LMR-CBT: Learning Modality-fused Representations with CB-Transformer for Multimodal Emotion Recognition from Unaligned Multimodal Sequences
Abstract
Learning modality-fused representations and processing unaligned multimodal sequences are meaningful and challenging in multimodal emotion recognition. Existing approaches use directional pairwise attention or a message hub to fuse language, visual, and audio modalities. However, those approaches introduce information redundancy when fusing features and are inefficient without considering the complementarity of modalities. In this paper, we propose an efficient neural network to learn modality-fused representations with CB-Transformer (LMR-CBT) for multimodal emotion recognition from unaligned multimodal sequences. Specifically, we first perform feature extraction for the three modalities respectively to obtain the local structure of the sequences. Then, we design a novel transformer with cross-modal blocks (CB-Transformer) that enables complementary learning of different modalities, mainly divided into local temporal learning, cross-modal feature fusion and global self-attention representations. In addition, we splice the fused features with the original features to classify the emotions of the sequences. Finally, we conduct word-aligned and unaligned experiments on three challenging datasets, IEMOCAP, CMU-MOSI, and CMU-MOSEI. The experimental results show the superiority and efficiency of our proposed method in both settings. Compared with the mainstream methods, our approach reaches the state-of-the-art with a minimum number of parameters.
1 Introduction
Multimodal emotion recognition has attracted increasing attention due to its robustness and remarkable performance (Nguyen et al. 2018; Poria et al. 2020; Dai et al. 2021b). The goal of this task is to recognize human emotions from video clips, which involves three main modalities: natural language, facial expressions and audio signals. Emotion recognition is applied in areas such as social robotics, educational quality assessment, and healthcare, where the analysis of emotion is particularly important during COVID-19 (Chandra and Krishna 2021). Multimodality provides a wealth of information compared to single modality and can fully reflect emotional states. However, due to the different sampling rates of sequences from different modalities, the collected multimodal states are often unaligned. Manually aligning different modalities is often labor-intensive and requires domain knowledge (Tsai et al. 2019b; Pham et al. 2019). In addition, most of the networks with high performance cannot achieve a balance between the number of parameters and performance. To this end, we focus on the ability to learn the representation of fused modalities and efficiently perform multimodal emotion recognition on unaligned sequences.
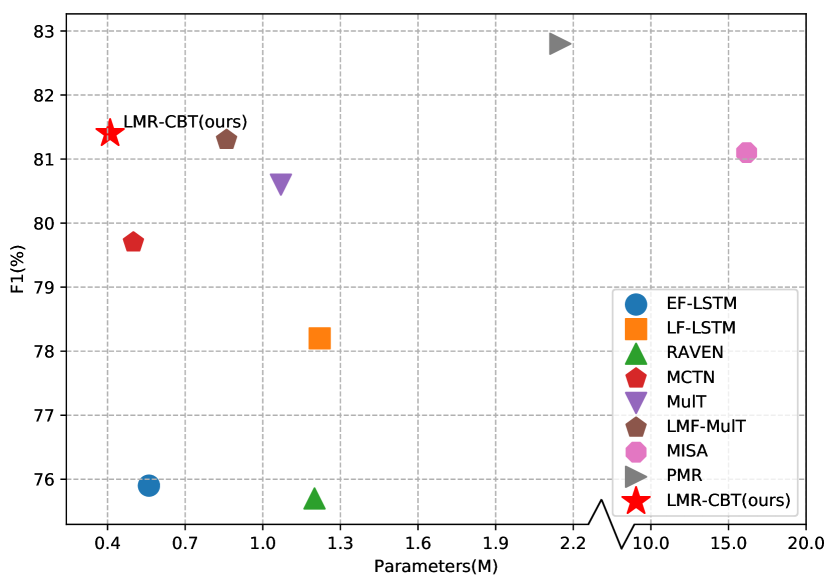
In the previous works (Sahay et al. 2020; Rahman et al. 2020; Hazarika, Zimmermann, and Poria 2020; Yu et al. 2021; Dai et al. 2021a), Transformers (Vaswani et al. 2017) are mostly used for unaligned multimodal emotion recognition. Typically, Tsai et al. (2019a) proposed the Multimodal Transformer (MulT) method to fuse information from different modalities in unaligned sequences without explicitly aligning the data. The approach learns the interactions between pairs of elements through a cross-modal attention module that iteratively reinforces features of one modality with features of other modalities. Recently, Lv et al. (2021) proposed the Progressive Modality Reinforcement (PMR) by introducing a message hub to exchange information with each modality. The approach uses a progressive strategy to utilize high-level source modality information for unaligned multimodal sequences fusion.
However, MulT only considers the fusion of features between modality pairs, ignoring the coordination of the three modalities. Besides, using a pairwise approach to fuse the modal features can produce redundant information. For example, the visual representations are repeated twice in the concatenation of visual-language features and visual-audio features. PMR considers the association among the three modalities, but fusing the modal features by designing a centralized message hub would sacrifice its efficiency. To be more specific, the information of the three modalities needs to interact closely and recursively with the message hub to ensure the integrity of the features, and such an operation requires a huge number of parameters. Meanwhile, this approach does not take into account the complementarity between modal information, while feature fusion can be accomplished by simply using the interaction between modalities without introducing a third party. What’s more, recent methods are too high in the number of parameters to be applicable to realistic scenarios due to pre-trained models.
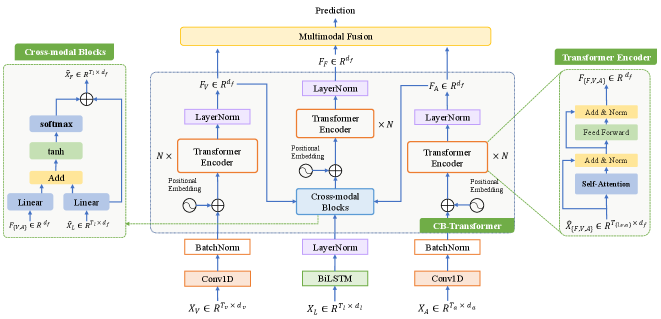
Therefore, to address the above limitations, we propose a neural network to learn modality-fused representations with CB-Transformer (LMR-CBT) for multimodal emotion recognition from unaligned multimodal sequences. Figure 2 shows the overall architecture of LMR-CBT. Specifically, we first perform feature extraction for the three modalities respectively to obtain the local structure of the sequences. For the audio and visual modalities, we obtain information about adjacent elements by 1D temporal convolution. For the language modality, we use Bi-directional Long and Short Term Memory (BiLSTM) to capture the long term dependencies and the contextual information between texts.
After obtaining feature representations of the three modalities, we design a novel transformer with cross-modal blocks (CB-Transformer) to achieve complementary learning of the different modalities, which is mainly divided into local temporal learning, cross-modal feature fusion and global self-attention representations. In the local temporal learning part, audio and visual features are used to obtain adjacent element-dependent representations of the two modalities through the transformer. In the cross-modal feature fusion part, residual-based modal interaction approach is used to obtain the fused features of the three modalities. In the global self-attention representations part, the transformer learns high-level representations within the fusion modality. The CB-Transformer can adequately represent the fused features without losing the original features and can efficiently handle unaligned multimodal sequences. Finally, we splice the modal fusion features with the original features to obtain the emotional categories. We perform word-aligned and unaligned experiments on three mainstream public datasets of multimodal emotion recognition, IEMOCAP (Busso et al. 2008), CMU-MOSI (Zadeh et al. 2016b) and CMU-MOSEI (Zadeh et al. 2018). The experimental results demonstrate the superiority of our proposed method. Moreover, we achieve a better trade-off between the performance and the efficiency. Compared with the mainstream methods, our approach reaches the state-of-the-art with a minimum number of parameters.
We summarize our three main contributions as follows:
-
•
We propose an efficient neural network to learn modality-fused representations with CB-Transformer (LMR-CBT) for multimodal emotion recognition from unaligned multimodal sequences (only 0.41M), which can effectively fuse the interactive information of the three modalities.
-
•
We design a novel transformer with cross-modal blocks (CB-Transformer) to achieve complementary learning of different modalities, which is mainly divided into local temporal learning, cross-modal feature fusion and global self-attention representations. The CB-Transformer can adequately represent the fused features without losing the original features and can efficiently handle unaligned multimodal sequences.
-
•
We obtain a better trade-off between the performance and the efficiency on three challenging datasets. Compared with the existing state-of-the-art methods, LMR-CBT achieves comparable or even higher performance with a minimal number of parameters.
2 Related Work
Multimodal emotion recognition has attracted a lot of attention in recent years. This task requires the fusion of cross-modal information of temporal sequential signals. According to the approaches of feature fusion, it can be divided into early fusion (Morency, Mihalcea, and Doshi 2011; Pérez-Rosas, Mihalcea, and Morency 2013), late fusion (Zadeh et al. 2016a; Wang et al. 2017) and model fusion. Previous works have focused on early or late fusion strategies. Early fusion strategies involve fusing the shallow inter-modal features and focusing on mixed-modal feature processing while late fusion strategies involve finding the confidence level of each modality and then coordinating them to make joint decisions. Although better performance can be obtained using these fusion strategies in comparison to single modality learning, they do not explicitly consider the intrinsic connection between sequence elements from different modalities, which is essential for effective multimodal fusion. Subsequently, model fusion is gradually applied and more complicated models are proposed. Wang et al. (2019) used visual and auditory features to shift words in text with attention. Rahman et al. (2020) introduced a multimodal adaptive gate that integrates visual and acoustic information into a large pretrained language model. Hazarika, Zimmermann, and Poria (2020) incorporated a combination of losses including distributional similarity, orthogonal loss, reconstruction loss and task prediction loss to learn modality-invariant and modality-specific representation. Dai et al. (2021b) introduced sparse cross-attention to achieve end-to-end emotion recognition. Dai et al. (2021a) proposed a multi-task learning approach using weak supervision for multimodal emotion recognition. Yu et al. (2021) proposed a way to fuse features from different modalities by combining self-supervised and multi-task learning. Although self-supervised and multi-task learning can effectively alleviate the problem of small samples, how to perform efficient cross-modal interactions is still a tremendously challenging issue for researchers. Therefore, the main motivation of this work is how to perform unaligned multimodal emotion recognition with a minimalist design excluding tricks like self-supervision or multi-tasking.
In order to fuse the information of unaligned multimodal sequences, early works have explored the dependencies between modal elements based on the maximum modal information criterion (Zeng et al. 2005). However, the performance of those early approaches is far from satisfactory due to the shallow model structures. Tsai et al. (2019a) proposed a multimodal transformer (MulT) to learn inter-modal correlations using a cross-modal attention mechanism. Sahay et al. (2020) proposed low rank fusion based transformers (LMT-MULT) to design LMF units for efficient modal feature fusion based on previous work. Lv et al. (2021) proposed progressive modality reinforcement (PMR) method. This method uses a message hub to interact with the three modal information and adopts the progressive strategy to fuse unaligned multimodal temporal sequences utilizing high level source modal information. Although those previous trials have made some performance improvement in unaligned multimodal emotion recognition, they still faces the problems of effective fusion of cross-modal features and the inability to ensure that information is not lost. In this paper, we mainly focus on reaching an accuracy-parameter balance by a novel information redundancy-free modal fusion strategy.
3 Methodology
3.1 Problem statement
The multimodal emotion recognition task mainly involves three modalities, language, visual and audio. We define that the three modalities are obtained through feature extraction as , where represents the length of the sequence and represents dimensions of the extracted features. Our goal is to efficiently extract features of different modalities from the unaligned multimodal sequences and to obtain a fused representation across modalities. We expect the multimodal representation to accurately predict the emotion category of the sequence.
3.2 Overall Architecture
We propose a neural network to learn modality-fused representations with CB-Transformer (LMR-CBT), and the overall architecture of the network is shown in Figure 2, where the cross-modal blocks and transformer encoder in CB-Transformer are located on the two sides of the figure, respectively. Next, we will describe the network in detail.
Feature Preprocessing.
The feature preprocessing is performed separately according to the temporal structure of the different modalities. For audio and visual modalities, to ensure that each element in the input sequence has sufficient perception of its neighboring elements, we put the two modalities into 1D temporal convolution separately by setting different convolution kernel sizes. The specific formula is as follows:
| (1) |
where stands for batch normalization, and is the size of the convolution kernel of modality , and represents a common dimension.
In terms of language modality, we consider that the language itself is characterized by long-time dependencies and associative contextual information. BiLSTM can better capture bidirectional long-time semantic dependencies and identify the emotional representations of languages. We use a two-layer BiLSTM for feature extraction:
| (2) |
where represents layer normalization. The purpose of layer normalization is to stabilize the distribution of each layer so that subsequent layers can learn the content of the previous layer in a stable manner. By the above operation, on the one hand, we can aggregate the features of adjacent elements, and on the other hand, we can pre-align the feature dimensions of unaligned multimodal data to the same dimension.
Transformer with Cross-modal Blocks.
We design a novel transformer with cross-modal blocks (CB-Transformer). CB-Transformer is divided into three parts: local temporal learning, cross-modal feature fusion and global self-attention representations. In this module, there are two important components: the transformer encoder and the residual-based cross-modal fusion, represented using and , respectively. For both components we will discuss in detail in Section 3.3 and 3.4.
In the local temporal learning, we use the transformer encoder, which is becoming increasingly popular in many areas such as computer vision and natural language processing due to its noticeable performance. We use this component to obtain temporal representations of audio and visual modality features that have undergone 1D temporal convolution. The specific process can be expressed by the following formula:
| (3) |
| (4) |
where computes the embeddings for each position index, and represents the result embedded through position, and represents the transformer encoder, which we will discuss in detail in Section 3.3. We use to represent the result of local temporal learning.
In the part of cross-modal feature fusion, we design a residual-based cross-modal fusion method, which takes and as inputs and the fused representation of the three modalities as outputs. The structure of residual can ensure that information is not lost. The specific formula is as follows:
| (5) |
where represents the residual-based cross-modal fusion, which we will discuss in detail in Section 3.4, and denotes the fusion features. We believe that the fused modal representation not only carries information from the language modality, but also fuses information from all the three modalities to ensure effective interaction of information. Similarly, Transformer Encoder is used to extract the representation of the fused features in the global self-attention representations.
Through global self-attention representations, we can obtain high-level complementary representations of the fused modalities. The specific formula is as follows:
| (6) |
where represents the global self-attention learning results for fused representations.
Prediction.
We carry out the emotion category prediction. Specifically, we perform a splicing operation on the fused modal representation and the audio/visual original modal representation to obtain . After that, we get the final output of the emotional category through the two-layer fully connected network:
| (7) |
where is the output dimensions of emotional categories, and are weight vectors, and are the bias, denotes the ReLU activation function.
Input: the audio and video modal representation with local temporal learning ; the language representation with BiLSTM processing: ; the batch size .
Output: the features that fuse the representation of the three modalities and the original text representation:
3.3 Transformer Encoder
We’ll introduce the details of transformer encoder used for both local temporal learning and global self-attention representations, as shown on the right side of Figure 2. Firstly, following (Vaswani et al. 2017), we abstract the data of the temporal series using the sinusoidal position embedding (PE). We encode the positional information of a sequence of length via the and functions with frequencies dictated by the feature indices:
| (8) |
Next, transformer encoder is mainly composed of self-attention, Feedforward and Add&Norm. Self-Attention is the focus of transformer encoder. The specific formula is as follows:
| (9) |
where denotes . is represented by different projection spaces with different parameter matrices, where represents the number of layers of transformer attention, .
The Feedforward layer is a two-layer fully connected layer and the activation function of the first layer is Relu:
| (10) |
3.4 Residual-based Cross-modal Fusion
Our residual-based cross-modal fusion method could effectively fuse the information of three modalities with less information loss (on the left side of Figure 2). Specifically, the method accepts input for two modalities, which is called and . We obtain the mapping representations of the features for the two modalities by a linear projection. And then we process the two representations by and activation function. Finally, the fused representation is obtained through . We believe that the final fused information contains not only the complementary information of the three modalities, but also the features of the language modality:
| (11) |
where stands for a linear projection.
In this process, in order to alleviate the information loss of language features, we use a residual connection between the fused representation and the original language representation. We use the algorithm 1 to represent the entire process.
4 Experiments
4.1 Datasets
In this paper, we use three mainstream multimodal emotion recognition datasets: IEMOCAP, CMU-MOSI and CMU-MOSEI. The experiments are conducted on both the word-aligned and unaligned settings. The code will be publicly available after the paper is accepted.
IEMOCAP.
IEMOCAP (Busso et al. 2008) is a multimodal emotion recognition dataset that contains 151 videos along with corresponding transcripts and audios. In each video, two professional actors conduct dyadic conversations in English. Its intended data segmentation consists of 2,717 training samples, 798 validation samples and 938 test samples. The audio and visual features are extracted at the sampling frequencies of 12.5 Hz and 15 Hz, respectively. Although the human annotation has nine emotion categories, following the prior works (Wang et al. 2019; Dai et al. 2020), we take four categories: neutral, happy, sad, and angry. Moreover, this is a multi-label task (e.g., a person can feel sad and angry at the same time). We report the binary classification accuracy and F1 scores for each emotion category according to (Lv et al. 2021).
| Setting | CMU-MOSEI | CMU-MOSI | IEMOCAP |
| Optimizer | Adam | Adam | Adam |
| Batch size | 32 | 8 | 32 |
| Learning rate | 1e-3 | 2e-3 | 1e-3 |
| Epochs | 120 | 100 | 60 |
| Feature size | 40 | 30 | 40 |
| Attention head | 8 | 10 | 5 |
| Kernel size (V/A) | 3/3 | 3/1 | 3/5 |
| Transformer layer | 5 | 4 | 5 |
| Method | #Params(M) | |||
| Conv1D | 0.38 | 50.6 | 78.5 | 80.1 |
| BiLSTM | 0.41 | 51.8 | 80.9 | 81.5 |
| V, L->A | 0.41 | 50.7 | 79.2 | 80.8 |
| L, A->V | 0.41 | 51.1 | 79.3 | 81.0 |
| V, A->L | 0.41 | 51.8 | 80.9 | 81.5 |
| Setting | Method | Happy | Sad | Angry | Neutral | ||||
| Aligned | EF-LSTM | 86.0 | 84.2 | 80.2 | 80.5 | 85.2 | 84.5 | 67.8 | 67.1 |
| LF-LSTM | 85.1 | 86.3 | 78.9 | 81.7 | 84.7 | 83.0 | 67.1 | 67.6 | |
| MFM | 90.2 | 85.8 | 88.4 | 86.1 | 87.5 | 86.7 | 72.1 | 68.1 | |
| RAVEN | 87.3 | 85.8 | 83.4 | 83.1 | 87.3 | 86.7 | 69.7 | 69.3 | |
| MCTN | 84.9 | 83.1 | 80.5 | 79.6 | 79.7 | 80.4 | 62.3 | 57.0 | |
| MulT* | 86.4 | 82.9 | 82.3 | 82.4 | 85.3 | 85.8 | 71.2 | 70.0 | |
| LMF-MulT | 85.3 | 84.1 | 84.1 | 83.4 | 85.7 | 86.2 | 71.2 | 70.8 | |
| PMR† | 91.3 | 89.2 | 87.8 | 87.0 | 88.1 | 87.5 | 73.0 | 71.5 | |
| LMR-CBT(ours) | 87.9 | 84.6 | 85.3 | 84.4 | 86.2 | 86.3 | 71.5 | 70.6 | |
| Unaligned | EF-LSTM | 76.2 | 75.7 | 70.2 | 70.5 | 72.7 | 67.1 | 58.1 | 57.4 |
| LF-LSTM | 72.5 | 71.8 | 72.9 | 70.4 | 68.6 | 67.9 | 59.6 | 56.2 | |
| RAVEN | 77.0 | 76.8 | 67.6 | 65.6 | 65.0 | 64.1 | 62.0 | 59.5 | |
| MCTN | 80.5 | 77.5 | 72.0 | 71.7 | 64.9 | 65.6 | 49.4 | 49.3 | |
| MulT (1.07M)* | 85.6 | 79.0 | 79.4 | 70.3 | 75.8 | 65.4 | 59.5 | 44.7 | |
| LMF-MulT (0.86M) | 85.6 | 79.0 | 79.4 | 70.3 | 75.8 | 65.4 | 59.2 | 44.0 | |
| PMR (2.15M)† | 86.4 | 83.3 | 78.5 | 75.3 | 75.0 | 71.3 | 63.7 | 60.9 | |
| LMR-CBT (0.34M) | 85.7 | 79.5 | 79.4 | 72.6 | 76.0 | 70.7 | 63.6 | 60.5 | |
CMU-MOSI.
CMU-MOSI (Zadeh et al. 2016b) is a dataset for multimodal emotion recognition and sentiment analysis, which comprises 2,199 short monologue video clips from 93 Youtube movie review videos. It contains 1,284 training samples, 229 validation samples and 686 test samples. The audio and visual features are extracted at the sampling frequencies of 12.5 Hz and 15 Hz, respectively. Human annotators label each sample with a sentiment score from -3 (strongly negative) to 3 (strongly positive). We use various metrics to evaluate the performance of the model, consistent with those used in previous work (Tsai et al. 2019a): 7-class accuracy (i.e. ), binary accuracy (i.e. ), and F1 score.
CMU-MOSEI.
CMU-MOSEI (Zadeh et al. 2018) is also a dataset for multimodal emotion recognition and sentiment analysis, which contains 3,837 videos from 1,000 diverse speakers. Its pre-determined data segmentation includes 16,326 training samples, 1,871 validation samples and 4,659 test samples. The audio and visual features are extracted at the sampling frequencies of 20 Hz and 15 Hz, respectively. In addition, each data sample is also annotated with a sentiment scores on a Likert scale [-3, 3]. We use the same performance metrics as above.
4.2 Implementation details
For feature extraction of the language modality, we convert video transcripts into pre-trained Glove (Pennington, Socher, and Manning 2014) model to obtain 300-dimensional word embeddings. For feature extraction of visual modality, we use Facet (Baltrušaitis, Robinson, and Morency 2016) to represent 35 facial action units, which record facial muscle movements for representing basic and high-level emotions in each frame. For the audio modality, we use COVAREP (Degottex et al. 2014) for extracting acoustic signals to obtain 74-dimensional vectors.
Table 1 shows the hyperparameters used in training and testing for each dataset. The kernel size is used to process the input sequences for the audio and visual modalities, and since BiLSTM is used for the language modality, no kernel size is involved. We train our model on a single RTX 2080Ti. The details are provided in the supplementary file.
4.3 Comparison with the State-of-the-arts
We compare the proposed approach with the existing state-of-the-art methods, including Early Fusion LSTM (EF-LSTM), Late Fusion LSTM (LF-LSTM), Multimodal Factorization Model (MFM) (Tsai et al. 2019b), Graph-MFN (GMFN), Recurrent Attended Variation Embedding Network (RAVEN) (Wang et al. 2019), Multimodal Cyclic Translation Network (MCTN) (Pham et al. 2019), Multimodal Transformer (MulT) (Tsai et al. 2019a), Low Rank Fusion based Transformers (LMF-MulT) (Sahay et al. 2020), Modality-Invariant and -Specific Representations (MISA) (Hazarika, Zimmermann, and Poria 2020), Progressive Modality Reinforcement (PMR) (Lv et al. 2021). Among these methods, LF-LSTM, MulT, LMF-MulT, and PMR can be directly applied the unaligned setting. For the other methods, we introduce the connectionist temporal classification (CTC) (Graves et al. 2006) module to make them applicable to unaligned settings.
Word-aligned setting.
This setting requires manual alignment of language words with visual and audio. We show the comparison of our method with other benchmarks in the upper part of Tables 3-5. The experimental results show that the proposed method achieves a comparable performance level to PMR (Lv et al. 2021) on different metrics for the three datasets. Compared with LMF-MulT (Sahay et al. 2020), which uses six transformer encoders, we achieve better performance on different datasets using half of the transformer encoders.
Unaligned setting.
This setting is more challenging than the word-aligned setting, where cross-modal information is extracted directly from unaligned multimodal sequences to classify emotions. We show the comparison of our approach with other benchmarks in the lower part of Tables 3-5. Moreover, Figure 1 demonstrates that our proposed model reaches the state-of-the-art with a minimum number of parameters (only 0.41M) on the CMU-MOSEI dataset. Compared with other approaches, our proposed light-weight network is more applicable to real scenarios. We can draw the following conclusions from the experimental results:
-
•
With the exception of MulT (Tsai et al. 2019a), LMF-MulT (Sahay et al. 2020), and PMR (Lv et al. 2021), most of the models perform poorly in the unaligned setting because they do not take into account the interactions between the modalities. In addition, the outstanding performance of MISA (Hazarika, Zimmermann, and Poria 2020) is due to the pre-trained model, which contains a large number of parameters.
-
•
Compared to LMF-MulT and MulT models, our approach outperforms in different metrics. Compared to PMR, we have comparable or better performance on different datasets with a minimal number of parameters.
-
•
What’s more, the number of parameters of MISA and PMR on the CMU-MOSEI dataset reaches 15.9 M and 2.15 M, respectively, while our proposed method uses only 0.41 M. For MISA, the number of parameters is equivalent to 38 times that of our proposed method, while PMR is equivalent to as much as 6 times.
| Setting | Method | |||
| Aligned | EF-LSTM | 33.7 | 75.3 | 75.2 |
| LF-LSTM | 35.3 | 76.8 | 76.7 | |
| MFM | 36.2 | 78.1 | 78.1 | |
| RAVEN | 33.2 | 78.0 | 76.6 | |
| MCTN | 35.6 | 79.3 | 79.1 | |
| MulT* | 33.1 | 78.5 | 78.4 | |
| LMF-MulT | 32.4 | 77.9 | 77.9 | |
| PMR† | 40.6 | 83.6 | 83.4 | |
| LMR-CBT(ours) | 39.2 | 81.6 | 79.8 | |
| Unaligned | EF-LSTM | 31.0 | 73.6 | 74.5 |
| LF-LSTM | 33.7 | 77.6 | 77.8 | |
| RAVEN | 31.7 | 72.7 | 73.1 | |
| MCTN | 32.7 | 75.9 | 76.4 | |
| MulT (1.07M)* | 34.3 | 80.3 | 80.4 | |
| LMF-MulT (0.84M) | 34.0 | 78.5 | 78.5 | |
| MISA (15.9M)‡ | 41.4 | 81.8 | 81.8 | |
| PMR (2.14M)† | 40.6 | 82.4 | 82.1 | |
| LMR-CBT (0.35M) | 39.5 | 81.2 | 81.0 |
| Setting | Method | |||
| Aligned | EF-LSTM | 47.4 | 78.2 | 77.9 |
| LF-LSTM | 48.8 | 80.6 | 80.6 | |
| G-MFN | 45.0 | 76.9 | 77.0 | |
| RAVEN | 50.0 | 79.1 | 79.5 | |
| MCTN | 49.6 | 79.8 | 80.6 | |
| MulT* | 49.3 | 80.5 | 81.1 | |
| LMF-MulT | 50.2 | 80.3 | 80.3 | |
| PMR† | 52.5 | 83.3 | 82.6 | |
| LMR-CBT(ours) | 50.7 | 80.5 | 80.9 | |
| Unaligned | EF-LSTM | 46.3 | 76.1 | 75.9 |
| LF-LSTM | 48.8 | 77.5 | 78.2 | |
| RAVEN | 45.5 | 75.4 | 75.7 | |
| MCTN | 48.2 | 79.3 | 79.7 | |
| MulT (1.07M)* | 50.4 | 80.7 | 80.6 | |
| LMF-MulT (0.86M) | 49.3 | 80.8 | 81.3 | |
| MISA (15.9M)‡ | 52.1 | 80.7 | 81.1 | |
| PMR (2.15M)† | 51.8 | 83.1 | 82.8 | |
| LMR-CBT (0.41M) | 51.8 | 80.9 | 81.5 |
4.4 Ablation study
Effectiveness of BiLSTM.
For the language modality, we adopt BiLSTM to capture the long-time dependency and the contextual information association between texts. We replace BiLSTM with Conv1D for the comparison of the experiments, and the experimental results (on the upper part of Table 2) demonstrate that compared to Conv1D, there is a dramatic noticeable improvement in performance despite a marginal increase in the number of parameters, with a 1.4% higher F1 score. This indicates that BiLSTM is more suitable for processing textual information and can adequately represent the features of the linguistic modality.
Effectiveness of CB-Transformer.
To implement a efficient cross-modal fusion mechanism, we integrate deep audio/visual features with the shallow language features, and this could be denoted by [V, A]->L. We compare the different operations of the three modalities in feature fusion. Specifically, [V, L]->A denotes the integration of visual and speech modalities into audio modalities to obtain fused features, and [L, A]->V denotes the integration of speech and audio modalities into visual modalities to obtain fused features. From the experimental results, as shown in the lower part of Table 2, [V, A]->L achieves the best performance compared to the remaining two settings with the same number of parameters. Meanwhile, we note that the results are the worst when we obtain the fused features through the audio, which indicates that we do not obtain a high-level feature representation of the audio. Moreover, we analyze the reason is that the BiLSTM already has a good representation of the language modality in the feature processing stage and can make the performance work out.
5 Conclusion and Future Work
In this paper, we propose a neural network to learn modality-fused representations with CB-Transformer (LMR-CBT) for multimodal emotion recognition from unaligned multimodal sequences. First of all, we perform feature preprocessing on each modality respectively. Unlike previous work, we use BiLSTM for the language modality to handle long-term dependencies and contextual information. Furthermore, we design a novel transformer with cross-modal blocks (CB-Transformer) that enables complementary learning of different modalities, which is mainly divided into local temporal learning, cross modal feature fusion and global self-attention representations. The CB-Transformer can represent the fused features without losing the original features, and can process unaligned multimodal sequences efficiently. Finally, we apply the proposed method to IEMOCAP, CMU-MOSI and CMU-MOSEI, respectively, and the experimental results show that our proposed method achieves comparable or better results compared to the existing state-of-the-art methods with the minimum number of parameters.
We also find that the initial features of the three modalities are highly important but limited by preprocessing. In future work, we will build an end-to-end multimodal learning network and introduce the learning of more modalities, such as body postures, to explore the relationship between different modalities.
References
- Baltrušaitis, Robinson, and Morency (2016) Baltrušaitis, T.; Robinson, P.; and Morency, L.-P. 2016. OpenFace: An open source facial behavior analysis toolkit. In 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), 1–10.
- Busso et al. (2008) Busso, C.; Bulut, M.; Lee, C.-C.; Kazemzadeh, A.; Mower Provost, E.; Kim, S.; Chang, J.; Lee, S.; and Narayanan, S. 2008. IEMOCAP: Interactive emotional dyadic motion capture database. Language Resources and Evaluation, 42: 335–359.
- Chandra and Krishna (2021) Chandra, R.; and Krishna, A. 2021. COVID-19 sentiment analysis via deep learning during the rise of novel cases. arXiv:2104.10662.
- Dai et al. (2021a) Dai, W.; Cahyawijaya, S.; Bang, Y.; and Fung, P. 2021a. Weakly-supervised Multi-task Learning for Multimodal Affect Recognition. arXiv:2104.11560.
- Dai et al. (2021b) Dai, W.; Cahyawijaya, S.; Liu, Z.; and Fung, P. 2021b. Multimodal End-to-End Sparse Model for Emotion Recognition. arXiv:2103.09666.
- Dai et al. (2020) Dai, W.; Liu, Z.; Yu, T.; and Fung, P. 2020. Modality-Transferable Emotion Embeddings for Low-Resource Multimodal Emotion Recognition. arXiv:2009.09629.
- Degottex et al. (2014) Degottex, G.; Kane, J.; Drugman, T.; Raitio, T.; and Scherer, S. 2014. COVAREP — A collaborative voice analysis repository for speech technologies. In 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 960–964.
- Graves et al. (2006) Graves, A.; Fernández, S.; Gomez, F.; and Schmidhuber, J. 2006. Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks. In Proceedings of the 23rd International Conference on Machine Learning, ICML ’06, 369–376. New York, NY, USA: Association for Computing Machinery. ISBN 1595933832.
- Hazarika, Zimmermann, and Poria (2020) Hazarika, D.; Zimmermann, R.; and Poria, S. 2020. MISA: Modality-Invariant and-Specific Representations for Multimodal Sentiment Analysis. arXiv preprint arXiv:2005.03545.
- Lv et al. (2021) Lv, F.; Chen, X.; Huang, Y.; Duan, L.; and Lin, G. 2021. Progressive Modality Reinforcement for Human Multimodal Emotion Recognition From Unaligned Multimodal Sequences. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2554–2562.
- Morency, Mihalcea, and Doshi (2011) Morency, L.-P.; Mihalcea, R.; and Doshi, P. 2011. Towards Multimodal Sentiment Analysis: Harvesting Opinions from the Web. In Proceedings of the 13th International Conference on Multimodal Interfaces, ICMI ’11, 169–176. New York, NY, USA: Association for Computing Machinery. ISBN 9781450306416.
- Nguyen et al. (2018) Nguyen, T.; Nguyen, K.; Sridharan, S.; Dean, D.; and Fookes, C. 2018. Deep Spatio-Temporal Feature Fusion with Compact Bilinear Pooling For Multimodal Emotion Recognition. Computer Vision and Image Understanding, 174.
- Pennington, Socher, and Manning (2014) Pennington, J.; Socher, R.; and Manning, C. 2014. Glove: Global Vectors for Word Representation. volume 14, 1532–1543.
- Pham et al. (2019) Pham, H.; Liang, P.; Manzini, T.; Morency, L.-P.; and Poczos, B. 2019. Found in Translation: Learning Robust Joint Representations by Cyclic Translations Between Modalities.
- Poria et al. (2020) Poria, S.; Hazarika, D.; Majumder, N.; and Mihalcea, R. 2020. Beneath the Tip of the Iceberg: Current Challenges and New Directions in Sentiment Analysis Research. IEEE Transactions on Affective Computing, PP: 1–1.
- Pérez-Rosas, Mihalcea, and Morency (2013) Pérez-Rosas, V.; Mihalcea, R.; and Morency, L.-P. 2013. Utterance-Level Multimodal Sentiment Analysis. volume 1.
- Rahman et al. (2020) Rahman, W.; Hasan, M. K.; Lee, S.; Zadeh, A.; Mao, C.; Morency, L.-P.; and Hoque, E. 2020. Integrating Multimodal Information in Large Pretrained Transformers. arXiv:1908.05787.
- Sahay et al. (2020) Sahay, S.; Okur, E.; Kumar, S. H.; and Nachman, L. 2020. Low Rank Fusion based Transformers for Multimodal Sequences. arXiv:2007.02038.
- Tsai et al. (2019a) Tsai, Y.-H. H.; Bai, S.; Liang, P. P.; Kolter, J. Z.; Morency, L.-P.; and Salakhutdinov, R. 2019a. Multimodal Transformer for Unaligned Multimodal Language Sequences. arXiv:1906.00295.
- Tsai et al. (2019b) Tsai, Y.-H. H.; Liang, P. P.; Zadeh, A.; Morency, L.-P.; and Salakhutdinov, R. 2019b. Learning Factorized Multimodal Representations. arXiv:1806.06176.
- Vaswani et al. (2017) Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A. N.; Kaiser, u.; and Polosukhin, I. 2017. Attention is All You Need. NIPS’17, 6000–6010. Red Hook, NY, USA: Curran Associates Inc. ISBN 9781510860964.
- Wang et al. (2017) Wang, H.; Meghawat, A.; Morency, L.-P.; and Xing, E. P. 2017. Select-additive learning: Improving generalization in multimodal sentiment analysis. In 2017 IEEE International Conference on Multimedia and Expo (ICME), 949–954.
- Wang et al. (2019) Wang, Y.; Shen, Y.; Liu, Z.; Liang, P.; Zadeh, A.; and Morency, L.-P. 2019. Words Can Shift: Dynamically Adjusting Word Representations Using Nonverbal Behaviors. Proceedings of the AAAI Conference on Artificial Intelligence, 33: 7216–7223.
- Yu et al. (2021) Yu, W.; Xu, H.; Yuan, Z.; and Wu, J. 2021. Learning Modality-Specific Representations with Self-Supervised Multi-Task Learning for Multimodal Sentiment Analysis. arXiv:2102.04830.
- Zadeh et al. (2018) Zadeh, A.; Liang, P.; Poria, S.; Cambria, E.; and Morency, L.-P. 2018. Multimodal Language Analysis in the Wild: CMU-MOSEI Dataset and Interpretable Dynamic Fusion Graph. 2236–2246.
- Zadeh et al. (2016a) Zadeh, A.; Zellers, R.; Pincus, E.; and Morency, L.-P. 2016a. MOSI: Multimodal Corpus of Sentiment Intensity and Subjectivity Analysis in Online Opinion Videos.
- Zadeh et al. (2016b) Zadeh, A.; Zellers, R.; Pincus, E.; and Morency, L.-P. 2016b. Multimodal Sentiment Intensity Analysis in Videos: Facial Gestures and Verbal Messages. IEEE Intelligent Systems, 31(6): 82–88.
- Zeng et al. (2005) Zeng, Z.; Tu, J.; Pianfetti, B.; Liu, M.; Zhang, T.; Zhang, Z.; Huang, T.; and Levinson, S. 2005. Audio-visual affect recognition through multi-stream fused HMM for HCI. In 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), volume 2, 967–972 vol. 2.