Synthesis on Probabilistic Systems
Abstract
Many systems are naturally modeled as Markov Decision Processes (MDPs), combining probabilities and strategic actions. Given a model of a system as an MDP and some logical specification of system behavior, the goal of synthesis is to find a policy that maximizes the probability of achieving this behavior. A popular choice for defining behaviors is Linear Temporal Logic (LTL). Policy synthesis on MDPs for properties specified in LTL has been well studied. LTL, however, is defined over infinite traces, while many properties of interest are inherently finite. Linear Temporal Logic over finite traces () has been used to express such properties, but no tools exist to solve policy synthesis for MDP behaviors given finite-trace properties. We present two algorithms for solving this synthesis problem: the first via reduction of to LTL and the second using native tools for . We compare the scalability of these two approaches for synthesis and show that the native approach offers better scalability compared to existing automaton generation tools for LTL.
1 Introduction
Many real-world systems are stochastic in nature. They evolve in the world according to action (control) decisions and the uncertainty embedded in the execution of those actions, resulting in stochastic behavior. Formal synthesis studies how the system should choose actions so that it can increase the chances of achieving a desirable behavior. To allow such reasoning, Markov Decision Processes (MDPs) are typically used to model these systems since MDPs effectively capture sequential decision-making and probabilistic evolutions [6]. The desired behavior is expressed in a formal language, which yields expressive and unambiguous specifications. Temporal logics are a common choice for this language since they allow a combination of temporal and boolean reasoning over the behavior of the system. Most temporal logics are interpreted over behaviors with infinite time durations, but some behaviors are inherently finite and can be expressed more intuitively and more practically using a temporal logic with finite semantics [16, 15]. This work investigates policy synthesis on MDPs for specifications expressed in a formal language called Linear Temporal Logic over finite traces () [11], which reasons over system behaviors with finite horizons.
A popular specification language in formal verification is Linear Temporal Logic (LTL) [22]. LTL provides a natural description of temporal properties over an infinite trace. LTL can express properties such as order, e.g., “first and next eventually ,” and lack of starvation, e.g., “globally eventually resources are granted.” While infinite-trace properties are essential for reasoning about many systems, other systems require finite-trace properties [16, 15], for example robot planning for finite behaviors. If a robot is to build an object, the interest is in the finite rather than the infinite traces that accomplish this task. In such cases [11] is a suitable alternative to LTL, cf. [15].
A number of recent studies has focused on developing efficient frameworks for solving -reasoning problems, e.g., [11, 12, 28, 16, 20, 15]. De Giacomo and Vardi [11] presented a translation of to LTL, implying that existing tools for LTL satisfiability and synthesis can be used for with suitable transformations. In [12], the problem of reactive synthesis from specifications that contain system (controllable) and environment (uncontrollable) variables is considered. The work shows that this problem reduces to strategy synthesis in a two-player automaton game, which is a 2EXPTIME-complete problem. To enable practical solutions to this problem, [28] introduces a symbolic approach to the synthesis problem. The applications of those results in the field of robot planning are studied in [16, 14, 15]. In [20], the fundamental problem of satisfiability checking is studied through a SAT-based approach. The results of those studies show that more scalable tools can be built by treating natively, rather than reducing to LTL, even though LTL reasoning is a more mature and extensively studied domain. The underlying assumption in all those works is that the system is either purely deterministic or purely nondeterministic. Hence, it is natural to ask whether similar results can be obtained for probabilistic systems. That is, do native techniques outperform reasoning by reduction to LTL?
Formal synthesis on probabilistic systems has been extensively studied in the formal-verification literature. In those studies, MDPs are a de facto modeling tool for the probabilistic system, and LTL and PCTL (probabilistic computation temporal logic) [6] are the specification languages of choice. For LTL synthesis, the approach is based on first translating the specification to a deterministic Rabin automaton (DRA) and then solving a stochastic shortest path problem [25, 10] on the product of the DRA with the MDP. Tools such as PRISM [19] can solve this LTL synthesis problem efficiently with their symbolic engine. synthesis for probabilistic systems, however, has not been studied, and it is not clear whether the same tools can be extended for reasoning with a similar efficiency.
Assigning rewards based on temporal goals has also been studied in the context of planning. In [24], a logic similar to , $FLTL, is considered; however, this logic cannot express properties such as “Eventually.” In [4, 5], PastLTL is used to describe finite properties associated with rewards. PastLTL and naturally express different properties (see [24]). In [8, 7], rewards can be attached to or linear dynamic logic on finite traces (LDLf) [11] formulas. In all of these MDP planning works, the goal is to maximize rewards rather than to study the behavior of the MDP. These approaches use approximations that give lower bounds and converge only in the limit. Thus, they cannot necessarily give a negative answer to a decision query about a synthesis problem (e.g., does a policy with at least 95% probability into success exist?).
In this work, we present the problem of synthesis for MDPs. In approaching this problem, we specifically seek to answer the empirical question of which approach is more efficient; an approach based on the mature and well-studied LTL synthesis or an approach based on the unique properties of itself. The answer to this question can have a broader impact on the employment of formal methods for probabilistic systems. Hence, we introduce two solutions to this problem. The first one is based on a reduction to an LTL synthesis problem, and the second one is a native approach. For the first approach, we show a translation of the specification to LTL and a corresponding augmentation of the MDP that allows us to use standard tools for LTL synthesis. For the second approach, we use specialized tools to obtain an automaton that we input to standard tools in order to solve the problem.
2 Problem Formulation
Our goal is to synthesize a policy for an MDP such that the probability of satisfying a given property is maximized. First we introduce the formalisms needed to define this problem. (For a detailed treatment, see [6]). In Section 2.1, we introduce Markov processes and define the labeling of a path on these processes and the probability measure associated with a set of paths. Next, we introduce LTL and the finite-trace version in Section 2.2. We then define when a path on an MDP satisfies an LTL or formula as well as the probability of satisfaction in Section 2.3. Finally, we give our formal problem definition in Section 2.4.
2.1 Markov Processes
Markov processes are frequently used to model systems that exhibit stochastic behavior. While this paper deals with MDPs, it is also important to define Discrete-Time Markov Chains (DTMCs) as they are needed to define probability measures.
Definition 1 (DTMC).
A labeled Discrete-Time Markov Chain (DTMC) is a tuple , where is a countable set of states, is the initial state, is a finite set of atomic propositions, is a labeling function, and is a transition probability function where for all .
An execution of a DTMC is given by a path as defined below.
Definition 2 (Path).
A path through a DTMC is an infinite sequence of states:
is the set of paths starting in . A finite path is a path with a last state . is the set of all finite paths starting in . For every path , denotes the set of prefixes of (similarly for ).
A trace or labeling of a path is the sequence of labels of the states in the path.
Definition 3 (Labeling of a Path).
A labeling (also referred to as valuation or trace) of an infinite path is the sequence The labeling of a finite path is defined analogously. We use to denote the labeling of .
To reason over the paths of a DTMC probabilistically, we need to define a probability space with a probability measure over infinite paths. To this end, we first define cylinder sets that extend a finite path to a set of infinite paths.
Definition 4 (Cylinder Set for DTMC).
The cylinder set for some finite path , denoted by , is the set of all infinite paths that share as a prefix:
| (1) |
Definition 5 (Probability Measure over Paths of a DTMC).
For the probability space , where sample space , event space is the smallest -algebra on containing the cylinder sets of all finite paths (i.e., for all ), the probability measure is defined as:
| (2) |
where . This probability measure is unique per Carathéodory’s extension theorem. We define .
Some systems exhibit not only probabilistic behavior but also non-deterministic behavior. These systems are typically modeled as Markov Decision Processes (MDPs). MDPs extend the definition of DTMCs by allowing choices of actions at each state.
Definition 6 (MDP).
A labeled Markov Decision Process (MDP) is a tuple: , where , and are as in Def. 1 and:
-
•
is a finite set of states;
-
•
is a finite set of actions, and denotes the set of actions enabled at state ;
-
•
is the transition probability function where for all and .
Example 1. An example of an MDP is shown in Figure 1. Actions () and probabilities are shown as edge labels. State names are within each state and state labels are above each state.
The notion of path can be straightforwardly extended from DTMCs to MDPs.
Definition 7 (Path through MDP).
A path through an MDP is a state followed by a sequence of action-state pairs:
such that , , and for all . , and are defined analogously to the DTMC case.
A policy (also known as an adversary or strategy) resolves the choice of actions. This induces a (possibly infinite) DTMC.
Definition 8 (Policy).
A policy maps every finite path to an element of , i.e., .111Here, we focus on deterministic policies as they are sufficient for optimality of LTL (and ) properties on MDPs [6].
The set of all policies is . A policy is stationary if only depends on the most recent state of denoted by . Under policy the action choices on are determined. This gives us a DTMC whose states correspond to the finite paths of the MDP. We call this the DTMC induced on by policy and denote this by . is shorthand for of . Therefore, the probability of the paths of the MDP under are defined according to , whose probability space includes a probability measure over infinite paths via cylinder sets that extend a finite path to a set of infinite paths. See [6] for details.
2.2 Linear Temporal Logic
Linear temporal logic (LTL) is a popular formalism used to specify temporal properties. Here, we are interested in LTL interpreted over finite traces, but we must still define LTL as we use a reduction to LTL as one of our two approaches to synthesis.
Definition 9 (LTL Syntax).
An LTL formula is built from a set of propositional symbols and is closed under the boolean connectives as well as the “next” operator and the “until” operator :
where
The common temporal operators “eventually” () and “globally” () are defined as: and . The semantics of LTL are defined over infinite traces (for full definition, see [22]). An LTL formula defines an -regular language over alphabet .
Next we define . To distinguish between the formulas of the two logics, we use for LTL and for formulas.
Definition 10 ( Syntax & Semantics).
An formula has identical syntax to LTL, but the semantics is defined over finite traces. Let and denote the length of trace and the symbol in the position in , respectively, and is read as: “the step of trace is a model of .” Then,
-
•
-
•
iff
-
•
iff
-
•
iff and
-
•
iff and
-
•
iff s.t. and and , , .
We say finite trace satisfies formula , denoted by , iff . An formula defines a language over the alphabet . is a star-free regular language [11].
2.3 Satisfaction of Temporal Logic Specification
Here, we define what it means for an MDP to satisfy an LTL or formula.
Definition 11 (Path satisfying LTL).
For a pair (, ) of an MDP and an LTL formula where the atomic propositions of match the propositions of (i.e., ), we say that an infinite path on satisfies specification if the labeling of is in the language of , i.e., .
Following [28], we define finite satisfaction (of an formula) as follows.
Definition 12 (Path satisfying ).
For a pair (, ) of an MDP and an formula where the atomic propositions of match the propositions of (i.e., ), we say that a (possibly finite) path of satisfies specification if at least one prefix of is in the language of , i.e.,
| (3) |
Intuitively, this corresponds to a system that can declare its execution complete after satisfying its goals. is suitable for specifications that are to be completed in finite time.
Definition 13 (Probability of satisfaction).
The probability of satisfying an property in under policy is .
2.4 Problem Statement
We formalize the problem of synthesis on MDPs as:
Problem 1 ( synthesis on MDPs).
Given MDP and an formula , compute a policy that maximizes the probability of satisfying , i.e.,
as well as this probability, i.e., .
3 Synthesis Algorithms
We introduce two approaches to policy synthesis on MDPs. The first approach is based on reduction to classical LTL policy synthesis on MDPs. The second approach is through a translation of formulas to first order logic formulas, which can be translated to a symbolic deterministic automaton. In this section, we detail these two algorithms, and in Section 4, we show that the second approach scales better than the classical LTL approach.
3.1 Reduction to LTL Synthesis
We can reduce the problem of policy synthesis on MDPs to a classical LTL policy synthesis. The algorithm consists of two main steps: (1) construction of an MDP from by augmenting it with an additional state and atomic proposition, and (2) translation of formula on the labels of to its equivalent LTL formula on the labels of .
3.1.1 Augmented MDP
Recall that the semantics of formulas is over finite traces whereas the interpretation of LTL formulas is over infinite traces. In order to reduce the synthesis problem to an LTL one, we need to be able to capture the finite paths (traces) of that satisfy and extend them to infinite paths (traces). Specifically, we need those satisfying finite paths that contain no -satisfying proper prefixes, i.e., satisfy for the first time. To this end, we allow the system (policy) to decide when to “terminate.” We view the system to be “alive” until termination, at which point it is no longer alive. Then, we define an LTL formula that requires the system to be alive while it has not satisfied and to terminate after satisfying .
To this end, we augment MDP with a terminal action and state and an atomic proposition . Formally, we construct MDP , where , , , ,
| (4) |
In this MDP, the system can decide to terminate by taking action , in which case it transitions to state with probability one and remains there forever. The labeling of the corresponding path includes the atomic proposition at every time step until is visited and is empty thereafter.
Example 2. Figure 2 illustrates the augmented MDP constructed from the example MDP in Figure 1. State along with the dashed edges and atomic proposition are added to . The dashed edges are enabled by action and have transition probability of one. The label of is the empty set, and the labels of the rest of the states contain .
With this augmentation, the system is able to terminate once a satisfying finite path is generated. We show that, for finite properties, the maximum probability of satisfaction in equals the maximum probability of satisfaction in under a policy that enforces a visit to .
Let be a set of finite paths of interest in arbitrary MDP . Denote the probability of satisfaction of infinite paths with prefixes from under policy by:
| (5) |
The following lemma states the equivalence of the maximum probability of satisfying this set of paths in and .
Lemma 1.
Let be a set of finite paths of interest of MDP . Further, let be the augmented version of and be the set of policies of that enforce a visit to state (take action ). Then, it holds that
| (6) |
Proof.
We prove the results by showing that LHS RHS and then LHS RHS.
Case 1. We want to prove that:
Consider policy on . We can construct policy on from as follows:
Recall the probability measure given by the cylinder set and that the transition probability under is always . Thus from optimal policy on , we can construct on with equal probability.
Case 2. Next we prove that:
Consider an optimal policy on . By assumption, we know that chooses at some finite point along any path. Consider an arbitrary path and let be chosen as the action: Let be the smallest natural number such that . Then consider policy which takes action at state and with probability 1 transitioned to state ( and may be identical). Recall the probability measure given by the cylinder set . Thus, because has probability 1, . We can map to a policy for with the same probability of satisfaction by changing every choice of to an arbitrary available action. Thus, from (optimal policy) we can construct a policy on with an equal probability of satisfaction.
∎
3.1.2 to LTL
To translate an formula on to its equivalent LTL formula on , we follow [11]. Let be the set of formulas defined over atomic propositions in and be the set of LTL formulas defined over . Then is defined as:
| (7) |
where is inductively defined as:
-
•
, where ;
-
•
;
-
•
;
-
•
;
-
•
.
In this construction, mapping ensures that is present in the last letter of every finite trace that satisfies . Then, translates to by requiring to be true until is satisfied and false thereafter. In other words, the translated LTL formula requires the system to terminate after it satisfies .
Theorem 1.
Given an MDP and its augmentation as well as an formula and the corresponding LTL formula , then
where is the set of all policies in .
Proof.
This follows through an application of Lemma 1 and a proof that the finite paths on satisfying correspond to the infinite paths on satisfying . First we note that the termination assumption of Lemma 1 (i.e., that policies visit ) is met because contains the clause . For all and . Recall that is a sink state with label . Then from [11] it follows that finite paths of that satisfy correspond to paths in that satisfy .
∎
A direct result of the above theorem is the reduction of policy synthesis to classical LTL policy synthesis on MDPs.
Corollary 1.
The policy synthesis to maximize the probability of satisfying formula on can be reduced to the LTL maximal policy synthesis problem.
Therefore, to solve Problem 1, we can use LTL synthesis on augmented MDP and property . The general LTL synthesis algorithm is well-established [6] and follows the following steps: (1) translation of the LTL formula to a DRA, (2) composition of the DRA with the MDP, which results in another MDP called the product MDP, (3) identification of the maximal end-components on the product MDP that satisfy the accepting condition of DRA, and finally (4) solving the maximal reachability probability problem (stochastic shortest path problem) [10] on the product MDP with the accepting end-components as the target states. There exist many tools such as PRISM [19] that can solve the LTL synthesis problem. Specifically, PRISM has a symbolic implementation of this algorithm, enabling fast computations. In Section 4, however, we show that the native approach introduced below outperforms the LTL-reduction approach even by using PRISM’s symbolic engine.
3.2 Native Approach
In the native approach, we first convert the formula into a deterministic finite automaton (DFA) using specialized tools [28]. Then we take the product of this automaton with the MDP. Finally, we synthesize a strategy by solving the maximal reachability probability problem on this product MDP.
3.2.1 Translation to DFA
A Deterministic Finite Automaton (DFA) is a tuple: , where is the set of states, the alphabet, the transition function, the initial state and the set of accept states. A finite run of a DFA on a trace , where , is the sequence of states such that for all . This run is accepting if .
Following [28], we translate to a DFA using MONA [17]. is expressively equivalent to First-order Logic on finite words, which in turn is a fragment of Weak Second-order Theory of One Successor. We use the translation given in [11] to convert formula to a First-order Logic formula. MONA offers translations from Weak Second-order Theory of One or Two Successors (WS1S/WS2S) to a DFA that accepts precisely the language of our formula . We denote this DFA by .
3.2.2 Product of DFA with MDP
Given DFA , we can take the product with the MDP to achieve a new MDP as follows. The product of MDP and DFA is an MDP
where , and
The paths of this product MDP have one-to-one correspondence to the paths of MDP as well as the runs of . Therefore, the projection of the paths of that reach state , where , on are accepting runs and on are -satisfy paths. Thus, we solve Problem 1 by synthesizing an optimal policy on this product MDP, using standard tools for the maximal reachability probability problem as discussed in Sec. 3.1. The resulting policy is stationary on the product MDP but history-dependent on .
In theory, both the LTL approach and the native approach exhibit runtimes doubly-exponential in the size of the formula, due to the need to construct deterministic automata [9, 12]. In practice, the native approach’s translation to a DFA using specialized tools offers better runtime and memory usage compared to the LTL-based approach. Additionally, it produces a minimal DFA, while the LTL pipeline produces an -automaton which cannot be minimized effectively by existing tools. We show the benefits of the native approach experimentally in Sec. 4.
4 Evaluation
We evaluate the proposed synthesis approaches through a series of benchmarking case studies. Below, we provide details on our implementation, experimental scenarios, and obtained results. A version of our tool along with examples is available on GitHub [26].
4.1 Experimental Framework
We run our experiments using the PRISM framework [19]. PRISM uses a symbolic encoding of MDPs as well as an encoding of automata as a list of edges, where the labels of edges are encoded symbolically using BDDs. PRISM supports several tools for the LTL-to-automata translation. We tested PRISM’s built-in translator as well as Rabinizer, LTL3DRA and SPOT [18, 3, 13]. Of these, PRISM’s built in conversion and SPOT performed significantly better than the others, and were used for evaluation.
We note that we also considered a comparison study against MoChiBa [23], a tool based on PRISM that uses Limit-Deterministic Büchi Automata. Unfortunately, it is not possible to conduct this study since the current implementation of MoChiBa does not support loading automata from external tools and only runs with a modified implementation of PRISM’s explicit engine. Our tests use PRISM’s Hybrid engine (enabled by default). We leave a comparison of our DFA-based approach for synthesis to an approach based on Limit-Deterministic Büchi Automata to future work.
In the implementation of the LTL-reduction approach, we augment the MDP and convert the formula into an equivalent LTL formula as described in Section 3.1. Then, we input both the LTL formula and the modified MDP into PRISM for synthesis. In the implementation of the native approach, we invoke PRISM on the original formula and MDP and use an external tool to convert the formula into a DFA using MONA [17] then convert from MONA’s format to the HOA format [2]. Note that external tools (SPOT and our native approach) read from hard disk, whereas using PRISM’s built-in conversion avoids this. Nevertheless, even including this time, the native approach (and sometimes SPOT) typically gives better performance as shown below. All experiments are run on a computer with an Intel i7-8550U and 16GB of RAM. PRISM is run using the default settings.
4.2 Experimental Scenarios
4.2.1 Test MDPs
We consider four types of MDPs: Gridworld, Dining Philosophers, Nim, and Double Counter. In Gridworld, an agent is given some goal as an formula and must maximize the probability of satisfaction. The agent has four actions: North, South, East, and West. Under each action, the probability of moving to the cell in the intended direction is 0.69, then 0.01 for its opposite cell, and finally 0.1 for each of the other directions and for remaining in the same cell. If the resulting movement would place the agent in collision with the boundary, the agent remains in its current cell. We model the motion of this agent as an MDP, where the states correspond to the cells of the grid and the set of actions is .
We base the Dining-Philosophers domain on the tutorial from the PRISM website. We consider a ring of five philosophers with two different specifications. Note that typical Dining-Philosophers specifications of interest are infinite-trace; our tests are merely meant to show that our approach works on MDPs other than Gridworld. Both Nim and Double Counter are probabilistic versions of games presented in [21].
4.2.2 Test formulas
Unfortunately, there is no standard set of formulas that we can use for benchmarking. In [28], random LTL formulas are used as the basis of benchmarks; however, because we also consider an MDP, random formulas are frequently tautologies or non-realizable with respect to the MDP. For instance, consider a randomly generated formula , where and are randomly assigned to the labels of the states in the Gridworld MDP. There is likely no path of the MDP that can satisfy this formula. As a matter of fact, in a test of more than 70 randomly generated formulas and Gridworld MDPs, only one was “interesting” (yielding probability between zero and one) on the corresponding MDP. For benchmarking, the interest is in sets of formulas that make sense in a probabilistic setting.
Therefore, as the first set of test formulas for the Gridworld MDP, we considered a natural finite-trace specification where the agent has goals to accomplish in any order, as well as a “safety” property where it must globally avoid some states. This is typical of e.g., a robotics domain [15]. We use Fn to denote this formula for a given . For the second set of test formulas, we keep regions to visit and avoid but introduce some ordering and repeat visits. OS is a short formula introducing order and OL is a longer formula that also contains nested temporal operators. All formulas are given in the appendix of the online version [27].
For the Dining Philosophers domains, typical examples focus on infinite-run properties. We test several finite-run properties on these domains. These properties are meant to illustrate our tool on an MDP other than Gridworld, but are not representative of typical finite-trace properties. One version (D5) asserts that all philosophers must eat at least once. The other (D5C) is a more complex property involving orders of eating. Both formulas are available in the appendix of the online version [27].
For Nim, the game of Nim is played against a stochastic opponent. To increase difficulty, the specifications require that randomly chosen stack heights are to be reached or avoided by the system player. For Double Counter, two four-bit binary counters are used. One counter is controlled by a stochastic environment, and the other is controlled by the system. The aim of the system is to make its counter match that of the environment.
4.3 Experimental Results
We provide experiments varying the complexity of the formulas and of the MDPs. Total runtime is shown in seconds. We refer to the translation to LTL as the “LTL pipeline” and the translation to a DFA via MONA as the “Native pipeline.” All plots are best viewed in color.
4.3.1 Automata Construction
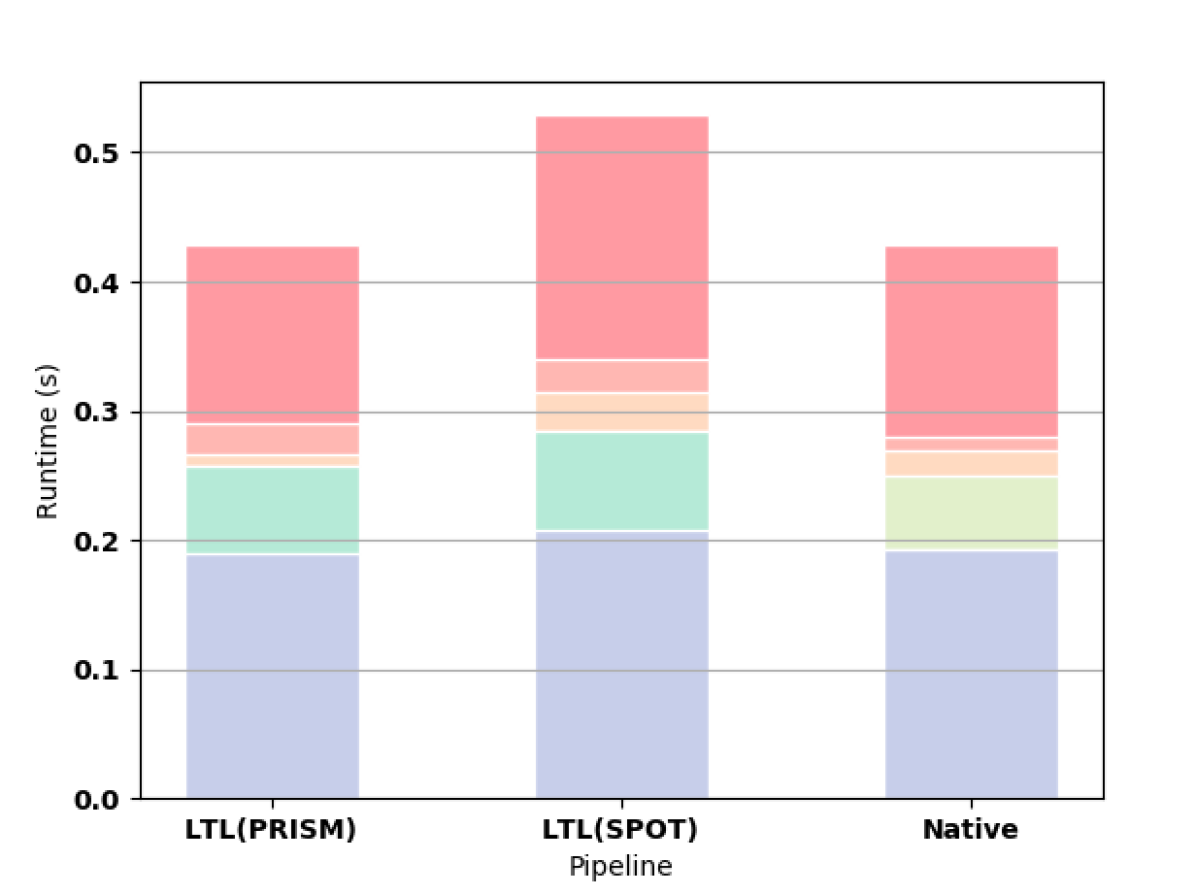
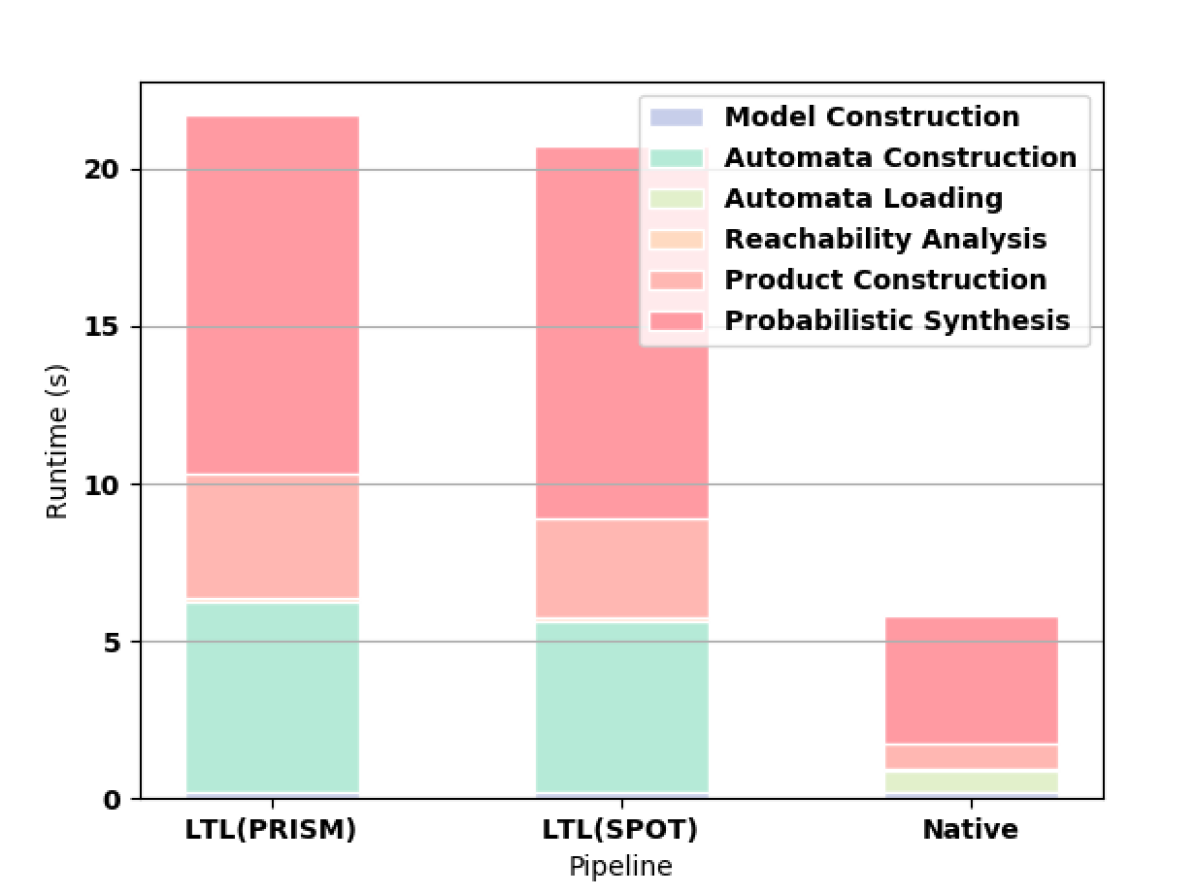
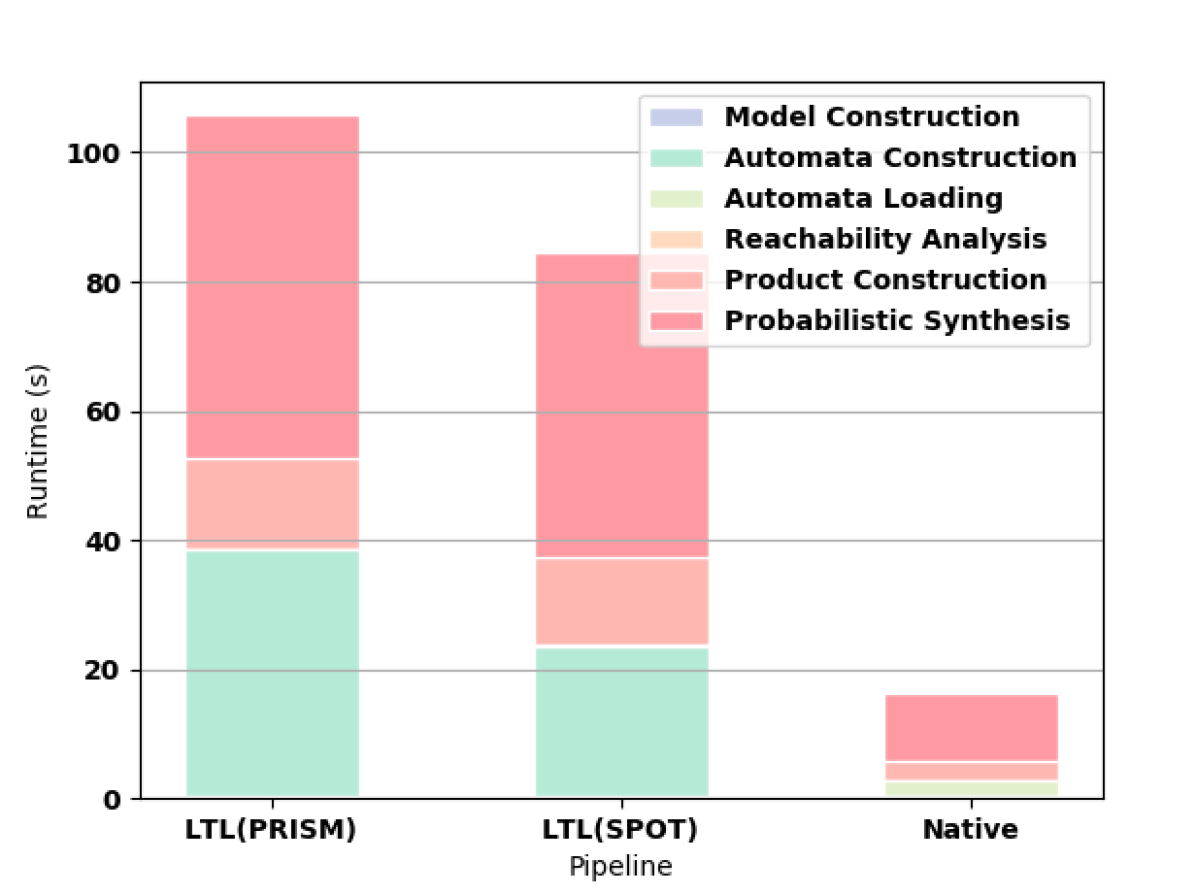
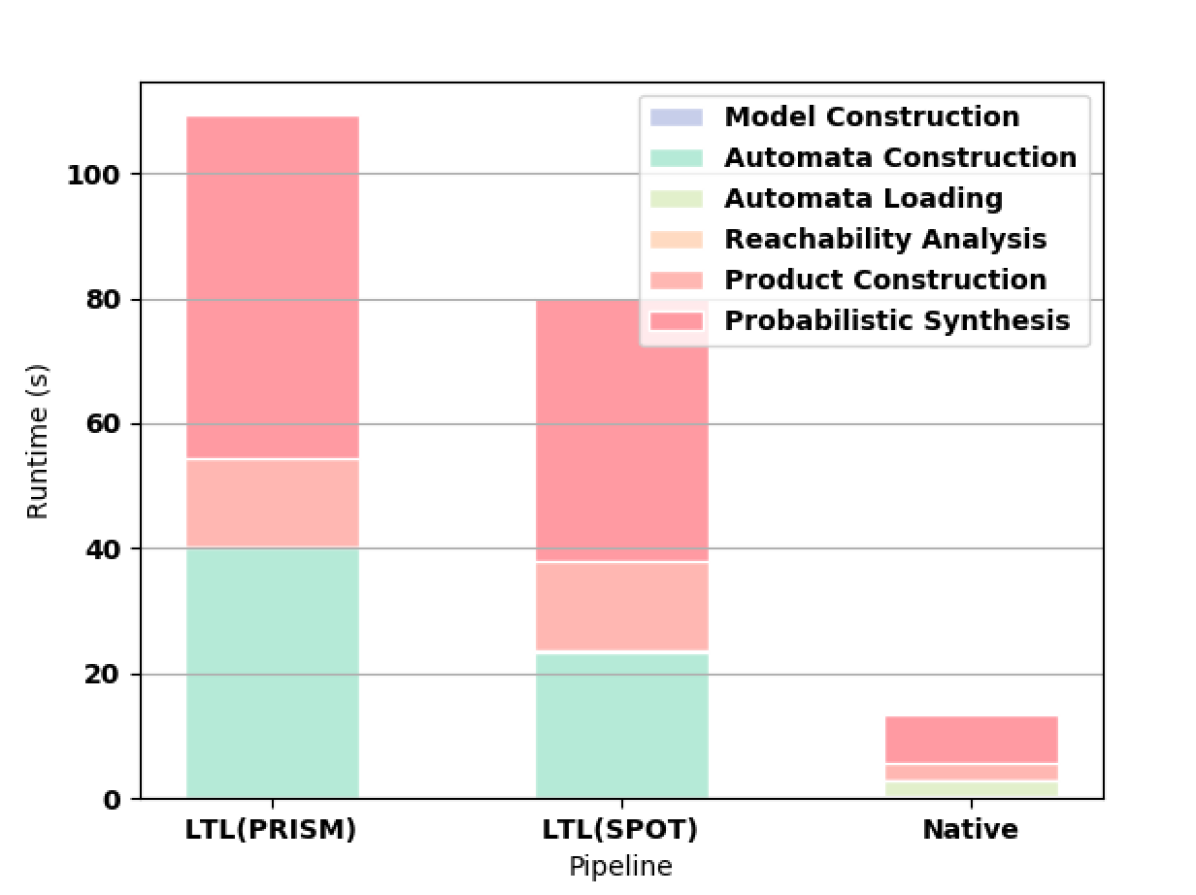
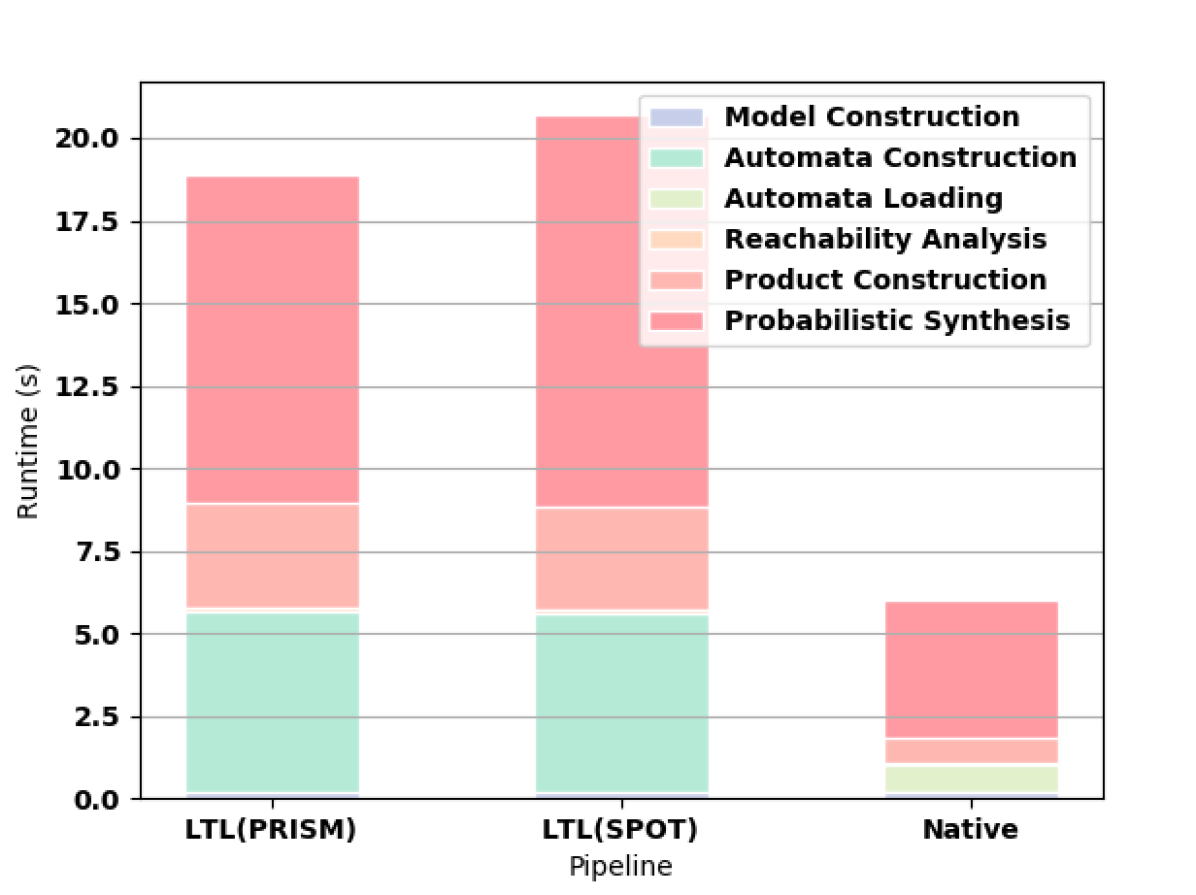
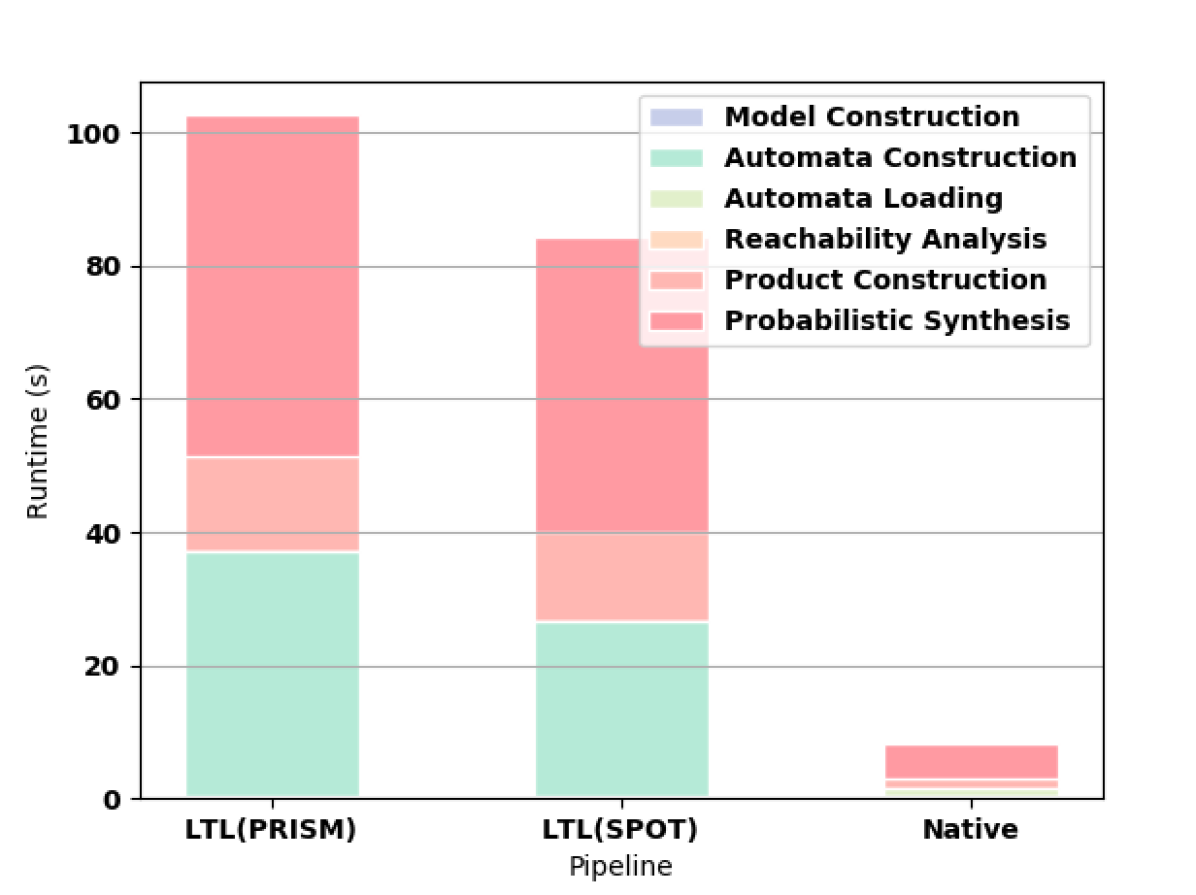
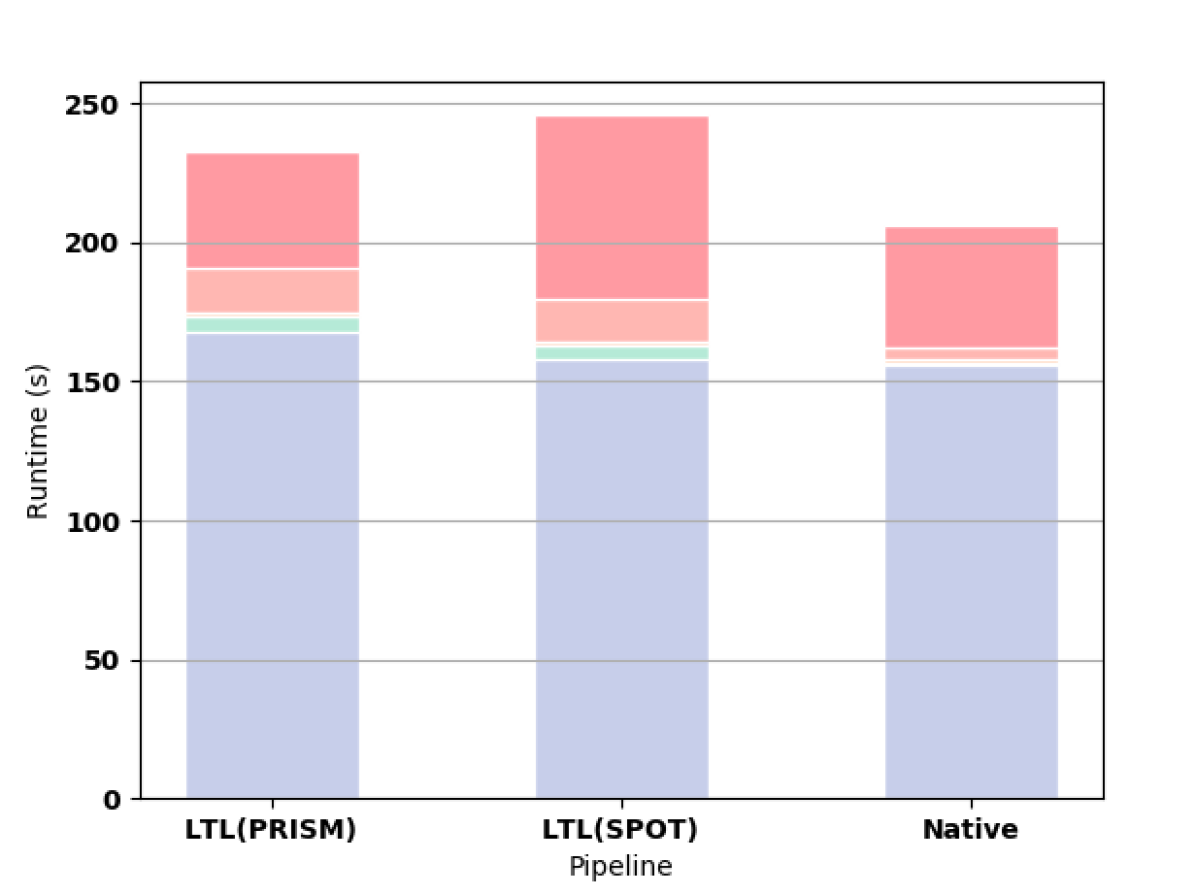
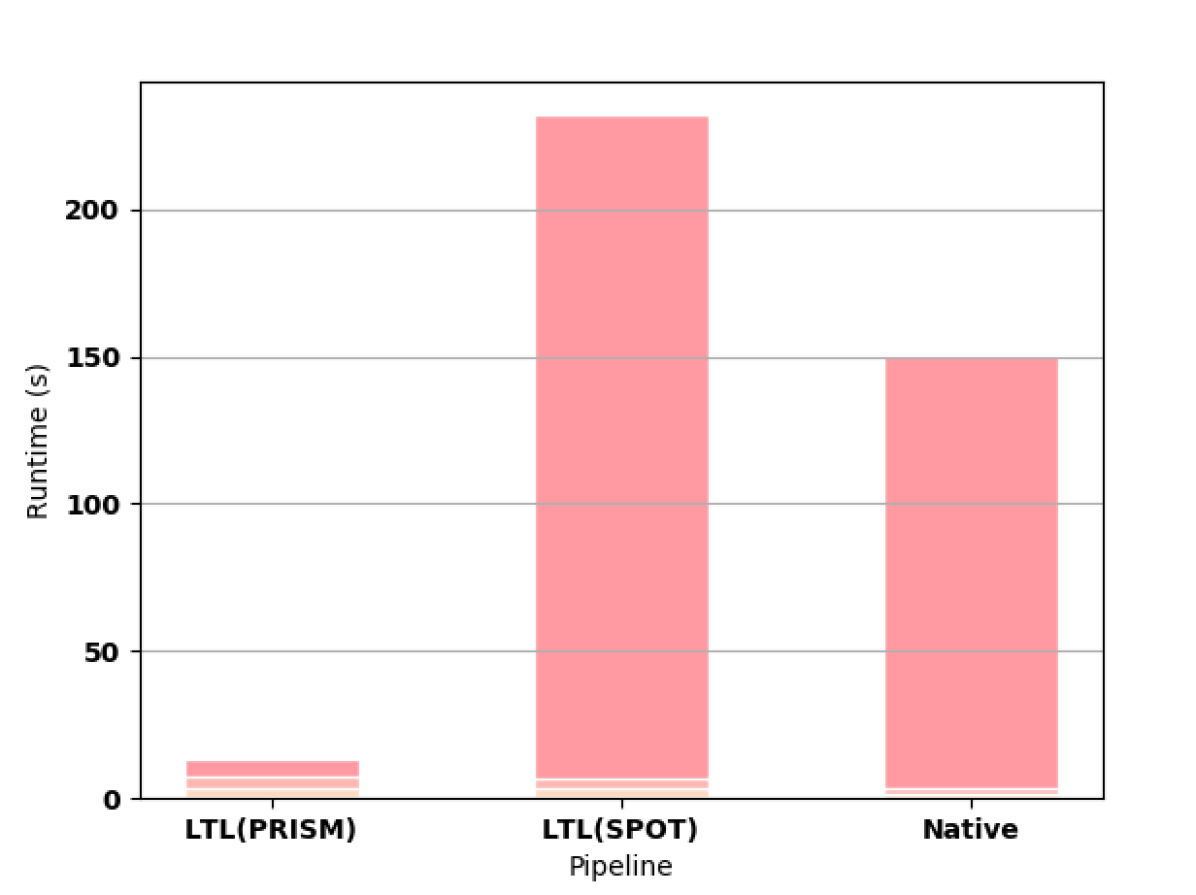
First we measure how the length of the formula affects the synthesis computation time. For all of these experiments, we use a Gridworld as the original MDP. For small formulas, the time needed to read the HOA file from hard disk outweighs the shorter construction time and smaller automata of the native approach as shown in 3(a). For formulas longer than F3, the native approach offers better computation time (e.g., see 3(b) and 3(c)).
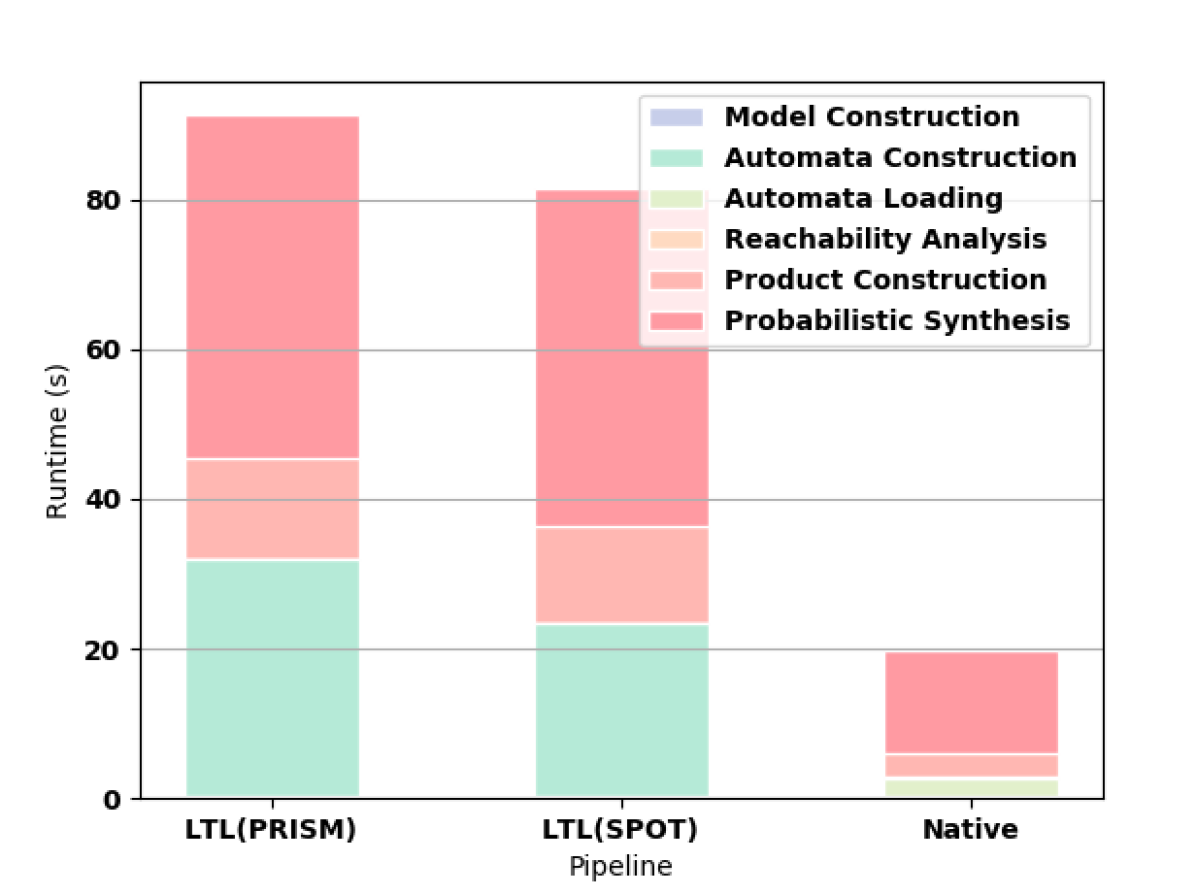
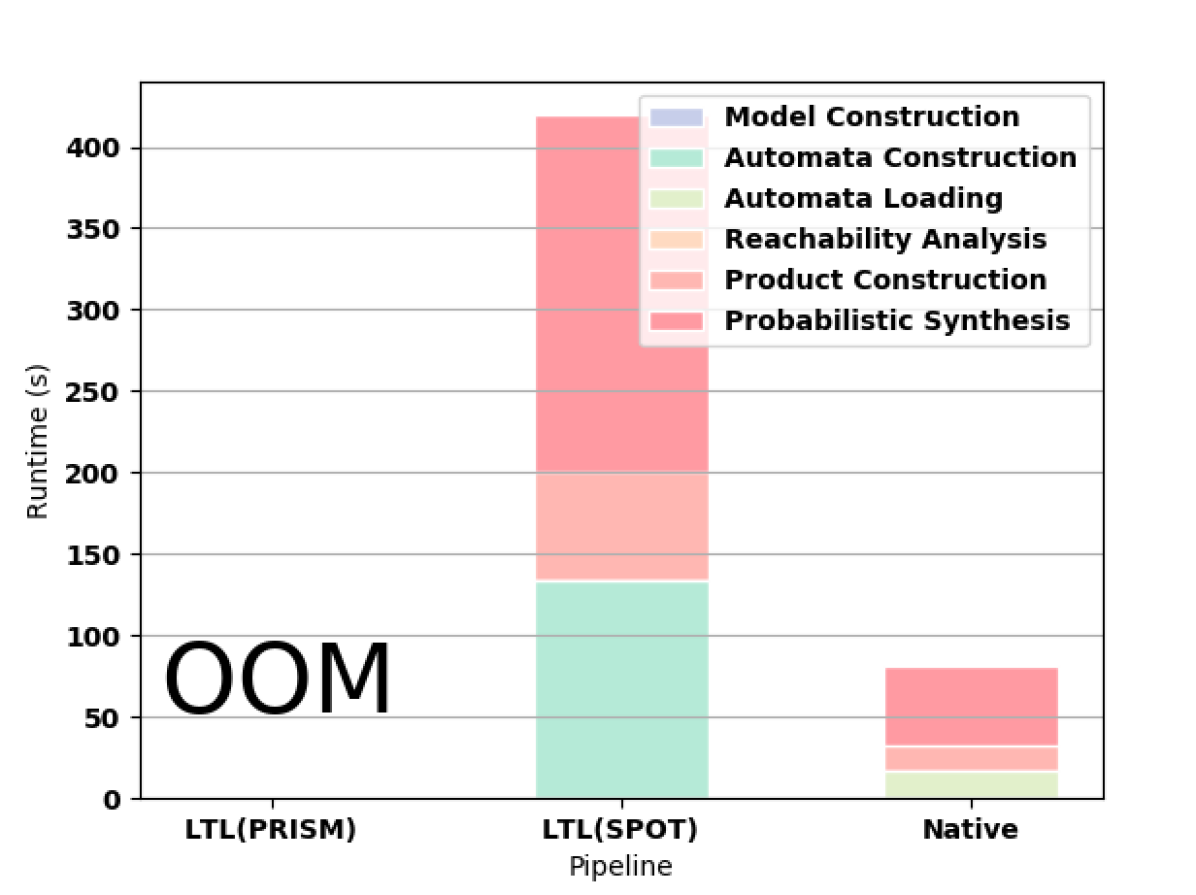
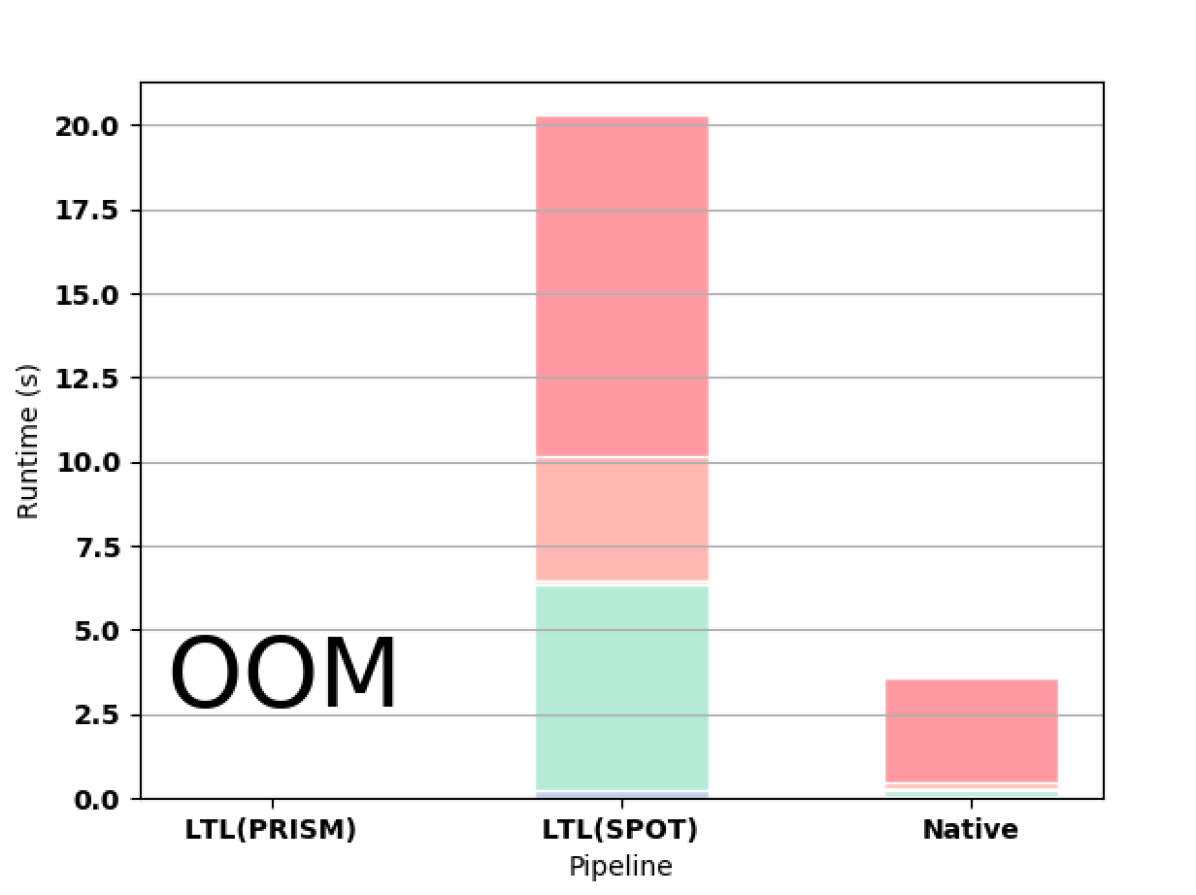
PRISM successfully builds automata for formulas up to F9. In 3(d), we highlight the superiority of the native approach in constructing the automaton for F10. For this formula, PRISM runs out of memory when constructing the automaton according to the LTL pipeline. SPOT completes for F10 but runs out of memory on F11. MONA works for formulas up to F17, which takes 8.586 seconds to compute, though writing the resulting file to disk is prohibitively expensive (the file is larger than 10GB). MONA runs out of memory constructing the automaton for F18.
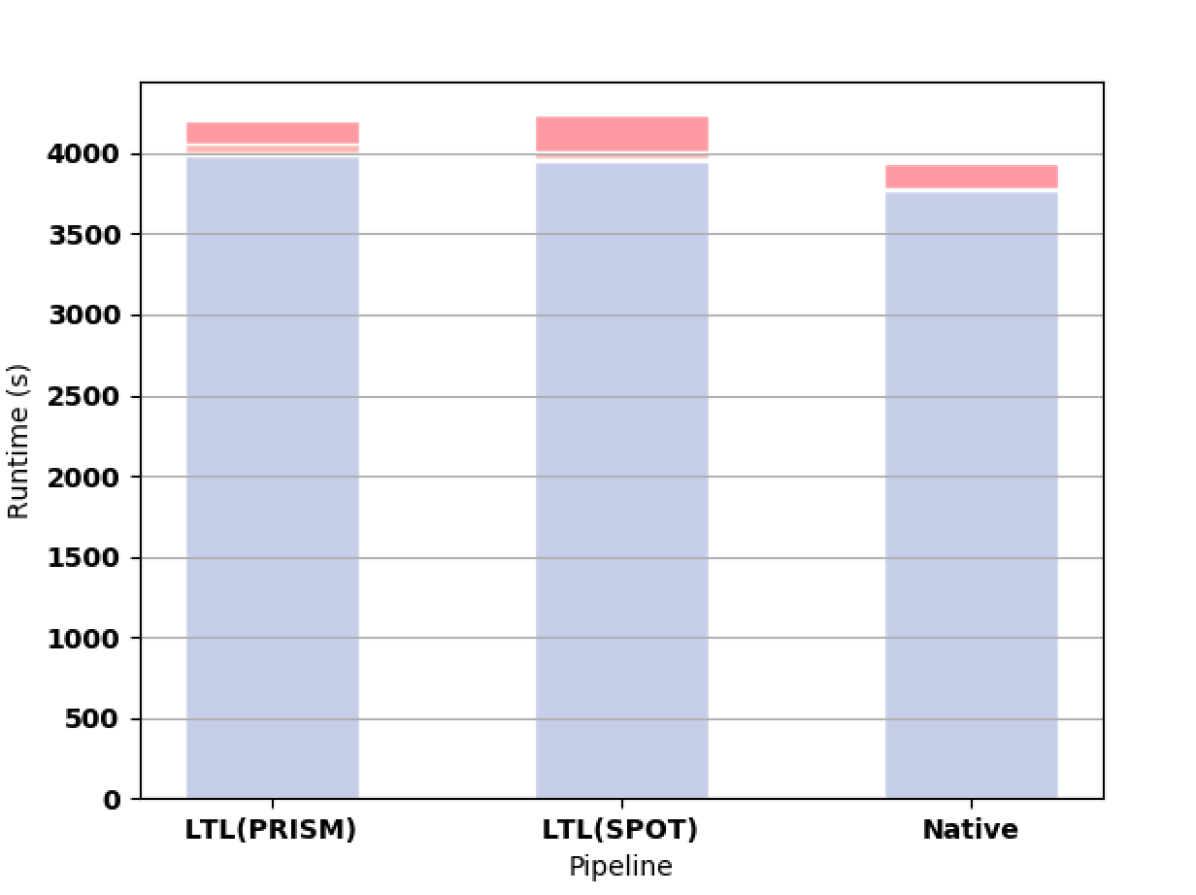
We also considered a Gridworld with random obstacles (3(e)) and with hallways (3(f)), both with the formula F9. Finally, we consider two other formulas (OS and OL) in 3(g) and 3(h) to demonstrate that our improvement is not tied to the specific form of the specification.
For the Dining-Philosophers example, we consider five philosophers. Again, our results show that the native pipeline is faster and more memory efficient than the other approaches for automata construction (3(l)). However, the Dining-Philosophers example illustrates an issue where PRISM’s built-in automata translation sometimes constructs automata such that computing the maximal accepting end-component using BDDs within PRISM is significantly faster (3(k)). The automata construction is still slower than both SPOT and our native approach, and the automata returned have more states, but the BDD representation is more efficient. This issue affects some automata, not only for our tool, but also for other external tools we tested. This means not only automata construction and size, but also the BDD representation are important for overall runtime. However, PRISM’s built-in translator’s memory usage scales more poorly than SPOT or our native approach. On a more complex formula 3(l), PRISM’s built-in construction runs out of memory, even though SPOT and the native approach can finish construction in less than ten seconds. Thus, for sufficiently complex formulas, PRISM’s built-in translation is not viable. This suggests a need for automata construction methods that are not only more efficient but also produce automata that work well within PRISM.
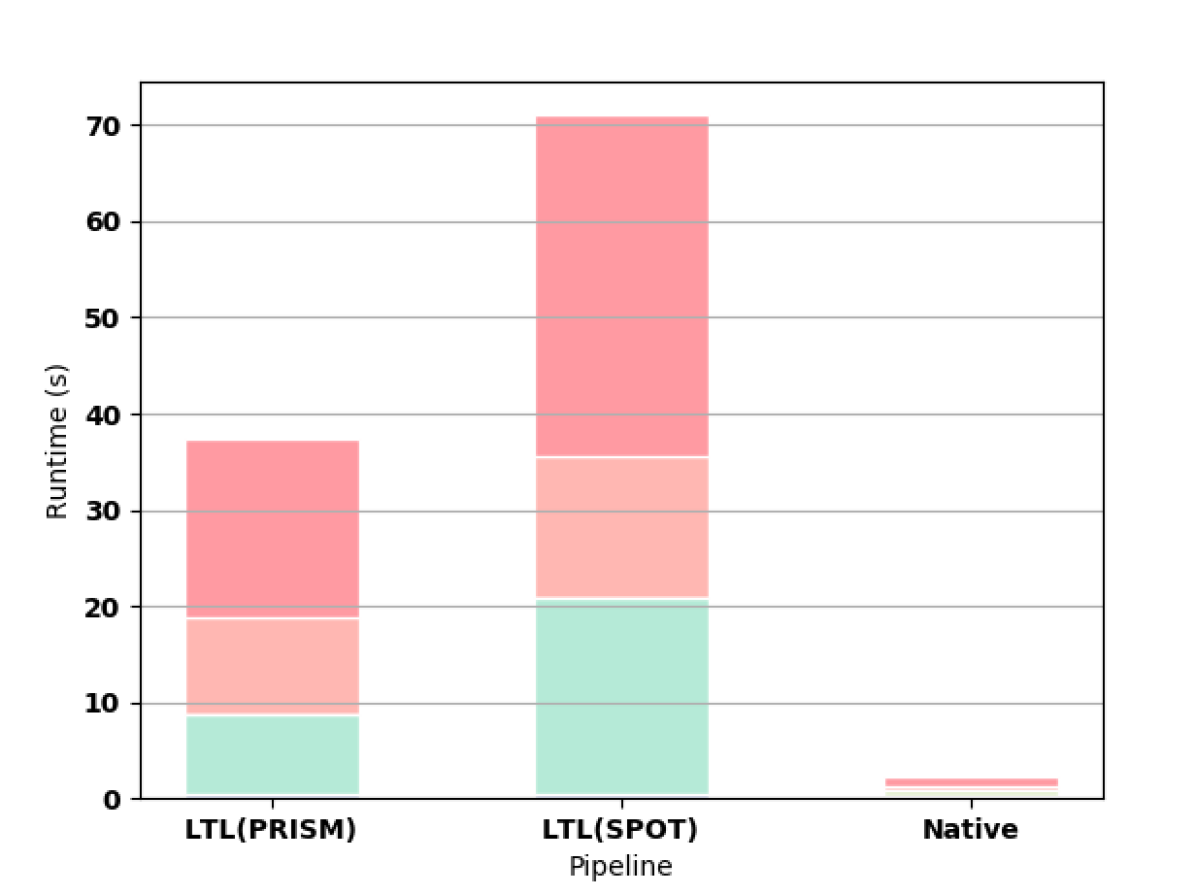
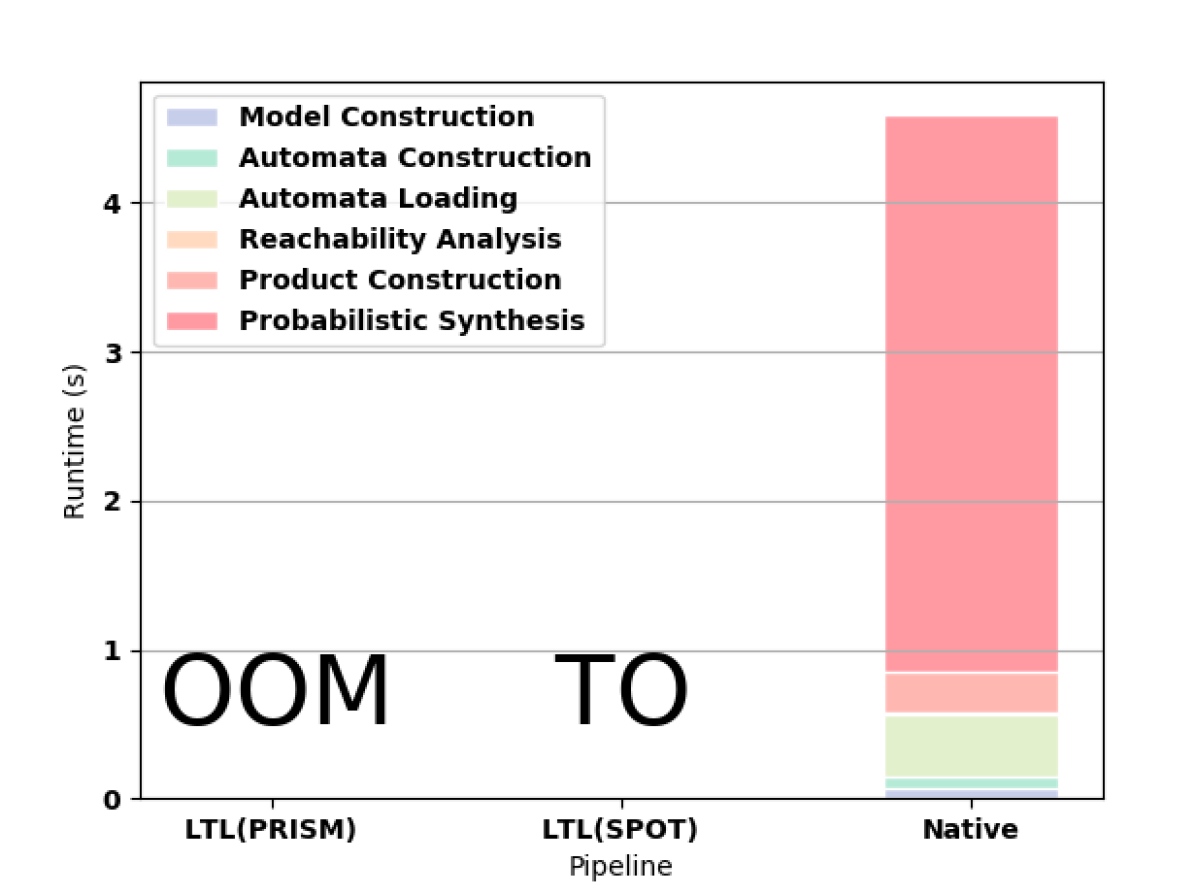
In the Nim game, the native approach far outperforms both PRISM and PRISM with SPOT (4(a)). In the Double-Counter game, PRISM runs out of memory and PRISM with SPOT times out after more than 3 hours, whereas the native approach completes synthesis is less than 5 seconds.
Overall we observe that for large formulas the native pipeline offers significantly better scalability than the LTL pipeline (tested with PRISM’s built-in translator, SPOT, Rabinizer, and LTL3DRA automata translators). With an implementation that does not access the hard disk, we expect even better performance of the native pipeline.
4.3.2 Automata Size
The DFA generated by the native pipeline is minimal and typically much smaller than the LTL pipeline’s DRA. SPOT and PRISM typically produce similarly sized DRAs. Because we take the product of the input MDP with these automata, we expect the size of the resulting product to be smaller in the native pipeline. Table 1 shows the automaton sizes for the various formulas. Table 2 shows the sizes of the product MDPs for the LTL and native pipelines respectively.
Interestingly, while the size of the DFA obtained from MONA is roughly half the size of the DRA constructed by PRISM, the final sizes of the products of the MDP and the automata are comparable for both approaches. The number of states, transitions and nondeterministic choices are all measured after reachability analysis is performed. We see time savings in the reachability analysis and product construction phases (both about two times faster), but the final products are similar in size. However, the product from the native pipeline has fewer nondeterministic transitions than the product from the LTL pipeline. The improvements from this are small relative to the time it takes to construct a large gridworld MDP (3(j)).
Examples of this are shown in 3(i) and 3(j). Note that the majority of the computation time is spent constructing the MDPs. For the LTL pipeline, this construction takes slightly longer time because of the augmented MDP. It is important to note that the native approach allows us to use larger formulas with these models whereas the LTL pipeline is limited to F10 or smaller.
In summary, we observe that the native pipeline is the most efficient in terms of both runtime and memory. There are two possible drawbacks to the native pipeline. First, it requires reading from disk, which for small formulas negates the advantage in automata construction time. Second, PRISM’s built-in automata translation sometimes constructs automata whose BDD representations work better within PRISM than automata from any external tools we tested (3(k)).
| F3 | F8 | F9 | F10 | OS | OL | D5 | D5C | Nim | Counter | |
|---|---|---|---|---|---|---|---|---|---|---|
| DRA states | 19 | 512 | 1,027 | NA | 515 | 1,028 | 67 | NA | 701 | NA |
| DFA states | 10 | 258 | 514 | 1,026 | 258 | 259 | 33 | 29 | 67 | 130 |
| 10x10 F3 | 10x10 F8 | 10x10 F9 | 50x50 F8 | 100x100 F8 | 10x10 F10 | 10x10 OS | |
| States (LTL) | 890 | 24,678 | 48,998 | 641,478 | 2,568,978 | NA | 24,678 |
| States (Native) | 881 | 24,421 | 48,485 | 641,221 | 2,568,721 | 96357 | 24,421 |
| Transitions (LTL) | 17,130 | 475,030 | 942,742 | 13,265,398 | 53,537,298 | NA | 475,030 |
| Transitions (Native) | 16,256 | 450,468 | 893,760 | 12,623,936 | 50,968,336 | 1775424 | 450,368 |
| Choices (LTL) | 4,410 | 122,358 | 242,934 | 3,206,358 | 12,843,858 | NA | 122,358 |
| Choices (Native) | 3,524 | 97,684 | 193,940 | 2,564,884 | 10,274,884 | 385428 | 97,684 |
| OL | 10x10 rand | 10x10 halls | 5 Phil D5 | 5 Phil D5C | Nim | Counter | |
| States (LTL) | 24,935 | 44,253 | 19,476 | 4,548,220 | NA | 2115 | NA |
| States (Native) | 24,519 | 43,740 | 19,187 | 1,476,976 | 93,068 | 404 | 449 |
| Transitions (LTL) | 475,287 | 804,097 | 310,996 | 46,948,710 | NA | 8343 | NA |
| Transitions (Native) | 452,172 | 759,856 | 291,536 | 7,891,750 | 494,420 | 1205 | 908 |
| Choices (LTL) | 122,615 | 219,209 | 96,220 | 44,059,330 | NA | 6297 | NA |
| Choices (Native) | 98,076 | 174,960 | 76,748 | 6,895,580 | 437,050 | 808 | 460 |
5 Conclusion
We introduced the problem of synthesis for probabilistic systems and presented two approaches. The first one is a reduction of to LTL with a corresponding augmentation of the MDP. The second approach uses native tools to construct an automaton and then takes the product of this automaton with the MDP to construct a product MDP that can be used for synthesis through standard techniques. We showed that this native approach offers better scalability than the reduction to LTL. Our work opens the door to the use of synthesis on practical domains such as robotics, cf. [15]. Our tool is on GitHub [26].
For future work we would like to expand our results to include probability minimization (c.f. Theorem 1). Our native approach extends easily, but there are subtleties that prevent applying the LTL pipeline to minimization. We are also interested in a fully symbolic methodology, where the automaton is represented symbolically and the product is also taken symbolically. The experiment in 3(k) and our experiences with MoChiBa both indicate that implementing methods optimized for PRISM may be more efficient than external tools. We are also interested in applying the work to robotics domains.
Acknowledgments
Work on this project by AMW has been supported by NASA 80NSSC17K0162; by ML has been supported by the University of Colorado Boulder Autonomous Systems Interdisciplinary Research Theme and the NSF Centerfor Unmanned Aircraft Systems; by LEK has been supported in part by NSF grant IIS-1830549; and by MYV has been supported in part by NSF grants IIS-1527668, CCF-1704883, IIS-1830549, and an award from the Maryland Procurement Office. The authors would like to thank Gabriel Santos and Joachim Klein from the University of Oxford for their insightful comments and suggestions for efficient implementation of the framework in PRISM. We would like to thank Salomon Sikert from the Technical University of Munich for his aid in running MoChiBa.
References
- [1]
- [2] Tomáš Babiak, František Blahoudek, Alexandre Duret-Lutz, Joachim Klein, Jan Křetínský, David Müller, David Parker & Jan Strejček (2015): The Hanoi Omega-Automata Format. In: Computer Aided Verification, Springer Intl. Publishing, Cham, pp. 479–486, 10.1007/978-3-319-21690-4_31.
- [3] Tomáš Babiak, František Blahoudek, Mojmír Křetínskỳ & Jan Strejček (2013): Effective translation of LTL to deterministic Rabin automata: Beyond the (F, G)-fragment. In: Automated Technology for Verification and Analysis, Springer, pp. 24–39, 10.1007/10722167_21.
- [4] Fahiem Bacchus, Craig Boutilier & Adam Grove (1996): Rewarding Behaviors. In: Proc. of the Thirteenth Natl. Conf. on Artificial Intelligence - Volume 2, AAAI’96, AAAI Press, p. 1160–1167.
- [5] Fahiem Bacchus, Craig Boutilier & Adam Grove (1997): Structured Solution Methods for Non-Markovian Decision Processes. In: Proc. of the (AAAI-97) and (IAAI-97), AAAI’97/IAAI’97, AAAI Press, p. 112–117.
- [6] Christel Baier & Joost-Pieter Katoen (2008): Principles of Model Checking. The MIT Press.
- [7] Ronen I. Brafman, Giuseppe De Giacomo & Fabio Patrizi (2018): LTLf/LDLf Non-Markovian Rewards. In: Proc. of (AAAI-18), (IAAI-18), and (EAAI-18), New Orleans, Louisiana, USA, February 2-7, 2018, AAAI Press, pp. 1771–1778.
- [8] Alberto Camacho, Oscar Chen, Scott Sanner & Sheila A. McIlraith (2017): Non-Markovian Rewards Expressed in LTL: Guiding Search Via Reward Shaping. In: SOCS.
- [9] Costas Courcoubetis & Mihalis Yannakakis (1995): The Complexity of Probabilistic Verification. J. ACM 42(4), pp. 857–907, 10.1145/210332.210339.
- [10] Luca De Alfaro (1998): Formal Verification of Probabilistic Systems. Ph.D. thesis, Stanford, CA, USA.
- [11] Giuseppe De Giacomo & Moshe Y Vardi (2013): Linear Temporal Logic and Linear Dynamic Logic on Finite Traces. In: Intl. Joint Conf. on Artificial Intelligence (IJCAI), 13, pp. 854–860.
- [12] Giuseppe De Giacomo & Moshe Y Vardi (2015): Synthesis for LTL and LDL on Finite Traces. In: Intl. Joint Conf. on Artificial Intelligence (IJCAI), 15, pp. 1558–1564.
- [13] Alexandre Duret-Lutz, Alexandre Lewkowicz, Amaury Fauchille, Thibaud Michaud, Étienne Renault & Laurent Xu (2016): Spot 2.0 — a framework for LTL and -automata manipulation. In: Automated Technology for Verification and Analysis (ATVA’16), Lecture Notes in Computer Science 9938, Springer, pp. 122–129, 10.1007/3-540-60915-6_6.
- [14] Keliang He, Morteza Lahijanian, Lydia E Kavraki & Moshe Y Vardi (2018): Automated Abstraction of Manipulation Domains for Cost-Based Reactive Synthesis. IEEE Robotics and Automation Letters 4(2), pp. 285–292, 10.1109/LRA.2018.2889191.
- [15] Keliang He, Andrew M Wells, Lydia E Kavraki & Moshe Y Vardi (2019): Efficient Symbolic Reactive Synthesis for Finite-Horizon Tasks. In: 2019 Intl. Conf. on Robotics and Automation (ICRA), IEEE, pp. 8993–8999, 10.1109/ICRA.2019.8794170.
- [16] Keling He, Morteza Lahijanian, Lydia E. Kavraki & Moshe Y. Vardi (2017): Reactive Synthesis for Finite Tasks Under Resource Constraints. In: Int. Conf. on Intelligent Robots and Systems (IROS), IEEE, Vancouver, BC, Canada, pp. 5326–5332, 10.1109/IROS.2017.8206426.
- [17] Jesper G Henriksen, Jakob Jensen, Michael Jørgensen, Nils Klarlund, Robert Paige, Theis Rauhe & Anders Sandholm (1995): Mona: Monadic second-order logic in practice. In: Intl. Workshop on Tools and Algorithms for the Construction and Analysis of Systems, Springer, pp. 89–110, 10.1007/3-540-60630-0_5.
- [18] Jan Křetínský, Tobias Meggendorfer, Salomon Sickert & Christopher Ziegler (2018): Rabinizer 4: From LTL to Your Favourite Deterministic Automaton. In: Computer Aided Verification, Springer International Publishing, Cham, pp. 567–577, 10.1007/978-3-319-46520-3_9.
- [19] M. Kwiatkowska, G. Norman & D. Parker (2011): PRISM 4.0: Verification of Probabilistic Real-time Systems. In: Proc. 23rd Intl. Conf. on Computer Aided Verification (CAV’11), LNCS 6806, Springer, pp. 585–591, 10.1007/3-540-45657-0_17.
- [20] Jianwen Li, Kristin Y Rozier, Geguang Pu, Yueling Zhang & Moshe Y Vardi (2019): SAT-Based Explicit LTLf Satisfiability Checking. In: Proc. of the AAAI Conf. on Artificial Intelligence, 33, pp. 2946–2953, 10.1007/978-3-030-25543-5_1.
- [21] Lucas Martinelli Tabajara & Moshe Y. Vardi (2019): Partitioning Techniques in LTLf Synthesis. In: Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI-19, International Joint Conferences on Artificial Intelligence Organization, pp. 5599–5606, 10.24963/ijcai.2019/777.
- [22] Amir Pnueli (1977): The temporal logic of programs. In: Foundations of Computer Science, 1977., 18th Annual Symposium on, IEEE, pp. 46–57.
- [23] Salomon Sickert & Jan Kretínský (2016): MoChiBA: Probabilistic LTL Model Checking Using Limit-Deterministic Büchi Automata. In: Automated Technology for Verification and Analysis (ATVA’16), Lecture Notes in Computer Science 9938, pp. 130–137, 10.1007/978-3-319-45856-4.
- [24] Sylvie Thiébaux, Charles Gretton, John Slaney, David Price & Froduald Kabanza (2006): Decision-Theoretic Planning with Non-Markovian Rewards. J. Artif. Int. Res. 25(1), p. 17–74, 10.1613/jair.1676.
- [25] Moshe Y. Vardi (1985): Automatic Verification of Probabilistic Concurrent Finite State Programs. In: Proceedings of the 26th Annual Symposium on Foundations of Computer Science, SFCS ’85, IEEE Computer Society, USA, p. 327–338, 10.1109/SFCS.1985.12.
- [26] Andrew M. Wells: LTLf for PRISM. Available at https://github.com/andrewmw94/ltlf_prism.
- [27] Andrew M Wells, Morteza Lahijanian, Lydia E Kavraki & Moshe Y Vardi: LTLf Synthesis on Probabilistic Systems (Online version). Available at http://www.andrewmwells.com/ltlf-synthesis-on-probabilistic-systems/.
- [28] Shufang Zhu, Lucas M Tabajara, Jianwen Li, Geguang Pu & Moshe Y Vardi (2017): Symbolic LTLf synthesis. In: Proc. of the 26th Intl. Joint Conf. on Artificial Intelligence, AAAI Press, pp. 1362–1369.