Look Before You Leap: Using Serialized State Machine
for Language Conditioned Robotic Manipulation
Abstract
Imitation learning frameworks for robotic manipulation have drawn attention in the recent development of language model grounded robotics. However, the success of the frameworks largely depends on the coverage of the demonstration cases: When the demonstration set does not include examples of how to act in all possible situations, the action may fail and can result in cascading errors. To solve this problem, we propose a framework that uses serialized Finite State Machine (FSM) to generate demonstrations and improve the success rate in manipulation tasks requiring a long sequence of precise interactions. To validate its effectiveness, we use environmentally evolving and long-horizon puzzles that require long sequential actions. Experimental results show that our approach achieves a success rate of up to 98% in these tasks, compared to the controlled condition using existing approaches, which only had a success rate of up to 60%, and, in some tasks, almost failed completely.
I Introduction
The recent advancements in combining Large Language Models (LLMs) with robotic systems have shown potential in automating complex task planning and execution [1, 2, 3, 4, 5, 6, 7]. Yet, LLMs have limited capacity for translating high-level task description text into strong, executable policies over manipulation tasks with long horizons. Existing approaches, such as those that leverage LLMs to generate task demonstration code for imitation learning [3, 4], extend on the classic philosophy of using language-conditioned policies to set goals and transfer concepts across different tasks [8]. The required training after the demonstration collection makes the framework data-dependent. These demonstrations can be human-curated [8] or LLM-generated [3, 4], and they often rely on an assumption for the task where all the objects are randomly spawned in simulation when generating a demonstration.
While the current approaches work well for short-horizon tasks where only a few sequential actions are required or loosely constrained tasks where precise positioning or ordering is less critical, they may not scale to scenarios that require precise state-dependent reasoning. For example, the reliance on vision for imitation learning [8, 3] leads to failures in manipulation when encountering previously unseen environmental structures during the execution of long-horizon tasks.
This limitation becomes evident in our experimental findings: Current frameworks are prone to cascading failure in these tasks using vision. For example, in Tower of Hanoi [8, 3], the primitive tasks are to move a ring in a certain color to a stand in another color, as shown in Fig. 1. Existing approaches with objects spawned arbitrarily on the table are trained on randomly initialized sub-task demonstrations. They may place rings on incorrect stands or miss valid pick points during the tests. This occurs because randomized training distributions fail to capture the structural consistency required for sequential spatial reasoning (e.g., stand/ring relationships depend on prior moves). In other words, when objects are subject to dynamically evolving spatial constraints, policies trained on randomly initialized demonstrations can experience performance degradation due to the divergence of the training and the evolving execution environment structures.


Our work aims to address this issue by dividing complex tasks into sub-actions, predicting possible intermediate environment structures, and training the imitation framework on all or most predicted states. These can be concluded into two key principles: “divide and concur” and “look before you leap”. To achieve this, we propose a state-aware imitation learning pipeline that systematically links finite state machine (FSM) with environment-conditioned robot policy training (Fig. 2). We validate our framework on long-horizon tasks and found that it improves the success rate from up to 60% in existing approaches to almost 100%. In summary, the proposed framework has the following features that distinguish this work from previous research:
-
•
By introducing the State Machine Serialization Language (SMSL) as a guide into demonstration generation for imitation learning, the system ensures that the resulting policy training is aware of the precise geometric constraints of complex long-horizon tasks.
-
•
The planning process is highly deterministic because our framework uses SMSL’s state transitions to propagate and record the geometric configuration of objects at each step of the task. These configurations are stored as persistent environmental states, enabling deterministic scene initialization for demonstrations.
-
•
The predicted states are filtered with constraints to ensure the correctness, and the entire demonstration generation process, including the planning, filtering, and code generation, are all performed by LLM.
II Related Works
II-A Robot Task Planning
A common solution to complex robotic tasks is to split them into easier, more manageable sub-tasks. When a robot needs to achieve a goal that cannot be done with a single action, it will have to plan the entire sequence of actions. Most of these approaches solve high-level planning through search-based methods within predefined domains [9, 10, 11]. Some research also focuses on heuristic strategies for robot task planning [12, 13, 14]. Recent works leverage LLMs for robot task planning because LLMs can perform multi-task generalization when provided with a designed prompt input. Many recent works utilize prompt engineering for LLMs to generate text as a guide for robot task planning [15, 16, 17, 18]. For long horizon tasks, approaches generally plan in a hierarchical manner for the defined task-primitives, and common methods include trees or optimization-based algorithms [19, 20]. In [21], the authors introduce situated awareness in LLM-based robot task planning, fulfilling the missing state feedback from the environment when using LLM for task planning. To make the process more deterministic, Liu and Armand [18] proposed using LLM-generated FSMs. This aligns with our goal of addressing the problem of unseen environmental states.
II-B Imitation Learning for Robotics Manipulation
In traditional methods, machines and robots could only learn autonomous behaviors when experts spend time writing hard-coded rules for them. Imitation learning offers a way to teach robots by “showing” them what to do, simplifying the training of robots to perform new tasks [22, 23, 24]. It has demonstrated effectiveness in learning grasping and pick-and-place tasks from low-dimensional states [25, 26]. Some previous works also focus on the few-shot imitation learning, which enables the systems to learn new tasks from just a handful of demonstrations [27, 28].
Language-conditioned imitation learning is an important advancement in this field. It combines natural language instructions with demonstration-based learning to create more flexible and intuitive robot control. This approach allows users to guide robots through natural language commands [29, 30, 31, 8].
Robot demonstration generation is an important concept in the stream of research. LLMs have been used to automatically generate simulations for different purposes [32, 33]. Gensim [3] introduced an approach that leverages LLMs to automatically generate diverse robotic simulation environments and expert demonstrations. However, this approach has limitations for a wide range of tasks, such as long-horizon tasks or those requiring precise state awareness. Our approach expands the domain of solvable tasks by utilizing LLM-generated finite state machines as guides for demonstration collection.
III Method
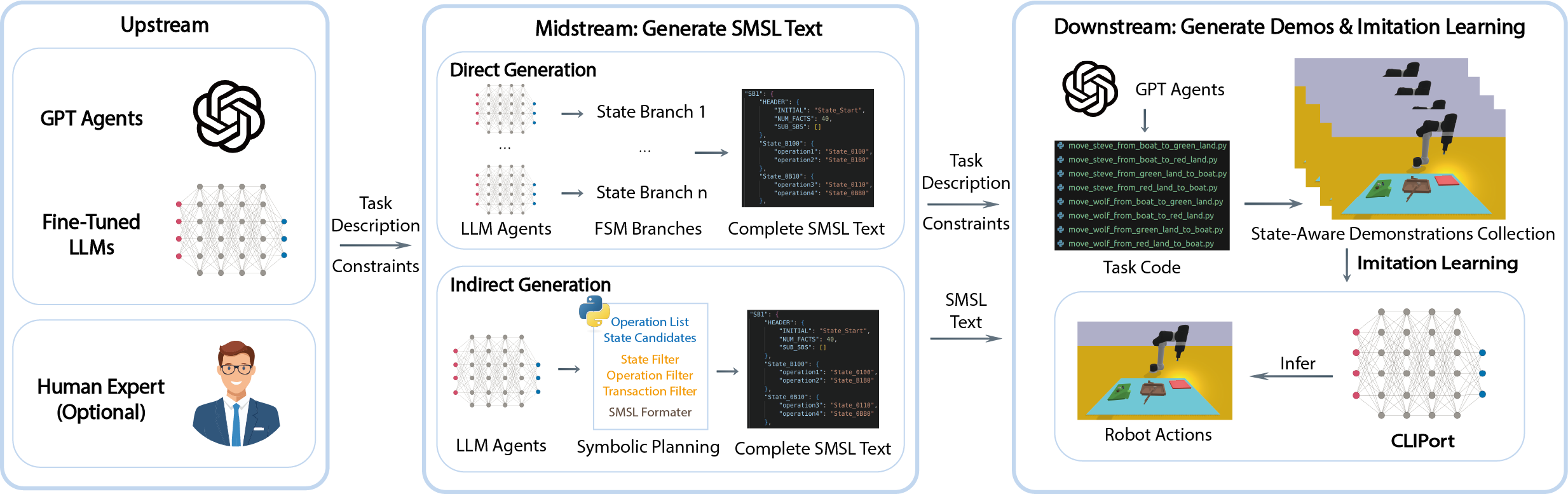
III-A SMSL Generation via LLM-Based States, Operations and Transitions Filtering
The proposed framework uses State Machine Serialization Language (SMSL) to guide demonstration collection for robot manipulation tasks. SMSL is a data language that stores the definition of FSMs in a text format, which can represent the workflow of tasks [18]. While LLMs could potentially generate plans for complex tasks directly, creating comprehensive planning for complex tasks with a large number of states and transitions from unstructured descriptions is still challenging and lacks scalability. To address this limitation, we implement an indirect SMSL text generation approach that utilizes LLMs to generate and complete executable scripts. The generation process has the following steps:
-
•
First, the LLM analyzes the task description to list all independent operations (e.g., “move Object A to Position B”) and find an optimized symbolic representation for the states based on the task requirements (e.g., “State_A”).
-
•
Second, the LLM defines the state representation and state space, then generates a script that enumerates all possible states through Cartesian product, without considering the task constraints. These states serve as candidates for state filtering.
-
•
Third, based on the constraints of the task, the LLM constructs filter functions to rule out states that violate the constraints. After filtering, the LLM will list all valid state-operation pairs and add an operation filter script to prevent transitions from invalid states. It then writes a script to infer state transitions based on the valid state-operation pairs, which will lead to the goal state of this transition. The system applies the state filter again to verify if these goal states are valid; if not, then it removes the entire transition.
-
•
Finally, the LLM formats the remaining transitions into SMSL text.
The overall algorithm for this LLM-based SMSL generation process is presented in Algorithm 1, with a mathematical formulation of the filter representation for a river-crossing puzzle provided in the Appendix.
III-B State-Aware Task Demonstration Code Design
Existing approaches like GenSim generate demonstration code for the task that initializes the environments to random object placement [3, 4], which will introduce discrepancies between the task description and the demonstration when applied to longer horizon, more complex tasks. An example of this format of tasks is given in Listing 1 in Appendix. We design our state-aware task code to establish environment-state persistence via decoupled environment initialization from task logic. Listing 2 in Appendix illustrates what our modified task format looks like. It features three improvements:
Randomize Environment Under Constraints: In our workflow, a randomized environment will be created for the initial state under the constraints defined in the setup script, guaranteeing compliance with symbolic state requirements.
Environment Passing: Rather than resetting the environment and spawning the objects in the task code, we will directly pass the environment to the task code.
Deterministic Object Referencing: To ensure that objects across multiple episodes are referenced deterministically, we create a persistent dictionary which maps each entity (URDF handle) to a runtime object ID.
These changes ensure two functionalities can be performed correctly: First, they free LLMs from locking on low-level objects instantiation towards high-level task goal and constraints understanding. We also expose entity handles to LLMs and allow it to inspect geometric feature when necessary (e.g., chessboard blocks or arbitrary slots), and calculate placement offsets from a target object’s pose. Second, it preserves dataset diversity via randomizing all initial pose configurations, while ensuring the state configurations are consistent to the object poses in the environment.
III-C Prompt Engineering for Task Generation Agents
Our code generation pipeline transforms symbolic operations into executable task demonstration scripts by leveraging multiple LLM agents to use our structured prompts. The first stage of the process is broken into two subcomponents, and the second and third stages are recursively applied to each of the operations in the SMSL text:
Agent 0 / Human: Initial-State Environment Setup Script
An LLM agent will process task descriptions, spatial constraints from expert knowledge and scene entity library references to produce the initialization scripts that:
-
•
Spawn objects at random poses under geometric constraints only for the initial state.
-
•
Establish persistent mappings between scene entities and simulation object IDs.
Verifications can be made to ensure this initialization script can have the spawned environment consistent with the initial state’s configurations before passing it to the next LLM agent.
Agent 1: Task Specification Generation
Another LLM agent will read through this initial state environment setup script and task description to generate a structured task specification in JSON format containing:
-
•
Entity List: Categorized URDF file names of used meshes by their physics types (fixed or rigid).
-
•
Entity to Inspect: A URDF file name that requires geometric inspection by the task generation agent.
-
•
Natural language task summary.
Agent 2: Task Code Generation
The final LLM agent will read through CLIPort’s API to understand the definition of the “task” class, then to review examples of success and failure with the type of failure. It creates the task code according to the JSON description extracted from the task specification and also inspects the URDF if it’s listed in “entity to inspect”, so that it knows how to properly set the offset for the target pose.
III-D Demonstration Dataset Generation
Our framework provides automatic demonstration dataset generation in a two-phase approach using the constructed FSM, the workflow and the comparison with the existing LLM-centralized workflow for task generation is illustrated in Fig. 3. At first, we apply graph search approach in order to find either a single path that covers all the states or, if that fails, generate multiple minimum-length paths to cover all states: We employ a depth-first search that maximizes state coverage; the algorithm seeks to find a single path containing every state by tracking visited states with bitmasking and if failed, produces several minimum-length paths using a coverage-optimized queue. These paths provide guidance for exploration of states, which also infers the sequence of operations applied to the initial environment.
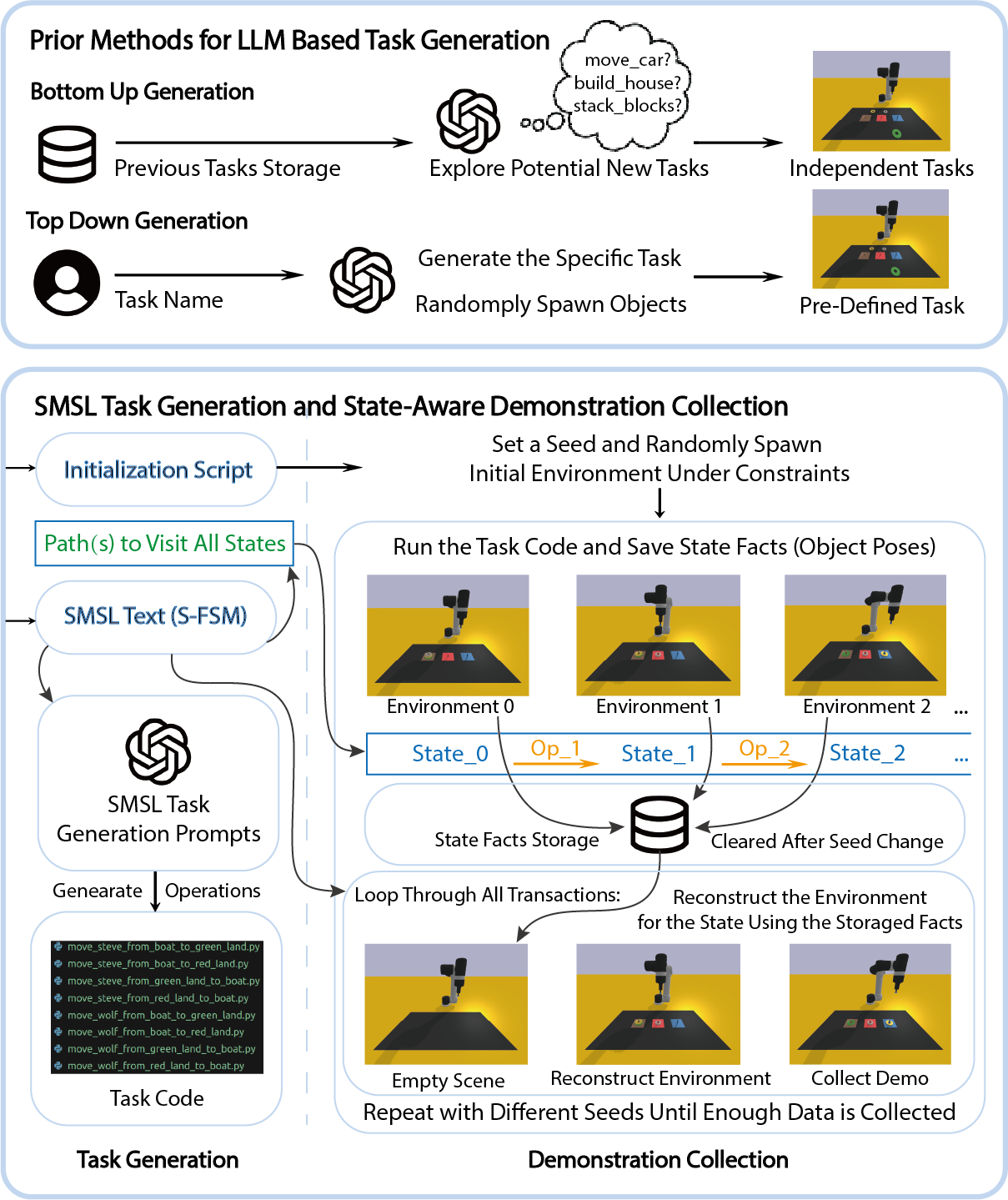
The second stage uses the paths to generate training demonstrations for CLIPort [8]. It starts with spawning an environment of the initial state and storing the accurate state configurations in the storage. Then, it applies the first operation in the path to the environment and collects the state configurations as well. This process is then repeated until it has collected all or exemplary state configurations in case of exceedingly large state space. Following this, the framework loops over all of the transitions as defined in the SMSL, reconstructs the environment from the stored configurations, performs the operation, and generates the demonstration. To be more specific, we denote the object poses for each transition in the path as:
| (1) |
where represents the set of all entities (objects) in the environment, “get_object_pose” is a script function that will take the object id as input and output the object pose. During each transition , the environment is initialized with constraint-compliant random poses, followed by saving the object poses as state configurations . The system then executes operation using LLM-generated task scripts with the current environment and save the resulting state configurations as . This process continues along the paths until all state configurations are collected, where these configurations are stored in a state dictionary unique to each randomized initialization. This approach enables deterministic state reconstruction and effectively separates the demonstration collection process from environment randomization.
The demonstration collection iterates through all transitions in SMSL (in any order, allowing parallel execution), where for each transition, the system spawns an environment using stored state configurations, executes the corresponding task code, and collects the required data for CLIPort (RGB-D observations, language goals, and actions). The environment is then initialized in random poses that are consistent with constraints.
III-E Design of Experiments
The experimental evaluation includes three complex tabletop manipulation tasks, each representing a distinct finite state machine (FSM) with varying complexity levels according to Table I.
Towers of Hanoi: The set-up includes three stands (blue, red, and brown) and three rings: gray, yellow, and green in increasing radius. Following standard rules, only smaller rings can be placed on larger ones, the robot can only move one of the rings at a time. The three stands are spawned randomly on the table while the rings are all located on the brown stand.
River Crossing: A puzzle with the Human, Wolf, Sheep, and Grass entities that initially begin in four on red land. However, the sheep cannot be alone with both the wolf and grass in the absence of Human. For any two-object boat transport, Human must be present. A detailed task description and constraints representation are provided in the Appendix.
Chess: The Chess Board puzzle has nine blocks and two chess pieces. Among the nine blocks, three of them are impassable. Pieces can be placed on top of each other in the same block, and the state “star chess is on top of the circle chess” is different than the state “circle chess is on top of the star chess”. At the start of the game, the star chess is spawned at the bottom left block as seen in Fig. 4(c), and the circle chess is spawned at the bottom right block. The goal is to switch the positions of the pieces.



| Towers of Hanoi | River Crossing | Chess | |
|---|---|---|---|
| Rigid Objects | 3 | 4 | 2 |
| Valid Operations | 9 | 16 | 18 |
| Valid States | 27 | 40 | 90 |
| Valid Transitions | 78 | 92 | 324 |
IV Results and Discussion
Notably, unlike traditional puzzle-solving scenarios, our implementation does not focus on reaching specific goal states. Instead we use these designed puzzle tasks to illustrate complex FSM navigation, where intermediate states hold equal importance to final states. It better represents the real world applications, where there could be many transitions in states and intermediate configurations that are equally valid targets. By applying this philosophy to our sample collection process, we collect demonstrations covering the entire state space or exemplary states if the state space is too large, rather than only goal-oriented trajectories.
We evaluated our method by training on our collected dataset across three puzzles. We trained the model with 200, 500, and 1000 demonstrations for each operation, and we used the average success rate across all operations as the evaluation metric. To highlight the necessity of state-aware demonstration collection for these complex long-horizon tasks, we compared our method against a control condition where all objects are randomly placed on the table when collecting demos - a typical setting in previous methods. We also trained with 200, 500, and 100 demonstrations per operation for this control condition and tested in the same puzzle-solving contexts. Results demonstrate that the policy trained on random object placement demos does not generalize well to situations where objects need to understand dynamically changing state dependencies. Table II presents the detailed comparative results.
| Method | Number of Demonstrations | ||
|---|---|---|---|
| 200 | 500 | 1000 | |
| Hanoi (tolerance 0.01m, 15 degrees) | |||
| Our Method | 0.849 | 0.942 | 0.980 |
| GenSim | 0.587 | 0.606 | 0.580 |
| River Crossing (tolerance 0.06m, 15 degrees) | |||
| Our Method | 0.716 | 0.947 | 0.962 |
| GenSim | 0.027 | 0.077 | 0.055 |
| Chess (tolerance 0.01m, 15 degrees) | |||
| Our Method | 0.890 | 0.929 | 0.980 |
| GenSim | 0.394 | 0.443 | 0.430 |
We show that with LLM-based simulation generation, our proposed method can successfully perform long-horizon complex tasks while the control condition (randomly placing objects on the table) fails. Our contributions allow LLM-powered robots to be capable of performing real world tasks where environmental states must be rigorously tracked and propagated across long-horizon complex tasks.
V Conclusion
Current demonstration generation approaches using LLMs in imitation learning frameworks are limited by the coverage of the sample set. When the demonstration set lacks examples for dynamically evolving situations, the model may fail to generalize, leading to cascading errors during robotic execution. Our experiments confirm that existing frameworks are particularly prone to such failures in long-horizon tasks. To address this limitation, we propose a state-aware approach that enhances demonstration coverage. Our implementation improves the success rate of long-horizon tasks, achieves an up to 98% success rate in these tasks, compared to the controlled condition for the existing approach, which only had a success rate of up to 60%, and some tasks experience catastrophic failure.
Appendix
V-A Formalism of the River Crossing Puzzle
To demonstrate our methodology, here we use the river crossing task as an example, which is a task with constraints that requires reasoning while robot moving. The game involves four entities—Human, Sheep, Wolf, and Grass. They must be transported from red land to green land via a boat with limited capacity. We define the following constraints to the task:
-
•
The robot can move one entity per operation between adjacent locations (red land - boat - green land).
-
•
Sheep cannot coexist with Wolf or Grass without the Human presence.
-
•
The boat holds no more than two entities, requiring Human’s presence when occupied by two.
We now present our LLM-based symbolic planning approach, through the following formalization steps.
V-A1 State Space Definition
We formalize the problem as a 4-tuple where:
-
•
1. (Positions)
-
•
2. (Entities)
-
•
3. : 16 possible move operations between positions
-
•
4. : Safety and capacity constraints
The complete state space is generated through a Cartesian product:
| (2) |
Each state is encoded as:
| (3) |
V-A2 States Filtering
Here for this river-crossing task, we define the constraint as :
| (4) | |||||
| (5) | |||||
where is the indicator function that equals 1 when the condition is true and 0 otherwise, corresponds to the second constrains and corresponds to the third constraint. For example, state violates (sheep and wolf unsupervised), while violates (3 entities in boat). The LLM agent will generate filter code that implements the above logic. After applying these constraints, the state space is reduced from 81 state candidates to 40 valid states.
V-A3 Operations and Transitions Filtering
We here define a transition to be the complete path of a source state, an operation, and a resultant state. Valid transitions require operation-specific preconditions and post-validation. For a transition :
| (6) | ||||
where is the precondition for operation in state , is the location of entity , is the source location, is the destination location, and is a constraint ensuring the boat capacity isn’t exceeded in the resulting state . This precondition states that an entity must be at the source location, and either we are moving from the boat to a land, or from a land to the boat (if capacity allows). For example, moving sheep from boat to green land requires: 1) Sheep is in boat, 2) Human remains with Wolf/Grass, and 3) Boat capacity remains valid. LLM agent generate executable filter script for the same logic, and after applying these LLM-generated filters, we can construct an accurate SMSL text for the FSM with much less human validation and correction compared to direct generation using LLM.
V-B Task Demonstration Generation Code
References
- [1] T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell et al., “Language models are few-shot learners,” Advances in neural information processing systems, vol. 33, pp. 1877–1901, 2020.
- [2] M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. D. O. Pinto, J. Kaplan, H. Edwards, Y. Burda, N. Joseph, G. Brockman et al., “Evaluating large language models trained on code,” arXiv preprint arXiv:2107.03374, 2021.
- [3] L. Wang, Y. Ling, Z. Yuan, M. Shridhar, C. Bao, Y. Qin, B. Wang, H. Xu, and X. Wang, “Gensim: Generating robotic simulation tasks via large language models,” arXiv preprint arXiv:2310.01361, 2023.
- [4] P. Hua, M. Liu, A. Macaluso, Y. Lin, W. Zhang, H. Xu, and L. Wang, “Gensim2: Scaling robot data generation with multi-modal and reasoning llms,” arXiv preprint arXiv:2410.03645, 2024.
- [5] J. Wu, R. Antonova, A. Kan, M. Lepert, A. Zeng, S. Song, J. Bohg, S. Rusinkiewicz, and T. Funkhouser, “Tidybot: Personalized robot assistance with large language models,” Autonomous Robots, vol. 47, no. 8, pp. 1087–1102, 2023.
- [6] S. H. Høeg and L. Tingelstad, “More than eleven thousand words: Towards using language models for robotic sorting of unseen objects into arbitrary categories,” in Workshop on language and robotics at CoRL 2022, 2022.
- [7] J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichter, P. Florence, and A. Zeng, “Code as policies: Language model programs for embodied control,” in 2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 9493–9500.
- [8] M. Shridhar, L. Manuelli, and D. Fox, “Cliport: What and where pathways for robotic manipulation,” in Conference on robot learning. PMLR, 2022, pp. 894–906.
- [9] R. E. Fikes and N. J. Nilsson, “Strips: A new approach to the application of theorem proving to problem solving,” Artificial intelligence, vol. 2, no. 3-4, pp. 189–208, 1971.
- [10] C. R. Garrett, T. Lozano-Pérez, and L. P. Kaelbling, “Pddlstream: Integrating symbolic planners and blackbox samplers via optimistic adaptive planning,” in Proceedings of the international conference on automated planning and scheduling, vol. 30, 2020, pp. 440–448.
- [11] Y.-q. Jiang, S.-q. Zhang, P. Khandelwal, and P. Stone, “Task planning in robotics: an empirical comparison of pddl-and asp-based systems,” Frontiers of Information Technology & Electronic Engineering, vol. 20, pp. 363–373, 2019.
- [12] J. A. Baier, F. Bacchus, and S. A. McIlraith, “A heuristic search approach to planning with temporally extended preferences,” Artificial Intelligence, vol. 173, no. 5-6, pp. 593–618, 2009.
- [13] J. Hoffmann, “Ff: The fast-forward planning system,” AI magazine, vol. 22, no. 3, pp. 57–57, 2001.
- [14] M. Helmert, “The fast downward planning system,” Journal of Artificial Intelligence Research, vol. 26, pp. 191–246, 2006.
- [15] M. Ahn, A. Brohan, N. Brown, Y. Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gopalakrishnan, K. Hausman et al., “Do as i can, not as i say: Grounding language in robotic affordances,” arXiv preprint arXiv:2204.01691, 2022.
- [16] P. A. Jansen, “Visually-grounded planning without vision: Language models infer detailed plans from high-level instructions,” arXiv preprint arXiv:2009.14259, 2020.
- [17] S. S. Kannan, V. L. Venkatesh, and B.-C. Min, “Smart-llm: Smart multi-agent robot task planning using large language models,” in 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 12 140–12 147.
- [18] Y. Liu and M. Armand, “A roadmap towards automated and regulated robotic systems,” arXiv preprint arXiv:2403.14049, 2024.
- [19] L. P. Kaelbling and T. Lozano-Pérez, “Hierarchical task and motion planning in the now,” in 2011 IEEE International Conference on Robotics and Automation. IEEE, 2011, pp. 1470–1477.
- [20] W. Huang, F. Xia, T. Xiao, H. Chan, J. Liang, P. Florence, A. Zeng, J. Tompson, I. Mordatch, Y. Chebotar et al., “Inner monologue: Embodied reasoning through planning with language models,” arXiv preprint arXiv:2207.05608, 2022.
- [21] I. Singh, V. Blukis, A. Mousavian, A. Goyal, D. Xu, J. Tremblay, D. Fox, J. Thomason, and A. Garg, “Progprompt: Generating situated robot task plans using large language models,” in 2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 11 523–11 530.
- [22] T. Osa, J. Pajarinen, G. Neumann, J. A. Bagnell, P. Abbeel, J. Peters et al., “An algorithmic perspective on imitation learning,” Foundations and Trends® in Robotics, vol. 7, no. 1-2, pp. 1–179, 2018.
- [23] H. Ravichandar, A. S. Polydoros, S. Chernova, and A. Billard, “Recent advances in robot learning from demonstration,” Annual review of control, robotics, and autonomous systems, vol. 3, no. 1, pp. 297–330, 2020.
- [24] S. Schaal, “Is imitation learning the route to humanoid robots?” Trends in cognitive sciences, vol. 3, no. 6, pp. 233–242, 1999.
- [25] B. D. Argall, S. Chernova, M. Veloso, and B. Browning, “A survey of robot learning from demonstration,” Robotics and autonomous systems, vol. 57, no. 5, pp. 469–483, 2009.
- [26] A. Billard, Y. Epars, S. Calinon, S. Schaal, and G. Cheng, “Discovering optimal imitation strategies,” Robotics and autonomous systems, vol. 47, no. 2-3, pp. 69–77, 2004.
- [27] Y. Duan, M. Andrychowicz, B. Stadie, O. Jonathan Ho, J. Schneider, I. Sutskever, P. Abbeel, and W. Zaremba, “One-shot imitation learning,” Advances in neural information processing systems, vol. 30, 2017.
- [28] C. Finn, T. Yu, T. Zhang, P. Abbeel, and S. Levine, “One-shot visual imitation learning via meta-learning,” in Conference on robot learning. PMLR, 2017, pp. 357–368.
- [29] E. Jang, A. Irpan, M. Khansari, D. Kappler, F. Ebert, C. Lynch, S. Levine, and C. Finn, “Bc-z: Zero-shot task generalization with robotic imitation learning,” in Conference on Robot Learning. PMLR, 2022, pp. 991–1002.
- [30] A. Brohan, N. Brown, J. Carbajal, Y. Chebotar, X. Chen, K. Choromanski, T. Ding, D. Driess, A. Dubey, C. Finn et al., “Rt-2: Vision-language-action models transfer web knowledge to robotic control,” arXiv preprint arXiv:2307.15818, 2023.
- [31] O. M. Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu et al., “Octo: An open-source generalist robot policy,” arXiv preprint arXiv:2405.12213, 2024.
- [32] A. Zeng, M. Liu, R. Lu, B. Wang, X. Liu, Y. Dong, and J. Tang, “Agenttuning: Enabling generalized agent abilities for llms,” arXiv preprint arXiv:2310.12823, 2023.
- [33] M. Hu, P. Zhao, C. Xu, Q. Sun, J. Lou, Q. Lin, P. Luo, S. Rajmohan, and D. Zhang, “Agentgen: Enhancing planning abilities for large language model based agent via environment and task generation,” arXiv preprint arXiv:2408.00764, 2024.