LLaVA-SG: Leveraging Scene Graphs as Visual Semantic Expression in Vision-Language Models
Abstract
Recent advances in large vision-language models (VLMs) typically employ vision encoders based on the Vision Transformer (ViT) architecture. The division of the images into patches by ViT results in a fragmented perception, thereby hindering the visual understanding capabilities of VLMs. In this paper, we propose an innovative enhancement to address this limitation by introducing a Scene Graph Expression (SGE) module in VLMs. This module extracts and structurally expresses the complex semantic information within images, thereby improving the foundational perception and understanding abilities of VLMs. Extensive experiments demonstrate that integrating our SGE module significantly enhances the VLM’s performance in vision-language tasks, indicating its effectiveness in preserving intricate semantic details and facilitating better visual understanding.
Index Terms:
Vision-Language Model, Scene Graph, Large Multimodal ModelI Introduction
Large vision-language models (VLMs) integrate data from visual and language modalities, enabling comprehensive multimodal understanding [1, 2, 3]. With images and query text as input, VLMs can answer queries by incorporating the visual information. However, most VLMs utilize the Vision Transformer (ViT) [4] as their visual backbone, which results in perceiving images as fragmented patches, as shown in Fig. 1(a) with LLaVA as the VLM baseline[5]. This fragmented approach fails to preserve the intrinsic semantic information in images, thus limiting the VLMs’ visual comprehension capabilities [5]. To address this limitation, we propose using scene graphs, which express the objects in a scene and the relationships between them to retain and structurally express the complex semantic information in images, as shown in Fig. 1(b). In this way, the visual perception and understanding capabilities of VLMs are enhanced with the proposed Scene Graph Expression (SGE) module.
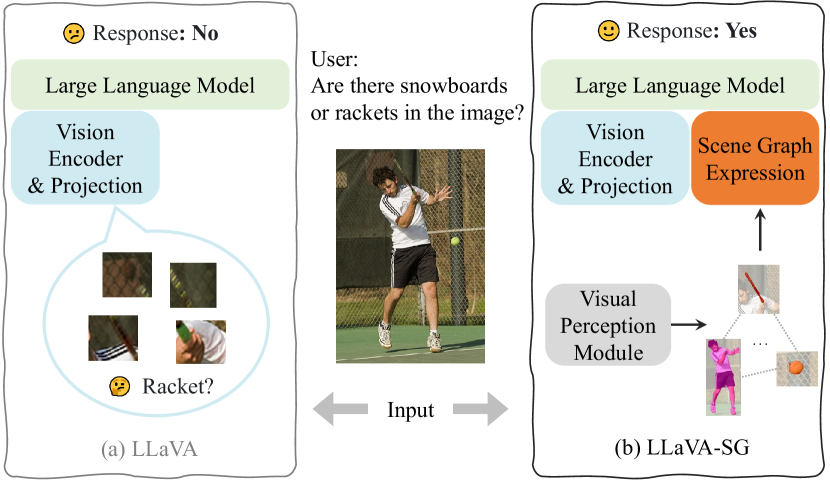
Improving the perceptual capabilities of VLMs has been the focus of several research efforts. For instance, Lyrics [6] introduces a visual refiner to incorporate semantic-aware visual objects. IVE [7] integrates multitask encoders and visual tools into existing models. Several studies have also explored the use of scene graphs in VLMs [1, 8]. However, training directly on scene graph data or fine-tuning on scene graph text has not yielded optimal results [1, 8].
To achieve the structured expression of visual semantic information without directly training on scene graph data, we designed the Scene Graph Expression module. Specifically, we use pretrained visual models to extract entities from images, preserving semantic information at the entity level rather than the patch level. Next, we construct a scene graph using these entities and perform message passing between the nodes in the scene graph. Building on LLaVA [5], we construct LLaVA-SceneGraph (LLaVA-SG), a model that incorporate SGE module to enhance the foundational perception and understanding capabilities of VLMs. To enhance visual understanding, we train LLaVA-SG to classify visual relationships between the extracted entities, avoiding the catastrophic forgetting that might occur with direct training on scene graph data. Our contributions are threefold:
-
•
We design a Scene Graph Expression (SGE) module to extract and structurally express the intrinsic semantic information in images.
-
•
We incorporate SGE into VLM, resulting in the LLaVA-SG model to enhance the foundational visual perception and understanding capabilities.
-
•
We conduct extensive evaluations of the trained LLaVA-SG model on multiple benchmarks, demonstrating that the integration of SGE significantly improves visual perception and understanding capabilities of VLM.
II Method
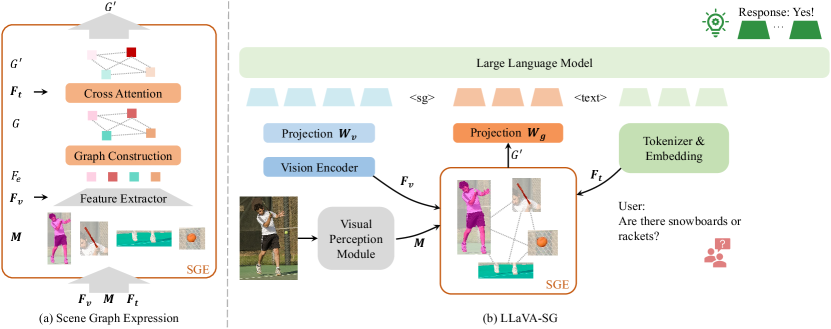
In this section, we first introduce the scene graph construction to preserve and express complex semantic information within images. Next, we detail the integration of SGE module into standard VLM models, forming the LLaVA-SG model. Finally, we present the training strategies devised for LLaVA-SG. An overview of our approach is shown in Fig. 2(b).
II-A Semantic Information Expression
II-A1 Visual Entity Extraction
To achieve the structured expression of semantic information in a scene, we first extract the entities within the scene. Specifically, in the Visual Perception Module in Fig. 2(b), we first perform image tagging on the input to identify the categories of the entities it contains. Taking the input image in Fig. 2(b) as an example, the image tagging process will output tags such as ”man”, ”racket”, ”tennis ball”, and ”sports field”. The object detection module then detects the bounding boxes of these entities based on the tagging results. The bounding boxes are rectangular boxes that represents the position and size of each entity. Next, we conduct semantic segmentation within the bounding boxes to obtain the pixels comprising each entity, achieving pixel-level semantic understanding with the help of segmentation masks. We denote the segmentation masks as , where is the number of segmented entities. and denote the height and width of masks.
To express the semantic information in images, we design the Scene Graph Expression module, as depicted in Fig. 2(a). The segmentation masks serve as the input of the SGE module representing entities in the input image.
| Model | LLM | Benchmarks | Fine-Grained Ability from MMBench | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| VQAv2 | GQA | SQAI | MMB | MMBCN | POPE | LR | AR | RR | FP-S | FP-C | CP | ||
| BLIP-2 [14] | Vicuna-7B | 65.0 | 41 | 61 | - | - | 85.3 | - | - | - | - | - | - |
| mPlug-OWL2 [15] | LLaMA2-7B | 79.4 | 56.1 | 68.7 | 64.5 | 36.2 | - | 32.2 | 72.4 | 60.9 | 68.6 | 60.1 | 79.4 |
| InstructBLIP [16] | Vicuna-7B | - | 49.2 | 60.5 | 36.0 | 23.7 | - | 21.6 | 47.4 | 22.5 | 33.0 | 24.4 | 41.1 |
| QwenVL [17] | Qwen-7B | 78.8 | 59.3 | 67.1 | 38.2 | 7.8 | - | 9.8 | 43.1 | 30.3 | 32.9 | 27.9 | 36.4 |
| QwenVL-chat [17] | Qwen-7B | 78.2 | 57.5 | 68.2 | 61.8 | 56.7 | - | 40.5 | 74.3 | 47.9 | 66.3 | 46.2 | 72.8 |
| LLaVA-1.5 [18] | Vicuna-7B | 78.5 | 62.0 | 66.8 | 64.2 | 57.6 | 85.9 | 33.1 | 70.4 | 58.3 | 65.9 | 55.2 | 77.4 |
| LLaVA-SG-7B | Vicuna-7B | 79.2 | 63.5 | 68.7 | 68.0 | 58.7 | 86.7 | 39.8 | 70.3 | 68.7 | 69.6 | 59.4 | 80.1 |
| LLaVA-SG-13B | Vicuna-13B | 80.1 | 63.6 | 71.1 | 68.7 | 61.7 | 86.9 | 41.5 | 70.4 | 60.0 | 73.4 | 61.5 | 80.7 |
II-A2 Scene Graph Expression
We introduce the Scene Graph Expression (SGE) module to structurally preserve and express the semantic information in a scene at the entity level. A scene graph is a graphical representation that captures and expresses the entities and their relationships in a scene. Scene graphs aid in visual comprehension of images and videos, and facilitate scene understanding [19]. Entities in a scene are represented as entities in a scene graph. Additionally, we introduce the prompt feature to activate key nodes in the scene graph. Next, we detail the steps involved in the SGE module.
To construct the scene graph for the input image, we first extract the visual features of the entities within the image to represent the nodes. Specifically, we use to denote the visual features of the input image obtained from the pretrained vision encoder, where is the dimension of . and denote the shape of the feature map. Following [20], we extract the features of points in the masks from using bilinear interpolation. Then, for each mask in , we average the features of the points it contains to obtain the feature representation of the mask. The features of masks are collectively denoted as , representing the visual features of the corresponding entities. Second, we construct the scene graph with these entities as nodes of the graph and as the node features. Edges among the nodes depict their relationships. We perform message passing among the nodes to implicitly encode the relationship information between nodes. Third, to make the scene graph expression adaptive, we utilize the prompt feature to activate the key nodes within . We use to denote the prompt feature where is the number of prompt tokens, and is the dimension of the prompt feature. Specifically, we adopt the attention mechanism to inject the prompt feature into , highlighting the nodes in that are relevant to the prompt feature. The updated scene graph is denoted as , which is the output of the SGE module, representing the structured semantic information contained in the input image.
II-B Scene Graph Expression in VLM
To address the degradation of complex semantic information in VLMs caused by the processing of images as set of patches, we introduce the SGE module into the VLM, as shown in Fig. 2(b). Using LLaVA [18] as the base framework, the image is input into the pretrained vision encoder, and the obtained visual features are used as the input of SGE module, that is, . Utilizing the pretrained visual perception module, we obtain the semantic segmentation masks of the input image. The input text is tokenized, and the embeddings are used as the prompt feature for SGE module, denoted as . Together, , , and serve as inputs to the SGE module, constructing the scene graph activated by the prompt feature. Similar to the projection layer after the pretrained vision encoder, we apply a trainable projection layer to convert the nodes in into language embedding tokens. With the same dimensionality, the converted scene graph tokens are then fed into the Large Language Model, along with the visual tokens and the text tokens. We add two special tokens to the LLM, namely <sg> and <text>, which are inserted before and after the scene graph tokens, respectively. Consequently, the sequence of these tokens is fed into the LLM to generate language response tokens as follows:
| (1) |
where denotes the output of the LLM, serving as the response to the input image and text.
II-C Training
Following LLaVA [5], we train our LLaVA-SG on the prediction tokens of the LLM using an auto-regressive training objective. Building on LLaVA’s original two-stage training, we insert an additional training stage specifically for our SGE module. The training of LLaVA-SG thus includes the following three stages:
Visual Feature Alignment. We initialize the image encoder and the LLM of LLaVA-SG with pretrained weights and keep them frozen. We do not use the SGE module at this stage. Only the visual projection layer is trainable. The dataset of 558K LAION-CCSBU image-text pairs[21, 5] is adopted for training in this stage.
SGE training. In the second stage, we focus training the SGE module and the corresponding projection layer . The visual encoder, visual projection layer, and LLM are all frozen during this stage. Considering that a scene graph contains both entities and the relationships between them, we endow the SGE module with the ability to preserve and express visual semantic information from both perspectives. For entity recognition, we use the pretrained visual perception module. For expressing the relationships between entities, we train the SGE module and the projection layer on visual relationship understanding datasets. Specifically, the visual relationship understanding datasets we use are derived from two sources. First, existing fine-grained visual understanding datasets, such as Visual Genome [22] and Open Image V6 [23], are reformatted into the visual question-answering format. However, the relationships in these datasets are limited and not open-vocabulary. Therefore, we also construct an open-vocabulary visual relationship understanding dataset based on the large-scale visual grounding dataset GRIT [24], utilizing GPT-4v to produce the data.
Fine-tuning. In the third stage, only the visual encoder remains frozen, while all other parameters are trained in LLaVA-SG. We use the 665K image-text instruction dataset from LLaVA-1.5 [18], which contains diverse instructions for fine-tuning in this stage.
III Experiments
III-A Experimental Setup
In LLaVA-SG, we adopt CLIP ViT-L/14@336p [4, 25] as the vision encoder and Vicuna [26] as the LLM. The pretrained visual perception module includes RAM [27] for image tagging, Grounding-DINO [28] for detection, and SAM [29] for semantic segmentation. The message passing and attention mechanism in the SGE module are implemented using lightweight transformers. In the first stage, the learning rate for the trainable parameters is set to . In the second and third stages, we use a learning rate of .
| SG | MP | Prompt | GQA | MMB | COCO | Rel |
|---|---|---|---|---|---|---|
| 61.97 | 64.80 | 110.38 | 77.49 | |||
| ✓ | 62.93 | 65.63 | 111.90 | 76.19 | ||
| ✓ | ✓ | 63.06 | 65.89 | 112.37 | 79.42 | |
| ✓ | ✓ | 63.03 | 67.01 | 112.24 | 80.16 | |
| ✓ | ✓ | ✓ | 63.48 | 68.04 | 112.55 | 80.69 |
| SGE-D | SGE | SGE-T | GQA | MMB | COCO | Rel |
|---|---|---|---|---|---|---|
| ✓ | 62.32 | 65.72 | 108.45 | 80.23 | ||
| ✓ | ✓ | 62.75 | 66.41 | 110.92 | 80.32 | |
| ✓ | ✓ | ✓ | 63.48 | 68.04 | 112.55 | 80.69 |
III-B Overall Performance Assessments
The comparison results of LLaVA-SG and baseline models are summarized in Table I following the evaluation metrics of [30]. The reported results of the compared models are collected from the corresponding papers. Analyzing the experimental results in Table I, it is evident that our LLaVA-SG model shows significant and consistent improvements over the baseline models. The improvements of LLaVA-SG-7B over LLaVA-1.5-7B highlight that our SGE module effectively preserves and expresses visual semantic information with a nearly negligible increase in parameters, achieving significant performance gains. With Vicuna-13B, the LLaVA-SG-13B achieves better results than LLaVA-SG-7B.
The detailed results on MMBench are presented in Table I. MMBench assesses large vision-language models across multiple capability dimensions including LR for Logical Reasoning, AR for Attribute Reasoning, RR for Relation Reasoning, FP-S for Fine-grained Perception (Single Instance), FP-C for Fine-grained Perception (Cross Instance) and CP for Coarse Perception. Analyzing the comparative results in this table, our LLaVA-SG shows significant improvements over LLaVA-1.5 in the capabilities that require entity perception and relationship analysis, specifically in RR, FP-S, FP-C, and CP.
We present example outputs of LLaVA-1.5 and LLaVA-SG in Fig. 3. The middle column shows the masks of entities included in the scene graph of the SGE module. With the visual semantic information expressed by SGE, LLaVA-SG exhibits enhanced multimodal capabilities. For example, in the first case shown in Fig. 3, without explicitly preserving the visual semantic information in the image, the counting problem becomes difficult for LLaVA. Relying solely on the fragmented visual tokens output by ViT makes it challenging to accurately determine the number of dogs in the image. However, equipped with the SGE module, our LLaVA-SG can leverage tokens that explicitly represent entities in the image, enabling it to provide an accurate count of the dogs.
III-C Ablation Study
We perform ablation experiments to explore the effect of the SGE module and the effect of training strategies. These ablation experiments are based on LLaVA-SG-7B.

The Effect of the SGE Module. We conduct ablation studies on the components within the Scene Graph Expression module. The results are shown in Table II. ”SG” denotes the construction and use of a basic scene graph without message passing and prompt feature adaptation. ”MP” denotes the message passing among nodes in . ”Prompt” denotes the attention mechanism with the prompt feature. ”Rel” indicates that the test sets from Visual Genome and Open Images are used for evaluating visual relationship classification. As shown in Table II, each component contributes to the improvement of the LLaVA baseline.
The Effect of Training Strategies. We performed ablation experiments on the additional visual relationship understanding data used for training the SGE module and the separate SGE training stage. The results are shown in Table III. The first row shows the results without using the SGE module, where the visual relationship understanding data used for the second training stage, i.e., the SGE-D in Table III is simply appended to the fine-tuning data for training the LLaVA model. The second row shows the results without a separate SGE training stage, where SGE-D is incorporated into the fine-tuning stage and SGE is trained together with the LLM. The third row shows the performance of LLaVA-SG under the full training strategy. The comparison between the first and third rows of Table III indicates that the improvement of LLaVA-SG over LLaVA is not primarily due to the additional visual relationship understanding data. Instead, the SGE module plays a crucial role. The comparison between the second and third rows highlights the necessity of the separate SGE training stage. The separate SGE training stage allows the SGE module to focus more specifically on expressing the visual semantic information within the input images.
IV Conclusion
In this paper, we propose a Scene Graph Expression (SGE) module to extract and express visual semantic information structurally for VLM. With the SGE module, the perception and understanding abilities of VLMs are enhanced. The LLaVA-SG model, constructed based on the SGE module, shows significant and consistent performance improvements over the baseline methods.
References
- [1] R. Herzig, A. Mendelson, L. Karlinsky, A. Arbelle, R. Feris, T. Darrell, and A. Globerson, “Incorporating structured representations into pretrained vision & language models using scene graphs,” in Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023, pp. 14 077–14 098.
- [2] Y. Yang, X. Zhang, J. Xu, and W. Han, “Empowering vision-language models for reasoning ability through large language models,” in ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 10 056–10 060.
- [3] D. Zhang, Y. Yu, C. Li, J. Dong, D. Su, C. Chu, and D. Yu, “Mm-llms: Recent advances in multimodal large language models,” arXiv preprint arXiv:2401.13601, 2024.
- [4] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” in International Conference on Learning Representations, 2020.
- [5] H. Liu, C. Li, Q. Wu, and Y. J. Lee, “Visual instruction tuning,” Advances in neural information processing systems, vol. 36, 2024.
- [6] J. Lu, R. Gan, D. Zhang, X. Wu, Z. Wu, R. Sun, J. Zhang, P. Zhang, and Y. Song, “Lyrics: Boosting fine-grained language-vision alignment and comprehension via semantic-aware visual objects,” arXiv preprint arXiv:2312.05278, 2023.
- [7] X. He, L. Wei, L. Xie, and Q. Tian, “Incorporating visual experts to resolve the information loss in multimodal large language models,” arXiv preprint arXiv:2401.03105, 2024.
- [8] C. Mitra, B. Huang, T. Darrell, and R. Herzig, “Compositional chain-of-thought prompting for large multimodal models,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 14 420–14 431.
- [9] Y. Goyal, T. Khot, D. Summers-Stay, D. Batra, and D. Parikh, “Making the v in vqa matter: Elevating the role of image understanding in visual question answering,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 6904–6913.
- [10] D. A. Hudson and C. D. Manning, “Gqa: A new dataset for real-world visual reasoning and compositional question answering,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 6700–6709.
- [11] P. Lu, S. Mishra, T. Xia, L. Qiu, K.-W. Chang, S.-C. Zhu, O. Tafjord, P. Clark, and A. Kalyan, “Learn to explain: Multimodal reasoning via thought chains for science question answering,” Advances in Neural Information Processing Systems, vol. 35, pp. 2507–2521, 2022.
- [12] Y. Liu, H. Duan, Y. Zhang, B. Li, S. Zhang, W. Zhao, Y. Yuan, J. Wang, C. He, Z. Liu et al., “Mmbench: Is your multi-modal model an all-around player?” arXiv preprint arXiv:2307.06281, 2023.
- [13] Y. Li, Y. Du, K. Zhou, J. Wang, W. X. Zhao, and J.-R. Wen, “Evaluating object hallucination in large vision-language models,” in Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023, pp. 292–305.
- [14] J. Li, D. Li, S. Savarese, and S. Hoi, “Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models,” in International conference on machine learning. PMLR, 2023, pp. 19 730–19 742.
- [15] Q. Ye, H. Xu, J. Ye, M. Yan, A. Hu, H. Liu, Q. Qian, J. Zhang, and F. Huang, “mplug-owl2: Revolutionizing multi-modal large language model with modality collaboration,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 13 040–13 051.
- [16] W. Dai, J. Li, D. Li, A. M. H. Tiong, J. Zhao, W. Wang, B. Li, P. Fung, and S. Hoi, “Instructblip: Towards general-purpose vision-language models with instruction tuning,” 2023.
- [17] J. Bai, S. Bai, S. Yang, S. Wang, S. Tan, P. Wang, J. Lin, C. Zhou, and J. Zhou, “Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond,” arXiv preprint arXiv:2308.12966, 2023.
- [18] H. Liu, C. Li, Y. Li, and Y. J. Lee, “Improved baselines with visual instruction tuning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 26 296–26 306.
- [19] J. Wang, C. Zhang, J. Huang, B. Ren, and Z. Deng, “Improving scene graph generation with superpixel-based interaction learning,” in Proceedings of the 31st ACM International Conference on Multimedia, 2023, pp. 1809–1820.
- [20] X. Zou, J. Yang, H. Zhang, F. Li, L. Li, J. Wang, L. Wang, J. Gao, and Y. J. Lee, “Segment everything everywhere all at once,” Advances in Neural Information Processing Systems, vol. 36, 2024.
- [21] J. Li, D. Li, C. Xiong, and S. Hoi, “Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation,” in International conference on machine learning. PMLR, 2022, pp. 12 888–12 900.
- [22] R. Krishna, Y. Zhu, O. Groth, J. Johnson, K. Hata, J. Kravitz, S. Chen, Y. Kalantidis, L.-J. Li, D. A. Shamma et al., “Visual genome: Connecting language and vision using crowdsourced dense image annotations,” International journal of computer vision, vol. 123, pp. 32–73, 2017.
- [23] J. Zhang, K. J. Shih, A. Elgammal, A. Tao, and B. Catanzaro, “Graphical contrastive losses for scene graph generation.” CoRR, vol. abs/1903.02728, 2019.
- [24] Z. Peng, W. Wang, L. Dong, Y. Hao, S. Huang, S. Ma, and F. Wei, “Kosmos-2: Grounding multimodal large language models to the world,” arXiv preprint arXiv:2306.14824, 2023.
- [25] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning transferable visual models from natural language supervision,” in International conference on machine learning. PMLR, 2021, pp. 8748–8763.
- [26] W.-L. Chiang, Z. Li, Z. Lin, Y. Sheng, Z. Wu, H. Zhang, L. Zheng, S. Zhuang, Y. Zhuang, J. E. Gonzalez et al., “Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality,” See https://vicuna. lmsys. org (accessed 14 April 2023), vol. 2, no. 3, p. 6, 2023.
- [27] Y. Zhang, X. Huang, J. Ma, Z. Li, Z. Luo, Y. Xie, Y. Qin, T. Luo, Y. Li, S. Liu et al., “Recognize anything: A strong image tagging model,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 1724–1732.
- [28] H. Zhang, F. Li, S. Liu, L. Zhang, H. Su, J. Zhu, L. Ni, and H.-Y. Shum, “Dino: Detr with improved denoising anchor boxes for end-to-end object detection,” in The Eleventh International Conference on Learning Representations, 2022.
- [29] A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo et al., “Segment anything,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 4015–4026.
- [30] K. Z. F. P. X. D. e. a. Bo Li, Peiyuan Zhang, “Lmms-eval: Accelerating the development of large multimoal models,” March 2024. [Online]. Available: https://github.com/EvolvingLMMs-Lab/lmms-eval