Linear Inverse Problems Using a Generative Compound Gaussian Prior
Abstract
Since most inverse problems arising in scientific and engineering applications are ill-posed, prior information about the solution space is incorporated, typically through regularization, to establish a well-posed problem with a unique solution. Often, this prior information is an assumed statistical distribution of the desired inverse problem solution. Recently, due to the unprecedented success of generative adversarial networks (GANs), the generative network from a GAN has been implemented as the prior information in imaging inverse problems. In this paper, we devise a novel iterative algorithm to solve inverse problems in imaging where a dual-structured prior is imposed by combining a GAN prior with the compound Gaussian (CG) class of distributions. A rigorous computational theory for the convergence of the proposed iterative algorithm, which is based upon the alternating direction method of multipliers, is established. Furthermore, elaborate empirical results for the proposed iterative algorithm are presented. By jointly exploiting the powerful CG and GAN classes of image priors, we find, in compressive sensing and tomographic imaging problems, our proposed algorithm outperforms and provides improved generalizability over competitive prior art approaches while avoiding performance saturation issues in previous GAN prior-based methods.
Index Terms:
Inverse problems, generative adversarial networks, nonlinear programming, alternative direction method of multipliers, compound Gaussian, dual-structured priorI Introduction
I-A Motivation
Inverse problems (IPs), the problem of recovering input model parameters – e.g., an image – representing a physical quantity from observed output data – e.g., an undersampling or corruption – produced by a forward measurement mapping, arise throughout many applications in scientific and engineering fields. In imaging, for example, compressive sensing (CS), X-ray computed tomography (CT), magnetic resonance imaging (MRI), super-resolution, radar imaging, and sonar imaging are just a handful of practical applications of linear IPs where the forward mapping, from input model parameters to output data, is effectively captured by a linear operator. Typically, forward mappings arising from scientific and engineering applications are non-injective, creating (linear) IPs that are ill-posed since the forward mapping sends multiple distinct input model parameterizations to the same observed output data. To alleviate ill-posedness, outside prior information about the input model parameters – e.g., sparsity or known statistics – is incorporated into the solution of the (linear) IPs. That is, given observed output data, the solution to the (linear) IP is input model parameters that, in addition to mapping to the observed output data via the forward measurement mapping, satisfies statistical or structural conditions imposed by the prior information.
Model-based methods – in particular, within a Bayesian maximum a posteriori (MAP) framework – are a primary approach of solving (linear) IPs and often involve the minimization of a cost function via an iterative algorithm. Prior information is encapsulated by the cost function through a regularization term, which renders unique IP solutions. Examples of model-based methods, which have been prevalent over the last two decades, include the Iterative Shrinkage and Thresholding Algorithm (ISTA) [1, 2], Bayesian Compressive Sensing [3], and Compressive Sampling Matching Pursuit [4, 5]. These previous approaches can be viewed, from a Bayesian MAP perspective, as implementing a generalized Gaussian prior [2, 1, 5]. Based upon the fact that the generalized Gaussian prior is subsumed by the compound Gaussian (CG) prior, which better captures statistical properties of images [6, 7, 8, 9, 10, 11], the authors have previously developed an improved set of model-based methods for linear IPs utilizing a CG prior, which have shown state-of-the-art performance in tomographic imaging and CS [8, 12, 9, 13, 14, 15].
With advancements in artificial intelligence and deep learning (DL), a new approach to improve IP solutions is to utilize a learned prior rather than a handcrafted prior (i.e., generalized Gaussian or CG). One such approach is to create a deep neural network (DNN) by applying algorithm unrolling [16] to a model-based method in which a parameterization of the regularization term is learned [8, 14, 17, 18, 19, 20]. Another approach, as originally proposed by Bora et al. [21], is to employ a generative adversarial network (GAN) [22], trained to sample from the distribution of the IP input model parameters, as the learned prior. In solving the (linear) IP, these GAN-prior approaches constrain the output from a model-based method onto the range of the GAN [21, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33]. While these previous GAN-prior approaches have produced excellent empirical results and outperformed state-of-the-art model-based methods in cases where the forward measurement mapping severely undersamples the input model parameters, they suffer from a number of limitations including:
-
•
The GAN must capture a superb representation of the IP input model parameters. Typically, this is achieved by training the GAN with a substantial amount of data.
-
•
Generalization to alternative datasets of IP input model parameters inherently results in significant performance loss or requires the training of another GAN.
-
•
Performance, in the quality of the IP solutions, saturates with increasing sampling by the forward measurement mapping.
-
•
Theoretical guarantees are often elusive, due to the non-convex GAN as a prior.
In this paper, we introduce a novel method incorporating a dual-structured prior, based on both the CG and GAN priors, to address the aforementioned four limitations.
Lastly, we remark that some previous works with GAN priors incorporate training of the GAN while solving the (linear) IP, which can boost performance and reduce saturation [34, 35, 36, 37]. While we could incorporate such techniques into our proposed method, we focus on the case of using pretrained GAN priors and leave the case of adaptive GAN optimization (i.e., training the GAN while solving the IP) as an important topic of future work. Additionally, these adaptive GAN optimization approaches require substantial computational time and resources as a new GAN must be trained for each forward measurement mapping considered.
I-B Contributions
This paper constructs an iterative estimation algorithm with a CG-GAN-prior to solve linear IPs. Specifically, we:
- 1.
-
2.
Derive a theoretical convergence analysis for the proposed A-CG-GAN to provide insight into the performance of the algorithm.
-
3.
Present ample empirical results for A-CG-GAN on CS and CT linear IPs. We demonstrate the effectiveness of A-CG-GAN even with modestly trained GANs and show that the performance of A-CG-GAN does not saturate with higher sampling from the forward measurement mapping. Furthermore, we present a clear improvement over state-of-the-art GAN-prior approaches in reconstructed image quality and generalizability.
Our proposed CG-GAN iterative algorithm can be viewed as an expansion on [25] by incorporating the powerful CG prior into the IP framework as in [13, 41, 12, 8, 9, 15]. By combining these two techniques we gain the advantage of using a GAN-prior while generalizing to a broader signal prior within the CG-prior context. We remark that our proposed algorithm can reduce to [25] as a special case, which has shown excellent empirical performance when the image to be reconstructed lies in the range of the generator. As such, our proposed algorithm directly inherits such performance in the case of a GAN perfectly capturing the desired true images.
I-C Preliminaries
In this section, we briefly introduce the CG prior and GANs as a prior as these are the key components we combine to furnish the novel method of this paper. First, the forward measurement mapping we consider throughout this paper is
| (1) |
where are the output observations (or measurements), is a sensing matrix, are the unknown input model parameters, and is additive white noise. In many applications of interest, and is decomposed as for a measurement matrix and a change of basis dictionary. This formulation results from representing some original input model parameters, , with respect to (w.r.t) as . The problem of signal reconstruction, or estimation, is the linear IP of recovering , or , given , , and .
I-C1 Compound Gaussian Prior
A fruitful way to formulate IPs is by Bayesian estimation. In particular, the maximum a posteriori (MAP) estimate of from (1) is
| (2) |
where is the assumed prior density of . Clearly, the prior density of , which incorporates domain-level knowledge into the IP, is crucial to a successful MAP estimate. Many previous works employ a generalized Gaussian prior [6, 7] such as a Gaussian prior for Tikhonov regression [42] or a Laplacian prior as is predominant in the CS framework [4, 1, 2, 5].
Through the study of the statistics of image sparsity coefficients, it has been shown that coefficients of natural images exhibit self-similarity, heavy-tailed marginal distributions, and self-reinforcement among local coefficients [7]. Such properties are not encompassed by the generalized Gaussian prior. Instead, CG densities [13], also known as Gaussian scale mixtures [6, 7], better capture these statistical properties of natural images and images from other modalities such as radar [10, 11]. A useful formulation of the CG prior lies in modeling as the Hadamard product
| (3) |
such that , is a sparse or heavy-tailed positive random vector, and and are independent [7, 13]. We call and the Gaussian variable and scale variable, respectively. By suitably defining the distribution of , the CG prior subsumes many well-known distributions including the generalized Gaussian, student’s , -stable, and symmetrized Gamma distributions [7, 8].
We note that decomposing as in (3), the joint MAP estimate of and from (1) is
| (4) |
where the estimated input model parameters, , are then given by That is, from (2) we set , which, due to the independence of and , splits the prior term into the sum of a prior term for and a prior term for .
Previously, the CG prior has been used, with a log-normal distributed scale variable, to estimate images through an iterative MAP estimation [13, 41, 8, 12] and an algorithm unrolled DNN [8, 12]. Additionally, a learned scale variable distribution in the CG prior was used to estimate images through an alternative algorithm unrolled DNN [9, 14]. Finally, the CG prior, using a real-valued random scale variable, has been successfully used for image denoising [43] and hyperspectral image CS [44].
I-C2 GANs as a Prior
To illustrate the usage of GANs as a prior in IPs, we overview the seminal work of Bora et al. [21]. Let be the generative neural network (NN) from a GAN, which we assume has been adversarially trained against a discriminator NN to sample from some distribution (e.g., produces “natural” images). Often , implying that the generative DNN maps from a low-dimensional latent space to a high-dimensional space of interest. Given a low-dimensional latent distribution, , over , most commonly , we can generate a distribution from as for .
A generative NN is incorporated as a prior by assuming that from (1), satisfies That is, there exists a latent vector such that Therefore, rather than optimize for the solution to the IP directly as in (2), we optimize over the latent space to find the best such that . On this front, consider the MAP estimate of from (1), when , given by
| (5) |
Intuitively, if is a “natural” image and samples from the distribution of “natural” images then we can expect that for some
II ADMM with CG-GAN Prior (A-CG-GAN)
To solve the linear IP to (1) for the unknown vector , we incorporate both the CG prior, as in (4), and GAN prior, as in (5), by setting the scale variable to lie within the range of a generative NN. Mathematically, we consider the following constrained optimization problem
| (6) |
where
| (7) |
is a generative NN, is a convex regularization function, and are positive scaling parameters, and and are the convex domains of , and , respectively. We remark that the cost function, , consists of a data fidelity term, a regularization term enforcing sparsity of , an implicit regularization term on , and a regularization term enforcing Gaussianity of .
We utilize ADMM [38, 39, 40] to solve the constrained minimization problem of (6). For this, define the feasibility gap
| (8) |
and let . Additionally, define the augmented Lagrangian
| (9) |
for a positive scalar and a dual variable . Therefore, the optimization problem of (6) is equivalent to
| (10) |
and our A-CG-GAN algorithm iteratively solves (10) through an ADMM block coordinate descent [45] as given in Algorithm 1.
To detail Algorithm 1, let and define
| (11) | ||||
| (12) | ||||
As the feasibility terms in (9) are convex w.r.t , we minimize in (9) w.r.t using a standard fast ISTA (FISTA) [2] technique. We will write
Next, for the update of , which requires optimizing over the non-convex generative NN , we, similar to [21, 24, 23], use adaptive moment estimation (Adam) [46], a gradient descent (GD)-based optimizer, with a step size of The gradient, , for each GD step is calculated using backpropagation and automatic differentiation [47] in TensorFlow [48]. We will write
As this update requires to be differentiable, we instead use ISTA or proximal gradient descent (PGD) steps to minimize w.r.t when is non-smooth and also denote these steps as for simplicity.
The dual variable, , is updated via a single gradient ascent step on as is typical in ADMM [38, 39, 40]. That is,
where is a real-value step size parameter.
As specified in Algorithm 1, the initial estimates are given by , , , and where, for ,
for . This particular choice of is inspired by previous work in regularizing IPs with a CG prior [8, 9].
Lastly, define and similarly define and . Convergence of Algorithm 1 is determined by for a tolerance parameter . This stopping condition, informed by previous ADMM work [38, 25], ensures that the mean squared error in both the feasibility gap and the change in each of the four primal variables is sufficiently small.
We make a few remarks about Algorithm 1. First, (11) and (12) can be quickly calculated using SVD. Specifically, if is the SVD of , then (11) can be rewritten as
which is easily calculated since is a diagonal matrix. Similarly, for (12), since is symmetric and positive definite then the SVD of has the form , which will reduce the matrix inverse in (12) to inverting a diagonal matrix. Therefore, by performing the SVD of and upfront, only diagonal matrices need to be inverted during the iterations of Algorithm 1, which provides a considerable time reduction.
Finally, as A-CG-GAN expands on the methodology introduced by [25], we briefly explain the core difference. In [25], only a single constraint from the GAN prior, specifically , is imposed. Accordingly, each iteration of the ADMM algorithm in [25] consists of two primal variable updates for and , similar to lines 3 and 4 in Algorithm 1, and one dual variable update , similarly to line 7 in Algorithm 1. In our proposed A-CG-GAN, we have a similar GAN prior constraint now involving the generator, , and the scale variable, , as we constrain to be in the range of . Uniquely, we introduce a second constraint to additionally enforce the CG prior by constraining to be the product of a scale variable, , and Gaussian variable, .
III Convergence Results
III-A Preliminaries
For our theoretical analysis in this section and the Appendix, we will use the following notation and nomenclature:
-
1.
, , , and
-
2.
, , , and
-
3.
, , , and
-
4.
, , and
-
5.
and
-
6.
-
7.
-
8.
-
9.
and
-
10.
and
-
11.
and for defined in (14)
-
12.
-
13.
-
14.
-
15.
Additionally, we will generalize the cost function in (7) to
| (13) |
where is a data fidelity term and and are regularization functions on and , respectively. We make the following assumptions about the terms of (13).
Assumption 1.
Each function and is continuous, convex, and has Lipschitz continuous gradient with constant and , respectively.
We define as in (9) with now given in (13) and define an adjusted augmented Lagrangian as
| (14) |
That is, is the augmented Lagrangian without the regularization terms. Despite the generalization of the cost function, we assume that, as holds in Section II, the minimizer of w.r.t each individually is well approximated by GD/ISTA/FISTA steps (or for and is analytically known).
Note that we set , , , and . Furthermore, to prove convergence, we will take an adaptive dual-variable step size of
| (15) |
for some initial step size , which is utilized in [25] and motivated by [39] as a guarantee on maintaining a bounded dual-variable. While such a step size is chosen to provide theoretical guarantees, we find, in practice, that a constant step size is sufficient for bounded dual-variables.
Lastly, as our results build off of the convergence properties discussed in [25], which again considers an ADMM algorithm with a single GAN prior constraint, we import necessary assumptions on , the generative NN, from [25].
Assumption 2.
For any the following bounds hold
for positive constants and .
III-B Core Theoretical Guarantees
In this section, we provide our main technical results for the convergence of our generalized A-CG-GAN algorithm, which are inspired by the previous work in [25]. For this, we let be some solution of (6), with given in (13), and be the corresponding optimal dual variable from (10).
First, we present four propositions bounding the augmented Lagrangian change over an update of each primal variable.
Proposition 1.
Let for any . Then for any and the following bound holds
Proposition 2.
Let for any Then for any and there exists a such that
Proposition 3.
Let for any Then for any and the following bound holds
Proposition 4.
For , let . Then for any the following bound holds
Proofs of propositions 1, 2, 3, and 4 are provided respectively in Appendices VI-C, VI-D, VI-E, and VI-F.
Next, we combine the previous four propositions to bound the augmented Lagrangian change over one iteration of A-CG-GAN.
Proposition 5.
For any and every there exists positive constants such that
Proposition 5, which provides a bound on the change in the augmented Lagrangian, is proved in Appendix VI-G.
Finally, we present our main convergence theorem.
Theorem 6.
A proof of Theorem 6 is provided in Appendix VI-H. We remark that Theorem 6 states that outside of a neighborhood about some solution , our A-CG-GAN algorithm will converge, at worst, linearly with rate to this neighborhood. As the size of the neighborhood is proportional to , which in turn is inversely proportional to , we can decrease the size of the neighborhood by increasing the augmented Lagrangian penalty parameter .
IV Empirical Results
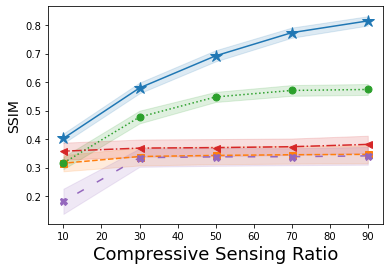
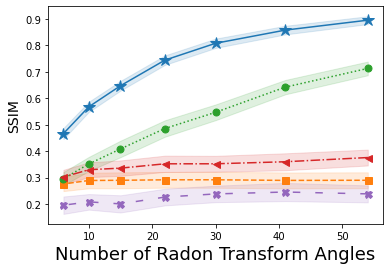

We examine our proposed Algorithm 1 for two linear IPs in imaging, namely CS (where has entries sampled ) and X-ray computed tomography (where corresponds to a Radon transform at a number of uniformly spaced angles). Comparisons are made against four prior-art methods that similarly consider a GAN-prior in solving IPs, which we denote by Bora [21], Dhar [24], Shah [23], and Latorre [25]. Note that Bora, Shah, and Latorre all find a solution to the IP within the range of a generative NN while Dhar considers a dual sparsity-GAN prior by finding a solution to the IP within sparse deviations from the range of a generative NN.
For data, we use CIFAR10 [49] images and CalTech101 [50] images downsampled to size (and ). With the CIFAR10 and CalTech101 datasets, we set aside 100 images to serve as the testing data and we train a DCGAN [51] on the remaining images, which are augmented using rotation and reflection. We use , with , to denote the DCGAN generator.
For training , which has a output activation function, we scale and shift the training images onto the range by replacing training image by where is the max pixel value of . For testing – i.e., solving the IP to (1) – we scale the testing images onto the range by replacing test image by A measurement matrix is applied to each test image, after which white noise is added, producing noisy measurements, , at a specified signal-to-noise-ratio (SNR). Additionally, for testing, we scale and shift the outputs from onto the range by considering the generator . Note that scaling to the range for testing is conducted so that we can use the structural similarity index measure (SSIM), which requires input images with positive pixel values, to assess the reconstruction performance.
For our A-CG-GAN algorithm, we will take the generative NN , where is a sparsity change-of-basis matrix. We apply the change-of-basis matrix since we desire for the generative NN to produce sparse scale variables rather than the image directly. Furthermore, we set , , , , , and for all testing of A-CG-GAN. Instead, for each comparison method [21, 24, 23, 25], we use as the generative NN prior and a grid search is performed to find the best hyperparameters for each of the four comparison methods. Finally, for each comparison method, random restarts were implemented as specified in each work respectively [21, 23, 24, 25]. We remark that using the same underlying image-generating NN provides fairness in the test IP comparisons since we guarantee the generative NN used in our method and each comparison method has the same training and quality.
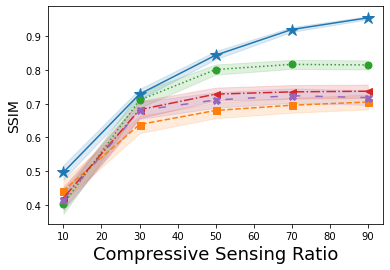
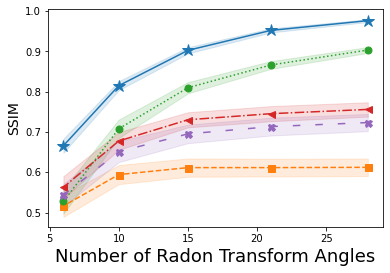
Shown in Fig. 1 is the average SSIM – larger values denote a reconstruction more closely matching the original image – over the reconstructions of one hundred images from A-CG-GAN and each of the four comparison methods. Each plot in Fig. 1 gives both the average SSIM and 99% confidence interval – visualized by the background shading – as the dimension of is varied in both CS and CT problems. The underlying DCGAN generator, , used for each of these IPs has been trained on 50000 CIFAR10 images. Through a grid search, we set the hyperparameters of A-CG-GAN to be and for CT reconstructions from 60dB and 40dB, respectively. Furthermore, we set as the hyperparameters of A-CG-GAN for CS reconstructions. Additionally, we use discrete cosine transformation and for CS and CT problems, respectively.
In Figs. 1(a), 1(b) and Figs. 1(c), 1(d), CIFAR10 images are reconstructed from CS and CT measurements with an SNR of 60dB and 40dB, respectively. Instead, in Figs. 1(e), 1(f), 1(g), and 1(h), we show the generalizability of our method by reconstructing CalTech101 images, that have been downsampled to size , while using the same CIFAR10 trained .

We observe, from Fig. 1, that A-CG-GAN outperforms, or performs comparably to, each of the four prior art methods in all scenarios. In particular, we highlight that the performance of A-CG-GAN does not saturate as the dimension of increases – i.e., the sampling from the forward measurement mapping increases – while the performance of the comparisons in general does. Additionally, A-CG-GAN is able to generalize well to image distributions outside of the GAN training distribution as shown in Figs. 1(e), 1(f), 1(g), and 1(h).
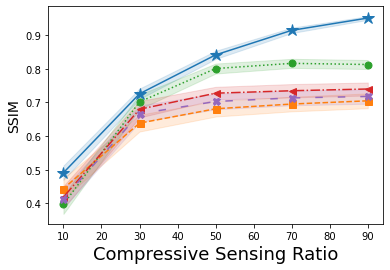
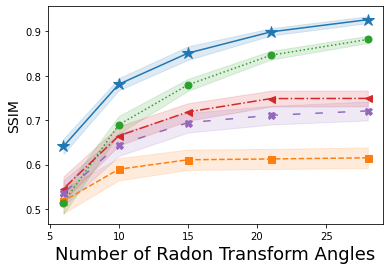
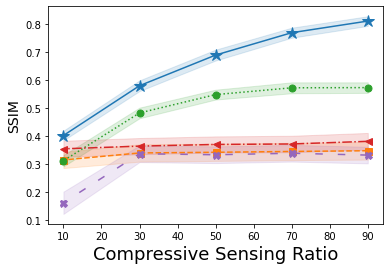
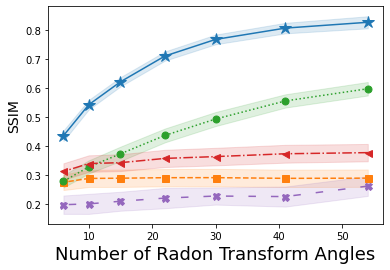
Next, shown in Fig. 2 is the average SSIM over the reconstructions of one hundred images from A-CG-GAN and each of the four comparison methods. Each plot in Fig. 2 gives both the average SSIM and 99% confidence interval – visualized by the background shading – as the amount of sampling from the forward measurement mapping – i.e., the dimension of – is varied in both CS and CT problems. The underlying DCGAN generator, , used for each of these IPs has been trained on a minimal dataset of roughly 9000 CalTech101 images of size . Empirically, we choose in A-CG-GAN for CS reconstructions, for 40dB CT reconstructions, and otherwise use the same setup as in the image reconstruction cases.
We observe from Fig. 2, that A-CG-GAN outperforms each of the four prior art methods in all scenarios. We highlight, in particular, that while a sub-optimal generator, due to a small training dataset, severely diminished the performance of each of the four comparison methods, A-CG-GAN still provides relatively high-quality reconstructed images as measured by SSIM. This is perhaps anticipated given the dual prior basis our method implements, which alleviates a complete dependence on the generative NN prior as in Bora, Shah, and Latorre [21, 23, 25]. Additionally, we again observe, from Fig. 2, that A-CG-GAN eliminates the performance saturation with increasing sampling from the forward measurement mapping.
Lastly, we remark that Dhar [24] is, in general, the best comparison method to ours as seen in Fig. 1 and Fig. 2. This provides further credence to the benefit of using dual prior information in addition to the GAN prior as Dhar, similar to our dual CG-GAN prior, incorporates a dual sparsity-GAN prior.
V Conclusion and Future Work
Utilizing a dual-structured prior that consists of the powerful CG class of densities and a generative NN, we developed a novel iterative estimate algorithm for linear IPs. Specifically, we proposed an algorithm, called A-CG-GAN, that finds an IP solution satisfying the CG structure of (3) where the scale variable portion of the CG prior is constrained onto the range of a generative NN. Hence, within the informative CG class of distributions, the generative NN captures a rich scale variable statistical representation, which provides a wide, but informative, IP regularization.
We conducted a theoretical analysis on the convergence of A-CG-GAN and showed that, under mild assumptions on the generative NN, a linear rate of convergence is guaranteed up to a neighborhood about a constrained minimizer solution. Subsequently, thorough numerical validation of A-CG-GAN in tomographic imaging and CS IPs was presented. Across multiple datasets and a wide array of forward measurement mappings, we empirically demonstrated that A-CG-GAN outperforms competitive state-of-the-art techniques to IPs that use a GAN prior. Specifically, A-CG-GAN displays three key properties missing from previous techniques using GAN priors for IPs:
-
1.
Performance does not saturate with less undersampling from the forward measurement mapping
-
2.
Generalization to alternative dataset distributions other than the GAN training distributions is possible
-
3.
A sub-optimal generative NN, possibly due to a lack of training data or inadequate training, still provides relatively high-quality reconstructions
Building upon the new foundations established in this paper, we illuminate numerous opportunities for future exploration including: analyzing the performance of A-CG-GAN on larger image reconstructions and on data corrupted by different noise models. Studying each of these objectives can provide greater insight into the practical, real-world applicability of our method.
Another intriguing line of work would be to use a generative NN in A-CG-GAN that has been trained to produce scale variables directly rather than sparsifying an image-generating NN as is done in this paper. We could anticipate a possible improvement in reconstruction performance over the numerical results presented in this paper as the generative NN would directly capture the statistics of the scale variables rather than implicitly capturing these statistics from the overall images.
A last point of future work is to empirically study A-CG-GAN, and each of the four comparisons methods, when the generative NN has been trained on a single category of images. In particular, analyzing image reconstruction performance when the test images are from versus distinct from the training category. The datasets employed in this paper contain images from multiple categories – e.g., CIFAR10 has 10 categories and CalTech101 has 101 categories – creating a significant statistical variability in the datasets, which can result in lower quality images from a generative NN. Instead, when a generative NN is trained on a single category, it is often able to produce higher quality images from this single category. Accordingly, we conjecture that A-CG-GAN would handle the reconstructions of test images distinct from the training category significantly better than the four comparison methods, in much of the same manner that we observed in the CalTech101 reconstructions. Furthermore, we conjecture that A-CG-GAN (with ) may have minimal improvement, or be matched by, the four comparison methods when test images are sampled from the training category.
VI Appendix
In this appendix, we provide mathematical proof details for the main theoretical results of A-CG-GAN, presented in Section III-B, by extending the proof ideas in [25] from ADMM with a single GAN-prior constraint to our case of ADMM with dual-structured CG-GAN-prior constraints.
VI-A Preliminary Tools
Lemma 1 ( [25]).
Let be a differentiable function and a convex possibly non-smooth function, then
Lemma 2 ( [40]).
Let be differentiable and have -Lipschitz continuous gradient. For any
| (16) |
Lemma 3.
Let be a differentiable function satisfying (16) for some positive constant , some , and any . Let be a convex and possibly non-smooth function. Let . If , then for any and
Proof.
Lemma 4.
The function has Lipschitz continuous gradient with respect to , , and separately.
Proof.
Observe
| (17) |
which implies , , and . Therefore, , , and since has -Lipschitz continuous gradient. ∎
Lemma 5.
For any it holds that
Proof.
Using the triangle inequality observe
Lemma 6.
For any it holds that .
Proof.
VI-B Dual-Variable Update Bound
Lemma 7.
For any there exists positive constants such that
Proof.
Using the feasibility condition , the triangle inequality, Assumption 2, and observe
and
Combining the above two inequalities with and produces the desired bound for , , , and . ∎
Corollary 7.
For every
VI-C Proof of Proposition 1
VI-D Proof of Proposition 2
VI-E Proof of Proposition 3
Define and let be a single ISTA step on w.r.t from Since is the output of multiple FISTA/ISTA steps on w.r.t from , which decrease the cost function at least as much as a single ISTA step, then
| (23) |
Note that has -Lipschitz continuous gradient by Lemma 4. Hence, satisfies (16) by Lemma 2. Combining (23) with Lemma 3 where and gives
| (24) |
VI-F Bound on x Update (Proof of Proposition 4)
First, we provide two lemmas to simplify the proof of Proposition 4. For these lemmas, define as
Lemma 8.
For every and any
Proof.
First note that for any it holds that
Therefore
where we use the Cauchy-Schwarz inequality and Assumption 2 to furnish the final inequality. ∎
Lemma 9.
For every any the inequality (16) holds for , and .
Proof.
We now prove the desired bound on the adjusted augmented Lagrangian over an update of
VI-G Complete Iteration Bound (Proof of Proposition 5)
In order to prove Proposition 5 we first derive two simplifying lemmas.
Lemma 10.
Let for and For every
Proof.
Lemma 11.
Let for and . For every
Proof.
First, note that
| (27) |
Hence
where we use the convexity of to produce the final inequality. Applying Lemma 10 produces the desired result. ∎
We now prove the desired bound on the augmented Lagrangian over one iteration of Algorithm 1.
VI-H Convergence (Proof of Theorem 6)
We first establish a handful of preliminary results through the following lemmas in order to prove Theorem 6.
Lemma 12.
For assume that and where . Let and . Set and . Then
for positive constants , and .
Proof.
Note that the first order optimality conditions of (6), with given in (13), are and where is the subdifferential of at . By the definition of a subdifferential
Lemma 13.
Proof.
We now prove the main convergence result for our proposed A-CG-GAN algorithm
References
- [1] I. Daubechies, M. Defrise, and C. De Mol, “An Iterative Thresholding Algorithm for Linear Inverse Problems with a Sparsity Constraint,” Commun. Pure Appl. Math, vol. 57, no. 11, pp. 1413–1457, Nov 2004.
- [2] A. Beck and M. Teboulle, “A Fast Iterative Shrinkage-Thresholding Algorithm for Linear Inverse Problems,” SIAM Journal on Imaging Sciences, vol. 2, no. 1, pp. 183–202, Jan 2009.
- [3] S. Ji, Y. Xue, and L. Carin, “Bayesian Compressive Sensing,” IEEE Transactions on Signal Processing, vol. 56, no. 6, pp. 2346–2356, 2008.
- [4] S. Foucart and H. Rauhut, A Mathematical Introduction to Compressive Sensing. Springer New York, 2013.
- [5] D. Needell and J. A. Tropp, “CoSaMP: Iterative signal recovery from incomplete and inaccurate samples,” Applied and Computational Harmonic Analysis, vol. 26, no. 3, pp. 301–321, May 2009.
- [6] M. J. Wainwright and E. P. Simoncelli, “Scale Mixtures of Gaussians and the Statistics of Natural Images.” in Advances in Neural Information Processing Systems, vol. 12. MIT Press, 1999, pp. 855–861.
- [7] M. J. Wainwright, E. P. Simoncelli, and A. S. Willsky, “Random Cascades on Wavelet Trees and Their Use in Analyzing and Modeling Natural Images,” Applied and Computational Harmonic Analysis, vol. 11, no. 1, pp. 89–123, 2001.
- [8] C. Lyons, R. G. Raj, and M. Cheney, “A Compound Gaussian Least Squares Algorithm and Unrolled Network for Linear Inverse Problems,” IEEE Transactions on Signal Processing, vol. 71, pp. 4303–4316, 2023.
- [9] C. Lyons, R. G. Raj, and M. Cheney, “Deep Regularized Compound Gaussian Network for Solving Linear Inverse Problems,” IEEE Transactions on Computational Imaging, vol. 10, pp. 399–414, 2024.
- [10] Z. Chance, R. G. Raj, and D. J. Love, “Information-theoretic structure of multistatic radar imaging,” in IEEE RadarCon (RADAR), 2011, pp. 853–858.
- [11] Z. Idriss, R. G. Raj, and R. M. Narayanan, “Waveform Optimization for Multistatic Radar Imaging Using Mutual Information,” IEEE Transactions on Aerospace and Electronics Systems, vol. 57, no. 4, pp. 2410–2425, Aug 2021.
- [12] C. Lyons, R. G. Raj, and M. Cheney, “CG-Net: A Compound Gaussian Prior Based Unrolled Imaging Network,” in 2022 IEEE Asia-Pacific Signal and Information Processing Association Annual Summit and Conference, 2022, pp. 623–629.
- [13] R. G. Raj, “A hierarchical Bayesian-MAP approach to inverse problems in imaging,” Inverse Problems, vol. 32, no. 7, p. 075003, Jul 2016.
- [14] C. Lyons, R. G. Raj, and M. Cheney, “A Deep Compound Gaussian Regularized Unfoled Imaging Network,” in 2022 56th Asilomar Conference on Signals, Systems, and Computers, 2022, pp. 940–947.
- [15] C. Lyons, R. G. Raj, and M. Cheney, “On Generalization Bounds for Deep Compound Gaussian Neural Networks,” arXiv preprint arXiv:2402.13106, 2024, in review by IEEE Transactions on Information Theory.
- [16] K. Gregor and Y. LeCun, “Learning fast approximations of sparse coding,” in Proceedings of the 27th International Conference on Machine Learning, 2010, pp. 399–406.
- [17] J. Song, B. Chen, and J. Zhang, “Deep Memory-Augmented Proximal Unrolling Network for Compressive Sensing,” International Journal of Computer Vision, vol. 131, no. 6, pp. 1477–1496, Jun 2023.
- [18] Y. Su and Q. Lian, “iPiano-Net: Nonconvex optimization inspired multi-scale reconstruction network for compressed sensing,” Signal Processing: Image Communication, vol. 89, p. 115989, 2020.
- [19] J. Adler and O. Öktem, “Learned Primal-Dual Reconstruction,” IEEE Transactions on Medical Imaging, vol. 37, no. 6, pp. 1322–1332, 2018.
- [20] T. Meinhardt, M. Moller, C. Hazirbas, and D. Cremers, “Learning Proximal Operators: Using Denoising Networks for Regularizing Inverse Imaging Problems,” in Proceedings of the IEEE International Conference on Computer Vision, 2017, pp. 1781–1790.
- [21] A. Bora, A. Jalal, E. Price, and A. G. Dimakis, “Compressed Sensing using Generative Models,” in Proceedings of the International Conference on Machine Learning, vol. 70, 2017, pp. 537–546.
- [22] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative Adversarial Nets,” in Advances in Neural Information Processing Systems 27 (NIPS 2014), vol. 27, 2014.
- [23] V. Shah and C. Hegde, “Solving Linear Inverse Problems Using GAN Priors: An Algorithm with Provable Guarantees,” in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2018, pp. 4609–4613.
- [24] M. Dhar, A. Grover, and S. Ermon, “Modeling Sparse Deviations for Compressed Sensing using Generative Models,” in Proceedings of the 35th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 80. PMLR, 10–15 Jul 2018, pp. 1214–1223.
- [25] F. Latorre, A. Eftekhari, and V. Cevher, “Fast and Provable ADMM for Learning with Generative Priors,” in Advances in Neural Information Processing Systems (NeurlIPS), vol. 32, 2019.
- [26] G. Song, Z. Fan, and J. Lafferty, “Surfing: Iterative Optimization Over Incrementally Trained Deep Networks,” in Advances in Neural Information Processing Systems (NeurlIPS), vol. 32, 2019.
- [27] A. Jalal, L. Liu, A. G. Dimakis, and C. Caramanis, “Robust Compressed Sensing using Generative Models,” in Advances in Neural Information Processing Systems (NeurlIPS), H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., vol. 33, 2020, pp. 713–727.
- [28] M. Asim, M. Daniels, O. Leong, A. Ahmed, and P. Hand, “Invertible generative models for inverse problems: mitigating representation error and dataset bias,” in International Conference on Machine Learning. PMLR, 2020, pp. 399–409.
- [29] M. Asim, F. Shamshad, and A. Ahmed, “Blind Image Deconvolution Using Deep Generative Priors,” IEEE Transactions on Computational Imaging, vol. 6, pp. 1493–1506, 2020.
- [30] M. Asim, F. Shamshad, and A. Ahmed, “Solving Bilinear Inverse Problems using Deep Generative Priors,” CoRR, 2018.
- [31] B. Aubin, B. Loureiro, A. Baker, F. Krzakala, and L. Zdeborová, “Exact asymptotics for phase retrieval and compressed sensing with random generative priors,” in Proceedings of The First Mathematical and Scientific Machine Learning Conference, ser. Proceedings of Machine Learning Research, J. Lu and R. Ward, Eds., vol. 107. PMLR, 20–24 Jul 2020, pp. 55–73.
- [32] P. Hand and B. Joshi, “Global Guarantees for Blind Demodulation with Generative Priors,” Advances in Neural Information Processing Systems (NeurlIPS), vol. 32, 2019.
- [33] P. Hand, O. Leong, and V. Voroninski, “Phase Retrieval Under a Generative Prior,” in Advances in Neural Information Processing Systems (NeurlIPS), S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, Eds., vol. 31, 2018.
- [34] G. Jagatap and C. Hegde, “Phase Retrieval using Untrained Neural Network Priors,” in NeurIPS 2019 Workshop on Solving Inverse Problems with Deep Networks, 2019.
- [35] M. Kabkab, P. Samangouei, and R. Chellappa, “Task-Aware Compressed Sensing with Generative Adversarial Networks,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 32, 2018.
- [36] D. Ulyanov, A. Vedaldi, and V. Lempitsky, “Deep Image Prior,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
- [37] M. Mardani, E. Gong, J. Y. Cheng, S. S. Vasanawala, G. Zaharchuk, L. Xing, and J. M. Pauly, “Deep Generative Adversarial Neural Networks for Compressive Sensing MRI,” IEEE Transactions on Medical Imaging, vol. 38, no. 1, pp. 167–179, 2019.
- [38] S. Boyd, N. Parikh, E. Chu, B. Peleato, and J. Eckstein, “Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers,” Foundations and Trends® in Machine learning, vol. 3, no. 1, pp. 1–122, 2011.
- [39] D. P. Bertsekas, “On Penalty and Multiplier Methods for Constrained Minimization,” SIAM Journal on Control and Optimization, vol. 14, no. 2, pp. 216–235, 1976.
- [40] S. Boyd and L. Vandenberghe, Convex Optimization. Cambridge University Press, Mar 2004.
- [41] J. McKay, R. G. Raj, and V. Monga, “Fast stochastic hierarchical Bayesian map for tomographic imaging,” in 51st Asilomar Conference on Signals, Systems, and Computers. IEEE, Oct 2017, pp. 223–227.
- [42] M. Bertero, C. De Mol, and E. R. Pike, “Linear inverse problems with discrete data: II. Stability and regularisation,” Inverse Problems, vol. 4, no. 3, pp. 573–594, Aug 1988.
- [43] J. Portilla, V. Strela, M. J. Wainwright, and E. P. Simoncelli, “Image Denoising Using Scale Mixtures of Gaussians in the Wavelet Domain,” IEEE Transactions on Image Processing, vol. 12, no. 11, pp. 1338–1351, Nov 2003.
- [44] T. Huang, W. Dong, X. Yuan, J. Wu, and G. Shi, “Deep Gaussian Scale Mixture Prior for Spectral Compressive Imaging,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 16 216–16 225.
- [45] S. J. Wright, “Coordinate descent algorithms,” Mathematical Programming, vol. 151, no. 1, pp. 3–34, Jun 2015.
- [46] D. P. Kingma and J. L. Ba, “Adam: A Method for Stochastic Optimization,” International Conference on Learning Representations, 2015.
- [47] A. G. Baydin, B. A. Pearlmutter, A. A. Radul, and J. M. Siskind, “Automatic Differentiation in Machine Learning: a Survey,” Journal of Machine Learning Research, vol. 18, 2018.
- [48] M. Abadi, P. Barham, J. Chen, Z. Chen, A. Davis, J. Dean, M. Devin, S. Ghemawat, G. Irving et al., “TensorFlow: A System for Large-Scale Machine Learning,” in 12th USENIX Symposium on Operating Systems Design and Implementation, vol. 16, 2016, pp. 265–283.
- [49] A. Krizhevsky, “Learning Multiple Layers of Features from Tiny Images,” University of Toronto, Tech. Rep., 2009.
- [50] L. Fei-Fei, R. Fergus, and P. Perona, “Learning Generative Visual Models from Few Training Examples: An Incremental Bayesian Approach Tested on 101 Object Categories,” in Conference on Computer Vision and Pattern Recognition Workshop, 2004, pp. 178–178.
- [51] A. Radford, L. Metz, and S. Chintala, “Unsupervised representation learning with deep convolutional generative adversarial networks,” arXiv preprint arXiv:1511.06434, 2015.