MAIL: Malware Analysis Intermediate Language
1 Introduction
Intermediate languages are used in compilers [1] to translate the source code into a form that is easy to optimize and increase portability. The term intermediate language also refers to the intermediate language used by the compilers of high level languages that does not produce any machine code, such as Java and C#. An example of adding two numbers in the intermediate language CIL (Common Intermediate Language) used in implementing C# is as follows:
a = a + b; is translated to the following CIL code: ldloc.0 ; Push the first local on the stack ldloc.1 ; Push the second local on the stack add ; Pop the two locals, add them and push the result on the stack stloc.0 ; Pop the result and store it in the first local
CIL is a stack based language, i.e: the data is pushed on the stack instead of pulling from the registers. That is one of the reasons why, in the example above, one simple add statement is translated into four stack-based statements. The same add statement can be translated into the three address code [1] as:
a := a + b
The three address code is an intermediate language used by most of the compilers. The two popular open source compilers GCC [20] and LLVM [12] use three address code as part of there intermediate languages.
1.1 Hidden Malwares (Obfuscation)
Detecting whether a given program is a malware (virus) is an undecidable problem [5, 15]. Antimalware software detection techniques are limited by this theoretical result. Malware writers exploit this limitation to avoid detection.
In the early days the malware writers were hobbyists but now the professionals have become part of this group because of the financial gains [3] attached to it. One of the basic techniques used by a malware writer is obfuscation [14]. Such a technique obscure a code to make it difficult to understand, analyze and detect malwares embedded in the code.
Initial obfuscators were simple and were detected by signature-based detectors. These signature-based detectors work on simple signatures such as byte sequences, instruction sequences and string signatures (pattern of a malware that uniquely identifies it). They lack information about the semantics or behavior of the malicious program. To counter these detectors the obfuscation techniques evolved. Some of the mutations used in polymorphic and metamorphic [16] malwares are:
-
•
Instruction reordering: By changing the ordering of instructions with commutative or associative operators, the structure of the instructions can be changed. This reordering does not change the behavior of the program. As a simple example:
a = 10; b = 20; a = 10; b = 20; x = a * b; can be changed to: x = b * a original machine code and assembly: c7 45 f4 0a 00 00 00 Ψ movl [rbp-0xc], 0xa ; a = 10 c7 45 f8 14 00 00 00 Ψ movl [rbp-0x8], 0x14 ; b = 20 8b 45 f4 Ψ mov eax, [rbp-0xc] ; 0f af 45 f8 Ψ imul eax, [rbp-0x8] ; a * b 89 45 fc Ψ mov [rbp-0x4], eax ; x = a * b changed machine code and assembly: c7 45 f4 0a 00 00 00 Ψ movl [rbp-0xc], 0xa ; a = 10 c7 45 f8 14 00 00 00 Ψ movl [rbp-0x8], 0x14 ; b = 20 8b 45 f8 Ψ mov eax, [rbp-0x8] ; (reordered) 0f af 45 f4 imul eax, [rbp-0xc] ; b * a (reordered) 89 45 fc mov [rbp-0x4], eax ; x = b * a
Because of the two reordered instructions the original and the changed machine codes have different signatures. Other instructions can also be reordered if no dependency exists between the instructions.
-
•
Dead code insertion: Dead code is a code that either does not execute or has no effect on the results of a program. Following is an example of dead code insertion:
mov ebx, [ebp+4] add ebx, 0x0 ; dead code nop ; dead code jmp ebx
-
•
Register renaming: To avoid detection registers are reassigned in a fragment of a binary code. This changes the byte sequence (signature) of the machine code. A signature-based detector will not be able to match the signature if it is searching for a specific register. An example of register renaming is given below (register eax is renamed to edx):
lea eax, [RIP+0x203768] lea edx, [RIP+0x203768] add eax, 0x10 add edx, 0x10 jmp eax jmp edx
-
•
Order of instructions: To change the control flow of a program the order of instructions is changed in the binary image of the program, keeping the order of execution the same by using jump instructions.
-
•
Branch functions: A branch function is used [14] to obscure the flow of control in a program. The target of all or some of the unconditional branches in a program is replaced by the address of a branch function. The branch function makes sure the branch is correctly transferred to the right target for each branch.
Because of the financial gains attached with the malware industry, malware writers are always targeting new technologies. To improve the detection of malwares, especially metamorphic malwares, we need to develop new methods and techniques to analyze behavior of a program, to make a better detection decision with few false positives.
1.2 Why an Intermediate Language for Malware Analysis
Here we are going to list some of the reasons why we need to transform a program in an assembly language to an intermediate language for malware analysis:
-
•
There are hundreds of different instructions in any assembly language. For example the number of instructions in the two most popular ISAs (Instruction Set Architectures) are: Intel x86-64 = 800+ [7] and ARM = 400+ [17]. We need to reduce the number of these instructions considerably to optimize the static analysis of any such assembly program.
-
•
Not only the different instructions are big in numbers but they are also big in complexity, such as Intel x86-64 instruction’s PREFETCHh, MOVD and MOVQ. The instruction PREFETCHh moves data from the memory to the cache. Is this action important, if we are performing a static analysis for detecting malwares? Our answer is ’NO’. There are other such instructions that are not required for malware analysis. So our intermediate language hide/ignore these instructions and make the language transparent to the static analysis. The instructions MOVD and MOVQ copy a double word or a quad word respectively, from the source operand to the destination operand. Here we have to ask a question do we need to take into account the size of the word being copied in our static analysis? If the answer is ’NO’, then in our intermediate language we can replace these kind of instructions with a much simpler Assignment instruction. Using such techniques an intermediate language allows us to use simple instructions to make our static analysis much simpler.
-
•
We want a common intermediate language that can be used with different platforms, such as Intel x86-64 and ARM. So we do not have to perform separate static analysis for each platform. The intermediate language could be used for any of the above mentioned or other such platforms.
-
•
Assembly instructions can have multiple hidden side effects, such as effecting the flags etc, that can substantially increase the efforts required for the static analysis. In this case there are three options that an intermediate language can use to make the static analysis easier: Either remove all the side effects, or have only one side effect, or explicitly define side effect(s) in the instruction. Because our focus is mainly on malware analysis, out of these three, in our opinion the first option is the best option. We will use this option in our intermediate language, and the instructions used in our language that we call MAIL (Malware Analysis Intermediate Language) will not have any side effects.
-
•
Unknown branch addresses in an assembly makes it difficult to build a correct CFG. This problem will be taken care of by the MAIL. For example, for indirect jumps and calls (branches whose target is unknown or cannot be determined by static analysis) only a change in the source code can change them, so it is safe to ignore these branches for malware analysis where the change is only carried out in the machine code. We explain this using an example from one of the PARSEC [4] benchmarks.
The following example shows the function Condition() from one of the benchmarks in the PARSEC benchmark suite [4]. This function initializes a static condition variable of a thread. A local variable rv is used in a switch statement to jump to an appropriate exception generated by a pthread_cond_init() function. This function initializes the condition variable of a thread and returns zero if successful otherwise returns an error number. The value returned by the pthread_cond_init() function can only be determined at runtime and so the value of rv.
The C++ source code with the translated (disassembled) assembly code: Condition::Condition(Mutex &_M) throw(CondException) { 471b50: push %rbp int rv; 471b51: push %rbx M = $_M; 471b52: sub $0x38,%rsp nWaiting = 0; 471b52: sub $0x38,%rsp nWakeupTickets = 0; 471b56: mov %rsi,(%rdi) rv = pthread_cond_init(&c, NULL); 471b59: movl $0x0,0x8(%rdi) 471b60: movl $0x0,0xc(%rdi) 471b67: xor %esi,%esi 471b69: add $0x10,%rdi 471b6d: callq 404b60 <pthread_cond_init@plt> switch(rv) { [ rv UNKNOWN ] 471b72: cmp $0x16,%eax case 0: 471b75: jbe 471bb0 <Condition:Mutex> break; 471b77: mov 0x21934a(%rip),%r8 case EAGAIN: 471b7e: mov $0x8,%edi case ENOMEM: { 471b83: lea 0x10(%r8),%rbp CondResourceException e; 471b87: mov %rbp,(%rsp) throw e; 471b8b: callq 404d00 <allocate_exception@plt> break; 471b90: mov 0x219359(%rip),%rdx } 471b97: mov 0x219342(%rip),%rsi case EBUSY: 471b9e: mov %rax,%rdi case EINVAL: { 471ba1: mov %rbp,(%rax) CondInitException e; 471ba4: callq 404da0 <cxa_throw@plt> throw e; 471ba9: nopl 0x0(%rax) break; 471bb0: lea 0x6995(%rip),%rcx <MutexInitException> } 471bb7: mov %eax,%ebx default: { 471bb9: movslq (%rcx,%rbx,4),%rax CondUnknownException e; 471bbd: lea (%rax,%rcx,1),%rdx throw e; 471bc1: jmpq *%rdx [ UNKNOWN BRANCH TARGET ] break; 471bc3: nopl 0x0(%rax,%rax,1) } 471bc8: mov 0x219231(%rip),%rdi } 471bcf: lea 0x10(%rdi),%rbx } 471bd3: mov $0x8,%edi 471bd8: mov %rbx,0x10(%rsp)Dynamic analysis can be used to determine the value of rv, but it is possible that such an analysis may not be able to reach (in one of the runs) one of the executable paths (the switch statement) in the case of the rv being always zero and changes only in rare cases. These rare cases may not get executed or execute only after running the program for a very long time, that may render the analysis impractical. A malware writer can exploit this weakness and inject the malware code by changing the target address of any of the branches inside the switch statement to his/her own malicious code. In such a case the dynamic analysis will not be able to detect this malicious behavior.
That is where static (binary) analysis can help by building a CFG that covers all the available execution paths, in this case the switch statement. This CFG may not be correct, because by looking at the disassembled (the assembly) code above we can see it generates an unknown branch target address. This address cannot be computed using static analysis. Is it safe to ignore this branch target address while building the CFG for malware analysis? It is not possible for a malware writer to use this particular instruction as it is for malicious code. He/she will have to change this instruction to make it easy to use, such as the register rdx can be loaded with an address of a malicious code before the jmpq *%rdx instruction, which is trivial to detect because in this case the branch target address will become known.
The language MAIL is specifically designed for malware analysis, so we create a new construct/keyword UNKNOWN that takes care of these branches. This construct will be helpful not only in static but also in dynamic analysis of the malwares.
-
•
A language such as MAIL can be easily translated into a string, a tree or a graph and hence can be optimized for various analysis that are required for malware analysis and detection, such as pattern matching and data mining. Special patterns are introduced (Sections 2.5, 2.6 and 2.8) in the MAIL language for annotating MAIL statements that can be used for pattern matching.
-
•
To reduce the number of different instructions for static analysis, functionally equivalent assembly instructions can be grouped together in one intermediate language instruction, such as:
(xor eax, eax) | (add eax, 0) | (sub eax, eax) => mov eax, 0 (add ebx, 0x2000) & (add eax, ebx) | (lea eax, [ebx + 0x2000]) => load eax, expr where expr = (ebx + 0x2000) and its value can be known or unknown depending on the value of ebx. This information should be explicitly defined in the language.
In the following Sections we introduce the new language called MAIL (Malware Analysis Intermediate Language) for malware analysis and detection. In Section 2 we describe its detail design and how a binary program is translated to MAIL. We also cover the CFG (Control Flow Graph) construction and annotation and how graph and pattern matching techniques are used to detect metamorphic malwares [16]. We carried out an empirical study in Section 3 to test the use of MAIL in a tool. Using the MAIL language the tool was able to fully automate the process of malware analysis and detection and achieved 100% results. We finaly conclude in Section 4.
2 Design of MAIL
In the previous Section we provided motivations for a new language for malware analysis and detection. This Section, introduces and provides the design of, this new language called MAIL. The language MAIL is based on binary analysis to optimize malware detection, so before explaining it’s design we first give some background on binary analysis for malware detection.
2.1 Binary Analysis for Malware Detection
Almost all the malwares use binaries (instructions that a computer can interpret and execute) to infiltrate a computer system, which can be a desktop, a server, a laptop, a kiosk or a mobile device. Binary analysis is the process of automatically analysing the structure and behavior of a binary program. There are various purposes of this analysis and some of them are: optimization, verification, profiling, performance tuning and computer security. We further explain how binary analysis can help us understand a program and detect malwares in the program, by using a simple binary program (a function called sort) that is part of the class Merge in a sorting program. This function performs a merge sort on an array of integers. It’s binary analysis (performed using an in-house developed tool) information is listed below and explained in the following paragraphs:
Listing 1.1 Binary Analysis of The Disassembled Function Merge::sort(int key[], int size)
Column I Column II
0 40108e 55 PUSH RBP : 5 40113b 488b45c8 MOV RAX, [RBP-0x38]
0 40108f 4889e5 MOV RBP, RSP : 5 40113f 4189f9 MOV R9D, EDI
0 401092 53 PUSH RBX : 5 401142 4189f0 MOV R8D, ESI
0 401093 4883ec48 SUB RSP, 0x48 : 5 401145 4889de MOV RSI, RBX
0 401097 48897dc8 MOV [RBP-0x38], RDI : 5 401148 4889c7 MOV RDI, RAX
0 40109b 488975c0 MOV [RBP-0x40], RSI : 5 40114b e8e2fdffff CALL 0x400f32
0 40109f 8955bc MOV [RBP-0x44], EDX : 5 401150 8b45e8 MOV EAX, [RBP-0x18]
0 4010a2 8b45bc MOV EAX, [RBP-0x44] : 5 401153 01c0 ADD EAX, EAX
0 4010a5 4898 CDQE : 5 401155 0145ec ADD [RBP-0x14], EAX
0 4010a7 48c1e002 SHL RAX, 0x2 : 6 401158 8b45e8 MOV EAX, [RBP-0x18]
0 4010ab 4889c7 MOV RDI, RAX : 6 40115b 8b55bc MOV EDX, [RBP-0x44]
0 4010ae e8e9f9ffff CALL 0x400a9c : 6 40115e 89d1 MOV ECX, EDX
0 4010b3 488945d8 MOV [RBP-0x28], RAX : 6 401160 29c1 SUB ECX, EAX
0 4010b7 c745e801000000 MOV DWORD [RBP-0x18], 0x1 : 6 401162 89c8 MOV EAX, ECX
0 4010be e9f2000000 JMP 0x4011b5 (11): 6 401164 3b45ec CMP EAX, [RBP-0x14]
1 4010c3 c745ec00000000 MOV DWORD [RBP-0x14], 0x0 : 6 401167 0f9fc0 SETG AL
1 4010ca e989000000 JMP 0x401158 (6) : 6 40116a 84c0 TEST AL, AL
2 4010cf 8b45e8 MOV EAX, [RBP-0x18] : 6 40116c 0f855dffffff JNZ 0x4010cf (2)
2 4010d2 8b55ec MOV EDX, [RBP-0x14] : 7 401172 c745ec00000000 MOV DWORD [RBP-0x14], 0x0
2 4010d5 8d0402 LEA EAX, [RDX+RAX] : 7 401179 e923000000 JMP 0x4011a1 (9)
2 4010d8 0345e8 ADD EAX, [RBP-0x18] : 8 40117e 8b45ec MOV EAX, [RBP-0x14]
2 4010db 3b45bc CMP EAX, [RBP-0x44] : 8 401181 4898 CDQE
2 4010de 0f8e11000000 JLE 0x4010f5 (4) : 8 401183 48c1e002 SHL RAX, 0x2
3 4010e4 8b45ec MOV EAX, [RBP-0x14] : 8 401187 480345c0 ADD RAX, [RBP-0x40]
3 4010e7 8b55bc MOV EDX, [RBP-0x44] : 8 40118b 8b55ec MOV EDX, [RBP-0x14]
3 4010ea 89d1 MOV ECX, EDX : 8 40118e 4863d2 MOVSXD RDX, EDX
3 4010ec 29c1 SUB ECX, EAX : 8 401191 48c1e202 SHL RDX, 0x2
3 4010ee 89c8 MOV EAX, ECX : 8 401195 480355d8 ADD RDX, [RBP-0x28]
3 4010f0 2b45e8 SUB EAX, [RBP-0x18] : 8 401199 8b12 MOV EDX, [RDX]
3 4010f3 eb03 JMP 0x4010f8 (5) : 8 40119b 8910 MOV [RAX], EDX
4 4010f5 8b45e8 MOV EAX, [RBP-0x18] : 8 40119d 8345ec01 ADD DWORD [RBP-0x14], 0x1
5 4010f8 8945e4 MOV [RBP-0x1c], EAX : 9 4011a1 8b45ec MOV EAX, [RBP-0x14]
5 4010fb 8b45ec MOV EAX, [RBP-0x14] : 9 4011a4 3b45bc CMP EAX, [RBP-0x44]
5 4010fe 4898 CDQE : 9 4011a7 0f9cc0 SETL AL
5 401100 48c1e002 SHL RAX, 0x2 : 9 4011aa 84c0 TEST AL, AL
5 401104 4889c1 MOV RCX, RAX : 9 4011ac 0f85ccffffff JNZ 0x40117e (8)
5 401107 48034dd8 ADD RCX, [RBP-0x28] : 10 4011b2 d165e8 SHL DWORD [RBP-0x18], 0x1
5 40110b 8b45ec MOV EAX, [RBP-0x14] : 11 4011b5 8b45e8 MOV EAX, [RBP-0x18]
5 40110e 4863d0 MOVSXD RDX, EAX : 11 4011b8 3b45bc CMP EAX, [RBP-0x44]
5 401111 8b45e8 MOV EAX, [RBP-0x18] : 11 4011bb 0f9cc0 SETL AL
5 401114 4898 CDQE : 11 4011be 84c0 TEST AL, AL
5 401116 488d0402 LEA RAX, [RDX+RAX] : 11 4011c0 0f85fdfeffff JNZ 0x4010c3 (1)
5 40111a 48c1e002 SHL RAX, 0x2 : 12 4011c6 488b45d8 MOV RAX, [RBP-0x28]
5 40111e 4889c2 MOV RDX, RAX : 12 4011ca 4889c7 MOV RDI, RAX
5 401121 480355c0 ADD RDX, [RBP-0x40] : 12 4011cd e82af9ffff CALL 0x400afc
5 401125 8b45ec MOV EAX, [RBP-0x14] : 12 4011d2 4883c448 ADD RSP, 0x48
5 401128 4898 CDQE : 12 4011d6 5b POP RBX
5 40112a 48c1e002 SHL RAX, 0x2 : 12 4011d7 c9 LEAVE
5 40112e 4889c3 MOV RBX, RAX : 12 4011d8 ff0502000000 INC_A [RIP+0x02]
5 401131 48035dc0 ADD RBX, [RBP-0x40] : 12 4011de eb04 JMP_A 0x4011e4
5 401135 8b7de4 MOV EDI, [RBP-0x1c] : 12 4011e0 00000000 CTR_A
5 401138 8b75e8 MOV ESI, [RBP-0x18] : 12 4011e4 c3 RET
The listing shown above is divided into two columns numbered I and II separated by a colon (:). There are total 104 assembly instructions in this function. The first column lists the first 52 instructions and the second column lists the rest of the 52 instructions. This function is part of a binary program (in ELF x86-64 file) that is first disassembled and then binary analysis is performed on the disassembled program for building CFGs of each function in this program. In the listing above each instruction is assigned a block number and an address. Columns I and II are further divided into five columns: Column 1 is the block number, column 2 is the address, column 3 is the machine code, column 4 and 5 are the assembly instructions in Intel syntax.
The total number of blocks in this function are 12. Each block contains different number of instructions. For example block number 4 has only 1 instruction whereas block number 5 has 30 instructions. A block is a basic block [1] that has the following properties: (1) It has only one entry but can have more than one exit points. (2) An instruction with a branch to another block in the same function ends the block. (3) If an instruction is a target of another branch within the same function then that instruction starts a new block.
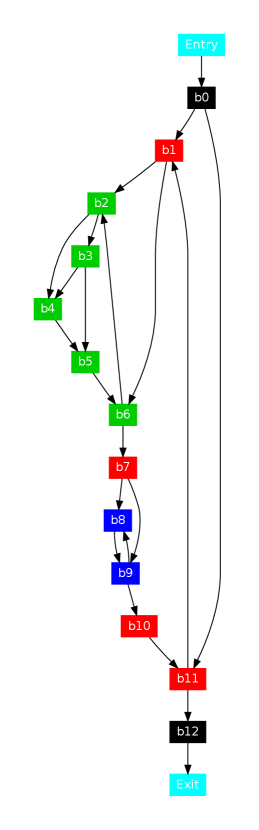
If an instruction branches to another block in the function listed above, the target instruction’s block number is listed at the end enclosed in brackets. For example the last instruction in block 1 ends with (6), because this instruction is branching to the address 401158 and the instruction at this address belongs to (is the first instruction of) block 6. Based on the analysis information listed above we build a CFG of this function that is shown in Figure 1 (a). We are going to compare this CFG with the source code of this function in C++ which is shown in Figure 1 (b).

The source code was not made available to our binary analysis tool, and the CFG that is build by this tool is only based on the information available in the binary program. Now we want to see how much this analysis helps us to get information about the function for malware detection.
This function has been instrumented, i.e: additional code has been added to this function. There are three instructions at the end (number 101, 102 and 103) in Listing 1.1 that has been added to this function. The first of these instructions INC_A increment a 32 bit counter CTR_A at address 4011e0. The second instruction JMP_A jumps over the counter storage space to address 4011e4 which contains the RET instruction. The counter counts the number of times this function is called. This kind of instrumentation is done for profiling a program for further optimizations.
The CFG starts at block 0 and ends at block 12. Block 11 jumps back to block 1. This indicates a possibility of a loop. If we look at the CFG there is a loop that starts at block 1 and ends at block 11. The blocks that belong to this loop are in red, green and blue colors. This outer loop has two inner loops that are colored green and blue. The source code of the function Merge::sort() has exactly one outer loop and the outer loop has exactly two inner loops.
A malware writer can change (just the machine code) the last instruction of block 11 in Listing 1.1:
from: 11 4011c0 0f85fdfeffff JNZ 0x4010c3 (1) to: 11 4011c0 ebfdfeffffff JMP 0x4010c3 (1)
This will make the outer loop an infinite loop and when the function Merge::sort() is called the program will never return. The malware writer in this case has added an unconditional back jump, which in general is a legal jump. Similarly other back jumps (last instructions of blocks 6 and 9) can also be changed by a malware writer to make more infinite loops. So a signature based malware detection tool will not be able to detect such kind of malwares. Without the behavioral information, obtained either statically or dynamically, about a binary program a manual detection with a debugger is required to detect such malwares. This manual labor is very time consuming and financially can become very expensive.
To automate this process, a further binary analysis on the CFG will be able to detect this infinite loop as follows: We have already identified all the identifiable (more on this latter) loops in the function. We will further analyse all the blocks that contain a back jump. In this case analysing block 11, we see that the TEST instruction is followed by an unconditional jump instruction (added by the malware writer), which indicates an illegal infinite loop and hence a malware. In the case where a malware writer also replaces all the other four instructions with some other instructions, we will have to find the unconditional jump instruction to block 1 in block 11 (starting and ending blocks of the loop) to detect the malware, which in the presence of the CFG is trivial.
What if this unconditional jump instruction is a legal instruction, i.e: it has not been added by a malware writer and is part of the program? For example event-based programs contain one or more infinite loops. In this case we may need to build specific control flow patterns and compare them with the previous control flow patterns of malwares of such kind.
Other malicious changes, such as the following register renaming and control flow change, in block 2 in Listing 1.1, cannot be detected by a signature based malware detector:
from: 2 4010cf 8b45e8 MOV EAX, [RBP-0x18] 2 4010d2 8b55ec MOV EDX, [RBP-0x14] 2 4010d5 8d0402 LEA EAX, [RDX+RAX] 2 4010d8 0345e8 ADD EAX, [RBP-0x18] 2 4010db 3b45bc CMP EAX, [RBP-0x44] 2 4010de 0f8e11000000 JLE 0x4010f5 to: 2 4010cf 8b45e8 MOV EBX, [RBP-0x18] 2 4010d2 8b55ec MOV EDX, [RBP-0x14] 2 4010d5 8d0402 LEA EBX, [RDX+RBX] 2 4010d8 0345e8 ADD EBX, [RBP-0x18] 2 4010db 3b45bc CMP EBX, [RBP-0x44] 2 4010de 0f8e10100000 JLE 0x4011e5 ; Jump to some malicious code
In order to detect such anomaly based malwares automatically, we need control flow information as provided by the binary analysis presented in this Section.
Another technique used by malware writers to deceive signature based detectors is to use instructions other than JMP and CALL to change the control flow of a program. We show this by replacing the last instruction with two instructions in block 7 in Listing 1.1 as follows:
from: 7 401179 e923000000 JMP 0x4011a1
to: 7 401179 68e5114000 PUSH QWORD 0x4011e5
7 40117e c3 RET
This change in Listing 1.1 is not finished here. For the code to work correctly the addresses following these instructions and all the effected jump target addresses needs to be updated. A malware writer may or may not update them depending on the complexity of the malware. A tool could be used by the malware writer that can automate updating these addresses.
A further binary analysis on the above instructions reveals that the last value pushed on the stack before the RET statement is 4011e5, so the RET instruction will move the value 4011e5 to the RIP register, the instruction pointer. Next time the instruction at address 4011e5 (malicious code) will be executed.
The added instruction at address 40117e indicates the end of a function. Sometimes the binary provides information about the start and end of all the functions in a program. But if this information is not available it is difficult to find the exact start and end of some of the functions, e.g: the addition of the two instructions shown above in the function in Listing 1.1 divides the function into two functions and makes it difficult to find the original function. For malware detection, we may only need to find where the control is flowing (i.e: just the behavior and not the function boundaries) and then compare this behavior with the previous samples of malwares available to detect such malwares.
In the above paragraphs we have shown using an elaborate example, how trivial changes in the binary can make the malware analysis and detection intricate, difficult and expensive. But with suitable tools and appropriate binary analysis it is possible to analyse and detect such malwares automatically. We have build a CFG (Figure 1 (a)) from the disassembled instructions of the function in Listing 1.1 for malware analysis and detection. In the next Section we describe the design of the intermediate language MAIL that automates and optimizes this step.
2.2 Design
We believe a good language must start small and simple, and must give opportunities to the language developers to grow (extend) the language with the users. Therefore MAIL is designed as a small and simple, and an extensible language. In this and next Sections we describe how MAIL is designed in detail.
The basic purpose of the language MAIL is to represent structural and behavioral information of an assembly program for malware analysis and detection. MAIL will also make the program more readable and understandable by a human malware analyst. An assembly program can comprise of the following type of instructions. We use Intel x86-64 assembly instructions [7] as sample instructions:
-
1.
Control instructions: These instructions include instructions that can change the control flow of the program, such as JMP, CALL, RET, CMP, CMPS, CMPPS, PCMPEQW, REP and LOOP instructions.
-
2.
Arithmetic instructions: These instructions perform arithmetic operations, such as ADD, SUB, MUL, DIV, FSIN, FCOS, PADDW, PSUBW, ADDPS, ADDPD, PMULLD, PAVGW, DPPD, SHR and SHL.
-
3.
Logical instructions: These include instructions that perform logical operations, such as AND, OR and NOT.
-
4.
Data transfer instructions: These instructions involve data moving instructions, such as MOV, CMOV, XCHG, PUSH, POP, LODS, STOS, MOVS, MOVAPS, MOVAPD, IN, OUT, INS, OUTS, LAHF, SAHF, PREFETCH, FLDPI, FLDCW, FXSAVE, LEA and LDS.
-
5.
System instructions: These instructions provide support for operating systems and include instructions LOCK, LGDT, SGDT, LTR, STR and XSAVE etc.
-
6.
Miscellaneous instructions: All other instructions that do not fit into any other group are included in this group of instructions, such as NOP, CPUID, SCAS, CLC, STC, CLI, HLT, WAIT, MFENCE, PACKSSWB, MAXPS, and UD (undefined instruction).
Designing a language that is small and simple, and accurately represent all these instructions for structural and behavioral information is non-trivial. Our goal is to create as few statements as possible in the intermediate language and map as many instructions as possible to these statements. For example we do not translate (i.e: ignore) the following x86 instructions:
CLFLUSH: Flush caches CLTS: Clear TLB) SMSW: Restore machine status word VERR: Verify if a segment can be read WBINVD: Writing back and flushing of external caches XRSTOR: Restore processor extended states from memory XSAVE: Save processor extended states from memory
The complete list of x86 and ARM instructions that are not translated into the MAIL statements is given in Appendix B
2.3 MAIL Statements
Majority of the assembly instructions are data moving instructions, as shown above. In the following two MAIL assignment statements we cover the data transfer, arithmetic, logical and some of the system instructions. We use EBNF [8] notation to define these statements:
assignment_s ::= register_s
| address_s ;
register_s ::= register ’=’ (math_operator)? expr
| register ’=’ (expr)? math_operator expr
| register ’=’ lib_call_s ;
address_s ::= address ’=’ (math_operator)? expr
| address ’=’ (expr)? math_operator expr
| address ’=’ lib_call_s ;
expr ::= register
| address
| digit+ ;
register ::= ’eflags’
| ’gr_’ digit+
| ’fr_’ digit+
| ’sp’
| register_name (’:’ register_name)? ;
register_name ::= letter+ [’0’ - ’9’]?
| ’ZF’
| ’CF’
| ’PF’
| ’SF’
| ’OF’ ;
address ::= ’[’ digit+ ’]’
| reg_address
| ’UNKNOWN’ ;
Control instructions are very important because they can change the behavior of a program, and they can be changed or added by polymorphic and metamorphic malwares to avoid detection. The following MAIL control statement represent the control instructions:
control_s ::= ( ’if’ condition_s (jump_s | assignment_s) )
( ’else’ (jump_s | assignment_s) )? ;
jump_s ::= ’jmp’ address ;
lib_call_s ::= letter+ ’(’ address (, args)* ’)’ ;
function_s ::= ’start_function_’ digit+ statement ’end_function_’ digit+ ;
condition_s ::= (expr rel_operator expr)+ ;
All the MAIL language statements can be divided into the following 8 basic statements. The complete MAIL grammar is given in Appendix A:
statements ::= ( statement* ) ;
statement ::= assignment_s+
| control_s+
| condition_s+
| function_s+
| jump_s+
| lib_call_s+
| ’halt’
| ’lock’ ;
Every statement in the MAIL language has a type also called a pattern that can be used for pattern matching during malware analysis and detection. These patterns are introduced and explained in Section 2.5. MAIL has its own registers but also reuses the registers present in the architecture that is being translated to the MAIL language. There are other special registers such as:
Flag registers: ZF (zero flag), CF (crry flag), PF (parity flag), SF (sign flag) and OF (overflow falg). These flag registers are of size one byte and are used in conditional statements. e.g: if (ZF == 1) jmp 405632;. eflags: stores the flag registers. sp: To keep track of the stack pointer. gr and fr: These are infinite number of general purpose registers for use in integer and floating point instructions respectively.
2.4 MAIL Library
We have added 22 library functions to the MAIL language. Table 1 gives details about all these library functions. These library functions can help in translating most of the complex assembly instructions present in current processors architecture. The purpose of these functions is not to capture the exact functionality of the assembly instruction(s) but to help in analysing the structure and the behavior of the assembly program, and capturing some of the patterns in the program that can help detect malwares.
| Function | Semantics |
|---|---|
| abs(op) | Returns the absolute value of the parameter op |
| aes(op, mode) | Performs AES encryption/decryption on op; mode=0 for encrypt and vice versa |
| allocate(n) | Allocate memory from the heap of size n bytes |
| atan(op) | Returns the arc tangent of the parameter op |
| avg(op1, op2) | Computes the average of the parameters op1 and op2 |
| bit(op, index, len) | Selects len number of bits in op starting at index |
| clear(op, index, len) | Clears the bits in op at index upto len |
| compare(op1, op2) | Compares two values op1 and op2 and then set the flag register |
| complement(op, index) | Complements the bit in op at index |
| convert(value) | Convert the value to either int or float |
| cos(op) | Returns the cosine of the parameter op |
| count(op) | Counts the number of ones in the op |
| len(obj) | Computes the length of the parameter obj |
| log(op) | Computes the log of the parameter op |
| max(op1, op2) | Returns the maximum of the parameters op1 and op2 |
| min(op1, op2) | Returns the minimum of the parameters op1 and op2 |
| rev(op) | Reverses the bit order in op |
| round(op) | Rounds the parameter op |
| scanf(op1, op2) | Stores the index of the first bit one, found in op1, in op2 (forward scan) |
| scanr(op1, op2) | Stores the index of the last bit one, found in op1, in op2 (reverse scan) |
| set(op, index, len) | Sets the bit in op at index upto len |
| sin(op) | Returns the sine of the parameter op |
| sqrt(op) | Computes the square root of the parameter op |
| substr(value, offset, len) | Returns the sub string from the string value starting at offset upto len |
| swap(op1, op2) | Swaps the bits in op2 and write back in op1 |
| swap(op) | Swaps the bits in op |
| tan(op) | Returns the tangent of the parameter op |
2.5 MAIL Patterns for Annotation
MAIL language can also be used to annotate a CFG of a program using different patterns available in the MAIL language. The purpose of these annotations is to assign patterns to MAIL statements that can be used latter for pattern matching during malware detection. Section 2.6 gives an example of a CFG with pattern annotation and Section 2.8 explains how they are used in malware detection. More than one statements in the MAIL langauge can have one pattern. There are total 21 patterns in the MAIL language and are listed and explained as follows:
-
•
ASSIGN: An assignment statement. e.g: EAX = EAX + ECX;
-
•
ASSIGN_CONSTANT: An assignment statement including a constant. e.g: EAX = EAX + 0x01;
-
•
CONTROL: A control statement where the target of the jump is unknown. e.g: if (ZF == 1) JMP [EAX+ECX+0x10];
-
•
CONTROL_CONSTANT: A control statement where the target of the jump is known. e.g: if (ZF == 1) JMP 0x400567;
-
•
CALL: A call statement where the target of the call is unknown. e.g: CALL EBX;
-
•
CALL_CONSTANT: A call statement where the target of the call is known. e.g: CALL 0x603248;
-
•
FLAG: A statement including a flag. e.g: CF = 1;
-
•
FLAG_STACK: A statement including flag register with stack. e.g: EFLAGS = [SP=SP-0x1];
-
•
HALT: A halt statement. e.g: HALT;
-
•
JUMP: A jump statement where the target of the jump is unknown. e.g: JMP [EAX+ECX+0x10];
-
•
JUMP_CONSTANT: A jump statement where the target of the jump is known. e.g: JMP 0x680376
-
•
JUMP_STACK: A return jump. e.g: JMP [SP=SP-0x8]
-
•
LIBCALL: A library call. e.g: compare(EAX, ECX);
-
•
LIBCALL_CONSTANT: A library call including a constant. e.g: compare(EAX, 0x10);
-
•
LOCK: A lock statement. e.g: lock;
-
•
STACK: A stack statement. e.g: EAX = [SP=SP-0x1];
-
•
STACK_CONSTANT: A stack statement including a constant. e.g: [SP=SP+0x1] = 0x432516;
-
•
TEST: A test statement. e.g: EAX and ECX;
-
•
TEST_CONSTANT: A test statement including a constant. e.g: EAX and 0x10;
-
•
UNKNOWN: Any unknown assembly instruction that cannot be translated.
-
•
NOTDEFINED: The default pattern. e.g: All the new statements when created are assigned this default value.
2.6 Binary to MAIL Translation
For translating a binary program, we first disassemble the binary program into an assembly program. Then we translate this assembly into MAIL program. We use a sample program, one of the malware samples, to give an example of the steps invlove in the translation as shown in Figure 2. This example shows how x86 assembly program is translated to MAIL program. In Section 2.6.1 we give an example of translating an ARM assembly program to MAIL program.

The binary analysis of the function shown in Figure 2 have identified 5 blocks in this function labelled 18 - 25. There are two columns separated by . The first column lists the x86 assembly instructions and the second column lists the corresponding translated MAIL statements. The mathematical instructions are translated to an assignment statement with the appropiate operator added. Most of the data instructions are translated to simple assignement statements. Conditional jump instructions, such as JZ and JNZ, are translated to an if statement. Some of the instructions are translated to more than one MAIL statements. For example the instruction XCHG in block 25 is translated to three MAIL statements. The MAIL library functions are used to translate some of the instructions, such as the instrucion CMP in blocks 20 and 21 is translated using the library function compare. All the MAIL library functions are explained in Section 2.4
In addition to its own registers the MAIL language reuses all the x86 registers. There is a special register sp used in the MAIL language to keep track of the stack pointer in the program. The example shows data embedded inside the code section in block 27. This block is used to store, load and process data by the function as pointed out by the underlined addresses in the blocks. There are five instructions that change the control flow of the program and are indicted by the arrows in the Figure. There are two back edges and . These edges indicate the presence of loops in the program. The jump in block 24 jumps out of the function. MAIL also keeps track of the flags using boolean values. For example the instruction CLD sets the direction flag in block 19.
Each MAIL statement is associated with a type also called a pattern. There are total 21 patterns in the MAIL language as explained in Section 2.5. For example an assignment statement with a constant value and an assignment statement without a constant value are two different patterns. Jump statements can have upto three patterns. Following are the patterns that are assigned during translation to the statements in block 21 shown in Figure 2:
21 EAX = EAX + -0x1; --> ASSIGN_CONSTANT 21 compare(EAX, 0x0); --> CALL_CONSTANT 21 if (ZF == 1) jmp 0x401267; --> CONTROL_CONSTANT
These patterns are used to annotate a CFG for pattern matching. Section 2.8 explains how they help and improve malware detection.
2.6.1 Translation of an ARM Program to MAIL Program
In the previous Section we gave an example of translating x86 assembly program to MAIL program. As already mentioned that MAIL as a common language for different platforms, such as x86 and ARM binaries, helps malware analysis and detection tools to achieve platform independence. In this Section we provide an example of translating an ARM assembly program to MAIL program. Figure 3 shows an example of such a translation.

The main obvious difference in an ARM program and a x86 program is the length of the instructions as shown in Figures 2 and 3. The size of the hex dump of each instruction of the x86 program is different. Whereas the size of the hex dump of the ARM program is the same for each instruction. For the sake of completeness we also show the CFG of this program in Figure 4.
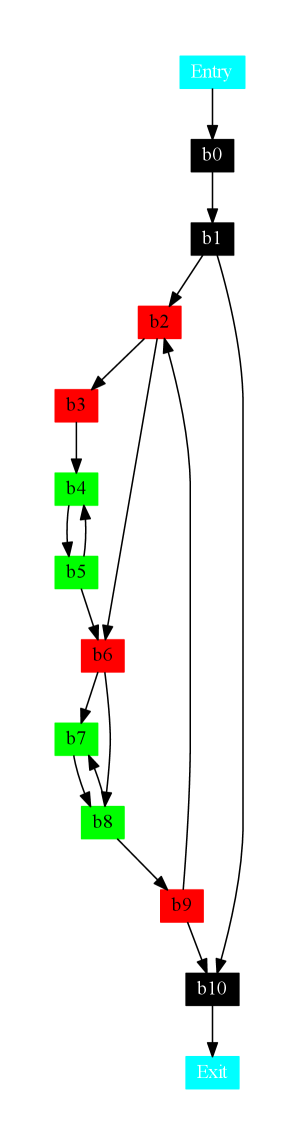
As shown in Figure 3 the binary analysis have identified 10 blocks in the program. The mathematical, load and mov instructions are translated to assignment statements. The one conditional move movele instruction is translated to a control statement. Branch instructions are translated to either simple jump or control statements. The instruction cmp is translated using the MAIL library function compare().
2.7 CFG Construction
Figure 5 shows the CFG of the sample program shown in Figure 2. The CFG clearly indicates two back edges and two forward edges that change the control flow of the program. The fifth edge that jumps out of the function shown in Figure 2 is not shown in this CFG. There are two loops one outer loop {19, 20, 21, 22, 23} and one inner loop {20, 21, 22}.
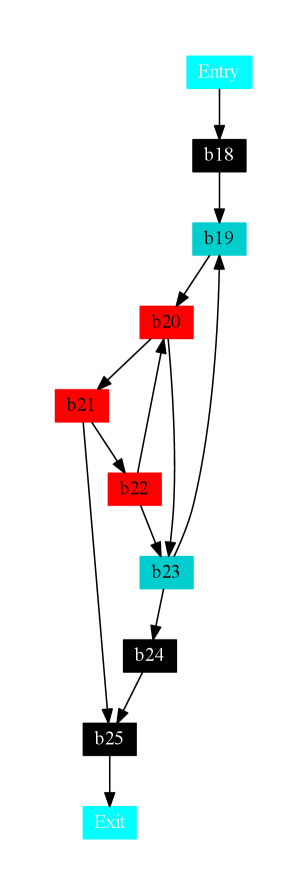
2.8 Subgraph and Pattern Matching
After the binary analysis performed above we get a CFG of a program as shown in Figure 5. For detecting if a program contains a malware we compare the CFG of a program with the CFG of a known malware. If the CFG of the malware matches the complete or part of the CFG of the program then the program contains a malware, i.e; the program is not benign. We formulate this problem of malware detection as follows:
Let is graph of the program and is graph of the malware, where and are the vertices and edges of the graphs respectively. Let where and . If then is not benign.
We solve this problem using subgraph isomorphism (matching). Given the input of two graphs it determines if one of the graphs contains a subgraph that is isomorphic (similar in shape) to the other graph. Generally subgraph isomorphism is an NP-Complete problem [6]. A CFG of a program is a sparse graph therefore it is possible to compute the isomorphism of two CFGs in a reasonable amount of time.
Very small graphs when matched against a large graph can produce a false positive matching. We conducted an experiment (more details in the next paragraph) and found that some of the malware samples after normalization were reduced to a small graph of 3 nodes as shown in Table 4 and were responsible for producing a large number (87.85%, see Table 3) of false positives. To take care of these and other such graphs we also implemented a Pattern Matching sub-component within the Subgraph Matching component. Every statement in the language MAIL is assigned a pattern as explained in Section 2.5. We use this pattern to match each statement in the matching nodes of the two graphs.
An example of Pattern Matching of two isomorphic CFGs is shown in Figure 6. One of the CFGs of a malware sample, shown in Figure 6 (a), is isomorphic to a subgraph of one of the CFGs of a benign program, shown in Figure 6 (b). Considering these two CFGs as a match for malware detection will produce a wrong result, a false positive. The statements in the benign program do not match with the statements in the malware sample. To reduce this false positive we have two options: (1) we can match each statement exactly with each other or (2) assign patterns to these statements for matching. Option (1) will not be able to detect unknown malware samples and is time consuming, so we use option (2) in our approach, which in addition to reducing false positives has the potential of detecting unknown malware samples.

For a successful pattern matching we require all the statements in the matching blocks to have the same patterns. In Figure 6, only the statements in block 0 satisfy this requirement. The statements in all the other blocks do not satisfy this requirement, therefore these CFGs fail the pattern matching.
To verfiy that by adding the Pattern Matching component to the Subgraph Matching component we have improved the metamorphic malware matching technique, an experimental study was performed. The dataset used for the experiment consisted of total 4289 samples, including 266 malware samples. Out of the 266 malware samples 250 were metamorphic malwares. Out of these 250 metamorphic malware samples we randomly selected 27 samples (10.11% of all the malware samples) for use in the experiment for matching. Dataset distribution based on the size of the CFG after normalization is shown in Table 2.
| 27 | 4289 | ||
| Malware Samples Used For Matching | Benign and Malware Samples | ||
| Size of | Number of | Size of | Number of |
| CFG | Samples | CFG | Samples |
| 3 | 19 | 0 – 4 | 476 |
| 92 | 1 | 5 – 200 | 402 |
| 93 | 2 | 201 – 1000 | 753 |
| 95 | 1 | 1001 – 4997 | 1215 |
| 96 | 1 | 5007 – 9987 | 579 |
| 99 | 2 | 10012 – 19979 | 464 |
| 100 | 1 | 20032 – 29889 | 187 |
| 30109 – 63289 | 213 | ||
The complexity (size) of these graphs range from 0 nodes to 63289 nodes. Some of the Windows DLLs (dynamic link libraries) that were used in the experiment do not have code but only data (cannot be executed) and that is why they have 0 node graphs (CFGs). All the 4289 samples were matched against the 27 selected malware samples. The results of this experiment are shown in Table 3. There are 87.85% false positives when only the Subgraph Matching technique is used. The reason for this large number of false positives, as explained earlier, is because of the small size (3 nodes as shown in Table 2) of the graph samples matched. This large false positive has been reduced to 0 when in addition to the Subgraph Matching technique the Pattern Matching technique is used.
An interesting observation: When we used the Pattern Matching technique in addition to the Subgraph Matching technique the number of graphs matched were not 27 but 168. The 27 malware graph samples were not only matched with the same 27 graphs but they were also matched with additional 141 metamorphic malware graphs. When checked manually the nodes matched contained the same patterns as found in one of the 27 malware graph samples used for matching. That means some of the unknown metamorphic malwares were also detected because of the use of the Pattern Matching technique.
| Component(s) Used | TNG 11footnotemark: 1 | NGUM 22footnotemark: 2 | NGM 33footnotemark: 3 | NMGM 44footnotemark: 4 | False Positives |
|---|---|---|---|---|---|
| Subgraph Matching | 4289 | 27 | 4018/93.68% | 257 55footnotemark: 5 | 3768/87.85% |
| Subgraph Matching | |||||
| and | 4289 | 27 | 168/3.92% | 168 66footnotemark: 6 | 0/0% |
| Pattern Matching |
| 1 TNG: Total number of graphs (both benign and malware samples) |
| 2 NGUM: Number of graphs (only malware samples) used for matching |
| 3 NGM: Number of graphs (both benign and malware samples) matched |
| 4 NMGM: Number of malware graphs matched |
| 5 The graphs matched were the 250 metamorphic malwares and the 7 other |
| malwares. |
| 6 An interesting observation: The 27 malware graph samples were not |
| only matched with the same 27 graphs but they were also matched with |
| additional 141 metamorphic malware graphs. When checked manually the |
| nodes matched contained the same patterns as found in one of the 27 |
| malware graph samples used for matching. |
| Machine used: Intel Core i5 CPU M 430 @ 2.27 GHz |
| RAM: 4 GB |
| Operating System: Windows 8 Professional |
This experimental study confirms the improved results of these two matching components for detecting an already known metamorphic malware and the 100% detection rate we achieved also confirms these results as shown in Table 5.
3 Empirical Study of Using the MAIL Language
We carried out an empirical study to analyse the correctness and the efficiency of our techniques described above using the MAIL language. This Section describes this empirical study. We developed a prototype tool called MARD that uses MAIL for malware analysis and detection as described above. We collected different metamorphic malwares and Windows programs as samples to use in our tool.
3.1 Dataset
Our dataset for the experiments consisted of 1387 programs. Out of these: 250 are metamorphic malware samples collected from two different resources [18, 19], and the other 1137 are Windows benign programs. Table 4 gives more details about this dataset.
| 250 | 1137 | ||
| Malware Samples | Benign Programs | ||
| Size of | Number of | Size of | Number of |
| CFG | Samples | CFG | Samples |
| 3 | 200 | 17 | 127 |
| 88 | 1 | 30 | 44 |
| 91 – 99 | 38 | 44 – 998 | 412 |
| 100 – 104 | 10 | 1000 – 9765 | 535 |
| 129 | 1 | 10118 – 15343 | 19 |
The data set contains a variety of programs with simple CFGs to complex CFGs for testing. As shown the size of the CFG of the malware samples range from 3 nodes to 129 nodes, and the size of the CFG of the benign programs range from 17 nodes to 15343 nodes. This variety in the samples provides a good testing platform for graph and pattern matching techniques used in our tool.
3.2 Experiments and Results
Two experiments were carried out using our tool MARD to detect metamorphic malwares: (1) In the first experiment we wanted to see if the tool can detect all the known malwares. This experiment consisted of 250 known malware samples in the test data set. (2) In the second experiment we wanted to see if the tool can detect the unknown malwares. This experiment consisted of 225 unknown malware samples in the test data set. The results for this experiment were obtained using 10-fold cross validation. This Section gives details about these experiments and the results obtained.
3.2.1 Experiment (1): To detect known malwares
The tool MARD first builds the training dataset, also called Malware Templates, using the 250 malware samples. After a program (sample) is translated to MAIL and to a CFG the tool detects the presence of malwares in the program, using the Malware Templates and applying the graph and the pattern matching techniques described above. We ran the experiment on the two machines with 2 (using 8 threads) and 4 Cores (using 64 threads) listed in Table 5. There was no manual intervention during the complete run. The tool automatically generated the report after all the samples were processed.
| Experiment | Analysis | Detection | False | Data Set Size | Real-Time11footnotemark: 1 | Platform22footnotemark: 2 |
|---|---|---|---|---|---|---|
| Number | Type | Rate | Positives | Benign/Malware | ||
| Static | 100% | 0% | 1137 / 250 | ✓ | Win 32 | |
| Static | 93.92% | 3.02% | 1137 / 250 | ✓ | Win 32 | |
| Static | 99.6% | 3.43% | 1137 / 250 | ✓ | Win 32 | |
| Static | 100% | 3.43% | 1137 / 250 | ✓ | Win 32 |
| 1 Real-time here means the detection is fully automatic and finishes in a reasonable amount of time. |
| 2 All the samples (benigns and malwares) used were Windows 32 programs. |
| Machines used in the experiments: |
| 3 With 2 Cores: Intel Core i5 CPU M 430 @ 2.27 GHz |
| RAM: 4 GB |
| Operating System: Windows 8 Professional |
| 4 With 4 Cores: Intel Core 2 Quad CPU Q6700 @ 2.67 GHz |
| RAM: 4 GB |
| Operating System: Windows 7 Professional |
| 5 Results obtained using 10-fold cross validation |
| Training dataset: 25 samples Unknown malware samples: 225 |
| 6 Training dataset: 100 samples, Unknown malware samples: 150 |
| 7 Training dataset: 200 samples, Unknown malware samples: 50 |
3.2.2 Experiment (2): To detect unknown malwares
For this experiment we selected 25 malware samples out of the 250 malwares. These 25 malware samples were used to train the tool MARD to classify a program as benign or malware. These two steps were repeated 10 times and each time different set of 25 malware samples were selected for training (10-fold cross validation). After the program (sample) is translated to MAIL a CFG for each function in the program is build. Instead of using one large CFG as done in Experiment (1), we divide a program into smaller CFGs. A program that contains some percenatge of the control flow of a training malware sample, can be classified as a malware. The CFGs of a program help the tool MARD to detect such unknown malwares as explained below.
| Threshold | Detection | False |
|---|---|---|
| Rate | Positives 11footnotemark: 1 | |
| 10 22footnotemark: 2 | 100% | 3.07% |
| 20 | 99.2% | 3.07% |
| 25 33footnotemark: 3 | 99.2% | 3.07% |
| 30 | 93.2% | 3.07% |
| 40 | 86.4% | 3.07% |
| 50 | 82.8% | 3.07% |
| 60 | 76% | 3.07% |
| 70 | 76% | 3.07% |
| 80 | 76% | 3.07% |
| 90 | 76% | 3.07% |
| 1 The same set of training dataset is used for all the experiments, |
| therefore all of them have the same number of false positives. |
| 2 We did not pick 10 as the threshold because we used only |
| one set of dataset and 100% detection rate seems too perfect. |
| 3 We picked 25 as the threshold because after this the |
| detection rate started falling considerably. |
| Test dataset size: 1137 benigns and 250 malwares. |
| Training dataset size: 25 malwares. |
| Machine used in the experiment: |
| With 4 Cores: Intel Core 2 Quad CPU Q6700 @ 2.67 GHz |
| RAM: 4 GB |
| Operating System: Windows 7 Professional |
Applying the graph and the pattern matching techniques described above the tool MARD matches CFGs of each 25 malware samples with the CFGs of a program to classify the program as either benign or malware. We base these classifications on a threashold value of 25%. That is, if 25% or more of the CFGs of a malware sample matches with the CFGs of a program then the program is classified as malware, else the program is classified as benign. The threshold value was computed by carrying out experiments with different range of threshold values as shown and explained in Table 6. The results of experiment (2) are listed in Table 5. The detection rate is 93.92% because of the use of small number (25) of training dataset. The detection rate improved to 99.6% and 100% when we used a training dataset of 100 and 200 samples respectively.
3.3 Limitations of MAIL
A program translated to MAIL when executed may not produce the same output as the original program. The language MAIL is designed to perform static binary analysis and is not suitable for performing dynamic binary analysis.
The patterns developed if used with a behavioral signature of a binary program such as a CFG have the capability to produce useful classifications for malware analysis and detection, as shown by the results of the above experiments. But if the patterns are used alone, it may not produce the desired results.
The side effects of an assembly instruction is not directly translated to the MAIL statement. With the presence of various flag registers in the MAIL language it is possible for a malware analysis tool to include the side effect(s) of an assembly instruction by generating more statements and updating the affected flag registers.
The MAIL language is most useful in capturing the behavior (including structural and functional) of a binary program and can be used as part of different malware detection techniques such as described in this paper and in [13, 11, 10, 9]. These techniques require behavioral, structural or functional information about a program. In its current form the MAIL language cannot be used as part of other signature-based malware detection techniques, such as [21, 19, 18]. These techniques build the signatures using the opcodes of a binary program.
4 Conclusion
We have developed the new language MAIL for malware anlaysis and have used it successfully in our tool MARD for malware analysis and detection. We carried out an experimental study and showed that we can achieve detection rates of: 100% with 0% false positives for known malwares and (94 – 100)% with (3 – 3.5)% false positives for unknown malwares, as shown in Table 5. The two main contributions of the language MAIL are: (1) Providing platform independence and automation for malware analysis and detection tools, as is shown by its use in the tool MARD. (2) Optimizing the creation of a behavioral signature of a program, as is shown by creating a ACFG (Annotated Control Flow Graph), a CFG with patterns, of a binary program. We have shown how this ACFG is used for reliable malware analysis and detection in real-time. More recent examples of the use of MAIL can be found in [2].
Currently we are carrying out further research into optimizing the tool to increase its accuracy and efficiency for detecting unknown metamorphic malwares. We found that the behavioral signatures generated by the tool MARD using the MAIL language, and the graph and the pattern matching techniques, are helpful in detecting metamorphic malwares as shown in Table 5. We are collecting more metamorphic malware samples to use in our research and carry out experiments to further improve malware classification and detection.
References
- [1] Alfred V. Aho, Monica S. Lam, Ravi Sethi, and Jeffrey D. Ullman. Compilers: Principles, Techniques, and Tools (2nd Edition). Addison-Wesley Longman Publishing Co., Inc., Boston, MA, USA, 2006.
- [2] Shahid Alam, R Nigel Horspool, Issa Traore, and Ibrahim Sogukpinar. A framework for metamorphic malware analysis and real-time detection. Computers & Security, 48:212–233, February 2015.
- [3] J.M. Bauer, M.J.G. Eeten, and Y. Wu. Itu study on the financial aspects of network security: Malware and spam. ©International Telecommunications Union (http://www.itu.int), 2008.
- [4] Christian Bienia, Sanjeev Kumar, Jaswinder Pal Singh, and Kai Li. The parsec benchmark suite: Characterization and architectural implications. In Proceedings of the 17th international conference on Parallel architectures and compilation techniques, PACT ’08, pages 72–81, New York, NY, USA, 2008. ACM.
- [5] F. Cohen. Computer viruses: Theory and experiments. Comput. Security., 6(1):22–35, Feburary 1987.
- [6] Stephen A. Cook. The complexity of theorem-proving procedures. In Proceedings of the third annual ACM symposium on Theory of computing, STOC ’71, pages 151–158, New York, NY, USA, 1971. ACM.
- [7] Intel Corporation. Intel ® 64 and IA-32 Architectures Software Developer’s Manual Volume 2 (2A, 2B & 2C): Instruction Set Reference, A-Z, January 2013.
- [8] International Standard Organization document reference ISO/IEC. Information Technology - Syntactic Metalanguage - Extended Backus-Naur Form, 14977 : 1996(E), 1996.
- [9] Mojtaba Eskandari and Sattar Hashemi. Ecfgm: Enriched control flow graph miner for unknown vicious infected code detection. Journal in Computer Virology, 8(3):99–108, August 2012.
- [10] Mojtaba Eskandari and Sattar Hashemi. A graph mining approach for detecting unknown malwares. Journal of Visual Languages and Computing, 23(3):154–162, June 2012.
- [11] Parvez Faruki, Vijay Laxmi, M. S. Gaur, and P. Vinod. Mining control flow graph as api call-grams to detect portable executable malware. In Proceedings of the Fifth International Conference on Security of Information and Networks, SIN ’12, pages 130–137, New York, NY, USA, 2012. ACM.
- [12] Chris Lattner and Vikram Adve. Llvm: A compilation framework for lifelong program analysis & transformation. In Proceedings of the international symposium on Code generation and optimization: feedback-directed and runtime optimization, CGO ’04, Washington, DC, USA, 2004. IEEE Computer Society.
- [13] Jusuk Lee, Kyoochang Jeong, and Heejo Lee. Detecting metamorphic malwares using code graphs. In Proceedings of the 2010 ACM Symposium on Applied Computing, SAC ’10, pages 1970 – 1977, New York, NY, USA, 2010. ACM.
- [14] Cullen Linn and Saumya Debray. Obfuscation of executable code to improve resistance to static disassembly. In Proceedings of the 10th ACM conference on Computer and communications security, CCS ’03, pages 290–299, New York, NY, USA, 2003. ACM.
- [15] David M. Chess and Steve R. White. An undetectable computer virus. Virus Bulletin Conference, September 2000.
- [16] Philip OKane, Sakir Sezer, and Kieran McLaughlin. Obfuscation: The hidden malware. IEEE Security and Privacy, 9(5):41–47, September 2011.
- [17] ARM Holdings plc. ARM ® Architecture Reference Manual ARMv7-A and ARMv7-R edition, January 2012.
- [18] B.B. Rad, M. Masrom, and S. Ibrahim. Opcodes histogram for classifying metamorphic portable executables malware. In e-Learning and e-Technologies in Education (ICEEE), 2012 International Conference on, pages 209–213, sept. 2012.
- [19] Neha Runwal, Richard M. Low, and Mark Stamp. Opcode graph similarity and metamorphic detection. J. Comput. Virol., 8(1-2):37–52, May 2012.
- [20] GCC Team. GCC: The GNU Compiler Collection. http://gcc.gnu.org, 2013.
- [21] P. Vinod, V. Laxmi, M.S. Gaur, and G. Chauhan. Momentum: Metamorphic malware exploration techniques using msa signatures. In Innovations in Information Technology (IIT), 2012 International Conference on, pages 232–237, March 2012.
Appendix A Appendix
TITLE: MAIL (Malware Analysis Intermediate Language) Grammar in EBNF
AUTHOR: Shahid Alam (salam@cs.uvic.ca)
DATED: March 24, 2013
REVISION: 1.0 (March 24, 2013)
DESCRIPTION:
The grammar can be defined by a 3-tuple G = (T, N, P) where
T = set of terminals
N = set of non-terminals
P = set of production rules
This document describes the grammar for MAIL. The grammar uses the EBNF syntax, where
’|’ means a choice, ? means optional, * means zero or more times and + means one or more
times. Line Comments start with "--". Terminator symbol is ";". Terminals are enclosed
in single quotes.
----------------------------------------------------------------------------------------
-- PRODUCTION RULES --
----------------------------------------------------------------------------------------
statements ::= ( statement* ) ;
statement ::= assignment_s+
| control_s+
| condition_s+
| function_s+
| jump_s+
| lib_call_s+
| ’halt’
| ’lock’ ;
assignment_s ::= register_s
| address_s ;
register_s ::= register ’=’ (math_operator)? expr
| register ’=’ (expr)? math_operator expr
| register ’=’ lib_call_s ;
address_s ::= address ’=’ (math_operator)? expr
| address ’=’ (expr)? math_operator expr
| address ’=’ lib_call_s ;
control_s ::= ( ’if’ condition_s (jump_s | assignment_s) )
( ’else’ (jump_s | assignment_s) )? ;
jump_s ::= ’jmp’ address ;
lib_call_s ::= letter+ ’(’ address (, args)* ’)’ ;
function_s ::= ’start_function_’ digit+ statement ’end_function_’ digit+ ;
condition_s ::= (expr rel_operator expr)+ ;
----------------------------------------------------------------------------------------
-- HELPER RULES --
----------------------------------------------------------------------------------------
expr ::= register
| address
| digit+ ;
register ::= ’eflags’
| ’gr_’ digit+
| ’fr_’ digit+
| ’sp’
| register_name (’:’ register_name)? ;
register_name ::= letter+ [’0’ - ’9’]? ;
address ::= ’[’ digit+ ’]’
| reg_address
| ’UNKNOWN’ ;
reg_address ::= ’[’ register ( arith_operator (register | digit+) )* ’]’
| ’[’ sp ’=’ sp (’+’ | ’-’) digit+ ’]’
| ’[’ register (’:’ register)? ’]’ ;
letter ::= [’a’ - ’z’] [’A’ - ’Z’] ;
digit ::= ’0x’ [’0’ - ’9’] | [’A’ - ’F’] ;
math_operator ::= arith_operator | log_operator ;
arith_operator ::= ’+’ | ’-’ | ’*’ | ’/’ | ’%’ | ’.’ ;
log_operator ::= ’and’ | ’or’ | ’xor’ | ! | ’<<’ | ’>>’ ;
args ::= address (’,’ address)* ;
rel_operator ::= ’<’ | ’>’ | ’<=’ | ’>=’ | ’==’ | ’!=’ ;
comment ::= ’--’ blank | tab | character | comment* newline ;
character ::= ’!’ | ’"’ | ’#’ | ’$’ | ’%’ | ’&’ | ’’’ | ’(’ | ’)’
| ’[’ | ’\’ | ’]’ | ’^’ | ’_’ | ’‘’ | ’{’ | ’|’ | ’}’
| ’*’ | ’+’ | ’-’ | ’/’ | ’,’ | ’.’ | ’~’
| ’:’ | ’;’ | ’<’ | ’=’ | ’>’ | ’?’ | ’@’
| [’0’ - ’9’]Ψ| letter ;
----------------------------------------------------------------------------------------
-- TOKENS --
----------------------------------------------------------------------------------------
WS ::= blank | tab | newline ;
COMMENT ::= ’--’ blank | tab | character | comment* newline ;
NUM ::= digit+ ;
COMMA ::= ’,’ ;
COLON ::= ’:’ ;
SCOLON ::= ’;’ ;
LOP ::= ’and’ | ’or’ | ’xor’ | ! | ’<<’ | ’>>’ ;
AOP ::= ’+’ | ’-’ | ’*’ | ’/’ | ’%’ | ’.’ ;
ROP ::= ’<’ | ’>’ | ’<=’ | ’>=’ | ’==’ | ’!=’ ;
SFUN :: ’start_function_’ digit+ ;
EFUN :: ’end_function_’ digit+ ;
EQUAL :: ’=’ ;
MUL ::= ’*’ ;
DIV ::= ’/’ ;
PLUS ::= ’+’ ;
MINUS ::= ’-’ ;
LBRKT1 ::= ’(’ ;
RBRKT1 ::= ’)’ ;
LBRKT2 ::= ’[’ ;
RBRKT2 ::= ’]’ ;
IF ::= ’if’ ;
ELSE ::= ’else’ ;
UNKNOWN ::= ’UNKNOWN’ ;
Appendix B Appendix
List of x86 and ARM instructions, in alphabetical order, that are not translated to MAIL statements:
x86
3DNOW AAA, AAD, AAM, AAS, AESDEC, AESDECLAST, AESENC AESENCLAST, AESIMC, AESKEYGENASSIST, ARPL BOUND DAA, DAS EMMS, ENTER GETSEC CLFLUSH, CLTS, CMC, CPUID, CRC32 FCLEX, FDECSTP, FEDISI, FEEMS, FENI, FFREE, FINCSTP, FINIT FLDCW, FLDENV, FNCLEX, FNINIT, FNSAVE, FNSTCW, FNSTENV FNSTSW, FRSTOR, FSAVE, FSETPM, FSTCW, FSTENV, FSTSW FXRSTOR, FXRSTOR64, FXSAVE, FXSAVE64, FXTRACT INT 3, INVD, INVEPT, INVLPG, INVLPGA, INVPCID, INVVPID LEAVE, LFENCE, LZCNT MFENCE, MONITOR, MPSADBW, MWAIT PAUSE, PREFETCH, PSAD, PSHUF, PSIGN RCL, RCR, RDRAND, RDTSC, RDTSCP, ROL, ROR, RSM SFENCE, SHUFPD, SHUFPS, SKINIT, SMSW SYSCALL, SYSENTER, SYSEXIT, SYSRET VAESDEC, VAESDECLAST, VAESENC, VAESENCLAST, VAESIMC VAESKEYGENASSIST, VERR, VERW, VMCALL, VMCLEAR, VMFUNC VMLAUNCH, VMLOAD, VMMCALL, VMPSADBW, VMREAD, VMRESUME VMRUN, VMSAVE, VMWRITE, VMXOFF, VSHUFPD, VSHUFPS VZEROALL, VZEROUPPER WAIT, WBINVD XRSTOR, XSAVE, XSAVEOPT
ARM
BKPT CDP, CDP2, CLREX, CLZ, CPS, CPSID, CPSIE, CRC32, CRC32C DBG, DCPS1, DCPS2, DCPS3, DMB, DSB HVC ISB LDC, LDC2 MCR, MCR2, MCRR, MCRR2, MRC, MRC2, MRRC, MRRC2 PLD, PLDW, PLI, PRFM SETEND, SEV, SHA1C, SHA1H, SHA1M, SHA1P, SHA1SU0, SHA1SU1 SHA256H, SHA256H2, SHA256SU0, SHA256SU1, SMC SSAT, SSAT16, STC, STC2, SVC USAT, USAT16 VCVT, VCVTA, VCVTB, VCVTM, VCVTN, VCVTP, VCVTR, VCVTT, VEXT VLD1, VLD2, VLD3, VLD4, VLD1, VLD2, VLD3, VLD4 VQRDMULH, VQRSHL, VQRSHRN, VQRSHRN, VQRSHRUN, VQRSHRUN, VQSHL, VQSHLU, VQSHL, VQSHRN, VQSHRN, VQSHRUN, VQSHRUN VRINTA, VRINTM, VRINTN, VRINTP, VRINTR, VRINTX, VRINTZ VRSHL, VRSHR, VRSHRN, VRSRA, VRSUBHN VST1, VST2, VST3, VST4, VTBL, VTBX, VTRN, VUZP, VZIP WFE, WFI, YIELD