Link Prediction for Temporally Consistent Networks
Abstract
Dynamic networks have intrinsic structural, computational, and multidisciplinary advantages. Link prediction estimates the next relationship in dynamic networks. However, in the current link prediction approaches, only bipartite or non-bipartite but homogeneous networks are considered. The use of adjacency matrix to represent dynamically evolving networks limits the ability to analytically learn from heterogeneous, sparse, or forming networks. In the case of a heterogeneous network, modeling all network states using a binary-valued matrix can be difficult. On the other hand, sparse or currently forming networks have many missing edges, which are represented as zeros, thus introducing class imbalance or noise. We propose a time-parameterized matrix (TP-matrix) and empirically demonstrate its effectiveness in non-bipartite, heterogeneous networks. In addition, we propose a predictive influence index as a measure of a node’s boosting or diminishing predictive influence using backward and forward-looking maximization over the temporal space of the n-degree neighborhood. We further propose a new method of canonically representing heterogeneous time-evolving activities as a temporally parameterized network model (TPNM). The new method robustly enables activities to be represented as a form of a network, thus potentially inspiring new link prediction applications, including intelligent business process management systems and context-aware workflow engines. We evaluated our model on four datasets of different network systems. We present results that show the proposed model is more effective in capturing and retaining temporal relationships in dynamically evolving networks. We also show that our model performed better than state-of-the-art link prediction benchmark results for networks that are sensitive to temporal evolution.
Index Terms:
Dynamic Networks, Link Prediction, Graph Modeling, Neural NetworksI Introduction
Link prediction estimates the next relationship in dynamic networks. This research area continues to attract interest [1] for its intrinsic applicability to various problem domains, including language translation using word sequence networks [2], image classification using pixel networks [3], and author relationship using citation networks [4]. Its multidisciplinary applications are evident in a range of AI fields, including molecular biology, genomics, social networks, signal processing, and acoustics [5]. However, dynamic networks present significant challenges with varying degrees of learning complexity due to their different structural properties. Continuously changing contexts in local networks are one of the learning complexities [6]. Learning the structure-function relationship of dynamic networks is complex. It entails learning models that are adaptive to the changing network topology. In addition, the evolution of time, neighboring networks, and other external factors may influence network behavior.
Recent work tackled network modeling with temporal aspect and/or with global network features. A link prediction approach that considers global network features was introduced in [7]. Later, a network propagation model that captured temporal features and weights of the evolutionary network over multiple timesteps was introduced [8]. However, the spatial and temporal consistency presented in [8] only works on the assumption that the nodes within a network are similar. Therefore, it does not work with structurally heterogeneous networks whose nodes have dissimilar features. A heterogeneous network or graph with type(s) of vertices and type(s) of edges is defined as a graph in which or [9]. Conversely, a homogeneous graph is one in which .
To the best of our knowledge, current link prediction solutions only address either bipartite networks or non-bipartite networks with structurally and temporally homogeneous nodes. Figure 1 shows an example of existing link prediction solutions in contrast with heterogeneous activity networks.

The key contributions of this paper are as follows.
-
•
We propose a novel model, called temporally parameterized network model (TPNM), for canonically representing heterogeneous time-evolving activities. We argue this can inspire further research in practical deep learning applications, such as business workflow optimizations, viral marketing with time-relevant advertisement placement, and talent recruitment process recommendations.
-
•
We introduce a new time-parameterized matrix (TP-matrix) as an alternative to adjacency matrix. We empirically show that TP-matrix is more suitable for heterogeneous, time-evolving networks.
-
•
In support of continuous prediction capability, we design a new approach that distinguishes and separately learns from the time-function relationship and structure-function relationship. This new approach addresses a limitation in current link prediction methods that consider the network evolution as a function of continuous snapshots.
The rest of the content is organized as follows. We review existing link prediction approaches in Section II before we broaden our discussion to related AI research areas. Our proposed model and algorithms are presented in Section III. The experiment design, datasets, and results are covered in Section IV. In Section VI, we discuss our work’s real-world application prospects and how it extends the benefits of using dynamic networks and AI to new domain areas. Section VII concludes the paper.
II Related Work
Huang et al. [10] studied relationship mining for subsequent events. They proposed the use of a sequence index and density ratio to measure the significance of a sequential pattern. An index implies a follow relationship between two events, an index implies a repel relationship, and an index implies an independent relationship. Link prediction is a popular method for predicting future relationships. Missing link prediction considers the mere structural properties of a network to estimate unobserved relationships. Temporal link prediction considers both structural and temporal properties of a network [11, 12]. The predictive influence of temporal properties in evolving networks was originally viewed with less importance [13]. However, many researchers are taking the view that temporal properties are of equal importance, if not more, than the structural properties [14]. Time properties were considered key predictors in continuously evolving customer relationship management (CRM) [15]. In this work, we focus on temporal link prediction. In this emerging research area, a temporal matrix factorization approach (TMF) was first introduced [16]. However, TMF only considered network structure from the previous timestep. This work was extended by [8], introducing LIST, which is both backward and forward-looking link prediction. LIST supports multiple timesteps, in the sense that the network state (snapshot) is observed at each timestep. The network, rather than the nodes within the network, progresses over time. LIST works on the assumption of node similarity. As a result, it does not work well with networks with evolving features over multiple timesteps. An example of such a network is business workflows with correlated but heterogeneous activities.
We now review two related but distinguishable AI research areas. These are task recommendation and sequence prediction.
Reactive task recommendation is widely studied in autonomous agents modeling. Autonomous agents can make a deterministic or stochastic choice based on fixed or continuously changing contexts [6]. In multi-agent systems, the context can include the acting agent, its opponents, or collaborators. Task recommendation models predict the next action based on a current state or past actions. A recommendation algorithm, SPEED, can predict the next activity of a smart home inhabitant based on past episodes of activities [17]. Task recommendation can be formally defined as: . One of the challenges with the task recommendation is the modeling of changing behavior and context [6]. Another limitation of the task recommendation is its lack of temporal consideration. A model may recommend turning the lights off after observing recent activities such as turning off TV and thermostat. However, the time distance of prior activities may increase the error rate of task recommendation models. Sequence prediction and dynamic network link prediction both incorporate timeliness in their predictive modeling.
| Node | Adjacency | Activity |
|---|---|---|
| 1 | 2,3 | Start |
| 2 | 3,4,7,9 | Client initiated contact through walk-in, iLead, phone, Email, SMS, etc |
| 3 | 4,7,9 | Actual contact though in-person, phone, Email reply or SMS reply |
| 4 | 5 | Appointment set |
| 5 | 6 | Appointment confirmed |
| 6 | 7,11 | Appointment complete |
| 7 | 8,9,10 | In-person visit |
| 8 | 9,10,12 | Test drive |
| 9 | 8,10,12 | Deal negotiation |
| 10 | 4,11 | Turn-over |
| 11 | 8,9,10,12 | Be-back (Subsequent in-person Visit) |
| 12 | Deal Closed |
A sequence prediction, formally defined as [18], exploits hidden and observable states of a set of sequence data and maps it to the next sequence. Applications of sequence prediction include automated language translations, speech recognition, and user action sequence learning.
III Our Approach
A challenge in learning dynamic networks lies in the complexity of adapting to continuously evolving time and context [6, 16, 12]. The influence of time is intuitively understood for a temporal network. However, the degree of influence depends on the network’s sensitivity to granular temporal relations. Before we describe our approach, we start by describing the type of network that is mainly under consideration in this work (Subsection III-A). We then discuss our a new approach of canonically representing heterogeneous time-evolving activities as a TP-matrix (Subsection III-B). The limitation of the adjacency matrix is explained before we show the use of TP-matrix is more suitable for evolving networks. In Subsection III-C, we demonstrate the retention of temporal relationships from the global network can be further enhanced using a time-parameterized predictive influence (TPPI).
III-A Temporally Consistent Networks
Earlier in the paper, we mentioned that link prediction estimates the next relationship in a dynamic network. Temporally consistent networks are a special kind of dynamic networks that smoothly evolve or devolve based on an observed or hidden relationship [8]. Temporal consistency has its roots in physics, but it was recently used to improve predictions in image-based graphics and video sequencing [19]. We now formally define the properties that hold true for temporally consistent networks.
Definition 1.
Temporally Consistent Networks Let a sequence of network snapshots represent the evolution of a temporally consistent network. The nodes in 1) are temporally interconnected, 2) influence the network evolution, and 3) contribute to an internal or external outcome.
Examples of temporally consistent networks include activity networks, road traffic networks, and social networks. The evolution of phenomena can be predicted using the spatial, temporal, or thematic relationships of a temporally consistent network.
III-B Time-parameterized Matrix
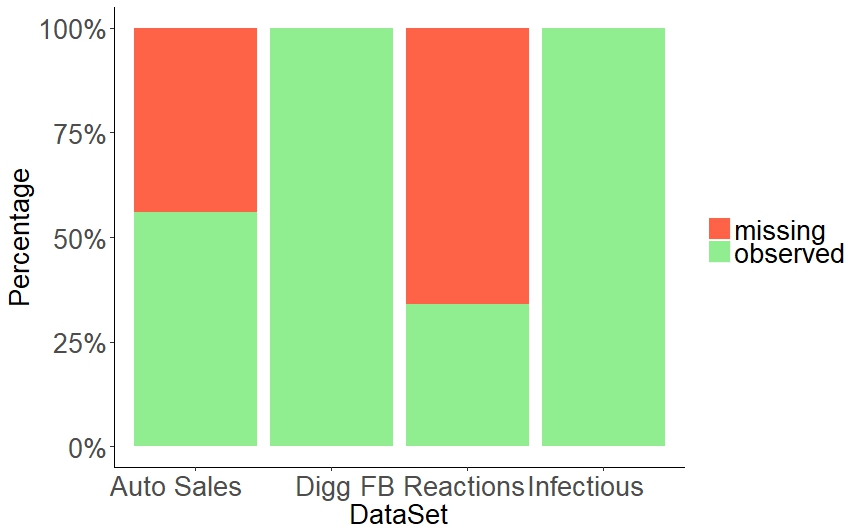
Time-parameterized matrix (TP-matrix) is our resolution for class imbalance which hampers the effectiveness of link prediction models using an adjacency matrix [12]. The use of adjacency matrix or binary edge weights (0, 1) to indicate a link between two nodes limits the ability to model all states in a global network [16]. This limitation is particularly evident in forming networks with a large number of unobserved links. In addition, Figure 2 shows graphs of real-world events tend to be sparse. The absence of a link conveys more noise than information when binary edge weights are used [16]. We now explore the suitability of (TP-matrix) for modeling heterogeneous, time-evolving networks.

We will illustrate our approach by using concrete examples from a real-world dataset of sales activities. We transform a sequence of observed activities and their timestamps into a network in the form of a TP-matrix. Each row represents one instance of a sale. Each column represents an event or an activity during the lifetime of a corresponding sale. The values of the matrix represent timed edges . In lieu of using binary edge weights, we use temporal residuals. Each value contains the transition timestamp from node , the initial event of the instance of a sale to node , which represents the corresponding activity. In the absence of a transition between node to node , the value is the time distance between the initial event (i.e. the receipt of a sales request) and the running time . We use the term ’time-parameterization’ with respect to the node-level timestamps and time distances. At the network level, the term ’temporal parameterization’ is more appropriate as it emphasizes the relationship aspect of all temporal properties. We make this distinction to note that our reference to time-parameterization in this paper emphasizes the timing aspect whereas temporal parameterization emphasizes the evolutionary aspect of temporal relationship at the global network. The computation of the TP-matrix is presented below. First, we use the running time in Equation 1 to eliminate class imbalance due to missing edges.
| (1) |
Second, we normalize the temporal values obtained in Equation 1 to . The normalization method is shown in Equation 2.
| (2) |
This normalization maintains the non-zero scale to avoid re-introducing noise. It is similar to normalizing user-item ratings in collaborative filtering for recommendation systems [20], where each user’s rating is divided by the maximum rating allowed. In our case, we cannot use the global denominator because temporal distances between activities are continuously variable.
III-C Time-evolving Predictive Influence
In subsection III-B, we looked at how we better capture the evolution of network structure through time. In this section, we will concentrate on the evolution of time and its predictive influence. The distinction between structure-function and time-function relationships are often overlooked, but it is a significant research problem for dynamic networks. Figure 3 shows a dynamic network timeline split into observed and unobserved parts. The current state of the art in link prediction considers the evolution as a function of continuous snapshots. A fixed time interval between timesteps must be defined during training. This means the prediction can happen only at the same fixed interval. A model trained with a 2-day fixed interval expects the same 2-day interval at prediction time. This is not ideal for practical applications because a random, on-demand prediction is not possible. An alternative approach would be to make the time interval user-configurable rather than fixed. However, that would exponentially increase the number of trained models. To make a continuous prediction possible as illustrated by the green diamonds in Figure 3, it is important to separate or decouple the time-function relationship from the structure-function relationship. We develop a time-parameterized predictive influence (TPPI) to capture the influence of time in a temporal relationship.
We start by evaluating the contribution of a given node to the evolutionary progress of its network.
Definition 2.
Time-Parameterized Predictive Influence Given a node at time and a predictive influence threshold , the predictive influence of is:
| (3) |
The predictive influence of each node is maximized given the node’s feature vector using Equation 4.
| (4) |
Backward and forward-looking maximization is used over the temporal space in between and , where is a tunable hyperparameter, which allows for the adjustment of the temporal degree of the neighborhood during model training. TPPI learns from feature vectors of each pair of nodes ( and their temporal weights obtained from Equation 2, yielding the following Equation 5.
| (5) |
Note that a higher influence threshold makes TPPI more conservative. A value of is equivalent to using no threshold. The threshold hyperparameter helps balance or fine-tune the temporal and structural context sensitivities of the network being modeled.
III-D Comparative analysis of variance and correlation
The correlation matrix using Pearson correlation coefficients is effective for showing pair-wise correlations of more than two independent variables. The matrix values are correlation confidence values in the interval [-1, 1]. A smaller or larger absolute value, respectively, indicates a weaker or stronger pair-wise correlation, whereas the negative or positive (-/+) sign shows the direction of the correlation. For predictive influence and feature selection analysis, the maximum confidence value of indicates a collinearity problem where the pair-wise relation of two variables is so high they are likely identical. A confidence value of shows no linear relationship.
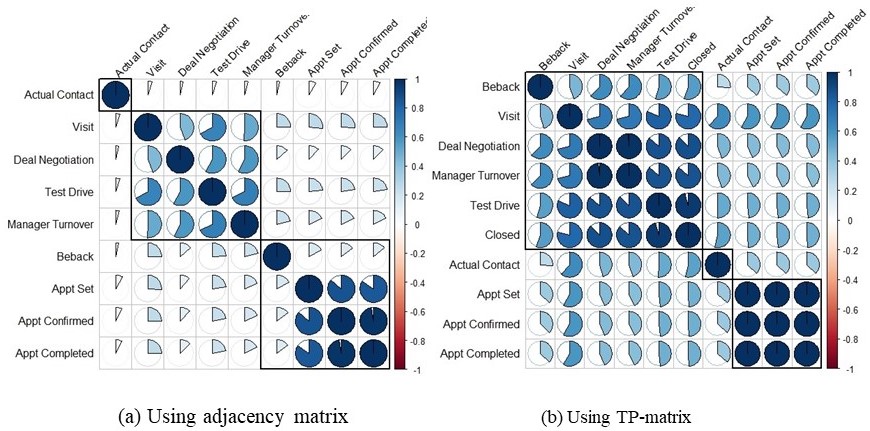
Now, we will show TP-matrix can capture the spatiotemporal correlation among network nodes relatively better than the adjacency matrix. The graphical representation of the correlation matrix for sales activities are shown in Figure 4. The Pearson correlation with hierarchical clustering is shown for both the adjacency matrix and TP-matrix. We can observe several benefits of the TP-matrix over the adjacency matrix. The adjacency matrix shows a weak intra-node correlation because of the sparsity of the graph data. The TP-matrix conveys more spatiotemporal correlation with more realistic clustering. For example, a vehicle test drive, a deal negotiation, a referral to a sales manager (manager turn-over), and a conclusion of a deal (closed) usually all happen in one initial or subsequent visit to a dealership showroom. The clustering of these activities in (b) of Figure 4 is, therefore, more realistic. In addition, we can observe that it is not possible to calculate the pair-wise correlation coefficient between and any other activity using the adjacency matrix. Since the dataset included successful deals only, an adjacency matrix would have the value for all instances. As a result, a variance and, therefore, a Pearson’s correlation coefficient cannot be calculated. This supports our claim (and that of others [16]) that the adjacency matrix cannot model all states in a global network. We summarize our findings below.
-
1.
Using the running timestep eliminated a key limitation due to missing edges when using the adjacency matrix. With this approach, the absence of a link conveys latent feature variance and relevance with respect to observed links.
-
2.
Using timed edges improved the retention of temporal relationships with respect to the global network. It also highlighted more granular relationships among sub-groups of nodes. The rectangles in (b) of Figure 4 show clusters of correlated activities that matched the mental model of automotive experts. For example, independent activities that deal with appointment scheduling and tracking are in the same cluster. During deal negotiation, a sales manager may get involved. Such activity is tracked as ’Manager Turnover’.
-
3.
With this approach, the model variance is reduced because 1) the model is less prone to the cold start problem at the initial phase when the network is forming, and 2) the model regulates itself with a decay function as the network grows larger. We will expand on this in the next subsection.
| D(t) = Eq. (6) | |||||||
| Example 1 | Example 1 | Example 2 | |||||
| Node | - | - | - | ||||
| - | 0.5 | 0.4 | 0.5 | 0.4 | |||
| - | 0.8 | 0.7 | 0.8 | 0.7 | |||
| - | 0.1 | 0.0 | 0.1 | 0.4 | |||
| - | 0.7 | 0.6 | 0.7 | 0.7 | |||
| 6 | 0.525 | 0.425 | 0.525 | 0.55 | |||
| D(t) | 0.548 | 0.622 | 0.563 | 0.622 | 0.638 | ||
III-E Regularization Method
Regularization is a technique used to reduce model variance. In its simplest form, a uniform decay can be applied to an objective function. A much popular approach is to use a decay function with a parameter . The parameter regulates how fast the decay hastens. In temporal link prediction, an exponential decay function with time is commonly used to regulate the importance of the current network snapshot compared to previous snapshots [16, 8, 14].
As the network progresses, the farthest network states become less relevant than the current network state. The acceleration of the irrelevance (decay) depends on the problem and can be estimated by the decay parameter . However, one can argue that an exponential decay function for a temporal link prediction is not necessarily a strictly monotonically decreasing function. This is especially true for temporally consistent networks. Let us consider the citation network, which is sensitive to temporal evolution. On the question of the most impactful papers, aging papers with continuous and active citations may have higher relevance than recent papers without proven staying power. This supports our argument that previous network states are not necessarily less relevant than the current state. We can take this argument further by pointing out that, on a more granular level, certain nodes may continue to contribute to a network’s evolution at a much higher rate than other nodes. With this in mind, we define a relative exponential decay function in (6) by first taking the Mean TPPI (See Equation 3) of the current network state. A lower Mean TPPI infers more nodes that are not contributing to the network evolution. We then use it as the decay parameter since it better reflects a node-level temporal decay of the network state rather than a mere time decay.
| (6) |
Table II shows synthetic examples of a network decay with four nodes. We assume that and for the commonly used decay function. With our relative exponential decay, you can see that an over-performing node (in terms of its predictive influence) can slow down the temporal decay of the overall network, even when the influence of other nodes are diminishing. In contrast, the commonly used decay function is a function of time decay and, therefore, a strictly decreasing function overtime.
| Parameter Name | Description | Average Degree |
|---|---|---|
| The temporal range of neighborhood (e.g. 2, 3 or more +/- hops) during training and inference. |
Optional
Default value: 3 |
|
| The learning rate or step size used during optimization. |
Optional
Default value: 0.1 Valid values: A positive float value from 0.1 to . |
|
| Predictive influence threshold. A higher value gives more weight to the structural context, whereas a lower value gives more weight to temporal context. |
Required
Valid values: positive float value in (0, 1] |
|
| The momentum for the stochastic gradient descent (SGD) algorithm. |
Optional
Default value: 0.9 Valid values: A positive float value in (0, 1] |
|
| Maximum number of iterations. |
Optional
Default value: Valid values: A positive integer value |
III-F TPNM Model Training
We trained our model using stochastic gradient descent (SGD) with momentum [21]. The momentum , learning rate , and the temporal range are tunable, user-defined hyperparameters that are initially set (as default values) to 0.9, 0.1 and 3, respectively. We chose these default values because they are widely accepted as initial values and also worked well for our model. The complete list of hyperparameters is in table III.
The model is iteratively trained until it converges. Convergence is achieved when the minimum loss variation is consistently below a tolerance threshold of for the last 10 epochs. More specifically, the training stops when the stop condition in Equation 7 is satisfied, where is the error vector produced in a maximal number of boosting iterations .
| (7) |
Given a TP-Matrix (t) and TPPI-matrix (t) at time , we minimize the following objective function for and .
| (8) | |||
We carried out most of the time-dependent optimization legwork in subsection III-C. The first term is regulated with the relative exponential decay function D(t), whereas the other two terms are regulated by a learning rate that is continuously reduced from its initial value to .
We show the derivatives of the objective function below.
| (9) |
| (10) |
The pseudocode for our model is presented in Algorithm 1.
IV Experiment Setting
While this work involves link prediction, we are interested in different types of graphs that have not been addressed in most link prediction studies. In the absence of related studies we could use as a baseline, we first start our experiment with networks that are traditionally used for link prediction problems. We evaluate how our approach works on two datasets used in temporal link prediction and then expand our evaluation to more complex networks.
| Dataset | Total Nodes | Average Degree | Absent:Observed Edge Ratio |
|---|---|---|---|
| Infectious | 410 | 84 | 0 |
| Digg | 30,398 | 21.5 | 0 |
| CRM Activities | 120,000 | 3.5 | 11:14 |
| Facebook Reactions | 2,088 | 4 | 691:353 |
IV-A Dataset
We used a total of four datasets of dynamic networks. Two of them, Infectious and Digg, were part of KONECT111http://konect.uni-koblenz.de/networks/ networks, which are widely used in link prediction. These two datasets were used for baseline comparative analysis. The third dataset was a collection of social reactions on Facebook posts from the British Broadcasting Corporation (FBReactions222https://github.com/naman/fb-posts-dataset). It contained 348 Facebook posts on a wide range of topics with at least one of 6 possible social reactions (like, love, wow, haha, sad, angry). Missing edges (e.g., missing reaction type angry) were high (66% of all edges). The published social reactions dataset did not include timestamps on social reactions. A timestamp was randomly generated for each reported social reaction. Posts without at least one social reaction were removed from consideration. Since Facebook uses the same 6 reactions across their social media platform, this experiment should apply to Facebook Live videos as well. The fourth was a real industry dataset (AutoSales) collected from a live automotive CRM [15]. This dataset contained 10,000 anonymized sales events, each representing a network with 12 nodes. Missing edges (e.g., missing activity type sales appointment) accounted for 44% of all possible edges. Table IV shows the properties of the datasets.
| Method | Infectious | Digg | FBReactions | AutoSales |
|---|---|---|---|---|
| WCN | 0.97190.8300 | 0.27190.2064 | Not evaluated | Not evaluated |
| HPLP | 0.58830.6767 | 0.27020.2034 | Not evaluated | Not evaluated |
| CPTM | 0.88470.9367 | 0.21960.2469 | Not evaluated | Not evaluated |
| TMF | 0.53090.1185 | 0.00320.0011 | 0.54750.2205 | 0.51070.9288 |
| LIST | 0.38240.1114 | 0.00260.0005 | 0.52060.0008 | 0.47590.4803 |
| TPNM (ours) | 0.16810.6295 | 0.11290.6420 | 0.13380.94610 | 0.07830.1611 |
IV-B Experiment Design and Evaluation Metric
Like most link prediction algorithms, our work is a regression task. It uses the structure and time relationships within a network to learn its evolution. Root-Mean-Square Error (RMSE) is used to evaluate the generalization capability of regression-based algorithms. In this paper, we will report both the iterative (epoc steps) and overall RMSE performance. Mean absolute error (MAE) is also reported as an additional performance evaluation. In addition, we show the training run-time performance with six different network samples. The graph representation allows for evaluating the accuracy performance of regression-based link prediction using the area under the curve (AUC) binary measurement. AUC has been used extensively as an evaluation metric for link prediction problems [16]. However, this requires the preparation of the test data in a certain way. We now describe our approach using the automotive CRM dataset.
CRM activities were converted into a sequence of states and their corresponding timestamps . For uniformity during training and evaluation, each state or activity was assigned an identifier, as shown in Table I. The temporal property of each activity was then captured by a TP-matrix. The goal of this experiment setup was to enable the evaluation of our link prediction approach against our baseline, TMF, using AUC. For example, 1200 different networks, with ten different nodes each, were tested. For any network, we ran link predictions at most stages. That is for every node in the network at any given time except the destination node at T. Our training data was the activity sequence data represented as a network at timestep . For our test data, we removed the node at . We considered the test positive if the predicted node matched with the node at . Otherwise, we considered it negative. We can now use the binary measurement and compare our results with our baseline TMF.
V Results
We compared our method with the recent link prediction benchmark results using four datasets. Table V summarizes the RMSE performance of TPNM compared to the baseline method (TMF) and four additional methods. Interestingly, the Digg dataset did not perform well using our approach. This could be explained by the weak temporal relations in user ratings. Digg is a dataset that contains stories and their ratings (how many users dig a given story) at a given time. It can be argued the temporal span of ratings does not affect the outcome (e.g., whether a story is going to trend or not). More specifically, the timing of ratings and how they are scattered over the lifespan of a story may not have more predictive influence than the ratings. Therefore, our approach may not work for networks that are less sensitive to temporal evolution than they are on topological evolution. On the contrary, we observed that our model performed well for the activity or social reaction networks because timing is more critical for these networks.
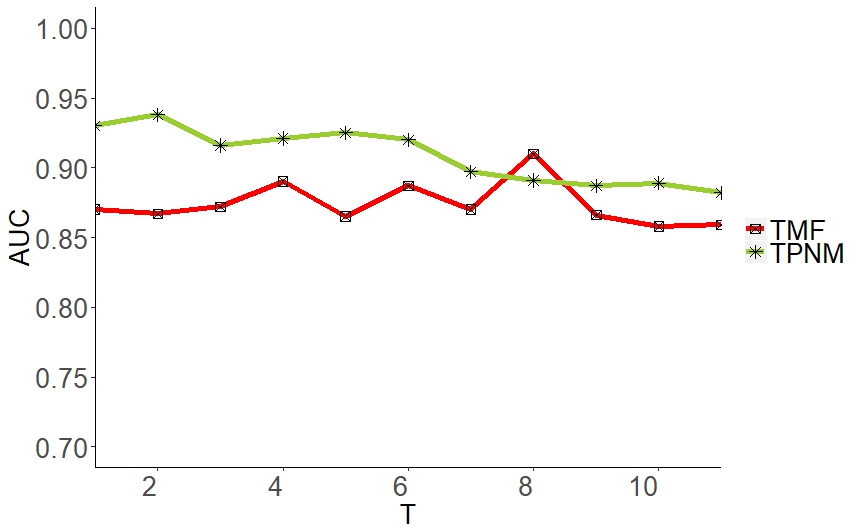
Using AUC, TPNM obtained a better overall accuracy than the baseline TMF as shown in Figure 5 with 93% compared to 87%. In this case, we used the automotive CRM dataset only. The fluctuation of the baseline method is reduced. We believe the temporal retention across nodes (discussed in Section III improved the accuracy of the link prediction.
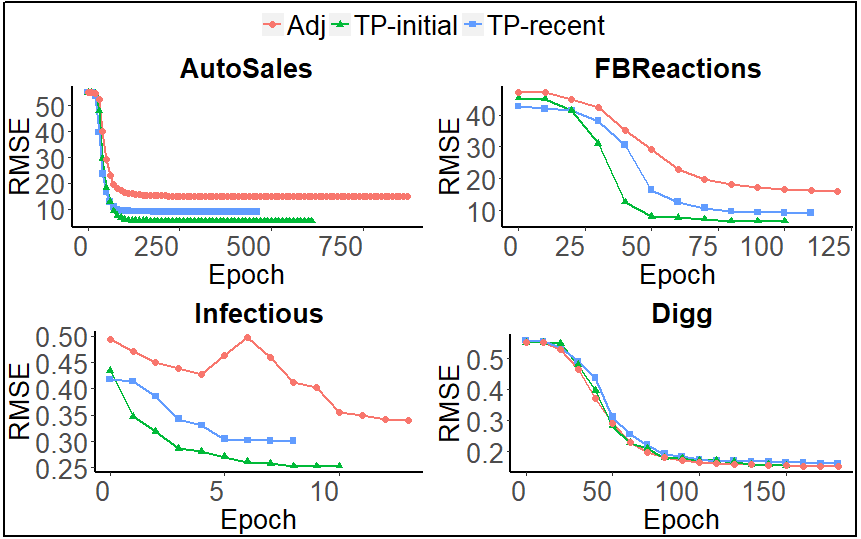
We now extend our evaluation to the RMSE performance results obtained from an iterative model training. Three experiments were carried out to evaluate the training performance of TPNM using TP-matrix. In the first experiment (Adj), we simply used the adjacency matrix. In the second and third experiments, we used TP-matrix with the initial (i.e., the network conception) event of the network influencing all other events (TP-initial) or with the most recent event influencing the current event (TP-recent). An example of computing TP-matrix using the initial event was explained in Equation 1. Using the most recent event means simply rewriting to in the same equation. Our findings, as shown in Figure 6, showed that the use of TP-matrix improved the RMSE performance compared to the adjacency matrix. The use of TP-matrix using the initial event (TP-initial) performed better than when the most recent event (TP-recent) is used. That is because the initial event provides a more stable temporal consistency among all nodes (i.e., a smooth network evolution) over the most recent event. The curve stops when our iterative training obtains the least RMSE rate, which was 0.07 for the activity dataset.
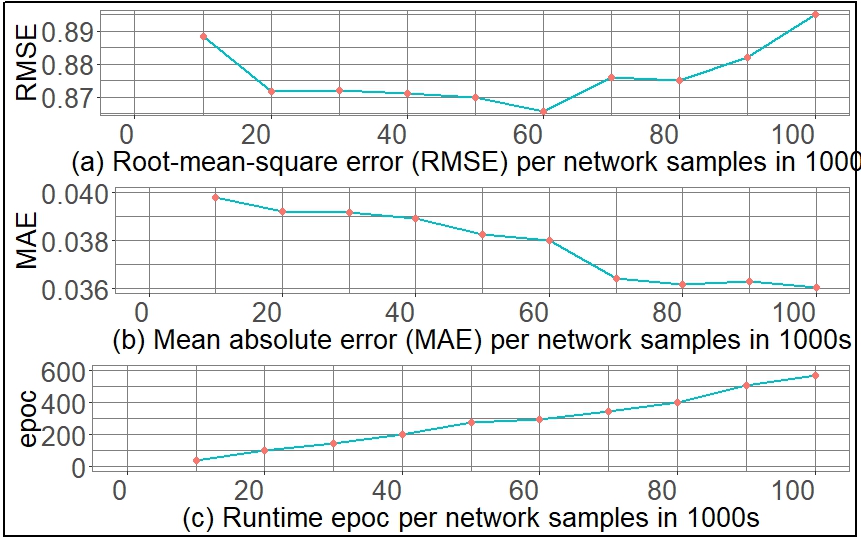
Finally, Figure 7 shows the overall iterative training performance using RMSE and MAE. It also shows the runtime of the TPNM algorithm as a function of the size of the network instances. For 100,000 networks with over 1.1 million nodes, the training completed just under 10 minutes.
VI Applications
Many real-world tasks involve time-sensitive steps whose timely or untimely completion affects the desired outcome. Time-parameterization of link prediction opens the doors to link prediction applications that were otherwise hard to apply. In the following lines, we discuss a few promising applications of our approach.
Business Workflow Optimization
Optimizing a workflow using intelligent decision points requires context-sensitive learning based on what activities occurred at what time, what activities could happen at the current state, and how that could affect the desired outcome of a workflow. This presents the challenges of heterogeneity and dynamicity that we discussed earlier. In sales workflows, activities are correlated but heterogeneous, and paths to a sale (i.e., the desired outcome) are dynamic and depend on the network state. More specifically, in automotive sales workflow, a deal negotiation may be recommended early for online consumers, because they are more likely to complete their product research on the Web before they even initiate contact with a seller. The same activity may be recommended much later for in-store consumers. Therefore, timing and other side information (e.g., deal negotiation) may present boosting or diminishing predictive influence. Our new approach of representing heterogeneous activities as a temporally parameterized network and retaining temporal relationships with respect to the global network enables researchers to extend link prediction applications to business workflow optimization.
Viral Marketing
Link prediction was recently used for influence maximization in viral marketing [22]. For product promotion, influence users in social networks are grouped based on their in-degree (followers) and out-degree (friends) relationship. The idea is to predict the next social connection of a target group for marketing campaigns. Another viral marketing trend includes Facebook’s live video advertisement. Social reactions to a Facebook live video are essentially time-evolving activities. Our new approach can be used to predict the optimal time to show an advertisement in a live video feed with active social reactions.
Talent Acquisition Recommendation
Talent acquisition, unlike recruitment, is an evolving strategy to actively and passively attract top talent. Similar to the business workflow, timing is critical when identifying top candidates that are showing signs of job market activities. Job market events and candidate activities can be learned as a network to predict the optimal time to engage a prospective talent.
VII Conclusions
In this paper, we presented a new approach, TPNM, to link prediction that enables and motivates the interdisciplinary application of artificial intelligence and dynamic networks for new domain areas, including business workflow optimization, viral marketing, and context-aware action recommendation. We reviewed the limitation of using the adjacency matrix in link prediction and presented a new time-parameterized matrix as a solution for class imbalance and feature noise due to missing edges. Our research showed that networks that model real-world events or activities contain a high proportion of missing links. In addition, we showed that these events or activities tend to be heterogeneous with dissimilar features. Our empirical evaluation showed that the use of a time-parameterized matrix with a predictive influence index is more suitable for heterogeneous time-evolving networks. We used two published datasets to compare our approach to existing link prediction methods. In addition, we tested our approach with two additional datasets for heterogeneous sales activities and social reactions. For all the datasets we evaluated, we achieved an RMSE smaller than 0.17. For time-evolving datasets, the results were much better with 0.13 and 0.07 RMSE for social reactions and automotive sales activities respectively.
Acknowledgment
This research was partially funded by the University of Missouri-Kansas City, School of Graduate Studies.
References
- [1] V. Martínez, F. Berzal, and J.-C. Cubero, “A survey of link prediction in complex networks,” ACM Computing Surveys (CSUR), vol. 49, no. 4, p. 69, 2017.
- [2] D. T. Wijaya, B. Callahan, J. Hewitt, J. Gao, X. Ling, M. Apidianaki, and C. Callison-Burch, “Learning translations via matrix completion,” in Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, 2017, pp. 1452–1463.
- [3] J. Lu, G. Wang, and J. Zhou, “Simultaneous feature and dictionary learning for image set based face recognition,” IEEE Transactions on Image Processing, vol. 26, no. 8, pp. 4042–4054, 2017.
- [4] D. Wang, P. Cui, and W. Zhu, “Structural deep network embedding,” in Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2016, pp. 1225–1234.
- [5] Z. Zhao, B. Gao, V. W. Zheng, D. Cai, X. He, and Y. Zhuang, “Link prediction via ranking metric dual-level attention network learning.” in IJCAI, 2017, pp. 3525–3531.
- [6] S. V. Albrecht and P. Stone, “Autonomous agents modelling other agents: A comprehensive survey and open problems,” Artificial Intelligence, vol. 258, pp. 66–95, 2018.
- [7] S. Gao, L. Denoyer, and P. Gallinari, “Temporal link prediction by integrating content and structure information,” in Proceedings of the 20th ACM international conference on Information and knowledge management. ACM, 2011, pp. 1169–1174.
- [8] W. Yu, W. Cheng, C. C. Aggarwal, H. Chen, and W. Wang, “Link prediction with spatial and temporal consistency in dynamic networks,” in Proceedings of the 26th International Joint Conference on Artificial Intelligence. AAAI Press, 2017, pp. 3343–3349.
- [9] H. Cai, V. W. Zheng, and K. C.-C. Chang, “A comprehensive survey of graph embedding: Problems, techniques, and applications,” IEEE Transactions on Knowledge and Data Engineering, vol. 30, no. 9, pp. 1616–1637, 2018.
- [10] Y. Huang, L. Zhang, and P. Zhang, “A framework for mining sequential patterns from spatio-temporal event data sets,” IEEE Transactions on Knowledge and data engineering, vol. 20, no. 4, pp. 433–448, 2008.
- [11] E. Acar, D. M. Dunlavy, and T. G. Kolda, “Link prediction on evolving data using matrix and tensor factorizations,” in Data Mining Workshops, 2009. ICDMW’09. IEEE International Conference on. IEEE, 2009, pp. 262–269.
- [12] A. K. Menon and C. Elkan, “Link prediction via matrix factorization,” in Joint european conference on machine learning and knowledge discovery in databases. Springer, 2011, pp. 437–452.
- [13] Y. Yang, R. N. Lichtenwalter, and N. V. Chawla, “Evaluating link prediction methods,” Knowledge and Information Systems, vol. 45, no. 3, pp. 751–782, 2015.
- [14] M. Yang, J. Liu, L. Chen, Z. Zhao, X. Chen, and Y. Shen, “An advanced deep generative framework for temporal link prediction in dynamic networks,” IEEE Transactions on Cybernetics, 2019.
- [15] M. Ali and Y. Lee, “Crm sales prediction using continuous time-evolving classification,” in Thirty-Second AAAI Conference on Artificial Intelligence, 2018.
- [16] W. Yu, C. C. Aggarwal, and W. Wang, “Temporally factorized network modeling for evolutionary network analysis,” in Proceedings of the Tenth ACM International Conference on Web Search and Data Mining. ACM, 2017, pp. 455–464.
- [17] M. R. Alam, M. B. I. Reaz, and M. M. Ali, “Speed: An inhabitant activity prediction algorithm for smart homes,” IEEE Transactions on Systems, Man, and Cybernetics-Part A: Systems and Humans, vol. 42, no. 4, pp. 985–990, 2012.
- [18] I. Sutskever, O. Vinyals, and Q. V. Le, “Sequence to sequence learning with neural networks,” in Advances in neural information processing systems, 2014, pp. 3104–3112.
- [19] C. Eom, H. Park, and B. Ham, “Temporally consistent depth prediction with flow-guided memory units,” IEEE Transactions on Intelligent Transportation Systems, 2019.
- [20] R. Mu, “A survey of recommender systems based on deep learning,” IEEE Access, vol. 6, pp. 69 009–69 022, 2018.
- [21] S. Ruder, “An overview of gradient descent optimization algorithms,” arXiv preprint arXiv:1609.04747, 2016.
- [22] W. Zhu, W. Yang, S. Xuan, D. Man, W. Wang, and X. Du, “Location-aware influence blocking maximization in social networks,” IEEE Access, vol. 6, pp. 61 462–61 477, 2018.