Localized spherical deconvolution
Abstract
We provide a new algorithm for the treatment of the deconvolution problem on the sphere which combines the traditional SVD inversion with an appropriate thresholding technique in a well chosen new basis. We establish upper bounds for the behavior of our procedure for any loss. It is important to emphasize the adaptation properties of our procedures with respect to the regularity (sparsity) of the object to recover as well as to inhomogeneous smoothness. We also perform a numerical study which proves that the procedure shows very promising properties in practice as well.
doi:
10.1214/10-AOS858keywords:
[class=AMS] .keywords:
., and
1 Introduction
The spherical deconvolution problem was first proposed by Rooij and Ruymgaart vanRooijRuymgaart and subsequently solved in Healy, Hendriks and Kim HealyHendriksKim . Kim and Koo Kimoptimalspherical established minimaxity for the -rate of convergence. The optimal procedures obtained there are using orthogonal series methods associated with spherical harmonics. One important problem arising with these procedures is their poor local performances due to the fact that spherical harmonics are spread all over the sphere. This explains for instance the fact that although they are optimal in the sense, they cease to be optimal for other losses, such as losses for instance.
In our approach, we focus on two important points. We aim at a procedure of estimation which is efficient from a point of view, as well as it performs satisfactorily from a local point of view (for other losses for instance).
Deconvolution is an inverse problem and in such there is a notable conflict between the inversion part which in presence of noise creates an instability reasonably handled by a Singular Value Decomposition (SVD) approach and the fact that the SVD basis is very rarely localized and capable of representing local features of images, which are especially important to recover. Our strategy is to follow the approach started in Kerkyacharian et al. KerkPetruPicaWiller for the Wicksell case, Kerkyacharian et al. 5authors for the Radon transform, which utilizes the construction borrowed from Narcowich, Petrushev and Wald NarcoPetruWard , NPW of a tight frame (i.e., a redundant family) staying sufficiently close to the SVD decomposition but which enjoys at the same time enough localization properties to be successfully used for statistical estimation (see, for instance, Baldi et al. BaldiKerkMariPica , subsampling , Pietrobon et al. notice for other types of applications). The construction NPW produces a family of functions which very much resemble wavelets, the needlets.
To achieve the goals presented above, and especially adaptation to different regularities and local inhomogeneous smoothness, we essentially use a projection method on the needlets (which enables a stable inversion of the deconvolution, due to the closeness to the SVD basis) with a subsequent fine tuning thresholding process.
This provides a reasonably simple algorithm with very good performances, both from a theoretical point of view and a numerical point of view. In effect, this new algorithm provides a much better spatial adaptation, as well as adaptation to wider classes of regularity. We give here upper bounds obtained by the procedure over a large class of Besov spaces and any losses as well as . We find back these results in the simulation study where the effect of the localization are highlighted for instance by a comparison of the performances, on a bell-density example between the procedure provided here and the SVD methods (detailed below) proving that our quality of reconstruction of the peak is notably better.
It is important to notice that especially because we consider different losses, we provide rates of convergence of new types attained by our procedure, which, of course, coincide with the usual ones for losses.
Again, the problem of choosing appropriated spaces of regularity on the sphere in a serious question, and we decided to consider the spaces which may be the closest to our natural intuition: those which generalize to the sphere case the classical approximation properties of usual regularity spaces such as Hölder spaces and include at the same time the Sobolev regularity spaces used in Kim and Koo Kimoptimalspherical .
Sphere deconvolution has a vast domain of application such as medical imaging (see Tournier et al. TournierCalamanteGadianConnelly ) and astrophysics. Indeed, our results are especially motivated by many recent developments in the area of observational astrophysics.
It is a common problem in astrophysics to analyze data sets consisting of a number of objects (such as galaxies of a particular type) or of events (such as cosmic rays or gamma ray bursts) distributed on the celestial sphere. In many cases, such objects trace an underlying probability distribution on the sphere, which itself depends on the physics which governs the production of the objects and events.
The case for instance of ultra high energy cosmic rays (UHECR) illustrates well the type of applications covered by our results. Ultra high energy cosmic rays are particles of unknown nature which arrive at the earth from apparently random directions of the sky. They could originate from long-lived relic particles from the Big Bang, about 13 billion years old. Alternatively, they could be generated by the acceleration of standard particles, such as protons, in extremely violent astrophysical phenomena, such as cluster shocks. They could also originate from Active Galactic Nuclei (AGN), or from neutron stars surrounded by extremely high magnetic fields.
Hence, in some hypotheses, the underlying probability distribution for the directions of incidences of observed UHECRs would be a finite sum of point-like sources—or near point like, taking into account the deflection of the cosmic rays by magnetic fields. In other hypotheses, the distribution could be uniform, or smooth and correlated with the local distribution of matter in the universe. The distribution could also be a superposition of the above. Identifying between these hypotheses is of primordial importance for understanding the origin and mechanism of production of UHECRs.
Of course, the observations of these events (’s in the sequel) are always most often perturbated by a secondary noise () which leads to the deconvolution problem described below. Following Healy, Hendriks and Kim HealyHendriksKim , Kim and Koo Kimoptimalspherical , the spherical deconvolution problem can be described as follows. Consider the situation where we observe i.i.d. observations with
| (1) |
where the ’s are i.i.d. random elements in (the group of rotation matrices), and the ’s and ’s are i.i.d. random elements of (two-dimensional unit sphere of ) random elements, with and assumed to be independent. We suppose that the distributions of and are absolutely continuous with respect to the uniform probability measure on , and that the distribution of is absolutely continuous with respect to the Haar measure of . We will denote the densities of resp. and resp. .
Then
| (2) |
where denotes convolution and is defined below. In the sequel, will be denoted by to emphasize the fact that it is the object to recover.
The following paragraph recalls the necessary definitions. It is largely inspired by Kim and Koo Kimoptimalspherical and Healy, Hendriks and Kim HealyHendriksKim .
2 Some preliminaries about harmonic analysis on and
We will provide a brief overview of Fourier analysis on and . Most of the material can be found in an expanded form in Vilenkin Vilenkin , Talman Talman , Terras Terras , Kim and Koo Kimoptimalspherical , and Healy, Hendriks and Kim HealyHendriksKim . Let
where, . It is well known that any rotation matrix can be decomposed as a product of three elemental rotations, one about the -axis first by an angle , followed by a rotation about the -axis by an angle , and finally by another rotation again about the -axis by an angle . Indeed, the well-known Euler–Angle decomposition says that any can almost surely be uniquely represented by three angles , with the following formula (see Healy, Hendriks and Kim HealyHendriksKim for details):
| (3) |
where . Consider the functions, known as the rotational harmonics,
| (4) |
where the associated Legendre functions for are fully described in Vilenkin Vilenkin . The functions for are the eigenfunctions of the Laplace Beltrami operator on , hence, is a complete orthonormal basis for with respect to the probability Haar measure. In addition, if we define the matrices by
| (5) |
where for and , they constitute the collection of inequivalent irreducible representations of (for further details, see Vilenkin Vilenkin ).
Hence, for , we define the rotational Fourier transform on by
| (6) |
where is the probability Haar measure on and we define the following matrix of dimension
The rotational inversion can be obtained by
(2) is to be understood in -sense although with additional smoothness conditions, it can hold pointwise.
A parallel spherical Fourier analysis is available on . Any point on can be represented by
with, . We also define the functions
| (8) |
for and where are the Legendre functions.
The functions obey
| (9) |
The set is forming an orthonormal basis of , generally referred to as the spherical harmonic basis.
Again, as above, for , we define the spherical Fourier transform on by
| (10) |
where is the uniform probability measure on the sphere . The spherical inversion can be obtained by
| (11) |
The bases detailed above are important because they realize a singular value decomposition of the convolution operator created by our model. In effect, we define for the convolution by the following formula:
and we have for all
| (12) |
2.1 The SVD method
The singular value method (see Healy, Hendriks and Kim HealyHendriksKim and Kim and Koo Kimoptimalspherical ) consists in expanding in the spherical harmonics basis and estimating the spherical Fourier coefficients using the formula above (12). We get the following estimator of the spherical Fourier transform of :
provided, of course, that these inverse matrices exist, and then the estimator of the distribution is
| (14) |
where is depending on the number of observations and has to be properly selected.
3 Needlet construction
This construction is due to Narcowich et al. NarcoPetruWard . Its aim is essentially to build a very well localized tight frame constructed using spherical harmonics, as discussed below. It was recently extended to more general Euclidean settings with fruitful statistical applications (see Kerkyacharian et al. KerkPetruPicaWiller , Baldi et al. BaldiKerkMariPica , subsampling , Pietrobon et al. notice ). As described above, we have the following decomposition:
| (15) |
where is the space spanned by of spherical harmonics of , of degree (which dimension is ).
The orthogonal projector on can be written using the following kernel operator:
| (16) |
where,
and where is the standard scalar product of , and is the Legendre polynomial of degree , defined on and verifying
| (17) |
where is the Kronecker symbol.
Let us point out the following reproducing property of the projection operator:
| (18) |
The following construction is based on two fundamental steps: Littlewood–Paley decomposition and discretization, which are summarized in the two following subsections.
3.1 Littlewood–Paley decomposition
Let be a function on , symmetric and decreasing on supported in such that and if .
so that
| (19) |
Remark that only if . Let us now define the operator and the associated kernel
We obviously have
| (20) |
and if , then
| (21) |
3.2 Discretization and localization properties
Let us define
the space spanned by the spherical harmonics of of degree less than .
The following quadrature formula is true: for all there exists a finite subset of and positive real numbers , indexed by the elements of such that
| (22) |
Then the operator defined in the subsection above is such that
so that
and we can write
This implies
We denote
It can also be proved that the set of cubature points can be chosen so that
| (23) |
for some . It holds, using (20):
The main result of Narcowich et al. NarcoPetruWard is the following localization property of the , called needlets: for any there exists a constant such that, for every ,
| (24) |
where is the natural geodesic distance on the sphere (). In other words, needlets are almost exponentially localized around their associated cubature point, which motivates their name.
A major consequence of this localization property can be summarized in the following properties which will play an essential role in the sequel. Their proof can be found in NarcoPetruWard , NPW , also in kyoto .
For any , there exist positive constants , , , and such that
| (25) | |||||
| (26) | |||||
| (27) | |||||
| (28) | |||||
| (29) |
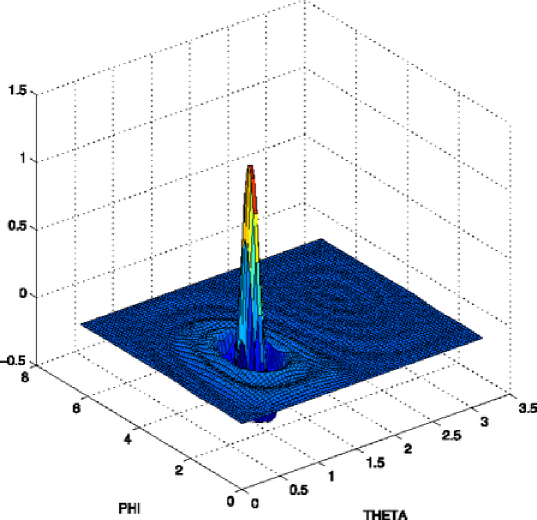
To conclude this section, let us give a graphic representation of a spherical needlet in the spherical coordinates in order to illustrate the above theory. In the following graphic, we chose and .
3.3 Besov spaces on the sphere
The problem of choosing appropriated spaces of regularity on the sphere in a serious question, and we decided to consider the spaces which may be the closest to our natural intuition: those which generalize to the sphere case the classical approximation properties used to define for instance Sobolev spaces. In this section, we summarize the main properties of Besov spaces which will be used in the sequel, as established in NarcoPetruWard .
Let be a measurable function. We define
the distance between and the space of spherical harmonics of degree less than . The Besov space is defined as the space of functions such that
Remarking that is decreasing, by a standard condensation argument this is equivalent to
and the following theorem states that as it is the case for Besov spaces in , the needlet coefficients are good indicators of the regularity and in fact Besov spaces of are Besov bodies, when expressed using needlet expansion. We provide in Figure 1 a graphical representation of a needlet which shows its localization around the associated cubature point.
Theorem 1
Let , , . Let be a measurable function and define
provided the integrals exist. Then belongs to if and only if, for every
where .
As has been shown above,
for some positive constants , the Besov space turns out to be a Banach space associated to the norm
| (30) |
and using standard arguments (reducing to comparisons of norms), it is easy to prove the following embeddings:
Moreover, it is also true that for , if belongs to , then it is continuous, and as a consequence bounded.
In the sequel, we shall denote by the ball of radius of the Besov space .
4 Needlet algorithm: Thresholding the needlet coefficients
The first step is to construct a needlet system (frame) as described in Section 3.
The needlet decomposition of any takes the form
Using Parseval’s identity, we have with and .
Thus,
| (32) |
is an unbiased estimate of . We recall that has been defined in (2.1). It is worthwhile pointing out that the SVD-estimate of the Fourier coefficient appears in the expression of the estimate . This underlines that the Needlet dictionary does not depart too much from the Fourier basis and hence benefits from the inversion property while being very well localized.
Notice that from the needlet construction (see the previous section) it follows that the sum above is finite. More precisely, only for .
Let us consider the following estimate of :
| (33) |
where is a thresholding operator defined by
| (34) | |||||
| (35) | |||||
| (36) |
Here is a tuning parameter of the method which will be properly selected later on. is chosen such that . The choice of these parameters will be discussed later. Notice that the thresholding depends on the resolution level through the constant . As usual in inverse problems, the upper level of details will be chosen depending of the degree of ill-posedness. It is precisely defined in Theorem 2.
4.1 Performances of the procedure
The following theorem considers the case of a loss with . The case is studied in Theorem 3.
Theorem 2
Let , , and let us assume that
| (37) |
is chosen such that . Let us choose such that and . Let us also take with as in and is a positive constant. Then if , with the restriction if , there exists a constant such that
| (38) |
where
The following theorem considers the case of norm loss.
Theorem 3
For , let us assume that there exist two constants , such that
| (39) |
is chosen such that . Let us choose such that and . Let us also take with as in and is a positive constant. Then if , , there exists a constant such that
| (40) |
where
The proof of these theorems is given in Section 6.
-
1.
In Theorem 2, the rates of convergence obtained for larger are usually referred to as the dense case, whereas the other case is referred to as the sparse case.
-
2.
The parameter appearing here is often called degree of ill-posedness of the problem (DIP). It appears here through conditions (37) and (39) which are essential in this problem. In Kimoptimalspherical , for instance, and very often in diverse inverse problems, this DIP parameter is introduced with the help of the eigenvalues of the operator (i.e., here the discrepancy of the coefficients of in its expansion along the rotational harmonics). In the following subsection, we prove that (37) and (39) are in fact a consequence of (and even equivalent to) the standard “ordinary smooth” condition.
-
3.
The rates of convergence found here are standard in inverse problems. They can be related to rates found in Kim and Koo Kimoptimalspherical in the same deconvolution problem, with a loss and constraints on the spaces comparable to . In the deconvolution problem on the interval, similar rates are found even for losses (with standard modifications since the dimension here is 2 instead of 1): see, for instance, Johnstone et al. jkpr . These results are proved to be minimax (see Kim and Koo Kimoptimalspherical ) up to logarithmic factors, for the case with a constraint on the object to estimate. With methods comparatively similar to those in Willer Thomas , it could be proved that our rates are also minimax in the general case (again up to logarithmic factors) if we assume condition (39) (or, in other terms, that the DIP is exactly of the order ).
- 4.
-
5.
It is worthwhile noticing that the procedure is adaptive, meaning that it does not require a priori knowledge on the regularity (or sparsity) of the function. It also adapts to nonhomogeneous smoothness of the function. The logarithmic factor is a standard price to pay for adaptation.
-
6.
The procedure requires the knowledge of the constant which is corresponding to the norm of the density . It is obvious (because of the convolution) that . However, it should be better to obtain a procedure not depending on either. For that, we advocate that can be replaced by in practice where is an undersmoothed needlet estimator of the density close to those introduced in Baldi et al. BaldiKerkMariPica but with no thresholding and with the level chosen so that . Standard arguments similar as in Giné and Nickl GineNickl10b ) imply that this random quantity exponentially concentrates around . We can also adopt a more straightforward strategy as detailed in Section 5.
4.2 Conditions (37), (39) and the smoothness of
Following Kim and Koo (Kimoptimalspherical , condition (3.6)), we can define the smoothness of spectrally. We place ourselves in the “ordinary smooth” case
| (41) |
for some positive constants , and nonnegative constant , and where the operator norm of the rotational Fourier transform is defined as
being the -dimensional vector space spanned by .
The following proposition states that condition (37) [resp. (39)] is verified in the ordinary smooth case by the needlets system.
Proposition 1
If , then there exists a constant such that
If , then there exists a constant such that
The proof of this proposition is given in the supplement article (Kerkyacharian et al. KerkPhamPicardA ).
Notice also that the super smooth case (corresponding to exponential spectral decreasing) is also considered in Kim and Koo Kimoptimalspherical . We will not consider this case here, although this could be done, basically because this case corresponds to very poor rates of convergence (logarithmic in ). As well, this case does not require a thresholding since the adaptation is obtained almost for free.
We now give a brief review of some examples of smooth distributions which are discussed in depth in Healy, Hendriks and Kim HealyHendriksKim and Kim and Koo Kimoptimalspherical .
4.2.1 Rotational Laplace distribution
This distribution can be viewed as an exact analogy on of the Laplace distribution on . Spectrally, for some , this distribution is characterized by
| (42) |
for and and where if and otherwise.
4.2.2 The Rosenthal distribution
This distribution has its origin in random walks in groups (for details, see Rosenthal Rosenthal ).
If one considers the situation where is a -fold convolution product of conjugate invariant random for a fixed axis, then Rosenthal (Rosenthal , page 407) showed that
for and and where and .
5 Practical performances
In this section, we produce the results of numerical experiments on the sphere . Numerical work has been conducted using the spherical pixelization HEALPix software package. HEALPix provides an approximate quadrature of the sphere with a number of data points of order and a number of quadrature weights of order , for some positive constant . This approximation is considered as reliable enough and commonly used in astrophysics.
In the two examples below, we considered samples of cardinality . The maximal resolution level is taken such that . In order not to have more cubature points than observations, we set for . We recall the expression of the estimate of the needlets coefficients of the density of interest:
| (43) |
where the quadrature weight are approximately uniform, . We replace the rotational Fourier transform [defined in (6)] by its empirical version, more tractable in our simulation study. Note also that this situation is very likely to occur for instance in the context of astrophysics.
We precise again that denotes the element of the matrix which is the inverse of the matrix . In order to get the empirical version of , we have first to compute the empirical matrix then to inverse it to get the matrix . The entry of the matrix is given by the formula
where the rotational harmonics have been defined in (4). The ’s are i.i.d. realizations of the variable .
For the generation of the random variable , we chose Oz as the rotation axis and an angle following a uniform law with different supports such as , , . The larger the support of distribution is, the more intense the effect of the noise will be.
This particular choice of rotation matrix entails that in the decomposition of an element of [see formula (3)] the angles and are both equal to zero. For this specific setting of perturbation, we deduce the following form for the rotational harmonics:
where and is a positive constant which will be specified later.
Choosing . As one may notice, the estimator [see (33)] relies on the knowledge of which controls the sup norm of the density and appears in the formula of , see (36). Different ways to circumvent this difficulty can be used, for instance, estimating it as explained above. However, we have adopted in this section a different approach. The quantity constitutes a control of the variance of the estimated coefficients as it is shown by inequality (5) in the supplementary material (see Kerkyacharian et al. KerkPhamPicardA ). Using this remark, instead of using an upper bound of the variance of , we will directly plug in an estimation of this variance. Hence, in (34) is replaced by
where
and
Remark that .
Hence, for the reconstruction of the density , we have the following Needlet estimator:
Choosing the tuning parameter . Before entering into the details of the numerical results, we will dwell on the methodology used in this part to calibrate the tuning paramater in practice. In a first time, we focus on the uniform density. Indeed, we make an upstream study with the uniform density which will allow us to determine a reasonable value for which will be kept in the sequel for other types of densities. On the one hand, the choice of the uniform density is not fortuitous because we know that in theory the needlet coefficient for all and . On the other hand, for an upstream study, a prerequisite is to deal with a simple density, which is the case. Hence, we test various values of and see how many coefficients survive thresholding. Then we look at the smallest value of for which all the estimated coefficients are killed. It turns out that . Consequently for we have noise-free reconstructions of the uniform density. Accordingly, this particular value of plays a benchmark value for the other types of density that we highlight. In other words, in the Example 2, which concerns the unimodal density we set .
We can form a parallel to what happens on the real line. Indeed, in a certain way, this strategy for choosing in practise meets up with the universal threshold put forward by Donoho and Johnstone DonohoJohnstone in the context of fixed design regression on in order to “kill” asymptotically all the coefficients when estimating the zero function. Then, we compute the and losses and give the graphic reconstructions. This choice of turns out to be very reasonable and fruitful as the results prove to be good enough.
=265pt 0 7 30 110 0 0 2 6 0 0 0 3
=265pt 2 3 77 350 0 0 4 10 0 0 0 6
Example 1.
In this first example, we consider the case of the uniform density . It is easy to verify that for every and every . Following Baldi et al. BaldiKerkMariPica , a simple way of assessing the performance of the Needlet procedure is to count the number of coefficients surviving thresholding.
Example 2.
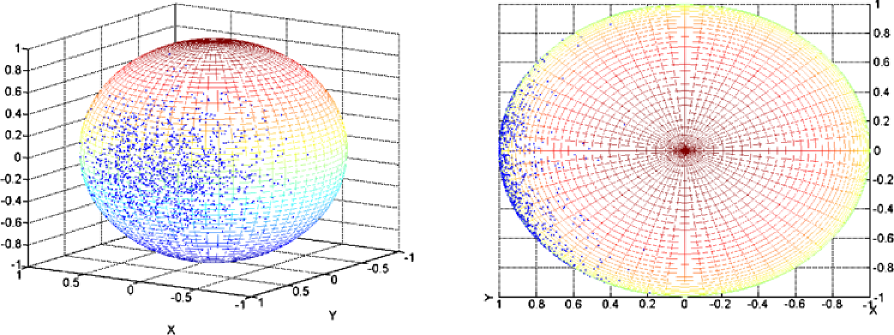
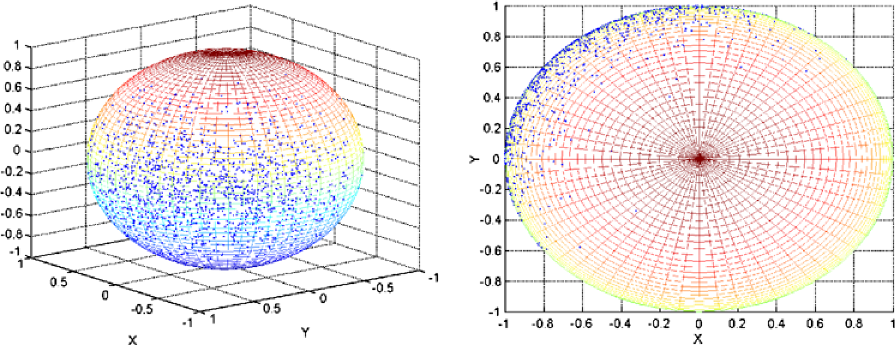
We will now deal with the example of a density of the form , with and . The graph of in the spherical coordinates (longitude, , colatitude, ) is given in Figure 2. We also plot the noisy observations for different cases of perturbations. For big rotation angles such that or , the observations tend to be spread over a large region on the sphere and not to be concentrated in a specific region any more. Consequently, denoising might prove to be difficult. In the context of the deconvolution on the sphere, a large amount of noise corresponds to a rotation about the Oz axis by a large angle.
As motivated above, in the sequel, the tuning parameter for the Needlet procedure is set to both for computing the quadratic loss, the loss and the graphic reconstructions.
=265pt 0.3335 0.5523 0.7830 0.1019 0.1677 0.1928
First of all, we have computed an estimate of the and the norms of the difference between our Needlet estimator and (see Table 3). For the quadratic loss, we took the square root of the sum of the squares of the coefficients. As for the distance, we chose an almost uniform grid of the sphere given by the HEALPix pixelization program. We recall that
where the are the points of a uniform grid of the sphere. Here, we chose . All the estimated losses were computed over runs and for observations. We considered the three cases of noise level described above. The results are summarized in the following table of errors which shows that the estimator performs quite well. In particular, its performances are deteriorating when the noise becomes more important (which was expected) and give very good results in norm. We concentrated on particular phenomena instead of performing a large scanning of the errors in very diverse situations because the computations—although feasible—are rather costly in time when used repeatedly. For instance, to our knowledge, and probably for the same reason, no such study has been performed for the SVD method.
SVD versus needlet on a particular problem. A central issue in Astrophysics is to detect the place of the peak of the bell which in the present density case is localized in . For each case of noise, we plot the observations both on the sphere and on the flattened sphere and give the reconstructed density in the spherical coordinates for the Needlet procedure and the SVD estimator (see Figures 2, 4 and 6).
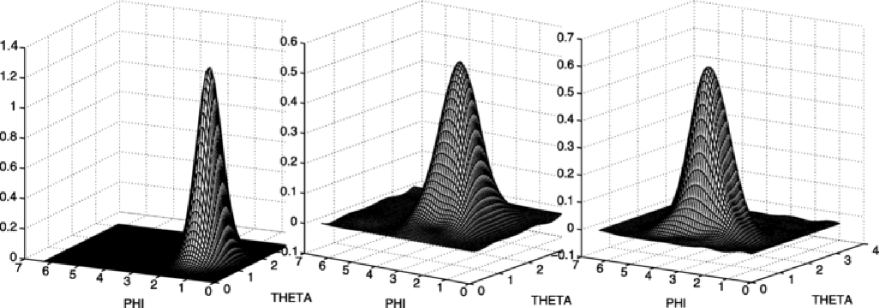
For each of the three groups of graphic reconstructions of the target density presented below corresponding to three cases of noise, you will find in order, the exact target density, then the one estimated with the Needlet procedure and finally the density estimated with the SVD method (see Figures 3, 5 and 7).
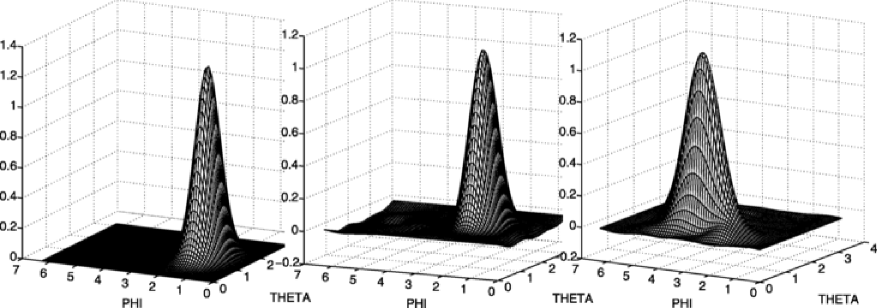
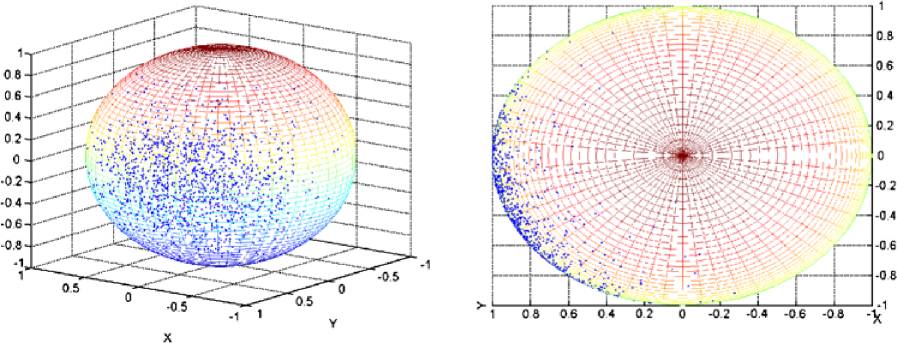
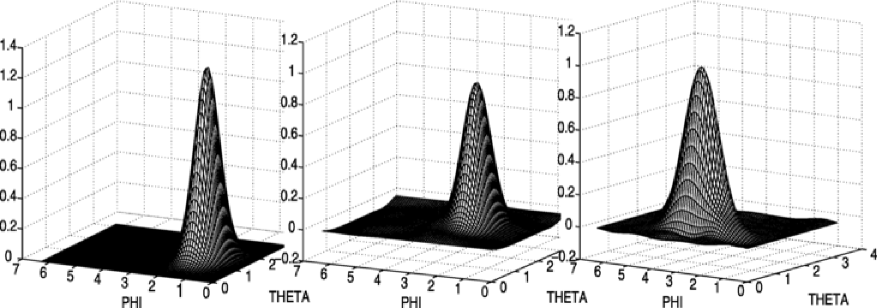
At a closer inspection, we notice that the position of the peak of the estimated bell is well localized by the Needlet procedure whatever the amount of noise, it is especially true for . Only in the case of the law , the longitude coordinate of the peak tends to slightly move away from the true value. As for the SVD method, for the three reconstructions, it fails to detect properly the exact position of the peak. Therefore, even if in the case of big rotations such that and especially , the Needlet procedure allows us to have a rather good detection of the position of the peak. This is of course due to the remarkable concentration of the needlet. Of course, one remarks that the base of the bell tends to become a bit larger when the noise increases, this is due to the fact that the observations are not concentrated in a specific region any longer, but the genuine form of the density is well preserved.
6 Proof of Theorems 2 and 3
In this proof, will denote an absolute constant which may change from one line to the other.
We begin with the following proposition.
Proposition 2
For any there exist constants , such that, as soon as ,
| (44) | |||||
| (45) | |||||
| (46) | |||||
| (47) |
The proof of this proposition is given in the supplementary material (see Kerkyacharian et al. KerkPhamPicardA ).
6.1 Proof of Theorem 2
Now, to get the result of Theorem 2, we begin by the following decomposition:
The term is easy to analyze, as follows. We observe first that since for , this case will be assimilated to the case and from now on, we will only consider . Since belongs to , using the embedding results recalled above in (3.3), we have that also belongs to , for some constant and for . Hence,
Then we only need to verify that is always larger that , which is not difficult.
Indeed, on the first zone . So,
which entails that
. We need to
check that . We have that
since and .
On the second zone, we obviously have that is always larger than .
Bounding the term I is more involved. Using the triangular inequality together with Hölder inequality, and property (28) for the second line, we get
Now, we separate four cases:
We have the following upper bounds for the terms and :
It is easy to check that in any cases if the terms and are smaller than the rates announced in the theorem. For the details of the above upper bounds of the terms and , see the supplementary material (Kerkyacharian et al. KerkPhamPicardA ).
Using Proposition 2, we have
So in both cases we have the same bound to investigate. We will write this bound on the following form (forgetting the constant):
The constants and will be chosen depending on the cases, with the only constraint .
We recall that we only need to investigate the case , since when , .
Let us first consider the case where , put
and observe that on the considered domain, and . In the sequel, it will be useful to observe that we have . Now, taking , we get
Now, as
and
with (this last thing is a consequence of the fact that ), we can write
The last inequality is true for any if and for if . Notice that is equivalent to Now if we choose such that , we get the bound
which exactly gives the rate announced in the theorem for this case. As for the first part of the sum (before ), we have, taking now , with (and also since we investigate the case ), so that, we get
The last two lines are valid if is chosen strictly smaller than (this is possible since ).
Let us now consider the case where , and choose now
In such a way that we easily verify that . Furthermore, we also have . Hence, taking and using again the fact that belongs to ,
This is true since is also strictly positive since . If we now take , we get the bound
which is the rate announced in the theorem for this case.
6.2 Proof of Theorem 3
The proof of this theorem is entirely given in the supplementary material (see Kerkyacharian et al. KerkPhamPicardA ).
[id=suppA]
\stitleSupplement to “Localized spherical deconvolution”
\slink[doi]10.1214/10-AOS858SUPP
\sdatatype.pdf
\sfilenamesupplementA_Annals.pdf
\sdescriptionWe give in the supplement some technical details
for the understanding of the proofs of Propositions 1 and 2 and of
Theorems 2 and 3.
Acknowledgments
The authors would like to thank Erwan Le Pennec for many helpful discussions and suggestions concerning the simulations. We would also like to thank an Associate Editor and two anonymous referees for their insightful comments on a first draft of this work.
References
- (1) Baldi, P., Kerkyacharian, G., Marinucci, D. and Picard, D. (2009). Adaptive density estimation for directional data using needlets. Ann. Statist. 37 3362–3395. \MR2549563
- (2) Baldi, P., Kerkyacharian, G., Marinucci, D. and Picard, D. (2009). Subsampling needlet coefficients on the sphere. Bernoulli 15 438–463. \MR2543869
- (3) Donoho, D. L and Johnstone, I. M. (1994). Ideal spatial adaptation by wavelet shrinkage. Biometrika 81 425–455. \MR1311089
- (4) Giné, E. and Nickl, R. (2010). Adaptive estimation of a distribution function and its density in sup-norm loss by wavelet and spline projections. Bernoulli. To appear.
- (5) Healy Jr., D. M., Hendriks, H. and Kim, P. T. (1998). Spherical deconvolution. J. Multivariate Anal. 67 1–22. \MR1659108
- (6) Johnstone, I., Kerkyacharian, G., Picard, D. and Raimondo, M. (2004). Wavelet deconvolution in a periodic setting. J. R. Stat. Soc. Ser. B Stat. Methodol. 66 547–573. \MR2088290
- (7) Kerkyacharian, G., Kyriazis, G., Le Pennec, E., Petrushev, P. and Picard, D. (2010). Inversion of noisy Radon transform by SVD based needlets. Appl. Comput. Harmonic Anal. 28 24–45. \MR2563258
- (8) Kerkyacharian, G. and Picard, D. (2009). New generation wavelets associated with statistical problems. In The 8th Workshop on Stochastic Numerics 119–146. Research Institute for Mathematical Sciences, Kyoto Univ.
- (9) Kerkyacharian, G., Pham Ngoc, T. M and Picard, D. (2010). Supplement to “Localized spherical deconvolution.” DOI:10.1214/10-AOS858SUPP.
- (10) Kerkyacharian, G., Petrushev, P., Picard, D. and Willer, T. (2007). Needlet algorithms for estimation in inverse problems. Electron. J. Statist. 1 30–76 (electronic). \MR2312145
- (11) Kim, P. T. and Koo, J. Y. (2002). Optimal spherical deconvolution. J. Multivariate Anal. 80 21–42. \MR1889831
- (12) Narcowich, F., Petrushev, P. and Ward, J. (2006). Decomposition of Besov and Triebel–Lizorkin spaces on the sphere. J. Funct. Anal. 238 530–564. \MR2253732
- (13) Narcowich, F., Petrushev, P. and Ward, J. (2006). Local tight frames on spheres. SIAM J. Math. Anal. 38 574–594. \MR2237162
- (14) Pietrobon, D., Baldi, P., Kerkyacharian, G., Marinucci, D. and Picard, D. (2008). Spherical needlets for CMB data analysis. Monthly Notices of the Roy. Astron. Soc. 383 539–545.
- (15) Rosenthal, J. S. (1994). Random rotations: Characters and random walks on . Ann. Probab. 22 398–423. \MR1258882
- (16) Talman, J. D. (1968). Special Functions: A Group Theoretic Approach. W. A. Benjamin, New York. \MR0239154
- (17) Terras, A. (1985). Harmonic Analysis on Symmetric Spaces and Applications. I. Springer, New York. \MR0791406
- (18) Tournier J. D., Calamante, F., Gadian, D. G. and Connelly, A. (2004). Direct estimation of the fiber orientation density function from diffusion-weighted mri data using spherical deconvolution. NeuroImage 23 1176–1185.
- (19) van Rooij, A. C. M. and Ruymgaart, F. H. (1991). Regularized deconvolution on the circle and the sphere. In Nonparametric Functional Estimation and Related Topics (Spetses, 1990). NATO Adv. Sci. Inst. Ser. C Math. Phys. Sci. 335 679–690. Kluwer Academic, Dordrecht. \MR1154359
- (20) Vilenkin, N. J. (1969). Fonctions spéciales et théorie de la représentation des groupes. Traduit du Russe par D. Hérault. Monographies Universitaires de Mathématiques 33. Dunod, Paris. \MR0243143
- (21) Willer, T. (2009). Optimal bounds for inverse problems with Jacobi-type eigenfunctions. Statist. Sinica 19 785–800. \MR2514188