Learning with Constraint Learning:
New Perspective, Solution Strategy and Various Applications
Abstract
The complexity of learning problems, such as Generative Adversarial Network (GAN) and its variants, multi-task and meta-learning, hyper-parameter learning, and a variety of real-world vision applications, demands a deeper understanding of their underlying coupling mechanisms. Existing approaches often address these problems in isolation, lacking a unified perspective that can reveal commonalities and enable effective solutions. Therefore, in this work, we proposed a new framework, named Learning with Constraint Learning (LwCL), that can holistically examine challenges and provide a unified methodology to tackle all the above-mentioned complex learning and vision problems. Specifically, LwCL is designed as a general hierarchical optimization model that captures the essence of these diverse learning and vision problems. Furthermore, we develop a gradient-response based fast solution strategy to overcome optimization challenges of the LwCL framework. Our proposed framework efficiently addresses a wide range of applications in learning and vision, encompassing three categories and nine different problem types. Extensive experiments on synthetic tasks and real-world applications verify the effectiveness of our approach. The LwCL framework offers a comprehensive solution for tackling complex machine learning and computer vision problems, bridging the gap between theory and practice.
Index Terms:
Learning with Constraint Learning, Hierarchical Optimization, Gradient-Response, Learning and Vision Applications.1 Introduction
In recent years, a plethora of endeavors have emerged to tackle contemporary intricate problems such as GAN and its variants [1, 2], multi-task and meta learning [3, 4], hyper-parameter learning [5, 6], and various challenging real-world vision applications [7, 8]. In contrast to these conventional learning paradigms that solely focus on a single learning objective (e.g., classification and regression), these aforementioned modern complex problems often necessitate the simultaneous handling of multiple interrelated learning tasks. For instance, the well-known generative adversarial networks often require discriminatorassisted branches in the process of adversarial game [9, 10]. Similarly, multi-task and meta learning introduce task-specific classifiers as supportive sub-tasks to facilitate the acquisition of enhanced generalization representations of meta-features [11, 12]. Hyper-parameter learning involves the construction of simple classifiers as interconnected tasks, aiding the base model in attaining optimal hyper-parameters [13, 14]. Despite the presence of diverse motivations and mechanisms, all these issues encounter the challenge of simultaneously addressing multiple interrelated tasks with coupled structures. This hierarchical coupling induces complexity in the learning process and constitutes the fundamental factor exacerbating the difficulties encountered in problem-solving.
While considerable advancements have been achieved, the present state-of-the-art techniques employed to tackle these modern complex problems still encounter numerous challenges. On the one hand, certain approaches, which typically involve constructing task-specific methodologies tailored to specific scenarios, heavily rely on extensive models and datasets. Often, these task-specific methods exhibit limited transferability to other tasks, resulting in subpar generalization capabilities. On the other hand, accurately characterizing the coupling relationships between the primary task and multiple related learning tasks proves challenging due to the empirical and trial-and-error nature of most learning strategy designs. For instance, simplistic alternating iterative learning strategies that optimize one aspect while keeping another fixed overlook the potential coupling constraints and dynamic game states among the multiple interdependent tasks. Therefore, it becomes imperative to integrate diverse modeling approaches into a unified framework and explore the inherent connections among multiple tasks.
In the following, this paper endeavors to establish a unified and coherent optimization perspective that explores the intrinsic relationships of these modern complex problems, considering their potential coupling. Termed as Learning with Constraint Learning (LwCL) in this paper, this perspective offers a comprehensive framework for understanding and formulating these problems. Essentially, the LwCL problem can be formulated as follows:
Problem 1.
Learning with Constraint Learning (LwCL) represents an innovative learning mechanism, distinguished by a hierarchical arrangement of two interconnected learning tasks. Within LwCL, the fulfillment of the primary objective task (referred to as the Objective Learner or OL) relies upon the successful completion of a lower-level learning task (referred to as the Constraint Learner or CL)111The detailed concepts and applications of this framework will be presented in Sections 3 and 4, respectively.. This hierarchical structure endows the learning process with added depth, as the CL acts as a constraint that must be satisfied, effectively guiding and shaping the optimization process towards the attainment of the overarching objective. Through this nested hierarchy, LwCL enhances the learning process, fostering a more structured and directed approach to achieving the desired learning outcome.
In essence, LwCL embodies a nested hierarchy of learning tasks, where each subtask contributes to the accomplishment of the overarching objective. This intricate nested framework adds complexity to the learning process and requires a more sophisticated approach to problem-solving. It can be challenging because the optimization process must balance the competing objectives of completing the subtasks at each layer while also optimizing the overall objective of the entire system. Nevertheless, by leveraging the hierarchical structure of the problem, LwCL can improve performance on complex tasks and enable efficient transfer learning.
Based on the above analysis, the primary objective of this paper is to present a unified perspective, termed LwCL, which aims to reinterpret and elucidate the underlying mechanisms of modern complex problems. Building upon this foundation, we have developed a generic hierarchical optimization framework, encompassing reformulation and algorithmic components, to unveil the potential coupling constraints among multiple tasks. Additionally, leveraging the concept of dynamic best response, we have employed an outer-product-based Hessian approximation technique to devise a rapid solving strategy from the standpoint of implicit gradients. This approach enables accurate tracing of the gradient feedback dynamics between the OL and the CL, thereby yielding unprecedented advancements in training stability and performance. Importantly, our proposed method exhibits remarkable flexibility and adaptability, as it can be seamlessly integrated into a diverse range of contemporary complex learning problems, owing to the inherent tolerance of the constraint learning paradigm towards the requirements of the objective function. We also demonstrate that our proposed framework can efficiently address a wide range of LwCL applications in the fields of learning and vision, including three categories of problems, with a total of nine different types.
Our contributions can be summarized as follows:
-
•
From a comprehensive and in-depth point of view, we introduce a unified perspective, termed as Learning with Constraint Learning (LwCL), to analyze, reformulate, and address a wide array of complex learning problems that exhibit underlying coupled relationships in the domains of machine learning and computer vision.
-
•
We propose a hierarchical optimization framework that effectively formulates the potential dependencies and uncovers the inherent coupling among multiple tasks within LwCLs. This framework facilitates precise optimization of the two learning tasks through a synergistic and interactive approach, incorporating the proposed gradient-response feedback.
-
•
To alleviate high computational complexity issues associated with naive learning strategy, we design an implicit gradient scheme with outer-product Hessian approximation as fast solution strategy to efficiently solve the nested optimization process, which is more computation-friendly and suitable for diverse high-dimensional large-scale real-world applications.
-
•
We demonstrate that LwCL can efficiently address a wide range of modern complex learning and vision applications, including three categories of problems, with a total of nine different types. The versatility and effectiveness of our proposed LwCL framework is verified through extensive experiments on both synthetic tasks and real-world applications.
2 Review of Related Works within LwCL
Based on Problem 1, we now proceed to comprehensively understand and (re)formulate existing modern works from the unified perspective of LwCL. Specifically, we categorize these works into three classes, including Adversarial Learning (AL), Auxiliary with Related Tasks (ART), and Task Divide and Conquer (TDC), utilizing the lens of LwCL.
AL-type Applications. As one of the most popular LwCTs, AL-based methods exhibit a strong ability to model specific data distribution by addressing the assisted discriminative tasks via a dynamic adversarial game. OL and CL can be regarded as generator learning and discriminator learning, respectively. For example, vanilla GAN [1], as a discriminator-assisted learning problem, can be interpreted as a dynamic adversarial game that greedily finds the solution of the minmax formula through an alternating iterative strategy. Metz et al. [15] proposed the idea that gradients can be back-propagated through the unrolled optimization procedure in a differentiable way to address the challenges of unstable optimization. Accordingly, various variants of loss types and regulation (i.e., second-order gradient loss [15], Hinge loss [16], and Lipschitz penalty [17]) also appear in the optimization objectives of GAN-variants. Nonetheless, these methods still suffer from poor generation quality, training oscillations, and other challenges that have not been fully addressed. In addition to the narrowly defined GANs and their variants, a series of adversarial vision tasks in cutting-edge areas, such as image generation [9, 18, 19, 20], style transfer [10, 21] and imitation learning [22, 23] have risen in recent years. These problems employ different task-specific losses and strategies to mitigate the reconstruction discrepancy between different image domains in training process. For example, Zhu et al. [24] constructed bi-directional cycle generative-discriminative architecture and cycle consistency loss to complete cross-domain style transfer. In reinforcement learning, Pfau et al. [25] treated the discriminator as a regression task providing scalar values rather than a binary classifier and opened up new avenues of research by treating adversarial learning programs as an actor-critic problem. Despite the good intentions of these approaches, existing AL-based strategies still suffer from several major challenges, such as training instability, oscillations and mode collapse. The underlying reason is the inability of learning mechanisms that rely on alternating iterations to accurately portray the intrinsically complex dynamics between the considered task and the introduced adversarial task. Therefore, we proceed to present new mathematical tools to model and solve such AL-type problems.
ART-type Applications. In recent decades, a category of typical learning tasks towards sophisticated applications have addressed considered learning tasks with related auxiliary learning devices, named auxiliary with related tasks, such as medical image analysis (i.e., medical image registration and segmentation [26, 27, 28, 29] and low-light image enhancement [30, 31]) and hyper-parameter learning [5, 32, 13, 14, 33]. OL and CL can be regarded as objective learning task and auxiliary learning task, respectively. For example, in the spirit that medical image registration can provide more label information for one-shot image segmentation, Xu et al. [7] developed a joint model for simultaneous image registration and segmentation. For low-light scenes, Xue et al. [31] proposed to introduce additional detection and segmentation models to assist the low-light enhancement task. Actually, these approaches often generally rely on naive empirical strategies (i,e., alternate learning) to solve the problem and often suffer from disadvantages such as low training efficiency, low performance, and poor generalization. Similarly, in order to assist the base model for obtaining optimal hyper-parameters, hyper-parameter learning usually introduces simple classifiers that contain only a few fully connected layers as auxiliary tasks, with first-order gradient based algorithms [5, 32]. However, such methods possess a high algorithmic complexity and are usually limited to low-dimensional data scenarios. Overall, an in-depth exploration focusing on how to uniformly and efficiently formulate and address these ART-type tasks is essential and necessary.
TDC-type Applications. There is another class of learning task construction ideas, i.e., dividing a complete learning process into multiple subtask learning processes, called task divide and conquer, with typical applications such as image deblur [8, 34] and multi-task meta learning [11, 3, 11, 4, 35, 6]. OL and CL can be regarded as meta-feature/prior learning and task-specific classifier/fidelity learning, respectively. For example, meta-feature learning methods [3, 4] generally separated the network structure into meta-feature extraction modules and task-specific modules. The latter guides better learning of generalization representations of meta-features by constructing losses for multiple different tasks. Admittedly, the above methods are usually confined to small-scale, low-dimensional simulation scenarios, and still suffer from various unsolved challenges such as training instability and computational inefficiency for real-world high-dimensional applications. For image deblur task, Zhang et al. [36] proposed semi-quadratic split-based deep unrolling method to enhance deblurred images, divided into the fidelity learning and a prior learning subproblems. Among them, the prior learning task introduce a plug-and-play denoiser. Unfortunately, the fixed pre-trained denoiser, lacks generalization applicability to various complex scenarios. In the subsequent sections, we will develop a deeper understanding, modeling and solving such TDC-type problems from the LwCL perspective.
 |
3 Learning with Constraint Learning
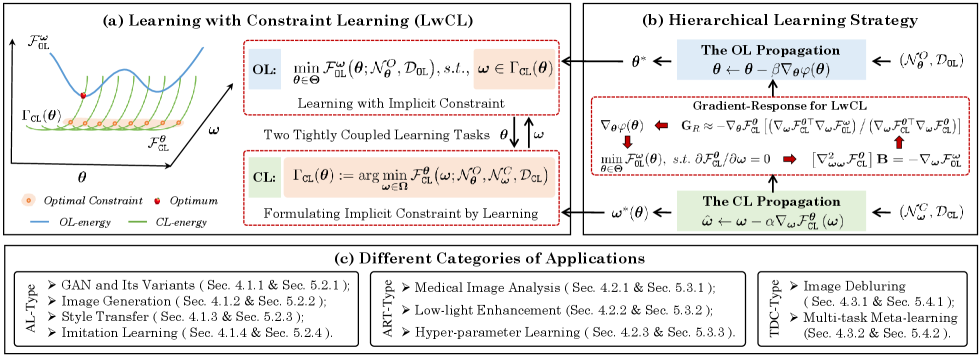
In this section, we endeavor to establish a comprehensive hierarchical optimization framework and a dynamic best response-based fast solution strategy that enable a unified formulation and resolution of various types of LwCL problems. The overall framework is depicted in Fig. 1. In (a), we introduce a novel perspective to comprehensively investigate and address contemporary complex problems (i.e., AL, ART and TDC) in a unified manner. To effectively handle the nested optimization process, (b) illustrates a comprehensive hierarchical optimization framework that aims to redefine and reformulate LwCLs, and proposes a specially designed gradient-response solution strategy tailored specifically for LwCL (as denoted by the dashed rectangle). Finally, (c) provides a comprehensive enumeration of nine major problem categories across three broad application areas that our method can effectively tackle.
3.1 Hierarchical Optimization Formulation for LwCL
Our investigation is centered around contemporary and intricate LwCL problems, as delineated in Problem 1. Specifically, we regard that the essence of LwCL lies in the construction of an OL, denoted as with parameterization , which aims to optimize the performance of the desired objective learning task, such as generator learning or meta-feature learning. This endeavor can be expressed as an optimization problem with respect to , whereby the OL energy encapsulates the optimization objective base on the OL dataset .
Given the inherent complexities in directly solving the OL, it is customary to introduce multiple interrelated learning tasks in the form of auxiliary CL, denoted as with parameterization , to assist the overarching objective of OL. To elucidate the aforementioned notion, we generally introduce the more abstract formulation of energy-constrained learning, which is expressed as
| (1) |
where denotes the optimal constraint with respect to . Due to the tight coupling and potential dependency between the two variables, combined with the difficulty in accurately determining , the aforementioned problem in Eq. (1) becomes extremely complex.
Given this, we introduce a learning modeling approach with constraints that characterizes the optimization process concerning the variable . This auxiliary learning task can likewise be framed as an optimization problem, wherein the CL energy characterizes the performance of CL with variable , formulated as
| (2) |
By combining Eqs. (1) and (2), we observe that, the intrinsic hierarchical relationship between the two learners (i.e., and ) is explicitly encoded by the task-specific energy functions (i.e., and )222The detailed design of and in specific applications will be presented in Section 4.. Furthermore, it is worth noting that the energy functions are continuous, while the set represents a nonempty feasible region, and denotes the feasible set for the variables. In this context, we refer to and as the outer-level (or OL-level) variables and and as the outer-level (or OL-level) energy and inner-level (or CL-level) energy, respectively. Building upon the principles of Stackelberg game theory [37], we strive to present a robust hierarchical optimization framework, serving as a novel mathematical instrument to explicitly inscribe the coupling dependencies of two key players.
Inherently, a notable asymmetry is observed between the two levels of learning tasks, where assumes the role of a constraint upon , facilitating the derivation of optimal feedback to be passed onto the core optimization objective. This dynamic constrained learning process entails a high degree of interdependence between the variables and , such that every incremental update of is inevitably influenced by the state of . Notably, this framework can also be interpreted as a more encompassing bilevel optimization problem. To address practical applications in high-dimensional real-world scenarios, we proceed to propose a rapid and efficient solution strategy characterized by dynamic best response.
3.2 Solution Strategy with Gradient-Response
Commencing from the dynamic gradient-response, we further define the value-function , leading us to the minimization problem, Progressing further, the key to resolving this problem lies in computing the gradient of the OL optimization objective:
| (3) |
Notably, the direct gradient term showcases a straightforward reliance on the OL variable and can be readily obtained through simple computations in practice. Conversely, the second gradient term, denoted as poses challenges in its calculation due to the varying rate of with respect to . Nonetheless, accurately captures the best response gradient (in connection with and ) between the two learning tasks and assumes a pivotal role in optimizing LwCLs. Essentially, equipped with Eq. (3), the gradient of can be dynamically and accurately back-propagated to at each iteration, effectively aiding in the optimization of its parameters.
Undoubtedly, evaluating the exact best response gradient of Eq. (3) poses significant computational challenges for most existing strategies, particularly when the dimensions of and are high. To address this challenge, we leverage implicit methods, which offer a direct and precise estimation of the optimal gradient. Inspired by the implicit function theorem, we derive the following equation based on the best response gradient, i.e., . In contrast to the solution strategy, the best response gradient is then substituted with an implicit equation, wherein is derived as:
| (4) |
Considering the formidable challenges associated with computing the Hessian and its inverse, we propose a fast solution strategy by simplifying the second derivative to the first derivative, enabling the calculation of the best response Jacobian. This strategy involves two key computational steps: implicit gradient estimation and outer-product approximation.
Implicit Gradient Estimation. To circumvent the direct calculation of multiple Hessian products and their inversions, we introduce a linear solver system based on Eq. (4), allowing us to avoid the complexity associated with computing . Consequently, the indirect response gradient can be reformulated as:
| (5) |
where denotes the transposition operation. Through this formulation, is solely dependent on the first-order condition, effectively decoupling the computational burden from the solution trajectory of the constrained sub-task. This decoupling greatly alleviates the pressure of propagating the backward gradient in the constrained dynamics.
However, it is worth noting that the calculation of second-order derivatives in remains intractable. The pressing need to approximate the repeated computation of two Hessian matrices, and , has led to the emergence of the concept of outer-product approximation.
Outer-Product Approximation. To further suppress the complexity of constrained optimization, we consider replacing the original Hessian operation with the Gauss-Newton strategy and introduce two corresponding outer products, as follows:
| (6) |
By separating the gradient, this approach converts the highly complex second-order derivative into a simple product operation involving the first-order derivative, which significantly reduces the algorithm’s complexity, especially in terms of memory consumption. By combining Eqs. (5)-(6), we establish the nonlinear least squares problem by approximating the Gauss-Newton formula. Plugging into the Eq. (5), thus we can obtain
| (7) |
To over simplify, we can express with as follows where Ultimately, we obtain an approximate representation of the response gradient as follows:
| (8) |
Drawing upon the aforementioned derivations, we can succinctly outline the comprehensive solution strategy as Algorithm 1. During the training phase, given the current parameter set , we initiate the optimization of based on the objective function , iteratively refining it to approximate the dynamic best response, denoted as . Subsequently, we propagate the updated to , where we calculate the response gradient utilizing our proposed implicit gradient strategy (i.e., Eq. (8)). This computed gradient, in turn, facilitates the iterative update of until convergence is attained.
3.3 Discussion
By fundamentally elucidating the underlying coupling relationships among multiple learning tasks in complex problems, our methodology provides a comprehensive understanding of their intricate interplay. Moreover, the proposed dynamic best response based solution strategy not only showcases scalability, adaptability, and generalizability but also empowers its application across a broad spectrum of large-scale, high-dimensional real-world scenarios.
Unveiling the Intrinsic Coupling Relationships for Complex Learning Problems. Traditional approaches in the past have often relied on task-specific methodologies, limiting their generalization capabilities and hindering their transferability to different tasks. Moreover, accurately capturing the interdependencies between multiple related learning tasks has proven challenging due to the empirical nature of designing learning strategies. Hence, the need for a unified framework arises, one that can reconcile diverse modeling approaches and explore the inherent connections among these tasks. The LwCL framework tackles these challenges by explicitly considering the nested structure of learning tasks. Its hierarchical optimization framework provides a profound understanding of the potential coupling relationships among tasks, allowing for accurate characterization. Additionally, the framework offers flexibility in integrating various task constraints, rendering it suitable for addressing a wide array of complex learning problems. By leveraging the hierarchical structure, the LwCL framework not only enhances performance on intricate tasks but also enables efficient transfer learning across different domains.
Implicitly-derived Fast and Efficient Solution Strategy. Indeed, the most straightforward idea towards real-world vision applications is to employ alternating iterative algorithms, where one component is fixed while the other is optimized. While the alternating iterative mechanism exhibits sound design principles, it often leads to a fragmentation between the two learning tasks in practical implementations. Specifically, in Eq (3), conventional alternating methods directly overlook the computation of the coupling term , thereby disregarding the gradient feedback from CL to OL during the back-propagated process. In contrast, our proposed method addresses this limitation by emphasizing the collaborative synergy between the CL and OL, which is unattainable in traditional alternating approaches. Our proposed solution strategy accurately computes the optimal gradient-response during each iteration of the back-propagation, ensuring a more stable and expeditious convergence in the learning process. In addition to the aforementioned intuitive solutions, the development of bilevel optimization methods capable of performing gradient-based explicit and implicit algorithms through automatic differentiation holds significance [38]. Nevertheless, classical first-order gradient-based algorithms typically suffer from high complexity and low operational efficiency due to the computation of the recursive or Hessian gradient for , rendering them impractical for high-dimensional complex real-world scenarios.
We would like to emphasize that our proposed fast solution strategy accurately computes the gradient-response . Furthermore, it exhibits significant superiority over state-of-the-art gradient-based bilevel optimization methods, particularly in terms of convergence speed and computational complexity. In regards to computational complexity, Alg. 1 circumvents the need for unfolded recurrent iterations or Hessian inversions for , thereby avoiding any computations involving Hessian- or Jacobian-vector products. The complexity of our strategy primarily stems from computing the first-order gradient. Considering that the calculation of the function’s first derivative and the Hessian-vector product share similar time and space complexity, our proposed approximate method simplifies the process of computing the gradient-response to evaluating the first-order derivative a few fixed times. In the subsequent experimental section, we undertake a comprehensive set of numerical and real experiments to compare various traditional gradient-based bilevel optimization methods and our fast solution strategy. Through these experiments, we aim to substantiate the exceptional performance of our strategy, specifically in terms of convergence speed and memory utilization. More details on the comparative mechanisms can be found in Sec. 5.
4 Applications of LwCL
In this section,we provide an elaborate discussion on the versatility of our proposed framework as a general methodology, which can be seamlessly applied to a diverse array of LwCL applications, spanning domains such as AL, ART and TDC within the realms of vision and learning. By applying our framework to these diverse applications, we aim to demonstrate its broad applicability and effectiveness across different domains and tasks.
4.1 AL-type Applications
In the realm of AL-type LwCL applications, our focus lies on the introduction various discriminator learning tasks to assist with the generator learning tasks . We emphasize that CL entails the incorporation of discriminators (potentially multiple), classifiers, and critics, each equipped with specialized architectures designed to address diverse applications within the realms of vision and learning. As for the constraint energy function , its fundamental concept lies in establishing the relationship between the output distribution of and the distribution of the desired solution for . In the subsequent discussion, we primarily delve into four prominent categories of representative applications, namely vanilla GAN, image generation, style transfer and imitation learning, which serve as exemplars to showcase the versatility of our framework and its efficacy in these domains.
4.1.1 GAN and Its Variants
Formally, the learning process of GAN can be conceptualized as the minimization of a distance metric, denoted as , between the generated distribution and the data distribution , represented as Under the standard definition, vanilla GAN dynamics advocate the incorporation of an auxiliary discriminator to facilitate the training of the generator through an alternating learning strategy, seeking to minimize the divergence in the objective . In essence, as the most representative instance of LwCL, it can be formulated as a dynamically coupled game process, expressed as
By employing an alternating direction iteration strategy, the original learning strategy establishes two gradient flows using gradient descent: and This leads to two independent optimization branches for and that proceed in parallel. However, the optimization of the generator depends on the discriminator’s parameters from the previous step, rather than the current step. This inaccurate approximation fails to capture the coupled best response gradient term depicted in Eq. (3). In contrast, our LwCL framework accurately formulates and characterizes the potential dependency of on the current . Consequently, the optimization of the discriminator can be described by an exact estimated dynamic best response, which is then dynamically back-propagated to the optimization process for the generator dynamics. In light of these considerations, our proposed framework fundamentally circumvents the occurrence of training instabilities and mitigates mode collapse issues. To validate its effectiveness in addressing these challenges, we conduct a comprehensive set of experiments in Sec. 5, which showcase the results of these experiments and provide compelling support for the effectiveness of our framework.
4.1.2 Image Generation
Image generation aims to generate intricate and diverse images from compact seed inputs. Existing research focuses on developing diverse generative models, but they often encounter challenges during model training and require manual tuning techniques to mitigate mode collapse issues. With the versatility of our proposed framework, we apply our learning strategy to state-of-the-art generative model architectures. Specifically, we introduce different constrained objectives, referred to as CL energy functions , such as binary cross-entropy loss, least squares loss and 1-Lipschitz limit-loss with spectral norm. These objectives correspond to discriminators with different network structures. Remarkably, our LwCL framework seamlessly integrates into various advanced GAN variants without necessitating architectural modifications or loss selection changes, thereby consistently enhancing performance. In Sec. 5, we present comprehensive experimental results to demonstrate the effectiveness and efficiency of our LwCL framework. These results showcase more stable training performance and improved generalization capabilities, substantiating the practical benefits of our approach.
4.1.3 Style Transfer
Style transfer aims to impose style constraints by optimizing the adversarial loss between two distinct datasets, while ensuring content preservation through reverse transformations. Drawing inspiration from the circular generative adversarial architecture proposed in Zhu et al. [10], we establish a bidirectional adversarial learning framework to guide the style transfer task. Specifically, by creating a cyclic mapping between two domains, denoted as and , we introduce two generators, namely and , along with two discriminators, denoted as and . To capture the complexity of unsupervised learning, we design two components for our loss functions: the least squares loss and cycle consistency loss , which account for the original input and the output after inverse transformation. Within our LwCL framework, we define the objective learner and the constraint learner as the two generators with parameters and the two discriminative classifiers with parameters , respectively. The OL and CL objectives can then be expressed as . More details on the setup of the forward and backward cyclic consistency functions can be found in the experimental section.
4.1.4 Imitation Learning
Imitation learning endeavors to achieve optimal decision-making by interacting with the environment and acquiring knowledge from experiences. The objective of imitation learning is to simultaneously learn a state-action value function, denoted as , which predicts the expected discounted cumulative reward, and an optimal policy that aligns with the value function. Formally, we have: where and denote dynamics of the environment and reward function, respectively. Here, and are the state and action, and refer to the i-th and j-th steps in the learning process. Within our LwCL paradigm, the actor and critic correspond to the objective learner and constraint learner , respectively. Let denote the parameters of the state-action value-function and denote the parameters of the policy . The expressions for and are given by: and where represents any divergence and . For specific settings of the state-action value function, please refer to the experimental section.
4.2 ART-type Applications
As mentioned previously, ART-type LwCL tasks solving sophisticated applications have introduced related tasks as auxiliary CL devices to augment the considered OL tasks. In the subsequent subsections, we delve into three specific applications that leverage auxiliary task constraints: medical image analysis, low-light image enhancement and hyper-parameter learning.
4.2.1 Medical Image Analysis
Medical image analysis involves the extraction of anatomical structures or lesions from medical images. Drawing inspiration from the concept that learning registration can provide additional pseudo-labeled training data to assist segmentation [26], we leverage our LwCL framework to dynamically address inter-task dependencies. In our framework, the registration process serves as the objective learner , while the segmentation process acts as the constraint learner . Building upon a base model [7], we incorporate a semantic consistency constraint into the segmentation task. Under our LwCL framework, the OL procedures for the registration task can be formulated as , where represents the registration network with learnable parameters , and and denote the moving image and fixed image, respectively. Subsequently, by obtaining the warped image , the CL procedures for the segmentation task can be formulated as , where represents the segmentation network with learnable parameters . Please refer to the experimental section in Sec. 6 for specific details on the settings of the loss functions.
4.2.2 Low-light Image Enhancement
Low-light image enhancement aims to reveal hidden information in dark areas to improve overall image quality. Drawing on the principles of the Retinex theory, we delve into the impact of downstream perceptual tasks, such as object detection, on the performance of upstream enhancement tasks. Guided by this concept, we construct a low-light enhancement network, inspired by recent advancements [39], as our objective learner . Furthermore, we introduce a face detector proposed by [40] as an auxiliary constraint learner . Within our LwCL framework, we employ the unsupervised illumination learning loss as the OL function. Here, and represent the pixel fidelity term and smoothness term, respectively, which evaluate the performance of the upstream enhancement task. For the energy function of the constraint learner, we introduce the anchor-based multi-task loss and progressive anchor loss to assess the detection performance, defined as: . Detailed configurations of the training loss and hyper-parameters can be found in the experimental Sec. 6.
4.2.3 Hyper-parameter Learning
Hyper-parameter learning aims to determine the optimal configuration of hyper-parameters for a given machine learning task. Hyper-parameters are parameters that remain fixed during the training process of a machine learning model. In essence, the goal of hyper-parameter learning is to find a set of hyper-parameters that minimizes the loss or maximizes the accuracy of the objective learning task. Mathematically, it can be expressed as , where represents the objective function, denotes the learning algorithm applied to the hyper-parameters , and the model is trained on the training dataset and validated on the validation dataset . Within our LwCL framework, the objective learner aims to minimize the loss on the validation set with respect to the hyper-parameters , which include parameters such as learning rate, batch size, optimizer, and loss weights. On the other hand, the constraint learner is responsible for generating a learning algorithm by minimizing the training loss with respect to the model parameters , which encompass weights and biases.
4.3 TDC-type Applications
As mentioned previously, TDC-type LwCL tasks, inspired by the concept of “divide and conquer” aim to analyze and formulate the coupling relationship. This approach involves decomposing the overall learning task into two distinct components: the objective learner and the constraint learner . In the subsequent sections, we delve into the practical implementations of two notable application types, namely image deblurring and multi-task meta-learning learning and These applications serve as representative examples to showcase the efficacy and versatility of the the LwCL paradigm in addressing diverse learning challenges.
 |
 |
| Metric | ADI | RHG | BDA | CG | NS | Ours | |
| T | N/C | 0.984 | 1.126 | 5.292 | 0.492 | 0.150 | |
| M | 9.961 | 10.552 | 2.032 | 1.983 | 0.065 | ||
| T | N/C | 18.829 | 18.688 | 92.420 | 9.286 | 1.428 | |
| M | 98.552 | 98.823 | 20.076 | 19.585 | 0.552 | ||
| T | N/C | 330.795 | 325.92 | 1957.161 | 193.13 | 14.346 | |
| M | 1004.681 | 1012.842 | 200.560 | 195.642 | 5.310 | ||
| T | N/C | N/A | N/A | N/A | N/A | 144.425 | |
| M | 53.030 |
4.3.1 Image Deblurring
Image deblurring aims to recover a latent clear image u from a blurred counterpart b. The physical model governing this process is represented by , where K, n, and denote the blur kernel, additional noise, and the two-dimensional convolution operator, respectively. Typically, image deblurring entails two main tasks: deconvolution, involving the estimation of sharp images from blurred observations, and denoising. Drawing inspiration from the plug-and-play framework, which leverages semi-quadratic splitting, the deblurring problem is decomposed into alternating iterations of two sub-problems concerning u and an auxiliary variable z. Within our LwCL framework, we define the constraint learner as the fidelity learning sub-problem, addressing u and z. This can be formulated as where represents a penalty parameter, and W denotes the wavelet transform matrix. The objective learner can be viewed as the prior learning process, governed by a denoiser , with regard to the variable . Mathematically, it can be expressed as . For further details on the parameter configurations, please refer to Sec. 6.
4.3.2 Multi-task Meta-learning
Multi-task meta-learning represents a formidable challenge that revolves around swiftly adapting to novel tasks with limited examples. Among these tasks, meta-feature learning stands out as a prominent representative of multi-task and meta-learning, with the objective of acquiring a shared meta feature representation that encompasses all tasks. This is achieved by bifurcating the network architecture into two distinct components: the meta feature extraction part, responsible for generating the cross-task intermediate representation layers (parameterized by ), and the task-specific part, characterized by the multinomial logistic regression layer (parameterized by ). This framework allows for building accurate machine learning models utilizing a smaller training dataset, especially in the context of few-shot classification tasks, which are widely recognized in the field. Within the LwCL framework we propose, the intermediate representation layers that produce the meta-features can be viewed as the objective learner for multiple task-specific assignments. Consequently, we optimize the performance of these meta-features using the validation set through the defined loss function . Additionally, the forward propagation of the classification layers at the network’s end serves as the constraint learner , wherein the training set loss is utilized to guide the learning process.
5 Experimental Results
In this section, we first evaluate the learning mechanism of our proposed framework through a meticulous examination of numerical examples. This comprehensive evaluation will facilitate a profound understanding of the framework’s underlying principles and intricacies of its learning processes. Subsequently, we proceed to conduct a series of rigorous and extensive experiments, aimed at meticulously scrutinizing the efficacy and viability of our proposed framework across a diverse array of learning paradigms and visual applications. All of these experiments are carried out on a high-performance computing system comprising an Intel Core i7-7700 CPU operating at a frequency of 3.6 GHz, 32GB of RAM, and an NVIDIA GeForce RTX 2060 GPU with 6GB of dedicated memory.
5.1 Mechanism Evaluation
First and foremost, we commence by assessing the convergence performance and computational complexity of our proposed algorithm on a numerical example. Specifically, we introduce a challenging toy example [41] wherein the CL problem is formulated as a non-convex optimization task:
| (9) | ||||
where denotes the -th component of , and denote adjustable parameters. For this particular numerical example, we set and . The optimal solution for this numerical example is as follows
where and the optimal value is . To evaluate the convergence properties and computational complexity, we conducted two sets of experiments: one in low-dimensional simple scenarios with , and the other in high-dimensional scenarios with larger values of .
 |
 |
| CIFAR10 | |
 |
 |
| CIFAR100 | |
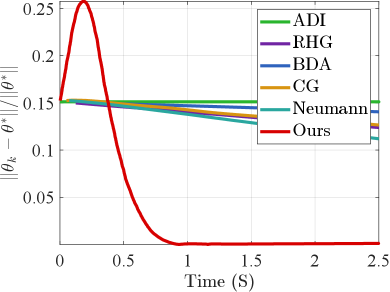
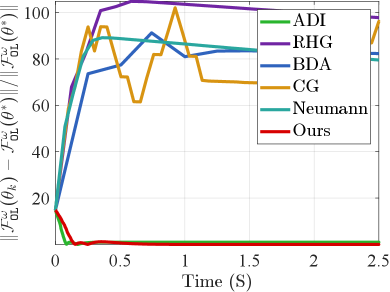
In the case of one dimension, we initialize the point at and the optimal solution is . Fig. 2 compares the convergence curves of and among series of mainstream bilevel optimization strategies, including Alternating Direction Iteration (ADI), CG [13], Neumann [14], RHG [5], and BDA [33]. It can be observed that these methods either deviate from the optimal solution throughout the iteration process or fail to achieve fast convergence. In contrast, our proposed LwCL algorithm converges to the optimal solution more rapidly, showcasing its superiority. To assess computational efficiency, we compare the time and space complexity between our algorithm and current mainstream algorithms in high-dimensional data scenarios. As depicted in Tab. I, due to the non-convex nature of the inner constrained objective function, ADI fails to converge in high-dimensional scenarios. Implicit gradient methods such as CG and Neumann exhibit lower computational complexity compared to explicit gradient methods like RHG and BDA, as they efficiently avoid the computationally expensive Hessian inverse. Conversely, our LwCL strategy surpasses these algorithms in terms of time consumption and memory footprint. When the dimension of the variable reaches , all algorithms except ours lead to a sharp increase in time and memory complexity, potentially resulting in crashes.
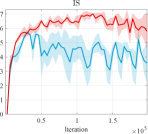
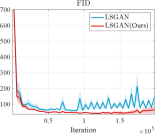
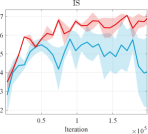
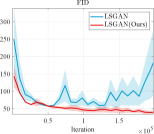
Furthermore, we conducted experiments on real-world datasets to validate the superiority of our learning strategy. We employed the LSGAN [42] as the foundational network architecture to validate the stability of our learning mechanism. Fig. 3 reports the score comparison of FID and JS in each training iteration of LSGAN on the CIFAR10 [43] and CIFAR100 [44]. The results clearly demonstrate that when combined with our LwCL framework, LSGAN exhibits enhanced training stability and achieves superior FID and Inception Score (IS) performance compared to directly applying alternating learning strategies.
| Target | VGAN | WGAN | ProxGAN | LCGAN | NAL |
|
|
|||||
 |
 |
 |
 |
LwCL | |
 |
 |
 |
 |
||
| 2D Ring | |||||
| Target | VGAN | WGAN | ProxGAN | LCGAN | NAL |
| |
|||||
| LwCL | |||||
| 3D Cube | |||||
| Method | LwCL | 2D Ring (max mode=8) | 2D Random (max mode=10) | ||||
| FID | JS | Mode | FID | JS | Mode | ||
| VGAN | ✗ | 193.2065.30 | 0.630.12 | 3.501.00 | 77.5871.49 | 8.740.02 | 3.750.71 |
| ✓ | 34.1610.23 | 0.400.16 | 7.501.00 | 23.2910.63 | 3.410.07 | 7.750.96 | |
| LCGAN | ✗ | 15.0115.30 | 0.630.12 | 3.501.00 | 77.5811.49 | 0.710.02 | 2.000 |
| ✓ | 1.191.23 | 0.400.16 | 7.501.00 | 23.290.63 | 0.330.07 | 7.500.71 | |
| WGAN | ✗ | 0.420.21 | 0.650.13 | 6.251.53 | 97.980.10 | 0.750 | 1.731.63 |
| ✓ | 0.160.09 | 0.270.25 | 7.000.82 | 97.301.49 | 0.700.06 | 7.330.81 | |
| ProxGAN | ✗ | 15.0115.30 | 0.630.12 | 3.501.00 | 74.058.77 | 0.750.17 | 3.501.91 |
| ✓ | 8.8217.25 | 0.580.26 | 6.503.00 | 20.4411.28 | 0.360.01 | 7.500.71 | |
| Method | LwCL | 2D Grid (max mode=25) | 3D Cube (max mode=27) | ||||
| FID | JS | Mode | FID | JS | Mode | ||
| VGAN | ✗ | 10.14 1.36 | 0.790.24 | 12.501.00 | 12.2826.10 | 0.480.08 | 8.501.00 |
| ✓ | 0.810.24 | 0.620.13 | 18.51.00 | 0.5280.16 | 0.610.30 | 23.001.40 | |
| LCGAN | ✗ | 50.7347.08 | 0.640.21 | 11.508.1 | 68.8060.85 | 0.870.17 | 6.003.16 |
| ✓ | 0.420.13 | 0.620.27 | 17.257.27 | 30.545.81 | 0.700.30 | 17.3314.15 | |
| WGAN | ✗ | 171.3177.46 | 0.890.29 | 5.001.30 | 12.000.90 | 0.620.07 | 15.000.41 |
| ✓ | 15.911.43 | 0.680.14 | 18.500.58 | 0.800.20 | 0.210.03 | 24.000.51 | |
| ProxGAN | ✗ | 38.2947.08 | 0.670.21 | 11.58.10 | 111.6463.96 | 0.850.03 | 3.672.89 |
| ✓ | 0.460.24 | 0.600.23 | 18.257.63 | 52.1086.98 | 0.690.30 | 17.6714.47 | |
 |
 |
| StyleGAN | |
 |
 |
| Ours | |
5.2 AL-type Applications
In the subsequent analysis, we explore four distinct applications, namely GAN and its variants, image generation, style transfer, and imitation learning, in order to validate the efficacy and versatility of our methodology. Importantly, we showcase that despite their diverse motivations and formulations, a wide range of AL-type LwCL applications, ALL can be uniformly improved by our flexible methodology.
| Method | LwCL | CIFAR10 | CIFAR100 | ||
| IS | FID | IS | FID | ||
| DCGAN | ✗ | 6.63 | 49.03 | 6.56 | 57.37 |
| ✓ | 7.06 | 42.23 | 6.87 | 44.18 | |
| LSGAN | ✗ | 5.57 | 66.68 | 3.81 | 145.54 |
| ✓ | 7.54 | 32.50 | 7.30 | 35.72 | |
| SNGAN | ✗ | 7.48 | 26.51 | 7.99 | 25.33 |
| ✓ | 7.58 | 22.81 | 8.27 | 21.37 | |
 |
| Target |
 |
| CycleGAN |
 |
| Ours |
| Epoch 20 | Epoch 40 | Epoch 60 | Epoch 80 | Epoch 100 | Epoch 120 |
 |
 |
 |
 |
 |
 |
| CycleGAN | |||||
 |
 |
 |
 |
 |
 |
| Ours | |||||
5.2.1 GAN and Its Variants
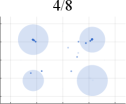
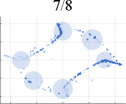
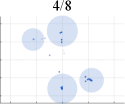
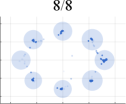
Initially, we conduct extensive experiments on synthesized datasets following a Mixed of Gaussian (MOG) distribution. These experiments aim to provide a quantitative and qualitative evaluation of our algorithm, considering aspects such as mode generation, computational efficiency, and training stability. To establish a performance comparison, we benchmark our approach against several state-of-the-art GAN architectures, including VGAN [1], WGAN [9], ProxGAN [18], and LCGAN [20]. For the synthetic data, we generate four distinct types of MOG distributions: 2D Ring (consisting of 5 or 8 2D Gaussians arranged in a ring), 2D Random (comprising 10 2D Gaussians with random magnitudes and positions), 2D Grid (comprising 25 2D Gaussians arranged in a grid), and 3D Cube (comprising 27 3D Gaussians within a cube). Each Gaussian distribution has a fixed variance of 0.02. During the training phase, we construct training batches with 512 samples from each mixture of Gaussian models, consisting of both real and generated data. Additionally, we sample 512 generated images for testing purposes.
To optimize the two networks, we uniformly employ the Adam optimizer, with a learning rate of for the discriminator and for the generator. Both the generator and discriminator adopt a 3-layer linear network with a width of 256. The activation function utilized is a leaky ReLU with a threshold of 0.2. To provide a comprehensive comparison, we employ three well-established metrics: Frechet Inception Distance (FID) [47], Jensen-Shannon divergence (JS) [1], number of Modes (Mode). These metrics serve as a basis for evaluating and contrasting the performance of different approaches.
 |
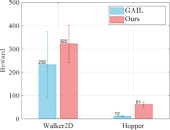 |
Fig. 4 presents a comprehensive comparison of the number of generated samples among various advanced GAN methods, both with and without our LwCL methodology. When VGAN and LCGAN are combined with the NAL strategy, they exhibit a mapping of diverse inputs to the same output, resulting in limited capturing of different distributions. It is evident that the original GAN models struggle to capture a significant number of distributions, leading to severe mode collapse and unsatisfactory performance. However, when integrated into our framework, these methods are able to capture a relatively larger number of distributions with the assistance of our approach, ultimately generating a more diverse range of realistic distributions. In the case of the 3D Cube distribution, ProxGAN and LCGAN, when combined with our methodology, demonstrate the ability to fit almost all Gaussian distributions accurately, preserving intricate details. Tab. II further demonstrates the effectiveness of our methodology in alleviating the mode collapse issue. Specifically, WGAN combined with LwCL achieves the lowest FID score in the 2D Ring distribution, and obtains the lowest JS score in the 3D Cube dataset. It is noteworthy that our flexible LwCL methodology uniformly improves a wide range of existing GANs, enhancing their overall performance.
 |
 |
| Method | Dice | HD95 | ASD |
| Medical Image Registration | |||
| Initial | 64.5 6.0 | 2.99 0.79 | 0.55 0.15 |
| VxM | 76.8 1.5 | 2.39 0.51 | 0.43 0.09 |
| LKU-Net | 77.2 1.5 | 2.28 0.47 | 0.41 0.09 |
| TransMorph | 77.9 1.3 | 2.40 0.48 | 0.42 0.09 |
| SST | 74.2 2.6 | 2.89 0.58 | 0.51 0.12 |
| DeepAtlas | 76.9 2.1 | 2.58 0.57 | 0.46 0.13 |
| DataAug | 78.1 1.9 | 2.34 0.54 | 0.40 0.11 |
| BRBS | 80.1 1.9 | 2.35 0.53 | 0.42 0.13 |
| Ours | 80.3 1.4 | 2.23 0.49 | 0.39 0.10 |
| Medical Image Segmentation | |||
| UNet | 58.1 7.5 | 12.8 3.23 | 2.47 0.98 |
| MASSL | 66.2 4.5 | 10.7 2.95 | 1.79 0.57 |
| CPS | 73.1 4.2 | 3.66 1.34 | 0.67 0.19 |
| SST | 76.5 2.2 | 2.93 0.72 | 0.55 0.18 |
| DeepAtlas | 77.8 1.7 | 2.89 0.62 | 0.53 0.15 |
| DataAug | 78.9 3.0 | 2.97 0.46 | 0.56 0.16 |
| BRBS | 82.3 1.8 | 2.84 0.59 | 0.50 0.19 |
| Ours | 83.4 1.3 | 2.55 0.54 | 0.43 0.15 |
5.2.2 Image Generation
In our experimental evaluation, we examine the performance of several well-established generative models, namely DCGAN [19], LSGAN [42], and SNGAN [48]. To assess their capabilities, we employ widely used benchmark datasets, including CIFAR10 [43], CIFAR100 [44] and CelebA-HQ [45]. For evaluating the generative models, we employ two widely recognized metrics: Inception Score (IS) for evaluating generation quality and diversity, and Fréchet Inception Distance (FID) for capturing the issue of mode collapse. Under our LwCL framework, we consider DCGAN, which incorporates standard binary cross-entropy loss for unsupervised training and employs a coupled game process of OL and CL. The objective functions and for DCGAN are defined as follows: , and . Similarly, for LSGAN, which employs a least squares loss, the objective functions and are constructed as follows: , and . As for SNGAN, it incorporates spectral normalization to ensure the 1-Lipschitz continuity constraint. The objective function for SNGAN is defined as follows: . Furthermore, in our face generation experiment on the high-resolution CelebA-HQ dataset [45], we employ StyleGAN as the backbone architecture.
Tab. III further highlights the consistent performance improvements achieved by state-of-the-art GAN architectures when incorporated into our LwCL framework. Moreover, Fig. 5 visually demonstrates the efficacy of our LwCL methodology in conjunction with StyleGAN. It showcases the superior style-content trade-off achieved, validating the versatility and effectiveness of our flexible solution strategy. Notably, our approach excels in generating realistic facial structures while effectively mitigating twist distortion.
 |
 |
 |
 |
 |
 |
| - | DE=6.710 | DE=6.819 | DE=6.817 | DE=6.717 | DE=7.106 |
 |
 |
 |
 |
 |
 |
| - | DE=7.331 | DE=7.444 | DE=7.334 | DE=7.284 | DE=7.537 |
| Input | RetinexNet | DeepUPE | ZeroDCE | SCI | Ours |
 |
||||||
| – | – | (18.41, 0.61) | (25.24, 0.86) | (27.63, 0.91) | (27.93, 0.91) | (28.01, 0.92) |
 |
||||||
| – | – | (18.45, 0.55) | (24.41, 0.83) | (26.17, 0.88) | (26.55, 0.88) | (26.61, 0.89) |
| Input | Ground Truth | FDN | IRCNN | IRCNN | DPIR | Ours |
5.2.3 Style Transfer
We select the CycleGAN model [10] as the foundation for our architecture and conduct experiments on the FFHQ dataset [46] to explore unsupervised style transfer. Our approach leverages two Generator networks and two Discriminator networks, forming a bidirectional LwCL framework. This framework incorporates cycle-consistency loss in two loops to assess the ability to reconstruct an image from its transformed counterpart. The cycle consistency loss, denoted as , captures the discrepancy between the original image and its reconstructed version in both the forward and backward mapping processes. Mathematically, it is defined as the summation of the norm of the difference between the transformed and reconstructed images, computed as In the bidirectional mapping process, the optimization of variables in the two objective functions can be mutually exchanged and modeled. We ensure a fair comparison by following the experimental setups and model architecture detailed in [10].
Fig. 6 visually demonstrates the remarkable advantages of our proposed framework in generating samples of higher quality and richer detailed textures. In comparison to the sparse and unrealistic textures produced by the standard CycleGAN, it is evident that the network integrated with our LwCL framework can generate zebra stripes that are more abundant, natural, and realistic. In Fig. 7, we observe significant fluctuations in the visual perceptual quality of the generated images by the standard CycleGAN throughout the training process. With the standard CycleGAN, high-quality zebra images can be generated at 40 epochs. However, at 60 epochs, a small amount of background stripes starts to appear, and by 120 epochs, the stripes that should be generated on the horse are completely transferred to the background. In contrast, when our LwCL strategy is incorporated, the generation of zebra patterns becomes gradually stable, and the authenticity of the texture is significantly enhanced. This improvement effectively mitigates the occurrence of mode collapse, ensuring the preservation of desirable characteristics in the generated images.
| Metric | RetinexNet | DeepUPE | KinD | ZeroDCE |
| DE | 7.125 | 7.089 | 7.053 | 7.150 |
| LOE | 555.990 | 144.242 | 277.523 | 142.544 |
| Metric | FIDE | DRBN | SCI | Ours |
| DE | 6.106 | 7.187 | 7.005 | 7.254 |
| LOE | 280.616 | 495.748 | 84.745 | 78.976 |
5.2.4 Imitation Learning
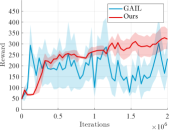
In the formulated Markov decision process, denoted as , we define the action space , state space , and reward function . The initial state is drawn from the distribution , and the discount factor is applied. In this context, the actor interacts with the environment to learn the state-action value function , followed by the update of the actor based on . The objective of the policy is to maximize the expected discounted cumulative reward, given by: where , , and represent the initial state, initial action, and initial state distribution, respectively. For our experiment, we employ the PyBullet physics simulator and publicly available datasets tailored for data-driven deep reinforcement learning. Following the definitions and experimental settings of recent studies [22, 23], we design an agent with an actor-critic structure to predict actions that deceive the discriminator. The discriminator, on the other hand, is trained to distinguish between samples generated by the policy and an expert policy . To compute the reward function , we adopt the form Additionally, both Generative Adversarial Imitation learning (GAIL) and our method incorporate the gradient penalty regularizers.
Fig. 8 presents the average policy return and standard error for two simulated environments, namely “Walker2D” and “Hopper”. The average policy return and its standard error are plotted to illustrate the performance of GAIL. It is evident that the GAIL curve exhibits significant instability and lacks a convergent trend. In contrast, our proposed solution technique ensures a more stable convergence during training with reduced deviation. Additionally, we provide the final return achieved throughout the training episodes, which serves as an indicator of the performance improvement achieved by GAIL when employing our novel solution techniques.
5.3 ART-type Applications
In the subsequent sections, we delve into three distinct applications, each accompanied by the introduction of relevant task constraints. These applications encompass medical image analysis, low-light image enhancement, and hyper-parameter learning.
5.3.1 Medical Image Analysis
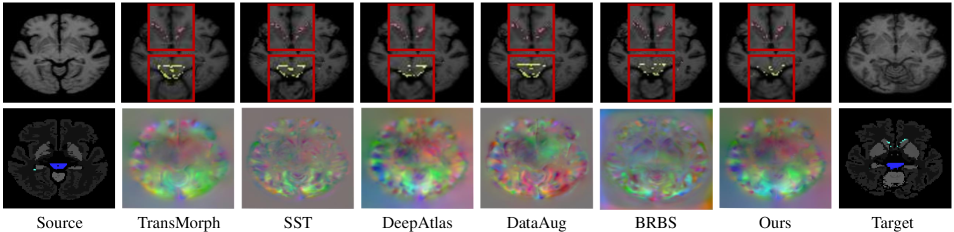
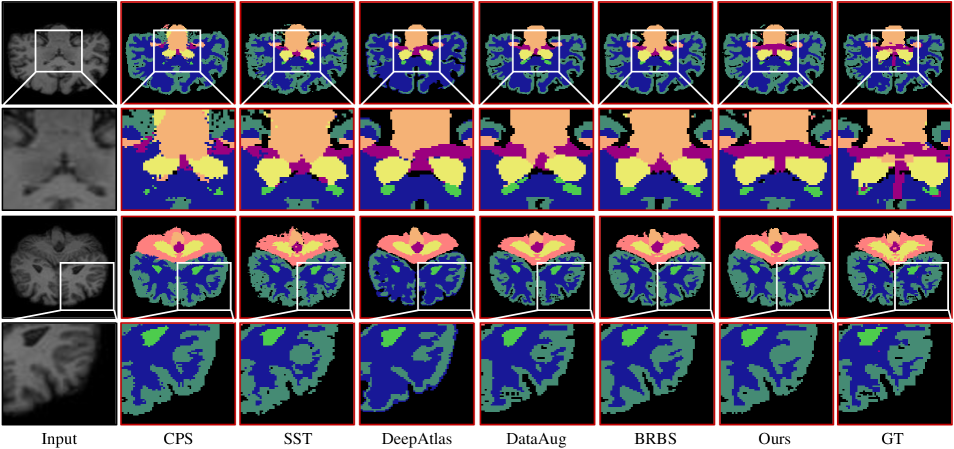
We evaluate the segmentation performance on a hybrid dataset by using 426 mixed medical scans, which is sampled from three standard datasets, ABIDE [49], ADNI [50] and PPMI [51]. During the training phase, the scanned images are divided into 346, 40, and 40 volumes for training, validation, and testing, respectively. To capture both global and local differences in appearance, we define the energy function , where is the multi-scale local cross-correlation in appearance, and is the semantic content consistency loss, i.e., . Here denotes the Kullback-Leibler divergence, and and are the warped prediction and target prediction, respectively. For segmentation, the energy function is defined as a hybrid loss composed of multi-class cross entropy loss and Dice coefficient loss . In our training, we empirically set the balancing parameters and , and use ADAM optimizer with learning rate of . To evaluate the performance of registration and segmentation, we employed well-established metrics such as the Dice score, Hausdorff distance (HD95), and average surface distance (ASD). We compare our method to several state-of-the-art methods, including a) Deep learning registration-based segmentation methods, VxM[52], LKU-Net[53], and TransMorph[54]. b) Deep learning segmentation methods, UNet[7], MASSL[55], and CPS[56]. d) joint registration and segmentation methods, SST[28], DeepAtlas[26], DataAug[29], and BRBS[27].
Tab. IV presents quantitative comparisons for joint registration and segmentation tasks, demonstrating that our method achieved the highest Dice score and the lowest HD95 and ASD metrics in registration and segmentation, respectively. Fig. 9 illustrates the two-dimensional visualization results of the registration method compared to other approaches. The framework solely relying on registration and segmentation tends to exhibit more misalignment errors along anatomical boundaries. In contrast, our method demonstrates the smallest mislabeling regions on the lateral ventricle (LV) and brainstem (BS), as indicated by the yellow and pink areas. Additionally, we provide qualitative results in Fig. 10, illustrating the robust segmentation performance of our method at complex termination sites in the structural white matter of the brain and the finer segmentation quality achieved on the cerebellar tissue and the 3/4 ventricles.
5.3.2 Low-light Image Enhancement
We conduct low-light enhancement experiments on DarkFace [57] dataset, and adopt the well-known no reference metrics (i.e., DE and LOE). To benchmark our method, we compare it against several state-of-the-art approaches, including MBLLEN [58], RetinexNet [59], KinD [60], ZeroDCE [61], DeepUPE [62], FIDE [63], DRBN [64] and SCI [39]. As mentioned in [39], we introduce the pixel fidelity term and a smoothness term for , which are formulated as , , where denotes the self-calibrated variable, is the total number of pixels, represents the weight function. As for , we also introduce the anchor-based multi-task loss and progressive anchor loss [40], defined as: . Here, where and indicate the number of positive and negative anchors, and the number of positive anchors, respectively. is the smooth loss between the predicted box and ground-truth box using the anchor , and is the softmax loss in terms of two classes.
| Method | MNIST | FashionMNIST | CIFAR10 | |||
| F1 score | Time (s) | F1 score | Time (s) | F1 score | Time (s) | |
| CG | ||||||
| Neumann | ||||||
| RHG | ||||||
| T-RHG | ||||||
| BDA | ||||||
| Ours | ||||||
In Fig. 11, we compare the visualization results. It can be seen that although some methods can successfully enhance the brightness of the image, none of them can restore the clear image texture. The DE score is reported below, and a higher DE value indicates better visual quality. In comparison, our method produces the most visually pleasing results, can not only learns to enhance the dark area while restoring more visible details but also avoids over-exposure artifacts. We report the quantitative results in Tab. V. It can be seen that our method numerically outperforms existing methods by large margins and ranks first across all metrics. This further endorses the superiority of our method over current state-of-the-art methods in generating high-quality visual results.
| Blur Kernel | Metric | Method | ||||
| FDN | IRCNN | IRCNN | DPIR | Ours | ||
| PSNR | 18.741 | 26.281 | 27.761 | 28.168 | 28.236 | |
| SSIM | 0.472 | 0.876 | 0.880 | 0.889 | 0.890 | |
| PSNR | 17.977 | 27.361 | 27.532 | 28.066 | 28.132 | |
| SSIM | 0.437 | 0.881 | 0.874 | 0.887 | 0.888 | |
| PSNR | 17.775 | 28.364 | 27.586 | 28.295 | 28.364 | |
| SSIM | 0.431 | 0.895 | 0.868 | 0.890 | 0.891 | |
| PSNR | 17.905 | 25.291 | 27.400 | 27.918 | 27.970 | |
| SSIM | 0.435 | 0.858 | 0.872 | 0.884 | 0.885 | |
| PSNR | 18.273 | 27.642 | 27.640 | 28.450 | 28.471 | |
| SSIM | 0.436 | 0.879 | 0.866 | 0.888 | 0.888 | |
| Method | -way | -way | -way | -way | ||||
| -shot | -shot | -shot | -shot | -shot | -shot | -shot | -shot | |
| MAML | 98.70 | 95.80 | 98.90 | 86.86 | 96.86 | 85.98 | 94.46 | |
| Meta-SGD | 97.97 | 98.96 | 93.98 | 98.42 | 89.91 | 96.21 | 87.39 | 95.10 |
| Reptile | 97.68 | 99.48 | 89.43 | 97.12 | 85.40 | 95.28 | 82.50 | 92.79 |
| iMAML | 99.67 0.12 | 94.46 0.42 | 98.69 | 89.52 | 96.51 | 87.28 | 95.27 | |
| RHG | 98.64 | 99.58 | 93.92 | |||||
| T-RHG | 98.74 | 95.82 | 98.95 | 98.39 | 90.73 | |||
| Ours | 99.67 | |||||||
5.3.3 Hyper-parameter Learning
We consider a specific data hyper-cleaning example [66]. In this scenario, we aim to train a linear classifier using a given image dataset, but encounter the issue of corrupted training labels. To address this, we adopt softmax regression with parameters as our classifier and introduce hyperparameters to assign weights to the training samples. Initially, we define the cross-entropy function which measures the classification loss using the classification parameter and the data pairs . The training and validation sets are denoted as and , respectively. Next, we introduce the CL function as the following weighted training loss, given by . Here represents the hyperparameter vector that penalizes the objective for different training samples. The element-wise sigmoid function is applied to restrict the weights within the range of . Furthermore, we define as the cross-entropy loss with regularization on the validation set, i.e., , where is the trade-off parameter. Three well known datasets including MNIST, FashionMNIST and CIFAR10 are used to conduct the experiments. Specifically, the training, validation and test sets consist of 5000, 5000, 10000 class-balanced samples randomly selected to construct , and , then half of the labels in are tampered. We adopted the architectures proposed by [5] as the feature extractor for all the compared methods.
Tab. VI presents a comprehensive comparison of our LwCL framework with various hyperparameter optimization methods, including CG [13], Neumann [14], RHG [5], Truncated RHG (T-RHG) [6], and BDA [33] in terms of F1 score and running time. The results clearly demonstrate the superior performance of our method in terms of F1 score compared to the other hyperparameter optimization techniques. Notably, our method significantly outperforms all relevant algorithms in terms of running time, achieving a substantial improvement of nearly an order of magnitude.
5.4 TDC-type Applications
In the subsequent sections, we proceed to showcase the efficacy of LwCL through the evaluation of its performance in two prominent TDC-type LwCL applications: image deblurring and multi-task meta-learning.
5.4.1 Image Deblurring
We conduct image deblurring experiment on a data benchmark, containing 400 images from the Berkeley Segmentation dataset, 4744 images from the Waterloo Exploration database, 900 images from the DIV2K dataset and 2750 images from the Flick2K dataset. More specifically, we used the DRUNet in DPIR [8] containing four scales as the base network. In the specific implementation, the subproblem for u is solved by closed-form solution based on the fast Fourier transform, and the subproblem on z is obtained by an updated denoiser . Unlike the original method that treats the denoiser as a fixed pre-trained network, under our LwCL framework, the parameters of the deblurring network are dynamically updated as learnable variables. As discussed earlier, it can be understood that the lower variable is a combination about two optimized variables, i.e., . Thus, by jointly learning two sub-tasks, our method can improve robustness and generalization to various complex noise scenarios. Each scale has a skip connection between the 2 × 2 stride convolution downscale and the 2 × 2 transpose convolution upscale operations. The number of channels per layer from the first to the fourth scale is 64, 128, 256 and 512 respectively. Four consecutive blocks of residuals are used in the down-sampling operation and up-sampling operation at each scale.
We qualitatively and quantitatively evaluated the performance of a series of relevant methods, including FDN [65], IRCNN [34], IRCNN and DPIR [8]). As shown in Tab. VII, we report the performance of the current methods under five different sizes of blur kernel settings (i.e., ). All experiments were performed under a uniform noise criterion with a default noise level . In comparison, our method achieves the best PSNR scores under all five blurs and performs best in both average PSNR and SSIM scores. In addition, we show a visualization of the perceptual results in Fig. 12. As can be seen, for the deblurring task, our method outperforms other methods in terms of color recovery, detail retention and the quantitative metric PSNR, and achieves the best visual performance. This further endorses the superiority of our method over current state-of-the-art methods in image deblurring.
5.4.2 Multi-task Meta-learning
We conduct the -way -shot classification experiments where each task is to discriminate separate classes and it is to learn the hyper-parameter such that each task can be solved only with training samples. Typically, we separate the network architecture into two parts: the cross-task intermediate representation layers (parameterized by ) outputs the meta features and the multinomial logistic regression layer (parameterized by ) as our ground classifier for the -th task. During training, we conduct our experiment on a meta training data set , where is linked to the -th task. Then, we consider the cross-entropy function as the task-specific loss for the -th task and thus the can be defined as . Similarly, we also utilize the cross-entropy function but define it based on as . We validate the performance based on the widely used Omniglot [67] dataset, and consider ResNet-12 with Residual blocks as the backbone. Besides, we introduce the task-and-layer-wise attenuation [68] to control the influence of prior knowledge for each task and layer.
As illustrated in Tab. VIII, we followed the experimental protocol [11] and compared our algorithm to several state-of-the-art approaches, such as MAML [11], Meta-SGD [4], Reptile [35], iMAML [3], RHG [5], and T-RHG [6]. In comparison, our LwCL achieved the highest classification accuracy except in the 5-way 5-shot and 20-way 5-shot tasks. Indeed, with more complex few-shot classification problems (such as 30-way and 40-way), our LwCL showed significant advantages over other methods.
6 Conclusions and Future Works
In this work, we have introduced a novel perspective called Learning with Constraint Learning (LwCL) to provide a deeper understanding of their underlying coupling mechanisms for efficiently solving contemporary complex problems in machine learning and computer vision. Our proposed framework provides a unified understanding of the intrinsic mechanisms behind diverse problems. By establishing a general hierarchical optimization framework and a dynamic best response-based fast solution strategy, we have demonstrated the effectiveness of our approach in formulating and addressing LwCLs. Through extensive experiments we have verified the efficiency of our proposed framework in solving a wide range of LwCL problems, spanning three categories and nine different types. Future research can focus on further exploring and extending the capabilities of LwCL in addressing even more challenging problems and advancing the state-of-the-art in machine learning and computer vision. The findings presented in this paper contribute to a deeper understanding and efficient resolution of complex problems in learning and vision, providing valuable insights for future research and applications in the field.
Acknowledgments
This work is partially supported by the National Key R&D Program of China (2022YFA1004101), and the National Natural Science Foundation of China (No. U22B2052).
References
- [1] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,” NeurIPS, vol. 27, 2014.
- [2] Y. Zhong and W. Deng, “Adversarial learning with margin-based triplet embedding regularization,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 6549–6558.
- [3] A. Rajeswaran, C. Finn, S. Kakade, and S. Levine, “Meta-learning with implicit gradients,” 2019.
- [4] Z. Li, F. Zhou, F. Chen, and H. Li, “Meta-sgd: Learning to learn quickly for few-shot learning,” arXiv preprint arXiv:1707.09835, 2017.
- [5] L. Franceschi, M. Donini, P. Frasconi, and M. Pontil, “Forward and reverse gradient-based hyperparameter optimization,” in International Conference on Machine Learning. PMLR, 2017, pp. 1165–1173.
- [6] A. Shaban, C.-A. Cheng, N. Hatch, and B. Boots, “Truncated back-propagation for bilevel optimization,” in AISTATS, 2019.
- [7] Ö. Çiçek, A. Abdulkadir, S. S. Lienkamp, T. Brox, and O. Ronneberger, “3d u-net: Learning dense volumetric segmentation from sparse annotation,” in Medical Image Computing and Computer-Assisted Intervention - MICCAI 2016, ser. Lecture Notes in Computer Science, vol. 9901, 2016, pp. 424–432.
- [8] K. Zhang, Y. Li, W. Zuo, L. Zhang, L. Van Gool, and R. Timofte, “Plug-and-play image restoration with deep denoiser prior,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 10, pp. 6360–6376, 2021.
- [9] M. Arjovsky, S. Chintala, and L. Bottou, “Wasserstein generative adversarial networks,” in ICML, 2017, pp. 214–223.
- [10] J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros, “Unpaired image-to-image translation using cycle-consistent adversarial networks,” in ICCV, 2017, pp. 2223–2232.
- [11] L. Collins, A. Mokhtari, and S. Shakkottai, “Task-robust model-agnostic meta-learning,” 2020.
- [12] K. Ji, J. D. Lee, Y. Liang, and H. V. Poor, “Convergence of meta-learning with task-specific adaptation over partial parameters,” in Advances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds. Curran Associates, Inc., 2020, pp. 11 490–11 500.
- [13] F. Pedregosa, “Hyperparameter optimization with approximate gradient,” in International conference on machine learning. PMLR, 2016, pp. 737–746.
- [14] J. Lorraine, P. Vicol, and D. Duvenaud, “Optimizing millions of hyperparameters by implicit differentiation,” in International Conference on Artificial Intelligence and Statistics. PMLR, 2020, pp. 1540–1552.
- [15] L. Metz, B. Poole, D. Pfau, and J. Sohl-Dickstein, “Unrolled generative adversarial networks,” arXiv:1611.02163, 2016.
- [16] A. Brock, J. Donahue, and K. Simonyan, “Large scale gan training for high fidelity natural image synthesis,” arXiv:1809.11096, 2018.
- [17] H. Petzka, A. Fischer, and D. Lukovnicov, “On the regularization of wasserstein gans,” arXiv:1709.08894, 2017.
- [18] F. Farnia and A. Ozdaglar, “Do gans always have nash equilibria?” in ICML, 2020.
- [19] F. Gao, Y. Yang, J. Wang, J. Sun, E. Yang, and H. Zhou, “A deep convolutional generative adversarial networks (dcgans)-based semi-supervised method for object recognition in synthetic aperture radar (sar) images,” Remote Sensing, vol. 10, no. 6, p. 846, 2018.
- [20] J. Engel, M. Hoffman, and A. Roberts, “Latent constraints: Learning to generate conditionally from unconditional generative models,” arXiv preprint arXiv:1711.05772, 2017.
- [21] S. Azadi, M. Fisher, V. G. Kim, Z. Wang, E. Shechtman, and T. Darrell, “Multi-content gan for few-shot font style transfer,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 7564–7573.
- [22] J. Fu, K. Luo, and S. Levine, “Learning robust rewards with adversarial inverse reinforcement learning,” arXiv preprint arXiv:1710.11248, 2017.
- [23] K. Arulkumaran and D. O. Lillrank, “A pragmatic look at deep imitation learning,” arXiv preprint arXiv:2108.01867, 2021.
- [24] Y. Jiang, X. Gong, D. Liu, Y. Cheng, C. Fang, X. Shen, J. Yang, P. Zhou, and Z. Wang, “Enlightengan: Deep light enhancement without paired supervision,” IEEE Transactions on Image Processing, vol. 30, pp. 2340–2349, 2021.
- [25] D. Pfau and O. Vinyals, “Connecting generative adversarial networks and actor-critic methods,” arXiv preprint arXiv:1610.01945, 2016.
- [26] Z. Xu and M. Niethammer, “Deepatlas: Joint semi-supervised learning of image registration and segmentation,” in Medical Image Computing and Computer Assisted Intervention - MICCAI 2019, ser. Lecture Notes in Computer Science, vol. 11765. Springer, 2019, pp. 420–429.
- [27] Y. He, R. Ge, X. Qi, Y. Chen, J. Wu, J.-L. Coatrieux, G. Yang, and S. Li, “Learning better registration to learn better few-shot medical image segmentation: Authenticity, diversity, and robustness,” IEEE Transactions on Neural Networks and Learning Systems, 2022.
- [28] D. Tomar, B. Bozorgtabar, M. Lortkipanidze, G. Vray, M. S. Rad, and J. Thiran, “Self-supervised generative style transfer for one-shot medical image segmentation,” in IEEE/CVF Winter Conference on Applications of Computer Vision, WACV 2022. IEEE, 2022, pp. 1737–1747.
- [29] A. Zhao, G. Balakrishnan, F. Durand, J. V. Guttag, and A. V. Dalca, “Data augmentation using learned transformations for one-shot medical image segmentation,” in IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019. Computer Vision Foundation / IEEE, 2019, pp. 8543–8553.
- [30] R. Liu, L. Ma, T. Ma, X. Fan, and Z. Luo, “Learning with nested scene modeling and cooperative architecture search for low-light vision,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 5, pp. 5953–5969, 2022.
- [31] X. Xue, J. He, L. Ma, Y. Wang, X. Fan, and R. Liu, “Best of both worlds: See and understand clearly in the dark,” in Proceedings of the 30th ACM International Conference on Multimedia, 2022, pp. 2154–2162.
- [32] R. Liu, Y. Liu, S. Zeng, and J. Zhang, “Towards gradient-based bilevel optimization with non-convex followers and beyond,” Advances in Neural Information Processing Systems, vol. 34, pp. 8662–8675, 2021.
- [33] R. Liu, P. Mu, X. Yuan, S. Zeng, and J. Zhang, “A general descent aggregation framework for gradient-based bi-level optimization,” 2021.
- [34] K. Zhang, W. Zuo, S. Gu, and L. Zhang, “Learning deep cnn denoiser prior for image restoration,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 3929–3938.
- [35] A. Nichol, J. Achiam, and J. Schulman, “On first-order meta-learning algorithms,” arXiv preprint arXiv:1803.02999, 2018.
- [36] L. Franceschi, M. Donini, P. Frasconi, and M. Pontil, “A bridge between hyperparameter optimization and learning-to-learn,” arXiv:1712.06283, 2017.
- [37] S. Dempe, “Bilevel optimization: Theory, algorithms, applications and a bibliography,” in Bilevel Optimization, 2020, pp. 581–672.
- [38] R. Liu, J. Gao, J. Zhang, D. Meng, and Z. Lin, “Investigating bi-level optimization for learning and vision from a unified perspective: A survey and beyond,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 12, pp. 10 045–10 067, 2021.
- [39] L. Ma, T. Ma, R. Liu, X. Fan, and Z. Luo, “Toward fast, flexible, and robust low-light image enhancement,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 5637–5646.
- [40] J. Li, Y. Wang, C. Wang, Y. Tai, J. Qian, J. Yang, C. Wang, J. Li, and F. Huang, “Dsfd: dual shot face detector,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 5060–5069.
- [41] R. Liu, X. Liu, S. Zeng, J. Zhang, and Y. Zhang, “Value-function-based sequential minimization for bi-level optimization,” arXiv preprint arXiv:2110.04974, 2021.
- [42] X. Mao, Q. Li, H. Xie, R. Y. Lau, Z. Wang, and S. Paul Smolley, “Least squares generative adversarial networks,” in ICCV, 2017.
- [43] A. Krizhevsky and G. Hinton, “Convolutional deep belief networks on cifar-10,” Unpublished manuscript, vol. 40, no. 7, pp. 1–9, 2010.
- [44] A. Krizhevsky, G. Hinton et al., “Learning multiple layers of features from tiny images,” 2009.
- [45] Z. Liu, P. Luo, X. Wang, and X. Tang, “Deep learning face attributes in the wild,” in ICCV, 2015.
- [46] T. Karras, S. Laine, and T. Aila, “A style-based generator architecture for generative adversarial networks,” in CVPR, 2019.
- [47] M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter, “Gans trained by a two time-scale update rule converge to a local nash equilibrium,” Advances in neural information processing systems, vol. 30, 2017.
- [48] T. Miyato, T. Kataoka, M. Koyama, and Y. Yoshida, “Spectral normalization for generative adversarial networks,” arXiv preprint arXiv:1802.05957, 2018.
- [49] A. Di Martino, C.-G. Yan, Q. Li, E. Denio, F. X. Castellanos, K. Alaerts, J. S. Anderson, M. Assaf, S. Y. Bookheimer, M. Dapretto et al., “The autism brain imaging data exchange: towards a large-scale evaluation of the intrinsic brain architecture in autism,” Molecular psychiatry, vol. 19, no. 6, pp. 659–667, 2014.
- [50] S. G. Mueller, M. W. Weiner, L. J. Thal, R. C. Petersen, C. R. Jack, W. Jagust, J. Q. Trojanowski, A. W. Toga, and L. Beckett, “Ways toward an early diagnosis in alzheimer’s disease: the alzheimer’s disease neuroimaging initiative (adni),” Alzheimer’s & Dementia, vol. 1, no. 1, pp. 55–66, 2005.
- [51] K. Marek, D. Jennings, S. Lasch, A. Siderowf, C. Tanner, T. Simuni, C. Coffey, K. Kieburtz, E. Flagg, S. Chowdhury et al., “The parkinson progression marker initiative (ppmi),” Progress in neurobiology, vol. 95, no. 4, pp. 629–635, 2011.
- [52] G. Balakrishnan, A. Zhao, M. R. Sabuncu, J. V. Guttag, and A. V. Dalca, “Voxelmorph: A learning framework for deformable medical image registration,” IEEE Trans. Medical Imaging, vol. 38, no. 8, pp. 1788–1800, 2019.
- [53] X. Jia, J. Bartlett, T. Zhang, W. Lu, Z. Qiu, and J. Duan, “U-net vs transformer: Is u-net outdated in medical image registration?” in Machine Learning in Medical Imaging, MLMI 2022, ser. Lecture Notes in Computer Science, vol. 13583. Springer, 2022, pp. 151–160.
- [54] J. Chen, E. C. Frey, Y. He, W. P. Segars, Y. Li, and Y. Du, “Transmorph: Transformer for unsupervised medical image registration,” Medical Image Anal., vol. 82, p. 102615, 2022.
- [55] S. Chen, G. Bortsova, A. G. Juárez, G. van Tulder, and M. de Bruijne, “Multi-task attention-based semi-supervised learning for medical image segmentation,” in Medical Image Computing and Computer Assisted Intervention - MICCAI 2019, ser. Lecture Notes in Computer Science, vol. 11766. Springer, 2019, pp. 457–465.
- [56] X. Chen, Y. Yuan, G. Zeng, and J. Wang, “Semi-supervised semantic segmentation with cross pseudo supervision,” in IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021. Computer Vision Foundation / IEEE, 2021, pp. 2613–2622.
- [57] W. Yang, Y. Yuan, W. Ren, J. Liu, W. J. Scheirer, Z. Wang, T. Zhang, Q. Zhong, D. Xie, S. Pu et al., “Advancing image understanding in poor visibility environments: A collective benchmark study,” IEEE Transactions on Image Processing, vol. 29, pp. 5737–5752, 2020.
- [58] F. Lv and F. Lu, “Attention-guided low-light image enhancement,” arXiv preprint arXiv:1908.00682, 2019.
- [59] W. Chen, W. Wang, W. Yang, and J. Liu, “Deep retinex decomposition for low-light enhancement,” in BMVC, 2018.
- [60] Y. Zhang, J. Zhang, and X. Guo, “Kindling the darkness: A practical low-light image enhancer,” in ACM MM, 2019.
- [61] C. Guo, C. Li, J. Guo, C. C. Loy, J. Hou, S. Kwong, and R. Cong, “Zero-reference deep curve estimation for low-light image enhancement,” in CVPR, 2020, pp. 1780–1789.
- [62] R. Wang, Q. Zhang, C.-W. Fu, X. Shen, W.-S. Zheng, and J. Jia, “Underexposed photo enhancement using deep illumination estimation,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 6849–6857.
- [63] K. Xu, X. Yang, B. Yin, and R. W. Lau, “Learning to restore low-light images via decomposition-and-enhancement,” in CVPR, 2020, pp. 2281–2290.
- [64] W. Yang, S. Wang, Y. Fang, Y. Wang, and J. Liu, “From fidelity to perceptual quality: A semi-supervised approach for low-light image enhancement,” in CVPR, 2020, pp. 3063–3072.
- [65] J. Kruse, C. Rother, and U. Schmidt, “Learning to push the limits of efficient fft-based image deconvolution,” in Proceedings of the IEEE International Conference on Computer Vision, 2017, pp. 4586–4594.
- [66] R. Liu, X. Liu, W. Yao, S. Zeng, and J. Zhang, “Towards extremely fast bilevel optimization with self-governed convergence guarantees,” arXiv preprint arXiv:2205.10054, 2022.
- [67] B. M. Lake, R. Salakhutdinov, and J. B. Tenenbaum, “Human-level concept learning through probabilistic program induction,” Science, vol. 350, no. 6266, pp. 1332–1338, 2015.
- [68] S. Baik, S. Hong, and K. M. Lee, “Learning to forget for meta-learning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 2379–2387.