11email: {az2407,zw2627,hy2612,sc250}@columbia.edu
Learning Visual Commonsense
for Robust Scene Graph Generation
Abstract
Scene graph generation models understand the scene through object and predicate recognition, but are prone to mistakes due to the challenges of perception in the wild. Perception errors often lead to nonsensical compositions in the output scene graph, which do not follow real-world rules and patterns, and can be corrected using commonsense knowledge. We propose the first method to acquire visual commonsense such as affordance and intuitive physics automatically from data, and use that to improve the robustness of scene understanding. To this end, we extend Transformer models to incorporate the structure of scene graphs, and train our Global-Local Attention Transformer on a scene graph corpus. Once trained, our model can be applied on any scene graph generation model and correct its obvious mistakes, resulting in more semantically plausible scene graphs. Through extensive experiments, we show our model learns commonsense better than any alternative, and improves the accuracy of state-of-the-art scene graph generation methods.
1 Introduction
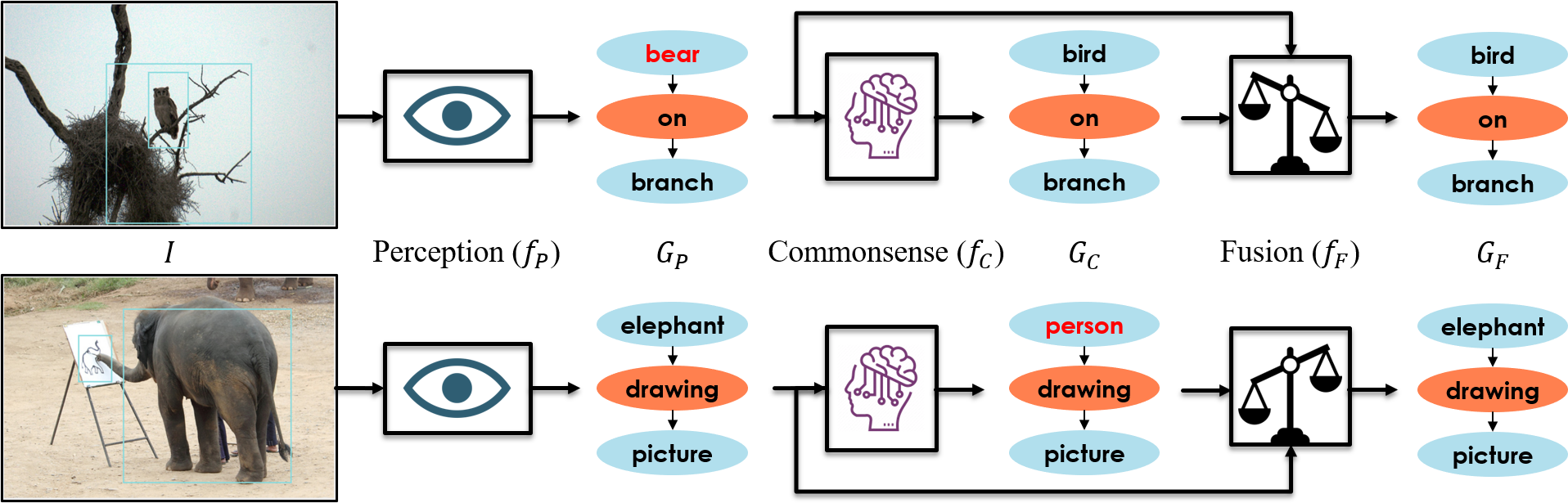
In recent computer vision literature, there is a growing interest in incorporating commonsense reasoning and background knowledge into the process of visual recognition and scene understanding [9, 31, 13, 8, 33]. In Scene Graph Generation (SGG), for instance, external knowledge bases [7] and dataset statistics [2, 34] have been utilized to improve the accuracy of entity (object) and predicate (relation) recognition. The effect of these techniques is usually to correct obvious perception errors, and replace with more plausible alternatives. For instance, Figure 1 (top) shows an SGG model mistakenly classifies a bird as a bear, possibly due to the dim lighting and small object size. However, a commonsense model can correctly predict bird, because bear on branch is a less common situation, less aligned with intuitive physics, or contrary to animal behavior.
Nevertheless, existing methods to incorporate commonsense into the process of visual recognition have two major limitations. Firstly, they rely on an external source of commonsense, such as crowd-sourced or automatically mined commonsense rules, which tend to be incomplete and inaccurate [7], or statistics directly gathered from training data, which are limited to simple heuristics such as co-occurrence frequency [2]. In this paper, we propose the first method to learn graphical commonsense automatically from a scene graph corpus, which does not require external knowledge, and acquires commonsense by learning complex, structured patterns beyond simple heuristics.
Secondly, most existing methods are strongly vulnerable to data bias as they integrate data-driven commonsense knowledge into data-driven neural networks. For instance, the commonsense model in Figure 1 mistakes the elephant for a person, in order to avoid the bizarre triplet elephant drawing picture, while the elephant is quite clear visually, and the perception model already recognizes it correctly. None of the existing efforts to equip scene understanding with commonsense have studied the fundamental question of whether to trust perception or commonsense, i.e., what you see versus what you expect. In this paper, we propose a way to disentangle perception and commonsense into two separately trained models, and introduce a method to exploit the disagreement between those two models to achieve the best of both worlds.
To this end, we first propose a mathematical formalization of visual commonsense, as a problem of auto-encoding perturbed scene graphs. Based on the new formalism, we propose a novel method to learn visual commonsense from annotated scene graphs. We extend recently successful transformers [23] by adding local attention heads to enable them to encode the structure of a scene graph, and we train them on a corpus of annotated scene graphs to predict missing elements of a scene via a masking framework similar to BERT [5]. As illustrated in Figure 2, our commonsense model learns to use its experience to imagine which entity or predicate could replace the mask, considering the structure and context of a given scene graph. Once trained, it can be stacked on top of any perception (i.e., SGG) model to correct nonsensical mistakes in the generated scene graphs.
The output of the perception and commonsense models can be seen as two generated scene graphs with potential disagreements. We devise a fusion module that takes those two graphs, along with their classification confidence values, and predicts a final scene graph that reflects both perception and commonsense knowledge. The degree to which our fusion module trusts each input varies for each image, and is determined based on the estimated confidence of each model. This way, if the perception model is uncertain about the bird due to darkness, the fusion module relies on the commonsense more, and if perception is confident about the elephant due to its clarity, the fusion module trusts its eyes.
We conduct extensive experiments on the Visual Genome datasets [12], showing (1) The proposed GLAT model outperforms existing transformers and graph-based models in the task of commonsense acquisition; (2) Our model learns various types of commonsense that are absent in SGG models, such as object affordance and intuitive physics; (3) The proposed model is robust to dataset bias, and shows commonsensical behavior even in rare and zero-shot scenarios; (4) The proposed GLAT and Fusion mechanism can be applied on any SGG method to correct their mistakes and improve their accuracy. The main contributions of this paper are the following:
-
•
We propose the first method for learning structured visual commonsense, Global-Local Attention Transformer (GLAT), which does not require any external knowledge, and outperforms conventional transformers and graph-based networks.
-
•
We propose a cascaded fusion architecture for Scene Graph Generation, which disentangles commonsense reasoning from visual perception, and integrates them in a way that is robust to the failure of each component.
-
•
We report experiments that showcase our model’s unique ability of learning commonsense without picking up dataset bias, and its utility in downstream scene understanding.
2 Related Work
2.1 Commonsense in computer vision
Incorporating commonsense knowledge has been explored in various computer vision tasks such as object recognition [3, 28, 14], object detection [13], semantic segmentation [19], action recognition [9], visual relation detection [31], scene graph generation [2, 34, 7], and visual question answering [18, 22]. There are two aspects to study about these methods: where their commonsense comes from, and how they use it.
Most methods either adopt an external curated knowledge base such as ConceptNet [21, 7, 28, 14, 19, 18], or acquire commonsense automatically by collecting statistics over an often annotated corpus [3, 2, 34, 13, 22, 31]. Nevertheless, the former group are limited to incomplete external knowledge, and the latter are based on ad-hoc, hard-coded heuristics such as the co-occurrence frequency of categories. Our method is the first to formulate visual commonsense as a machine learning task, and train a graph-based neural network to solve it. There are a third group of works that focus on a particular type of commonsense by designing a specialized model, such as intuitive physics [6], or object affordance [4]. We put forth a more general framework that includes but is not limited to physics and affordance, by exploiting scene graphs as a versatile semantic representation. The most similar to our work is [26], which only models object co-occurrance patterns, while we also incorporate object relationships and scene graph structure.
When it comes to utilizing commonsense, existing methods integrate it within the inference pipeline, either by retrieving a set of relevant facts from a knowledge base and feeding as additional features to the model [18, 7, 22], or by employing a graph-based message propagation process to embed the structure of the knowledge graph within the intermediate representations of the model [3, 9, 2, 28, 14]. Some other methods distill the knowledge during training through auxiliary objectives, making the inference simple and free of external knowledge [19, 31]. Nevertheless, in all those approaches, commonsense is seamlessly infused into the model and cannot be disentangled. This makes it hard to study and evaluate commonsense and perception separately, or control their influence. Few methods have modeled commonsense as a standalone module which is late-fused into the prediction of the perception model [13, 34]. Yet, we are the first to devise separate perception and commonsense models, and adaptively weigh their importance based on their confidence, before fusing their predictions.
2.2 Commonsense in scene graph generation
Zellers et al. [34] were the first to explicitly incorporate commonsense into the process of scene graph generation. They biased predicate classification logits using a pre-computed frequency prior that is a static distribution, given each entity class pair. Although this significantly improved their overall accuracy, the improvement is mainly due to the fact that they favor frequent triplets over others, which is statistically rewarding. Even if their model classifies the relation between a person and a hat as holding, their frequency bias would most likely change that to wearing, which is more frequent.
More recently, Chen et al. [2] employed a less explicit way to incorporate the frequency prior within the process of entity and predicate classification. They embed the frequencies into the edge weights of their inference graph, and utilize those weights within their message propagation process. This improves the results especially on less frequent predicates, since it less strictly enforces the statistics on the final decision. However, this way commonsense is integrated implicitly into the SGG model and cannot be probed or studied in isolation. We remove the adverse effect of statistical bias while keeping the commonsense model disentangled from perception.
Gu et al. [7] exploits ConceptNet [21] rather than dataset statistics, which is a large-scale knowledge graph comprising relational facts about concepts, e.g. dog is-a animal or fork is-used-for eating. Given each detected object, they retrieve ConceptNet facts involving that object class, and employ a recurrent neural net and an attention mechanism to encode those facts into the object features, before classifying objects and predicates. Nevertheless, ConceptNet is not exhaustive, since it is extremely hard to compile all commonsense facts. Our method does not depend on a limited source of external knowledge, and acquires commonsense automatically, via a generalizable neural network.
2.3 Transformers and graph-based neural networks
Transformers were originally proposed to replace recurrent neural networks for machine translation, by stacking several layers of multi-head attention [23]. Ever since, transformers have been successful in various vision and language tasks [5, 27, 16]. Particularly, BERT [5] randomly replaces some words from a given sentence with a special MASK token and tries to reconstruct those words. Through this self-supervised game, BERT acquires natural language, and can transfer its language knowledge to perform well in other NLP tasks. We use a similar self-supervised strategy to learn to complete missing pieces of a scene graph. Rather than language, our model acquires the ability to imagine a scene in a structured, semantic way, which is a hallmark of human commonsense.
Transformers treat their input as a set of tokens, and discard any form of structure among them. To preserve the order of tokens in a sentence, BERT augments the initial embedding of each token with a position embedding before feeding into transformers. Scene graphs, on the other hand, have a more complex structure that cannot be embedded in such a trivial way. Recently, Graph-based Neural Networks (GNN) have been successful to encode graph structures into node representations, by applying several layers of neighborhood aggregation. More specifically, each layer of a GNN represents each node by a trainable function that takes the node as well as its neighbors as input. Graph convolutional nets [11], gated graph neural nets [15], and graph attention nets [24] all implement this idea with different computational models for neighborhood aggregation. GNNs have been widely utilized for scene graph generation by incorporating context [29, 30, 32], but we are the first to exploit GNNs to learn visual commonsense.
We adopt graph attention nets due to their similarity to transformers in using attention. The main difference of graph attention nets to transformers is that instead of representing each node by an attention over all other nodes, they only compute an attention over immediate neighbors. Inspired by that, we use a BERT-like transformer network, but replace half of its attention heads by local attention, simply by enforcing the attention between non-neighbor nodes to zero. Through ablation experiments in Section 4, we show the proposed Global-Local Attention Transformers (GLAT) outperforms conventional transformers, as well as widely used graph-based models such as graph convolution nets and graph attention nets.
3 Method
In this section, we first formalize the task, and propose a novel formulation of visual commonsense in connection with visual perception. We then provide an overview of the proposed architecture (Figure 1), followed by an in-depth description of each proposed module.
We define a scene graph as , where is a set of entity nodes, is a set of predicate nodes, is a set of edges from each predicate to its subject (which is an entity node), and is a set of edges from each predicate to its object (that also is an entity node). Each entity node is represented with an entity class and a bounding box , while each predicate node is represented with a predicate class and is connected to exactly one subject and one object. Note that this formulation of scene graph is slightly different from the conventional one [29], as we formulate predicates as nodes rather than edges. This tweak does not cause any limitation since every scene graph can be converted from the conventional representation to our representation. However, this formulation allows multiple predicates between the same pair of entities, and it also enables us to define a unified attention over all nodes no matter entity or predicate.
Given a training dataset with many images paired with ground truth scene graphs , our goal is to train a model that takes a new image and predicts a scene graph that maximizes . This is equivalent of maximizing , which breaks the problem into what we call perception and commonsense. In our proposed intuition, commonsense is the mankind’s ability to predict which situations are possible and which are not, or in other words, what makes sense and what does not. This can be seen as a prior distribution over all possible situations in the world, represented as scene graphs. Perception, on the other hand, is the ability to form symbolic belief from raw sensory data, which are respectively and in our case. Although the goal of computer vision is to solve the Maximum a Posteriori (MAP) problem (maximizing ), neural nets often fail to estimate the posterior, unless the prior is explicitly enforced in the model definition [17]. This is while in computer vision, the prior is often overlooked, or inaccurately considered to be a uniform distribution, making MAP equivalent to Maximum Likelihood (ML), i.e., finding that maximizes [20].
We propose the first method to explicitly approximate the MAP inference by devising an explicit prior model (commonsense). Since posterior inference is intractable, we propose a two-stage framework as an approximation: We first adopt any off-the-shelve SGG model as the perception model, which takes an input image and produces a perception-driven scene graph, , that approximately maximizes the likelihood. Then we propose a commonsense model, which takes as input, and produces a commonsense-driven scene graph, , to approximately maximize the posterior, i.e.,
| (1) | ||||
| (2) |
where and are the perception and commonsense models. The commonsense model can be seen as a graph-based extension of denoising autoencoders [25], which evidently can learn the generative distribution of data [10, 1], that is in our case. Accordingly, can take any scene graph as input and produce a more plausible graph by only slightly changing the input. A key design choice here is the fact that does not take the image as input. Otherwise, it would be hard to ensure it is purely learning commonsense and not perception.
Ideally, is the best decision to make, since it maximizes the posterior distribution. However, in practice autoencoders tend to under-represent long-tailed distributions and only capture the modes. This means the commonsense model may fail to predict less common structures, in favor of more statistically rewarding alternatives. To alleviate this problem, we propose a fusion module that takes and as input, and outputs a fused scene graph, , which is the final output of our system. This can be seen as a decision-making agent that has to decide how much to trust each model, based on how confident they are.
Figure 1 illustrates an overview of the proposed architecture. In the rest of this section, we elaborate each module in detail.
3.1 Global-Local Attention Transformers
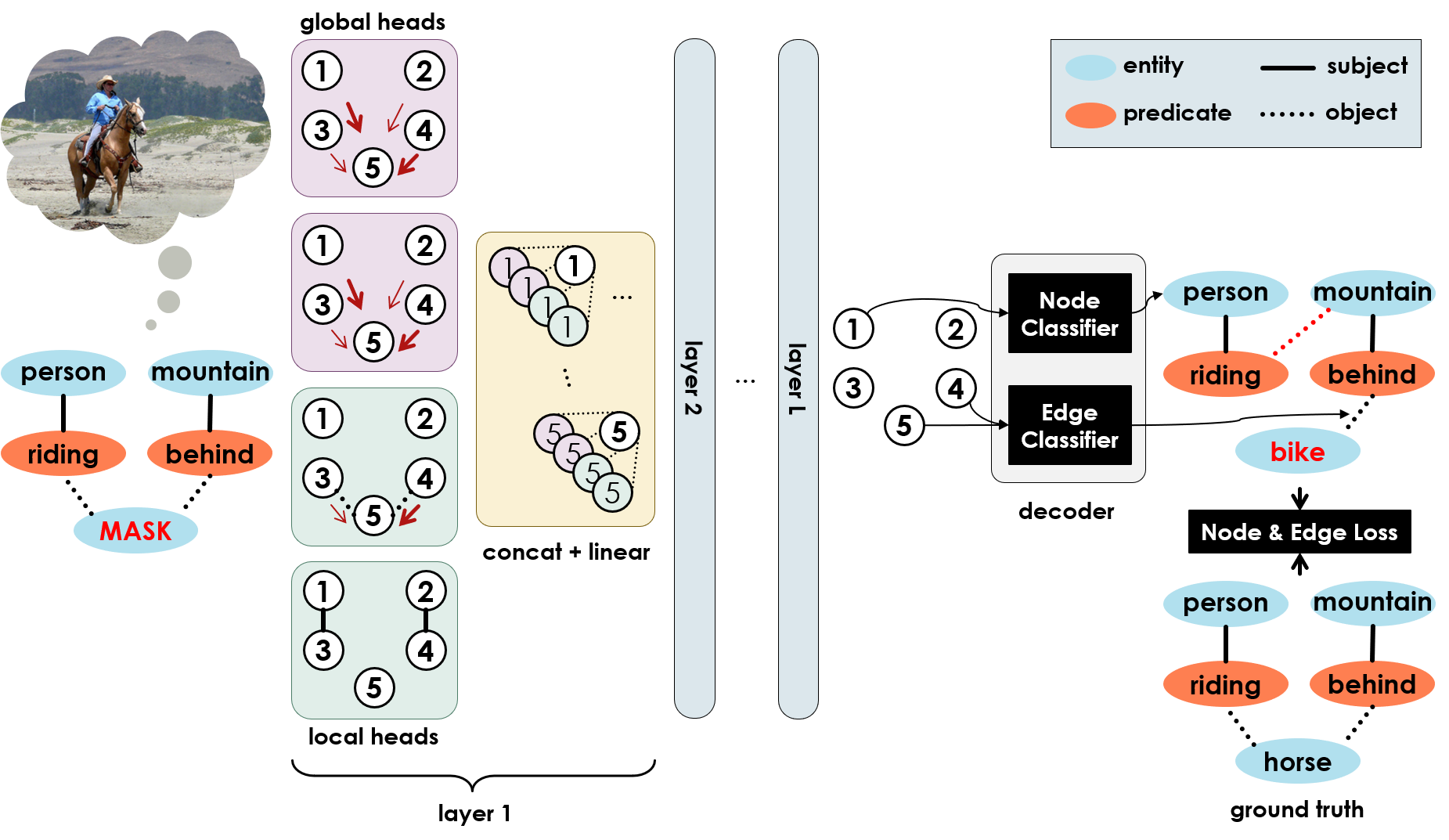
We propose the first graph-based visual commonsense model, which learns a generative distribution over the semantic structure of real-world scenes, through a denoising autoencoder framework. Inspired by BERT [5], which reconstructs masked tokens in a sentence through stacked layers of multi-head attention, we propose Global-Local Attention Transformers (GLAT) that take a graph with masked nodes as input, and reconstructs the missing nodes. Figure 2 illustrates how GLAT works. Given an input scene graph , we represent node as a one-hot vector , that includes entity and predicate categories, as well as a special MASK class. We stack node representations as rows of a matrix for notation purposes.
GLAT takes as input and represents each node by encoding the structure and context. To this end, it applies layers of multi-head attention on the input nodes. Each layer creates new node representations , by applying a linear layer on the concatenated output of that layer’s attention heads. More specifically,
| (3) |
where is the set of attention heads for layer , and are trainable fusion weights and bias for that layer, and the concatenation operates along columns. We use two types of attention head, namely global and local. Each node can attend to all other nodes through global attention, while only its neighbors through local attention. We further divide local heads based on the type of edge they use, in order to differentiate the way subjects and objects interact with predicates, and vice versa. Therefore, we can write:
| (4) |
All heads within each subset are identical, except they have distinct parameters that are initialized and trained independently. Each global head operates as a typical self-attention would:
| (5) |
where are query, key, and value heads, each a fully connected network, typically (but not necessarily) with a single linear layer. A local attention is the same, except queries can only interact with keys of their immediate neighbor nodes. For instance in subject heads,
| (6) |
where is the adjacency matrix of subject edges, which is 1 between from each predicate to its subject and vice versa, and 0 elsewhere. We similarly define and for object edges.
Once we get contextualized, structure-aware representations for each node , we devise a simple decoder to generate the output scene graph , using a fully connected network that classifies each node to an entity or predicate class, and another fully connected network that classifies each pair of nodes into an edge type (subject, object or no edge). We train the encoder and decoder end-to-end, by randomly adding noise to annotated scene graphs from Visual Genome, feeding the noisy graph to GLAT, reconstructing nodes and edges, and comparing each with the original scene graph before perturbation. We train the network using two cross-entropy loss terms on the node and edge classifiers. The details of training including the perturbation process are explained in Section 4.1.
3.2 Fusing Perception and Commonsense
The perception and commonsense models each predict the output node categories using a classifier that computes a probability distribution over all classes by applying a softmax on its logits. The class with highest probability is chosen and assigned a confidence score equal to its softmax probability. More specifically, node from has a logit vector that has or dimensions depending of whether it is an entity node or predicate node. Similarly node from has a logit vector . Note that these two nodes correspond to the same entity or predicate in the image, since GLAT does not change the order of nodes. Then the confidence of each node can be written as
| (7) |
and similarly is defined given .
The fusion module takes each node of and the corresponding node of , and computes a new logit vector for that node, as a weighted average of and . The weights determine the contribution of each model in the final prediction, and thus have to be proportional to the confidence of each model. Therefore, we compute the fused logits as:
| (8) |
Finally, a softmax is applied on to compute the final classification distribution for node .
4 Experiments
In this section, we describe our experiments on the Visual Genome (VG) dataset in detail. We first evaluate how well our GLAT model learns visual commonsense, by comparing it to other models on the task of masked scene graph reconstruction. Then we provide a statistical analysis of our model prediction to show the kinds of commonsense knowledge it acquires, and distinguish it from bias. Next, we evaluate how effective GLAT and our fusion mechanism are for the downstream task of SGG, when applied on various perception models. We also provide several examples of how the commonsense model corrects the perceived output, and how the fusion model combines the two.
4.1 Implementation details
We train the perception and commonsense models separately using the ground truth scene graphs from VG [12], particularly the version most widely used for SGG [29], which has 150 entity and 50 predicate classes. We then stack commonsense on top of perception and fine-tune it on VG, this time with actual scene graphs generated by perception, to adapt to the downstream task. The fusion module does not have trainable parameters and is thus only used during inference. We use the 75k VG scene graphs for training all models, and use the other 25k for test. We hold a small portion of the train set for validation. Our GLAT model (and other baselines when applicable) have 6 layers, each with 8 attention heads, and has a 300-dimensional representation for each node. While training GLAT, we randomly mask 30% of the nodes, which is the average number of nodes mistaken by a typical SGG model. We average the classification loss over all nodes and edges classified by the decoder, no matter masked or not. For fine-tuning and inference, we prune the output of the perception model before feeding to GLAT, by keeping the top 100 most confident predicates and all entities connected to those.
4.2 Evaluating commonsense
Once GLAT is trained, we evaluate it on the same task of reconstructing ground truth VG graphs that are perturbed by randomly masking 30% of their nodes. We evaluate the accuracy of our model in classifying the masked nodes, and report the accuracy (Table 1) separately for entity nodes and predicate nodes, as well as overall. This is a good measure of how well the model has learned commonsense, because it mimics mankind’s ability to imagine what would a real-world scene look like, given some context. In Figure 2, for instance, given the fact that there is a person riding something that is masked, we can immediately tell it is probably a bike, a motorcycle, or a horse. If we also know there is a mountain behind the masked object, and the masked object has a face and legs (not shown in the figure for brevity), then we can more certainly imagine it is a horse. By incorporating the global context of the scene, as well as the local structure of the graph, GLAT is able to effectively imagine the scene and predict the class of the entity or predicate that was masked, at a significantly higher accuracy compared to all baselines.
More specifically, we compare GLAT to: (1) A transformer [5] that is the same as our model, except it only has global heads; (2) A Graph Attention Net [24] which is also the same as our model, but only with local heads; and (3) A Graph Convolutional Network [11], which has only one local head at each layer, and the attention is fixed to be equal for all neighbors of each node. We also compare our method with the frequency prior used by Zellers et al. [34], which can only be applied for masked predicates, and simply predicts the most frequent predicate given its subject and object. As Table 1 shows, our method significantly outperforms all aforementioned baselines, which are a good representative of any existing method to learn semantic graph reconstruction.
To provide a better sense of the commonsense knowledge our model learns, we apply GLAT on the entire VG test set, using the procedure detailed below (Section 4.3), and collect its prediction statistics in a diverse set of situations. We elaborate using an example, shown in the top left cell of Table 2. Out of all triplets from all scene graphs produced by our model, we collect those triplets that match the certain template of person [X] horse, and show our sorted top 5 predictions in terms of frequency. The 5 predicates most often predicted by our method between a person and a horse are on, riding, near, watching, and behind. These are all possible interactions between a person and a horse, and all follow the affordance properties of both person and horse. Nevertheless, when we get the same statistics from the output of a state-of-the-art scene graph generation model (IMP [29]), we observe that it frequently predicts person wearing horse, which does not follow the affordance of horse. This can be attributed to the high frequency of wearing in VG annotation, which biases the IMP model, while our commonsense model is prone to such bias, and has learned affordances through the self-supervised training framework.
| Method | Entity | Predicate | Both |
|---|---|---|---|
| Triplet Frequency [34] | - | 44.4 | - |
| Graph Convolutional Nets [11] (local-only, fixed attention) | 8.7 | 43.4 | 19.7 |
| Graph Attention Nets [24] (local-only) | 12.0 | 45.0 | 22.3 |
| Transformers [5] (global-only) | 14.0 | 42.3 | 22.9 |
| Global-Local Attention Transformers (ours) | 22.3 | 60.7 | 34.4 |
Table 2 provides several more scenarios like this, demonstrating our proficiency in three types of commonsense: object affordance, intuitive physics, and object composition. As an example of physics, we choose the triplet template [X] under bed, and show that our model predicts plausible objects such as pot, shoe, drawer, book, and sneaker. This is while IMP predicts bed under bed, counter under bed, and sink under bed, which are all physically counter-intuitive. More interestingly, one of our frequent predictions, book under bed, is a composition that does not exist in training data, suggesting the knowledge acquired by GLAT is not merely a biased memory of frequent compositions in training data.
The last type of commonsense in our illustration is object composition, i.e., the fact that certain objects are physical parts of other objects. For [X] has ear, we predict head, cat, elephant, zebra, and person, out of which head has ear and person has ear are not within the 10 most frequent triplets in training data that match the template. Yet our model frequently predicts them, demonstrating its unbiased knowledge. Not to mention, 4 out of 5 top predictions made by IMP are nonsensical.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/5ee5d3ea-c65f-4876-b999-b5f439629700/comse_examples.png)
4.3 Evaluating scene graph generation
Now that we showed the efficacy of GLAT in learning visual commonsense and correcting perturbed scene graphs, we apply and evaluate it on the downstream task of scene graph generation. We adopt existing SGG models as our perception model, and compare their output , to the ones corrected by our commonsense model , as well as the final output of our system after fusion . We compare those 3 outputs for 3 different choices of perception model, all of which have competitive state-of-the-art performance. More specifically, we use Iterative Message Passing (IMP [29]) as a strong baseline that is not augmented by commonsense. We also use Stacked Neural Motifs (SNM [34]) that late-fuse a frequency prior with their output, and Knowledge-Embedded Routing Networks (KERN [2]) that encode frequency prior within their internal message passing.
To evaluate, we conventionally compute the mean recall of the top 50 (mR@50) and top 100 (mR@100) triplets predicted by each model. Each triplet is considered correct if the subject, predicate, and object are all classified correctly, and the bounding box of the subject and object have more than 50% overlap (intersection over union) with the ground truth. We compute the recall for the triplets of each predicate class separately, and average over classes. The aforementioned metrics are measured in 2 sub-tasks: (1) SGCls is the main scenario where we classify entities and predicates given annotated bounding boxes. This way the performance is not limited by proposal quality. (2) PredCls provides the model with ground truth object labels, which helps evaluation focus on predicate recognition accuracy. Table 3 shows the full comparison of all methods on all metrics. We observe that GLAT improves the performance of IMP which does not have commonsense, but does not significantly change the performance of SNM and KERN which already use dataset statistics. However, our full model which uses both the output of the perception model as well as commonsense model consistently improves SGG performance. In the supplementary material, we provide a more detailed analysis by breaking the results down into subgroups based on triplet frequency, and showing our performance boost is consistent in frequent and rare situations.
| Method | PredCls | SGCls | ||
|---|---|---|---|---|
| mR@50 | mR@100 | mR@50 | mR@100 | |
| IMP [29] | 9.8 | 10.5 | 5.8 | 6.0 |
| IMP + GLAT | 11.1 | 11.9 | 6.2 | 6.5 |
| IMP + GLAT + Fusion | 12.1 | 12.9 | 6.6 | 7.0 |
| SNM [34] | 13.3 | 14.4 | 7.1 | 7.5 |
| SNM + GLAT | 13.6 | 14.6 | 7.3 | 7.8 |
| SNM + GLAT + Fusion | 14.1 | 15.3 | 7.5 | 7.9 |
| KERN [2] | 17.7 | 19.2 | 9.4 | 10.0 |
| KERN + GLAT | 17.6 | 19.1 | 9.3 | 10.0 |
| KERN + GLAT + Fusion | 17.8 | 19.3 | 9.9 | 10.4 |
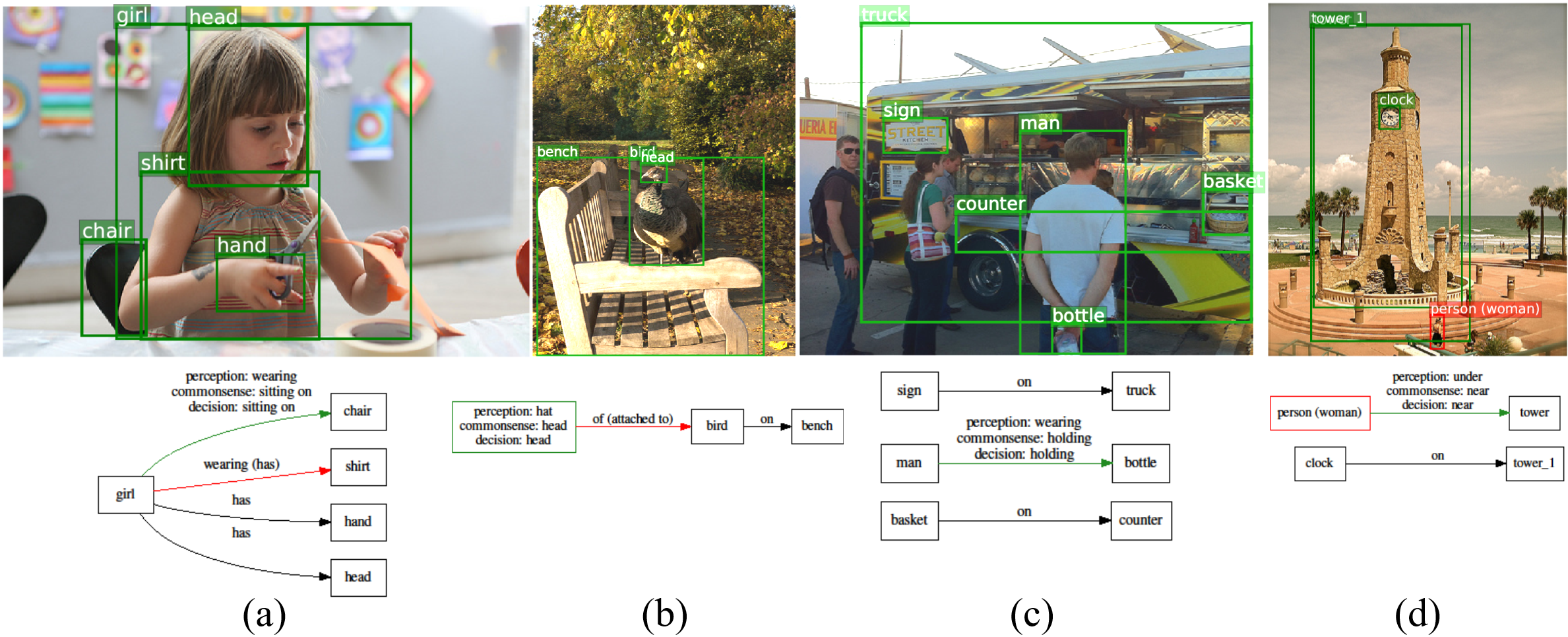
Finally, we provide several examples in Figure 4 to illustrate how our commonsense model fixes perception errors in difficult scenarios, and improves the robustness of our model. To save space, we merge the three scene graphs predicted by the perception, commonsense, and fusion models into a single graph, and emphasize any node or edge where these three models disagree. In example (a), the chair is not fully visible, and the visible part does not visually show the action of sitting, thus the perception model incorrectly predicts wearing, which is likely to be also affected by the bias due to the prevalence of wearing annotations in Visual Genome. However, it is trivial for the commonsense model that the affordance of chair is sitting. The fusion module correctly prefers the output of the commonsense model, due to its higher confidence. In (b), the perception model mistakes the head of the bird for a hat, due to the complexity of the lighting and the similarity of foreground and background colors. This might be also affected by the bias of head instances in VG, which are usually human heads, and the fact that hat instances typically co-occur with a head. Nevertheless, our commonsense model has the knowledge of object composition and knows brids typically have heads but not hats. Example (c) is an unusual case of holding, in terms of visual attributes such as arm pose. Hence, the perception model fails to predict holding correctly, while our commonsense model corrects that mistake by incorporating the affordance of bottle. Finally, in (d), the person is perceived under the tower due to the camera angle, but for the commonsense model that is unlikely due to intuitive physics. Hence, it corrects the mistake and the fusion module accepts that fix. More examples are provided in the supplementary material.
5 Conclusion
We presented the first method to learn visual commonsense automatically from a scene graph corpus. Our method learns structured commonsense patterns, rather than simple co-occurrence statistics, through a novel self-supervised training strategy. Our unique way of augmenting transformers with local attention heads significantly outperforms transformers, as well as widely used graph-based models such as graph convolutional nets. Furthermore, we proposed a novel architecture for scene graph generation, which consists of two individual models, perception and commonsense, which are trained differently, and can complement each other under uncertainty, improving the overall robustness. To this end, we proposed a fusion mechanism to combine the output of those two models based on their confidences, and showed our model correctly determines when to trust its perception and when to fall back on its commonsense. Experiments show the effectiveness of our method for scene graph generation, and encourage future work to apply the same methodology on other computer vision tasks.
Acknowledgement This work was supported in part by Contract N6600119C4032 (NIWC and DARPA). The views expressed are those of the authors and do not reflect the official policy of the Department of Defense or the U.S. Government.
References
- [1] Alain, G., Bengio, Y.: What regularized auto-encoders learn from the data-generating distribution. The Journal of Machine Learning Research 15(1), 3563–3593 (2014)
- [2] Chen, T., Yu, W., Chen, R., Lin, L.: Knowledge-embedded routing network for scene graph generation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 6163–6171 (2019)
- [3] Chen, X., Li, L.J., Fei-Fei, L., Gupta, A.: Iterative visual reasoning beyond convolutions. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 7239–7248 (2018)
- [4] Chuang, C.Y., Li, J., Torralba, A., Fidler, S.: Learning to act properly: Predicting and explaining affordances from images. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 975–983 (2018)
- [5] Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018)
- [6] Groth, O., Fuchs, F.B., Posner, I., Vedaldi, A.: Shapestacks: Learning vision-based physical intuition for generalised object stacking. In: Proceedings of the European Conference on Computer Vision (ECCV). pp. 702–717 (2018)
- [7] Gu, J., Zhao, H., Lin, Z., Li, S., Cai, J., Ling, M.: Scene graph generation with external knowledge and image reconstruction. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 1969–1978 (2019)
- [8] Jiang, C., Xu, H., Liang, X., Lin, L.: Hybrid knowledge routed modules for large-scale object detection. In: Advances in Neural Information Processing Systems. pp. 1552–1563 (2018)
- [9] Kato, K., Li, Y., Gupta, A.: Compositional learning for human object interaction. In: Proceedings of the European Conference on Computer Vision (ECCV). pp. 234–251 (2018)
- [10] Kingma, D.P., Welling, M.: Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114 (2013)
- [11] Kipf, T.N., Welling, M.: Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907 (2016)
- [12] Krishna, R., Zhu, Y., Groth, O., Johnson, J., Hata, K., Kravitz, J., Chen, S., Kalantidis, Y., Li, L.J., Shamma, D.A., et al.: Visual genome: Connecting language and vision using crowdsourced dense image annotations. International Journal of Computer Vision 123(1), 32–73 (2017)
- [13] Kumar Singh, K., Divvala, S., Farhadi, A., Jae Lee, Y.: Dock: Detecting objects by transferring common-sense knowledge. In: Proceedings of the European Conference on Computer Vision (ECCV). pp. 492–508 (2018)
- [14] Lee, C.W., Fang, W., Yeh, C.K., Frank Wang, Y.C.: Multi-label zero-shot learning with structured knowledge graphs. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1576–1585 (2018)
- [15] Li, Y., Tarlow, D., Brockschmidt, M., Zemel, R.: Gated graph sequence neural networks. arXiv preprint arXiv:1511.05493 (2015)
- [16] Lu, J., Batra, D., Parikh, D., Lee, S.: Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. In: Advances in Neural Information Processing Systems. pp. 13–23 (2019)
- [17] Malinin, A., Gales, M.: Predictive uncertainty estimation via prior networks. In: Advances in Neural Information Processing Systems. pp. 7047–7058 (2018)
- [18] Narasimhan, M., Schwing, A.G.: Straight to the facts: Learning knowledge base retrieval for factual visual question answering. In: Proceedings of the European Conference on Computer Vision (ECCV). pp. 451–468 (2018)
- [19] Qi, M., Wang, Y., Qin, J., Li, A.: Ke-gan: Knowledge embedded generative adversarial networks for semi-supervised scene parsing. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 5237–5246 (2019)
- [20] Romaszko, L., Williams, C.K., Moreno, P., Kohli, P.: Vision-as-inverse-graphics: Obtaining a rich 3d explanation of a scene from a single image. In: Proceedings of the IEEE International Conference on Computer Vision Workshops. pp. 851–859 (2017)
- [21] Speer, R., Chin, J., Havasi, C.: Conceptnet 5.5: An open multilingual graph of general knowledge. In: Thirty-First AAAI Conference on Artificial Intelligence (2017)
- [22] Su, Z., Zhu, C., Dong, Y., Cai, D., Chen, Y., Li, J.: Learning visual knowledge memory networks for visual question answering. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 7736–7745 (2018)
- [23] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is all you need. In: Advances in neural information processing systems. pp. 5998–6008 (2017)
- [24] Veličković, P., Cucurull, G., Casanova, A., Romero, A., Lio, P., Bengio, Y.: Graph attention networks. arXiv preprint arXiv:1710.10903 (2017)
- [25] Vincent, P., Larochelle, H., Bengio, Y., Manzagol, P.A.: Extracting and composing robust features with denoising autoencoders. In: Proceedings of the 25th international conference on Machine learning. pp. 1096–1103 (2008)
- [26] Wang, T., Huang, J., Zhang, H., Sun, Q.: Visual commonsense r-cnn. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10760–10770 (2020)
- [27] Wang, X., Girshick, R., Gupta, A., He, K.: Non-local neural networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 7794–7803 (2018)
- [28] Wang, X., Ye, Y., Gupta, A.: Zero-shot recognition via semantic embeddings and knowledge graphs. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 6857–6866 (2018)
- [29] Xu, D., Zhu, Y., Choy, C.B., Fei-Fei, L.: Scene graph generation by iterative message passing. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 5410–5419 (2017)
- [30] Yang, J., Lu, J., Lee, S., Batra, D., Parikh, D.: Graph r-cnn for scene graph generation. In: Proceedings of the European conference on computer vision (ECCV). pp. 670–685 (2018)
- [31] Yu, R., Li, A., Morariu, V.I., Davis, L.S.: Visual relationship detection with internal and external linguistic knowledge distillation. In: Proceedings of the IEEE international conference on computer vision. pp. 1974–1982 (2017)
- [32] Zareian, A., Karaman, S., Chang, S.F.: Weakly supervised visual semantic parsing. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3736–3745 (2020)
- [33] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From recognition to cognition: Visual commonsense reasoning. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 6720–6731 (2019)
- [34] Zellers, R., Yatskar, M., Thomson, S., Choi, Y.: Neural motifs: Scene graph parsing with global context. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 5831–5840 (2018)
Supplementary Material
In the following, we provide additional details and analysis that was not included in the main paper due to limited space. We first provide more implementation details, followed by a novel evaluation protocol that reveals insightful statistics about the data and the state of the art performance. We finally provide more qualitative examples to showcase what our commonsense model learns.
Appendix 0.A Implementation Details
We have three training stages: perception, commonsense, and joint fine-tuning. We train the perception model by closely following the implementation details of each method we adopt [29, 34, 2], with the exception that for IMP [29], we use the implementation by Zellers et al. [34], because it performs much better. We separately train the commonsense model (GLAT) once, independent of the perception model, as we described in the main paper. Then we stack GLAT on top of each perception model and perform fine-tuning, without the fusion module. Finally, we add the fusion model for inference.
Our GLAT implementation has 6 layers each with 8 attention heads, each with 300-D representations. We train it with a 30% masking rate on Visual Genome (VG) training scene graphs, using an Adam optimizer with a learning rate of 0.0001, for 100 epochs. To stack the trained GLAT model on top of a perception model, we take the scene graph output of the perception model for a given image, keep the top 100 most confident triplets and remove the rest, and represent each remaining entity and predicate with a one-hot vector that specifies the top-1 predicted class. We intentionally discard the class distribution predicted by the perception model, to let the commonsense model reason independently in an abstract, symbolic space. Perception confidence is later taken into account by our fusion module.
The resulting one-hot graph is represented in the same way as a VG graph, that we have pretrained GLAT on, and is fed into GLAT without masking any node. The GLAT decoder predicts new classes for each node, and new edges, but we ignore the new edges and keep the structure fixed. Hence, the output of GLAT looks like the output of the perception model with the exception that the classification logits of each node are changed. We perform 25 epochs of fine-tuning with 0.00001 learning rate and Adam, using the same entity and predicate loss that is typically used to train SGG models [2].
Appendix 0.B Quantitative Evaluation
| Statistic/Method | Frequency Bins | Average | |||||
|---|---|---|---|---|---|---|---|
| # instances in train data | 1-3 | 4-9 | 10-27 | 28-81 | 82-243 | 243-369 | - |
| # unique triplets in bin | 86247 | 21994 | 4937 | 766 | 89 | 4 | - |
| % unique triplets in bin | 75.6 | 19.3 | 4.3 | 0.7 | 0.1 | 0.00004 | - |
| Total % of test data | 14.7 | 21.0 | 28.0 | 22.5 | 10.6 | 3.1 | - |
| IMP [29] | 13.2 | 23.0 | 34.8 | 45.7 | 58.2 | 78.2 | 36.1 |
| IMP + GLAT | 13.2 | 23.0 | 34.8 | 45.9 | 58.5 | 78.7 | 37.0 |
| IMP + GLAT + Fusion | 13.3 | 23.1 | 35.0 | 46.2 | 58.7 | 79.2 | 37.4 |
| SNM [34] | 15.0 | 24.8 | 36.6 | 48.4 | 58.4 | 74.9 | 37.8 |
| SNM + GLAT | 15.1 | 24.8 | 36.6 | 49.0 | 58.4 | 75.2 | 37.9 |
| SNM + GLAT + Fusion | 15.1 | 24.8 | 36.7 | 49.5 | 58.5 | 75.3 | 38.0 |
| KERN [2] | 16.7 | 26.2 | 37.5 | 48.4 | 59.6 | 77.1 | 38.8 |
| KERN + GLAT | 16.7 | 26.6 | 37.5 | 48.4 | 59.6 | 77.6 | 38.8 |
| KERN + GLAT + Fusion | 16.7 | 26.8 | 37.5 | 48.5 | 59.7 | 78.1 | 38.8 |
Here we revisit the conventional evaluation process in the SGG literature, analyze its limitations, and provide an alternative to use in future work. Xu et al. [29] originally used overall recall (R@50 and R@100), which means for each image, they get the top 50 (or 100) triplets predicted by their model, compare to the ground truth triplets of that image, compute recall (number of matched triplets divided by the number of ground truth triplets), and average over all images. Later Chen et al. [2] revealed that since ground truth triplets in Visual Genome (both in train and test splits) have highly disproportional statistics, overall recall does not necessarily measure the usefulness of the model. In fact, a simple heuristic that always predicts the most frequent relationship for each pair of object classes, based on a fixed lookup table computed over training data (frequency baseline in [34]), performs not much worse than the state of the art of that time, MotifNet [34].
Chen et al. [2] proposed an alternative metric, mean recall (mR@50 and mR@100), in which ground truth triplets are divided into 50 bins, based on their predicate type, the recall is computed for each bin separately, averaged over images, and then averaged over the 50 bins. This way, frequent predicates do not dominate the performance, and simplistic models are not praised for merely picking up bias.
Nevertheless, mean recall does not completely solve the imbalance problem, since even within each bin (predicate type), some compositions are much more common than others. For instance, since VG has a focus on sports, the triplet person holding racket dominates the bin holding, while person holding cellphone has much lower frequency, although intuitively more common in real world. Instead of dividing triplets based on their predicate type, we propose to divide them based on the frequency of each triplet in training data, which highly correlates with the frequency in test data as well. This way, each bin consists of triplets with roughly the same frequency, and no triplet can dominate others. After computing recall for each bin, we also report the average over bins, which can be seen as a triplet-balanced version of mean recall. Using trial and error, we found the best strategy is to divide bins in logarithmic scale, using powers of 3. This way we will not have too few or not too many bins.
Table 4 shows the statistics of each bin in our proposed evaluation setting. Despite the logarithmic scale, we still observe a significant imbalance in the dataset. Specifically, our first bin consists of the rarest triplets, which only appear between 1 and 3 times in training data, and comprise 14.7% of all triplets in the test set of VG, 75.6% if we count each unique triplet only once. The state of the art [2] only achieves 16.7% recall on that significant portion of data, while achieves 77.1% recall on the last bin (4 most frequent triplets, 3.1% of the test set and 0.00004% of unique triplets). This strong disproportion suggests how conventional methods over-invest on few unimportant triplets, at the expense of a large portion of (rare but plausible) real-world situations. Accordingly, we believe our new evaluation metric would encourage further research aiming to close the gap.
Appendix 0.C Qualitative Results

To provide more diverse cases of commonsense learned by our model, Figure 4 shows additional examples of corrections made by our GLAT model to perceived scene graphs. In example (a), the perception model mistakes the giraffe’s head for a dog, but our commonsense model corrects that since head of giraffe makes more sense than dog of giraffe. The fusion module correctly prefers the output of the commonsense model, due to its higher confidence. In (b), the perception model mistakes the train for an engine, possibly due to the abnormal color palette. Our commonsense model corrects that since wheel more likely belongs to a train. In (c), the vase has an unusual shape, and is mistaken for a glass by the perception model, also because it is made of glass, but the commonsense model takes into account the fact that the “glass” is holding a flower, which is what vases do. Moreover, in (d), the pizza is visually on the cardboard, but technically in the box. We, humans, know the latter based on our past experience, and so does the proposed commonsense model.
In example (e), the man is holding the laptop and using it at the same time. The perception model predicts holding because it is a more visual concept, while the commonsense model predicts using which is more a abstract concept, and in fact a more salient and important verb here. In (f), the image is not very clear, and there is no visual distinction between the boy’s body parts and clothing. This makes it hard for the perception model to tell the boy is wearing the pants but has the leg. The commonsense model is robust in such scenarios because it does not rely on the image, but instead considers past experience. Similarly, (g) makes it hard to distinguish man has arm from man wearing shirt, since the bounding box of arm is highly overlapping with shirt, and there is little visual distinction between their content. Hence, commonsense has a crucial role in distinguishing their interactions by abstracting them into symbolic concepts and ignoring their visual features. Finally, (h) is a rare case, where the prediction of the commonsense model is wrong, while perception’s output was already correct. More specifically, we miscorrect leg of bench to leg on bench, because usually things are on benches in real world. This is while for perception, it is obvious that the legs are not positioned on the bench. Interestingly, Our fusion module prefers the perceived output this time, and rejects the change made by the commonsense model.