Lecture Notes on Support Preconditioning
Preface
These lecture notes were written in 2007. They were available since then at https://www.tau.ac.il/˜stoledo/Support. I compiled them and uploaded them without any editing in December 2021.
Chapter 1 Motivation and Overview
In this chapter we examine solvers for two families of linear systems of equations. Our goal is motivate certain ideas and techniques, not to explain in detail how the solvers work. We focus on the measured behaviors of the solvers and on the fundamental questions that the solvers and their performance pose.
1.1. The Model Problems: Two- and Three Dimensional Meshes
The coefficient matrices of the linear systems that we study arise from two families of undirected graphs: two- and three-dimensional meshes. The vertices of the graphs, which correspond to rows and columns in the coefficient matrix , are labeled through . The edges of the graph correspond to off-diagonal nonzeros in , the value of which is always . If is an edge in the graph, then . If is not an edge in the mesh for some , then . The value of the diagonal elements in is selected to make the sums of elements in rows exactly , and to make the sum of the elements in the first row exactly . We always number meshes so that vertices that differ only in their coordinates are contiguous and numbered from small coordinates to large ones; vertices that have the same coordinate are also contiguous, numbered from small coordinates to high ones. Figure 1.1.1 shows an example of a two-dimensional mesh and the matrix that corresponds to it. Figure 1.1.2 shows an example of a small three-dimensional mesh.
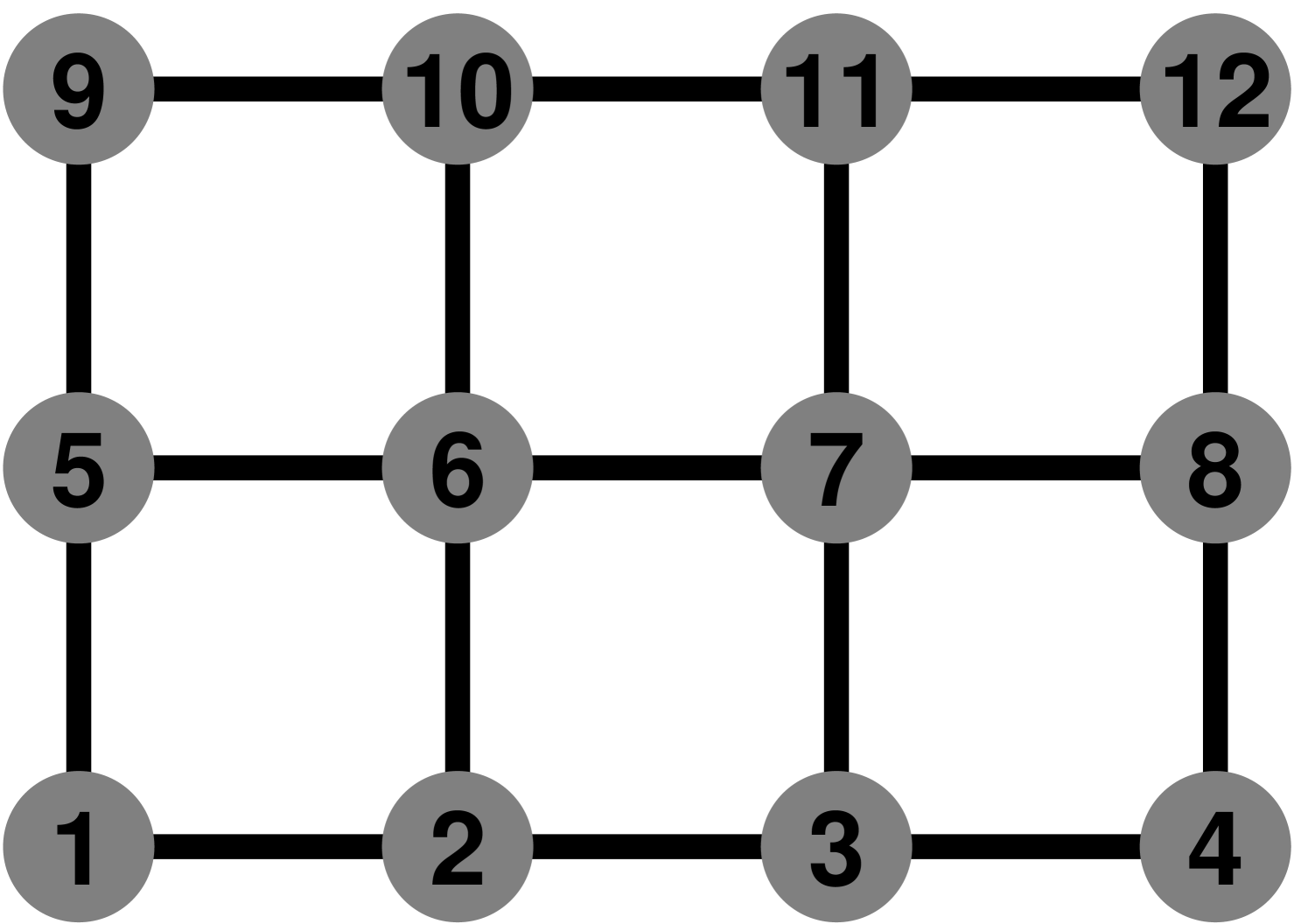
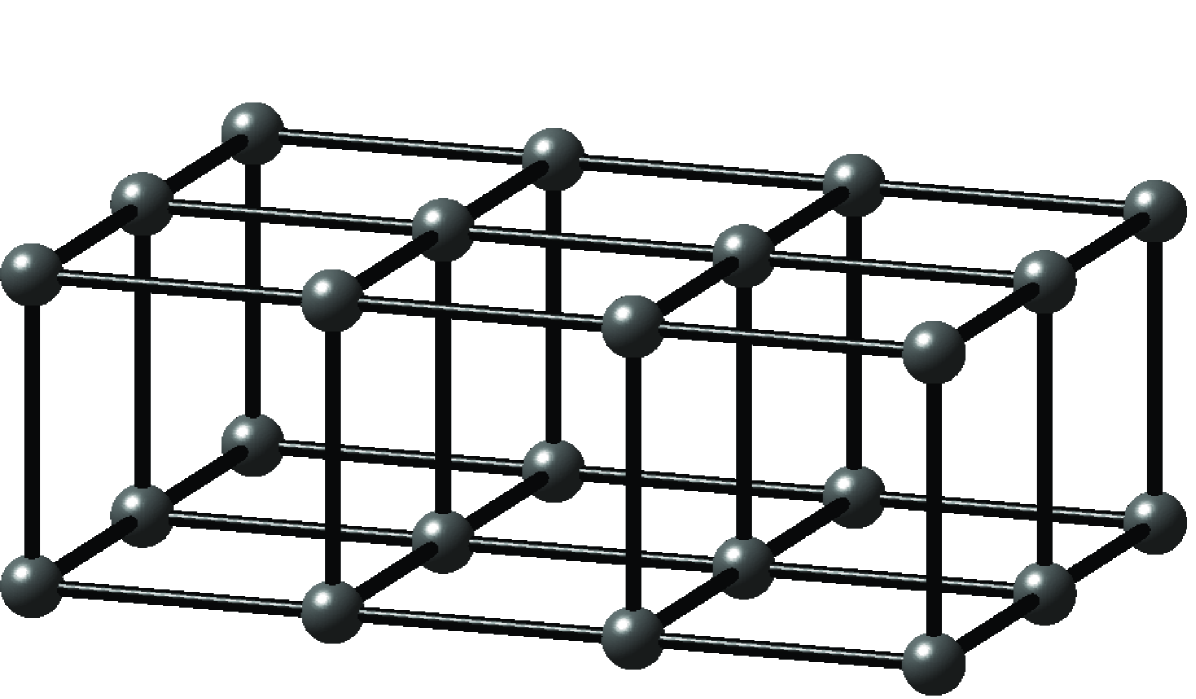
Matrices similar to these do arise in applications, such as finite-difference discretizations of partial differential equations. These particular families of matrices are highly structured, and the structure allows specialized solvers to be used, such as multigrid solvers and spectral solvers. The methods that we present in this book are, however, applicable to a much wider class of matrices, not only to those arising from structured meshes. We use these matrices here only to illustrate and motivate various linear solvers.
The experimental results that we present in the rest of the chapter all use a solution vector with random uniformly-distributed elements between and .
1.2. The Cholesky Factorization
Our matrices are symmetric (by definition) and positive definite. We do not show here that they are positive definite (all their eigenvalues are positive); this will wait until a later chapter. But they are positive definite.
The simplest way to solve a linear system with a positive definite coefficient matrix is to factor into a produce of a lower triangular factor and its transpose, . When is symmetric positive definite, such a factorization always exists. It is called the Cholesky factorization, and it is a variant of Gaussian Elimination. Once we compute the factorization, we can solve by solving two triangular linear systems,
Solvers for linear systems of equations that factor the coefficient matrix into a product of simpler matrices are called direct solvers. Here the factorization is into triangular matrices, but orthogonal, diagonal, tridiagonal, and block diagonal matrices are also used as factors in direct solvers.
The factorization can be computed recursively. If is -by-, then . Otherwise, we can partition and into 4 blocks each, such that the diagonal blocks are square,
This yields the following equations, which define the blocks of ,
| (1.2.1) | |||||
| (1.2.2) | |||||
| (1.2.3) |
We compute by recursively solving Equation 1.2.1 for . Once we have computed , we solve Equation 1.2.2 for by substitution. The final step in the computation of is to subtract from and to factor the difference recursively.
This algorithm is reliable and numerically stable, but if implemented naively, it is slow. Let be the number of arithmetic operations that this algorithm performs on a matrix of size . To estimate , we partition so that is -by-. The partitioning does not affect , but this particular partitioning makes it easy to estimate . With this partitioning, computing involves computing one square root, dividing an -vector by the root, computing the symmetric outer product of the scaled -vector, subtracting this outer product from a symmetric -by- matrix, and recursively factoring the difference. We can set this up as a recurrence relation,
This yields
The little- notation means that we have neglected terms that grow slower than for any constant .
Cubic growth means that for large meshes, a Cholesky-based solver is slow. For a mesh with a million vertices, the solver needs to perform more than arithmetic operations. Even at a rate of operations per second, the factorization takes almost 4 days. On a personal computer (say a 2005 model), the factorization will take more than a year. A mesh with a million vertices may seem like a large mesh, but it is not. The mesh has less than million edges in two dimensions and less than million in three dimensions, so its representation does not take a lot of space in memory. We can do a lot better.
1.3. Sparse Cholesky
One way to speed up the factorization is to exploit sparsity in . If we inspect the nonzero pattern of , we see that most of its elements are zero. If is derived from a 2-dimensional mesh, only 5 diagonals contain nonzero elements. If is derived from a 3-dimensional mesh, only 7 diagonals are nonzero. Figure 1.3.1 shows the nonzero pattern of such matrices. Only elements out of in are nonzero.
Sparse factorization codes exploit the sparsity of and avoid computations involving zero elements (except, sometimes, for zeros that are created by exact cancellations). Figure 1.3.2 compares the running times of a sparse Cholesky solver with that of a dense Cholesky solver, which does not exploit zeros. The sparse solver is clearly must faster, especially on 2-dimensional meshes.
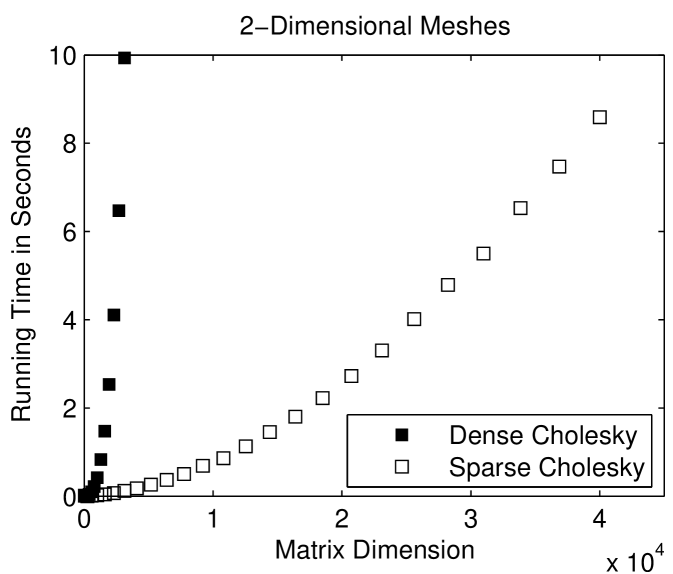
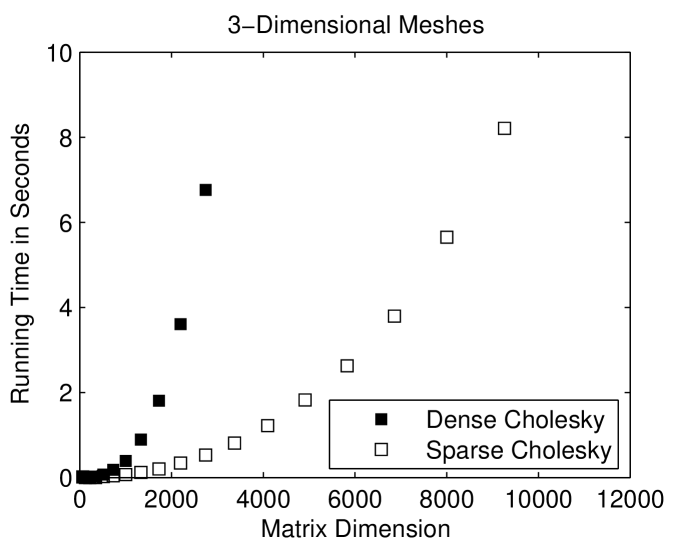
To fully understand the performance of the sparse solver, it helps to inspect the nonzero pattern of the Cholesky factor , shown in Figure 1.3.3. Exploiting sparsity pays off because the factor is also sparse: it fills, but not completely. It is easy to characterize exactly where the factor fills. It fills almost completely within the band structure of , the set of diagonals that are closer to the main diagonal than a nonzero diagonal. Outside this band structure, the elements of are all zero. For a -by- mesh, the outer diagonal is , so the total amount of arithmetic in a sparse factorization is . For large , this is a lot less than the dense bound. For three dimensional meshs, exploiting sparsity helps, but not as much. In a matrix corresponding to a -by--by- mesh, the outer nonzero diagonal is , so the amount of arithmetic is .
1.4. Preordering for Sparsity
Sparse factorization codes exploit zero elements in the reduced matrices and the factors. It turns out that by reordering the rows and columns of a matrix we can reduce fill in the reduced matrices and the factors. The most striking example for this phenomenon is the arrow matrix,
When we factor this matrix, it fills completely after the elimination of the first column, since the outer product is full (has no zeros). But if we reverse the order of the rows and columns, we have
The Cholesky factor of is as sparse as
Solving a linear system with a Cholesky factorization of a permuted coefficient matrix is trivial. We apply the same permutation to the right-hand-side before the two triangular solves, and apply the inverse permutation after the triangular solves.
For matrices that correspond to meshes, there is no permutation that leads to a no-fill factorization, but there are permutations that reduce fill significantly. Figure 1.4.1 shows a theoretically-effictive fill-reducing permutation of the matrix of an -by- mesh and its Cholesky factor. This symmetric reordering of the rows and columns is called a nested dissection ordering. It reorders the rows and columns by finding a small set of vertices in the mesh whose removal breaks the mesh into two separate components of roughly the same size. This set is called a vertex separator and the corresponding rows and columns are ordered last. The rows and columns corresponding to each connected component of the mesh minus the separator are ordered using the same strategy recursively. Figure 1.4.2 illustrates this construction.
The factorization of the nested-dissection-ordered matrix of a a -by- mesh performs arithmetic operations.111explain asymptotic notation. (We don’t give here the detailed analysis of fill and work under nested-dissection orderings.) For large meshes, this is a significant improvement over the operations that the factorization performs without reordering. For a -by--by- mesh, the factorization performs operations. This is again an improvement, but the solution cost is too high for many applications.
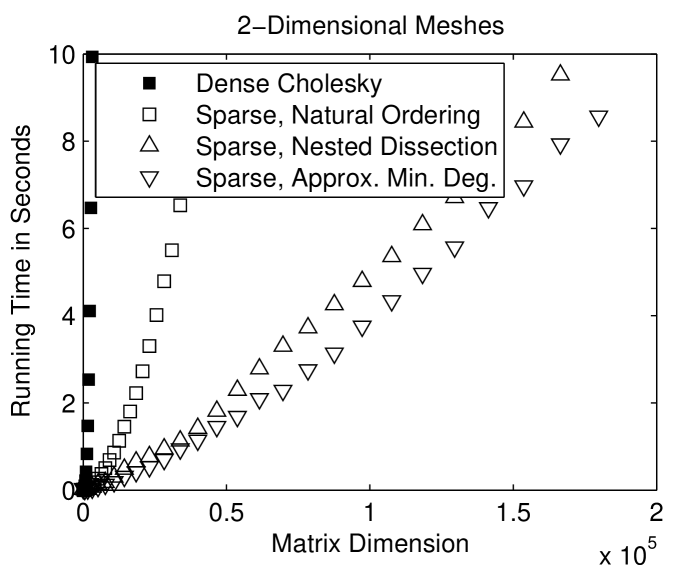
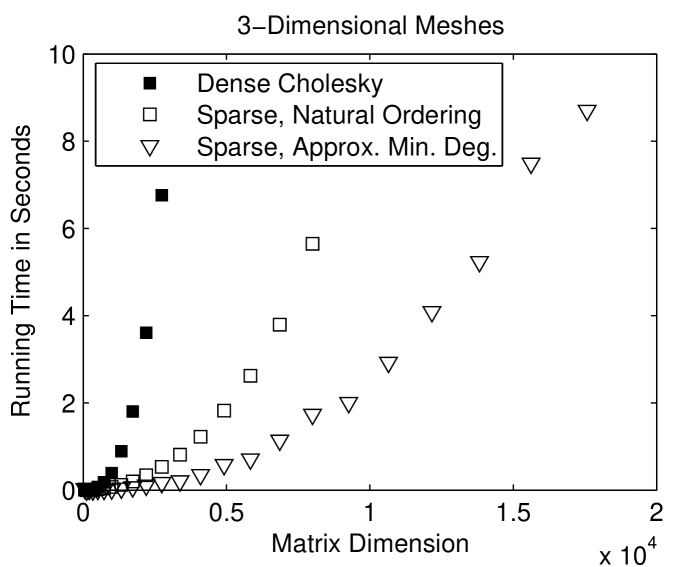
Figure 1.4.3 compares the running times of sparse Choesky applied to the natural ordering of the meshes and to fill-reducing orderings. The nested-dissection and minimum-degree orderings speed up the factorization considerably.
Unfortunately, nested-dissection-type orderings are usually the best we can do in terms of fill and work in sparse factorization of meshes, both structured and unstructured ones. A class of ordering heuristics called minimum-degree heuristics can beat nested dissection on small and medium-size meshes. On larger meshes, various hybrids of nested-dissection and minimum-degree are often more effective than pure variants of either method, but these hybrids have the same asymptotic behavior as pure nested-dissection orderings.
To asymptotically beat sparse Cholesky factorizations, we something more sophisticated than a factorization of the coefficient matrix.
1.5. Krylov-Subspace Iterative Methods
A radically different way to solve is to to find the vector that minimizes in a subspace of , the subspace that is spanned by . This subspace is called the Krylov subspace of and , and such solvers are called Krylov-subspace solvers. This idea is appealing because of two reasons, the first obvious and the other less so. First, we can create a basis for this subspace by repeatedly multiplying vectors by . Since our matrices, as well as many of the matrices that arise in practice, are so sparse, multiplying by a vector is cheap. Second, it turns out that when is symmetric, finding the minimizer is also cheap. These considerations, taken together, imply that the work performed by such solvers is proportional to . If converges quickly to , the total solution cost is low. But for most real-world problems, as well as for our meshes, convergence is slow.
The conjugate gradients method (cg) and the minimal-residual method (minres) are two Krylov-subspace methods that are appropriate for symmetric positive-definite matrices. Minres is more theoretically appealing, because it minimizes the residual in the -norm. It works even if is indefinite. Its main drawback is that it suffers from a certain numerically instability when implemented in floating point. The instability is almost always mild, not catastrophic, but it can slow convergence and it can prevent the method from converging to very small residuals. Conjugate gradients is more reliable numerically, but it minimizes the residual in the -norm, not in the -norm.
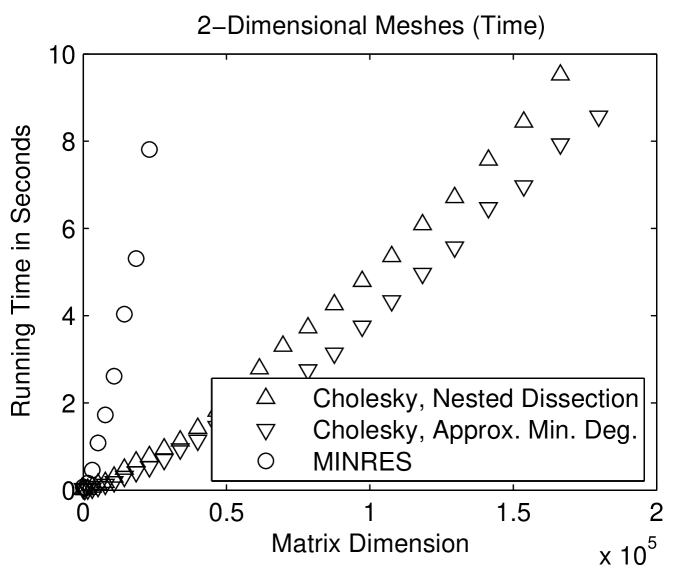
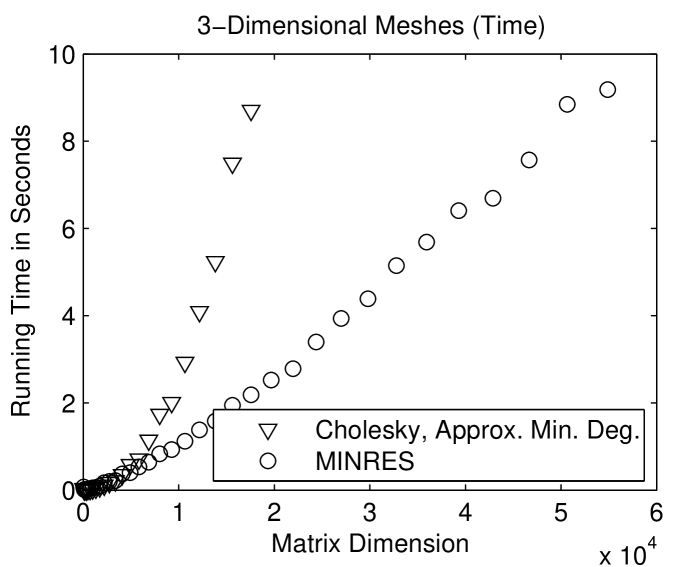
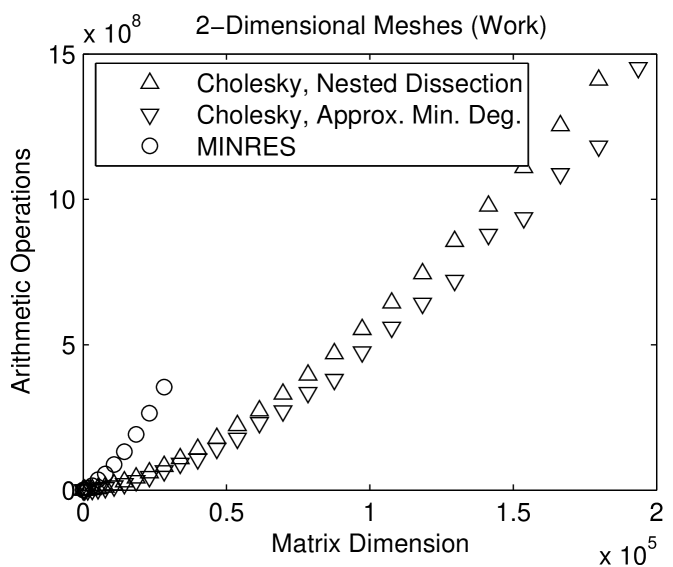
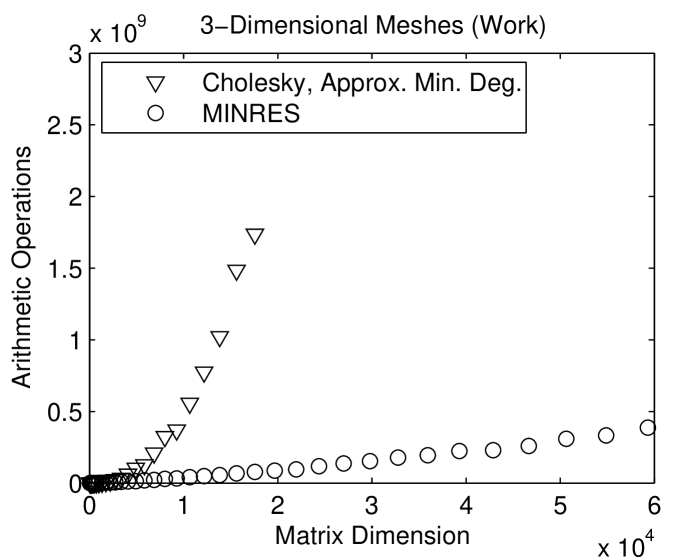
Figure 1.5.1 compares the performance of a sparse direct solver (with a fill-reducing ordering) with the performance of a minres solver. The performance of an iterative solver depends on the prescribed convergence threshold. Here we instructed the solver to halt once the relative norm of the residual
is or smaller. On 2-dimensional meshes, the direct solver is faster. On 3-dimensional meshes, the iterative solver is faster. The fundamental reason for the difference is the size of the smallest balanced vertex separators in 2- and 3-dimensional meshes. In a 2-dimensional mesh with a bounded aspect ratio, the smallest balanced vertex separator has vertices; in a 3-dimensional mesh, the size of the smallest separator is . The larger separators in 3-dimensional meshes cause the direct solver to be expensive, but they speed up the iterative solver. This is shown in Figure 1.5.2: minres converges after fewer iterations on 2-dimensional meshes than on 3-dimensional meshes. The full explanation of this behavior is beyond the scope of this chapter, but this phenomenon shows how different direct and iterative solvers are. Something that hurts a direct solver may help an iterative solver.
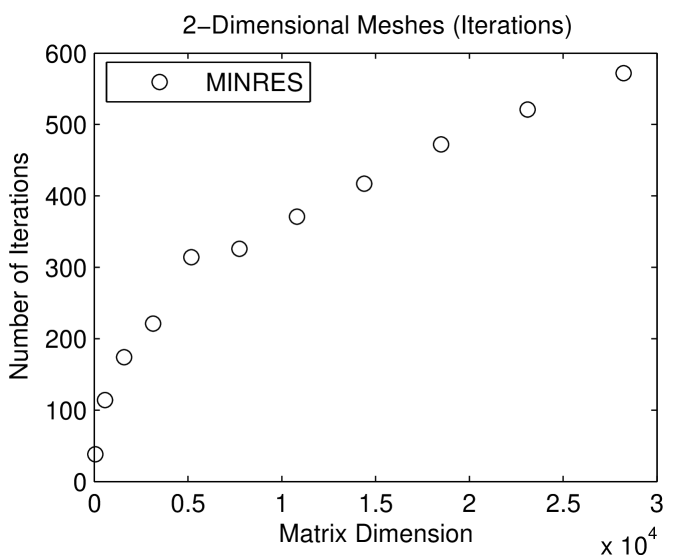
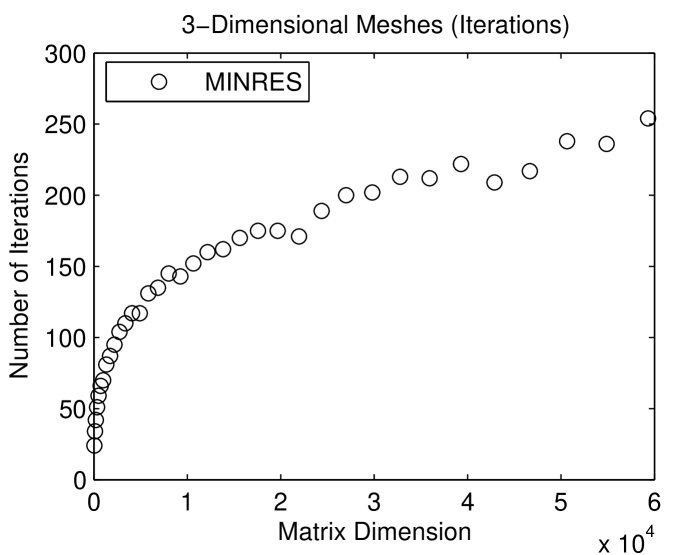
As long as is symmetric and positive definite, the performance of a sparse Cholesky solver does not depend on the values of the nonzero elements of , only on ’s nonzero pattern. The performance of an iterative solver, on the other hand, depends on the values of the nonzero elements. The behavior of minres displayed in Figures 1.5.1 and 1.5.2 depend on our way of assigning values to nonzero elements of .
Comparing the running times of sparse and iterative solvers does not reveal all the differences between them. The graphs that present the number of arithmetic operations, in Figure 1.5.1, reveal another aspect. The differences in the amount of work that the solvers perform are much greater than the differences in running times. This indicates that the direct solver performs arithmetic at a much higher rate than the iterative solver. The exact arithmetic-rate ratio is implementation dependent, but qualitatively, direct solvers usually run at higher computational rates than iterative solvers. Most of the difference is due to the fact that it is easier to exploit complex computer architectures, in particular cache memories, in direct solvers.
Another important difference between direct and iterative solvers is memory usage. A solver like minres only allocates a few -vectors. A direct solver needs more memory, because, as we have seen, the factors fill. The Cholesky factor of a 3-dimensional mesh contains nonzeros, so the memory-usage ratio between a direct and iterative solver worsens as the mesh grows.
1.6. Preconditioning
How can we improve the speed of Krylov-subspace iterative solvers? We cannot significantly reduce the cost of each iteration, because for matrices as sparse as ours, the cost of each iteration is only . There is little hope for finding a better approximation in the span of , because minres already finds the approximation that minimizes the norm of the residual.
To understand what can be improved, we examine simpler iterative methods. Given an approximate solution to the system , we define the error and the residual . The error is the required correction to ; if we add to , we obtain . We obviously do not know what is, but we know what is: it is , because
Computing the correction requires solving a linear system of equation whose coefficient matrix is , which is what we are trying to do in the first place. The situation seems cyclic, but it is not. The key idea is to realize that even an inexact correction can bring us closer to . Suppose that we had another matrix that is close to and such that linear systems of the form are much earsier to solve than systems whose coefficient matrix is . Then we could solve for a correction and set . Since , we can express directly in terms of ,
Therefore, if converges quickly to a zero matrix, then quickly towards . This is the precise sense in which must be close to : should converge quickly to zero. This happens if the spectral radius of is small (the spectral radius of a matrix is the maximal absolute value of its eigenvalues).
The convergence of more sophisticaded iterative methods, like minres and cg, can also be accelerated using this technique, called preconditioning. In every iteration, we solve a correction equation . The coefficient matrix of the correction equation is called a preconditioner. The convergence of preconditioned minres and preconditioned cg also depends on spectral (eigenvalue) properties associated with and . For these methods, it is not the spectral radius that determines the convergence rate, but other spectral properties. But the principle is the same: should be close to in some spectral metric.
In this book, we mainly focus on one family of methods to construct and analyze preconditioners. There are many other ways. The constructions that we present are called support preconditioners, and our analysis method is called support theory.
We introduce support preconditioning here using one particular family of support preconditioners for our meshes. These preconditioners, which are only effective for regular meshes whose edges all have the same weights (off-diagonals in all have the same value), are called Joshi preconditioners. We construct a Joshi preconditioner for a mesh matrix by dropping certain edges from the mesh, and then constructing a coefficient matrix for the sparsified mesh using the procedure given in Section 1.1. Figures 1.6.1 and 1.6.2 present examples of such sparsified meshes.
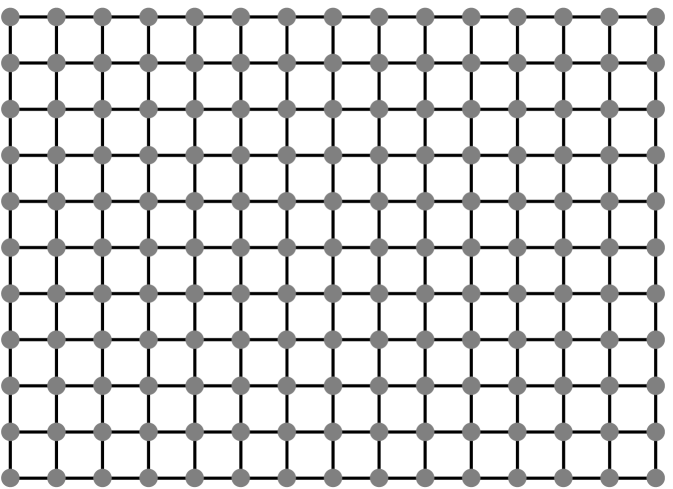
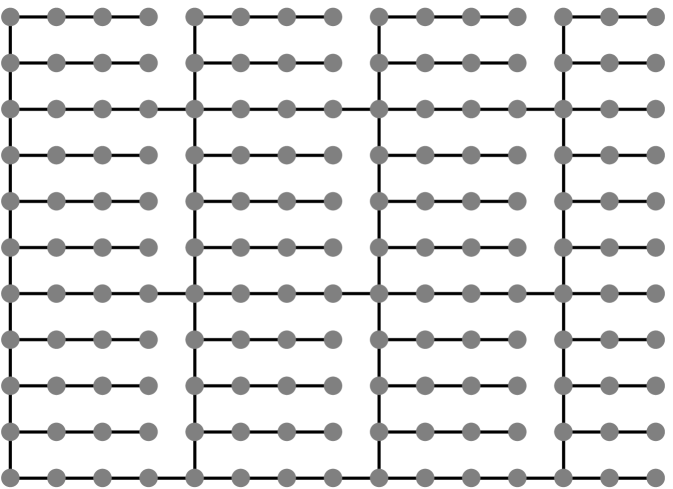
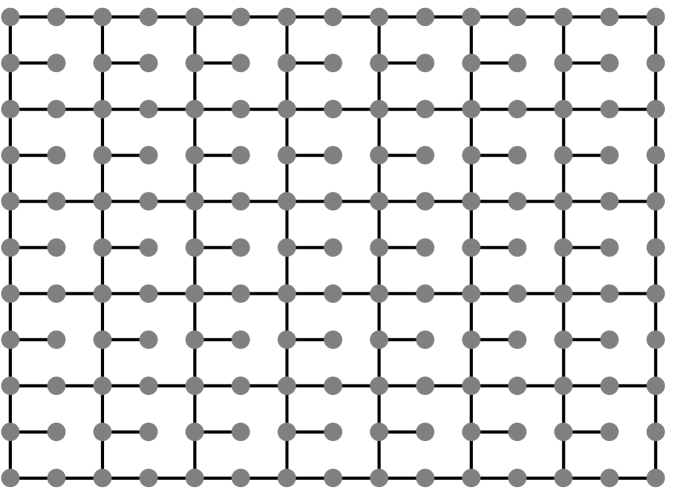

To solve the correction equations during the iterations, we compute the sparse Cholesky factorization of , where is a fill-reducing permutation for .
The construction of Joshi preconditioners depends on a parameter . For small , the mesh of the preconditioner is similar to the mesh of . In particular, for we obtain . As we shall see, Joshi preconditioners with a small lead to fast convergence rates. But Joshi preconditioners with a small do not have small balanced vertex separators, so their Cholesky factorization suffers from significant fill. Not as much as in the Cholesky factor of , but still significant. This fill slows down the preconditioner-construction phase of the linear solver, in which we construct and factor , and it also slows down each iteration. As gets larger, the similarity between the meshes diminishes. Convergence rates are worse than for small , but the factorization of and the solution of the correction equation in each iteration become cheaper. In particular, when is at least as large as the side of the mesh, the mesh of is a tree, which has single-vertex balanced separators; factoring it costs only operations, and its factor contains only nonzeros.
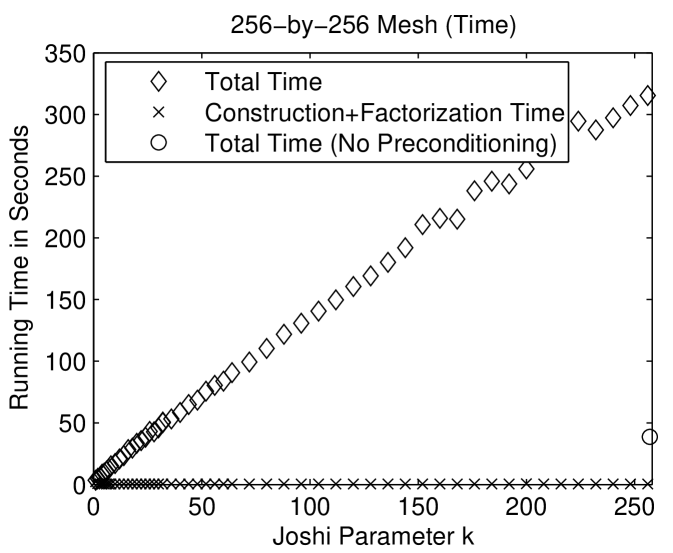
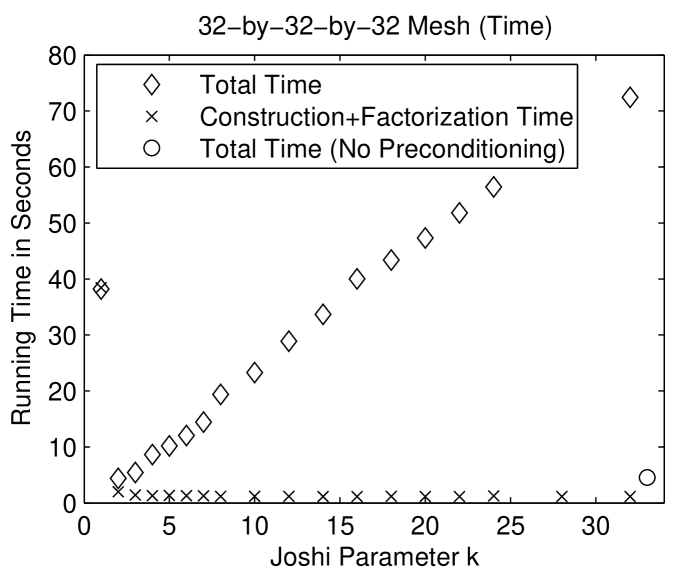
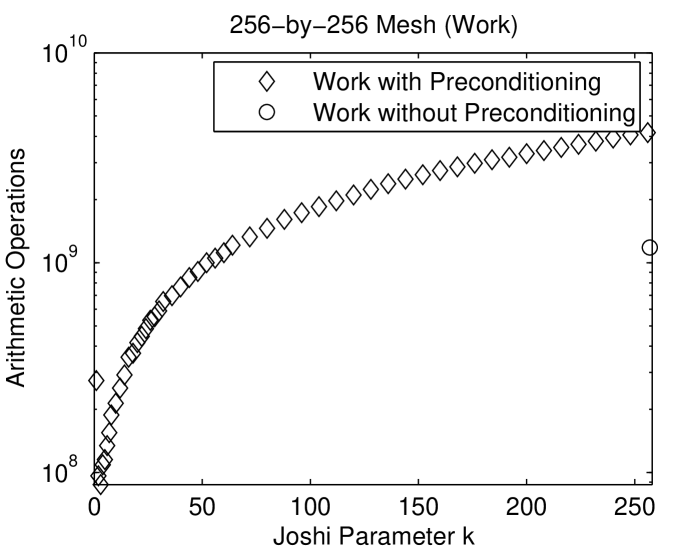
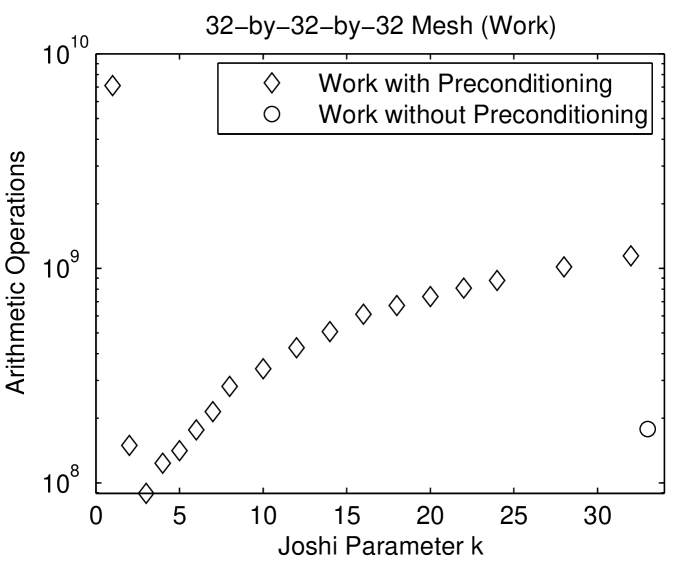
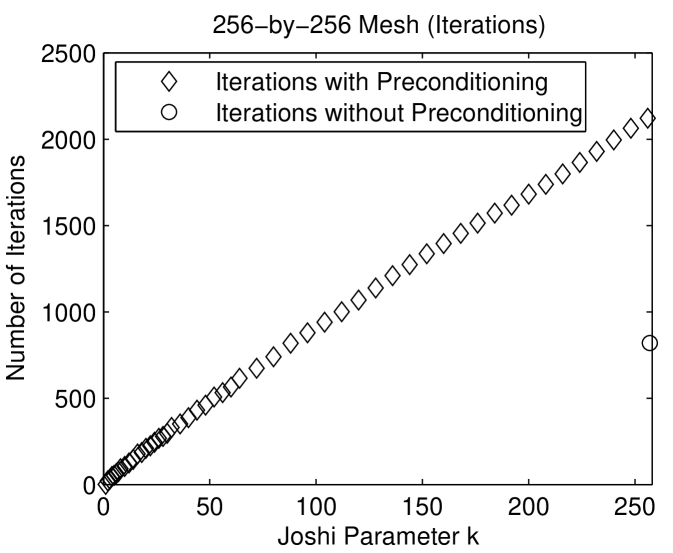
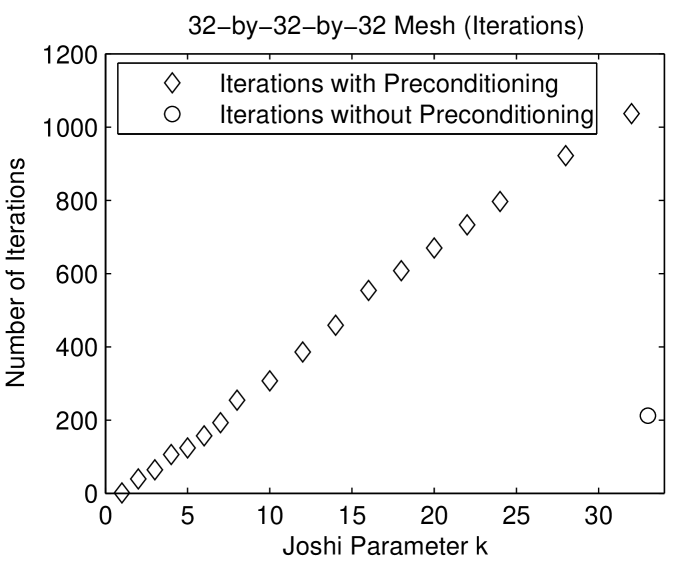
Figure 1.6.3 presents the performance of preconditioned minres with Joshi preconditioners on two meshes. On the three dimensional mesh, the preconditioned iterative solver is much faster than the direct solver and about as fast as the unpreconditioned minres solver. The preconditioned solver performs fewer arithmetic operations than both the direct solver and the unpreconditioned solver. In terms of arithmetic operations, the Joshi preconditioner for is the most efficient. For small , the preconditioned solvers perform fewer iterations than the unpreconditioned solver. The number of iteration rises with . Perhaps the most interesting aspect of these graphs is the fact that the cost of the factorization of drops dramatically from , where , to . Even slightly sparsifying the mesh reduces the cost of the factorization dramatically. The behavior on the 2-dimensional mesh is similar, except that in terms of time, the cost of the solver rises monotonically with . In particular, the direct solver is fastest. But in terms of arithmetic operations, the preconditioned solver with is the most efficient.
1.7. The Main Questions
We have now set the stage to pose the main questions in support theory and preconditioning. The main theme in support preconditioning is the construction of preconditioners using graph algorithms. Given a matrix , we model it as a graph . From the we build another graph , which approximates in some graph-related metric. From we build the preconditioner . The preconditioner is usually factored as preparation for solving correction equations , but sometimes the correction equation is also solved iteratively. This raises three questions
-
(1)
How do we model matrices as graphs?
-
(2)
Given two matrices and and their associated graphs and , how do we use the graphs to estimate or bound the convergence of iterative linear solvers in which preconditions ?
-
(3)
Given the graph of a matrix , how do we construct a graph in a metric that ensures fast convergence rates?
Support theory addresses all three questions: the modeling question, the analysis qustion, and the graph-approximation question.
The correspondence between graphs and matrices is usually an isomorphism, to allow the analysis to yield useful convergence-rate bounds. It may seem useless to transform one problem, the matrix-approximation probem, into a completely equivalent one, a graph-approximation question. It turns out, however, that many effective constructions only make sense when the problem is described in terms of graphs. They would not have been invented as matrix constructions. The Joshi preconditioners are a good example. They are highly structured when viewed as graph constructions, but would make little sense as direct sparse-matrix constructions. The analysis, on the other hand, is easier, more natural, and more general when carried out in terms of matrices. And so we transform the orignal matrix to a graph to allow for sophisticaed constructions, and then we transform the graphs back to matrices to analyze the convergence rate.
The preconditioning framework that we presented is the main theme of support theory, but there are other themes. The combinatorial and algebraic tools that were invented in order to develop preconditioners have also been used to analyze earlier preconditioners, to bound the extreme eigenvalues of matrices, to analyze the null spaces of matrices, and more.
Chapter 2 Iterative Krylov-Subspace Solvers
Preconditioned Krylov-subspace iterations are a key ingredient in many modern linear solvers, including in solvers that employ support preconditioners. This chapter presents Krylov-subspace iterations for symmetric semidefinite matrices. In particular, we analyze the convergence behavior of these solvers. Understanding what determines the convergence rate is key to designing effective preconditioners.
2.1. The Minimal Residual Method
The minimal-residual method (minres) is an iterative algorithm that finds in each iteration the vector that minimizes the residual in a subspace of . These subspaces, called the Krylov subspaces, are nested, , and the dimension of the subspace usually grows by one in every iteration, so the accuracy of the approximate solution tends to improve from one iteration to the next. The construction of the spaces is designed to allow an efficient computation of the approximate solution in every iteration.
Definition 1.
The Krylov subspace is the subspace that is spanned by the columns of the matrix . That is,
Once we have a basis for , we can express the minimization of in as an unconstrained linear least-squares problem, since
There are three fundamental tools in the solution of least squares problems with full-rank -by- coefficient matrices with . The first tool is unitary transformations. A unitary matrix preserves the -norm of vectors, for any (a square matrix with orthonormal columns, or equivalently, a matrix such that ). This allows us to transform least squares problem into equivalent forms
| (2.1.1) |
An insight about matrices that contain only zeros in rows through is the second tool. Consider the least squares problem
If the coefficient matrix has full rank, then the square block must be invertible. The solution to the problem is the vector that minimizes the Euclidean distance between and is minimal. But it is clear what is this vector: . This vector yields , and we clearly cannot any closer. The third tool combines the first two into an algorithm. If we factor into a product of a unitary matrix and an upper trapezoidal matrix , which is always possible, then we can multiply the system by to obtain
We can now compute the minimizer by substitution. Furthermore, the norm of the residual is given by .
In principle, we could solve (2.1.1) for using a factorization of . Once we find , we can compute . There are, however, two serious defects in this approach. First, it is inefficient, because is dense. Second, as grows, tends to the subspace spanned by the dominant eigenvectors of (the eigenvectors associated with the eigenvalues with maximal absolute value). This causes to become ill conditioned; for some vectors with , the vector such that has huge elements. This phenomenon will happen even if we normalize the columns of to have unit norm, and it causes instabilities when the computation is carried out using floating-point arithmetic.
We need a better basis for for stability, and we need to exploit the special properties of for efficiency. Minres does both. It uses a stable basis that can be computed efficiently, and it it combines the three basic tools in a clever way to achieve efficiency.
An orthonormal basis for would work better, because for we would have . There are many orthonormal bases for . We choose a particular basis that we can compute incrementally, one basis column in each iteration. The basis that we use consists of the columns of the factor from the factorization of , where is orthonormal and is upper triangular. We compute using Gram-Schmidt orthogonalization. The Gram-Schmidt process is not always numerically stable when carried out in floating-point arithmetic, but it is the only efficient way to compute one column at a time.
We now show how to compute, given , the next basis column . The key to the efficient computation of is the special relationship of the matrices with . We assume by induction that and that . If , then it is not hard to show that the exact solution is in , so we would have found it in one of the previous iterations. If we reached iteration , then , so . Expanding the last column of , we get
We now isolate to obtain
so
Because , clearly . Furthermore, if we reached iteration , then , because if then . Therefore, we can orthogonalize with respect to and normalize to obtain
These expressions allows us not only to compute , but also to express as a linear combination of ,
where , and where for . The same argument also holds for , so in matrix terms,
The matrix is upper Hessenberg: in column , rows to are zero. If we multiply both sides of this equation from the left by , we obtain
We denote the first rows of by to obtain
Because is symmetric, must be symmetric, and hence tridiagonal. The symmetry of implies that in column of and , rows through are also zero. This is the key to the efficiency of minres and similar algorithms, because it implies that for , ; we do not need to compute these inner products and we do not need to subtract from in the orthogonalization process. As we shall shortly see, we do not even need to store for .
Now that we have an easy-to-compute orthonormal basis for , we return to our least-squares problem
Our strategy now is to compute the minimizer from the expression in the last line. Once we compute , the minimizer in is . To compute the minimizer, we use the equality
where is the first unit vector. The equality holds because is the orthogonal factor in the factorization of , whose first column is . To solve this least-squares problem, we will use a factorization of : the minimizer is then defined by . Because is triadiagonal we can compute its factorization with a sequence of of Givens rotations, where the th rotation transforms rows and of and of . A Given rotation is a unitary matrix of the form
We choose so as to anihilate the subdiagonal element in column of .
One difficulty that arises is that changes completely in every iteration, so to form , we need to either store all the columns of to produce the approximate solution , or to recompute again once we obtain a that ensures a small-enough residual. Fortunately, there is a cheaper alternative that only requires storing a constant number of vectors. Let , and let . Instead of solving for , we only compute . Because the the rotation only transforms rows and of , we can compute one entry at a time. Since , we can accumulate using the columns of . We compute the columns of one at a time using the triangular linear system ; in iteration , we compute the last column of from and the last column of .
minres()
the first column
of
the first element
of the vector
for until convergence
compute
Apply rotation to
if then else
Apply rotation to
if then
else
compute , the Givens rotation such
that
Apply rotation to
Apply rotation to form
next column of
end for
2.2. The Conjugate Gradients Algorithm
Minres is a variant of an older and more well-known algorithm called the Conjugate Gradients method (cg). The Conjugate Gradients method is only guaranteed to work when is symmetric positive definite, whereas minres only requires to be symmetric. Conjugate Gradients also minimizes the norm of the residuals over the same Krylov subspaces, but not the -norm but the -norm,
This is equivalent to minimizing the -norm of the error,
Minimizing the -norm of the residual may seem like an odd idea, because of the dependence on in the measurement of the residual and the error. But there are several good reasons not to worry. First, we use the -norm of the residual as a stoping criterion, to stop the iterations only when the -norm is small enough, not when the -norm is small. Second, even when the stopping criterion is based on the -norm of the residual, Conjugate Gradients usually converges only slightly slower than minres. Still, the minimization of the -norm of the residual in minres is more elegant.
Why do people use Conjugate Gradients if minres is more theoretically appealing? The main reason that that the matrices and that are used in minres to form can be ill conditioned. This means that in floating-point arithmetic, the computed are not always accurate minimizers. In the Conjugate Gradients method, the columns of the basis matrix (the equivalent of ) are -conjugate, not arbitrary. This reduces the inaccuracies in the computation of the approximate solution in each iterations, so the method is numerically more stable than minres.
We shall not derive the details of the Conjugate Gradient method here. The derivation is similar to that of minres (there are also other ways to derive cg), and is presented in many textbooks.
2.3. Convergence-Rate Bounds
The appeal of Krylov-subspace iterations stems to some extent from the fact that their convergence is easy to understand and to bound.
The crucial step in the analysis is the expression of the residual as a application of a univariate polynomial to and a multiplication of the resulting matrix by . Since , for some . That is, . Therefore,
If we denote , we obtain .
Definition 2.
Let be an approximate solution of and let be the corresponding residual. The polynomial such that is called the solution polynomial of the iteration and the polynomial is called the residual polynomial of the iteration.
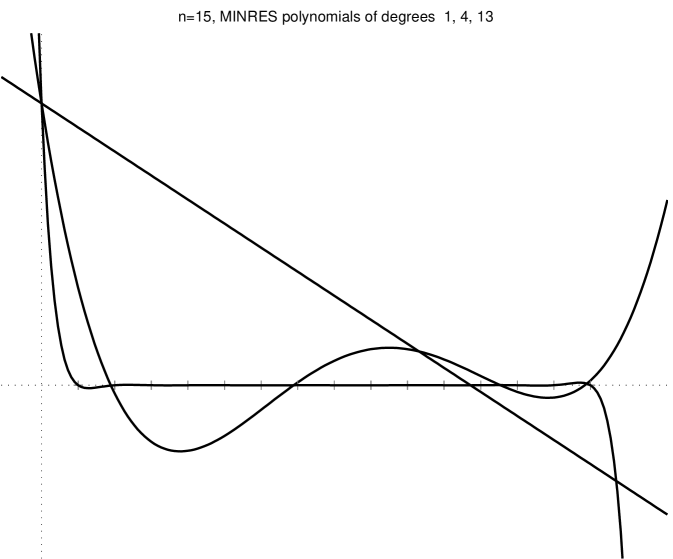
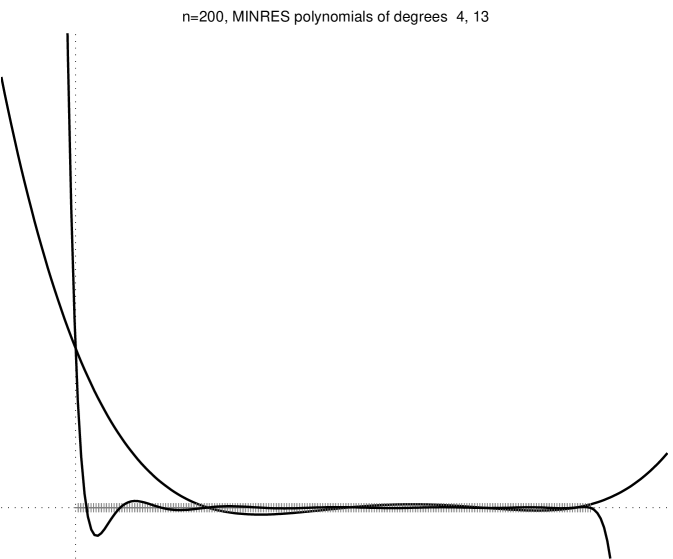
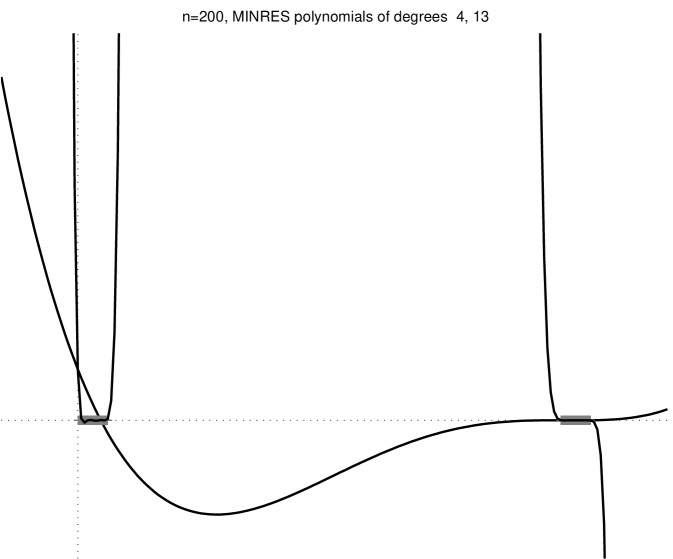
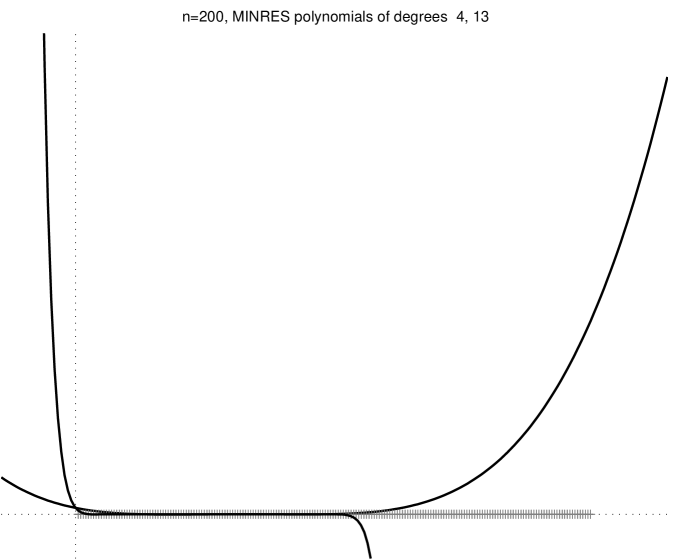
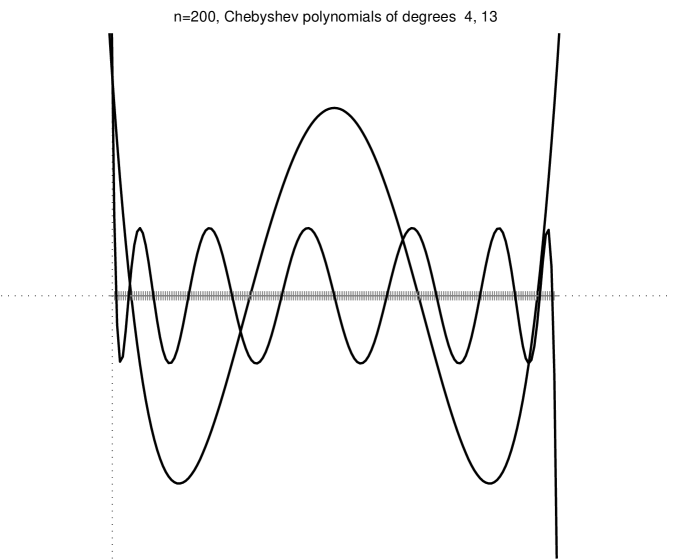
Figure 2.3.1 shows several minres residual polynomials.
 |
 |
 |
 |
We now express in terms of the eigendecomposition of . Let be an eigendecomposition of . Since is Hermitian, is real and is unitary. We have
so
| (2.3.1) |
We can obtain several bounds on the norm of the residual from this expression. The most important one is
The last equality follows from the facts that is a diagonal matrix and that the -norm of a diagonal matrix is the largest absolute value of an element in it. This proves the following result.
Theorem 3.
The relative -norm of the residual in the th iteration of minres,
is bounded by for any univariate polynomial of degree such that , where the ’s are the eigenvalues of .
We can strenghen this result by noting that if is a linear combination of only some of the eigenvectors of , then only the action of on corresponding eigenvalues matters (not on all the eigenvalues). An example of this behavior is shown in the bottom-right plot of Figure 2.3.1. More formally, from (2.3.1) we obtain
In general, if is orthogonal or nearly orthogonal to an eigenvector of , then the product can be small even if is quite large. But since right-hand sides with this property are rare in practice, this stronger bound is not useful for us.
Theorem 3 states that if there are low-degree polynomials that are low on the eigenvalues of and assume the value at , the minres converges quickly. Let us examine a few examples. A degree- polynomial can satisfy and simulteneously for any set of nonzero eigenvalues . Therefore, in the absense of rounding errors minres must converge after iterations to the exact solution. We could also derive this exact-convergence result from the fact that , but the argument that we just gave characterizes the minres polynomials at or near convergence: their roots are at or near the eigenvalues of . If has repeated eigenvalues, then it has fewer than distinct eigenvalues, so we expect exact convergence after fewer than iterations. Even if does not have repeated eigenvalues, but it does have only a few tight clusters of eigenvalues, then minres will converge quickly, because a polynomial with one root near every cluster and a bounded derivative at the roots will assume low values at all the roots. On the other hand, a residual polynomial cannot have small values very close to , because it must assume the value at . These examples lead us to the most important observation about Krylov-subspace solvers:
Symmetric Krylov-subspace iterative methods for solving linear systems of equations converge quickly if the eigenvalues of form a few tight clusters and if does not have eigenvalues very close to .
Scaling both and can cluster the eigenvalues or move them away from zero, but has no effect at all on convergence. Scaling up and moves the eigenvalues away from zero, but distributes them on a larger interval; scaling and down clusters the eigenvalues around zero, but this brings them closer to zero. Krylov-subspace iterations are invariant to scaling.
This observation leads to two questions, one analytic and one constructive: (1) Exactly how quickly does the iteration converges given some characterization of the spectrum of ? (2) How can we alter the specturm of in order to accelerate convergence? We shall start with the second question.
2.4. Preconditioning
Suppose that we have a matrix that approximates (in a sense that will become clear shortly), and whose inverse is easier to apply than the inverse of . That is, linear systems of the form are much easier to solve for than linear systems . Perhpas the sparse Cholesky factorization of is cheaper to compute than ’s, and perhaps there is another inexpensive way to apply to . If approximates in the sense that is close to the identity, then an algorithm like minres will converge quickly when applied to the linear system
| (2.4.1) |
because the eigenvalues of the coefficient matrix are clustered around . We will initialize the algorithm by computing the right-hand side , and in every iteration we will multiply by and then apply to the product. This technique is called preconditioning.
The particular form of preconditioning that we used in (2.4.1) is called left preconditioning, because the inverse of the preconditioner is applied to both sides of from the left. Left preconditioning is not appropriate to algorithms line minres and Conjugate Gradients that exploit the symmetry of the coefficient matrix, because in general is not symmetric. We could replace minres by a Krylov-subspace iterative solver that is applicable to unsymmetric matrices, but this would force us to give up either the efficiency or the optimality of minres and Conjugate Gradients.
Fortunately, if is symmetric positive definite, then there are forms of preconditioning that are appropriate for symmetric Krylov-subspace solvers. One form of symmetric preconditioning solves
| (2.4.2) |
for . A clever transformation of Conjugate Gradients yields an iterative algorithm in which the matrix that generates the Krylov subspace is , but which only applies and in every iteration. In other words, is never used, not even as a linear operator. We shall not show this transformation here.
We will show how to use a simpler but equally effective form of preconditioning. Let be the Cholesky factorization of . We shall solve
| (2.4.3) |
for using minres, and then we will solve by substitution. To form the right-hand side , we solve for it by substitution as well. The coefficient matrix is clearly symmetric, so we can indeed apply minres to it. To apply the coefficient matrix to in every iteration, we apply by substitution, apply , and apply by substitution.
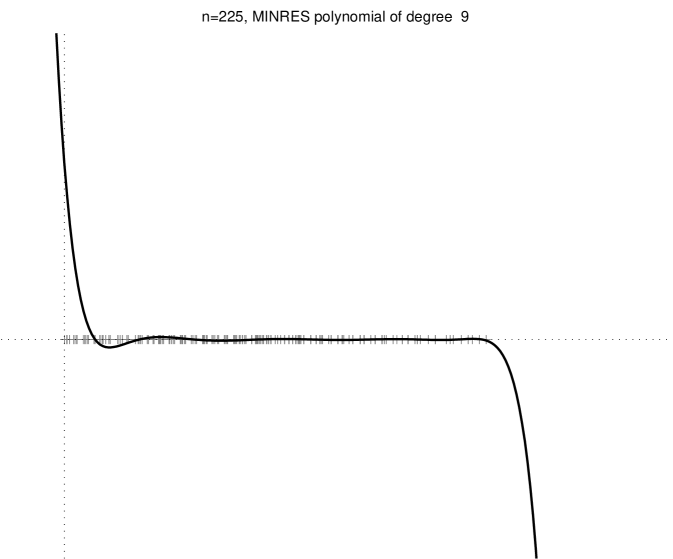 |
Figure 2.4.1 shows the spectrum and one minres polynomial for two matrices: a two-dimensional mesh and the same mesh preconditioned as in (2.4.3) with a Joshi preconditioner . We can see that this particular preconditioner causes three changes in the spectrum. The most important change is the small eigenvalues of are much larger than the small eigenvalues of . This allows the minres polynomial to assume much smaller vaues on the spectrum. The minres polynomials must assume the value at , so they tend to have large values on the neighborhood of as well. Therefore, a specturm with larger smallest eigenvalues leads to faster convergence. Indeed, the preconditioned problem decreased the size of the residual by a factor in iterations, whereas the unpreconditioned problem took iterations to achieve a residual with a similar norm. Two other changes that the preconditioner caused are a large gap in the middle of the spectrum, which is a good thing, and a larger largest eigenvalue, which is not. But these two changes are probably less important than the large increase in the smallest eigenvalues.
The different forms of preconditioning differ in the algorithmic details of the solver, but they all have the same spectrum.
Theorem 4.
Let be a symmetric matrix and let be a symmetric positive-definite matrix. A scalar is either an eigenvalue of all the following eigenvalue problems or of none of them:
Proof.
The following relations prove the equivalence of the specta:
∎
We can strengthen this theorem to also include certain semidefinite preconditioners.
Theorem 5.
Let be a symmetric matrix and let be a symmetric positive-semidefinite matrix such that . Denote by the pseudo-inverse of a matrix . A scalar is either an eigenvalue of all the following eigenvalue problems or of none of them:
Proof.
We note that . Therefore, is an eigenvalue of all the above problems. If is an eigenvalue of one of the above problems, then the corresponding eigenvector is not in . This implies that the relations defined in the proof of Theorem 4, with inverses replaced by pseudo-inverses, define relations between nonzero vectors. Therefore, is an eigenvalue of all the eigenvalue problems. ∎
Even though the different forms of preconditioning are equivalent in terms of the spectra of the coefficient matrices, they are different algorithmically. If symmetry is not an issue (e.g., if itself is unsymmetric), the form is the most general. When is symmetric, we usually require that is symmetric positive-definite (or semi-definite with the same null space as ). In this case, the form , when coupled with the transformation that allows multiplications only by (and not by ), is more widely applicable than the form , because the latter requires a Cholesky factorization of , whereas in the former any method of applying can be used.
One issue that arizes with any form of preconditioning is the definition of the residual. If we apply minres to , say, it minimizes the -norm of the preconditioned residual
Thus, the true residual in preconditioned minres may not be minimal. This is roughly the same issue as with the norms used in Conjugate Gradients: we minimize the residual in a norm that is related to .
2.5. Chebyshev Polynomials and Convergence Bounds
The link between Krylov-subspace iterations and polynomials suggests another idea. Given some information on the spectrum of , we can try to analytically define a sequence of solution polynomials such that for any the vector is a good approximation to , the exact solution of . More specifically, we can try to define such that the residuals are small. We have seen that the residual can be expressed as , where is the residual polynomial. Therefore, if is such that assumes low values on the eigenvalues of and satisfies , then is a good approximate solution. This idea can be used both to construct iterative solvers and to prove bounds on the convergence of methods like minres and Conjugate Gradients.
One obvious problem is that we do not know what the eigenvalues of are. Finding the eigenvalues is more difficult than solving . However, in some cases we can use the structure of (even with preconditioning) to derive bounds on the smallest and largest eigenvalues of a positive-definite martrix , denoted and .
Suppose that we somehow obtained bounds on the extereme eigenvalues of ,
We shall not discuss here how we might obtain and ; this is the topic of much of the rest of the book. It turns out that we can build a sequence of polynomials such that
-
(1)
, and
-
(2)
is as small as possible for a degree polynomial with value at .
The polynomials that solve this optimization problem are derived from Chebyshev polynomials, which can be defined using the recurrence
The polynomials that reduce the residual are
An Iterative Linear Solver based on Chebyshev Polynomials
Our first application of Chebyshev polynomials is an iterative Krylov-subspace solver based on them. We will refer to this solver as the Krylov-Chebyshev solver111The algorithm that we describe below is related to a more well-known Chebychev linear solver that is used with matrix splittings.. The polynomials implicitly define polynomials that we can use to construct approximate solutions. The residual for an approximate solution is . If we define , we have .
We now derive recurrences for and . To keep the notation simple, we define and . For the two base cases we have
This implies that
For we have
To compute from this recurrence, we need and , three elements of the sequence , and one multiplication of a vector by . Therefore, we can compute and concurrently in a loop. From the recurrence for we can derive a recurrence for ,
so
 |
This algorithm converges more slowly than minres and Conjugate Gradients. Minres is guaranteed to minimize the residual over all in . The solution that we obtain from the Krylov-Chebyshev recurrences is in , so it cannot yield a smaller residual than the minres solution. Its main algorithmic advantage over minres and Conjugate Gradients is that the polynomials that it produces depend only on and on and , but they do not depend on . Therefore, is a fixed linear operator, so it can be used as a preconditioner . In contrast, the polynomials that minres and Conjugate Gradients generate depend on , so we cannot use these solvers as preconditioners unless we set very strict convergence bounds, in which case an application of these solvers is numerically indistiguishable from an application of .
Since this algorithm does not exploit the symmetry of , it can be used with left preconditioning, not only with symmetric forms of preconditioning.
Chebyshev-Based Convergence Bounds
We can also use the Chebyshev iteration to bound the convergence of minres and Conjugate Gradients. The key is the following theorem, which we state without a proof.
Theorem 6.
Let be the Chebyshev polynomials defined above with respect to the interval . Denote by the ratio . For any we have
In this theorem, are arbitrary positive numbers that denote then end of the inteval that defines . But when these numbers are the extreme eigenvalues of a symmetric positive definite matrix, the ratio plays an important-enough role in numerical linear algebra to deserve a name.
Definition 7.
Let be a symmetric semidefinite matrix, and let and be its extreme nonzero eigenvalue. The ratio
is called the spectral condition number of . The definition
generalizes the condition number to any matrix and to any norm.
We can use Theorem 6 to bound the residuals in minres.
Theorem 8.
Consider the application of minres to the linear system . Let be the minres residual at iteration . Then
Proof.
The residual is the minimal residual for any . Let be the Krylov-Chebyshev residual for and and let be the Krylov-Chebyshev residual polynomial. Let be an eigendecomposition of . The theorem follows from the following inequalities.
∎
Similar results can be stated for the error and residual of Conjugate Gradients in the and norms, respectively.
For small , we can expect convergence to a fixed tolerance, say within a constant number of iterations. As grows,
so we are guaranteed convergence to a fixed tolerance within iterations.
Chapter 3 Computing the Cholesky Factorization of Sparse Matrices
In many support preconditioners, the preconditioner is factored before the iterations begin. The Cholesky factorization of allows us to efficiently solve the correction equations . This chapter explains the principles behind the factorization of sparse symmetric positive definite matrices.
3.1. The Cholesky Factorization
We first show that the Cholesky factorization of a symmetric positive-definite (spd) matrix always exists.
A matrix is positive definite if for all . The same definition extends to complex Hermitian matrices. The matrix is positive semidefinite if for all and for some .
To prove the existence of the factorization, we use induction and the construction shown in Chapter XXX. If is -by-, then , so , so it has a real square root. We set and we are done. We now assume by induction that all spd matrices of dimension or smaller have a Cholesky factorization. We now partition into a -by- block matrix and use the partitioning to construct a factorization,
Because is spd, must also be spd. If it is not positive definite, then a vector such that can be extended with zeros to a vector such that . Therfore, has a Choleskyh factor by induction. The Cholesky factor of a nonsingular matrix must be nonsingular, so we can define ( denotes the inverse of ). The key step in the proof is to show that the Schur complement is also positive definite. Suppose for contradition that it is not, and let be such that . We define
Now we have
which is impossible, so our supposition was wrong. Because is spd, it has a Cholesky factor by induction. The three blocks , , and form a Cholesky factor for , since
Symmetric positive semidefinite (spsd) matrices also have a Cholesky factorization, but in floating-point arithmetic, it is difficult to compute a Cholesky factor that is both backward stable and has the same rank as . To see that a factorization exists, we modify the construction as follows. If is -by-, then if it is singular than it is exactly zero, in which case we can set . Otherwise, we partition , selecting to be -by-. If , then it is invertible and we can continue with the same proof, except that we show that the Schur complement is semidefinite, not definte. If , then it is not hard to show that must be zero as well. This implies that the equation is zero on both sides for any choice of . We set and continue.
The difficulty in a floating-point implementation lies in deciding whether a computed would be zero in exact arithmetic. In general, even if the next diagonal element in exact arithmetic, in floating-point it might be computed as a small nonzero value. Should we round it (and ) to zero? Assuming that it is a nonzero when in fact is should be treated is a zero leads to an unstable factorization. The small magnitude of the computed can cause the elements of to be large, which leads to large inaccuracies in the Schur complement. On the other hand, rounding small values to zero always leads to a backward stable factorization, since the rounding is equivalent to a small perturbation in . But rounding a column to zero when the value in exact arithmetic is not zero causes the rank of to be smaller than the rank of . This can later cause trouble, since some vectors that are in the range of are not in the range of . In such a case, there is no such that even if is consistent.
3.2. Work and Fill in Sparse Cholesky
When is sparse, operations on zeros can be skipped. For example, suppose that
There is no need to divide by to obtain (the element in row and column ; from here on, expressions like denote matrix elements, not submatrices). Similarly, there is no need to subtract from the , the second diagonal element. If we represent zeros implicitly rather than explicitly, we can avoid computations that have no effect, and we can save storage. How many arithmetic operations do we need to perform in this case?
Definition 9.
We define to be the number of nonzero elements in a matrix . We define to be the number of arithmetic operations that some algorithm performs on an input matrix , excluding multiplications by zeros, divisions of zeros, additions and subtractions of zeros, and taking square roots of zeros. When the algorithm is clear from the context, we drop the subscript in the notation.
Theorem 10.
Let be a sparse Cholesky factorization algorithm that does not multiply by zeros, does not divide zeros, does not add or subtract zeros, and does not compute square roots of zeros. Then for a symmetric positive-definite matrix with a Cholesky factor we have
Proof.
Every arithmetic operation in the Cholesky factorization involves an element or two from a column of : in square roots and divisions the output is an element of , and in multiply-subtract the two inputs that are multiplied are elements from one column of . We count the total number of operations by summing over columns of .
Let us count the operations in which elements of are involved. First, one square root. Second, divisions of by that square root. We now need to count the operations in which elements from this column update the Schur complement. To count these operations, we assume that the partitioning of is into a -by- block matrix, in which the first diagonal block consists of rows and columns and the second of . The computation of the Schur complement is
This is the only Schur-complement computation in which is involved under this partitioning of . It was not yet used, because it has just been computed. It will not be used again, because the recursive factorization of the Schur complement is self contained. The column contributes one outer product . This outer product contains nonzero elements, but it is symmetric, so only its lower triangle needs to be computed. For each nonzero element in this outer product, two arithmetic operations are performed: a multiplication of two elements of and a subtraction of the product from another number. This yields the total operation count. ∎
Thus, the number of arithmetic operations is asymptotically proportional to the sum of squares of the nonzero counts in columns of . The total number of nonzeros in is, of course, simply the sum of the nonzero counts,
This relationship between the arithmetic operation count and the nonzero counts shows two things. First, sparser factors usually (but not always) require less work to compute. Second, a factor with balanced nonzero counts requires less work to compute than a factor with some relatively dense columns, even if the two factors have the same dimension and the same total number of nonzeros.
The nonzero structure of and does not always reveal everything about the sparsity during the factorization. Consider the following matrix and its Cholesky factor,
The element in position is zero in and in , but it might fill in one of the Schur complements. If we partition into two -by- blocks, this element never fills, since
However, if we first partition into a -by- block and a -by- block, then the element fills in the Schur complement,
When we continue the factorization, the element in the Schur complement must cancel exactly by a subsequent subtraction, because we know it is zero in (The Cholesky factor is unique). This example shows that an element can fill in some of the Schur complements, even if it zero in . Clearly, even an position that is not zero in can become zero in due to similar cancelation. For some analyses, it helps to define fill in a way that accounts for this possibility.
Definition 11.
A fill in a sparse Cholesky factorization is a row-column pair such that and which fills in at least one Schur complement. That is, and for some .
3.3. An Efficient Implemention of Sparse Cholesky
To fully exploit sparsity, we need to store the matrix and the factor in a data structure in which effect-free operations on zeros incur no computational cost at all. Testing values to determine whether they are zero before performing an arithmetic operation is a bad idea: the test takes time even if the value is zero (on most processor, a test like this takes more time than an arithmetic operation). The data structure should allow the algorithm to implicitly skip zeros. Such a data structure increases the cost of arithmetic on nonzeros. Our goal is to show that in spite of the overhead of manipulating the sparse data structure, the total number of operations in the factorization can be kept proportional to the number of arithmetic operations.
Another importan goal in the design of the data structure is memory efficiency. We would like the total amount of memory required for the sparse-matrix data structure to be proportional to the number of nonzeros that it stores.
Before we can present a data structure that achieves these goals, we need to reorder the computations that the Cholesky factorization perform. The reordered variant that we present is called column-oriented Cholesky. In the framework of our recursive formulations, this variant is based on repartitioning the matrix after the elimination of each column. We begin with a partitioning of into the first row and column and the rest of the matrix,
We compute and divide to by the root to obtain . Now comes the key step. Instead of computing all the Schur complement , we compute only its first column, . The first column of the Schur complement allows us to compute the second column of . At this point we have computed the first two columns of and nothing else. We now view the partitioning of as
We have already computed and . We still need to compute . We do so in the same way: computing the first column of the Schur complement and eliminating it. The algorithm, ignoring sparsity issues, is shown in Figure XXX.
for
end
We now present a data structure for the efficient implementation of sparse column-oriented Cholesky. Our only objective in presenting this data structure is show that sparse Cholesky can be implemented in time proportional to arithmetic operations and in space proportional to the number of nonzeros in and . The data structure that we present is not the best possible. Using more sophisticated data structures, the number of operations in the factorization and the space required can be reduced further, but not asymptotically.
We store using an array of linked lists. Each linked list stores the diagonal and subdiagonal nonzeros in one column of . Each structure in the linked-list stores the value of one nonzero and its row index. There is no need to store the elements of above its main diagonal, because (1) is symmetric, and (2) column-oriented Cholesky never references them. There is also no need to store the column indices in the linked-list structures, because each list stores elements from only one column. The linked lists are ordered from low row indices to high row indices.
We store the already-computed columns of redundantly. One part of the data structure, which we refer to as columns, stores the columns of in exactly the same way we store . The contents of the two other parts of the data structure, called cursors and rows, depend on the number of columns that have already been computed. Immediately before step begins, these parts contains the following data. Cursors is an array of pointers. The first pointers, if set, point to linked-list elements of columns. points to the first element with row index larger than in , if there is such an element. If not, it is not set (that is, it contains a special invalid value). The other elements of cursors are not yet used. Like columns, rows is an array of linked list. The th list stores the elements of , but in reverse order, from high to low column indices. Each element in such a list contains a nonzero value and its column index.
The column of the Schur complement is represented by a data structure s called a sparse accumulator. This data structure consists of an array s.values of real or complex numbers, an array s.rowind of row indices, and array s.exists of booleans, and an integer s.nnz that specifies how many rows indices are actually stored in s.rowind.
Here is how we use these data structures to compute the factorization. Step begins by copying to s. To do so, we start by setting s.nnz to zero. We then traverse the list that represents . For a list element that represents , we increment s.nnz, store in store in , and set to a true value.
Our next task is to subtract from . We traverse to find the nonzero elements in . For each nonzero that we find, we subtract from . To subtract, we traverse starting from . Let be a nonzero found during this traversal. To subtract from , we first check whether is true. If it is, we simply subtract from . If not, then was zero until now (in step ). We increment s.nnz, store in store in , and set to a true. During the traversal of , we many need to advance to prepare it for subsequent steps of the algorithm. If the first element that we find in the travelral has row index , we advance to the next element in . Otherwise, we do not modify .
Finally, we compute and insert it into the nonzero data structure that represents . We replace by its square root. For each rows index stored in one of the first entries of , we divide by . We now sort elements though of , to ensure that the elements are linked in ascending row order. We traverse the row indices stored in . For each index such that , we allocate a new element for , link it to the previous element that we created, and store in it and . We also set to false, to prepare it for the next iteration.
We now analyze the number of operations and the storage requirements of this algorithm.
Theorem 12.
The total number of operations that the sparse-cholesky algorithm described above performs is . The amount of storage that the algorithm uses, including the representation of its input and output, is .
Proof.
Let’s start with bounding work. Step starts with copying column of into the sparse accumulator, at a total cost of . No aritmetic is performed, but we can charge these operations to subsequent arithmetic operations. If one of these values is modified in the accumulator, we charge the copying to the subsequent multiply-subtract. If not, we charge it to either the square root of the diagonal element or to the division of subdiagonal elements. We cannot charge all the copying operations to roots and divisions, becuase some of the copied elements might get canceled before they are divided by .
The traversal of and the subtractions of scaled columns of from the accumulator are easy to account for. The processing of an element of is charged to the modification of the diagonal, . The traversal of the suffix of performs arithmetic operations and non-arithmetic operations, so all operations are accounted for.
After the column of the Schur complement is computed, the algorithm computes a square root, scales elements, sorts the indices of , and creates a linked-list to hold the elements of . The total number of operations in these computations is clearly , even if we use a quadratic sorting algorithm, so by using Theorem 10, we conclude that the operation-count bound holds.
Bounding space is easier. Our data structure includes a few arrays of length and linked lists. Every linked-list element represents a nonzero in or in , and every nonzero is represented by at most two linked-list elements. Therefore, the total storage requirements is . ∎
The theorem shows that the only way to asymptotically reduce the total number of operations in a sparse factorization is to reduce the number of arithmetic operations. Similarly, to asymptotically reduce the total storage we must reduce the fill. There are many ways to optimize and improve both the data structure and the algorithm that we described, but these optimizations can reduce the number of operations and the storage requirements only by a constant multiplicative constant.
Improvements in this algorithm range from simple data-structure optimizations, through sophisticated preprocessing steps, to radical changes in the representation of the Schur complement. The most common data-structure optimization, which is used by many sparse factorization codes, is the use of compressed-column storage. In this data structure, all the elements in all the list are stored in two contiguous arrays, one for the actual numerical values and another for the row indices. A integer third array of size points to the beginning of each column in these arrays (and to the location just past column ). Preprocessing steps can upper bound the number of nonzeros in each column of (this is necessary for exact preallocation of the compressed-column arrays) and the identity of potential nonzeros. The prediction of fill in can can eliminate the conditional in the inner loop that updates the sparse accumulator; this can significantly speed up the computation. The preprocessing steps can also construct a compact data structured called the elimination tree of that can be used for determining the nonzero structure of a row of without maintaining the lists. This also speeds up the computation significantly. The elimination tree has many other uses. Finally, multifrontal factorization algorithms maintain the Schur complement in a completely different way, as a sum of sparse symmetric update matrices.
The number of basic computational operations in an algorithm is not an accurate predictor of its running time. Different algorithms have different mixtures of operations and different memory-access patterns, and these factors affect running times, not only the total number of operations. We have seen evidence for this in Chapter XXX, were we have seen cases where direct solvers run at much higher computational rates than iterative solvers. But to develop fundamental improvements in algorithms, it helps to focus mainly on operation counts, and in particular, on asymptotic operation counts. Once new algorithms are discovered, we can and should optimize them both in terms of operation counts and in terms of the ability to exploit cache memories, multiple processors, and other architectural features of modern computers. But our primary concern here is asymptotic operation counts.
3.4. Characterizations of Fill
If we want to reduce fill, we need to characterize fill. Definition 11 provides an characterization, but this characterization is not useful for predicting fill before it occurs. One reason that predicting fill using Definition 11 is that it for cancellations, which are difficult to predict. In this section we provide two other characterizations. They are not exact, in the sense that they characterize a superset of the fill. In many cases these characterizations are exact, but not always. On the other hand, these charactersizations can be used to predict fill before the factorization begins. Both of them are given in terms of graphs that are related to , not in terms of matrices.
Definition 13.
The pattern graph of an -by- symmetric matrix is an undirected graph whose vertices are the integers through and whose edges are pairs such that .
Definition 14.
Let be an undirected graph with vertices . A vertex elimination step on vertex of is the transformation of into another undirected graph . The edge set of is the union of the edge set of with a clique on the neighbors of in whose indices are larger than ,
The fill graph of is the graph
The edges of the fill graph provide a bound on fill
Lemma 15.
Let be an -by- symmetric positive-definite matrix. Let . If or is a fill element, then is an edge of .
Proof.
The elimination of a vertex only adds edges to the graph. The fill graph is produced by a chain of vertex eliminations, starting from the graph of . If , then is an edge of the graph of , and therefore also an edge of its fill graph.
We now prove by induction on that a fill element is also an edge in
The claim hold for because if and only if . Therefore, there are no fill edges for , so the claims holds. We now prove the claim for . Assume that is a fill element, and let be the Schur complement just prior to the th elimination step,
Since is a fill element, but . Therefore, for some . This implies that and . By induction, and are edges of
Therefore, is an edge of
Since edges are never removed by vertex eliminations, is also an edge of
This proves the claim and the entire lemma. ∎
The converse is not true. An element in a Schur complement can fill and then be canceled out, but the edge in the fill graph remains. Also, fill in a Schur complement can cancel exactly an original element of , but the fill graph still contains the corresponding edge.
The following lemma provides another characterization of fill.
Lemma 16.
The pair is an edge of the fill graph of if and only if contains a simple path from to whose internal vectices all have indices smaller than .
Proof.
Suppose that contains such a path. We prove that edge of the fill graph by induction on the length of the path. If path contains only one edge then is an edge of , so it is also an edge of . Suppose that the claim holds for paths of length or shorter and that a path of length connects and . Let be the smallest-index vertex in the path. The elimination of vertex adds an edge connecting its neighbors in the path, because their indices are higher than . Now there is a path of length between and ; the internal vertices still have indices smaller than . By induction, future elimination operations on the graph will create the fill edge .
To prove the other direction, suppose that is an edge of . If is an edge of , a path exists. If not, the edge is created by some elimination step. Let be the vertex whose elimination creates this edge. We must have , otherwise the th elimination step does not create the edge. Furthermore, when is eliminated, the edges and exist. If they are original edge of , we are done—we have found the path. If not, we use a similar argument to show that there must be suitable paths from to and from to . The concatenation of these paths is the sought after path. ∎
3.5. Perfect and Almost-Perfect Elimination Orderings
The Cholesky factorization of symmetric positive definite matrices is numerically stable, and symmetrically permuting the rows and columns of an spd matrix yields another spd matrix. Therefore, we can try to symmetrically permute the rows and columns of a sparse matrix to reduce fill and work in the factorization. We do not have to worry that the permutation will numerically destabilize the factorization. In terms of the graph of the matrix, a symmetric row and column pemutation corresponds to relabeling the vertices of the graphs. In otherwords, given an undirected graph we seek an elimination ordering for its vertices.
Some graphs have elimination orderings that generate no fill, so that . Such orderings are called perfect-elimination orderings. The most common example are trees.
Lemma 17.
If is a tree or a forest, then .
Proof.
On a tree or forest, any depth-first-search postorder is a perfect-elimination ordering.
By Lemma 16, all the fill edges occur within connected components of . Therefore, it is enough to show that each tree in a forest has a perfect-elimination ordering. We assume from here on that is a tree.
Let be an arbitrary vertex of . Perform a depth-first traversal of starting from the root , and number the vertices in postorder: give the next higher index to a vertex immediately after the traversal returns from the last child of , starting from index . Such an ordering guarantees that in the rooted tree rooted at , a vertex has a higher index than all the vertices in the subtree rooted at .
Under such an ordering, the elimination of a vertex creates no fill edges at all, because has at most one neighbor with a higher index, its parent in the rooted tree. ∎
Most graphs do not have perfect-elimination orderings, but some orderings are almost as good. The elimination of a vertex with only one higher-numbered neighbor is called a perfect elimination step, because it produces no fill edge. Eliminating a vertex with two higher-numbered neighbors is not perfect, but almost: it produces one fill edge. If contains an isolated path
such that the degree of in is , then we can eliminate (in any order), producing only fill edges and performing only operations. This observation is useful if we try to sparsify a graph so that the sparsified graph has a good elimination ordering.
3.6. Symbolic Elimination and the Elimination Tree
We can use the fill-characterization technique that Lemma 15 describes to create an efficient algorithm for predicting fill. Predicting fill, or even predicting just the nonzero counts in rows and columns of the factor, can lead to more efficient factorization algorithms. The improvements are not asymptotic, but they can be nonetheless significant.
The elimination of vertex adds to the graph the edges of a clique, a complete subgraph induced by the higher-numbered neighbors of . Some of these edges may have already been part of the graph, but some may be new. If we represent the edge set of the partially-eliminated graph using a clique-cover data structure, we efficiently simulate the factorization process and enumerate the fill edges. An algorithm that does this is called a symbolic elimination algorithm. It is symbolic in the sense that it simulates the sparse factorization process, but without computing the numerical values of elements in the Schur complement or the factor.
A clique cover represents the edges of an undirected graph using an array of linked lists. Each list specifies a clique by specifying the indices of a set of vertices: each link-list element specifies one vertex index. The edge set of the graph is the union of the cliques. We can create a clique-cover data structure by creating one two-vertex clique for each edge in the graph.
A clique cover allows us to simulate elimination steps efficiently. We also maintain an array of vertices. Each element in the vertex array is a doubly-linked list of cliques that the vertex participates in. To eliminate vertex , we need to create a new clique containing its higher-numbered neighbors. These neighbors are exactly the union of higher-than- vertices in all the cliques that participates in. We can find them by traversing the cliques that participates in. For each clique that participates in, we traverse ’s list of vertices and add the higher-than- vertices that we find to the new clique. We add a vertex to the new clique at most once, using a length- bit vector to keep track of which vertices have already been added to the new clique. Before we move on to eliminate vertex , we clear the bits that we have set in the bit vector, using the vertices in the new clique to indicate which bits must be cleared. For each vertex in the new clique, we also add the new clique to the list of cliques that participates in.
The vertices in the new clique, together with , are exactly the nonzero rows in column of a cancellation-free Cholesky factor of . Thus, the symbolic-elimination algorithm predicts the structure of if there are no cancellations.
We can make the process more efficient by not only creating new cliques, but merging cliques. Let be a clique that participates in, and let and be vertices in . The clique represents the edge . But the new clique that the elimination of creates also represents , because both and belong to the new clique. Therefore, we can partially remove clique from the data structure. The removal makes the elimination of higher-than- vertices belonging to it cheaper, because we will not have to traverse it again. To remove , we need each element of the list representing to point to the element representing in the appropriate vertex list. Because the vertex lists are doubly-linked, we can remove elements from them in constant time.
Because each clique either represents a single nonzero of or the nonzeros in a single column of a cancellation-free factor , the total size of the data structure is . If we do not need to store the column structures (for example, if we are only interested in nonzero counts), we can remove completely merged cliques. Because we create at most one list element for each list element that we delete, the size of the data structure in this scheme is bounded by the size of the original data structure, which is only .
The number of operations in this algorithm is , which is often much less than the cost of the actual factorization,
To see that this is indeed the case, we observe that each linked-list element is touched by the algorithm only twice. An element of a clique list is touched once when it is first created, and another time when the clique is merged into another clique. Because the clique is removed from vertex lists when it is merged, it is never referenced again. An element of a vertex list is also touched only once after it is created. Either the element is removed from the vertex’s list before the vertex is eliminated, or it is touched during the traveral of the vertex’s list.
The process of merging the cliques defines an important structure that plays an important role in many sparse-matrix factorization algorithms, the elimination tree of . To define the elimination tree, we name some of the cliques. Cliques that are created when we initialize the clique cover to represent the edge set of have no name. Cliques that are formed when we eliminate a vertex are named after the vertex. The elimination tree is a rooted forest on the vertices . The parent of vertex is the name of the clique into which clique is merged, if it is. If clique is not merged in the symbolic-elimination process, is a root of a tree in the forest. There are many alternative definitions of the elimination tree. The elimination tree has many applications. In particular, it allows us to compute the number of nonzeros in each row and column of a cancellation-free Cholesky factor in time almost linear in , even faster than using symbolic elimination.
3.7. Minimum-Degree Orderings
The characterization of fill in Lemma 15 also suggests an ordering heuristic for reducing fill. If the elimination of a yet-uneliminated vertex creates a clique whose size is the number of the uneliminated neighbors of the chosen vertex, it makes sense to eliminate the vertex with the fewer uneliminated neighbors. Choosing this vertex minimizes the size of the clique that is created in the next step and minimizes the arithmetic work in the next step. Ordering heuristics based on this idea are called minimum-degree heuristics.
There are two problems in the minimum-degree idea. First, not all the edges in the new cliques are new; some of them might be part of or might have already been created by a previous elimination step. It is possible to minimize not the degree but the actual new fill, but this turns out to be more expensive algorithmically. Minimizing fill in this way also turns out to produce orderings that are not significantly better than minimum-degree orderings. Second, an optimal choice for the next vertex to eliminate may be suboptimal globally. There are families of matrices on which minimum-degree orderings generate asymptotically more fill than the optimal ordering. Minimum-degree and minimum-fill heuristics are greedy and myopic. They select vertices for elimination one at a time, and the lack of global planning can hurt them. This is why minimum fill is often not much better than minimum fill.
Even though minimum-degree algorithms are theoretically known to be suboptimal, they are very fast and often produce effective orderings. On huge matrices nested-dissection orderings, which we discuss next, are often more effective than minimum-degree orderings, but on smaller matrices, minimum-degree orderings are sometimes more effective in reducing fill and work.
Minimum-degree algorithms usually employ data structures similar to the clique cover used by the symbolic elimination algorithm. The data structure is augmented to allow vertex degrees to be determined or approximated. Maintaining exact vertex degrees is expensive, since a vertex cover does not represent vertex degrees directly. Many successful minimum-degree algorithms therefore use degree approximations that are cheaper to maintain or compute. Since the minimum-degree is only a heuristic, these approximations are not neccessarily less effective in reducing fill than exact degrees; sometimes they are more effective.
3.8. Nested-Dissection Orderings for Regular Meshes
Nested-dissection orderings are known to be approximately optimal, and on huge matrices that can be significantly more effective than other ordering heuristics. On large matrices, the most effective orderings are often nested-dissection/minimum-degree hybrids.
Nested-dissection orderings are defined recursively using vertex subsets called separators.
Definition 18.
Let be an undirected graph with . Let and be real positive constants, and let be a real function over the positive integers. An vertex separator in is a set of vertices that satisfies the following conditions.
- Separation::
-
There is a partition such that for any and , the edge .
- Balance::
-
.
- Size::
-
.
Given a vertex separator in , we order the rows and columns of of the separator last, say in an arbitrary order (but if contains many connected components then a clever ordering of can further reduce fill and work), and the rows and columns corresponding to and first. By Lemma 16, this ensures that for any and , the edge is not a fill edge, so . Therefore, the interleaving of vertices of and has no effect on fill, so we can just as well order all the vertices of before all the vertices of .
The function of the separator in the ordering is to ensure that for any and . Any ordering in which the vertices of appear first, followed by the vertices of , followed by the vertices of , ensures that a -by- rectangular block in does not fill. A good separator is one for which this block is large. The size of determines the circumference of this rectangular block, because half the circumference is . The size imbalance between and determines the aspect ratio of this rectangle. For a given circumference, the area is maximized the rectangle is as close to square as possible. Therefore, a small balanced separator reduces fill more effectively than a large or unbalanced separator.
By using separators in the subgraphs of induced by and to order the diagonal blocks of that correspond to and , we can avoid fill in additional blocks of . These blocks are usually smaller than the top-level -by- block, but they are still helpful and significant in reducing the total fill and work. If or are small, say smaller than a constant threshold, we order the corresponding subgraphs arbitrarily.
Let us see how this works on square two-dimensional meshes. To keep the analysis simple, we use a cross-shaped separator that partitions the mesh into four square or nearly-square subgraphs. We assume that is an -by- where and where . The size of a cross-shaped separator in is . To see this, we note that if then . Otherwise, without loss of generality , so . The separator breaks the mesh into four subgraphs, each of which is almost square (their and dimensions differ by at most ), of size at most . This implies that throught the recursion, each size- subgraph that is produced by the nested-dissection ordering has a -way separator that we use in the ordering.
We analyze the fill and work in the factorization by blocks of columns. Let be the top-level separator and let be the vertex sets of the separated subgraphs. We have
Bounding the fill in a block of columns that corresponds to one of the separated subgraphs is tricky. We cannot simply substitute a similar expression to form a reccurence. The matrix is square, but when we analyze fill in one of these column blocks, we need to account for fill in both the square diagonal block and in the subdiagonal block. If and and , then elements in can fill. A accurate estimate of how much fill occurs in such blocks of the factor is critical to the analysis of nested dissection algorithms. If we use the trivial bound , we get an asymptotically loose bound on fill.
To achieve an asymptotically tight bound, we set up a recurrence for fill in a nested-dissection ordering of the mesh. Let be a bound on the fill in the columns corresponding to an -by- submesh (with ). At most edges connect the submesh to the rest of the mesh. Therefore we have
The first term in the right-hand side bounds fill in the separator’s diagonal block. The second term, which is the crucial ingredient in the analysis, bounds fill in the subdiagonal rows of the separator columns. The third term bounds fill in the four column blocks corresponding to the subgraphs of the separated submesh. If we cast the recurrence in terms of we obtain
By the Master Theorem CLR2ed_Thm_4.1, The solution of the recurrence is . Since , we have . We can analyze work in the factorization in a similar way. We set up a recurrence
whose solution leads to . It is possible to show that these two bounds are tight and that under such a nested-dissection ordering for a two-dimensional mesh, and .
For a three-dimensional mesh, a similar analysis yields and .
In practice, we can reduce the constants by stopping the recurrence at fairly large subgraphs, say around , and to order these subgraphs using a minimum-degree ordering. This does not change the asymptotic worst-case bounds on work and fill, but it usually improves the actual work and fill counts. There are other nested-dissection/minimum-degree hybrids that often improve the work and fill counts without hurting the asymptotic worst-case bounds.
Definition 19.
A class of graphs satisfies an vertex-separator theorem (or a separator theorem for short) if every -vertex graph in the class has an vertex separator.
3.9. Generalized Nested-Dissection Orderings
When is not a regular mesh, the analysis becomes much harder. When applied to general graphs, the ordering framework that we described in which a small balanced vertex separator is ordered last and the connected components are ordered recursively is called generalized nested dissection.
Definition 20.
A class of graphs satisfies an vertex-separator theorem (or a separator theorem for short) if every -vertex graph in the class has an vertex separator.
For example, planar graphs satisfy an separator theorem. Since nested dissection orders subgraphs recursively, we must ensure that subgraphs belong to the same class of graphs, so that they can be ordered effectively as well.
Definition 21.
A class of graphs is said to be closed under subgraph if every subgraph of a graph in the class is also in the class.
There are two ways to use small balanced vertex separators to order an arbitrary graph. The first algorithm, which we call the lrt algorithm, guarantees an effective ordering for graphs belonging to a class that satisfies a separator theorem and is closed under subgraph. The algorithm receives an input a range of indices and graph with vertices, of which may already have been ordered. If , then the ordered vertices have indices . The algorithm assigns the rest of the indices, , to the unnumbered vertices. The algorithm works as follows.
-
(1)
If is small enough, , the algorithm orders the unnumbered vertices arbitrarily and returns.
-
(2)
The algorithm finds a small balanced vertex separator in . The separator separates the graph into subgraphs with vertex sets and . The two subgraphs may contain more than one connected componet each.
-
(3)
The algorithm arbitrarily assigns indices to the vertices of .
-
(4)
The algorithm recurses on the subgraphs induced by and by . The unnumbered vertices in the first subgraph are assigned the middle range of and the second the first range (starting from ).
We initialize the algorithm by setting and .
The second algorithm, called the gt algorithm, finds a separator, orders its vertices last, and then recurses on each connected component of the graph with the separator removed; the vertices of each component are ordered consecutively. In each recursive call the algorithm finds a separator that separates the vertices of one component, ignoring the rest of the graph. This algorithm does not guarantee an effective orderings to any graph belonging to a class that satisfies a separator theorem and is closed under subgraph; additional conditions on the graphs are required, such as bounded degree or closure under edge contractions. Therefore, we analyze the first algorithm.
Theorem 22.
Let be a graph belonging to a class that satisfies an separator theroem and closed under subgraph. Ordering the vertices of using the LRT algorithm leades to fill edges.
Proof.
We prove the theorem by induction on . If , the theorem holds by setting the constant in the big- notation high enough so that for all . Suppose that the theorem holds for all graphs with fewer than vertices.
The algorithm finds a separator that splits the graph into subgraphs induced by and by . We partition the fill edges into four categories: (1) fill edges with two endpoints in ; (2) fill edges with one endpoint in and the other in one of the already-numbered vertices; (3,4) fill edges with at least one endpoint in or in . Since there are no fill edges with one endpoint in and the other in , categories 3 and 4 are indeed disjoint.
The number of fill edges in Category 1 is at most .
The number of fill edges in Category 2 is at most .
Let be an upper bound on the number of fill edges in the ordering produced by the algorithm on a graph with vertices, of which are already numbered.
The number of fill edges in Category 3 is at most , where is the number of already-numbered vertices in after the vertices of have been numbered. Note that may be smaller than because some of the vertices that are initially numbered be in . Similarly, the number of fill edges in Category 4 is at most .
By summing the bounds for the four categories, we obtain a recurrence on ,
| (3.9.1) |
We claim that
| (3.9.2) |
for some constants and . Since initially , this bound implies the bound on fill.
To prove the bound, we denote and and note the following bounds:
The first inequality follows from the fact that every alread-numbered vertex in the input to the two recursive calls is either one of the initially-numbered vertices or a vertex of . An initially-numbered vertex that is not in is passed to only one of the recursive calls; vertices in are be passed as already numbered to the two calls, but there are at most of them. The second inequality follows from the fact that the subgraphs passed to the two recursive calls contain together all the vertices in and that vertices are passed to the both of the recursive calls. The third inequality follows from the guarantees on , , and under the separator theroem.
A similar analysis yields an analysis on arithmetic operations.
Theorem 23.
Let be a graph belonging to a class that satisfies an separator theroem and closed under subgraph. Ordering the vertices of using the LRT algorithm leads to arithmetic operations in the algorithm.
These results can be applied directly to matrices whose pattern graphs are planar, and more generally to graphs that can be embedded in surfaces with a bounded genus. Such graphs are closed under subgraph and satisfy a separator theorem. Furthermore, the separator in an -vertex graph of this family can be found in operations, and it is possible to show that we can even find all the separators required in all the levels of the recursive algorithm in time.
For the gt algorithm, which is somewhat easier to implement and which finds separators faster (because the separator is not included in the two subgraphs to be recursively partitioned), a separator theorem is not suffiecient to guarantee comparable bounds on fill and work. To ensure that the algorithm leads to similar asymptotic bounds, one must also assume that the graphs are closed under edge contraction or that they have a bounded degree. However, the two algorithms have roughly the same applicability, because planar graphs and graphs that can be embedded on surfaces with a bounded genus are closed under edge contraction. It is not clear which of the two algorithms is better in practice.
The fill and work results for both the lrt and the gt algorithms can be extended to graphs that satisfy separator theorems with separators smaller or larger than . See the original articles for the asymptotic bounds.
Finally, we mention that an algorithm that finds approximately optimal balanced vertex separators can be used to find a permutation that approximately minimizes fill and work in sparse Cholesky. The algorithm is similar in principle to the lrt and gt algorithms. This result shows that up to a polylogarithmic factors, the quality of vertex separators in a graph determines sparsity that we can achieve in sparse Cholesky.
3.10. Notes and References
Bandwidth and envelope reduction orderings.
The idea of nested dissection, and the analysis of nested dissection on regular meshes is due to George XXX. The lrt generalized-nested-dissection algorithm and its analysis are due to Lipton, Rose, and Tarjan XXX. The gt algorithm and its analysis are due to Gilbert and Tarjan XXX.
Exercises
Exercise 24.
The proof of Theorem 10 was essentially based on the fact that the following algorithm is a correct implementation of the Cholesky factorization:
-
for
for
for
end
end
end
-
(1)
Show that this implementation is correct.
-
(2)
Show that in each outer iteration, the code inside the inner loop, the loop, performs nontrivial subtractions (subtractions in which a nonzero value is subtracted).
-
(3)
This implementation of the Cholesky factorization is often called Cholesky, because the ordering of the loops is first (outermost), then , and finally , the inner loop. In fact, all permutations of the loop indices yield correct Cholesky factorizations; the expression inside the inner loop should is the same in all the permutations. Show this by providing appropriate Matlab functions.
-
(4)
For each of the permutations, consider the middle iteration of the outer loop. Sketch the elements of , the elements of , and the elements of that are referenced during this iteration of the outer loop. For the loop ordering shown above, is not referenced inside outer loop, and for and the sketches shown above.
Exercise 25.
In this exercise we explore fill and work in the Cholesky factorization of banded and low-profile matrices. We say that a matrix has a half-bandwidth if for all we have .
-
(1)
Suppose that corresponds to an -by- two-dimensional mesh whose vertices are ordered as in the previous chapter. What is the half bandwidth of ? What happens when is larger than , and what happens when is larger? Can you permute to achieve a minimal bandwidth in both cases?
-
(2)
Show that in the factorization of a banded matrix, all the fill occurs within the band. That is, is also banded with the same bound on its half bandwidth.
-
(3)
Compute a bound on fill and work as a function of and .
-
(4)
In some cases, is banded but with a large bandwidth, but in most of the rows and/or columns all the nonzeros are closer to the main diagonal than predicted by the half-bandwidth. Can you derive an improved bound that takes into account the local bandwidth of each row and/or column? In particular, you need to think about whether a bound on the rows or on the columns, say in the lower triangular part of , is more useful.
-
(5)
We ordered the vertices of our meshes in a way that matrices come out banded. In many applications, the matrices are not banded, but they can be symmetrically permuted to a banded form. Using an -by- mesh with as a motivating example, develop a graph algorithm that finds a permutation that clusters the nonzeros of near the main diagonal. Use a breadth-first-search as a starting point. Consider the previous quesion in the exercise as you refine the algorithm.
-
(6)
Given an -by- mesh with , derive bounds for fill and work in a generalized-nested-dissection factorization of the matrix corresponding to the mesh. Use separators that approximately bisect along the dimention until you reach subgraphs with a square aspect ratio. Give the bounds in terms of and .
Chapter 4 Symmetric Diagonally-Dominant Matrices and Graphs
Support theory provides effective algorithms for constructing preconditioners for diagonally-dominant matrices and effective ways to analyze these preconditioners. This chapter explores the structure of diagonally-dominant matrices and the relation between graphs and diagonallly-dominant matrices. The next chapter will show how we can use the structure of diagonally-dominant matrices to analyze preconditioners, and the chapter that follows presents algorithms for constructing algorithms.
4.1. Incidence Factorizations of Diagonally-Dominant Matrices
Definition 26.
A square matrix is called diagonally-dominant if for every we have
Symmetric diagonally dominant matrices have symmetric factorizations such that each column of has at most two nonzeros, and all nonzeros in each column have the same absolute values. We now establish a notation for such columns.
Definition 27.
Let , . A length- positive edge vector, denoted , is the vector
A negative edge vector is the vector
The reason for the assignment of signs to edge vectors will become apparent later. A vertex vector is the unit vector
We now show that a symmetric diagonally dominant matrix can always be expressed as a sum of outer products of edge and vertex vectors, and therefore, as a symmetric product of a matrix whose columns are edge and vertex vectors.
Lemma 28.
Let be a diagonally dominant symmetric matrix. We can decompose A as follows
Proof.
The terms in the summations in lines 1 and 4 are clearly equal (we only distributed the scalars), and so are the terms in lines 2 and 5 and in lines 3 and 6. Therefore, the second equality holds.
We now show that the first equality holds. Consider the rank- matrix
and similarly,
(in both matrices the four nonzeros are in rows and columns and ). Suppose for some . The only contribution to element from the three sums is from a single term in the first sum, either the term or the term , depending on whether . The element of this rank- matrix is . If , a similar argument shows that only (assuming ) contributes to the element, and that the value of the element . The third summation ensures that the values of diagonal elements is also correct. ∎
The matrix decompositions of this form play a prominent role in support theory, so we give them a name:
Definition 29.
A matrix whose columns are scaled edge and vertex vectors (that is, vectors of the forms , , and ) is called an incidence matrix. A factorization where is an incidence matrix is called an incidence factorization. An incidence factorization with no zero columns, with at most one vertex vector for each index , with at most one edge vector for each index pair , and whose positive edge vectors are all of the form is called a canonical incidence factorization.
Lemma 30.
Let be a diagonally dominant symmetric matrix. Then has an incidence factorization , and a unique canonical incidence factorization.
Proof.
The existence of the factorization follows directly from Lemma 28. We now show that the canonical incidence factorization is uniquely determined by . Suppose that . Then cannot have a column which is a nonzero multiple of , , or , since if it did, there would be only one such column, which would imply . Now suppost that . Then must have a column . Similarly, if , then must have a column . The uniqueness of the edge vectors implies that the scaled vertex vectors in are also unique. ∎
4.2. Graphs and Their Laplacians Matrices
We now define the connection between undirected graphs and diagonally-dominant symmetric matrices.
Definition 31.
Let be an undirected graph on the vertex set with no self loops or parallel edges. That is, the edge-set consists of unordered pairs of unequal integers such that and . The degree of a vertex is the numbers of edges incident on it. The Laplacian of is the matrix such that
Lemma 32.
The Laplacian of an undirected graph is symmetric and diagonally dominant.
Proof.
The Laplacian is symmetric because the graph is undirected. The Laplacian is diagonally dominant because the number of off-diagonal nonzero entries in row is exactly and the value of each such nonzero is . ∎
We now generalize the definition of Laplacians to undirected graphs with positive edge weights.
Definition 33.
Let be a weighted undirected graph on the vertex set with no self loops, and with a weight function . The weighted Laplacian of is the matrix such that
If some of the edge weights are negative, we call a signed graph, otherwise, we simply call it a weighted graph.
Lemma 34.
The Laplacian of a weighted undirected graph (signed or unsigned) is symmetric and diagonally dominant.
Proof.
Again symmetry follows from the fact that the graph is undirected. Diagonal dominance follows from the following equation, which holds for any , :
∎
If we allow graphs to have nonnegative vertex weights as well as edge weights, then this class of graphs becomes completely isomorphic to symmetric diagonally-dominant matrices.
Definition 35.
Let be a weighted undirected graph on the vertex set with no self loops, and with weight functions and . The Laplacian of is the matrix such that
A vertex such that is called a strictly dominant vertex.
Lemma 36.
The Laplacians of the graphs defined in Definition 35 are symmetric and diagonally dominant. Furthermore, these graphs are isomorphic to symmetric diagonally-dominant matrices under this Laplacian mapping.
Proof.
Symmetry again follows from the fact that the graph is undirected. For any we have
so
because . This shows that Laplacians are diagonally dominant. The isomorphism follows from the fact that the following expressions uniquely determine the graph associated with a diagonally-dominant symmetric matrix:
| iff | ||||
∎
We prefer to work with vertex weights rather than allowing self loops because edge and vertex vectors are algebraically different. As we shall see below, linear combinations of edge vectors can produce new edge vectors, but never vertex vectors. Therefore, it is convenient to distinguish edge weights that correspond to scaling of edge vectors from vertex weights that correspond to scaling of vertex vectors.
In algorithms, given an explicit representation of a diagonally-dominant matrix , we can easily compute an explicit representation of an incidence factor (including the canonical incidence factor if desired). Sparse matrices are often represented by a data structure that stores a compressed array of nonzero entries for each row or each column of the matrix. Each entry in a row (column) array stores the column index (row index) of the nonzero, and the value of the nonzero. From such a representation of we can easily construct a sparse representation of by columns. We traverse each row of , creating a column of for each nonzero in the upper (or lower) part of . During the traversal, we can also compute all the ’s. The conversion works even if only the upper or lower part of is represented explicitly.
We can use the explicit representation of as an implicit representation of , with each off-diagonal nonzero of representing an edge-vector column of . If has no strictly-dominant rows, that is all. If has strictly dominant rows, we need to compute their weights using a linear traversal of .
4.3. Laplacians and Resistive Networks
Weighted (but unsigned) Laplacians model voltage-current relationships in electrical circuits made up of resistors. This fact has been used in developing some support preconditioners. This section explains how Laplacians model resistive networks.
Let be an edge-weighted graph and let be its Laplacian. We view as an electrical circuit with nodes (connection points) and with resistors. If , then there is a resistor with capacitance between nodes and (equivalently, with resistence ).
Given a vector of node potentials, the voltage drop across resistor is . If the voltage drop is nonzero, current will flow across the resistor. Current flow has a direction, so we need to orient resistors in order to assign a direction to current flows. We arbitrarily orient resistors from the lower-numbered node to the higher-numbered one. In that direction, the directional voltage drop across is
We denote and we denote
Using this notation, the vector is the vector of all directional voltage drops. The directional current flow across resistor is . We denote by the diagonal matrix with . Then the vector is the vector of directional current flow across the resistors.
Next, we compute nodal currents, the net current flowing in or out of each node. If we set the potential of node to , this means that we have connected node to a voltage source, such as a battery. The voltage source keeps the potential at at exactly volts. To do so, it might need to send current into or to absorb currect flowing out of . These current flows also have a direction: we can either compute the current flowing into , or the current flowing out of . We will arbitrarily compute the current flowing into . How much current flows into node ? Exactly the net current flowing into it from its neighbors in the circuit, minus the current flowing from it to its neighbors. Let . If , then represents the current flowing from to , which is positive if . If then current flowing from to will have a negative sign (even though it too is flowing out of if ) and we have to negate it before we add it to the total current flowing from to its neighbors, which is exactly the net current flowing into from the voltage source. That is, the total current from a node to its neighbors is
Therefore, the vector of net node currents is exactly . We can also compute the total power dissipated by the circuit. We multiply the current flowing across each resistor by the voltage drop and sum over resistors, to obtain .
We summarize the various voltage-current relationships:
These relationships provide physical interpretations to many quantities and equations that we have already seen. Given a vector of nodal voltages, is the corresponding vector of nodal currents, where is the Laplacian of the circuit. Conversely, given a vector of nodal currents, solving determines the corresponding nodal voltages. The maximal eigenvalue of measures the maximum power that the circuit can dissipate under a unit vector of voltages, and the minimal nonzero eigenvalue measures the minimum power that is dissipated under a unit voltage vector that is orthogonal to the constant vector (which spans the null space of ).
Laplacians with strictly-dominant rows arise when the boundary conditions, the known quantities in the circuit, include a mixture of nodal voltages and nodal currents. Suppose that we know the currents in all the nodes except for one, say , where we know the voltage, not the current. Let us assume that the voltage at node is Volts. We want to compute the voltages at nodes to . We cannot use the linear system directly, because we do not know , and on the other hand, we do know that . Therefore, we drop the last row from this linear system, since we do not know its right-hand side. We have
or
We have obtained a new square and symmetric coefficient matrix and a known right-hand side. The new matrix is still diagonally dominant, but now has strictly-dominant rows: if , then row in the new coefficient matrix is now strictly-dominant, since we removed from it. If we know the voltages at other nodes, we repeat the process and drop more rows and columns, making the remaining coefficient matrix even more dominant.
Given two resistive networks with the same number of unknown-voltage nodes, what is the interpretation of a path embedding ? An embedding of in shows, for each edge in , a path between and in . That path can carry current and its conductance, which is the inverse of the sum of resistances along the path, serves as a lower bound on the conductance between and in . Intuitively, an embedding allows us to show that is, up to a certain factor, “as good as” , in the sense that for a given vector of voltages, currents in are not that much smaller than the currents in .
Chapter 7 Augmented Spanning-Tree Preconditioners
It’s time to construct a preconditioner! This chapter combinatorial algorithms for constructing preconditioners that are based on augmenting spanning trees with extra edges.
7.1. Spanning Tree Preconditioners
We start with the simplest support preconditioner, a maximum spanning tree for weighted Laplacians. The construction of the preconditioner aims to achieve three goals:
-
•
The generalized eigenvalues should be at least .
-
•
The preconditioner should be as sparse as possible and as easy to factor as possible.
-
•
The product of the maximum dilation and the maximum congestion should be low, to ensure that generalized eigenvalues of the pencil are not too large. (We can also try to achieve low stretch.)
These objectives will not lead us to a very effective preconditioner. It usually pays to relax the second objective and make the preconditioner a little denser in order to achive a smaller . But here we strive for simplicity, so we stick with these objectives.
We achieve the first objective using a simple technique. Given , we compute its canonical incidence factor . We construct by dropping some of the columns of . If we order the columns of so that the columns that we keep in appear first, then
This is a subset preconditioner, so
We now study the second objective, sparsity in . By Lemma LABEL:lemma:preconditioner-connectedness, we should as connected as . That is, we cannot drop so many columns from that connected components of become disconnected in . How sparse can we make under this constraint? A spanning forest of . That is, we can drop edges from until no cycles remain in . If there are cycles, we can clearly drop an edge. If there are no cycles, dropping an edge will disconnect a connected component of . A spanning subgraph with no cycles is called a spanning forest. If is connected, the spanning forest is a spanning tree. A spanning forest of is always very sparse; the number of edges is minus the number of connected components in . The weighted Laplacian of a spanning forest can be factored into triangular factors in time, the factor requires words of memory to store, and each preconditioning step requires arithmetic operations.
Which edges should we drop, and which edges should we keep in the spanning forest? If is a spanning forest of , than for every edge there is exactly one path in between and . Therefore, if is a spanning forest, then there is a unique path embedding of the edges of into paths in . The dropping policy should try to minimize the maximum congestion and dilation of the embedding (or the stretch/crowding of the embedding). The expressions for congestion, dilation, stretch, and crowsing are sums of ratios whose denominators are absolute values or squares of absolute values of entries of . Therefore, to reduce the congestion, dilation, and stretch, we can try to drop edges that correspond to with small absolute values, and keep “heavy” edges that correspond to entries of with large absolute values.
One class of forests that are easy to construct and that favor heavy edges are maximum spanning forests. A maximum spanning forest maximizes the sum of the weights of the edges of the forest. One property of maximum spanning forest is particularly useful for us.
Lemma 37.
Let be a maximum spanning forest of the weighted (but unsigned) graph , and let be the path with endpoints and in . Then for we have .
Proof.
Suppose for contradition that for some , . If we add to , we create a cycle. If we then drop , the resulting subgraph again becomes a spanning forest. The total weight of the new spannign forest is more than that of , contradicting the hypothesis that is a maximum spanning forest. ∎
It follows that in all the summations that constitute the congestion, dilation, stretch and crowding, the terms are bounded by . This yields the following result.
Lemma 38.
Let and be weighted Laplacians with identical row sums, such that is a maximum spanning forest of . Then
where is the order of and and is the number of nonzeros in the strictly upper triangular part of .
Proof.
Let correspond to the path embedding of in . For an edge in we have
The rightmost inequality holds because the number of edges in a simple path in a graph is at most , the number of vertices minus one. The total number of paths that use a single edge in is at most , the number of edges in , and hence the number of paths (in fact, its not hard to see that the number of paths is at most ). Therefore,
A similar argument shows that the stretch of an edge is at most , and since there are at most edges, is at most . ∎
Algorithms for constructing minimum spanning trees and forests can easily be adapted to construct maximum spanning forests. For example, Kruskal’s algorithm starts out with no edges in . It sorts the edges of by weight and processes from heavy to light. For each edge, the algorithm determines whether its endpoints are in the same connected component of the current forest. If the endpoints are in the same component, then adding the edge would close a cycle, so the edge is dropped from . Otherwise, the edge is added to . This algorithm requires a union-find data structure to determine whether two vertices belong to the same connected components. It is easy to implement the algorithm so that it performs operations. The main data structure in another famous algorithm, Prim’s, is a priority queue of vertices, and it can be implemented so that it performs operations. If is very sparse, Prim’s algorithm is faster.
When we put together the work required to construct a maximum-spanning-forest preconditioner, to factor it, the condition number of the preconditioned system, and the cost per iteration, we can bound the total cost of the linear solver.
Theorem 39.
Let be a weighted Laplacians of order with nonzeros. Then a minimal-residual preconditioned Krylov-subspace method with a maximum-spanning-forest preconditioner can solve a consistent linear system using operations.
Proof.
Constructing the preconditioner requires work. Computing the Cholesky factorization of the preconditioner requires work. The cost per iteration is operations, because has nonzeros and the factor of the preconditioner only . The condition number of the preconditioned system is bounded by , so the number of iteration to reduce the relative residual by a constant factor is . Thus, the total solution cost is
∎
Can we do any better with spanning forest preconditioner? It seems that the congesion-dilation-product bound cannot give a condition-number bound better than .††margin: Is there a lower bound? But the stretch bound can. Constructions for low-stretch trees can construct a spanning forest for such that
where is the embedding of edges of into paths in . Like maximum spanning forests, lowe-stretch forests also favor heavy edges, but their optimization criteria are different. The number of operations required to construct such a forest is . The constructoin details are considerably more complex than those of maximum spanning forests, so we do not give them here. The next theorem summarizes the total cost to solve a linear system with a low-stretch forest preconditioner.
Theorem 40.
Let be a weighted Laplacians of order with nonzeros. A minimal-residual preconditioned Krylov-subspace method with a low-stretch-forest preconditioner can solve a consistent linear system using operations.
Proof.
Constructing the preconditioner requires work. Computing the Cholesky factorization of the preconditioner requires work. The cost per iteration is . The condition number of the preconditioned system is . Thus, the total solution cost is
∎
7.2. Vaiyda’s Augmented Spanning Trees
The analysis of spanning-tree preconditioners shows how they can be improved. The construction of the preconditioner is cheap, the factorization of the preconditioner is cheap, each iteration is cheap, but the solver performs many iterations. This suggests that it might be better to make the preconditioner a bit denser. This would make the construction and the factorization more expensive, and it would make every iteration more expensive. But if we add edges cleverly, the number of iterations can be dramatically reduced.
The following algorithm adds edges to a maximum spanning tree in an attempt to reduce the bounds on both the congestion and the dilation. The algorithm works in two phases. In the first phase, the algorithm removes edges to partition the tree into about subtrees of roughly the same size. In the second phase, the algorithm adds the heaviest edge between every two subtrees. The value is a parameter that controls the density of the preconditioner. When is small, the preconditioner remains a tree or close to a tree. As grows, the preconditioner becomes denser and more expensive to construct and to factor, the cost of every iteration grows, but the number of iterations shrinks.
The partitioning algorithm, called TreePartition, is recursive and works as follows. It maintains an integer vector . The element is the number of vertices in the subtree rooted at . We begin by calling TreePartition on the root of the maximum spanning tree. The algorithm starts processing
TreeParition(vertex , integer array )
for each child of
if
TreePartition(,)
7.3. Notes and References
The low-stretch forests are from Elkin-Emek-Spielman-Teng, STOC 2005. This is an improvement over Alon-Karp-Peleg-West.
Appendix A Linear Algebra Notation and Definitions
This appendix provides notation, definitions and some well known results, mostly in linear algebra. We assume that all matrices and vectors are real unless we explicitly state otherwise.
A square matrix is symmetric if .
A.1. Eigenvalues and Eigenvectors
A square matrix is positive definite if for all and positive semidefinite if for all .
The eigendecomposition of a square matrix is a factorization where is diagonal. The columns of are called eigenvectors of and the diagonal elements of are called the eigenvalues of . A real matrix may have complex eigenvalues. The expression denotes the set of eigenvalues of .
Not all matrices have an eigendecomposition, but every symmetric matrix has one. In particular, the eigenvalues of symmetric matrices are real and their eigenvectors are orthogonal to each other. Therefore, the eigendecomposition of symmetric matrices is of the form . The eigenvalues of positive definite matrices are all positive, and the eigenvalues of positive semidefinite matrices are all non-negative.
For any matrix , the product is symmetric and positive semidefinite.
A.2. The Singular Value Decomposition
Every matric , has a singular value decomposition (SVD) where with orthonormal columns, with orthonormal columns, and is non-negative and diagonal. (This decomposition is sometimes called the reduced SVD, the full one being with a rectangular and an -by- .) The columns of are called left singular vectors, the columns of are called right singular vectors, and the diagonal elements of are called singular values. The singular values are non-negative. We denote the set of singular values of by .
A.3. Generalized Eigenvalues
Preconditioning involves two matrices, the coefficient matrix and the preconditioners. The convergence of iterative linears solvers for symmetric semidefinite problems depends on the generalized eigenvalues of the pair of matrices. A pair of matrices is also called a pencil.
Definition 41.
Let and be -by- complex matrices. We say that a scalar is a finite generalized eigenvalue of the matrix pencil (pair) if there is a vector such that
and . We say that is a infinite generalized eigenvalue of if there exist a vector such that but . Note that is an eigenvalue of if and only if is an eigenvalue of . The finite and infinite eigenvalues of a pencil are determined eigenvalues (the eigenvector uniquely determines the eigenvalue). If both for a vector , we say that is an indeterminate eigenvector, because for any scalar .
We order from smallest to largest. We will denote the th eigenvalue of by , and the th determined generalized eigenvalue of by . Therefore and , where is the number of eigenvalues has, and is the number of determined eigenvalues that has.
Definition 42.
A pencil is Hermitian positive semidefinite (H/PSD) if is Hermitian, is positive semidefinite, and .
The generalized eigenvalue problem on H/PSD pencils is, mathematically, a generalization of the Hermitian eigenvalue problem. In fact, the generalized eigenvalues of an H/PSD can be shown to be the eigenvalues of an equivalent Hermitian matrix. The proof appears in the Appendix. Based on this observation it is easy to show that other eigenvalue properties of Hermitian matrices have an analogy for H/PSD pencils. For example, an H/PSD pencil, , has exactly determined eigenvalues (counting multiplicity), all of them finite and real.
A useful tool for analyzing the spectrum of an Hermitian matrix is the Courant-Fischer Minimax Theorem [MatrixComp].
Theorem 43.
(Courant-Fischer Minimax Theorem) Suppose that is an Hermitian matrix, then
and
As discussed above, the generalized eigenvalue problem on H/PSD pencils is a generalization of the eigenvalue problem on Hermitian matrices. Therefore, there is a natural generalization of Theorem 43 to H/PSD pencils, which we refer to as the Generalized Courant-Fischer Minimax Theorem. We now state the theorem. For completeness the proof appears in the Appendix.
Theorem 44.
(Generalized Courant-Fischer Minimax Theorem) Suppose that is an Hermitian matrix and that is an Hermitian positive semidefinite matrix such that . For we have
and