Leveraging Multiple Legacy Wi-Fi Links for Human Behavior Sensing
Abstract
Taking advantage of the rich information provided by Wi-Fi measurement setups, Wi-Fi-based human behavior sensing leveraging Channel State Information (CSI) measurements has received a lot of research attention in recent years. The CSI-based human sensing algorithms typically either rely on an explicit channel propagation model or, more recently, adopt machine learning so as to robustify feature extraction. In most related work, the considered CSI is extracted from a single dedicated Access Point (AP) communication setup. In this paper, we consider a more realistic setting where a legacy network of multiple APs is already deployed for communications purposes and leveraged for sensing benefits using machine learning. The use of legacy network presents challenges and opportunities as many Wi-Fi links can present with richer yet unequally useful data sets. In order to break the curse of dimensionality associated with training over a too large dimensional CSI, we propose a link selection mechanism based on Reinforcement Learning (RL) which allows for dimension reduction while preserving the data that is most relevant for human behavior sensing. The method is based on a sequential state decision-making process in which the CSI is modeled as a part of the state. From actual experiment results, our method is shown to perform better than state-of-the-art approaches in a scenario with multiple available Wi-Fi links.
Index Terms:
CSI, multiple APs, link selection, reinforcement learning, human behavior sensingI Introduction
With the ubiquitous deployment of Wi-Fi infrastructure and aided by the Channel State Information (CSI) made accessible in commodity Wi-Fi chipsets [2], Wi-Fi-based human behavior sensing has become an active research area in both industry and academia [3, 4, 5, 6, 7]. Applications range from human detection [8, 9, 10], fall detection [11, 12], human authentication [13, 14, 15, 16], gesture recognition [17, 18, 19, 20], daily activity recognition [21, 22, 23, 24, 25, 26, 27, 28] to human imaging [29, 30, 31]. Further, in a dynamic setting, it is in principle possible to monitor changes in human behaviors by leveraging the temporal dimension of Wi-Fi CSI. Wi-Fi CSI-based human behavior sensing offers many advantages, including being a low-cost, non-invasive, and highly practical solution for smart homes, elderly monitoring, intrusion detection, among others.
CSI-based human behavior sensing is rooted in the principle of multipath imaging, as human bodies can absorb or bounce radio waves thereby modifying our perception of multipath. CSI hence captures the various reflection, diffraction and scattering effects, which can in turn be traced back to a certain body location and pose.
Previous Wi-Fi CSI-based human behavior sensing systems can be roughly divided into two categories according to the types of the algorithms used: modeling-based systems and learning-based systems. To be specific, modeling-based systems capture human movement through Wi-Fi CSI by building an explicit propagation model [32, 33, 34, 35, 36, 37, 38] while learning-based systems distinguish human behaviors through features extracted from Wi-Fi CSI based on machine learning [22, 39, 9, 40, 41, 42, 43, 44, 45, 46, 47, 29, 30, 31].
In most cases so far, these systems have been investigated in simple Wi-Fi environments, typically consisting of a single dedicated Access Point (AP) and one or several Wi-Fi receivers (Rxs). Furthermore, the Wi-Fi devices are often deployed at locations that are intuitively perceived as potentially favorable for human sensing purposes. The most common one is that an AP and two Rxs forming two orthogonal segments in space [35, 29, 31], as a pair of transceiver can only sense the motion component perpendicular to the Line of Sight (LoS) path between them according to [48].
The physical modeling approach is attractive in settings where one can get away with a small number of parameters, for instance simple propagation (single bounce) environments with one (or a small number of) Wi-Fi device(s). However, since we are likely to see a larger number of APs and more complex propagation settings, a physical modeling approach is unpractical, making a learning approach the preferred option [42]. Unfortunately, the learning task in the case of a possibly large network of Wi-Fi devices is made much more challenging for the reasons below.
One reason is the over-dimensioned nature of CSI data extracted from multiple access points, leading to increased training time and overall system complexity. Furthermore, realistic Wi-Fi deployments mean that APs are located non-optimally from a human sensing point of view, resulting in certain links contributing mostly noise rather than meaningful data for the sensing and classification tasks at hand, in comparison to other links.
In this paper we ask the following question: Is there a way to leverage the rich CSI data arising from a legacy Wi-Fi network with multiple devices for human behavior sensing while mitigating the curse of dimensionality, i.e., keeping training time reasonable and pruning out noise-dominated data?
To answer this question, this paper proposes an approach based on the dynamic selection of Wi-Fi CSI data by a Reinforcement Learning (RL) agent. Intuitively, the principle is to decide and select in real-time the small subset of radio links that are the most relevant to human behavior sensing. Clearly, the difficulty of this task is the definition of a proper “relevance” metric.
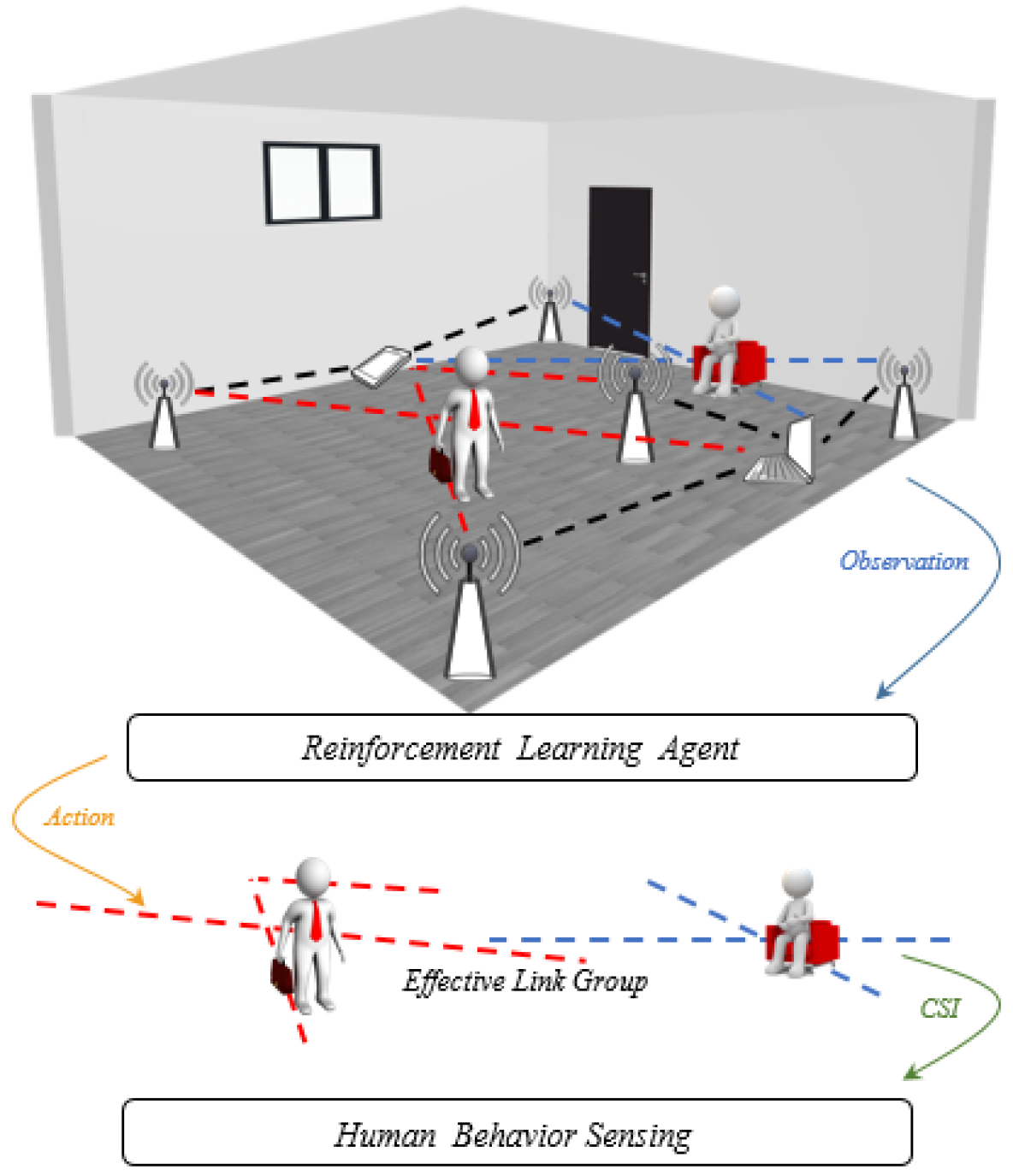
To achieve this goal, we construct a link selection algorithm that will help describe the most representative set of links for human behavior sensing. We formulate this link selection as a sequential decision making process, which is naturally modeled by RL [49]. The workflow of our method is illustrated in Figure 1.
At each time step, the RL agent receives the environment’s state, which relates to the human’s dynamic behavior. Relying on the received state, the agent chooses an action to the more suitable subset of radio links until convergence. The chosen action depends on the policy network, which is a probability distribution function that maps the current state to the action space. After a time step, we get a sensing reward as a result of the action, and the system transits to a new state. A carefully designed reward function is proposed according to sensing goals, and our objective is to prioritize the data from the set of links that maximize the total sum of the rewards.
Remarkably, we also develop a proof-of-concept prototype and apply the proposed link selection framework to recognize 5 activities at 16 different locations, with four radio links (corresponding to two Wi-Fi APs and two Wi-Fi Rxs at non-optimized locations). The prototype allows to test our algorithms, and compare them with relevant methods selected from the state-of-the-art (see section II for a description of such methods), hence showing the benefits of our approach.
The main contributions of this paper are summarized as follows.
-
•
We propose a novel link selection mechanism for improving the performance of machine learning-based human behavior sensing in a scenario with multiple legacy Wi-Fi links. We intuitively formulate the link selection process as a sequential decision making process.
-
•
RL is adopted to solve the formulated sequential decision problem. A novel framework that takes both context information and historical states into consideration for decision making is designed.
-
•
For better decision making and human behavior sensing, a reward function is designed, together with an overall loss function based on a useful analogy with the problem of frame selection in the independent context of video processing [50].
-
•
We measure the performance of the RL-based framework with extensive actual experiments. We also compare our method with start-of-the-art methods. Experimental results attest the effectiveness of our framework.
The rest of the paper is organized as follows. Related work is discussed in Section II. And the preliminaries and methodology are elaborated in Section III and Section IV, respectively. The implementation details of the experiments are presented in Section V. The performance evaluation is shown in Section VI, followed by some discussions and future work in Section VII.
| Category | Reference | Number of Txs | Number of Rxs | Links | Learning-Assisted? | Applications |
|---|---|---|---|---|---|---|
| Physical Modeling-Based | CARM [32] | 1 | 1 | – | ✓ | Activity Recognition |
| [33] | 1 | 1 | – | Both | Activity Recognition | |
| GAITWAY [34] | 1 | 1 | – | ✓ | Gait Recognition | |
| WiDance [35] | 1 | 2 | Orthogonal | ✓ | Activity Recognition | |
| WiSee [36] | 1 | 1 | – | ✓ | Gesture Recognition | |
| WiRIM [37] | 1 | 1 | – | ✓ | Activity Recognition | |
| Wi-Chase [38] | 1 | 1 | – | ✓ | Activity Recognition | |
| Machine Learning-Based | PADS [9] | 1 | 1 | – | – | Human Detection |
| Wi-Fall [40] | 2 | 2 | Two Links | – | Fall Detection | |
| MAR [41] | 1 | 1 | – | – | Gait Recognition | |
| [42] | 9 | 3 | Random | – | Activity Recognition | |
| E-eyes [43] | 1 | 3 | Random | – | Activity Recognition | |
| WiAnti [44] | 1 | 1 | – | – | Activity Recognition | |
| WiFinger [45] | 1 | 1 | – | – | Gesture Recognition | |
| WiKey [46] | 1 | 1 | – | – | Keystroke Recognition | |
| WiReader [47] | 1 | 1 | – | – | Handwriting Recognition | |
| Wi-Pose [29] | 1 | 2 | Orthogonal | – | Human Imaging | |
| WiPose [30] | 1 | 3 | Random | – | Human Imaging | |
| Wi-Mose [31] | 1 | 2 | Orthogonal | – | Human Imaging |
II Related Work
In this section, we discuss some existing representative works from the two categories of Wi-Fi based sensing methodologies so far reported in the literature, namely physical modeling-based and machine learning-based.
II-A Physical Modeling-Based Systems
Wang et al. [32] propose the CSI-Speed Model, which quantifies the correlation between CSI amplitude dynamics and the speed of path length change of the reflected paths caused by human movement. Based on the CSI-speed model and Hidden Markov Model (HMM), they build an activity recognition system called CARM which can differentiate and recognize eight predefined activities. Zhang et al. [51] [52] develop the one-side and two-sides Fresnel diffraction model, which characterizes the relationship between the geometrical position of the sensing target and the induced CSI amplitude variations caused by the motion of the target. They demonstrate that the Fresnel diffraction model is effective and robust in recognizing exercises and daily activities [33]. Wu et al. [34] present a scattering model, which treats environmental objects as multiple scatters and reveals that the CSI statistically embodies the target’s moving speed when accounting for a number of scattering multipaths. Upon the scattering model, they develop GAITWAY, which can monitor and recognize gait speed through the walls. Doppler phase shift [35] [36], Angle of Arrival (AoA) [37] and Time of Flight (ToF) [38] are also popular models for CSI-based human behavior sensing. However, due to the complexity of human behavior, these models still need machine learning methods to distinguish reliably between various activity classes.
Specific information about the number and placement of transceivers of these systems are shown in Table I, which indicates the above models are all built in simple Wi-Fi environments. At the same time, in order to realize the recognition of activities or gestures, they often need to do classification with the help of machine learning methods.
II-B Machine Learning-Based Systems
There exists a significant body of work related to the the use of machine learning for Wi-Fi-aided human behavior classification. For instance, PADS [9] uses One-Class Support Vector Machine (SVM) for human detection. Wi-Fall [40] utilizes the k-Nearest Neighbors algorithm (kNN) and One-Class SVM for fall detection. MAR [41] tries to identify multiple-variations of body parts and applies CANDECOMP/ PARAFAC (CP) and Dynamic Time Wrapping (DTW) to recognize activities. [42] designs a Convolutional Neural Network (CNN) model for activity recognition. E-eyes [43] exploits Multi-Dimensional DTW and Pattern Matching to recognize household activities such as washing dishes and taking a shower. WiAnti [44] is a Wi-Fi-based human activity recognition system that is robust to Co-Channel Interference (CCI) and it evaluates the performance with six different classifiers. WiFinger [45] also utilizes Multi-Dimensional DTW and Pattern Matching and further designs a series of signal processing techniques to recognize finger gestures. WiKey [46] proposes to use kNN and DTW for keystroke detection and recognition. WiReader [47] generates a energy feature matrix an combines with Long Short-Term Memory (LSTM) to realize the recognition of different handwriting actions. Wi-Pose [29], WiPose [30], and Wi-Mose [31] exploit Cross-Modal networks to achieve 2D or 3D human pose estimation.
Specific information about the number and placement of transceivers of these systems are also shown in Table I. Most of the current machine learning-based works focus on simple Wi-Fi environments with typically just one Wi-Fi AP. One exception is [42], which suggests that machine learning-based approaches have the potential to sense human behaviors in multi-AP environments albeit at a high complexity cost, since [42] does not prune out the links that bear little relevance to the actual classification task at hand.
In contrast, in this work, we focus on possibly complex Wi-Fi deployments with multiple APs and highlight the importance of reducing the data dimensionality by selecting the subset of radio links that are most informative about the classification task. This problem is challenging as the Wi-Fi deployment is not optimized for this problem. We show however how this can be recast into a novel data-driven decision making framework exploiting RL.
III preliminaries
III-A Principle of CSI-based Human Sensing
CSI characterizes how Wi-Fi signals propagate from the transmitter (Tx) to the Rx at different subcarriers. The basic form of CSI can be expressed as:
| (1) |
where amplitude and phase at the subcarrier are impacted by the multipaths in the environment resulting in amplitude attenuation and phase shift. The presence of human or tiny body movement will affect the multipaths thus leading some changes to CSI. Assisted by physical modeling or machine learning algorithms, we can sense human behaviors by exploring the changes of CSI caused by humans. In this paper, we are considering the particular problem of classifying human behavior as one of a finite number of human activity classes (walk, run, stand, sit, and bend).
The Linux CSI tool [2] provides CSI for 30 out of 56 subcarriers for each antenna. Specifically, CSI values are available in a sample, where and are the number of antennas in Tx and Rx respectively. However, given a complex Wi-Fi environment with Txs and Rxs, there will be CSI values at each time, which will increase the difficulty of data processing and network complexity. Thus finding an effective way to extract the most representative features for human behavior sensing from such a huge amount of data is the key objective in this work.
III-B Effective Link Selection
A link refers to the combination of Wi-Fi multipath signals which correspond to a particular pair of transceivers. Given a complex Wi-Fi environment with Txs and Rxs, as previously mentioned, there will be links in the environment, leading to CSI values at each time sample. However, the intuition we put forward in this paper is that in a typical arbitrary Wi-Fi deployment scenario, the subset of links that are significantly affected by a single human behavior is limited. Dynamically picking out the links that are the most relevant to human behavior can significantly reduce the dimensionality of data processing at each time, hence improving classification performance for a given system complexity and training overhead.
Therefore, we firstly define the concept of effective link group to describe the most relevant set of links for human behavior sensing here.
Notation: Given the set of APs and the set of Rxs , the effective link group corresponding to a certain behavior performed at a certain location at the time step is expressed as . Note that refers to the link between AP and Rx .
We now proceed to construct a RL agent, capable of identifying the most effective link group through a link selection algorithm.
IV Methodology
IV-A Problem Formulation
We propose an iterative algorithm for identifying the effective link group . Hence the agent initially considers all Wi-Fi links and iteratively selects individual links based on a reward maximization policy.
The process of link selection can be formalized as a Markov Decision Process (MDP), whereby a sequential decision-making problem is solved at each iteration. As is known, a generic MDP problem can be naturally solved by a RL agent which is further detailed below.
IV-B Data Preprocessing
Prior to link selection and to reduce the computation burden of the model and improve the accuracy, we preprocess the CSI of all the links, i.e., links, as follows.
Because a time series of CSI phase differences and amplitudes can detect the minute changes of the environment that alter signal propagation, we can use these measurements to capture relevant human behaviors [37]. Here, we first calculate , the phase differences between adjacent antennas. Then we apply the Principal Component Analysis (PCA) algorithm to the CSI streams for each link (), as PCA is widely used for helping fully extract the behavior-related features while greatly reducing the data dimensions and removing unrelated information [53]. We use the second principal component for further processing since it clearly captures human behaviors [32]. Let the two CSI streams of link be , where and is the second principal component of the phase difference and amplitude at the time step , respectively.
Then we choose the zero-mean normalization method to normalize the two CSI streams with zero mean and unit variance to reduce the calculation cost and improve the classification performance, and then obtain :
| (2) |
for and , where and are the mean and standard deviation of the , respectively.
IV-C Framework Design
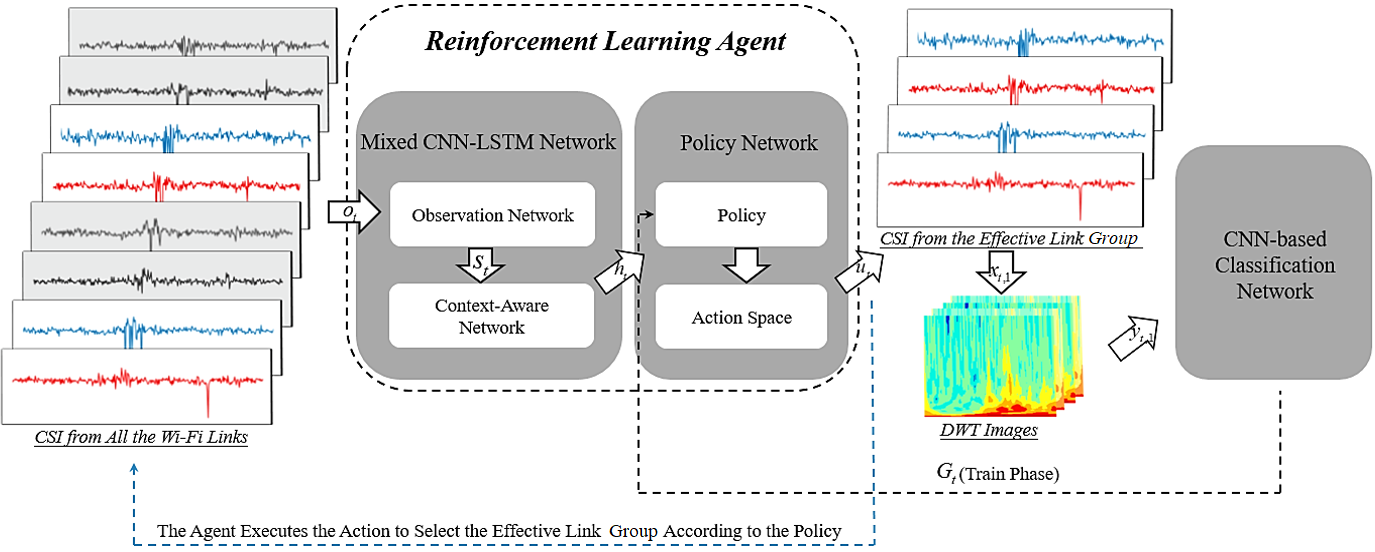
Figure 2 summarizes the overall framework, which consists of the following modules: an agent which decides the link group based on its context information together with a CNN-based classification network which is used to recognize the human behavior, but also to compute the RL reward. To be specific, the agent exploits two networks: a mixed CNN-LSTM network which encodes the context information and historical states and also a policy network which generates a proper action from a predefined action space at each step.
In this section, we represent the framework by a tuple , referring to states, actions, transition, reward, and policy, and we introduce the details for each of them one by one, as follows.
IV-C1 State S
The RL agent first needs to encode the explored environment into a feature vector reflecting the context information. Therefore, we adopt an observation network and a context-aware network as the mixed CNN-LSTM network, parameterized by and respectively.
The observation network , composed of three convolution layers, is designed at the beginning of the mixed CNN-LSTM network to effectively reduce the dimension of the data and significantly simplify the training procedure. At the time step , the agent observes a state:
| (3) |
for and , where is a linear weighted sum function, weights and biases constitute the parameter .
Furthermore, on the one hand, human behavior sensing should be sensitively context-aware in our situation. On the other hand, multi-LSTM models are capable of learning and recognizing hidden patterns. Therefore, we design a context-aware network , using three LSTM layers upon the observation network, to be aware of the context information and recognize the hidden patterns. The agent observes both a state and its previous hidden states as inputs of the context-aware network, then produces its current hidden states :
| (4) |
IV-C2 Action U
Action is the action space covers all the combination of Wi-Fi links, e.g., all possible link groups formed, and represents a set of discrete actions that our agent can take. At time step , decides a Wi-Fi link group from the set of possible actions according to the state .
IV-C3 Transition
In response to the selected action , function maps a state into a new state :
| (5) |
IV-C4 Policy
Then the agent feeds the feature vector into the following policy network to generate a proper action from the action space. This action adjusts the link group that the agent decides at the next time.
The policy network is composed of a fully connected layer parameterized by and uses a sigmoid activation function to output the probability value of each action.
Clearly, the generation of an action indicates that the agent decides the link group corresponding to the action. The policy is as follows:
| (6) |
where is the action probability distribution, is a sigmoid function, and are the weights and biases, which together constitute the parameter . The action with the highest probability, i.e., is estimated as the proper action.
IV-C5 Reward G
When the link groups decided by agent keep unchanged after performing a series of actions, we consider the link group as the effective link group at this time. A classification network will emit the prediction based on the .
The CNN-based classification network is parameterized by . Supposing there are a total of links in , for each link (), we firstly obtain the two CSI streams as mentioned before. Then we use Discrete Wavelet Transform (DWT) [29] to extract the temporal-frequency features from CSI phase differences and amplitudes. Based on this, we extract the DWT spectrum images at the time step from the link , defined as:
| (7) |
for and .
As the input data of the CNN-based classification network, the DWT images are then processed in convolution layers, dropout layers, maximum pooling layers and fully connected layers. The detailed architecture of the CNN-based classification network is presented in Section V. Note that we deploy the Rectified Linear Unit (ReLU) function in each convolution layer. The last fully connected layer uses a softmax function to output the probability value of each class.
The predicted distribution according to link is:
| (8) |
for and .
We then calculate the average predicted distribution over all the links in as the final predicted distribution:
| (9) |
The reward will be calculated from the predicted distribution , taking into account the performance of link selection. In this paper, we propose a strategy which is inspired from recent work in the area of computer vision where authors in [50] have addressed a problem of video frame selection for lowering the complexity of video processing. Albeit driven by completely independent applications and data scenarios, the problems of frame selection and Wi-Fi link selection bear some interesting analogies in that the objective is to identify a sub-sampled version of an original measured data that capture the greatest amount of relevance to a given data-drive classification problem. The goal of the reward function is to push the agent toward finding an effective link group that will gradually improve the classification accuracy. In other words, the reward is set to provoke the largest possible prediction gains (in identifying the correct ground-truth class) as compares with the previous iteration [50]. Hence, we set the reward received by the agent at the step as:
| (10) |
where is the probability value of class at step , and represents the ground-truth label of the behavior.
Inspired by the REINFORCE [54] algorithm of policy gradient, our agent objective is defined as:
| (11) |
where is a long-term discounted reward. Since the link selection is considered as a sequential decision-making problem, a long-term discounted reward is more suitable here, i.e., the further the reward, the lower the contribution to the current step.
To be specific, the discounted return at the step can be expressed as:
| (12) |
where is the discount rate. As can be seen from Equation (12), the parameter gets the most movement in directions, so that the favorable action can get the highest reward.
IV-D Objective Function
For one thing, the objective of the agent is to maximize its expected reward. For the other thing, we ought to minimize the loss of the classification network. We utilize the REINFORCE algorithm to updates the agent’s parameters and optimize the parameters with the error Back Propagation (BP) algorithm.
IV-D1 Policy Gradient
We aim at learning the parameters which can maximize Equation (11). The gradient of is:
| (13) |
As the dimension of the action space is high, Equation (13) results in a non-trivial optimization problem. Therefore, according to REINFORCE, a Monte-Carlo sampling method is used to estimate the gradient:
| (14) |
where is the number of samples. Via Monte-Carlo stochastic gradient descent, we can minimize the loss function, i.e., Equation (15), to updates the parameters .
| (15) |
IV-D2 Cross Entropy
We define the loss as the mean of binary cross entropy loss for each action in the action space:
| (16) | ||||
where is the probability of link at the step, is the true value of link at the step, which can only be 0 or 1. Therefore, the loss of the agent is a weighted sum of the two losses:
| (17) |
where is a constant.
| Layer | Name | Size | Strides | Activation |
|---|---|---|---|---|
| 1 | Conv 1D | 2 | ReLU | |
| 2 | Conv 1D | 2 | ReLU | |
| 3 | Conv 1D | 2 | ReLU | |
| 4 | Conv 1D | 2 | ReLU | |
| 5 | Max pooling | 2 | None | |
| 6 | LSTM | None | Tanh | |
| 7 | LSTM | None | Tanh | |
| 8 | LSTM | None | Tanh |
| Layer | Name | Size | Strides | Activation |
|---|---|---|---|---|
| 1 | Conv 2D | 2 | ReLU | |
| 2 | Dropout | rate=0.3 | ||
| 3 | Max pooling | 2 | None | |
| 4 | Dropout | rate=0.5 | ||
| 5 | FC | None | Softmax |
| Layer | Name | Size | Strides | Activation |
|---|---|---|---|---|
| 1 | Conv 2D | 2 | ReLU | |
| 2 | Max pooling | 2 | None | |
| 3 | Conv 2D | 2 | ReLU | |
| 4 | Dropout | rate=0.3 | ||
| 5 | Max pooling | 2 | None | |
| 6 | Dropout | rate=0.5 | ||
| 7 | FC | None | Softmax |
IV-D3 Classification Objective
We also define the loss as the mean of binary cross entropy loss for each class:
| (18) |
where is the number of classes, is the probability of class, is the true value of class, which can only be 0 or 1.
The overall objective of our model is to minimize the loss function:
| (19) |
where is a constant.
| Layer | Name | Size | Strides | Activation |
|---|---|---|---|---|
| 1 | Conv 2D | 2 | ReLU | |
| 2 | Max pooling | 2 | None | |
| 3 | Conv 2D | 2 | ReLU | |
| 4 | Dropout | rate=0.3 | ||
| 5 | Max pooling | 2 | None | |
| 6 | Conv 2D | 2 | ReLU | |
| 7 | Dropout | rate=0.3 | ||
| 8 | Max pooling | 2 | None | |
| 9 | Dropout | rate=0.5 | ||
| 10 | FC | None | Softmax |
| Layer | Name | Size | Strides | Activation |
|---|---|---|---|---|
| 1 | Conv 2D | 2 | ReLU | |
| 2 | Max pooling | 2 | None | |
| 3 | Conv 2D | 2 | ReLU | |
| 4 | Dropout | rate=0.3 | ||
| 5 | Max pooling | 2 | None | |
| 6 | Conv 2D | 2 | ReLU | |
| 7 | Dropout | rate=0.3 | ||
| 8 | Max pooling | 2 | None | |
| 9 | Conv 2D | 2 | ReLU | |
| 10 | Dropout | rate=0.3 | ||
| 11 | Max pooling | 2 | None | |
| 12 | Dropout | rate=0.5 | ||
| 13 | FC | None | ReLU | |
| 14 | Dropout | rate=0.5 | ||
| 15 | FC | None | Softmax |
V Experiments and Implementation
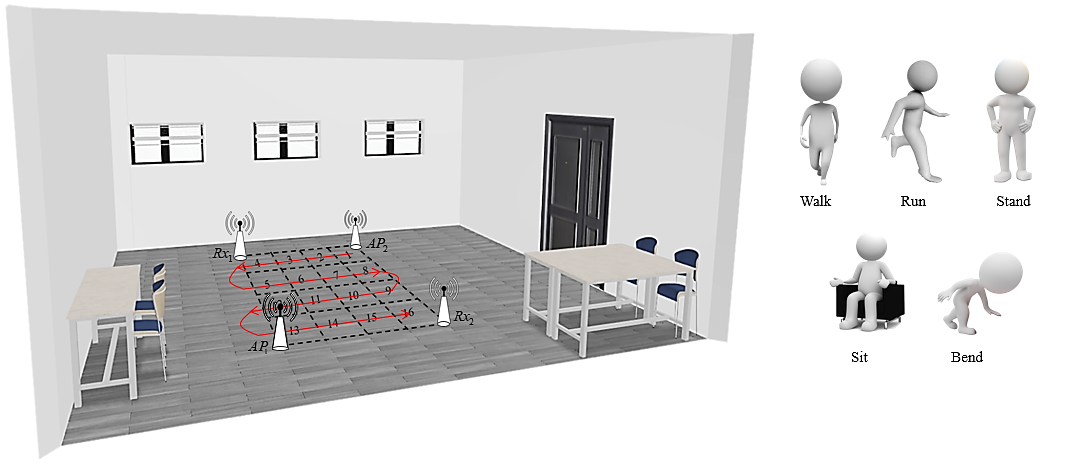
To validate the performance of our framework, we develop a proof-of-concept prototype and apply the proposed link selection method to recognize diverse activities, i.e., 5 activities in 16 different locations. We perform a comparison with other possible approaches in the context of commodity Wi-Fi namely random and exhaustive link selection (i.e., all Wi-Fi links are exploited for classification, or possibly a subset of links based on a classical selection method such as selecting links that form an orthogonal subset [35]) various layer architectures in order to understand the impact on effectiveness. Note that our framework can scale to an arbitrary number of deployed APs with reasonable complexity. However due to logistic constraints, we hereby limit our tests to the case of two APs and two Rxs (4 links in total). The details of the experiments and implementation are shown as follows.
V-A Experiment Setting
In our experiments, we use two mini-PCs as APs and two mini-PCs as Rxs, which are distributed in a square shape as shown in Figure 3. The devices are equipped with Intel Wireless Link 5300 NICs and installed CSI-Tool to measure CSI [2]. The Intel 5300 NIC reports 30 out of 56 subcarriers for each of its antennas. The APs use one antenna while the Rxs are equipped with three antennas. Note that all the antennas are off-the-shelf horizontally-polarized omni-directional antennas. The transceivers work in the frequency band with bandwidth. The sampling rate of CSI defaults to . In order to achieve a multiple legacy Wi-Fi link environment, both two Rxs can receive packets from two APs at the same time, thus forming four Wi-Fi links. In this paper, all APs are not subject to any strict time synchronization. Note that this does not affect the recognition results.
The environment is about , as shown in Figure 3. Other existing Wi-Fi networks such as the campus network are operated as usual during the whole experiments.
| Parameter | Value |
|---|---|
| Discount rate() | |
| Learning rate () | |
| Batch size () | |
| Infinitesimal parameter() |
V-B Data Sets
As shown in Figure 3, we divide the area surrounded by these Wi-Fi links into 16 locations, and the target randomly performs five daily activities of “Walk”, “Run”, “Stand”, “Sit”, “Bend”. We collect 2749 real CSI samples in the experiments, with 1949 samples as training and 800 samples as test data. In the test sets, there are 50 samples at each location. It should be noted that the target performs the same activity at all locations across the 16 locations in the trajectory in Figure 3, and then performs another run of the trajectory with another activity.
V-C Comparison Experiments
We compare the five following strategies for exploiting the various available Wi-Fi links:
-
•
Case 1: Use the link group decided by our agent.
-
•
Case 2: Use two Wi-Fi orthogonal links.
-
•
Case 3: Use all the Wi-Fi links.
-
•
Case 4: Use one random Wi-Fi link.
-
•
Case 5: Use one single (best) link decided by our agent.
Hence, the possible benefits of our method is illustrated in Case 1 and Case 5. For all cases, we utilize the CSI of different Wi-Fi links as the data sets for human activity recognition. Note that Case 2 is a classic heuristic approach that utilizes a pair of orthogonal transceivers which has been widely proved to be effective in many state-of-the-art studies [35, 40, 29, 31]. Furthermore, Case 4 and Case 5 use one Wi-Fi link which is a common practice in many current works. Finally note that Case 4 and Case 5 exhibit the same complexity.
| Parameter | Value |
|---|---|
| Learning rate () | |
| Batch size () | |
| Maximum epoch () | |
| Infinitesimal parameter() |
V-D Network Implementation
The network is implemented with TensorFlow [55] and the workstation for our experiments is equipped with 48 core CPUs of Intel Xeon(R) , 4GPUs of NVIDIA GeForce GTX1080Ti and 48GB memory.
For Case 1 and Case 5, as the input data of the agent, the normalized CSI streams are processed in the mixed CNN-LSTM network. TABLE II shows the architecture of the network. We note that Case 5 uses a softmax activation function to output the probability value of each action instead of the sigmoid function in the policy network. The architectures of the CNN-based classification networks with various layers are presented in TABLE III (CNN 1), TABLE IV (CNN 2), TABLE V (CNN 3) and TABLE VI (CNN 4). Other parameters of our model are shown in TABLE VII.
Case 2, Case 3 and Case 4 utilize networks with the same architectures but different parameters as the CNN-based classification networks for Case 1 and Case 5. TABLE VIII shows the parameters of Case 2, Case 3, and Case 4. Note that below each of the experimental settings are numbered in the following way: CNN c Case a, where Case a refers to one of the methods shown in Section V. C. with , and CNN c refers to the CNN architecture, .
VI Performance Evaluation
VI-A Evaluation Metrics
We evaluate the performance of our link selection framework based on the following metrics: (i) Overall Effectiveness. (ii) Characteristic Distribution. (iii) Confusion Matrix of Accuracy. (iv) Computational Cost. We also test those metrics against various scenarios, including changing the number of selected links or varying the target location.
VI-B Experimental Results
VI-B1 Overall Effectiveness
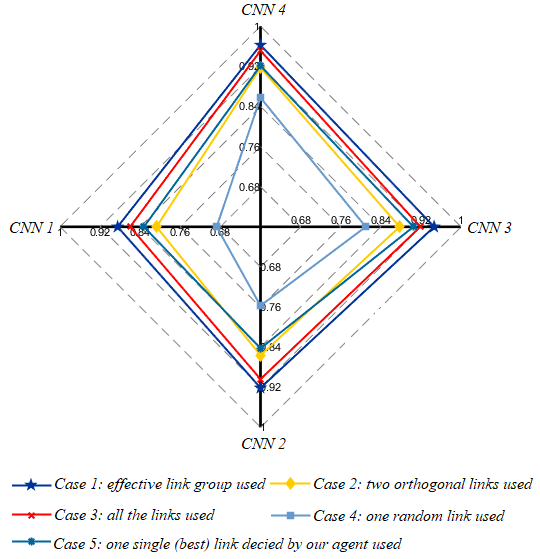
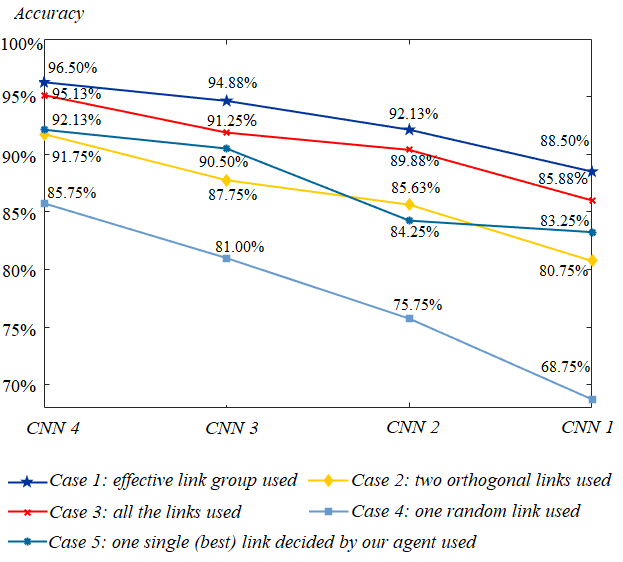
We explore the relationship between different types of CNN-based classification networks and the overall accuracies of human activity recognition in the five cases. The overall classification accuracies of Case a under CNN c are expressed through a radar graph (Figure 4) firstly. Through the radar graph, we can see that the performance of Case 1 is the best, and the performance of Case 5 mostly exceeds that of Case 2 even if it uses less CSI data.
Then we draw the accuracy curves of different cases with a decreasing number of CNN network layers, as shown in Figure 5. It can be seen that the accuracy of Case 1 declines the slowest and remains at the highest level from Figure 5. We can also see that the accuracy of CNN 2 Case 1 is much higher than that of CNN 3 Case 3, the accuracy of CNN 3 Case 1 is comparable to that of CNN 4 Case 3, which shows that the link selection framework can utilize a simpler network to achieve higher accuracy.
Our framework can significantly outperform the baseline methods. Even if only one single link is decided (Case 5), the accuracy is higher than using two orthogonal links (Case 2). Furthermore, the numbers of Wi-Fi links selected by our agent under CNN c are 2.90, 3.14, 2.49 and 2.35, respectively.
Due to the limited space, in what follows below we only focus on CNN 4, as it seems to give the best compromise between complexity and performance.
VI-B2 Characteristic Distribution
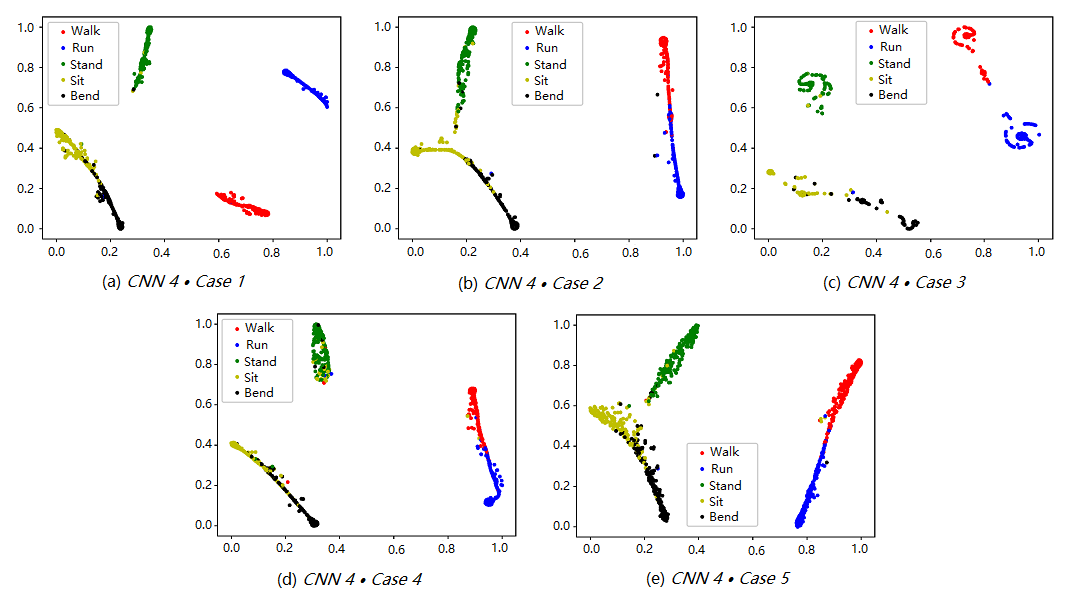
We examine the characteristics obtained by our proposed framework that underpins the successful performance of the agent in the Wi-Fi-based human activity recognition. The t-SNE algorithm is a technique developed for the visualization of high-dimensional data [56]. As expected, the t-SNE embeddings tend to map the characteristics of perceptually similar activities to nearby points. Thus we can utilize the t-SNE embeddings to estimate the performance of the human activity recognition. As shown in Figure 6, we plot the t-SNE embeddings transformed by the last layer features of the CNN classification network (CNN 4) in different cases.
The higher performance achieved by our method (Case 1) appears clearly from Figure 6(a). In that plot, the embeddings associated with each one of the 5 activities appear as fairly compact and well distinct groups of points, hence helping the classification task.
In contrast, the other methods result in embeddings that show up as groups of points with significant overlap or tend to be more scattered. This effect is particularly pronounced in Case 4, shown in Figure 6(d), where it is seen that totally random selection of one of the Wi-Fi links gives the worst performance. In comparison the selection of just one link but based on our RL strategy (Case 5) gives a clear improvement over Case 4, as see in Figure 6(e). Interestingly, Case 3, which systematically exploits all radio links performs better that a single random random link approach but not as well as a carefully selected subset of links, as shown in Figure 6(c) because some of the links tend to be more noisy or carry data less relevant to the classification task at hand, hence tend to confuse the network. Finally Case 2 corresponds to a widely used approach to heuristically select two radio links (based on orthogonality [35, 29, 31]), but again results in greater confusion probability as shown in Figure 6(b) when compared to our Case 1 in Figure 6(a).
VI-B3 Confusion Matrix of Accuracy
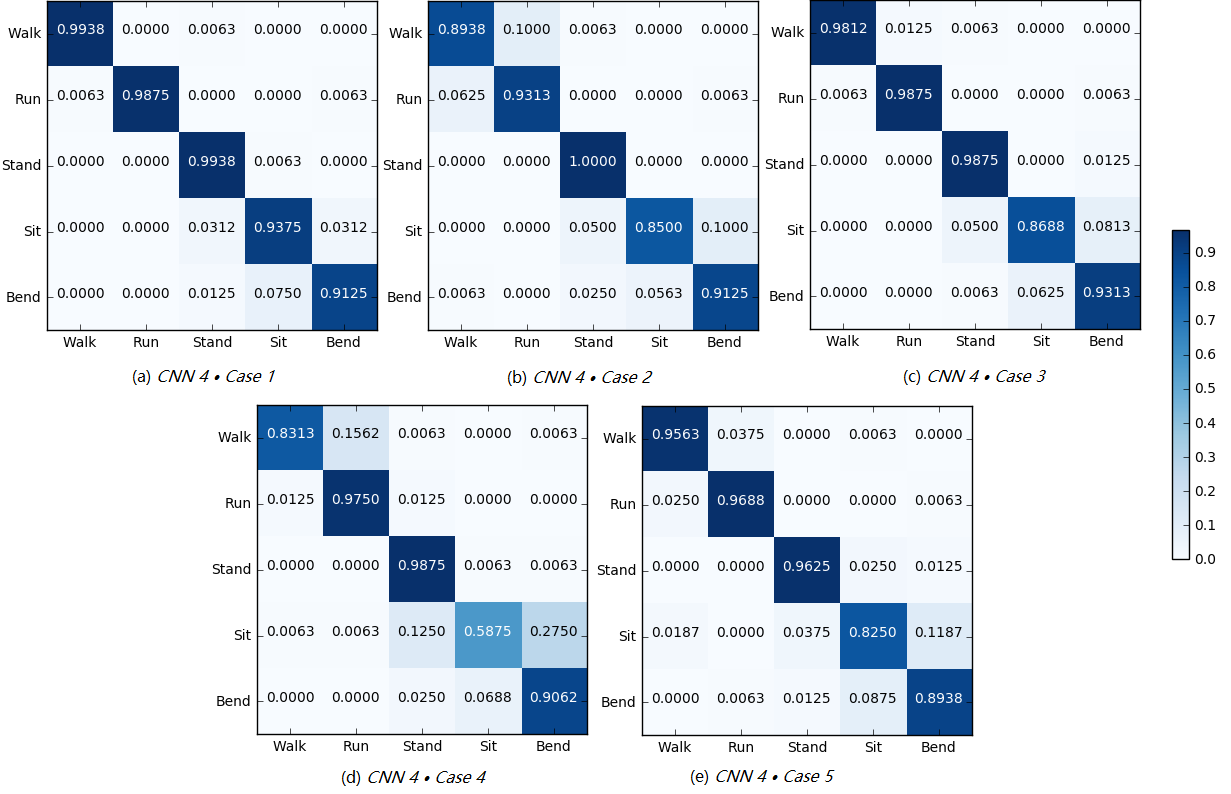
To evaluate a fine-grained performance, we present the confusion matrix of accuracy for each case under CNN 4 in Figure 7.
Case 1: Figure 7(a) shows the confusion matrix of accuracy for CNN 4 Case 1. Obviously, our proposed framework outperforms all others, reaching a recognition rate of 96.50. To be specific, the accuracy of each activity is 99.38, 98.75, 99.38, 93.75 and 91.25, respectively. The accuracy of each activity ranges from 91 to 100, indicating that the effective link group decided by our agent can not only accurately but also comprehensively classify the overwhelming majority of corresponding activity.
Case 2: Figure 7(b) shows the confusion matrix of accuracy for CNN 4 Case 2. The overall recognition accuracy for all activities in Case 2 reaches 91.75. Although Case 2 has a similar recognition accuracy to Case 1 in most activities, it has a poor recognition effect for “Walk” and “Sit”. As reflected in existing papers [35, 40, 29], Case 2 is applicable to some daily activities. However, it does not guarantee that the two orthogonal Wi-Fi links closest to the human location can extract the optimal activity characteristics in a legacy network of multiple APs. Especially in the application of wireless signals for human sensing, it is more important to choose links flexibly than to use fixed links.
Case 3: Figure 7(c) shows the confusion matrix of accuracy for CNN 4 Case 3. The overall recognition accuracy is 95.13, which is lower than that of Case 1. It can be seen that, “Sit” samples are more likely to be mistaken for “Bend”, which may be due to the fact that the duration of the two activities are quite similar. Some Wi-Fi links may not be sensitive enough to small differences in these characteristics, so such links need to be eliminated.
Case 4: Figure 7(d) shows the confusion matrix of accuracy for CNN 4 Case 4. We can see that randomly selecting a link is the least effective way to classify activities in all cases, with the overall accuracy of 85.75.
In conclusion, it is not feasible to use too much or too little information without filtering.
Case 5: Figure 7(e) shows the confusion matrix of accuracy for CNN 4 Case 5. This case performs slightly worse than Case 1 and Case 3, but better than the other two cases, with the overall recognition accuracy of 92.13. This illustrates, on the one hand, the limitation of using a single link for human sensing and, on the other hand, the effectiveness of our framework.
| Case 1 | Case 2 | Case 3 | Case 4 | Case 5 | |||
|---|---|---|---|---|---|---|---|
| Decision | Classification | Classification | Classification | Classification | Decision | Classification | |
| CNN 1 | 15.3ms | 5.3ms | 3.8ms | 6.3ms | 2.3ms | 13.8ms | 2.5ms |
| CNN 2 | 15.9ms | 5.5ms | 4.1ms | 6.3ms | 2.5ms | 14.5ms | 2.8ms |
| CNN 3 | 14.6ms | 5.1ms | 4.5ms | 6.6ms | 2.6ms | 14.4ms | 2.8ms |
| CNN 4 | 15.9ms | 5.2ms | 4.6ms | 7.3ms | 2.9ms | 14.2ms | 2.9ms |
VI-B4 Recognition Accuracy of Different Locations
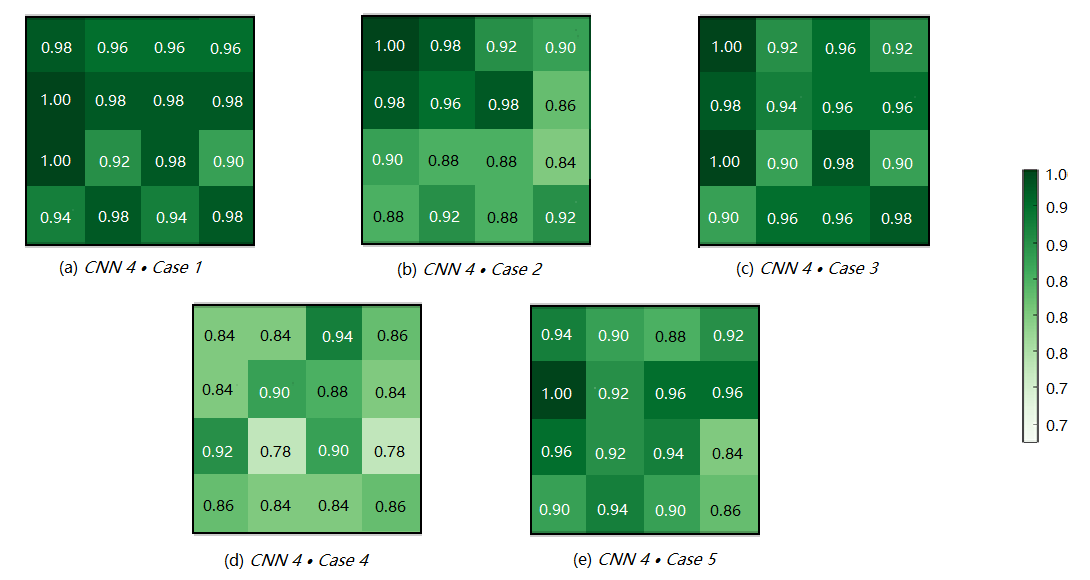
Then we calculate the human activity recognition accuracy of different locations under the five cases, as shown in Figure 8.
Case 1: Figure 8(a) shows the recognition accuracy of the 16 locations under CNN 4 Case 1. The recognition accuracy of each location reaches more than 90%, among which the lowest accuracies are in Location 9, but it could still reach 90%. In contrast, in other cases (except Case 3), the recognition accuracy in some locations are less than 90%, or even less than 80%. We also note that the performance of Case 1 is better than that of Case 3, as the accuracies of Case 1 over all locations distribute uniformly and the accuracy of each location is generally higher than that of Case 3. This indicates that our framework can select the effective link group () for different locations (), thus effectively improving the recognition accuracy.
Case 2: Figure 8(b) shows the recognition accuracy of the 16 locations under CNN 4 Case 2. In this case, the recognition accuracy of each location is lower than Case 1, especially the Location 8, Location 9, Location 10, Location 11, Location 13, Location 15, whose accuracies are lower than 90%. This shows that the two orthogonal links are not enough for each location to get the optimal sensing results. In addition, it shows that our framework can effectively improve the recognition accuracy of the difficult areas.
Case 3: Figure 8(c) shows the recognition accuracy of the 16 locations under CNN 4 Case 3. In this case, the recognition accuracies of most locations are lower than Case 1. Among them, the locations with the worst recognition accuracies are Location 9, Location 11 and Location 13, all are 90%. This indicates that there are some redundant links that affect the recognition accuracy, i.e., the links themselves do not contain activity-related features.
Case 4: Figure 8(d) shows the recognition accuracy of the 16 locations under CNN 4 Case 4. This case has the worst performance, which indicates that selecting a single link randomly has obvious disadvantages.
Case 5: Figure 8(e) shows the recognition accuracy of the 16 locations under CNN 4 Case 5. The performance of this case is slightly worse than Case 1 and Case 3, but better than Case 2, illustrating the necessity of link selection. In addition, for some locations, such as Location 2, Location 9 and Location 16, the recognition accuracy is lower, indicating that using one single link for recognition is not enough for these locations, i.e., utilizing only one single link for human sensing has limitations.
| CNN 1 | CNN 2 | CNN 3 | CNN 4 | |
|---|---|---|---|---|
| Best 2 Links Selected | 89.13% | 90.75% | 94.50% | 96.25% |
| Best 3 Links Selected | 89.88% | 91.75% | 95.38% | 96.88% |
| Undetermined Links | 88.50% | 92.13% | 94.88% | 96.50% |
| All Links | 85.88% | 89.88% | 91.25% | 95.13% |
VI-B5 Classification Accuracy vs. Number of Selected Links
To further evaluate the effectiveness of our framework, we make the agent select a fixed number of links in and then calculate the recognition accuracy. That is, our agent decides the best two or three links for classification each time. The experiment results under different layers of CNN-based classification networks are shown in TABLE X. The results demonstrate the effectiveness of our framework.
VI-B6 Computational Cost
Finally, we evaluate the computational cost of the five cases using different layers of CNN-based classification networks. We calculate the average test time over all the test samples and the results are shown in TABLE IX.
For one thing, the link selection process takes about 15, which is still in the acceptable range. Further, our framework brings a high gain in accuracy, which illustrates the significance of our framework.
For the other thing, the time required for the link selection process is constant. Because of the fixed numbers of links used, the test time of the classified network in Case 2-Case 4 increases with the complexity of the network. Therefore, in more densely deployed Wi-Fi environments, our framework will be more advantageous.
VII Discussion and Future work
In this paper, we present a RL-based link selection framework that is capable of identifying the most relevant group of radio links from multiple APs for human behavior sensing.
Our experimental results show that our proposed framework can achieve 96.50% accuracy when utilized to recognize 5 daily activities at 16 different locations in a Wi-Fi environment with up to four radio links available. This accuracy level is higher than what is obtained by using the data from all radio links, and is much higher than what is obtained with an arbitrary or random selection of links. In the given environment, our proposed method only relies on 2.35 links per sample on average as shown in Table XI. This table also indicates the average number of radio links exploited per different types of activity and human locations. As can be seen, some dynamic activities such as “Walk” and “Run” tend to rely on a higher number of links while more static ones can live with a fewer number of links and data. Our current setup is limited to four radio links but is scalable in practice. We believe performance will further increase with a higher number of links expected from a real-life dense Wi-Fi deployment.
| Human Location | Walk | Run | Stand | Sit | Bend | Average |
|---|---|---|---|---|---|---|
| 1 | 2.70 | 3.10 | 2.20 | 2.00 | 2.20 | 2.44 |
| 2 | 2.90 | 2.90 | 1.80 | 2.10 | 2.10 | 2.36 |
| 3 | 2.30 | 3.30 | 2.30 | 1.90 | 1.80 | 2.32 |
| 4 | 2.30 | 2.90 | 2.50 | 2.40 | 2.00 | 2.42 |
| 5 | 2.20 | 2.60 | 2.30 | 2.50 | 2.20 | 2.36 |
| 6 | 2.70 | 2.90 | 1.80 | 2.10 | 2.00 | 2.30 |
| 7 | 2.30 | 2.40 | 2.30 | 2.50 | 2.40 | 2.38 |
| 8 | 2.60 | 2.20 | 2.30 | 2.40 | 2.20 | 2.34 |
| 9 | 2.50 | 1.90 | 1.60 | 2.00 | 2.30 | 2.06 |
| 10 | 2.60 | 2.80 | 2.00 | 2.10 | 2.40 | 2.38 |
| 11 | 2.70 | 2.20 | 2.20 | 2.20 | 2.40 | 2.34 |
| 12 | 2.40 | 3.00 | 1.90 | 2.60 | 2.40 | 2.46 |
| 13 | 2.80 | 2.60 | 2.00 | 1.90 | 2.60 | 2.38 |
| 14 | 2.80 | 2.10 | 1.80 | 1.90 | 2.10 | 2.14 |
| 15 | 2.50 | 3.10 | 2.00 | 2.40 | 2.20 | 2.44 |
| 16 | 2.50 | 2.90 | 2.20 | 2.10 | 2.40 | 2.42 |
| Average | 2.55 | 2.68 | 2.08 | 2.19 | 2.23 | 2.35 |
Based on our proposed framework, one can continue to improve its functionality to deal with more diverse application scenarios, such as human imaging, or more complex Wi-Fi environments including through-wall setups.
Acknowledgment
This work was supported by Beijing Nova Program from Beijing Municipal Science & Technology Commission under Grant Z201100006820123 and National Key R & D Program of China under Grant 2018YFC0810204. The authors thank the volunteers for participating in the experiments. Finally, the authors sincerely thank the anonymous reviewers for their insightful comments.
References
- [1] X. Shen, L. Guo, Z. Lu, X. Wen, and S. Zhou, “WiAgent: Link selection for CSI-based activity recognition in densely deployed Wi-Fi environments,” in 2021 IEEE Wireless Communications and Networking Conference (WCNC), 2021, pp. 1–6.
- [2] D. Halperin, W. Hu, A. Sheth, and D. Wetherall, “Tool release: gathering 802.11n traces with channel state information,” ACM special interest group on data communication, vol. 41, no. 1, pp. 53–53, 2011.
- [3] S. Yousefi, H. Narui, S. Dayal, S. Ermon, and S. Valaee, “A survey on behavior recognition using WiFi channel state information,” IEEE Communications Magazine, vol. 55, no. 10, pp. 98–104, 2017.
- [4] Z. Wang, B. Guo, Z. Yu, and X. Zhou, “Wi-Fi CSI-based behavior recognition: From signals and actions to activities,” IEEE Communications Magazine, vol. 56, no. 5, pp. 109–115, 2018.
- [5] B. Guo, Y. J. Chen, N. Lane, Y. Liu, and Z. Yu, “Behavior recognition based on Wi-Fi CSI: Part 1,” IEEE Communications Magazine, vol. 55, no. 10, pp. 90–90, 2017.
- [6] ——, “Behavior recognition based on Wi-Fi CSI: Part 2,” IEEE Communications Magazine, vol. 56, no. 5, pp. 108–108, 2018.
- [7] L. Chen, X. Chen, L. Ni, Y. Peng, and D. Fang, “Human behavior recognition using Wi-Fi CSI: Challenges and opportunities,” IEEE Communications Magazine, vol. 55, no. 10, pp. 112–117, 2017.
- [8] H. Zhu, F. Xiao, L. Sun, R. Wang, and P. Yang, “R-TTWD: robust device-free through-the-wall detection of moving human with WiFi,” IEEE Journal on Selected Areas in Communications, vol. 35, no. 5, pp. 1090–1103, 2017.
- [9] K. Qian, C. Wu, Z. Yang, Y. Liu, F. He, and T. Xing, “Enabling contactless detection of moving humans with dynamic speeds using CSI,” ACM Transactions in Embedded Computing Systems, vol. 17, no. 2, p. 52, 2018.
- [10] Y. Gu, J. Zhan, Y. Ji, J. Li, F. Ren, and S. Gao, “MoSense: An RF-based motion detection system via off-the-shelf WiFi devices,” IEEE Internet of Things Journal, vol. 4, no. 6, pp. 2326–2341, 2017.
- [11] S. Palipana, D. Rojas, P. Agrawal, and D. Pesch, “FallDeFi: Ubiquitous fall detection using commodity Wi-Fi devices,” Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies archive, vol. 1, no. 4, p. 155, 2018.
- [12] H. Cheng, J. Zhang, Y. Gao, and X. Hei, “Deep learning Wi-Fi channel state information for fall detection,” in 2019 IEEE International Conference on Consumer Electronics - Taiwan (ICCE-TW), 2019.
- [13] H. Kong, L. Lu, J. Yu, Y. Chen, and F. Tang, “Continuous authentication through finger gesture interaction for smart homes using WiFi,” IEEE Transactions on Mobile Computing, pp. 1–1, 2020.
- [14] H. Liu, Y. Wang, J. Liu, J. Yang, Y. Chen, and H. V. Poor, “Authenticating users through fine-grained channel information,” IEEE Transactions on Mobile Computing, vol. 17, no. 2, pp. 251–264, 2018.
- [15] Y. Cao, Z. Zhou, C. Zhu, P. Duan, X. Chen, and J. Li, “A lightweight deep learning algorithm for WiFi-based identity recognition,” IEEE Internet of Things Journal, pp. 1–1, 2021.
- [16] B. Korany, H. Cai, and Y. Mostofi, “Multiple people identification through walls using off-the-shelf WiFi,” IEEE Internet of Things Journal, vol. 8, no. 8, pp. 6963–6974, 2021.
- [17] Y. Ma, G. Zhou, S. Wang, H. Zhao, and W. Jung, “SignFi: Sign language recognition using WiFi,” Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies archive, vol. 2, no. 1, p. 23, 2018.
- [18] J. Yang, H. Zou, Y. Zhou, and L. Xie, “Learning gestures from WiFi: A siamese recurrent convolutional architecture,” IEEE Internet of Things Journal, vol. 6, no. 6, pp. 10 763–10 772, 2019.
- [19] R. H. Venkatnarayan, S. Mahmood, and M. Shahzad, “WiFi based multi-user gesture recognition,” IEEE Transactions on Mobile Computing, pp. 1–1, 2020.
- [20] ——, “WiFi based multi-user gesture recognition,” IEEE Transactions on Mobile Computing, vol. 20, no. 3, pp. 1242–1256, 2021.
- [21] W. Wang, A. X. Liu, M. Shahzad, K. Ling, and S. Lu, “Device-free human activity recognition using commercial WiFi devices,” IEEE Journal on Selected Areas in Communications, vol. 35, no. 5, pp. 1118–1131, 2017.
- [22] W. Jiang, C. Miao, F. Ma, S. Yao, Y. Wang, Y. Yuan, H. Xue, C. Song, X. Ma, D. Koutsonikolas, W. Xu, and L. Su, “Towards environment independent device free human activity recognition,” in Proceedings of the 24th Annual International Conference on Mobile Computing and Networking, 2018, pp. 289–304.
- [23] Q. Gao, J. Wang, X. Ma, X. Feng, and H. Wang, “CSI-based device-free wireless localization and activity recognition using radio image features,” IEEE Transactions on Vehicular Technology, vol. 66, no. 11, pp. 10 346–10 356, 2017.
- [24] F. Xiao, J. Chen, X. H. Xie, L. Gui, and J. L. Sun, “SEARE: A system for exercise activity recognition and quality evaluation based on green sensing,” IEEE Transactions on Emerging Topics in Computing, pp. 1–1, 2018.
- [25] F. Wang, W. Gong, and J. Liu, “On spatial diversity in WiFi-based human activity recognition: A deep learning-based approach,” IEEE Internet of Things Journal, vol. 6, no. 2, pp. 2035–2047, 2019.
- [26] W. Zhang, S. Zhou, L. Yang, L. Ou, and Z. Xiao, “WiFiMap+: High-level indoor semantic inference with WiFi human activity and environment,” IEEE Transactions on Vehicular Technology, vol. 68, no. 8, pp. 7890–7903, 2019.
- [27] C. Feng, S. Arshad, S. Zhou, D. Cao, and Y. Liu, “Wi-Multi: A three-phase system for multiple human activity recognition with commercial WiFi devices,” IEEE Internet of Things Journal, vol. 6, no. 4, pp. 7293–7304, 2019.
- [28] J. Zhang, F. Wu, B. Wei, Q. Zhang, H. Huang, S. W. Shah, and J. Cheng, “Data augmentation and dense-LSTM for human activity recognition using WiFi signal,” IEEE Internet of Things Journal, vol. 8, no. 6, pp. 4628–4641, 2021.
- [29] L. Guo, Z. Lu, X. Wen, S. Zhou, and Z. Han, “From signal to image: Capturing fine-grained human poses with commodity Wi-Fi,” IEEE Communications Letters, vol. 24, no. 4, pp. 802–806, 2020.
- [30] W. Jiang, H. Xue, C. Miao, S. Wang, S. Lin, C. Tian, S. Murali, H. Hu, Z. Sun, and L. Su, “Towards 3D human pose construction using WiFi.” in Proceedings of the 26th Annual International Conference on Mobile Computing and Networking, 2020.
- [31] Y. Wang, L. Guo, Z. Lu, X. Wen, S. Zhou, and W. Meng, “From point to space: 3D moving human pose estimation using commodity WiFi,” IEEE Communications Letters, pp. 1–1, 2021.
- [32] W. Wang, A. X. Liu, M. Shahzad, K. Ling, and S. Lu, “Understanding and modeling of WiFi signal based human activity recognition,” in Proceedings of the 21st Annual International Conference on Mobile Computing and Networking, 2015, pp. 65–76.
- [33] F. Zhang, K. Niu, J. Xiong, B. Jin, T. Gu, Y. Jiang, and D. Zhang, “Towards a diffraction-based sensing approach on human activity recognition,” Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies archive, vol. 3, no. 1, p. 33, 2019.
- [34] C. Wu, F. Zhang, Y. Hu, and K. J. R. Liu, “GaitWay: Monitoring and recognizing gait speed through the walls,” IEEE Transactions on Mobile Computing, pp. 1–1, 2020.
- [35] K. Qian, C. Wu, Z. Zhou, Y. Zheng, Z. Yang, and Y. Liu, “Inferring motion direction using commodity Wi-Fi for interactive exergames,” in Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems, 2017, pp. 1961–1972.
- [36] Q. Pu, S. Gupta, S. Gollakota, and S. Patel, “Whole-home gesture recognition using wireless signals,” in Proceedings of the 19th annual international conference on Mobile computing and networking, 2013, pp. 27–38.
- [37] X. Shen, L. Guo, Z. Lu, X. Wen, and Z. He, “WiRIM: Resolution improving mechanism for human sensing with commodity Wi-Fi,” IEEE Access, vol. 7, pp. 168 357–168 370, 2019.
- [38] S. Arshad, C. Feng, Y. Liu, Y. Hu, R. Yu, S. Zhou, and H. Li, “Wi-Chase: A WiFi based human activity recognition system for sensorless environments,” in 2017 IEEE 18th International Symposium on A World of Wireless, Mobile and Multimedia Networks (WoWMoM), 2017, pp. 1–6.
- [39] J. Wang, L. Zhang, Q. Gao, M. Pan, and H. Wang, “Device-free wireless sensing in complex scenarios using spatial structural information,” IEEE Transactions on Wireless Communications, vol. 17, no. 4, pp. 2432–2442, 2018.
- [40] Y. Wang, K. Wu, and L. M. Ni, “WiFall: Device-free fall detection by wireless networks,” IEEE Transactions on Mobile Computing, vol. 16, no. 2, pp. 581–594, 2017.
- [41] H. Fei, F. Xiao, J. Han, H. Huang, and L. Sun, “Multi-variations activity based gaits recognition using commodity WiFi,” IEEE Transactions on Vehicular Technology, vol. 69, no. 2, pp. 2263–2273, 2020.
- [42] H. Li, K. Ota, M. Dong, and M. Guo, “Learning human activities through Wi-Fi channel state information with multiple access points,” IEEE Communications Magazine, vol. 56, no. 5, pp. 124–129, 2018.
- [43] Y. Wang, J. Liu, Y. Chen, M. Gruteser, J. Yang, and H. Liu, “E-eyes: device-free location-oriented activity identification using fine-grained WiFi signatures,” in Proceedings of the 20th annual international conference on Mobile computing and networking, 2014, pp. 617–628.
- [44] J. Huang, B. Liu, C. Chen, H. Jin, Z. Liu, C. Zhang, and N. Yu, “Towards anti-interference human activity recognition based on WiFi subcarrier correlation selection,” IEEE Transactions on Vehicular Technology, vol. 69, no. 6, pp. 6739–6754, 2020.
- [45] H. Li, W. Yang, J. Wang, Y. Xu, and L. Huang, “WiFinger: talk to your smart devices with finger-grained gesture,” in Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing, 2016, pp. 250–261.
- [46] K. Ali, A. X. Liu, W. Wang, and M. Shahzad, “Recognizing keystrokes using WiFi devices,” IEEE Journal on Selected Areas in Communications, vol. 35, no. 5, pp. 1175–1190, 2017.
- [47] Z. Guo, F. Xiao, B. Sheng, H. Fei, and S. Yu, “WiReader: Adaptive air handwriting recognition based on commercial Wi-Fi signal,” IEEE Internet of Things Journal, pp. 1–1, 2020.
- [48] D. Wu, D. Zhang, C. Xu, H. Wang, and X. Li, “Device-free WiFi human sensing: From pattern-based to model-based approaches,” IEEE Communications Magazine, vol. 55, no. 10, pp. 91–97, 2017.
- [49] R. Sutton and A. Barto, Reinforcement Learning: An Introduction, 1988.
- [50] W. Wu, D. He, X. Tan, S. Chen, and S. Wen, “Multi-agent reinforcement learning based frame sampling for effective untrimmed video recognition,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 6222–6231.
- [51] F. Zhang, D. Zhang, J. Xiong, H. Wang, K. Niu, B. Jin, and Y. Wang, “From Fresnel diffraction model to fine-grained human respiration sensing with commodity Wi-Fi devices,” Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies archive, vol. 2, no. 1, p. 53, 2018.
- [52] K. Niu, F. Zhang, Z. Chang, and D. Zhang, “A Fresnel diffraction model based human respiration detection system using COTS Wi-Fi devices,” in Proceedings of the 2018 ACM International Joint Conference and 2018 International Symposium on Pervasive and Ubiquitous Computing and Wearable Computers, 2018, pp. 416–419.
- [53] L. Guo, X. Wen, Z. Lu, X. Shen, and Z. Han, “WiRoI: Spatial region of interest human sensing with commodity WiFi,” in 2019 IEEE Wireless Communications and Networking Conference (WCNC), 2019, pp. 1–6.
- [54] R. J. Williams, “Simple statistical gradient-following algorithms for connectionist reinforcement learning,” Machine Learning, vol. 8, no. 3, pp. 229–256, 1992.
- [55] M. Abadi, P. Barham, J. Chen, Z. Chen, A. Davis, J. Dean, M. Devin, S. Ghemawat, G. Irving, M. Isard, M. Kudlur, J. Levenberg, R. Monga, S. Moore, D. G. Murray, B. Steiner, P. Tucker, V. Vasudevan, P. Warden, M. Wicke, Y. Yu, and X. Zheng, “TensorFlow: a system for large-scale machine learning,” in OSDI’16 Proceedings of the 12th USENIX conference on Operating Systems Design and Implementation, 2016, pp. 265–283.
- [56] V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, S. Petersen, C. Beattie, A. Sadik, I. Antonoglou, H. King, D. Kumaran, D. Wierstra, S. Legg, and D. Hassabis, “Human-level control through deep reinforcement learning,” Nature, vol. 518, no. 7540, pp. 529–533, 2015.