Low-rank representation of tensor network operators with long-range pairwise interactions
Abstract
Tensor network operators, such as the matrix product operator (MPO) and the projected entangled-pair operator (PEPO), can provide efficient representation of certain linear operators in high dimensional spaces. This paper focuses on the efficient representation of tensor network operators with long-range pairwise interactions such as the Coulomb interaction. For MPOs, we find that all existing efficient methods exploit a peculiar “upper-triangular low-rank” (UTLR) property, i.e. the upper-triangular part of the matrix can be well approximated by a low-rank matrix, while the matrix itself can be full-rank. This allows us to convert the problem of finding the efficient MPO representation into a matrix completion problem. We develop a modified incremental singular value decomposition method (ISVD) to solve this ill-conditioned matrix completion problem. This algorithm yields equivalent MPO representation to that developed in [Stoudenmire and White, Phys. Rev. Lett. 2017]. In order to efficiently treat more general tensor network operators, we develop another strategy for compressing tensor network operators based on hierarchical low-rank matrix formats, such as the hierarchical off-diagonal low-rank (HODLR) format, and the -matrix format. Though the pre-constant in the complexity is larger, the advantage of using the hierarchical low-rank matrix format is that it is applicable to both MPOs and PEPOs. For the Coulomb interaction, the operator can be represented by a linear combination of MPOs/PEPOs, each with a constant bond dimension, where is the system size and is the accuracy of the low-rank truncation. Neither the modified ISVD nor the hierarchical low-rank algorithm assumes that the long-range interaction takes a translation-invariant form.
keywords:
Matrix product operator, projected entangled-pair operator, upper-triangular low-rank matrix, hierarchical off-diagonal low-rank, -matrix, fast multipole methodAMS:
15A69, 41A99, 65Z051 Introduction
Tensor network states [37, 36], particularly presented by the matrix product states (MPS) [37, 28, 31] and projected entangled-pair states (PEPS) [34, 35, 25], are among the most promising classes of variational methods for approximating high-dimensional functions in quantum physics. Besides their successes for treating strongly correlated quantum systems [38, 23], the MPS (also known as the tensor train method (TT) [27, 26, 21]), have become useful in a wide range of applications [30, 32, 19]. A core component of tensor network algorithms is the efficient representation of linear operators. In MPS the operator representation is called the matrix product operator (MPO), and in PEPS the projected entangled-pair operator (PEPO). These forms of representation are naturally designed for short-range interactions, such as interactions of nearest-neighbor type on a regular lattice. For long-range interactions, such as those naturally appearing from electronic structure calculations due to the Coulomb interaction, a straightforward representation would lead to a large MPO/PEPO rank, which can be prohibitively expensive. Therefore efficient representation of tensor network operators with long-range interactions is crucial for the success of the methods.
In this paper, we focus on the tensor network operators with long-range pairwise interactions, such as the Coulomb interaction. A tensor network operator with pairwise interaction can be defined as
| (1) |
Here is a symmetric matrix, called the coefficient matrix of , and is called a number operator. The precise definition of , as well as the connection to the Coulomb interaction will be discussed in Section 2.
There have been a number of proposals to treat MPOs with long-range pairwise interactions. Using the exponential fitting techniques based on finite state machines (FSM) [12, 29, 14, 11, 13], the Coulomb interaction and other translation-invariant long-range interactions on one-dimensional lattice systems can be efficiently represented. For the Coulomb interaction, the MPO rank can be bounded by , where is the number of sites and is the target accuracy. For one-dimensional systems without the translation-invariance property, recently a method based on a sequence of singular value decomposition (SVD) compression operations [11, 33] has been developed. This method is observed to yield a compact MPO representation for the Coulomb interaction with basis functions arising from electronic structure calculations that are not translation-invariant. On the other hand, this is a greedy method, and there is no a priori upper bound for the MPO rank. For two-dimensional and higher dimensional lattice systems, PEPOs can provide more efficient representation of linear operators than MPOs. To our knowledge, the only efficient PEPO representation for long-range interaction is given by the recently developed correlation function valued PEPO (CF-PEPO) [24]. CF-PEPO uses a fitting method, which maps the original lattice system with translation-invariant long-range interactions to an effective system defined on a superlattice but with short-range interactions. There is no a priori upper bound for the PEPO rank. Neither is it clear whether the CF-PEPO method can be efficiently generalized to non-translation-invariant systems.
Contribution: The contribution of this paper is two-fold. First, we find that the success of both the exponential fitting method and the SVD compression method rests on the assumption that satisfies the “upper-triangular low-rank” (UTLR) property, i.e. the upper-triangular part of can be extended into a matrix that is approximately low-rank, while can be a full-rank matrix. Therefore the problem can be viewed as a special type of matrix completion problem [10]. However, this matrix completion problem is highly ill-conditioned, and standard matrix completion algorithms suffer from numerical stability problems [9, 20, 22, 8, 2]. Based on the work of [8], we develop a modified incremental singular value decomposition method (ISVD) to simultaneously find the low-rank structure in a numerically stable fashion, and to construct the MPO representation. The algorithm yields an MPO representation equivalent to that in the SVD compression method [33]. The ISVD method is not restricted to translation-invariant systems, and numerical results indicate that the performance of ISVD is comparable to (in fact is marginally better than) that of the exponential fitting methods for translation-invariant systems.
Second, we propose a new way for representing long-range interactions based on the framework of hierarchical low-rank matrices. In particular, we focus on the hierarchical off-diagonal low-rank (HODLR) format [1], and the -matrix format [15, 17]. The main advantage of the hierarchical low-rank format is that it allows us to construct efficient representation for both MPOs and PEPOs. For the Coulomb interaction, we can represent using a linear combination of MPOs/PEPOs, and the bond dimension of each MPO/PEPO is bounded by a constant. From a computational perspective, such a format can be more preferable than a single MPO/PEPO operator with bond dimension bounded by . Furthermore, the hierarchical low-rank format can also be applied to systems without the translation-invariance property.
Notation:
Throughout the paper all vectors and operators are defined on finite-dimensional spaces. We use hatted letters such as to denote high-dimensional linear operators. Vectors, matrices and tensor cores are denoted by bold font letters such as . The tensor product of and is denoted by . We use the matlab notation such as to denote sub-matrices, where are index sets. Given a certain global ordering of all indices, the notation means that for any and , we have .
Organization: The rest of the paper is organized as follows. In Section 2 we briefly introduce the MPO and PEPO representation. In Section 3 we introduce and use the UTLR structure to construct MPO representation of long-range interaction for 1D systems. In Section 4 we introduce the method to construct MPO/PEPO representation using the hierarchical low-rank matrix format. Numerical results are presented in Section 6. We conclude our work in Section 7. The rules of finite state machine (FSM) for representing non-overlapping MPOs and PEPOs are given in the Appendix A and B, respectively.
2 Preliminaries
We first briefly review the construction of MPS/MPO, as well as of PEPS/PEPO. For more detailed information we refer readers to [31, 25]. A single vector can be interpreted as an order- tensor, where the -tuple is called the size of the tensor. We assume that the index follows a lexicographic ordering (a.k.a. row-major ordering). Each entry can be accessed using multi-indices . A linear operator is an order -tensor, with each entry denoted by
The application of to gives a tensor as
which can be written in short-hand notation as .
In (1), we used as the site indices and . The sites can be organized into lattices of one, two and three dimensions. For Coulomb interaction in 1D for , and we set . In higher dimensions we use the notation to represent a lattice site. For example, on an 2D lattice we have for . For a pairwise interaction in the form of (1), the coefficient matrix has as its entries , using a row-major order, and this is written more compactly as hereafter. The Coulomb interaction takes the form , where is the Euclidean distance. Using this notation, the pairwise interaction is called translation-invariant if is a function of (in the presence of periodic boundary conditions, we may simply redefine ). In Eq. (1), we may assume for simplicity that . acts only on a single-site and should be interpreted as , where is the identity matrix of size and is an matrix. can be understood as a spin operator for quantum spin systems, or a number operator for quantum fermionic systems, though the precise form of is not relevant for the purpose of this paper.
2.1 Matrix product operators
A vector is represented by an MPS/TT format if each entry can be represented as as a matrix product
| (2) |
where each is a matrix of size . Since is a scalar, by definition . Each , called a core tensor, can be viewed as a -tensor of size , and the matrix is called the -th slice of . Since the first and third indices of are to be contracted out via matrix-multiplication operations, they are called the internal indices, while the second index is called the external index. The -tuple is called the bond dimension (a.k.a. the MPO/TT rank). Sometimes the bond dimension also refers to a single scalar .
The MPO format of a linear operator is
| (3) |
Each is also called a core tensor, and is of size . The first and the fourth indices are called the internal indices, and the second and third indices the external indices. The matrix is called a slice. Again . The -tuple , or sometimes simply , is called the bond dimension.
Consider the application of the linear operator on , denoted by , then the vector has an MPS representation as
Using the MPO representation, we may readily find that
The bond dimension of is .
The simplest example of the MPO is an operator in the tensor product form, i.e.
where is a matrix, i.e. is a scalar. In the component form
Clearly the MPO bond dimension is .
The second example is an operator with nearest-neighbor interaction, e.g.
where is the identity matrix of size . In the component form
| (4) |
can be viewed as the linear combination of MPOs in the tensor product form, and if so the resulting MPO rank would be . However, note that we may define
and
Then it can be readily verified that the MPO of the form that agrees with the component form . Hence the MPO rank is independent of and is always .
When the context is clear, we may also identify with . Then
In the MPO form, we may also omit the indices and write
The third example is an operator with a special form of long-range interaction:
We assume , and omit the component form for simplicity. The length of the interaction is characterized by . A straightforward term-by-term representation would lead to an MPO of rank . Nonetheless, using the fact that
can also be written as an MPO with rank- as
In physics literature, this is a special case of the finite state machine (FSM) [13]. For more complex settings, the FSM rule often specifies the row/column indices of each core tensor as input/output signals. We will use the language of input/output signals only in the Appendices A and B.
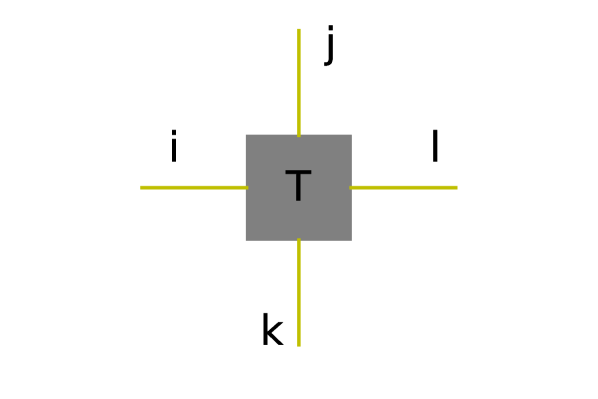
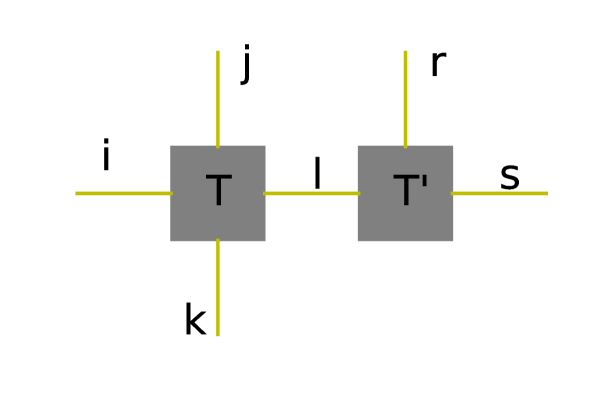
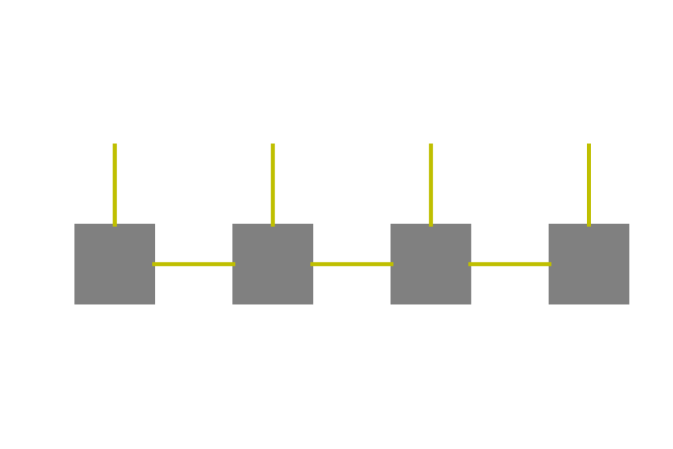
In order to proceed with the discussion of PEPS/PEPO, it is no longer productive to keep using the component form. Instead, the graphical representation of tensors is preferred. Fig. 1 shows an example of the graphical representation of tensors and tensor contraction operations. A tensor is visualized as a vertex and each index (internal and external) is represented as an edge. When two vertices are linked by an edge, the corresponding index is contracted out. A more detailed introduction can be found in [5]. Using this representation, MPS and MPO can be represented using graphs in Fig. 2 (a) and (b) respectively.
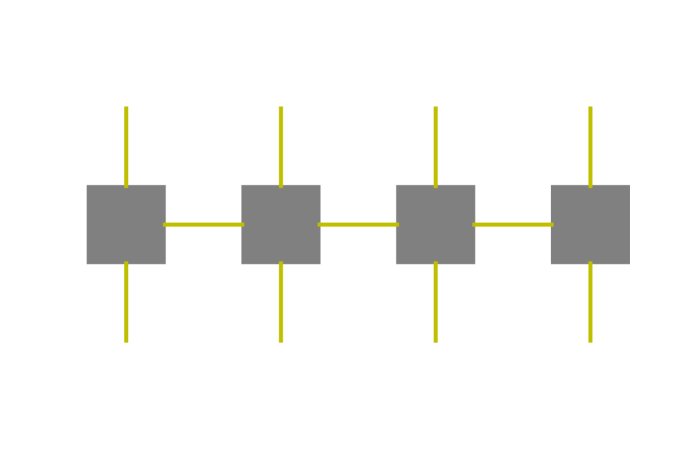
2.2 Projected entangled-pair operators
The MPS and MPO impose an intrinsically one-dimensional structure on the tensor following the index . This is a very efficient representation for certain problems defined on a one-dimensional lattice. For problems defined on a two-dimensional lattice and beyond, the PEPS and PEPO often provide a more efficient representation of vectors and linear operators, respectively. The PEPS/PEPO can be most conveniently represented using the graphical representation (see Fig. 3 (a) and (b)).
In the two-dimensional case, each core tensor in the PEPS/PEPO format has up to 5/6 indices, respectively. Similar to what we have done for MPS/MPO, the (up to 4) contracted indices are called internal indices, while remaining ones are called external indices.
3 Long-range interaction MPO in 1D systems
In this section we focus on a 1D system consisting of sites. The simplest example of constructing a long-range interaction MPO in 1D system is the exponential fitting method [29, 12, 14]. We briefly describe this method used for the Coulomb interaction. First we approximate the inverse-distance by the sum of exponentials
| (5) |
Then the tensor corresponding to the Coulomb interaction can be approximated by
where . This can be done analytically through the quadrature of an integral representation [7], or numerically through a least squares procedure. Following the discussion of the finite state machine in Section 2.1, the operator on the right-hand side can be represented by an MPO of bond dimension , the MPO tensor of which at site has the form
| (6) |
where , , and . This is true for . For the tensors at the beginning and end of the MPO we only need to use the last row and first column of the above matrix respectively. Then in order to achieve a target accuracy for a system of size , we only need [3, 6].
For the Coulomb interaction, there are two main methods for performing the exponential fitting procedure. One way is to represent as an integral, e.g.
and then approximate the right hand side with a quadrature scheme with points, such as the Gauss quadrature. This procedure results in pointwise error of in a fixed size finite interval where with upper bounded by terms [4, 7, 6]. Another way is to solve a nonlinear least squares problem to find the fitting parameters. However, this optimization problem can have many stationary points, making finding the global minimum difficult. We can only start from different reasonable initial guesses to increase the chance of obtaining the global minimum.
The exponential fitting method is efficient when is strictly decaying and translation-invariant. When either of these two conditions is not satisfied, this method needs some modification. There are methods to deal with the former by introducing complex exponents [29]. The generalization to non-translation-invariant systems can be more difficult.
In this work we propose a new perspective based on matrix completion, which naturally generalizes the exponential fitting method to situations where is neither strictly decaying nor translation-invariant. We define a rank matrix by
| (7) |
The success of the exponential fitting method rests on the fact that can agree very well with in the upper-triangular part, but can differ with arbitrarily on the diagonal part and the lower-triangular part. Indeed, the lower-triangular part of grows exponentially with respect to , while that of decays with respect to due to the symmetry of . Despite the difference, the tensor very well approximates .
More generally, we shall demonstrate that it is possible to construct an efficient MPO representation of , if the matrix satisfies the following upper triangular low rank (UTLR) property.
Definition 1 (Upper-triangular low-rank matrix).
A symmetric matrix is an upper-triangular low-rank (UTLR) matrix, if for any , there exists , and a rank- matrix , such that for any index sets ,
For a UTLR matrix , we may find its rank- approximation by solving the following optimization problem
| (8) | ||||
where denotes the set of indices corresponding to the upper-triangular part of the matrix, and is an restriction operation that returns only the elements in the set . Eq. (8) is a matrix completion problem [10].
Once the low-rank solution is obtained, where and are both matrices, we let , denote the transpose of the -th row of and respectively. Then . Therefore we can construct an MPO with the following tensor at site ():
| (9) |
Again the core tensor for and are given by the last row and the first column of Eq. (9). In order to recover the MPO construction in the exponential fitting method (6), we may define
The extra term is introduced to keep the notation consistent with a more general case discussed later.
3.1 An online matrix completion algorithm
The matrix completion problem (9) has several features:
-
1.
The sparsity pattern is always fixed to be all the upper-triangular entries.
-
2.
We are actually not concerned about restoring the missing data. The missing data only serves to support a low-rank structure, and they do not necessarily need to be explicitly computed.
-
3.
The matrix completion problem is ill-conditioned, i.e. the ratio between the largest singular value and the smallest nonzero singular value scales exponentially with respect to the system size. Therefore explicit computation of the missing entries can easily lead to an overflow error.
The last feature requires some explanation. Consider the matrix restored by the exponential fitting procedure as in (7). The lower left corner of the matrix is . Therefore this entry, and nearby entries, grow exponentially with respect to the system size. This also results in an exponential growth of the largest singular value.
For the matrix completion problem, both convex optimization-based approaches [9] and alternating least squares (ALS)-based approaches [20, 22] require some regularization term. In our case, the regularization term will become dominant even if the regularization parameter is chosen to be very small. Online matrix completion algorithms, which applies SVD compression operations incrementally [8, 2], also suffer from the exponential growth of matrix entries in the low-rank approximation. More importantly, the largest singular value, which grows exponentially with system size, also makes the matrix completion problem difficult to solve.
We introduce a modified incremental SVD (ISVD) algorithm with missing data, which avoids the computation of the SVD of the whole matrix and therefore improves the numerical stability. This method is modified from the ISVD algorithm with missing data introduced in [2, 8]. The main modification is that we add a QR factorization step which makes the method stable even for extremely ill-conditioned matrices. We also find that the resulting MPO representation is equivalent to that in [33]. For clarity, we first introduce how to apply the original ISVD with missing data on the present matrix completion problem in this section and Section 3.2. In Section 3.3 we introduce the modified algorithm.
The algorithm proceeds in a row-by-row fashion. Define the set of column indices corresponding to the sparsity pattern in the -th row, and correspondingly . Suppose we have already completed the first rows, and the completed matrix is . This matrix is rank- and has an SVD . Now we want to complete the first rows denoted by the matrix . Note that the first rows of are just , and on the -th row we have . Our goal is to choose the unknown entries , so that can also be approximated by a rank- matrix. Now assume , where . If , then is already a rank- matrix. Otherwise
| (10) |
Note that on the third line of Eq. (10), both the first and the third matrices are orthogonal matrices. Hence the smallest singular value of is upper bounded by . In order to approximate by a rank- matrix, we want to be as small as possible. This corresponds to the following optimization problem:
It is easy to see that the solution is
where denotes the Moore–Penrose inverse of . Then we obtain the truncated SVD
| (11) |
where is an matrix, are column orthogonal matrices of size . Thus we may approximate by
Thus letting
we can proceed to the next row. The , and we get in the end gives the SVD of the completed matrix (noting that ).
3.2 Constructing the MPO
We now apply the above procedure to the coefficient matrix . Let and , and use (9), we get an MPO that represents the interaction . However, this procedure is not numerically stable. Let us consider the Coulomb interaction approximated with exponential fitting method. Then the ratio grows exponentially with respect to the system size, and so is .
To solve this problem, we will make use of the interior part of the MPO tensor. Write
then we have
Thus
where . Therefore we have
Now define
| (12) |
we then have
| (13) |
Therefore we can construct an MPO whose tensors are of the form
| (14) |
to represent . This is analogous to (6) in the exponential fitting. The algorithm is summarized in Algorithm 1. Due to the fact that , as a practical algorithm we do not need to keep track of or , but only .
Note that Eq. (12) is not the only possible choice for . If the matrix is exactly of rank , then
This relation becomes approximately correct for the case when is numerically low-rank. Therefore we may set
| (15) |
We argue that Eq. (15) is in fact a better choice. Just like we can obtain without computing that grows exponentially with the system size, we want to do the same with so that it does not rely on computing either. And this is achieved by our new choice for the value of . Also, the new can be expected to give a more accurate approximation than the original one, because for an element of on the -th column, the error of the approximation using this only comes from the first SVDs, and does not depend on any future steps.
Furthermore, using the fact that , we do not need to explicitly fill out the missing data either, thereby avoiding computing and storing the lower triangular part of the matrix . We can avoid computing the missing part for each row as well. The pseudocode for the resulting algorithm is presented in Algorithm 1. Note that there is some abuse of notation involved in the algorithm, as we use to denote the last rows of the matrix we described previously.
3.3 A modified practical algorithm
Despite that Algorithm 1 computes directly, in practice it can still become unstable when becomes large. This is because the singular values of grows exponentially with respect to . Then in Algorithm 1, the SVD step (11) also increasingly ill-conditioned as increases.
We now further modify the ISVD algorithm as follows. Instead of trying to approximate the SVD of for each as is done in the previous sections, we compute the approximate SVD for each off-diagonal block , which avoids the exponential growth of singular values. This can be implemented by introducing only an extra QR factorization step.
Denoting the approximate SVD obtained for as (note this is different from the one defined previously), we perform a QR factorization on . Then we have
Then we perform SVD on the matrix in the middle of the right-hand side, and use this to obtain , , . The pseudocode for the algorithm is described in Algorithm 2. The extra QR factorization step is in Line 6 in Alg. 2 We remark that the MPO representation obtained from Algorithm 2 is equivalent to that obtained in [33].
Below we demonstrate that one can reconstruct the UTLR low-rank factors from the , , obtained from Algorithm 2. First, note that not all ’s are square matrices, though all ’s are full-rank matrices. Each for is an matrix, and each for is an matrix. Each ’s in the middle is an matrix. Therefore the first ’s have right inverses, the last ’s have left inverses, and every in the middle has an inverse. We denote these left or right inverses as
Now we define
and it can be checked that for any . Therefore we have a upper-triangular low-rank approximation for the matrix .
4 Representing long-range interaction via the hierarchical low-rank format
In this section we present an alternative method to construct tensor network operators with long-range pairwise interactions using the hierarchical low-rank format. The advantage of this method is that it can be naturally generalized to higher dimensional tensors represented by PEPOs. Compared to the CF-PEPO approach [24] which relies on a fitting procedure and therefore is difficult to establish the a priori error bound, we demonstrate that our algorithm yields a sum of PEPOs whose bond dimension is bounded by a constant for the Coulomb interaction.
We study the case when can be represented as a hierarchical off-diagonal low-rank (HODLR) matrix and a -matrix respectively. Furthermore, the hierarchical low-rank representation is not restricted to translation-invariant operators.
4.1 Rank-one MPOs and PEPOs
We first introduce some terminologies with respect to the MPOs and PEPOs we are going to use in this section. There are mainly two types of operators we are going to use extensively, which can be efficiently represented by MPOs and PEPOs. Consider a rank-one operator in 1D
where and are local operators defined on sites and , and as a result they commute with each other. This operator can be represented by an MPO with bond dimension 3, since we can treat it as a special case of the interaction in (2.1) in which .
The notion of rank-one operators can be easily generalized to a 2D system, for operators in the form
where is some order assigned to the system. This can be represented by a snake-shaped MPO [24] with bond dimension 3. The coefficient matrix is a UTLR matrix of rank 1. We add some bonds with bond dimension 1 to make it a PEPO. The bond dimension of the PEPO is still 3. A graphical illustration of the PEPO is provided in Fig. 5.
Sometimes the operator acts trivially everywhere except for a given region (described by an index set ) in the system, we may order the sites in such a way that all sites in are labeled before the rest of the sites. Then the operator is . In such cases we call the set the support of operator . Now suppose are rank-one operators in a 1D system. Integer intervals are the supports of each operator respectively. If , then the operators are non-overlapping. The sum of these operators can be expressed as an MPO with bond dimension 5. We give the MPO rules in Appendix A.
This notion of two operators being non-overlapping can be easily extended to 2D systems. Instead of intervals the supports are replaced by boxes. The sum of these operators can be expressed as a PEPO with bond dimension 5. We will also give the PEPO rules in Appendix B. As mentioned before, in 2D we need to define an order for the rank-one operators. However when we consider a sum of non-overlapping rank-one operators, the order only needs to be defined locally within each support, i.e. we do not need to impose a global ordering valid for all rank-one operators.
4.2 Hierarchical low-rank matrix
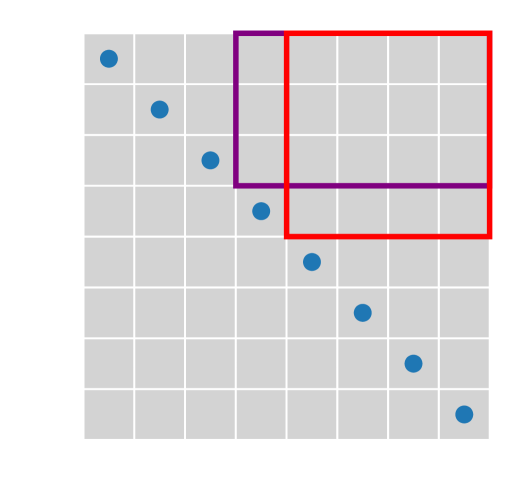
In this section we introduce the hierarchical low-rank matrix, and its use to construct MPO and PEPO representation of tensor network operators with long-range interactions. Consider the 1D system first. We denote by the set of all sites in the system. Note that we use zero-based indexing for sites in the system from now on. We divide the domain hierarchically. At the first level, we divide the system into two equal parts and . At the second level there will be four such intervals, and third level eight intervals, and so on. In general we define , where . There are in total levels. Each interval has a neighbor list containing all the other intervals on the same level that are neighbors of .
The intervals defined in this way give rise to a tree structure. When an interval , then we say is a child of , or equivalently is a parent of . When two intervals are children of the same parent we call them siblings.
A key component of the definition of the hierarchical low-rank matrix is the interaction list, which we denote by for each interval . If is a hierarchical low-rank matrix, and , then can be approximated by a low-rank matrix. The two hierarchical low-rank matrix formats considered in this paper, the HODLR and the -matrix formats, differ only in the choice of interaction lists. Given a set of interaction lists, we are ready to define the hierarchical low-rank matrix:
Definition 2 (Hierarchical low-rank matrix).
A symmetric matrix is a hierarchical low-rank matrix, if for any index set and any index set , there exists a rank matrix such that
From Definition 2, we immediately recognize that a UTLR matrix must be a hierarchical low-rank matrix. To see this, we simply pick to be the -th matrix block of given by the UTLR format. The reverse statement is not true, since the matrix blocks in a hierarchical low-rank matrix may not be related at all to each other.
The concept above can be naturally extends to two-dimensional and higher dimensional systems. Instead of intervals, the interaction lists are defined using boxes. We will first use hierarchical low-rank structure in 1D to build MPOs, and then discuss its generalization to 2D for constructing PEPOs.
4.3 HODLR format
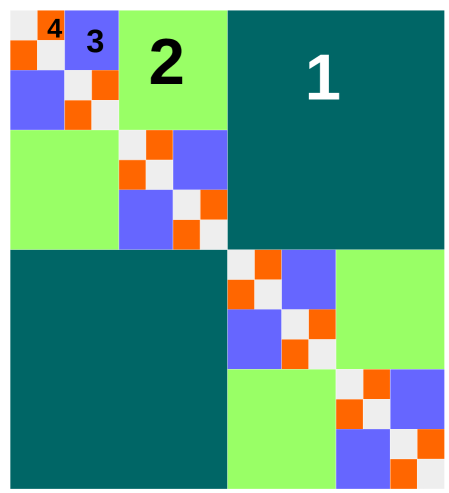
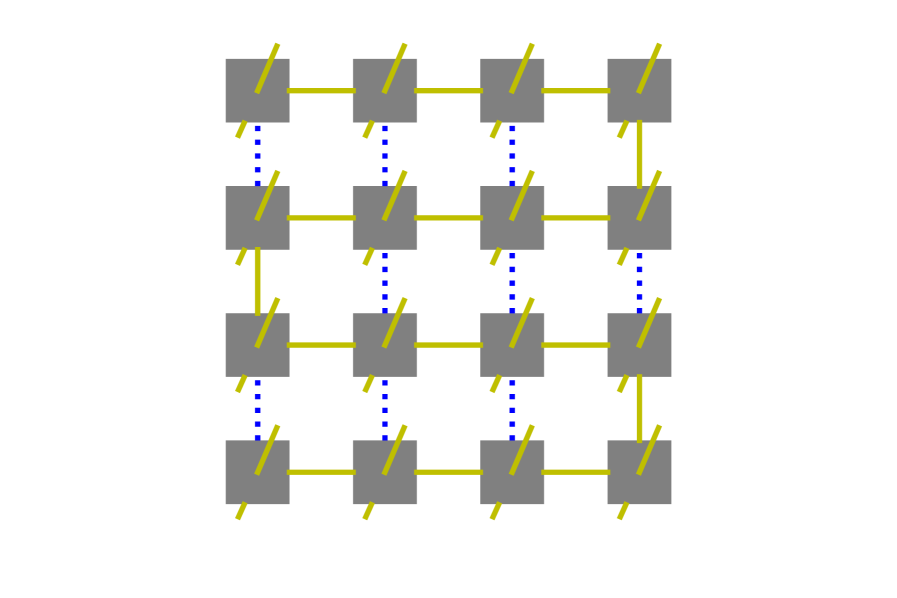
A matrix of the HODLR format can be constructed as follows. For an interval on level , we define the interaction list to be the set of all such that is a sibling of . For level 1 the two intervals have each other as the only member in their respective interaction list. Each matrix block for then has a low-rank structure and therefore admits a low-rank approximation. Using this interaction list we can divide the whole matrix into non-overlapping blocks each with a low-rank structure. The division is shown in Fig. 6 (a).
Now we construct the MPOs from this format. At level , define
| (16) |
for . The sum of all the interactions at level can be written as
Note only interactions allowed in the interaction list is covered on this level, which is an important fact that enables us to construct MPOs with a small bond dimension. Then we can decompose the tensor as
This sum covers all the interactions in .
Because of the hierarchical low-rank structure, we can yield some approximate low-rank decomposition . Then
Note that on the right-hand side each indexes a rank-one operator. The support of each rank-one operator is .
Therefore, for each , we have rank-one operators. For each , we pick one from these operators correspond to a given index , and sum them up to get,
and then we have
Hence all the interactions at level can be collected into operators , each one is a sum of non-overlapping rank-one operators. From this procedure, we have collected all interactions at level into a sum of MPOs each with bond dimension 5. can be chosen to be for the coefficient matrix to have a 2-norm error of . The system contains levels so in total we need MPOs, each with a bounded rank.
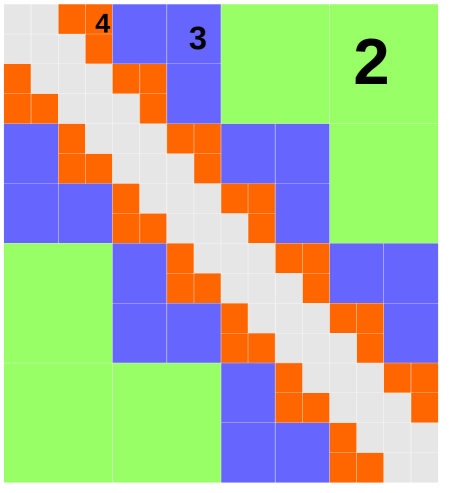
4.4 -matrix format
In the HODLR matrix, a matrix block is low-rank as long as are non-overlapping and are at the same level. This is also called the weak-admissibility condition [18]. The -matrix is a more general class of hierarchical low-rank matrices, which requires the strong-admissibility condition, i.e. are not only non-overlapping, but their distance should be comparable to their sizes, i.e. .
In the -matrix format, we define the interaction list of an interval in the following way: an interval if and only if the parent of and the parent of are neighbors, and is not a neighbor of . Therefore in 1D it is guaranteed that if . A hierarchical low-rank matrix with interaction list defined in this way is called an -matrix. A graphical illustration is shown in Fig. 6 (b).
We first consider a 1D system. The system is divided into intervals hierarchically the same way as in Section 4.3. Sill we divide the interactions into different levels
| (17) |
where contains only nearest-neighbor interactions. Note that the lowest level is in this format, as the interaction list at level is empty. Based on the interaction list of the -matrix, is defined as
where is defined in Eq. (16). One can see how this corresponds to the -matrix interaction list from Fig. 6 (b).
Now we want to efficiently represent the operator as linear combination of MPOs. Similar to the previous section we first write
where is a rank-one operator defined in (4.1). The low-rank decomposition is done by performing truncated SVD and cutting off singular values smaller than for some . Then
However, unlike in the HODLR case, these operators can be overlapping for different . For example and are overlapping. Also and are overlapping as well. Therefore we need to further separate the terms as
| (18) | ||||
| (19) |
For each of the six terms on the right-hand side we construct MPOs. Each term represents a sum of non-overlapping rank-one operators, and therefore has bond dimension 5. Operators on the first line we call type-0 and on the second line we call type-1. They can be visualized on the coefficient matrix, as shown in Fig. 6.
From the discussion we construct MPOs each with bond dimension 5. Since the system contains levels in total we have MPOs. To ensure the 2-norm error of the coefficient matrix to be smaller than , we need to choose for some constant . Then we have . The total number of MPOs is .
In practical calculation, we may further reduce the constant prefactor from to without increasing . This is because the strong admissibility condition allows one to concatenate certain blocks together only with a mild increase of the numerical rank [18]. For example, matrices and can be concatenated into a single matrix . This allows us to combine some of the operators and thereby reduce the prefactor. The reduction of the prefactor becomes more significant in 2D and higher-dimensional cases.
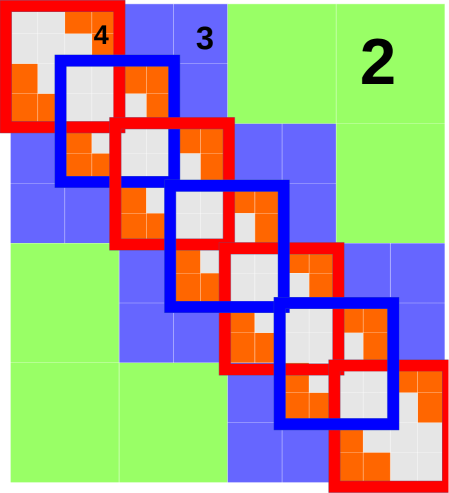
4.5 Higher dimensional cases


When the coefficient matrix satisfies the hierarchical low-rank format, the tensor can be efficiently represented by PEPOs when the lattice dimension is larger than . We consider the 2D case below, and the 3D case follows similarly. We consider an lattice, with each site indexed by .
In the 2D case, the intervals are replaced by boxes. We define a box on level , indexed by , by
and interaction between two level- boxes , is denoted as , similar to (16).
Similar to -matrices in 1D, the interaction list is the set of all boxes such that
-
1.
The parent of is a neighbor of the parent of ,
-
2.
and are not neighbors.
Fig. 7 (a) shows an example of the allowed interactions at level . All the interactions at level are collected into an operator , and we have the same decomposition as in (17).
In the previous section we have divided the interactions at level into type-0 and type-1, and further into six terms in (18) and (19) respectively. Here we divide all interactions into four types: type- for . And we write
where covers most, but not all interactions at level (to avoid double counting) between boxes for , . The boxes can be divided into a array. Some examples are given in Fig. 7 (b). In general, with the same but different are non-overlapping, and therefore can be summed up without increasing the bond dimension beyond 5. A graphical description of the rules is given in Fig. 7 (c).
Using the simplest scheme each contains at most 78 interactions between pairs of boxes at level . The number 78 is obtained as follows: there are pairwise interactions between boxes in , as can be seen in Fig. 7 (b). 42 of these pairwise interactions are between adjacent boxes (sharing an edge or vertex), and therefore in total there are 78 permissible ones. Note that there will be double counting if we include all 78 interactions in each , so in fact this maximum is only attained at the lower-right corner according to the assignment rule in Fig. 7 (c).
However, using the fact that for , we may directly compress the interactions between and . This is the same as what we have done for the 1D case in the previous section. Using this method, all pairwise interactions involving one box in the box array can be merged into one. Any interaction included has to involve one of the 12 boxes that are not among the 4 boxes at the lower-right corner. The result is that we can reduce the number of interactions to 12 for and 8 for all other cases.
Each of the 12 or 8 interactions, which we index by , is then approximated by the linear combination of rank-one operators. Therefore
where for and 8 otherwise, and each is a rank-one operator. We simply add zero operators when there is not enough . It is clear that this is not the most efficient method, but it gives us the desired scaling in the end. The rank-one operators are obtained using a low-rank decomposition similar to (4.4), which is in turn obtained from a truncated SVD.
Then we can define
Everything we have done above is to make this a sum of non-overlapping rank-one operator introduced in Section 4.1. It can be represented by a PEPO with bond dimension 5.
Therefore all the interactions at level can be written as
This is a linear combination of PEPOs with bond dimension 5.
The total number of PEPOs needed for the system will be . To ensure the coefficient matrix 2-norm error to be below we need and . The number of PEPOs needed will scale like . We remark that this is in fact a rather loose upper bound. Our numerical experiments indicate that for small-to-medium sized systems (e.g. ), the actual number of PEPOs needed is usually much smaller.
5 Error analysis for the Coulomb matrix
The modified ISVD algorithm and the hierarchical low-rank representation can be applied to general pairwise interactions with or without the translation-invariance property. To illustrate the efficiency of the compressed representation, in this section we briefly list some known results for the Coulomb interaction.
For the Coulomb interaction, the error bound for the exponential fitting method using the quadrature scheme is given in [3, 6]. In particular, and any , there exist numbers such that
| (20) |
A more general approximation can be obtained from classical results in the fast multipole method (e.g. [16, Theorem 3.2]). Consider the two-dimensional case for example, we may obtain the following approximate low-rank decomposition of the off-diagonal part of the Coulomb kernel: for two regions and , such that and , , then for any , there exists and , such that for any , ,
| (21) |
This immediately implies that in order to control the pointwise error up to , the rank can be bounded by . In order to control the 2-norm of each low-rank block, can be bounded by . Note that the separation between the sets is crucial for the error estimate, which corresponds to the strong admissibility condition. For 2D and higher dimensional Coulomb interaction, the separation is indeed crucial to bound the PEPO rank. Hence we only consider the -matrix format for 2D systems in the numerical examples below.
6 Numerical examples
In this section we present numerical results for 1D and 2D systems using the methods we introduced above. As before, we will only focus on long-range pairwise interactions of the form (1).
6.1 Quasi 1D system
We compare the numerical performance of the exponential fitting method and the modified ISVD described in Algorithm 2 on Coulomb interaction of the form
where . We always choose , so that this mimics a quasi-1D system. Define the error matrix as , and we measure the error using the 2-norm of the error matrix.
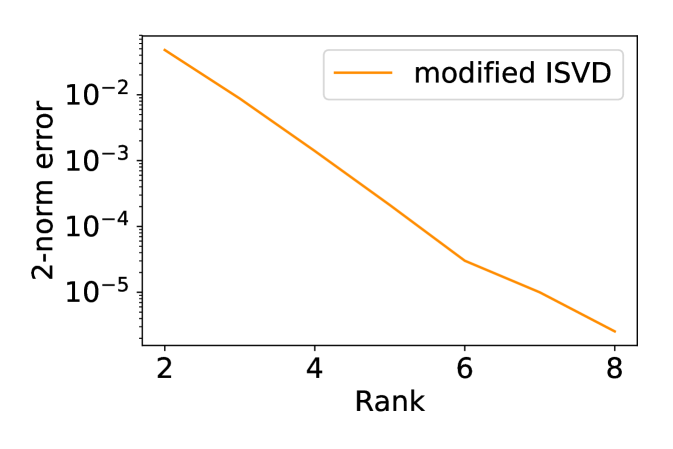
In the first example we let all . The resulting system is translation invariant, and we can apply the exponential fitting method as well as modified ISVD. The numerical results are shown in Fig. 8.
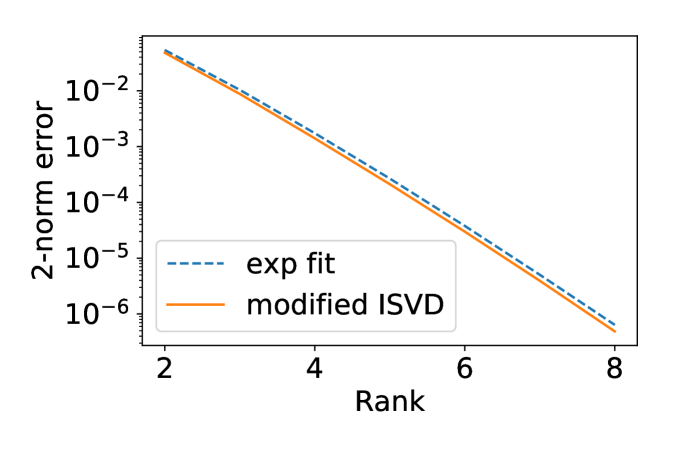
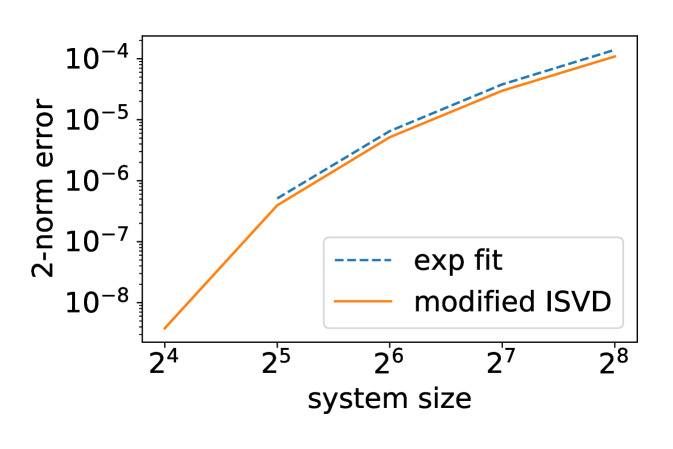
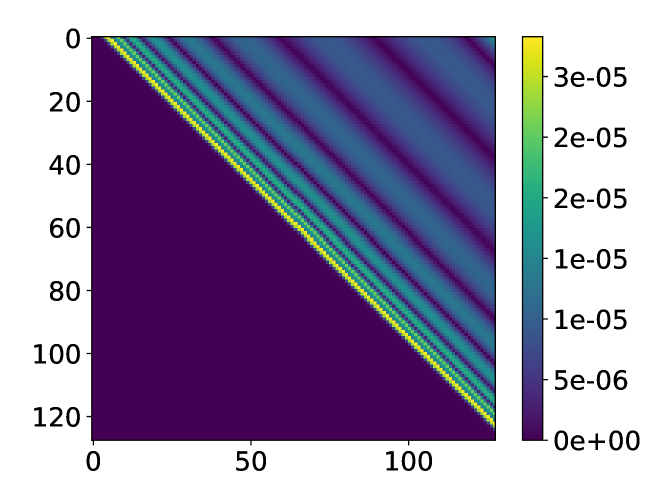
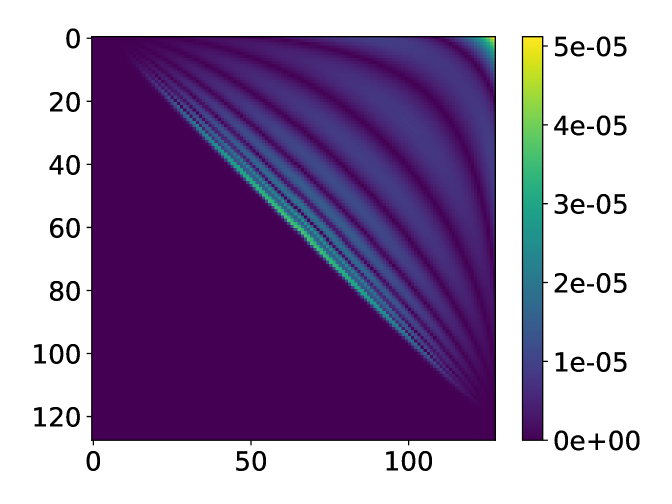
Fig. 8 shows that the accuracy of the two methods is comparable, and the modified ISVD outperforms exponential fitting by a small margin in terms of 2-norm error. However, the distribution of the error of the two methods is very different. The error of the modified ISVD is concentrated at the upper-right corner of the matrix, which is the interaction between the two ends of the system. This can be expected from Eq. (13), where the error accumulation becomes more significant as more matrices are multiplied together. On the other hand, the error of exponential fitting is concentrated some distance away from the diagonal.
In the second example we set to be random numbers drawn uniformly from . system is then no longer translation-invariant, and the exponential fitting method is not applicable. However, the modified ISVD still performs well. In Fig. 9 we can see that the convergence of error with respect to and error distribution are both very similar to the translation-invariant case.
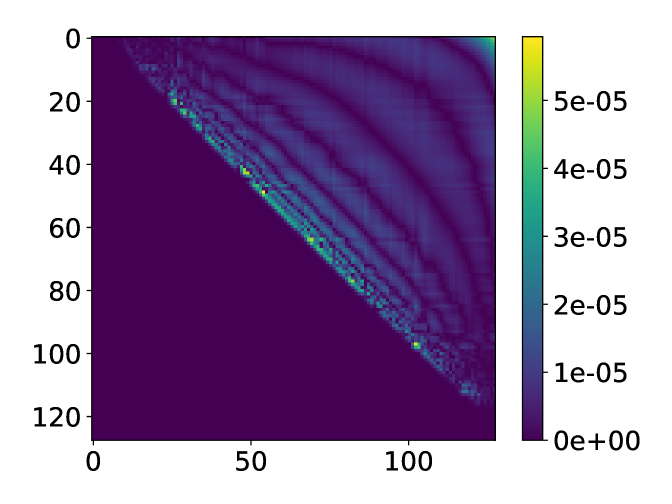
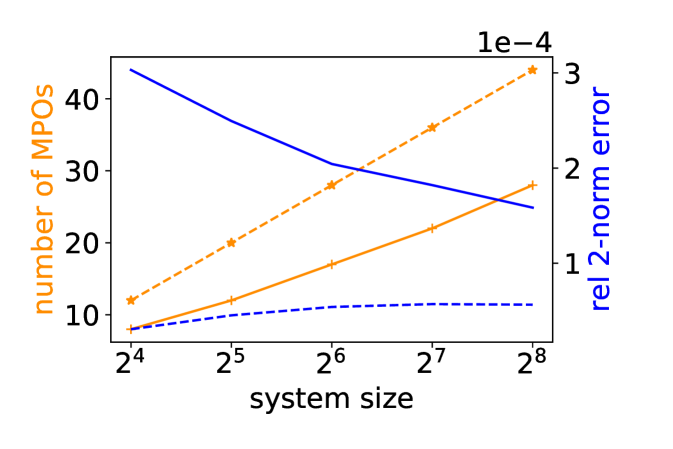
We also test the performance of HODLR and -matrix based MPO construction on this model with . The number of MPOs needed with fixed singular value threshold and the relative 2-norm error is plotted in Fig. 10 (a). The -matrix format requires a large number of MPOs than the HODLR format. The error distribution is plotted for system size , in Fig. 10 (b) (c).
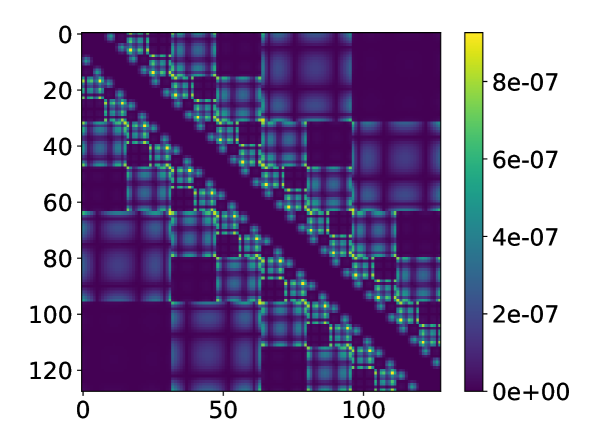
| system size | number of PEPOs | maximal rank |
|---|---|---|
| 328 | 13 | |
| 756 | 14 | |
| 1221 | 15 | |
| 1696 | 15 |
6.2 2D system
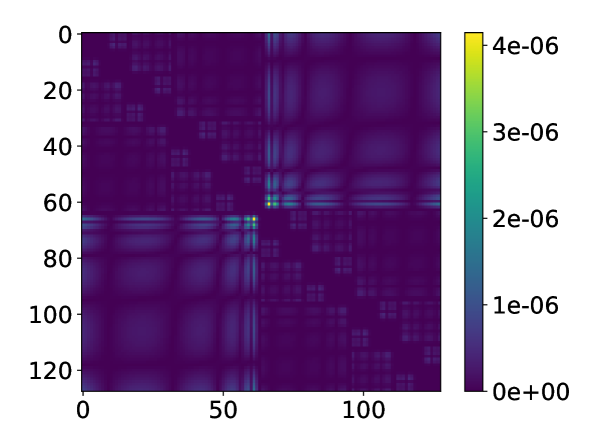
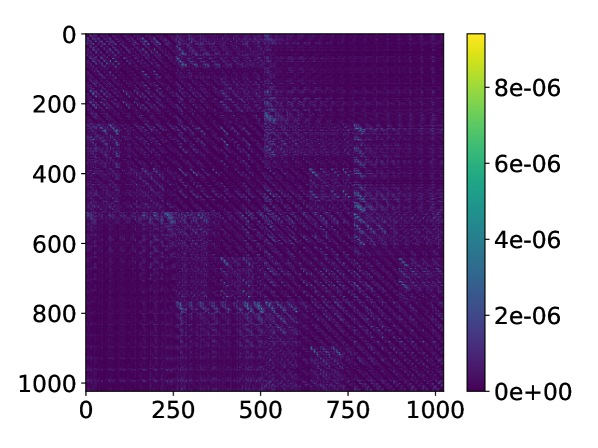
We then consider a 2D system with sites on a uniform grid. For the 2D system we only show the numerical results for the -matrix format, since the Coulomb interaction in 2D only satisfies the strong admissibility condition. In other words, the growth of the rank becomes unfavorable using the HODLR format. The error distribution is plotted in Fig. 10 (d). Table 1 shows the number of PEPOs, as well as the maximal PEPO rank for different system sizes in order to achieve the same truncation criterion (we truncate singular values for block ) at threshold ). We observe that the maximal rank grows very mildly with respect to the system size. The number of PEPOs increases more noticeably when the system size is small, and the growth becomes slower as the side length increases from to . The number of PEPOs should eventually become only logarithmic with respect to .
7 Conclusion
We introduced two methods for constructing efficient MPO and PEPO representation of tensors with pairwise long-range interactions, without assuming that the system is translation-invariant. Using the upper-triangular low-rank (UTLR) structure, the construction of the MPO representation can be solved as a matrix completion problem. We developed a modified ISVD algorithm to solve the matrix completion problem with in a numerically stable fashion. Although we do not yet have a theoretical error bound for the accuracy of the modified ISVD algorithm, numerical results indicate that the error of the modified ISVD method is comparable to that of the exponential fitting method, which indicates that for Coulomb interaction, the MPO rank from the modified ISVD method can be bounded by . The hierarchical low-rank format can be used to construct both MPOs and PEPOs. For the Coulomb interaction, the tensor can be approximated by the linear combination of MPOs/PEPOs, and the rank of each MPO/PEPO is bounded by a constant. The hierarchical low-rank format leads to an MPO representation with a higher MPO rank than that from the modified ISVD method. However, the linear combination representation may naturally facilitate parallel computation, and this is particularly the case for the PEPO representation where a relatively large number of PEPOs can be needed. On the other hand, the MPOs/PEPOs from our hierarchical low-rank format have many zero entries. It would be of practical interest to develop alternative algorithms to reduce the number of zeros and to obtain a more compact representation with reduced preconstants.
Acknowledgments
This work was partially supported by the Department of Energy under Grant No. DE-SC0017867, No. DE-AC02-05CH11231 (L. L.), by the Air Force Office of Scientific Research under award number FA9550-18-1-0095 (L.L. and Y. T.). We thank Garnet Chan, Matthew O’Rourke and Miles Stoudenmire for helpful discussions.
Appendix A FSM rules for sum of non-overlapping MPOs
For a 1D system we divide into intervals such as done in our construction of the hierarchical low-rank matrix. First we clarify some notations. For an operator defined in an interval we use the notation . For example, the identity operator defined in an interval is . Tensors and operators defined on a single site are still denoted as , , etc. We want to represent an operator of the form
using an MPO, where we already have an MPO representation of each operator defined on interval .
Using the finite state machine (FSM) description of MPOs [12, 14], we assume there are the following general finite state machine rules for each shown in Table 2. It is equivalent to the equation
where , and is an operator for each . The MPO rules for are shown in Table 3.
| position | rule num | input state | operator | output state |
|---|---|---|---|---|
| ALL | 1 |
| rule num | input state | operator | output state | |
|---|---|---|---|---|
| HEAD | 1 | |||
| 2 | ||||
| 3 | ||||
| BODY | 4 | |||
| 5 | ||||
| 6 | ||||
| TAIL | 7 | |||
| 8 | ||||
| 9 |
For the FSM rules of the operators , we assume the FSM is in state 1 at the very beginning and will be in state 1 at the end. This means on the first site in interval an operator is activated and then the FSM goes to state , and on the last site an operator is activated, and the FSM goes into state 1. The first site in the interval is called the head and the last site is called the tail. Note that the FSM rules on the head and tail sites are different from on other sites inside the interval.
Now we construct the FSM rules for . We add two states and into the FSM. is the default state meaning a non-trivial operator, i.e. , has not been activated, and means such an operator has been activated, and only identity operators should be picked afterwards. The FSM is in state both at the very beginning and at the end.
At the first site, i.e. the head, of each interval , the input signal from the left is either or . If the signal is , then we choose either to not activate and pass along the signal , as in rule 1 of Table 3, or to activate , as in rule 3 of the same table. If the signal is , then cannot be activated and a signal is passed down. This is done in rule 2.
In the middle, or body, of each interval , if has been activated at the first site, then we follow the FSM rules for the individual (rule 6). If we receive either or then we pass the signal down (rules 4 and 5).
At the last site, or the tail, of each interval, if has been activated, then the output signal is (rule 9). Otherwise the output signal is whatever this interval received from the beginning (rules 7 and 8).
An important fact is that we have only added two signals into the original set of signals. This means if the original MPOs have a maximum bond dimension , then the new MPO for the sum has a bond dimension . In the case of the sum of non-overlapping rank-one operators as discussed in 4.1, the bond dimension of the sum is 5.
Appendix B FSM rules for sum of non-overlapping PEPOs
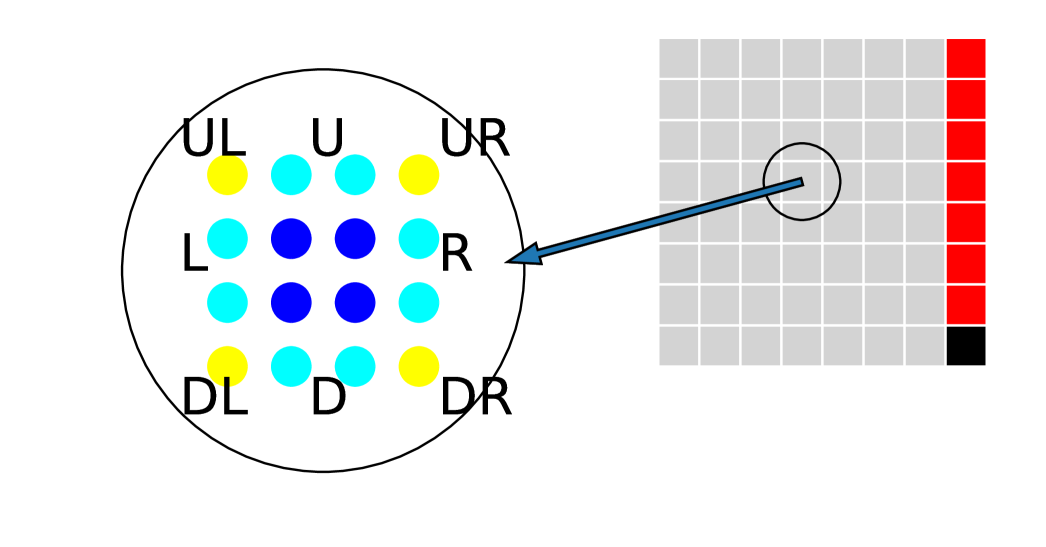
The FSM rules for PEPOs are more complex. To describe our FSM rules for PEPOs, we first divide the sites inside a given box into different parts, as shown in the right part of Fig. 11. Different FSM rules should be applied to different parts. Sites in a box are labeled based on their position in the box, as shown in the left part of Fig. 11. For example, the box at the upper-right corner of a box is labeled UR.
We assume for each individual PEPO , we have the FSM rules specified in Table 4. Note that not all PEPO tensors have 4 internal indices and 2 physical indices, as can be seen from Fig. 3 (b). For example, the tensors on the edges have 3 internal indices. In this case, we simply add bonds with bond dimension 1 to make them have 4 internal indices, similar to what we have done in the snake-shaped PEPO construction in 4.1. These extra indices all take the value 1.
Now we design a set of FSM rules to represent
where gives the lexicographical order defined in Section 1. One key difference between 2D and 1D is that in 2D we no longer have a fixed direction for the signal of FSM to be passed along. Therefore we require that signals between boxes (there are signals passing within boxes according to the original FSM rules in Table 4, which we leave unchanged) only pass rightward or downward, making it easier to design FSM rules.
| position | rule num | operator | |
|---|---|---|---|
| ALL | 1 |
We first design the FSM rules for all parts of the system except for the upper-right corner, the right edge, and the lower-right corner (the colored parts in Fig. 11 (b)). The rules are shown in Table 5. Just like in the 1D case, we introduce two signals and . is the default signal. We change the value of the extra indices we added at the edges and corners from 1 to .
At the UL site of each box , there are two input signals from left and up. When both are , then it means can be activated in this box (rule 3), but we can also choose not to activate it and pass along the signal (rule 1). If the site receives a signal from the left, and from above, then it means an has already been activated for some to the left, and the only thing that can be done now is to pass down the signal to the right until the right edge (rule 2), where other FSM rules will process it.
| rule num | operator | ||
|---|---|---|---|
| UL | 1 | ||
| 2 | |||
| 3 | |||
| U | 4 | ||
| 5 | |||
| 6 | |||
| UR | 7 | ||
| 8 | |||
| 9 | |||
| R | 10 | ||
| 11 | |||
| DR | 12 | ||
| 13 | |||
| D | 14 | ||
| 15 | |||
| DL | 16 | ||
| 17 | |||
| L | 18 | ||
| 19 | |||
| BODY | 20 | ||
| 21 |
Other rules in Table 5 are either identical to the FSM rules for , or to pass along signals and . Note that the signal is only passed along the upper edge (UL, U, and UR in Fig. 11 (a)) as specified in rules 2, 5, 8. If has been activated then a signal will be passed to the box to the right from the UR site (rule 9).
| rule num | operator | ||
|---|---|---|---|
| UL | 1 | ||
| 2 | |||
| 3 | |||
| 4 | |||
| U | 5 | ||
| 6 | |||
| UR | 7 | ||
| 8 | |||
| R | 9 | ||
| 10 | |||
| DR | 11 | ||
| 12 | |||
| D | 13 | ||
| 14 | |||
| DL | 15 | ||
| 16 | |||
| 17 | |||
| L | 18 | ||
| 19 | |||
| 20 | |||
| BODY | 21 | ||
| 22 |
We then describe the FSM rules for the upper-right corner and the right edge of the system as shown in Table 6. Together with the FSM rules for the lower-right corner in Table 7, these FSM rules are to ensure that either only one signal is passed down from the left, or exactly one is activated in this part of the system.
Here we explain the rules in Table 6. For the UL site of each box , there are four possible incoming signal combinations it can receive. The first possibility is that it receives two signals. In this case it means no has been activated to the left or from above, we can choose whether to activate or not (rules 1 and 4). If only one of the signals is then it means an has been activated elsewhere, and it is only allowed to pass the signal downward (instead of rightward as in Table 5). This is specified in rule 2. Other rules exist to pass along the signals or are the same as those for the individual . At the DL site, if has been activated, then a signal is passed to the next box below (rule 16). The signal is only passed along the left boundary, as opposed to along the upper boundary in Table 5.
| rule num | operator | ||
|---|---|---|---|
| UL of R | 1 | ||
| 2 | |||
| 3 | |||
| U of R | 4 | ||
| 5 | |||
| UR of R | 6 | ||
| 7 | |||
| R of R | 8 | ||
| 9 | |||
| DR of R | 10 | ||
| 11 | |||
| D of R | 12 | ||
| 13 | |||
| DL of R | 14 | ||
| 15 | |||
| L of R | 16 | ||
| 17 | |||
| BODY of R | 18 | ||
| 19 |
Now all that is left is to formulate the FSM rules for the lower-right corner of the system. The rules are shown in Table 7. If the UL site receives exactly one signal and exactly one signal form left and above respectively, then this means everything is good and we only need to pass the signal to the boundaries without activating the operator (rules 1 and 2). If it receives two signals then it means no has been activated in any other box, and therefore has to be activated in the current box (rule 3). No signal will be passed down beyond this point.
The rules in Tables 5, 6, 7 ensure that exactly one operator is going to be activated in the system. Otherwise some box on the right boundary (upper-right corner, right edge, and lower-right corner) will have two signals incoming at the UL site, which is not allowed in the FSM rules and therefore will return a zero operator, making the whole tensor product zero.
Similar to the 1D case, the bond dimension of each PEPO we constructed in this way is the bond dimension of the original PEPO plus 2. In the case of rank-one operators the sum PEPO has a bond dimension of 5.
References
- [1] S. Ambikasaran and E. Darve, An fast direct solver for partial hierarchically semi-separable matrices, J. Sci. Comput., 57 (2013), pp. 477–501.
- [2] L. Balzano and Stephen J Wright, On grouse and incremental svd, in 5th IEEE International Workshop on Computational Advances in Multi-Sensor Adaptive Processing (CAMSAP), IEEE, 2013, pp. 1–4.
- [3] G. Beylkin and M. J. Mohlenkamp, Numerical operator calculus in higher dimensions, Proc. Natl. Acad. Sci. U.S.A., 99 (2002), pp. 10246–10251.
- [4] G. Beylkin and L. Monzón, On approximation of functions by exponential sums, Appl. Comput. Harmon. A., 19 (2005), pp. 17–48.
- [5] J. Biamonte and V. Bergholm, Tensor networks in a nutshell, arXiv preprint arXiv:1708.00006, (2017).
- [6] D. Braess and W. Hackbusch, Approximation of 1/x by exponential sums in , IMA J. Numer. Anal., 25 (2005), pp. 685–697.
- [7] , On the efficient computation of high-dimensional integrals and the approximation by exponential sums, in Multiscale, nonlinear and adaptive approximation, Springer, 2009, pp. 39–74.
- [8] Matthew Brand, Incremental singular value decomposition of uncertain data with missing values, in European Conference on Computer Vision, Springer, 2002, pp. 707–720.
- [9] J.-F. Cai, E. J. Candès, and Z. Shen, A singular value thresholding algorithm for matrix completion, SIAM J. Optim., 20 (2010), pp. 1956–1982.
- [10] E. J. Candès and B. Recht, Exact matrix completion via convex optimization, Found. Comput. Math., 9 (2009), p. 717.
- [11] G. K.-L. Chan, A. Keselman, N. Nakatani, Z. Li, and S. R. White, Matrix product operators, matrix product states, and ab initio density matrix renormalization group algorithms, J. Chem. Phys., 145 (2016), p. 014102.
- [12] G. M. Crosswhite and D. Bacon, Finite automata for caching in matrix product algorithms, Phys. Rev. A, 78 (2008), p. 012356.
- [13] G. M Crosswhite, A. C. Doherty, and G. Vidal, Applying matrix product operators to model systems with long-range interactions, Phys. Rev. B, 78 (2008), p. 035116.
- [14] F. Fröwis, V. Nebendahl, and W. Dür, Tensor operators: Constructions and applications for long-range interaction systems, Phys. Rev. A, 81 (2010), p. 062337.
- [15] L. Grasedyck and W. Hackbusch, Construction and arithmetics of h-matrices, Computing, 70 (2003), pp. 295–334.
- [16] L. Greengard and V. Rokhlin, A new version of the fast multipole method for the laplace equation in three dimensions, Acta Numer., 6 (1997), pp. 229–269.
- [17] W. Hackbusch, A sparse matrix arithmetic based on -matrices. part i: Introduction to -matrices, Computing, 62 (1999), pp. 89–108.
- [18] W. Hackbusch, B. N. Khoromskij, and R. Kriemann, Hierarchical matrices based on a weak admissibility criterion, Computing, 73 (2004), pp. 207–243.
- [19] Z.-Y. Han, J. Wang, H. Fan, L. Wang, and P. Zhang, Unsupervised generative modeling using matrix product states, Phys. Rev. X, 8 (2018), p. 031012.
- [20] Y. Hu, Y. Koren, and C. Volinsky, Collaborative filtering for implicit feedback datasets., in ICDM, vol. 8, Citeseer, 2008, pp. 263–272.
- [21] C. Lubich, T. Rohwedder, R. Schneider, and B. Vandereycken, Dynamical approximation by hierarchical tucker and tensor-train tensors, SIAM J. Matrix Anal. A., 34 (2013), pp. 470–494.
- [22] A. Mnih and R. R. Salakhutdinov, Probabilistic matrix factorization, in Advances in neural information processing systems, 2008, pp. 1257–1264.
- [23] M. R. Norman, Colloquium: Herbertsmithite and the search for the quantum spin liquid, Rev. Mod. Phys., 88 (2016), p. 041002.
- [24] M. J. O’Rourke, Z. Li, and G. K.-L. Chan, Efficient representation of long-range interactions in tensor network algorithms, Phys. Rev. B, 98 (2018), p. 205127.
- [25] R. Orús, A practical introduction to tensor networks: Matrix product states and projected entangled pair states, Ann. Phys., 349 (2014), pp. 117–158.
- [26] I. V. Oseledets, Tensor-train decomposition, SIAM J. Sci. Comput., 33 (2011), pp. 2295–2317.
- [27] I. V. Oseledets and E. E. Tyrtyshnikov, Breaking the curse of dimensionality, or how to use svd in many dimensions, SIAM J. Sci. Comput., 31 (2009), pp. 3744–3759.
- [28] S. Östlund and S. Rommer, Thermodynamic limit of density matrix renormalization, Phys. Rev. Lett., 75 (1995), p. 3537.
- [29] B. Pirvu, V. Murg, J. I. Cirac, and F. Verstraete, Matrix product operator representations, New J. Phys., 12 (2010), p. 025012.
- [30] M. Rakhuba and I. Oseledets, Calculating vibrational spectra of molecules using tensor train decomposition, J. Chem. Phys., 145 (2016), p. 124101.
- [31] U. Schollwöck, The density-matrix renormalization group in the age of matrix product states, Ann. Phys., 326 (2011), pp. 96–192.
- [32] E. Stoudenmire and D. J. Schwab, Supervised learning with tensor networks, in Advances in Neural Information Processing Systems, 2016, pp. 4799–4807.
- [33] E. M. Stoudenmire and S. R. White, Sliced basis density matrix renormalization group for electronic structure, Phys. Rev. Lett., 119 (2017), p. 046401.
- [34] F. Verstraete and J. I. Cirac, Renormalization algorithms for quantum-many body systems in two and higher dimensions, arXiv preprint cond-mat/0407066, (2004).
- [35] F. Verstraete, M. M. Wolf, D. Perez-Garcia, and J. I. Cirac, Criticality, the area law, and the computational power of projected entangled pair states, Phys. Rev. Lett., 96 (2006), p. 220601.
- [36] G. Vidal, Classical simulation of infinite-size quantum lattice systems in one spatial dimension, Phys. Rev. Lett., 98 (2007), p. 070201.
- [37] S. R. White, Density matrix formulation for quantum renormalization groups, Phys. Rev. Lett., 69 (1992), p. 2863.
- [38] S. Yan, D. A. Huse, and S. R. White, Spin-liquid ground state of the s= 1/2 kagome heisenberg antiferromagnet, Science, 332 (2011), pp. 1173–1176.