
| (1) |
where is the learning rate for thr -th update. The parameter updating with stochastic gradient descent is:
| (2) |
Let be the gradient noise in mini-batch updating, where is the weights of a DNN. Then we can transform Equation (2) into:
| (3) |
The covariance of the gradients over the entire dataset can be calculated as:
| (4) |
Therefore, the covariance of the gradient noise is:
| (5) |
Since for any we have , we can represent as , where is a random distribution whose mean is zero and covariance matrix is an identity matrix. Here, can be any distributions, including Guassian distribution [12] and distribution [34].
The primary objective of our work is to suggest a new generalization bound that incorporates more comprehensive trajectory-related information. The key aspects of this information are: 1) It should be adaptive and change according to different learning trajectories. 2) It should not rely on the extra information from data distribution except from the training data .
3.1 Investigating generalization alone learning trajectory
As annotated before, the learning trajectory is represented by a function , which defines the relationship between the model weights and the training timesteps . denotes the model weights after times updating. Note that depends on , because it comes from the equation . We simply use to represent the function after -times update. Our goal is to analyze the generalization error, i.e., , where represents the total training steps.
We reformulate the function corresponding to the finally obtained model as:
| (6) |
Therefore, the generalization error can be rewritten as:
| (7) |
In this form, we divide the generalization error into two parts. is the generalization error before the training. is the generalization error caused by -step update.
Typically, there is independence between and the data . Therefore, we have . Combining with this, we have:
| (8) |
Analyzing the generalization error after training can be transformed into analyzing the increase of generalization error for each update. This is a straighforward and quite different way to extract the information from learning trajectory compared with previous work. Here, we list two techniques that most used by previous works to extract the information from learning trajectory.
-
•
(T1). This method leverages the chaining rule of mutual informaton to calculate a upper bound of the mutual information between and the training data , i.e. . is the value of concerning for their theory.
-
•
(T2). This method assumes we have another data , which is obtained by replacing one sample in data with another sample drawing from distribution . is the learning trajectory trained from data with same randomness value as . Denote and assume . Then, the value of concerning is . The upper bound of is calculate by iterately apply the formular .
(T1) is commonly utilized in analyzing Stochastic Gradient Langevin Dynamics(SGLD)[18, 2, 28], while (T2) is frequently employed in stability-based works for analyzing SGD[11, 15, 5]. Our method offers several benefits, including: 1) We directly focus on the change in generalization error, rather than intermediate values such as and , 2) The generalization error is equivalent to the sum of , while (T1) and (T2) takes the upper bound value of and , and 3) From this perspective, We can extract more in-depth trajectory-related information. For (T1), the computation of primarily involves the information of , which is inaccessible to us (Detail in Appendix D and Neu et al. [24]). (T2) faces the challenge that only the upper bounds of and can be calculated. The upper bounds remain unchanged across various learning trajectories. Consequently, both (T1) and (T2) have difficulty conveying meaningful trajectory information.
3.2 A New Generalization Bound
In this section, we introduce the generalization bound based on our aforementioned modeling. Let us start with the definition of commonly used assumptions.
Definition 3.1.
The function is -Lipschitz, if for all and for all , wherein we have .
Definition 3.2.
The function is -smooth, if for all and for all , wherein we have .
Definition 3.3.
The function is convex, if for all and for all , wherein we have .
Here, -lipschitz assumption implies that the holds. -smooth assumption indicates the largest eignvalue of is smaller than . The convexity indicates the smallest eigenvalue of are positive. These assumptions tell us the constraints of gradients and Hessian matrices of the training data and the unseen samples in the test set. Since the values of gradients and Hessian matrices in the training set are accessible, the key role of these assumptions is to deliver knowledge about the unseen samples in the test set.
In the following, we introduce a new generalization bound. We give the assumption required by our new generalization bound in the following.
Assumption 3.4.
There is a value , so that for all , we have .
Remark 3.5.
Assumption 3.4 gives a restriction with the norm of popular gradient . This assumption is easily satisfied when is a large number, because we have . When the is not large enough, the assumption will hold before SGD enter the neighbourhood of convergent point. Under the case that SGD enters the neighbourhood of convergent point, we give a relaxed assumption and its corresponding generalization bound in Appendix B. According to paper [41], this case will ununsually happen in real situation. Section 4 gives experiments to explore the assumption.
Theorem 3.6.
Under Assumption 3.4, given , let , where denoted the SGD or GD algorithm training with steps, we have:
| (9) |
where , , and .
Remark 3.7.
Our generalization bound mainly relies on the information from gradients. is related to the variance of the gradient. When the variance of the gradients across different samples in the training set is large, then the value of is small, and vice versa. Note that we have due to . Our bound will became trival if . This rarely happens in real case, because it requires that for all , we have . A example of linear regression case is given in Appendix LABEL:subsec:example. We also give a relaxed assumption version of this theorem in Appendix B. The generalization bound provides a clear insight into how the reduction of training loss leads to a increase in generalization error.
Proof Sketch
The proof of this theorem is placed in Appendix A. Here, we give the sketch for this proof.
Step 1
Beginning with Equation (8), we decomposite the into a linear part () and nonlinear part(). We have , where . The nonlinear part is . We takle these two parts differently. Here, we focus on analyzing because it dominates under small learning rate. Detail discussion of is given in Appendix (Propositon A.1 and Subsection C.3)
Step 2
We construct the addictive linear space , where . Then , where .
Step 3
Finally, we compute the upper bound of , which follows same techniques used in Radermacher Complexity theory. By combining this with Proposition A.1, we establish the theorem.
Technical Novety
Directly applying the Rademacher complexity to calculate the generalization error bound fails because the large complexity of neural network’s function space leads to trival bound[40]. In this work, we want to calculate the complexity of the function space that can be explored during the training process. However, there are two challenges here. First, the trajectory of neural network is a "line", instead of a function space that can be calculated the complexity. To solve this problem, we indroduce the addictive linear space . This space contains the local information of learning trajectory, and can serve as the pseudo function space. Second, the function space has a dependent on the sample set , while the theory of Rademacher complexity requires that the function space is independent with training samples. To decouple this dependence, we adapt the Rademacher complexity and we obtain that . Here, is indroduced to decouple the dependent fact mentioned above.
Compared with Previous Works
In Table 1, we present a summary of stability-based methods, while other methods are outlined in Appendix D. We focus on generalization bounds from previous works that eliminate terms dependent on extra information about data distribution , apart from the training data , using assumptions such as smoothness or Lipschitz continuity. Analyzing Table 1 reveals that most prior works primarily depend on the learning rate and the total number of training steps . This suggests that we can achieve the same bound by using an identical learning rate schedule and total training steps, which does not align with our practical experience. Our proposed generalization bound considers the evolution of function values, gradient covariance, and gradient norms throughout the training process. As a result, our bounds encompass more comprehensive information about the learning trajectory.
Asymptotic Analysis
We will first analyze the dependent of for . The is calculated as . Obviously, the gradient of individual sample is unrelated to the sample size . And . Therefore, . Similarly, we have . As for the term in Theorem 3.6, we have according to Proposition A.1. We simply assume that . Therefore, our bound has
Next, in order to draw a clearer comparison with the stability-based method, we present the following corollary. This corollary employs the -smooth assumption to bound and leverages a similar learning rate setting to that found in stability based works.
Corollary 3.8.
If function is -smooth, under Assumption 3.4 given , let , , and , where denoted the SGD or GD algorithm training with steps, we have:
| (10) | ||||
where , and .
3.3 Analysis
3.3.1 Generalization Bounds
Our obtained generalization bound is:
| (11) |
The "Bias of Training Set" refers to the disparity between the characteristics of the training set and those of the broader population. To measure this difference, we use the distance between the norm of the popular gradient and that of the training set gradient, as specified in Assumption 3.4. The "Diversity of Training Set" can be understood as the variation among the samples in the training set, which in turn affects the quality of the training data. The ratio gives us the property of information conveyed by the training set. It is important to consider the properties of the training set, as the data may not contribute equally to the generalization[35]. The detail version of the equation can be found in Theorem 3.6.
3.3.2 Comparison with Uniform Stability Results
| Uniform Stability[11] | Ours | |
|---|---|---|
| Assumption | ||
| Modelling Method of SGD | Epoch Structure | Full Batch Gradient + Stochastic Noise |
| Batch Size | 1 | |
| Trajectory Information in Bound | Learning rate and number of training step | Values in Trajectory (gradient norm and covariance) |
| Perspective | Stability of Algorithm | Complexity of Learning Trajectory |
The concept of uniform stability is commonly used to evaluate the ability of SGD in generalizaton, by assessing its stability when a single training sample is altered. Our primary point of comparison is with Hardt et al. [11], as their work is considered the most representative in terms of analyzing the stability of SGD.
First, the assumption of Uniform Stability requires the gradient norm of all input samples for all weights being bounded by , whereas our assumption only limits the expectation of the gradients for the weights during the learning trajectory. Secondly, Uniform Stability uses an epoch structure to model the stochastic gradient descent, whereas our approach regards each stochastic gradient descent as full batch gradient descent with added stochastic noise. The epoch structure complicates the modelling process because it requires a consideration of sampling. As a result, in Hardt et al. [11], the author only considers the setting with batch size 1. Thirdly, the bound of Uniform Stability only uses hyperparameters setting such as learning rate and number of training step. In contrast, our bound contains more trajectory-related information, such as the gradient norm and covariance. Finally, the Uniform Stability provides the generalization bound based on the stability of the algorithm, while our approach leverages the complexity of the learning trajectory. In summary, there are some notable differences between our approach and Uniform Stability, such as the assumptions made, the modelling process, the type of information used in the bound, and the perspectives.
4 Experiments
4.1 Tightness of Our Bounds
| Gen Error | Ours | Hardt et al. [11] | Zhang et al. [42] |
|---|---|---|---|
| 1.49 | 3.62 | 4.04 | 4417 |
In a toy dataset setting, we compare our generalization bound with stability-based methods.
Reasons for toy examples
1) Some values in the bounds are hard to be calculated. Calculating (under the -smooth assumption) and (under the -Lipschitz assumption) in stability-based work, as well as the values of and in our proposed bound, are challenging. 2) Stability-based methods require a batch size of 1. The training is hard for batch size of 1 with learning rate setting in complex datasets.
Constuction of the toy examples
In the following, we discuss the construction of the toy dataset used to compare the tightness of the generalization bounds. The training data is . All the data is sampled from Guassian distribution . Sampling ,the ground truth is generated by . The weights for learning is denoted as . The predict is calculated as . The loss for a simple data point is . The training loss is . The test data is , where and . We use 100 samples for training and 1,000 samples for evaluation. The model is trained using SGD for 200 epochs.
We evaluate the tightness of our bound by comparing our results with those in references Hardt et al. [11] and Zhang et al. [42] from the original paper. We set the learning rate as . Our reasons for comparing with these two papers are: 1) Hardt et al. [11] is a representative study, 2) Both papers have theorems using a learning rate setting of , which aligns with Corollary 3.8 in our paper, and 3) They do not assume convexity. The generalization bounds we compare include Corollary 3.8 from our paper, Theorem 3.12 from Hardt et al. [11], and Theorem 5 from Zhang et al. [42].
Our results are given in Table 3. Our bound is tighter under this setting.
4.2 Capturing the trend of generalization error
In this section, 1) we conduct the deep learning experiment to verify Assumption 3.4 and 2) Verify whether our proposed generalization bound can capture the changes of generalization error. In this experiment, we mainly consider the term . We omit the term and , because all the trajectory related information that we want to explore is stored in . Capturing the trend of generalization error is regarded as an important problem in Nagarajan [21]. Unless further specified, we use the default setting of the experiments on CIFAR-10 dataset [14] with the VGG13 [33] network. The experimental details for each figure can be found in Appendix C.2.
Our observations are:
-
•
Assumption 3.4 is valid when SGD is not exhibiting extreme overfitting.
-
•
The term of can depict how the generalization error varies along the training process. And it can also track the changes in generalization error when adjustments are made to learnling rates and label noise levels
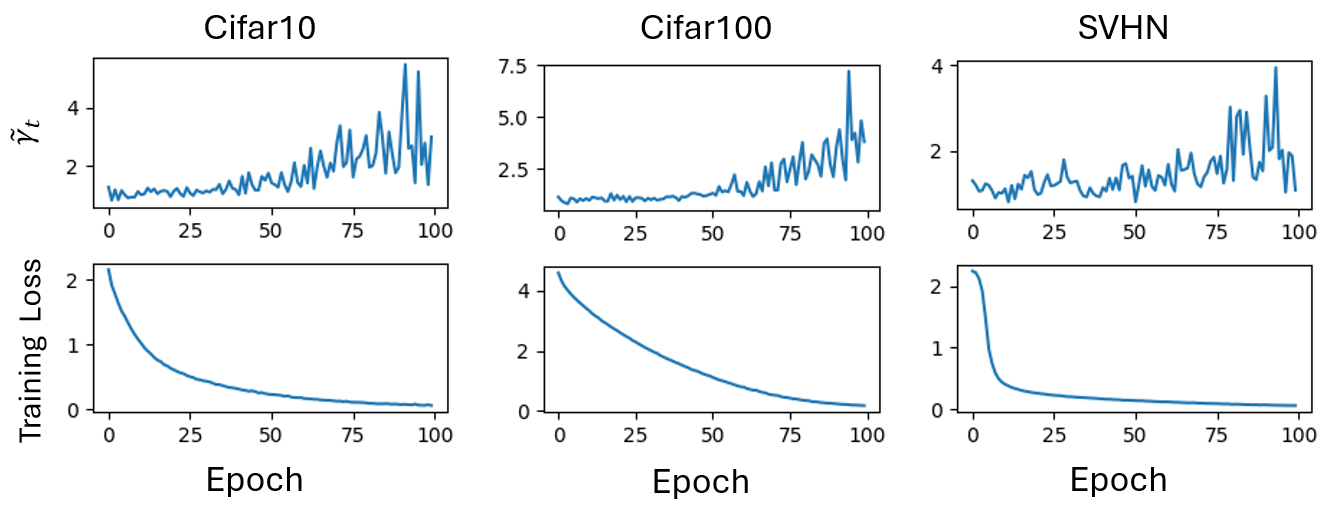
Exploring the assumption 3.4 for different dataset during the training process
To explore the Assumption 3.4, we define and , where is another data set i.i.d sampled from distribution . Because is independent with , we have . We found that is stable around 1 during the early stage of training(Figure 1). When the training loss is reaching a relative small value, increases as we continue training. This phenomenon remain consistant aross the Cifar10, Cifar100 and SVHN datasets. The in Assumption 3.4 can be assigned as . We can always find such if the optimizer is not extreme overfitting. Under the extremely overfitting case, we can use the relaxed theorem in Appendix B to bound the generalization error.
The bound capturing the trend of generalization error during training process
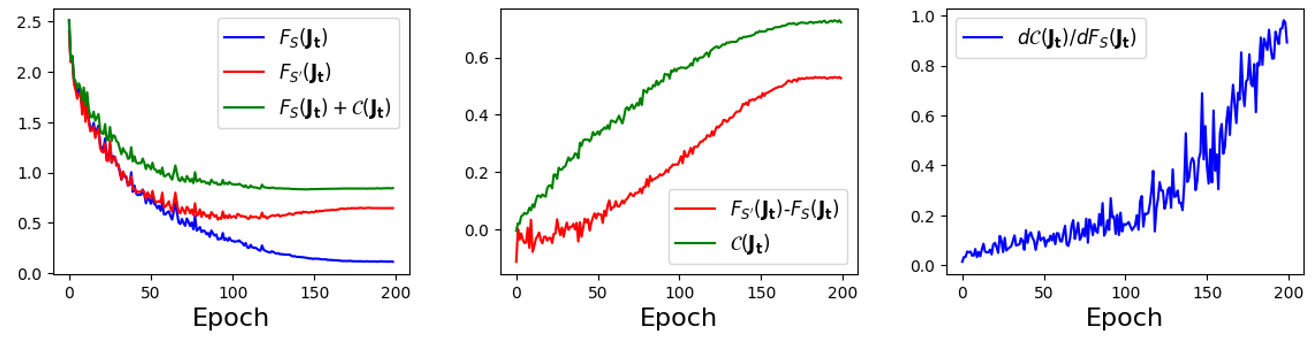
The generalization error and the both changes as the training continues. Therefore, we want to verify whether they correlate with each other during the training process. Here, we use the term to approximate the generalization error. We find that has similar trend with (Figure 2 Center). What’s more, we also find that the curve of exhibits a comparable pattern with the curve (Figure 2 Left). To explore whether reveals influence of the change of to the generalization error, we plot (Figure 2 Right) during the training process. increases slowly during the early stage of training, but surge rapidly afterward. This discovery is aligned with our intuition about the overfitting.
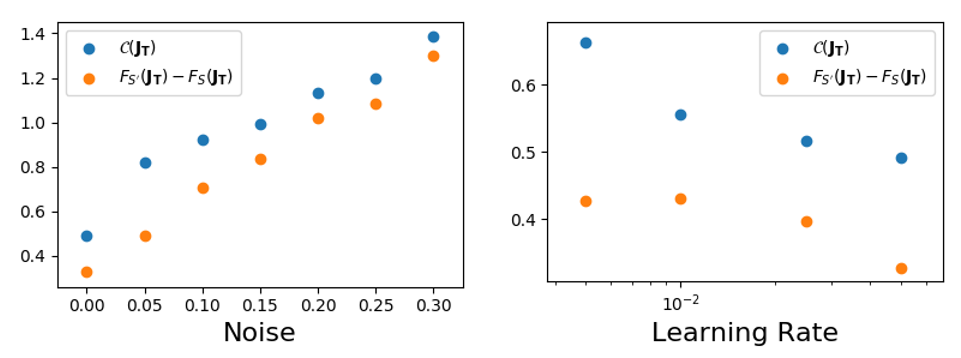
The complexity of learning trajectory correlates with the generalization error
In Figure 3, we carry out experiments under various settings. Each data point in the figure represents the average of three repeated experiments. The results demonstrate that both the generalization error and increase as the level of label noise is raised (Figure 3 Left). The another experiments measure and generalization error for different learning rate and discover that can capture the trend generalization error. The reasons behind a larger learning rate resulting in a smaller generalization error have been explored in Li et al. [17], Barrett and Dherin [3]. Additionally, Appendix E discusses why a larger learning rate can lead to a smaller .
5 Limitation
The assumption of small learning rate is required by our method. But this assumption is also common use in previous works. For example, Hardt et al. [11], Zhang et al. [42], Zhou et al. [43] explicitly requires that the learning rate should be small and is decayed with a rate of . Some methods have no explict requirements about this but show that large learning rate pushes the generalization bounds to a trivial point. For example, the generalization bounds in works [5, 16] have a term that is not decayed as the data size increases. The value of this term is unignorable when the learning rate is large. The small learning assumption widens the gap between theory and practice. Eliminating this assumption is crucial for future work.
6 Conclusion
In this study, we investigate the relation between learning trajectories and generalization capabilities of Deep Neural Networks (DNNs) from a unique standpoint. We show that learning trajectories can serve as reliable predictors for DNNs’ generalization performance. To understand the relation between learning trajectory and generalization error, we analyze how each update step impacts the generalization error. Based on this, we propose a novel generalization bound that encompasses extensive information related to the learning trajectory. The conducted experiments validate our newly proposed assumption. Experimental findings reveal that our method effectively captures the generalization error throughout the training process. Furthermore, our approach can also track changes in generalization error when adjustments are made to learning rates and the level of label noises.
7 Acknowledgement
We thank all the anonymous reviewers for their valuable comments. The work was supported in part with the National Natural Science Foundation of China (Grant No. 62088102).
References
- Ahn et al. [2022] K. Ahn, J. Zhang, and S. Sra. Understanding the unstable convergence of gradient descent. In International Conference on Machine Learning, pages 247–257. PMLR, 2022.
- Banerjee et al. [2022] A. Banerjee, T. Chen, X. Li, and Y. Zhou. Stability based generalization bounds for exponential family langevin dynamics. arXiv preprint arXiv:2201.03064, 2022.
- Barrett and Dherin [2020] D. G. Barrett and B. Dherin. Implicit gradient regularization. arXiv preprint arXiv:2009.11162, 2020.
- Bartlett and Mendelson [2002] P. L. Bartlett and S. Mendelson. Rademacher and gaussian complexities: Risk bounds and structural results. Journal of Machine Learning Research, 3(Nov):463–482, 2002.
- Bassily et al. [2020] R. Bassily, V. Feldman, C. Guzmán, and K. Talwar. Stability of stochastic gradient descent on nonsmooth convex losses. Advances in Neural Information Processing Systems, 33:4381–4391, 2020.
- Belkin et al. [2019] M. Belkin, D. Hsu, S. Ma, and S. Mandal. Reconciling modern machine-learning practice and the classical bias–variance trade-off. Proceedings of the National Academy of Sciences, 116(32):15849–15854, 2019.
- Bousquet and Elisseeff [2002] O. Bousquet and A. Elisseeff. Stability and generalization. The Journal of Machine Learning Research, 2:499–526, 2002.
- Chandramoorthy et al. [2022] N. Chandramoorthy, A. Loukas, K. Gatmiry, and S. Jegelka. On the generalization of learning algorithms that do not converge. arXiv preprint arXiv:2208.07951, 2022.
- Cohen et al. [2021] J. M. Cohen, S. Kaur, Y. Li, J. Z. Kolter, and A. Talwalkar. Gradient descent on neural networks typically occurs at the edge of stability. arXiv preprint arXiv:2103.00065, 2021.
- Haghifam et al. [2020] M. Haghifam, J. Negrea, A. Khisti, D. M. Roy, and G. K. Dziugaite. Sharpened generalization bounds based on conditional mutual information and an application to noisy, iterative algorithms. Advances in Neural Information Processing Systems, 33:9925–9935, 2020.
- Hardt et al. [2016] M. Hardt, B. Recht, and Y. Singer. Train faster, generalize better: Stability of stochastic gradient descent. In International conference on machine learning, pages 1225–1234. PMLR, 2016.
- Jastrzebski et al. [2017] S. Jastrzebski, Z. Kenton, D. Arpit, N. Ballas, A. Fischer, Y. Bengio, and A. Storkey. Three factors influencing minima in sgd. arXiv preprint arXiv:1711.04623, 2017.
- Jastrzebski et al. [2021] S. Jastrzebski, D. Arpit, O. Astrand, G. B. Kerg, H. Wang, C. Xiong, R. Socher, K. Cho, and K. J. Geras. Catastrophic fisher explosion: Early phase fisher matrix impacts generalization. In International Conference on Machine Learning, pages 4772–4784. PMLR, 2021.
- Krizhevsky et al. [2009] A. Krizhevsky, G. Hinton, et al. Learning multiple layers of features from tiny images. 2009.
- Lei [2022] Y. Lei. Stability and generalization of stochastic optimization with nonconvex and nonsmooth problems. arXiv preprint arXiv:2206.07082, 2022.
- Lei and Ying [2020] Y. Lei and Y. Ying. Fine-grained analysis of stability and generalization for stochastic gradient descent. In International Conference on Machine Learning, pages 5809–5819. PMLR, 2020.
- Li et al. [2019] Y. Li, C. Wei, and T. Ma. Towards explaining the regularization effect of initial large learning rate in training neural networks. Advances in Neural Information Processing Systems, 32, 2019.
- Luo et al. [2022] X. Luo, B. Luo, and J. Li. Generalization bounds for gradient methods via discrete and continuous prior. Advances in Neural Information Processing Systems, 35:10600–10614, 2022.
- McAllester [1999] D. A. McAllester. Pac-bayesian model averaging. In Proceedings of the twelfth annual conference on Computational learning theory, pages 164–170, 1999.
- Mohri et al. [2018] M. Mohri, A. Rostamizadeh, and A. Talwalkar. Foundations of machine learning. MIT press, 2018.
- Nagarajan [2021] V. Nagarajan. Explaining generalization in deep learning: progress and fundamental limits. arXiv preprint arXiv:2110.08922, 2021.
- Nagarajan and Kolter [2019] V. Nagarajan and J. Z. Kolter. Uniform convergence may be unable to explain generalization in deep learning. Advances in Neural Information Processing Systems, 32, 2019.
- Negrea et al. [2019] J. Negrea, M. Haghifam, G. K. Dziugaite, A. Khisti, and D. M. Roy. Information-theoretic generalization bounds for sgld via data-dependent estimates. Advances in Neural Information Processing Systems, 32, 2019.
- Neu et al. [2021] G. Neu, G. K. Dziugaite, M. Haghifam, and D. M. Roy. Information-theoretic generalization bounds for stochastic gradient descent. In Conference on Learning Theory, pages 3526–3545. PMLR, 2021.
- Nikolakakis et al. [2022] K. E. Nikolakakis, F. Haddadpour, A. Karbasi, and D. S. Kalogerias. Beyond lipschitz: Sharp generalization and excess risk bounds for full-batch gd. arXiv preprint arXiv:2204.12446, 2022.
- Oksendal [2013] B. Oksendal. Stochastic differential equations: an introduction with applications. Springer Science & Business Media, 2013.
- Park et al. [2022] S. Park, U. Simsekli, and M. A. Erdogdu. Generalization bounds for stochastic gradient descent via localized -covers. Advances in Neural Information Processing Systems, 35:2790–2802, 2022.
- Pensia et al. [2018] A. Pensia, V. Jog, and P.-L. Loh. Generalization error bounds for noisy, iterative algorithms. In 2018 IEEE International Symposium on Information Theory (ISIT), pages 546–550. IEEE, 2018.
- Russo and Zou [2016] D. Russo and J. Zou. Controlling bias in adaptive data analysis using information theory. In Artificial Intelligence and Statistics, pages 1232–1240. PMLR, 2016.
- Russo and Zou [2019] D. Russo and J. Zou. How much does your data exploration overfit? controlling bias via information usage. IEEE Transactions on Information Theory, 66(1):302–323, 2019.
- Sagun et al. [2017] L. Sagun, U. Evci, V. U. Guney, Y. Dauphin, and L. Bottou. Empirical analysis of the hessian of over-parametrized neural networks. arXiv preprint arXiv:1706.04454, 2017.
- Shalev-Shwartz and Ben-David [2014] S. Shalev-Shwartz and S. Ben-David. Understanding machine learning: From theory to algorithms. Cambridge university press, 2014.
- Simonyan and Zisserman [2014] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014.
- Simsekli et al. [2019] U. Simsekli, L. Sagun, and M. Gurbuzbalaban. A tail-index analysis of stochastic gradient noise in deep neural networks. In International Conference on Machine Learning, pages 5827–5837. PMLR, 2019.
- Sorscher et al. [2022] B. Sorscher, R. Geirhos, S. Shekhar, S. Ganguli, and A. Morcos. Beyond neural scaling laws: beating power law scaling via data pruning. Advances in Neural Information Processing Systems, 35:19523–19536, 2022.
- Vapnik [1991] V. Vapnik. Principles of risk minimization for learning theory. Advances in neural information processing systems, 4, 1991.
- Vapnik [1999] V. Vapnik. The nature of statistical learning theory. Springer science & business media, 1999.
- Vapnik and Chervonenkis [2015] V. N. Vapnik and A. Y. Chervonenkis. On the uniform convergence of relative frequencies of events to their probabilities. In Measures of complexity, pages 11–30. Springer, 2015.
- Xu and Raginsky [2017] A. Xu and M. Raginsky. Information-theoretic analysis of generalization capability of learning algorithms. Advances in Neural Information Processing Systems, 30, 2017.
- Zhang et al. [2021] C. Zhang, S. Bengio, M. Hardt, B. Recht, and O. Vinyals. Understanding deep learning (still) requires rethinking generalization. Communications of the ACM, 64(3):107–115, 2021.
- Zhang et al. [2022a] J. Zhang, H. Li, S. Sra, and A. Jadbabaie. Neural network weights do not converge to stationary points: An invariant measure perspective. In International Conference on Machine Learning, pages 26330–26346. PMLR, 2022a.
- Zhang et al. [2022b] Y. Zhang, W. Zhang, S. Bald, V. Pingali, C. Chen, and M. Goswami. Stability of sgd: Tightness analysis and improved bounds. In Uncertainty in Artificial Intelligence, pages 2364–2373. PMLR, 2022b.
- Zhou et al. [2022] Y. Zhou, Y. Liang, and H. Zhang. Understanding generalization error of sgd in nonconvex optimization. Machine Learning, 111(1):345–375, 2022.
- Zhu et al. [2018] Z. Zhu, J. Wu, B. Yu, L. Wu, and J. Ma. The anisotropic noise in stochastic gradient descent: Its behavior of escaping from sharp minima and regularization effects. arXiv preprint arXiv:1803.00195, 2018.
Appendix A Proof of Theorem 3.6
| (12) |
and
| (13) |
Using Taylor expansion for the function , we have:
| (14) |
Therefore, we can define as:
| (15) |
The can be decomposed as , where .
Then Equation 13 can be decomposited as:
| (16) |
Proposition A.1.
For the gradient descent or the stochastic gradient descent algorithm, we have:
| (17) |
If , we have:
| (18) |
where , and we have:
| (19) |
Remark A.2.
Furthermore, we give a experimental exploration of the in Appendix C.3. We discover that if the optimizer doesn’t enter the EoS (Edge of Stability) regime[9], we have . One of common used assumption in stability based generalization theories is . For gradient descent, we have that maximum eigenvalue of Hessian hovers above when the optimizers enter EoS. This indicates that the assumption is valid only when the optimizer doesn’t enter EoS. In addition, we observe that the proposed bound can effectively represent the generalization error trend in Section 4 under common used experiment settings.
Proof.
Analyzing of
Combining with Formula (3), we have
| (21) |
Analyzing of
Here, we denote . According to the definition of .
| (22) | ||||
Because all the element of training set is sampled from distribution , we have Therefore:
| (23) |
What’s more, we also have:
| (24) |
Because , we have:
| (25) |
∎
According to the Equation (17), we analyze the generalization error of as a proxy for analyzing generalization error of the function trained using SGD or GD algorithm. The value of is equal to the generalization error of . To analyze , we construct an addictive linear space as , where . Here, we use to emphasize that depends on .
Under Assumption 3.4 (that is introduced in the main paper), we can have the following lemma.
Lemma A.3.
Proof.
For a function , we define that and . Given a function space, the maximum generalization error of the space can be defined as:
| (27) | ||||
where is another i.i.d sample set drawn from and denotes the Rademacher variable. The in denotes that belongs to or . if , otherwise, .
| (28) | ||||
where and , and .
| (29) | ||||
where is a subset of with . Defining , we have:
| (30) | ||||
∎
Lemma A.4.
Given , the formula can be upper bounded with:
| (31) |
Proof.
Let us start with the calculation of :
| (32) | ||||
where represents using the relation that for satisfying , we have .
Because is independent of if , we have:
| (33) | ||||
The covariance of gradient noise can be calculated as:
| (34) | ||||
When is small, holds, therefore we have:
| (36) | ||||
∎
Theorem A.5.
Under Assumption 3.4, given , let , where denotes the SGD or GD algorithm training with steps, we have:
| (37) |
where , and .
Proof.
We rewrite Equation 2 of the update of SGD with batchsize here:
| (38) |
where we simplify the as , then we can expand the function at as:
| (39) | ||||
Note that when the learning rate is small, we have .
The difference between the distributional value and the empirical value of the linear function can be calculated as:
| (40) | ||||
where using the equation that , according to Equation 20.
∎
Corollary A.6.
If function is -smooth, under Assumption 3.4 given , let , , and , where denoted the SGD or GD algorithm training with steps, we have:
| (41) | ||||
where , and .
Proof.
If is -smooth, we have:
| (42) | |||
| (43) |
Combining the two equations, we obtain:
| (44) | ||||
The generalization error can be divided into three parts:
| (45) | ||||
The term“” is caused by using to replace . The term "" is induced by . Then, we want to give a upper bound of using :
| (46) | ||||
where is due to the Equation 44, is due to the update rule of and is que to Hölder’s inequality. In the following, we use to give a upper bound for :
| (47) | ||||
Taking the upper bound value of "(A)" and "(B)" into Equation 45, we obtain the result.
∎
Appendix B Relaxed Assumption and Corresponding Bound
Assumption B.1.
There is a value , and , so that for all , we have and for all , we have .
Theorem B.2.
Under Assumption B.1, given , let , where denotes the SGD or GD algorithm training with steps, we have:
| (48) |
where , and .
Proof.
Most of the proofs in this part are the same as those in Appendix A, except for Equation 30. The Equation 30 is replaced by:
| (49) | ||||
∎
Remark B.3.
Compared of Theorem 3.6, we have a extra term here. Since the unrelaxed assumption is not satisfied only when is relative small, the term is small value.
Appendix C Experiments
C.1 Calculation of
To reduce the calculation, we construct a randomly sampled subset .
Denote the weights after -epoch training as . We can roughly calculated
C.2 Experimental Details
Here, we give a detail setting of the experiment for each figure.
Figure 1 The learning rate is fixed to 0.05 during all the training process. The batch size is 256. All experiments is trained with 100 epoch. The test accuracy for CIFAR-10, CIFAR-100, and SVHN are 87.64%, 55.08%, and 92.80%, respectively.
Figure 2 The initial learning rate is set to 0.05 with the batch size of 1024. We use the Cosine Annealing LR Schedule to adjust the learning rate during training.
Figure 3 Each point is an average of three repeated experiments. We stop training when the training loss is small than 0.2.
C.3 Experimental exploration of
In this section, our aim is to investigate the conditions under which . Since directly calculating the difference is challenging, we concentrate on the upper bound value .
We conduct the experiment using cifar10-5k dataset and fc-tanh network, following the setting of paper [9]. Cifar10-5k[9] is a subset of cifar10 dataset. Building upon the work of [1], we compute the Relative Progress Ratio (RP) and Test Relative Progress Ratio (TRP) throughout the training process. We initially consider the case of gradient descent. The definitions of RP and TRP for gradient descent are as follows:
| (50) | |||
| (51) |
Therefore, we have:
| (52) | ||||
Following the same way, we have:
| (53) | ||||
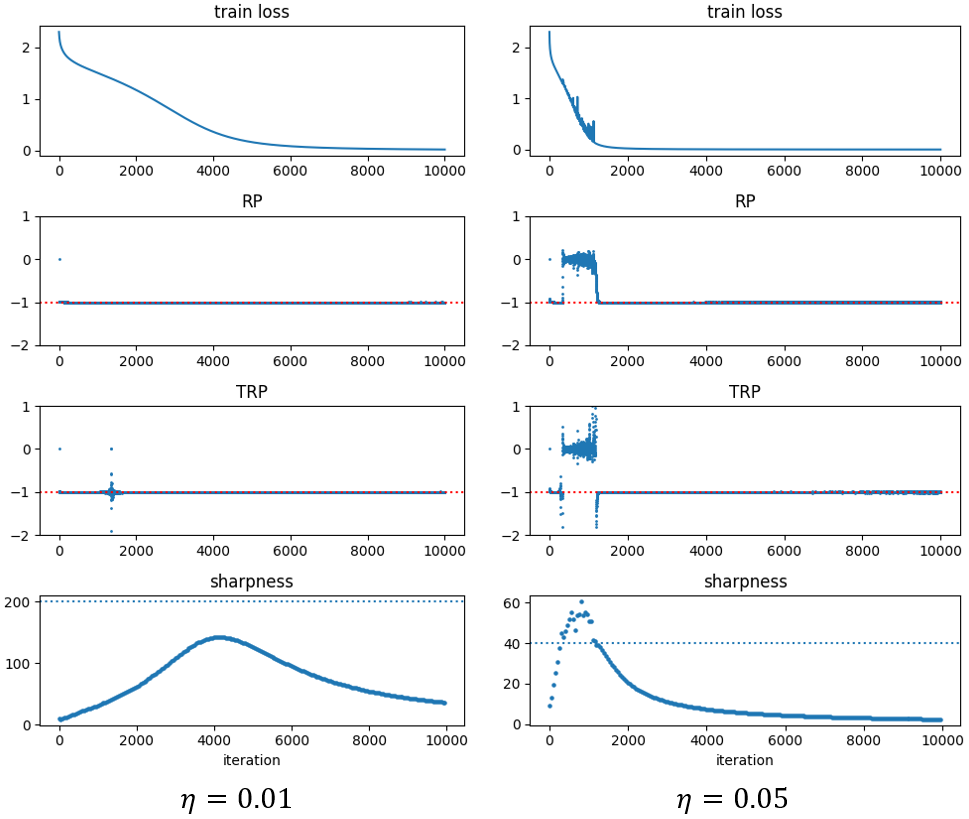
Combining Equation (52) and Equation (53), we have:
| (54) | ||||
Therefore, if we have for all , and , then .
From Figure 4 we find that in stable regime, where the sharpness is below the , we have . Under small learning rate, the gradient descent doesn’t enter the regime of edge of stability and we have during whole training process and .
Next, we consider the case of Stochastic Gradient Descent (SGD). Due to the stochastic estimation of the gradient, we need to rely on some approximations. Let represent the weights after the -epoch and -th iteration of training. We assume a constant learning rate for SGD. The gradient is approximated as follows:
| (55) |
and we appximate as:
| (56) |
Therefore, we have:
| (57) | |||
| (58) |
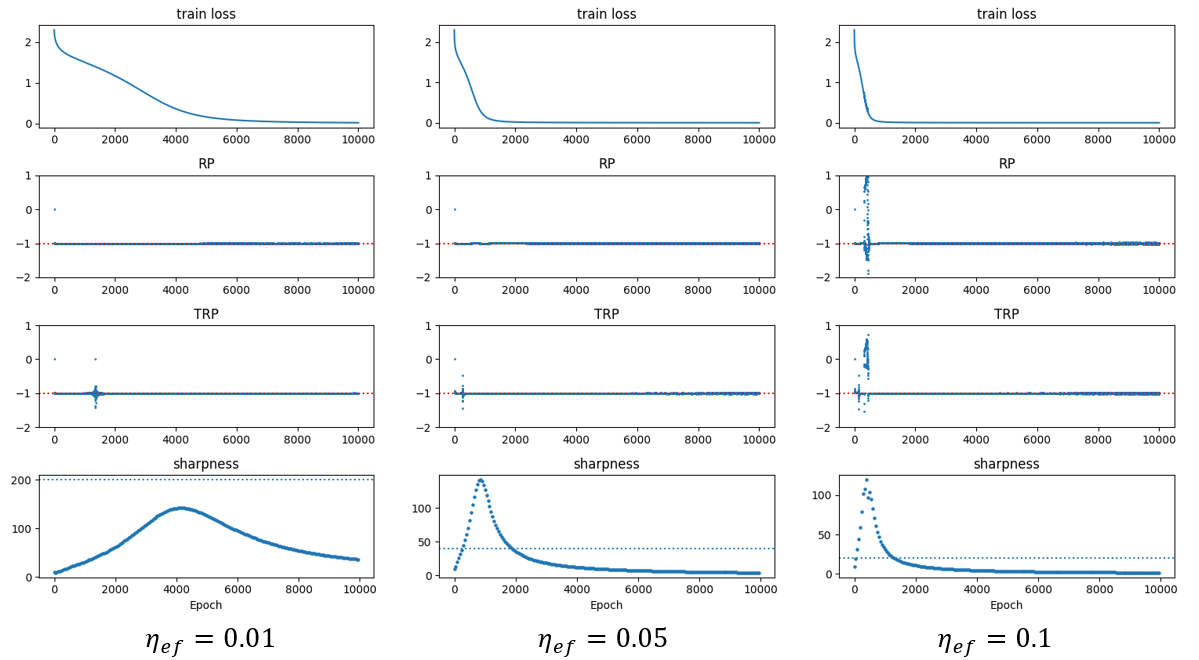
We calculated the effect learning rate for SGD as . Figure 5 shows that the conclusions of SGD are similar as GD, except that the conditions of entering EoS are different.
Appendix D Other Related Work
This part compares the works that is not listed in Table 2. Table 4 gives other trajectory based generalization bounds. [25] is a stability based work designed mainly for generalization of gradient descent. It removes the Lipschitz assumption, and replaced by the term in the generalization bounds. This helps enrich the trajectory information in the bounds. The limitation of this work is that it can only apply to the gradient descent and it is hard to extend to the stochastic gradient descent. Neu et al. [24] adapt the information-theretical generalization bound to the stochastic gradient descent. The Theorem 1 in Neu et al. [24] contains rich information about the learning trajectory, but most is about , which is unavailable for us. Therefore, we mainly consider the result of Corollary 2 in Neu et al. [24], which removes the term by the assumption listed in Table 4. For this Collorary, the remained information within trajectory is merely the . Althouth Neu et al. [24] dosen’t require the assumption of small learning rate, the bound contains the dimension of model, which is large for deep neural network. Compared with these work, our proposed method has advantage in that it can both reveal rich information about learning trajectory and applied to stochastic gradient descent.
Chandramoorthy et al. [8] analyzes the generalization behavior based on statistical algorithmic stability. The proposed generalization bound can be applied into algorithms that don’t converge. Let be the dataset obtained by replace in with another sample draw from distribution .The generalization bound relies on the stability measure . We don’t directly compare with this method because the calculation of relies on which contains sample outside of . Therefore, we treat this result as intermediate results. More assumption is needed to remove this dependence of the information about the unseen samples, i.e., the samples outside set .
Appendix E Effect of Learning Rate and Stochastic Noise
In this part, we want to analyze how learning rate and the stochastic noise jointly affect our proposed generalization bound. Specifically, we denote as the distribution of the during the training with multiple training steps. Following the work [12], we consider the SDE function as an approximation, which is shown as below:
| (59) |
The SDE can be regarded as the continuous counterpart of Equation(3) when sets the distribution of noise term in Equation(3) as Gaussian distribution. The influence of the noise on is shown in the following theorem.
Theorem E.1.
When the updating of the weight follows Equation (59), the covariance matrix is a hessian matrix of a function with a scalar output, then we have:
| (60) |
Remark E.2.
Previous studies ([44, 31, 12]) tell that the covariance matrix is proximately equal to the hessian matrix of the loss function with respect to the parameters of DNN. Thus, the above condition that the covariance matrix is a hessian matrix of a function with scalar output is easy to be satisfied. Formula (60) contains three parts. The item enlarge the probability of parameters being located in the parameter space with low . and ususally contradict with each other. enlarge the probability of parameters being located in the parameter space with low value, while serves as a damping factor to prevent the probability from concentrating on a small space. Therefore, setting larger learning rate gives stronger force for the weight to the area with lower values. According to Equation 5, we also have a lower . As a result, large learning rate causes a small lower bound in Theorem 3.6
Proof.
Based on the condition described above, we can infer that , where G is a function with a scalar output.
We first prove that as below:
| j | (61) | |||
So far, we can infer that . According to Fokker-Planck equation( [26]), we have:
| (62) | ||||
Therefore, the theorem is proven. ∎