Look in Different Views: Multi-Scheme Regression Guided Cell Instance Segmentation
Abstract
Cell instance segmentation is a new and challenging task aiming at joint detection and segmentation of every cell in an image. Recently, many instance segmentation methods have applied in this task. Despite their great success, there still exists two main weaknesses caused by uncertainty of localizing cell center points. First, densely packed cells can easily be recognized into one cell. Second, elongated cell can easily be recognized into two cells. To overcome these two weaknesses, we propose a novel cell instance segmentation network based on multi-scheme regression guidance. With multi-scheme regression guidance, the network has the ability to look each cell in different views. Specifically, we first propose a gaussian guidance attention mechanism to use gaussian labels for guiding the network’s attention. We then propose a point-regression module for assisting the regression of cell center. Finally, we utilize the output of the above two modules to further guide the instance segmentation. With multi-scheme regression guidance, we can take full advantage of the characteristics of different regions, especially the central region of the cell. We conduct extensive experiments on benchmark datasets, DSB2018, CA2.5 and SCIS. The encouraging results show that our network achieves SOTA (state-of-the-art) performance. On the DSB2018 and CA2.5, our network surpasses previous methods by 1.2% (AP50). Particularly on SCIS dataset, our network performs stronger by large margin (3.0% higher AP50). Visualization and analysis further prove that our proposed method is interpretable.
Introduction
With the rapid development of instance segmentation task, cell instance segmentation gradually becomes an promising application in modern medical treatment. This application aims at joint detection and segmentation of every cell in an image. There are two widely used imaging methods for living cells in medical application: fluorescence techniques and non-invasive techniques. Image boundaries using fluorescence techniques are clearer, while non-invasive techniques allows imaging cells without damaging the cell structure.

Recently, many instance segmentation methods have made great success in this field (Bouyssoux, Fezzani, and Olivo-Marin 2022; Yi et al. 2019a). The existing notable instance segmentation methods can be divided into two categories: single-stage and multi-stage methods. The multi-stage methods decompose the instance segmentation task into two parts: object detection and mask segmentation (He et al. 2017; Liu et al. 2018). The single-stage methods integrate detection and segmentation into a whole architecture, where some methods are followed single-stage target detection networks (Wang et al. 2020a; Bolya et al. 2019) and others are inspired by anchor-free detection models (Xie et al. 2020; Sofiiuk, Barinova, and Konushin 2019). Even though huge success has been achieved, there still exists two main weaknesses shown in Fig. 1. Intuitively, densely packed cells be recognized into one cell (Fig.1 (a)) and elongated cells be recognized into two cells (Fig.1 (b)).
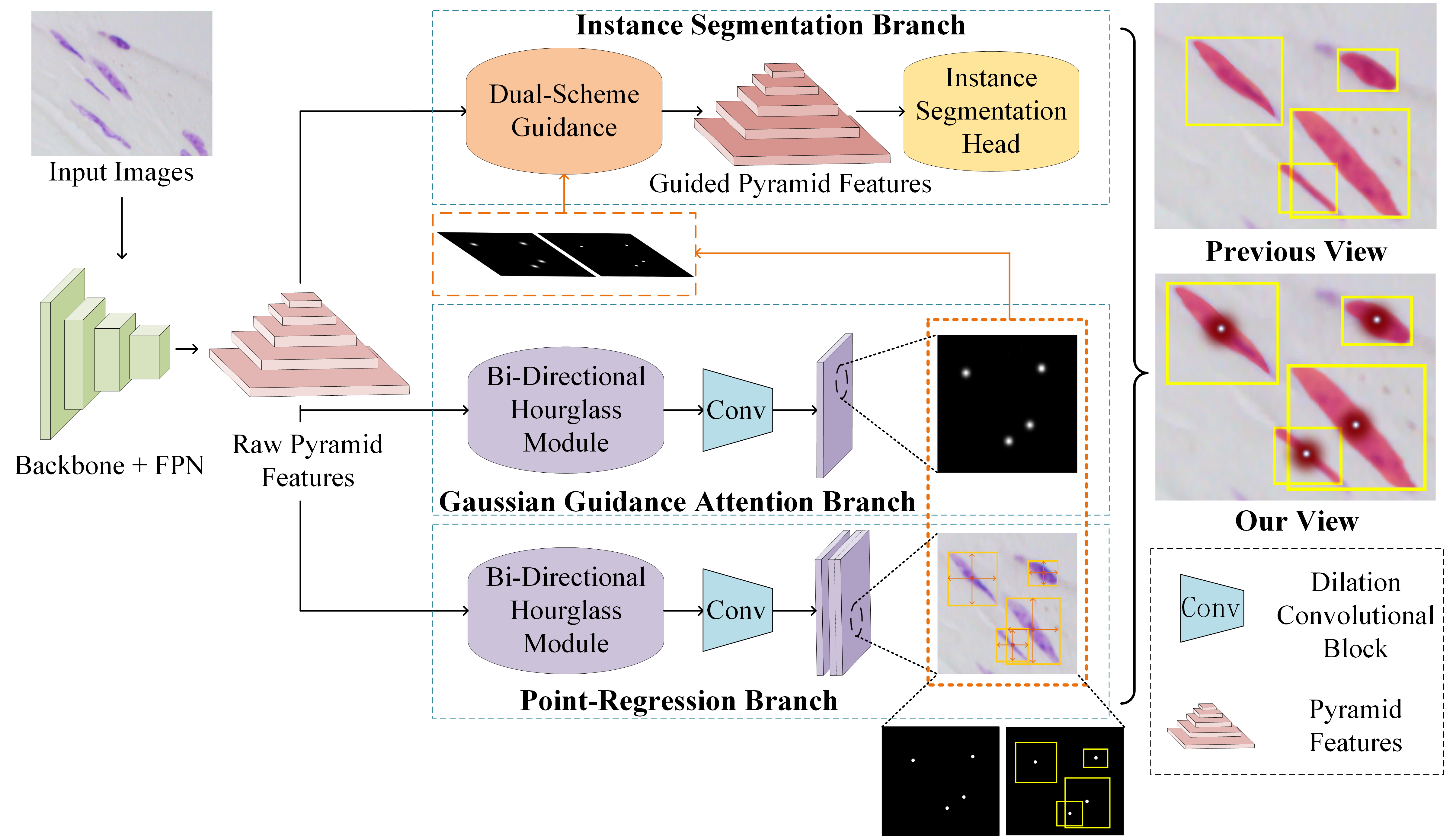
In this paper, we propose a multi-scheme regression guided cell instance segmentation network, MSRNet, to address the weaknesses above. By applying multi-scheme regression, MSRNet makes it easier to regress the correct cell center location. Since MSRNet pays more attention to the center of the cell, the discriminating ability between different individual cells has been improved. As shown in Fig. 2, we propose a gaussian guidance attention branch (GGAB) and point-regression branch (PRB) alongside with instance segmentation branch. Specifically, GGAB predicts the approximate location of the cell center on the image. In this branch, a bi-directional hourglass module is used to make the output features have both the detailed lower level features and necessary higher level features. gaussian labels are used to supervise the learning. With this design, the weakness shown in Fig.1 (b) can be maximally eased, because the instance segmentation branch focus more on the regions around cell center so that one cell is not easily be recognized into two. PRB locates the cell centers in a fine-grained manner. In this branch, after a bi-directional hourglass module, the point-wise masks and the height and width information of each cell are used to supervise the learning. With this design, the weakness shown in Fig.1 (a) can be maximally eased, because gaussian mask can’t easily recognize densely packed cells, while more fine-grained point-regression branch can correctly localize these cells’ center points. Besides, we present a dual-scheme guidance module before instance segmentation head. This module could guide the instance segmentation branch with two types of masks from the output of GGAB and PRB. Compared to previous method, our proposed MSRNet regress the cell position from multiple schemes, in order to correctly locate each cell center. Basically, our proposed MSRNet can look cells in different views. Extensive experiments demonstrate that MSRNet achieves SOTA performance on DSB2018, CA2.5 (Huang et al. 2021) and SCIS (Edlund et al. 2021) datasets. Noteworthy, MSRNet performs stronger by large margin (3.0% higher AP50) on SCIS dataset. Visualization and analysis further demonstrate the interpretability of our proposed MSRNet. The contributions of this paper are summarized as follows:
-
•
We propose a gaussian guidance attention branch to make the instance segmentation branch focus on the regions around cell center.
-
•
We propose a point-regression branch in order to enhance the regression ability of MSRNet to locate the cell center in a fine-grained manner, which can further distinguish densely packed cells.
-
•
We present a dual-scheme guidance module to guide the instance segmentation branch receive from two types of masks from the output of the other two branches.
- •
Related Work
Medical Image Instance Segmentation
There are currently two main categories for instance segmentation: single-stage and multi-stage methods. The process of multi-stage methods is to first find out the bounding boxes by means of object detection, then pixel-wise segmentation is been performed within the proposed regions. Mask R-CNN (He et al. 2017) is the most famous method under this approach, which merges a mask branch parallel to the bounding boxes branch for Faster R-CNN (Ren et al. 2017). A large number of Mask R-CNN based instance segmentation works have been proposed in recent years. For example, Cascade Mask R-CNN (Cai and Vasconcelos 2021) uses cascade regressors and detectors to enable instance segmentation head to better fit the data; Hybrid Task Cascade (HTC) (Chen et al. 2019a) crosses the bounding box regression branch and mask prediction branch, and use information from semantic labels to guide instance segmentation. Sample Consistency Network (SCNet) (Vu, Kang, and Yoo 2021) improves the network structure of Cascade Mask R-CNN to ensure that the IoU distribution in training time and inference time is close. In recent years, many excellent works relate to single-stage instance segmentation have been published, some of these methods are faster and more accurate than Mask R-CNN. For example, SOLO (Wang et al. 2020a) transforms the instance segmentation task into a classification task. The main method of SOLO is to divide the image into S*S regions and use two branches to predict category and mask of each instance. SOLOv2 (Wang et al. 2020b) further enhances the performance of SOLO.
For medical image instance segmentation tasks, especially cell instance segmentation tasks, the difficulties encountered in segmentation are mainly the dense distribution of instances, unclear instance boundaries and the variability in the appearance of different instances(Yi et al. 2018b, a). These cause difficulties for the regression of cell locations. For this task, many specialized instance segmentation networks are proposed. For example, DCAN (Li et al. 2020b) is an efficient net which uses two different branches to output the results of object detection and contours segmentation. STARDIST (Schmidt et al. 2018) uses the prior that cells are all convex polygon shapes for segmentation, which requires that the cells in the dataset be convex. CosineEmbedding (Payer et al. 2018) recognizes cells by clustering, while it tends to produce a large number of false positives due to the different clustering results of each cell.
Point-guided Attention Mechanism
The attention mechanism is a module inspired by human visual mechanism that helps model to focus on the more critical parts of the input image. Attention mechanism was first proposed in a language translation task (Cho et al. 2014), now it has been used for all aspects of tasks including classification (Yang et al. 2016), object detection (Schlemper et al. 2018), and image segmentation (Oktay et al. 2018) and can be divided into two categories: soft attention and hard attention (Xu et al. 2015). Guided Attention Inference Network (GAIN) (Li et al. 2020a) explains what the learner focus on, and can feeds back with direct guidance towards specific tasks. Mask-guided Contrastive Attention Model (Song et al. 2018) helps the feature extractor focus on body region instead of background region, so that the network will be more adaptable to the background. In this paper, we introduce a gaussian cell center annotation to supervise the gaussian guidance attention branch. We take inspiration of some networks based on gaussian guidance. MCNN (Zhang et al. 2016) is proposed to regress gaussian maps for different head sizes with multi-column convolutions. CSRNet (Li, Zhang, and Chen 2018) uses a series of dilated convolutional blocks to have a large field of perception and be able to extract deep features. Ma et al. present a bayesian loss (Ma et al. 2019) which directly use the point annotations as supervision, use expectations instead of pseudo labels to calculate loss. We take advantage of such methods and propose a gaussian guidance attention branch for instance segmentation.
Method
In this paper, we propose MSRNet for cell instance segmentation. With multi-scheme regression mechanism, the weaknesses encountered (Fig.1) in cell instance segmentation will be alleviated. The overview of our proposed network is illustrated in Fig. 2. Generally, there are three branches, which are instance segmentation branch, gaussian guidance attention branch and point-regression branch.
Gaussian Guidance Attention Branch
Single cell recognized as multiple cells is a serious weakness in cell instance segmentation. When cells are elongated, they are easily to be incorrectly recognized into two separated smaller cells. Aiming at this weakness, we propose a gaussian guidance attention branch. During training phase, this attention branch will learn to generate gaussian prediction masks for cell images. With optimization, our backbone will pay more attention on the center region of cells. On this branch, we first use the instance segmentation label to construct a gaussian mask for each input image. In this paper, we use the object center positions to construct our gaussian masks. Specifically, around the center position, we generate each cell’s mask processed by a gaussian kernel. We treat the upper limit of the gaussian radius as a hyperparameter in this paper. When the length of the bounding box’s short edge is shorter than this gaussian radius, this short edge’s length will be used as the new gaussian radius to prevent the gaussian circle from overflowing the bounding box range.
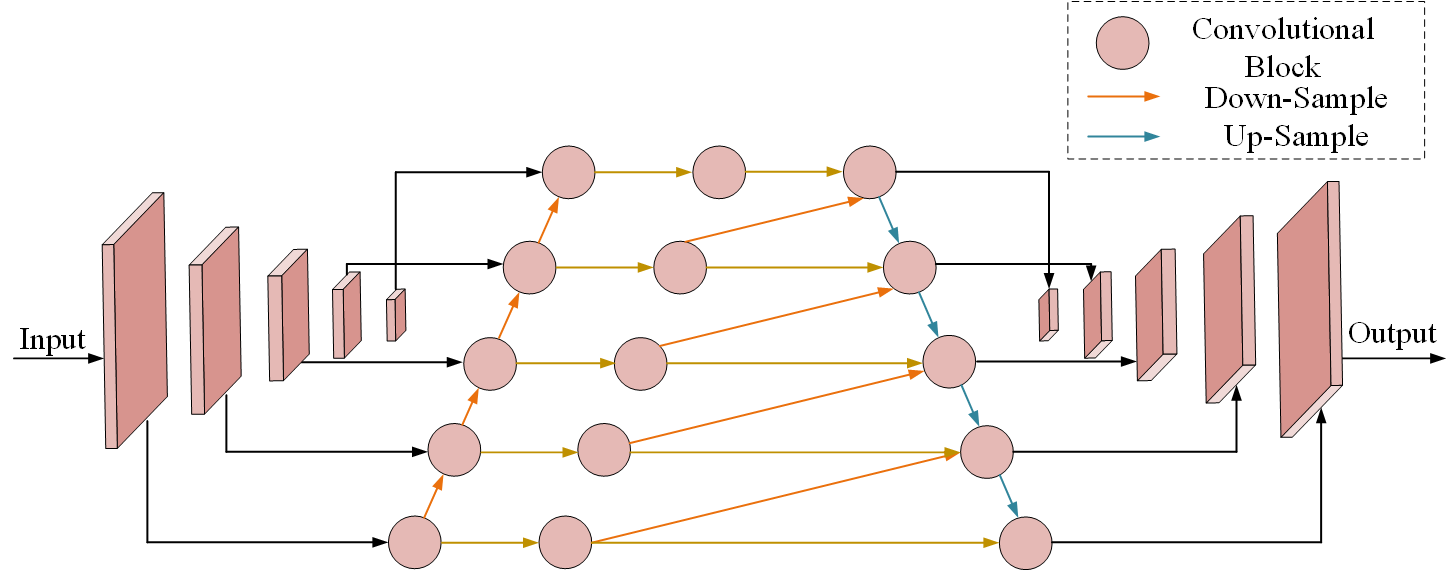
In general, low-level features contain more detailed information, which is urgently needed for instance segmentation of densely packed cells. To take full advantage of the multi-level features, we present a bi-directional hourglass module. In this module, a bottom-up fusion is first applied to the pyramid features to make each layer of features obtain detailed features. Then the highest level feature map is processed by multiple up-samplers. After each up-sampling, a channel-wise concatenation is fused with the features at same stage and previous stage (requires an additional down-sampling). This module enables the output features to preserve as much detailed information as possible and necessary high level feature map’s information. Some dilation convolutional blocks are then applied to the output feature. Finally, we adopt a MSE (Mean-Square Error) loss to supervise the learning using the gaussian mask.
| (1) | ||||
where means convolutional blocks while and are learnable parameters that control the proportion learn from each input feature map. indicates upsamplers and .
To solve the weakness (b) showing in Fig. 1, we propose GGAB to improve the network’s perception of the cell’s central region. This module can help the feature map to generate sufficient activation in central region, thus prevent the cells from being truncated.
Point-Regression Branch
Paralleled to GGAB, we propose a point-regression branch. Similar to GGAB, raw pyramid features is processed by a bi-directional hourglass module. Then, passed through some convolutional blocks, two types of masks are generated, which are center point masks and height-width predictions. These should be supervised by two types of ground truths constructed by instance segmentation labels. The center point mask has a non-zero value only at the cell-centered pixels. The height-width label is a 2-channel tensor that contains the height and width data of each boundary boxes of instance segmentation labels. Only the center point masks are used to guide the instance segmentation branch in the dual-scheme guidance module, while the height-width predictions are only used to assist the PRB to regress the correct cell center’s position.
By applying this module, we aim to solve the weakness (a) showing in Fig. 1. When two cells are densely packed, gaussian masks may have difficulty distinguishing between these two cells, because predicted gaussian masks may also be densely packed. Under this situation, instance segmentation branch may recognize these two cells as one with confusing guidance. On solving this weakness, we propose point regression branch to regress the location of cells in a fine-grained manner.
Although PRB is effective, using PRB alone without GGAB is far less effective than using two branches at the same time. Because PRB cannot generate enough activation in the central region, using PRB alone cannot efficiently resolve weakness (a) showing in Fig. 1.
Dual-Scheme Guidance Module
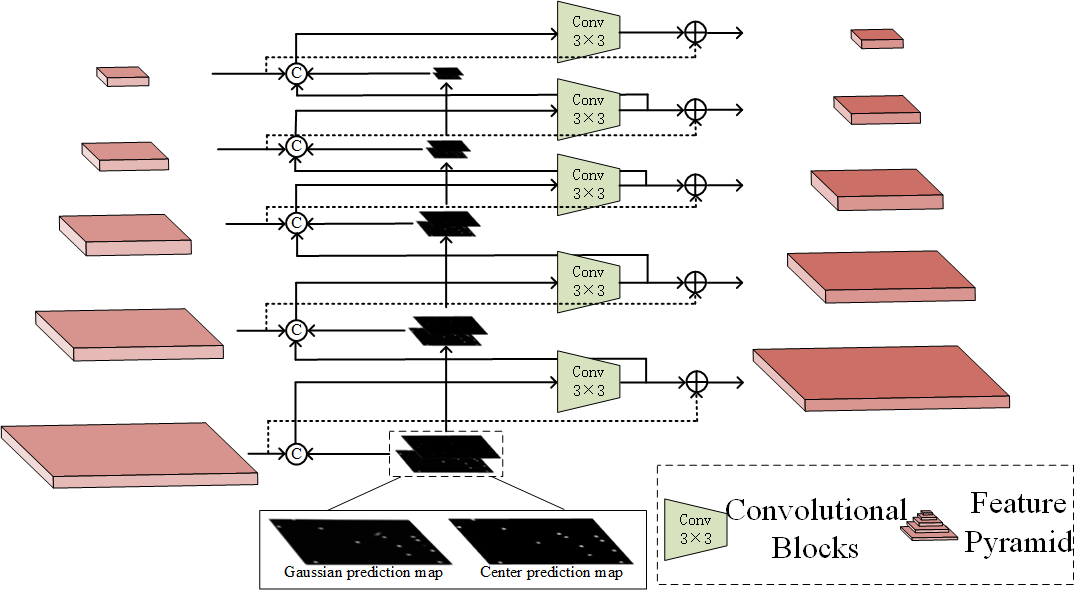
Gaussian masks obtained in GGAB () and the point masks obtained in the PRB () contain information of each cell’s center position. Therefore, the raw pyramid features can enhance cell location ability guided by these two masks. Through dual-scheme guidance, MSRNet can adapt to the cells of various appearances. Specifically, The prediction masks need to be processed by a series of max-pooling layers, then be concatenated into the feature map of the same size in pyramid features. At the same time, output features of the lower level layers will be processed by a downsampler and be concatenated to upper level input features. Convolutional blocks are then applied to the features after concatenation is completed, and the output feature maps have the same number of channels as the raw pyramid features. Finally, raw pyramid features need to be added to these feature maps, which are used for enable the fused feature map to retain the features in the original pyramid features. The framework of our dual-scheme guidance module is shown in Fig. 4. Through this guidance, we obtain the input pyramid features of instance segmentation branch (Ren et al. 2015).
| (2) |
| (3) |
where represents the feature map of the ith level of features in the output pyramid features, similarly, the represents the ith level of input pyramid features. The and represents and feature maps be processed by i downsamplers.
Such processing allows the feature maps at each level to retain the detailed information while accept the useful information from dual-scheme prediction masks.
Loss Functions
By using a multi-task loss, we train our MSRNet in an end-to-end manner.
| (4) |
The gaussian mask prediction loss measures the distance between our predict gaussian masks and gaussian ground truths. represents the batch size. denotes the value of ground truths at the point , while the denotes the value of predictions at the point .
| (5) |
where indicates the value of ground truths at the point , while the represents the value of predictions at the point . represents the batch size, and and are hyper-parameters.
| (6) |
where n represents the total number of cells in the input image. The and are width and length of each cell in our prediction. Only when the predicted cell center location is exactly the same as the actual cell location, the cell length and width will be calculated in the Loss function. The and represents the ground truths of height and width of cells. S represents the scale_factor. Combining these two parts, the is as follows:
| (7) |
| Methods | DSB2018 | CA2.5 | ||
|---|---|---|---|---|
| Mask R-CNN (He et al. 2017) | 69.9 | 54.7 | 87.5 | 80.2 |
| DCAN (Li et al. 2020b) | 51.9 | 23.5 | 72.4 | 62.8 |
| CE (Payer et al. 2018) | 17.9 | 3.4 | 47.4 | 24.4 |
| KG (Yi et al. 2019b) | 71.6 | 59.8 | - | - |
| SCNet (Vu, Kang, and Yoo 2021) | 75.8 | 61.2 | 90.5 | 83.2 |
| Ours | 77.0 | 62.2 | 91.7 | 84.0 |
| Methods | SCIS | |
|---|---|---|
| Mask R-CNN (He et al. 2017) | 18.2 | 1.6 |
| CM R-CNN (Cai and Vasconcelos 2021) | 26.5 | 3.9 |
| HTC (Chen et al. 2019a) | 28.6 | 4.1 |
| SCNet (Vu, Kang, and Yoo 2021) | 30.4 | 4.2 |
| Ours | 33.4 | 4.9 |
represents the loss of cell centroid regression, while is the loss used in height-width regression. In summary, The multi-task loss is as follows:
| (8) |
where is similar to the Loss function used in the Cascade Mask R-CNN (Cai and Vasconcelos 2021), is the loss used in predicting the gaussian masks in the GGAB, is the loss used in PRB. The , and are all hyper-parameters.
Experiments
Experimental Settings
Datasets
We evaluate MSRNet on three cell instance segmentation datasets including the 2018 Data Science Bowl (DSB2018), CA2.5 (Huang et al. 2021) and Sartorius Cell Instance Segmentation (SCIS) datasets. DSB2018 dataset contains a total of 670 images, and the difficulty of this dataset mainly lies in the variety of image sizes, magnifications, imaging types and cell types. The CA2.5 dataset consists of 524 fluorescence images of 512×512 size, which contains some severely densely packed cell images with large differences in the brightness. The Sartorius Cell Instance Segmentation (SCIS) dataset is from a Kaggle‘s cell instance segmentation competition recently, which focus on neuronal cell instance segmentation. This dataset consists of a total of 606 images of 520×704 size. The images in this dataset are from LIVECell dataset, a large-scale dataset for label-free live cell segmentation (Edlund et al. 2021).
Implementation Details
We use ResNet101 (He et al. 2016) as the backbone and experiment on three datasets. For the experiments on all datasets, images are resized to 512×512 and randomly divided into train, validation and test sets in the ratio of 6:2:2. Using Pytorch (Paszke et al. 2019) and MMDetection (Chen et al. 2019b), we conduct experiments on a 3090ti GPU with a batch_size of 4 for 24 epochs using AdamW (Loshchilov and Hutter 2019) optimizer. The detection and segmentation results are evaluated with the standard COCO-style Average Precision (AP) metric.
Results
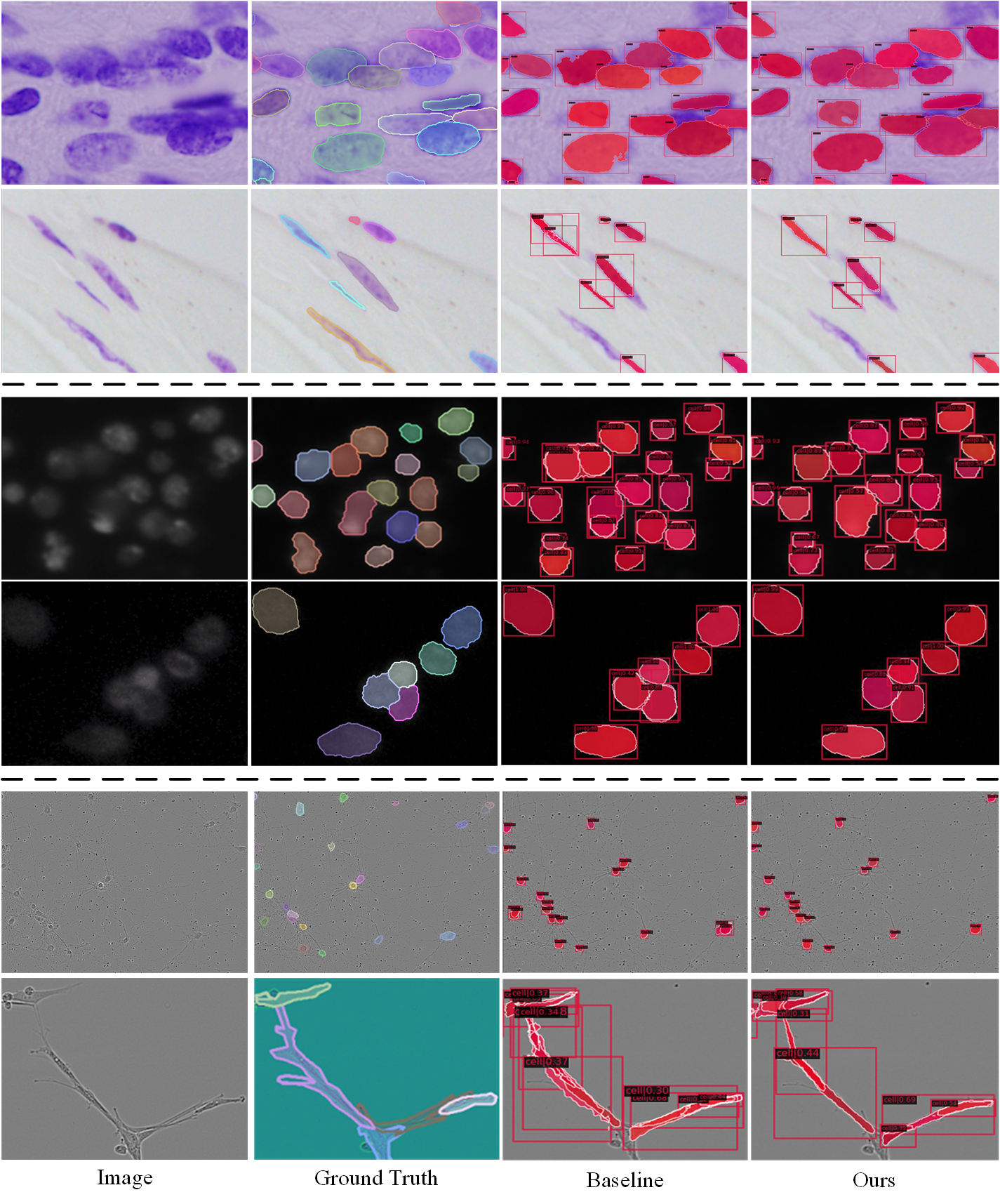
The performance of our method are compared with other SOTA instance segmentation methods, such as Mask R-CNN (He et al. 2017), DCAN (Li et al. 2020b), CosineEmbedding (Payer et al. 2018) and SCNet (Vu, Kang, and Yoo 2021). Specially, due to the CA2.5 and SCIS dataset is very new, few result is available from other papers. So we use a series of SOTA methods on these datasets to get the baseline result. The results of the SOTA instance segmentation methods are shown in Tab. 1 and Tab. 2. Obviously, our proposed method shows the best AP50 and AP75 scores compared with other SOTA methods. The visual comparisons of our proposed method with our baseline SCNet are shown in Fig. 5, clearly, especially under dense conditions, our method performs better performance. The first line of this figure shows a simple case that our approach does not break the validity of the baseline method. Other rows contain some hard cases. For example, a single cell be recognized into two different cells (the cell in the upper left corner of the second row, and the cells on the left and right side of the fifth row, etc.). Besides, cells of the third and forth row show the densely packed cells be recognized into one cell. The last line shows an image that is very difficult for instance segmentation, for which our method has achieve some improvements compared to baseline.
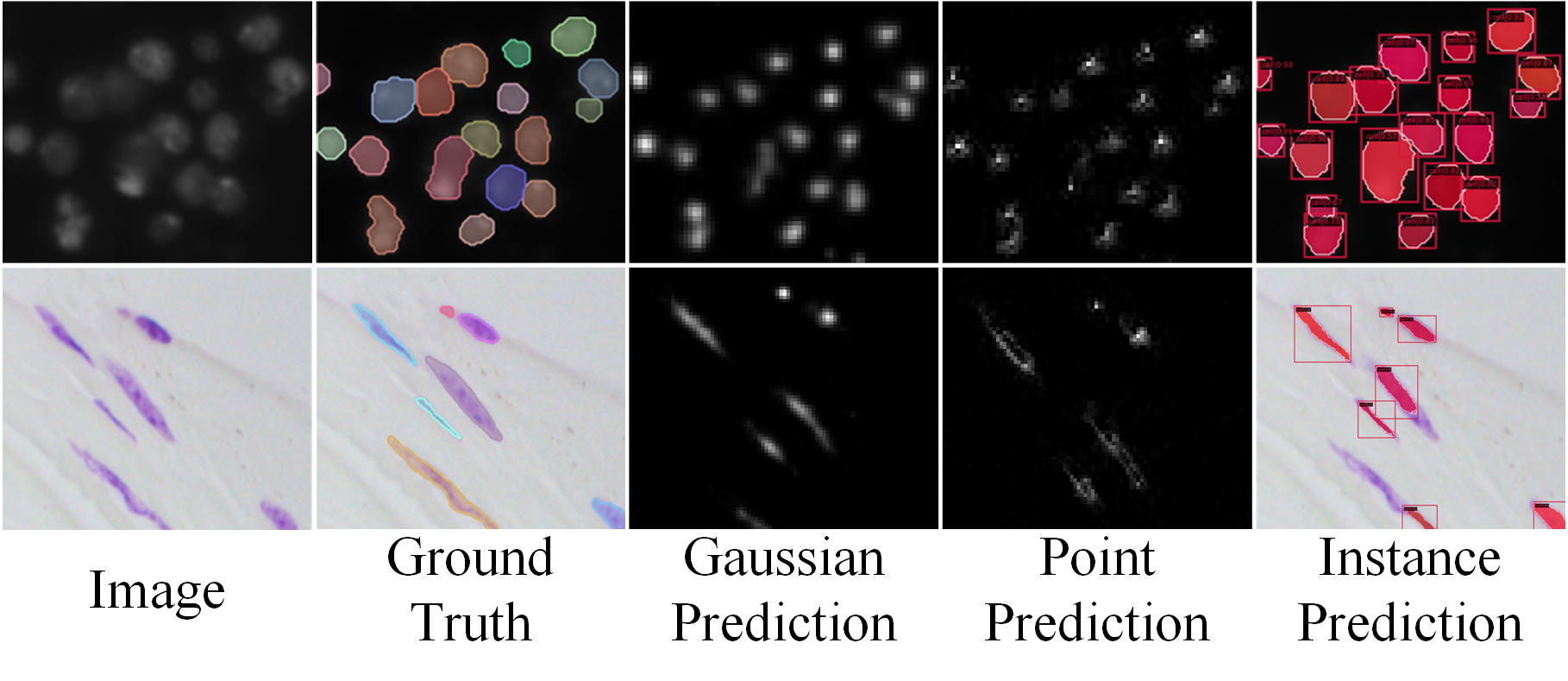
Fig. 7 shows the difference between MSRNet and baseline in terms of feature maps, from which we can directly explain the improvements of instance segmentation results. The first two columns show why our method can correctly recognize densely packed cells: in the original feature map, the feature regions of two cells are almost connected and indistinguishable, while our method’s feature maps shows significant activation in each cell’s central region, and the two activation do not overlap each other. MSRNet can use this feature to distinguish densely packed cells. The third column demonstrates why our method improves the recognition of elongated cells. MSRNet pays more attention to the central part of the cell, making it less likely be recognized into two cells. The fourth column demonstrates the improvement of the detection capability of our proposed MSRNet. MSRNet effectively reduces the probability of missing small cells by using multiple regression. In particular, fine-grained point-regression branch is useful for the detection and segmentation of small cells. Fig. 8 shows the gaussian prediction masks and point prediction masks. As can be seen from the figure, these two branches are able to correctly predict the location of each cell centers’ position.
| B | + | + | + | DSB2018 | CA2.5 | SCIS | |||
|---|---|---|---|---|---|---|---|---|---|
| ✓ | - | - | - | 75.8 | 61.2 | 90.5 | 83.2 | 30.4 | 4.2 |
| ✓ | ✓ | - | - | 76.6 | 61.3 | 91.2 | 83.6 | 31.5 | 4.7 |
| ✓ | - | ✓ | - | 76.2 | 61.2 | 90.8 | 83.2 | 31.2 | 4.5 |
| ✓ | - | - | ✓ | 76.0 | 61.3 | 91.0 | 83.4 | 31.5 | 4.2 |
| ✓ | ✓ | ✓ | - | 76.8 | 61.5 | 91.4 | 83.8 | 31.7 | 4.9 |
| ✓ | ✓ | - | ✓ | 77.0 | 62.0 | 91.6 | 84.2 | 32.4 | 4.8 |
| ✓ | ✓ | ✓ | ✓ | 77. 0 | 62.2 | 91.7 | 84. 0 | 33.4 | 4.9 |
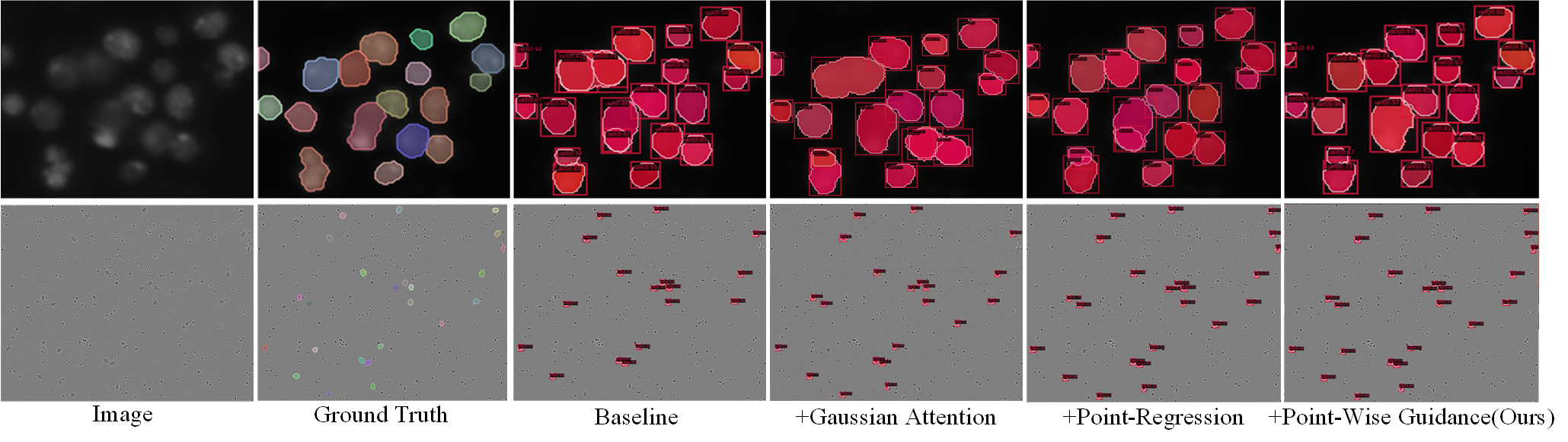

Ablation Study
Component-wise Analysis
A global component analysis was performed on our proposed MSRNet in order to show the effectiveness of it and the results are showed in Tab. 3. The baseline SCNet (Vu, Kang, and Yoo 2021) achieves the mask AP50 of 75.8% on DSB2018 dataset. After GGAB is added, the mask AP50 improves 0.8%. Then the dual-scheme guidance module is applied, the mask AP50 improves 0.1%. After PRB is added, the mask AP50 improves 0.3%. Overall, our proposed network obtains a total of 1.2% AP50 improvement on the DSB2018 dataset, while obtains a total of 1.2% improvement on the CA2.5(Huang et al. 2021) dataset and a total of 3.0% improvement on the SCIS dataset(Edlund et al. 2021).
From Fig. 6, we can intuitively observe the effectiveness of each module. The GGAB mainly solves the weakness of single cell be recognized into multiple cells, while the PRB is primarily dedicated to solve the weakness of multiple cells be recognized into a single cell. The dual-scheme guidance module can guide the instance segmentation branch using the output of GGAB and PRB.
Gaussian Guidance Attention Branch
The importance of GGAB has been clearly indicated in Tab. 3. After GGAB is applied on the DSB2018 dataset, the mask AP50 is improved from 75.8% to 76.6%. The mask AP50 on the other two datasets are also improved from 90.5% to 91.2% and 30.4% to 31.5%. To prove that our bi-directional hourglass module is effective, we compare the segmentation results before and after adding this module, as shown in Tab. 4. Tab. 5 shows the effect of changing the hyper-parameter gaussian radius. This table shows that changing the value of gaussian radius has a great impact on the performance of MSRNet. When the gaussian radius is too small, harsh conditions can lead to regression difficulties, while when the gaussian radius is too large, it will be more difficult for MSRNet to recognize densely packed cells.
| Methods | DSB2018 | CA2.5 | SCIS | |||
|---|---|---|---|---|---|---|
| Ours w/o H | 76.8 | 61.9 | 91.5 | 83.7 | 33.1 | 4.8 |
| Ours w/o C | 76.7 | 61.7 | 91.6 | 83.8 | 31.9 | 4.5 |
| Ours | 77.0 | 62.2 | 91.7 | 84.0 | 33.4 | 4.9 |
| Gaussian Radius | DSB2018 | CA2.5 | ||
|---|---|---|---|---|
| 1 / pixel | 75.9 | 61.3 | 90.7 | 83.3 |
| 2 / pixel | 76.6 | 61.5 | 91.4 | 83.7 |
| 3 / pixel | 77.0 | 62.0 | 91.6 | 84.2 |
| 4 / pixel | 76.8 | 61.8 | 91.5 | 84.0 |
| 5 / pixel | 76.4 | 61.0 | 91.3 | 83.8 |
Dual-Scheme Guidance Branch
This branch can guide the instance segmentation branch by two types of masks from the output of GGAB and PRB. After applying this branch, the mask AP50 on DSB2018 dataset is improved from 76.6% to 76.8%. The mask AP50 on the other two datasets are also improved from 91.2% to 91.6% and 31.5%to 32.4%.
Point-Regression Branch
Tab. 3 shows how much this branch can improve the performance of our proposed MSRNet. After this regression module is applied , the mask AP50 score on DSB2018 dataset has been improved from 76.8% to 77.0%. The mask AP50 scores on the other two datasets are also improved from 91.6% to 91.7% and 32.4% to 33.4%. Experimental results show that this fine-grained manner is effective, especially on the SCIS dataset, because the cell size in this dataset is smaller than those in other datasets.
Conclusions
In this paper, we propose a novel framework MSRNet for cell instance segmentation. By introducing the GGAB and the PRB, MSRNet can regress cell locations more accurately and be able to have a stronger perception of cell’s central region features. In addition, the dual-scheme guidance module is introduced to guide the instance segmentation branch using the output of the other two branches. Our proposed MSRNet combines the idea of multi-scheme regression with cell instance segmentation, enabling the use of different views to understand the cellular characteristics and combining the information of each views for cell instance segmentation. Our MSRNet shows improvements over the baselines on the DSB2018, CA2.5 and SCIS datasets.
References
- Bolya et al. (2019) Bolya, D.; Zhou, C.; Xiao, F.; et al. 2019. YOLACT: Real-Time Instance Segmentation. In IEEE/CVF International Conference on Computer Vision, 9156–9165.
- Bouyssoux, Fezzani, and Olivo-Marin (2022) Bouyssoux, A.; Fezzani, R.; and Olivo-Marin, J. 2022. Cell Instance Segmentation Using Z-Stacks in Digital Cytology. In IEEE International Symposium on Biomedical Imaging, 1–4.
- Cai and Vasconcelos (2021) Cai, Z.; and Vasconcelos, N. 2021. Cascade R-CNN: High Quality Object Detection and Instance Segmentation. IEEE Trans. Pattern Anal. Mach. Intell., 1483–1498.
- Chen et al. (2019a) Chen, K.; Pang, J.; Wang, J.; et al. 2019a. Hybrid Task Cascade for Instance Segmentation. In IEEE Conference on Computer Vision and Pattern Recognition, 4974–4983.
- Chen et al. (2019b) Chen, K.; Wang, J.; Pang, J.; et al. 2019b. MMDetection: Open MMLab Detection Toolbox and Benchmark. CoRR.
- Cho et al. (2014) Cho, K.; van Merrienboer, B.; Gülçehre, Ç.; et al. 2014. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. In Moschitti, A.; Pang, B.; and Daelemans, W., eds., ACL Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, 1724–1734.
- Edlund et al. (2021) Edlund, C.; Jackson, T. R.; Khalid, N.; et al. 2021. LIVECell—A large-scale dataset for label-free live cell segmentation. Nature methods, 1038–1045.
- He et al. (2017) He, K.; Gkioxari, G.; Dollár, P.; et al. 2017. Mask R-CNN. In IEEE International Conference on Computer Vision, 2980–2988.
- He et al. (2016) He, K.; Zhang, X.; Ren, S.; et al. 2016. Deep Residual Learning for Image Recognition. In IEEE Conference on Computer Vision and Pattern Recognition, 770–778.
- Huang et al. (2021) Huang, J.; Shen, Y.; Shen, D.; et al. 2021. CA-Net Nuclei Segmentation Framework with a Microscopy Cell Benchmark Collection. In de Bruijne, M.; Cattin, P. C.; Cotin, S.; et al., eds., MICCAI Medical Image Computing and Computer Assisted Intervention, Lecture Notes in Computer Science, 445–454.
- Li et al. (2020a) Li, K.; Wu, Z.; Peng, K.; et al. 2020a. Guided Attention Inference Network. IEEE Trans. Pattern Anal. Mach. Intell., 2996–3010.
- Li et al. (2020b) Li, S.; Liu, C. H.; Lin, Q.; et al. 2020b. Domain Conditioned Adaptation Network. In The Thirty-Fourth AAAI Conference on Artificial Intelligence, 11386–11393.
- Li, Zhang, and Chen (2018) Li, Y.; Zhang, X.; and Chen, D. 2018. CSRNet: Dilated Convolutional Neural Networks for Understanding the Highly Congested Scenes. In IEEE Conference on Computer Vision and Pattern Recognition, 1091–1100.
- Liu et al. (2018) Liu, S.; Qi, L.; Qin, H.; et al. 2018. Path Aggregation Network for Instance Segmentation. In IEEE Conference on Computer Vision and Pattern Recognition, 8759–8768.
- Loshchilov and Hutter (2019) Loshchilov, I.; and Hutter, F. 2019. Decoupled Weight Decay Regularization. In 7th International Conference on Learning Representations.
- Ma et al. (2019) Ma, Z.; Wei, X.; Hong, X.; et al. 2019. Bayesian Loss for Crowd Count Estimation With Point Supervision. In IEEE/CVF International Conference on Computer Vision, 6141–6150.
- Oktay et al. (2018) Oktay, O.; Schlemper, J.; Folgoc, L. L.; et al. 2018. Attention U-Net: Learning Where to Look for the Pancreas. CoRR.
- Paszke et al. (2019) Paszke, A.; Gross, S.; Massa, F.; et al. 2019. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Wallach, H. M.; Larochelle, H.; Beygelzimer, A.; et al., eds., Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems, 8024–8035.
- Payer et al. (2018) Payer, C.; Stern, D.; Neff, T.; et al. 2018. Instance Segmentation and Tracking with Cosine Embeddings and Recurrent Hourglass Networks. In Frangi, A. F.; Schnabel, J. A.; Davatzikos, C.; et al., eds., MICCAIMedical Image Computing and Computer Assisted Intervention, 3–11.
- Ren et al. (2015) Ren, S.; He, K.; Girshick, R. B.; et al. 2015. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Cortes, C.; Lawrence, N. D.; Lee, D. D.; et al., eds., Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems, 91–99.
- Ren et al. (2017) Ren, S.; He, K.; Girshick, R. B.; et al. 2017. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell., 1137–1149.
- Schlemper et al. (2018) Schlemper, J.; Oktay, O.; Chen, L.; et al. 2018. Attention-Gated Networks for Improving Ultrasound Scan Plane Detection. CoRR.
- Schmidt et al. (2018) Schmidt, U.; Weigert, M.; Broaddus, C.; et al. 2018. Cell Detection with Star-Convex Polygons. In Frangi, A. F.; Schnabel, J. A.; Davatzikos, C.; et al., eds., MICCAI Medical Image Computing and Computer Assisted Intervention, 265–273.
- Sofiiuk, Barinova, and Konushin (2019) Sofiiuk, K.; Barinova, O.; and Konushin, A. 2019. AdaptIS: Adaptive Instance Selection Network. In IEEE/CVF International Conference on Computer Vision, 7354–7362.
- Song et al. (2018) Song, C.; Huang, Y.; Ouyang, W.; et al. 2018. Mask-Guided Contrastive Attention Model for Person Re-Identification. In IEEE Conference on Computer Vision and Pattern Recognition, 1179–1188.
- Vu, Kang, and Yoo (2021) Vu, T.; Kang, H.; and Yoo, C. D. 2021. SCNet: Training Inference Sample Consistency for Instance Segmentation. In AAAI Conference on Artificial Intelligence, AAAI 2021, Thirty-Third Conference on Innovative Applications of Artificial Intelligence, IAAI 2021, The Eleventh Symposium on Educational Advances in Artificial Intelligence, EAAI 2021, Virtual Event, February 2-9, 2021, 2701–2709.
- Wang et al. (2020a) Wang, X.; Kong, T.; Shen, C.; et al. 2020a. SOLO: Segmenting Objects by Locations. In Vedaldi, A.; Bischof, H.; Brox, T.; et al., eds., Computer Vision - ECCV 16th European Conference, Lecture Notes in Computer Science, 649–665.
- Wang et al. (2020b) Wang, X.; Zhang, R.; Kong, T.; et al. 2020b. SOLOv2: Dynamic and Fast Instance Segmentation. In Larochelle, H.; Ranzato, M.; Hadsell, R.; et al., eds., Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems.
- Xie et al. (2020) Xie, E.; Sun, P.; Song, X.; et al. 2020. PolarMask: Single Shot Instance Segmentation With Polar Representation. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, 12190–12199.
- Xu et al. (2015) Xu, K.; Ba, J.; Kiros, R.; et al. 2015. JMLRShow, Attend and Tell: Neural Image Caption Generation with Visual Attention. In Bach, F. R.; and Blei, D. M., eds., Proceedings of the 32nd International Conference on Machine Learning, 2048–2057.
- Yang et al. (2016) Yang, Z.; Yang, D.; Dyer, C.; et al. 2016. Hierarchical Attention Networks for Document Classification. In Knight, K.; Nenkova, A.; and Rambow, O., eds., NAACL The 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 1480–1489.
- Yi et al. (2018a) Yi, J.; Wu, P.; Hoeppner, D. J.; et al. 2018a. Pixel-wise neural cell instance segmentation. In IEEE International Symposium on Biomedical Imaging, 373–377.
- Yi et al. (2019a) Yi, J.; Wu, P.; Huang, Q.; et al. 2019a. Context-Refined Neural Cell Instance Segmentation. In IEEE International Symposium on Biomedical Imaging, 1028–1032.
- Yi et al. (2019b) Yi, J.; Wu, P.; Huang, Q.; et al. 2019b. Multi-scale Cell Instance Segmentation with Keypoint Graph Based Bounding Boxes. In Shen, D.; Liu, T.; Peters, T. M.; et al., eds., MICCAI Medical Image Computing and Computer Assisted Intervention, 369–377.
- Yi et al. (2018b) Yi, J.; Wu, P.; Jiang, M.; et al. 2018b. Instance Segmentation of Neural Cells. In Leal-Taixé, L.; and Roth, S., eds., Computer Vision - ECCV 2018 Workshops, Lecture Notes in Computer Science, 395–402.
- Zhang et al. (2016) Zhang, Y.; Zhou, D.; Chen, S.; et al. 2016. Single-Image Crowd Counting via Multi-Column Convolutional Neural Network. In IEEE Conference on Computer Vision and Pattern Recognition, 589–597.