Limit Results for Estimation of Connectivity Matrix in Multi-layer Stochastic Block Models
Abstract
Multi-layer networks arise naturally in various domains including biology, finance and sociology, among others. The multi-layer stochastic block model (multi-layer SBM) is commonly used for community detection in the multi-layer networks. Most of current literature focuses on statistical consistency of community detection methods under multi-layer SBMs. However, the asymptotic distributional properties are also indispensable which play an important role in statistical inference. In this work, we aim to study the estimation and asymptotic properties of the layer-wise scaled connectivity matrices in the multi-layer SBMs. We develop a novel and efficient method to estimate the scaled connectivity matrices. Under the multi-layer SBM and its variant multi-layer degree-corrected SBM, we establish the asymptotic normality of the estimated matrices under mild conditions, which can be used for interval estimation and hypothesis testing. Simulations show the superior performance of proposed method over existing methods in two considered statistical inference tasks. We also apply the method to a real dataset and obtain interpretable results.
Keywords: Multi-layer networks, Asymptotic properties, Spectral methods
1 Introduction
The multi-layer network has gained widespread attention for its ability to represent multiple relationships among the same entities of interest, thereby enhancing the understanding of complex network data (Mucha et al., 2010; Holme and Saramäki, 2012; Kivelä et al., 2014; Han et al., 2015). For example, the Worldwide Food and Agricultural Trade (WFAT) multi-layer trade network (De Domenico et al., 2015), encompassing trade relationships among the same countries (nodes) across different commodities (layers), offers a richer insight than a single-layer trade network.
The multi-layer stochastic block model (multi-layer SBM) (Han et al., 2015; Paul and Chen, 2016) has been popularly used for the community detection task in the multi-layer network, where each layer corresponds to a stochastic block model (SBM) (Holland et al., 1983). In particular, given common unobserved communities (blocks), the edges in each layer are generated according to a layer-wise block probability matrix or the so-called connectivity matrix. Various methods have been proposed to detect the communities of multi-layer networks under the multi-layer SBM, see, e.g., Han et al. (2015); Bhattacharyya and Chatterjee (2018); Paul and Chen (2020); Jing et al. (2021); Arroyo et al. (2021); Lei and Lin (2023).
Most of the aforementioned literature on community detection of multi-layer SBMs is devoted to the statistical consistency. However, the asymptotic distributional properties are also vital and particularly useful in subsequent inference tasks. In the context of single-layer SBMs or other related models, various versions of asymptotically Gaussian behavior emerged for different purposes (Agterberg and Cape, 2023). Specifically, Tang and Priebe (2018) provided a central limit theorem for the eigenvectors of the normalized Laplacian matrix under the random dot product graph (RDPG) model (Young and Scheinerman, 2007). Rubin-Delanchy et al. (2022) extended these asymptotic results to the generalized RDPG and applied the theory to SBMs. Bickel et al. (2013) and Tang et al. (2022) established the asymptotic normality results for the estimation of the connectivity matrix using the maximum likelihood method and spectral embedding, respectively. Fan et al. (2022b) tested whether two nodes from a mixed-membership model (Airoldi et al., 2008) have the same membership parameters by establishing the asymptotic distributional properties. Jin et al. (2023) proposed a goodness-of-fit approach to select the number of communities and the asymptotic null distribution of the test statistic is normal. Also see Agterberg and Cape (2023) for a comprehensive overview of asymptotic normality in SBMs.
In the multi-layer SBM, the asymptotic distributional properties are crucial for subsequent inferences especially for those tailored for the multi-layer networks. However, as far as we are aware, the asymptotic properties under multi-layer SBMs are largely unexplored. An important inference task in multi-layer SBMs is to test whether networks across different layers are generated from the same SBM, essentially the same connectivity matrix given the consensus community memberships. For instance, in analyzing the WFAT multi-layer network, the goal extends beyond the community detection to ascertaining whether trading patterns across different commodities are similar. Asymptotic properties play a fundamental role in such inference. In the literature, Arroyo et al. (2021) and Zheng and Tang (2022) showed that the connectivity matrices estimated using the spectral embedding are asymptotically normal under the common subspace independent edge graph (COSIE) model. These studies necessitate that the connectivity matrices for all network layers are full rank. However, in practical multi-layer networks like WFAT, not all layers carry comprehensive cluster information, potentially leading to missing clusters, which results in the rank-deficiency of individual connectivity matrices (Su et al., 2024). Moreover, the methods in Arroyo et al. (2021) and Zheng and Tang (2022) treat multi-layer SBMs as special case of their COSIE model, rather than being specifically tailored for them.
Motivated by the above problems, we study the asymptotic properties in the estimation of connectivity matrices under multi-layer SBMs, without imposing the full rank assumption on their populations. We develop a simple and efficient spectral clustering-based method for the scaled connectivity matrix estimation, where the scaled connectivity matrix is also called the score matrix (Arroyo et al., 2021). Under proper conditions, we establish the asymptotic normality of the estimated scaled connectivity matrices under multi-layer SBMs and its variants, the degree-corrected multi-layer SBM. We emphasize that the asymptotic properties can be used to perform various statistical inferences, such as interval estimation and hypothesis testing.
The main contributions of this paper are threefold. First, we systematically study and specifically tailor the asymptotic normality of the scaled connectivity matrix estimation under the multi-layer SBM and its variant, the multi-layer degree-corrected SBM. To the best of our knowledge, the asymptotic normality under the degree-corrected SBM is less explored, let alone the multi-layer degree-corrected SBM. Second, the conditions under which our results hold are relatively mild. Compared to previous work which necessitated full rank in each layer (Arroyo et al., 2021; Zheng and Tang, 2022), we allow individual connectivity matrices to be rank-deficient and only require their squared summation to be full rank. This adaptability makes our approach particularly suitable for analyzing multi-layer networks where each layer only captures partial underlying communities. Third, we apply the established asymptotic normality to two statistical inference tasks, one for interval estimation of the scaled connectivity matrices, and the other for testing whether the population matrices corresponding to different layers are the same. The numerical results show superior performance of the proposed method over compared methods in these tasks. The analysis of a real-world trade network dataset provides interpretable results.
The rest of the paper is organized as follows. Section 2 introduces the estimation method of individual connectivity matrices in the multi-layer SBM. Section 3 provides the asymptotic normality of the estimates. Section 4 extends the method to multi-layer degree-corrected SBMs and presents the corresponding asymptotic normality results. Sections 5 and 6 include the simulation and real data experiment. Section 7 concludes the paper and provides possible extensions. Technical proofs are included in the Appendix.
2 Methodology
In this section, we first present and reparameterize the multi-layer stochastic block model. Then we propose the method for estimating the individual connectivity matrices. The following notation is used throughout the paper.
Notation: We use to denote the set . For a matrix , and denote the Frobenius norm and the maximum row-wise norm, respectively. The spectral norm of a matrix and the Euclidean norm of a vector are denoted by . The notation is used to denote a diagonal matrix formed from either a vector or the diagonal elements of a matrix. The notation refers to the vectorization of the upper triangular part of a symmetric matrix, proceeding in a column-wise order. For two sequences and , we write if there exists some constant such that , and use to denote the case where both and . The notation denotes that as goes to infinity, while means that .
2.1 Multi-layer SBMs
Consider the multi-layer network comprising layers and shared nodes, with its symmetric adjacency matrices represented by , where for all . The multi-layer SBM (Han et al., 2015; Valles-Catala et al., 2016; Paul and Chen, 2016) is as follows.
Assume the nodes are partitioned into layer-independent communities with the community assignment of node denoted by . With this community assignment, the element of is generated independently as the following SBM (Holland et al., 1983),
where controls the overall sparsity of the generated networks, denotes the heterogeneous connectivity matrix, and we assume the diagonal entries ’s are all 0.
It is easy to see that
is the population matrix for , in the sense that , where denotes the membership matrix with if and only if and otherwise. Define , where each diagonal element represents the number of nodes in community , we can then rearrange as
| (1) |
where and . Here, is an orthogonal column matrix with different rows and serves as the eigenspace of the population matrix . The symmetric matrix is referred to as the scaled connectivity matrix or the score matrix. We will study its estimation and asymptotic normality in subsequent sections. Note that Arroyo et al. (2021) first considered this type of decomposition when they developed the COSIE model.
Through the decomposition in (1), the multi-layer SBM can be reparameterized by (). Note that such parametrization is identifiable up to orthogonal transformation because for any orthogonal matrix , provides another valid decomposition, where represents the set consists of all orthogonal matrices.
2.2 Estimation of the scaled connectivity matrices
In order to estimate the scaled connectivity matrices , we first estimate the common eigenspace .
To utilize the information across layers, we regard as the eigenspace of the following ,
where we squared ’s before summing them up to avoid the community cancellation by direct summation (Lei and Lin, 2023). Suppose is of full rank, and recalling that is a full rank diagonal matrix, then is also of full rank. Denote the by , where and is a diagonal matrix. Then we have
Hence, are the eigenvectors of .
Therefore, we can estimate using the eigenvectors of the sample version . Specifically, to mitigate the bias introduced by the diagonal part of , we conduct eigendecomposition on the following bias-adjusted sum of squares of the adjacency matrices
where is an diagonal matrix with representing the degree of node in layer . The resulting eigenvectors are denoted by .
Given , we are ready to estimate the matrices by recalling the decomposition of the population matrix in (1). Specifically, we can obtain the following estimator for each layer :
| (2) |
Remark 1.
Similar estimation approaches for scaled connectivity matrices have been used by Arroyo et al. (2021), where the common eigenspace is derived based on distributed estimation techniques (Fan et al., 2019). By contrast, our methodology utilizes the bias-adjusted sum of squares of the adjacency matrices to estimate the eigenspace, aiming to avoid potential signal cancellation. This aggregation method was initially proposed by Lei and Lin (2023); however, their primary focus was on the statistical consistency of community detection instead of the asymptotic normality in the estimation of connectivity matrices.
3 Asymptotic properties
In this section, we present the asymptotic properties of the individual estimates of the scaled connectivity matrices in the multi-layer SBM.
To establish the asymptotic normality of , we need the following assumptions.
Assumption 1.
The number of communities is fixed. The community sizes are balanced, that is, there exists some constant such that each community size is in .
Assumption 1 also indicates that there exist positive constants , and an orthogonal matrix , such that for all and . This is referred to as eigenvector delocalization (Rudelson and Vershynin, 2015; He et al., 2019). Indeed, by recalling the relationship and choosing the orthogonal matrix with for each and each pair , the delocalization of follows by Assumption 1.
Assumption 2.
The minimum eigenvalue of is at least for some constant .
Assumption 2 specifies the growth rate of the minimum eigenvalue of in order to make the theoretical bound of the estimated common eigenspace around concrete. The linear growth rate is reasonable because when the connectivity matrices are common, Assumption 2 holds naturally.
Assumption 3.
Suppose the sum of the variance of the edges satisfies
for all .
Assumption 3 is critical to ensure the Lindeberg conditions for the Central Limit Theorem are met. For balanced community sizes, Assumption 3 simplifies to , which suffices if .
Before stating the next assumption, we first define the following matrix ,
| (3) |
for each and . Also, define with to be the noise matrix. As we will see, actually serves as the covariance matrix of the vectorized , denoted by , where we focus on the upper triangular part of the symmetric . Specifically, for any , the th entry in corresponds to .
Assumption 4.
for all , where denotes the smallest eigenvalue.
Similar to Assumption 3, Assumption 4 contributes to verifying the Lindeberg conditions for the Central Limit Theorem. By Assumption 3 and the discussions after Assumption 1, we can conclude that each entry of is . Hence, Assumption 4 is stronger than Assumption 3.
With these assumptions, we obtain the following entry-wise and vector-wise asymptotic properties of the estimated scaled connectivity matrices under the multi-layer SBM.
Theorem 1.
Suppose Assumptions 1 and 2 hold for the multi-layer SBM, and a positive constant exists such that . Then the estimate obtained from (2) has the following asymptotic properties.
(b) If Assumption 4 holds, then for any given , we have
as goes to infinity. Here, is a standard normal distribution in dimensions.
In (a) and (b), is a orthogonal matrix, and is a diminishing term satisfying with high probability for some positive constant .
Remark 3.
Remark 4.
The bias term is negligible because it is dominated by . This is also numerically verified in Section 5.
4 Extension to multi-layer degree-corrected SBMs
In this section, we extend the proposed method and the corresponding asymptotic normality results to multi-layer degree-corrected stochastic block models, which is a counterpart of the multi-layer SBM but in each layer the network is assumed to be generated from a degree-corrected SBM (DCSBM) (Karrer and Newman, 2011).
The SBM can not capture the degree heterogeneity inherent in the networks. To address this, the DCSBM extends the standard SBM by incorporating node specific parameters, allowing degrees to vary within the same community.
We now introduce the multi-layer DCSBM, where the layer-wise networks are generated from the DCSBM. Without specification, the notes and notation are the same as those in Section 2. Define to be the degree heterogeneity parameter which measures the propensity of a node in forming edges with other nodes and is consensus among layers. For identifiability, we assume for all (Lei and Rinaldo, 2015; Zhang et al., 2022). Given , the community assignments , the connectivity matrix , and the network sparsity parameter , the element is generated independently as follows
and and . The population adjacency matrix of is then
To facilitate further analysis, we now give some additional notation. For each , define as the set of nodes whose community membership is . Let be an vector that matches on the index set and is zero elsewhere. Define , where each diagonal element represents the effective community size of community . This allows us to reformat as
where and . It can be shown that .
As described in the case of multi-layer SBMs, we regard as the eigenspace of the following ,
Suppose is of full rank, then is of full rank as well. Similar to the case of multi-layer SBMs, we perform the eigendecomposition on the bias-adjusted sum of squares of the adjacency matrices , where recall is an diagonal matrix with and the resulting eigenvectors are denoted by . We further obtain with the help of through (2).
The following Assumptions E1, E3, and E4 are needed for establishing the asymptotic normality of , which are counterparts of the assumptions under the multi-layer SBM.
Assumption E1.
The number of communities is fixed and for all .
Assumption E3.
.
Assumption E4.
for all , where denotes the smallest eigenvalue.
Assumption E1 requires that the node propensity parameters restricted to each community have the same order of Euclidean norm. This condition is frequently imposed in the analysis of the DCSBM; see Su et al. (2020); Jin et al. (2023) and Agterberg et al. (2022). Generally, Assumptions E3 and E4 are more stringent than Assumptions 3 and 4 because ; while in the special case of multi-layer SBMs where and , Assumptions E3 and E4 reduce to Assumptions 3 and 4, respectively. With these assumptions, the entry-wise and vector-wise asymptotic normality hold for the estimated scaled connectivity matrix under the multi-layer DCSBM.
Theorem 2.
Suppose Assumptions E1 and 2 hold for the multi-layer DCSBM, and a positive constant exists such that . Consider the estimate obtained from (2), which has the following asymptotic properties.
(b) If Assumption E4 holds, then for any given , we have
as goes to infinity. Here, is a standard normal distribution in dimensions.
In (a) and (b), is a orthogonal matrix, and is a bias term satisfying with high probability for some positive constant .
Remark 6.
reveals the degree of heterogeneity to some extent. A larger would lead to a smaller bias . When , the upper bound of does not exceed up to log factors, where is some positive constant. In this case, when , the bias term is dominated by .
5 Simulations
In this section, we conduct simulations to investigate the finite sample performance of the proposed method. In Section 5.1, we verify the vanishing behavior of the bias term in the formulation of asymptotic normality. In Sections 5.2 and 5.3, we test the efficacy of the derived asymptotic normality in two downstream statistical inference tasks, one for the interval estimation of the entries of the scaled connectivity matrices and the other for hypothesis testing to infer whether the multi-layer network exhibits homogeneity.
The proposed method is denoted by SCCE, namely, the abbreviation for spectral clustering-based method for connectivity matrix estimation. Since studies on the asymptotic properties under multi-layer SBMs are relatively limited, we compare SCCE with the Multiple Adjacency Spectral Embedding (MASE) method studied in Arroyo et al. (2021) and Zheng and Tang (2022).
5.1 Bias evaluation
As shown in Theorems 1 and 2, exhibits asymptotic normality with a bias term for all . The theoretical results indicate that for a fixed number of nodes , the bias tends to zero in Frobenius norm as the number of layers increases and the edge density decreases. The exact formulation for can be found in the proofs and (A1).
In this experiment, we numerically verify the vanishing behavior of the bias . To this end, we generate the following multi-layer SBM. Consider nodes per network with communities proportional to the number of nodes via . We set for and for , with
and
where
| (4) |
We test how the bias varies against the number of layers . The average results over 100 replications are displayed in Figure 1. Specifically, in Figure 1(a), the number of nodes is fixed to be 500 and we test the method for various fixed . The bias decreases as increases and decreases. In particular, when is large, our upper bound on the bias indicates that is the dominating term and large will not decrease the bias. The numerical result with coincides with this theoretical finding. In Figure 1(b), the overall edge density is fixed to be 0.1 and we test the results for various fixed . The results are also consistent with the theoretical bound, showing that the bias decreases as the number of layers or the number of nodes increases.
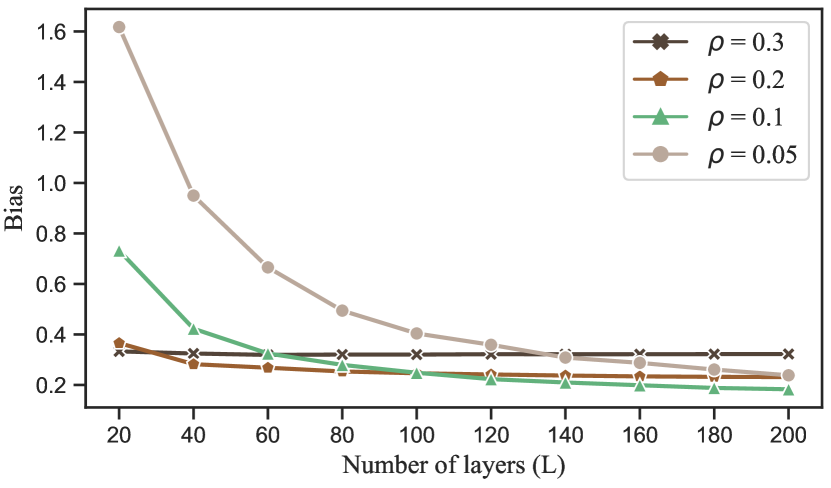
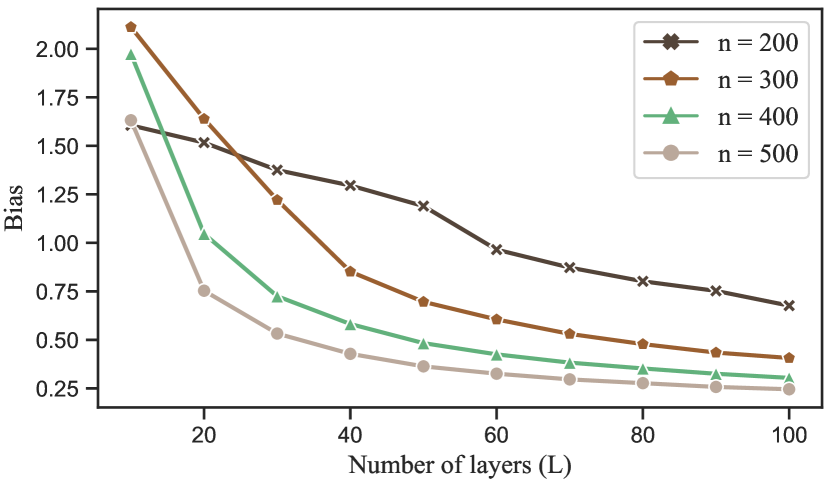
5.2 Interval estimation
The asymptotic distribution of helps to establish the interval estimate of for and . In particular, the interval estimate for , as indicated by Theorems 1 and 2, is given by
where is the -th percentile of the standard normal distribution, and represents the estimated covariance matrix, which is the counterpart of (3) with and ’s replaced by and ’s, respectively.
In this experiment, we test the accuracy of the estimated interval using the probability of the estimated interval covering the true underlying parameter over 200 replications. We consider two model set-ups, one for the multi-layer SBM and the other for the multi-layer DCSBM. In the multi-layer SBM, the network generation process is similar to that described in Section 5.1. We consider various combinations of and . For each combination of , we consider two different numbers of layers, , set at 50 and 100, respectively. In the multi-layer DCSBM, the network generation process is also similar to that in Section 5.1 with the number of nodes except that we introduce the degree heterogeneity parameter . For each , we independently generate from the uniform distribution and set (Jin et al., 2023). Here we set the corresponding to 10.4, 12 and 13.4 when the number of nodes is 300, 400 and 500, respectively.
Tables 1 and 2 show the average rate of the 95% confidence intervals covering the true parameters over 200 replications for the multi-layer SBM and multi-layer DCSBM, respectively. In particular, we calculate the average coverage rate over all the triples . The results show that as , , and increase, the coverage rate under both multi-layer SBMs and multi-layer DCSBMs improves. The proposed method consistently outperforms the MASE over all range of the considered parameter settings. In addition, we observe that the 95% confidence intervals do not achieve a 95% coverage rate, which can be attributed to the presence of a bias term or to an inadequate number of nodes and network layers. Nevertheless, as the number of layers and nodes increases, the coverage rate becomes close to 95%.
| SCCE | MASE | SCCE | MASE | SCCE | MASE | SCCE | MASE | ||
|---|---|---|---|---|---|---|---|---|---|
| 100 | 50 | 0.860 | 0.764 | 0.752 | 0.696 | 0.787 | 0.697 | 0.817 | 0.743 |
| 100 | 0.906 | 0.864 | 0.846 | 0.728 | 0.811 | 0.732 | 0.854 | 0.753 | |
| 200 | 50 | 0.920 | 0.876 | 0.902 | 0.782 | 0.705 | 0.655 | 0.726 | 0.530 |
| 100 | 0.924 | 0.906 | 0.919 | 0.872 | 0.865 | 0.715 | 0.755 | 0.598 | |
| 300 | 50 | 0.924 | 0.895 | 0.920 | 0.799 | 0.831 | 0.618 | 0.588 | 0.550 |
| 100 | 0.928 | 0.917 | 0.929 | 0.885 | 0.905 | 0.756 | 0.724 | 0.636 | |
| 400 | 50 | 0.925 | 0.917 | 0.928 | 0.832 | 0.903 | 0.456 | 0.630 | 0.467 |
| 100 | 0.927 | 0.923 | 0.928 | 0.894 | 0.922 | 0.658 | 0.857 | 0.490 | |
| 500 | 50 | 0.929 | 0.926 | 0.927 | 0.854 | 0.911 | 0.404 | 0.752 | 0.413 |
| 100 | 0.929 | 0.929 | 0.927 | 0.903 | 0.925 | 0.602 | 0.886 | 0.419 | |
| n | L | SCCE | MASE | SCCE | MASE | SCCE | MASE | SCCE | MASE |
|---|---|---|---|---|---|---|---|---|---|
| 300 | 50 | 0.883 | 0.555 | 0.732 | 0.537 | 0.621 | 0.438 | 0.721 | 0.581 |
| 100 | 0.915 | 0.692 | 0.881 | 0.579 | 0.664 | 0.434 | 0.758 | 0.577 | |
| 400 | 50 | 0.905 | 0.480 | 0.843 | 0.450 | 0.522 | 0.363 | 0.660 | 0.463 |
| 100 | 0.924 | 0.697 | 0.905 | 0.531 | 0.700 | 0.428 | 0.679 | 0.457 | |
| 500 | 50 | 0.916 | 0.441 | 0.880 | 0.365 | 0.480 | 0.351 | 0.561 | 0.402 |
| 100 | 0.925 | 0.634 | 0.914 | 0.434 | 0.796 | 0.433 | 0.583 | 0.392 | |
5.3 Hypothesis testing
In multi-layer networks, an interesting statistical inference task is to test whether there is homogeneity across different layers, specifically whether some layer-wise adjacency matrices come from the same population. In the multi-layer SBM, recall the model can be reparameterized by (), as described in (1), which implies that for any pair with and , the populations are identical, namely , if and only if . Consequently, this type of homogeneity manifests as a partition of the scaled connectivity matrices , say
Here is the index in . All pairs within a set of the partition are equal, and two ’s in different partitions are unequal. To infer the homogeneity of the multi-layer SBM, we consider the simultaneous testing of the hypotheses
| (5) |
and use a Holm type step-down procedure to control the family-wise error rate (Lehmann and Romano, 2005). The totality of acceptance and rejection statements resulting from the multiple comparison procedure may lead to a partition of the connectivity matrices. In the Holm procedure, null hypotheses are considered successively, from most significant to least significant, with further tests depending on the outcome of earlier ones. If any hypothesis is rejected at the level , the denominator of for the next test is and the criterion continues to be modified in a stage-wise manner, with the denominator of reduced by 1 each time a hypothesis is rejected, so that tests can be conducted at successively higher significance levels. This type of multiple comparison procedure is commonly used (Dudoit et al., 2008; Noble, 2009).
The primary challenge lies in how to test the individual hypotheses, which can be facilitated using the asymptotic distribution of the estimated scaled connectivity matrices. Specifically, to test each individual hypothesis at the specified significance level, we employ the Frobenius norm of the difference between the estimated scaled connectivity matrices as the test statistic. The distribution of the test statistic can be determined with the help of asymptotic distribution of .
We first specify the distribution of . In Theorem 1, we have provided the asymptotic distribution of , with the vanishing bias term excluded. However, the dependence between and prevents a straightforward summation to obtain the asymptotic distribution of , which, under the hypothesis , reduces to the distribution of . Fortunately, by leveraging the analogous technique used in the proof of Theorem 1, specifically the decomposition (A2), we can obtain the limiting distribution of . Specifically, we have
for each distinct pair and satisfying , where and are negligible under certain conditions and the notation is the same as those in Theorem 1. The conclusion holds for both the multi-layer SBM and the multi-layer DCSBM. As a result, under the hypothesis and omitting the bias terms, we can approximate the asymptotic distribution of by . With the help of asymptotic distribution of , we estimate the distribution of the test statistic by drawing samples from and calculating the empirical distribution of the Frobenius norm, where and denote the estimated covariance matrices defined in Section 5.2. The above procedure to determine the distribution of the test statistic is denoted by SCCE.
Experiment 1.
The distribution of the test statistic enables the testing of the individual hypothesis . In this experiment, we evaluate the power of the test statistic in testing for a given pair . Both the multi-layer SBM and the multi-layer DCSBM are considered. We fix , and . The number of nodes in three communities is assigned according to . The overall edge density is fixed at 0.2. The network generation processes of both models are similar with that in Section 5.2 except the definitions of ’s. In this experiment, we set for , and for , where and are defined in Section 5.1. For the first layer , and for the second layer , the is defined to be the same as except for the first entry . We vary to obtain a sequence of matrices. Under these parameter settings, we test the individual hypothesis at a specified significance level.
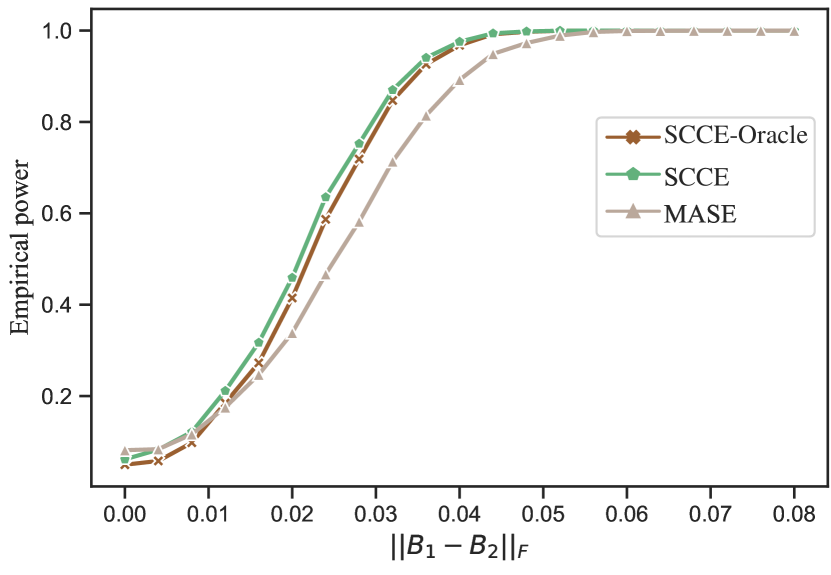
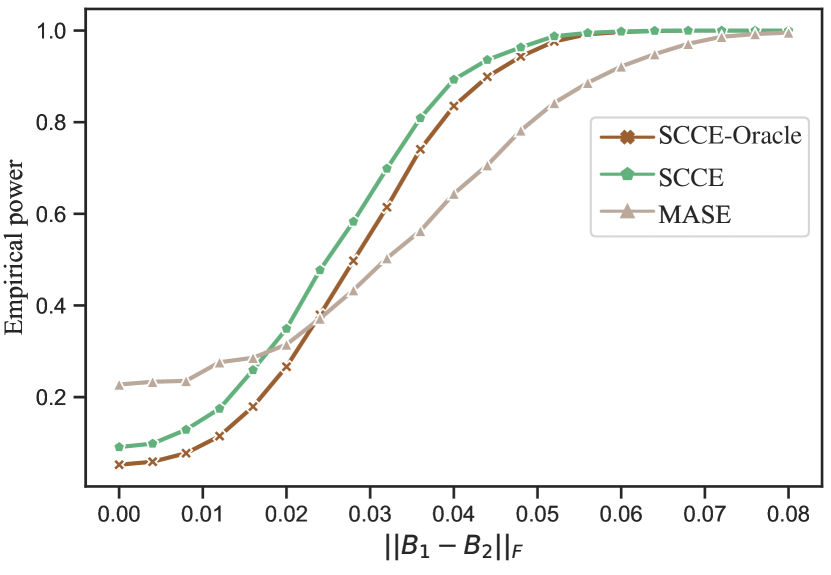
Figure 2 shows the averaged empirical power to reject the individual hypothesis at a 0.05 significance level with increasing over 100 replications. In our comparisons, we compare SCCE with a counterpart SCCE-Oracle, which differs from SCCE primarily in that it does not use the asymptotic distribution of . Instead, SCCE-Oracle generates various samples from the population to obtain various and uses the empirical distribution to approximate the real distribution of the test statistic . Another comparison method, MASE, is defined similarly with SCCE except that we use the estimator and the asymptotic distribution derived in Arroyo et al. (2021). The results in Figure 2 show that the proposed method SCCE has power close to that of SCCE-Oracle, demonstrating the accuracy of the asymptotic distributions. In addition, the proposed method SCCE has higher power than MASE under both network models, showing the efficacy of the proposed method in hypothesis testing.
Experiment 2.
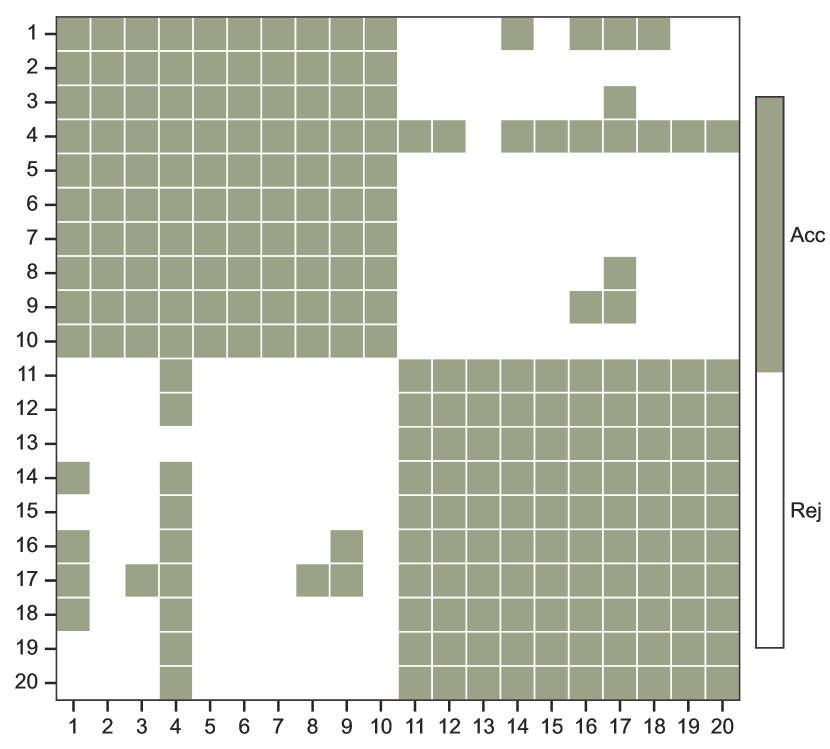
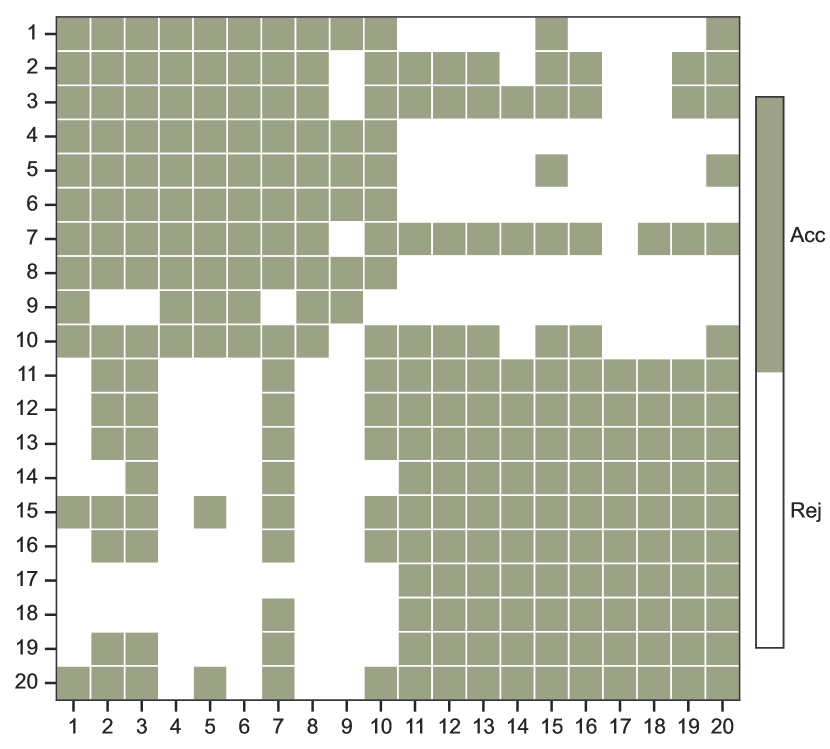
We shall now consider the simultaneous testing of the hypotheses (5) by means of a Holm type step-down procedure for inferring homogeneity of multi-layer networks. For this purpose, we consider the multi-layer SBM with two distinct connectivity matrices, where all connectivity matrices constitute a partition as follows:
All pairs within a set of the partition are equal, and two ’s in different partitions are unequal. It is clear that the overall network is heterogeneous, while the network layers within each partition exhibit homogeneity. Specifically, we set for and for , with
and
where is defined as in (4). We set , and , with the number of nodes in three communities proportioned at . The overall edge density is fixed at 0.2. Recall the definition of , the difference in between different partitions is now given by .
Figure 3 presents the outcomes of the multiple comparisons conducted using a Holm type step-down procedure, where olive green signifies acceptance and white signifies rejection of the individual hypotheses. We control the Holm procedure to ensure that the family-wise error rate is no bigger than . In the results of the proposed method SCCE, two distinct blocks are observed within which all individual hypotheses are simultaneously accepted, demonstrating the presence of homogeneity within these blocks. This is consistent with our experimental setup. However, MASE cannot accurately infer the true homogeneity. Moreover, in cases where the true hypothesis is false, the proposed method SCCE almost always rejects them.
6 Real data analysis
In this section, we use the proposed method SCCE to measure the homogeneity across all layers of a real multi-layer network, specifically the WFAT dataset (De Domenico et al., 2015). For this purpose, we simultaneously test the hypotheses
using a Holm type step-down procedure. Next, we provide the data description and the results for the real dataset.
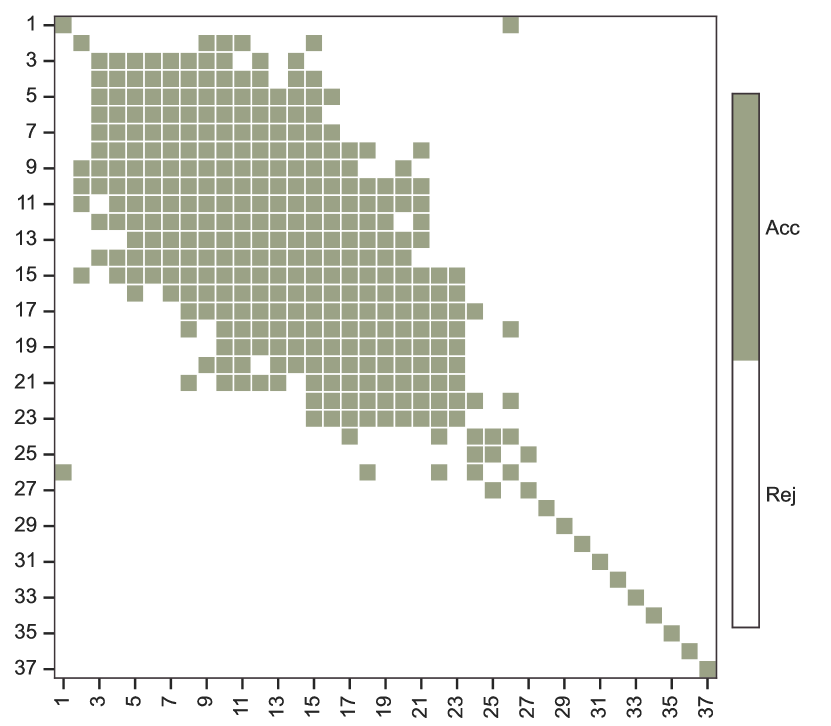
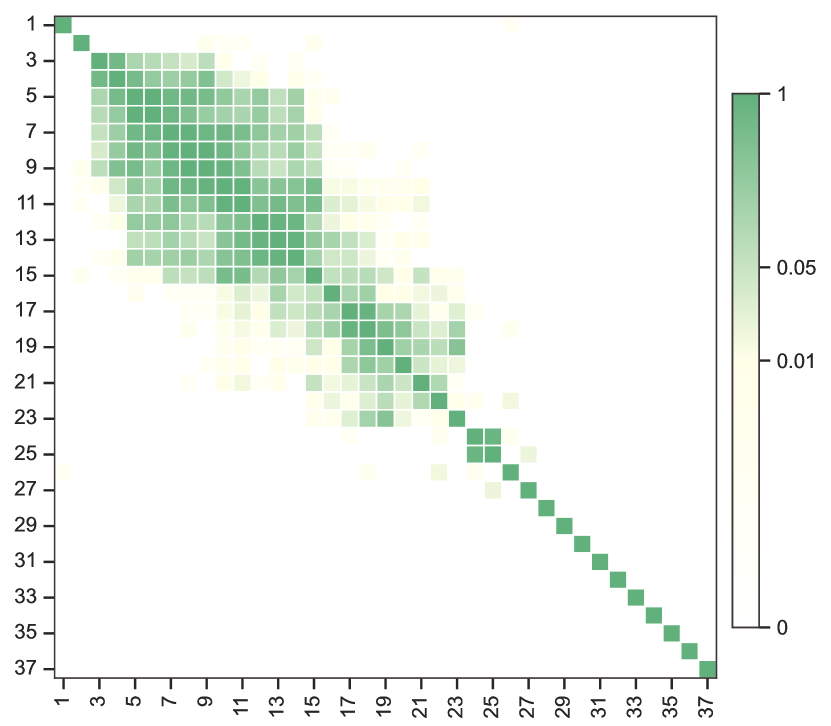
The WFAT dataset, sourced from the Food and Agriculture Organization (FAO) of the United Nations, contains annual trade records for over 400 food and agricultural products across all countries globally. Our analysis focuses specifically on 2020 trade data for cereals, a category defined by the FAO and detailed in Table A3. We constructed a multi-layer network using this data. Each layer represents a different type of cereal, with nodes representing countries and edges within each layer representing the trade relationships with respect a specific cereal. In particular, a trade link between countries is established if the trade value for a cereal exceeds . To ensure network connectivity, we excluded countries with a total degree over 37 layers less than 23. This guarantees that each node is linked to at least one other node in at least half of the layers. The resulting network consists of 37 layers, each containing 114 common nodes, denoted by . The five continents, including America, Africa, Asia, Europe, and Oceania, suggest the choice (Noroozi and Pensky, 2024).
Figure 4 shows the results of the multiple comparisons conducted using a Holm type step-down procedure, where olive green indicates the acceptance and white denotes the rejection of the individual hypotheses. We control the Holm procedure to ensure that the family-wise error rate is no greater than . Additionally, the -value matrix for individual hypothesis tests across all network layers is shown. In Figure 4(a), several distinct blocks are observed where all individual hypotheses within each block are simultaneously accepted, demonstrating the presence of homogeneity within the multi-layer network. For instance, layers 5 to 14, corresponding to ‘Germ of maize’, ‘Triticale’, ‘Cereals n.e.c.’, ‘Millet’, ‘Sorghum’, ‘Bran of maize’, ‘Bran of cereals n.e.c.’, ‘Flour of mixed grain’, ‘Flour of rice’, and ‘Rye’, exhibit no rejections of the individual hypotheses in any pairwise comparisons. This outcome suggests a significant similarity in trade patterns among these cereal products. Notably, most of these cereals are consumed primarily by Asia, which might lead to simultaneous acceptance of the individual hypotheses. This observation suggests the need for an integrated analysis of the trade patterns of these cereals.
7 Conclusion
In this paper, we focused on the asymptotic normality in the estimation of the scaled connectivity matrix under multi-layer SBMs and multi-layer DCSBMs. To this end, we first leveraged the leading eigenvectors of the bias-adjusted sum of squares of the adjacency matrices to estimate the common eigenspaces across layers (Lei and Lin, 2023). Building on this, we further derived efficient estimates for the layer-wise scaled connectivity matrices. These estimates are shown to satisfy asymptotic normality under mild additional assumptions. To corroborate the theoretical results, we conducted a series of simulations to apply the derived asymptotic normality to statistical inference tasks, including interval estimation and hypothesis testing. Finally, we applied the method to a real-world network dataset to infer the population homogeneity within the multi-layer network.
There are many ways to extend the content of this paper. First, we assume the connectivity matrices are different among layers. However, in practice, the network layers are often grouped such that connectivity matrices are the same within each group (Jing et al., 2021; Fan et al., 2022a). It is thus meaningful to make use of all the network layers within each group to estimate the connectivity matrices, which would lead to improved estimation accuracy and a weakened requirement for network sparsity. Second, we focused on the undirected multi-layer networks. It is of great importance to extend the method and theory to multi-layer directed networks (Zheng and Tang, 2022; Su et al., 2024). Third, we assumed the number of communities is known and fixed. In the future, it is important to study the estimation of the number of communities under multi-layer SBMs.
Appendix
Appendix A.1 provides the technical lemmas that are needed to prove the central limit theorems. Appendix A.2 includes the proof of main theorems in the main text. Appendix A.3 contains auxiliary lemmas. Appendix A.4 provides the additional results for real data analysis.
A.1 Technical lemmas
Lemma A1.
Proof.
The bias-adjusted sum-of-squares of the adjacency matrices can be decomposed into a signal term and for noise terms
where , , , and . Recall that in the context of multi-layer SBMs, , and .
According to Theorem 1 of Lei and Lin (2023), the minimum eigenvalue of the signal term is lower bounded by for some positive constant . Note that we use to represent the generic constant and it may be different from line to line. We proceed to establish upper bounds for the spectral norms of all noise terms. The first noise term satisfies Regarding , under the condition , we have with high probability. For , by Theorem 4 of Lei and Lin (2023), under the condition , we have with probability at least . Finally, for , given for all , it follows that .
Integrating the bounds of all terms, we have with high probability,
Let be the matrices that contain the leading eigenvectors of . In accordance with Proposition 2.2 of Vu and Lei (2013) and the Davis-Kahan sin theorem (Theorem VII.3.1 of Bhatia (1997)), there exists a orthogonal matrix such that
The proof is completed. ∎
Lemma A2.
Proof.
Following the approach used in the proof of Lemma A1, we separately bound the signal term and the noise terms. Recall that in the context of multi-layer degree-corrected SBMs, , and . Given the balanced effective community sizes assumption and the fixed number of communities, the minimum eigenvalue of is lower bounded by for some positive constant . Then we have
where denotes the Loewner partial order, in particular, let and be two Hermitian matrices of order , we say that if is positive semi-definite. The latter is derived from Assumption 2. Recall that is an orthogonal column matrix, the smallest eigenvalue of is lower bounded by . For the bounds of the spectral norms of all noise terms, they are consistent with those established in Lemma A1.
Combining the bounds of all terms, Proposition 2.2 of Vu and Lei (2013) and the Davis-Kahan sin theorem, there exists a orthogonal matrix such that
holds with high probability. The proof is completed. ∎
A.2 Main proofs
Proof of Theorem 1
Recall that and the noise matrix , where for all . Then the estimator can be rearranged as
| (A1) | |||||
where in the final equality represents all terms from the penultimate equality excluding and . Here, is a orthogonal matrix. Thus,
| (A2) |
We initiate our argument by establishing that tends towards zero as the number of nodes and layers increase, and the edge density decreases. We accomplish this by exerting control over each term in .
The upper bound of is provided in Lemma A1. With regards to the term , it holds that . For , applying Lemma A3, we have
with probability at least . Note that we use and to represent the generic positive constants and it may be different from line to line. Consequently, it can be deduced that
with high probability. Additionally, given that every element of is at most , both and do not exceed . Thus, we can deduce that . As the number of layers increase, and the overall edge probability decrease, tends to vanish.
Consequently, demonstrating the central limit theorem can be reduced to verifying the asymptotic normality of . The covariance of any pair and , where and , is
That is the term defined in (3). Regarding the expectation term, given that , it is straightforward to see that each element of has a zero-mean, as each element sums terms with zero-mean. In other words, we have for all .
Part (a): Note that
| (A3) |
where we let denote . Given , it is clear that the terms are zero-mean and independent of each other for all . By the definition of and according to Assumption 1, we have for all and , where is some positive constant. To affirm the Lindeberg condition, we proceed by calculating the sum of for all . Given Assumption 3 and the premise of balanced community sizes, it follows that . Therefore, for any and sufficiently large , we can state that . This leads to the Lindeberg condition as given by
| (A4) |
is satisfied. It should be emphasised that here , and are all related to . For simplicity, we have not notated the display. By the Lindeberg-Feller Central Limit Theorem, we have
for each . The claim follows by combining the above discussion with (A2).
Part (b): To complete the central limit theorem for vectorlized , we first show that this term can be expressed as a summation of independent zero-mean random variables. Let and consider an arbitrary vector .
| (A5) | |||||
where we let denote the portion enclosed in braces in the second equality, and the first equality follows from (A3). Given , it is obvious that the terms are zero-mean and independent of each other for all . In accordance with Assumption 4, we have
for all and . To affirm the Lindeberg condition, we proceed by calculating the sum of for all . By a simple calculation, we have . Therefore, for any and sufficiently large , it holds true that . This subsequently satisfies the Lindeberg condition as given by
We should also emphasize that , , and are all dependent on . For the sake of simplicity, we have not explicitly displayed the dependence on in our notation. By the Lindeberg-Feller Central Limit Theorem and the Cramér-Wold theorem (Thoerem 3.9.5 of Durrett (2010)), we have
for each . Here, is a dimensional standard normal distribution. The claim follows by combining the above discussion with (A2).
Proof of Theorem 2
Consistent with the proof of Theorem 1, a random matrix exists such that A2 holds. According to Theorem A2, the bias term satisfies
with high probability. Furthermore, given that every element of is at most , neither nor exceeds . Thus, we can deduce that . Under certain setting for , tends to vanish as the number of layers increase, and as the overall edge density decrease.
To demonstrate the central limit theorem, it suffices to ascertain the asymptotic normality of . For part (a), recall that the decomposition of in A3 for all . By the definition of , that is here, and according to Assumption E1, we have for all and . Combing with Assumption E3, the Lindeberg condition in (A4) holds. For part (b), recall that the decomposition of and the definition of in (A5). Under Assumption E4, it follows that . The rest proof is similar to that of Theorem 1, we omit it here.
A.3 Auxiliary lemmas
Lemma A3 (Theorem 5.2 of Lei and Rinaldo (2015)).
Let be the adjacency matrix of a random graph on nodes in which edges occur independently. Set for , and assume that for and . Then, for any there exists a constant such that
with probability at least .
A.4 Additional results for data analysis
| 1.Malt, whether or not roasted; 2.Rice; 3.Canary seed; 4.Buckwheat; 5.Germ of |
| maize; 6.Triticale; 7.Cereals n.e.c.; 8.Millet; 9.Sorghum; 10.Bran of maize; 11.Bran |
| of cereals n.e.c.; 12.Flour of mixed grain; 13.Flour of rice; 14.Rye; 15.Malt extract; |
| 16.Rice, milled (husked); 17.Oats; 18.Cereal preparations; 19.Oats, rolled; 20.Bran of |
| wheat; 21.Flour of cereals n.e.c.; 22.Rice, broken; 23.Flour of maize; 24.Gluten feed |
| and meal; 25.Bread; 26.Husked rice; 27.Wheat and meslin flour; 28.Communion |
| wafers, empty cachets of a kind suitable for pharmaceutical use, sealing wafers, rice |
| paper and similar products; 29.Barley; 30.Breakfast cereals; 31.Uncooked pasta, not |
| stuffed or otherwise prepared; 32.Maize (corn); 33.Wheat; 34.Mixes and doughs for |
| the preparation of bakers’ wares; 35.Food preparations of flour, meal or malt extract; |
| 36.Rice, milled; 37.Pastry |
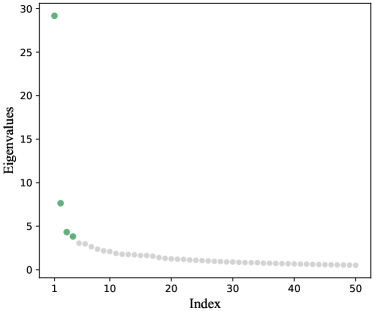
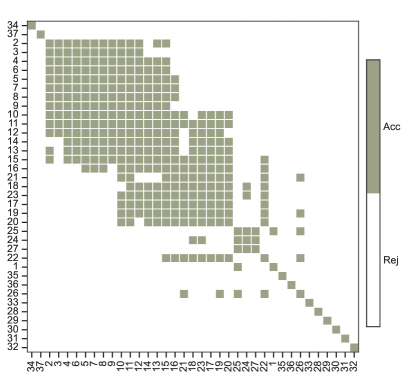
This section presents the additional experimental results that are not shown in the main text. In Section 6, for the WFAT dataset, we initially chose the number of communities as in the multi-layer SBM analysis, corresponding naturally to the geographical division into five continents. Here, we adopt an alternative approach to determine . By observing an elbow in the scree plot of the top absolute eigenvalues of the sum of squared adjacency matrices at the 4th position, as shown in Figure A5, we select . Figure A6 presents the outcomes of the multiple comparisons using a Holm type step-down procedure, where olive green indicates the acceptance and white denotes the rejection of the individual hypotheses. We control the Holm procedure to ensure that the family-wise error rate is no greater than . In this setup, layer corresponds to the cereal numbered in Table A3. Similar to Figure 4(a), the outcomes of this multiple comparison procedure also exhibit several distinct blocks where all individual hypotheses are simultaneously accepted within each block. Moreover, the results are largely consistent with those observed when . This strongly suggests that some global cereal trade patterns are similar and also demonstrates the stability of our method.
References
- Agterberg and Cape (2023) Agterberg, J. and J. Cape (2023). An overview of asymptotic normality in stochastic blockmodels: Cluster analysis and inference. arXiv preprint arXiv:2305.06353.
- Agterberg et al. (2022) Agterberg, J., Z. Lubberts, and J. Arroyo (2022). Joint spectral clustering in multilayer degree-corrected stochastic blockmodels. arXiv preprint arXiv:2212.05053.
- Airoldi et al. (2008) Airoldi, E. M., D. Blei, S. Fienberg, and E. Xing (2008). Mixed membership stochastic blockmodels. Journal of Machine Learning Research 9(65), 1981–2014.
- Arroyo et al. (2021) Arroyo, J., A. Athreya, J. Cape, G. Chen, C. E. Priebe, and J. T. Vogelstein (2021). Inference for multiple heterogeneous networks with a common invariant subspace. Journal of Machine Learning Research 22(142), 1–49.
- Bhatia (1997) Bhatia, R. (1997). Matrix analysis. Springer-Verlag, New York.
- Bhattacharyya and Chatterjee (2018) Bhattacharyya, S. and S. Chatterjee (2018). Spectral clustering for multiple sparse networks: I. arXiv preprint arXiv:1805.10594.
- Bickel et al. (2013) Bickel, P., D. Choi, X. Chang, and H. Zhang (2013). Asymptotic normality of maximum likelihood and its variational approximation for stochastic blockmodels1. The Annals of Statistics 41(4), 1922–1943.
- De Domenico et al. (2015) De Domenico, M., V. Nicosia, A. Arenas, and V. Latora (2015). Structural reducibility of multilayer networks. Nature Communications 6, 6864.
- Dudoit et al. (2008) Dudoit, S., M. J. Van Der Laan, and M. J. van der Laan (2008). Multiple testing procedures with applications to genomics. Springer, New York.
- Durrett (2010) Durrett, R. (2010). Probability: theory and examples. Cambridge University Press, New York.
- Fan et al. (2022a) Fan, J., Y. Fan, X. Han, and J. Lv (2022a). Asymptotic theory of eigenvectors for random matrices with diverging spikes. Journal of the American Statistical Association 117(538), 996–1009.
- Fan et al. (2022b) Fan, J., Y. Fan, X. Han, and J. Lv (2022b). Simple: Statistical inference on membership profiles in large networks. Journal of the Royal Statistical Society Series B: Statistical Methodology 84(2), 630–653.
- Fan et al. (2019) Fan, J., D. Wang, K. Wang, and Z. Zhu (2019). Distributed estimation of principal eigenspaces. The Annals of Statistics 47(6), 3009–3031.
- Han et al. (2015) Han, Q., K. Xu, and E. Airoldi (2015). Consistent estimation of dynamic and multi-layer block models. In International Conference on Machine Learning, pp. 1511–1520. PMLR.
- He et al. (2019) He, Y., A. Knowles, and M. Marcozzi (2019). Local law and complete eigenvector delocalization for supercritical Erdős–Rényi graphs. The Annals of Probability 47(5), 3278 – 3302.
- Holland et al. (1983) Holland, P. W., K. B. Laskey, and S. Leinhardt (1983). Stochastic blockmodels: First steps. Social Networks 5(2), 109–137.
- Holme and Saramäki (2012) Holme, P. and J. Saramäki (2012). Temporal networks. Physics Reports 519(3), 97–125.
- Jin et al. (2023) Jin, J., Z. T. Ke, S. Luo, and M. Wang (2023). Optimal estimation of the number of network communities. Journal of the American Statistical Association 118(543), 2101–2116.
- Jing et al. (2021) Jing, B.-Y., T. Li, Z. Lyu, and D. Xia (2021). Community detection on mixture multilayer networks via regularized tensor decomposition. The Annals of Statistics 49(6), 3181–3205.
- Karrer and Newman (2011) Karrer, B. and M. E. Newman (2011). Stochastic blockmodels and community structure in networks. Physical Review E 83(1), 016107.
- Kivelä et al. (2014) Kivelä, M., A. Arenas, M. Barthelemy, J. P. Gleeson, Y. Moreno, and M. A. Porter (2014). Multilayer networks. Journal of Complex Networks 2(3), 203–271.
- Lehmann and Romano (2005) Lehmann, E. L. and J. P. Romano (2005). Testing statistical hypotheses. Springer, New York.
- Lei and Lin (2023) Lei, J. and K. Z. Lin (2023). Bias-adjusted spectral clustering in multi-layer stochastic block models. Journal of the American Statistical Association 118(544), 2433–2445.
- Lei and Rinaldo (2015) Lei, J. and A. Rinaldo (2015). Consistency of spectral clustering in stochastic block models. The Annals of Statistics 43(1), 215–237.
- Mucha et al. (2010) Mucha, P. J., T. Richardson, K. Macon, M. A. Porter, and J.-P. Onnela (2010). Community structure in time-dependent, multiscale, and multiplex networks. Science 328(5980), 876–878.
- Noble (2009) Noble, W. S. (2009). How does multiple testing correction work? Nature Biotechnology 27(12), 1135–1137.
- Noroozi and Pensky (2024) Noroozi, M. and M. Pensky (2024). Sparse subspace clustering in diverse multiplex network model. Journal of Multivariate Analysis 203, 105333.
- Paul and Chen (2016) Paul, S. and Y. Chen (2016). Consistent community detection in multi-relational data through restricted multi-layer stochastic blockmodel. Electronic Journal of Statistics 10(2), 3807–3870.
- Paul and Chen (2020) Paul, S. and Y. Chen (2020). Spectral and matrix factorization methods for consistent community detection in multi-layer networks. The Annals of Statistics 48(1), 230–250.
- Rubin-Delanchy et al. (2022) Rubin-Delanchy, P., J. Cape, M. Tang, and C. E. Priebe (2022). A statistical interpretation of spectral embedding: The generalised random dot product graph. Journal of the Royal Statistical Society Series B: Statistical Methodology 84(4), 1446–1473.
- Rudelson and Vershynin (2015) Rudelson, M. and R. Vershynin (2015). Delocalization of eigenvectors of random matrices with independent entries. Duke Mathematical Journal 164(13), 2507–2538.
- Su et al. (2020) Su, L., W. Wang, and Y. Zhang (2020). Strong consistency of spectral clustering for stochastic block models. IEEE Transactions on Information Theory 66(1), 324–338.
- Su et al. (2024) Su, W., X. Guo, X. Chang, and Y. Yang (2024). Spectral co-clustering in multi-layer directed networks. Computational Statistics & Data Analysis 198, 107987.
- Tang et al. (2022) Tang, M., J. Cape, and C. E. Priebe (2022). Asymptotically efficient estimators for stochastic blockmodels: The naive mle, the rank-constrained mle, and the spectral estimator. Bernoulli 28(2), 1049–1073.
- Tang and Priebe (2018) Tang, M. and C. E. Priebe (2018). Limit theorems for eigenvectors of the normalized laplacian for random graphs. The Annals of Statistics 46(5), 2360–2415.
- Valles-Catala et al. (2016) Valles-Catala, T., F. A. Massucci, R. Guimera, and M. Sales-Pardo (2016). Multilayer stochastic block models reveal the multilayer structure of complex networks. Physical Review X 6(1), 011036.
- Vu and Lei (2013) Vu, V. Q. and J. Lei (2013). Minimax sparse principal subspace estimation in high dimensions. The Annals of Statistics 41(6), 2905–2947.
- Young and Scheinerman (2007) Young, S. J. and E. R. Scheinerman (2007). Random dot product graph models for social networks. In International Workshop on Algorithms and Models for the Web-Graph, pp. 138–149. Springer.
- Zhang et al. (2022) Zhang, H., X. Guo, and X. Chang (2022). Randomized spectral clustering in large-scale stochastic block models. Journal of Computational and Graphical Statistics 31(3), 887–906.
- Zheng and Tang (2022) Zheng, R. and M. Tang (2022). Limit results for distributed estimation of invariant subspaces in multiple networks inference and pca. arXiv preprint arXiv:2206.04306.