Machine Learning Enhanced Hankel Dynamic-Mode Decomposition
Abstract
While the acquisition of time series has become more straightforward, developing dynamical models from time series is still a challenging and evolving problem domain. Within the last several years, to address this problem, there has been a merging of machine learning tools with what is called the dynamic mode decomposition (DMD). This general approach has been shown to be an especially promising avenue for accurate model development. Building on this prior body of work, we develop a deep learning DMD based method which makes use of the fundamental insight of Takens’ Embedding Theorem to build an adaptive learning scheme that better approximates higher dimensional and chaotic dynamics. We call this method the Deep Learning Hankel DMD (DLHDMD). We likewise explore how our method learns mappings which tend, after successful training, to significantly change the mutual information between dimensions in the dynamics. This appears to be a key feature in enhancing the DMD overall, and it should help provide further insight for developing other deep learning methods for time series analysis and model generation.
This work uses machine learning to develop an accurate method for generating models of chaotic dynamical systems using measurements alone. A number of challenging examples are examined which show the broad utility of the method and point towards its potential impacts in advancing data analysis and modeling in the physical sciences. Finally, we present quantitative studies of the information theoretic behavior of the machine learning tools used in our work, thereby allowing for a more detailed understanding of what can otherwise be an inscrutable method.
1 Introduction
The incorporation of modern machine learning methodology into dynamical systems is creating an ever expanding array of techniques pushing the boundaries of what is possible with regards to describing and predicting nonlinear multi-dimensional time series. Longstanding problems such as finding optimal Takens’ embeddings [1, 2] now have powerful and novel deep learning based algorithmic approaches [3] which would not have been feasible even ten years ago. Likewise, the field of equation free modeling using Koopman operator methods, broadly described by Dynamic Mode Decomposition (DMD), has seen several innovative deep learning based methods emerge over the last several years [4, 5, 6] which have been shown to greatly expand the accuracy and flexibility of DMD based approaches. There have also been related and significant advances in model identification and solving nonlinear partial differential equations via deep learning techniques [7, 8, 9, 10].
With this background in mind, in this work we focus on extending the methods in [6] which were called Deep Learning DMD (DLDMD). In that work, a relatively straightforward method merging auto-encoders with the extended DMD (EDMD) was developed. This was done by using an encoder to embed dynamics in a sufficiently high enough dimensional space which then generated a sufficiently large enough space of observables for the EDMD to generate accurate linear models of the embedded dynamics. Decoding then returned the embedded time series to the original variables in such a way as to guarantee the global stability of iterating the linear model to generate both reconstructions and forecasts of the dynamics. The DLDMD was shown to be very effective in finding equation-free models which were able to both reconstruct and then forecast from data coming from planar dynamical systems.
However, when chaotic time series from the Lorenz-63 system were examined, the performance of the DLDMD was found to degrade. While this clearly makes the DLDMD approach limited in its scope, we note that the successful use of DMD based approaches to accurately reconstruct or forecast chaotic dynamics are not readily available. Other methods such as HAVOK [11] or SINDy [12] are more focused on the analysis of chaotic time series or the discovery of model equations which generate chaotic dynamics, though of course if one has an accurate model, then one should be able to generate accurate forecasts. In this vein, there are also methods using reservoir computing (RC) [13, 14], though again, nonlinear models are essentially first learned and then used to generate forecasts. However, both SINDy and RC rely on proposing libraries of terms to build models which are then fit (or learned from) data.
While effective, such approaches do not allow for the spectral or modal analysis which has proven to be such an attractive and useful feature of DMD based methods. Likewise, they require a number of user decisions about how to construct the analytic models used in later regressive fitting that amount to a guess and check approach to generating accurate reconstructions and forecasts. Therefore in this work, using insights coming from the Takens’ Embedding Theorem (TET) [15, 3], we expand the DLDMD framework so as to make it accurate in both generating reconstructions and forecasts of chaotic time series. This is done by first making the EDMD over embedded coordinates global as opposed to the local approach of [6]; see also [4, 5]. Second, we develop an adaptive Hankel matrix based ordering of the embedded coordinates which adds more expressive power for approximating dynamics to the deep learning framework. To study our method, we use data generated by the Lorenz-63 and Rossler systems as well as twelve-dimensional projections of data from the Kuramoto–Sivashinksky (KS) equation. In all of these cases, we show that by combining our proposed modifications to the DLDMD that we are able to generate far more accurate reconstructions and forecasts for chaotic systems than with DLDMD alone. Moreover, we have built a method which still allows for the straightforward modal analysis which DMD affords and keeps user choices to a handful of real-valued hyperparamters while still producing results competitive with other approaches in the literature.
Further, motivated by the classic information theory (IT) studies of the TET [1], as well as modern insights into the role that information plays in deep learning [16, 17], we study how the fully trained encoder changes the information content of the dynamics coming from the Lorenz-63 and Rossler systems. For the Lorenz-63 system, the encoder tends to either slightly decrease the mutual information or cause strong phase shifts which decrease the coupling times across dimensions. However, the characteristic timescales corresponding to lobe switching in the Lorenz ‘butterfly’ are clearly seen to be preserved in the dynamics of the information for the Lorenz-63 system. In contrast then, for the Rossler system, the slow/fast dichotomy in the dynamics seen in the original coordinates is made more uniform so that rapid transients in the information coupling are removed by the encoder. Thus in either case, we see that the encoder generates significant differences in the information content between dimensions in the latent coordinates relative to the original ones, and that this strong change in information content is a critical feature in successful training.
Of course, the present work is ultimately preliminary, and there are a number of important questions left to be resolved. First, while we are able to easily display computed spectra, the affiliated global Koopman modes we find are not as straightforward to show. We generate our results from random initial conditions, so the most effective means of constructing the global Koopman modes would be via radial-basis functions, but the implementation would be nontrivial due to the infamous ill-conditioning issues which can plague the approach [18]. Second, there is a clear need for a comparison across SINDy, RC, and our DLHDMD methods. In particular, the present work generates excellent reconstructions, but so far the predictive horizon is relatively short and difficult to increase. How well other methods address this issue relative to their reconstruction and other diagnostic properties, and then how all of these methods compare in these several different ways is as yet unclear. While acknowledging then the limitations of the present work, we defer addressing the above issues till later works where each of the above issues can be dealt with in the detail that is needed.
The structure of this paper is as follows. In Section 2, we provide an introduction to the Extended DMD and then explain the extensions we develop which are critical to the success of the present work. In Section 3, we introduce the Hankel DMD and, incorporating the extensions introduced in Section 2, we show how well it does and does not perform on several examples. Then in Section 4 we introduce the Deep Learning Hankel DMD and provide results on its performance as well as an analysis of how the mutual information changes in the latent variables. Section 5 presents our results on mutual information. Section 6 provides conclusion and discussion.
2 Extended Dynamic Mode Decomposition
To begin, we suppose that we have the data set where
where is the time step at which data is sampled and is a flow map such that . From the flow map, we define the affiliated Koopman operator such that for a given scalar observable , one has
so that the Koopman operator linearly tracks the evolution of the observable along the flow. We likewise define the associated Hilbert space of observables, say , or more tersely as , so that if
where is some appropriately chosen measure. This makes the infinite-dimensional Koopman operator a map such that
Following [19, 20], given our time snapshots , we suppose that any observable of interest lives in a finite-dimensional subspace described by a given basis of observables so that
Given this ansatz, we then suppose that
where is the associated error which results from the introduction of the finite-dimensional approximation of the Koopman operator represented by . We can then find by solving the following minimization problem
| (1) | ||||
where , , the inner product is the standard one over , and the symbol denotes complex conjugation. It is straightforward to show that an equivalent and easier to solve form of this optimization problem is given by
| (2) |
where is the Frobenius norm, and the matrices are given by
In practice, we solve this equation using the Singular-Value Decomposition (SVD) of so that
This then gives us
To complete the algorithm, after diagonalizing so that
| (3) |
then one can show that the Koopman eigenfunctions are found via the equations
| (4) |
From here, one can, starting from the initial conditions, approximate the dynamics via the reconstruction formula
| (5) |
where and the Koopman modes solve the initial-value problem
Again, in matrix/vector notation, keeping in mind that and that in general , we have
where is the matrix whose columns are the Koopman modes . As can be seen then, generically, one can only find the Koopman modes through least-squares solutions of the non-square problem. In this regard, one would do well to have information from as many initial conditions as possible to over-determine the problem.
2.1 Global EDMD
To wit, if we had a collection of initial conditions with corresponding path data , we can extend the optimization problem in Equation (1) to be
so that now the problem of finding is no longer strictly localized to a particular path labeled by the initial condition . Following the same optimization argument as above leads one to concatenate across observables column wise when generating the matrices so that
where
The matrix is defined similarly. Using then the EDMD algorithm outlined above, we arrive at the following matrix problem for determining
where
Likewise, given that Equation (4) gives us time series of the Koopman eigenfunctions, which necessarily must satisfy, assuming sufficient accuracy of the approximation implied by Equation (3), the identity
we can generalize Equation (5) via the model
| (6) |
where , , and
which generates a reconstruction of the data for time steps and a forecast for steps with index . Using this formula allows for far greater flexibility in employing the EDMD since we can control how many times steps for which we wish to generate reconstructions. This is in contrast to generating forecasts through the iteration of the diagonal matrix , which is a process that is generally sensitive to small variations in the position of the eigenvalues , especially for those near the unit circle in the complex plane. We will make great use of this generalization in the later sections of this paper. We also note that in order to avoid introducing complex values, which can cause significant complications when using current machine learning libraries, we will do all later computations in terms of and as in Equation (6).
3 Hankel DMD
When implementing EDMD, the most natural observables are the projections along the canonical Cartesian axes, i.e.
If we stick to this space of observables, the EDMD method reduces to the standard DMD method. Thus the idea with EDMD is to include more nonlinear observables to hopefully represent a richer subspace of dynamics and thereby make the approximation of corresponding Koopman operator more accurate and sophisticated.
With this in mind, [15] built upon the classic idea of Takens embeddings [21] and explored using affiliated Hankel matrices to generate natural spaces of observables for EDMD, and approach we describe as Hankel DMD (HDMD). Also of note in this direction is the HAVOK method developed in [11], though in some ways HAVOK is more akin to the embedology methods explored in such classic works as [22, 2].
HDMD thus begins with an affiliated scalar measurement of our time series, say . From this, by introducing a window size one builds the affiliated Hankel matrix where
where the number of observables .
What one sees then is that each row of is some iteration of the Koopman operator . From here then, each row of time steps is defined to be its own separate observable , i.e.
One then proceeds as above with the EDMD algorithm, where we emphasize that is replaced by . This is an interesting feature, or arguably limitation, of the HDMD method in which we generate matrices (see Equation (4)) up to the time index . Thus later times are used to build approximations at prior times. This makes the issue of forecasting data more difficult since one must iterate the EDMD results, as is done via Equation (6), from time index up to to reconstruct the original data that was used in the first place. Throughout the remainder of the paper then, we take care to distinguish between iterated reconstructions and actual forecasts which make novel predictions beyond the given data.
Finishing our explanation of HDMD, if one has data along multiple initial conditions, say , we can extend the above algorithm by concatenating Hankel matrices so that we perform EDMD on the combined matrix so that
The inclusion of other observables can be done in a similar fashion.
3.1 Results for HDMD
The ultimate promise of the HDMD is that it should facilitate an adaptable implementation of the EDMD framework which allows for the number of observables to simply be adjusted by the window size. To see this, in all of the following results we let , , and we use random initial conditions which are then stacked together. For HDMD, observables along each dimension of the dynamical system are used so that
Reconstructions and forecasts are generated using Equation (6) for , which for a time step of , means forecasts are produced up to a unit of non-dimensional time. We note though that the choice of sets the window size value , so that instead of using EDMD on data from , we now use data from where .
If we then take data from the Van der Pol oscillator, where
we find, as seen in Figure 1, that does not produce especially accurate reconstructions or forecasts. By increasing to though, we are able to generate far more accurate results, though at the cost of being able to forecast beyond the given time series. We further note that by fixing and letting , we get essentially the same degree of degradation in the forecast as when we chose and .
 |
 |
In contrast to these results, we find that the Lorenz Equations
| (7) |
where
provide a case in which the HDMD is not able to adequately capture the dynamics for any reasonable choices of . This is not necessarily surprising since for the parameter choices made, we know that the dynamics traces out the famous Butterfly strange attractor as seen in the top row of Figure 2. Given that we are trying to approximate dynamics on a strange attractor, we would reasonably anticipate the HDMD to struggle.
However, as seen in the bottom row of Figure 2, the method essentially fails completely for parameter choices identical to those used above for the Van der Pol oscillator. That all said, further adaptation of the HDMD method might produce more desirable results. We will see how to realize this through the use of neural networks in the following section.
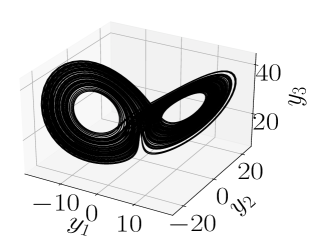 |
|
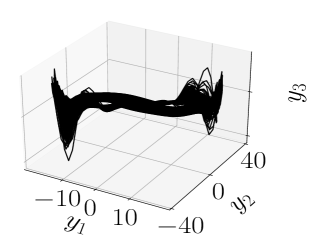 |
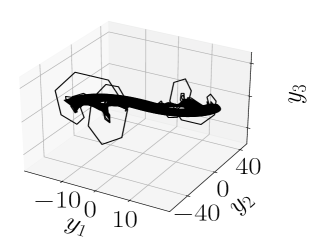 |
4 Deep Learning HDMD
To improve the HDMD such that it is able to deal with chaotic systems such as the Lorenz equation, we now turn to and adapt the framework of the deep learning DMD (DLDMD) developed in [6]. Our deep learning enhanced HDMD begins with an autoencoder composed of neural networks (the encoder) and (the decoder) such that
and such that our auto-encoder is a near identity, i.e.
Note, we call the encoded coordinates latent variables or latent dimensions in line with the larger literature on machine learning. Motivated by our results in [6], we take . We then have in the later EDMD step that , so that larger values of correspond to more observables to represent the dynamics through an approximation to the Koopman operator.
The encoded coordinates should represent a set of observables which should enhance the overall accuracy of HDMD approximations of the dynamics. To train for this, after making reasonable choices for how to initialize the weights of the auto-encoder, and fixing a choice for , given the training data , after shuffling into batches of batch size , over a given batch , we use the following loss function
where
with denoting averaging over a given batch, and denoting averaging over the to timesteps. We also emphasize here that the matrices , , and are defined globally over a given batch of trajectories. This is in contrast to the methods in [6] or [4] which computes equivalent matrices over each trajectory. Arguably then, our approach is learning more global representations of the Koopman operator, the consequences of which we will explore in future work, though see the Appendix for a brief exploration on this point.
4.0.1 Updating
One of the most compelling reasons to use Hankel-DMD in our learning algorithm is that it easily allows us to change the model without having to change the underlying neural networks represented by and . We note that this is in marked contrast to the method of [6], which while allowing for varying models by changing the dimensionality of the range of , then must fix that output dimension for the length of training. This can make finding good models a challenging task. Thus, we anticipate by allowing to change that we can develop far more flexible models which are ultimately easier to train and use.
To update , we first train the networks and by optimizing over a given epoch. Then, fixing the weights in the networks, we take a subset of the training data and compute . We then compute and compare to . If either of the variant models gives a lower value of and causes a relative change greater than some chosen tolerance , then we update the model by changing . Note, the choice of the range of values of comes from trial and error with a particular emphasis on computational efficiency and cost. Likewise, introducing the relative change threshold was found to be useful in ignoring what amounted to spurious changes in the model parameters. We collect the details of our learning method in Algorithm 1, which we call the Deep Learning HDMD (DLHDMD).
4.1 Results for DLHDMD
We now show how the DLHDMD performs on several dynamical systems. We take as our training set randomly chosen initial conditions with their affiliated trajectories. For the lower dimensional systems, we use 1000 randomly chosen initial conditions for testing purposes. For the higher dimensional systems, we use 500 randomly chosen trajectories for testing. The networks and consist of 5 layers each. Two of the layers are for input and output, while the remaining three are hidden nonlinear layers using the ReLU activation function. Alternate architectures with more or less hidden layers were studied with the present choice being found to lead to the most efficient training. The training is done in PyTorch [23] over epochs for the lower dimensional systems and epochs for the KS system. In all cases, the training used an ADAM optimizer with learning rate .
4.1.1 Hyperparameter Tuning
Before runtime then, the user must specify , , , , , , and an initial choice for . was chosen relative to considerations of the underlying dynamical systems themselves as explained later. For our tuning results, we found that setting and letting our adaptive scheme update was generally sufficient to produce useful suggestions for parameter choices. This also helped manage the computational cost of tuning. To determine optimal choices of , , and , we used the Ray tuner [24] set to perform hyperband optimization across six samples at a time. The batch size was chosen from the values , was chosen from a log-uniform sampling of values between and , and was chosen from a log-uniform sampling of values from and . For Lorenz-63 and Rossler, we started with while for the KS system, we started from . Significantly smaller or larger choices for the initial value of in all cases resulted in less than desirable performance as determined through trial and error. We also note that when tuning, we chose a fraction of , say , so as to facilitate a more rapid tuning process. While this did not need to be especially large for the Lorenz or KS systems, Rossler was a different matter, and small choices of lead to very unstable training.
Determining good choices of turned out to be the most difficult task. Generally speaking, after trial and error, we found that one wanted large enough so that the model did not spuriously increase in place of forcing the encoder and decoder to better learn the dynamics. Thankfully, we consistently observed that if , which corresponds to the models losing any predictive capacity, during training, then would drop several orders of magnitude, thereby becoming essentially irrelevant. Thus if we observe during training that , this clearly indicates that we should increase . That said, we also need to keep small enough so that the model can take advantage of increasing so as to stabilize training and improve model performance. A strategy to address this issue was to auto-tune for relatively small values of for low choices of which then let us get a reasonable estimate on good choices for , , and . We would then run these models and see if our choice of allowed during longer training runs. If so, we would raise the value of and rerun our model, and if this produced a model with low and converging while keeping , we kept those parameter choices. Otherwise, we would retune across another six samples at a higher value of and possibly . For each system, this amounted to about three to four tuning experiments overall to produce a good results. This approach did allow us to ultimately converge on parameter choices which produced excellent results, but we also acknowledge that this is a time consuming process. Clearly, developing a loss function which helps manage choosing good values is desirable and will be a subject of future research.
The results for all of our experiments are presented in Table 1. As can be seen, the underlying differences in dynamics manifest as significant changes to the batch size and learning rate. Most notably, Rossler’s multiscale features demand both a longer number of testing epochs, larger batch size, and lower learning rate reflecting the greater difficulty that the machine has in learning a reasonable optimization path. From this, as a general rule of thumb, when all else fails, raising and lowering gives the optimization routine more chance to find training paths.
| Lorenz-63 | Rossler | KS | |
| (te) | 10 | 10 | 5 |
| (te) | .05 | .25 | .15 |
| (te) | 20 | 40 | 10 |
| (tn) | 64 | 256 | 64 |
| (tn) | |||
| (tn) | .000507 | .0001 | .00081 |
Finally, we briefly address the performance of our algorithm with respect to the system size . For Lorenz-63 and Rossler, , while for the KS system, . This is a significant difference, but it does raise the question of whether our method has an upper limit beyond which it can no longer readily train. To find this, we studied the Lorenz-96 equations [25] for , , and . We were able to get successful training for all but . Even by following our previous advice of increasing and decreasing , we could not find a combination of parameters which allowed for reasonable training. Why this is the case, and possible remedies, will be a subject of future research.
4.1.2 DLHDMD for the Lorenz-63 System
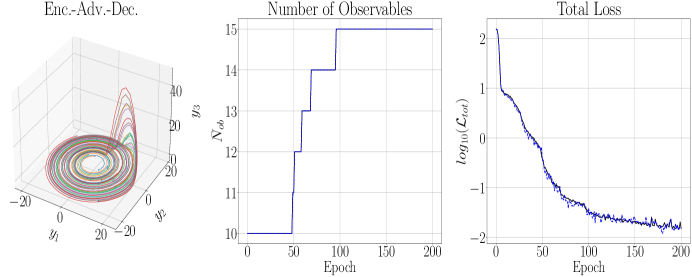
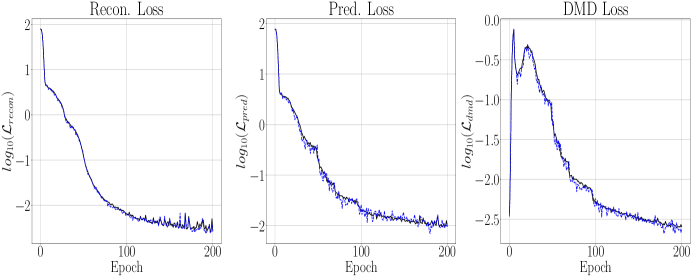
The results of running the DLHDMD for the Lorenz-63 system are found in Figures 3 and 4. The maximum positive Lyupanov exponent, say , for the Lorenz-63 system can be numerically computed using the methods of [26], and we find that . In this case then, our prediction window is only slightly less than , so that we are making predictions up to the point where the strange attractor would tend to induce significant separations in what were initially nearby trajectories. First taking and , as can be seen in Figure 3, the overall reconstruction and forecast, plotted for times such that , shows excellent agreement with the plot of the Lorenz Butterfly in the top row of Figure 2. This degree of accuracy is quantified by the graph of in Figure 4, which shows a relative accuracy of about by the epoch. To achieve this, we see that the DLHDMD progressively raises the value of . As seen in Figure 3, this process continues until about the epoch, at which point and then stays at this value for the remaining epochs. What is particularly striking is that for the length of training, which means that our trained model is able to make novel forecasts while still providing excellent reconstructions. We note that larger choices of were examined, and generally they prevented the model from updating and thus degrading model performance.
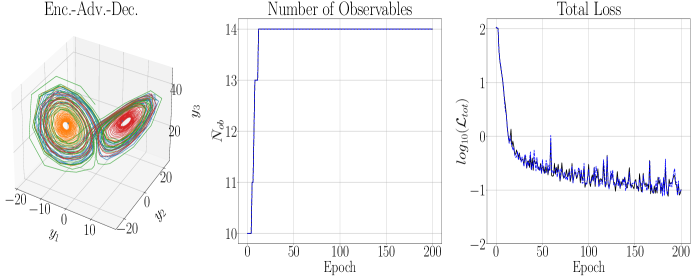
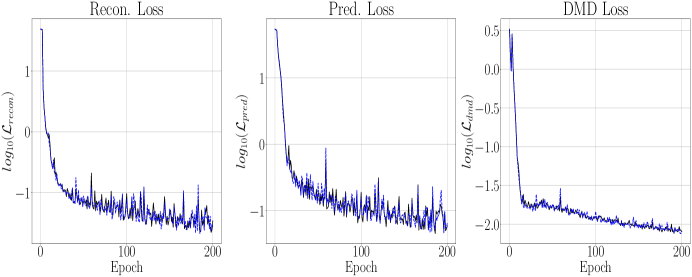
We now examine the effect of increasing the embedding dimension so that . We first note that we had to increase in order to keep from reaching and surpassing , which it rapidly did when . Otherwise we keep all of the other parameters the same for the sake of comparison. That said, as can be seen in Figures 5 and 6, while the training exhibits larger variance around the net trend in the loss, the model is able to converge to an even lower overall loss while still only needing observables. However, the difference is not even an order of magnitude better, and this generally reflects that the performance of our models is not drastically affected by changing the embedding dimension. We also note that the average training time per epoch when is 22 s while for it is 44 s. We then see that raising the embedding dimension is a fraught affair. While it can improve model performance, it becomes much more computationally costly for what appear to be relatively nominal returns.
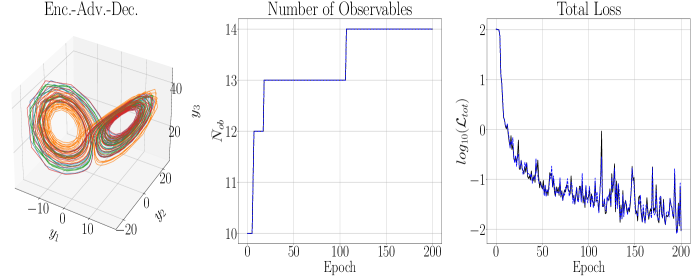
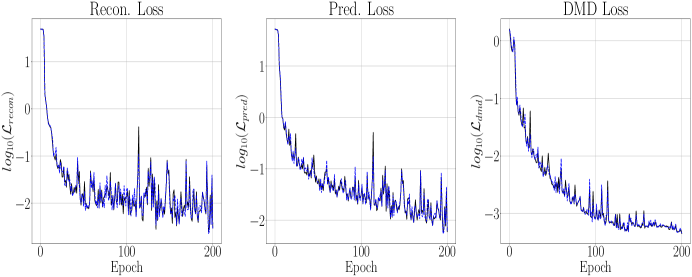
Of course, one might wonder to what extent increasing can be exchanged for increasing . Thus, we set so that we do not perform any update of during training. The results of doing this for can be seen in Figure 7. Comparing across Figures 3, 5, and 7, we see that increasing but not updating gets us a model of intermediate accuracy, though again the overall differences are relatively nominal relative to order of magnitudes present in the original data sets. Ultimately then, we see that the updating scheme controlled by improves model performance, though the update threshold needs to be chosen carefully to be large enough to make sure changing does not preclude the encoder/decoder networks from doing the harder work of learning the dynamics while at the same time not choosing so large that no update moves are made. Finally, we refer the reader to the Appendix where we examine not only setting , but also fixing , thereby “turning off” Hankel DMD in our algorithm. We also compare using the global EDMD method with a local one, which then essentially reduces to the DLDMD method of [6]. In all cases, we find the results significantly worse than what is presented in this section, thereby showing our additions to the DLDMD method have markedly improved model development.
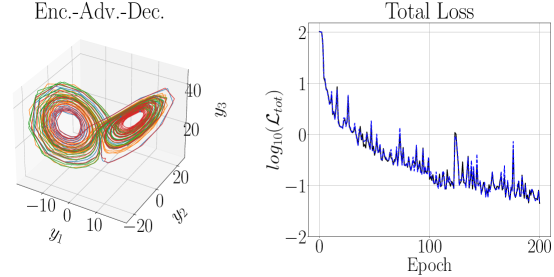
4.1.3 DLHDMD for the Rossler System
We now study the Rossler system given by
where
Aside from the dynamics coalescing onto a strange attractor, the disparity in parameter values gives rise to multiscale phenomena so that there are slow and fast regimes of the dynamics. The slow portions are approximated by harmonic motion in the plane, and the fast portion moves along the coordinate. This strong disparity in time scales also appears by way of , which is more than double the maximal Lyupanov exponent for the Lorenz-63 system. Thus dynamics separate along the strange attractor twice as fast.
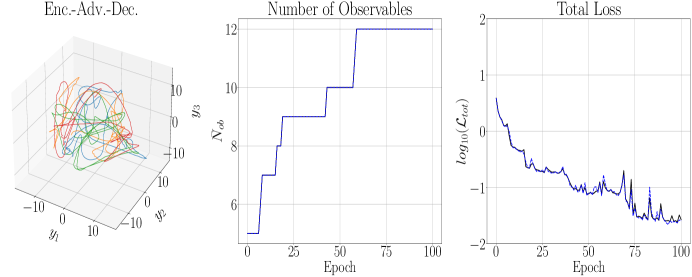
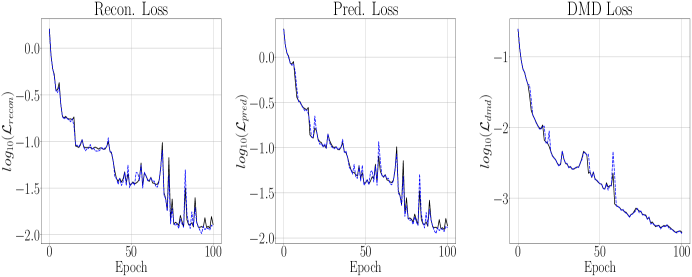
Using the parameter choices in Table 1 and taking , in Figures 8 and 9 we get the training and testing results of DLHDMD. We immediately observe that, relative to the Lorenz-63 system, the much larger choice of and much smaller choice of learning rate produce a far less noisy training/validation curve; see in particular Figure 9. Somewhat suprisingly, we are able to train to overall lower loss values even with the significantly larger choice for . We note that even nominally smaller choices of resulted in the collapse of the term, so the slow/fast dynamics create very concrete differences between the Rossler and Lorenz-63 models. That said, we are still able to keep the final value of and still get excellent reconstruction, so it is clear that our overall approach is working very well. We also note that we examined the impact of letting and generally found no significant improvement in training or testing. In this case then, we see that there is no hard and fast rule about using higher embedding dimensions to improve model performance, and so it must be treated as a general hyperparameter which can induce significant computational cost.
4.1.4 DLHDMD for the KS Equation
To see the edges of our method, we now examine spatio-temporal chaos generated by the KS equation with periodic-boundary conditions in the form
Note, given the vast size of the literature around the KS equation, we refer the reader to [27] for an extensive bibliography with regards to details and pertinent proofs of facts used in this section. Introducing the rescalings
and taking the balances
we get the equivalent KS equation (dropping tildes for ease of reading)
Looking at the linearized dispersion relationship , we see that the parameter acts as a viscous damping term. Thus, as the system size is increased, the effective viscosity is decreased, thereby allowing for more complex dynamics to emerge. As is now well known, for sufficiently large, a fractional-dimensional-strange attractor forms which both produces intricate spatio-temporal dynamics while also allowing for a far simpler representation of said dynamics. It is has been shown in many different works (see for example [28]) that generates a strange attractor with dimension between eight and nine, and that this is about the smallest value of which is guaranteed to generate chaotic dynamics. We therefore set throughout the remainder of this section.
To study the DLDHMD on the KS equation, we use KS data numerically generated by a pseudo-spectral in space and fourth-order exponential-differencing Runge-Kutta in time method [29] of lines approach. For the pseudo-spectral method, total modes are used giving an effective spatial mesh width of , while the time step for the Runge-Kutta scheme is set to . These particular choices were made with regards to practical memory and simulation time length constraints. After a burn in time of , which is the time scale affiliated with the fourth-order spatial derivative for the chosen value of , 8000 trajectories of total simulation time length were used with gaps of in between to allow for nonlinear effects to make each sample significantly different from its neighbors. Each of the 8000 space/time trajectories was then separated via a POD into space and time modes; see [30]. Taking modes captured between 97.8% and 99.4% of the total energy. The choice of the total time scale also ensured that the ratio of the largest and smallest singular values affiliated with the POD was between and so that the relative importance of each of the modes was roughly the same across all samples. We take this as an indication that each 12-dimensional affiliated time series is accurately tracing dynamics along a common finite-dimensional strange attractor as expected in the KS equation. Again, using the methods of [26], we can find across batches that typically the largest positive Lyupanov exponent , so that is the time after which we anticipate that the strange attractor fully pulls trajectories apart.
With regards to the details of the DLHDMD, we again use samples for training, and 500 for testing. The best results with regards to window size were found when we initially set and . The iterated reconstruction/forecast horizon determined by the choice of was chosen so that , corresponding to the time scale over which nonlinear advection acts. Thus, reconstruction is done on each sample for values of such that , and iterated reconstruction/forecasting is done for such that . Note, for our initial choice of , we have that initially . The results of DLHDMD training on the dimensional POD reduction of the KS dynamics is shown in Figures 10, 11, and 12. Likewise, our prediction window is longer than the timescale set by , so we argue our forecasts are over time scales for which chaotic effects are significant. We see that the reconstruction and predictions appear accurate; see in particular the comparisons in Figure 12, as seen in Figure 11. Likewise, by choosing , we prevent collapse in and keep .
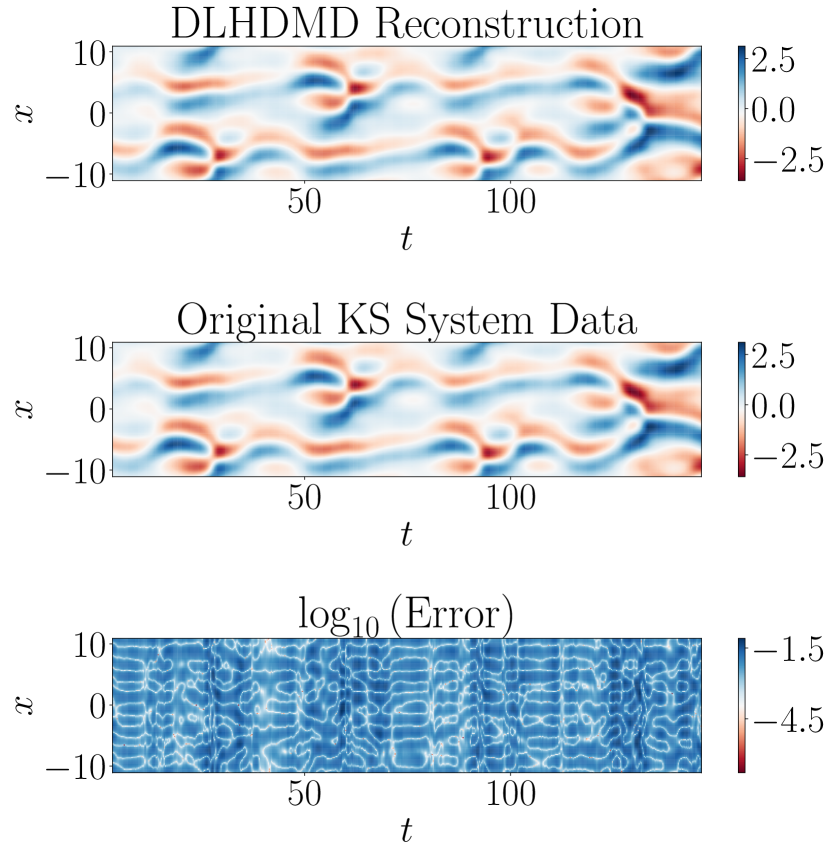
Overall then, we find that through careful parameter tuning, especially with regards to how one chooses , we are able to generate models exhibiting high reconstruction accuracy while also providing nontrivial time horizons for prediction of future dynamics, measured by the difference between relative to . That said, the parameter tuning process can be time consuming, and more automatic methods would be necessary to develop before attempting to improve the results presented in this work.
5 Mutual Information for Characterizing Embeddings
Given the success of the DLHDMD in reconstructing and forecasting dynamics along a strange attractor, especially when compared to the relative failure of trying to do the same using just the HDMD or DLDMD alone, it is of further interest to try to assess exactly what role the auto-encoder plays in improving the outcome of the HDMD. While we can certainly point to the performance of the components of the loss function to explain the impact of the encoder, this does not provide us with any more explanatory power. In [6], it was empirically shown that the role of the encoder was to generally transform time series to nearly monochromatic periodic signals, which is to say, the effect of encoding was to generate far more localized Fourier spectral representations of the original time series. This does not turn out to be the case though for the DLHDMD. Instead, inspired both by the evolving understanding of how mutual information better explains results in dynamical systems [1, 31] and machine learning [16, 17], we assess the impact of the encoder on the DLHDMD by tracking how the information across dimensions and time lags changes in the original and latent variables.
For two random variables and with joint density , the mutual information (MI) between them is defined to be
where and are the affiliated marginals. One can readily show that and if and only if and are independent. Thus information gives us a stronger metric of statistical coupling between random variables than more traditional tools in time series analysis such as correlation measurements. We also should note here that , which is to say it is symmetric. We also note that MI is invariant under the action of diffeomorphisms of the variables. Thus we cannot expect to get much use from computing the multidimensional MI of the original and latent variables, thereby allowing for meaningful differences to appear between original and latent variable computations.
Instead, using the trajectories in the test data, we define the -step averaged lagged self-information (ALSI) between the and dimensions to be
We refer to the parameter as a lag. In words then, after averaging over the ensemble of initial conditions in the test data, we compute the degree to which the signal becomes statistically independent from itself across all of the dimensions along which the dynamics evolve. We emphasize that due to the strong nonlinearities in our dynamics, we compute the lagged information as opposed to the more traditional auto-correlation so as to get a more accurate understanding of the degree of self-dependence across dimension in our dynamics. Further, by measuring the lagged MI across isolated dimensions, we break the invariance of MI with respect to diffeomorphisms.
5.1 MI for the Lorenz-63 System
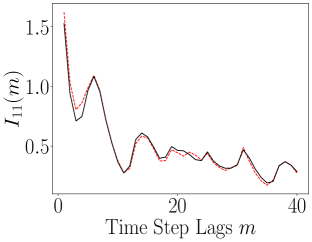
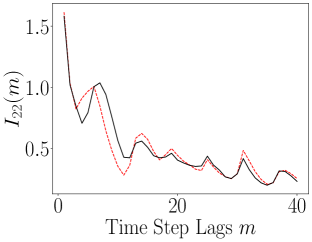
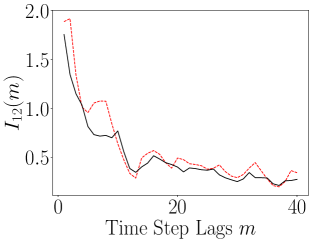
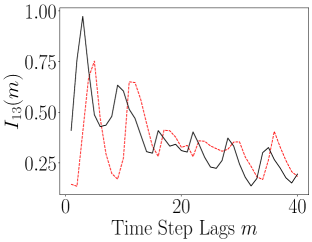
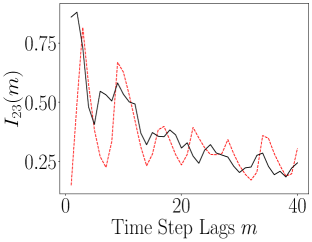
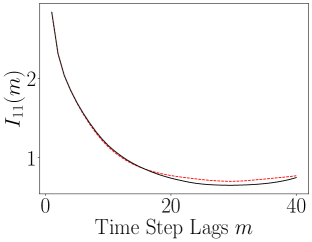
The results of computing the ALSI for the Lorenz-63 system are plotted in Figure 13. As can be seen, the impact of the encoder is to either weakly attenuate the dependency between dimensions; see , or as for and , leave the ALSI essentially unchanged. Finally, we also see significant phase shifts in the lag count; see and . In these phase shifts, we see that the shift is always left towards shorter lags, so that the dependence in the latent variables decays more rapidly than in the original variables. In this sense then, the overall tendency of the encoder is to either reduce MI or cause time series to become more independent more rapidly. Otherwise though, the timescales of oscillation in the latent variables are essentially identical to those seen in the latent variables. In terms of the DLHDMD, we might then say that the encoder assists the HDMD by generally making the rows of the affiliated Hankel matrices more independent, especially over longer time scales, and therefore more meaningful with regards to their generating more accurate approximations of the underlying Koopman operator.
 |
 |
| (a) | (b) |
 |
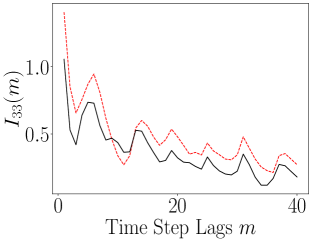 |
| (c) | (d) |
 |
 |
| (e) | (f) |
5.2 MI for the Rossler System
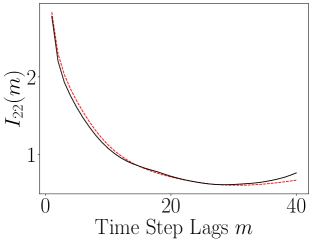
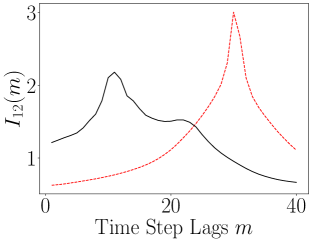
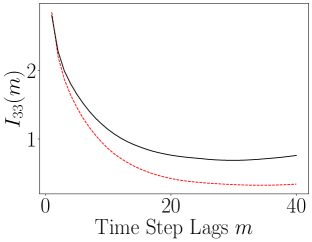
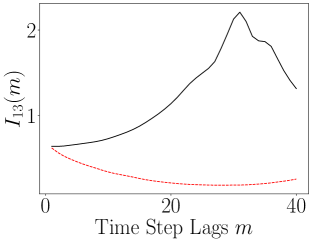
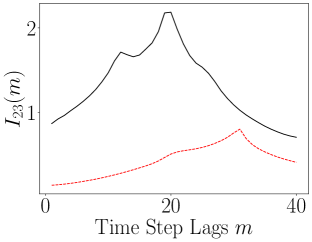
When we examine the evolution over lags of the ALSI, we see in Figure 14 that the encoder is causing large and significant changes to the dynamics. In particular, when we look at the plots of and , we see that the sharp transients in the ALSI for the original coordinates is removed and the overall ALSI is relatively flattened in the latent coordinates. This would seem to indicate that the slow/fast dichotomy in the Rossler dynamics is removed and so made more uniform. Also of note though is which shows that the dependency between the and axes is enhanced relative to the coupling between and and that said dependency increases with lags.
 |
 |
| (a) | (b) |
 |
 |
| (c) | (d) |
 |
 |
| (e) | (f) |
6 Conclusion and Discussion
In this work, we have developed a machine learning enhanced version of the HDMD and DLDMD which we call the DLHDMD. We have shown that its performance is significantly better than just the HDMD, and when comparing against existing results in [6] we see radical improvement over the DLDMD method for the Lorenz-63 system. Likewise, we find that our method is successful across several challenging chaotic dynamical systems varying in dynamical features and size. Thus, we have an accurate parallel approach fitting within the larger framework of Koopman operator based methods. Moreover, we have a method which computes Koopman modes globally. Finally, our analysis of the relative information dynamics across physical dimensions in the original and latent variables provides us a means of understanding the impact of the encoder network on the dynamics in line with modern thinking in machine learning as well as better pointing towards an understanding that the HDMD is enhanced by decreasing the relative statistical dependence across physical dimensions. As explained in detail in the Introduction, there are of course a number of questions that remain to be addressed, and they will certainly be the subject of future research.
7 Acknowledgements
C.W. Curtis would like to acknowledge the generous support of the Office of Naval Research and their Summer Research Faculty Program for providing the support of this project. D.J. Alford-Lago acknowledges the support of the Naval Information Warfare Center. E. Bollt was funded in part by the U.S. Army Research Office grant W911NF- 16-1-0081, by the U.S. Naval Research Office, the Defense Advanced Research Projects Agency, the U.S. Air Force Research Office STTR program, and the National Institutes of Health through the CRCNS. We also wish to thank both anonymous reviewers for a number of insightful comments and questions which helped dramatically improve the paper.
8 Appendix
8.1 Models without HDMD for the Lorenz-63 System
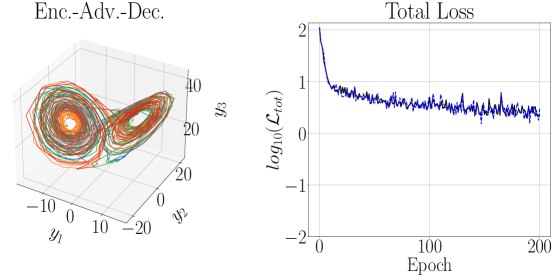
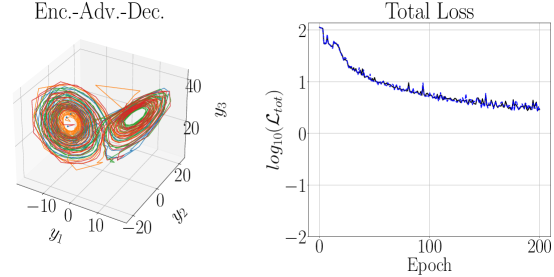
Here, for the Lorenz-63 system, we explore the impact of fixing , which is equivalent to setting and then removing any Hankel observables from our computations. We also examine the difference between using a global EDMD versus a local one, at which point we are essentially using the DLDMD, i.e. local EDMD, algorithm presented in [6]. Parameter choices are kept the same for the sake of ready comparison. For the DLDMD model, we also explored a range of embedding dimension choices where , and . We found that gave the best results in tuning experiments. That said, we emphasize that the worst results were found for , and the differences between the choices in embedding dimension were not striking. We can see the results of our final training and testing in Figure 15. In either the global or local case, the results are far from desirable, especially compared to what we have thus far obtained through increasing . That said, while the rate of training is improved for the global EDMD model, in the end there is little difference in the final outcome between the local and global methods, and both clearly struggle to learn the dynamics, especially in comparison to our results using larger values of , which is to say using Hankel DMD.
 |
 |
References
- [1] A. M. Fraser and H.L. Swinney. Independent coordinates for strange attractors from mutual information. Phys. Rev. A, 33:1134–1140, 1986.
- [2] T. Sauer, J. A. Yorke, and M. Casdagli. Embedology. J. Stat. Phys., 65:579–616, 1991.
- [3] W. Gilpin. Deep reconstruction of strange attractors from time series. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 204–216, 2020.
- [4] B. Lusch, J. N. Kutz, and S. L. Brunton. Deep learning for universal linear embeddings of nonlinear dynamics. Nature Comm., 9:4950, 2018.
- [5] O. Azencot, N. B. Erichson, V. Lin, and M. Mahoney. Forecasting sequential data using consistent koopman autoencoders. In Hal Daumé III and Aarti Singh, editors, Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 475–485, 2020.
- [6] D. J. Alford-Lago, C. W. Curtis, A. T. Ihler, and O. Issan. Deep learning enhanced dynamic mode decomposition. Chaos, 32:033116, 2022.
- [7] K. Champion, B. Lusch, J. N. Kutz, and S. L. Brunton. Data-driven discovery of coordinates and governing equations. Proceedings of the National Academy of Sciences, 116(45):22445–22451, 2019.
- [8] K. Kadierdan, J.N. Kutz, and S.L. Brunton. SINDy-PI: a robust algorithm for parallel implicit sparse identification of nonlinear dynamics. Proc. Roc. Soc. A, 476:20200279, 2020.
- [9] M. Raissi, P. Perdikaris, and G. E. Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J. Comp. Phys., 378:686–707, February 2019.
- [10] Z. Li, H. Zheng, N. B. Kovachki, D. Jin, H. Chen, B. Liu, A. Stuart, K. Azizzadenesheli, and A. Anandkumar. Physics-informed neural operator for learning partial differential equations, 2021.
- [11] S.L. Brunton, B.W. Brunton, J.L. Proctor, , E. Kaiser, and J.N. Kutz. Chaos as an intermittently forced linear system. Nature Comm., 8, 2017.
- [12] S. L. Brunton, J. L. Proctor, and J. N. Kutz. Discovering governing equations from data by sparse identification of nonlinear dynamical systems. PNAS, 113(15):3932–3937, 2016.
- [13] E. Bollt. On explaining the surprising success of resevoir computing forecaster of chaos? The universal machine learningn dynamical system with contrast to var and dmd. Chaos, 31:013108, 2021.
- [14] D.J. Gauthier, E. Bollt, A. Griffith, and W.A.S. Barbosa. Next generation resevoir computing. Nat. Comm., 12:55674, 2021.
- [15] H. Arbabi and I. Mezic. Ergodic theory, dynamic mode decomposition, and computation of spectral properties of the Koopman operator. SIAM Appl. Dyn. Sys., 16:2096–2126, 2017.
- [16] N. Tishby and N. Zaslavsky. Deep learning and the information bottleneck principle. In 2015 IEEE Information Theory Workshop (ITW), pages 1–5, 2015.
- [17] O. Calin. Deep Learning Architectures: A Mathematical Approach. Springer, Cham, 2020.
- [18] G.F. Fasshauer. Meshfree Appoximation Methods with Matlab. World Scientific, Hackensack, NJ, 2007.
- [19] M.O. Williams, I. G. Kevrekidis, and C. W. Rowley. A data-driven approximation of the Koopman operator: extending dynamic mode decomposition. J. Nonlin. Sci., 25:1307–1346, 2015.
- [20] M.O. Williams, C. W. Rowley, and I. G. Kevrekidis. A kernel-based method for data driven Koopman spectral analysis. J. Comp. Dyn., 2:247–265, 2015.
- [21] F. Takens. Detecting strange attractors in turbulence. In Dynamical Systems and Turbulence, Lecture Notes in Mathematics, pages 366–381. 1981.
- [22] D.S. Broomhead and G.P. King. Extracting qualitative dynamics from experimental data. Physica D, 20:217–236, 1986.
- [23] A. Paszke, S. Gross, F. Massa, and et al. Pytorch: An imperative style, high-performance deep learning library. In Advances in Neural Information Processing Systems 32, pages 8024–8035. Curran Associates, Inc., 2019.
- [24] R. Liaw, E. Liang, R. Nishihara, P. Moritz, and et al. Tune: A research platform for distributed model selection and training. arXiv preprint arXiv:1807.05118, 2018.
- [25] E. N. Lorenz. Predictability – a problem partly solved, page 40–58. Cambridge University Press, 2006.
- [26] H.D.I. Abarbanel, R. Brown, and M.B. Kennel. Local Lyupanov exponents computed from observed data. J. Nonlinear Sci., 2:343–365, 1992.
- [27] J.C. Robinson. Infinite Dimensional Dynamical Systems. Cambridge University Press, Cambridge, UK, 2001.
- [28] N. B. Budanur, P. Cvitanović, R. L. Davidchack, and E. Siminos. Reduction of so(2) symmetry for spatially extended dynamical systems. Phys. Rev. Lett., 114:084102, Feb 2015.
- [29] AK Kassam and L.N. Trefethen. Fourth-order time-stepping for stiff PDEs. SIAM J. Sci. Comp., 26:1214–1233, 2005.
- [30] G. Berkooz, P. Holmes, J.L. Lumley, and C.W. Rowley. Turbulence, Coherent Structures, Dynamical Systems, and Symmetry. Cambridge University Press, Cambridge, UK, 2012.
- [31] E.M. Bollt and N. Santitissadeekorn. Applied and Computational Measurable Dynamics. SIAM, Philadelphia, PA, 2013.