Machine Learned Phase Transitions in a System of Anisotropic Particles on a Square Lattice
Abstract
The area of Machine learning (ML) has seen exceptional growth in recent years. Successful implementation of ML methods in various branches of physics has led to new insights. These methods have been shown to classify phases in condensed matter systems. Here we study the classification problem of phases in a system of hard rigid rods on a square lattice around a continuous and a discontinuous phase transition using supervised learning (with prior knowledge about the transition points). On comparing a number of ML models we find that convolutional neural network (CNN) classifies the phases with the highest accuracy when only snapshots are given as inputs. We study how the system size affects the model performance. We compare the performance of CNN in classifying the phases around a continuous and a discontinuous phase transition. Further, we show that one can even beat the accuracy of CNN with simpler models by using physics-guided features. Lastly, we show that the critical point in this system can be learned without any prior estimate by using only the information of the ordered phase (as training set). Our study reveals the ML techniques that have been successful in studying spin systems can be easily adapted to more complex systems.
I Introduction
The area of Machine learning has seen a tremendous growth in the last two decades. Researchers have made great progress in areas like computer vision Sultana et al. (2018), natural language processing Young et al. (2018), medical diagnostics de Bruijne (2016); Ahmed et al. (2019) using deep learning methods LeCun et al. (2015); Schmidhuber (2015). The availability of a large amount of data and higher computing power due to the advancements in hardware have made the growth possible. Machine learning techniques usually perform better with a large amount of data. Data-rich branches of physics like High energy physics and Astronomy thus have employed Machine learning techniques successfully in extracting physical insights from the data BALL and BRUNNER (2010); Baldi et al. (2014); Albertsson et al. (2018); Das Sarma et al. (2019). In recent years Machine learning has made its way into other branches like Condensed matter physics and Statistical physics. Both supervised and unsupervised learning methods have been successfully employed to detect phase transitions and classify different phases Arai et al. (2018); Broecker et al. (2017); Iakovlev et al. (2018); Carrasquilla and Melko (2017); Wetzel (2017); Wang (2016a); Bedolla-Montiel et al. (2020); Liu and van Nieuwenburg (2018); Ponte and Melko (2017); Ch’ng et al. (2017); Boattini et al. (2019); Wang (2016b). Neural networks have shown great potential in identifying new exotic phases and phase transitions even in systems where the order parameter cannot be defined explicitly Li et al. (2018); Lian et al. (2019). Generative neural networks like restricted Boltzmann machines and variational autoencoders have been employed to model physical probability distributions and extract features in spin models D’Angelo and Böttcher (2020); Morningstar and Melko (2018).
Here, we focus on the specific application of machine learning in classifying different phases separated by a phase transition. Usually, in case of a structural phase transition one can construct a suitable order parameter to distinguish between the different phases. Away from the transition point, one may even be able to identify the phases just by looking at the snapshots. However, this distinction gets blurry as one approaches the transition more and more closely (at least for a continuous or a weakly first-order transition). Especially, in the vicinity of a critical point, large fluctuations are expected to interfere. Now the question is whether one can train a statistical classifier to distinguish between such phases just by using the configurations. The classification of the ordered and disordered phases, and the study of the critical properties of Ising model have been extensively investigated in recent times Morningstar and Melko (2018); D’Angelo and Böttcher (2020); Wang (2016b); Mehta et al. (2019); Tanaka and Tomiya (2017). After the success of Machine learning methods in characterizing simpler models like Ising model, they are now being explored in studying more complex systems, like liquid crystals. In experiments, liquid crystals are usually studied using optical imaging Zola et al. (2013). Recently Machine learning techniques are applied to classify phases and predict the physical properties of liquid crystals from the experimental data Terao (2020); Sigaki et al. (2019); Minor et al. (2019). Convolutional neural networks (CNNs) have been shown to successfully classify nematic and isotropic phases in continuum with very high accuracy Sigaki et al. (2020). In this case the isotropic-nematic transition is first-order in nature where the order parameter changes abruptly in the vicinity of the transition point.
In this context, we ask how difficult is the classification task near a continuous transition when compared with the same around a first-order transition. We investigate how different machine learning models perform on this classification task and how the system size affects the performance. We further ask if physics-guided features help in learning the phases. In addition, we examine if the method of Learning by confusion can be extended to the system of rods to determine the critical (without any prior estimate) using the information about the ordered phase van Nieuwenburg et al. (2017); Tan and Jiang (2020). This technique is quite powerful as the usual supervised ML techniques rely on the prior knowledge of the critical point to be trained– this may not always be possible for all complex systems van Nieuwenburg et al. (2017). Understanding these issues can help us extending ML techniques to more complex systems and also tackling systems where the identification of structural order (if exists) is nontrivial, e.g., amorphous systems Bapst et al. (2020) .
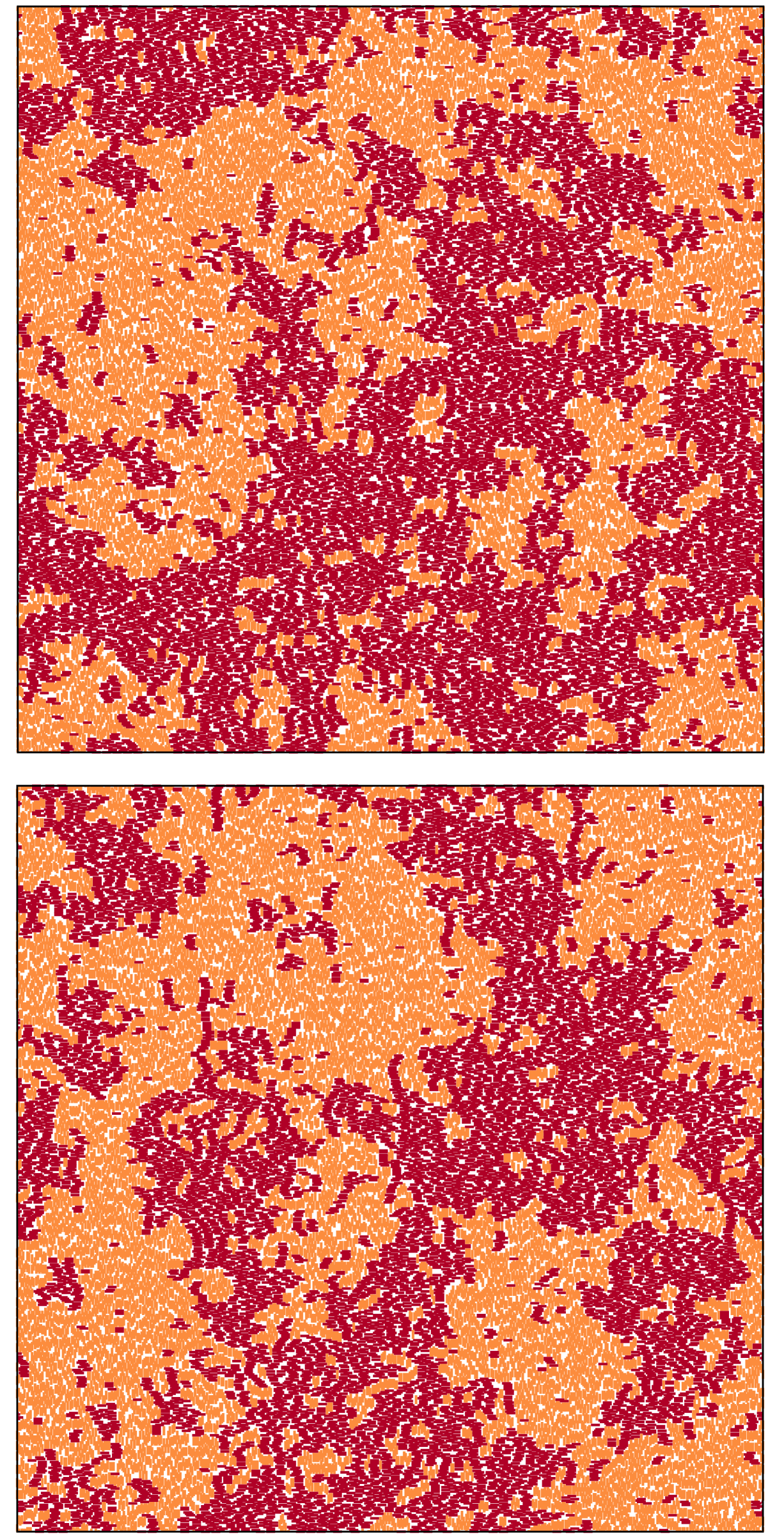
To investigate the above questions, we study a model of long hard rods on a two-dimensional square lattice that undergoes isotropic-nematic-disordered phase transitions with increasing density. Note that, systems of hard rectangles with finite width exhibit more complex liquid crystalline phases Kundu and Rajesh (2014). Such hard core lattice gas models are, in general, relevant for understanding self-assembly of nanoparticles Rabani et al. (2003), glass transition Diaz-Sanchez et al. (2002), adsorption of gas molecules on metal substrates Taylor et al. (1985); Bak et al. (1985); Patrykiejew et al. (2000) and entropy-driven phase transitions (realized in liquid crystalline assemblies of various colloidal systems Kuijk et al. (2011, 2012); M. P. B. van Bruggen and Lekkerkerker (1996); Zhao et al. (2011); Barry and Dogic (2010)). In contrast to the continuum model, the high-density phase of the system of hard rods on a lattice is an orientationally disordered phase that remained inaccessible until recently due to large relaxation times Kundu et al. (2012, 2013); Kundu and Rajesh (2014). Using a novel Monte Carlo algorithm with nonlocal moves one can thermalize the system at very high densities to show that it undergoes two continuous transitions with increasing density: first from a low-density isotropic to an intermediate density nematic phase and second, from the nematic phase to a high-density disordered phase Kundu et al. (2013); Kundu and Rajesh (2014). We generate Monte Carlo sampled data for the hard rods system on a square lattice to classify the isotropic (I) and nematic (N) phases around the first I-N critical point using various Machine learning techniques. We show how the system size affects the performance of the models. Note that this classification task is trivial when the I and N phases are far from the critical point. However, closer to the critical point, these two phases are not visually distinguishable (see Fig. 1) as discussed above, making the task much harder. The same is true for the Ising critical point Mehta et al. (2019). Next, by breaking the symmetry between the two different orientations, we induce a first-order phase transition in the system to further show that the classification task gets easier around an abrupt transition. We then train logistic regression and random forest on physical features and compare the results with the models trained on lattice data. Further, we show that one can use simple features rather than the raw snapshots to get better accuracy with simpler ML models.
In the above-mentioned methods of classifying the phases, one must know the critical point in advance to label the data for training. Other methods such as clustering can be used which do not need prior knowledge of the critical point. It is shown that the neural networks can be trained to calculate the critical point with only theoretical ground state snapshots of ordered phase for models like ferromagnetic and anti-ferromagnetic Potts models Tan and Jiang (2020); Tan et al. (2020). Here we employ a similar strategy by training CNN on ordered phase ground state lattice to estimate the critical point.
The rest of the manuscript is organized as follows. We briefly describe the model, the algorithm to generate the equilibrium configurations, and the phenomenology in Sec. II. In Sec. III, we discuss the classification task around the I-N critical point using three machine learning techniques- logistic regression, deep neural networks, and convolutional neural networks that are trained on the I-N transition data. Next, we show the results including the performance of the classification tasks near the second-order and the first-order transitions in Sec. IV. We then show how physical features improve the performance of the models like logistic regression and random forests. In Sec. V we show how the nematic phase information can be used to estimate the critical point of the system of hard rods. Finally, we conclude in Sec. VI.
II Model, Algorithm and the Phenomenology
We consider a system of hard rods of length on a square lattice of size with periodic boundary conditions. Each rod occupies consecutive lattice sites along one lattice direction and thus, can have two possible orientations: horizontal and vertical. The only constraint is that no two rods can overlap. All the configurations with no overlap are equally likely. Each rod is associated with an activity where is chemical potential. The system is treated using grand canonical ensemble where controls the density (fraction of sites occupied by the rods) of the system.
To simulate the system, we use the algorithm presented in this ref. Kundu and Rajesh (2014). The Monte Carlo algorithm is described below: at each step a row or a column is randomly selected. If a row(column) is selected all the horizontal(vertical) rods in that row are removed. This is the evaporation step. Now we end up with segments of empty sites separated by the forbidden sites due to the vertical rods passing through them. The next step is to reoccupy these empty segments with horizontal rods following correct statistical weights. The problem of occupying the empty row is reduced to filling the empty sites in one dimension. And the probabilities of the new configuration can be calculated exactly Kundu et al. (2013, 2012). This is a deposition step. A Monte Carlo step consists of such evaporation-deposition steps. The equilibration is performed for MC steps. And then the snapshots of the system are taken at an interval of MC steps to ensure they are uncorrelated.
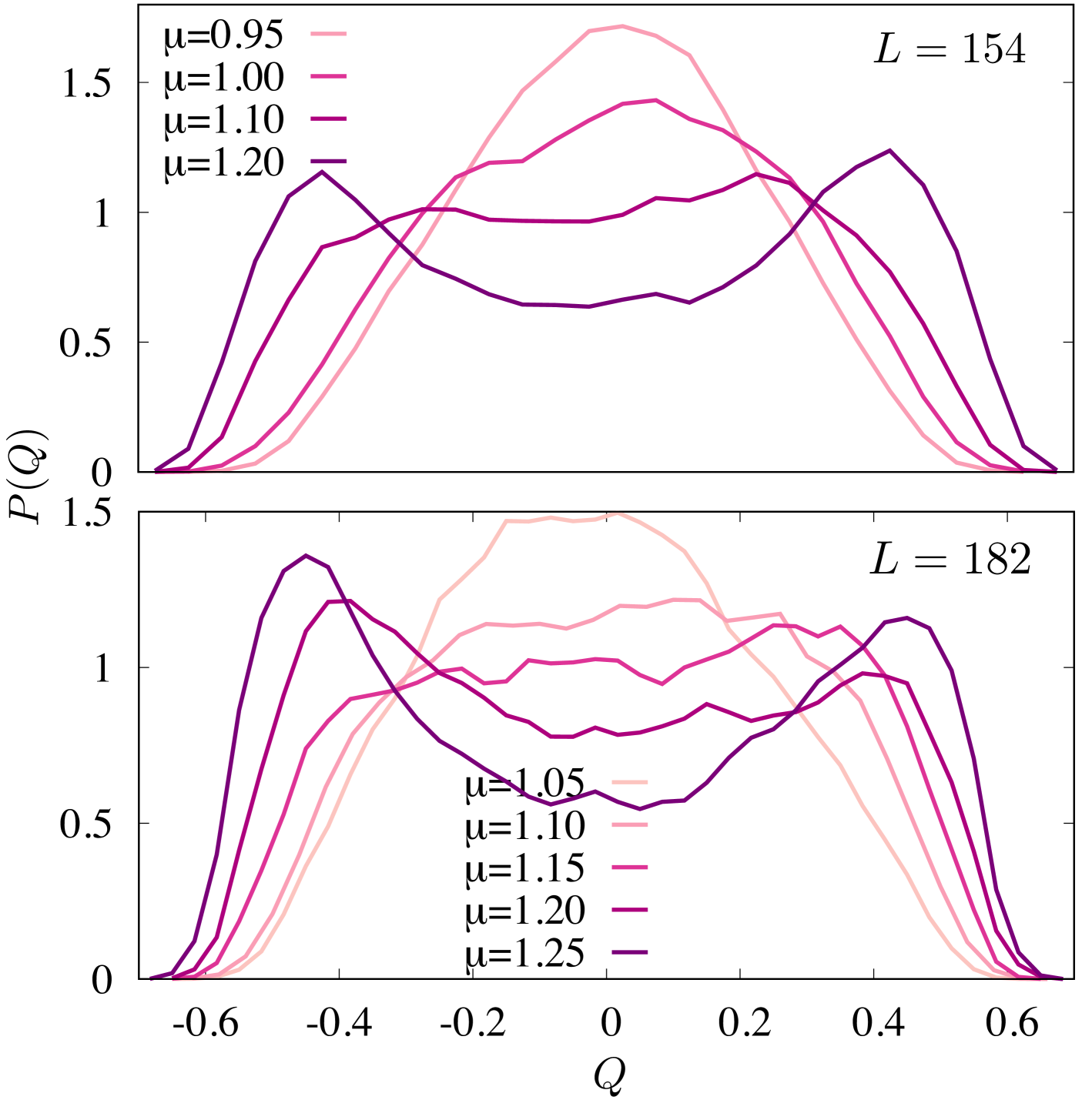
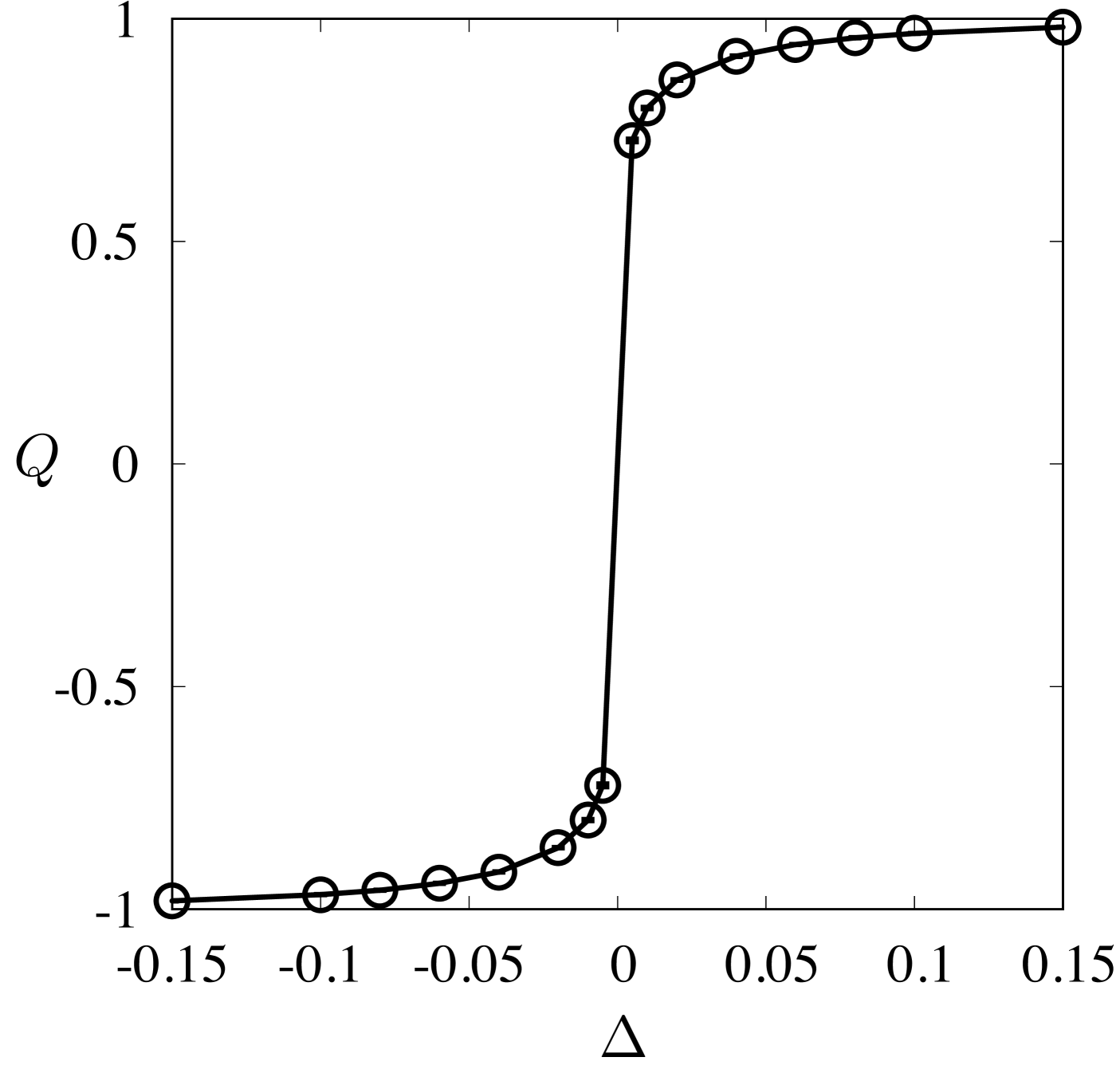
The system undergoes two continuous phase transitions with increasing density when : first from a low-density isotropic phase to a nematic phase and second, from the nematic phase to a high-density disordered phase. We try to classify the isotropic and the nematic phases around the first transition. The critical chemical potential is determined from the probability distribution of the order parameter defined as , where and are the number of horizontal and vertical rods correspondingly (note for the nematic phase and for the isotropic phase ). Below , has only a single peak around corresponding to the isotropic phase and above , develops two symmetric peaks corresponding to the nematic phase (see Fig. 2). Further, we study a first-order transition in the system by introducing a variable (equivalent to the external magnetic field in Ising model) that breaks the symmetry between horizontal and vertical rods. The corresponding chemical potentials for the two types of rods are and . As is varied from a negative to a positive value at a given , the system undergoes a first-order transition from a horizontal rod rich phase to a vertical rod rich phase (both are nematic). The order parameter changes abruptly as shown in Fig. 3. In the following sections, we discuss the classification problem around the I-N criticality and the first-order transition point as mentioned above.
III Classification around the critical point
Typical snapshots of the system in the disordered and the nematic phases close to the I-N critical point are shown in Fig. 1. It is evident from the snapshots that they are not visually distinguishable. Hence, we attempt to classify them using Machine learning. The data around the I-N critical point is trained on logistic regression, deep neural network (DNN) and convolutional neural network (CNN). The data are for lattice size and rod length . snapshots are generated at each value. Equal number of data points are taken on the either side of the critical point for training. The snapshots below as labeled 0 and above are labeled 1. The data is divided into 3 parts. First the data is divided into 85% train set and 15% test set. The train set is further divided in two sets. The model is trained of 85% of the train set and validated on 15% of the train set.
III.1 Logistic regression
Logistic regression is the simplest classification algorithm. The algorithm takes the weighted sum of the input features with added bias and evaluates a non-linear sigmoid function. The sigmoid function outputs a number between 0 and 1, representing the probability of the input being phase labeled 1. The loss function is log loss and the optimizer is a stochastic gradient descent optimizer. To train this model the 2D data is flattened to a 1D array and fed into the model. The logistic regression is trained using SGD classifier from Sci-kit library Pedregosa et al. (2011).
| Accuracy | |||
|---|---|---|---|
| Logistic Regression | DNN | CNN | |
| 0.8245 | 0.545 | 0.620 | 0.880 |
| 0.8730 | 0.48 | 0.560 | 0.793 |
| 1.0670 | 0.435 | 0.555 | 0.796 |
| 1.1155 | 0.55 | 0.590 | 0.890 |
III.2 Deep Neural Networks
Deep neural networks (DNNs) have been shown to classify the phases of the Ising model near criticality with accuracy between 0.80 to 0.90 Mehta et al. (2019). At each layer every node takes input from all the nodes from the previous layer. A node calculates the weighted sum of all the inputs with added bias and evaluates a non-linear activation function. These values are fed as input to the next layer. The weights are updated iteratively with an optimizer to decrease the loss function. The DNN we trained consists of 5 layers with 392, 294, 196, 98, 1 nodes in each layer respectively. We chose the number of nodes in each layer to be of the order of the input size. The depth of the network is increased gradually from a single layer until optimal results are obtained. And other hyperparameters are chosen by random search Bergstra and Bengio (2012). The flattened 1D data is fed to the network. The Activation function in the first four layers is relu activation and in the last layer is sigmoid activation. The last layer is the same as the logistic regression. The loss function is binary cross-entropy and the optimizer is ADAM. The data is trained on batches of batch size 64. To avoid overfitting regularization is added to each layer. The hyperparameters like the number of layers, number of nodes in each layer, batch size, regularization value are chosen by trial and error method. This Neural network is trained using Keras Chollet et al. (2015) and Tensorflow framework Abadi et al. (2015).
III.3 Convolutional Neural Networks
Convolutional neural networks (CNN) have been shown to classify images and detect objects in the images with very high accuracy Taigman et al. (2014). The main difference between DNN and CNN is the convolution layer. In the convolution layer, a 2D filter is convoluted over the 2D input feature space. The filter slides over the input space and calculates the sum of the element-wise multiplication at each step. Convolution layers are followed by a pooling layer. The pooling layer summarises the feature by averaging (average pooling) or taking the maximum value (max pooling). The filters in the convolution layer detect low-level features at different parts of the input and the convolution layer does not change the spatial structure of the input. The pooling layers decreases the dimensions of the feature space. After a few Convolution Pooling layers the 2D output is flattened into a 1D array and fed into the fully connected layers. There are many possible combinations of CNNs. The architecture is dependent on the input data and is generally inspired by previously successful networks. Our architecture is inspired from Ref. Sigaki et al. (2020); Smith and Topin (2016); Krizhevsky et al. (2012) and the optimized hyperparameters are chosen after a random search Bergstra and Bengio (2012). In this work we chose 2 layers of Convolution + Max pool with sized 4 filters in each convolution layers and sized filter with stride in pooling layers. These are followed by three fully connected layers with 256, 128, 1 nodes respectively. The activation in all layers is relu except for the output layer with sigmoid activation. The loss function is binary cross-entropy, the optimizer is ADAM. To avoid overfitting, regularization term is added to each convolution layer and a dropout layer is added before the fully connected layers. The data is trained in batches. This CNN is trained using Keras Chollet et al. (2015) and Tensorflow framework Abadi et al. (2015).
III.4 Random Forest
Random forest is a simple and powerful machine learning model that can be used for both classification and regression tasks. The main idea of random forest is to build a bunch of decision trees and all these trees as an ensemble will solve the problem at hand. Physical features are given as input instead of lattice snapshot like in earlier mentioned models. Random forest is trained using a random forest classifier from Sci-kit library. Hyper parameters like maximum depth, number of trees are chosen by random search. In this work we chose random forest of maximum depth 4 with 4000 estimators.
IV Results
We compare the accuracy of the phase classification problem around the I-N transition for the three models in Table. 1. It is evident that the CNN outperforms the logistic regression and DNN. This observation is intuitive as CNN is designed to capture the relevant features. Thus, for further study we use CNN with the same architecture and discuss the classification results in detail. We calculate the error bars using Bootstrapping.
IV.1 Learning near second-order transition
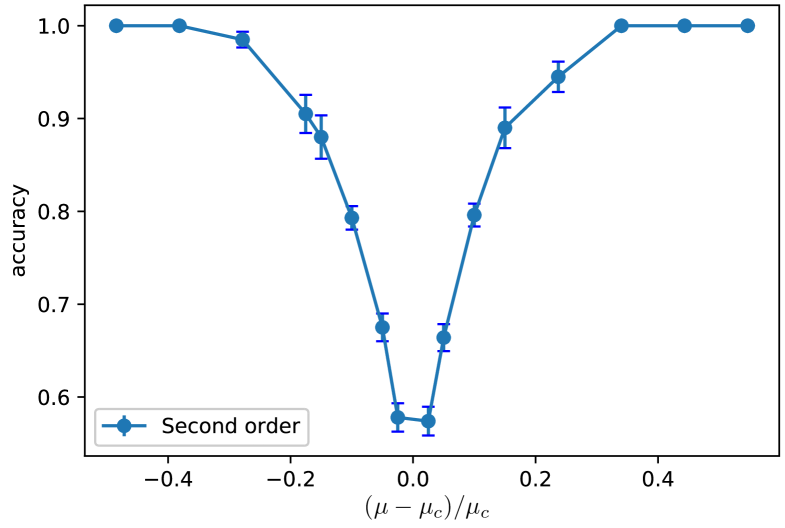
The classification far from the critical point is a trivial task. As we move towards the critical point the classification gets difficult and the performance of the model worsens. This can be seen in Table. 2. In Fig. 4, we plot the accuracy as a function of the distance from the critical point– it is evident that the performance of the CNN reduces as we approach the critical point . Long wavelength fluctuations and diverging correlation length make the classification task difficult near criticality.
| System size L = 98 | |
|---|---|
| Accuracy | |
| 0.50 | 1.000 |
| 0.60 | 1.000 |
| 0.70 | 0.985 |
| 0.80 | 0.905 |
| 1.10 | 0.900 |
| 1.20 | 0.945 |
| 1.30 | 1.000 |
| 1.40 | 1.000 |
IV.2 Finite size effects
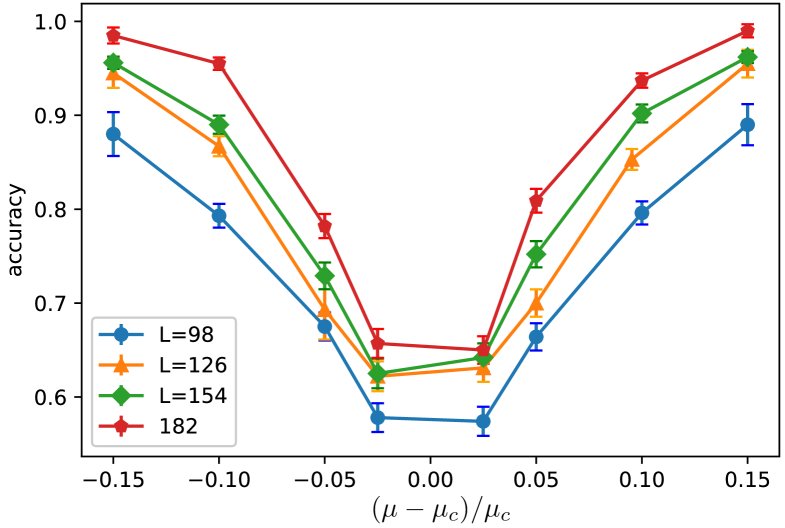
We train the same CNN architecture on larger systems to see how the model performance changes with system size. The additional trained systems sizes are , and . The results in Table. 3 clearly show that as the lattice size increases the model performance also increases. And for a given system size the accuracy decreases as the value approaches – see Fig. 5. This increase in performance as the system size increase can be attributed to finite-size effects. Close to the critical point the correlation length becomes of the order of the system size. Thus larger system sizes are better in representing the criticality which leads to better predictability of phases compared to the smaller system sizes.
| Accuracy | ||||
|---|---|---|---|---|
| 0.880 | 0.945 | 0.956 | 0.985 | |
| 0.793 | 0.867 | 0.890 | 0.955 | |
| 0.796 | 0.853 | 0.902 | 0.937 | |
| 0.890 | 0.955 | 0.962 | 0.990 | |
IV.3 Learning near First-order transition
To study the first-order transition we use the variable as discussed in Sec. II. The data are trained on the same CNN architecture. The order parameter in this case changes abruptly unlike in the case of a second-order transition. Hence, it should be easier for the model to classify the phases around a first-order phase transition. The accuracy of the model as a function of the distance from the transition point is presented in Table. 4 and in Fig.6. On comparison, the model (CNN) performs better in classifying phases around the first-order transition (this can be seen from the Fig. 4 and Fig. 6)– in case of the first-order transition, the accuracy reaches when the relative distance from the transition point , while in case of the second-order transition, the same quantity (for ). Thus, the model is able to classify the phases around the first-order transition at values that are very close to the transition point with very high accuracy.
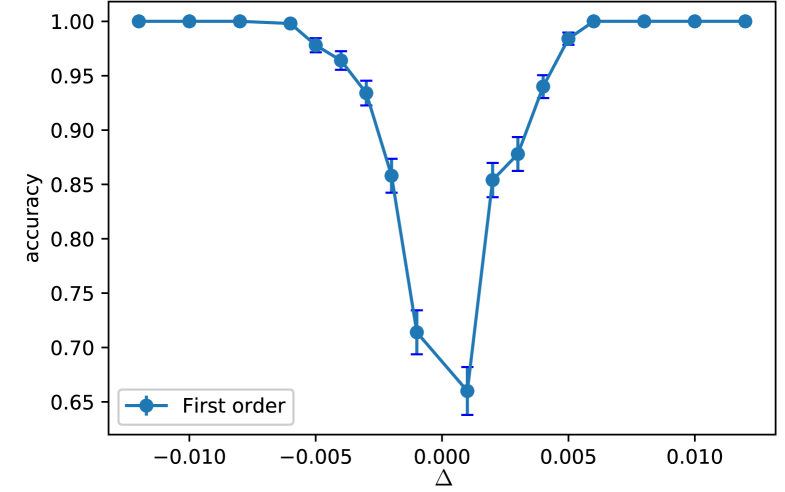
| Accuracy | Accuracy | ||
|---|---|---|---|
| -0.001 | 0.714 | 0.001 | 0.660 |
| -0.002 | 0.858 | 0.002 | 0.854 |
| -0.003 | 0.934 | 0.003 | 0.878 |
| -0.004 | 0.964 | 0.004 | 0.940 |
| -0.005 | 0.978 | 0.005 | 0.984 |
| -0.006 | 0.998 | 0.006 | 1.000 |
| -0.008 | 1.000 | 0.008 | 1.000 |
| -0.010 | 1.000 | 0.010 | 1.000 |
| -0.012 | 1.000 | 0.012 | 1.000 |
IV.4 Classification using physical features
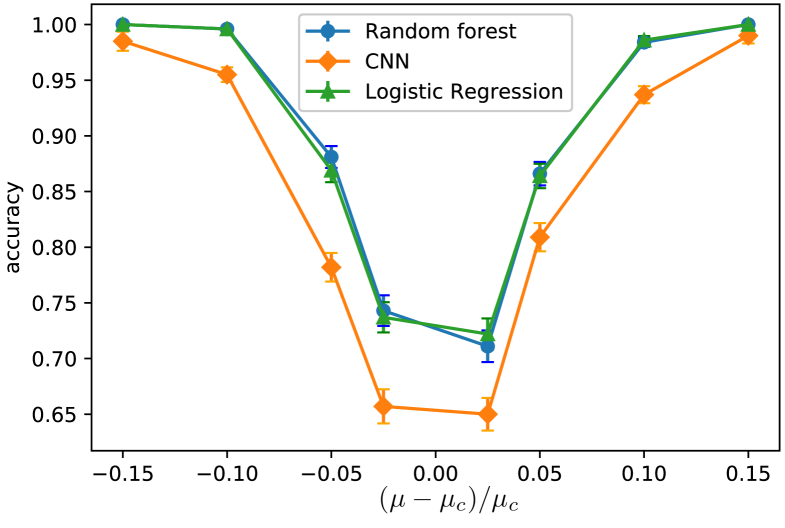
In this section, we see how the accuracy of the models changes if some physical features are given as inputs instead of lattice snapshots. The physical features we chose are density (fraction of occupied sites) and order parameter (as defined above). These can be calculated from the snapshots. We train logistic regression and random forests with these two input features. Upon comparing the results in Table.5 and Table.3, it is evident that the performance of both the models are better than that of the CNN trained on the configurations or snapshots. One should note that if we use regular snapshots as inputs, the simpler models like Logistic regression and Random forest perform poorly as discussed before. It is evident from Fig.7 that Logistic regression and Random forests trained on physical features outperforms the CNN model. This result also infers that these ML models fail to capture the complex correlations that represent criticality. To improve the performance near a critical point one needs to include more complex features distinguishing the two sides of criticality.
| Logistic regression | Random forests | |
|---|---|---|
| 1.00 | 1.00 | |
| 0.996 | 0.996 | |
| 0.869 | 0. 881 | |
| 0.737 | 0.743 | |
| 0.722 | 0.711 | |
| 0.864 | 0.866 | |
| 0.986 | 0.984 | |
| 1.00 | 1.00 |
V Estimating critical point using ML
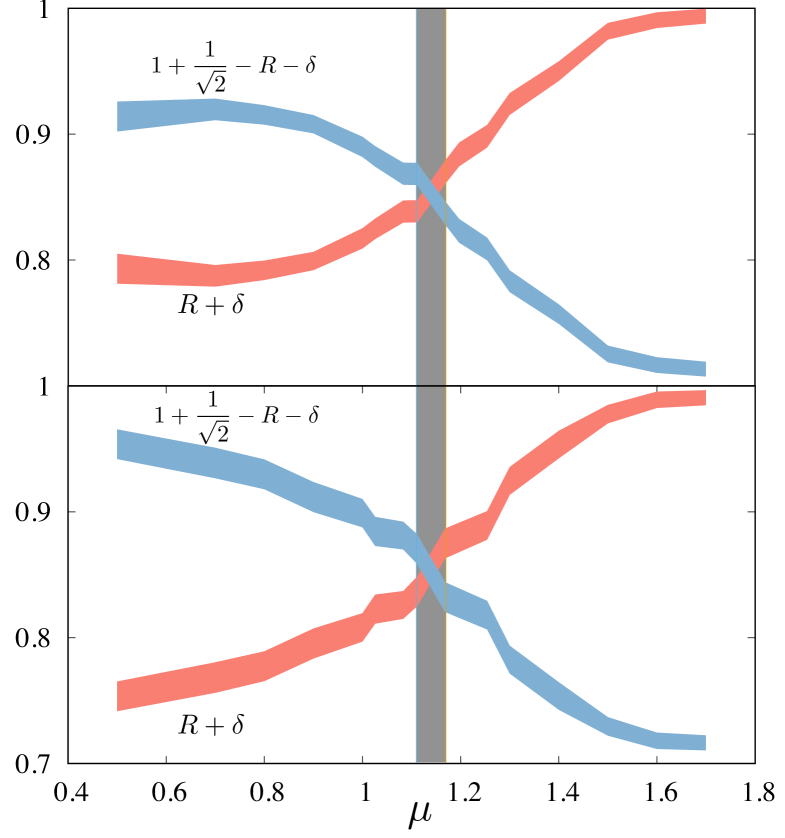
To estimate the critical point of the system of hard rods we train neural networks on ground state snapshots of the ordered phase. This method is successfully used to estimate critical points of models like ferromagnetic and anti-ferromagnetic Potts models, 3D classical , 2D XY models Tan and Jiang (2020); Tan et al. (2020). Nematic phase configurations of the system size are used as the training set. The data are generated as mentioned in Sec. II by breaking the symmetry between horizontal and vertical rods upon introducing the variable . Snapshots are generated at and . At this value of , the system becomes almost fully ordered (). All the vertical (horizontal) rods in the horizontal (vertical) rich snapshots are removed to obtain snapshots in which rods are completely aligned in one direction with order parameter being . The vertically aligned snapshots are labeled and the horizontally aligned snapshots are labeled . Note that the nematic phase has two possible configurations– all horizontal and all vertical. CNN is trained using this data with one convolution layer followed by max pooling layer and two dense layers with softmax activation in the output layer, regularization is used to avoid overfitting. The loss, optimizer and activation used in training this model are categorical cross-entropy, adam optimizer, and relu activation. We also train Logistic regression with the physics-guided features as discussed above. In this case we work with values (almost fully ordered). These trained models are then used to predict the labels of snapshots over a range of values. The norm of the predicted label, , is calculated. The true value of can vary from 1 to where corresponds to the fully ordered nematic phase and corresponds to the case when the model fails to classify the phase as horizontal or vertical rich nematic phase. As the model is trained only with (almost) fully ordered phases, if one tests the output for a disordered phase, the output vector would ideally be and the value of would be . The norm of the predicted labels of ordered states which are fully packed with rods in one direction should ideally be 1. To correct this, the difference between and the value of the predicted labels of the fully packed nematic phase, [where and () is the norm of the predicted label of the fully packed nematic phase snapshot corresponding to vertical (horizontal) rods] is added to . This is plotted against values to estimate the critical point. Assuming linearity of with near criticality, should be associated with the mid-point and is given by the intersection of the two curves and . As shown in the Fig 8, the intersection point of and is the estimated critical point. The estimated values of by both the models are in close agreement (within error bars) with the numerical value obtained from the probability distribution of the order parameter (see Fig. 2)
In addition, the modulus of the difference between two elements of the output vector , can be treated as a Machine learned order parameter– the ordered phase will correspond to a value , and in the isotropic phase it will be .
VI Conclusion
In this work, we classify the phases of the system of hard rods on a square lattice. Although the classification task is trivial far from the transition point, sufficiently close to criticality system spanning fluctuations set in, making the phases visually indistinguishable and thus, the classification problem becomes harder. Three machine learning models, logistic regression, deep neural network, and convolutional neural network are trained to classify the phases around the isotropic-nematic transition. CNN has been shown to classify the phases with higher accuracy than the other two methods. We showed that the model performance improves with the increase in the system size– this is attributed to the finite-size effects. We further induce a first-order phase transition into the system using a field variable and the CNN is trained to classify phases around the transition. We demonstrate that classifying phases is easier around a first-order transition than around a second-order transition. Although the classification problem around the first-order transition is not the same as that around the second-order transition, our conclusions are not affected by that. We have also shown that physics-guided features drastically improve the performance of simpler models like logistic regression and random forest. In fact, with such feature engineering, they outperform more complex models like CNN (where the raw snapshots are used as inputs). We then estimate the critical point of the system of hard rods using only the information about the ordered phase. This estimate is in strong agreement with the value calculated by traditional methods. As discussed above, the Machine learned order parameter can be used to perform the finite size scaling analysis to compute the critical exponents. Our work infers that these methods may further be useful in studying transitions in more complex systems where defining an order parameter is nontrivial cite QCD. Another interesting question that emerges from our work is how to capture the critical correlations near a continuous phase transition using ML techniques. These will be future areas of investigation.
Acknowledgements.
We thank Sudhir N. Pathak for useful discussions. JK acknowledges support from the IIT Hyderabad Seed grant.References
- Sultana et al. (2018) F. Sultana, A. Sufian, and P. Dutta, in 2018 Fourth International Conference on Research in Computational Intelligence and Communication Networks (ICRCICN) (2018) pp. 122–129.
- Young et al. (2018) T. Young, D. Hazarika, S. Poria, and E. Cambria, IEEE Computational Intelligence Magazine 13, 55 (2018).
- de Bruijne (2016) M. de Bruijne, Medical Image Analysis 33 (2016), 10.1016/j.media.2016.06.032.
- Ahmed et al. (2019) M. R. Ahmed, Y. Zhang, Z. Feng, B. Lo, O. T. Inan, and H. Liao, IEEE Reviews in Biomedical Engineering 12, 19 (2019).
- LeCun et al. (2015) Y. LeCun, Y. Bengio, and G. Hinton, Nature 521, 436 (2015).
- Schmidhuber (2015) J. Schmidhuber, Neural Networks 61, 85 (2015).
- BALL and BRUNNER (2010) N. M. BALL and R. J. BRUNNER, International Journal of Modern Physics D 19, 1049 (2010).
- Baldi et al. (2014) P. Baldi, P. Sadowski, and D. Whiteson, Nature Communications 5 (2014), 10.1038/ncomms5308.
- Albertsson et al. (2018) K. Albertsson, P. Altoe, D. Anderson, J. Anderson, M. Andrews, J. P. A. Espinosa, A. Aurisano, L. Basara, A. Bevan, W. Bhimji, D. Bonacorsi, B. Burkle, P. Calafiura, M. Campanelli, L. Capps, F. Carminati, S. Carrazza, Y. fan Chen, T. Childers, Y. Coadou, E. Coniavitis, K. Cranmer, C. David, D. Davis, A. D. Simone, J. Duarte, M. Erdmann, J. Eschle, A. Farbin, M. Feickert, N. F. Castro, C. Fitzpatrick, M. Floris, A. Forti, J. Garra-Tico, J. Gemmler, M. Girone, P. Glaysher, S. Gleyzer, V. Gligorov, T. Golling, J. Graw, L. Gray, D. Greenwood, T. Hacker, J. Harvey, B. Hegner, L. Heinrich, U. Heintz, B. Hooberman, J. Junggeburth, M. Kagan, M. Kane, K. Kanishchev, P. Karpiński, Z. Kassabov, G. Kaul, D. Kcira, T. Keck, A. Klimentov, J. Kowalkowski, L. Kreczko, A. Kurepin, R. Kutschke, V. Kuznetsov, N. K hler, I. Lakomov, K. Lannon, M. Lassnig, A. Limosani, G. Louppe, A. Mangu, P. Mato, N. Meenakshi, H. Meinhard, D. Menasce, L. Moneta, S. Moortgat, M. Neubauer, H. Newman, S. Otten, H. Pabst, M. Paganini, M. Paulini, G. Perdue, U. Perez, A. Picazio, J. Pivarski, H. Prosper, F. Psihas, A. Radovic, R. Reece, A. Rinkevicius, E. Rodrigues, J. Rorie, D. Rousseau, A. Sauers, S. Schramm, A. Schwartzman, H. Severini, P. Seyfert, F. Siroky, K. Skazytkin, M. Sokoloff, G. Stewart, B. Stienen, I. Stockdale, G. Strong, W. Sun, S. Thais, K. Tomko, E. Upfal, E. Usai, A. Ustyuzhanin, M. Vala, J. Vasel, S. Vallecorsa, M. Verzetti, X. Vilas s-Cardona, J.-R. Vlimant, I. Vukotic, S.-J. Wang, G. Watts, M. Williams, W. Wu, S. Wunsch, K. Yang, and O. Zapata, “Machine learning in high energy physics community white paper,” (2018), arXiv:1807.02876 [physics.comp-ph] .
- Das Sarma et al. (2019) S. Das Sarma, D.-L. Deng, and L.-M. Duan, Physics Today 72, 48 (2019).
- Arai et al. (2018) S. Arai, M. Ohzeki, and K. Tanaka, Journal of the Physical Society of Japan 87, 033001 (2018).
- Broecker et al. (2017) P. Broecker, F. F. Assaad, and S. Trebst, “Quantum phase recognition via unsupervised machine learning,” (2017), arXiv:1707.00663 [cond-mat.str-el] .
- Iakovlev et al. (2018) I. A. Iakovlev, O. M. Sotnikov, and V. V. Mazurenko, Physical Review B 98 (2018), 10.1103/physrevb.98.174411.
- Carrasquilla and Melko (2017) J. Carrasquilla and R. G. Melko, Nature Physics 13, 431 (2017).
- Wetzel (2017) S. J. Wetzel, Physical Review E 96 (2017), 10.1103/physreve.96.022140.
- Wang (2016a) L. Wang, Phys. Rev. B 94, 195105 (2016a).
- Bedolla-Montiel et al. (2020) E. A. Bedolla-Montiel, L. C. Padierna, and R. Casta eda-Priego, “Machine learning for condensed matter physics,” (2020), arXiv:2005.14228 [physics.comp-ph] .
- Liu and van Nieuwenburg (2018) Y.-H. Liu and E. P. L. van Nieuwenburg, Phys. Rev. Lett. 120, 176401 (2018).
- Ponte and Melko (2017) P. Ponte and R. G. Melko, Phys. Rev. B 96, 205146 (2017).
- Ch’ng et al. (2017) K. Ch’ng, J. Carrasquilla, R. G. Melko, and E. Khatami, Phys. Rev. X 7, 031038 (2017).
- Boattini et al. (2019) E. Boattini, M. Dijkstra, and L. Filion, The Journal of Chemical Physics 151, 154901 (2019).
- Wang (2016b) L. Wang, Physical Review B 94 (2016b), 10.1103/physrevb.94.195105.
- Li et al. (2018) L. Li, Y. Yang, D. Zhang, Z.-G. Ye, S. Jesse, S. V. Kalinin, and R. K. Vasudevan, Science Advances 4 (2018).
- Lian et al. (2019) W. Lian, S.-T. Wang, S. Lu, Y. Huang, F. Wang, X. Yuan, W. Zhang, X. Ouyang, X. Wang, X. Huang, L. He, X. Chang, D.-L. Deng, and L. Duan, Phys. Rev. Lett. 122, 210503 (2019).
- D’Angelo and Böttcher (2020) F. D’Angelo and L. Böttcher, Phys. Rev. Research 2, 023266 (2020).
- Morningstar and Melko (2018) A. Morningstar and R. G. Melko, Journal of Machine Learning Research 18, 1 (2018).
- Mehta et al. (2019) P. Mehta, M. Bukov, C.-H. Wang, A. G. Day, C. Richardson, C. K. Fisher, and D. J. Schwab, Physics Reports 810, 1 (2019).
- Tanaka and Tomiya (2017) A. Tanaka and A. Tomiya, Journal of the Physical Society of Japan 86, 063001 (2017), https://doi.org/10.7566/JPSJ.86.063001 .
- Zola et al. (2013) R. S. Zola, L. R. Evangelista, Y.-C. Yang, and D.-K. Yang, Phys. Rev. Lett. 110, 057801 (2013).
- Terao (2020) T. Terao, Soft Materials , 1 (2020).
- Sigaki et al. (2019) H. Y. D. Sigaki, R. F. de Souza, R. T. de Souza, R. S. Zola, and H. V. Ribeiro, Phys. Rev. E 99, 013311 (2019).
- Minor et al. (2019) E. N. Minor, S. D. Howard, A. A. S. Green, C. S. Park, and N. A. Clark, “End-to-end machine learning for experimental physics: Using simulated data to train a neural network for object detection in video microscopy,” (2019), arXiv:1908.05271 [cond-mat.soft] .
- Sigaki et al. (2020) H. Y. D. Sigaki, E. K. Lenzi, R. S. Zola, M. Perc, and H. V. Ribeiro, Scientific Reports 10 (2020), 10.1038/s41598-020-63662-9.
- van Nieuwenburg et al. (2017) E. P. L. van Nieuwenburg, Y.-H. Liu, and S. D. Huber, Nature Physics 13, 435 (2017).
- Tan and Jiang (2020) D.-R. Tan and F.-J. Jiang, Physical Review B 102 (2020), 10.1103/physrevb.102.224434.
- Bapst et al. (2020) V. Bapst, T. Keck, A. Grabska-Barwińska, C. Donner, E. Cubuk, S. Schoenholz, A. Obika, A. Nelson, T. Back, D. Hassabis, and P. Kohli, Nature Physics 16, 1 (2020).
- Kundu and Rajesh (2014) J. Kundu and R. Rajesh, Phys. Rev. E 89, 052124 (2014).
- Rabani et al. (2003) E. Rabani, D. R. Reichman, P. L. Geissler, and L. E. Brus, Nature 426, 271 (2003).
- Diaz-Sanchez et al. (2002) A. Diaz-Sanchez, A. de Candia, and A. Coniglio, J. Phys.: Condens. Matter 14, 1539 (2002).
- Taylor et al. (1985) D. E. Taylor, E. D. Williams, R. L. Park, N. C. Bartelt, and T. L. Einstein, Phys. Rev. B 32, 4653 (1985).
- Bak et al. (1985) P. Bak, P. Kleban, W. N. Unertl, J. Ochab, G. Akinci, N. C. Bartelt, and T. L. Einstein, Phys. Rev. Lett. 54, 1539 (1985).
- Patrykiejew et al. (2000) A. Patrykiejew, S. Sokolowski, and K. Binder, Surf. Sci. Rep. 37, 207 (2000).
- Kuijk et al. (2011) A. Kuijk, A. v. Blaaderen, and A. Imhof, J. Am. Chem. Soc. 133, 2346 (2011).
- Kuijk et al. (2012) A. Kuijk, D. V. Byelov, A. V. Petukhov, and A. v. Blaaderen, Faraday Discuss. 159, 181 (2012).
- M. P. B. van Bruggen and Lekkerkerker (1996) F. M. v. d. K. M. P. B. van Bruggen and H. N. W. Lekkerkerker, J. Phys. Condens. Matter 8, 9451 (1996).
- Zhao et al. (2011) K. Zhao, R. Bruinsma, and T. G. Mason, Proc. Natl. Acad. Sci. 108, 2684 (2011).
- Barry and Dogic (2010) E. Barry and Z. Dogic, Proc. Natl. Acad. Sci. 107, 10348 (2010).
- Kundu et al. (2012) J. Kundu, R. Rajesh, D. Dhar, and J. Stilck, AIP Conf. Proc. , 113 (2012).
- Kundu et al. (2013) J. Kundu, R. Rajesh, D. Dhar, and J. F. Stilck, Phys. Rev. E 87, 032103 (2013).
- Tan et al. (2020) D.-R. Tan, C.-D. Li, W.-P. Zhu, and F.-J. Jiang, New Journal of Physics 22, 063016 (2020).
- Pedregosa et al. (2011) F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay, Journal of Machine Learning Research 12, 2825 (2011).
- Bergstra and Bengio (2012) J. Bergstra and Y. Bengio, J. Mach. Learn. Res. 13, 281 (2012).
- Chollet et al. (2015) F. Chollet et al., “Keras,” https://keras.io (2015).
- Abadi et al. (2015) M. Abadi, A. Agarwal, P. Barham, E. Brevdo, Z. Chen, C. Citro, G. S. Corrado, A. Davis, J. Dean, M. Devin, S. Ghemawat, I. Goodfellow, A. Harp, G. Irving, M. Isard, Y. Jia, R. Jozefowicz, L. Kaiser, M. Kudlur, J. Levenberg, D. Mané, R. Monga, S. Moore, D. Murray, C. Olah, M. Schuster, J. Shlens, B. Steiner, I. Sutskever, K. Talwar, P. Tucker, V. Vanhoucke, V. Vasudevan, F. Viégas, O. Vinyals, P. Warden, M. Wattenberg, M. Wicke, Y. Yu, and X. Zheng, “TensorFlow: Large-scale machine learning on heterogeneous systems,” (2015), software available from tensorflow.org.
- Taigman et al. (2014) Y. Taigman, M. Yang, M. Ranzato, and L. Wolf, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2014).
- Smith and Topin (2016) L. N. Smith and N. Topin, “Deep convolutional neural network design patterns,” (2016), arXiv:1611.00847 [cs.LG] .
- Krizhevsky et al. (2012) A. Krizhevsky, I. Sutskever, and G. Hinton, Neural Information Processing Systems 25 (2012), 10.1145/3065386.